第1篇 目标检测概述 —(1)目标检测基础知识

前言:Hello大家好,我是小哥谈。目标检测是计算机视觉领域中的一项任务,旨在自动识别和定位图像或视频中的特定目标,目标可以是人、车辆、动物、物体等。目标检测的目标是从输入图像中确定目标的位置,并使用边界框将其标记出来。🎉为了让大家能够牢固地掌握目标检测基础知识,本系列文章就对目标检测进行详细介绍,希望大家学习之后能够有所收获!🌈
目录
🚀1.简介
💥💥1.1 什么是目标检测?
💥💥1.2 目标检测算法难点
💥💥1.3 目标检测主流目标检测技术
💥💥1.4 目标检测算法未来趋势
💥💥1.5 目标检测算法应用
🚀2.目标检测发展历程与现状
💥💥2.1 目标检测算法发展历程
💥💥2.2 目标检测算法分类
🚀3.目标检测原理
💥💥3.1 候选区域产生
💥💥3.2 数据表示
💥💥3.3 效果评估
💥💥3.4 非极大值抑制
🚀4.目标检测常用的数据集
💥💥4.1 PASCAL VOC
💥💥4.2 MS COCO
💥💥4.3 Google Open Image
💥💥4.4 ImageNet
💥💥4.5 DOTA
🚀5.目标检测常用标注工具
💥💥5.1 LabelImg
💥💥5.2 labelme
💥💥5.3 Labelbox
💥💥5.4 RectLabel
💥💥5.5 CVAT
💥💥5.6 VIA
💥💥5.7 其他标注工具
🚀6.目标检测常用术语表

🚀1.简介
💥💥1.1 什么是目标检测?
目标检测是计算机视觉领域中的一个任务,其目的是在图像或视频中确定和定位感兴趣的物体。目标检测模型不仅可以识别物体的类别,还能够提供每个物体的边界框位置。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测⼀直是计算机视觉领域最具有挑战性的问题。目标检测通常涉及两个主要步骤:分类(判断物体类别)和定位(确定边界框位置)。🌴
目标检测的位置信息一般由两种格式(以图片左上角为原点(0,0)):
🍀(1)极坐标表示:(xmin, ymin, xmax, ymax)
- xmin,ymin:x,y坐标的最小值
- xmin,ymin:x,y坐标的最大值
🍀(2)中心点坐标:(x_center, y_center, w, h)
- x_center,y_center:目标检测框的中心点坐标
- w,h:目标检测框的宽、高
在深度学习领域,目标检测通常使用卷积神经网络(CNN)模型来实现。常见的目标检测方法包括:
R-CNN系列:包括R-CNN、Fast R-CNN、Faster R-CNN等,这些方法使用候选区域提取技术(如选择性搜索)来生成感兴趣区域,然后通过分类器和回归器对这些区域进行分类和定位。
YOLO系列:包括YOLO、YOLOv2、YOLOv3等,这些方法将目标检测问题转化为一个回归问题,并将物体位置和类别同时预测出来,具有较快的速度和较高的精度。
SSD(Single Shot MultiBox Detector):SSD将目标检测问题转化为一个多尺度检测问题,通过在不同层次上预测不同尺度的边界框和类别信息来实现目标检测。
等等......🍉 🍓 🍑 🍈 🍌 🍐
计算机视觉中关于图像识别有四大类任务:
📗分类-Classification:解决“是什么?”的问题,即给定⼀张图⽚或⼀段视频判断里面包含什么类别的目标。
📗定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
📗检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个⽬标的的位置并且知道目标物是什么。
📗分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每⼀个像素属于哪个目标物或场景”的问题。
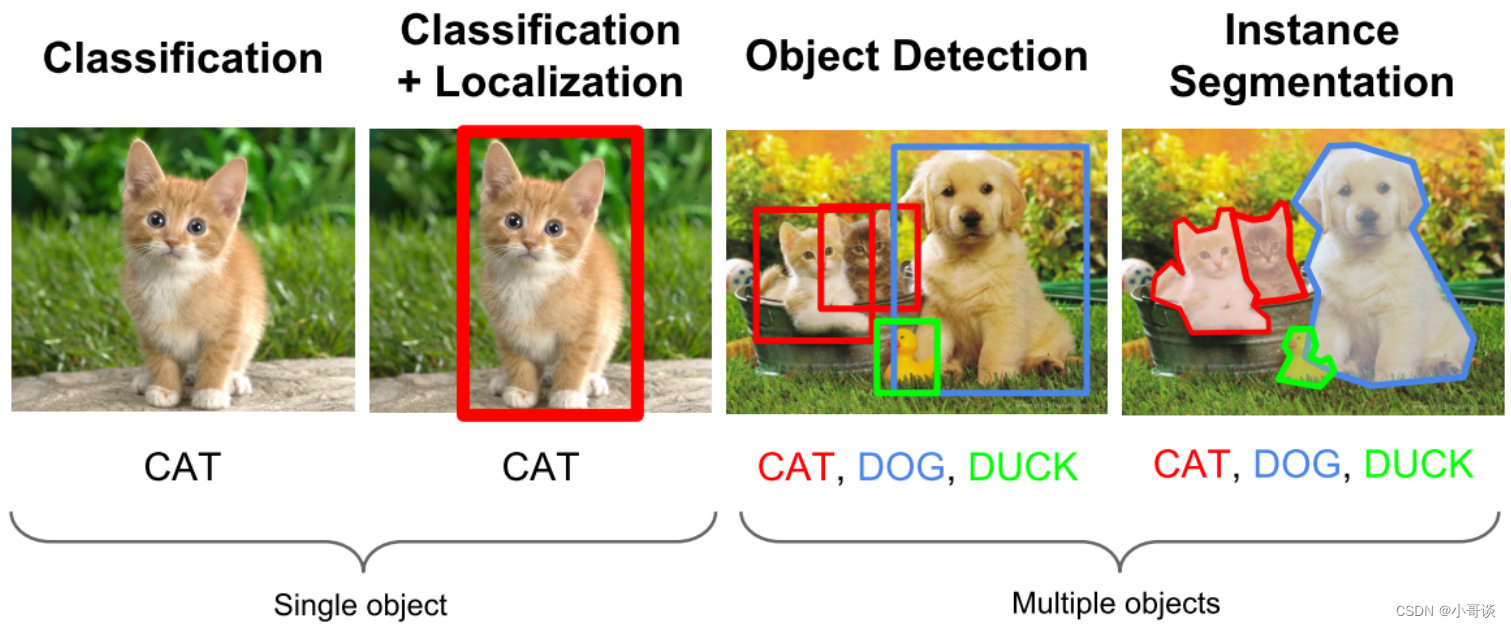
除了图像分类之外,目标检测要解决的核心问题是:
- 目标可能出现在图像的任何位置。
- 目标有各种不同的大小。
- 目标可能有各种不同的形状。
💥💥1.2 目标检测算法难点
目标检测算法的主要难点和挑战:
- 待检测目标尺寸很小,导致占比小,检测难度大。
- 待检测目标尺度变化大,网络难以提取出高效特征。
- 待检测目标所在背景复杂,噪音干扰严重,检测难度大。
- 待检测目标与背景颜色对比度低,网络难以提取出具有判别性的特征。
- 各待检测目标之间数量极度不均衡,导致样本不均衡。
- 检测算法的速度与精度难以取得良好平衡。
等等......🍉 🍓 🍑 🍈 🍌 🍐
💥💥1.3 目标检测主流目标检测技术
目前国内主流的目标检测技术:
- YOLOX:由中国的旷视科技研发,是目前国际上运行速度最快的一种深度学习模型。
- YOLOV1-V5:Yolov1-yolov3由Joseph Redmon研发,yolov4-yolov5则是由yolo团队内部成员完成的。
- Transformer:原来是做为语音识别的一个模型,现在用在图像的目标识别上面也有不俗的表现。
- ViT:当考虑预训练模型的计算成本时,ViT的性能非常好,以较低的预训练成本在大多数识别基准上达到了最先进的水平。
等等......🍉 🍓 🍑 🍈 🍌 🍐
💥💥1.4 目标检测算法未来趋势
随着技术的发展和成熟应用,目标检测算法未来的发展趋势主要有:
- 轻量型目标检测
- 与AutoML结合的目标检测
- 领域自适应的目标检测
- 弱监督目标检测
- 小目标检测
- 视频检测
- 信息融合目标检测
等等......🍉 🍓 🍑 🍈 🍌 🍐
💥💥1.5 目标检测算法应用
目标检测具有巨大的实⽤价值和应⽤前景。🐳
🍀(1)人脸检测
- 智能门控
- 员工考勤签到
- 智慧超市
- 人脸支付
- 车站、机场实名认证
- 公共安全:逃犯抓捕、走失人员检测
🍀(2)行人检测
- 智能辅助驾驶
- 智能监控
- 暴恐检测(根据面相识别暴恐倾向)
- 移动侦测、区域入侵检测、安全帽/安全带检测
🍀(3)车辆检测
- 自动驾驶
- 违章查询、关键通道检测
- 广告检测(检测广告中的车辆类型,弹出链接)
🍀(4)遥感检测
- 大地遥感,如土地使用、公路、水渠、河流监控
- 农作物监控
- 军事检测
🚀2.目标检测发展历程与现状
💥💥2.1 目标检测算法发展历程
