zookeeper + kafka
Zookeeper 概述
Zookeeper是一个开源的分布式服务管理框架。存储业务服务节点元数据及状态信息,并负责通知再 ZooKeeper 上注册的服务几点状态给客户端
Zookeeper 工作机制
Zookeeper从设计模式角度来理解: 是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
也就是说【 Zookeeper = 文件系统 + 通知机制 】
Zookeeper 特点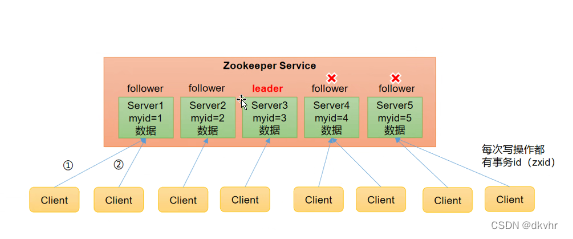
-
Zookeeper:一个领导者 (Leader)多个跟随者 (Follower) 组成的集群
-
Zookeepe集群中只要有半数以上节点存活,集群就能正常服务。所以适合安装奇数台服务器 (>=3的奇数)
-
全局数据一致:每个Server保存一份相同的数据副本,client无论连接到哪个Server,数据都是一致的
-
更新请求顺序执行,来自同一个client的更新请求按其发送顺序依次执行,即先进先出
-
数据更新原子性,一次数据更新要么成功,要么失败
-
实时性,在一定时间范围内,client能读到最新数据
Zookeeper 数据结构
-
与Linux文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能多存储1M的数据,每个znode都可以通过其路径唯一标识
Zookeeper 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等
统一命名服务
-
统一命名服务在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如: Ip不容易记住,而域名容易记住
统一配置管理
-
分布式环境下,配置文件同步非常常见。一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka朱群。对配置文件修改后希望能够快速同步到各个节点上
-
配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode。各个客户端服务器监听这个Znode。一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器
统一集群管理
-
分布式环境中,实时堂握每个节点的状态是必要的。可根据节占实时状态做出一些调整
-
ZooKeeper可以实现实时监控节点状态变化。可将节点信息写入ZooKeeper上的一个 ZNode。监听这个2Node可获取它的实时状态变化
服务器动态上下线
-
客户端能实时洞察到服务器上下线的变化
软负载均衡
-
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
Zookeeper 选举机制
通过比较 Myid,Myid最大的获取选票,当选票过半数确定 Leader节点,之后再加入的节点 无论 Myid 多大都会作为 Follower 加入这个集群
Zookeeper 非第一次启动选举机制
当原 Leader 故障,其他节点会选举新的 Leader,先比较 EPOCH 最大的值直接胜出 ,如果 EPOCH 相同再比较事务 ID,最大的胜出,如果事务ID也相同,最后比较服务器 ID,大的胜出
部署 Zookeeper 集群
准备 3 台服务器做 Zookeeper 集群
192.168.86.44
192.168.86.55
192.168.86.661.安装前准备
//关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0//安装 JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version//下载安装包
官方下载地址:https://archive.apache.org/dist/zookeeper/
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz2.安装 Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
