【深度学习实验】线性模型(五):使用Pytorch实现线性模型:基于鸢尾花数据集,对模型进行评估(使用随机梯度下降优化器)
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入库
1. 线性模型linear_model
2. 损失函数loss_function
3. 鸢尾花数据预处理
4. 初始化权重和偏置
5. 优化器
6. 迭代
7. 测试集预测
8. 实验结果评估
9. 完整代码
一、实验介绍
线性模型是机器学习中最基本的模型之一,通过对输入特征进行线性组合来预测输出。本实验旨在展示使用随机梯度下降优化器训练线性模型的过程,并评估模型在鸢尾花数据集上的性能。
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
0. 导入库
import torch
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn import metrics- PyTorch
- 优化器模块(
optim)
- 优化器模块(
- scikit-learn
- 数据模块(load_iris)
- 数据划分(train_test_split)
- 评估指标模块(
metrics)
1. 线性模型linear_model
该函数接受输入数据x,使用随机生成的权重w和偏置b,计算输出值output。这里的线性模型的形式为 output = x * w + b。
def linear_model(x):return torch.matmul(x, w) + b2. 损失函数loss_function
这里使用的是均方误差(MSE)作为损失函数,计算预测值与真实值之间的差的平方。
def loss_function(y_true, y_pred):loss = (y_pred - y_true) ** 2return loss3. 鸢尾花数据预处理
-
加载鸢尾花数据集并进行预处理
-
将数据集分为训练集和测试集
-
将数据转换为PyTorch张量
-
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
x_train = torch.tensor(x_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
x_test = torch.tensor(x_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)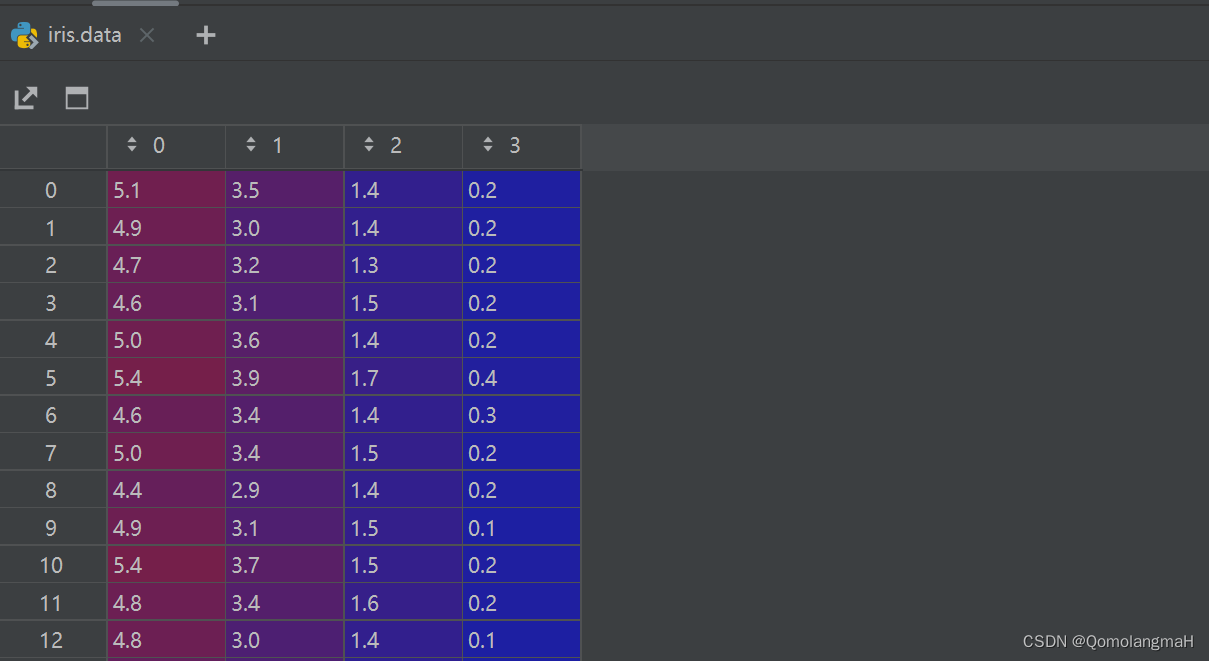
4. 初始化权重和偏置
w = torch.rand(1, 1, requires_grad=True)
b = torch.randn(1, requires_grad=True)5. 优化器
使用随机梯度下降(SGD)优化器进行模型训练,指定学习率和待优化的参数w, b。
optimizer = optim.SGD([w, b], lr=0.01) # 使用SGD优化器
6. 迭代
num_epochs = 100
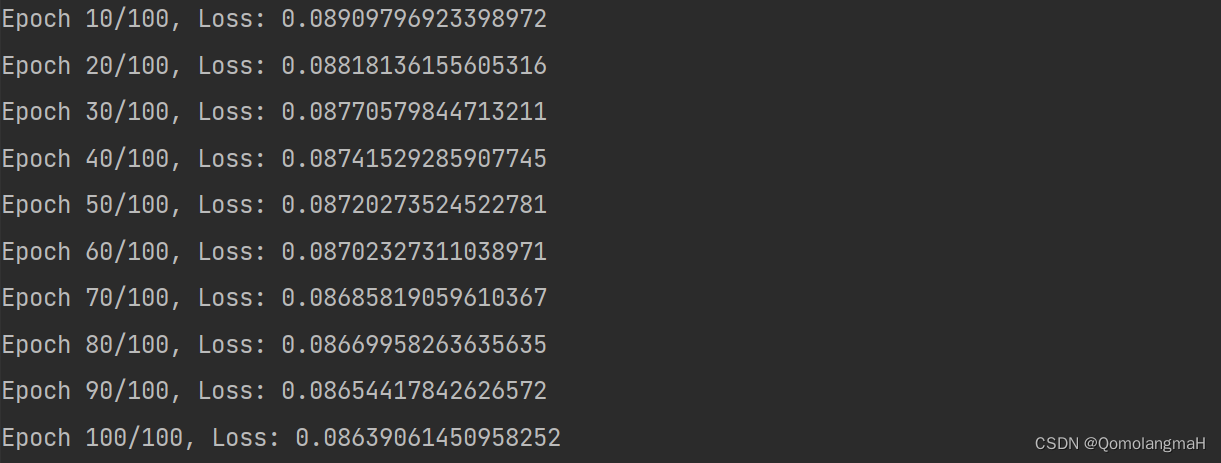
for epoch in range(num_epochs):optimizer.zero_grad() # 梯度清零prediction = linear_model(x_train, w, b)loss = loss_function(y_train, prediction)loss.mean().backward() # 计算梯度optimizer.step() # 更新参数if (epoch + 1) % 10 == 0:print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.mean().item()}")
