【C++从0到王者】第三十一站:map与set
文章目录
- 一、关联式容器
- 二、pair键值对
- 三、set
- 1. set的介绍
- 2. set的部分接口以及应用
- 3. count
- 4. lower_bound和upper_bound
- 5. equal_range
- 6. multiset容器
- 四、map
- 1. map的介绍
- 2. map的一些常见接口以及使用
- 3. map的[]运算符重载
- 4. 使用map改进一些题
- 5. multimap容器
- 五、map和set相关力扣题
- 总结
一、关联式容器
STL中的部分容器,比如:vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。
那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高
二、pair键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息
stl里面对于pair的定义是这样的
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2()){}pair(const T1& a, const T2& b) : first(a), second(b){}
};
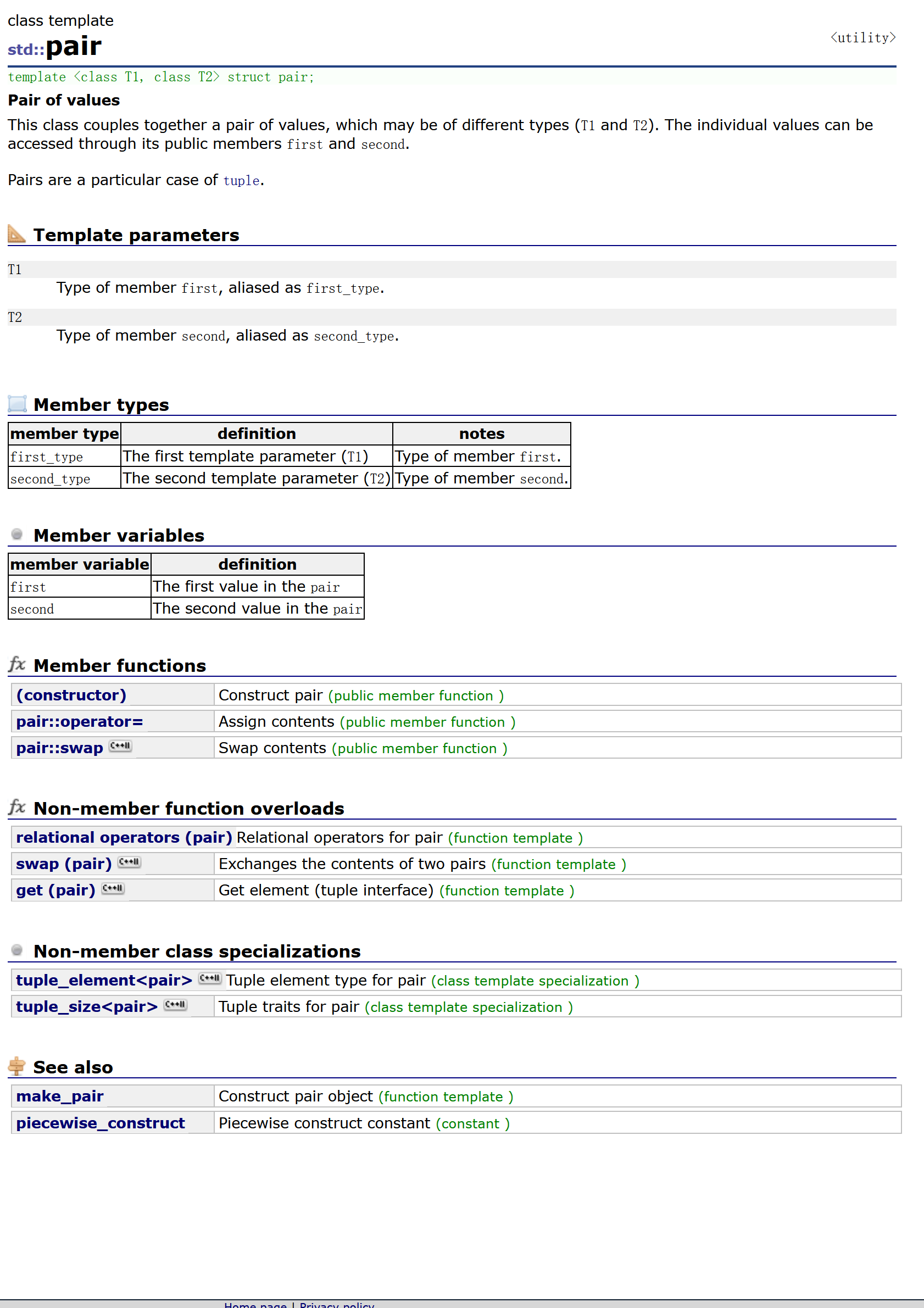
pair有三种构造函数,不难看出,分别是无参的构造,拷贝构造,以及通过两个值来进行构造

除了三种构造函数以外,它还有一种方式,也可以生成pair对象。这个不是一个成员函数,所以可以直接使用。
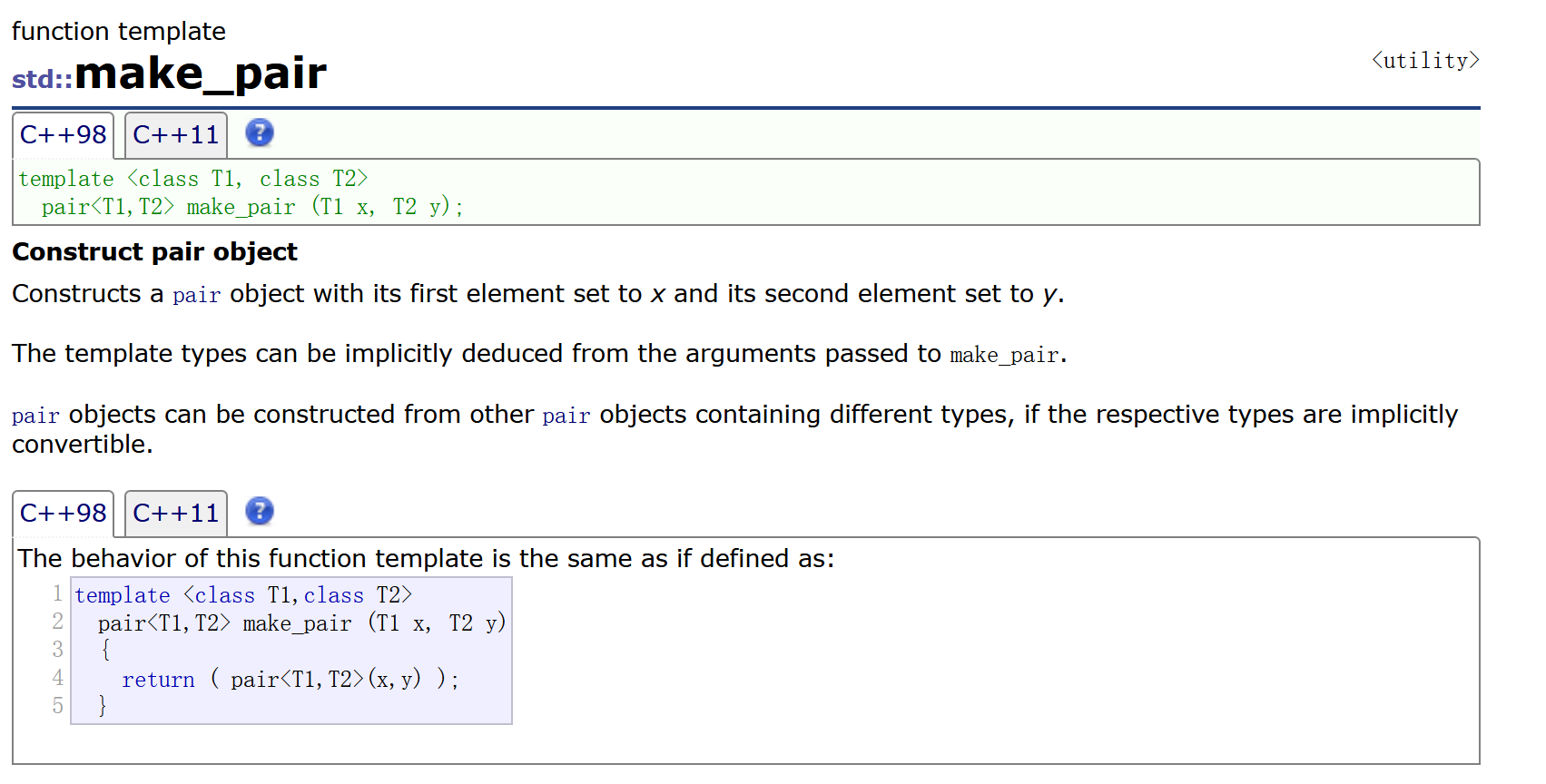
如上的一些构造函数的使用将在map中进行演示
三、set
1. set的介绍
如下图所示:
我们可以注意到它的模板参数是要比其他容器多一个的,这个容器我们也可以看到是一个仿函数。我们使用优先级队列的时候也用过这个仿函数

集合是按照特定顺序存储唯一元素的容器。
在一个集合中,元素的值也标识它(值本身就是键,类型为 T),并且每个值必须是唯一的。集合中元素的值在容器中不能修改(元素总是 const 类型的),但是可以从容器中插入或删除元素。
在内部,集合中的元素总是按照其内部比较对象(类型为 Compare )指示的特定严格弱排序标准排序。
在通过键访问单个元素时,set 容器通常比 unordered_set 容器慢,但是它们允许基于次序对子集进行直接迭代。
集合通常以二叉搜索树的形式实现。这颗二叉搜索树是红黑树。
set其实就相当于key模型的二叉搜索树
注意:set里面的值是不可以被修改的,它实现这一点的原理就是将迭代器和const迭代器都是const迭代器没有任何区别。

2. set的部分接口以及应用
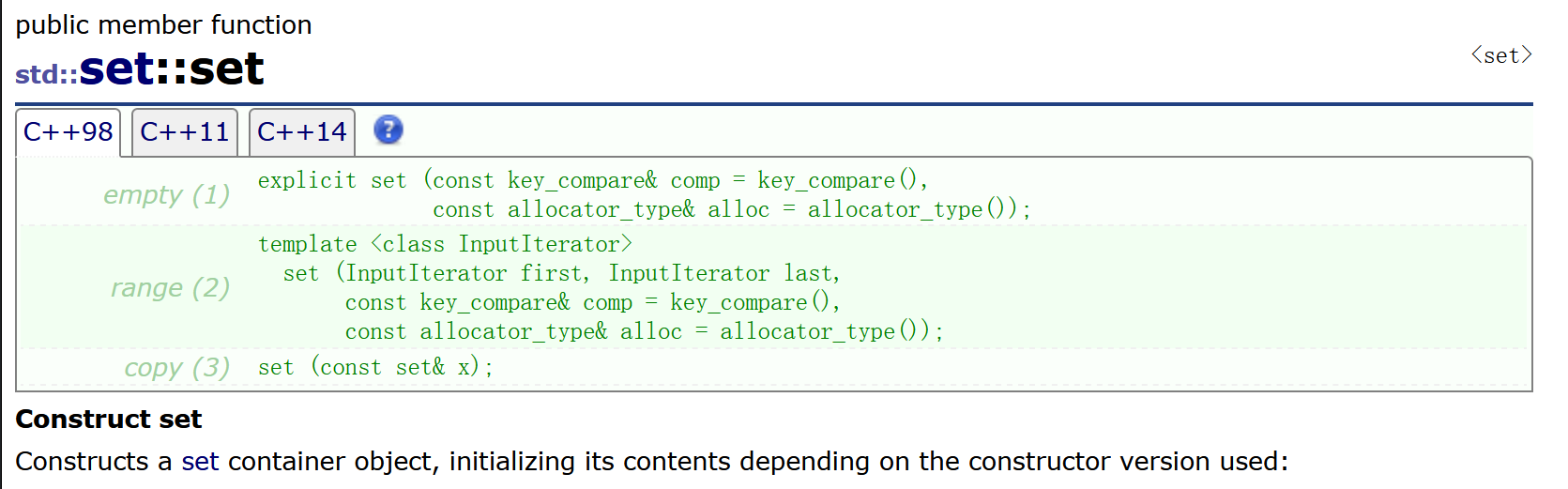
可以注意到,一共有三个构造函数,第一个是全缺省的默认构造函数,第二个是迭代器区间构造,第三个是拷贝构造。
不过这个拷贝构造的代价比较大,因为它是一个树的拷贝,而且析构也一样有很大的代价。
还有一个接口是insert
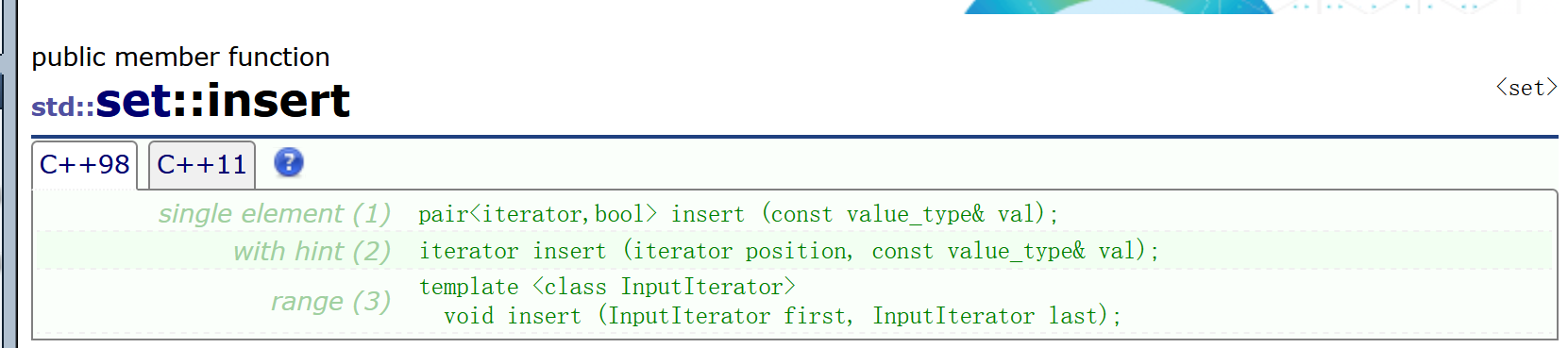
这里的value_type就是T

