YOLOv5、YOLOv8改进:C3STR(Swin Transformer)
目录
1.介绍
2. YOLOv5、YOLOv8改进
2.1 common.py配置
2.2 yolo.py配置
2.3 yaml配置文件
1.介绍
视觉领域正在见证从 CNN 到 Transformers 的建模转变,纯 Transformer 架构在主要视频识别基准测试中达到了最高准确度。这些视频模型都建立在 Transformer 层之上,Transformer 层在空间和时间维度上全局连接块。在本文中,我们提倡视频 Transformer 中的局部归纳偏差,与以前的方法相比,即使使用时空分解,也可以在全局范围内计算自注意力,从而实现更好的速度-精度权衡。所提出的视频架构的局部性是通过调整为图像域设计的 Swin Transformer 实现的,同时继续利用预训练图像模型的力量。我们的方法在广泛的视频识别基准测试中实现了最先进的准确度,包括动作识别(Kinetics-400 上的 84.9 top-1 准确度和 Kinetics-600 上的 85.9 top-1 准确度,减少了约 20× 预训练数据和小模型尺寸的 3 倍)和时间建模(SomethingSomething v2 上的 69.6 top-1 准确率)。
论文地址Swin-Transformer论文下载论文地址
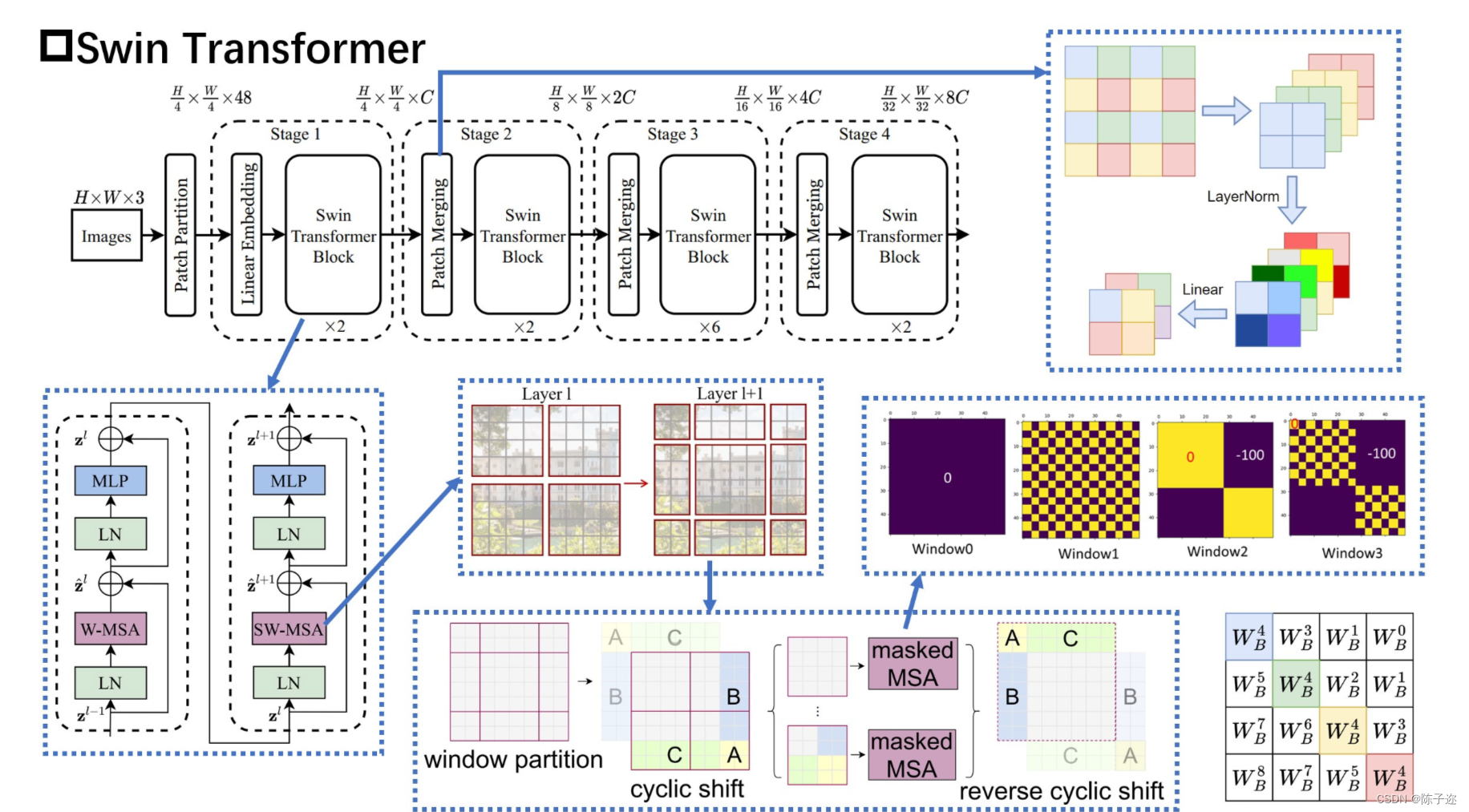
该论文介绍了一种名为 Swin Transformer 的新视觉 Transformer,它能够作为计算机视觉的通用主干。将 Transformer 从语言适应到视觉的挑战来自两个领域之间的差异,例如视觉实体的规模变化很大,以及与文本中的单词相比,图像中像素的高分辨率。为了解决这些差异,我们提出了一种分层 Transformer,其表示是用移位窗口计算的。移位窗口方案通过将 self-attention 计算限制在不重叠的本地窗口上,同时还允许跨窗口连接,从而带来更高的效率。这种分层架构具有在各种尺度上建模的灵活性,并且具有相对于图像大小的线性计算复杂度。Swin Transformer 的这些特性使其与广泛的视觉任务兼容,包括图像分类(ImageNet-1K 上 86.4 top-1 准确度)和密集预测任务,例如对象检测(COCO 测试上 58.7 box AP 和 51.1 mask AP dev)和语义分割(ADE20K val 为 53.5 mIoU)。它的性能大大超过了之前的 state-of-the-art,在 COCO 上 +2.7 box AP 和 +2.6 mask AP,在 ADE20K 上 +3.2 mIoU,展示了基于 Transformer 的模型作为视觉骨干的潜力。代码和模型将在 它的性能大大超过了之前的 state-of-the-art,在 COCO 上 +2.7 box AP 和 +2.6 mask AP,在 ADE20K 上 +3.2 mIoU,展示了基于 Transformer 的模型作为视觉骨干的潜力。代码和模型将在 它的性能大大超过了之前的 state-of-the-art,在 COCO 上 +2.7 box AP 和 +2.6 mask AP,在 ADE20K 上 +3.2 mIoU,展示了基于 Transformer 的模型作为视觉骨干的潜力。
面临问题:
作者提出了将Swin Transformer缩放到30亿个参数的技术 ,并使其能够使用高达1536×1536分辨率的图像进行训练。在很多方面达到了SOTA。
目前,视觉模型尚未像NLP语言模型那样被广泛探索,部分原因是训练和应用中的以下差异:
(1)视觉模型通常在规模上面临不稳定性问题;
(2)许多下游视觉任务需要高分辨率图像,如何有效地将低分辨率预训练的模型转换为高分辨率模型尚未被有效探索,也就是跨窗口分辨率迁移模型时性能下降。
(3)当图像分辨率较高时,GPU显存消耗也是一个问题。
解决思路:
为了解决这些问题,作者提出了几种技术,并在本文中以Swin Transformer进行了说明:
(1)提高大视觉模型稳定性的后归一化(post normalization) 技术和缩放余弦注意力(scaled cosine attention)方法,以提高大型视觉模型的稳定性;
(2)一种对数间隔连续位置偏差技术(log-spaced continuous position bias technique) ,用于有效地将在低分辨率图像中预训练的模型转换为其高分辨率对应模型。
(3)分享节约GPU内存消耗方法,使得训练大分辨率模型可行;
2. YOLOv5、YOLOv8改进