-
在每个迭代中:
-
将优化器的梯度缓存清零,然后使用当前的权重和偏置对输入
x进行预测,得到预测结果prediction。 -
使用
loss_function计算预测结果与真实标签之间的损失,得到损失张量loss。 -
调用
loss.mean().backward()计算损失的平均值,并根据计算得到的梯度进行反向传播。 -
调用
optimizer.step()更新权重和偏置,使用优化器进行梯度下降更新。 -
每隔 10 个迭代输出当前迭代的序号、总迭代次数和损失的平均值。
-
7. 测试集预测
在测试集上进行预测,使用训练好的模型对测试集进行预测
with torch.no_grad():test_prediction = linear_model(x_test, w, b)test_prediction = torch.round(test_prediction) # 四舍五入为整数test_prediction = test_prediction.detach().numpy()8. 实验结果评估
- 使用
metrics模块计算分类准确度(accuracy)、精确度(precision)、召回率(recall)和F1得分(F1 score)。 - 输出经过优化后的参数
w和b,以及在测试集上的评估指标。
accuracy = metrics.accuracy_score(y_test, test_prediction)
precision = metrics.precision_score(y_test, test_prediction, average='macro')
recall = metrics.recall_score(y_test, test_prediction, average='macro')
f1 = metrics.f1_score(y_test, test_prediction, average='macro')
print("The optimized parameters are:")
print("w:", w.flatten().tolist())
print("b:", b.item())print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)
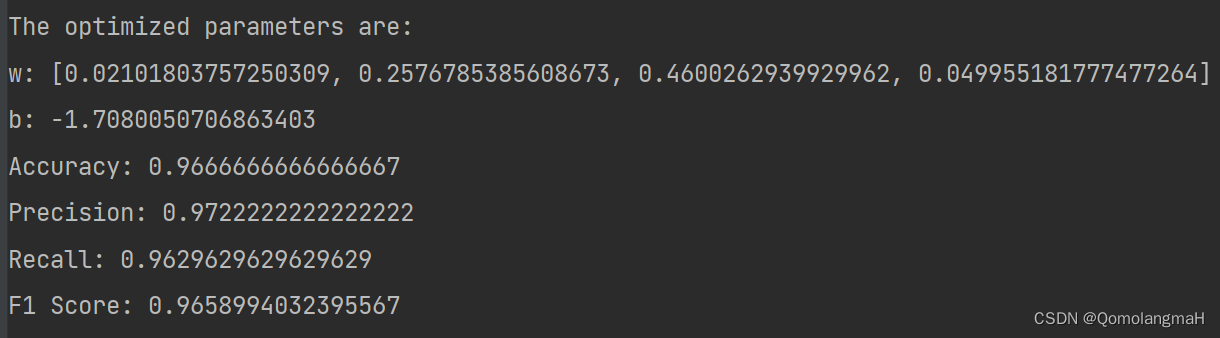
本实验使用随机梯度下降优化器训练线性模型,并在鸢尾花数据集上取得了较好的分类性能。实验结果表明,经过优化后的模型能够对鸢尾花进行准确的分类,并具有较高的精确度、召回率和F1得分。
9. 完整代码
import torch
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn import metricsdef linear_model(x, w, b):return torch.matmul(x, w) + bdef loss_function(y_true, y_pred):loss = (y_pred - y_true) ** 2return loss# 加载鸢尾花数据集并进行预处理
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
x_train = torch.tensor(x_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