//修改配置文件
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连:接端口
#添加集群信息
server.1=192.168.86.44:3188:3288
server.2=192.168.86.55:3188:3288
server.3=192.168.86.66:3188:3288
【server.A=B:C:D】A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。B是这个服务器的地址。C是这个服务器Follower与集群中的Leader服务器交换信息的端口。D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口拷贝配置好的 Zookeeper 配置文件到其他机器上
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.86.55:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.86.66:/usr/local/zookeeper-3.5.7/conf///在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs//分别在每个节点的dataDir指定的目录下创建一个 myid 的文件
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid//配置 Zookeeper 启动脚本
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)echo "---------- zookeeper 启动 ------------"$ZK_HOME/bin/zkServer.sh start
;;
stop)echo "---------- zookeeper 停止 ------------"$ZK_HOME/bin/zkServer.sh stop
;;
restart)echo "---------- zookeeper 重启 ------------"$ZK_HOME/bin/zkServer.sh restart
;;
status)echo "---------- zookeeper 状态 ------------"$ZK_HOME/bin/zkServer.sh status
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac// 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper//分别启动 Zookeeper
service zookeeper start//查看当前状态
service zookeeper status
kafka(消息队列)
为什么要使用消息队列(MQ)
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻寒。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应
我们使里消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、Rocketmo、Kafka等
使用消息队列的好处
-
解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束
-
可恢复性:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的相合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理
-
缓冲:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况
-
灵活性 & 峰值处理能力:在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无能是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃
-
异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们

消息队列的两种模式
点对点模式 (一对一,消费者主动拉取数据,消息收到后消息清除)【用的较少】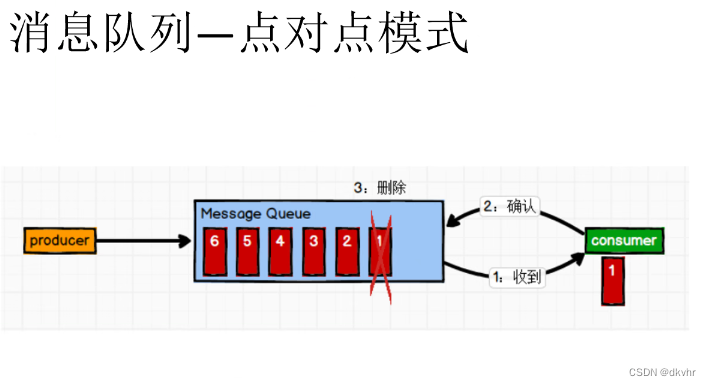
-
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
发布/订阅模式(一对多,又叫观察者模式,消费完不会清除数据)
-
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic的消息会被所有订阅者消费。
-
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目对标象)的状态发生改变,则所有依赖于它的对象 (观察者对象)部得到通知并自动更新
对 kafka 的概述
Kafka 是城初由 Linkedin 公司开发,是一个分布式、支持分区的 (partition)、多副本的 (replica) ,基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop的批处理系统、低延迟的实时系统、Spark/Elink 流式处理引,nginx 访问日志,消息服务等等,用 cala 语言编写,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
定义
-
是一个分布式的基于发布/订阅模式的消息队列 (MQ,Message Queue )主要应用于大数据实时处理领域
kafka 的特性
-
高吞吐量、低延迟:Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个Partition,Consumer Group 对 Partition进行消费操作,提高负载均衡能力和消费能力
-
可扩展性:kafka 集群支持热扩展
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
-
容错性:允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
-
高并发:支持数千个客户端同时读写
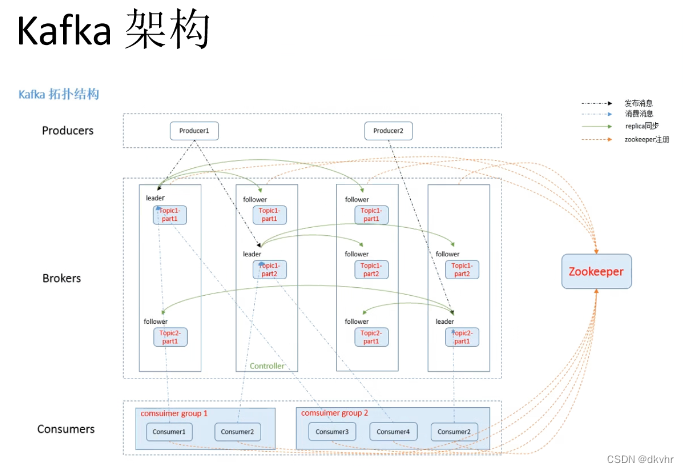
kafka 的系统架构
-
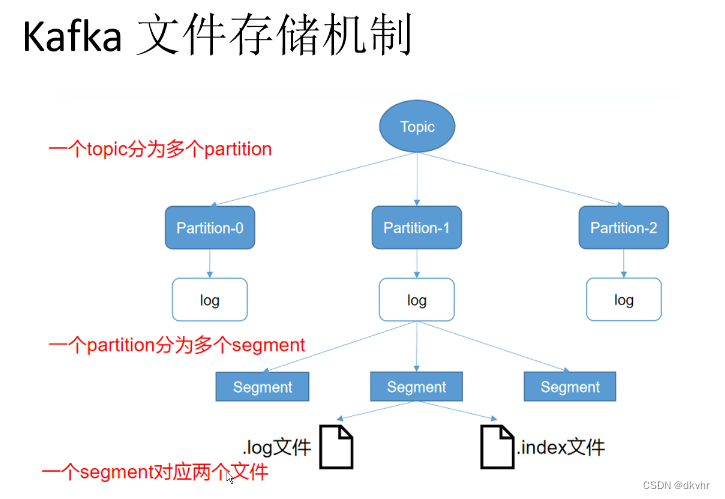
Partition:分区
-
brokers:服务器
-
producers:生产者 两角色: Leader负责读写、Follower负责备份
-
Topic:消息主题 或者 表 或者键 存数据的表和键
-
replica:副本
-
Consumer:消费者可以从 broker 中 pull 拉取数据。消费者可以消费多个 topic 中的数据
-
Consumer Group (CG):消费者组,由多个 consumer 组成。
-
offset 偏移量:可以唯一的标识一条消息。偏移量决定读取数据的位置(路径),不会有线程安全的问题
 4
4
原理:
生产者要推送到 kafka 集群需要先通过 zookeeper 确定 kafka 的位置,消费者消费的数据到哪里也要根据数据在存储 zookeeper 上的 offset ,来确定 offset偏移量记录上一条消费者的消息数据位置,以便在故障恢复后可以接着下一次数据继续消费
几个 kafka服务就是几个 broker【服务器】,生成推送数据到 topic【消费主题】,topic 可以被分区多个 partition【分区】,一个 partition可以有多个 relica(副本),relica可以是一个 leader【领导者】和多个 follower【跟随者】,leader负责数据的读写,follower仅负责数据备份,消费者面向 topic【主题】进行数据消费
ack 应答机制
-
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 follower 全部接收成功。所以Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡选择
