探索智能应用的基石:多模态大模型赋能文档图像处理

目录
- 0 写在前面
- 1 文档图像分析新重点
- 2 token荒:电子文档助力大模型
- 3 大模型赋能智能文档分析
- 4 文档图像大模型应用可能性
- 4.1 专有大模型
- 4.2 多模态模型
- 4.3 设计思路
- 总结
0 写在前面
中国智能产业高峰论坛(CIIS@2023)旨在为政企研学各界学者专家提供同台交流的机会,在成果分享、观点碰撞、经验互鉴中,共促智能科技引领行业创新变革、驱动数字经济快速发展。本次高峰论坛聚焦大模型、元宇宙、行业智能化、数字安全、智慧教育等热门议题,吸引了政府机构、高等院校、科研院所、科技企业等产业各方代表参会交流。此次论坛围绕当前人工智能产业领域的热点话题、核心技术以及社会关注的问题,研究探讨人工智能发展趋势及面临的机遇与挑战,是一次沟通交流、开阔眼界的难得机会。
合合信息作为文档图像处理领域的代表性科技企业,在本次高峰论坛中分享了关于文档图像处理与大语言模型相结合的应用前景,让我们一起看看吧!
1 文档图像分析新重点
随着信息技术的发展和应用场景的不断扩大,人们需要处理和利用大量的文档信息。而传统的手动处理方法效率低下,无法满足现代生活和工作的需求。文档图像智能分析与处理就是一个重要且极具挑战性的研究问题。合合信息的丁凯博士指出:
虽然文档图像分析已经有了将近一百年的历史,但是到目前为止仍有大量的问题没有得到很好地解决
例如文档的多样性和复杂性问题:文档类型和格式繁多,包括报告、合同、发票、证明、证件等等。不同类型的文档有不同的格式和布局,难以用统一的方法处理。而且智能文档处理受到图像质量、文字字体、文字大小、文字颜色等噪声因素的影响,容易出现误识别。此外,还有图像质量不一、文档获取繁琐等等。

在传统方法中,针对这些问题已经有了相应的解决方案。随着大语言模型的快速发展,能否和这些传统方法相结合,发挥出更强大的优势,注入更鲜活的生命力呢?丁凯博士对此进行了进一步的探讨和分析,相信对这个领域感兴趣的同学一定有所收获!

2 token荒:电子文档助力大模型
通用大语言模型(Large Language Model, LLM)就是AIGC技术中的核心模型之一。如今以Transformer架构和注意力机制为基础的大语言模型,使用大规模数据集进行训练,以学习语言的语法、语义和上下文,并能够生成连贯、具有逻辑性的文本回复
从2018年GPT约1.2亿的参数量,到2019年GPT2的15亿参数,再到2022年InstructGPT超1750亿的规模,在信息时代的浪潮中,大语言模型正以惊人的速度和无限的创造力引领着人工智能的新纪元

在信息时代的浪潮中,大语言模型正以惊人的速度和无限的创造力引领着人工智能的新纪元。大语言模型不仅能够理解和分析人类语言,还能够生成高质量、富有创意的文本。从写作助手到内容创作,从自动化客服到医疗诊断,它们正在推动各行各业的创新。 这些模型不断通过海量数据进行自我学习,不断提升自己的表现。它们能够从多个领域的知识中吸取灵感,生成创新性的想法和解决方案
虽然大语言模型正在改变人工智能发展的范式,但丁凯博士指出了阻碍大语言模型进步的瓶颈问题——token荒,有机构预测,到2026年全世界可以用于做大模型训练的高质量语料将被耗尽。

在这种情况下,电子文档对大语言模型训练就产生了重要意义。首先,电子文档作为海量的语言数据源,提供了丰富多样的文本内容。这些文档涵盖了各种领域的知识、专业术语、实际应用场景等。将电子文档作为语料库,可以使得大语言模型在训练过程中接触到更广泛、多样化的语言表达,提高其语言理解和生成能力;其次,电子文档通常被精心编写、编辑和组织,具有较高的语言质量和结构性。这些文档中的标注、标题、章节、段落等信息可以为大语言模型提供更可靠的上下文提示和语言规则,帮助模型更好地理解和生成文本。此外,通过使用电子文档进行训练,大语言模型能够学习到不同的语境和用法,更好地理解和应对各种现实世界的语言任务和挑战。所以,合理地将电子文档与大语言模型相结合,能够更好地应对token荒问题,并推动语言模型技术的发展
考虑到电子文档中存在大量的扫描件,因此文档图像处理技术的发展与大语言模型的进步密切相关
3 大模型赋能智能文档分析
针对大语言模型助力智能文档分析,丁凯博士举了两个例子:多模态GPT4处理文档图像以及多模态Google Bard处理文档图像。从结果来看,大模型能够识别文档图像中的关键信息、主题、实体等,并抽取文档中的重要段落、关键句子和核心观点。这种对语言的理解,赋予了智能文档处理系统强大的问题解答能力。用户可以通过提问来获取关于文档内容、特定领域知识或技术问题的准确答案


