【Redis】深入探索 Redis 主从结构的创建、配置及其底层原理
文章目录
- 前言
- 一、对 Redis 主从结构的认识
- 1.1 什么是主从结构
- 1.2 主从结构解决的问题
- 二、主从结构创建
- 2.1 配置并建立从节点
- 2.2.1 从节点配置文件
- 2.2.2 启动并连接 Redis 主从节点
- 2.2.3 SLAVEOF 命令
- 2.2.4 断开主从关系
- 2.2 查看主从节点的信息
- 2.2.1 INFO REPLICATION 命令
- 2.2.2 对于各个信息字段的说明
- 三、主从复制的拓扑结构
- 3.1 一主一从结构
- 3.2 一主多从结构
- 3.3 树形主从结构
- 四、主从复制原理剖析
- 4.1 主从节点建立复制流程
- 4.2 PSYNC 命令
- 4.3 runid 和 replid
- 4.3.1 runid 和 replid 的区别
- 4.3.2 查看 runid 和 replid
- 4.4 数据同步
- 4.4.1 复制偏移量
- 4.4.2 复制积压缓冲区
- 4.4.3 主节点运行 ID
- 五、主从结构的全量复制、部分复制与实时复制
- 5.1 全量复制
- 5.2 部分复制
- 5.3 实时复制
- 六、其他问题
- 6.1 关于 Redis 从节点晋升为主节点的时机问题
- 6.2 关于 Redis 配置了主从结构后无法启动的问题
前言
在分布式系统中,为了解决单点问题,通常需要将数据复制成多个副本,并将它们分别部署在不同的服务器上,以实现故障恢复和负载均衡等需求。
单点问题:
分布式系统中的单点问题(Single Point of Failure,简称SPOF)指的是系统中存在的一些关键组件或节点,如果出现故障,将导致整个系统或部分系统无法正常运行。这个关键组件或节点是系统中的薄弱环节,因为其故障或不可用性会对系统的可用性、稳定性和可靠性产生重大影响。
对于 Redis 来说,它也提供了这样的复制功能,可以实现多个 Redis 实例之间的数据复制。这个复制功能是 Redis 高可用性的基础,而 Redis 的其他机制,如哨兵和集群,都是在这个复制功能的基础上构建的。
本文的主要内容的深入探讨 Redis 复制功能的创建、配置以及底层原理。希望通过阅读本文,可以帮助我们对 Redis 的主从结构产生更加深刻的理解。
一、对 Redis 主从结构的认识
1.1 什么是主从结构
在 Redis 中,主从结构是一种数据复制机制,它包括一个 Redis 主节点(Master)和一个或多个 Redis 从节点(Slave)。其中主节点主要负责处理写数据操作(数据的写入和更新),而从节点则负责复制主节点的数据并处理读请求。通过这样的主从结构,提高了 Redis 服务器的性能和高可用。
1.2 主从结构解决的问题
主从结构解决了多个问题,包括但不限于:
- 高可用性: 主节点故障时,从节点可以接管服务,保证系统的可用性。
- 负载均衡: 读操作可以分担到多个从节点上,分散主节点的读压力。
- 数据备份: 数据可以在多个节点上备份,提高数据的安全性。
- 数据分发: 可以将数据分发到不同地理位置的从节点,降低访问延迟。
二、主从结构创建
2.1 配置并建立从节点
2.2.1 从节点配置文件
由于现在我只有一个云服务器,因此就需要为不同的节点分配不同的端口号来启动多个 Redis 服务器。在此处约定,本来的 6379 端口号对应的 Redis 服务器作为主节点,另外分配两个端口号 6380 和 6381 作为从节点。
此时,就需要分别为这两个从节点分别创建一个 Redis 配置文件。
例如,为从节点 6380 创建配置文件:
1)首先直接拷贝一份原本 Redis 的配置文件
[root@VM-16-9-ubuntu redis-conf]# cp /etc/redis/redis.conf ./slave1.conf
2)需要对 slave1.conf 修改的地方如下
- 端口号
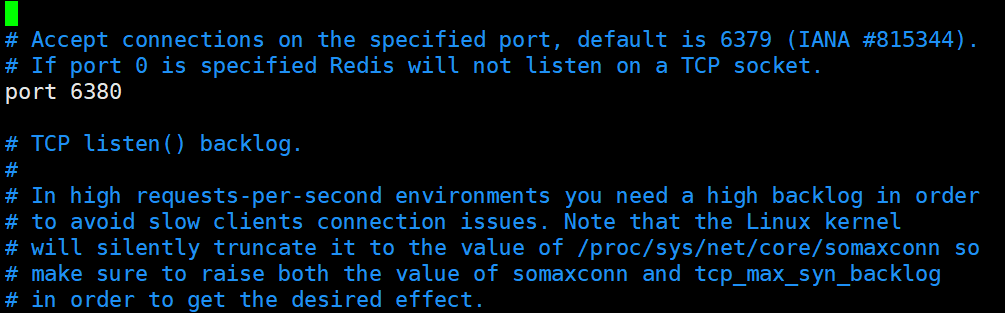
- RDB 和 AOF 文件的存放路径
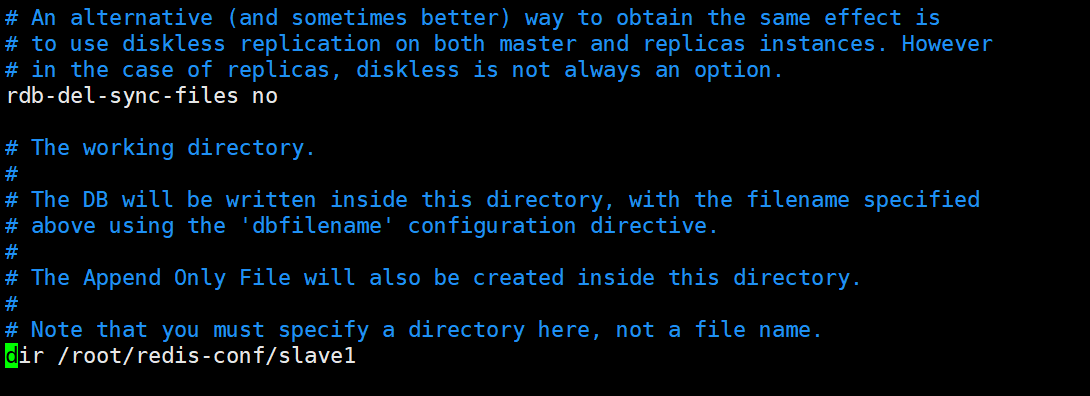
将其修改为:/root/redis-conf/slave1。其目的在于不要让从节点的持久化文件与主节点的配置文件相同,造成主节点无法启动的问题;同时也增加了对数据的备份次数,提高了数据的安全性。
3)添加 slaveof 命令
在配置文件的结尾添加命令:salveof 127.0.0.1 6379。其作用是让当前从节点以端口号为 6379 的节点为自己的主节点。
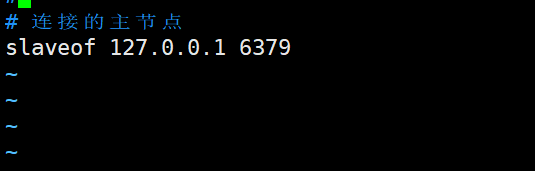
此时关于从节点 slave1 的配置就完成了,然后可以使用同样的方式对从节点 slave2 进行配置。
2.2.2 启动并连接 Redis 主从节点
启动主从节点:
所有的从节点都配置完成后,就可以启动主从节点了。主节点已经启动了,直接启动从节点:
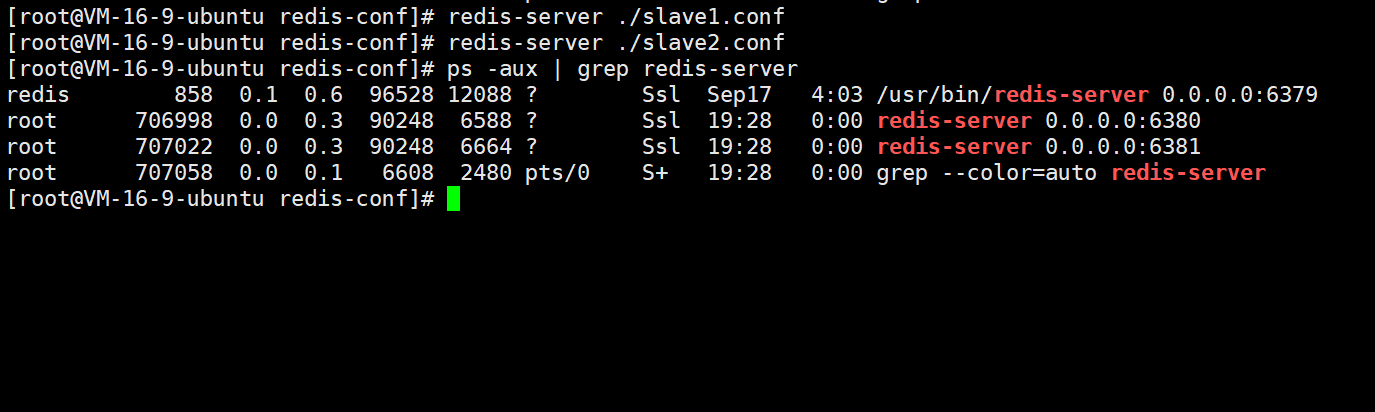
注意,在启动从节点的时候,需要在 redis-server 命令后面指定该从节点的配置文件。最后通过 ps 命令即可查看当前服务器中所有的 redis-server 服务了。
连接主从节点:
主节点:
主节点的连接方式直接使用 redis-cli 命令连接即可。
从节点:
注意在连接从节点的时候,需要使用 redis -p xxxx命令,其中 -p 代表需要连接指定的端口号的 Redis 节点。
当所有的主从节点都连接完成之后,我们可尝试进行一下读写操作:
主节点写入数据:
使用两个从节点分别读取数据:
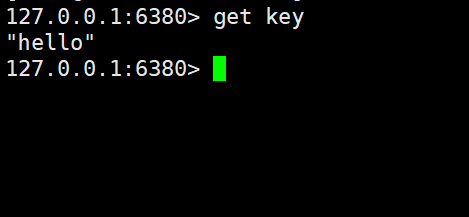
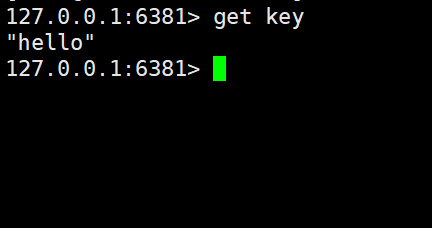
此时发现,向主节点写入的数据,也同步到了两个从节点中。
但是,如果尝试向从节点写入数据,能否写入成功呢?
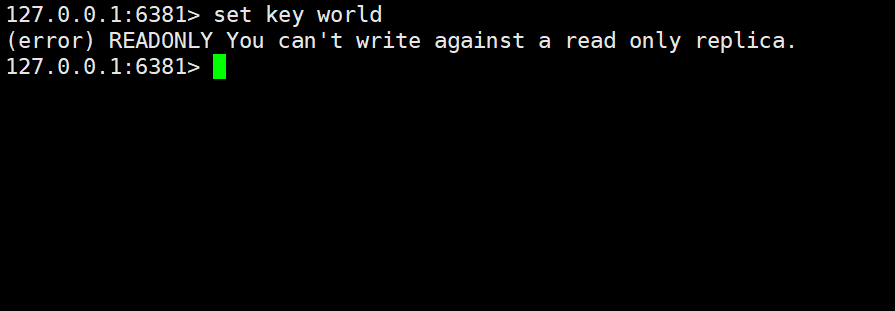
此时发现报错了,错误信息提示当前节点只能够读取,不能够进行写入。
2.2.3 SLAVEOF 命令
SLAVEOF 命令是 Redis 中用于配置主从复制关系的命令。它用于当前服务设置为指定服务器的从节点,从而实现主从结构。SlAVEOF 命令的使用语法如下:
SLAVEOF masterip masterport
masterip是主节点的 IP 地址masterport是主节点的端口号
执行了上面的命令之后,当前的 Redis 则会成为指定主节点的从节点,然后开始从主节点上复制数据。
这个命令不但可以在 Redis 的客户端上发送执行,也可以像上文那样将其设置到 Redis 的配置文件中,再启动 Redis 服务器的时候就会自动执行该命令成为指定节点的从服务器。
例如:在刚才启动的主从服务器中,我们可以使用 SALVEOF 命令让 salve2 变成 slave1 的从节点:
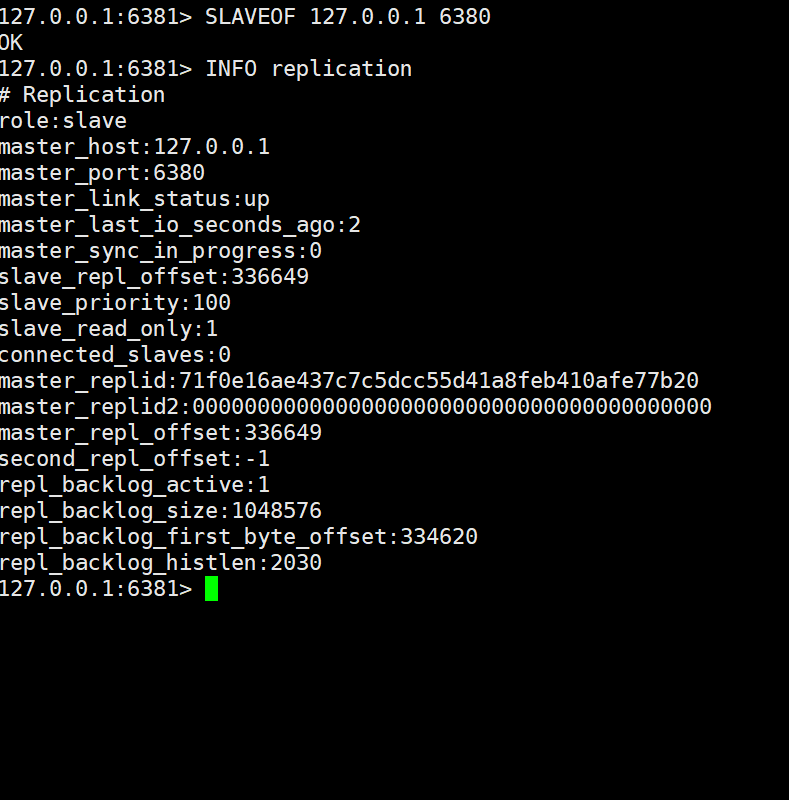
然后可以使用命令 INFO replication 查看主从关系相关信息,可以发现此时 slave2 就成为了 slave1 的从节点了。
2.2.4 断开主从关系
如果想要断开主从关系,也需要使用到 SLAVEOF 命令,其语法如下:
SLAVEOF NO ONE
其含义表示,当前节点不再作为其他节点的从节点了,自己要成为一个独立的节点。
例如,让 slave2 断开与 slave1 的主从关系:

