C# 流Stream详解(3)——FileStream源码
【FileStream】
构造函数
如果创建一个FileStream,常见的参数例如路径Path、操作方式FileMode、权限FileAccess。
这里说下FileShare和SafeFileHandle。
我们知道在读取文件时,通常会有两个诉求:一是如何更快的读取文件内容;二是如何减少读取文件的消耗。常见的加快读取文件的方式是多线程读取,每个线程读取文件的一部分,这就涉及到文件的共享,有以下几种模式:
- None:拒绝共享,其他线程(进程)将不能打开、写入、删除该文件
- Read:允许读取,其他线程可以自己new一个FileStream实例来读取文件,线程之间读文件不影响,其中一个线程的FileStream释放后,不影响其他线程读文件。
- Write:允许写入,其他线程之间并行写入,需要注意的是,不同线程要在不同的流位置和流区间写入,不要重叠,否则重叠的部分是串行的。
- ReadWrite:允许读写,这种方式不常用,在并行时最需要保证的是不同线程读写文件的不同区间,不要重叠。
- Delete:允许删除
- Ineritable:允许文件句柄由子进程继承
SafeFileHandle用的很少,一般来多语言交互的时候用到,比如在C++打开了一个文件,要把引用传递给C#,C#这边来读取文件,或者C#打开文件,传递给C++读取文件。这种情况出现的很少,如果真的需要C++和C#传递文件数据,一般会将文件路径传递,打开读取文件在一端进行,或者在一端打开读取文件后将包含数据的buffer传递到另一端。如果要用的话,示例如下:
[DllImport("kernel32.dll", SetLastError = true, CharSet=CharSet.Unicode)]static extern SafeFileHandle CreateFile(string lpFileName, uint dwDesiredAccess,uint dwShareMode, IntPtr lpSecurityAttributes, uint dwCreationDisposition,uint dwFlagsAndAttributes, IntPtr hTemplateFile);public void ReadFile()
{
SafeFileHandle fileHandle = CreateFile(
"example.txt",
GENERIC_READ,
FILE_SHARE_READ,
IntPtr.Zero,
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL,
IntPtr.Zero
);byte[] buffer = new byte[1024];
using (FileStream fileStream = new FileStream(fileHandle, FileAccess.Read))
{
int bytesRead = fileStream.Read(buffer, 0, buffer.Length);
//FileStream.SafeFileHandle.DangerousGetHandle() 获取文件句柄
}
}方法
Read、Write、Dispose和Close没什么好说的,很常用。这里看看不常用的其他方法。
- Flush:读写文件是一个很复杂的过程,当我们调用write方法尝试将数据写到磁盘上时,即使我们调用了同步的方法,也不是立即写入磁盘,而是先写入FileStream的buffer中。FileStream buffer的默认大小为4kb,我们可以在实例化的时候指定buffer大小。当调用Write方法时,会先将数据写入buffer,如果buffer满了,就将数据写入操作系统的buffer中。(buffer在写入时会分配内存,如果第一次写入的count大于buffersize,那么直接写入操作系统buffer中,否则即使count>buffersize,也是先把buffer填满,再写入操作系统中,这里是个优化的点)。Flush()相当于Flush(false),会立即将buffer中的数据写入操作系统的buffer,并清空buffer中;Flush(true)会将操作系统的buffer也清空,并执行写入磁盘的操作。
- Lock:锁定文件流void Lock (long position, long length),将文件流的一部分锁定进行独占访问。与之对应的是UnLock。
-
Read(Span<Byte>):如果不了解Span,可以先了解下。Span表示一段连续的内存,有时我们希望直接操作一段内存,安全的方式是先将这段内存的内容copy出来,但是这样性能不高。想要高性能,就要使用指针去访问,但这样不安全。Span提供安全高效的内存访问。用该方法,可以直接将读取的字节序列放到Span引用的连续内存中。
-
ReadExactly:其与Read的区别是,在读取一定的字节序列后,会推进流的位置,也即改变Position属性的值。
源码(反编译来的)
对于上层调用者来说,FileStream提供了一个中间缓存层。每多一个中间层,就需要在中间层中处理好中间层和下层的共同属性之间的关系,这里指Position的关系。
读取数据
public override int Read([In][Out] byte[] array, int offset, int count)
{if (array == null){throw new ArgumentNullException("array", Environment.GetResourceString("ArgumentNull_Buffer"));}if (offset < 0){throw new ArgumentOutOfRangeException("offset", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (count < 0){throw new ArgumentOutOfRangeException("count", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (array.Length - offset < count){throw new ArgumentException(Environment.GetResourceString("Argument_InvalidOffLen"));}if (_handle.IsClosed)//这是SafeFileHandle{__Error.FileNotOpen();}bool flag = false;int num = _readLen - _readPos;//read和write共用一个buffer,readlen表示用于读数据的长度,这里求的是读数据buffer的剩余可用大小if (num == 0)//用于读的buffer的长度和位置相等,表示用于读的buffer用满了{if (!CanRead){__Error.ReadNotSupported();}if (_writePos > 0)//此时需要清空写入的buffer{FlushWrite(calledFromFinalizer: false);}if (!CanSeek || count >= _bufferSize)//如果要求的count大于buffer的大小时,会直接将读出来的数据放入到指定的array中,少了copy的步骤{ //如果FilsStream只是用于读数据,可以指定小的buffersize,将读到的数据直接放入指定的array中,减少从buffer到array的拷贝num = ReadCore(array, offset, count);_readPos = 0;_readLen = 0;return num;}if (_buffer == null)//实例化buffer{_buffer = new byte[_bufferSize];}num = ReadCore(_buffer, 0, _bufferSize);//注意,如果指定的count小于buffer,那么实际是按照buffersize的大小来读取数据的if (num == 0) //这样做是为了减少IO消耗,底层在读取磁盘数据时,会一次性读取扇区里的全部内容,而不是按照上层指定的读取只读取几个字节//因此,读文件的操作不一定真的有IO消耗,如果每次读的小,会用到这里的缓存数据{return 0;}flag = (num < _bufferSize);//这种情况表示文件大小(或者文件剩余大小)小于指定的buffer大小,buffer大小默认4kb_readPos = 0;_readLen = num;}if (num > count){num = count;}Buffer.InternalBlockCopy(_buffer, _readPos, array, offset, num);//将buffer里的数据copy到指定的array中_readPos += num;//读数据时流的位置会增加if (!