还有很多接口其实看一眼就大概知道啥意思
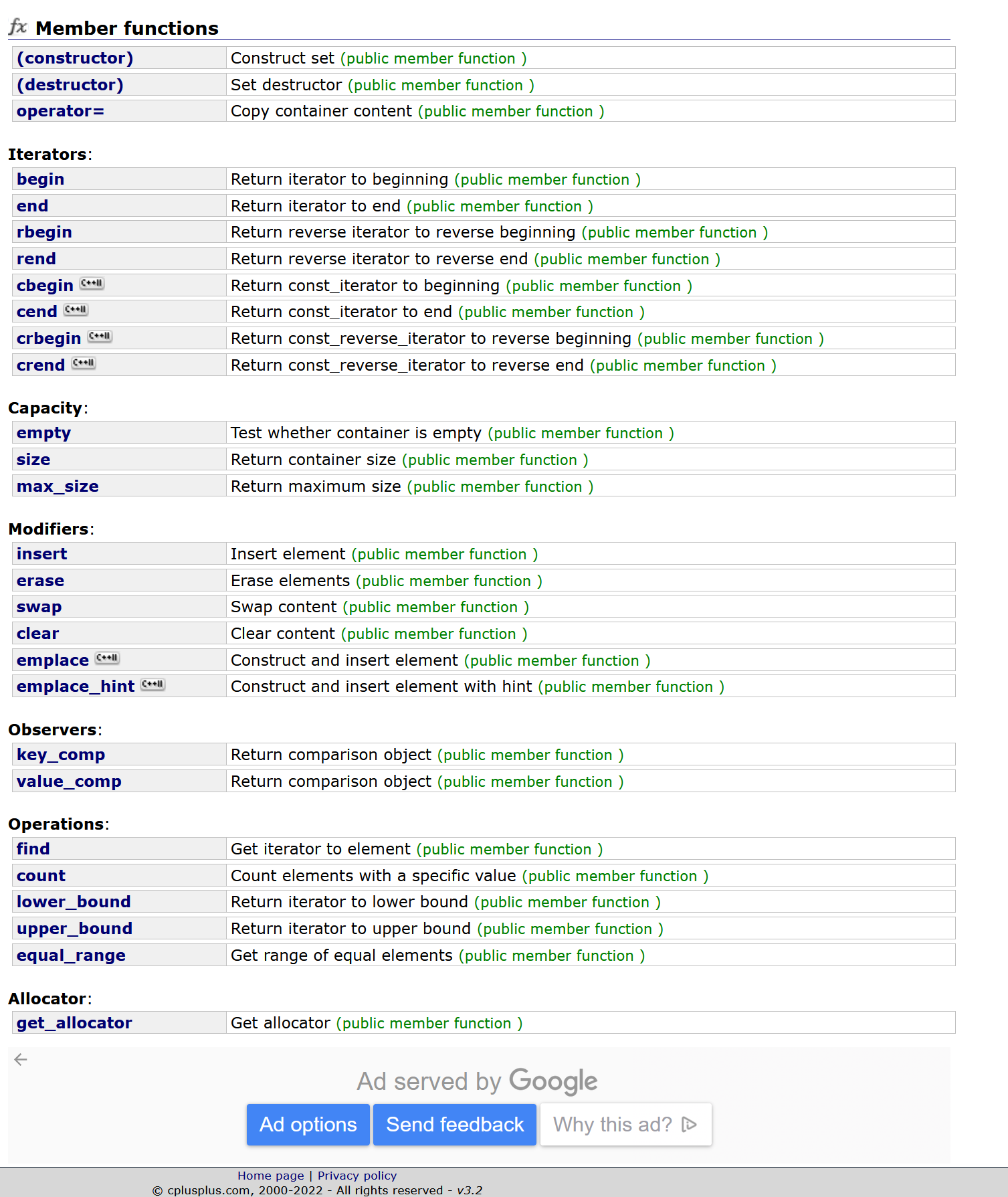
比如如下代码:可以简单的测试一下代码
void test_set1()
{set<int> s;s.insert(1);s.insert(5);s.insert(2);s.insert(2);s.insert(2);s.insert(2);s.insert(4);s.insert(4);s.insert(4);s.insert(3);set<int>::iterator it = s.begin();while (it != s.end()){cout << *it << " ";it++;}cout << endl;
}
int main()
{test_set1();return 0;
}
我们可以发现,set可以自动去重和排序
而它的去重原理就是:一个值已经有了,我们就不插入即可
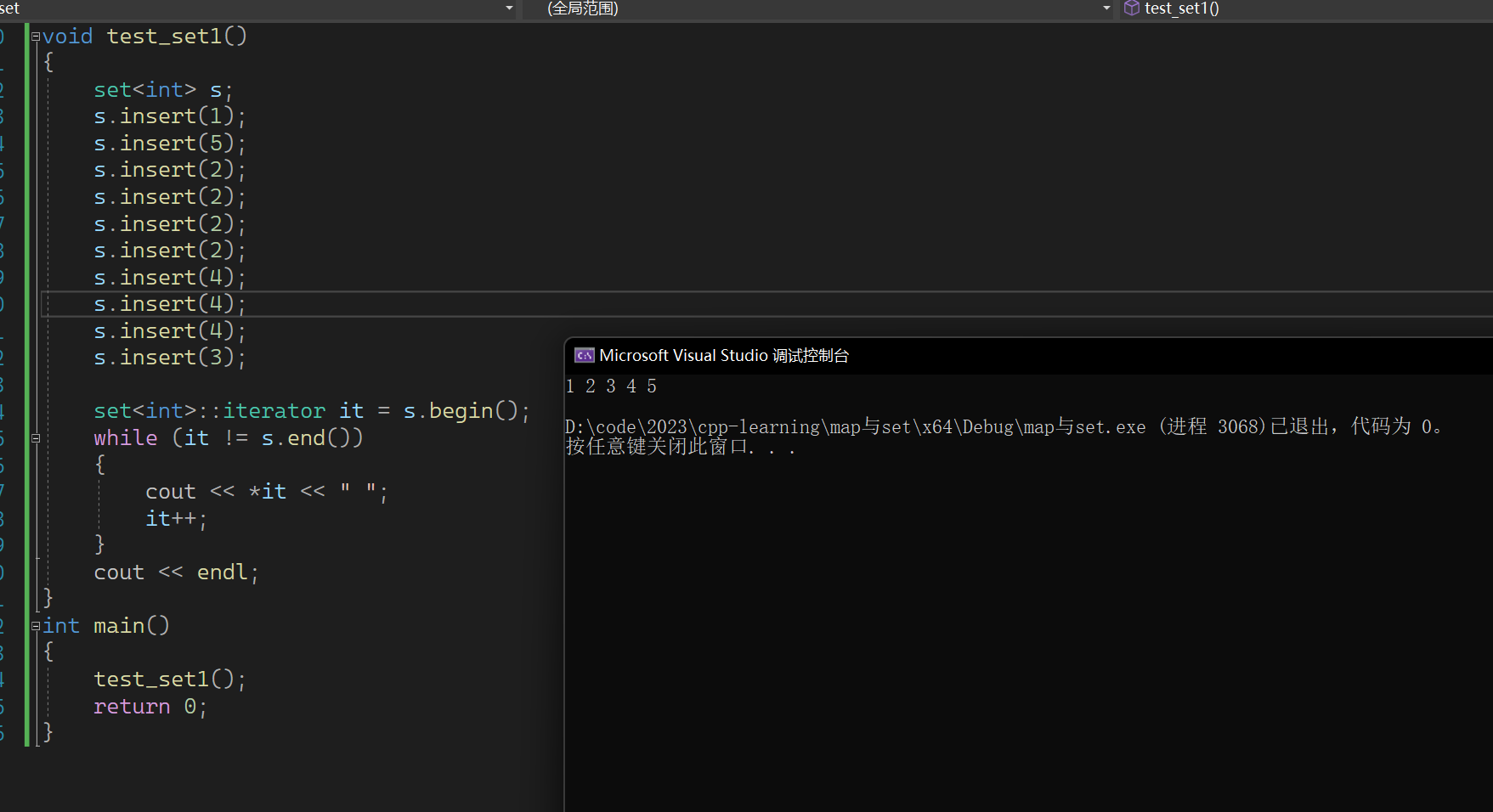
同时我们也可以试一下set的删除