此时,slave2 就成为了一个独立的节点。
2.2 查看主从节点的信息
2.2.1 INFO REPLICATION 命令
想要查看主从关系的相关信息可以使用命令 INFO REPLICATION 来查看。
例如:

2.2.2 对于各个信息字段的说明
-
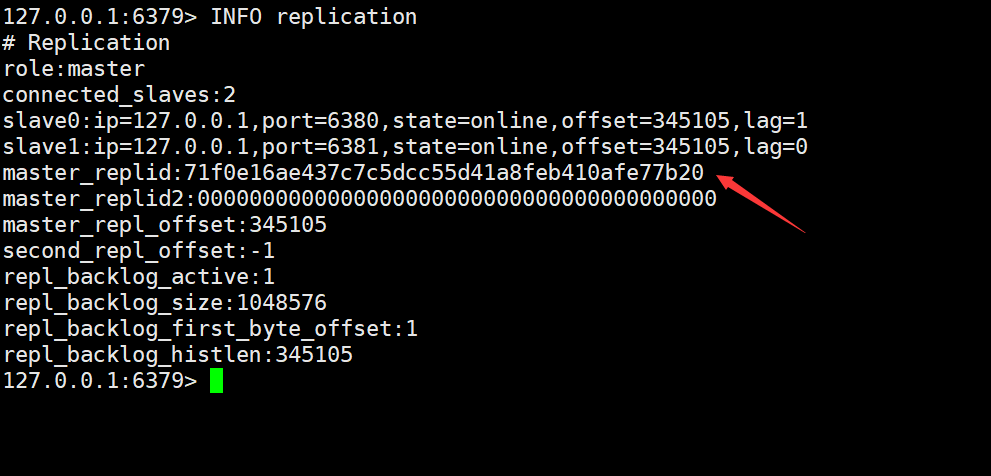
role: 表示当前 Redis 服务器的角色。在这个示例中,它是主服务器(master)。Redis 可以扮演主服务器或从服务器的角色,主服务器负责处理写操作,而从服务器复制主服务器的数据并处理读操作。
-
connected_slaves: 表示当前主服务器连接的从服务器数量。在这个示例中,主服务器连接了两个从服务器。
-
slave0 和 slave1: 这两行提供了与每个从服务器相关的详细信息。在这个示例中,有两个从服务器,分别是
slave0和slave1。ip和port: 表示从服务器的 IP 地址和端口号。state: 表示从服务器的状态。在这个示例中,两个从服务器都处于 “online” 状态,表示它们正常工作。offset: 表示从服务器已复制的主服务器的偏移量。偏移量用于追踪从服务器复制的进度。lag: 表示从服务器相对于主服务器的滞后时间,单位是字节。在这个示例中,lag为 0 和 1,分别表示两个从服务器相对于主服务器的数据同步滞后情况。
-
master_replid: 表示当前主服务器的复制ID(Replication ID)。这个ID用于唯一标识主服务器,从服务器使用它来识别主服务器的复制数据。在这个示例中,
master_replid是一个长字符串。 -
master_replid2: 这个字段在主服务器上通常为全零,只在一些特殊情况下才会用到,用于实现故障切换。
-
master_repl_offset: 表示当前主服务器的复制偏移量。这个偏移量表示主服务器上的数据复制到了哪个位置,从服务器使用它来追赶主服务器的数据。
-
second_repl_offset: 这个字段通常为 -1,它表示一个备用的复制偏移量,一般不使用。
-
repl_backlog_active: 表示复制日志(replication backlog)是否处于激活状态。如果为1,表示复制日志正在使用;如果为0,表示未使用。
-
repl_backlog_size: 表示复制日志的大小,以字节为单位。在这个示例中,大小为 1048576 字节(1MB)。
-
repl_backlog_first_byte_offset: 表示复制日志中的第一个字节的偏移量。
-
repl_backlog_histlen: 表示复制日志的历史长度,也就是复制日志中包含了多少字节的数据。
这些信息一起提供了关于 Redis 复制状态的详细信息,包括主从服务器的关系、复制进度以及滞后情况等。这对于监控和管理 Redis 复制非常有用,可以帮助我们确保数据的一致性和高可用性。
三、主从复制的拓扑结构
在 Redis 主从复制中,可以根据需求选择不同的拓扑结构来构建主从关系,以满足不同的应用场景和需求。以下是三种常见的主从复制拓扑结构:
3.1 一主一从结构
一主一从结构是最简单的主从复制拓扑,它包括一个主服务器(Master)和一个从服务器(Slave)。主服务器负责处理所有写操作(数据的写入和更新),而从服务器复制主服务器的数据,并处理读操作。这种结构适用于小规模的应用场景,其中对高可用性和负载均衡的需求不是特别高。