2.1 common.py配置
在./models/common.py文件中增加以下模块,直接复制即可
class SwinTransformerBlock(nn.Module):def __init__(self, c1, c2, num_heads, num_layers, window_size=8):super().__init__()self.conv = Noneif c1 != c2:self.conv = Conv(c1, c2)# remove input_resolutionself.blocks = nn.Sequential(*[SwinTransformerLayer(dim=c2, num_heads=num_heads, window_size=window_size,shift_size=0 if (i % 2 == 0) else window_size // 2) for i in range(num_layers)])def forward(self, x):if self.conv is not None:x = self.conv(x)x = self.blocks(x)return x
class WindowAttention(nn.Module):def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Wwself.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)nn.init.normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask=None):B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)# print(attn.dtype, v.dtype)try:x = (attn @ v).transpose(1, 2).reshape(B_, N, C)except:#print(attn.dtype, v.dtype)x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass SwinTransformerLayer(nn.Module):def __init__(self, dim, num_heads, window_size=8, shift_size=0,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.SiLU, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeself.mlp_ratio = mlp_ratio# if min(self.input_resolution) <= self.window_size:# # if window size is larger than input resolution, we don't partition windows# self.shift_size = 0# self.window_size = min(self.input_resolution)assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def create_mask(self, H, W):# calculate attention mask for SW-MSAimg_mask = torch.zeros((1, H, W, 1)) # 1 H W 1h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1mask_windows = mask_windows.view(-1, self.window_size * self.window_size)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))return attn_maskdef forward(self, x):# reshape x[b c h w] to x[b l c]_, _, H_, W_ = x.shapePadding = Falseif min(H_, W_) < self.window_size or H_ % self.window_size!=0 or W_ % self.window_size!