-
0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是员低的。当broker障时有可能丢失数据
-
1(默认配置):这意味着 producer在 ISR中的 leader已成功收到的数据并得到确认后发送下一条message。如果在 follower同步成功之 leader故障那么将会丢失数据
-
-1(或者是all):producer需要等待ISR中的所有 follower都确认接收到数据后才算一次发送完成,可靠性最高。但是如果在 follower同步完成后,broker 发送ack 之前,leader 发生故障,那么会造成数据重复
部署 kafka 集群
1.下载安装包
官方下载地址:http://kafka.apache.org/downloads.htmlcd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz2.安装 Kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}vim server.properties
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.86.44:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.86.44:2181,192.168.86.55:2181,192.168.86.66:2181 ●123行,配置连接Zookeeper集群地址//修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile//配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka//分别启动 Kafka
service kafka start
3.Kafka 命令行操作
//创建topic
kafka-topics.sh --create --zookeeper 192.168.86.44:2181,192.168.86.55:2181,192.168.86.66:2181 --replication-factor 2 --partitions 3 --topic test
kafka-topics.sh --create --zookeeper 192.168.86.44:2181,192.168.86.55:2181,192.168.86.66:2181 --replication-factor 2 --partitions 3 --topic ky30
-------------------------------------------------------------------------------------
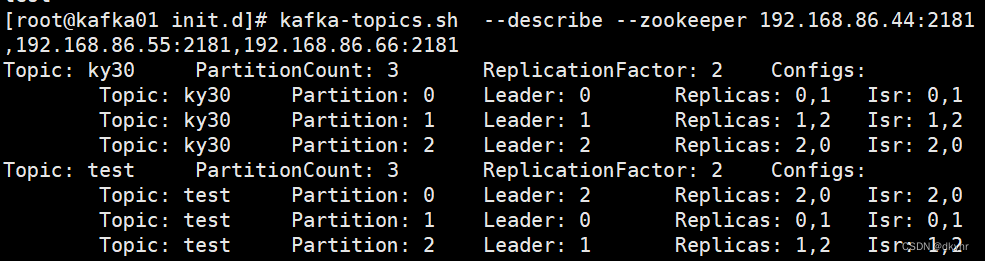
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
-------------------------------------------------------------------------------------//查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.86.44:2181,192.168.86.55:2181,192.168.86.66:2181
//查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.86.44:2181,192.168.86.55:2181,192.168.86.66:2181
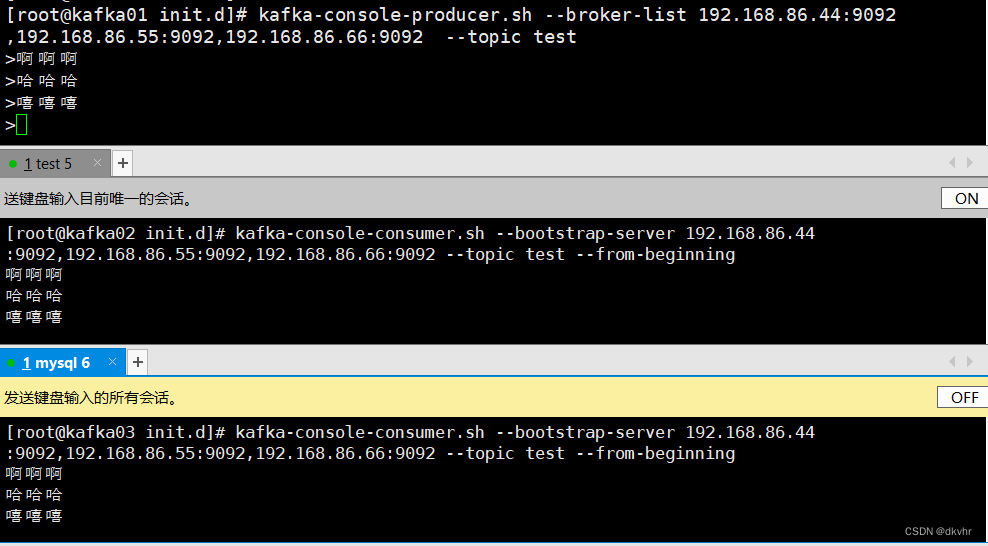
//发布消息
kafka-console-producer.sh --broker-list 192.168.86.44:9092,192.168.86.55:9092,192.168.86.66:9092 --topic test
