【RocketMQ专题】快速实战及集群架构原理详解
目录
- 课程内容
- 一、MQ简介
- 基本介绍
- *作用(解决什么问题)
- 二、RocketMQ产品特点
- 2.1 RocketMQ介绍
- 2.2 RocketMQ特点
- 2.3 RocketMQ的运行架构
- 三、RocketMQ快速实战
- 3.1 快速搭建RocketMQ服务
- 3.2 快速实现消息收发
- 3.3 搭建Maven客户端项目
- 3.4 搭建RocketMQ可视化管理服务
- 3.5 升级分布式集群
- 四、理解 RocketMQ的消息模型
- 学习总结
- 感谢
课程内容
一、MQ简介
基本介绍
MQ:即MessageQueue,消息队列。是在互联网中使用非常广泛的一系列服务中间件。 这个词可以分两个部分来看:
- Message:消息。消息是在不同进程之间传递的数据。这些进程可以部署在同一台机器上,也可以分布在不同机器上
- Queue:队列。队列原意是指一种具有FIFO(先进先出)特性的数据结构,是用来缓存数据的。
对于消息中间件产品来说,能不能保证FIFO特性,尚值得考量。但是,所有消息队列都是需要具备存储消息,让消息排队的能力。广义上来说,只要能够实现消息跨进程传输以及队列数据缓存,就可以称之为消息队列。例如我们常用的QQ、微信、阿里旺旺等就都具备了这样的功能。只不过他们对接的使用对象是人,而我们这里讨论的MQ产品需要对接的使用对象是应用程序。
*作用(解决什么问题)
作用一:异步
例子:我们购物的时候,通常需要跟库存系统、支付系统、订单系统、以及物流系统打交道
我们先来看一个,有MQ跟没MQ的时候,电商购物场景下的模型图。
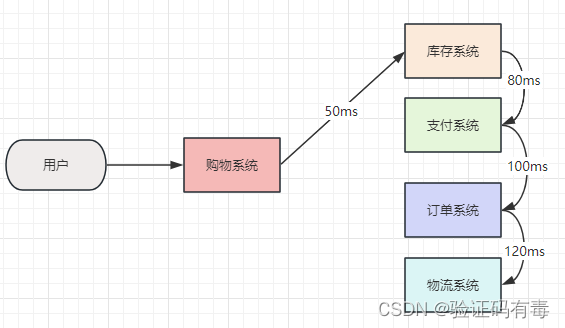
分析:在无MQ场景下,我们购物下单的时候,我们可能会串行地执行每一个系统,只有等所有系统执行完了,才会返回结果给用户。所以,用户购物的时候,需要等待50ms + 80ms + 100ms + 120ms=350ms才行
(也许有朋友会反驳我说:我没MQ难道不能用线程池吗?是这样,这里为了引出异步,我特意把场景画成了同步。事实上,要想实现异步的方式有很多,不止是MQ)
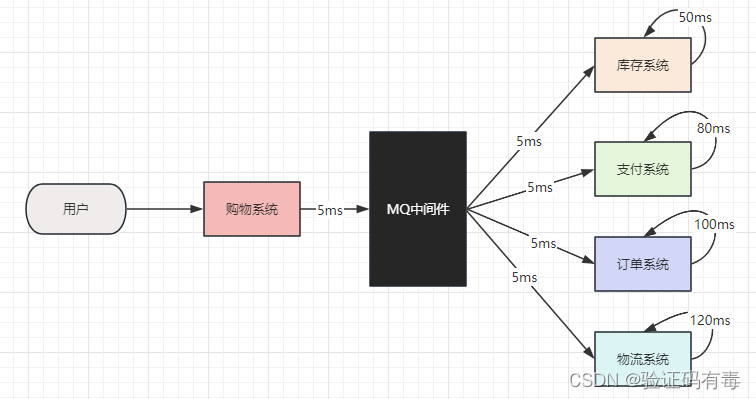
我们再看看上图有MQ的场景下。我们购物下单的时候,无需等待每一个系统执行完了,而只是把这件事情告诉MQ即可。此时,我们只需要等待5ms即可。
通过上面的分析,我们不难看出,使用MQ,具有:异步能提高系统的响应速度、吞吐量的作用。
作用二:解耦
例子:其实还是上面的电商场景,就可以看出来。在串行系统下,有一个很明显的特点,那就是整个购物系统会跟库存系统、支付系统、订单系统、以及物流系统等直接耦合。这导致什么问题?那就是一旦某个环节出错了,那整个购物操作就失败了。
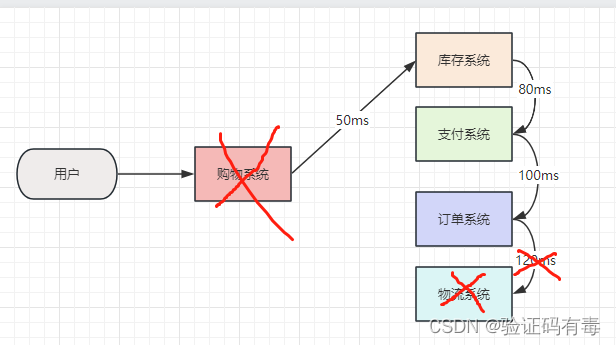
但是,有了MQ,购物系统不再与其他各个系统直接耦合,而是变成了与MQ直接耦合。即:
- 购物系统-----耦合-----MQ
- MQ-----耦合-----其他系统
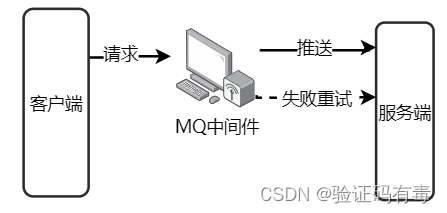
这样,一旦【其他系统】中某个环节出错,他是不会影响到【购物系统–耦合–MQ】这段关系的结果的,只会影响【MQ–耦合–其他系统】的结果。而且,大部分MQ还提供了很好的失败重试机制,提升了容错性和可维护性。
通过上面的分析,我们不难看出,使用MQ还具有如下作用:
- 服务之间进行解耦,可以减少服务之间的影响,提高系统整体的稳定性以及可扩展性。
(Q1:解耦是什么意思?
答:即,解除耦合。什么是【耦合】?在Java中,若class A的成员属性中,有一class B的对象,则我们称A与B是耦合的。在下图的系统中。若订单服务直接调用库存系统,则称订单服务与库存系统是耦合的。
- 另外,解耦后可以实现数据分发。生产者发送一个消息后,可以由一个或者多个消费者进行消费,并且消费者的增加或者减少对生产者没有影响。
作用三:削峰填谷
例子:在电商秒杀场景下, 有可能会出现瞬时流量增多的情况。比如平时每秒最多100单,但是秒杀活动开始后,一下子有成千上万单进来。瞬时的流量暴增,很可能把我们系统给打崩的。通过MQ,可以把这波流量从1秒1W单,转换成10秒1000单的平稳流量,到我们系统。
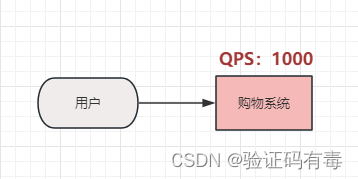
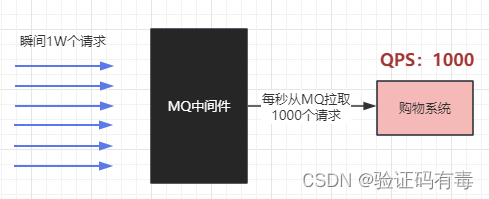
使用了 MQ 之后,限制消费消息的速度为1000,这样一来,高峰期产生的数据势必会被积压在 MQ 中,高峰就被“削”掉了,但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000,直到消费完积压的消息,这就叫做“填谷”。
所以,使用MQ的作用还有:以稳定的系统资源应对突发的流量冲击。
二、RocketMQ产品特点
2.1 RocketMQ介绍
RocketMQ是阿里巴巴开源的一个消息中间件,在阿里内部历经了双十一等很多高并发场景的考验,能够处理亿万级别的消息。2016年开源后捐赠给Apache,现在是Apache的一个顶级项目。
早期阿里使用ActiveMQ,但是,当消息开始逐渐增多后,ActiveMQ的IO性能很快达到了瓶颈。于是,阿里开始关注Kafka。但是Kafka是针对日志收集场景设计的,他的高级功能并不是很贴合阿里的业务场景。尤其当他的Topic过多时,由于Partition文件也会过多,这就会加大文件索引的耗时,会严重影响IO性能。于是阿里才决定自研中间件,最早叫做MetaQ,后来改名成为RocketMQ。最早他所希望解决的最大问题就是多Topic下的IO性能压力。但是产品在阿里内部的不断改进,RocketMQ开始体现出一些不一样的优势。
2.2 RocketMQ特点