_isPipe && num < count && !flag)//isPipe一般为false,这种情况表示指定的count比读数据buffer的可用数据大{ //步骤是先将buffer里的数据copy到指定的array中,然后再从文件中读剩余(count-num)个数据int num2 = ReadCore(array, offset + num, count - num);num += num2;_readPos = 0;//读数据的Buffer被读取完了,流的位置和大小都回置为0_readLen = 0;}return num;
}写入数据
public override void Write(byte[] array, int offset, int count)
{if (array == null){throw new ArgumentNullException("array", Environment.GetResourceString("ArgumentNull_Buffer"));}if (offset < 0){throw new ArgumentOutOfRangeException("offset", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (count < 0){throw new ArgumentOutOfRangeException("count", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (array.Length - offset < count){throw new ArgumentException(Environment.GetResourceString("Argument_InvalidOffLen"));}if (_handle.IsClosed){__Error.FileNotOpen();}if (_writePos == 0{if (!CanWrite){__Error.WriteNotSupported();}if (_readPos < _readLen)//这种情况表示要写数据时,buffer中还有一些数据没被上层读完,需要情况,回退读的位置{ //读写共用一个buffer,读时清空写的数据,写时清空读的数据FlushRead();}_readPos = 0;_readLen = 0;}if (_writePos > 0){int num = _bufferSize - _writePos;//计算剩余可写入大小,if (num > 0){if (num > count){num = count;}Buffer.InternalBlockCopy(array, offset, _buffer, _writePos, num);//将array中的数据copy了一份到buffer中,不是立即写入,会在关闭流的时候再写入_writePos += num;//更新写入流的位置if (count == num){return;//这种情况是剩余的写入大小大于指定的count}offset += num;count -= num;}if (_isAsync){IAsyncResult asyncResult = BeginWriteCore(_buffer, 0, _writePos, null, null);EndWrite(asyncResult);}else{WriteCore(_buffer, 0, _writePos);//能走到这里,是因为count>num,此时buffer中数据已满,需要写入磁盘中}_writePos = 0;}if (count >= _bufferSize)//如果剩余的count或首次的count大于buffer大小,直接写入{ //这里写入是先将buffer填满再写入,多余的直接写入WriteCore(array, offset, count);}else if (count != 0){if (_buffer == null){_buffer = new byte[_bufferSize];}Buffer.InternalBlockCopy(array, offset, _buffer, _writePos, count);//如果写入指定的count小于剩余的写入大小,只是将array中的数据copy了一份到buffer中,不是立即写入,会在关闭流的时候再写入_writePos = count;//更新写入流的位置}
}寻找位置
public override long Position
{[SecuritySafeCritical]get{if (_handle.IsClosed){__Error.FileNotOpen();}if (!CanSeek){__Error.SeekNotSupported();}if (_exposedHandle)//该值一般为false,get文件句柄时会被设置为true,此时文件流的位置,需要重新确定{VerifyOSHandlePosition();}//这里获取的不是真正的文件流的位置,而是上层调用者认为的流的位置return _pos + (_readPos - _readLen + _writePos);}set{if (value < 0){throw new ArgumentOutOfRangeException("value", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (_writePos > 0)//如果有需要写入的内容,会将内容先写入{FlushWrite(calledFromFinalizer: false);}_readPos = 0;_readLen = 0;Seek(value, SeekOrigin.Begin);//Position属性表示以流开始为起点的位置}
}public override long Seek(long offset, SeekOrigin origin)
{if (origin < SeekOrigin.Begin || origin > SeekOrigin.End){throw new ArgumentException(Environment.GetResourceString("Argument_InvalidSeekOrigin"));}if (_handle.IsClosed){__Error.FileNotOpen();}if (!CanSeek){__Error.SeekNotSupported();}if (_writePos > 0){FlushWrite(calledFromFinalizer: false);}else if (origin == SeekOrigin.Current){offset -= _readLen - _readPos;//如果以当前为起点,_readPos表示FilsStream的buffer的Pos,而不是文件流的真正的Position} //offset表示调用者认为的Position,(_readLen - _readPos)表示文件流真正的Position和调用者认为的Position之间的差值if (_exposedHandle){VerifyOSHandlePosition();//实际上时调用SeekCore(0L, SeekOrigin.Current),重新定位下文件流的位置}long num = _pos + (_readPos - _readLen);//计算出来的文件流的真正位置long num2 = SeekCore(offset, origin);//重新定位文件流的位置if (_appendStart != -1 && num2 < _appendStart){SeekCore(num, SeekOrigin.Begin);throw new IOException(Environment.GetResourceString("IO.IO_SeekAppendOverwrite"));}if (_readLen > 0)//这表示之前已经读取了部分文件信息{if (num == num2)//一般是这种情况{if (_readPos > 0)//以readPos为分界线,把buffer中后面的数据拷贝到前面,这样readPos为0了,readLen减少了{Buffer.InternalBlockCopy(_buffer, _readPos, _buffer, 0, _readLen - _readPos);_readLen -= _readPos;_readPos = 0;}if (_readLen > 0)//恢复文件流的真正位置{SeekCore(_readLen, SeekOrigin.Current);}}else if (num - _readPos < num2 && num2 < num + _readLen - _readPos)//表示重新定位的文件流的位置小于计算出来的文件流的位置{ //大于上次读取文件流时得位置int num3 = (int)(num2 - num);Buffer.InternalBlockCopy(_buffer, _readPos + num3, _buffer, 0, _readLen - (_readPos + num3));_readLen -= _readPos + num3;_readPos = 0;if (_readLen > 0){SeekCore(_readLen, SeekOrigin.Current);}}else{_readPos = 0;_readLen = 0;}}return num2;
}
//可以看到Seek流程很复杂,为了提高性能,应该避免再读数据时比默认buffersize大,直接读到指定的array中,不要经过FileStream的buffer。
//一定要避免写数据和读数据交叉进行
//因为filsStream的设计考虑了通用,当我们按照一定的规范去使用时,可以减少很多为通用情况而做的耗费性能的设计【MemoryStream】
构造函数
只需要关注红色方框里的两个构造函数即可,其他的都是重载。

 memorystream也有一个buffer来缓存数据,在new的时候可以指定这个buffer的大小,那么这个buffer的实例化在new的时候完成,如果在写数据时这个buffer的大小不够用,则会自动扩容。
memorystream也有一个buffer来缓存数据,在new的时候可以指定这个buffer的大小,那么这个buffer的实例化在new的时候完成,如果在写数据时这个buffer的大小不够用,则会自动扩容。
也可以自己实例化一个buffer,并在new的时候通过index和count来指定memorystream可以用这个buffer的哪一部分。通过这种方式new时,如果写数据时大小不够用,是不能扩容的。
writable表示是否可以写入
publiclyVisible表示是否可以拿到memorystream内部的buffer
方法
写入数据
public override void Write(byte[] buffer, int offset, int count)
{if (buffer == null){throw new ArgumentNullException("buffer", Environment.GetResourceString("ArgumentNull_Buffer"));}if (offset < 0){throw new ArgumentOutOfRangeException("offset", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (count < 0){throw new ArgumentOutOfRangeException("count", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (buffer.Length - offset < count){throw new ArgumentException(Environment.GetResourceString("Argument_InvalidOffLen"));}if (!_isOpen){__Error.StreamIsClosed();}EnsureWriteable();//确保可以写入,不能不能写入会报错,不继续执行了int num = _position + count; //计算加入全部写入时流的位置if (num < 0) //超出int可表示的最大值的检查,可以注意下,一般自己写代码时很少会做这种检查,虽然一般情况下也不需要{ //MemoryStream的最大容量是int.MaxValuethrow new IOException(Environment.GetResourceString("IO.IO_StreamTooLong"));}if (num > _length)//全部写入时流的位置大于buffer的长度,就需要扩容了{bool flag = _position > _length;if (num > _capacity && EnsureCapacity(num)){flag = false;}if (flag)//流的位置大于Buffer长度,需要清除多余的部分{Array.Clear(_buffer, _length, num - _length);}_length = num;}if (count <= 8 && buffer != _buffer) //当字节小于8时则一个个读{int num2 = count;while (--num2 >= 0){_buffer[_position + num2] = buffer[offset + num2];}}else//将提供的buffer数据拷贝到MemoryStream的buffer种{ //Buffer.BlockCopy比Array.Copy更快//https://stackoverflow.com/questions/1389821/array-copy-vs-buffer-blockcopyBuffer.InternalBlockCopy(buffer, offset, _buffer, _position, count);}_position = num;//更新流的位置
}private bool EnsureCapacity(int value)
{if (value < 0){throw new IOException(Environment.GetResourceString("IO.IO_StreamTooLong"));}if (value > _capacity){int num = value;if (num < 256){num = 256;//容量小于256时,会被规范为256}if (num < _capacity * 2){num = _capacity * 2;//两倍扩容}if ((uint)(_capacity * 2) > 2147483591u)//处理超限{num = ((value > 2147483591) ? value : 2147483591);}Capacity = num;return true;}return false;
}public virtual int Capacity