主要特点:
- 单一主服务器负责写入和更新数据,从服务器负责读取数据,可以提高读操作的性能。
- 从服务器可以用于备份主服务器的数据,提高数据的安全性。
- 适用于简单的应用场景,不需要复杂的主从关系。
3.2 一主多从结构
一主多从结构包括一个主服务器和多个从服务器。主服务器负责处理写操作,而多个从服务器复制主服务器的数据并处理读操作。这种结构适用于需要高读性能和负载均衡的应用场景,因为多个从服务器可以并行处理读请求,分担主服务器的读负载。
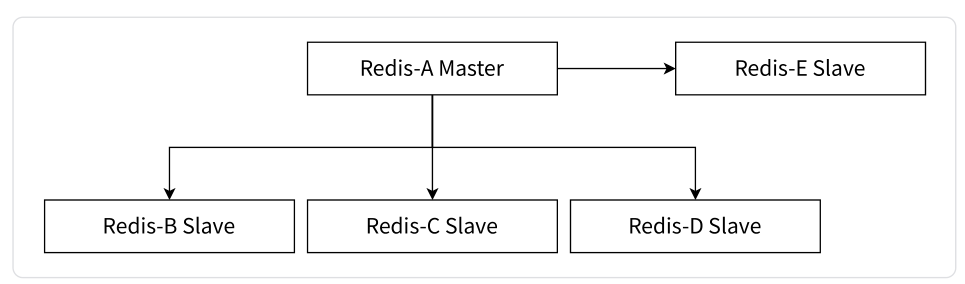
主要特点:
- 主服务器负责写操作,多个从服务器负责读操作,可以提高读性能和负载均衡。
- 适用于读多写少的应用场景,可以有效减轻主服务器的负担。
- 多个从服务器之间可以互相复制数据,提高数据的可用性和冗余性。
3.3 树形主从结构
树形主从结构是一种更复杂的拓扑结构,其中多个从服务器不仅复制主服务器的数据,还可以成为其他从服务器的主服务器,形成一个层级结构。这种结构适用于复杂的数据分发和备份需求,可以构建多层级的主从关系。
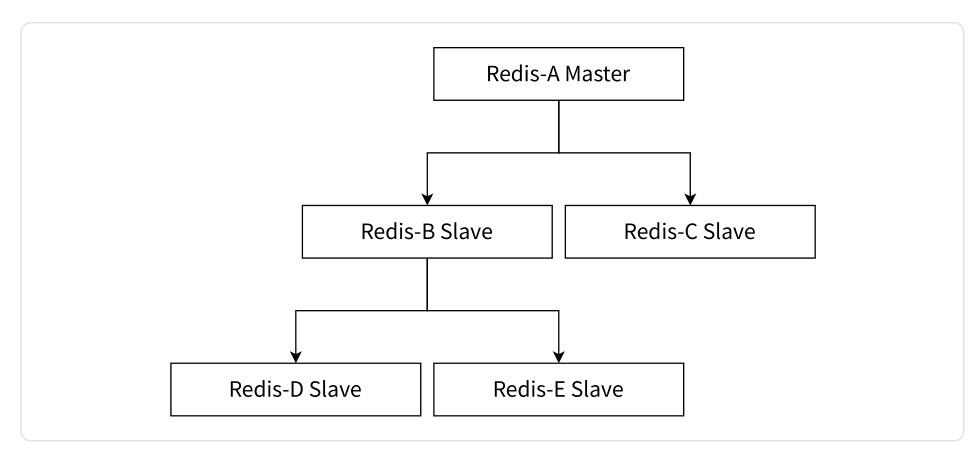
主要特点:
- 主服务器负责写操作,多个从服务器可以复制主服务器的数据。
- 从服务器不仅可以复制主服务器的数据,还可以成为其他从服务器的主服务器,构建多层级的主从关系。
- 适用于需要将数据分发到不同地理位置或数据中心的应用场景,以提高数据的可用性和冗余性。
四、主从复制原理剖析
4.1 主从节点建立复制流程
主从节点建立复制流程图如下:
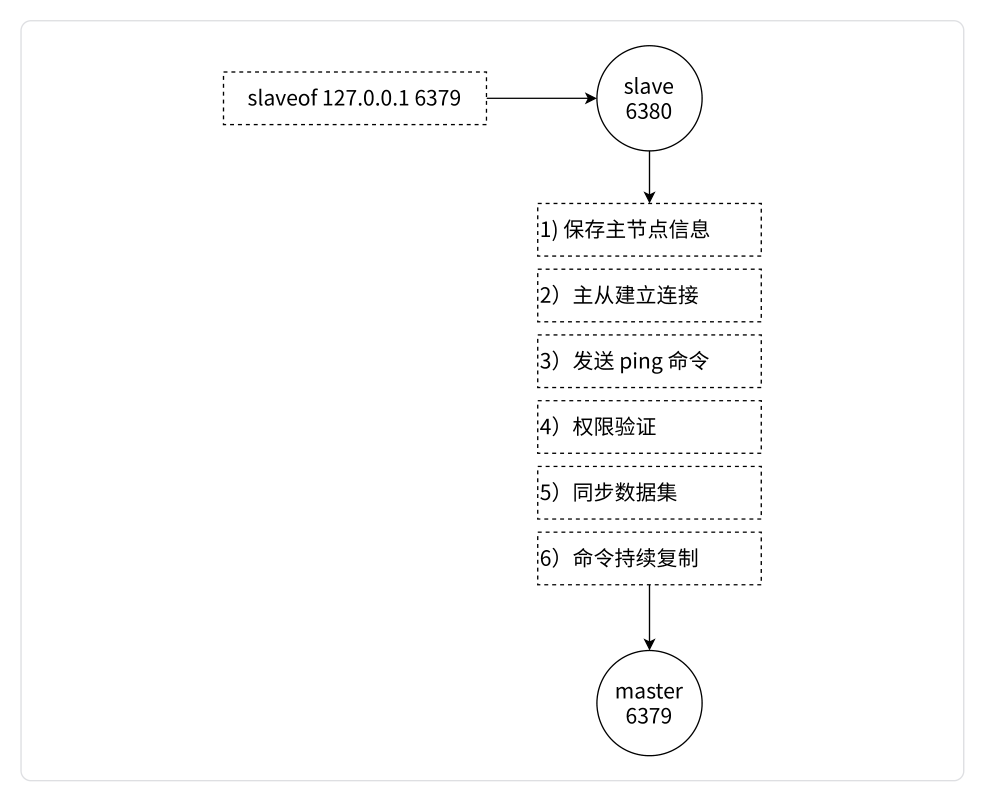
下面是主从节点建立复制的详细流程说明:
-
保存主节点信息:
- 在开始配置主从同步关系之前,从节点只保存主节点的地址信息,如IP地址和端口号。此时复制流程还没有开始,从节点的连接状态为下线。
-
建立网络连接:
- 从节点内部通过每秒运行的定时任务维护复制相关逻辑。
- 定时任务会尝试与主节点建立基于TCP的网络连接。
- 如果连接失败,定时任务会无限重试直到连接成功或者用户停止主从复制。
-
发送PING命令:
- 连接建立成功后,从节点会发送PING命令给主节点,用来确认主节点在应用层上正常工作。
- 如果PING命令的结果为PONG回复超时,从节点会断开TCP连接,并等待定时任务下次重新建立连接。
-
权限验证:
- 如果主节点设置了requirepass参数(即密码验证),则需要密码验证。
- 从节点通过配置masterauth参数来设置密码,如果验证失败,从节点的复制将会停止。
-
同步数据集:
- 对于首次建立复制的场景,主节点会将当前持有的所有数据全部发送给从节点。这是耗时最长的步骤,因此可以分为两种情况:全量同步和部分同步。
- 全量同步:主节点发送完整的数据集给从节点,确保从节点的数据与主节点一致。
- 部分同步:一旦全量同步完成,主节点将持续发送写入命令给从节点,以确保从节点跟踪主节点的数据变化。
这个过程确保了主从节点之间的数据一致性,并允许主节点的数据更新能够被从节点复制,从而实现了主从复制的基本功能。主从复制对于数据备份、提高读性能和实现高可用性非常有用。
4.2 PSYNC 命令
从节点使用 PSYNC 命令来完成部分复制和全量复制的功能。PSYNC 命令的格式为 PSYNC {runId} {offset},其中参数的含义如下:
{runId}:从节点所复制的主节点的运行ID。{offset}:当前从节点已复制的数据偏移量。
PSYNC 命令的执行流程如下图所示:
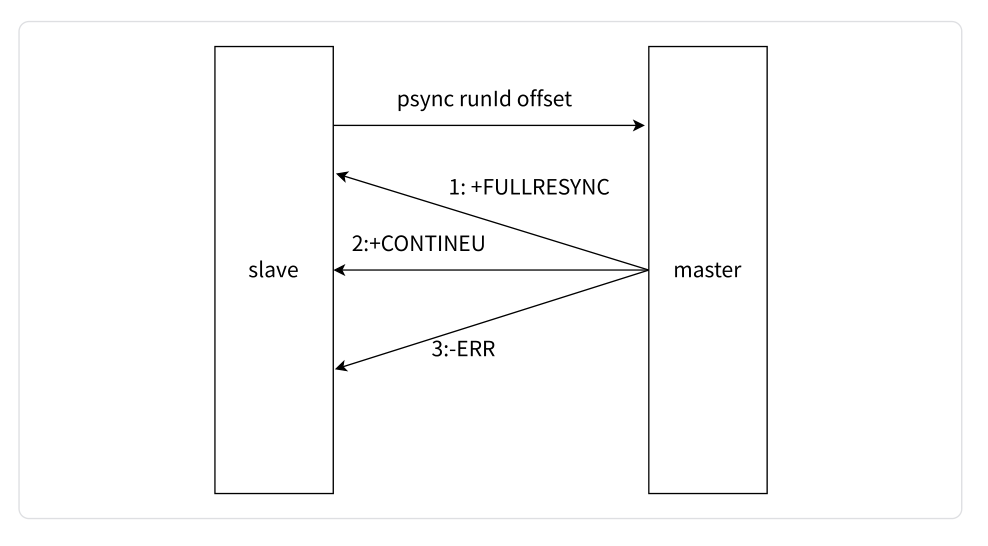
-
从节点发送 PSYNC 命令给主节点,其中
runId和offset的默认值分别是 “?” 和 “-1”。 -
主节点根据 PSYNC 命令的参数和自身数据情况来决定响应结果:
- 如果主节点回复 “+FULLRESYNC runId offset”,则从节点需要执行全量复制流程。
- 如果主节点回复 “+CONTINUE”,从节点执行部分复制流程。
- 如果主节点回复 “-ERR”,说明 Redis 主节点的版本过低,不支持 PSYNC 命令。从节点可以使用 SYNC 命令来进行全量复制。
需要注意的是,PSYNC 命令不需要手动执行,Redis 会在主从复制模式下自动调用执行。 PSYNC 命令的目的是确保从节点能够正确获取主节点的增量数据更新,以保持数据的一致性。根据主节点的响应,从节点将执行全量复制或部分复制流程。
4.3 runid 和 replid
4.3.1 runid 和 replid 的区别
在 Redis 主从复制中,runid 和 replid 是两个重要的标识符,用于唯一标识主节点和从节点以及它们之间的复制关系。
-
runid(Run ID):
runid是 Redis 服务器的运行标识符,用于唯一标识 Redis 服务器的每个运行实例。- 每次 Redis 服务器启动时,都会生成一个新的
runid,并在运行过程中保持不变,除非服务器重新启动。 - 在主从复制中,主节点和从节点都有自己的
runid,用于唯一标识它们自己的运行实例。 - 主节点的
runid在复制关系建立时会被从节点保存,以便从节点可以识别主节点的身份。
-
replid(Replication ID):
replid是主节点用于标识自己的复制ID,它唯一标识主节点的数据副本。- 主节点在每次重新同步(如全量复制)或部分同步(如部分复制)时,都会生成一个新的
replid。 replid主要用于从节点识别主节点的数据更新,确保从节点可以正确复制主节点的数据。- 在主从复制中,从节点会定期向主节点发送请求,获取主节点的最新
replid,以便跟踪数据的变化。
综合来说,runid 用于标识 Redis 服务器的唯一性,每个 Redis 服务器都有自己的 runid,而 replid 用于标识主节点的数据副本,确保从节点可以正确复制主节点的数据。这两个标识符在主从复制中起到关键的作用,确保数据的一致性和正确性。通过使用这些标识符,Redis 可以准确识别不同的服务器实例以及它们之间的复制关系。
4.3.2 查看 runid 和 replid
在 Redis 中,可以通过以下命令来查看主节点(Master)和从节点(Slave)的 runid 和 replid:
-
查看
replid:- 可以使用
INFO replication命令来查看主从节点的runid:
- 可以使用
主节点:
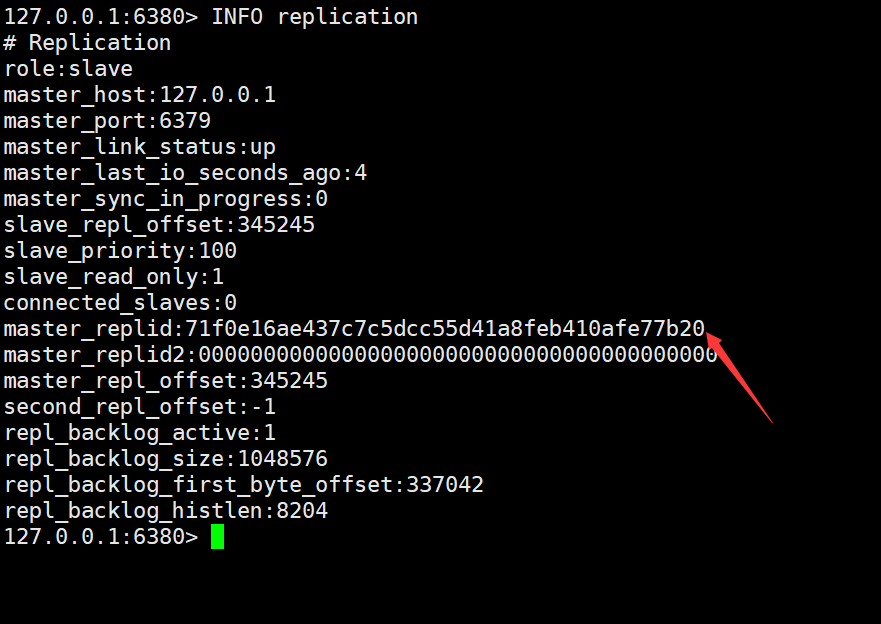
从节点 slave1:
从节点 slave2:
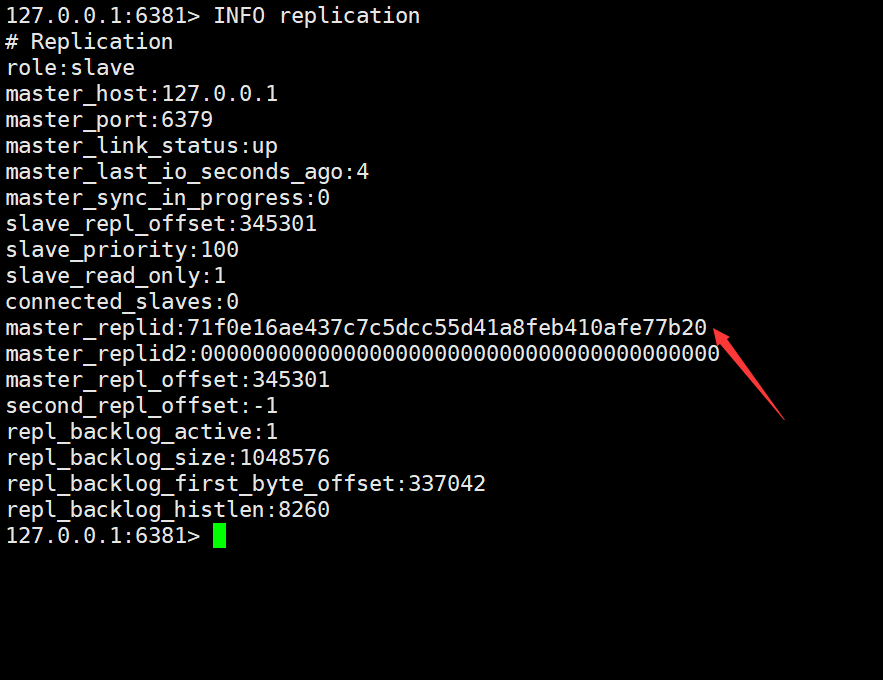
通过观察上面的信息可以发现,两个从节点的 master_replid 和主节点的 master_replid 一样,说明这两个从节点是从这个主节点上复制数据的。
-
查看
runid:- 查看主从节点的
runid,可以使用INFO server命令。
- 查看主从节点的
主节点:
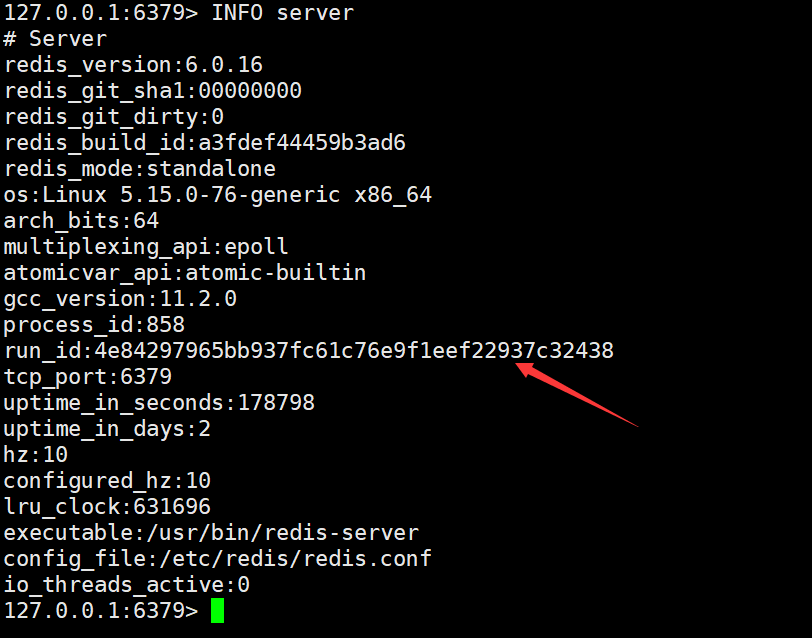
从节点 slave1:
从节点 slave2:

通过查看上面不同节点的信息可以发现其 runid 都是不同的,表明了 runid 是用于唯一标识 Redis 服务器的每个运行实例。
4.4 数据同步
在Redis中,数据同步是通过PSYNC命令完成的,主从数据同步过程分为全量复制和部分复制两种情况:
- 全量复制:
全量复制通常用于首次建立主从复制关系的情况。在早期版本的Redis中,只支持全量复制,这意味着主节点会将全部数据一次性发送给从节点。当数据量较大时,全量复制可能会对主从节点和网络造成较大的开销。
- 部分复制:
部分复制用于处理主从复制中由于网络断开等原因导致的数据丢失情况。当从节点重新连接到主节点时,如果条件允许,主节点会向从节点发送缺失的数据。由于补发的数据远小于全量数据,因此部分复制可以有效减少开销。
此外,PSYNC命令的运行需要以下组件的支持:
- 主从节点各自的复制偏移量(replication offset)。
- 主节点的复制积压缓冲区(replication backlog)。
- 主节点的运行 ID。
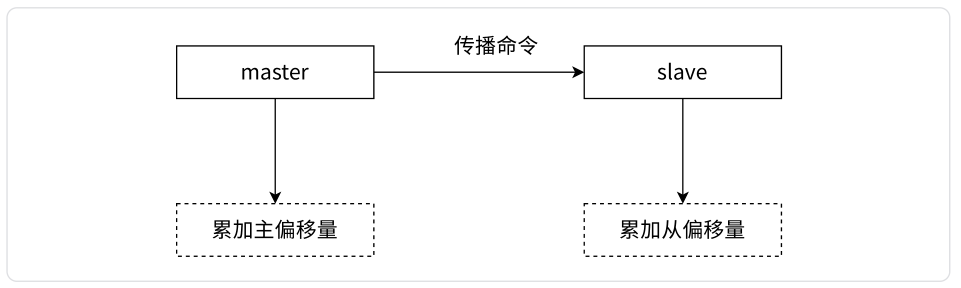
4.4.1 复制偏移量
参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在info replication中的master_repl_offset指标中:
127.0.0.1:6379> info replication
# Replication
role:master
...
master_repl_offset:1055130
从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量,统计指标如下:
127.0.0.1:6379> info replication
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=1055214,lag=1
从节点在接受到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在info replication中的slave_repl_offset指标中:
127.0.0.1:6380> info replication
# Replication
role:slave
...
slave_repl_offset:1055214
复制偏移量的维护如图所示,通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
4.4.2 复制积压缓冲区
复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB。当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不仅会把命令发送给从节点,还会写入复制积压缓冲区。
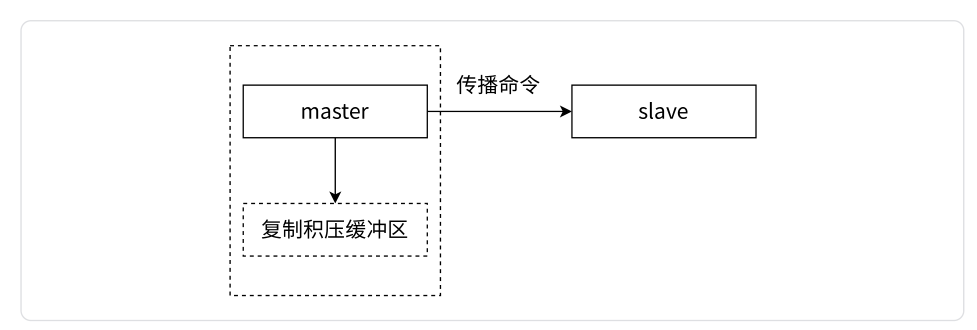
由于缓冲区本质上是先进先出的定长队列,所以能实现保存最近已复制数据的功能,用于部分复制和复制命令丢失的数据补救。复制缓冲区相关统计信息可以通过主节点的info replication中查看:
127.0.0.1:6379> info replication
# Replication
role:master
...
repl_backlog_active:1 // 开启复制缓冲区
repl_backlog_size:1048576 // 缓冲区最大长度
repl_backlog_first_byte_offset:7479 // 起始偏移量,计算当前缓冲区可用范围
repl_backlog_histlen:1048576 // 已保存数据的有效长度
根据统计指标,可以算出复制积压缓冲区内的可用偏移量范围:[repl_backlog_first_byte_offset, repl_backlog_first_byte_offset + repl_backlog_histlen]。
这个相当于一个基于数组实现的环形队列。上述区间中的值就是"数组下标"。
4.4.3 主节点运行 ID
每个 Redis 节点启动后都会动态分配一个40位的十六进制表示的运行 ID。运行 ID的主要作用是用来唯一标识 Redis 节点,比如从节点可以使用主节点的运行 ID 来识别自己正在复制的哪个主节点。这个 ID 随着 Redis 的重新启动会发生变化,可以通过info server命令查看当前节点的运行 ID:
127.0.0.1:6379> info server
# Server
...
run_id:545f7c76183d0798a327591395b030000ee6def9
运行 ID 在 Redis 集群和复制中都扮演着重要的角色,它确保了节点的唯一性和可识别性,有助于维护数据的一致性和跟踪节点的运行状态。
综上所述,Redis 的数据同步是通过 PSYNC 命令实现的,可以根据需要选择全量复制或部分复制,并且需要主从节点各自的复制偏移量、主节点的复制积压缓冲区以及主节点的运行 ID 的支持。这些组件共同协作,确保了数据在主从节点之间的高效同步和一致性维护。
五、主从结构的全量复制、部分复制与实时复制
5.1 全量复制
全量复制是 Redis 最早支持的复制方式,也是在建立主从复制关系时必须经历的阶段。全量复制的运行流程如下图所示:
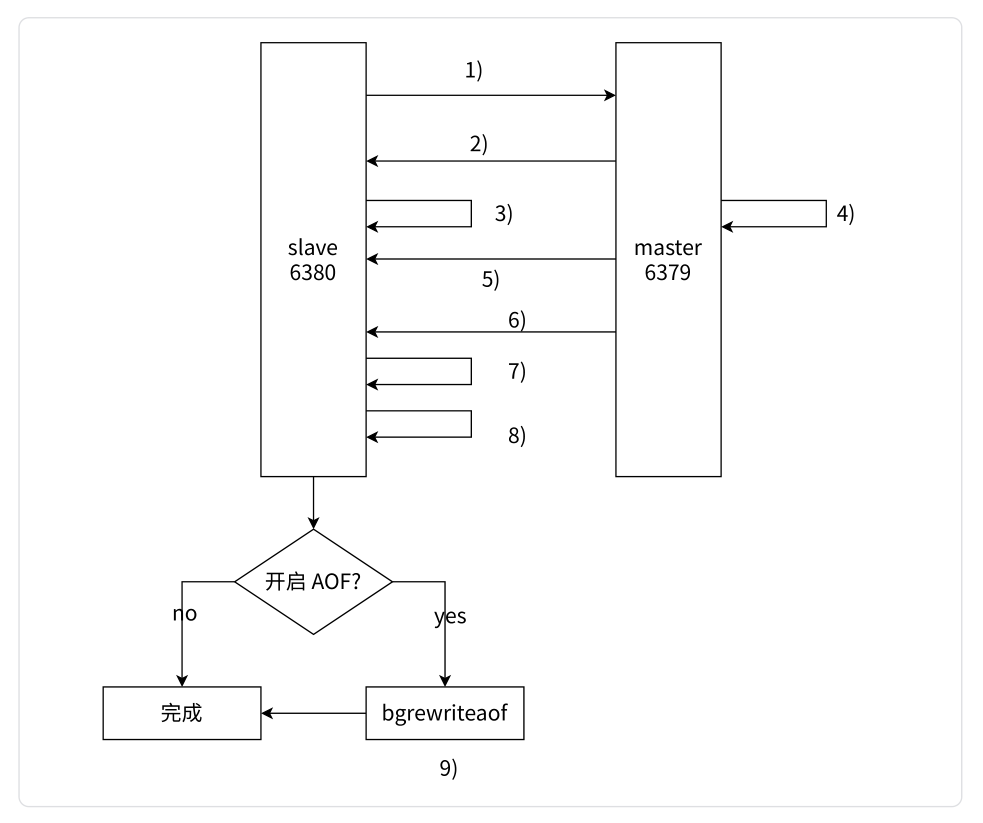
以下是各个步骤的说明:
-
从节点发送
psync命令给主节点以进行数据同步。由于是第一次进行复制,从节点没有主节点的运行ID和复制偏移量,因此发送psync时的参数是-1。 -
主节点根据命令解析出要进行全量复制,并回复
+FULLRESYNC响应。 -
从节点接收主节点的运行信息并保存。
-
主节点执行
bgsave操作来生成 RDB 文件,将数据持久化到磁盘。 -
从节点发送请求,要求主节点传输 RDB 文件,从节点接收并保存 RDB 数据到本地。
-
主节点在 RDB 生成期间会执行写命令,并将这些写命令的操作记录在缓冲区中。一旦从节点加载完 RDB 文件后,主节点将缓冲区内的数据补发给从节点,以保持主从数据的一致性。
-
从节点清空自身的旧数据,为加载 RDB 数据做准备。
-
从节点加载 RDB 文件,从而获得与主节点一致的数据。
-
如果从节点在加载 RDB 完成后开启了 AOF 持久化功能,它会执行
bgrewrite操作,以获取最新的 AOF 文件。