当今互联网MQ产品众多,其中,影响力和使用范围最大的当数Apache Kafka、RabbitMQ、Apache RocketMQ以及Apache Plusar。这几大产品虽然都是典型的MQ产品,但是由于设计和实现上的一些差异,造成他们适合于不同的细分场景。
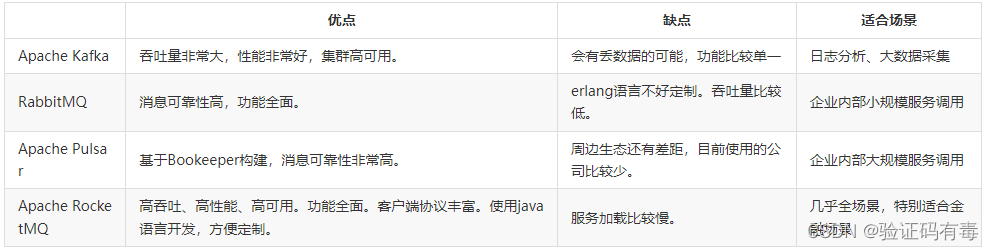
其中RocketMQ,孵化自阿里巴巴。历经阿里多年双十一的严格考验,RocketMQ可以说是从全世界最严苛的高并发场景中摸爬滚打出来的过硬产品,也是少数几个在金融场景比较适用的MQ产品。从横向对比来看,RocketMQ与Kafka和RabbitMQ相比。RocketMQ的消息吞吐量虽然和Kafka相比还是稍有差距,但是却比RabbitMQ高很多。在阿里内部,RocketMQ集群每天处理的请求数超过5万亿次,支持的核心应用超过3000个。而RocketMQ最大的优势就是他天生就为金融互联网而生。他的消息可靠性相比Kafka也有了很大的提升,而消息吞吐量相比RabbitMQ也有很大的提升。另外,RocketMQ的高级功能也越来越全面,广播消费、延迟队列、死信队列等等高级功能一应俱全,甚至某些业务功能比如事务消息,已经呈现出领先潮流的趋势。
2.3 RocketMQ的运行架构
图是RocketMQ运行时的整体架构:
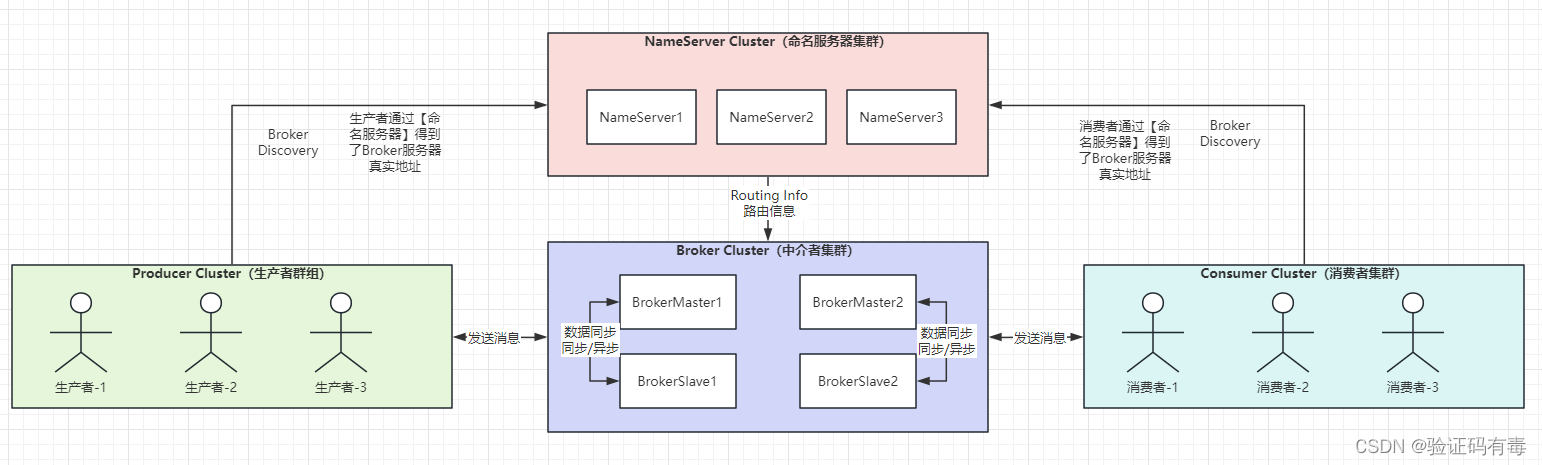
根据上面的架构模型图,整个MQ会包含以下概念:
-
NameServer命名服务器
NameServer是整个RocketMQ的【大脑】,主要存储Topic路由信息,以及Broker的地址信息。它是RocketMQ的服务注册中心,所以RocketMQ需要先启动NameServer再启动Broker。
Broker在启动时向所有NameServer注册自己的信息(主要是服务器地址等),生产者在发送消息之前先从NameServer获取Broker服务器地址列表(消费者一样),然后根据负载均衡算法从列表中选择一台服务器进行消息发送。
NameServer与每台Broker服务保持长连接,并间隔30S检查Broker是否存活,如果检测到Broker宕机,则从路由注册表中将其移除。这样就可以实现RocketMQ的高可用。 -
Broker消息存储中心
Broker服务器,是消息存储中心,主要作用是接收来自 Producer 的消息并存储,Consumer 从这里取得消息。它还存储与消息相关的元数据,包括用户组、消费进度偏移量、队列信息等。从部署结构图中可以看出 Broker 有 Master 和 Slave 两种类型,Master 既可以写又可以读,Slave不可以写只可以读。 -
Producer和Conumer(关注生产、消费者模型)
他们是一种逻辑概念。Producer即生产者,代表往MQ投递消息、任务的系统、模块等;Consumer即消费者,代表从MQ获取消息、任务的系统、模块等
三、RocketMQ快速实战
3.1 快速搭建RocketMQ服务
RocketMQ的官网地址: Rocket官网。在下载页面可以获取RocketMQ的源码包以及运行包。下载页面地址
当前最新的版本是5.x,这是一个着眼于云原生的新版本,给 RocketMQ 带来了非常多很亮眼的新特性。但是目前来看,企业中用得还比较少。因此,我们这里采用的还是更为稳定的4.9.5版本。
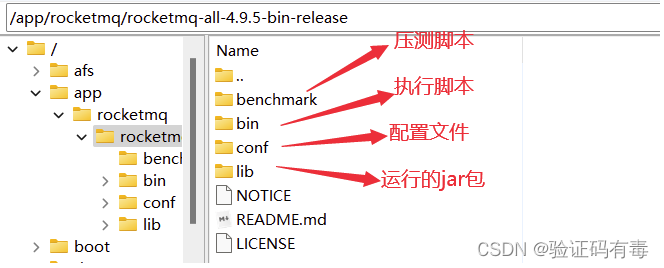
运行只需要下载Binary运行版本就可以了。 当然,源码包也建议下载下来,后续会进行解读。运行包下载下来后,就可以直接解压,上传到服务器上。我们这里会上传到/app/rocketmq目录。解压后几个重要的目录如下:
接下来,RocketMQ建议的运行环境需要至少12G的内存,这是生产环境比较理想的资源配置。但是,学习阶段,如果你的服务器没有这么大的内存空间,那么就需要做一下调整。进入bin目录,对其中的runserver.sh和runbroker.sh两个脚本进行一下修改。
使用vi runserver.sh指令,编辑这个脚本,找到下面的一行配置,调整Java进程的内存大小。
JAVA_OPT="${JAVA_OPT} -server -Xms512m -Xmx512m -Xmn256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
接着,同样调整runbroker.sh中的内存大小。(生产环境不建议调整)
JAVA_OPT="${JAVA_OPT} -server -Xms8g -Xmx8g"
修改为:
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g"
调整完成后,就可以启动RocketMQ服务了(PS:RocketMQ服务基于Java开发,所以需要提前安装JDK。JDK建议采用1.8版本即可)
RocketMQ的后端服务分为nameserver和broker两个服务,关于他们的作用,后面会给你分享。接下来我们先将这两个服务启动起来。
第一步:启动nameserver服务
cd /app/rocketmq/rocketmq-all-4.9.5-bin-release
nohup bin/mqnamesrv &
指令执行后,会生成一个nohup.out的日志文件。在这个日志文件里如果看到下面这一条关键日志,就表示nameserver服务启动成功了。
Java HotSpot(TM) 64-Bit Server VM warning: Using the DefNew young collector
with the CMS
collector is deprecated and will likely be removed in a future release
Java HotSpot(TM) 64-Bit Server VM warning: UseCMSCompactAtFullCollection is
deprecated and
will likely be removed in a future release.
