sql explain
目录
- 1. sql explain
- 每个字段对应的含义
- 1.1. id
- 1.2. select_type
- 1.3. table
- 1.4. partitions
- 1.5. type
- 1.6. possible_keys
- 1.7. key
- 1.8. key_len
- 1.9. ref
- 1.10. rows
- 1.11. Extra
- 索引实践
- 联合索引最左列原则
- 全值匹配
- 不建议在索引列上做任何操作, 否则索引会失效转而全表扫描
- 尽量使用覆盖索引 不需要再回表查询了 效率较高
- 再试用 `!=` 或 `<>` 不等于查询时, 会导致索引失效。
- 尽量不要使用 `or`, `in` 操作, 在某些情况下也会导致索引失效。
- is null, is not null 一般情况下也无法使用索引
- 是用字符串查询 不见引号 索引也会失效
- 针对范围查找的不走索引的优化
- like 查询建议使用 `xxx%` 方式匹配, `%xxx` 或者 `%xxx%` 索引失效
1. sql explain
使用 Explain 可以查看 sql 的性能瓶颈信息, 并根据结果进行 sql 的相关优化。在 select 语句前加上 explain 关键字, 执行的时候并不会真正执行 sql 语句, 而是返回 sql 查询语句对应的执行计划信息。
当然如果 select 语句的 from 后面有一个子查询的话, 就会执行子查询了并把结果放到一个临时表中。
有三张表:
-- 演员表CREATE TABLE `actor` (`id` INT ( 11 ) NOT NULL,`name` VARCHAR ( 45 ) DEFAULT NULL,`update_time` datetime DEFAULT NULL,PRIMARY KEY ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8;INSERT INTO `actor` (`id`, `name`, `update_time`) VALUES (1,'a','2017-12-22 15:27:18'), (2,'b','2017-12-22 15:27:18'), (3,'c','2017-12-22 15:27:18');-- 电影表
CREATE TABLE `film` (`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,`name` VARCHAR ( 10 ) DEFAULT NULL,PRIMARY KEY ( `id` ),KEY `idx_name` ( `name` )
) ENGINE = INNODB DEFAULT CHARSET = utf8;INSERT INTO `film` (`id`, `name`) VALUES (3,'film0'),(1,'film1'),(2,'film2');-- 演员和电影中间表
CREATE TABLE `film_actor` (`id` INT ( 11 ) NOT NULL,`film_id` INT ( 11 ) NOT NULL,`actor_id` INT ( 11 ) NOT NULL,`remark` VARCHAR ( 255 ) DEFAULT NULL,PRIMARY KEY ( `id` ),KEY `idx_film_actor_id` ( `film_id`, `actor_id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8;INSERT INTO `film_actor` (`id`, `film_id`, `actor_id`) VALUES (1,1,1),(2,1,2),(3,2,1);
执行 explain select * from actor;
结果:
mysql> explain select * from actor;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | actor | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
根据返回的信息可以分析 sql 的性能瓶颈从而进行优化。
下面分析其中每个字段对应的含义。
每个字段对应的含义
1.1. id
代表 sql 中查询语句的序列号, 序列号越大则执行的优先级越高, 序号一样谁在前谁先执行。id 为 null 则最后执行。
1.2. select_type
查询类型, 表示当前被分析的 sql 语句的查询的复杂度。这个字段有多个值。
- SIMPLE: 表示简单查询。
mysql> explain select * from actor;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | actor | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
-
PRIMARY: 表示复杂查询中的最外层的 select 查询语句。
-
SUBQUERY: 表是子查询语句 跟在 select 关键字后面的 select 查询语句;
mysql> explain select (select 1 from film where id =1) from actor;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | PRIMARY | actor | NULL | index | NULL | PRIMARY | 4 | NULL | 3 | 100.00 | Using index |
| 2 | SUBQUERY | film | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
- derived: 派生查询, 跟在一个 select 查询语句的 from 关键字后面的 select 查询语句 例如:
mysql> set session optimizer_switch='derived_merge=off'; -- 关闭 mysql5.7 新特性对衍生表的合并优化
Query OK, 0 rows affected (0.00 sec)mysql> explain select (select 1 from actor where id =1) from (SELECT * from film where id=1) ac;
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | PRIMARY | <derived3> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 3 | DERIVED | film | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 2 | SUBQUERY | actor | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | Using index |
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
1.3. table
表示当前访问的表的名称。
当 from 中有子查询时, table 字段显示的是 <derivedN> N 为 derived 的 id 的值。
1.4. partitions
返回的是数据分区的信息, 不常用 这里不做分析。
1.5. type
这个字段决定 mysql 如何查找表中的数据, 查找数据记录的大概范围。这个字段的所有值表示的从最优到最差依次为:
system > const > eq_ref > ref > range > index > all;
一般来说我们优化到 range 就可以了, 最好到 ref。
- null: type 字段的值如果为 null, 那么表示当前的查询语句不需要访问表, 只需要从索引树中就可以获取我们需要的数据;
一般如果是主键索引的话 , 查询主键字段或者唯一索引的话 查询主键字段 type 字段的值就为 null。
mysql> explain select id from actor where id =1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | actor | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