auto pos = s.find(3);s.erase(pos);s.erase(4);for (auto e : s){cout << e << " ";}cout << endl;
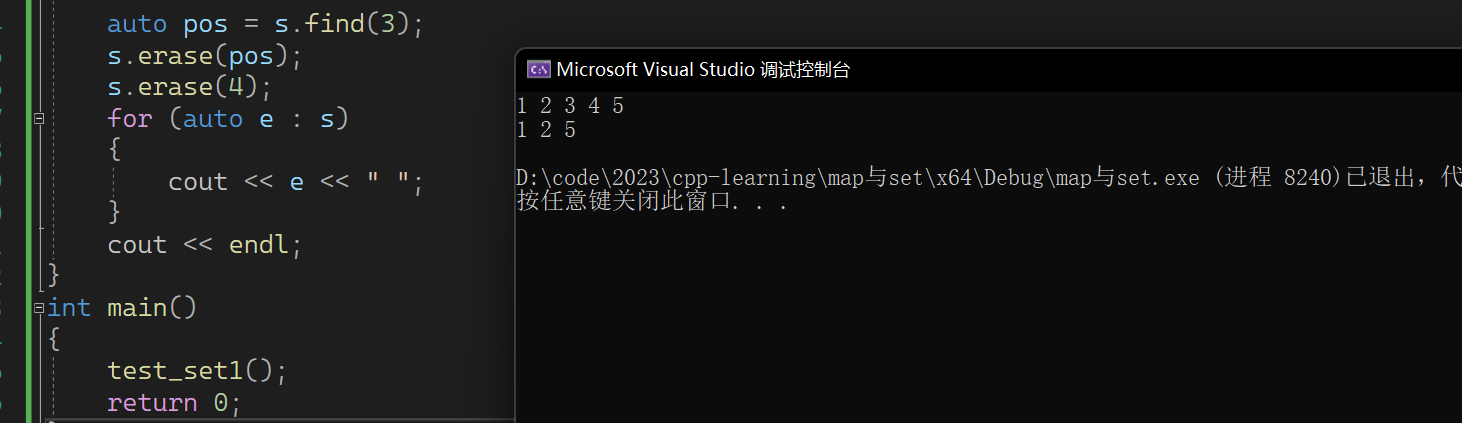
如上有演示了两种删除,从表面来看,看上去好像没有什么大的区别。我们可以认为下面的是通过上面的进行实现的。
不过在find中如果没有找到的话,是会直接报错的。
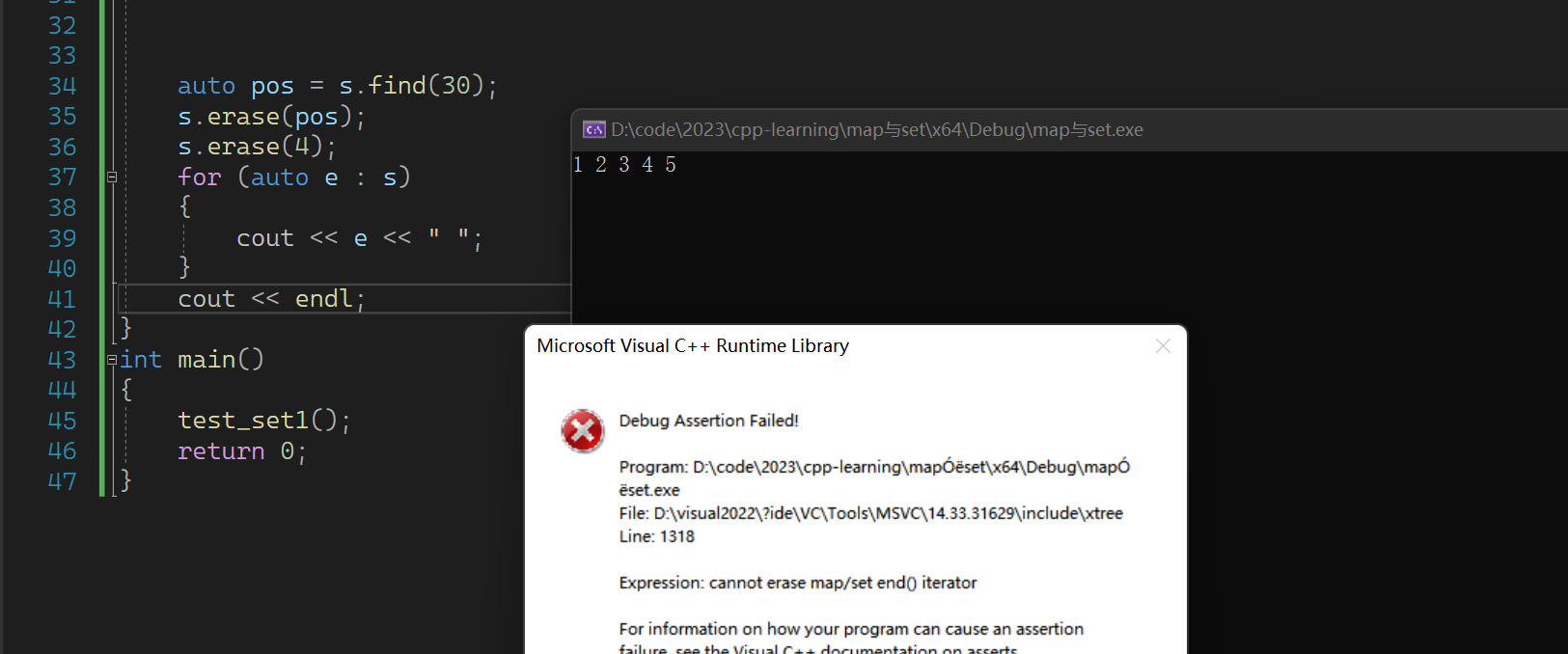
而下面如果没有找到是什么也不会发生的
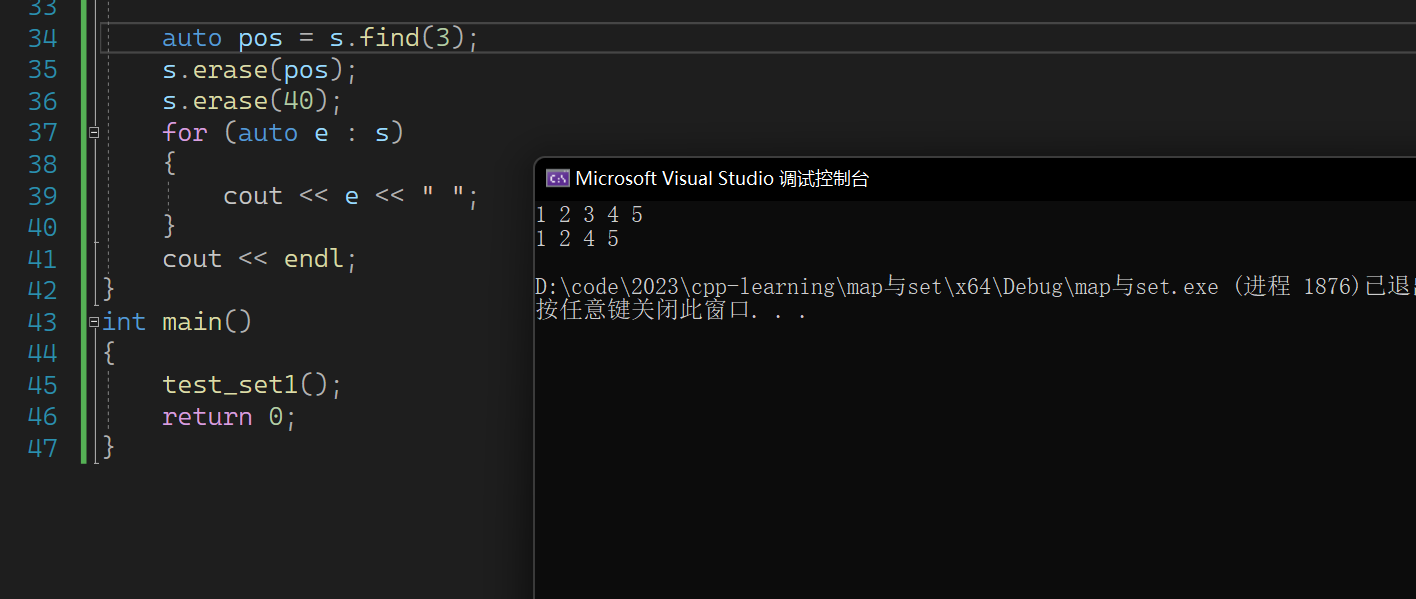
不过我们可以加一个判断来解决这个问题
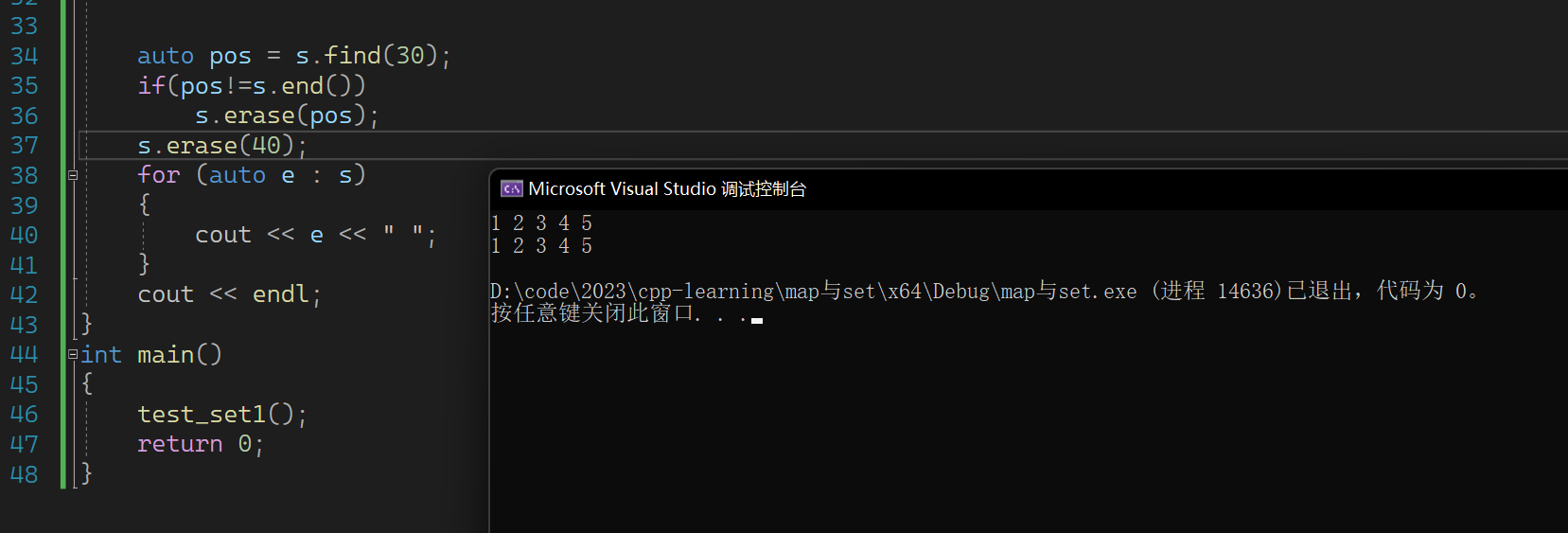
这是因为find找不到会返回一个end迭代器导致的
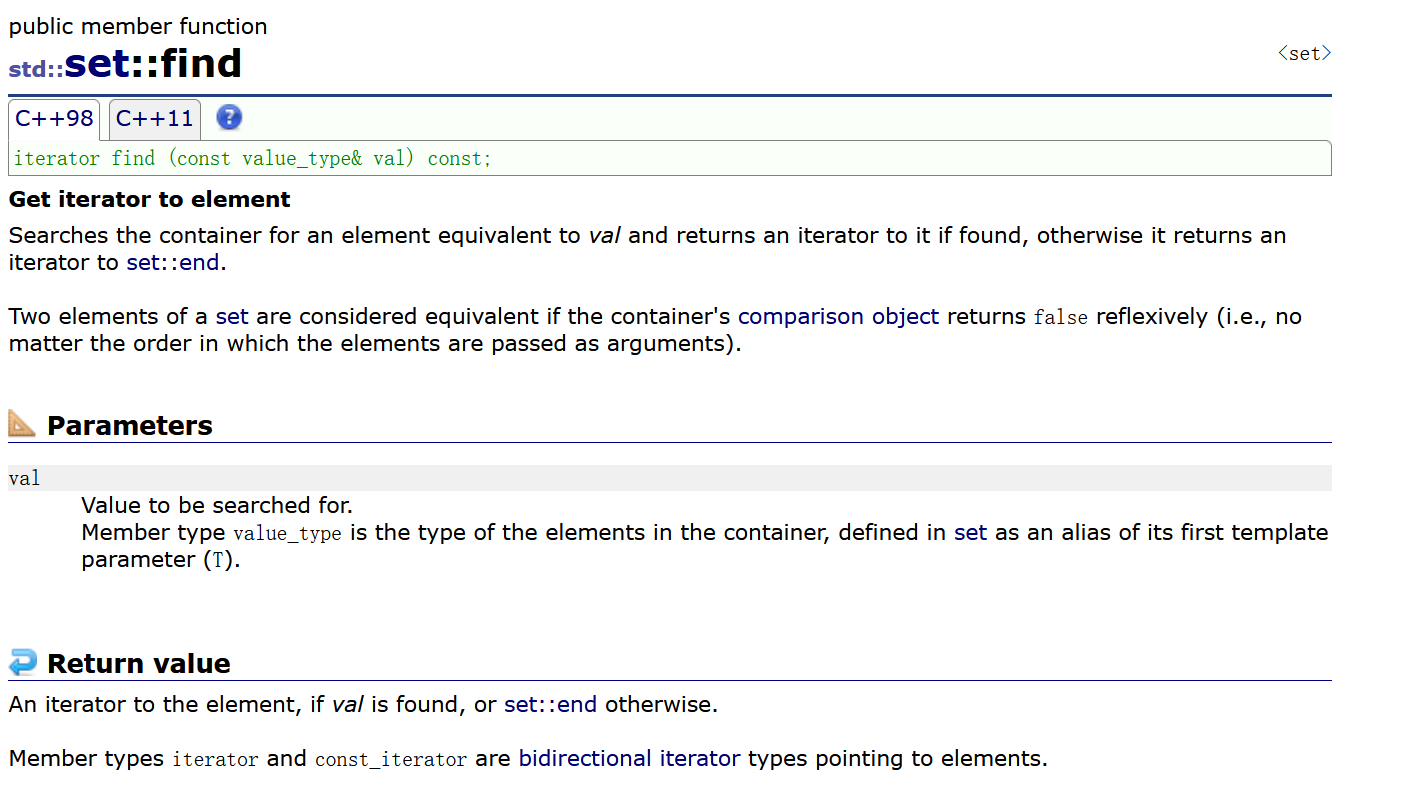
在容器中搜索与val等效的元素,如果找到则返回一个迭代器,否则返回一个迭代器给set::end。
但是我们知道算法库里面也有一个find,这个find似乎也能完成这个操作
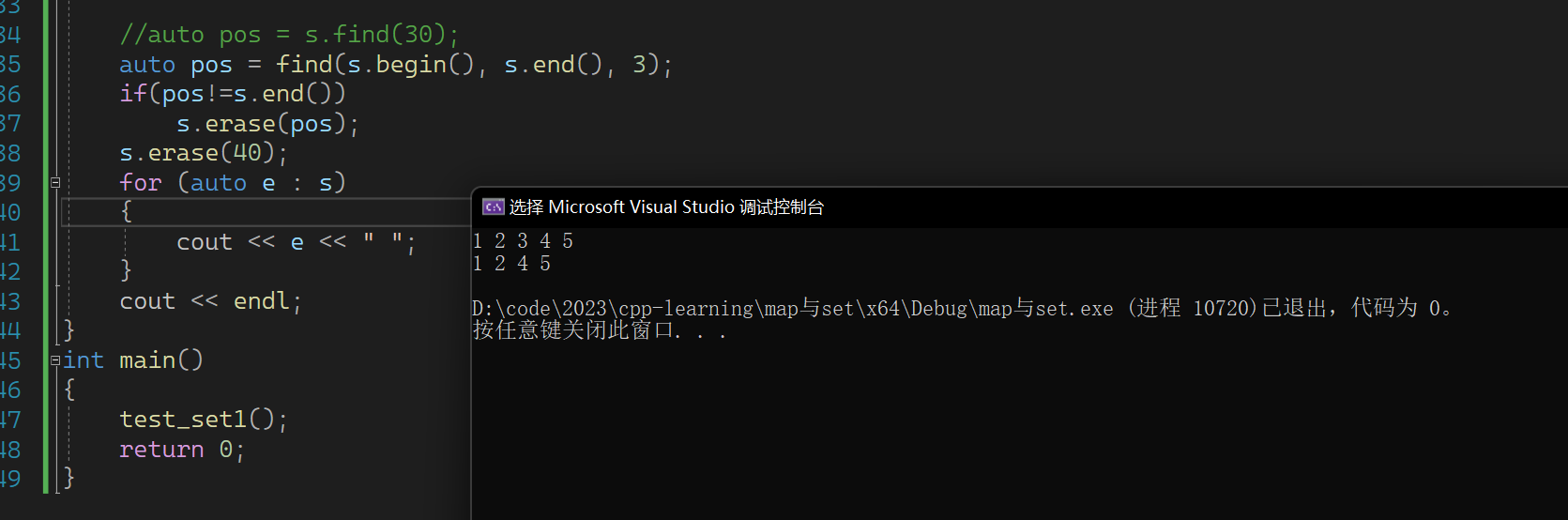
其实这两个find是存在一定的差异的,set里面的find是根据二叉搜索树的性质来进行查找的(其实是红黑树,效率更优),时间复杂度为O(logN),而算法库里面的find是一个一个查找的,时间复杂度为O(N)。
3. count