=0:Padding = True# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')pad_r = (self.window_size - W_ % self.window_size) % self.window_sizepad_b = (self.window_size - H_ % self.window_size) % self.window_sizex = F.pad(x, (0, pad_r, 0, pad_b))# print('2', x.shape)B, C, H, W = x.shapeL = H * Wx = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c# create mask from init to forwardif self.shift_size > 0:attn_mask = self.create_mask(H, W).to(x.device)else:attn_mask = Noneshortcut = xx = self.norm1(x)x = x.view(B, H, W, C)# cyclic shiftif self.shift_size > 0:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))else:shifted_x = x# partition windowsx_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, Cx_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C# W-MSA/SW-MSAattn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C# merge windowsattn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C# reverse cyclic shiftif self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = shifted_xx = x.view(B, H * W, C)# FFNx = shortcut + self.drop_path(x)x = x + self.drop_path(self.mlp(self.norm2(x)))x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h wif Padding:x = x[:, :, :H_, :W_] # reverse paddingreturn xclass C3STR(C3):# C3 module with SwinTransformerBlock()def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2, c2, n, shortcut, g, e)c_ = int(c2 * e)num_heads = c_ // 32self.m = SwinTransformerBlock(c_, c_, num_heads, n)
2.2 yolo.py配置
不需要
2.3 yaml配置文件
增加以下yolov5_swin_transfomrer.yaml文件
代码
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone by yoloair
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3STR, [256]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3STR, [512]], # 9 <--- ST2CSPB() Transformer module[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
修改完成
相关文章:
YOLOv5、YOLOv8改进:C3STR(Swin Transformer)
目录 1.介绍 2. YOLOv5、YOLOv8改进 2.1 common.py配置 2.2 yolo.py配置 2.3 yaml配置文件 1.介绍 视觉领域正在见证从 CNN 到 Transformers 的建模转变,纯 Transformer 架构在主要视频识别基准测试中达到了最高准确度。这些视频模型都建立在 Transformer 层之…...