过去的 20 年,目标检测的发展历程大致经历了两个历史时期:传统的目标检测时期(2014 年以前)和基于深度学习的检测时期(2014 年以后)。📚
传统的目标检测算法可以概括为以下几个步骤:👇
首先,采取滑动窗口的方式遍历整张图像,产生一定数量的候选框;
其次,提取候选框的特征;
最后,利用支持向量机(SVM)等分类方法对提取到的特征进行分类,进而得到结果。
由于当时缺乏有效的图像表示,人们只能设计复杂的特征表示,并通过各种加速技能来充分利用有限的计算资源。该时期主要的检测方法有:
- Viola Jones检测器: Viola Jones检测器由三个核心步骤组成,即Haar特征和积分图、Adaboost分类器以及级联分类器。
- HOG检测器:HOG检测器利用了方向梯度直方图(HOG特征描述子,通过计算和统计局部区域的梯度方向直方图来构建特征)。HOG特征与SVM分类器算法的结合,在行人检测任务中应用广泛且效果显著。然而,HOG检测器的缺点是始终需要保持检测窗口的大小不变,如果待检测目标的大小不一,那么HOG检测器需要多次缩放输入图像。
- 基于部件的可变形模型(DPM):DPM所遵循的思想是“分而治之”,训练过程中学习的是如何将目标物体进行正确地分解,而推理时则是将不同的部件组合到一起。比如说,检测“汽车”问题可以分解为检测“车窗”、“车身”和“车轮”等。
早期的目标检测任务提取特征时,主要的方式是人工提取,具有一定的局限性,手工特征的性能也趋于饱和。2012 年起,卷积神经网络的广泛应用使得目标检测也开启了新的征程。2014年R-CNN算法横空出世,目标检测开始以前所未有的速度快速发展。深度学习时代,目标检测算法根据检测思想的不同通常可以分为两大类别:两阶段(two-stage)检测和一阶段(one-stage)检测。🔖
两阶段检测算法基于提议的候选框,是一个“由粗到细”的过程。首先产生区域候选框,其次提取每个候选框的特征,最后产生位置框并预测对应的类别,特点是精度高但速度慢。最早期的R-CNN算法利用“选择性搜索”方法产生候选框、卷积神经网络提取特征、支持向量机分类器进行分类和预测。虽然R-CNN算法具有一定的开创性,但生成的候选框大量重叠,存在计算冗余的问题。
2014年提出的SPPNet算法利用空间金字塔池化层对不同尺度的特征图进行池化并生成固定长度的特征表示,减少反复缩放图像对检测结果造成的影响。然而,SPPNet的缺点是:模型的训练仍然是分多步的;SPPNet很难对SPP层之前的网络进行参数微调,导致效率降低。2015 年提出的Fast R-CNN算法,对R-CNN与SPPNet算法做出进一步改进,提出感兴趣区域池化层(ROI),使得检测的速度和精度大大提升。随后又出现的Faster R-CNN算法,实现了端到端地训练,用RPN网络代替选择性搜索,大大减少了训练和测试的时间。
一阶段检测算法基于边界框的回归,是一个“一步到位”的过程。一阶段检测网络在产生候选框的同时进行分类和边界框回归,特点是速度快但精度稍逊。2016年YOLO算法提出,该算法将图像分割成 S×S 个网格,基于每个网格对应的包围框直接预测类别概率和回归位置信息。随后有出现了SSD 算法,该算法借鉴YOLO算法的思想,并利用多尺度特征图进行预测。
💥💥2.2 目标检测算法分类
