【Hadoop】HDFS API 操作大全

🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
🍁🪁🍁 🪁🍁🪁🍁感谢点赞和关注 ,每天进步一点点!加油!🍁🪁🍁 🪁🍁🪁🍁
目录
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
一、FileSystem文件抽象类
1.1文件读取API
1.2文件操作API
1.3抽象FileSystem类的具体实现子类
1.4FileSystem IO输入系统相关类
1.5FileSystem IO输出系统相关类
二、HDFS的API操作
2.1测试集群版本信息
2.2文件上传下载和移动
2.3文件读写操作
2.4文件状态信息获取
2.5实战案例
一、FileSystem文件抽象类
为了提供对不同数据访问的一致接口,Hadoop借鉴了Linux虚拟文件系统的概念,为此Hadopo提供了一个抽象的文件系统模型FileSystem,HDFS 是其中的一个实现。
FileSystem是Hadoop中所有文件系统的抽象父类,它定义了文件系统所具有的基本特征和基本操作。
1.1文件读取API
| HadoopFileSystem操作 | Java操作 | Linux操作 | 描述 |
| URL.openStream FileSystem.open FileSystem.create FileSystem.append | URL.openStream | open | 打开一个文件 |
| FSDataInputStream.read | InputStream.read | read | 读取文件中的数据 |
| FSDataInputStream.write | OutputStream.write | write | 向文件中写入数据 |
| FSDataInputStream.close FSDataOutputStream.close | InputStream.close OutputStream.close | close | 关闭一个文件 |
| FSDataInputStream.seek | RandomAccessFile.seek | lseek | 改变文件读写位置 |
| FileSystem.getContentSummary | du/wc | 获取文件存储信息 |
1.2文件操作API
| HadoopFileSystem操作 | Java操作 | Linux操作 | 描述 |
| FileSystem.getFileStatus FileSystem.get* | File.get* | stat | 获取文件/目录的属性 |
| FileSystem.set* | File.set* | chomd | 修改文件属性 |
| FileSystem.createNewFile | File.createNewFile | create | 创建一个文件 |
| FileSystem.delete | File.delete | remove | 删除一个文件 |
| FileSystem.rename | File.renameTo | rename | 移动或先修改文件/目录名 |
| FileSystem.mkdirs | File.mkdir | mkdir | 创建目录 |
| FileSystem.delete | File.delete | rmdir | 从一个目录下删除一个子目录 |
| FileSystem.listStatus | File.list | readdir | 读取一个目录下的项目 |
| FileSystem.setWorkingDirectory | getcwd/getwd | 返回当前工作目录 | |
| FileSystem.setWorkingDirectory | chdir | 更改当前的工作目录 |
1.3抽象FileSystem类的具体实现子类

1.4FileSystem IO输入系统相关类
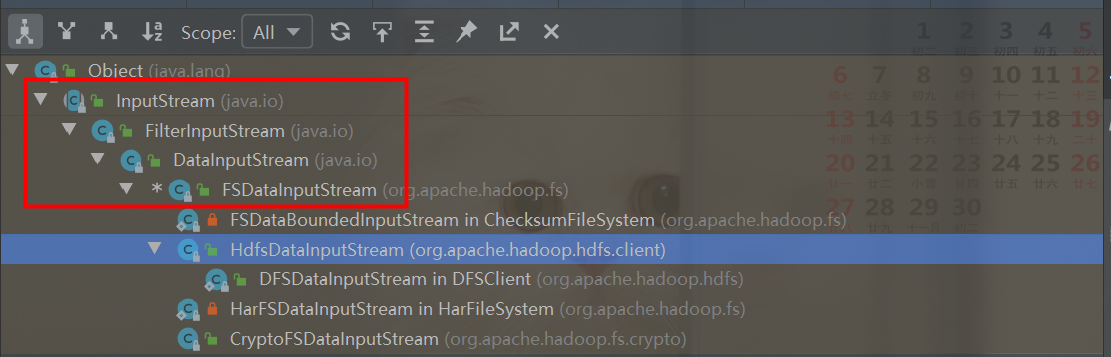
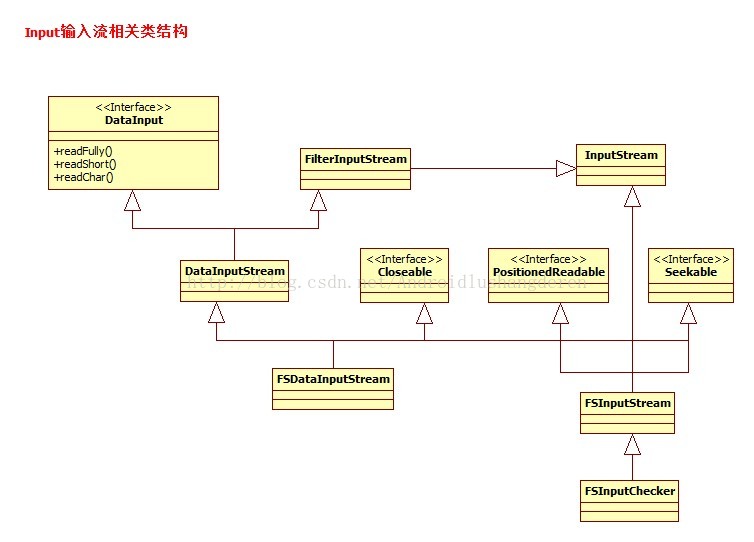
1.5FileSystem IO输出系统相关类
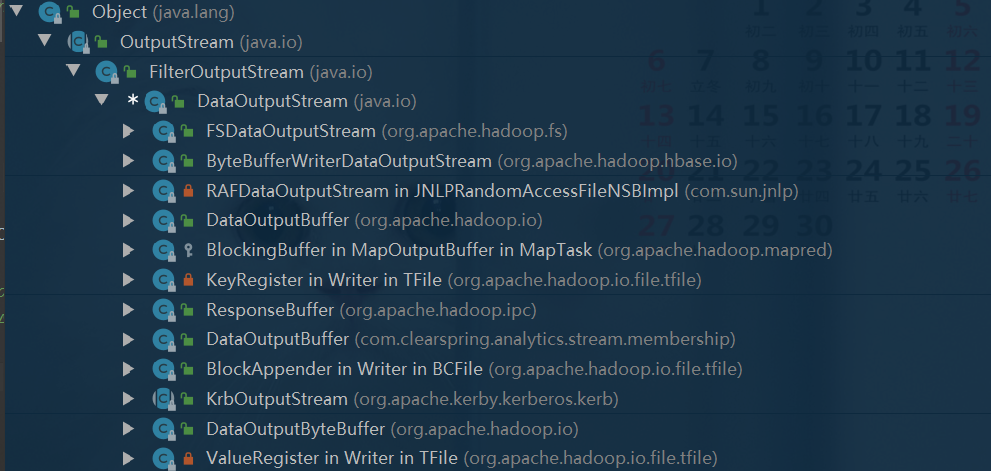

二、HDFS的API操作
2.1测试集群版本信息
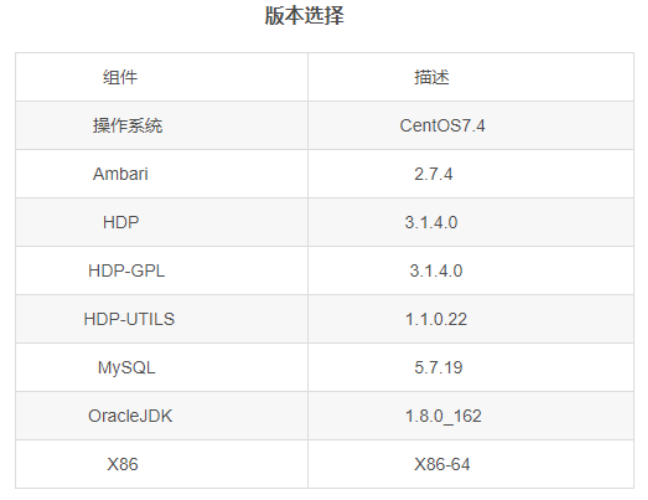
2.2文件上传下载和移动
/*** 本地文件上传到 HDFS** @param srcPath 本地路径 + 文件名* @param dstPath Hadoop路径* @param fileName 文件名*/
def copyToHDFS(srcPath: String, dstPath: String, fileName: String): Boolean = {var path = new Path(dstPath)val fileSystem: FileSystem = path.getFileSystem(conf)val isFile = new File(srcPath).isFile// 判断路径是否存在val existDstPath: Boolean = fileSystem.exists(path)if (!existDstPath) {fileSystem.mkdirs(path)}// 本地文件存在if (isFile) {// HDFS 采用 路径+ 文件名path = new Path(dstPath + File.separator + fileName)// false: 是否删除 目标文件,false: 不覆盖fileSystem.copyFromLocalFile(false, false, new Path(srcPath), path)return true}false