The Name Server boot success. serializeType=JSON
接下来,可以通过jsp指令进行验证。使用jps指令后,可以看到有一个NamesrvStartup的进程运行,也表示nameserver服务启动完成。
第二步:启动broker服务
启动broker服务之前,要做一个小小的配置。进入RocketMQ安装目录下的conf目录,修改broker.conf文件,在文件最后面加入一个配置:
autoCreateTopicEnable=true
注意:上面选项是为了便于进行后续实验。他的作用是允许 broker 端自动创建新的 Topic。另外,如果你的服务器配置了多张网卡,比如阿里云,腾讯云这样的云服务器,他们通常有内网网卡和外网网卡两张网卡,那么需要增加配置brokerIP1属性,指向服务器的外网IP 地址,这样才能确保从其他服务器上访问到RocketMQ 服务。
然后也可以用之前的方式启动broker服务。启动broker服务的指令是mqbroker:
cd /app/rocketmq/rocketmq-all-4.9.5-bin-release
nohup bin/mqbroker &
启动完成后,同样检查nohup.out日志文件,有如下一条关键日志,就表示broker服务启动正常了。
The broker[xxxxx] boot success. serializeType=JSON
3.2 快速实现消息收发
RocketMQ后端服务启动完成后,就可以启动客户端的消息生产者和消息消费者进行消息转发了。接下来,我们会先通过RocketMQ提供的命令行工具快速体验一下RocketMQ消息收发的功能。然后,再动手搭建一个Maven项目,在项目中使用RocketMQ进行消息收发。
1. 命令行快速实现消息收发
第一步:需要配置一个环境变量NAMESRV_ADDR,指向我们之前启动的nameserver服务。
通过vi ~/.bash_profile添加以下配置。然后使用source ~/.bash_profile让配置生效。
export NAMESRV_ADDR='localhost:9876'
第二步:通过指令启动RocketMQ的消息生产者发送消息。
tools.sh org.apache.rocketmq.example.quickstart.Producer
这个指令会默认往RocketMQ中发送1000条消息。在命令行窗口可以看到发送消息的日志:
SendResult [sendStatus=SEND_OK, msgId=C0A8E88007AC3764951D891CE9A003E7,
offsetMsgId=C0A8E88000002A9F00000000000317BF, messageQueue=MessageQueue
[topic=TopicTest, brokerName=worker1, queueId=1], queueOffset=249] 14:59:33.418 [NettyClientSelector_1] INFO RocketmqRemoting - closeChannel:
close the connection to remote address[127.0.0.1:9876] result: true 14:59:33.423 [NettyClientSelector_1] INFO RocketmqRemoting - closeChannel:
close the connection to remote address[192.168.232.128:10911] result: true
注:这部分日志中,并没有打印出发送了什么消息。上面SendResult开头部分是消息发送到Broker后的结果。最后两行日志表示消息生产者发完消息后,服务正常关闭了。
第三步:可以启动消息消费者接收之前发送的消息
tools.sh org.apache.rocketmq.example.quickstart.Consumer
消费者启动完成后,可以看到消费到的消息
ConsumeMessageThread_19 Receive New Messages: [MessageExt
[brokerName=worker1, queueId=2, storeSize=203, queueOffset=53, sysFlag=0,
bornTimestamp=1606460371999, bornHost=/192.168.232.128:43436,
storeTimestamp=1606460372000, storeHost=/192.168.232.128:10911,
msgId=C0A8E88000002A9F000000000000A7AE, commitLogOffset=42926,
bodyCRC=1968636794, reconsumeTimes=0, preparedTransactionOffset=0,
toString()=Message{topic='TopicTest', flag=0, properties={MIN_OFFSET=0,
MAX_OFFSET=250, CONSUME_START_TIME=1606460450150,
UNIQ_KEY=C0A8E88007AC3764951D891CE41F00D4, CLUSTER=DefaultCluster,
WAIT=true, TAGS=TagA}, body=[72, 101, 108, 108, 111, 32, 82, 111, 99, 107,
101, 116, 77, 81, 32, 50, 49, 50], transactionId='null'}]]
每一条这样的日志信息就表示消费者接收到了一条消息。
这个Consumer消费者的指令并不会主动结束,他会继续挂起,等待消费新的消息。我们可以使用CTRL+C停止该进程。
注:在RocketMQ提供的这个简单示例中并没有打印出传递的消息内容,而是打印出了消息相关的很多重要的属性。
其中有几个比较重要的属性: brokerId,brokerName,queueId,msgId,topic,cluster。这些属性的作用会在后续一起分享,这里你不妨先找一下这些属性是什么,消费者与生产者之间有什么样的对应关系。
3.3 搭建Maven客户端项目
之前的步骤实际上是在服务器上快速验证RocketMQ的服务状态,接下来我们动手搭建一个RocketMQ的客户端应用,在实际应用中集成使用RocketMQ。
第一步:创建一个标准的maven项目,在pom.xml中引入以下核心依赖
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-client</artifactId><version>4.9.5</version>
</dependency>
第二步:就可以直接创建一个简单的消息生产者
public class Producer {public static void main(String[] args) throws MQClientException, InterruptedException {//初始化一个消息生产者DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");// 指定nameserver地址producer.setNamesrvAddr("192.168.232.128:9876");// 启动消息生产者服务producer.start();for (int i = 0; i < 2; i++) {try {// 创建消息。消息由Topic,Tag和body三个属性组成,其中Body就是消息内容Message msg = new Message("TopicTest","TagA",("Hello RocketMQ " +i).getBytes(RemotingHelper.DEFAULT_CHARSET));//发送消息,获取发送结果SendResult sendResult = producer.send(msg);System.out.printf("%s%n", sendResult);} catch (Exception e) {e.printStackTrace();Thread.sleep(1000);}}//消息发送完后,停止消息生产者服务。producer.shutdown();}
}
运行其中的main方法,就会往RocketMQ中发送两条消息。在这个实现过程中,需要注意一下的是对于生产者,需要指定对应的nameserver服务的地址,这个地址需要指向你自己的服务器。
第三步:创建一个消息消费者接收RocketMQ中的消息。