GPT4和Google Bard都能在测试样例上很好地完成任务,例如解答数学题、进行图像到表格的转换等。这对于现有的文档处理技术来说并不容易,因为传统文档图像处理主要关注于对文档图像的识别、提取和分析,但对于文本内容的语义理解和生成能力有限。而多模态大模型通过深度学习技术,能够理解和生成自然语言文本,具备更强大的语义理解和生成能力。它能够更好地理解文档中的语言内容、上下文和逻辑,从而实现更高级别的文档处理任务。另一个方面,大语言模型通过在大规模语料库上进行训练,能够掌握丰富的背景知识和语言模式。与此相比,传统文档图像处理往往只能基于特定规则或固定模板进行处理,缺乏上下文感知和灵活性。因此,大语言模型能够更好地理解文档内容的复杂性和多样性,适应不同领域和应用场景的需求
然而,目前多模态大模型赋能智能文档分析仍有很大的局限性。丁凯博士提到显著文本(Salient Text)和密集文本(Dense Text)的概念,这两种文本描述了文档图像中的不同类型信息:
- 显著文本:指的是在文档图像中相对于背景而言较为显著、突出的文本区域。这些文本通常具有明显的颜色、对比度或其他视觉特征,与周围的背景有较大的差异,引起人们注意。例如,在一份页面扫描的文档中,显著文本可能是标题、副标题、重要段落或引导性信息等;
- 密集文本:指的是文档图像中布满、大量存在的文本区域。这些文本通常由连续的文字块组成,没有明显的分隔或边界。例如,在报纸、杂志、书籍等文档的页面图像中,正文内容通常会形成密集的文本区域
目前多模态大模型在密集文本处理方面几乎不能使用,一个很重要的原因是:多模态大模型主要基于文本进行语义理解,对于视觉感知和图像特征的提取能力有限。在处理密集文本时,相邻的文本可能会重叠、相互遮挡或无明显的边界,这需要对视觉特征进行准确地提取和分析,大语言模型的主要优势是在自然语言文本处理方面,而不是直接处理视觉信息。因此,在图像文档处理方面,由于视觉感知限制和文字识别困难,大语言模型并不适合直接应用于该领域。在处理密集文本时,需要借助于文本检测、分割和OCR等专门的技术和算法来实现准确的文本识别和提取
4 文档图像大模型应用可能性
接着,丁凯博士对现有的文档图像大模型进行了综述,为我们把握了当前领域的前沿发展方向。现有模型主要分为两类:文档图像专有大模型以及多模态模型
4.1 专有大模型
微软的LayoutLM系列模型是基于Transformer架构的大型预训练模型,专门用于文档布局分析和文本识别任务。LayoutLM结合了自然语言处理和计算机视觉技术,使其能够同时处理文本和图像信息。它通过对文档图像的布局进行建模,识别文本框、文字位置和语义信息,并将它们融合在一起进行训练和推理。而且,通过微调,LayoutLM可以在不同的领域和任务上进行跨域迁移学习,适应更多下游任务

LiLT是合合信息联合华南理工大学共同研究的一种多模态信息抽取框架。采用了解耦联合建模的方法,将视觉和语言信息分别送入对应的模型中进行处理。通过双向互补注意力模块(BiCAM),使视觉和文本这两个模态之间的权重可以自适应地调整,提高了模型的泛化能力和适应性,更好地融合了两者的信息。该框架在多语言小样本、零样本场景下表现出优越的性能