{[__DynamicallyInvokable]get{if (!_isOpen){__Error.StreamIsClosed();}return _capacity - _origin;}[__DynamicallyInvokable]set{if (value < Length){throw new ArgumentOutOfRangeException("value", Environment.GetResourceString("ArgumentOutOfRange_SmallCapacity"));}if (!_isOpen){__Error.StreamIsClosed();}if (!_expandable && value != Capacity){__Error.MemoryStreamNotExpandable();}if (!_expandable || value == _capacity)//new时指定了buffer就不能扩容了{return;}if (value > 0){byte[] array = new byte[value];if (_length > 0)//扩容时会将原来的数据copy到新的buffer种{Buffer.InternalBlockCopy(_buffer, 0, array, 0, _length);}_buffer = array;}else{_buffer = null;}_capacity = value;}
}读取数据
public override int Read([In][Out] byte[] buffer, int offset, int count)//理解了write后,read方法很简单
{if (buffer == null){throw new ArgumentNullException("buffer", Environment.GetResourceString("ArgumentNull_Buffer"));}if (offset < 0){throw new ArgumentOutOfRangeException("offset", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (count < 0){throw new ArgumentOutOfRangeException("count", Environment.GetResourceString("ArgumentOutOfRange_NeedNonNegNum"));}if (buffer.Length - offset < count){throw new ArgumentException(Environment.GetResourceString("Argument_InvalidOffLen"));}if (!_isOpen){__Error.StreamIsClosed();}int num = _length - _position;if (num > count){num = count;}if (num <= 0){return 0;}if (num <= 8){int num2 = num;while (--num2 >= 0){buffer[offset + num2] = _buffer[_position + num2];}}else{Buffer.InternalBlockCopy(_buffer, _position, buffer, offset, num);//将数据拷贝到指定的buffer中}_position += num;//读完后,流的position增加return num;
}【BinaryWriter】
构造函数

Stream参数,FileStream、MemoryStream都继承自Stream,这里传递进来主要是要用这些Stream的buffer
Encoding 编码类型,默认是new UTF8Encoding()
leaveOpen:表示close时要不要把stream要不要保持打开,默认为false,会将stream也close
方法
//可以每次写入实际是将数据写入Stream的buffer中,BinaryWriter将数据序列化了,这里只提供基本数据类型的序列化
public virtual void Write(bool value)//写入bool
{_buffer[0] = (byte)(value ? 1u : 0u);//bool也是byteOutStream.Write(_buffer, 0, 1);//BinaryWriter也有有个buffer,固定的长度,为16,之所以为16是因为有个decimal类型要有16个字节表示
}public virtual void Write(byte value)//byte直接写入
{OutStream.WriteByte(value);
}public virtual void Write(byte[] buffer)
{if (buffer == null){throw new ArgumentNullException("buffer");}OutStream.Write(buffer, 0, buffer.Length);//byte[]一样是直接写入到stream的buffer中
}public virtual void Write(short value)
{_buffer[0] = (byte)value;//先取到低八位_buffer[1] = (byte)(value >> 8);//右移取到高八位OutStream.Write(_buffer, 0, 2);
}public virtual void Write(int value)
{_buffer[0] = (byte)value;_buffer[1] = (byte)(value >> 8);_buffer[2] = (byte)(value >> 16);_buffer[3] = (byte)(value >> 24);OutStream.Write(_buffer, 0, 4);
}public virtual void Write(long value)
{_buffer[0] = (byte)value;_buffer[1] = (byte)(value >> 8);_buffer[2] = (byte)(value >> 16);_buffer[3] = (byte)(value >> 24);_buffer[4] = (byte)(value >> 32);_buffer[5] = (byte)(value >> 40);_buffer[6] = (byte)(value >> 48);_buffer[7] = (byte)(value >> 56);OutStream.Write(_buffer, 0, 8);
}public unsafe virtual void Write(string value)
{if (value == null){throw new ArgumentNullException("value");}int byteCount = _encoding.GetByteCount(value);Write7BitEncodedInt(byteCount);//会先写入字符串的byte长度if (_largeByteBuffer == null){_largeByteBuffer = new byte[256];//先尝试用一个256长度的Buffer做首次尝试_maxChars = _largeByteBuffer.Length / _encoding.GetMaxByteCount(1);//获取该编码格式下,最大的字符需要多少byte,maxChar表示largeByteBuffer最多可以容纳多少个字符}if (byteCount <= _largeByteBuffer.Length)//小256,就直接将编码得到的bytes放入largeByteBuffer,再copy到Stream的buffer中{_encoding.GetBytes(value, 0, value.Length, _largeByteBuffer, 0);OutStream.Write(_largeByteBuffer, 0, byteCount);return;}int num = 0;int num2 = value.Length;while (num2 > 0)//字符串的长度大于128时,将字符串拆分转为bytes,分别写入largeByteBuffer{int num3 = (num2 > _maxChars) ? _maxChars : num2;if (num < 0 || num3 < 0 || checked(num + num3) > value.Length){throw new ArgumentOutOfRangeException("charCount");}int bytes2;fixed (char* ptr = value){fixed (byte* bytes = _largeByteBuffer){//因为字符串不可修改,要使用指针读取,这个方法表示的意思和之前的_encoder.GetBytes是一样的,bytes2 = _encoder.GetBytes((char*)checked(unchecked((nuint)ptr) + unchecked((nuint)checked(unchecked((nint)num) * (nint)2))), num3, bytes, _largeByteBuffer.Length, num3 == num2);}}OutStream.Write(_largeByteBuffer, 0, bytes2);num += num3;num2 -= num3;}
