ChatGPT实战-Embeddings打造定制化AI智能客服
本文介绍Embeddings的基本概念,并使用最少但完整的代码讲解Embeddings是如何使用的,帮你打造专属AI聊天机器人(智能客服),你可以拿到该代码进行修改以满足实际需求。
ChatGPT的Embeddings解决了什么问题?
如果直接问ChatGPT:What is langchain? If you do not know please do not answer.,由于ChatGPT不知道2021年9月份之后的事情,而langchain比较新,是在那之后才有的,所以ChatGPT会回答不知道:
I’m sorry, but I don’t have any information on “langchain.” It appears to be a term that is not widely recognized or used in general knowledge.
如果我们用上Embeddings,用上面的问题提问,它可以给出答案:
LangChain is a framework for developing applications powered by language models.
有了这个技术,我们就可以对自己的文档进行提问,从而拓展ChatGPT的知识范围,打造定制化的AI智能客服。例如在官网接入ChatGPT,根据网站的文档让他回答用户的问题。
Embeddings相关基本概念介绍
什么是Embeddings?
在跳进代码之前,先简要介绍一下什么是Embeddings。在介绍Embeddings之前我们需要先学习一下「向量」这个概念。
我们可以将一个事物从多个维度来描述,例如声音可以从「时域」和「频域」来描述(傅里叶变换可能很多人都听过),维度拆分的越多就越能描述一个事物,在向量空间上的接近往往意味着这两个事物有更多的联系,而向量空间又是比较好计算的,于是我们可以通过计算向量来判断事物的相似程度。
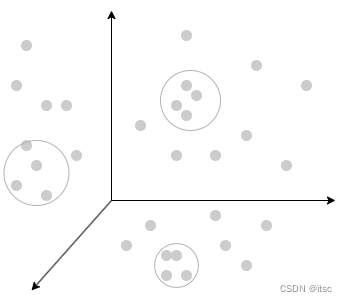
在自然语言处理 (NLP) 的中,Embeddings是将单词或句子转换为数值向量的一种方法。这些向量捕获单词或句子的语义,使我们能够对它们执行数学运算。例如,我们可以计算两个向量之间的余弦相似度来衡量它们在语义上的相似程度。

