接口自动化测试(Python+Requests+Unittest)
(1)接口自动化测试的意义、前后端分离思想
接口自动化测试的优缺点:
优点:
-
测试复用性。
-
维护成本相对UI自动化低一些。
为什么UI自动化维护成本更高? 因为前端页面变化太快,而且UI自动化比较耗时(比如等待页面元素的加载、添加等待时间、定位元素、操作元素、模拟页面动作这些都需要时间)为什么接口自动化维护成本较低? 因为接口较稳定,接口的响应时间基本上都是秒级、毫秒级别的,速度快,并且接口自动化本身也可以做一些有关联的操作、全流程的操作(比如:注册 --> 登录 --> 修改个人信息)。 -
回归方便。
-
可以运行更多更繁琐的测试。自动化的一个明显的好处是可以在较少的时间内运行更多的测试。
优点1、优点3、优点4是接口自动化和UI自动化公有的优点。
缺点:
- 不能完全取代手工测试。(自动化永远不能替代手工测试,只是提高测试效率)
- 手工测试比自动化测试发现的缺陷更多,自动化测试不容易发现新的BUG。
GET请求和POST请求的区别:
-
GET请求一般是
从后台服务器上获取数据用于前端页面的展示(例如:看到列表页面等),POST请求是向服务器传送数据(登录、注册、上传文件、发布文章)。什么时候用GET,什么时候用POST取决于开发。无论用POST请求还是GET请求,都能完成对数据的增删改查,分不同的请求方式更多的是一种约定。 -
GET请求的
请求参数是拼接在url后面的,只能以文本的形式传递参数,请求参数会显示在地址栏,数据长度受限于url的长度,传递的数据量小(4KB左右,不同浏览器会有差异),POST请求的请求参数是放在request body里面,传递数据量大(默认8M),对数据长度也没有要求。GET请求可以在浏览器中直接访问,而POST请求只能借助工具完成(比如:postman、jmeter)。 -
GET请求速度快,安全性不高;POST请求一般用于像登录这种安全性要求高的场合,请求不会被缓存,也不会保留在浏览器的历史记录中。
以前:get 查询;post 新增;put 编辑;delete 删除
现在:get 查询;post 新增 + 编辑 + 删除
或者:纯post走天下
前后端分离
开发模式
以前老的方式:
- 产品经理 / 领导 / 客户提出需求(提出文字需求)
- UI做出设计图
- 前端工程师做html页面(用户能看到的页面)
- 后端工程师将html页面套成jsp页面(前后端强依赖,后端必须要等到前端的html页面做好才能套jsp。如果html发生变更,就很麻烦,开发效率低)
- 集成出现问题
- 前端返工
- 后端返工
- 二次集成
- 集成成功
- 交付
新的方式:
- 产品经理 / 领导 / 客户提出需求(提出文字需求)
- UI做出设计图
- 前后端约定接口 & 数据 & 参数
- 前后端并行开发(无强依赖,可前后端并行开发,如果需求变更,只要接口 & 参数不变,就不用两边都修改代码,开发效率高)
- 前后端集成
- 前端页面调整
- 集成成功
- 交付
🤑通过F12打开浏览器开发者工具进行抓包,返回数据是json格式的就是前后端分离,返回时html页面就是没有前后端分离。
微服务的概念:
将大模块切分成小模块。减少代码的耦合度,从而降低模块与模块之间的影响。原先是一个jar包里面包含所有模块,改一个模块就有可能影响其他模块,现在是将一个一个的模块都打成一个一个的jar包,模块与模块之间的交互通过接口,哪个模块出了问题,只需要修改那个模块的jar包,避免因为修改一个模块的代码导致其他模块出错。
(2)Python requests框架讲解
接口自动化requests环境搭建
接口自动化核心库:requests
安装requests库的方法:
方法一:
命令行安装,打开cmd或者终端,输入以下命令:
pip install requests -i https://pypi.douban.com/simple/
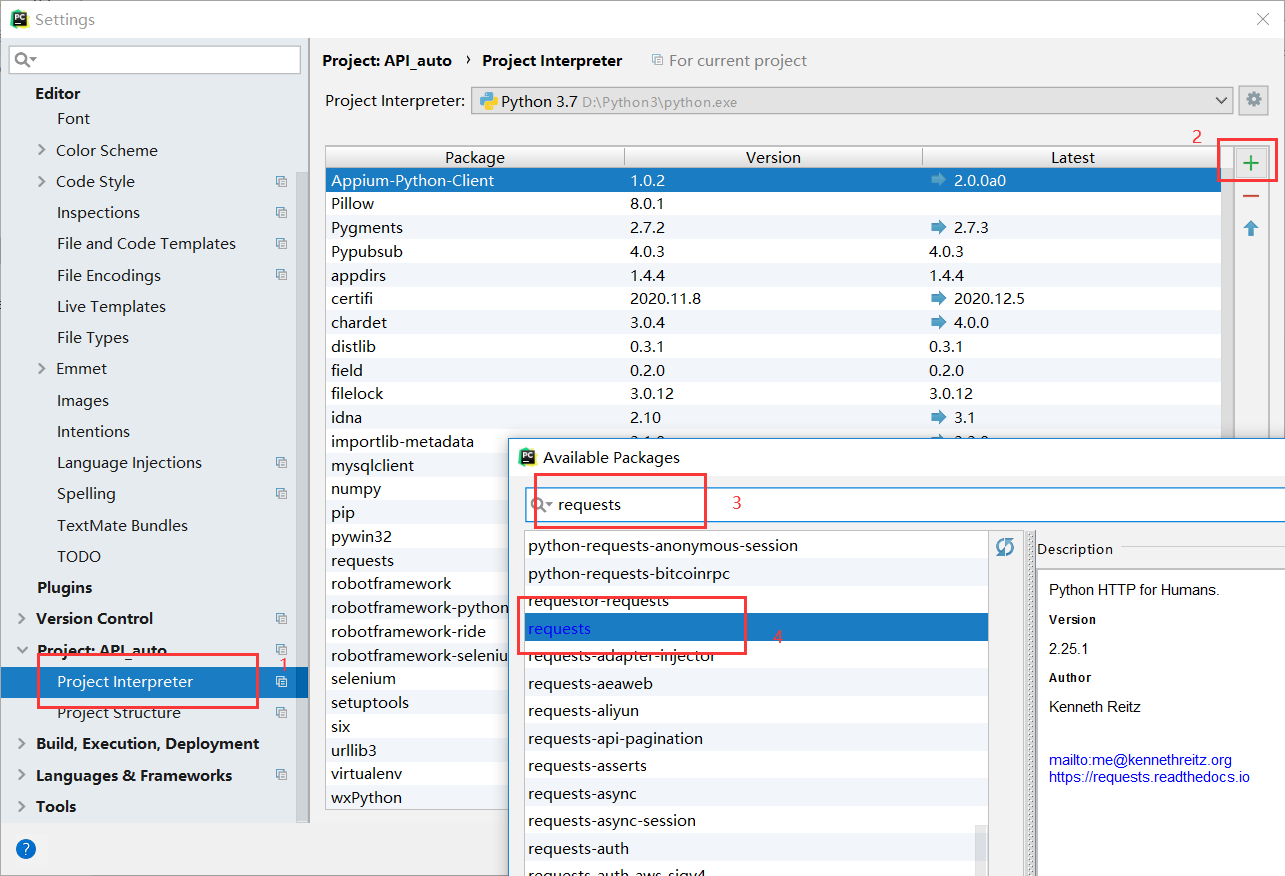
方法二:
在pycharm中安装,settings --> Project --> Project Interpreter --> 点击“+”号 --> 输入request安装
测试环境是否ok
# -*- coding:utf-8 -*-import requestsurl_toutiao = "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=10&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768"
# 方式一:
# result_toutiao = requests.get(url_toutiao)# 方式二:
result_toutiao = requests.get(url=url_toutiao)# 方式三:
# result_toutiao = requests.get(
# "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=1&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768")# print(result_toutiao.json())
# print(type(result_toutiao.json())) # <class 'dict'>
result = result_toutiao.json()
print(result)
expect_result = "华晨金杯汽车花朵朵"
actual_result = result["data"][0]["comment"]["user_name"]
print(actual_result)
if expect_result == actual_result:print("pass!")