}/*** Hadoop文件下载到本地** @param srcPath hadoop 源文件* @param dstPath 目标文件* @param fs 文件访问对象*/
def downLoadFromHDFS(srcPath: String, dstPath: String, fs: FileSystem): Unit = {val srcPathHDFS = new Path(srcPath)val dstPathLocal = new Path(dstPath)// false: 不删除源文件fs.copyToLocalFile(false, srcPathHDFS, dstPathLocal)
}/*** 检查Hadoop文件是否存在并删除** @param path HDFS文件*/
def checkFileAndDelete(path: String, fs: FileSystem) = {val dstPath: Path = new Path(path)if (fs.exists(dstPath)) {// false: 是否递归删除,否fs.delete(dstPath, false)}
}/*** 获取指定目录下,正则匹配后的文件列表** @param dirPath hdfs路径* @param regexRule 正则表达式 ,如:"^(?!.*[.]tmp$).*$" ,匹配非 .tmp结尾的文件*/def listStatusHDFS(dirPath: String, regexRule: String, fs: FileSystem): util.ArrayList[Path] = {val path = new Path(dirPath)val pattern: Pattern = Pattern.compile(regexRule)// 匹配的文件val fileList = new util.ArrayList[Path]()val fileStatusArray: Array[FileStatus] = fs.listStatus(path)for (fileStatus <- fileStatusArray) {// 文件 全路径val filePath: Path = fileStatus.getPath()val fileName: String = filePath.getName.toLowerCaseif (regexRule.equals("")) {// 如果匹配规则为空 则获取目录下的全部文件fileList.add(filePath)log.info("match file : " + fileName)} else {// 正则匹配文件if (pattern.matcher(fileName).matches()) {fileList.add(filePath)log.info("match file : " + fileName)}}}fileList
}/*** 文件移动或重命名到指定目录, 如:文件00000 重命名为00001** @param srcPath 源文件路径* @param dstPath 源文件路径* @param fs 文件操作对象*/
def renameToHDFS(srcPath: String, dstPath: String, fs: FileSystem): Boolean = {var renameFlag = falseval targetPath = new Path(dstPath)// 目标文件存在先删除if (fs.exists(targetPath)) {fs.delete(targetPath, false)}renameFlag = fs.rename(new Path(srcPath), targetPath)if (renameFlag) {log.info("renamed file " + srcPath + " to " + targetPath + " success!")} else {log.info("renamed file " + srcPath + " to " + targetPath + " failed!")}renameFlag
}2.3文件读写操作
Hadoop抽象文件系统也是使用流机制进行文件的读写。Hadoop抽象文件系统中,用于读文件数据的流是FSDataInputStream,对应地,写文件通过抽象类FSDataOutputStream实现。
/*** 读取HDFS文件** @param inPutFilePath 源文件路径* @param fs 文件操作对象*/