基于深度学习的⽬标检测算法主要分为两类:👇
🍀(1)Two stage目标检测算法
先进行区域生成(region proposal,RP)(⼀个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务:特征提取—>生成RP—>分类/定位回归。
常见的two stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。✅
🍀(2)One stage目标检测算法
不用RP,直接在网络中提取特征来预测物体分类和位置。
任务:特征提取—>分类/定位回归。
常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。✅
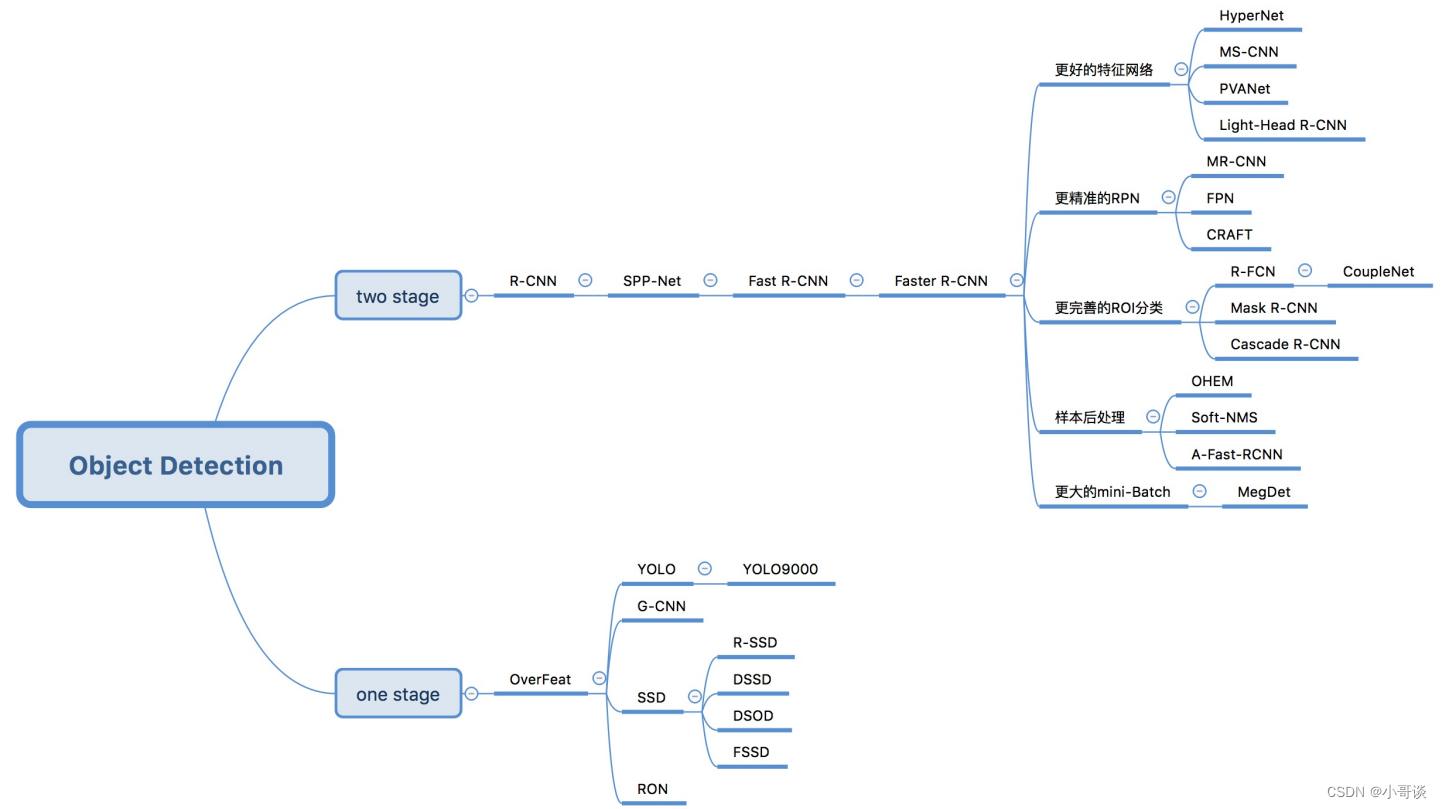
两阶段算法和一阶段算法对比:
| 算法类别 | 机制 | 优势 | 局限性 | 适用场景 |
| 两阶段算法 | 先生成候选区,再对候选区进行分类和回归。 | 算法精确度高 | 实时性差,检测小目标效果差。 | 高精度目标检测 |
| 一阶段算法 | 不生成候选区直接进行分类和回归 | 实时性高 | 成群目标和小目标检测精度低 | 实时目标检测 |
🚀3.目标检测原理
目标检测主要分为两大系列——RCNN系列和YOLO系列,RCNN系列是基于区域检测的代表性算法,YOLO是基于区域提取的代表性算法。🔖
💥💥3.1 候选区域产生
很多目标检测技术都会涉及候选框(bounding boxes)的生成,物体候选框获取当前主要使用图像分割与区域生长技术。区域生长(合并)主要由于检测图像中存在的物体具有局部区域相似性(颜色、纹理等)。目标识别与图像分割技术的发展进一步推动有效提取图像中信息。
🍀(1)滑动窗口
通过滑窗法流程图可以很清晰理解其主要思路:首先对输入图像进行不同窗口大小的滑窗进行从左往右、从上到下的滑动。每次滑动时候对当前窗口执行分类器(分类器是事先训练好的)。如果当前窗口得到较高的分类概率,则认为检测到了物体。对每个不同窗口大小的滑窗都进行检测后,会得到不同窗口检测到的物体标记,这些窗口大小会存在重复较高的部分,最后采用非极大值抑制(Non-Maximum Suppression, NMS)的方法进行筛选。最终,经过NMS筛选后获得检测到的物体。
滑窗法简单易于理解,但是不同窗口大小进行图像全局搜索导致效率低下,而且设计窗口大小时候还需要考虑物体的长宽比。所以,对于实时性要求较高的分类器,不推荐使用滑窗法。

说明:♨️♨️♨️
滑动窗口法中,事先规定一个固定大小的窗口,使用这个窗口在原图中滑动,滑动到每个位置,那么窗口与图像重合的部分就是一个候选区域,候选区域用来后续的检测任务(滑动窗口法类似于卷积神经网络中的卷积过程)。如果图片尺寸很大,会导致一张图片就能产生数量极多的候选区域。滑动窗口的尺寸设置需要与物体的尺寸相匹配才能带来好的效果,因此对于检测任务来说,滑动窗口法效率很低并且性能不优。
🍀(2)选择性搜索