- system/const: 用户主键索引或者唯一索引查询时, 只能匹配 1 条数据 一般可以对 sql 查询语句优化成一个常量, 那么 type 一般就是 system 或者 const, system 是 const 的一个特例。
mysql> explain select * from (select * from film where id = 1) tmp;
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 2 | DERIVED | film | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
- eq_ref: 在进行连接查询时, 例如 left join 时, 如果是使用主键索引或者唯一索引连接查询 , 结果返回一条数据, 则 type 的值为一般为 eq_ref。
mysql> explain SELECT * from film_actor left join film on film.id = film_actor.film_id;
+----+-------------+------------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-------+
| 1 | SIMPLE | film_actor | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL |
| 1 | SIMPLE | film | NULL | eq_ref | PRIMARY | PRIMARY | 4 | mysql.film_actor.film_id | 1 | 100.00 | NULL |
+----+-------------+------------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-------+
2 rows in set, 1 warning (0.01 sec)
分析下这个 sql, 首先我们需要查询的是 film_actor 中间表 且这个表是与 film 表进行主键关联的, 索引 film_actor 表中的 film_id 字段在 film 表中只有一个唯一值, 所以: eq_ref
那么, 反过来在看一下
mysql> explain SELECT * from film left join film_actor on film_actor.film_id = film.id;
+----+-------------+------------+------------+-------+-------------------+----------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-------------------+----------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | film | NULL | index | NULL | idx_name | 33 | NULL | 3 | 100.00 | Using index |
| 1 | SIMPLE | film_actor | NULL | ALL | idx_film_actor_id | NULL | NULL | NULL | 3 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+------------+------------+-------+-------------------+----------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.01 sec)
film 表和 film_actor 中间表关联查询, 根据 film 电影表中的主键 id 和 film_actor 表中的 film_id 字段进行关联的。电影表中的主键 id 在 film_actor 中并不是唯一的。所以: index ALL
对于 film 需要确定查询 id 从索引树中就可以获取值 所以是 index。对于 film_actor 就是全表扫描了。
- ref: 相比较 eq_ref, 不使用主键索引或者唯一索引, 使用的是普通索引或者唯一索引的部分前缀, 索引与一个值进行比较后可能获取到多个符合条件的行, 不在是唯一的行了。
简单查询, name 是普通索引
mysql> explain select * from film where name = 'film1';
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | film | NULL | ref | idx_name | idx_name | 33 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
复杂查询, film_actor 有联合索引 idx_film_actor_id('film_id','actor_id') 这里使用了联合索引的左前缀 film_id
mysql> explain select fa.film_id from film f left join film_actor fa on fa.film_id = f.id;
+----+-------------+-------+------------+-------+-------------------+-------------------+---------+------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+-------------------+-------------------+---------+------------+------+----------+-------------+
| 1 | SIMPLE | f | NULL | index | NULL | idx_name | 33 | NULL | 3 | 100.00 | Using index |
| 1 | SIMPLE | fa | NULL | ref | idx_film_actor_id | idx_film_actor_id | 4 | mysql.f.id | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+-------------------+-------------------+---------+------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
- range: 通常使用范围查找, 例如 between, in, <, >, >= 等使用索引进行范围检索。
mysql> explain select * from film where id >2;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | film | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
- index: 扫描索引树就能获取到的数据, 一般是扫描二级索引, 并且不会从根节点扫描, 一般直接扫描二级索引的叶子节点, 速度比较慢。因为二级索引叶子节点不保存表中其他字段数据 只保存主键, 所以二级索引还是比较小的, 扫描速度相比 All 还是很快的。这里用到了覆盖索引, 什么是覆盖索引: 可以直接遍历索引树就能获取数据叫做覆盖索引。这里遍历 name 索引树就可以获取到主键 id 的值就是覆盖索引。
mysql> explain select id from film;
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| 1 | SIMPLE | film | NULL | index | NULL | idx_name | 33 | NULL | 3 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
- ALL: 这是一种效率最低的 type, 需要扫描主键索引树的叶子节点, 获取数据是表中其他列的数据, 即全表扫描。
和 index 有什么区别呢?