//消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.86.44:9092,192.168.86.55:9092,192.168.86.66:9092 --topic test --from-beginning
相关文章:
zookeeper + kafka
Zookeeper 概述 Zookeeper是一个开源的分布式服务管理框架。存储业务服务节点元数据及状态信息,并负责通知再 ZooKeeper 上注册的服务几点状态给客户端 Zookeeper 工作机制 Zookeeper从设计模式角度来理解: 是一个基于观察者模式设计的分布式服务管理框架&…...

wordpress添加评论过滤器
给wordpress添加评论过滤器,如果用户留言包含 "http" (可以为任意字符串) 就禁止提交评论。 function filter_comment_content($comment_data) {$comment_contents $comment_data["comment_content"]; //获取评论表单的内容字段if (stripos($…...
工具篇 | Gradle入门与使用指南
介绍 1.1 什么是Gradle? Gradle是一个开源构建自动化工具,专为大型项目设计。它基于DSL(领域特定语言)编写,该语言是用Groovy编写的,使得构建脚本更加简洁和强大。Gradle不仅可以构建Java应用程序&#x…...
Wireshark TS | MQ 传输缓慢问题
问题背景 应用传输慢是一种比较常见的问题,慢在哪,为什么慢,有时候光从网络数据包分析方面很难回答的一清二楚,毕竟不同的技术方向专业性太强,全栈大佬只能仰望,而我们能做到的是在专注于自身的专业方向之…...
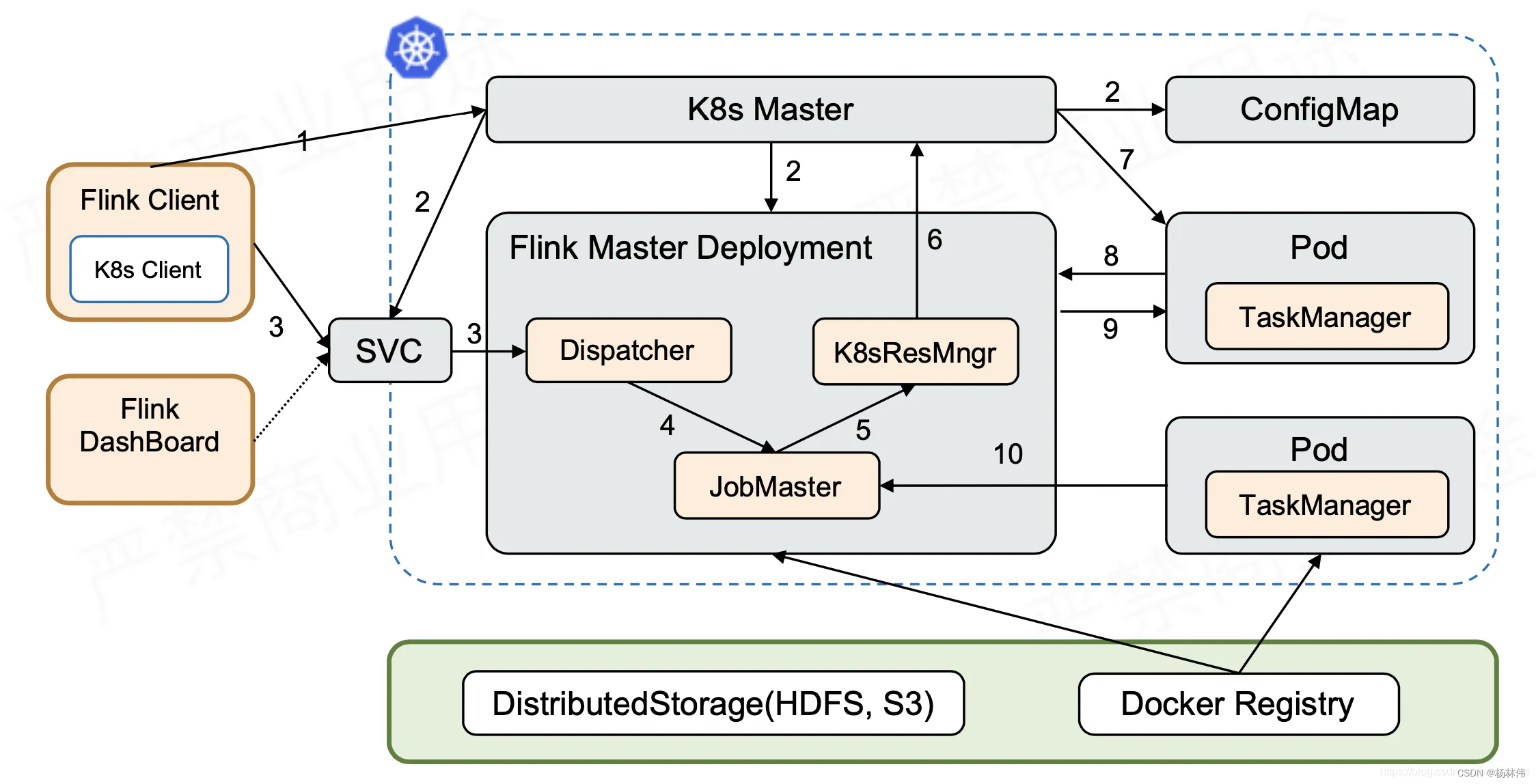
flink集群与资源@k8s源码分析-回顾
本章是分析系列最后一章,作为回顾,以运行架构图串联起所有分析场景 1 启动集群,部署集群(提交k8s),新建作业管理器组件 2 构建和启动flink master组件 3 提交作业,N/A...

学习心得09:C++新特性
现在语言越来越复杂,关键字也越来越多。所以我提出了关键字自动加标识的想法。 这些新特性也都是有用的,一般人也用不上。在这方面,我的主张是:除非你确实需要用到新特性,否则尽量不要用。保证了代码的可维护。 C很复杂…...
前端框架vBean admin
文章目录 引言I 数据库表设计1.1 用户表1.2 角色表1.3 菜单表II 接口引言 文档:https://doc.vvbin.cn/guide/introduction.html http://doc.vvbin.cn 仓库:https://github.com/vbenjs/vue-vben-admin git clone https://github.com/vbenjs/vue-vben-admin-doc 在线体验demo:…...

云原生周刊:Grafana Beyla 发布 | 2023.9.18
开源项目推荐 Komiser Komiser 是一个与云无关的开源资源管理器。它与多个云提供商(包括 AWS、Azure、Civo、Digital Ocean、OCI、Linode、腾讯和 Scaleway)集成,构建云资产库存,并帮助您在资源层面分解成本。 kr8s 这是一个用…...

C++ std::unique_lock 用法
文章目录 1.创建 std::unique_lock 对象2.自动加锁和解锁3.延迟加锁与手动加解锁4.尝试加锁5.配合条件变量使用6.小结参考文献 std::unique_lock 是 C11 提供的一个用于管理互斥锁的类,它提供了更灵活的锁管理功能,适用于各种多线程场景。 1.创建 std::u…...

Pytorch C++ 前端第二部分:输入、权重和偏差
本教程分为两部分 第 2.1 部分 – 基础知识速成课程。第 2.2 部分 – 使用 C++ 构建神经网络如果您已经了解神经网络的基础知识,那么无需阅读 Part-2.1 的内容,理解 Part-2.2 应该没有问题。我们试图通过动画 GIF 来可视化方程,从而使其简短而有趣。但请注意,我们根据在解释…...