滑窗法类似穷举进行图像子区域搜索,但是一般情况下图像中大部分子区域是没有物体的。学者们自然而然想到只对图像中最有可能包含物体的区域进行搜索以此来提高计算效率。选择搜索(selective search,简称SS)方法是当下最为熟知的图像bounding boxes提取算法,由Koen E.A于2011年提出。
选择搜索算法的主要思想:图像中物体可能存在的区域应该是有某些相似性或者连续性区域的。因此,选择搜索基于上面这一想法采用子区域合并的方法进行提取bounding boxes。
首先,对输入图像进行分割算法产生许多小的子区域。
其次,根据这些子区域之间相似性(相似性标准主要有颜色、纹理、大小等等)进行区域合并,不断的进行区域迭代合并。每次迭代过程中对这些合并的子区域做bounding boxes(外切矩形),这些子区域外切矩形就是通常所说的候选框。

选择性搜索流程:
- step0:生成区域集R
- step1:计算区域集R里每个相邻区域的相似度S={s1, s2,…}
- step2:找出相似度最高的两个区域,将其合并为新集,添加进R
- step3:从S中移除所有与step2中有关的子集
- step4:计算新集与所有子集的相似度
- step5:跳至step2,直至S为空
选择性搜索优点:
- 计算效率优于滑窗法;
- 由于采用子区域合并策略,所以可以包含各种大小的疑似物体框。
- 合并区域相似的指标多样性,提高了检测物体的概率。
💥💥3.2 数据表示
经过标记后的样本数据如下所示:

预测输出可以表示为:
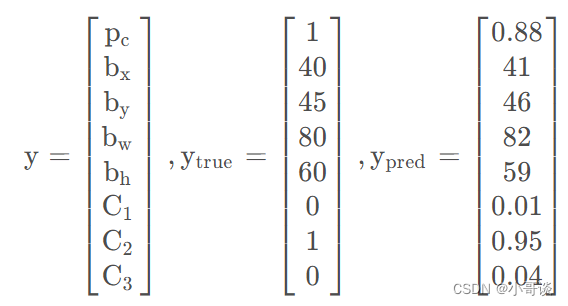
其中,为预测结果的置信概率,
,
,
,
为边框坐标,
,
,
为属于某个类别的概率。通过预测结果、实际结果,构建损失函数。
💥💥3.3 效果评估
使用IoU(Intersection over Union,交并比)来判断模型的好坏。所谓交并比,是指预测边框、实际边框交集和并集的比率,一般约定0.5为一个可以接收的值。

💥💥3.4 非极大值抑制
预测结果中,可能多个预测结果间存在重叠部分,需要保留交并比最大的、去掉非最大的预测结果,这就是非极大值抑制(Non-Maximum Suppression,简写作NMS)。
如下图所示,对同一个物体预测结果包含三个概率0.8/0.9/0.95,经过非极大值抑制后,仅保留概率最大的预测结果。

说明:♨️♨️♨️
置信度:置信度是介于0-1(或100%)之间的数字,它描述模型认为此预测边界框包含某类别目标的概率。
IoU(Intersection over Union,IoU):即两个边界框相交面积与相并面积的比值,边界框的准确度可以用IoU进行表示;一般约定,在检测中,IOU>0.5,则认为检测正确,一般阈值设为0.5。
总结就是置信度和IoU一起用来计算精确率。
🚀4.目标检测常用的数据集
💥💥4.1 PASCAL VOC
VOC数据集是⽬标检测经常⽤的⼀个数据集,⾃2005年起每年举办⼀次⽐赛,最开始只有4类,到2007年扩充 为20个类,共有两个常⽤的版本:2007和2012。
学术界常⽤5k的train/val 2007和16k的train/val 2012作为训练集,test 2007作为测试集,⽤10k的train/val 2007+test 2007和16k的train/val 2012作为训练集,test2012作为测试集,分别汇报结果。
