Scikit-Learn快速生成分类数据集
假如你学习了新的分类算法并想进一步探索研究、尝试不同的超参数评估模型性能,但问题是你找不到好的数据集用于实验。幸运的是Scikit-Learn 提供的 make_classification() 方法可以创建不同类型的数据集,它可以生成不同类型的数据集:二分类、多分类、平衡或不平衡数据集、难以分类的数据集等。本文通过示例详细说明,并结合随机森林分类算法进行验证。
make_classification函数
首先我们介绍该函数参数,以及常用参数及默认值:
n_samples: 生成多少条样本数据,缺省100条.n_features: 有几个数值类型特征,缺省为20.n_informative: 有用特征的个数,仅这些特征承载对分类信号.,缺省为2.n_classes: 分类标签的数量,缺省为2.
该函数返回包含函数Numpy 数组的tuple,分别为特征X,以及标签y。其他参数用到时再作说明。
生成二分类数据集
下面生成二分类数据集,即标签仅有两个可能的值:0 、1.
因此需要设置n_classes参数为2。我们需要生成1000条样本,包括5个特征,其中三个为有用特征,另外两个为冗余特征。
from sklearn.datasets import make_classificationX, y = make_classification(n_samples=1000, # 1000 observations n_features=5, # 5 total featuresn_informative=3, # 3 'useful' featuresn_classes=2, # binary target/label random_state=999 # if you want the same results as mine
)
下面需转换 make_classification 函数返回值为 padas 数据框。padas 数据框比Numpy数组更易分析。
import pandas as pd# Create DataFrame with features as columns
dataset = pd.DataFrame(X)
# give custom names to the features
dataset.columns = ['X1', 'X2', 'X3', 'X4', 'X5']
# Now add the label as a column
dataset['y'] = ydataset.info()
输出结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 6 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 X1 1000 non-null float641 X2 1000 non-null float642 X3 1000 non-null float643 X4 1000 non-null float644 X5 1000 non-null float645 y 1000 non-null int64
dtypes: float64(5), int64(1)
memory usage: 47.0 KB
和我们期望一致,该数据集包括1000个样本,包括5个特征,以及对应的响应目标标签。我们设置**n_informative** 为3,因此,仅 (X1, X2, X3)是重要的,另外两个 X4 和 X5, 是多余的。
现状我们检查标签y的基数和总数:
dataset['y'].value_counts()1 502
0 498
Name: y, dtype: int64
标签仅包括两个可能的值,因此属于二分类数据集。而且两者数量大致相当,因此标签分类相对平衡。下面查看前5条样本值:
dataset.head()
| X1 | X2 | X3 | X4 | X5 | y | |
|---|---|---|---|---|---|---|
| 0 | 2.501284 | -0.159155 | 0.672438 | 3.469991 | 0.949268 | 0 |
| 1 | 2.203247 | -0.331271 | 0.794319 | 3.259963 | 0.832451 | 0 |
| 2 | -1.524573 | -0.870737 | 1.004304 | -1.028624 | -0.717383 | 1 |
| 3 | 1.801498 | 3.106336 | 1.490633 | -0.297404 | -0.607484 | 0 |
| 4 | -0.125146 | 0.987915 | 0.880293 | -0.937299 | -0.626822 | 0 |
分类示例
生成数据集看上去不错,下面利用缺省超参数创建随机森林分类器。我们使用交叉验证衡量模型性能:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_validate# initialize classifier
classifier = RandomForestClassifier() # Run cross validation with 10 folds
scores = cross_validate(classifier, X, y, cv=10, # measure score for a list of classification metricsscoring=['accuracy', 'precision', 'recall', 'f1']
)scores = pd.DataFrame(scores)
scores.mean().round(4)
输出结果如下, 模型的 Accuracy, Precision, Recall, 和 F1 Score接近88%. 没有调整任何超参数情况下,表现尚可。
fit_time 0.1201
score_time 0.0072
test_accuracy 0.8820
test_precision 0.8829
test_recall 0.8844
test_f1 0.8827
dtype: float64
不易分类数据集
下面尝试创建要给不容易分类的数据集。我们可以使用下面**make_classification()**函数参数控制数据集的难度级别:
flip_y: 通过反转少量标签增加噪声数据 . 举例,改变少量标签值0的值为1,返回改变1为0. 该值越大噪声越多,缺省值为 0.01.class_sep: 类别之间的距离,默认值为1.0,表示原始特征空间中的类别之间的平均距离. 值越小分类越难.
下面代码使用flip_y较高的值与class_sep较低的值创建有挑战性的数据集:
X, y = make_classification(# same as the previous sectionn_samples=1000, n_features=5, n_informative=3, n_classes=2, # flip_y - high value to add more noiseflip_y=0.1, # class_sep - low value to reduce space between classesclass_sep=0.5
)# Check label class distribution
pd.DataFrame(y).value_counts()
1 508
0 492
dtype: int64
0 和 1 标签对应的样本量几乎相当。因此分类相对平衡。
分类较难数据集
我们再次构建随机森林模型,并使用默认超参数。这次使用较难的数据集:
classifier = RandomForestClassifier() scores = cross_validate(classifier, X, y, cv=10, scoring=['accuracy', 'precision', 'recall', 'f1']
)scores = pd.DataFrame(scores)
scores.mean()
fit_time 0.138662
score_time 0.007333
test_accuracy 0.756000
test_precision 0.764619
test_recall 0.760196
test_f1 0.759281
dtype: float64
模型的Accuracy, Precision, Recall, 和F1 Score 参数值大约在75~76%.相对前面88%有了明显下降。
flip_y 和**class_sep** 参数值起作用了,它们创建的数据集确实较难分类。
不平衡数据集
前面我们创建的数据集,每个分类对应样本大致相等。但有时我们需要不平衡数据集,即其中一个标签分类样本数据比较稀少。
我们可以使用参数weights去控制每个分类的比例。下面代码利用make_classification 函数给样本0值标签分配比例97%, 剩下了的分类值1占3%:
X, y = make_classification(# the usual parametersn_samples=1000, n_features=5, n_informative=3, n_classes=2, # Set label 0 for 97% and 1 for rest 3% of observationsweights=[0.97],
)pd.DataFrame(y).value_counts()
0 964
1 36
dtype: int64
从结果看,**make_classification()**函数分配了3%比例给标签值为1的样本,确实生成了不平衡数据集。
分类不平衡数据集
与前节一样,仍使用缺省超参数的随机森林模型训练不平衡数据集:
classifier = RandomForestClassifier() scores = cross_validate(classifier, X, y, cv=10, scoring=['accuracy', 'precision', 'recall', 'f1']
)scores = pd.DataFrame(scores)
scores.mean()
fit_time 0.101848
score_time 0.006896
test_accuracy 0.964000
test_precision 0.250000
test_recall 0.083333
test_f1 0.123333
dtype: float64
我们看到有趣的现象,我们的模型准确率很高(96%),但精确率和召回率很低(25% 和 8%)。这是典型的准确率悖论,当处理不平衡数据经常会发生。
多分类数据集
到目前为止,我们生成的标签仅有两种可能。如果你需要多分类数据做实验,则标签需要超过2个值。n_classes参数可以实现:
X, y = make_classification(# same parameters as usual n_samples=1000, n_features=5, n_informative=3,# create target label with 3 classesn_classes=3,
)pd.DataFrame(y).value_counts()
1 334 2 333 0 333 dtype: int64
从结果看,三个分类样本大致相当,数据集分类较平衡。
多分类不平衡数据集
我们也可以很容易创建不平衡多分类数据集,只需要使用参数 n_classes 和 weights :
X, y = make_classification(# same parameters as usual n_samples=1000, n_features=5, n_informative=3,# create target label with 3 classesn_classes=3, # assign 4% of rows to class 0, 48% to class 1# and the rest to class 2weights=[0.04, 0.48]
)pd.DataFrame(y).value_counts()
0 值分类占 4%, 1 值占 48%, 剩下的给值 2 标签。查看结果:
2 479 1 477 0 44 dtype: int64
1000个样本中 0 值标签仅有44个,和预期一致。
总结
现在你学会了使用scikit-learn的make_classification函数生成不同类型数据集了吧。包括二分类或多分类、不平衡数据集、挑战性难分类的数据集等。更多参数可以查看官方文档,本文参考:How to Generate Datasets Using make_classification | Proclus Academy。
相关文章:

Scikit-Learn快速生成分类数据集
假如你学习了新的分类算法并想进一步探索研究、尝试不同的超参数评估模型性能,但问题是你找不到好的数据集用于实验。幸运的是Scikit-Learn 提供的 make_classification() 方法可以创建不同类型的数据集,它可以生成不同类型的数据集:二分类、…...

西门子 S7 协议解析
目录 1 建立连接 2 读数据 3 写数据 1 建立连接 03 00 00 16 11 E0 00 00 00 01 00 C1 02 10 00 C2 02 03 01 C0 01 0A (第一次握手报文) 03 00 报文头 00 16 数据总长度:22 11 E0 00 00 00 01 00 C1 02 10 00 C2 02 03 01 C0 01 0A 报文结束…...

一、python解题——求序列最长递增
解题代码: import os import sys# 请在此输入您的代码 n int(input()) a list(map(int, input().split())) # 创建一个初始元素全为1的列表,用来存放每个递增序列的长度 b [1 for x in range(0, n)] # 设置num,用来控制b列表的下标 num …...

【Java 基础篇】Java线程:volatile关键字与原子操作详解
在多线程编程中,确保线程之间的可见性和数据一致性是非常重要的。Java中提供了volatile关键字和原子操作机制,用于解决这些问题。本文将深入讨论volatile关键字和原子操作的用法,以及它们在多线程编程中的重要性和注意事项。 volatile关键字…...

992. K 个不同整数的子数组
992. K 个不同整数的子数组 给定一个正整数数组 nums和一个整数 k,返回 nums 中 「好子数组」 的数目。 如果 nums 的某个子数组中不同整数的个数恰好为 k,则称 nums 的这个连续、不一定不同的子数组为 「好子数组 」。 例如,[1,2,3,1,2] 中…...

Vue 使用vue-cli构建SPA项目(超详细)
目录 一、什么是vue-cli 二,构建SPA项目 三、 运行SPA项目 前言: 在我们搭建SPA项目时候,我们必须去检查我们是否搭建好NodeJS环境 cmd窗口输入以下指令:去检查 node -v npm -v 一、什么是vue-cli Vue CLI(Vu…...

SpringBoot工程模板
spring脚手架:https://start.spring.io/ <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocati…...
学习SLAM:SLAM进阶(十)暴力更改ROS中的PCL库
话不多说,上活 1.1 为什么要这么做 项目中有依赖。。。。 1.2 安装VTK7.1.1 PCL1.8.0 略 1.3 移植到ROS 删除ROS依赖的vtk6.2和PCL1.8.0的动态链接库: liugongweiubuntu:~$ sudo mv /usr/lib/x86_64-linux-gnu/libvtk* Desktop/lib/ [sudo] password fo…...
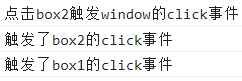
js 事件流、事件冒泡、事件捕获、阻止事件的传播
事件流 js 事件的执行过程分为捕获阶段(由外层节点传播到内层节点)和冒泡阶段(由内层节点传播到外层节点),即先执行捕获阶段的代码,后执行冒泡阶段的代码 事件冒泡 js 事件中的代码默认在冒泡阶段执行&…...

一家美国公司被黑,一个拉美国家政务服务瘫痪
政务系统承包商遭勒索攻击,导致哥伦比亚国家政务服务陷入瘫痪。 据报道,9月19日哥伦比亚的多个重要政府部门正在应对一次勒索软件攻击,官员们被迫大幅变更部门运作方式。 哥伦比亚卫生和社会保护部、司法部门、工商监管部门上周宣布&#x…...