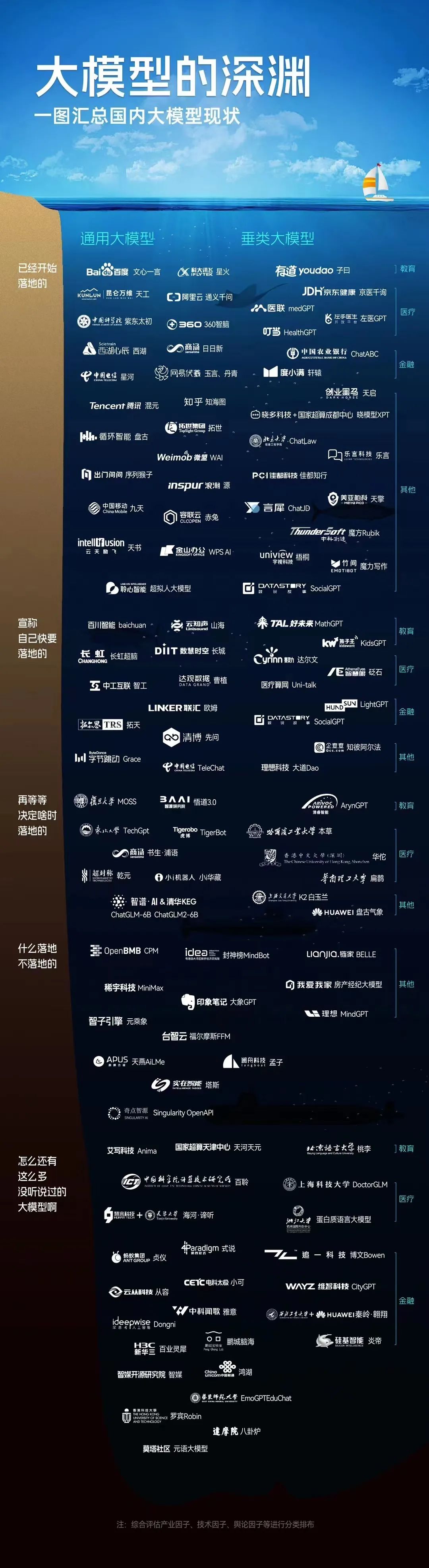
AIGC百模大战
AIGC Artificial Intelligence Generated Content, 或者Generative Artificial Intelligence,它能够生成新的数据、图像、语音、视频、音乐等内容,从而扩展人工智能系统的应用范围。 生成式人工智能有可能给全球经济带来彻底的变化。根据高盛…...
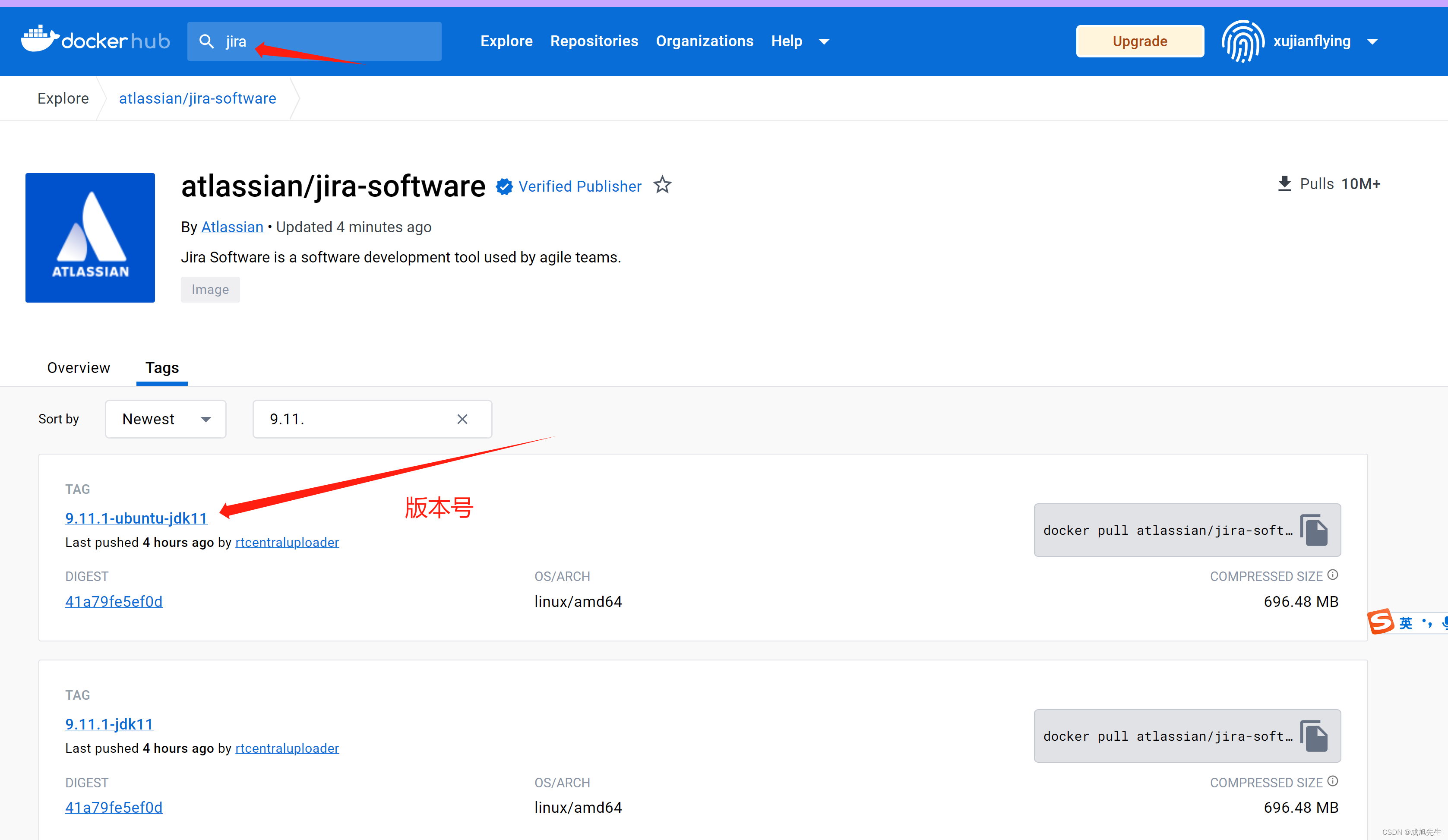
docker jira 一键安装含PJ(docker 一键安装jira)
docker jira 一键安装含PJ(docker 一键安装jira) 本文仅供参考学习,请勿用于商业用途本文用于Jira在Docker的安装,仅用于记录安装方式转载请注明来源Linux安装可参考链接Windows安装可查考链接Docker一键安装Confluence PJ条件允…...

认识一下Git
目录 Git Git下载 Git安装 Git初始化 Git操作 Git、GitLab、和Eclipse是公司中软件开发常用的组合: 1. Git:Git是一种分布式版本控制系统,用于跟踪文件和代码的变化。它提供了管理代码仓库的功能,可以记录每次提交的修改&am…...
只需4步使用Redis缓存优化Node.js应用
介绍 通过API获取数据时,会向服务器发出网络请求,收到响应数据。但是,此过程可能非常耗时,并且可能会导致程序响应时间变慢。 我们使用缓存来解决这个问题,客户端程序首先向API发送请求,将返回的数据存储…...

【react基础01】项目文件结构描述
react 项目文件结构描述 📂 REACTWORKSPACE📂 node_modules📂 public📄 favicon.ico📄 index.html📄 logo192.png📄 logo512.png📄 manifest.json📄 robots.txt …...