Embeddings使用流程讲解
如何让ChatGPT回答没有训练过的内容?流程如下,一图胜千言。
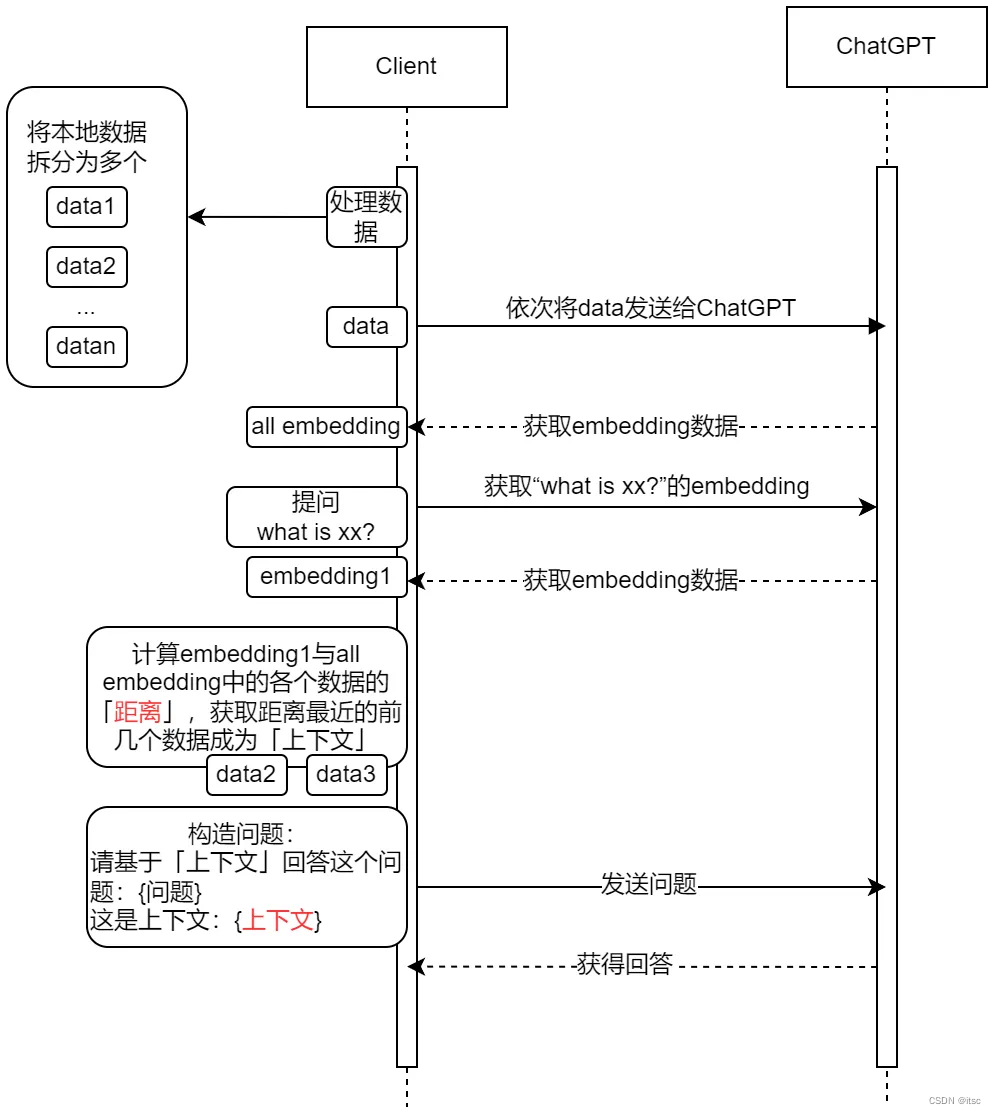
分步解释:
- 首先是获取本地数据的embeddings结果,由于一次embeddings调用的token数量是有限制的,先将数据进行分段然后以依次行调用获得所有数据的embeddings结果。
- 然后我们开始提问,同样的,将提问的内容也做一次embedding,得到一个结果。
- 再将提问的intending结果和之前所有数据的embedded结果进行距离的计算,这里的距离就是指向量之间的距离,然后我们获取距离最近的几段段数据来作为我们提问的「上下文」(例如这里找到data2/data3是和问题最相关的内容)。
- 获得上下文之后我们开始构造真正的问题,问题会将上下文也附属在后面一并发送给chat gpt,这样它就可以回答之前不知道的问题了。
总结来说:
之所以能够让ChatGPT回答他不知道的内容,其实是因为我们把相关的上下文传递给了他,他从上下文中获取的答案。如何确定要发送哪些上下文给他,就是通过计算向量距离得到的。
embedding实战代码(python)
让我来看看实际的代码。
前置条件
- Python 3.6 或更高版本。
- OpenAI API 密钥,或者其他提供API服务的也可以。
- 安装了以下 Python 软件包:
requests、beautifulsoup4、pandas、tiktoken、openai、numpy。 - 私有文本数据集。在这个示例中,使用名为
langchainintro.txt的文本文件,这里面是langchain官网的一些文档说明,文档比较新所以ChatGPT肯定不知道,以此来测试效果。
代码:
代码来自于OpenAI官网,我做了一些改动和精简。
import os
import numpy as np
import openai
import pandas as pd
import tiktoken
from ast import literal_eval
from openai.embeddings_utils import distances_from_embeddings
import tracebacktokenizer = tiktoken.get_encoding("cl100k_base")def get_api_key():return os.getenv('OPENAI_API_KEY')def set_openai_config():openai.api_key = get_api_key()openai.api_base = "https://openai.api2d.net/v1"def remove_newlines(serie):serie = serie.str.replace('\n', ' ')serie = serie.str.replace('\\n', ' ')serie = serie.str.replace(' ', ' ')serie = serie.str.replace(' ', ' ')return seriedef load_text_files(file_name):with open(file_name, "r", encoding="UTF-8") as f:text = f.read()return textdef prepare_directory(dir_name="processed"):if not os.path.exists(dir_name):os.mkdir(dir_name)def split_into_many(text, max_tokens):# Split the text into sentencessentences = text.split('. ')# Get the number of tokens for each sentencen_tokens = [len(tokenizer.encode(" " + sentence)) for sentence in sentences]chunks = []tokens_so_far = 0chunk = []# Loop through the sentences and tokens joined together in a tuplefor sentence, token in zip(sentences, n_tokens):# If the number of tokens so far plus the number of tokens in the current sentence is greater# than the max number of tokens, then add the chunk to the list of chunks and reset# the chunk and tokens so farif tokens_so_far + token > max_tokens:chunks.append(". ".join(chunk) + ".")chunk = []tokens_so_far = 0# If the number of tokens in the current sentence is greater than the max number of# tokens, split the sentence into smaller parts and add them to the chunkwhile token > max_tokens:part = sentence[:max_tokens]chunk.append(part)sentence = sentence[max_tokens:]token = len(tokenizer.encode(" " + sentence))# Otherwise, add the sentence to the chunk and add the number of tokens to the totalchunk.append(sentence)tokens_so_far += token + 1# Add the last chunk to the list of chunksif chunk:chunks.append(". ".join(chunk) + ".")return chunksdef shorten_texts(df, max_tokens):shortened = []# Loop through the dataframefor row in df.iterrows():# If the text is None, go to the next rowif row[1]['text'] is None:continue# If the number of tokens is greater than the max number of tokens, split the text into chunksif row[1]['n_tokens'] > max_tokens:shortened += split_into_many(row[1]['text'], max_tokens)# Otherwise, add the text to the list of shortened textselse:shortened.append(row[1]['text'])df = pd.DataFrame(shortened, columns=['text'])df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x)))return dfdef create_embeddings(df):df['embeddings'] = df.text.apply(lambda x: openai.Embedding.create(input=x, engine='text-embedding-ada-002')['data'][0]['embedding'])df.to_csv('processed/embeddings.csv')return dfdef load_embeddings():df = pd.read_csv('processed/embeddings.csv', index_col=0)df['embeddings'] = df['embeddings'].apply(literal_eval).apply(np.array)return dfdef create_context(question, df, max_len=1800, size="ada"