def readFromHDFS(inPutFilePath: String, OutputFilePath: String, fs: FileSystem) = {var fSDataInputStream: FSDataInputStream = nullvar bufferedReader: BufferedReader = nullval srcPath = new Path(inPutFilePath)if (fs.exists(srcPath)) {val fileStatuses: Array[FileStatus] = fs.listStatus(srcPath)for (fileStatus <- fileStatuses) {val filePath: Path = fileStatus.getPath// 判断文件大小if (fs.getContentSummary(filePath).getLength > 0) {fSDataInputStream = fs.open(filePath)bufferedReader = new BufferedReader(new InputStreamReader(fSDataInputStream))var line = bufferedReader.readLine()while (line != null) {print(line + "\n") // 打印line = bufferedReader.readLine()}}}}fSDataInputStream.close()bufferedReader.close()
}/*** 读取HDFS文件, 处理完成 重新写入** @param inPutFilePath 源文件路径* @param OutputFilePath 输出文件到新路径* @param fs 文件操作对象*/
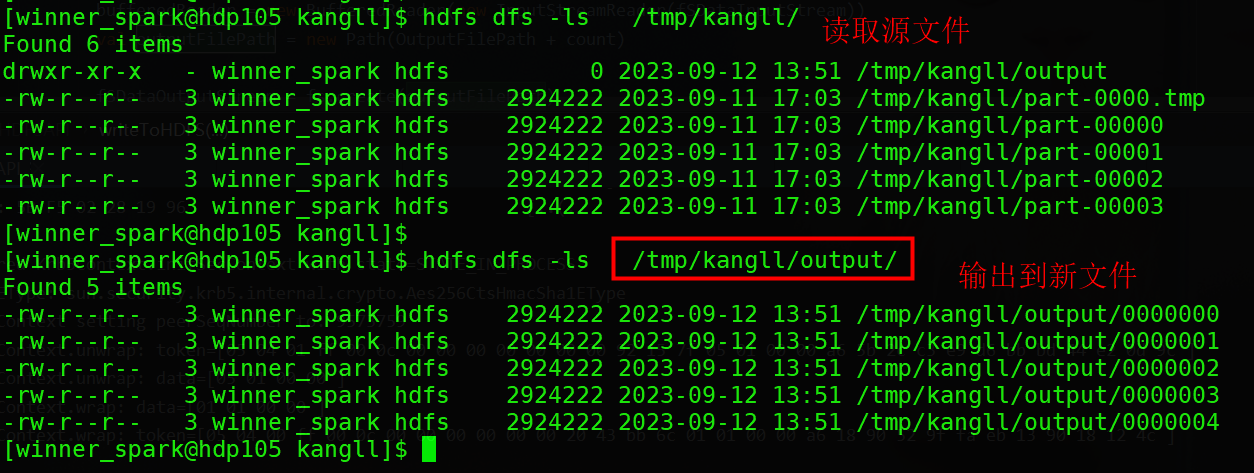
def writeToHDFS(inPutFilePath: String, OutputFilePath: String, fs: FileSystem) = {var fSDataInputStream: FSDataInputStream = nullvar fSDataOutputStream: FSDataOutputStream = nullvar bufferedReader: BufferedReader = nullvar bufferedWriter: BufferedWriter = nullval srcPath = new Path(inPutFilePath)var count = 0if (fs.exists(srcPath)) {val fileStatuses: Array[FileStatus] = fs.listStatus(srcPath)for (fileStatus <- fileStatuses) {val filePath: Path = fileStatus.getPath// 判断文件大小if (fs.getContentSummary(filePath).getLength > 0) {fSDataInputStream = fs.open(filePath)bufferedReader = new BufferedReader(new InputStreamReader(fSDataInputStream))val outputFilePath = new Path(OutputFilePath + count)fSDataOutputStream = fs.create(outputFilePath)bufferedWriter = new BufferedWriter(new OutputStreamWriter(fSDataOutputStream, "UTF-8"))var line = bufferedReader.readLine()while (line != null) {val bytes: Array[Byte] = line.getBytes("UTF-8")bufferedWriter.write(new String(bytes) + "\n")line = bufferedReader.readLine()}bufferedWriter.flush()count += 1}}}fSDataInputStream.close()bufferedReader.close()bufferedWriter.close()
}测试结果如下:
2.4文件状态信息获取
FileSystem. getContentSummary()提供了类似Linux命令du、df提供的功能。du表示"disk usage",它会报告特定的文件和每个子目录所使用的磁盘空间大小;命令df则是"diskfree"的缩写,用于显示文件系统上已用的和可用的磁盘空间的大小。du、df是Linux中查看磁盘和文件系统状态的重要工具。
getContentSummary()方法的输入是一个文件或目录的路径,输出是该文件或目录的一些存储空间信息,这些信息定义在ContentSummary,包括文件大小、文件数、目录数、文件配额,已使用空间和已使用文件配额等。
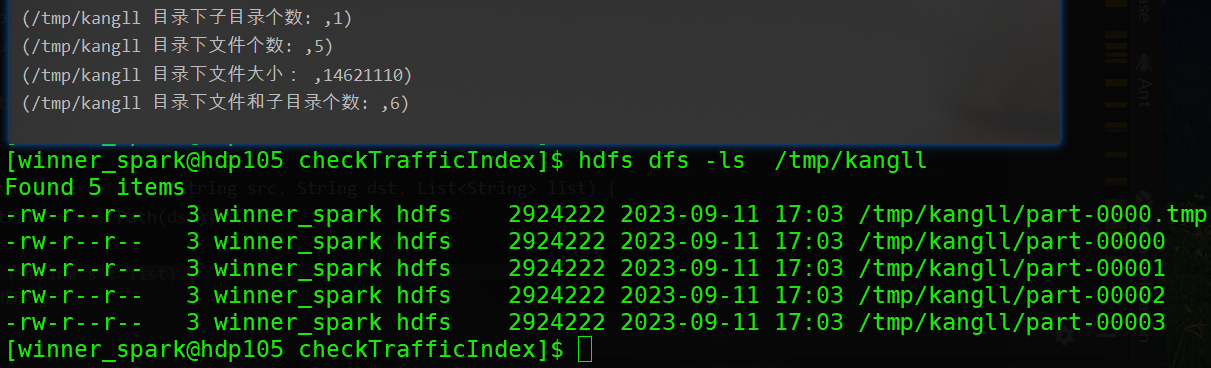