count的作用是,给一个值,然后返回它出现了几次。不过因为set容器里面的值是唯一的,所以一个元素在这里面,返回1,否则返回0
如下的代码可以演示find和count寻找一个数据的使用
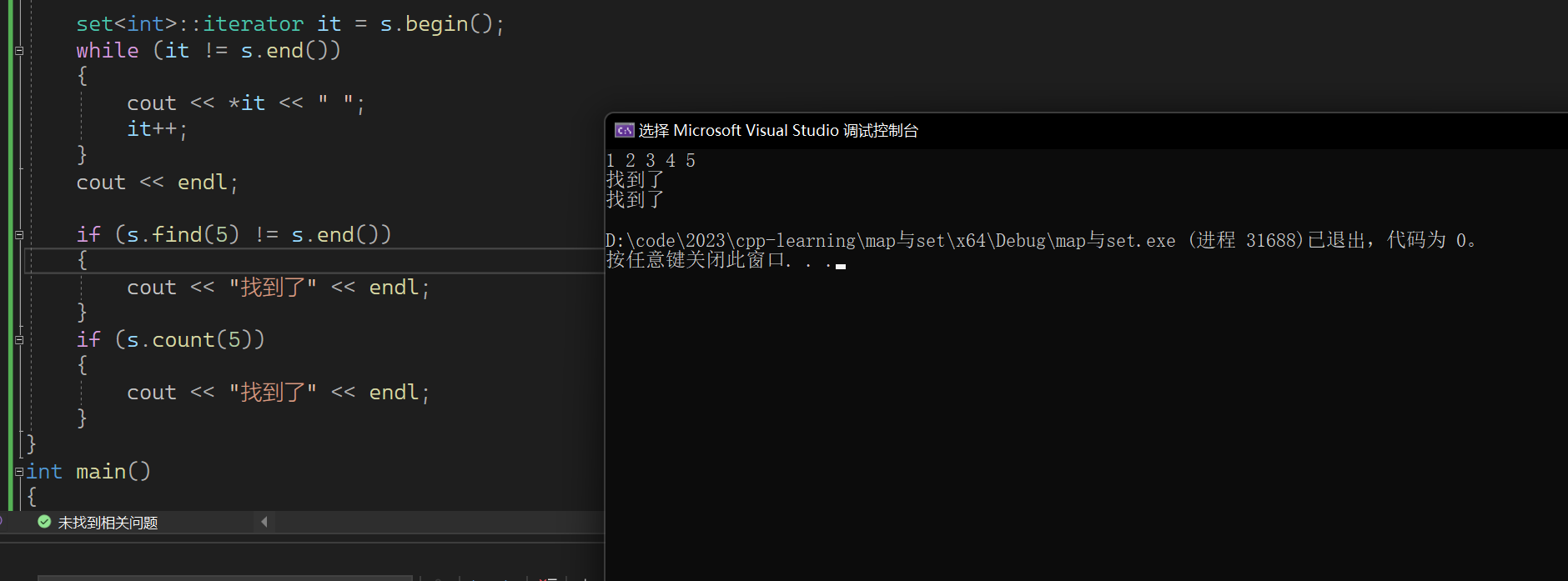
void test_set2()
{set<int> s;s.insert(1);s.insert(5);s.insert(2);s.insert(4);s.insert(4);s.insert(3);set<int>::iterator it = s.begin();while (it != s.end()){cout << *it << " ";it++;}cout << endl;if (s.find(5) != s.end()){cout << "找到了" << endl;}if (s.count(5)){cout << "找到了" << endl;}
}
int main()
{test_set2();return 0;
}
4. lower_bound和upper_bound