public class Consumer {public static void main(String[] args) throws InterruptedException, MQClientException {//构建一个消息消费者DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");//指定nameserver地址consumer.setNamesrvAddr("192.168.232.128:9876");consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);// 订阅一个感兴趣的话题,这个话题需要与消息的topic一致consumer.subscribe("TopicTest", "*");// 注册一个消息回调函数,消费到消息后就会触发回调。consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {msgs.forEach(messageExt -> {try {System.out.println("收到消息:"+new String(messageExt.getBody(), RemotingHelper.DEFAULT_CHARSET));} catch (UnsupportedEncodingException e) {}});return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});//启动消费者服务consumer.start();System.out.print("Consumer Started");}
}
运行其中的main方法后,就可以启动一个RocketMQ消费者,接收之前发到RocketMQ上的消息,并将消息内容打印出来。在这个实现过程中,需要重点关注的有两点。一是对于消费者,同样需要指定nameserver的地址。二是消费者需要在RocketMQ中订阅具体的Topic,只有发送到这个Topic上的消息才会被这个消费者接收到。
这样,通过几个简单的步骤,我们就完成了RocketMQ的应用集成。从这个过程中可以看到,RocketMQ的使用是比较简单的。但是这并不意味着这几个简单的步骤就足够搭建一个生产级别的RocketMQ服务。接下来,我们会一步步把我们这个简单的RocketMQ服务往一个生产级别的服务集群推进。
3.4 搭建RocketMQ可视化管理服务
方案一:
在之前的简单实验中,RocketMQ都是以后台服务的方式在运行,我们并不很清楚RocketMQ是如何运行的。RocketMQ的社区就提供了一个图形化的管理控制台Dashboard,可以用可视化的方式直接观测并管理RocketMQ的运行过程。
Dashboard服务并不在RocketMQ的运行包中,需要到RocketMQ的官网下载页面单独下载。
这里只提供了源码,并没有提供直接运行的jar包。将源码下载下来后,需要解压并进入对应的目录,使用maven进行编译。(需要提前安装maven客户端)
mvn clean package -Dmaven.test.skip=true
编译完成后,在源码的target目录下会生成可运行的jar包rocketmq-dashboard-1.0.1-SNAPSHOT.jar。接下来可以将这个jar包上传到服务器上。我们上传到/app/rocketmq/rocketmq-dashboard目录下
接下来我们需要在jar包所在的目录下创建一个application.yml配置文件,在配置文件中做如下配置:
rocketmq: config: namesrvAddrs: - 192.168.232.128:9876
主要是要指定nameserver的地址。
注:关于这个配置文件中更多的配置选项,可以参考一下dashboard源码当中的application.yml配置文件。
接下来就可以通过java指令执行这个jar包,启动管理控制台服务。
java -jar rocketmq-dashboard-1.0.1-SNAPSHOT.jar
应用启动完成后,会在服务器上搭建起一个web服务,我们就可以通过访问http://192.168.232.128:8080查看到管理页面。
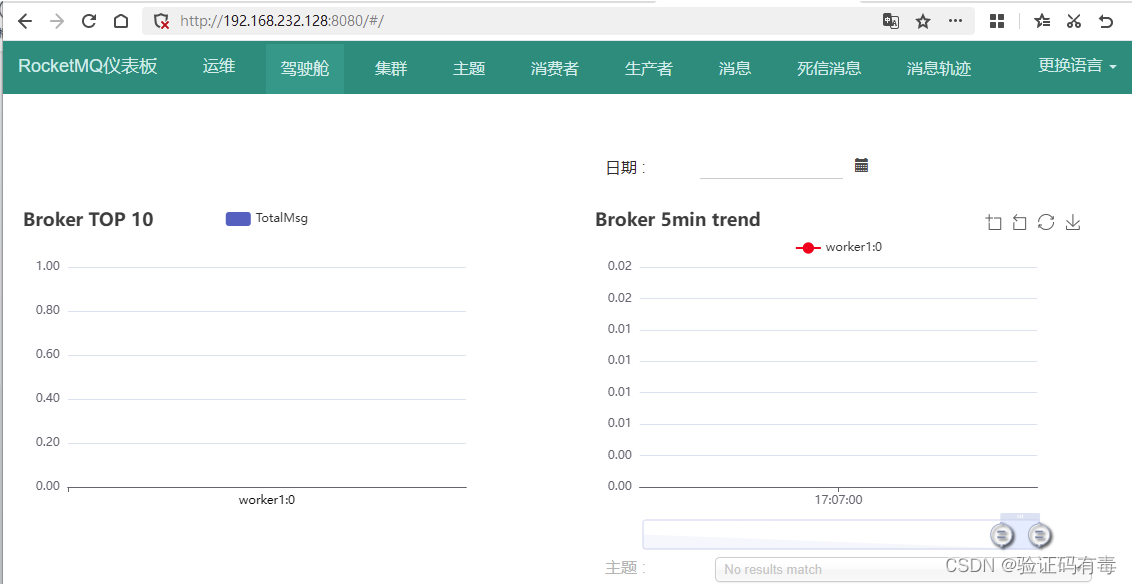
这个管理控制台的功能非常全面。驾驶舱页面展示RocketMQ近期的运行情况。运维页面主要是管理nameserver服务。集群页面主要管理RocketMQ的broker服务。很多信息都一目了然。在之后的过程中,我们也会逐渐了解DashBoard管理页面中更多的细节。
方案二:
目前发现很多小伙伴在实践过程中,会出现上述源码编译失败,这边提供一个通过docker启动的方案。这个毕竟只是拓展应用,没必要花这么大精力去解决。
docker run -d --name rocketmq-dashboard -e "JAVA_OPTS=-Drocketmq.namesrv.addr=10.xx.xx.xxx:9876" -p 8080:8080 -t apacherocketmq/rocketmq-dashboard:latest
其中10.xx.xx.xxx可以是外网地址
3.5 升级分布式集群
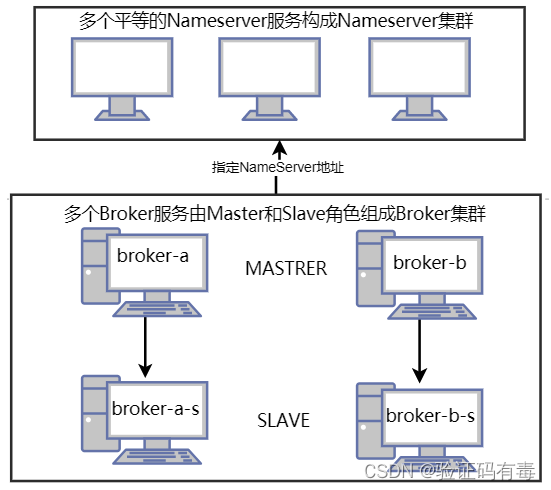
之前我们用一台Linux服务器,快速搭建起了一整套RocketMQ的服务。但是很明显,这样搭建的服务是无法放到生产环境上去用的。一旦nameserver服务或者broker服务出现了问题,整个RocketMQ就无法正常工作。而且更严重的是,如果服务器出现了问题,比如磁盘坏了,那么存储在磁盘上的数据就会丢失。这时RocketMQ暂存到磁盘上的消息也会跟着丢失,这个问题就非常严重了。因此,我们需要搭建一个分布式的RocketMQ服务集群,来防止单点故障问题。
RocketMQ的分布式集群基于主从架构搭建。在多个服务器组成的集群中,指定一部分节点作为Master节点,负责响应客户端的请求。指令另一部分节点作为Slave节点,负责备份Master节点上的数据,这样,当Master节点出现故障时,在Slave节点上可以保留有数据备份,至少保证数据不会丢失。
整个集群方案如下图所示:
接下来我们准备三台相同的Linux服务器,搭建一下RocketMQ的分布式集群。为了更清晰的描述这三台服务器上的操作,我们给每个服务器指定一个机器名。
cat /etc/hosts
192.168.232.128 worker1
192.168.232.129 worker2
192.168.232.130 worker3
为了便于观察,我们这次搭建一个2主2从的RocketMQ集群,并将主节点和节点都分别部署在不同的服务器上。预备的集群规划情况如下:

第一步:部署nameServer服务。
nameServer服务不需要做特别的配置,按照之前的步骤,在三台服务器上都分别部署nameServer服务即可
第二步:对Broker服务进行集群配置。
这里需要修改RocketMQ的配置文件,对broker服务做一些集群相关的参数部署。这些配置文件并不需要我们手动进行创建,在RocketMQ运行包的conf目录下,提供了多种集群的部署配置文件模板
- 2m-noslave: 2主无从的集群参考配置。这种集群存在单点故障。
- 2m-2s-async和2m-2s-sync: 2主2从的集群参考配置。其中async和sync表示主节点与从节点之间是同步同步还是异步同步。关于这两个概念,会在后续章节详细介绍
- dledger: 具备主从切换功能的高可用集群。集群中的节点会基于Raft协议随机选举出一个Leader,其作用类似于Master节点。其他的节点都是follower,其作用类似于Slave节点。
我们这次采用2m-2s-async的方式搭建集群,需要在worker2和worker3上修改这个文件夹下的配置文件。
1> 配置第一组broker-a服务
在worker2机器上配置broker-a的MASTER服务,需要修改conf/2m-2s-async/broker-a.properties。示例配置如下:
#所属集群名字,名字一样的节点就在同一个集群内
brokerClusterName=rocketmq-cluster
#broker名字,名字一样的节点就是一组主从节点。
brokerName=broker-a
#brokerid,0就表示是Master,>0的都是表示 Slave
brokerId=0
#nameServer地址,分号分割
namesrvAddr=worker1:9876;worker2:9876;worker3:9876
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
deleteWhen=04
fileReservedTime=120
#存储路径
storePathRootDir=/app/rocketmq/store
storePathCommitLog=/app/rocketmq/store/commitlog
storePathConsumeQueue=/app/rocketmq/store/consumequeue
storePathIndex=/app/rocketmq/store/index
storeCheckpoint=/app/rocketmq/store/checkpoint
abortFile=/app/rocketmq/store/abort
#Broker 的角色
brokerRole=ASYNC_MASTER
flushDiskType=ASYNC_FLUSH
#Broker 对外服务的监听端口