需要注意的是,全量复制是一项高成本的操作,它涉及主节点执行bgsave操作、RDB 文件在网络上传输、从节点清空旧数据、加载 RDB 数据等多个步骤。因此,一般情况下,应尽量避免对已经拥有大量数据集的 Redis 进行全量复制。全量复制适用于初次建立主从复制关系的场景,而在之后的数据同步中,更多地采用部分复制来减小复制的开销。
5.2 部分复制
部分复制是 Redis 为了优化全量复制的高开销而引入的一种复制方式,它使用psync命令结合runId和offset参数来实现。
-
在部分复制中,如果从节点在复制主节点的过程中遇到网络中断、命令丢失等异常情况,它可以向主节点请求补发丢失的命令数据。
-
如果主节点的复制积压缓冲区中存在相应的数据,主节点会直接将这些数据发送给从节点,从而保持主从节点之间的数据一致性。
-
由于补发的数据通常远小于全量数据,因此部分复制的开销较小。
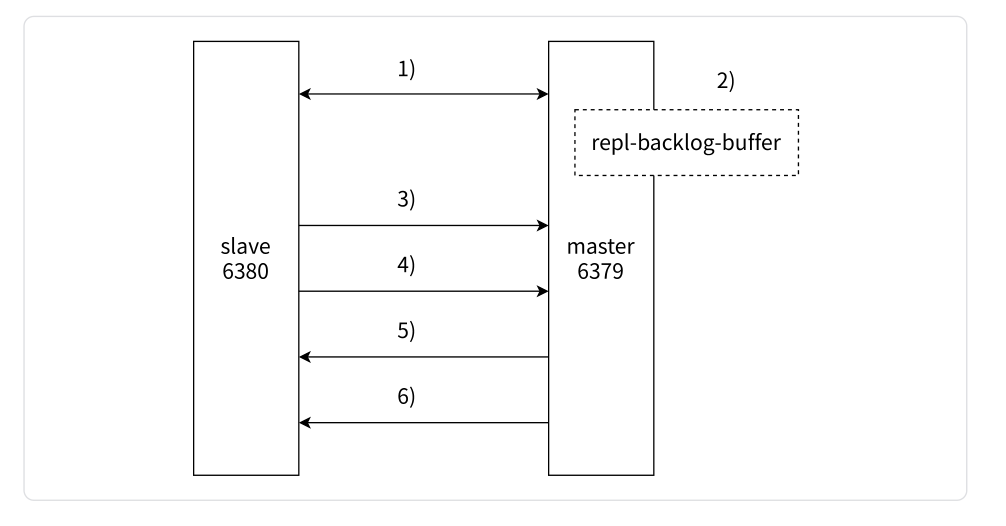
以下是部分复制的整体流程:
以下是各个步骤的说明:
-
当主从节点之间出现网络中断,并且超过了
repl-timeout所配置的时间,主节点会认为从节点故障,并终止复制连接。 -
主从连接中断期间,主节点依然响应命令,但这些复制命令由于网络中断而无法及时发送给从节点,因此主节点会将这些命令暂时保存在复制积压缓冲区中。
-
当主从节点之间的网络恢复后,从节点再次连接到主节点。
-
从节点将之前保存的运行ID和复制偏移量作为
psync命令的参数发送给主节点,请求进行部分复制。 -
主节点接收到
psync请求后,进行必要的验证。然后,根据offset参数查询复制积压缓冲区,找到合适的数据,并响应+CONTINUE给从节点。 -
主节点将需要同步给从节点的数据发送给它,最终完成数据的一致性。
需要注意的是,部分复制是一种用于处理主从节点之间网络闪断或命令丢失等异常情况的复制方式,它通过补发丢失的数据来保持数据的一致性,从而减小了全量复制的开销。
5.3 实时复制
实时复制是主从节点在建立复制连接后需要维护的长连接,并相互发送心跳命令以保持连接的活性和数据的一致性。
以下是实时复制的工作原理:
-
主从节点都具备心跳检测机制,它们模拟对方的客户端进行通信。
-
主节点默认每隔约10秒向从节点发送一条
PING命令,以检测从节点的存活性和连接状态。这可以帮助主节点确保从节点正常运行。 -
从节点默认每隔约 1 秒向主节点发送一条
REPLCONF ACK {offset}命令,其中{offset}表示从节点当前的复制偏移量。这样,从节点可以向主节点报告自己复制的进度。
如果主节点发现从节点的通信延迟超过了配置的 repl-timeout 值(默认为60秒),主节点会判定从节点为下线状态,并断开与从节点的复制客户端连接。当从节点恢复连接后,心跳机制会继续运行,确保主从节点之间的复制连接保持活跃。
实时复制的机制有助于确保主从节点之间的数据同步持续进行,并可以自动处理部分复制中出现的网络断连等异常情况,从而保持主从节点之间的数据一致性。
六、其他问题
6.1 关于 Redis 从节点晋升为主节点的时机问题
在 Redis 中,从节点(slave)可以在特定情况下晋升为主节点(master)。这种情况通常出现在以下两种情况下:
-
手动晋升: 管理员可以手动将从节点升级为主节点。这通常是在需要切换主节点或者原主节点故障时执行的操作。要手动晋升从节点为主节点,需要在从节点上执行
SLAVEOF NO ONE命令,这将取消从节点的复制关系并将其变成主节点。 -
自动故障切换: Redis Sentinel(哨兵机制) 或者 Redis Cluster 集群管理工具可以监控主节点的状态。如果主节点发生故障,监控工具可以自动将一个从节点晋升为新的主节点,以确保高可用性。这通常是在配置了 Redis 高可用性解决方案时使用的机制。
需要注意的是,将从节点升级为主节点会中断与先前主节点的复制关系,因此在执行此操作之前,需要确保已经备份了重要数据,并且明白这可能会导致数据不一致。此外,晋升后的新主节点将开始接受写入操作,因此需要确保新主节点的性能和资源足够满足写入操作的需求。
6.2 关于 Redis 配置了主从结构后无法启动的问题
如果在配置 Redis 主从结构后无法启动,通常是由于配置文件或者网络连接问题引起的。以下是一些可能导致启动问题的常见原因和解决方法:
-
配置文件错误: 检查 Redis 配置文件(redis.conf)中的主从配置是否正确。确保主节点的配置包含
slaveof指令,指向正确的主节点地址和端口。从节点的配置应包含slaveof指令,指向主节点。 -
网络连接问题: 确保主从节点之间的网络连接是正常的。尝试使用
ping命令或者其他网络工具测试主从节点之间的连通性。如果有防火墙或网络策略限制,确保已正确配置。 -
复制密码错误: 如果在主节点上启用了密码保护,需要在从节点的配置文件中设置正确的密码(使用
masterauth指令)。确保密码是正确的。 -
端口占用: 确保 Redis 使用的端口没有被其他进程占用。可以通过尝试更改 Redis 端口或者查看端口占用情况来解决。
-
数据目录权限: 检查 Redis 数据目录的权限设置。确保 Redis 进程具有足够的权限读写数据目录。
-
错误日志查看: 查看 Redis 错误日志文件(通常是 redis-server.log 或者 syslog 中的 Redis 相关日志),以查找有关启动失败的更多信息。日志文件通常会提供有关错误的详细信息,有助于排除问题。
-
配置项冲突: 确保配置文件中没有重复或冲突的配置项。有时候,错误的配置项可能导致启动问题。
在排除以上问题后,可以尝试使用 Redis 命令行工具以交互方式启动 Redis,这有助于在启动过程中看到错误消息并进行调试。例如,可以使用以下命令启动 Redis:
redis-server /path/to/redis.conf
替换 /path/to/redis.conf 为自己的配置文件路径。在启动过程中,Redis 会将错误消息输出到终端,有助于识别问题。
相关文章:
【Redis】深入探索 Redis 主从结构的创建、配置及其底层原理
文章目录 前言一、对 Redis 主从结构的认识1.1 什么是主从结构1.2 主从结构解决的问题 二、主从结构创建2.1 配置并建立从节点2.2.1 从节点配置文件2.2.2 启动并连接 Redis 主从节点2.2.3 SLAVEOF 命令2.2.4 断开主从关系 2.2 查看主从节点的信息2.2.1 INFO REPLICATION 命令2.…...