拿 film 电影表举例: 添加一个 remark 影评字段, film 表结构如下:
CREATE TABLE `film` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(10) DEFAULT NULL,`remark` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
表中建了两个索引: id 主键索引 idx_name(name) 二级索引。
那么:
mysql> explain select id,name from film ;
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| 1 | SIMPLE | film | NULL | index | NULL | idx_name | 33 | NULL | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
上述 sql 查询 id, name 两个字段, 分析 mysql 索引数据结构, 以及 mysql 优化后一般扫描二级索引, 索引会扫描 idx_name 索引树的叶子节点, 那么根据 B+Tree 树的结构, 叶子节点保存的是 name 字段的索引值 和 data 数据(主键 id)。而正好我们只需要查询 id 和 name 两个字段, 我们查询的字段被索引(二级索引)给覆盖了 这就是覆盖索引, 因此 type 的类型就是 index。
再来:
mysql> explain select remark from film ;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | film | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
比较上一个 sql, 这个 sql 只查询了一个字段: remark, 经过上面分析, 这个字段是不在 idx_name 索引树的叶子节点上的, 所以 mysql 不会在扫描 idx_name 索引树了, 直接扫描主键索引的叶子节点, 即进行全表扫描, 这个时候 type 类型为 ALL。
1.6. possible_keys
这个字段显示的是 sql 在查询时可能使用到的索引, 但是不一定真的使用, 只是一种可能。
如果在进行 explain 分析 sql 时, 发现这一列有值, 但是 key 列为 null, 因为 mysql 觉得可能会使用索引, 但是又因为表中的数据很少, 使用索引反而没有全表扫描效率高, 那么 mysql 就不会使用索引查找, 这种情况是可能发生的。
如果该列是 NULL, 则没有相关的索引。在这种情况下, 可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能, 然后用 explain 查看效果。
1.7. key
sql 执行中真正用到的索引字段。
1.8. key_len
用到的索引字段的长度, 通过这个字段可以显示具体使用到了索引字段中的哪些列(主要针对联合索引): 计算公式如下
- 字符串
- char(n): n 字节长度
- varchar(n): 如果是 utf-8, 则长度 3n + 2 字节, 加的 2 字节用来存储字符串长度
- 数值类型
- tinyint: 1 字节
- smallint: 2 字节
- int: 4 字节
- bigint: 8 字节
- 时间类型
- date: 3 字节
- timestamp: 4 字节
- datetime: 8 字节
- 如果字段允许为 NULL, 需要 1 字节记录是否为 NULL
索引最大长度是 768 字节, 当字符串过长时, mysql 会做一个类似左前缀索引的处理, 将前半部分的字符提取出来做索引。
1.9. ref
表示那些列或常量被用于查找索引列上的值
1.10. rows
表示在查询过程中检索了多少列 但是并不一定就是返回这么多列数据。
1.11. Extra
展示一些额外信息。
索引实践
以下实践以 employees 表为例。一个主键索引 一个联合索引
CREATE TABLE `employees` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',PRIMARY KEY (`id`),KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
联合索引最左列原则
例 1:
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei';
使用联合索引中的 name 字段索引。
例 2:
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22;
使用联合索引中的 name 和 gae 字段索引。
例 3:
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';
使用联合索引中的 name age position 字段索引。
例 4:
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
仅仅使用了联合索引中的 name 字段, 因为中间 age 字段断了, 所以 position 字段索引并未用到。解释一下:
索引是一个有序的数据结构, 也就是说使用索引时, 需要索引保证有序, 那么在联合索引中, 是先按照 name 排序, name 相同情况下, 在按照 age 排序, age 相同情况下 在按照 position 排序, 因此如果 age 不确定情况下, position 是无序的, 所以即使你是用 position 查询了 也无法走索引的。这就是最左列原则并且中间不能断。
例 5:
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age > 22 AND position ='manager';
这个使用了联合索引中的 name 和 age 字段, 没有使用 position, 为什么? 原理其实和上面差不多。分析一波:
首先按照顺序 name->age->position,name 已经确定了等于 LiLei, 那么 age 就是有序的了, 所以检索 age>22 的就很容易了 因为 age 有序。但是 age 值其实是不确定的, age 可以是 23,24,25… 等等, 所以在 age 不确定情况下 position 是无序的 因此是不走 position 索引字段的。