listenPort=10911
这里对几个需要重点关注的属性,做下简单介绍:
brokerClusterName: 集群名。RocketMQ会将同一个局域网下所有brokerClusterName相同的服务自动组成一个集群,这个集群可以作为一个整体对外提供服务brokerName: Broker服务名。同一个RocketMQ集群当中,brokerName相同的多个服务会有一套相同的数据副本。同一个RocketMQ集群中,是可以将消息分散存储到多个不同的brokerName服务上的。brokerId: RocketMQ中对每个服务的唯一标识。RocketMQ对brokerId定义了一套简单的规则,master节点需要固定配置为0,负责响应客户端的请求。slave节点配置成其他任意数字,负责备份master上的消息。brokerRole: 服务的角色。这个属性有三个可选项:ASYNC_MASTER,SYNC_MASTER和SLAVE。其中,ASYNC_MASTER和SYNC_MASTER表示当前节点是master节点,目前暂时不用关心他们的区别。SLAVE则表示从节点。namesrvAddr: nameserver服务的地址。nameserver服务默认占用9876端口。多个nameserver地址用;隔开。
接下来在worekr3上配置broker-a的SLAVE服务。需要修改conf/2m-2s-async/broker-a-s.properties。示例配置如下:
#所属集群名字,名字一样的节点就在同一个集群内
brokerClusterName=rocketmq-cluster
#broker名字,名字一样的节点就是一组主从节点。
brokerName=broker-a
#brokerid,0就表示是Master,>0的都是表示 Slave
brokerId=1
#nameServer地址,分号分割
namesrvAddr=worker1:9876;worker2:9876;worker3:9876
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
deleteWhen=04
fileReservedTime=120
#存储路径
storePathRootDir=/app/rocketmq/storeSlave
storePathCommitLog=/app/rocketmq/storeSlave/commitlog
storePathConsumeQueue=/app/rocketmq/storeSlave/consumequeue
storePathIndex=/app/rocketmq/storeSlave/index
storeCheckpoint=/app/rocketmq/storeSlave/checkpoint
abortFile=/app/rocketmq/storeSlave/abort
#Broker 的角色
brokerRole=SLAVE
flushDiskType=ASYNC_FLUSH
#Broker 对外服务的监听端口
listenPort=11011
其中关键是brokerClusterName和brokerName两个参数需要与worker2上对应的broker-a.properties配置匹配。brokerId配置0以为的数字。然后brokerRole配置为SLAVE。
这样,第一组broker服务就配置好了。
2> 配置第二组borker-b服务
与第一组broker-a服务的配置方式类似,在worker3上配置broker-b的MASTER服务。需要修改conf/2m-2s-async/broker-b.properties文件,配置示例如下:
#所属集群名字,名字一样的节点就在同一个集群内
brokerClusterName=rocketmq-cluster
#broker名字,名字一样的节点就是一组主从节点。
brokerName=broker-b
#brokerid,0就表示是Master,>0的都是表示 Slave
brokerId=0
#nameServer地址,分号分割
namesrvAddr=worker1:9876;worker2:9876;worker3:9876
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
deleteWhen=04
fileReservedTime=120
#存储路径
storePathRootDir=/app/rocketmq/store
storePathCommitLog=/app/rocketmq/store/commitlog
storePathConsumeQueue=/app/rocketmq/store/consumequeue
storePathIndex=/app/rocketmq/store/index
storeCheckpoint=/app/rocketmq/store/checkpoint
abortFile=/app/rocketmq/store/abort
#Broker 的角色
brokerRole=ASYNC_MASTER
flushDiskType=ASYNC_FLUSH
#Broker 对外服务的监听端口
listenPort=10911
在worker2上配置broker-b的SLAVE服务。需要修改conf/2m-2s-async/broker-b-s.properties文件,配置示例如下:
#所属集群名字,名字一样的节点就在同一个集群内
brokerClusterName=rocketmq-cluster
#broker名字,名字一样的节点就是一组主从节点。
brokerName=broker-b
#brokerid,0就表示是Master,>0的都是表示 Slave
brokerId=1
#nameServer地址,分号分割
namesrvAddr=worker1:9876;worker2:9876;worker3:9876
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
deleteWhen=04
fileReservedTime=120
#存储路径
storePathRootDir=/app/rocketmq/storeSlave
storePathCommitLog=/app/rocketmq/storeSlave/commitlog
storePathConsumeQueue=/app/rocketmq/storeSlave/consumequeue
storePathIndex=/app/rocketmq/storeSlave/index
storeCheckpoint=/app/rocketmq/storeSlave/checkpoint
abortFile=/app/rocketmq/storeSlave/abort
#Broker 的角色
brokerRole=SLAVE
flushDiskType=ASYNC_FLUSH
#Broker 对外服务的监听端口
listenPort=11011
这样就完成了2主2从集群的配置。配置过程汇总有几个需要注意的配置项:
- store开头的一系列配置:表示RocketMQ的存盘文件地址。在同一个机器上需要部署多个Broker服务时,不同服务的存储目录不能相同。
- listenPort:表示Broker对外提供服务的端口。这个端口默认是10911。在同一个机器上部署多个Broker服务时,不同服务占用的端口也不能相同。
- 如果你使用的是多网卡的服务器,比如阿里云上的云服务器,那么就需要在配置文件中增加配置一个brokerIP1属性,指向所在机器的外网网卡地址。
第三步:启动Broker服务
集群配置完成后,需要启动Broker服务。与之前启动broker服务稍有不同,启动时需要增加-c参数,指向我们修改的配置文件。
在worker2上启动broker-a的master服务和broker-b的slave服务:
cd /app/rocketmq/rocketmq-all-4.9.5-bin-release
nohup bin/mqbroker -c ./conf/2m-2s-async/broker-a.properties &
nohup bin/mqbroker -c ./conf/2m-2s-async/broker-b-s.properties &
在worker3上启动broker-b的master服务和broker-a的slave服务:
cd /app/rocketmq/rocketmq-all-4.9.5-bin-release
nohup bin/mqbroker -c ./conf/2m-2s-async/broker-b.properties &
nohup bin/mqbroker -c ./conf/2m-2s-async/broker-a-s.properties &
第四步:检查集群服务状态
对于服务的启动状态,我们依然可以用之前介绍的jps指令以及nohup.out日志文件进行跟踪。不过,在RocketMQ的bin目录下,也提供了mqadmin指令,可以通过命令行的方式管理RocketMQ集群。
例如下面的指令可以查看集群broker集群状态。通过这个指令可以及时了解集群的运行状态。