💥💥4.2 MS COCO
COCO数据集是微软团队发布的⼀个可以⽤来图像recognition+segmentation+captioning 数据集,该数据集收集了⼤量包含常见物体的⽇常场景图⽚,并提供像素级的实例标注以更精确地评估检测和分割算法的效果,致⼒于推动场景理解的研究进展。依托这⼀数据集,每年举办⼀次⽐赛,现已涵盖检测、分割、关键点识别、注释等机器视觉的中⼼任务,是继ImageNet Chanllenge以来最有影响⼒的学术竞赛之⼀。 相⽐ImageNet,COCO更加偏好⽬标与其场景共同出现的图⽚,即non-iconic images。这样的图⽚能够反映视觉上的语义,更符合图像理解的任务要求,⽽相对的iconic images则更适合浅语义的图像分类等任务。
COCO的检测任务共含有80个类,在2014年发布的数据规模分train/val/test分别为80k/40k/40k,学术界较为通⽤的划分是使⽤train和35k的val⼦集作为训练集(trainval35k),使⽤剩余的val作为测试集(minival),同时向官⽅的evaluation server提交结果(test-dev)。除此之外,COCO官⽅也保留⼀部分test数据作为⽐赛的评测集。
💥💥4.3 Google Open Image
Open Image是⾕歌团队发布的数据集。最新发布的Open Images V4包含190万图像、600个种类,1540万个 bounding-box标注,是当前最⼤的带物体位置标注信息的数据集。这些边界框⼤部分都是由专业注释⼈员⼿动绘制的,确保了它们的准确性和⼀致性。另外,这些图像是⾮常多样化的,并且通常包含有多个对象的复杂场景(平均每个图像 8 个)。
💥💥4.4 ImageNet
ImageNet是⼀个计算机视觉系统识别项⽬,是⽬前世界上图像识别最⼤的数据库。ImageNet是美国斯坦福的计算机科学家,模拟⼈类的识别系统建⽴的。能够从图⽚识别物体。Imagenet数据集⽂档详细,有专门的团队维护,使⽤⾮常⽅便,在计算机视觉领域研究论⽂中应⽤⾮常⼴,⼏乎成为了⽬前深度学习图像领域算法性能 检验的“标准”数据集。Imagenet数据集有1400多万幅图⽚,涵盖2万多个类别;其中有超过百万的图⽚有明确的类别标注和图像中物体位置的标注。
💥💥4.5 DOTA
DOTA是遥感航空图像检测的常⽤数据集,包含2806张航空图像,尺⼨⼤约为4kx4k,包含15个类别共计188282个实例,其中14个主类,small vehicle 和 large vehicle都是vehicle的⼦类。其标注⽅式为四点确定的任意形状和⽅向的四边形。航空图像区别于传统数据集,有其⾃⼰的特点,如:尺度变化性更⼤;密集的⼩物体 检测;检测⽬标的不确定性。数据划分为1/6验证集,1/3测试集,1/2训练集。⽬前发布了训练集和验证集,图像尺⼨从800x800到4000x4000不等。
🚀5.目标检测常用标注工具
💥💥5.1 LabelImg