CSS 滚动驱动动画 scroll-timeline ( scroll-timeline-name ❤️ scroll-timeline-axis )
scroll-timelinescroll-timeline-name❤️scroll-timeline-axis 解决问题语法 animation-timeline-nameanimation-timeline-axis scroll-timeline ( scroll-timeline-name ❤️ scroll-timeline-axis ) 在 scroll() 的最后我们遇到了因为定位问题导致滚动效果失效的情况, 当…...

9.19号作业
2> 完成文本编辑器的保存工作 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QFontDialog> #include <QFont> #include <QMessageBox> #include <QDebug> #include <QColorDialog> #include <QColor&g…...

Mybatis学习笔记9 动态SQL
Mybatis学习笔记8 查询返回专题_biubiubiu0706的博客-CSDN博客 动态SQL的业务场景: 例如 批量删除 get请求 uri?id18&id19&id20 或者post id18&id19&id20 String[] idsrequest.getParameterValues("id") 那么这句SQL是需要动态的 还…...
element表格 和后台联调
1.配置接口 projectList:/api/goods/xxx,//产品列表2.请求接口(get请求默认参数page) // 产品列表 pageprojectList(params){return axios.get(base.projectList,{params})}3.获取数据 直接放到created里边去了 刷新页面就可以看到 async projectList(page){let res await t…...
基于SSM的智慧城市实验室主页系统的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用Vue技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...