全值匹配
mysql> EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';
+----+-------------+-----------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | employees | NULL | ref | idx_name_age_position | idx_name_age_position | 140 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+------+-----------------------+-----------------------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
不建议在索引列上做任何操作, 否则索引会失效转而全表扫描
-- 查询 name 的最左变的两个字符为 Li 的行
mysql> EXPLAIN SELECT * FROM employees WHERE LEFT(name,2) = 'Li';
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
尽量使用覆盖索引 不需要再回表查询了 效率较高
再试用 != 或 <> 不等于查询时, 会导致索引失效。
mysql> EXPLAIN SELECT * FROM employees WHERE name != 'LiLei';
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | idx_name_age_position | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
尽量不要使用 or, in 操作, 在某些情况下也会导致索引失效。
- 第一种情况: 当表中只有两条数据 数据量很少的时候
mysql> explain SELECT * from employees where name in ('LiLei','abc');
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | idx_name_age_position | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
使用 in 查询, 没有走索引, 进行了全表扫描, 为什么? 分析一波:
首先 如果使用索引的话, mysql 大概会怎么操作? 应该先在 name 索引树中定位到 name=LiLei 这个节点(最少一次 I/O), 然后定位到 name=abc 这个节点(一次 I/O), 然后分别拿到主键 id, 在去主键索引树上扫描定位(最少又要两次 I/O), 总共 4 次 I/O。
如果不使用索引, 直接全表扫描, 那么直接扫描主键索引树的叶子节点 只需要两次 I/O 即可(因为只有两条数据), 所以 mysql 评估全表扫描效率可能会更高, 就不会在走索引了。
- 第二种情况: 当表中数据量很多, 例如 7 条数据
同样的 sql 查询
mysql> explain SELECT * from employees where name in ('LiLei','abc');
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | idx_name_age_position | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
结果: 走了索引
为什么会出现这种情况? 再来分析一波:
首先走索引的话 大概需要 4 次 I/O 上面已经分析过了。
那么不走索引的话 需要全表扫描 最坏的情况需要扫描 7 次, 进行 7 次 I/O,mysql 评估一下发现全表扫描的效率可能是低于走索引的, 所以就走了索引。
- 第三种情况: 数据还是 7 条, 但是我 in 查询时条件有 8 个
mysql> explain SELECT * from employees where name in ('LiLei','abc','cde','asc','ssw','2dff','wsa','sda');
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | idx_name_age_position | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
看下结果:
为啥又不走索引了呢? 经过上面的两波强势分析, 这里也很容知道原因, 就不过多的赘述了。or 查询的情况类似。
is null, is not null 一般情况下也无法使用索引
是用字符串查询 不见引号 索引也会失效
mysql> explain SELECT * from employees where name = 1324;
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | idx_name_age_position | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set, 3 warnings (0.00 sec)
针对范围查找的不走索引的优化
首先看个例子:
-- 先给 age 加一个独立索引
mysql> ALTER TABLE `employees` ADD INDEX `idx_age` (`age`) USING BTREE ;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0-- 查询 age 在 1 到 2000 分为内的数据
mysql> explain SELECT * from employees where age >1 and age < 2000 ;
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_age | idx_age | 4 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
显然并没有走索引 为什么? 再来强势分析一波:
首先, 我们脑海中要有一个 age 的索引树:
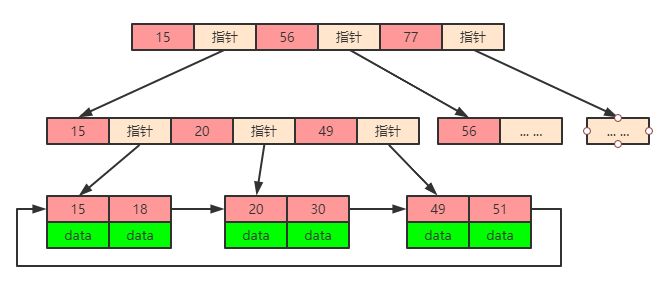
我们要找到 1-2000 的数据, 那么在这棵树书上怎么定位?