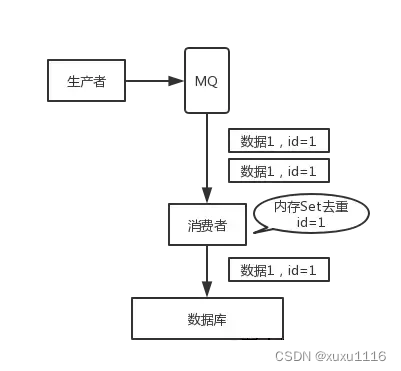
面试题:RocketMQ 如何保证消息不丢失,如何保证消息不被重复消费?
文章目录 1、消息整体处理过程Producer发送消息阶段手段一:提供SYNC的发送消息方式,等待broker处理结果。手段二:发送消息如果失败或者超时,则重新发送。手段三:broker提供多master模式,即使某台broker宕机…...
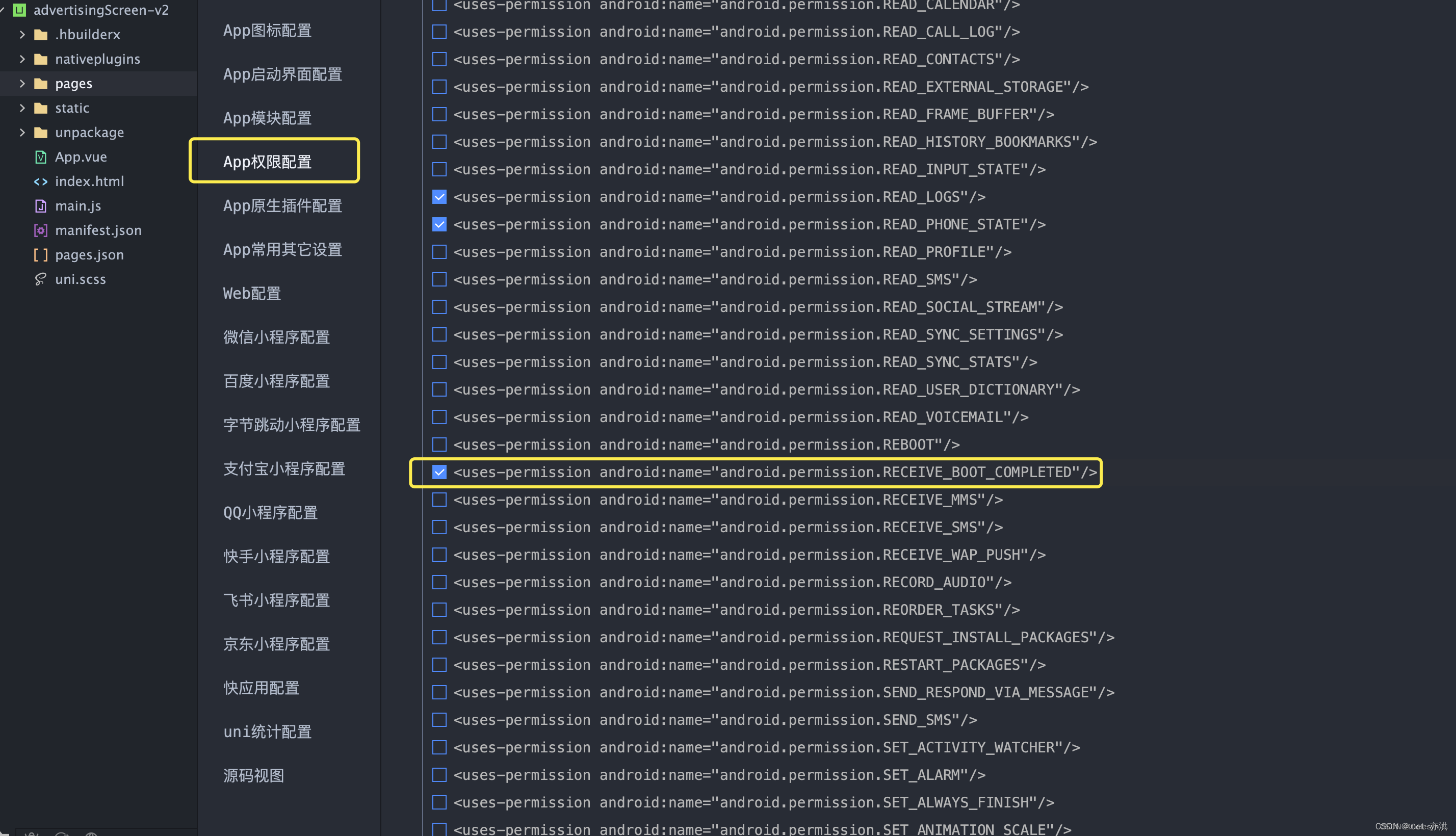
uniapp打包安卓后在安卓屏上实现开机自启动
实现开机自启动(使用插件) 打开插件地址安卓开机自启动 Fvv-AutoStart - DCloud 插件市场 使用方法 选择你要开启自启动的项目 在项目的manifest.json中app-plus下写入以下代码 注意需要替换 android_package_name 为自己的,不然无法进行安卓apk打包 "nativePlugins&q…...