/*** HDFS路径下文件信息统计** @param dirPath hdfs路径**/def listHDFSStatus(dirPath: String, fs: FileSystem) = {val path = new Path(dirPath)// 匹配的文件val contentSummary: ContentSummary = fs.getContentSummary(path)println("/tmp/kangll 目录下子目录个数: ", contentSummary.getDirectoryCount)println("/tmp/kangll 目录下文件个数: ", contentSummary.getFileCount)println("/tmp/kangll 目录下文件大小: ", contentSummary.getLength)println("/tmp/kangll 目录下文件和子目录个数: ", contentSummary.getFileAndDirectoryCount)}
/tmp/kangll目录信息获取结果:
2.5实战案例
案例说明: HDFS 文件清理, 根据文件大小、个数、程序休眠时间控制 匀速 批量删除 HDFS 文件,当文件越大 ,需要配置 删除个数更少,休眠时间更长,防止 NameNode 负载过大,减轻DataNode磁盘读写压力,从而不影响线上业务情况下清理过期数据。
package com.kangll.common.utilsimport java.text.SimpleDateFormat
import java.util.concurrent.TimeUnit
import java.util.{Calendar, Date, Properties}
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{ContentSummary, FileStatus, FileSystem, Path}
import org.apache.log4j.Loggerimport scala.collection.mutable.ListBuffer/** ***************************************************************************************** @auther kangll * @date 2023/09/12 12:10 * @desc HDFS 文件清理, 根据文件大小、个数、程序休眠时间控制 匀速 批量删除* HDFS 文件,当文件越大 ,需要配置 删除个数更少,休眠时间更长,防止* NameNode 负载过大,减轻DataNode磁盘读写压力,从而不影响线上业务下删除*** 1.遍历文件夹下的文件个数据, 当遍历的文件夹下的文件个数到达阈值时 将* 文件所述的 父路径直接删除** ****************************************************************************************/
object CleanHDFSFileUtil {// 删除文件总数统计var HDFS_FILE_SUM = 0// 批次删除文件个数显示var HDFS_FILE_BATCH_DEL_NUM = 0val start = System.currentTimeMillis()/**** @param fs 文件操作对象* @param pathName 文件根路径* @param fileList 批次清理的 buffer* @param saveDay 根据文件属性 获取文件创建时间 选择文件保留最近的天数* @param sleepTime 休眠时间,防止一次性删除太多文件 导致 datanode 文件负载太大* @param fileBatchCount 批次删除文件的个数, 相当于是 上报到 namenode 文件清理队列的大小,参数越大 队列越大,datanode 磁盘负载相对来说就高* @return*/def listPath(fs: FileSystem, pathName: String, fileList: ListBuffer[String], saveDay: Int, sleepTime: Long, fileBatchCount: Int): ListBuffer[String] = {val fm = new SimpleDateFormat("yyyy-MM-dd")// 获取当前时间val currentDay = fm.format(new Date())val dnow = fm.parse(currentDay)val call = Calendar.getInstance()call.setTime(dnow)call.add(Calendar.DATE, -saveDay)// 获取保留天前的时期val saveDayDate = call.getTime// 遍历文件val fileStatuses = fs.listStatus(new Path(pathName))for (status <- fileStatuses) {// 获取到文件名val filePath = status.getPathif (status.isFile) {// 获取到文件修改时间val time: Long = status.getModificationTimeval hdfsFileDate = fm.parse(fm.format(new Date(time)))if (saveDayDate.after(hdfsFileDate)) {fileList += filePath.toString// 获取文件个数val cs: ContentSummary = fs.getContentSummary(filePath)HDFS_FILE_SUM += cs.getFileCount.toIntHDFS_FILE_BATCH_DEL_NUM += cs.getFileCount.toIntif (HDFS_FILE_BATCH_DEL_NUM >= fileBatchCount) {val end = System.currentTimeMillis()println("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")println("++++++++++++++++ 遍历文件数量达到 " + HDFS_FILE_BATCH_DEL_NUM + " 个,删除HDFS文件 ++++++++++++++++")println("++++++++++++++++++++++++++++ 休眠 " + sleepTime + " S ++++++++++++++++++++++++++++")println("++++++++++++++++++++++++ 删除文件总数:" + HDFS_FILE_SUM + " ++++++++++++++++++++++++++")println("++++++++++++++++++++++++ 程序运行时间:" + (end - start) / 1000 + " s ++++++++++++++++++++++++")println("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")HDFS_FILE_BATCH_DEL_NUM = 0TimeUnit.MILLISECONDS.sleep(sleepTime)}// 文件删除根据绝对路径删除println("+++++ 删除文件: " + filePath + "+++++")// 递归删除fs.delete(filePath, true)}} else {// 递归文件夹listPath(fs, filePath.toString, fileList, saveDay, sleepTime, fileBatchCount)}}println("+++++++++++++++++++++++++ 删除文件总数:" + HDFS_FILE_SUM + " +++++++++++++++++++++++++")fileList}/*** 删除空文件夹** @param fs 文件操作对象* @param pathName 路径* @param pathSplitLength 文件按照"/"拆分后的长度*/def delEmptyDirectory(fs: FileSystem, pathName: String, pathSplitLength: Int) = {// 遍历文件val fileStatuses = fs.listStatus(new Path(pathName))for (status <- fileStatuses) {if (status.isDirectory) {val path: Path = status.getPath// /kangll/winhadoop/temp/wmall_batch_inout/day/1660878372 = 7val delPathSplitLength = path.toString.substring(6, path.toString.length).split("/").length// filePath /kangll/winhadoop/temp/wmall_batch_inout/day 子时间戳文件夹两个// val hdfsPathListCount = fileStatuses.lengthval hdfsPathListCount = fs.listStatus(path).lengthif (delPathSplitLength == pathSplitLength && hdfsPathListCount == 0) {println("+++++++++++++++++ 删除空文件夹 : " + path + " +++++++++++++++++++")fs.delete(path, true)}}}}def main(args: Array[String]): Unit = {val logger = Logger.getLogger("CleanHDFSFileUtil")val conf = new Configuration()conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem")conf.set("fs.file.impl", "org.apache.hadoop.fs.LocalFileSystem")val fs = FileSystem.get(conf)val fileList = new ListBuffer[String]val hdfsDir = if (args.size > 