[oper@worker1 bin]$ cd /app/rocketmq/rocketmq-all-4.9.5-bin-release/bin
[oper@worker1 bin]$ mqadmin clusterList
RocketMQLog:WARN No appenders could be found for logger (io.netty.util.internal.InternalThreadLocalMap).
RocketMQLog:WARN Please initialize the logger system properly.
#Cluster Name #Broker Name #BID #Addr #Version #InTPS(LOAD) #OutTPS(LOAD) #PCWait(ms) #Hour #SPACE
rocketmq-cluster broker-a 0 192.168.232.129:10911 V4_9_1 0.00(0,0ms) 0.00(0,0ms) 0 3425.28 0.3594
rocketmq-cluster broker-a 1 192.168.232.130:11011 V4_9_1 0.00(0,0ms) 0.00(0,0ms) 0 3425.28 0.3607
rocketmq-cluster broker-b 0 192.168.232.130:10911 V4_9_1 0.00(0,0ms) 0.00(0,0ms) 0 3425.27 0.3607
rocketmq-cluster broker-b 1 192.168.232.129:11011 V4_9_1 0.00(0,0ms) 0.00(0,0ms) 0 3425.27 0.3594
注:执行这个指令需要在机器上配置了NAMESRV环境变量
mqadmin指令还提供了非常丰富的管理功能。你可以尝试直接使用mqadmin指令,就会列出mqadmin支持的所有管理指令。如果对某一个指令不会使用,还可以使用mqadmin help 指令查看帮助。
另外,之前搭建的dashboard也是集群服务状态的很好的工具。只需要在之前搭建Dashboard时创建的配置文件中增加指定nameserver地址即可。
rocketmq: config: namesrvAddrs: - worker1:9876 - worker2:9876- worker3:9876
启动完成后,在集群菜单页就可以看到集群的运行情况
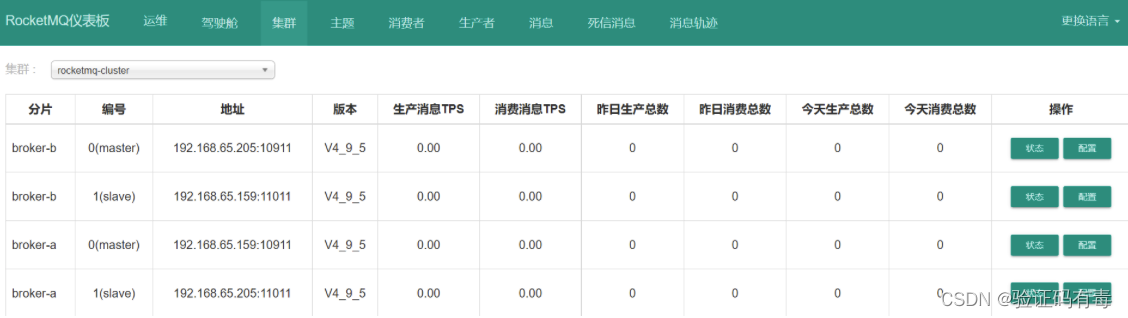
在RocketMQ的这种主从架构的集群下,客户端发送的消息会分散保存到broker-a和broker-b两个服务上,然后每个服务都配有slave服务,可以备份对应master服务上的消息,这样就可以防止单点故障造成的消息丢失问题。
四、理解 RocketMQ的消息模型
首先:我们先来尝试往RocketMQ中发送一批消息。
在上面的【RocketMQ快速实战】中我们提到,RocketMQ提供了一个测试脚本tools.sh,用于快速测试RocketMQ的客户端。
tools.sh org.apache.rocketmq.example.quickstart.Producer
这里调用的Producer示例实际上是在RocketMQ安装目录下的lib/rocketmq-example-4.9.5.jar中包含的一个测试类。tools.sh脚本则是提供Producer类的运行环境。
Producer这个测试类,会往RocketMQ中发送一千条测试消息。发送消息后,我们可以在控制台看到很多如下的日志信息。
SendResult [sendStatus=SEND_OK, msgId=7F000001426E28A418FC6545DFD803E7, offsetMsgId=C0A8E88100002A9F0000000000B4F6E5, messageQueue=MessageQueue [topic=TopicTest, brokerName=broker-a, queueId=2], queueOffset=124]
这是RocketMQ的Broker服务端给消息生产者的响应。这个响应信息代表的是Broker服务端已经正常接收并保存了消息生产者发送的消息。这里面提到了很多topic、messageQueue等概念,这些是什么意思呢?我们不妨先去RocketMQ的DashBoard控制台看一下RocketMQ的Broker是如何保存这些消息的。
访问DashBoard上的“主题”菜单,可以看到多了一个名为TopicTest的主题。
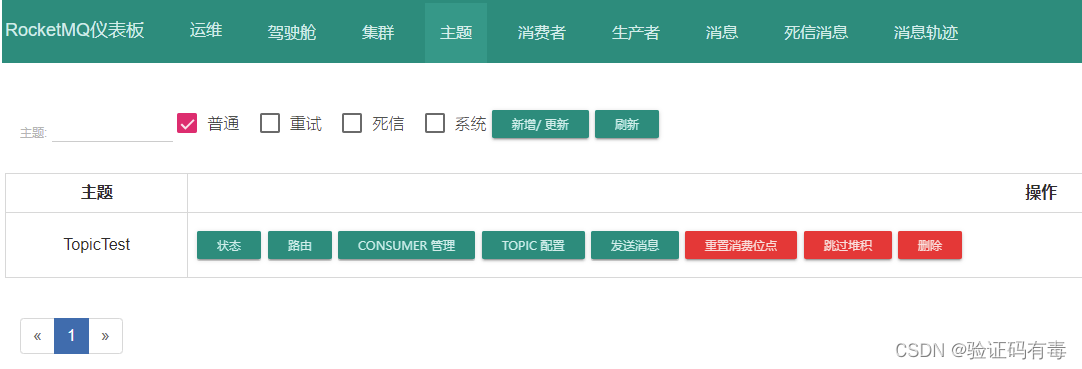
这个TopicTest就是我们之前运行的Producer创建的主题。点击“状态”按钮,可以看到TopicTest上的消息分布。
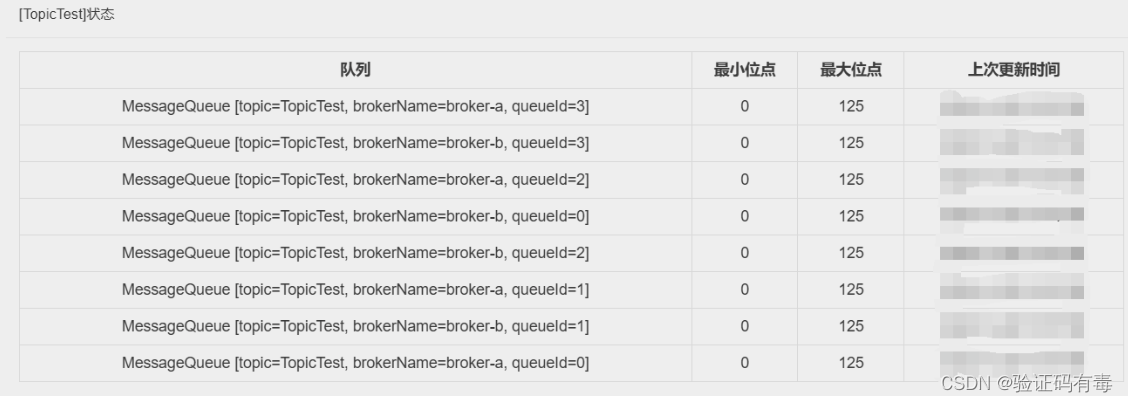
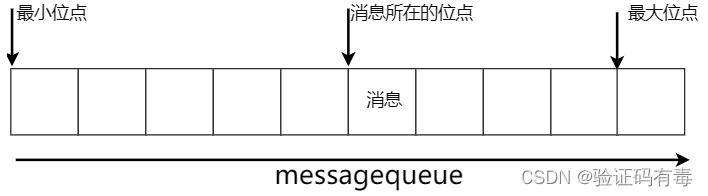
从这里可以看到,TopicTest这个话题下,分配了八个MessageQueue。这里的MessageQueue就是一个典型的具有FIFO(先进先出)特性的消息集合。这八个MessageQueue均匀的分布在了集群中的两个Broker服务上。每个MesasgeQueue都记录了一个最小位点和最大位点。这里的位点代表每个MessageQueue上存储的消息的索引,也称为offset(偏移量)。每一条新记录的消息,都按照当前最大位点往后分配一个新的位点。这个位点就记录了这一条消息的存储位置。
从Dashboard就能看到,每一个MessageQueue,当前都记录了125条消息。也就是说,我们之前使用Producer示例往RocketMQ中发送的一千条消息,就被均匀的分配到了这八个MessageQueue上。
这是,再回头来看之前日志中打印的SendResult的信息。日志中的MessageQueue就代表这一条消息存在哪个队列上了。而queueOffset就表示这条消息记录在MessageQueue的哪个位置。
然后:我们尝试启动一个消费者来消费消息
我们同样可以使用tools.sh来启动一个消费者示例。
tools.sh org.apache.rocketmq.example.quickstart.Consumer
这个Consumer同样是RocketMQ下的lib/rocketmq-example-4.9.5.jar中提供的消费者示例。Consumer启动完成后,我们可以在控制台看到很多类似这样的日志:
ConsumeMessageThread_3 Receive New Messages: [MessageExt [brokerName=broker-b, queueId=0, storeSize=194, queueOffset=95, sysFlag=0, bornTimestamp=1666252677571, bornHost=/192.168.232.128:38414, storeTimestamp=1666252678510, storeHost=/192.168.232.130:10911, msgId=C0A8E88200002A9F0000000000B4ADD2, commitLogOffset=11840978, bodyCRC=634652396, reconsumeTimes=0, preparedTransactionOffset=0, toString()=Message{topic='TopicTest', flag=0, properties={MIN_OFFSET=0, MAX_OFFSET=125, CONSUME_START_TIME=1666257428525, UNIQ_KEY=7F000001426E28A418FC6545DDC302F9, CLUSTER=rocketmq-cluster, TAGS=TagA}, body=[72, 101, 108, 108, 111, 32, 82, 111, 99, 107, 101, 116, 77, 81, 32, 55, 54, 49], transactionId='null'}]]
这里面也打印出了一些我们刚刚熟悉的brokerName,queueId,queueOffset这些属性。其中queueOffset属性就表示这一条消息在MessageQueue上的存储位点。通过记录每一个消息的Offset偏移量,RocketMQ就可以快速的定位到这一条消息具体的存储位置,继而正确读取到消息的内容。
接下来,我们还是可以到DashBoard上印证一下消息消费的情况。
在DashBoard的“主题”页面,选择对应主题后的“CONSUMER管理”功能,就能看到消费者的消费情况。
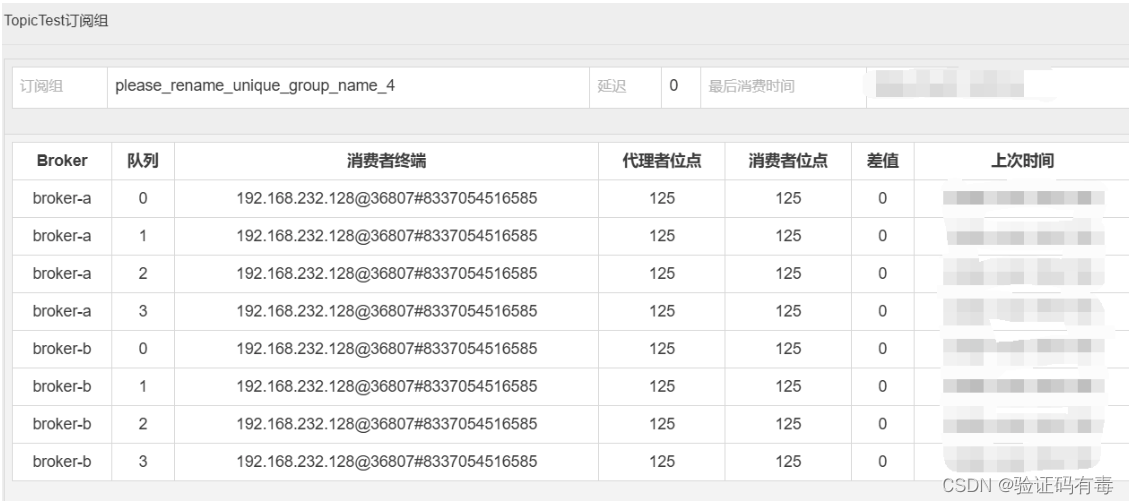
从这里可以看到,刚才的Comsumer示例启动了一个叫做please_rename_unique_group_name_4的消费者组。然后这个消费者从八个队列中都消费了数据。后面的代理者位点记录的是当前MessageQueue上记录的最大消息偏移量。而消费者位点记录的是当前消费者组在MessageQueue上消费的最大消息偏移量。其中的差值就表示当前消费者组没有处理完的消息。