如果我来定位的话 我会定位一个 age=2 在树上的位置 在定位一个 age=1999 在树上的位置, 然后从 age=2 的节点开始取右边的节点, 一直取下去 直到 age=1999 为止, 但是我们表总只有 7 条数据, mysql 觉得这样操作还没有全表扫描快, 毕竟一共才几条数据全表扫描反而更快些, 所以 mysql 就去全表扫描了。
怎么优化呢?
mysql> explain SELECT * from employees where age >1 and age < 1000 ;
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_age | idx_age | 4 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)mysql> explain SELECT * from employees where age >1001 and age < 2000 ;
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_age | idx_age | 4 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
把一个大的范围拆成多个小的范围 可以利用索引查询。
like 查询建议使用 xxx% 方式匹配, %xxx 或者 %xxx% 索引失效
mysql> EXPLAIN SELECT * FROM employees WHERE name like '%Lei';
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)mysql> EXPLAIN SELECT * FROM employees WHERE name like '%Lei%';
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
结果: 全表扫描
思考下在索引树上 name 的排序规则, 先按照第一个字符比较然后第二个字符依次向后比较, 如果是用 %xxx, 字符串前面的字符不确定, 怎么在树上定位呢? 显然没法按照顺序定位, 只能一个一个遍历比较 所以不会走索引。%xxx% 也一样。
在看下面这个例子
mysql> EXPLAIN SELECT * FROM employees WHERE name like 'Lei%';
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_name_age_position | idx_name_age_position | 74 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
结果: 走了索引
其实 Lei% 匹配相当于范围查询, 只要 name 的值的前三个字符为 Lei 符合条件, 等价于查找前三个字符 =Lei 的字符串, 这个在索引树上是有序的, 当然可以使用索引定位。
总结:
- 使用 explain 关键字, 可以分析出 sql 的性能瓶颈并加以优化
- 了解 explain 返回的各字段值代表的意义, 结合索引数据结构有助于我们对 sql 的查询效率的分析和优化
- 列举部分可能不会进行索引检索的情况, 例如 !=, <>, is null, like 的某些情况, or 或者 in 的某些情况, 字符串不加引号等
- 对某些不走索引查询的情况作了一些比较详细的分析
相关文章:
sql explain
目录 1. sql explain每个字段对应的含义1.1. id1.2. select_type1.3. table1.4. partitions1.5. type1.6. possible_keys1.7. key1.8. key_len1.9. ref1.10. rows1.11. Extra 索引实践联合索引最左列原则全值匹配不建议在索引列上做任何操作, 否则索引会失效转而全表扫描尽量使…...

【LeetCode-简单题】剑指 Offer 05. 替换空格
文章目录 题目方法一:常规做法:方法二:双指针做法 题目 方法一:常规做法: class Solution {public String replaceSpace(String s) {int len s.length() ;StringBuffer str new StringBuffer();for(int i 0 ; i &l…...

数字虚拟人制作简明指南
如何在线创建虚拟人? 虚拟人,也称为数字化身、虚拟助理或虚拟代理,是一种可以通过各种在线平台与用户进行逼真交互的人工智能人。 在线创建虚拟人变得越来越流行,因为它为个人和企业带来了许多好处。 推荐:用 NSDT编辑…...
Nginx 文件解析漏洞复现
一、漏洞说明 Nginx文件解析漏洞算是一个比较经典的漏洞,接下来我们就通过如下步骤进行漏洞复现,以及进行漏洞的修复。 版本条件:IIS 7.0/IIS 7.5/ Nginx <8.03 二、搭建环境 cd /vulhub/nginx/nginx_parsing_vulnerability docker-compos…...