else:print("failed!")
响应超时timeout
import requests# V部落:http://[服务器ip]:8081/index.html
# 文章列表
url_v_article = "http://[服务器ip]:8081/article/all"
v_headers = {"Cookie": "studentUserName=ctt01; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609742724,1609762306,1609841170,1609860946; adminUserName=admin; JSESSIONID=9D1FF19F333C5E25DBA60769E9F5248E"}
article_params = {"state": 1, # -1:全部文章 1:已发表 0:回收站 2:草稿箱"page": 1, # 显示第1页"count": 6, # 每页显示6条"keywords": "" # 包含的关键字}
keywords = ["大橘猫", "跑男", "牙"]
for keyword in keywords:article_params["keywords"] = keyword# headers和params是不定长的,根据定义的字典传参# timeout超时,单位为秒# 通过设置超时时间,告诉requests在经过多久后停止等待响应result = requests.get(url_v_article, headers=v_headers, params=article_params, timeout=30)print(result.json())
JSON、URL、text、encoding、status_code、encoding、cookies
print(result.json()) # 响应结果以json的形式打印输出
print(result.url) # 打印url地址
print(result.text) # 以文本格式打印服务器响应的内容
print(result.status_code) # 响应状态码
print(result.encoding) # 编码格式
print(result.cookies) # cookie
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
JSON格式在Python里面相当于字典类型。
JSON格式化:JSON在线视图查看器(Online JSON Viewer)
url在线编码转换:URL在线编码转换工具 - 编码转换工具 - W3Cschool
(3)get、post、put、delete请求方式的自动化实现
GET请求方式
# -*- coding:utf-8 -*-import requestsurl_toutiao = "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=10&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768"
# 方式一:
# result_toutiao = requests.get(url_toutiao)# 方式二:
result_toutiao = requests.get(url=url_toutiao)# 方式三:
# result_toutiao = requests.get(
# "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=1&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768")# print(result_toutiao.json())
# print(type(result_toutiao.json())) # <class 'dict'>
result = result_toutiao.json()
print(result)
expect_result = "华晨金杯汽车花朵朵"
actual_result = result["data"][0]["comment"]["user_name"]
print(actual_result)
if expect_result == actual_result:print("pass!")
else:print("failed!")运行结果:
{'message': 'success', 'err_no': 0, 'data': [{'comment': {'id': 6914864825282215951, 'id_str': '6914864825282215951', 'text': '藁城出国打工的人很多,重点检查藁城区!', 'content_rich_span': '{"links":[]}', 'user_id': 940799526971408, 'user_name': '华晨金杯汽车花朵朵',}, 'post_count': 0, 'stick_toast': 1, 'stable': True}
华晨金杯汽车花朵朵
pass!