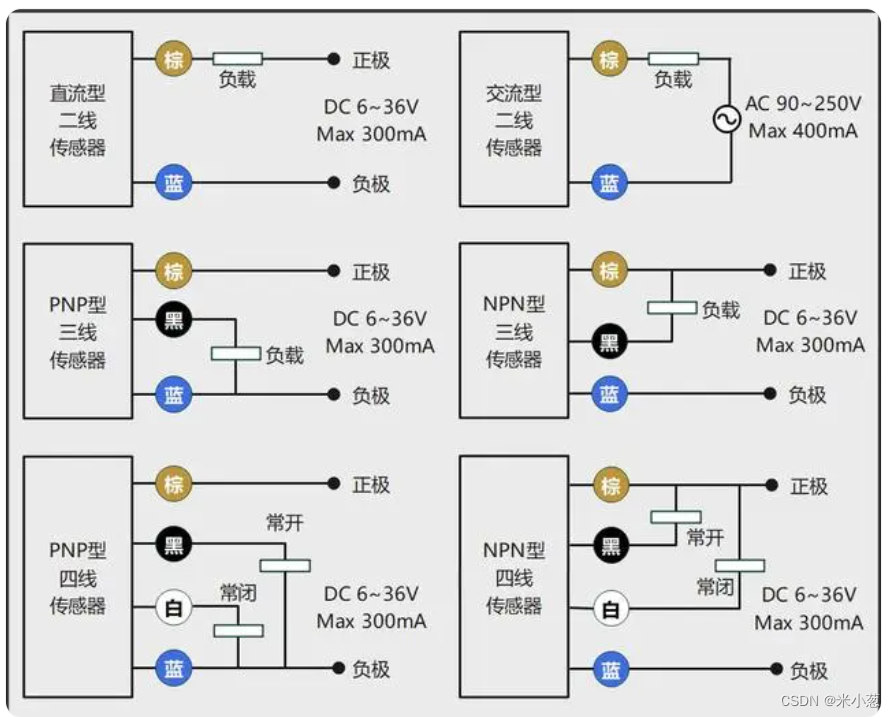
光电开关-NPN-PNP
基础概念 有信号 “检测到物体/有物体遮挡” 工作原理 NPN:表示共正电压,输出负电压【只能输出低电压或者悬空 常开常闭是指 输出有没有跟“地”接通】; NPN NO:表示常态下是常开的,检测到物体时黑色线输出一个负电压…...
学会使用Git 和 GitHub
Git 和 GitHub 都是程序员每天都要用到的东西 —— 前者是目前最先进的 版本控制工具,拥有最多的用户,且管理着地球上最庞大的代码仓库;而后者是全球最大 同性交友 代码托管平台、开源社区。 在没有这两个工具时,编程可能是这样的…...

SoftwareTest3 - 要了人命的Bug
软件测试基础篇 一 . 如何合理的创建一个 Bug二 . Bug 等级2.1 崩溃2.2 严重2.3 一般2.4 次要 三 . Bug 的生命周期四 . 跟开发产生争执应该怎么解决 Hello , 大家好 , 又给大家带来新的专栏喽 ~ 这个专栏是专门为零基础小白从 0 到 1 了解软件测试基础理论设计的 , 虽然还不足…...

Linux系统中MySQL库的操作,实操sql代码
Linux系统中MySQL库的操作 本文主要是对linux系统下MySQL库操作的总结,包含创建、删除、修改数据库,数据库的编码格式和校验格式以及数据库的恢复和备份。 1.创建数据库 1.1基本语法: CREATE DATABASE [IF NOT EXISTS] db_name [create_s…...

Python基础分享之面向对象的进一步拓展
我们熟悉了对象和类的基本概念。我们将进一步拓展,以便能实际运用对象和类。 调用类的其它信息 上一讲中提到,在定义方法时,必须有self这一参数。这个参数表示某个对象。对象拥有类的所有性质,那么我们可以通过self,调…...
Windows安装Docker Desktop并配置镜像、修改内存占用大小
启用Hyper-V Win S 搜索控制面板 安装WSL2 第一种方法(推荐) 以管理员运行命令提示符,然后重启Docker Desktop wsl --updatewsl --set-default-version 2第2种方法去微软官网下载WSL2并安装 《微软官网下载WSL2》 配置WSL2最大内…...

Zipping
Zipping 信息收集端口扫描目录扫描webbanner信息收集 漏洞利用空字节绕过---->失败sqlI-preg_match bypass反弹shell 稳定维持 提权-共享库漏洞 参考:https://rouvin.gitbook.io/ibreakstuff/writeups/htb-season-2/zipping#sudo-privileges-greater-than-stock-…...