并且,从这里还可以看出,RocketMQ记录消费者的消费进度时,都是以“订阅组”为单位的。我们也可以使用上一章节的示例,自己另外定义一个新的消费者组来消费TopicTest上的消息。这时,RocketMQ就会单独记录新消费者组的消费进度。而新的消费者组,也能消费到TopicTest下的所有消息。
接下来:我们就可以梳理出RocketMQ的消息记录方式
对之前的实验过程进行梳理,我们就能抽象出RocketMQ的消息模型。如下图所示:
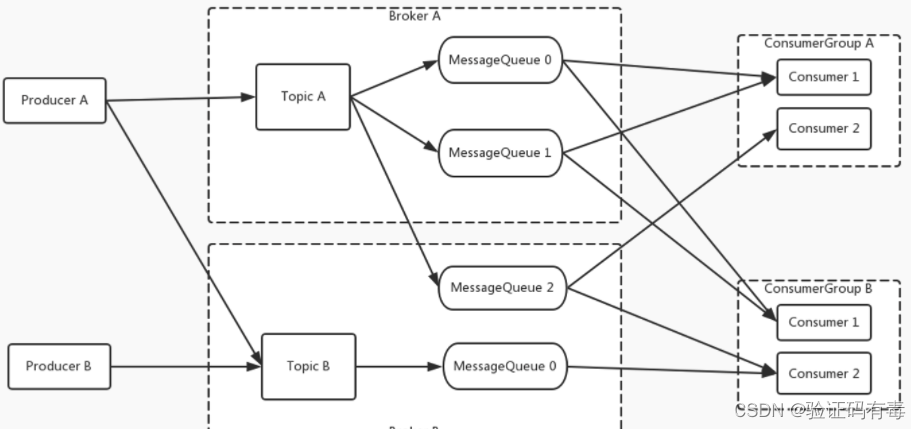
生产者和消费者都可以指定一个Topic发送消息或者拉取消息。而Topic是一个逻辑概念。Topic中的消息会分布在后面多个MessageQueue当中。这些MessageQueue会分布到一个或者多个broker中。
在RocketMQ的这个消息模型当中,最为核心的就是Topic。对于客户端,Topic代表了一类有相同业务规则的消息。对于Broker,Topic则代表了系统中一系列存储消息的资源。所以,RocketMQ对于Topic是需要做严格管理的。如果任由客户端随意创建Topic,那么服务端的资源管理压力就会非常大。默认情况下,Topic都需要由管理员在RocketMQ的服务端手动进行创建,然后才能给客户端使用的。而我们之前在broker.conf中手动添加的autoCreateTopic=true,就是表示可以由客户端自行创建Topic。这种配置方式显然只适用于测试环境,在生产环境不建议打开这个配置项。如果需要创建 Topic,可以交由运维人员提前创建 Topic。
而对于业务来说,最为重要的就是消息Message了。生产者发送到某一个Topic下的消息,最终会保存在Topic下的某一个MessageQueue中。而消费者来消费消息时,RocketMQ会在Broker端给每个消费者组记录一个消息的消费位点Offset。通过Offset控制每个消费者组的消息处理进度。这样,每一条消息,在一个消费者组当中只被处理一次。
从逻辑层面来看,RocketMQ 的消息模型和Kafka的消息模型是很相似的。没错,早期 RocketMQ 就是借鉴Kafka设计出来的。但是,在后续的发展过程中,RocketMQ 在Kafka的基础上,做了非常大的调整。所以,对于RocketMQ,你也不妨回顾下Kafka,与Kafka对比着进行学习。
例如,在Kafka当中,如果Topic过多,会造成消息吞吐量下降。但是在RocketMQ中,对Topic的支持已经得到很大的加强。Topic过多几乎不会影响整体性能。RocketMQ是怎么设计的?另外,之前Kafka课程中也分析过,Leader选举的过程中,Kafka优先保证服务可用性,而一定程度上牺牲了消息的安全性,那么 RocketMQ 是怎么做的呢?保留这些问题,后续我们一一解决。
学习总结
感谢
感谢作者【morris131】大佬的文章【RocketMQ】RocketMQ快速入门
相关文章:
【RocketMQ专题】快速实战及集群架构原理详解
目录 课程内容一、MQ简介基本介绍*作用(解决什么问题) 二、RocketMQ产品特点2.1 RocketMQ介绍2.2 RocketMQ特点2.3 RocketMQ的运行架构 三、RocketMQ快速实战3.1 快速搭建RocketMQ服务3.2 快速实现消息收发3.3 搭建Maven客户端项目3.4 搭建RocketMQ可视化…...
[设计模式] 浅谈SOLID设计原则
目录 单一职责原则开闭原则里氏替换原则接口隔离原则依赖倒转原则 SOLID是一个缩写词,代表以下五种设计原则 单一职责原则 Single Responsibility Principle, SRP开闭原则 Open-Closed Principle, OCP里氏替换原则 Liskov Substitution Principle, LSP接口隔离原则 …...

基于Java+SpringBoot+Vue的旧物置换网站设计和实现
基于JavaSpringBootVue的旧物置换网站设计和实现 源码传送入口前言主要技术系统设计功能截图数据库设计代码论文目录订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 源码传送入口 前言 摘 要 随着时代在一步一步在进步,旧物也成人们的烦恼,…...

Java基本语法2
目录 Java基本语法 第一个Java程序 基本语法 Java标识符 Java修饰符 Java变量 Java数组 Java枚举 Java关键字 Java注释 Java 空行 继承 接口 Java基本语法 一个Java程序可以认为是一系列对象的集合,而这些对象通过调用彼此的方法来协同工作。下面简要介…...

【数据结构】树的存储结构;树的遍历;哈夫曼树;并查集
欢~迎~光~临~^_^ 目录 1、树的存储结构 1.1双亲表示法 1.2孩子表示法 1.3孩子兄弟表示法 2、树与二叉树的转换 3、树和森林的遍历 3.1树的遍历 3.1.1先根遍历 3.1.2后根遍历 3.2森林的遍历 3.2.1先序遍历森林 3.2.2中序遍历森林 4、树与二叉树的应用 4.1哈夫曼树…...
CSS选择器练习小游戏
请结合CSS选择器练习小游戏进行阅读(网页的动态效果是没有办法通过静态图片展示的) 网址:请点击 有些题有多种答案,本文就不一一列出了 第一题 答案:plate第二题 答案:bento第三题 答案:#fa…...
Python运算符、函数与模块和程序控制结构
给我家憨憨写的python教程 ——雁丘 Python运算符、函数与模块和程序控制结构 关于本专栏一 运算符1.1 位运算符1.1.1 按位取反1.1.2 按位与1.1.3 按位或1.1.4 按位异或1.1.5 左移位 1.2 关系运算符1.3 运算顺序1.4 运算方向 二 函数与模块2.1 内建函数2.2 库函数2.2.1 标准库…...
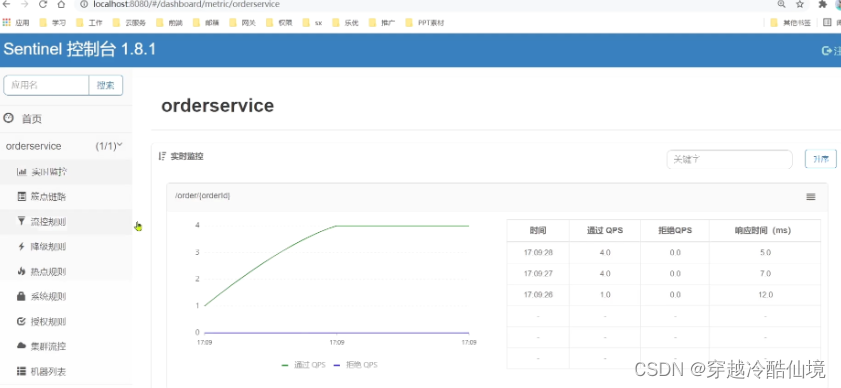
微服务保护-Sentinel
初识Sentinel 雪崩问题及解决方案 雪崩问题 微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。 如图,如果服务提供者I发生了故障,当前的应用的部分业务因为依赖于服务I,因此也会被阻塞。此时&a…...

Doris 导出表结构或数据
MYSQLDUMP 导出表结构或数据 Doris 在0.15 之后的版本已经支持通过mysqldump 工具导出数据或者表结构 使用示例 导出 导出 test 数据库中的 table1 表:mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test --tables table1导出 test 数…...

SELECT * from t_user where user_id = xxx,可以从那几个点去优化这句sql
优化SQL查询可以从以下几个方面入手: 1. 索引优化:通过为查询涉及的列添加合适的索引,可以提高查询的效率。在该SQL语句中, user_id 列被用作查询条件,可以为 user_id 列创建一个索引。 2. 避免使用 SELECT *…...

解决报错 java.lang.IllegalArgumentException: Cannot format given Object as a Date
报错原因:我们在SimpleDateFormat.format转化时间格式的时候,传入的值无法转换成date而报的错 我的代码大概就是下面这种 LocalDate now LocalDate.now();String format1 new SimpleDateFormat("yyyy-MM-dd").format(now); 发现SimpleDateF…...
【Git】03-GitHub
文章目录 1. GitHub核心功能2. GitHub搜索项目3. GitHub搭建个人博客4. 团队项目创建5. git工作流选择5.1 需要考虑的因素5.2 主干开发5.2 Git Flow5.3 GitHub Flow5.4 GitLab Flow(带生产分支)5.4 GitLab Flow(带环境分支)5.4 GitLab Flow(带发布分支) 6. 分支集成策略7. 启用…...

Java手写最短路径算法和案例拓展
Java手写最短路径算法和案例拓展 1. 算法手写的必要性 在实际开发中,经常需要处理图的最短路径问题。虽然Java提供了一些图算法库,但手写最短路径算法的必要性体现在以下几个方面: 理解算法原理:手写算法可以帮助我们深入理解最…...

深度学习实战51-基于Stable Diffusion模型的图像生成原理详解与项目实战
大家好,我是微学AI,今天给大家介绍一下深度学习实战51-基于Stable Diffusion模型的图像生成原理详解与项目实战。大家知道现在各个平台发的漂亮小姐姐,漂亮的图片是怎么生成的吗?这些生成的底层原理就是用到了Stable Diffusion模型。Stable Diffusion是一种基于深度学习的图…...