POST请求方式
# -*- coding:utf-8 -*-import requestsurl_v_login = "http://[服务器ip]:8081/login"
# 定义参数,字典格式
payload = {'username': 'sang', 'password': '123'}
# Content-Type: application/json --> json
# Content-Type: application/x-www-form-urlencoded --> data
result = requests.post(url_v_login, data=payload)
# 将返回结果转为json格式
result_json = result.json()
print(result_json) # {'status': 'success', 'msg': '登录成功'}
# 获取RequestsCookieJar
result_cookie = result.cookies
print(result_cookie, type(result_cookie)) # RequestsCookieJar
# 将RequestsCookieJar转化为字典格式
result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie)
print(result_cookie_dic) # {'JSESSIONID': 'D042C5FE4CFF337806D545B0001E7197'}
# 获取SESSION
final_cookie = "JSESSIONID=" + result_cookie_dic["JSESSIONID"] # SJSESSIONID=D042C5FE4CFF337806D545B0001E7197
print(final_cookie)
PUT请求方式
# V部落_编辑栏目# 定义请求头,自动获取cookie的方法详情请看下文
headers = {"Cookie": "VBlog(self.requests).get_cookie()"}
new_now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time()))
new_category_name = "更新栏目" + new_now_time
payload = {"id": 2010, "cateName": new_category_name}
self.requests.put("http://[服务器ip]:8081/admin/category/", headers=headers, data=payload)
DELETE请求方式
# 删除栏目
result = self.requests.delete("http://[服务器ip]:8081/admin/category/" + “2010”, headers=headers)
print(result.json()) # {'status': 'success', 'msg': '删除成功!'}
self.assertEqual("删除成功!", result.json()["msg"])
(4)接口自动化测试过程中cookie的处理
手动传入cookie的值(每次通过浏览器F12抓包,然后复制request header里面的cookie)
# -*- coding:utf-8 -*-
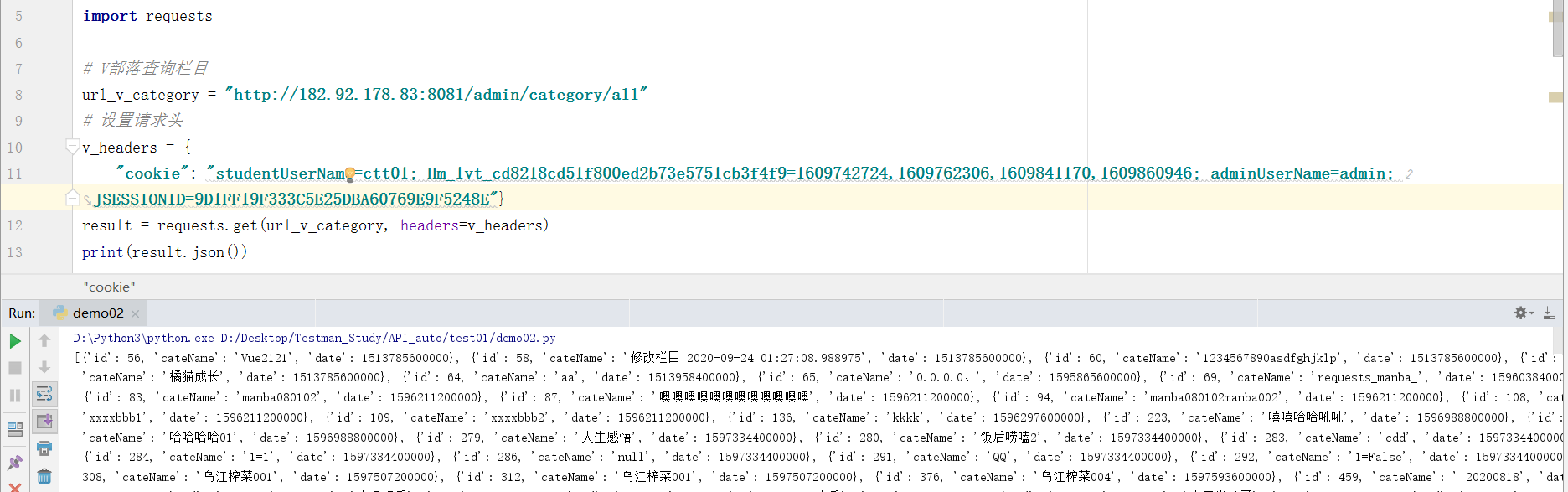
import requests# V部落查询栏目
url_v_category = "http://[服务器ip]:8081/admin/category/all"
# 定制请求头
# 如果你想为请求添加HTTP头部,只要简单地传递一个字典给headers参数就可以了
v_headers = {"cookie": "studentUserName=ctt01; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609742724,1609762306,1609841170,1609860946; adminUserName=admin; JSESSIONID=9D1FF19F333C5E25DBA60769E9F5248E"}
result = requests.get(url_v_category, headers=v_headers)
# 打印json格式的响应结果
print(result.json())
cookie自动获取
# -*- coding:utf-8 -*-import requestsurl_v_login = "http://[服务器ip]:8081/login"
# 定义参数,字典格式
payload = {'username': 'sang', 'password': '123'}
# Content-Type: application/json --> json
# Content-Type: application/x-www-form-urlencoded --> data
result = requests.post(url_v_login, data=payload)
# 将返回结果转为json格式
result_json = result.json()
print(result_json) # {'status': 'success', 'msg': '登录成功'}
# 获取RequestsCookieJar
result_cookie = result.cookies
print(result_cookie, type(result_cookie)) # RequestsCookieJar
# 将RequestsCookieJar转化为字典格式
result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie)
print(result_cookie_dic) # {'JSESSIONID': 'D042C5FE4CFF337806D545B0001E7197'}
# 获取SESSION
final_cookie = "JSESSIONID=" + result_cookie_dic["JSESSIONID"] # SJSESSIONID=D042C5FE4CFF337806D545B0001E7197
print(final_cookie)
批量获取cookie脚本
# -*- coding:utf-8 -*-import requestsdef get_cookie(username, password):"""通过考试系统学生登录获取单个cookie"""url_login = "http://[服务器ip]:8088/api/user/login"payload = {"userName": username, "password": password, "remember": False}result = requests.post(url_login, json=payload)# result_json = result.json()# print(result_json)# 获取RequestsCookieJarresult_cookie = result.cookies# print(result_cookie, type(result_cookie)) # RequestsCookieJar# 将RequestsCookieJar转化为字典格式result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie)# print(result_cookie_dic) # {'SESSION': 'YzFkM2IzN2QtZWY1OC00Nzc4LTgyOWYtNjg5OGRiZDZlM2E4'}# 获取SESSIONfinal_cookie = "SESSION=" + result_cookie_dic["SESSION"] # SESSION=Mzc2...return final_cookie
# -*- coding:utf-8 -*-from test01.demo04_student_login import get_cookie
import osdef get_batch_cookies():"""批量获取cookie"""# 获取cookie之前,先将cookies.csv文件内容清空# with open(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv", "w") as cookies_info:# cookies_info.write("")# 或者将文件删除os.remove(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv")# 读取csv文件with open(r"D:\Desktop\Testman_Study\API_auto\file\register.csv", "r") as user_info:for user in user_info:user_list = user.strip().split(",")# 调用获取单个cookies的方法,传入注册好的用户名和密码cookies = get_cookie(user_list[0], user_list[1])# 将cookie追加写入文件with open(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv", "a") as cookies_info:cookies_info.write(cookies + "\n")# 调用方法
get_batch_cookies()
register.csv(前提是这些账号和密码都是已经注册过的,可以直接登录)poopoo001,123456,1
poopoo002,123457,2
poopoo003,123458,3
poopoo004,123459,4
......
cookies.csvSESSION=ZmE3YmU4ZDctNDExZS00MDdhLWE0YjEtMjAyZjQxOTMxYmUx
SESSION=YjdkNTZhNTUtNGFmMi00MjVkLWEyNjctOTNiMmRmOTY1YTdm
SESSION=ZTJmMTYzMWEtZjUzOS00NTlhLWI0OWQtMzBmN2RkYmU4YmRi
SESSION=YTM0ZGRhOTctZjk5Ni00OWZhLTg1YTItZjUyMTMwZGE2MjVi
......