}protected void Write7BitEncodedInt(int value)//用于将整数值编码为7位压缩格式并写入流中。
{ //它通常用于数据序列化或网络通信过程中,以减小整数值的存储空间和传输开销。编码过程中,整数值按照7位的块进行分割,并将每个块的最高位设置为1,表示后面还有更多的块。每个块的其余7位用于存储整数值的一部分。uint num; //这样,较小的整数值可以用较少的字节进行编码,而较大的整数值则需要更多的字节。for (num = (uint)value; num >= 128; num >>= 7) //这种方式相比于之前的Write(int value),会减少存储空间{Write((byte)(num | 0x80));//0x80是 1000 0000,这里直接舍去了num的后七位}Write((byte)num);
}【BinaryReader】
构造函数

方法
//可以发现真正读数据都是Stream完成的,BinaryReader将读出来的数据反序列化了,这里只提供byte到基本数据类型的反序列化
public virtual byte ReadByte()//读byte
{if (m_stream == null){__Error.FileNotOpen();}int num = m_stream.ReadByte();//实际调用的是Stream的ReadByte方法,最低读8位if (num == -1){__Error.EndOfFile();}return (byte)num;
}public virtual short ReadInt16()//读short
{FillBuffer(2);//16/8=2return (short)(m_buffer[0] | (m_buffer[1] << 8));//低位在前面,高位在后面,这是小端模式存储
}public virtual int ReadInt32()//读int
{if (m_isMemoryStream)//new BinaryStream会判断下Stream是不是MemoryStream{if (m_stream == null){__Error.FileNotOpen();}MemoryStream memoryStream = m_stream as MemoryStream;return memoryStream.InternalReadInt32();}FillBuffer(4);//32/8=4return m_buffer[0] | (m_buffer[1] << 8) | (m_buffer[2] << 16) | (m_buffer[3] << 24);
}public unsafe virtual float ReadSingle()//读取float
{FillBuffer(4);uint num = (uint)(m_buffer[0] | (m_buffer[1] << 8) | (m_buffer[2] << 16) | (m_buffer[3] << 24));return *(float*)(&num);
}public unsafe virtual double ReadDouble()//读取double
{FillBuffer(8);uint num = (uint)(m_buffer[0] | (m_buffer[1] << 8) | (m_buffer[2] << 16) | (m_buffer[3] << 24));uint num2 = (uint)(m_buffer[4] | (m_buffer[5] << 8) | (m_buffer[6] << 16) | (m_buffer[7] << 24));ulong num3 = ((ulong)num2 << 32) | num;return *(double*)(&num3);
}public virtual string ReadString()
{if (m_stream == null){__Error.FileNotOpen();}int num = 0;int num2 = Read7BitEncodedInt();//读取字符串长度if (num2 < 0){throw new IOException(Environment.GetResourceString("IO.IO_InvalidStringLen_Len", num2));}if (num2 == 0){return string.Empty;}if (m_charBytes == null){m_charBytes = new byte[128];//这里是存储读取到的字节数组}if (m_charBuffer == null){m_charBuffer = new char[m_maxCharsSize];//这里存储的是字符数组 m_maxCharsSize = encoding.GetMaxCharCount(128);maxCharSize是该编码下128个字符的最大大小}StringBuilder stringBuilder = null;do{int count = (num2 - num > 128) ? 128 : (num2 - num);int num3 = m_stream.Read(m_charBytes, 0, count);if (num3 == 0){__Error.EndOfFile();}//每次将charBytes数组中起始节点为0,数量为num3的数据解码放大charBuffer中,在charBuffer中的起始地址为0int chars = m_decoder.GetChars(m_charBytes, 0, num3, m_charBuffer, 0);if (num == 0 && num3 == num2){return new string(m_charBuffer, 0, chars);//字符串长度小于128的就直接返回了}if (stringBuilder == null){stringBuilder = StringBuilderCache.Acquire(Math.Min(num2, 360));}stringBuilder.Append(m_charBuffer, 0, chars);num += num3;}while (num < num2);return StringBuilderCache.GetStringAndRelease(stringBuilder);
}protected internal int Read7BitEncodedInt()
{int num = 0;int num2 = 0;byte b;do{if (num2 == 35){throw new FormatException(Environment.GetResourceString("Format_Bad7BitInt32"));}b = ReadByte();num |= (b & 0x7F) << num2;num2 += 7;}while ((b & 0x80) != 0);return num;
}相关文章:
C# 流Stream详解(3)——FileStream源码
【FileStream】 构造函数 如果创建一个FileStream,常见的参数例如路径Path、操作方式FileMode、权限FileAccess。 这里说下FileShare和SafeFileHandle。 我们知道在读取文件时,通常会有两个诉求:一是如何更快的读取文件内容;二…...