0) args(0).toString else System.exit(0).toStringval saveDay = if (args.size > 1) args(1).toInt else 2val sleepTime = if (args.size > 2) args(2).toLong else 10val fileBatchCount = if (args.size > 3) args(3).toInt else 5/*默认不启用文件夹删除,参数为 文件夹绝对路径Split后的数组长度如 路径 /winhadoop/temp/wmall_batch_inout/thirty" 配置为 7*/val pathSplitLength = if (args.size > 4) args(4).toInt else 20// 删除文件listPath(fs, hdfsDir, fileList, saveDay, sleepTime, fileBatchCount)// 删除空文件夹delEmptyDirectory(fs, hdfsDir, pathSplitLength)fs.close()}
}
调用脚本
#
# 脚本功能: 过期文件清理
# 作 者: kangll
# 创建时间: 2023-09-14
# 修改内容: 控制删除文件的批次个数,程序休眠时间传入
# 当前版本: 1.0v
# 调度周期: 一天一次
# 脚本参数: 删除文件夹、文件保留天数、程序休眠时间、批次删除个数
# 1.文件根路径,子文件夹递归遍历
# 2.文件保留天数
# 3.程序休眠时间 防止 DataNode 删除文件负载过大,单位 秒
# 4.批次删除文件个数 ,如配置 100,当满足文件个数100时, 整批执行 delete,紧接着程序休眠
# 5.默认不启用文件夹删除,也就是不传参,参数为 文件夹绝对路径Split后的数组长度
# /winhadoop/temp/wmall_batch_inout/thirty/时间戳/ Split后 长度为7,默认删除时间戳文件夹
#### 对应的新删除程序
jarPath=/hadoop/project/del_spark2-1.0-SNAPSHOT.jar### 集群日志
java -classpath $jarPath com.kangll.common.utils.CleanHDFSFileUtil /spark2-history 3 10 100
参考 :
hadoop抽象文件系统filesystem框架介绍_org.apache.hadoop.fs.filesystem_souy_c的博客-CSDN博客
Hadoop FileSystem文件系统的概要学习 - 回眸,境界 - 博客园
hadoop抽象文件系统filesystem框架介绍_org.apache.hadoop.fs.filesystem_souy_c的博客-CSDN博客
相关文章:
【Hadoop】HDFS API 操作大全
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的帮助…...
Webpack打包图片
一、在js文件中引入图片 二、在package.config.js中配置加载器 module.exports {mode: "production", // 设置打包的模式:production生产模式 development开发模式module: {rules: [// 配置img加载器{test: /\.(jpg|png|gif)$/i,type:"asset/resou…...

DipC 构建基因组 3D 结构(学习笔记)
背景 本文主要记录了 DipC 数据的复现过程、学习笔记及注意事项。 目录 下载 SRA 数据使用 SRA Toolkit 转换 SRA 数据为 Fastq 格式使用 bwa 比对测序数据使用 Hickit 计算样本的基因组 3D 结构使用散点图展示 3D 结构计算 3D 结构重复模拟的稳定性其他 步骤 1. 下载 SRA…...

Qt中音频的使用
对于音频我们在使用的过程中一般是录制音频、播放音频。针对这两个需求介绍Qt中音频的使用。 Qt中音频的录制 步骤: 1、获取系统中的音频设备。 2、创建QAudioRecorder对象,指定使用的音频设备,通过QAudioRecorder的setAudioInput函数设置…...

[centos]centos7源码编译cmake报错Could NOT find OpenSSL
测试环境: centos7.9 cmake3.25.0 ./bootstrap以后报错如下: Could NOT find OpenSSL, try to set the path to OpenSSL root folder in the system variable OPENSSL_ROOT_DIR (missing: OPENSSL_CRYPTO_LIBRARY OPENSSL_INCLUDE_DIR) CMake Error …...
vue若依前端项目搭建
1.项目搭建 首先进入到你需要创建的项目目录下面,然后输入命令vue create .创建项目 接下来选择手动搭建,然后把下面图片中的内容选上 再然后继续配置一些参数信息 接下来运行npm run serve项目就启动起来了 2.配置登录界面文件 首先修改src/router…...