c++ QT 十八位时间戳转换
先说一下UTC: 它是协调世界时间,又称世界统一时间、世界标准时间、国际协调时间,简称UTC UTC时间与本地时间关系:UTC 时间差本地时间 如果UTC时间是 2015-05-01 00:00:00 那么北京时间就是 2015-05-01 08:00:00 解释:…...
全国职业技能大赛云计算--高职组赛题卷④(容器云)
全国职业技能大赛云计算--高职组赛题卷④(容器云) 第二场次题目:容器云平台部署与运维任务1 Docker CE及私有仓库安装任务(5分)任务2 基于容器的web应用系统部署任务(15分)任务3 基于容器的持续…...
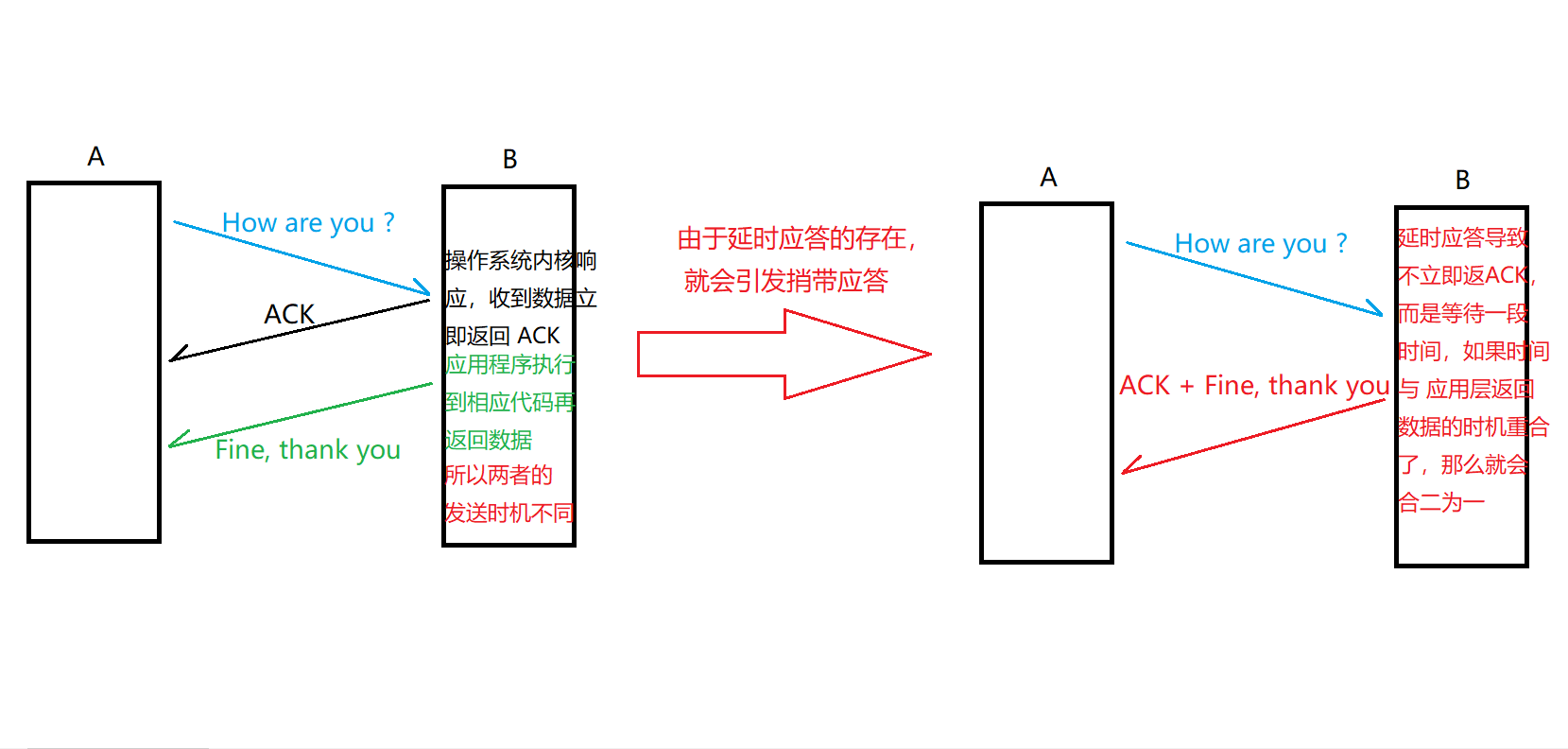
【TCP】延时应答 与 捎带应答
延时应答 与 捎带应答 一. 延迟应答(效率机制)二. 捎带应答(效率机制) 一. 延迟应答(效率机制) 延时应答:相当于 流量控制 的延伸。 流量控制是 踩下了刹车,是发送方发的不要太快&a…...

URL与URI小结
文章目录 一、URL是什么?URL的一般形式: 二、分类三、URI总结 一、URL是什么? 每条由Web服务器返回的内容都是和它管理的某个文件相关联的,这些文件中的每一个都有一个唯一的名字,叫做URL(通用资源定位符&…...

QT--day5
注册 mainwindow.h #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include<QPushButton> #include<QLineEdit> #include<QLabel> #include <QMessageBox> #include<QString> #include<QSqlDatabase> …...

在windows和linux上玩转Tensorrt
为避免重复,一些安装内容我直接贴其他大佬的帖子了,我是按照他们的步骤来操作的,趟过一遍,没有问题。 本篇着重在tensort在Cmakelist中如何配置,以及如何配置编译动/静态库,比较基础,也是想做个…...

七天学会C语言-第五天(函数)
1. 调用有参函数 有参函数是一种接受输入参数(参数值)并执行特定操作的函数。通过向函数传递参数,你可以将数据传递给函数,让函数处理这些数据并返回结果。 例1:编写一程序,要求用户输入4 个数字…...

340. 至多包含 K 个不同字符的最长子串
340. 至多包含 K 个不同字符的最长子串 vip...