x_test = torch.tensor(x_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)w = torch.rand(x_train.shape[1], 1, requires_grad=True)
b = torch.randn(1, requires_grad=True)
optimizer = optim.SGD([w, b], lr=0.01) # 使用SGD优化器num_epochs = 100
for epoch in range(num_epochs):optimizer.zero_grad() # 梯度清零prediction = linear_model(x_train, w, b)loss = loss_function(y_train, prediction)loss.mean().backward() # 计算梯度optimizer.step() # 更新参数if (epoch + 1) % 10 == 0:print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.mean().item()}")# 在测试集上进行预测
with torch.no_grad():test_prediction = linear_model(x_test, w, b)test_prediction = torch.round(test_prediction) # 四舍五入为整数test_prediction = test_prediction.detach().numpy()accuracy = metrics.accuracy_score(y_test, test_prediction)
precision = metrics.precision_score(y_test, test_prediction, average='macro')
recall = metrics.recall_score(y_test, test_prediction, average='macro')
f1 = metrics.f1_score(y_test, test_prediction, average='macro')
print("The optimized parameters are:")
print("w:", w.flatten().tolist())
print("b:", b.item())print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)
相关文章:
【深度学习实验】线性模型(五):使用Pytorch实现线性模型:基于鸢尾花数据集,对模型进行评估(使用随机梯度下降优化器)
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入库 1. 线性模型linear_model 2. 损失函数loss_function 3. 鸢尾花数据预处理 4. 初始化权重和偏置 5. 优化器 6. 迭代 7. 测试集预测 8. 实验结果评估 9. 完整代码 一、实验介…...
ADB底层原理
介绍 adb的全称为Android Debug Bridge,就是起到调试桥的作用。通过adb我们可以在Eclipse/Android Studio中方便通过DDMS来调试Android程序,说白了就是debug工具。adb是android sdk里的一个工具, 用这个工具可以直接操作管理android模拟器或者真实的and…...