然而,文档图像专有大模型由于大多是预训练模型,其迁移能力可能受限于特定领域和任务。端到端的多模态模型往往可以更好地适应不同领域和任务的需求,具有更大的迁移能力。
4.2 多模态模型
多模态文档图像处理大模型BLIP2设计了以下三个组件:
- 图像编码器:使用诸如
ViT的预训练图像编码器,将图像块转换为具有空间位置信息的向量表征,从而将图像的视觉特征编码为一系列更高维度的语义向量表示; - LLM解码器:采用诸如
OPT和FlanT5的LLM解码器处理文本任务,这些解码器在大规模语言数据上进行预训练,能够理解文本的语义和结构,并生成与输入文本相关的输出; - Q-Former连接:
Q-Former是一种轻量级的Transformer架构,在BLIP2中可以看作是一个将图像信息和文本信息进行多层次注意力机制融合的模块。它的主要作用是将图像的视觉特征和文本的语义信息进行融合,通过自适应地调整权重来促进两者之间的交互与对齐;
BLIP2的设计充分利用了图像和文本的互补性,使得BLIP2能够同时处理文档图像中的视觉和语义信息,从而在多模态文档图像处理任务中取得出色的性能表现。同时,通过训练Q-Former部分,BLIP2大大减少了整个模型的复杂性和计算成本,提高了模型的可训练性和实用性

除此之外,还有众多的多模态大模型用于处理文档图像问题。例如Google DeepMind的Flamingo增加了门控注意力层引入视觉信息; 微软的LLaVA 将CLIPViT-L和LLaMA采用全连接层连接,使用GPT-4和Self-Instruct2生成高质量的158k instruction following数据;MiniGPT-4采用ViT+Q-Former构建视觉通路、采用Vicuna构建语言通路,再使用全连接层衔接两大模态

然而,目前多模态大模型用于OCR领域仍然具有局限性。细粒度文本通常指的是文字较小、笔画细致、字形复杂的文本,如签名、古汉字、特殊符号等。这类文本在OCR领域中往往是非常具有挑战性的,因为它们往往涉及到字形和结构上的细微差异,很难直接从图像中提取出精确的文字信息。此外,在真实场景下,这些细粒度文本可能会受到光照、噪声、变形等各种干扰,这也增加了文字识别的难度。多模态大模型中的视觉编码器通常基于卷积神经网络或Transformer等模型,在处理图像时会受到分辨率的限制;另一方面,由于训练数据集中缺少针对细粒度文本的标注数据,模型很难从数据中学到有效的细粒度文本特征表示。因此,现有多模态大模型对显著文本的处理较好,但是对于细粒度文本的处理很差,要克服这些局限性,需要开展更深入的研究和探索
4.3 设计思路
丁凯博士给出了文档图像大模型的设计思路,主要是将文档图像识别分析的多种任务,通过序列预测的方式进行处理。具体来说,将每个任务所涉及的元素定义为一个序列,并设计相应的prompt来引导模型完成不同的OCR任务。例如,对于文本识别任务,可以使用prompt "识别文本: " 并将待处理的文本序列作为输入;对于段落分析任务,则可使用prompt "分析段落:"并将段落序列作为输入等等。这种方式可以保持一致的输入格式,方便模型进行多任务的处理。
此外,这个设计思路还支持篇章级的文档图像识别分析,可以输出Markdown/HTML/Text等标准格式,这样可以更好地适应用户的需求。同时,将文档理解相关的工作交给大语言模型,这意味着模型可以自动进行篇章级的文档理解和分析,从而提高了文档图像处理的效率和准确性。

总的来说,这种设计思路充分利用了序列预测的优势,在保持输入格式的统一性的同时,能够更好地解决文档图像处理中的多样化任务需求,并且通过与LLM的结合,实现了更高层次的文档理解和分析,为文档图像处理领域带来了更多可能性。
总结
看到智能文档处理与前沿技术结合的可能性,我感到非常兴奋。我相信前沿技术的相互碰撞将为用户带来更智能化、高效率和个性化的文档处理体验。未来随着技术的不断进步,这种结合将在商业、教育、科研等领域发挥越来越重要的作用。让我们拭目以待,期待合合信息在模式识别、深度学习、图像处理、自然语言处理等领域的深耕厚积薄发,用技术方案惠及更多的人!

相关文章:
探索智能应用的基石:多模态大模型赋能文档图像处理
目录 0 写在前面1 文档图像分析新重点2 token荒:电子文档助力大模型3 大模型赋能智能文档分析4 文档图像大模型应用可能性4.1 专有大模型4.2 多模态模型4.3 设计思路 总结 0 写在前面 中国智能产业高峰论坛(CIIS2023)旨在为政企研学各界学者专家提供同台交流的机会…...