):"""Create a context for a question by finding the most similar context from the dataframe"""# print(f'start create_context')# Get the embeddings for the questionq_embeddings = openai.Embedding.create(input=question, engine='text-embedding-ada-002')['data'][0]['embedding']# print(f'q_embeddings:{q_embeddings}')# Get the distances from the embeddingsdf['distances'] = distances_from_embeddings(q_embeddings, df['embeddings'].values, distance_metric='cosine')# print(f'df[distances]:{df["distances"]}')returns = []cur_len = 0# Sort by distance and add the text to the context until the context is too longfor i, row in df.sort_values('distances', ascending=True).iterrows():# print(f'i:{i}, row:{row}')# Add the length of the text to the current lengthcur_len += row['n_tokens'] + 4# If the context is too long, breakif cur_len > max_len:break# Else add it to the text that is being returnedreturns.append(row["text"])# Return the contextreturn "\n\n###\n\n".join(returns)def answer_question(df,model="text-davinci-003",question="Am I allowed to publish model outputs to Twitter, without a human review?",max_len=1800,size="ada",debug=False,max_tokens=150,stop_sequence=None
):"""Answer a question based on the most similar context from the dataframe texts"""context = create_context(question,df,max_len=max_len,size=size,)# If debug, print the raw model responseif debug:print("Context:\n" + context)print("\n\n")prompt = f"Answer the question based on the context below, \n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:"messages = [{'role': 'user','content': prompt}]try:# Create a completions using the questin and contextresponse = openai.ChatCompletion.create(messages=messages,temperature=0,max_tokens=max_tokens,stop=stop_sequence,model=model,)return response["choices"][0]["message"]["content"]except Exception as e:# print stacktraceback.print_exc()print(e)return ""def main():# 设置API keyset_openai_config()# 载入本地数据texts = []text = load_text_files("langchainintro.txt")texts.append(('langchainintro', text))prepare_directory("processed")# 创建一个dataframe,包含fname和text两列df = pd.DataFrame(texts, columns=['fname', 'text'])df['text'] = df.fname + ". " + remove_newlines(df.text)df.to_csv('processed/scraped.csv')# 计算token数量df.columns = ['title', 'text']df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x)))# print(f'{df}')df = shorten_texts(df, 500)# 如果processed/embeddings.csv已经存在,直接load,不存在则createif os.path.exists('processed/embeddings.csv'):df = load_embeddings()else:df = create_embeddings(df)print(f"What is langchain? If you do not know please do not answer.")ans = answer_question(df, model='gpt-3.5-turbo', question="What is langchain? If you do not know please do not answer.", debug=False)print(f'ans:{ans}')if __name__ == '__main__':main()代码流程与时序图的流程基本一致,注意api_key需要放入环境变量,也可以自己改动。
如果直接问ChatGPT:What is langchain? If you do not know please do not answer.,ChatGPT会回答不知道:
I’m sorry, but I don’t have any information on “langchain.” It appears to be a term that is not widely recognized or used in general knowledge.
运行上面的代码,它可以给出答案:
LangChain is a framework for developing applications powered by language models.
可以看到它使用了我们提供的文档来回答。
拓展
- 注意token消耗,如果你的本地数据非常多,embedding阶段将会消耗非常多的token,请注意使用。
- embedding阶段仍然会将本地数据传给ChatGPT,如果你有隐私需求,需要注意。
- 一般生产环境会将向量结果存入「向量数据库」而不是本地文件,此处为了演示直接使用的文本文件存放。
相关文章:
ChatGPT实战-Embeddings打造定制化AI智能客服
本文介绍Embeddings的基本概念,并使用最少但完整的代码讲解Embeddings是如何使用的,帮你打造专属AI聊天机器人(智能客服),你可以拿到该代码进行修改以满足实际需求。 ChatGPT的Embeddings解决了什么问题? …...