etcd之读性能主要影响因素
1、Raft模块-线性读ReadIndex-节点之间的RTT延时、磁盘IO 线性读时Follower节点首先会向Raft 模块发送ReadIndex请求,此时Raft模块会先向各节点发送心跳确认,一半以上节点确认 Leader 身份后由leader节点将已提交日志索引 (committed index) 封装成 Rea…...
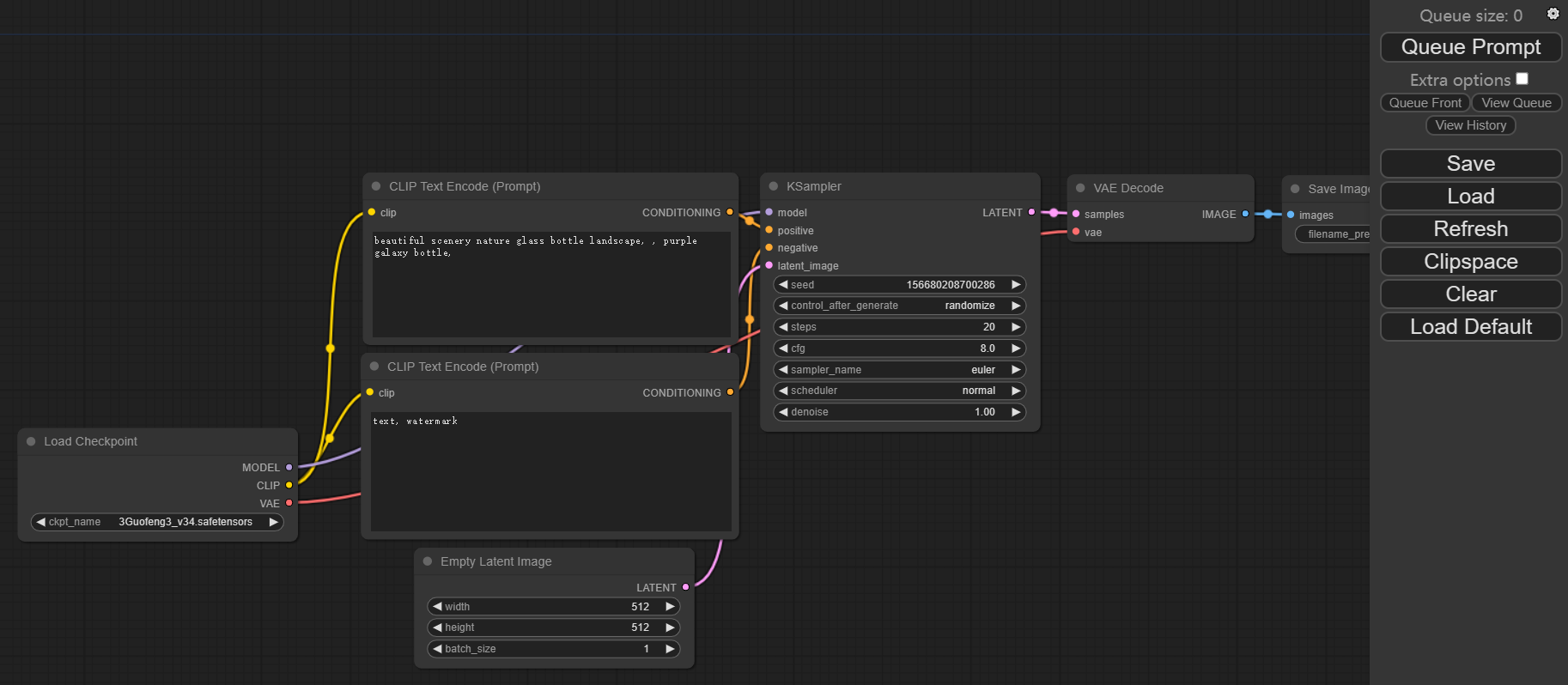
【Stable Diffusion】安装 Comfyui 之 window版
序言 由于stable diffusion web ui无法做到对流程进行控制,只是点击个生成按钮后,一切都交给AI来处理。但是用于生产生活是需要精细化对各个流程都要进行控制的。 故也就有个今天的猪脚:Comfyui 步骤 下载comfyui项目配置大模型和vae下载…...
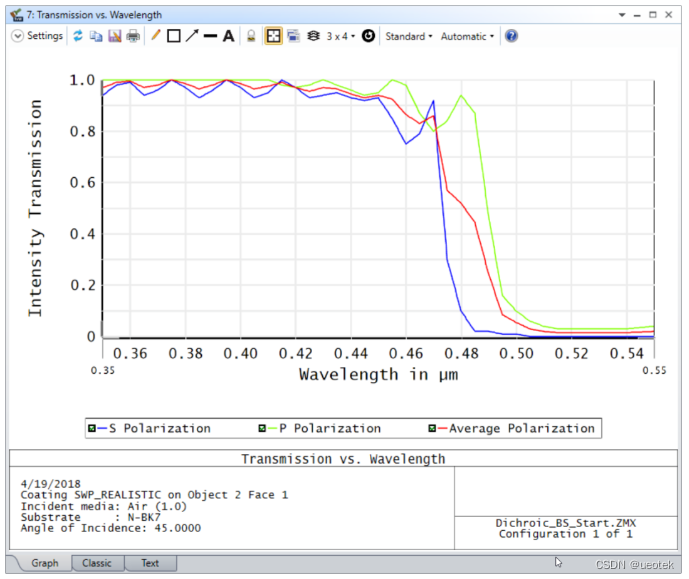
Ansys Zemax | 如何建立二向分色分光镜