返回迭代器到下界
返回一个迭代器,该迭代器指向容器中的第一个元素,该元素不被认为位于val之前(即,它要么等价,要么在val之后)。
该函数使用其内部比较对象(key_comp)来确定这一点,并返回一个迭代器,指向key_comp(element,val)将返回false的第一个元素。
如果用默认比较类型(less)实例化set类,则该函数返回一个指向不小于val的第一个元素的迭代器。
类似的成员函数upper_bound具有与lower_bound相同的行为,只是set包含一个与val等效的元素:在这种情况下,lower_bound返回一个指向该元素的迭代器,而upper_bound返回一个指向下一个元素的迭代器。
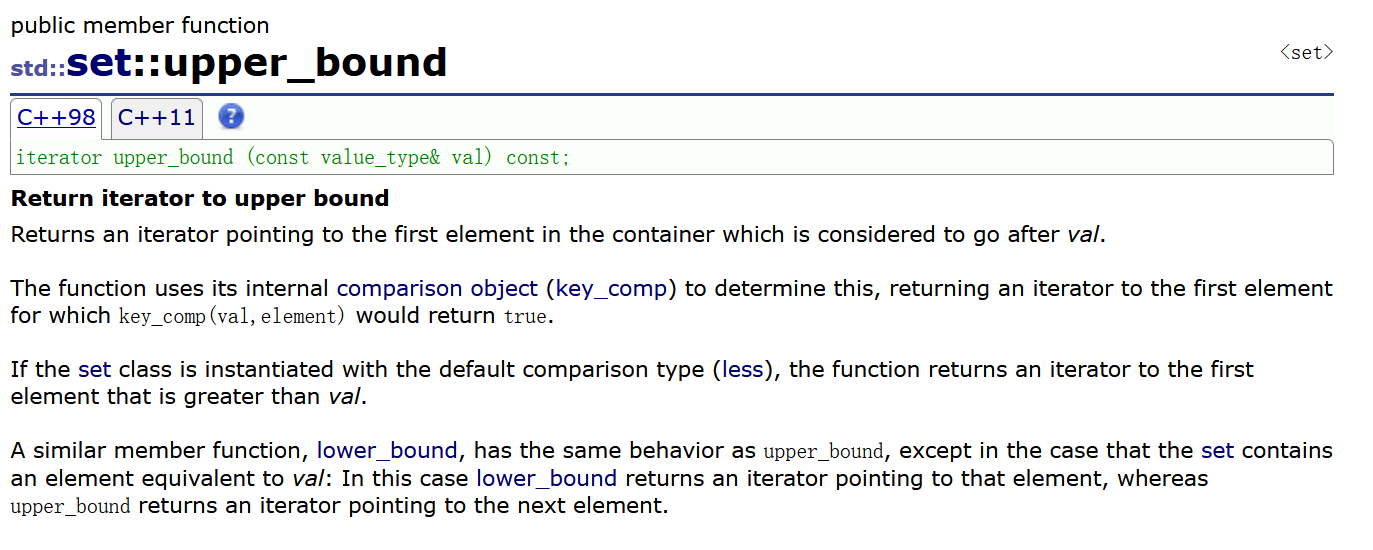
返回迭代器到上界
返回一个迭代器,该迭代器指向容器中被认为在val之后的第一个元素。
该函数使用其内部比较对象(key_comp)来确定这一点,并返回一个迭代器,指向key_comp(val,element)将返回true的第一个元素。
如果用默认比较类型(less)实例化set类,则该函数返回指向第一个大于val的元素的迭代器。
类似的成员函数lower_bound具有与upper_bound相同的行为,只是set包含一个与val等效的元素:在这种情况下,lower_bound返回一个指向该元素的迭代器,而upper_bound返回一个指向下一个元素的迭代器。
我们可以使用这段代码来进行验证
void test_set3()
{std::set<int> myset;std::set<int>::iterator itlow, itup;for (int i = 1; i < 10; i++) myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90itlow = myset.lower_bound(30); itup = myset.upper_bound(60); myset.erase(itlow, itup); // 10 20 70 80 90for (auto e : myset){cout << e << " ";}cout << endl;
}
int main()
{test_set3();return 0;
}
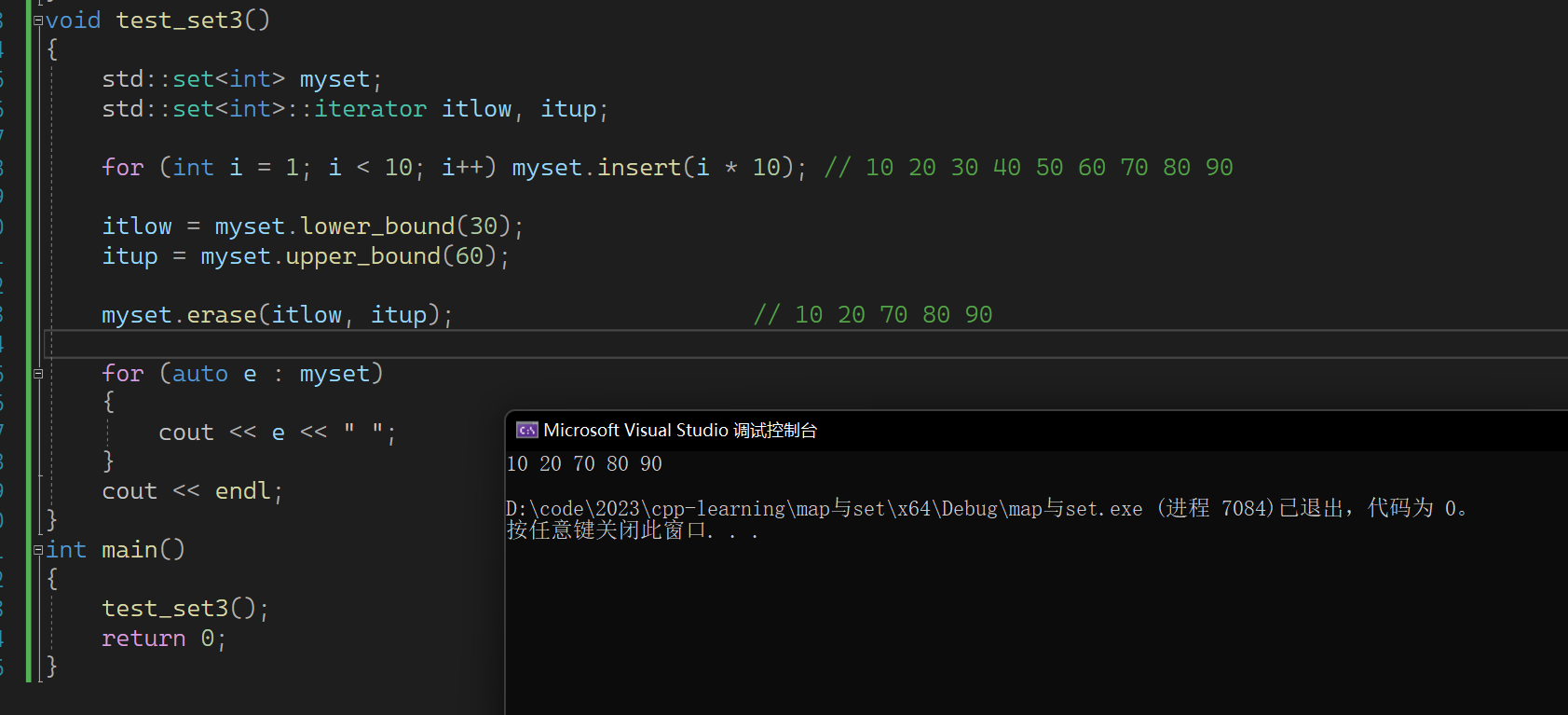
lower_bound和upper_bound一个设置为>=,一个设置为>。这样刚好可以将我们输入值所处的区间进行控制,刚好满足左闭右开。无论是构造也好,删除也好,插入也好都是刚好十分方便的。
5. equal_range
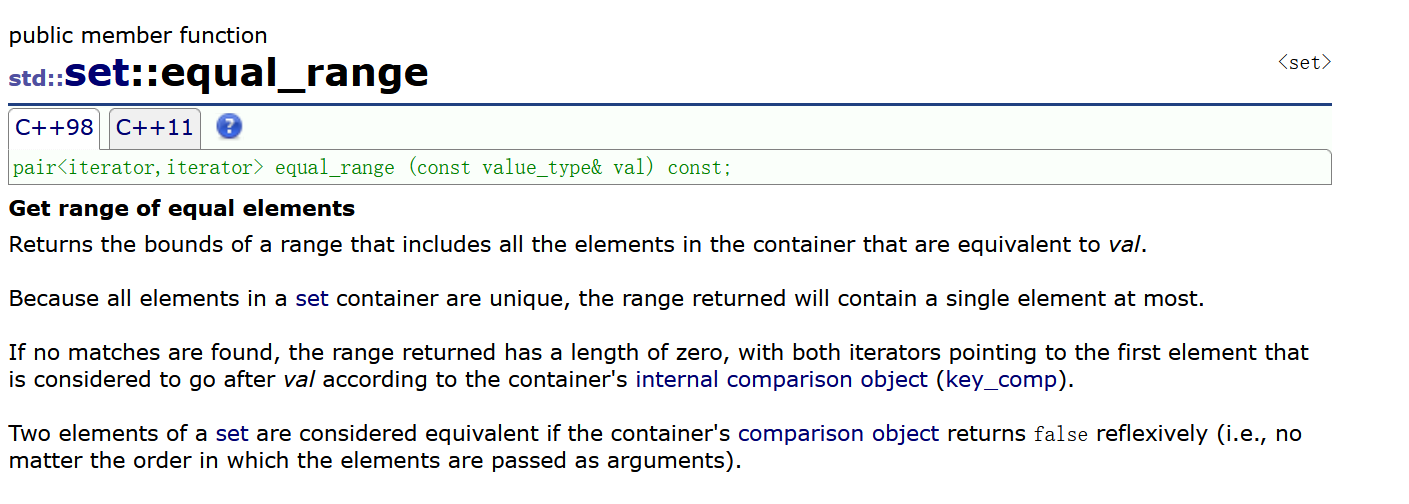
获取相等元素的范围
返回一个范围的边界,该范围包括容器中与val等效的所有元素。
因为set容器中的所有元素都是唯一的,所以返回的范围最多只包含一个元素。
如果没有找到匹配项,则返回的范围长度为0,两个迭代器都指向容器内部比较对象(key_comp)认为在val之后的第一个元素。
如果容器的比较对象自反性地返回false(即,无论元素作为参数传递的顺序如何),则认为集合中的两个元素相等。
该函数返回一个pair,其成员pair::first是范围的下界(与lower_bound相同),pair::second是上界(与upper_bound相同)。
成员类型iterator和 const_iterator是指向元素的双向迭代器类型。
我们可以看这段代码
void test_set4()
{std::set<int> myset;for (int i = 1; i <= 5; i++) myset.insert(i * 10); // myset: 10 20 30 40 50std::pair<std::set<int>::const_iterator, std::set<int>::const_iterator> ret;ret = myset.equal_range(35);std::cout << "the lower bound points to: " << *(ret.first) << '\n';std::cout << "the upper bound points to: " << *(ret.second)<< '\n';myset.erase(ret.first, ret.second);for (auto e : myset){cout << e << " ";}cout << endl;
}
int main()
{test_set4();return 0;
}
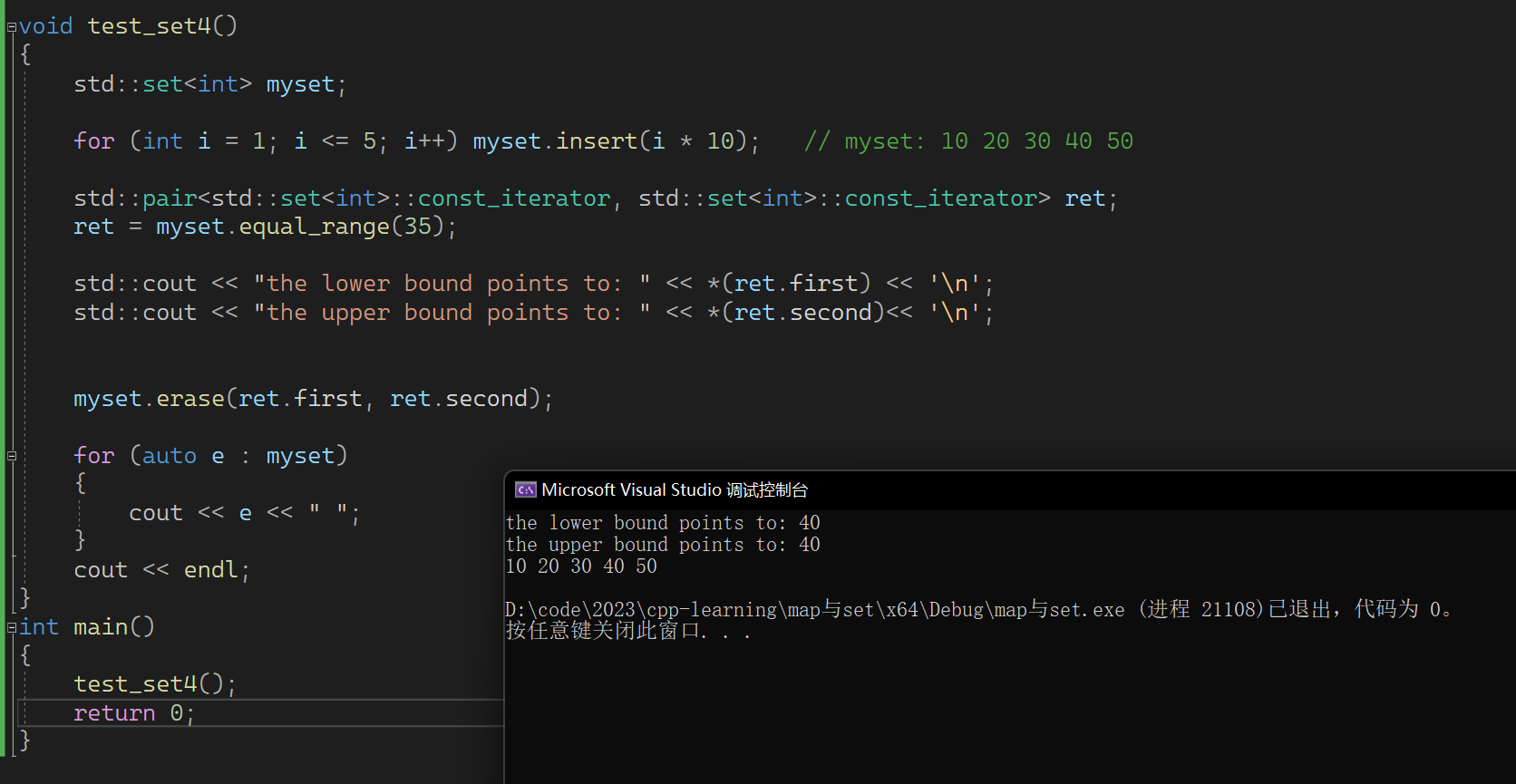
这是因为这段区间内并不存在35,所以会返回一个比他大的数值所在的区间。且这两个是相等的。
如果我们要找的是等于30的区间的话,就是这样的
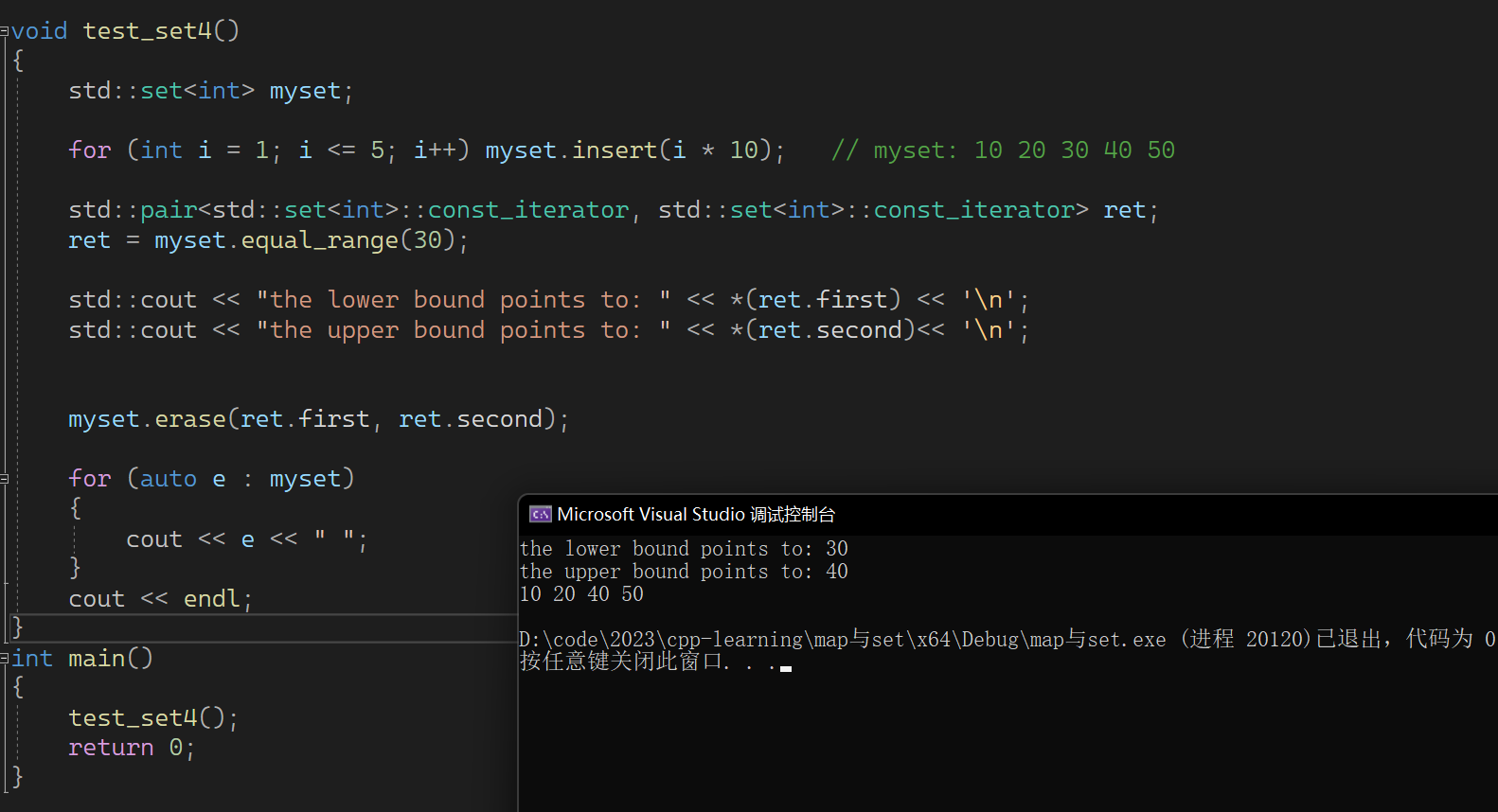
由于set里面没有重复元素,所以其实只能找到那一个元素,从这个容器的角度来看,似乎这个寻找相等区间的函数并没有什么太大的用处,还不如find呢?
其实关于这些函数,主要还是为了另外一个容器设置的
6. multiset容器
在库里面set还有一种是multiset。
这个容器是是一个允许键值冗余的一个容器,其接口和set一模一样。所以我们可以认为,刚刚的关于一些范围的容器,都是为了它而设计的
我们可以使用一下这个容器
void test_set5()
{multiset<int> s;s.insert(1);s.insert(5);s.insert(2);s.insert(2);s.insert(2);s.insert(2);s.insert(4);s.insert(4);s.insert(4);s.insert(3);multiset<int>::iterator it = s.begin();while (it != s.end()){cout << *it << " ";it++;}cout << endl;//找到的是中序的第一个2,即排序的第一个2auto pos = s.find(2);while (pos != s.end()){cout << *pos << " ";pos++;}cout << endl;cout << s.count(2) << endl;auto ret = s.equal_range(2);cout << *ret.first << " " << *ret.second << endl;s.erase(ret.first, ret.second);for (auto e : s){cout << e << " ";}cout << endl;
}
int main()
{test_set5();return 0;
}
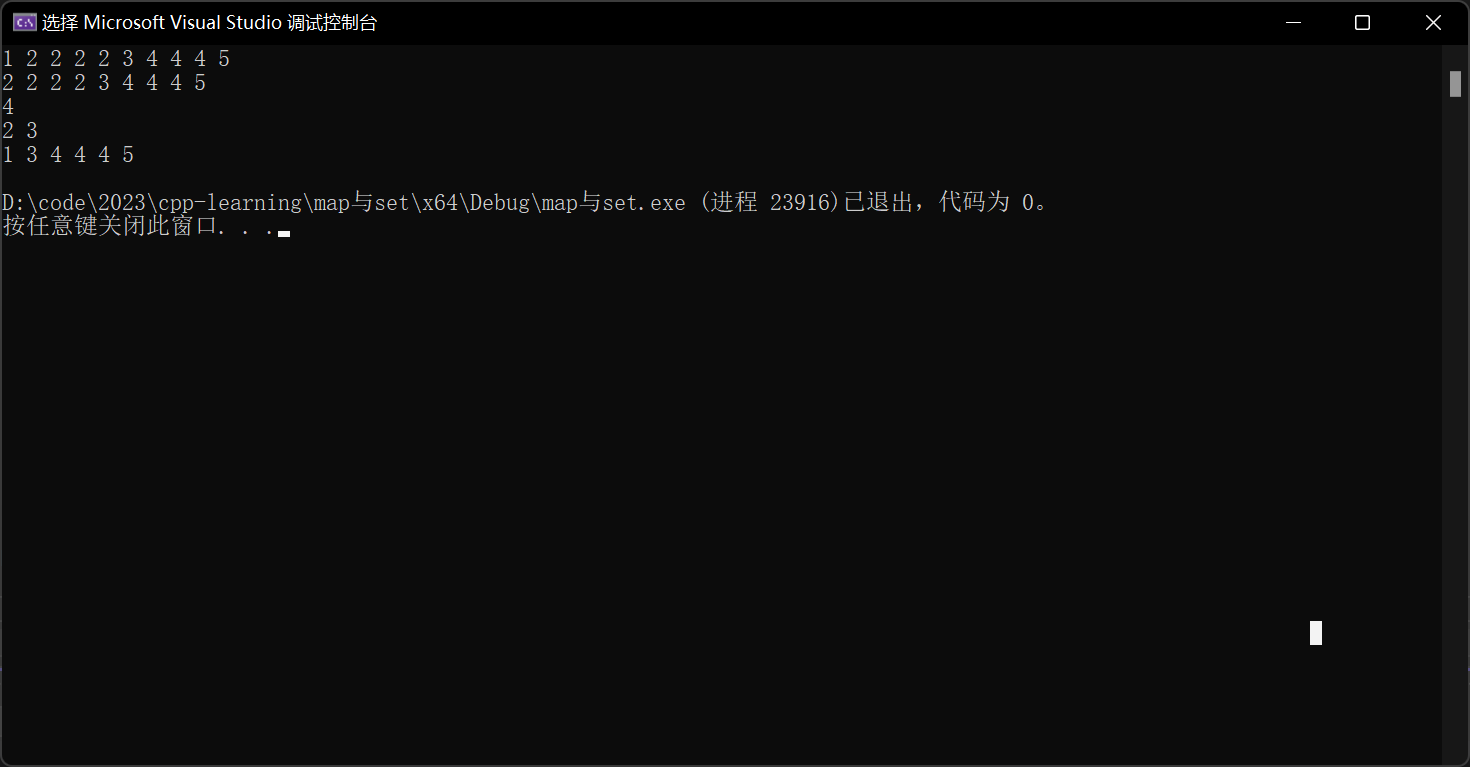
关于上面这段代码作出如下解释:
首先这个是一个允许键值冗余的容器,所以相比于set就不会进行去重了。其余的功能和set是一样的。
由于find找的是中序的第一个2,所以我们从找到的那个开始进行打印,就会将从2以后的全部打印
其次我们的count也就可以计算出2的数量了。之前的在set中的count,由于set天然的去重了,所以只能用于检测是否存在某个值,而现在的话就可以统计数量了。
然后关于我们的找某个数的范围,这个函数也就可以查找2的所有范围了。于是我们就可以删除掉2所在的区间了。
所以count和equal_range这两个函数对于multiset容器而言更有意义。
四、map
1. map的介绍
如下所示,这个容器一共有四个参数,Key和T