C语言指针,深度长文全面讲解
指针对于C来说太重要。然而,想要全面理解指针,除了要对C语言有熟练的掌握外,还要有计算机硬件以及操作系统等方方面面的基本知识。所以本文尽可能的通过一篇文章完全讲解指针。 为什么需要指针? 指针解决了一些编程中基本的问题。…...

云桌面打开部署在linux的服务特别卡 怎么解决
云桌面打开部署在 Linux 服务器上的服务卡顿可能是由多种因素引起的,包括服务器性能、网络连接、应用程序配置等。以下是一些可能的解决方法,可以帮助您缓解云桌面访问部署在 Linux 服务器上的服务时的卡顿问题: 优化服务器性能: …...
day5ARM
循环点亮三个led灯 方法1 ------------------led.h---------------- #ifndef __LED_H__ #define __LED_H__#define RCC (*(volatile unsigned int *)0x50000A28) #define GPIOE ((GPIO_t *)0x50006000) #define GPIOF ((GPIO_t *)0x50007000)//结构体封装 typedef struct {vo…...
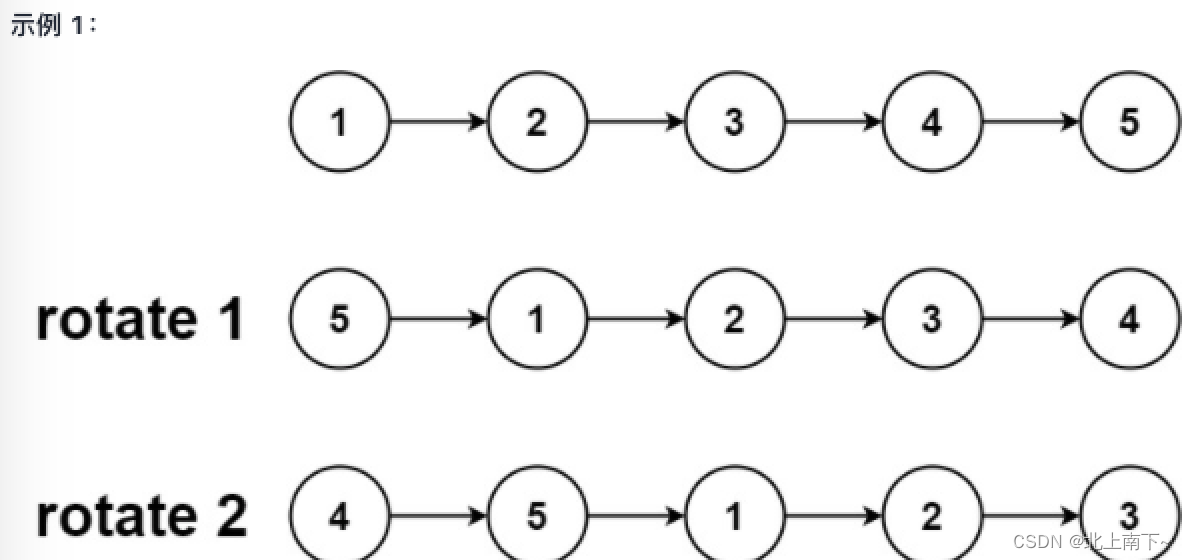
旋转链表-双指针思想-LeetCode61
题目要求:给定链表的头结点,旋转链表,将链表每个节点向右移动K个位置。 示例: 输入:head [1,2,3,4,5], k2 输出:[4,5,1,2,3] 双指针思想: 先用双指针策略找到倒数K的位置,也就是(…...