(5)不同类型请求参数的处理
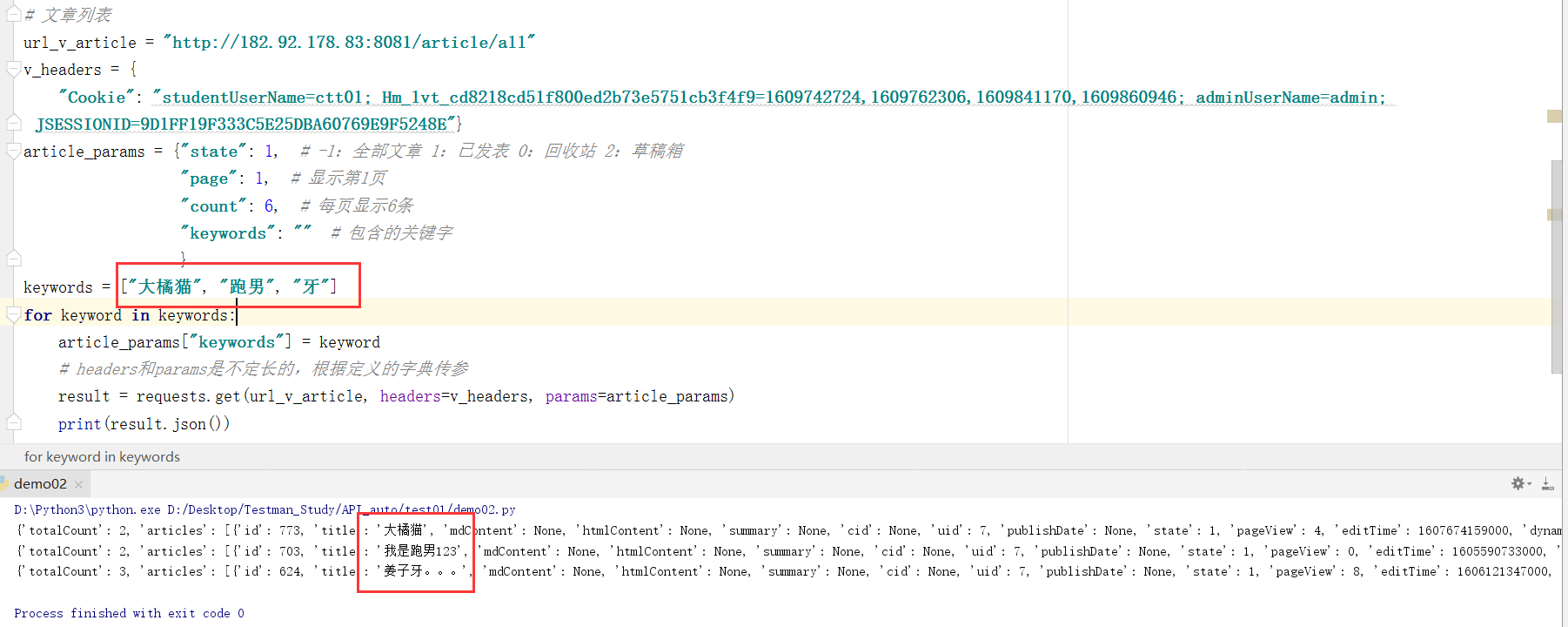
# -*- coding:utf-8 -*-import requests# 文章列表
url_v_article = "http://[服务器ip]:8081/article/all"
v_headers = {"Cookie": "studentUserName=ctt01; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609742724,1609762306,1609841170,1609860946; adminUserName=admin; JSESSIONID=9D1FF19F333C5E25DBA60769E9F5248E"}# 自定义url参数,定义一个字典,将参数拆分,再将字典传递给params变量即可
article_params = {"state": 1, # -1:全部文章 1:已发表 0:回收站 2:草稿箱"page": 1, # 显示第1页"count": 6, # 每页显示6条"keywords": "" # 包含的关键字}
keywords = ["大橘猫", "跑男", "牙"]
for keyword in keywords:article_params["keywords"] = keyword# headers和params是不定长的,根据定义的字典传参result = requests.get(url_v_article, headers=v_headers, params=article_params)print(result.json())
(6)结合Python+Requests+Unittest框架做接口自动化测试
unittest框架结构:

代码地址:https://github.com/itcaituotuo/unittest_api
if _name_ == '__main__':
if __name__ == '__main__'的意思是:
- 当.py文件被直接运行时,
if __name__ == '__main__'下的代码块将被运行; - 当.py文件以模块形式被导入时,
if __name__ == '__main__'下的代码块不被运行。
(7)接口自动化测试过程中高级断言
闭环断言(新增 --> 查询 --> 修改 --> 查询 --> 删除 -->查询)
def test_article(self):# ①V部落_新增文章now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time()))title = "123" + now_timepayload = {"id": -1, "title": title, "mdContent": "文章内容", "state": 1, "htmlContent": "<p>文章内容</p>","dynamicTags": "", "cid": 62}headers = {"Cookie": VBlog(self.requests).get_cookie()}result = self.requests.post("http://[服务器ip]:8081/article/", headers=headers, data=payload)# ②查询文章url_v_article = "http://[服务器ip]:8081/article/all"article_params = {"state": 1, # -1:全部文章 1:已发表 0:回收站 2:草稿箱"page": 1, # 显示第1页"count": 6, # 每页显示6条"keywords": title # 包含的关键字title}result = requests.get(url_v_article, headers=headers, params=article_params, timeout=30)print(result.json()) # 响应结果以json的形式打印输出ls = result.json()["articles"]act = 123# 查到新增的文章,说明新增成功for l in range(0, len(ls)):if ls[l]["title"] == title:act = "ok"article_id = ls[l]["id"]self.assertEqual("ok", act)# ③编辑文章now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time()))title = "修改文章" + now_timepayload = {"id": article_id, "title": title, "mdContent": "修改内容", "state": 1, "htmlContent": "<p>修改内容</p>","dynamicTags": "", "cid": 62}headers = {"Cookie": VBlog(self.requests).get_cookie()}self.requests.post("http://[服务器ip]:8081/article/", headers=headers, data=payload)# 编辑完,查询文章url_v_article = "http://[服务器ip]:8081/article/all"article_params = {"state": 1, # -1:全部文章 1:已发表 0:回收站 2:草稿箱"page": 1, # 显示第1页"count": 6, # 每页显示6条"keywords": title # 包含的关键字title}result = requests.get(url_v_article, headers=headers, params=article_params, timeout=30)print(result.json()) # 响应结果以json的形式打印输出ls = result.json()["articles"]act = 123# 查到修改过的文章,说明编辑成功for l in range(0, len(ls)):if ls[l]["title"] == title:act = "ok"article_id = ls[l]["id"]self.assertEqual("ok", act)# ④查看文章详情article_id = str(article_id)result = self.requests.get("http://[服务器ip]:8081/article/" + article_id, headers=headers)print(result.json())if result.json()["title"] == title:act = "ok"self.assertEqual(act, "ok")# ⑤删除文章payload = {'aids': article_id, 'state': 1}result = self.requests.put("http://[服务器ip]:8081/article/dustbin", headers=headers, data=payload)print(result.json())act = result.json()["msg"]self.assertEqual(act, "删除成功!")