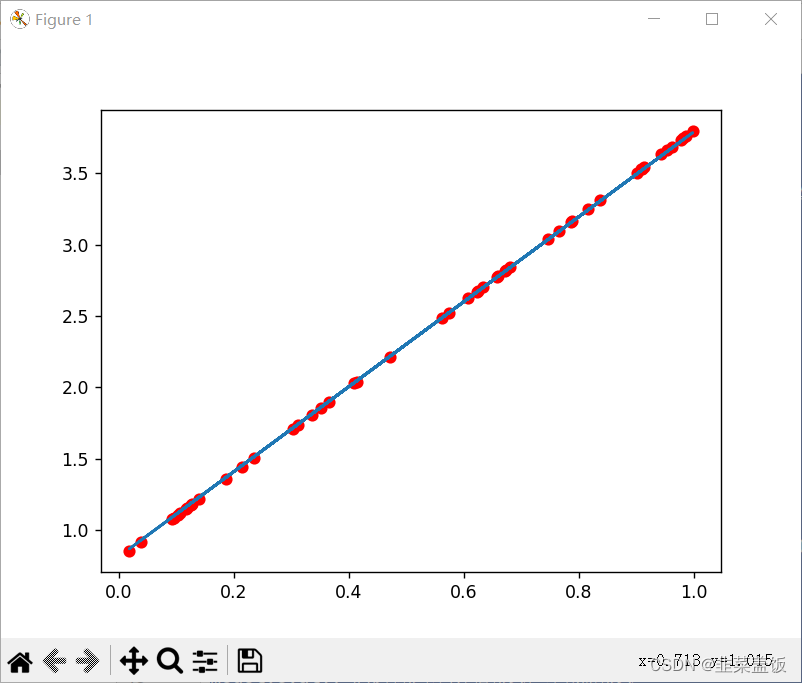
pytorch学习---实现线性回归初体验
假设我们的基础模型就是y wx b,其中w和b均为参数,我们使用y 3x0.8来构造数据x、y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8。 步骤如下: 准备数据计算预测值计算损失,把参数的梯度置为0,进行反向传播…...

别再乱写git commit了
B站|公众号:啥都会一点的研究生 写在前面 在很长的一段时间中,使用git commit都是随心所欲,log肥肠简洁,随着代码的迭代,当时有多偷懒,返过头查看git日志就有多懊悔,就和写代码不写doc string…...

八大排序(一)冒泡排序,选择排序,插入排序,希尔排序
一、冒泡排序 冒泡排序的原理是:从左到右,相邻元素进行比较。每次比较一轮,就会找到序列中最大的一个或最小的一个。这个数就会从序列的最右边冒出来。 以从小到大排序为例,第一轮比较后,所有数中最大的那个数就会浮…...

泊松分布简要介绍
泊松分布是一种常见的离散概率分布,它用于描述某个时间段或区域内随机事件发生的次数。它得名于法国数学家西蒙丹尼泊松。 泊松分布的概率质量函数表示某个时间段或区域内事件发生次数的概率。如果随机变量 X 服从泊松分布,记作 X ~ Poisson(λ)&#x…...

C语言每日一题(10):无人生还
文章主题:无人生还🔥所属专栏:C语言每日一题📗作者简介:每天不定时更新C语言的小白一枚,记录分享自己每天的所思所想😄🎶个人主页:[₽]的个人主页🏄…...

VSCode开发go手记
断点调试: 安装delve(windows): go get -u github.com/go-delve/delve/cmd/dlv 设置 launch.json 配置文件: ctrlshiftp 输入 Debug: Open launch.json 打开 launch.json 文件,如果第一次打开,会新建一…...

怎么选择AI伪原创工具-AI伪原创工具有哪些
在数字时代,创作和发布内容已经成为了一种不可或缺的活动。不论您是个人博主、企业家还是网站管理员,都会面临一个共同的挑战:如何在互联网上脱颖而出,吸引更多的读者和访客。而正是在这个背景下,AI伪原创工具逐渐崭露…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...