浅谈KNX总线智能照明控制系统在北京南站房中的应用
安科瑞 华楠 摘要:本文简要介绍了i-bus EIB/KNX智能建筑控制系统的基本原理及在北京南站房中的成功应用。阐述了这一系统强大的系统功能、灵活的控制方式节能效果。 关键词:i-bus智能建筑控制;控制系统;节能 1、工程概况 北京新…...

深入了解Java的核心库
掌握Java的核心库是成为一名优秀的Java开发者的关键。Java提供了丰富的核心库和API,包括集合框架、输入输出、多线程、异常处理等等。熟悉并掌握这些库的使用,可以提高编程效率和代码质量。在本文中,我们将深入讨论Java的核心库,并…...
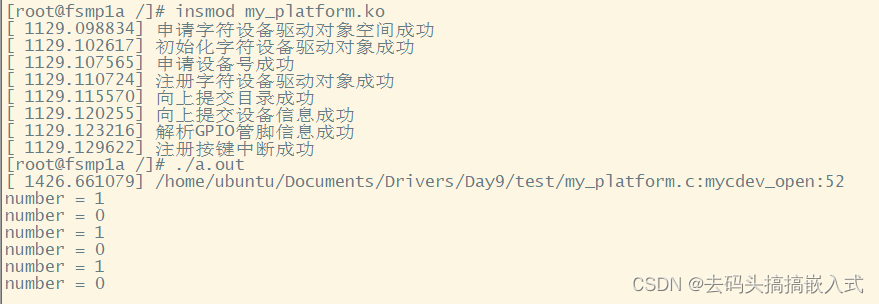
嵌入式:驱动开发 Day9
作业:通过platform总线驱动实现 a.应用程序通过阻塞的io模型来读取number变量的值 b.number是内核驱动中的一个变量 c.number的值随着按键按下而改变(按键中断) 例如number0 按下按键number1 ,再次按下按键number0 d.在按下按键的时候需要同时…...

【ComfyUI】安装 之 window版
文章目录 序言步骤下载comfyUI配置大模型和vae下载依赖组件启动 生成图片解决办法 序言 由于stable diffusion web ui无法做到对流程进行控制,只是点击个生成按钮后,一切都交给AI来处理。但是用于生产生活是需要精细化对各个流程都要进行控制的。 故也…...
iMazing 2 .17.9最新官方中文版免费下载安装激活
iMazing 2 .17.9最新版是一款帮助用户管理IOS手机的应用程序,iMazing2最新版能力远超iTunes提供的终极的iOS设备管理器。IMazing与你的iOS设备(iPhone、 iPad或iPod)相连,使用起来非常的方便。作为苹果指定的iOS设备同步工具。 mazing什么意思 iMazing…...