分光镜(Beam splitter)可被运用在许多不同的场合。一般而言,入射光抵达二向分色分光镜(dichroic beam splitter)时,会根据波长的差异产生穿透或反射的现象。这篇文章将说明如何在OpticStudio的非序列模式(non-sequential mode)中建立二向分色分光镜&…...
Mybatis学习笔记8 查询返回专题
1.返回实体类 2.返回List<实体类> 3.返回Map 4.返回List<Map> 5.返回Map<String,Map> 6.resultMap结果集映射 7.返回总记录条数 新建模块 依赖 目录结构 1.返回实体类 如果返回多条,用单个实体接收会出异常 2.返回List<实体类> 即使返回一条记…...
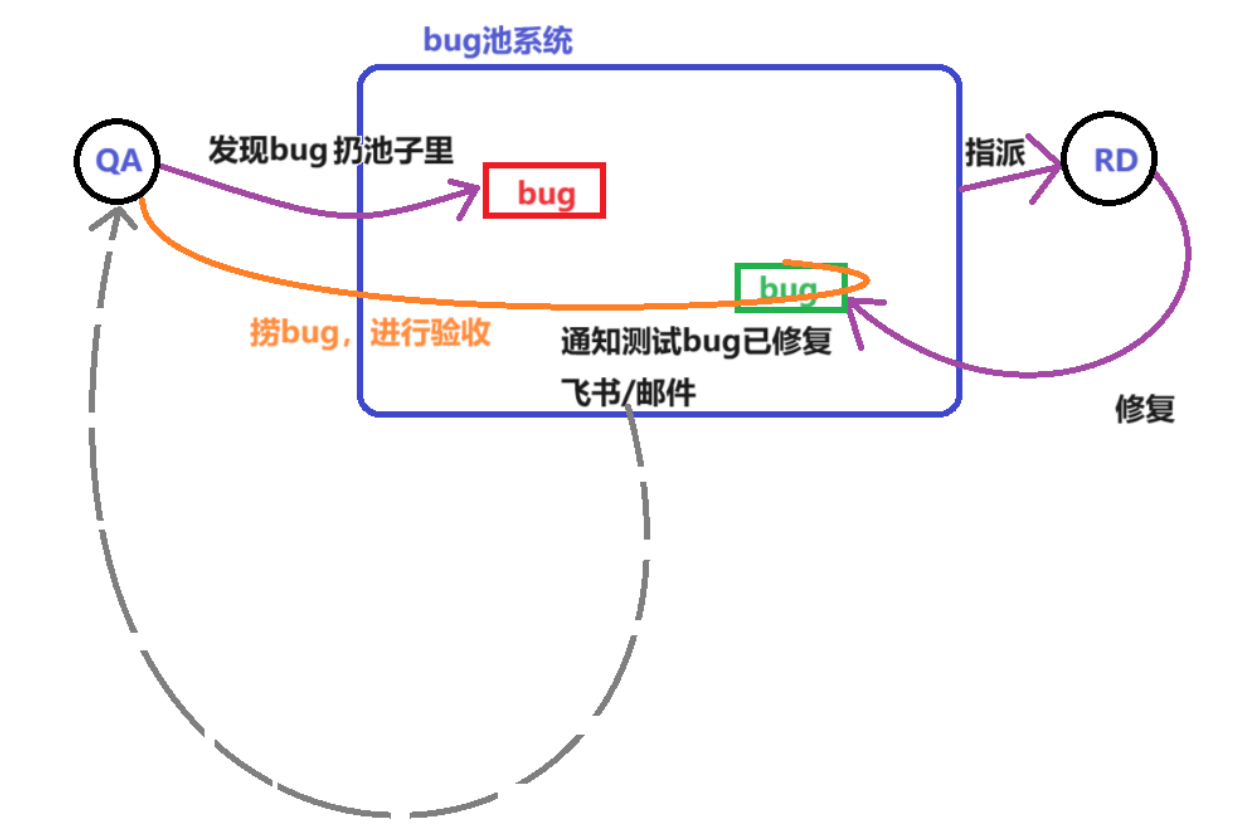
【测试开发】基础篇 · 专业术语 · 软件测试生命周期 · bug的描述 · bug的级别 · bug的生命周期 · 处理争执
【测试开发】基础篇 文章目录 【测试开发】基础篇1. 软件测试生命周期1.1 软件生命周期1.2 软件测试生命周期 2. 描述bug3. 如何定义bug的级别3.1 为什么要对bug进行级别划分3.2 bug的一些常见级别 4. bug的生命周期5. 产生争执这么怎么办(处理人际关系)…...