C语言的文件操作(炒详解)
⭐回顾回顾文件操作的相关细节⭐ 欢迎大家指正错误 📝在之前的学习中,不管增加数据,减少数据,当程序退出时,所有的数据都会销毁,等下次运行程序时,又要重新输入相关数据,如果一直像这…...
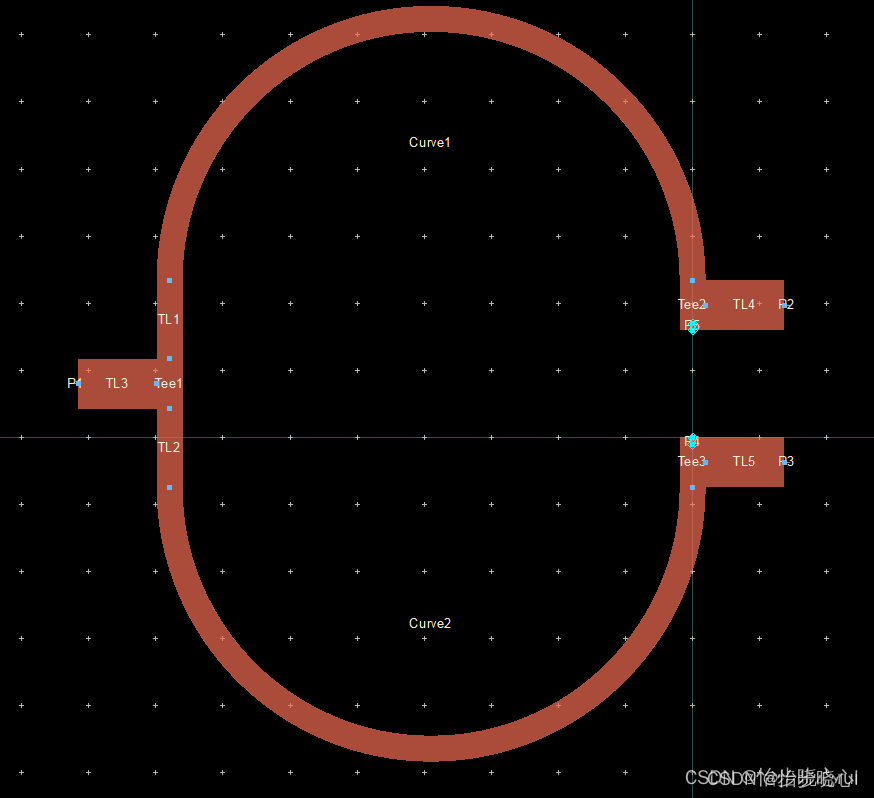
27.基于ADS的不等分威尔金森功分器设计
27.基于ADS的不等分威尔金森功分器设计 等分的威尔金森功分器可以使用ADS非常快速的设计出来,但是不等分的功分器却没有便捷的设计方法,在此给出快速的设计方法与案例,方便大家实际设计。 等分版本的威尔金森功分器设计教程:12、…...

Linux自用命令
sudo su/sudo -i:获取root权限 cd:目录切换 cd / 切换到根目录 cd … 切换到上一级目录 cd ~ 切换到home目录 cd - 切换到上次访问的目录 ls:目录查看 ls 查看当前目录下的所有目录和文件 ls -a 查看当前目录下的所有目录和文件(…...

clickhouse union all之后数据量不一致
环境: clickhouse版本:22.8.16.32 问题:clickhouse使用union all查询结果与每一段sql查询结果只和不一致 原因:因为clickhouse版本问题,官方给出不同的解释 解决方案:将union all的每一段sql用括号括起来…...
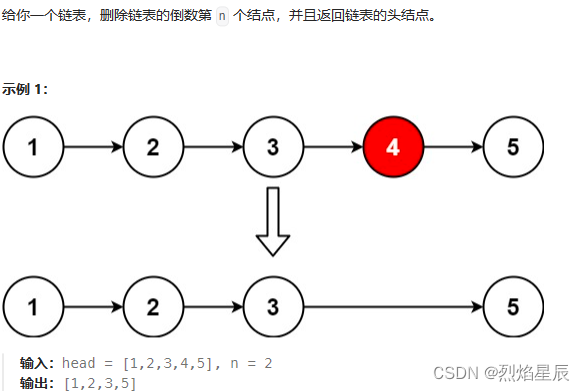
力扣刷题19-删除链表的倒数第N个节点
题目来源 题目描述: class Solution {public ListNode removeNthFromEnd(ListNode head, int n) {//为了删除的格式一样,引入虚拟头节点ListNode dummyNodenew ListNode(1);dummyNode.nexthead;ListNode slowdummyNode;ListNode fastdummyNode;for(int…...

Unity中的简单数据存储办法
这段代码演示了Unity中的简单数据存储办法 当涉及到不同类型的存储时,下面是一些示例代码来演示在Unity中如何使用不同的存储方法: 1. 临时存储示例代码(内存变量): csharp // 定义一个静态变量来存储临时计分 pub…...