怒赞,阿里P8推荐的Java面试宝典:41个专题PDF(史上最全+面试必备)
《尼恩Java面试宝典》 40岁老架构师 尼恩 经过对大量 Java面试题 的不断梳理、迭代, 编著成5000页的《尼恩Java面试宝典》,致力于体系化, 系统化,形象化 梳理,形成一个大的知识体系,从而帮助大家 进大厂&a…...

线程池各个参数设置说明
1. corePoolSize 核心线程数 看处理业务属于IO密集型还是属于cpu密集型IO密集型: 通常设置为N1,还有一个计算公式:线程数 cpu数*(线程等待时间/线程总的处理时间) 但是由于服务器除了这个服务可能还部署有其他服务,…...
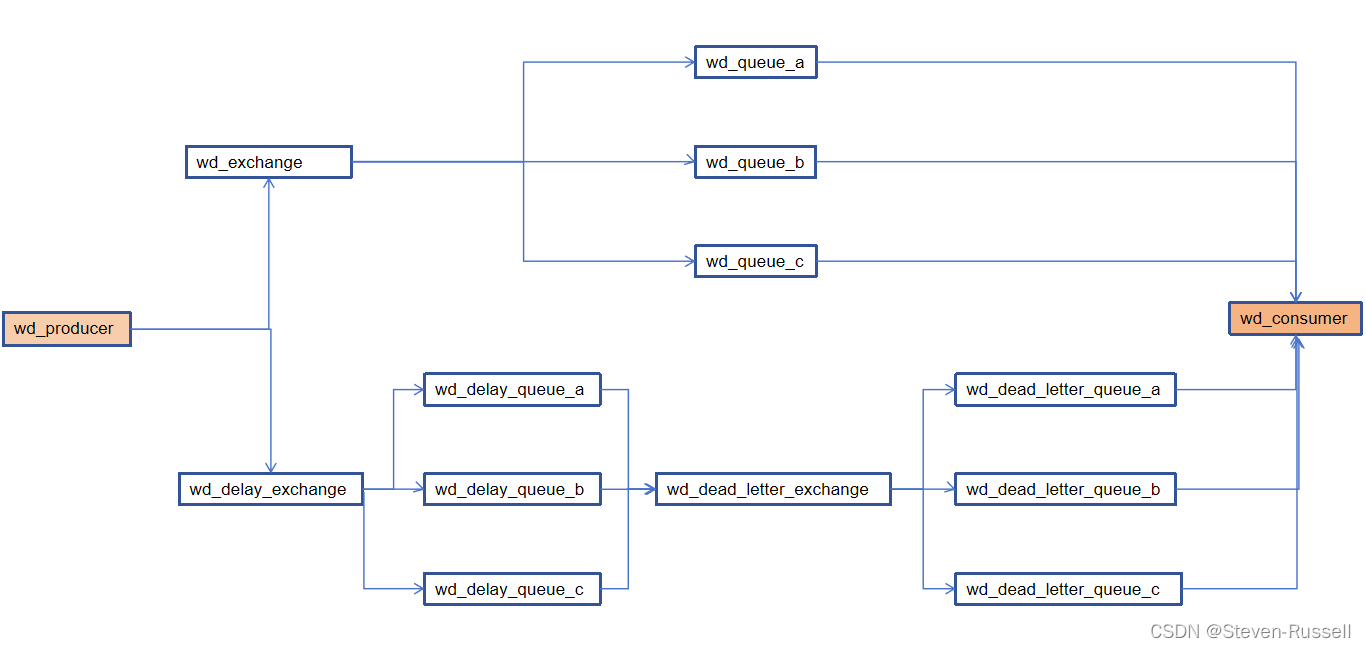
springBoot对接多个mq并且实现延迟队列---未完待续
mq调用流程 创建消息转换器 package com.wd.config;import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter; import org.springframework.amqp.support.converter.MessageConverter; import org.springframework.context.annotation.Bean; import o…...
Pytorch从零开始实战04
Pytorch从零开始实战——猴痘病识别 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——猴痘病识别环境准备数据集模型选择模型训练数据可视化其他模型图片预测 环境准备 本文基于Jupyter notebook,使用Python3.8,Pytor…...

北大C++课后记录:文件读写的I/O流
前言 文件和平常用到的cin、cout流其实是一回事,可以将文件看作一个有限字符构成的顺序字符流,基于此,也可以像cin、cout读键盘数据那样对文件进行读写。 读写指针 输入流的read指针 输出流的write指针 注:这里的指针并不是普…...

详解Linux的grep命令
2023年9月19日,周二晚上 先写这么多吧,以后有空再更新,还要一些作业没写完.... 目录 概述查看grep命令的所有选项grep的常用选项选项-i选项-v选项-n选项-c编辑选项-l组合使用 概述 grep命令在Linux系统中是一个很重要的文本搜索工具和过…...

spark6. 如何设置spark 日志
spark yarn日志全解 一.前言二.开启日志聚合是什么样的2.1 开启日志聚合MapReduce history server2.2 如何开启Spark history server 三.不开启日志聚合是什么样的四.正确使用log4j.properties 一.前言 本文只讲解再yarn 模式下的日志配置。 二.开启日志聚合是什么样的 在ya…...

glibc: strlcpy
https://zine.dev/2023/07/strlcpy-and-strlcat-added-to-glibc/ https://sourceware.org/git/?pglibc.git;acommit;h454a20c8756c9c1d55419153255fc7692b3d2199 https://linux.die.net/man/3/strlcpy https://lwn.net/Articles/612244/ 从这里看,这个strlcpy、st…...

如何在 Buildroot 中配置 Samba
在 Buildroot 中配置 Samba 在 Buildroot 中配置 Samba 可以通过以下步骤完成: 1. 进入 Buildroot 的根目录。 2. 执行 make menuconfig 命令,打开 Buildroot 的配置菜单。 3. 在配置菜单中,使用键盘导航到 "Target packages" 选…...

SSM02
SSM02 此时我们已经做好了登录模块接下来可以做一下学生管理系统的增删改查操作 首先,我们应当有一个登录成功后的主界面 在webapp下新建 1.main.html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"&…...
day3_QT
day3_QT 1、文件保存2、始终事件 -闹钟 1、文件保存 2、始终事件 -闹钟 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTimerEvent> #include <QTime> #include <QTextToSpeech>QT_BEGIN_NAMESPACE namespace Ui { clas…...

js-map方法中调用服务器接口
在 Array.prototype.map() 方法中调用服务器接口时,可以使用异步函数来处理。 示例: async function fetchData() {try {const response await fetch(https://api.example.com/data); // 通过 fetch 发送请求const data await response.json(); // 解…...

docker 已经配置了国内镜像源,但是拉取镜像速度还是很慢(gcr.io、quay.io、ghcr.io)
前言 国内用户在使用 docker 时,想必都遇到过镜像拉取慢的问题,那是因为 docker 默认指向的镜像下载地址是 https://hub.docker.com,服务器在国外。 网上有关配置 docker 国内镜像源的教程很多,像 腾讯、阿里、网易 等等都会提供…...
[linux(静态文件服务)] 部署vue发布后的dist网页到nginx
所以说: 1.windows下把开发好的vue工程打包为dist文件然后配置下nginx目录即可。 2.linux上不需要安装node.js环境。 3.这样子默认访问服务器ip地址,就可以打开,毕竟默认就是:80端口。...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...

CppCon 2015 学习:Reactive Stream Processing in Industrial IoT using DDS and Rx
“Reactive Stream Processing in Industrial IoT using DDS and Rx” 是指在工业物联网(IIoT)场景中,结合 DDS(Data Distribution Service) 和 Rx(Reactive Extensions) 技术,实现 …...
华为云Flexus+DeepSeek征文 | 基于Dify构建具备联网搜索能力的知识库问答助手
华为云FlexusDeepSeek征文 | 基于Dify构建具备联网搜索能力的知识库问答助手 一、构建知识库问答助手引言二、构建知识库问答助手环境2.1 基于FlexusX实例的Dify平台2.2 基于MaaS的模型API商用服务 三、构建知识库问答助手实战3.1 配置Dify环境3.2 创建知识库问答助手3.3 使用知…...
可视化预警系统:如何实现生产风险的实时监控?
在生产环境中,风险无处不在,而传统的监控方式往往只能事后补救,难以做到提前预警。但如今,可视化预警系统正在改变这一切!它能够实时收集和分析生产数据,通过直观的图表和警报,让管理者第一时间…...