映射是关联容器,存储由键值和映射值按照特定顺序组合而成的元素。
在map中,键值通常用于排序和唯一标识元素,而映射值存储与该键相关联的内容。键和映射值的类型可能不同,组合在成员类型value_type中,这是一种组合了两者的pair类型:
typdef pair<const Key, T> value_type;
在内部,map中的元素总是按照键进行严格的弱排序,排序标准由内部比较对象(类型为Compare)表示。
在通过键访问各个元素时,Map容器通常比unordered_map容器慢,但它们允许根据键的顺序直接迭代子集。
映射后的值可以通过方括号运算符((operator[])直接访问。
映射通常以二叉查找树的形式实现。
这里的模板参数中,Key和T类似于key-val模型中的key和val的模板参数。这些模板类型都被define为了key_type和mapped_type。
同时还有value_type就相当于将这两个给结合到一块,放到了pair容器中。方便我们操控里面的数据,并且里面的key_type给的是const类型,这就说明了map中的key是不可以被修改的,但是value是可以被修改的

2. map的一些常见接口以及使用
首先来看下insert,这个函数有三个重载,后两个是使用迭代器区间进行插入的。第一个是直接插入一个value_type类型的数据。value_type其实就是键值对,因为他是key-val模型的.

通过插入新元素扩展容器,实际上是插入元素的数量增加了容器的大小。
因为map中元素的键是唯一的,所以插入操作会检查每个被插入元素的键是否与容器中已经存在的元素的键相等,如果相等,则不插入该元素,并返回一个指向该元素的迭代器(如果该函数有返回值)。
有关允许重复元素的类似容器,请参阅multimap。
在map中插入元素的另一种方法是使用成员函数map::operator[]。
在内部,map容器按照比较对象指定的标准对所有元素的键进行排序。元素总是按照这种顺序插入到其各自的位置。
这些参数决定了有多少个元素被插入,以及它们被初始化到哪些值
在这里我们可能会好奇的是,为什么我们插入的值必须且最好是pair类型的呢?将这两个数据连接到一起有什么好处吗?而我们在实现key-val模型的二叉搜索树的时候却不需要呢?其实这是因为我们的二叉搜索树并没有去实现迭代器。我们如果要写迭代器一定会涉及到这个迭代器的解引用问题。而此时,我们的key-val模型里面有两种数据,而c++并不支持返回多个参数,所以只能将这两个数据给合并起来从而得以实现。
对于这个函数的返回值,他返回的也是一个pair类型的对象。
如果插入的时候key已经在树里面,那么返回pair<树里面key的迭代器,false>
如果插入的时候key并未在树里面,那么返回pair<新插入key的迭代器,true>
所以insert从某种程度上也具有了查找的功能
如下代码所示,该段代码演示了我们对map里面插入数据的几种用法,我们可以直接传一个pair对象过去,也可以传pair的匿名对象,也可以使用make_pair函数来进行,当然我们可能会认为make_pair函数要通过调用一个函数来进行创建对象对否开销有点大,其实不是的,在这里编译器会直接将这个变成内联函数进行优化,实际效率相当于直接传入一个对象。除了前面三种以外,C++11还支持了多参数的构造函数隐式类型转换。所以我们可以直接使用多参数的构造函数隐式类型转换。
上面几种方式都是非常不错的,但是比较建议使用make_pair函数来创建。这个比较简洁,且有的C++编译器如果不支持C++11的话这个函数也是可以直接使用的。
在map里面我们取出的数据都是pair类型的,这是因为C++只能返回一个值,不能返回多个值。所以我们必须使用pair对象进行返回。然后C++也不支持pair的流插入和流提取,因为并没有进行重载。所以我们需要解引用后,拿到的只是一个结构体,我们还需要在访问里面的值。或者我们可以直接使用->也是很方便的。
void test_map1()
{map<string, string> dict;pair<string, string> kv1("insert", "插入");dict.insert(kv1);dict.insert(pair<string, string>("sort", "排序"));dict.insert(make_pair("remove", "改革"));dict.insert({ "process","过程" });//C++11 多参数的构造函数隐式类型转换map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << (*it).first << (*it).second << endl;cout << it->first << it->second << endl;it++;}for (const auto& e : dict){cout << e.first << " " << e.second << endl;}
}int main()
{test_map1();return 0;
}
还需要注意的是,如果插入的时候,key相同,但是val不相同,是不会插入进去的,也不会覆盖进去的。即插入过程中,只比较key。key相同就不插入了。
上面是关于map的一些插入接口,还有一些接口是删除接口。也比较常见,三种删除,分别是直接删除某个迭代器位置的删除,或者给一个key去删除,注意不是val,只需要一个key就可以删除了。第三种就是删除一个迭代器区间。
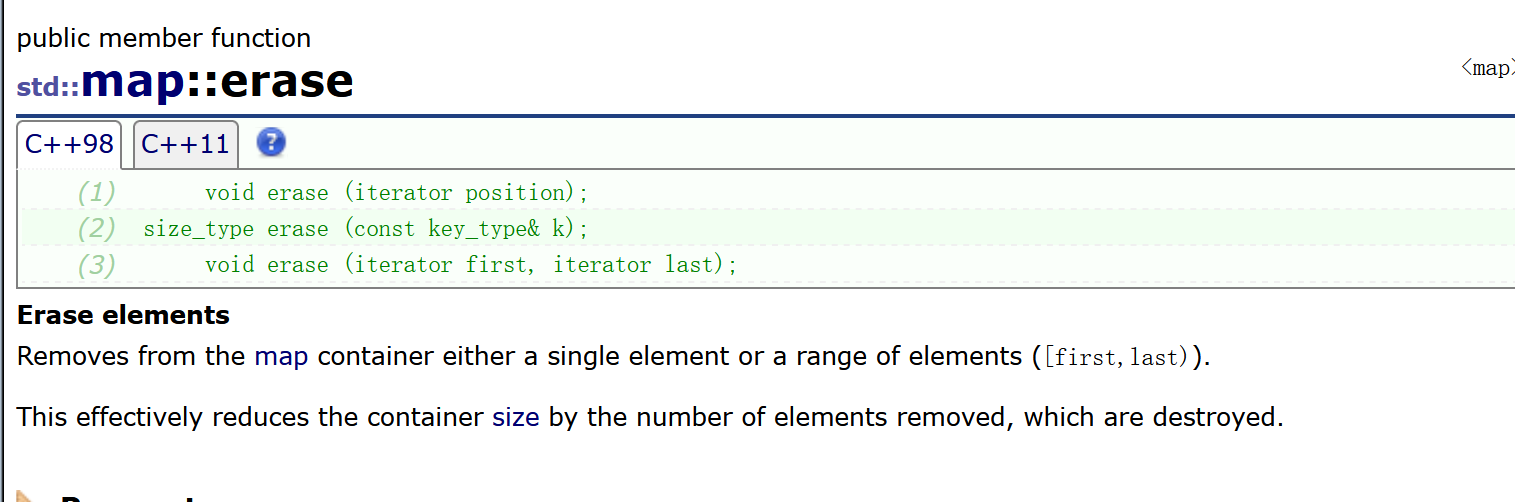
我们也可以注意到,查找和删除都只与key有关系,与其他无关。
还有如find,count这些接口也都是属于set的设计十分类似的