(8)通过HTMLTestRunner.py生成可视化HTML测试报告
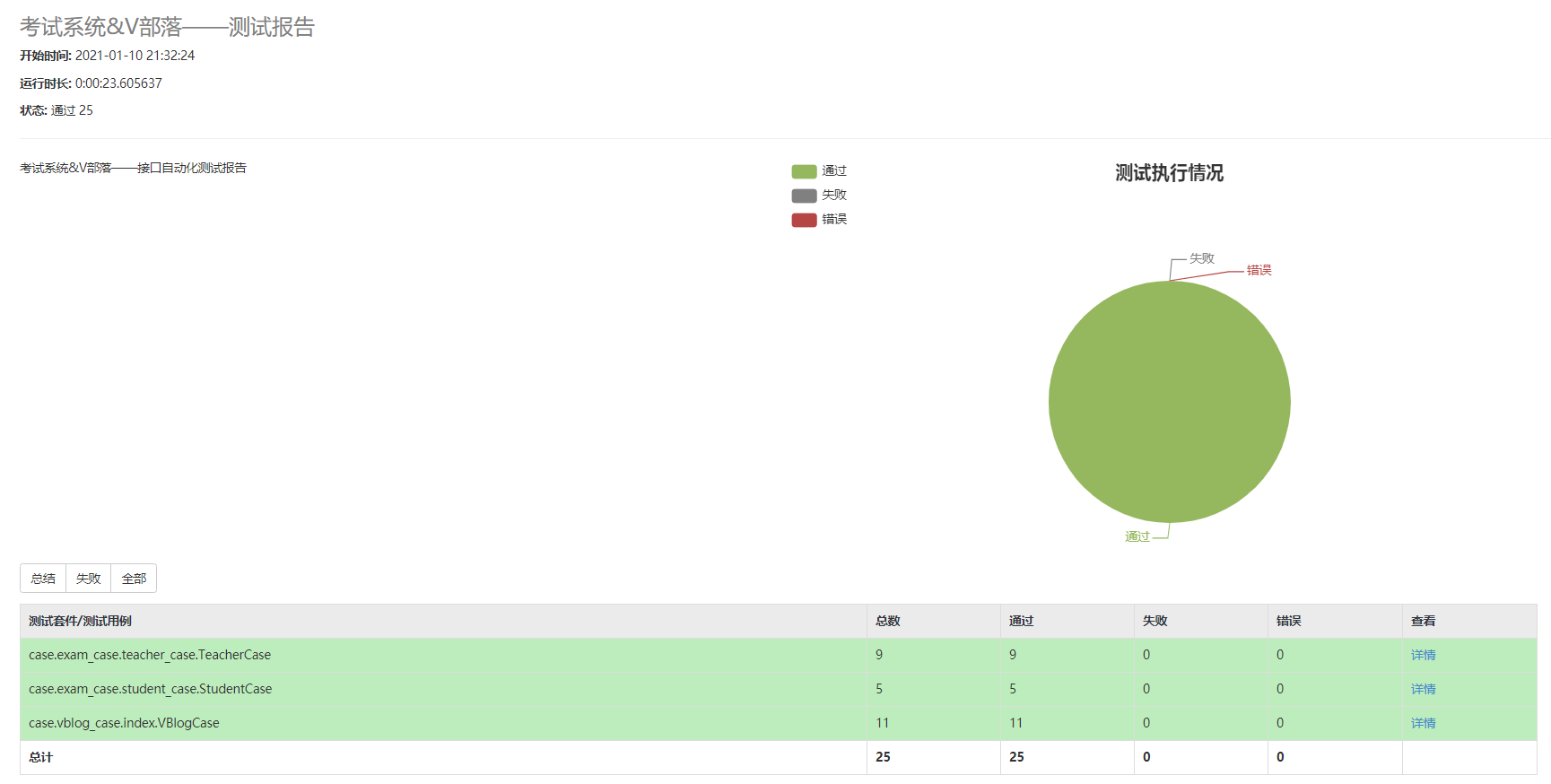
HTMLTestRunner.py百度网盘链接:
# -*- coding:utf-8 -*-from reports import HTMLTestRunner
from case.exam_case.teacher_case import TeacherCase
import unittest
import os
import time# 创建测试套件
suite = unittest.TestSuite()# 添加测试用例,根据添加顺序执行
# 添加单个测试用例
# suite.addTest(TeacherCase("test_001_admin_login"))# 添加多个测试用例
suite.addTests([TeacherCase("test_001_admin_login"),TeacherCase("test_002_insert_paper"),TeacherCase("test_003_select_paper"),])# 定义测试报告的存放的路径
path = r"D:\Desktop\Testman_Study\unittest_exam_system\reports"
# 判断路径是否存在
if not os.path.exists(path):# 如果不存在,则创建一个os.makedirs(path)
else:pass
# 定义一个时间戳用于测试报告命名
now_time = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime(time.time()))
reports_path = path + "\\" + now_time + "(exam_report).html"
reports_title = u"考试系统&V部落——测试报告"
desc = u"考试系统&V部落——接口自动化测试报告"
# 二进制写
fp = open(reports_path, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=reports_title, description=desc)
# 运行
runner.run(suite)
PYTHON 复制 全屏
postman、JMeter、requests总结:
- postman:接口功能测试
- JMeter:接口性能测试
- requests:接口自动化
- 🐵三个的共同特点:都能完成接口功能测试。
相关文章:
接口自动化测试(Python+Requests+Unittest)
(1)接口自动化测试的意义、前后端分离思想 接口自动化测试的优缺点: 优点: 测试复用性。 维护成本相对UI自动化低一些。 为什么UI自动化维护成本更高? 因为前端页面变化太快,而且UI自动化比较耗时(比如等待页面元素的…...