Lombok依赖
一.介绍 Project Lombok 是一个 Java 库,它会自动插入编辑器和构建工具,为您的 Java 增添趣味。永远不要再写另一个 getter 或 equals 方法,使用一个注释,您的类有一个功能齐全的构建器,自动化您的日志记录变量等等。…...
XML 和 JSON 学习笔记(基础)
XML Why XML 的出现背景:在实际开发中,不同语言(如Java、JavaScript等)的应用程序之间数据传递的格式不同,导致它们进行数据交换时很困难,XML就应运而生了!(XML 是一种通用的数据交…...

L1-005 考试座位号分数 15
每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生的考试座位号码,考试时考生需要换到考试…...

无涯教程-JavaScript - CEILING.MATH函数
描述 CEILING.MATH函数将数字四舍五入到最接近的整数或最接近的有效倍数。 Excel CEILING.MATH函数是Excel中的十五个舍入函数之一。 语法 CEILING.MATH (number, [significance], [mode])争论 Argument描述Required/OptionalNumberNumber must be less than 9.99E307 and …...
ChatGPT提示词(prompt)资源汇总
文章目录 awesome-chatgpt-promptsLearn PromptingSnack PromptFlow GPTPrompt VineChatGPT 指令大全AI Toolbox HubAI Short ChatGPT是一种强大的生成式AI模型,而提示词(prompt)则是与ChatGPT一起使用的指导性文本,用于引导模型生…...

MySQL 几种导数据的方法与遇到的问题
零、说在前面 MySQL导数据通常使用第三方工具和MySQL自身的工具,本文分别就这两类方法分别介绍。 一、第三方工具之 Navicat 1.1、Navicat的“数据传输”工具 打开Navicat,点击“工具”标签,找到“数据传输”,即可看到操作界面。…...
(21)多线程实例应用:双色球(6红+1蓝)
一、需求 1.双色球: 投注号码由6个红色球号码和1个蓝色球号码组成。 2.红色球号码从01--33中选择,红色球不能重复。 3.蓝色球号码从01--16中选择。 4.最终结果7个号码:61;即33选6(红) 16选1(蓝) 5.产品: …...
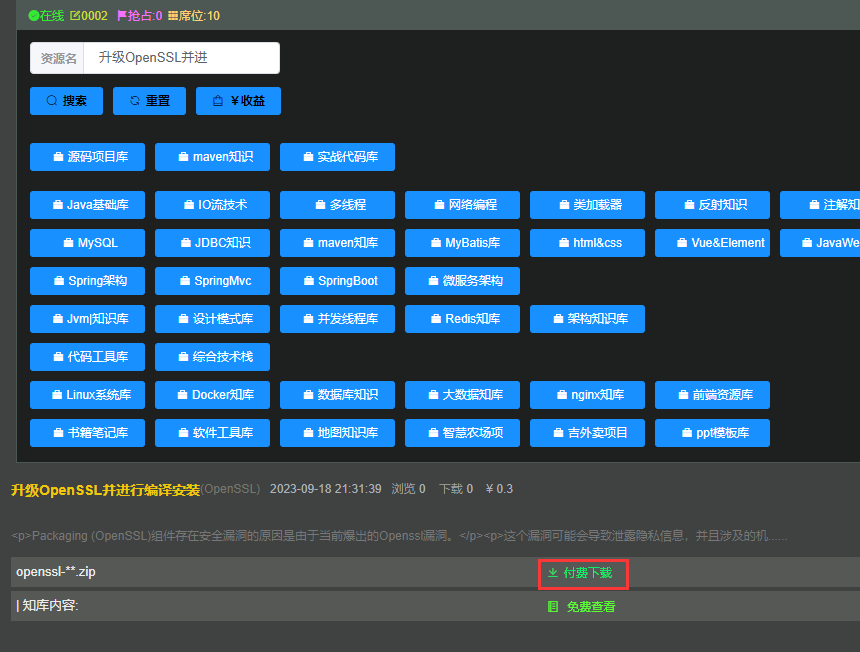
升级OpenSSL并进行编译安装
Packaging (OpenSSL)组件存在安全漏洞的原因是由于当前爆出的Openssl漏洞。 这个漏洞可能会导致泄露隐私信息,并且涉及的机器和环境也有所不同,因此修复方案也会有所不同。 目前,一些服务器使用的Nginx是静态编译OpenSSL,直接将Op…...