基于win32实现TB登陆滑动验证
这里写目录标题 滑动验证触发条件:失败条件:解决方法:清除cooKie 滑动验证方式一:win32 api获取窗口句柄,选择固定位置 成功率高方式二: 原自动化滑动,成功率中 案例 先谈理论,淘宝 taobao.com …...

vue学习-07todoList案例与浏览器本地存储
TodoList Todo List(任务列表)是一个简单的Web应用程序示例,用于管理任务、代办事项或清单。Vue.js 是一个非常适合构建这种类型应用程序的框架,因为它提供了数据绑定、组件化、响应式和轻松管理用户界面的能力。 以下是一个基本…...

探索智能应用的基石:多模态大模型赋能文档图像处理
目录 0 写在前面1 文档图像分析新重点2 token荒:电子文档助力大模型3 大模型赋能智能文档分析4 文档图像大模型应用可能性4.1 专有大模型4.2 多模态模型4.3 设计思路 总结 0 写在前面 中国智能产业高峰论坛(CIIS2023)旨在为政企研学各界学者专家提供同台交流的机会…...

自动化发布npm包小记
1.注册npm账号 打开npm官网,并注册自己的npm账号 2.申请AccessToken 1.登录npm官网,登录成功后,点开右上角头像,并点击Access Tokens选项 2.点开Generate New Token下拉框,点击Classic Token(和Granular Access To…...
详解机器视觉性能指标相关概念——混淆矩阵、IoU、ROC曲线、mAP等
目录 0. 前言 1. 图像分类性能指标 1.1 混淆矩阵(Confusion Matrix) 1.2 准确率(Precision) 1.3 召回率(Recall) 1.4 F1值(F1 score) 1.5 ROC曲线(接收者工作特征曲线,Receiver Operating Characteristic curve) 1.6 mAP(mean Average Precision) 2. 图像分…...
想要精通算法和SQL的成长之路 - 预测赢家
想要精通算法和SQL的成长之路 - 预测赢家 前言一. 预测赢家二. 石子游戏(预测赢家的进阶版)2.1 博弈论 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 预测赢家 原题链接 主要思路: 我们定义dp[i][j]:在区间 [i, j] 之间先…...
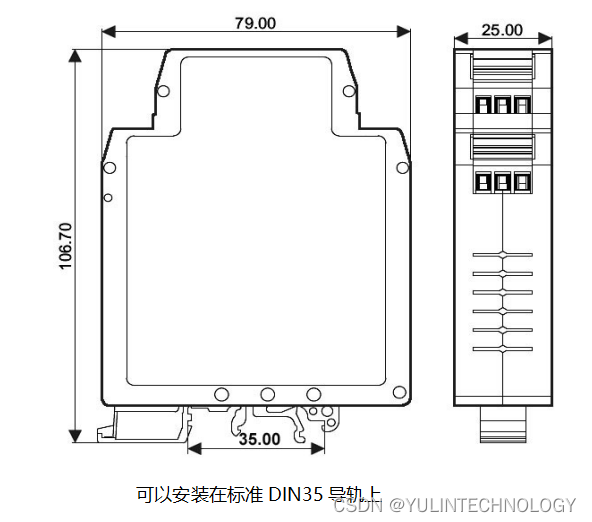
高精度PWM脉宽调制信号转模拟信号隔离变送器1Hz~10KHz转0-5V/0-10V/1-5V/0-10mA/0-20mA/4-20mA
主要特性: >>精度等级:0.1级。产品出厂前已检验校正,用户可以直接使用 >>辅助电源:8-32V 宽范围供电 >>PWM脉宽调制信号输入: 1Hz~10KHz >>输出标准信号:0-5V/0-10V/1-5V,0-10mA/0-20mA/4-20mA等&…...
Vue路由和Node.js环境搭建
文章目录 一、vue路由1.1 简介1.2 SPA1.3 实例 二、Node.js环境搭建2.1 Node.js简介2.2 npm2.3 环境搭建2.3.1 下载解压2.3.2 配置环境变量2.3.3 配置npm全局模块路径和cache默认安装位置2.3.4 修改npm镜像提高下载速度 2.4 运行项目 一、vue路由 1.1 简介 Vue 路由是 Vue.js…...

【Vue】使用vue-cli搭建SPA项目的路由,嵌套路由
一、SPA项目的构建 1、前期准备 我们的前期的准备是搭建好Node.js,测试: node -v npm -v2、利用Vue-cli来构建spa项目 2.1、什么是Vue-cli Vue CLI 是一个基于 Vue.js 的官方脚手架工具,用于自动生成vue.jswebpack的项目模板,它可以帮助开发者…...