获取元素的迭代器
在容器中搜索键值等于k的元素,如果找到则返回到该元素的迭代器,否则返回到map::end的迭代器。 如果容器的比较对象反射返回false,则认为两个键是等效的(即,无论元素作为参数传递的顺序如何)。 另一个成员函数map::count可以用来检查特定键是否存在。
如果找到具有指定键的元素,则返回该元素的迭代器,否则返回map::end。
如果map对象是const限定的,该函数返回一个const_iterator对象。否则,它返回一个迭代器。

计算具有特定键的元素数量
在容器中搜索键等于 k 的元素,并返回匹配的数量。
由于 map 容器中的所有元素都是唯一的,因此该函数只能返回 1(如果找到元素)或 0(否则)。
如果容器的 comparison 对象反射返回 false,则认为两个键是等效的(即,无论作为参数传递的键的顺序如何)。
3. map的[]运算符重载
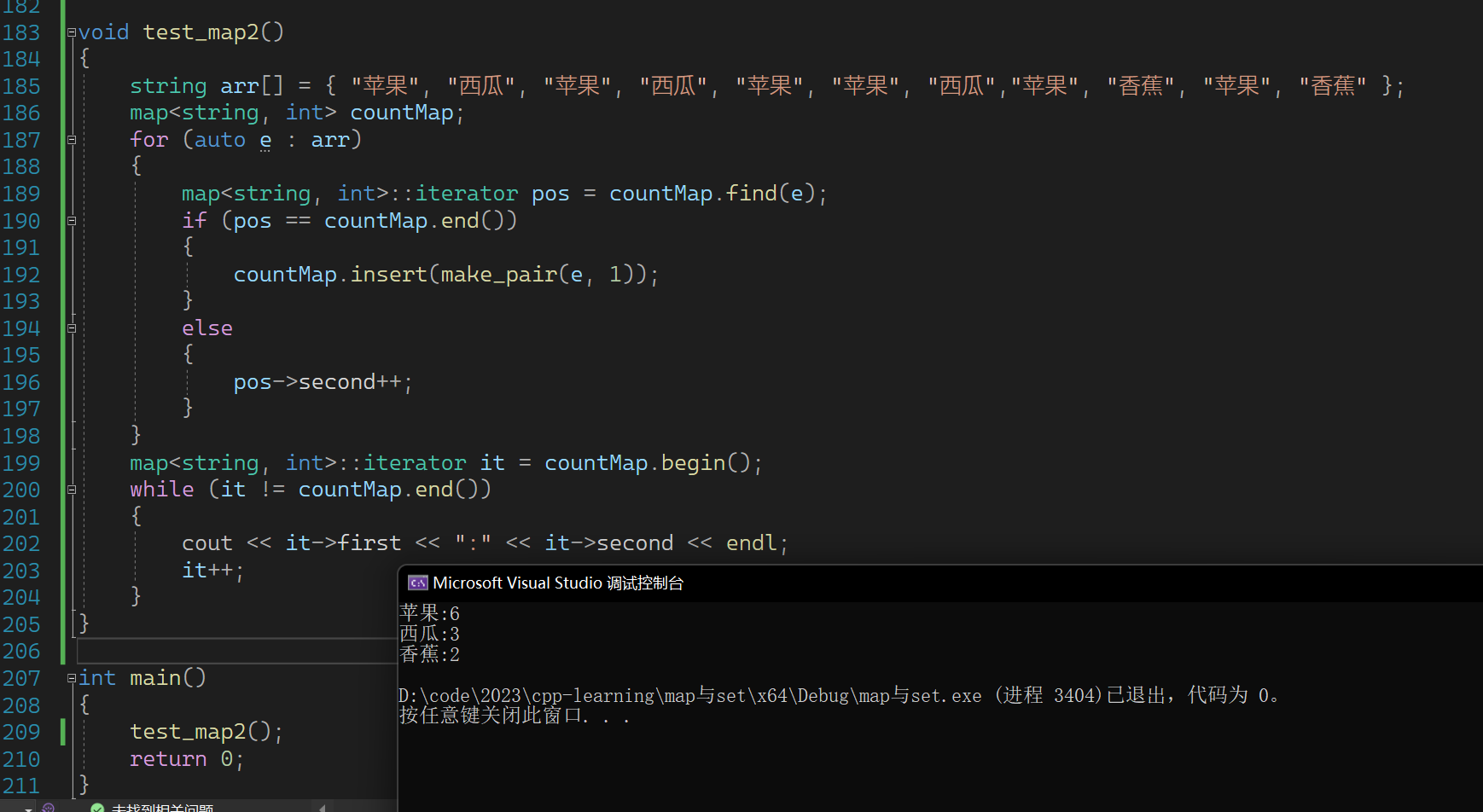
当我们使用map的insert接口和find接口的时候,我们可以来实现在之前二叉搜索树中的统计水果个数的代码。
void test_map2()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto e : arr){map<string, int>::iterator pos = countMap.find(e);if (pos == countMap.end()){countMap.insert(make_pair(e, 1));}else{pos->second++;}}map<string, int>::iterator it = countMap.begin();while (it != countMap.end()){cout << it->first << ":" << it->second << endl;it++;}
}int main()
{test_map2();return 0;
}
但是事实上我们可以将代码变得更加简洁。
我们来看一下map的[]运算符重载

访问元素
如果k与容器中某个元素的键匹配,则该函数返回对其映射值的引用。
如果k与容器中任何元素的键不匹配,则该函数用该键插入一个新元素,并返回对其映射值的引用。注意,这总是将容器的大小增加1,即使没有将映射值赋给元素(元素是使用其默认构造函数构造的)。
类似的成员函数map::at在具有键的元素存在时具有相同的行为,但在不存在时抛出异常。
调用此函数相当于:
(*((this->insert(make_pair(k,mapped_type()))).first)).second
简而言之,就是给一个key,如果这个key在map中存在,返回它的val,如果不存在,那么就创建一个pair对象插入进去,这个pair对象的first是key,pair中的second是val类型的默认构造函数。
这样我们就可以将上面代码简化为下面代码了。countMap对象中,它的两个参数是string和int,第一次的时候不存在,所以会创建一个pair<string,int>对象。int则会调用它的默认构造函数,即结果为0。然后有一个++,所以最终会将这个值给插入进去。
void test_map3()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto e : arr){countMap[e]++;}map<string, int>::iterator it = countMap.begin();while (it != countMap.end()){cout << it->first << ":" << it->second << endl;it++;}
}
int main()
{test_map3();return 0;
}
这个[]运算符重载其实就是靠插入函数实现的,因为无论插入成功与否,insert会返回一个pair对象,pair对象的first就是就是新插入进去结点或者已有结点的迭代器。然后我们直接访问这个迭代器指向的second即可。
除了上面的统计个数的场景,我们还可以试一下下面的单词翻译的场景
void test_map4()
{map<string, string> dict;pair<string, string> kv1("insert", "插入");dict.insert(kv1);dict.insert(pair<string, string>("sort", "排序"));dict.insert(make_pair("remove", "改革"));dict.insert({ "process","过程" });//C++11 多参数的构造函数隐式类型转换dict["remov"] = "xxx";dict["process"] = "进程";dict["access"] = "接受,道路";cout << (dict["set"] = "集合") << endl;for (auto e : dict){cout << e.first << " " << e.second << endl;}
}
int main()
{test_map4();return 0;
}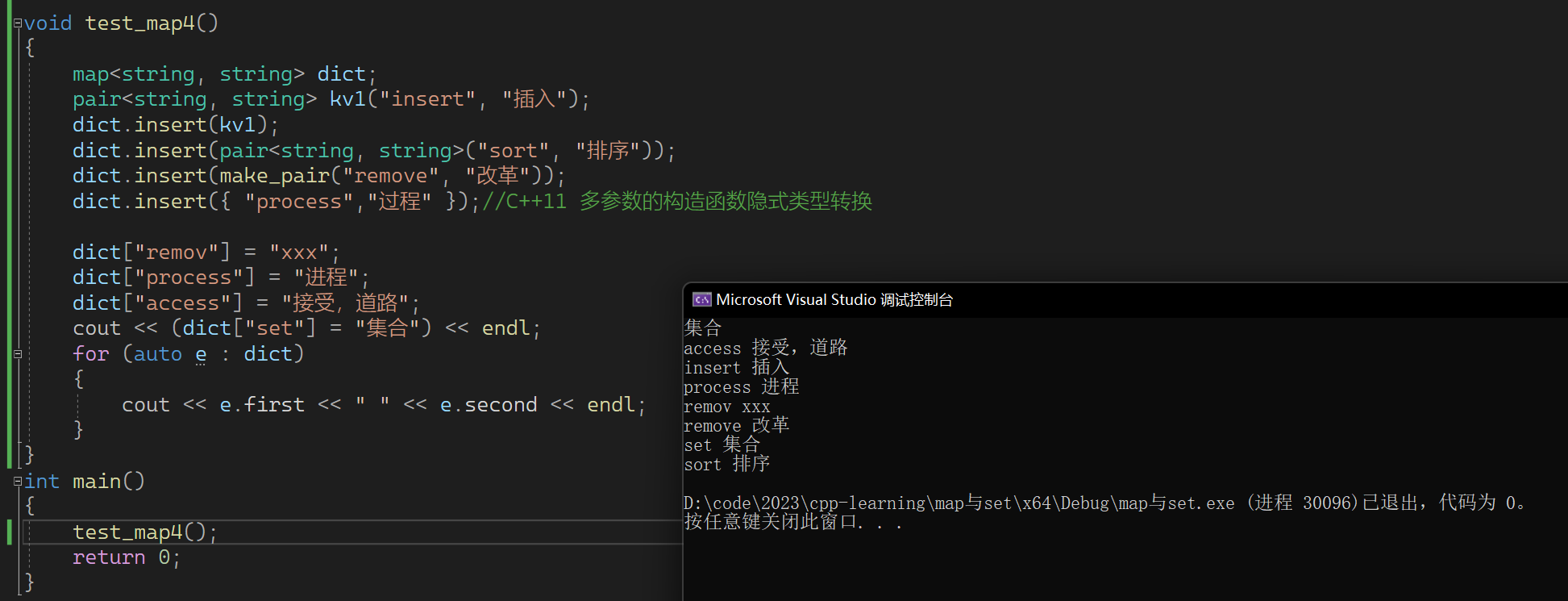
我们可以注意到,通过[]运算符重载,我们可以实现对原来的值进行修改,如果原来没有可以插入。也可以进行查找+插入等等一系列操作。
4. 使用map改进一些题
力扣链接:有效的括号
对于下面这道题,我们之前就是直接一个一个匹配,但是现在,我们已经可以使用map来进行维护了,这样的话如果还有更多的括号需要进行匹配的话只需要改变map里面存储的值即可
class Solution {
public:bool isValid(string s) {stack<char> st;map<char,char> matchMap;matchMap['('] = ')';matchMap['['] = ']';matchMap['{'] = '}';for(auto ch : s){if(matchMap.count(ch)){st.push(ch);}else{if(st.empty()){return false;}char top = st.top();st.pop();if(matchMap[top]!=ch){return false;}}}if(!st.empty())return false;elsereturn true;}
};
力扣链接:复杂链表的复制
这道题如果有了map的话,简直是太简单了。直接建立一个映射关系,然后先复制好每一个结点,然后利用[]运算符重载就可以很好的处理好每一个之间的关系。
/*
// Definition for a Node.
class Node {
public:int val;Node* next;Node* random;Node(int _val) {val = _val;next = NULL;random = NULL;}
};
*/
class Solution {
public:Node* copyRandomList(Node* head) {Node* cur = head;map<Node*,Node*> listMap;while(cur){listMap[cur] = new Node(cur->val);cur = cur->next;}cur = head;while(cur){listMap[cur]->next = listMap[cur->next];listMap[cur]->random = listMap[cur->random];cur = cur->next;}return listMap[head];}
};
5. multimap容器
这个容器与map之间的关系就好像set与multiset之间的关系一样。接口都是一样的,不同的就是这个容器允许重复元素出现
还有一共不同就是这个容器没有提供[]运算符重载了,其实也是比较合理的,因为此时一个key可以有很多个val,是没法确定要哪一个的。
insert也有一些变化,他的返回值就不在是一共pair了,里面就没有所谓的bool了,只是单纯的返回新插入结点的迭代器,因为他插入永远成功