Spring整合RabbitMQ
一、步骤 生产者 ① 创建生产者工程 ② 添加依赖 ③ 配置整合 ④ 编写代码发送消息 消费者 ① 创建消费者工程 ② 添加依赖 ③ 配置整合 ④ 编写消息监听器 二、代码 生产者工程 1.在生产者工程和消费者工程中都导入如下依赖 <dependencies><dependency&g…...

MySQL——事务和视图
2023.9.17 本章开始介绍TCL语言(Transaction Control Language 事务控制语言)。 事务 事务的概念:一个或一组sql语句组成一个执行单元,这个执行单元要么全部执行,要么全部不执行。 事务的特性:ÿ…...

做好制造项目管理的5个技巧
制造过程通常由不同的要素组成,如采购材料、与供应商合作、优化生产线效率等。制造商还需要处理库存、物流和分销。 为了确保制造项目在预算范围内按时完成,并且不遗漏任何环节,企业必须建立项目管理流程,以帮助改善组织流程和效…...
JavaScript中While循环
JavaScript中处理For循环,还有一种循环while循环; ● 例如我们之前写了一个模拟举重次数的For循环,如下所示 for (let rep 1; rep < 10; rep) {console.log(举重${rep}次); }● 我们也可以使用while循环去实现这种功能 let rep 1; whi…...

python经典百题之乒乓球比赛
题目: 两个乒乓球队进行比赛,各出三人。甲队为a,b,c三人,乙队为x,y,z三人。已抽签决定比赛名单。有人向队员打听比赛的名单。a说他不和x比,c说他不和x,z比,请编程序找出三队赛手的名单。第一种方式: 思路…...

【C++ Exceptions】Catch exceptions by reference!
catch exceptions 写一个catch子句时必须指明异常对象是如何传递到这个子句来的,三种方式: by pointerby valueby reference 接下来比较它们使用时会出现的问题,以说明最好的选择是by reference。 catch by pointer 无需复制对象&#x…...

高斯公式证明
高斯公式: 若空间闭区域 Ω \Omega Ω 由光滑的闭曲面 Σ \Sigma Σ 围成,则 ∫ ∫ ∫ Ω ( ∂ P ∂ x ∂ Q ∂ y ∂ R ∂ z ) d v ∮ ∮ Σ P d y d z Q d z d x R d x d y \int \int \int _{\Omega}(\frac{\partial P}{\partial x} \frac{\p…...

速卖通获得aliexpress商品详情 API 返回值说明
item_get-获得aliexpress商品详情 aliexpress.item_get 进入测试 公共参数 名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...
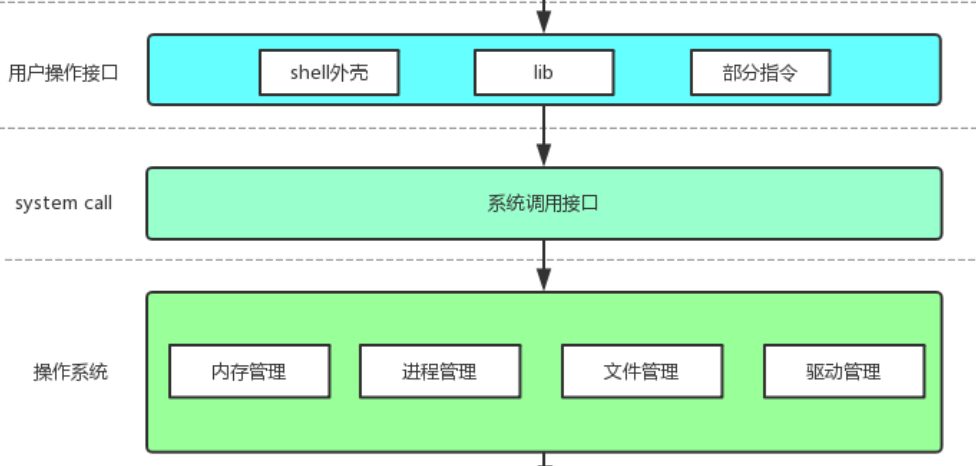
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...