自动化发布npm包小记
1.注册npm账号 打开npm官网,并注册自己的npm账号 2.申请AccessToken 1.登录npm官网,登录成功后,点开右上角头像,并点击Access Tokens选项 2.点开Generate New Token下拉框,点击Classic Token(和Granular Access To…...
详解机器视觉性能指标相关概念——混淆矩阵、IoU、ROC曲线、mAP等
目录 0. 前言 1. 图像分类性能指标 1.1 混淆矩阵(Confusion Matrix) 1.2 准确率(Precision) 1.3 召回率(Recall) 1.4 F1值(F1 score) 1.5 ROC曲线(接收者工作特征曲线,Receiver Operating Characteristic curve) 1.6 mAP(mean Average Precision) 2. 图像分…...
想要精通算法和SQL的成长之路 - 预测赢家
想要精通算法和SQL的成长之路 - 预测赢家 前言一. 预测赢家二. 石子游戏(预测赢家的进阶版)2.1 博弈论 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 预测赢家 原题链接 主要思路: 我们定义dp[i][j]:在区间 [i, j] 之间先…...
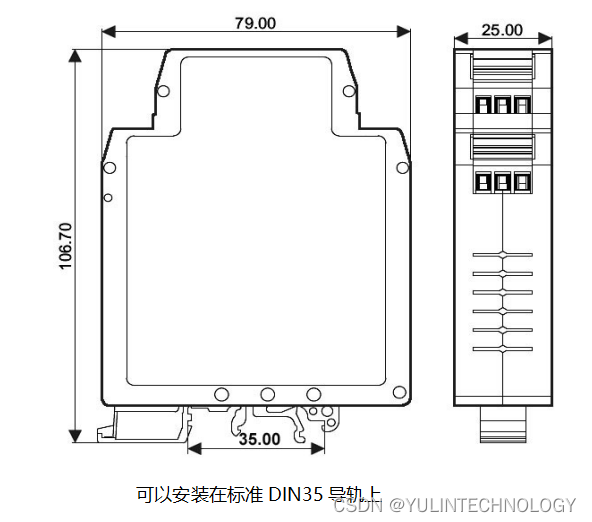
高精度PWM脉宽调制信号转模拟信号隔离变送器1Hz~10KHz转0-5V/0-10V/1-5V/0-10mA/0-20mA/4-20mA
主要特性: >>精度等级:0.1级。产品出厂前已检验校正,用户可以直接使用 >>辅助电源:8-32V 宽范围供电 >>PWM脉宽调制信号输入: 1Hz~10KHz >>输出标准信号:0-5V/0-10V/1-5V,0-10mA/0-20mA/4-20mA等&…...
Vue路由和Node.js环境搭建
文章目录 一、vue路由1.1 简介1.2 SPA1.3 实例 二、Node.js环境搭建2.1 Node.js简介2.2 npm2.3 环境搭建2.3.1 下载解压2.3.2 配置环境变量2.3.3 配置npm全局模块路径和cache默认安装位置2.3.4 修改npm镜像提高下载速度 2.4 运行项目 一、vue路由 1.1 简介 Vue 路由是 Vue.js…...