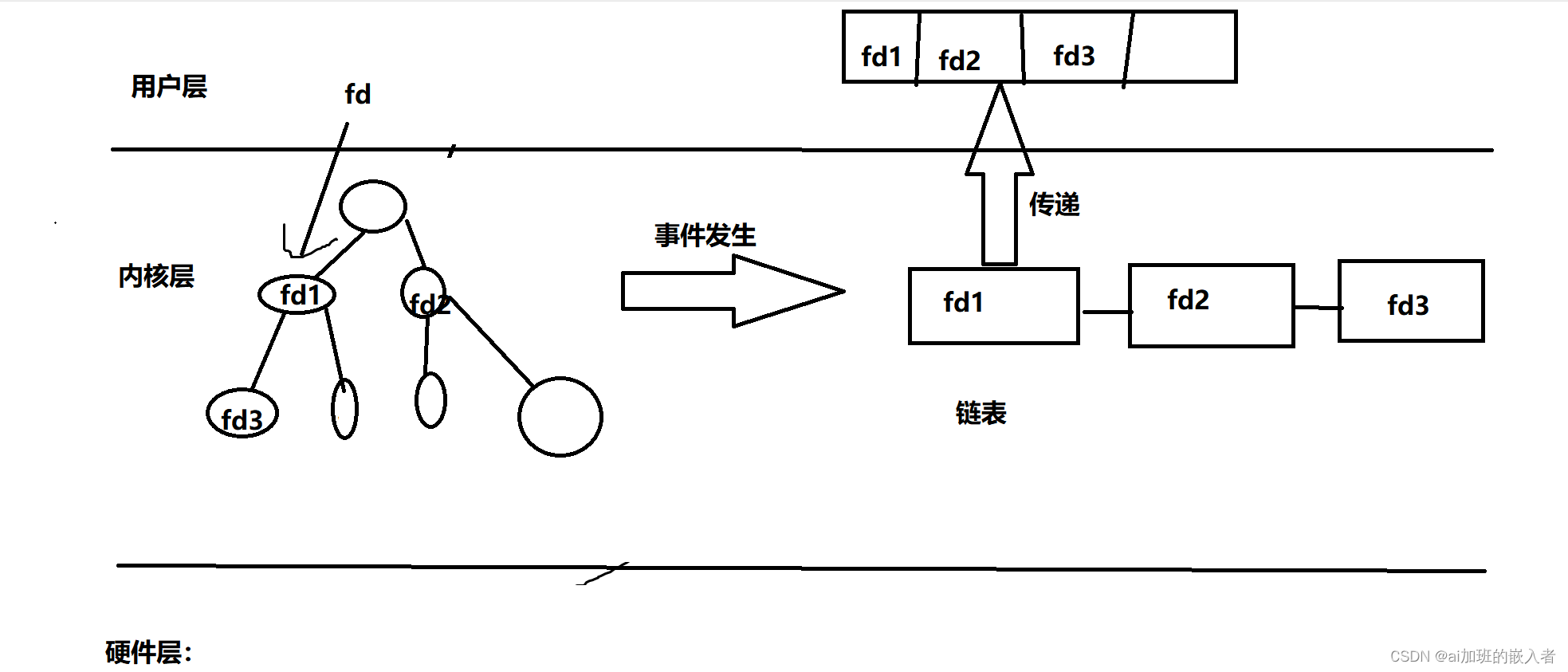
驱动开发,IO多路复用(select,poll,epoll三种实现方式的比较)
1.IO多路复用介绍 在使用单进程或单线程情况下,同时处理多个输入输出请求,需要用到IO多路复用;IO多路复用有select/poll/epoll三种实现方式;由于不需要创建新的进程和线程,减少了系统资源的开销,减少了上下…...
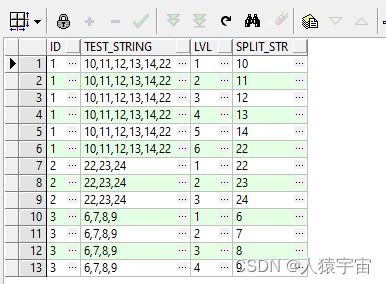
大数据-玩转数据-oracel字符串分割转化为多列
一、建表 create table split_string_test(id integer primary key,test_string varchar2(500) );二、插入测试数据 insert into split_string_test values(1, 10,11,12,13,14,22); insert into split_string_test values(2, 22,23,24); insert into split_string_test valu…...

GCP设置Proxy来连接Cloud SQL
在之前的文章用Google CDC来同步Cloud SQL的数据到Bigquery_gzroy的博客-CSDN博客中,我通过在一个VM上设置反向代理的方式,使得Datastream可以通过私用连接连到Cloud SQL数据库进行数据复制。但是这种方式不太方便,主要是VM的状态我们不太方便…...

Python:为何成为当下最热门的编程语言?
文章目录 🍋引言🍋1. 简单易学🍋2. 多领域应用🍋3. 强大的社区支持🍋4. 丰富的库和框架🍋5. 跨平台兼容🍋6. 开源和免费🍋7. 数据科学和人工智能的崛起🍋8. 自动化和脚本…...

【echarts入门】:vue项目中应用echarts
一.安装echarts 在项目集成终端下载echarts npm install echarts --save 二.全局引入 创建/components/echarts/index.js // 引入 echarts 核心模块,核心模块提供了 echarts 使用必须要的接口。 import * as echarts from "echarts/core";/** 引入任…...