bing许少辉乡村振兴战略下传统村落文化旅游设计images
bing许少辉乡村振兴战略下传统村落文化旅游设计images...

第三十一章 Classes - 继承规则
第三十一章 Classes - 继承规则 继承规则 与其他基于类的语言一样,可以通过继承组合多个类定义。 类定义可以扩展(或继承)多个其他类。这些类又可以扩展其他类。 请注意,类不能继承 Python 中定义的类(即 .py 文件中…...
华为云HECS安装docker并安装mysql
1、运行安装指令 yum install docker都选择y,直到安装成功 2、查看是否安装成功 运行版本查看指令,显示docker版本,证明安装成功 docker --version 3、启用并运行docker 3.1启用docker指令 systemctl enable docker 3.2 运行docker指令…...

MQ - 04 基础篇_存储_消息数据和元数据的存储设计
文章目录 导图概述元数据信息的存储消息数据的存储数据存储结构设计思路一 (Kafka的方案)思路二 (RocketMQ、RabbitMQ 和 Pulsar 的底层存储 BookKeeper 采用的方案)消息数据的分段实现根据偏移量定位根据索引定位 (RabbitMQ 和 RocketMQ的思路)使用场景消息数据存储格式…...

JavaScript:隐式转换、显示转换、隐式操作、显示操作
一、理解js隐式转换 JavaScript 中的隐式转换是指不需要显式地调用转换函数,而是在执行期间自动发生的数据类型的转换。即在使用不同类型的值进行操作时,JavaScript会自动进行类型转换。这种转换通常发生在不同数据类型之间进行运算或比较时。 序号分类…...
2023全新TwoNav开源网址导航系统源码 | 去授权版
2023全新TwoNav开源网址导航系统源码 已过授权 所有功能可用 测试环境:NginxPHP7.4MySQL5.6 一款开源的书签导航管理程序,界面简洁,安装简单,使用方便,基础功能免费。 TwoNav可帮助你将浏览器书签集中式管理&#…...