【Vue】使用vue-cli搭建SPA项目的路由,嵌套路由
一、SPA项目的构建 1、前期准备 我们的前期的准备是搭建好Node.js,测试: node -v npm -v2、利用Vue-cli来构建spa项目 2.1、什么是Vue-cli Vue CLI 是一个基于 Vue.js 的官方脚手架工具,用于自动生成vue.jswebpack的项目模板,它可以帮助开发者…...
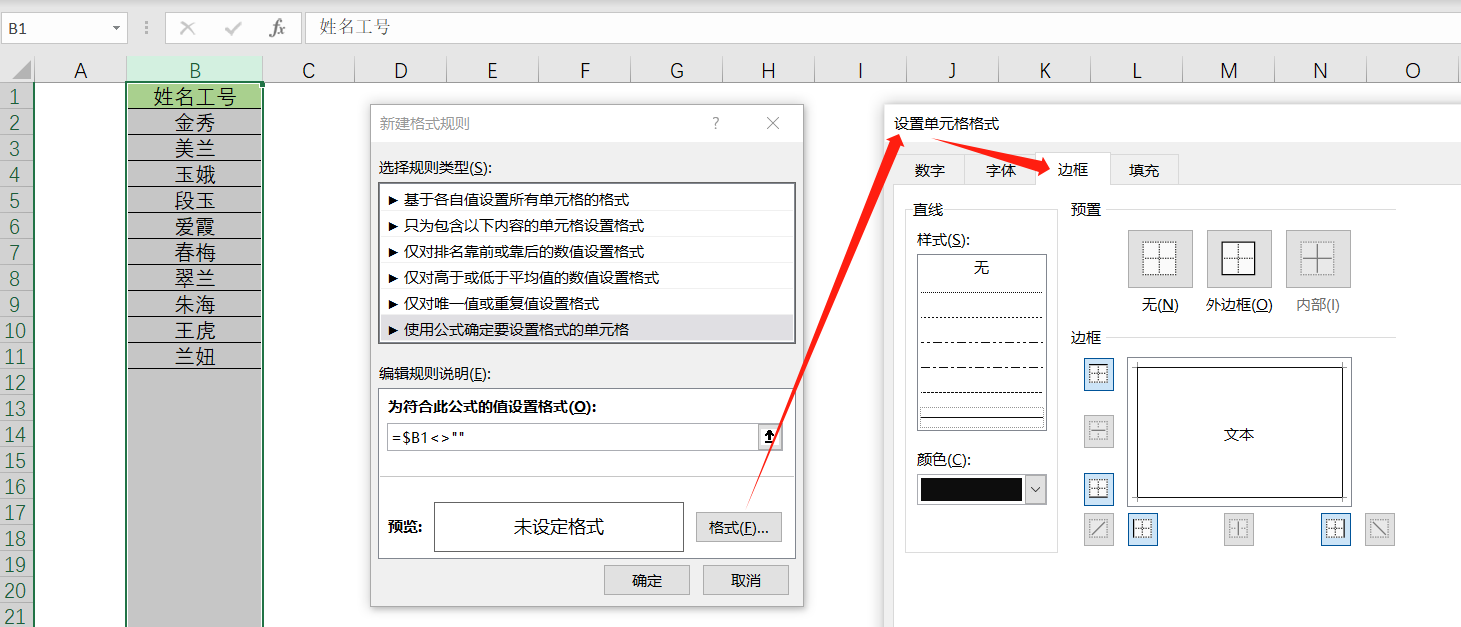
Excel 通过条件格式自动添加边框
每录入一次数据就需要手动添加一次边框,非常麻烦,这不是我们想要的。 那么有没有办法,在我们录入数据后,自动帮我们加上边框呢? 选中要自动添加边框的列,然后按箭头流程操作 ↓ ↓ ↓ ↓...

mysql 备份和还原 mysqldump
因window系统为例 在mysql安装目录中的bin目录下 cmd 备份 备份一个数据库 mysqldump -uroot -h hostname -p 数据库名 > 备份的文件名.sql 备份部分表 mysqldump -uroot -h hostname -p 数据库名 [表 [表2…]] > 备份的文件名.sql ## 多个表 空格隔开,中间…...

ELK日志分析系统+ELFK(Filebeat)
本章结构: 1、ELK日志分析系统简介 2、Elasticsearch介绍(简称ES) 3、Logstash介绍 4、Kibana介绍 5、实验,ELK部署 一、ELK日志分析系统简介 ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logst…...

ULID 在 Java 中的应用: 使用 `getMonotonicUlid` 生成唯一标识符
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
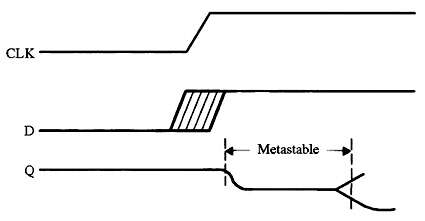
实用的嵌入式编码技巧:第三部分
每个触发器都有两个我们在风险方面违反的关键规格。“建立时间”是时钟到来之前输入数据必须稳定的最小纳秒数。“保持时间”告诉我们在时钟转换后保持数据存在多长时间。 这些规格因逻辑设备而异。有些可能需要数十纳秒的设置和/或保持时间;其他人则需要少一个数量…...

8个很棒的Vue开发技巧
1.路由参数解耦 通常在组件中使用路由参数,大多数人会做以下事情。 export default { methods: {getParamsId() {return this.$route.params.id} } } 在组件中使用 $route 会导致与其相应路由的高度耦合,通过将其限制为某些 URL 来限制组件的灵活性。…...