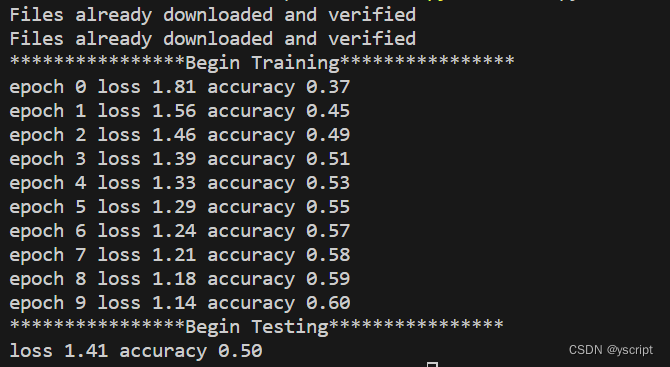
Pytorch-MLP-CIFAR10
文章目录 model.pymain.py参数设置注意事项运行图 model.py import torch.nn as nn import torch.nn.functional as F import torch.nn.init as initclass MLP_cls(nn.Module):def __init__(self,in_dim3*32*32):super(MLP_cls,self).__init__()self.lin1 nn.Linear(in_dim,1…...

SQL2 查询多列
描述 题目:现在运营同学想要用户的设备id对应的性别、年龄和学校的数据,请你取出相应数据 示例:user_profile iddevice_idgenderageuniversityprovince12138male21北京大学Beijing23214male复旦大学Shanghai36543female20北京大学Beijing42…...
)
算法分享三个方面学习方法(做题经验,代码编写经验,比赛经验)
目录 0 . 前言:(遇到OI不要慌)(只要道路对了,就不怕遥远) 1. 做题经验谈 1.1 做题的目的 1.2 我对于算法比赛的题目的看法 1.2.1 类似题 1.2.2 套模型: 1.3 在训练过程中如何做题 1.4 一些建议&…...

爬虫 — 验证码反爬
目录 一、超级鹰二、图片验证模拟登录1、页面分析1.1、模拟用户正常登录流程1.2、识别图片里面的文字 2、代码实现 三、滑块模拟登录1、页面分析2、代码实现(通过对比像素获取缺口位置) 四、openCV1、简介2、代码3、案例 五、selenium 反爬六、百度智能云…...

视频图像处理算法opencv模块硬件设计图像颜色识别模块
1、Opencv简介 OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上 它轻量级而且高效——由一系列 C 函数和少量 C 类构成,同时提供了Python、Rub…...

目标检测网络之Fast-RCNN
文章目录 Fast RCNN解决的问题Fast RCNN网络结构RoI pooling layer合并损失函数及其传播统一的损失函数损失函数的反向传播过程Fast RCNN的训练方法样本选择方法SGD参数设置多尺度图像训练SVD压缩全连接层对比实验对比实验使用到的网络结构VOC2010和VOC2012数据集结果VOC2007数…...
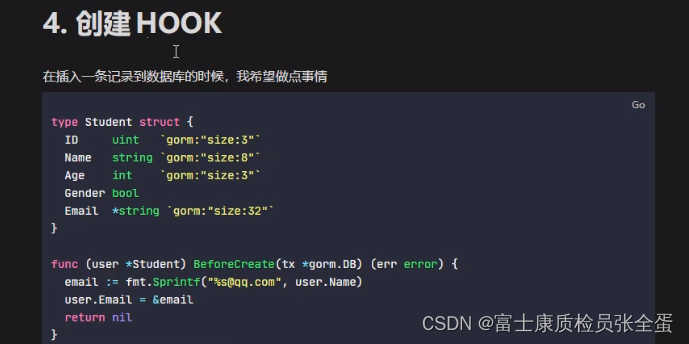
Golang Gorm 创建HOOK
创建的时候,在插入数据之前,想要做一些事情。钩子函数比较简单,就是实现before create的一个方法。 package mainimport ("gorm.io/driver/mysql""gorm.io/gorm" )type Student struct {ID int64Name string gorm:&q…...

计算机视觉的应用15-图片旋转验证码的角度计算模型的应用,解决旋转图片矫正问题
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用15-图片旋转验证码的角度计算模型的应用,解决旋转图片矫正问题,在CV领域,图片旋转验证码的角度计算模型被广泛应用于解决旋转图片矫正问题,有效解决机…...