使用自定义XML配置文件在.NET桌面程序中保存设置
本文将详细介绍如何在.NET桌面程序中使用自定义的XML配置文件来保存和读取设置。除了XML之外,我们还将探讨其他常见的配置文件格式,如JSON、INI和YAML,以及它们的优缺点和相关的NuGet类库。最后,我们将重点介绍我们为何选择XML作为…...
1787_函数指针的使用
全部学习汇总:GitHub - GreyZhang/c_basic: little bits of c. 前阵子似乎写了不少错代码,因为对函数指针的理解还不够。今天晚上似乎总算是梳理出了一点眉目,在先前自己写过的代码工程中做一下测试。 先前实现过一个归并排序算法,…...

解决nomachine扫描不出ip问题
IP扫描工具Advanced IP Scanner 快速的扫描局域网中存在ip地址以及pc机的活跃状态,还能列出局域网计算机的相关信息。并且ip扫描工具(Advanced IP Scanner)还能够单击访问更多有用的功能- 远程关机和唤醒 软件下载地址...

Web 3.0 发展到什么水平了?
最初,有互联网:电线和服务器的物理基础设施,让计算机和它们前面的人相互交谈。美国政府的阿帕网在1969年发出了第一条消息,但我们今天所知道的网络直到1991年才出现,当时HTML和URL使用户可以在静态页面之间导航。将此视…...

大模型:如何利用旧的tokenizer训练出一个新的来?
背景: 我们在用chatGPT或者SD的时候,发现如果使用英语写提示词得到的结果比我们使用中文得到的结果要好很多,为什么呢?这其中就有一个叫做tokenizer的东西在作怪。 训练一个合适的tokenizer是训练大模型的基础,我们既…...
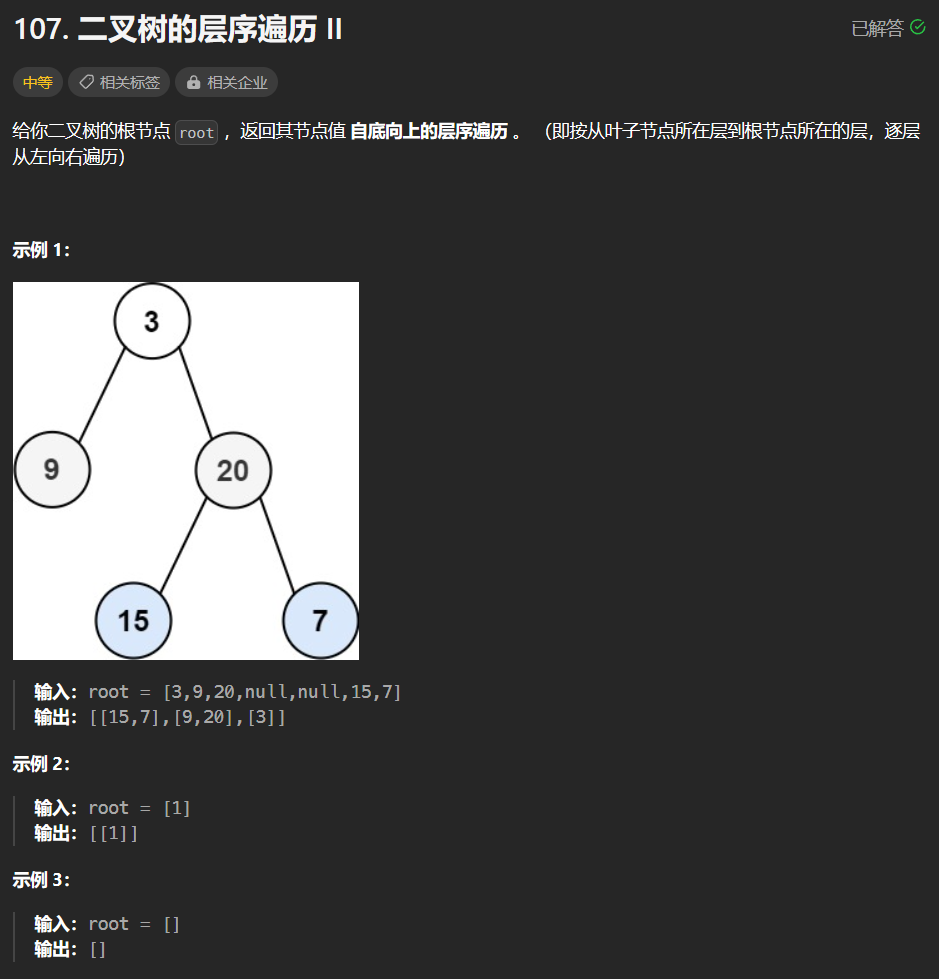
【LeetCode-中等题】107. 二叉树的层序遍历 II
文章目录 题目方法一:队列层序迭代 题目 方法一:队列层序迭代 解题详情:【LeetCode-中等题】102. 二叉树的层序遍历 res.add(0,zres); //效果是将 zres 列表作为 res 的第一个子列表,并将其它原本在第一位置及之后的子列表向后移…...