那么既然一个key可以有多个val,我们可以注意到他是可以根据key进行删除的,那么它是全删除掉吗?确实是这样的,multimap根据一个值去删除元素会将所有与key相关的全部删除掉。
五、map和set相关力扣题
力扣链接:两个数组的交集
这道题目求的是交集,我们的思路就是利用set来完成最为方便。首先先将两个数组里面的值都丢到set里面,可以天然的去重。然后我们再去遍历这两个set。由于正好也排好序了。所以我们就如果谁小,谁就++,否则相等的话,那么就进入数组,然后两个同时++即可
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {set<int> s1(nums1.begin(),nums1.end());set<int> s2(nums2.begin(),nums2.end());vector<int> v;auto it1 = s1.begin();auto it2 = s2.begin();while(it1 != s1.end() && it2 != s2.end()){if(*it1>*it2){it2++;}else if(*it1<*it2){it1++;}else {v.push_back(*it1);it1++;it2++;}}return v;}
};
如果题目要让我们求差集的话,也是很简单的,我们还是先丢到set里面,然后进行比对,将较小的进入数组,然后++。如果相等同时++即可。因为set天然的排好序了,所以,小的一定是独一无二的,而较大的,当小的++以后,可能就会出现重复了。
力扣链接:前K个高频单词
对于这道题,我们的思路也是比较简单的,我们首先先创建一个map,然后我们将words中的所有单词给放入map中,顺便统计好次数。这样以后,map中也正好天然的按照字典序排好了。接下来我们需要对map中的数据按照频率进行排序。不过这里的排序需要注意,我们不能直接对map进行排序,因为迭代器的类型不匹配。所以我们只能将数据都放入一个vector<pair<string,int>>中进行排序。在这里还有一个大坑,首先我们要按照降序排列,所以我们会写一个仿函数,让他按照降序排,其次这里我们不能直接用sort,因为sort底层是一个快排,它是不稳定的,会将字典序顺序打乱。所以我们需要使用一个稳定的排序,库里面正好提供了这个稳定的排序stable_sort。所以这下排序之后,我们就能完成这个题目了。
class Solution {
public:struct Greater{bool operator()(const pair<string,int>& p1,const pair<string,int>& p2){return p1.second>p2.second;}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> countMap;vector<string> v;for(auto& e : words){countMap[e]++;}vector<pair<string,int>> vpa(countMap.begin(),countMap.end());stable_sort(vpa.begin(),vpa.end(),Greater()); for(int i = 0; i < k; i++){v.push_back(vpa[i].first);}return v;}
};
上面最坑人的地方莫过于sort不是稳定的排序,我们可能甚至都没用过stable_sort这个排序。那么在我们不知道的情况下,该如何处理这道题呢?事实上,我们会发现,我们的仿函数其实还可以在详细一些,我们先按频率排,当频率相等的时候,在依据字典序排列即可
class Solution {
public:struct Greater{bool operator()(const pair<string,int>& p1,const pair<string,int>& p2){return p1.second>p2.second||((p1.second==p2.second)&&(p1.first<p2.first));}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> countMap;vector<string> v;for(auto& e : words){countMap[e]++;}vector<pair<string,int>> vpa(countMap.begin(),countMap.end());sort(vpa.begin(),vpa.end(),Greater()); for(int i = 0; i < k; i++){v.push_back(vpa[i].first);}return v;}
};
在这里其实还有第三种方式可以完成这道题
如下代码所示,我们可以先将countMap以字典序排好且统计出次数之后,然后使用一个multimap<int,string,greater<int>>以频率在排一次。注意使用第三个模板参数,即仿函数,因为我们是要以频率为降序进行排序。然后最后我们依次插入vector即可
class Solution {
public:vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> countMap;vector<string> v;for(auto& e : words){countMap[e]++;}multimap<int,string,greater<int>> sMap;for(auto& e : countMap){sMap.insert(make_pair(e.second,e.first));}auto it = sMap.begin();while(k--){v.push_back(it->second);it++;}return v;}
};
总结
本节主要讲解了map与set的基本使用。希望能对大家带来帮助!
相关文章:
【C++从0到王者】第三十一站:map与set
文章目录 一、关联式容器二、pair键值对三、set1. set的介绍2. set的部分接口以及应用3. count4. lower_bound和upper_bound5. equal_range6. multiset容器 四、map1. map的介绍2. map的一些常见接口以及使用3. map的[]运算符重载4. 使用map改进一些题5. multimap容器 五、map和…...
生产消费者模型的介绍以及其的模拟实现
目录 生产者消费者模型的概念 生产者消费者模型的特点 基于阻塞队列BlockingQueue的生产者消费者模型 对基于阻塞队列BlockingQueue的生产者消费者模型的模拟实现 ConProd.c文件的整体代码 BlockQueue.h文件的整体代码 对【基于阻塞队列BlockingQueue的生产者消费者模型…...

Unity ML-Agents默认接口参数含义
下面的含义就是训练中常用的yaml文件: behaviors:waffle:trainer_type: ppo #训练器类型,默认ppo。还有sac和pocahyperparameters:batch_size: 64 # 梯度下降每次迭代的经验数。应确保该值总是比 buffer_size小几倍。 在使用连续动作的情况下&#x…...

【python数据分析基础】—pandas中loc()与iloc()的介绍与区别
文章目录 前言一、loc[]函数二、iloc[]函数三、详细用法loc方法iloc方法 总结共同点不同点 前言 我们经常在寻找数据的某行或者某列的时常用到Pandas中的两种方法iloc和loc,两种方法都接收两个参数,第一个参数是行的范围,第二个参数是列的范…...
ad18学习笔记十一:显示和隐藏网络、铺铜
如何显示和隐藏网络? Altium Designer--如何快速查看PCB网络布线_ad原理图查看某一网络的走线_辉_0527的博客-CSDN博客 AD19(Altium Designer)如何显示和隐藏网络 如何显示和隐藏铺铜? Altium Designer 20在PCB中显示或隐藏每层铺铜-百度经验 AD打开与…...
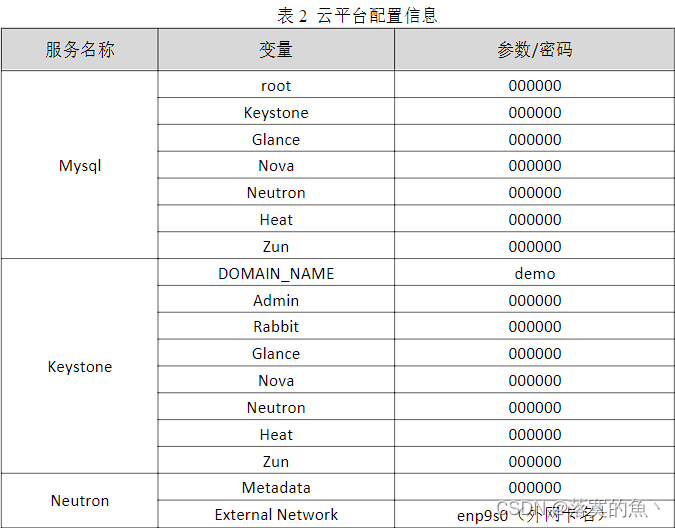
全国职业技能大赛云计算--高职组赛题卷④(私有云)
全国职业技能大赛云计算--高职组赛题卷④(私有云) 第一场次题目:OpenStack平台部署与运维任务1 基础运维任务(5分)任务3 OpenStack云平台运维(15分)任务4 OpenStack云平台运维开发(1…...

Camera Tunning ISP 模块面试总结
一.ISP的调试流程概述: 在ISP调试流程中,我们首先需要确认以下三个方面:项目需求、硬件问题确认和Sensor驱动配置确认。 项目需求方面,即Sensor需要出多大的分辨率去调效果;因为有些芯片有最大分辨率支持的限制&#x…...

AOSP源码中Android.mk文件中的反斜杠符号(\)的作用和使用
简介 在AOSP(Android Open Source Project)源码中的Android.mk文件中,反斜杠符号(\)的主要作用是将一行代码拆分成多行,以提高可读性并帮助组织较长的代码块。这对于定义复杂的构建规则和变量时特别有用。…...

如何查看mysql的存储引擎
要查看MySQL中的存储引擎,可以使用以下两种方法: 1. 使用 SQL 查询: 您可以使用SQL查询来查看MySQL中的存储引擎。打开MySQL客户端,并连接到您的MySQL服务器,然后运行以下SQL查询: SHOW TABLE STATUS;这…...

FPGA project : dht11 温湿度传感器
没有硬件,过几天上板测试。 module dht11(input wire sys_clk ,input wire sys_rst_n ,input wire key ,inout wire dht11 ,output wire ds ,output wire …...

std::string和QString的区别以及互转
一 区别 1.字符编码支持 std::string:默认情况下,使用 ASCII 或 UTF-8 编码。不直接提供对多字节字符的内置支持。 QString:提供对多种字符编码的支持,包括 ASCII、UTF-8、UTF-16 等。它更适合处理国际化和本地化的字符串。 2.…...
python+vue理发店管理系统
理发店管理系统主要实现角色有管理员和会员,管理员在后台管理用户表模块、token表模块、收藏表模块、商品分类模块、热卖商品模块、活动公告模块、留言反馈模块、理发师模块、会员卡模块、会员充值模块、会员模块、服务预约模块、服务项目模块、服务类别模块、热卖商品评论表模…...
基于微信小程序的个人健康管理系统的设计与实现(源码+lw+部署文档+讲解等)
前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 👇🏻…...

共聚焦显微镜在化学机械抛光课题研究中的应用
两个物体表面相互接触即会产生相互作用力,研究具有相对运动的相互作用表面间的摩擦、润滑与磨损及其三者之间关系即为摩擦学,目前摩擦学已涵盖了化学机械抛光、生物摩擦、流体摩擦等多个细分研究方向,其研究的数值量级也涵盖了亚纳米到百微米…...
本地Linux 部署 Dashy 并远程访问
文章目录 简介1. 安装Dashy2. 安装cpolar3.配置公网访问地址4. 固定域名访问 转载自cpolar极点云文章:本地Linux 部署 Dashy 并远程访问 简介 Dashy 是一个开源的自托管的导航页配置服务,具有易于使用的可视化编辑器、状态检查、小工具和主题等功能。你…...
)
互联网摸鱼日报(2023-09-18)
互联网摸鱼日报(2023-09-18) 36氪新闻 最前线 | 号外电摩12.68万元起订,配16.9度一体压铸电池包 本周双碳大事:CCER交易管理办法获生态环境部原则通过;明阳斥资100亿元加码光伏项目;“全路程”获2亿元D轮融资 200亿,…...

Kotlin中函数的基本用法以及函数类型
函数的基本用法 1、函数的基本格式 2、函数的缺省值 可以为函数设置指定的初始值,而不必要传入值 private fun fix(name: String,age: Int 2){println(name age) }fun main(args: Array<String>) {fix("张三") }输出结果为:张三2 …...

在macOS使用VMware踩过的坑
目录 MAC提示将对您的电脑造成伤害/MAC OS 升级到10.15.3后vmware虚拟机黑屏 mac系统下,vm虚拟机提示打不开/dev/vmmon mac VMware Workstation 在此主机上不支持嵌套虚拟化 mac VMware清理虚拟机空间 MAC提示将对您的电脑造成伤害/MAC OS 升级到…...

构建健壮的Spring MVC应用:JSON响应与异常处理
目录 1. 引言 2. JSON 1. 轻量级和可读性 2. 易于编写和解析 3. 自描述性 4. 支持多种数据类型 5. 平台无关性 6. 易于集成 7. 社区支持和标准化 3. 高效处理异常 综合案例 异常处理方式一 异常处理方式二 异常处理方式三 1. 引言 探讨Spring MVC中关键的JSON数据…...

那些配置服务器踩的坑
最近在配置内网,无外网的服务器,纯纯记录一下踩得坑,希望看到的人不要再走这条弯路。 ------------------------------------------------------------------------------------------------------------------------------- 任务ÿ…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...