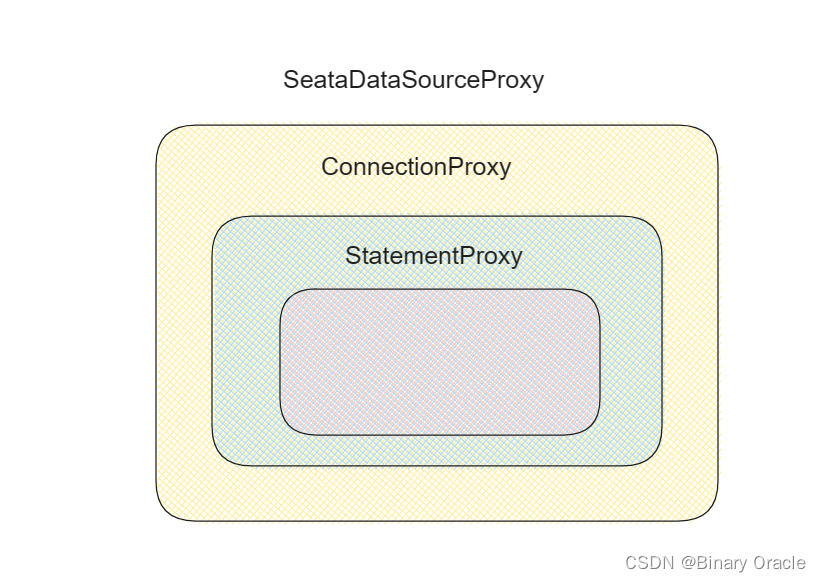
Seata 源码篇之AT模式启动流程 - 上 - 02
Seata 源码篇之AT模式启动流程 - 02 自动配置两个关键点 初始化初始化TM初始化RM初始化TC 全局事务执行流程TM 发起全局事务GlobalTransactional 注解处理全局事务的开启 TM 和 RM 执行分支事务IntroductionDelegatingIntroductionInterceptorDelegatePerTargetObjectIntroduct…...
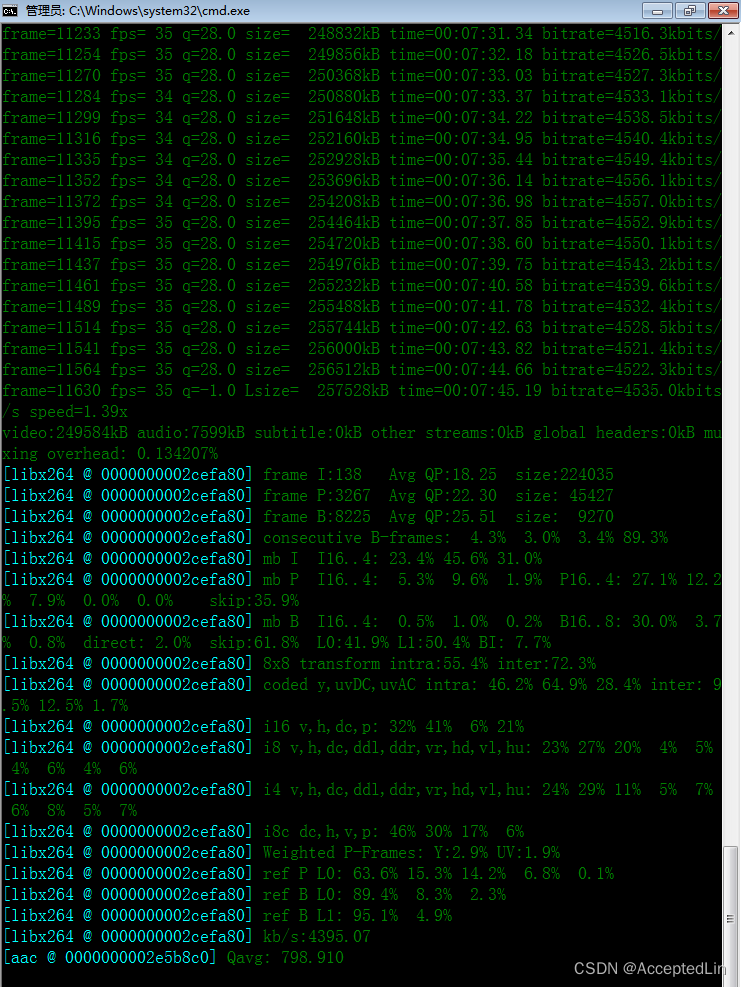
FFMPEG视频压缩与Python使用方法
一、简介 FFMPEG 是一个完整的,跨平台的解决方案,记录,转换和流音频和视频。 官网:https://ffmpeg.org/ 二、安装 1、Linux: sudo apt install ffmpeg 2、Mac: brew install ffmpeg 3、Windows: 下载文件&#…...

SpringMVC自定义注解---[详细介绍]
一,对于SpringMVC自定义注解概念 是一种特殊的 Java 注解,它允许开发者在代码中添加自定义的元数据,并且可以在运行时使用反射机制来获取和处理这些信息。在 Spring MVC 中,自定义注解通常用于定义控制器、请求处理方法、参数或者…...
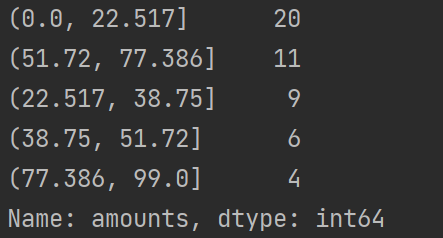
5.4 转换数据
5.4 转换数据 5.4.1 哑变量处理类别型数据5.4.2 离散化连续型数据1、等宽法2、等频法3、聚类分析法 数据集 E:/Input/ptest.csv 5.4.1 哑变量处理类别型数据 数据分析模型中有相当一部分的算法模型都要求输入的特征为数值型,但实际数据中特征的类型不一定只有数值…...

雷池社区WAF:保护您的网站免受黑客攻击 | 开源日报 0918
keras-team/keras Stars: 59.2k License: Apache-2.0 Keras 是一个用 Python 编写的深度学习 API,运行在机器学习平台 TensorFlow 之上。它 简单易用:减少了开发者认知负荷,使其能够更关注问题中真正重要的部分。灵活性强:通过逐…...