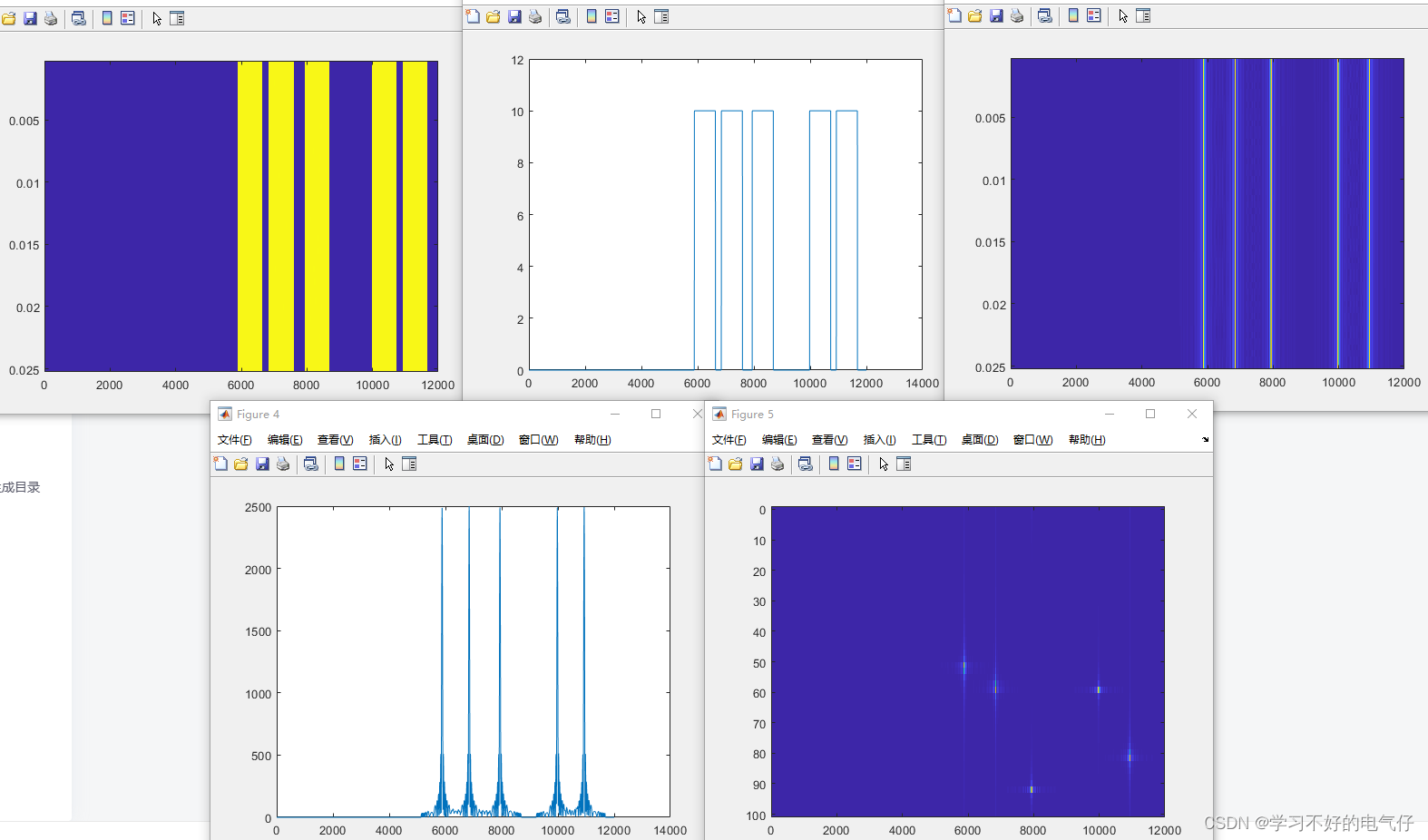
基于matlab实现的多普勒脉冲雷达回波仿真
完整程序: clear all;clc;close all; fc3e9; %载波频率 PRF2000; Br5e6; %带宽 fs10*Br; %采样频率 Tp5e-6; %脉宽 KrBr/Tp; %频率变化率 c3e8; %光速 lamda…...

Linux服务器中安装Anaconda+Tensorflow+Keras
Anaconda安装 从https://repo.anaconda.com/archive/查看你需要下载的Anaconda版本,例如2020.11的x86_64(uname -a 查看linux框架)版下载Anaconda到linux服务器, wget https://repo.anaconda.com/archive/Anaconda3-2020.11-Li…...

ubuntu+.net6+docker 应用部署教程
先期工作 1、本地首先安装 Docker Desktop 2、本地装linux in windows 3、生成镜像 后期工作 1、云服务器部署 生成镜像方法 1、生成Dockerfile配置文件 开发工具visual studio 2022 如果项目已经存在,可以选中项目,右键点击->选择添加Docker…...

Spring常见面试题总结
什么是Spring Spring是一个轻量级Java开发框架,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题,以提高开发效率。它是一个分层的JavaSE/JavaEE full-stack(一站式)轻量级开源框架,为开发Java应用程序…...
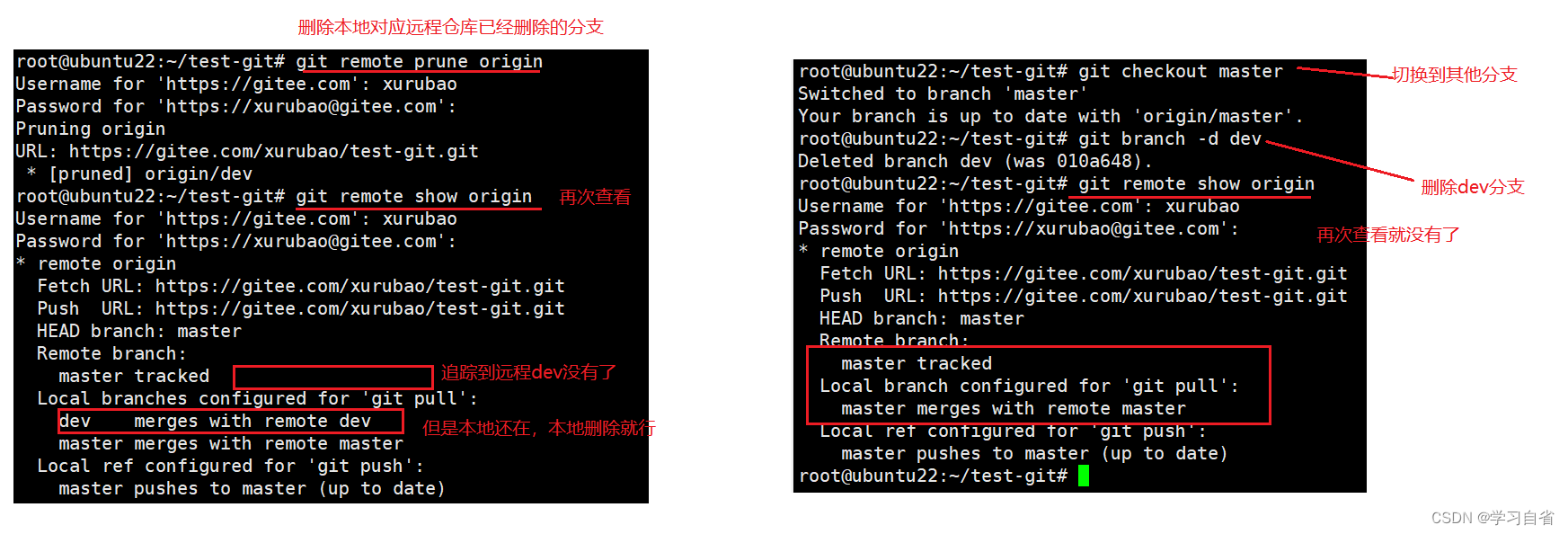
Git全套命令使用
日升时奋斗,日落时自省 目录 1、Git安装 1.1、创建git本地仓库 1.2、配置Git 1.3、认识Git内部区分 2、Git应用操作 2.1、添加文件 2.2、查看日志 2.3、查看修改信息 2.4、查看添加信息 3、版本回退 4、撤销修改 4.1、工作区撤销 4.2、已经add…...
【陕西理工大学-数学软件实训】数学实验报告(8)(数值微积分与方程数值求解)
目录 一、实验目的 二、实验要求 三、实验内容与结果 四、实验心得 一、实验目的 1. 掌握求数值导数和数值积分的方法。 2. 掌握代数方程数值求解的方法。 3. 掌握常微分方程数值求解的方法。 二、实验要求 1. 根据实验内容,编写相应的MATLAB程序,…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...
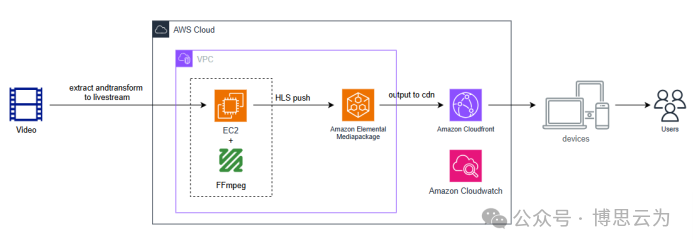
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...

StarRocks 全面向量化执行引擎深度解析
StarRocks 全面向量化执行引擎深度解析 StarRocks 的向量化执行引擎是其高性能的核心设计,相比传统行式处理引擎(如MySQL),性能可提升 5-10倍。以下是分层拆解: 1. 向量化 vs 传统行式处理 维度行式处理向量化处理数…...