Python - 小玩意 - 文字转语音
import pyttsx3 from tkinter import *def recognize_and_save():try:say pyttsx3.init()rate say.getProperty(rate) # 获取当前语速属性的值say.setProperty(rate, rate - 20) # 设置语速属性为当前语速减20text text_var.get()# 语音识别say.say(text)say.runAndWait()…...
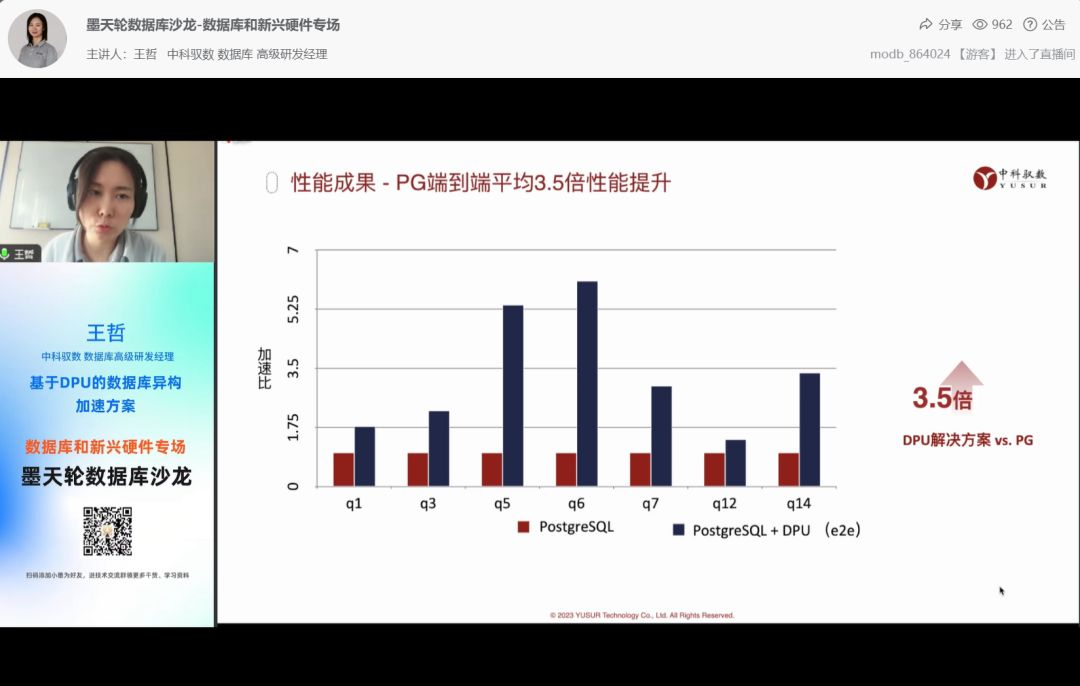
聚焦数据库和新兴硬件的技术合力 中科驭数受邀分享基于DPU的数据库异构加速方案
随着新型硬件成本逐渐降低,充分利用新兴硬件资源提升数据库性能是未来数据库发展的重要方向之一,SIGMOD、VLDB、CICE数据库顶会上出现越来越多新兴硬件的论文和专题。在需求侧,随着数据量暴增和实时性的要求越来越高,数据库围绕处…...

哨兵模式(sentinel)
为什么需要哨兵模式 redis的主从复制模式能够缓解“读压力”,但是存在两个明显问题。 主节点发生故障,进行主节点切换的过程比较复杂,需要人工参与,导致故障恢复时间无法保障主节点通过主从复制模式将读压力分散出去,…...

b站老王 自动驾驶决策规划学习记录(十二)
自动驾驶之速度规划详解:SL与ST迭代 上一讲:b站老王 自动驾驶决策规划学习记录(十一) 接着上一讲学习记录b站老王对自动驾驶规划系列的讲解 参考视频: 自动驾驶决策规划算法第二章第七节(上) 速度规划详解:SL与ST迭代…...

服务器租用机房机房的类型应该如何选择
服务器租用机房机房的类型应该如何选择 1.单电信机房 单电信服务器机房业务模式比较固定,访问量也不是很大,适合新闻类网站或政务类网站。如果网站的PV流量持续增加,建议后期采用租赁CDN的方式解决非电信用户访问网站速度过慢的问题。 2.双线…...

大数据运维一些常见批量操作命令
大数据运维中,批量操作是一项常见的任务。在使用flume进行数据采集的过程中,有时会出现故障导致采集停止,此时积累了大量的文件。如果想要将这些文件迁移到新的目录,直接使用"mv"命令可能会因为文件数目过多而报错。为了…...

测试人职场生存必须避开的5个陷阱
在互联网职场的工作发展道路上,软件测试人员其实在公司中也面临着各种各样的职场陷阱,有些可能是因为项目业务不熟练造成的,有些可能是自身技术能力不足导致的...等等。软件测试入门相对来说比较容易些,但是想要在测试行业长久发展…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...