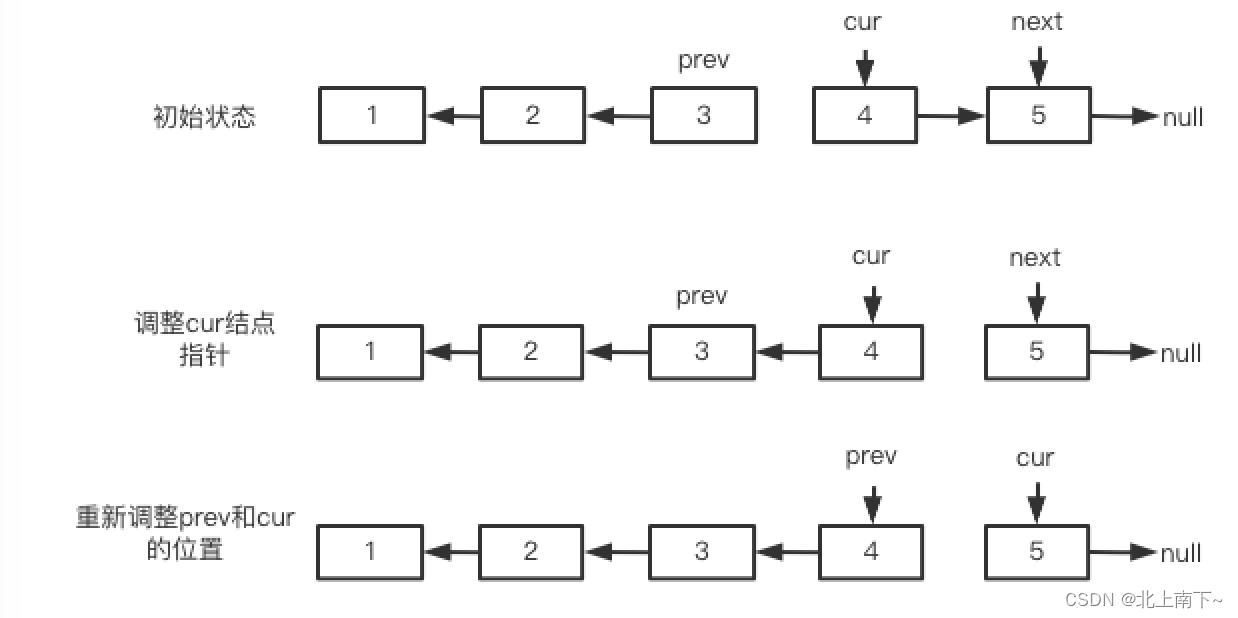
链表反转-LeetCode206
**题目:**给你单链表的头结点head,请反转链表,并返回反转后的链表。 示例: 输入:head [1,2,3,4,5] 输出:[5,4,3,2&#x…...

北邮22级信通院数电:Verilog-FPGA(3)实验“跑通第一个例程”modelsim仿真及遇到的问题汇总(持续更新中)
北邮22信通一枚~ 跟随课程进度更新北邮信通院数字系统设计的笔记、代码和文章 持续关注作者 迎接数电实验学习~ 获取更多文章,请访问专栏: 北邮22级信通院数电实验_青山如墨雨如画的博客-CSDN博客 注意:本篇文章所有绝对路径的展示都来自…...

4G工业路由器,开启智能工厂,这就是关键所在
提到工业物联网,首先联想到的就是数据传输。要把海量的工业数据从设备端传到控制中心,无线数传终端就发挥着重要作用。今天就跟着小编来看看它的“联”是怎么建立的吧! 原文:https://www.key-iot.com/iotlist/1838.html 一提到无线数传终端,相信大家首先想到的是…...

计组-机器字长、存储字长、指令字长以及和他们有关的机器位数
🌳🌳🌳前言:本文总结了机器字长、存储字长、指令字长的概念以及和它们相关的机器位数。 目录 字长 机器字长 指令字长 存储字长 寄存器的位数 总结 字长 🌟字长一个字中的二进制位数。 🌟字长由微处…...

解决express服务器接收post请求报错:“req.body==> undefined“
现象如下: 解决办法:在代码中加入body-parser解析 const bodyParser require("body-parser"); app.use(bodyParser.urlencoded({ extended: true })); app.use(bodyParser.json()); 参考: How to fix "req.body undefined&q…...
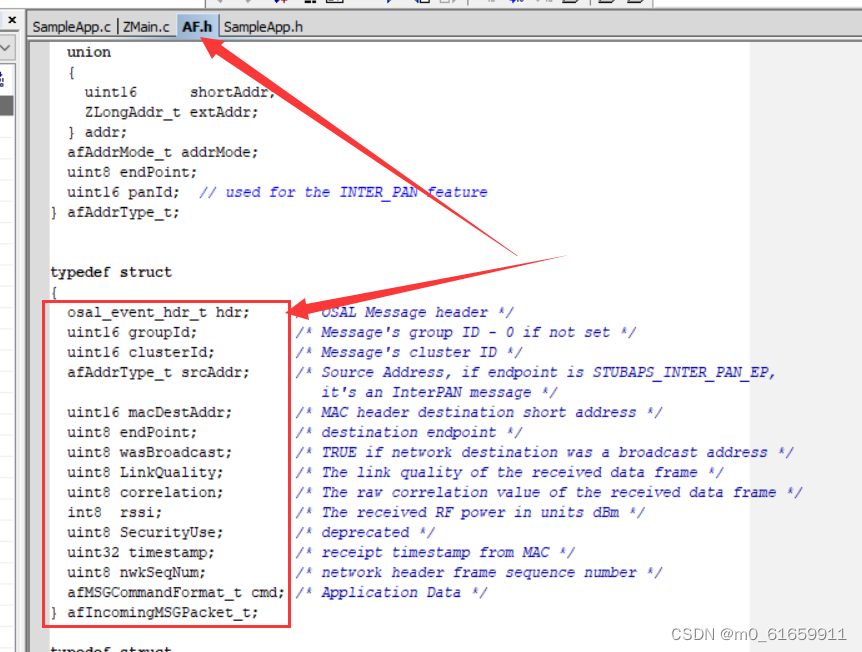
5.zigbee的开发,串口putchar重定向(使用print),单播实验,usb抓包实验
一。实验:单播 实验要求: 实现终端定时向协调器发送给“好好学习”字符串,并且从终端打印出来。 要求: 指定端点为 0x0005 指定簇为 0x0003 1.进入应用层SampleApp.c中,串口的重定向 报错ÿ…...

解决AU报“MME无法使用“问题
今天在Adobe Audition(简称AU)软件,打开麦克风时,弹出如下错误:“加载默认的输入和输出设备失败:MME设备内部错误”,如图(1)所示: 图(1) AU报“MME设备内部错误” 继续点击AU菜单栏上的【编辑】–》首选项–》音频硬件,…...

Maven 安装配置
Maven 安装配置 文章目录 Maven 安装配置一、下载 Maven二、解压Maven核心程序三、指定本地仓库四、配置阿里云镜像仓库4.1 将原有的例子配置注释掉4.2 加入新的配置 五、配置 Maven 工程的基础 JDK 版本六、配置环境变量6.1 检查 JAVAHOME 配置是否正确6.2 配置 MAVENHOME6.3 …...

vscode 配置网址
首先我的项目是一个面向医院的系统 我是在三个文件里都配置了网址 第一个文件:vue.config.js const path require(path) const webpack require(webpack) const createThemeColorReplacerPlugin require(./config/plugin.config)function resolve (dir) {retu…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...