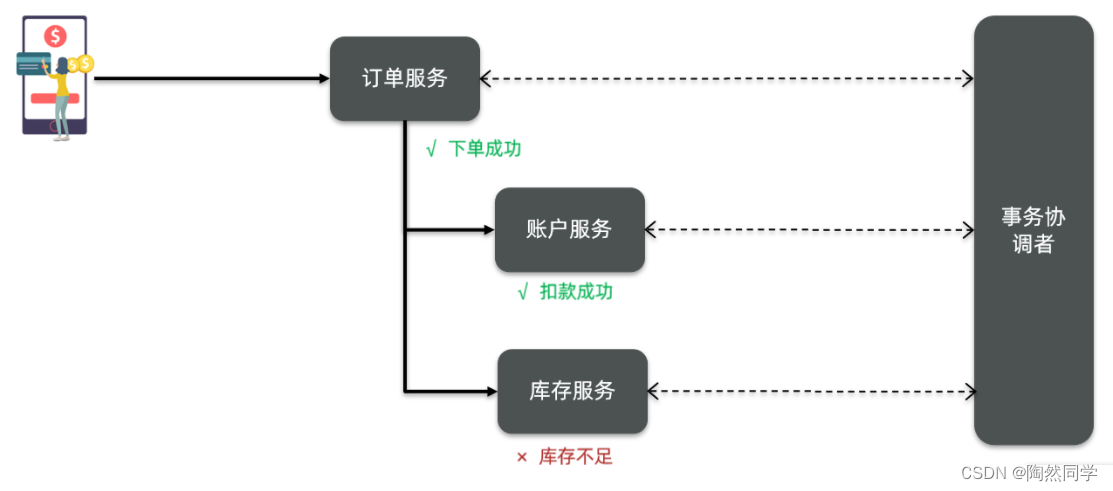
【Seata】分布式事务问题和理论基础
目录 1.分布式事务问题 1.1本地事务 1.2分布式事务 2.理论基础 2.1CAP定理 2.1.1一致性 2.1.2可用性 2.1.3分区容错 2.1.4矛盾 2.2BASE理论 2.3解决分布式事务的思路 1.分布式事务问题 1.1本地事务 本地事务,也就是传统的单机事务。在传统数据库事务中…...
文件打包解包的方法
在很多情况下,软件需要隐藏一些图片,防止用户对其更改,替换。例如腾讯QQ里面的资源图片,哪怕你用Everything去搜索也搜索不到,那是因为腾讯QQ对这些资源图片进行了打包,当软件运行的时候解包获取资源图片。…...
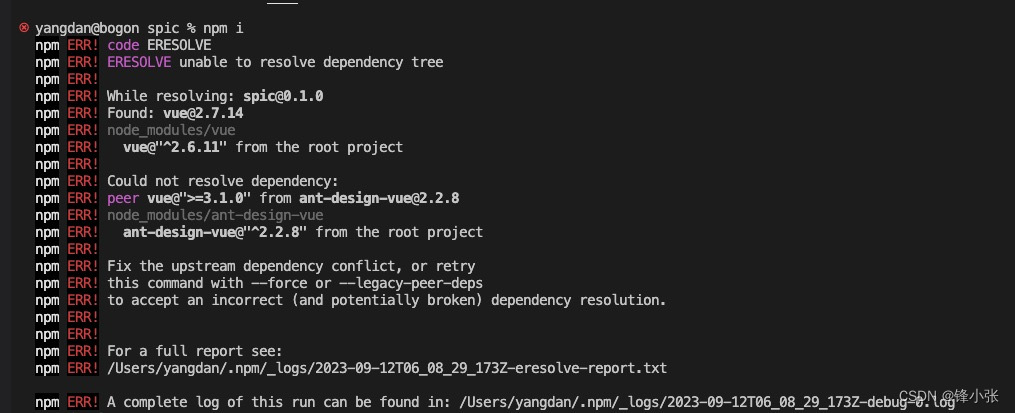
npm 清缓存(重新安装node-modules)
安装node依赖包的会出现失败的情况,如下图所示: 此时 提示有些依赖树有冲突,根据提示 “ this command with --force or --legacy-peer-deps” 执行命令即可。 具体步骤如下: 1、先删除本地node-modules包 2、删掉page-loacl…...
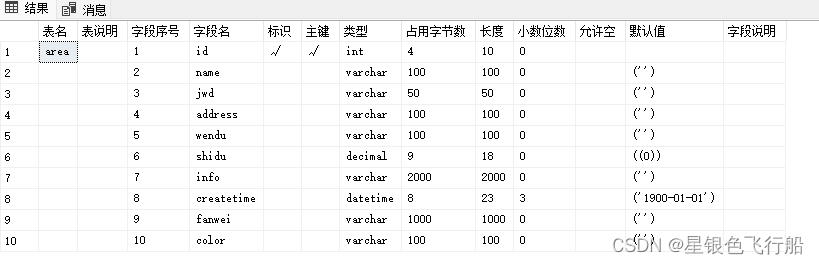
sqlserver查询表中所有字段信息
精简 SELECT 字段名 a.name,主键 case when exists(SELECT 1 FROM sysobjects where xtypePK and parent_obja.id and name in (SELECT name FROM sysindexes WHERE indid in( SELECT indid FROM sysindexkeys WHERE id a.id AND colida.colid))) then √ else …...
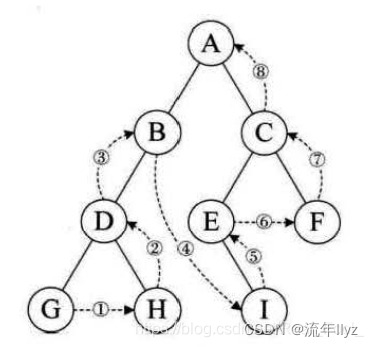
二叉树的概念、存储及遍历
一、二叉树的概念 1、二叉树的定义 二叉树( binary tree)是 n 个结点的有限集合,该集合或为空集(空二叉树),或由一个根结点与两棵互不相交的,称为根结点的左子树、右子树的二叉树构成。 二叉树的…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...