【分布式计算】副本数据Replicated Data
作用:可靠性、高性能、容错性 问题:如何保持一致、如何更新 问题:存在读写/写写冲突 一个简单的方法就是每个操作都保持顺序,但是因为网络延迟会导致问题 Data-centric models: consistency model?? ??? 读取时,…...
)
erlang练习题(二)
题目一 替换元组或列表中指定位置的元素,新元素作为参数和列表或元组一起传入函数内 解答 replaceIdx(List, Index, Val) ->replaceIdx(List, Index, Val, 1, []).replaceIdx([], _, _, _, Acc) ->lists:reverse(Acc);%% 到达替换位置的处理replaceIdx([_ …...
PixelArray:嵌入式平台高精度WS2812 LED控制库
1. PixelArray 库概述:面向嵌入式系统的 NeoPixel 兼容 LED 阵列控制框架PixelArray 是一个专为资源受限嵌入式平台设计的轻量级、高精度、可扩展的 NeoPixel 兼容 LED 控制库。其核心目标并非简单复刻 Adafruit_NeoPixel 的 Arduino 风格 API,而是从底层…...
)
从FMI7522/RC522无缝切换到SI522A:硬件不改、软件微调的国产化替换实战指南(附避坑点)
从FMI7522/RC522无缝切换到SI522A的工程实践全解析 在电子产品的生命周期中,芯片替换往往是一个既必要又充满挑战的环节。当原厂芯片面临供货不稳定、价格波动或技术迭代时,寻找一款PIN对PIN兼容的替代方案成为工程师的首选。SI522A作为国产13.56MHz射频…...

差分进化算法实战:用Python和Matlab解决优化问题的5个经典案例
差分进化算法实战:用Python和Matlab解决优化问题的5个经典案例 在工程优化和科学研究中,我们常常需要寻找某个复杂问题的最优解——可能是最小化成本、最大化效率,或是找到一组最佳参数组合。传统优化方法在面对非线性、多峰或高维问题时往往…...

DFRobot_ST7687S TFT LCD驱动详解:SPI显示模块硬件与API实战
1. 项目概述DFRobot_ST7687S 是一款基于 ST7687S 显示驱动芯片的 2.2 英寸 TFT LCD 显示模块(SKU: DFR0529),采用 30Pin 焊接式 FPC 接口,分辨率为 128128 像素。该模块专为嵌入式系统设计,支持全彩动态显示࿰…...

WwiseUtil:游戏音频处理的技术突破与创新方案
WwiseUtil:游戏音频处理的技术突破与创新方案 【免费下载链接】wwiseutil Tools for unpacking and modifying Wwise SoundBank and File Package files. 项目地址: https://gitcode.com/gh_mirrors/ww/wwiseutil 在游戏开发领域,音频资源的高效管…...

VSCode离线安装Python插件全攻略:Pylance和Python Debugger保姆级教程
VSCode离线安装Python插件全攻略:Pylance和Python Debugger保姆级教程 在软件开发领域,网络环境并非总是可靠。无论是企业内网的安全限制,还是远程工作时的网络波动,都可能阻碍开发者正常获取VSCode插件。本文将手把手教你如何在完…...

学术研究助手:OpenClaw+ollama-QwQ-32B文献分析工作流
学术研究助手:OpenClawollama-QwQ-32B文献分析工作流 1. 为什么需要AI辅助文献分析? 去年冬天,当我面对堆积如山的PDF论文时,突然意识到传统文献管理方式已经跟不上现代科研的节奏。手动标注关键结论、整理参考文献、绘制研究趋…...

STM32与淘晶驰串口屏通信:如何正确使用转义字符避免txt控件显示问题
STM32与淘晶驰串口屏通信:转义字符应用全解析与实战避坑指南 在嵌入式系统开发中,人机交互界面(HMI)的设计往往决定着产品的用户体验。淘晶驰串口屏以其易用性和性价比,成为众多STM32开发者的首选。然而,当开发者尝试将动态数据发…...
)
分布式存储实战:ROW与COW快照选型指南(含性能对比测试)
分布式存储实战:ROW与COW快照选型指南(含性能对比测试) 在构建高可用分布式存储系统时,快照技术是数据保护和灾难恢复的核心组件。面对不同的业务负载和性能需求,ROW(Redirect on Write)和COW&a…...
)
【数据结构与算法】KMP算法(next数组)
#include <iostream> #include <string> #include <vector> using namespace std; int main() {string s1, s2;cin >> s1 >> s2;int n s1.size();int m s2.size();// Step 1: 构建 next 数组 (border 长度数组)vector<int> next(m, 0);f…...