Android 12 源码分析 —— 应用层 六(StatusBar的UI创建和初始化)
Android 12 源码分析 —— 应用层 六(StatusBar的UI创建和初始化) 在前面的文章中,我们分别介绍了Layout整体布局,以及StatusBar类的初始化.前者介绍了整体上面的布局,后者介绍了三大窗口的创建的入口处,以及需要做的准备工作.现在我们分别来细化三大窗口的UI创建和…...
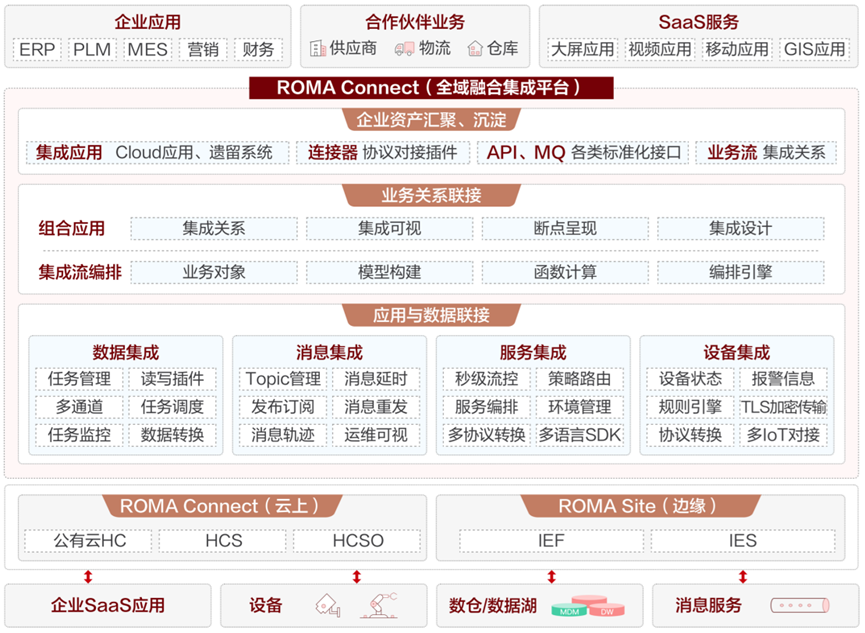
华为云ROMA Connect亮相Gartner®全球应用创新及商业解决方案峰会,助力企业应用集成和数字化转型
9月13日-9月14日 Gartner全球应用创新及商业解决方案峰会在伦敦举行 本届峰会以“重塑软件交付,驱动业务价值”为主题,全球1000多位业内专家交流最新的企业应用、软件工程、解决方案架构、集成与自动化、API等企业IT战略和新兴技术热门话题。 9月13日…...
虚拟线上发布会带来颠覆性新体验,3D虚拟场景直播迸发品牌新动能
虚拟线上发布会是近年来在数字化营销领域备受关注的形式,而随着虚拟现实技术的不断进步,3D虚拟场景直播更成为了品牌宣传、推广的新选择。可以说,虚拟线上发布会正在以其颠覆性的新体验,为品牌带来全新的活力。 1.突破时空限制&am…...