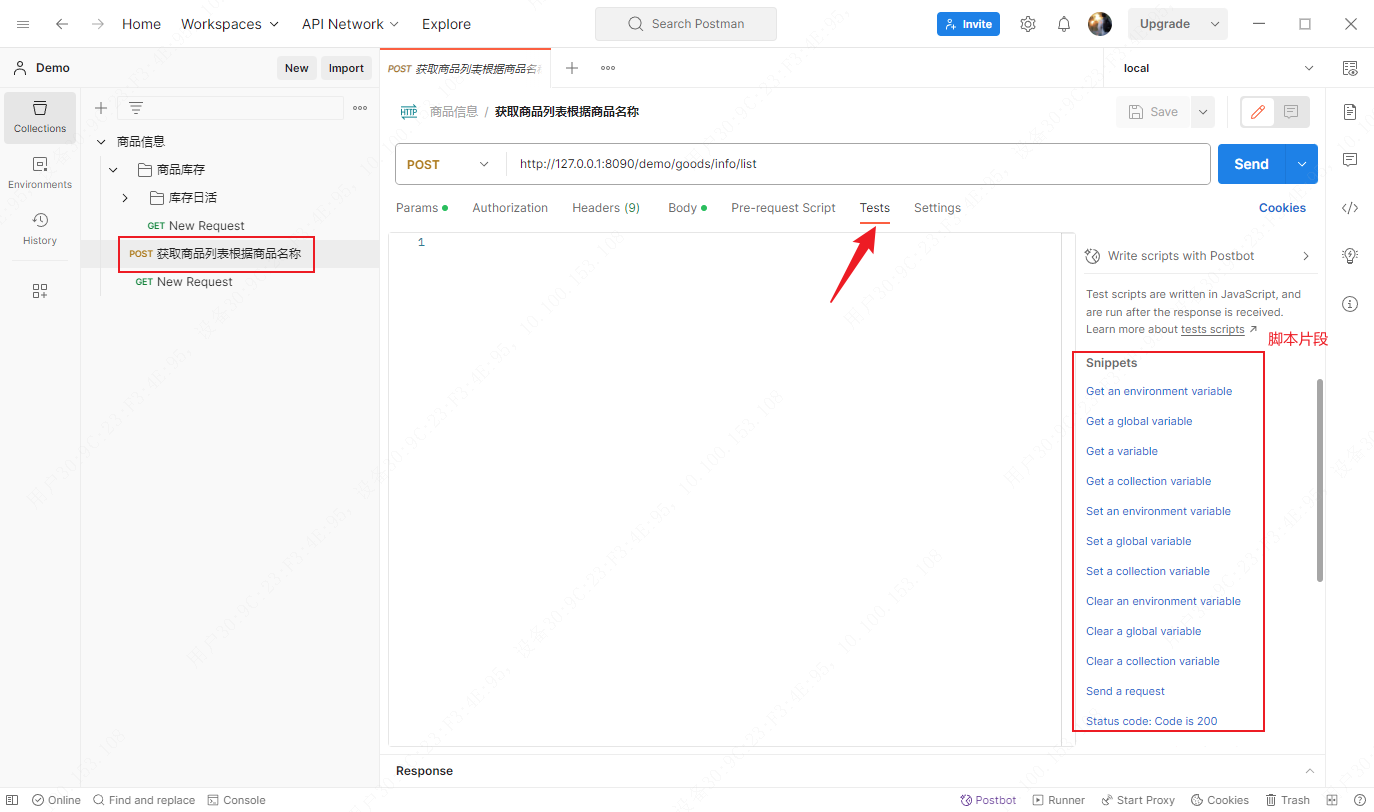
Postman应用——Pre-request Script和Test Script脚本介绍
文章目录 Pre-request Script所在位置CollectionFolderRequest Test Script所在位置CollectionFolderRequest Pre-request Script(前置脚本):可以使用在Collection、Folder和Request中,并在Request请求之前执行,可用于…...
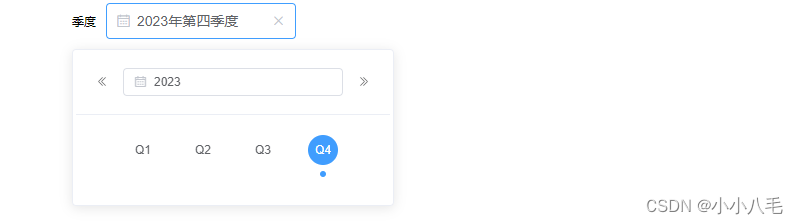
vue2中年份季度选择器(需要安装element)
调用 <!--父组件调用--><QuarterCom v-model"quart" clearable default-current/> 组件代码 <template><div><span style"margin-right: 10px">{{ label }}</span><markstyle"position:fixed;top:0;bottom:0…...
QT day5
数据库完成登入注册 mainwindow.h #ifndef MAINWINDOW_H #define MAINWINDOW_H #include <QMainWindow> #include<QDebug> #include<QPushButton> #include<QLineEdit> #include<QLabel> #include <QMainWindow> #include<QMessageBo…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...