斯坦福联合培养博士|专科生的逆袭之路
从山东医学高等专科学校到首都医科大学附属北京天坛医院神经外科博士,再到斯坦福医学院神经外科联合培养博士,知识人网小编带大家看看何世豪通往成功的逆袭之路。 上面照片中这位戴眼镜的主人公就是何志豪,他从山东医学高等专科学校考入泰山医…...

Verilog中parameter在仿真时的应用
parameter能够定义一个常量 例如 parameter [7:0]A 8d123; 在仿真时我们可以用它来改变模块的参数,而不会影响综合的结果。 考虑下面的模块,输入时钟是clk,频率为24MHz,输出一个1Hz的方波驱动小灯让其闪烁 module test1(in…...

v-model绑定导致的element UI文本框输入第一次值后被绑定,导致空文本框无法再输入文字
在工作岗位上,上边分配一个任务,创建一个页面,从0-1,全部自己搭建,也没有啥模版,就这么来,那就直接来吧,没办法,那就直接上手,开发过程中,我使用了…...
数据结构——KD树
KD树(K-Dimensional Tree)是一种用于多维空间的二叉树数据结构,旨在提供高效的数据检索。KD树在空间搜索和最近邻搜索等问题中特别有用,允许在高维空间中有效地搜索数据点。 重要性质 1.分割K维数据空间的数据结构 2.是一颗二叉树…...
python趣味编程-恐龙克隆游戏
Python 中使用 Turtle 的恐龙克隆游戏免费源代码 使用 Turtle 的恐龙克隆游戏是一个用Python编程语言编码的桌面游戏应用程序。该项目包含在 Chrome 浏览器中克隆实际恐龙游戏的多种功能。该项目可以使正在修读 IT 相关课程的学生受益。这个应用程序非常有趣,可以帮助您学习创…...

【漏洞复现】泛微e-office OfficeServer2.php 存在任意文件读取漏洞复现
文章目录 前言声明一、漏洞描述二、漏洞分析三、漏洞复现四、修复建议前言 泛微e-office OfficeServer2.php 存在任意文件读取漏洞,攻击者可通过构造特定Payload获取敏感数据信息。 声明 请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造…...

基于Yolov8的野外烟雾检测(4):通道优先卷积注意力(CPCA),效果秒杀CBAM和SE等 | 中科院2023最新发表
目录 1.Yolov8介绍 2.野外火灾烟雾数据集介绍 3.CPCA介绍 3.1 CPCA加入到yolov8 4.训练结果分析 5.系列篇 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型&a…...

程序员必掌握的核心算法:提升编程技能的关键路径
一:引言 作为程序员,算法是我们编程生涯中的灵魂。算法是解决问题的方法和步骤,它们在计算机科学中扮演着至关重要的角色。无论你是初学者还是经验丰富的专业人士,都需要掌握一些核心算法,因为它们在各种应用场景中频…...

面试算法10:和为k的子数组
题目 输入一个整数数组和一个整数k,请问数组中有多少个数字之和等于k的连续子数组?例如,输入数组[1,1,1],k的值为2,有2个连续子数组之和等于2。 分析 在从头到尾逐个扫描数组中的数字时求出前…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...