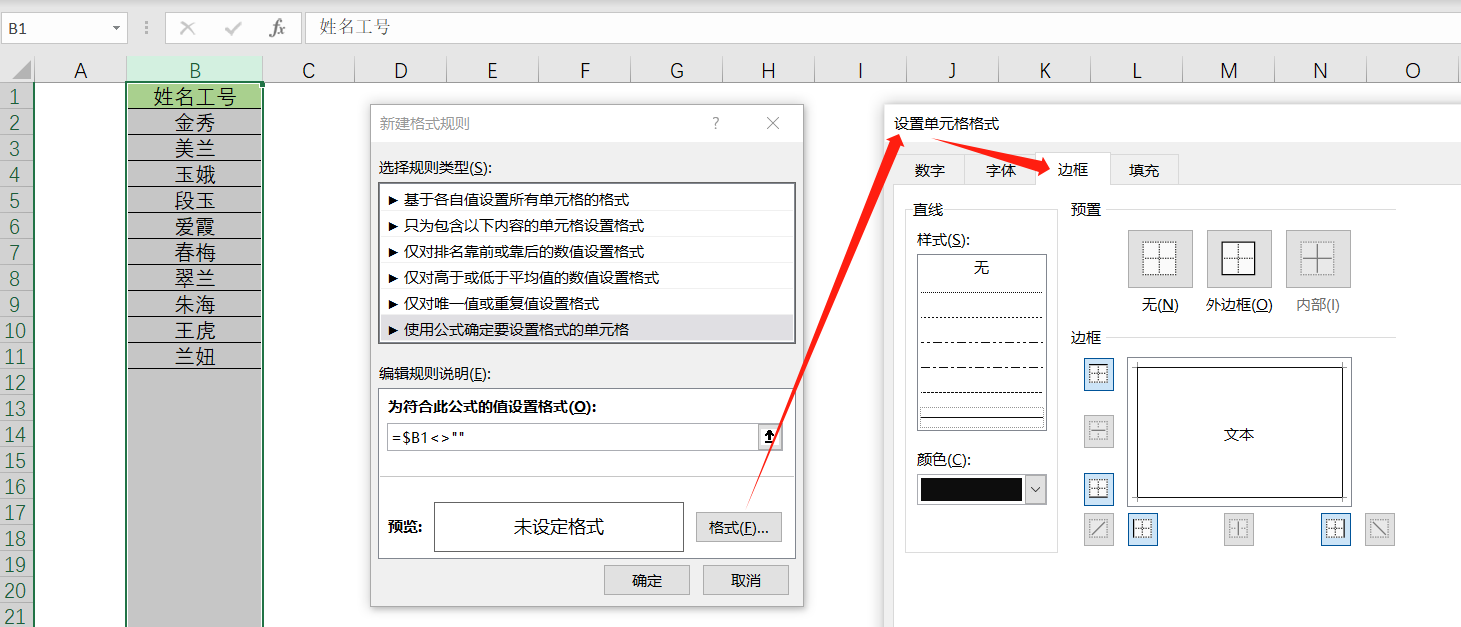
Excel 通过条件格式自动添加边框
每录入一次数据就需要手动添加一次边框,非常麻烦,这不是我们想要的。 那么有没有办法,在我们录入数据后,自动帮我们加上边框呢? 选中要自动添加边框的列,然后按箭头流程操作 ↓ ↓ ↓ ↓...

mysql 备份和还原 mysqldump
因window系统为例 在mysql安装目录中的bin目录下 cmd 备份 备份一个数据库 mysqldump -uroot -h hostname -p 数据库名 > 备份的文件名.sql 备份部分表 mysqldump -uroot -h hostname -p 数据库名 [表 [表2…]] > 备份的文件名.sql ## 多个表 空格隔开,中间…...

ELK日志分析系统+ELFK(Filebeat)
本章结构: 1、ELK日志分析系统简介 2、Elasticsearch介绍(简称ES) 3、Logstash介绍 4、Kibana介绍 5、实验,ELK部署 一、ELK日志分析系统简介 ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logst…...

ULID 在 Java 中的应用: 使用 `getMonotonicUlid` 生成唯一标识符
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
实用的嵌入式编码技巧:第三部分
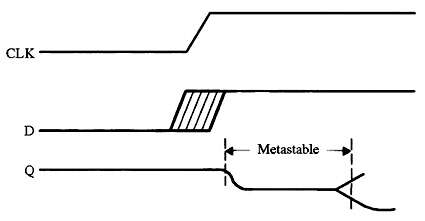
每个触发器都有两个我们在风险方面违反的关键规格。“建立时间”是时钟到来之前输入数据必须稳定的最小纳秒数。“保持时间”告诉我们在时钟转换后保持数据存在多长时间。 这些规格因逻辑设备而异。有些可能需要数十纳秒的设置和/或保持时间;其他人则需要少一个数量…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...