Linux arm64 pte相关宏
文章目录 一、pte 和 pfn1.1 pte_pfn1.2 pfn_pte 二、其他宏参考资料 一、pte 和 pfn // linux-5.4.18/arch/arm64/include/asm/pgtable.h#define pte_pfn(pte) (__pte_to_phys(pte) >> PAGE_SHIFT) #define pfn_pte(pfn,prot) \__pte(__phys_to_pte_val((phys_addr_t)…...
)
MVCC:多版本并发控制案例分析(一)
(笔记总结自b站马士兵教育课程) 一、简介 MVCC:全称multi-version Concurency control,多版本并发控制,是为了解决并发读写问题存在的。MVCC的实现原理由三部分组成:隐藏字段、undolog、readview。 二、概…...

以数据为中心的安全市场快速增长
根据Adroit Market Research的数据,2021年全球以数据为中心的安全市场规模估计为27.6亿美元,预计到2030年将增长至393.48亿美元,2021年至2030年的复合年增长率为30.9%。 研究人员表示,以数据为中心的安全强调保护数据本身&#x…...
)
AUTOSAR汽车电子嵌入式编程精讲300篇-经典 AUTOSAR 安全防御能力的分析及改善(下)
目录 4.4.2 Security 攻击 4.4.3 Security 要求 4.4.4 SDSA 有效性验证 经典 AUTOSAR 安全防御能力分析...
)
别再死记硬背了!用华为eNSP模拟器实战拆解OSPF的5种网络类型(BMA/P2P/P2MP/NBMA)
华为eNSP模拟器实战:OSPF五种网络类型深度解析与避坑指南 刚接触OSPF协议的网络工程师,往往会被BMA、P2P、P2MP、NBMA这些术语搞得晕头转向。教科书上的定义总是抽象难懂,而实际网络环境又千变万化。本文将通过华为eNSP模拟器,带您…...

魔兽争霸III终极兼容方案:WarcraftHelper完整使用指南
魔兽争霸III终极兼容方案:WarcraftHelper完整使用指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III》在现代电脑上…...

maven涉及的配置
1、settings.xml(1)本地仓库<localRepository>d:\temp\repo</localRepository>,用 <localRepository>括起来的表示本地仓库的位置。(2)镜像源<mirrors><mirror><id>nexus-aliyun&…...

G-Helper终极指南:释放华硕笔记本隐藏性能的简单秘诀
G-Helper终极指南:释放华硕笔记本隐藏性能的简单秘诀 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Sca…...

G2100、G2110、G2200、G2400、G2410、G2411、G2420、G2500、G2510、G2520、G2600报错5B00,P07,E08,1700,5b04废墨垫清零软件,有效
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

三大突破:FakeLocation如何通过应用级Hook技术实现Android精准虚拟定位
三大突破:FakeLocation如何通过应用级Hook技术实现Android精准虚拟定位 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 在移动应用生态中,位置隐私保护已成…...

文章目录23
文章目录 一、tarjan求强连通分量1:算法流程2:模板 二、tarjan缩点1:相关定义2:算法流程 三、tarjan求割点、桥1、什么是割点2.割点怎么求?3。割点tarjan模板&运行实例 tarjan可以做什么? 根据 Rob…...
的共享内存通信)
保姆级教程:在Ubuntu系统的AIxBoard上,用CODESYS V3.5 SP17配置软PLC,并打通Python(OpenVINO/YOLOv5)的共享内存通信
边缘智能控制实战:基于AIxBoard与CODESYS的软PLC-Python协同开发指南 当工业控制遇上人工智能,传统PLC的封闭性与现代AI算法的开放性如何实现无缝对接?本文将手把手带您完成从零搭建一个支持机器视觉的智能控制系统。不同于简单的理论概述&am…...

SpringMVC5.0
Spring留言板实现预期结果可以发布并显示点击提交后,显示并清除输入框并且再次刷新后,不会清除下面的缓存约定前后端交互接口Ⅰ 发布留言 url : /message/publish . param(参数) : from,to,say . return : true / false .Ⅱ 查询留言 url : /message/get…...

3个颠覆性功能让Pearcleaner成为Mac系统清理必备神器
3个颠覆性功能让Pearcleaner成为Mac系统清理必备神器 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否想过,为什么Mac电脑用久了会越来越慢…...