LabelImg 是⼀款开源的图像标注⼯具,标签可⽤于分类和⽬标检测,它是⽤ Python 编写的,并使⽤Qt作为其图形界⾯,简单好⽤。注释以 PASCAL VOC 格式保存为 XML ⽂件,这是 ImageNet 使⽤的格式。 此外,它还⽀持 COCO 数据集格式。
💥💥5.2 labelme
labelme 是⼀款开源的图像/视频标注⼯具,标签可⽤于⽬标检测、分割和分类。灵感是来⾃于 MIT 开源的⼀ 款标注⼯具 LabelMe。
labelme 具有的特点是:
- ⽀持图像的标注的组件有:矩形框,多边形,圆,线,点(rectangle, polygons, circle, lines, points)
- ⽀持视频标注
- GUI ⾃定义
- ⽀持导出 VOC 格式⽤于 semantic/instance segmentation
- ⽀出导出 COCO 格式⽤于 instance segmentation
💥💥5.3 Labelbox
Labelbox 是⼀家为机器学习应⽤程序创建、管理和维护数据集的服务提供商,其中包含⼀款部分免费的数据标签⼯具,包含图像分类和分割,⽂本,⾳频和视频注释的接⼝,其中图像视频标注具有的功能如下:
- 可⽤于标注的组件有:矩形框,多边形,线,点,画笔,超像素等(bounding box, polygons, lines, points,brush, subpixels)
- 标签可⽤于分类,分割,⽬标检测等
- 以 JSON / CSV / WKT / COCO / Pascal VOC 等格式导出数据
- ⽀持 Tiled Imagery (Maps)
- ⽀持视频标注 (快要更新)
💥💥5.4 RectLabel
RectLabel 是⼀款在线免费图像标注⼯具,标签可⽤于⽬标检测、分割和分类。具有的功能或特点:
- 可⽤的组件:矩形框,多边形,三次贝塞尔曲线,直线和点,画笔,超像素
- 可只标记整张图像⽽不绘制
- 可使⽤画笔和超像素
- 导出为YOLO,KITTI,COCO JSON和CSV格式
- 以PASCAL VOC XML格式读写
- 使⽤Core ML模型⾃动标记图像
- 将视频转换为图像帧
💥💥5.5 CVAT
CVAT 是⼀款开源的基于⽹络的交互式视频/图像标注⼯具,是对加州视频标注⼯具(Video Annotation Tool) 项⽬的重新设计和实现。OpenCV团队正在使⽤该⼯具来标注不同属性的数百万个对象,许多 UI 和 UX 的决策 都基于专业数据标注团队的反馈。具有的功能
- 关键帧之间的边界框插值
- ⾃动标注(使⽤TensorFlow OD API 和 Intel OpenVINO IR格式的深度学习模型)
💥💥5.6 VIA
VGG Image Annotator(VIA)是⼀款简单独⽴的⼿动注释软件,适⽤于图像、⾳频和视频。 VIA 在 Web 浏览 器中运⾏,不需要任何安装或设置。页⾯可在⼤多数现代Web浏览器中作为离线应⽤程序运⾏。
- ⽀持标注的区域组件有:矩形,圆形,椭圆形,多边形,点和折线
💥💥5.7 其他标注工具
liblabel:⼀个⽤ MATLAB 写的轻量级语义/⽰例(semantic/instance) 标注⼯具。
ImageTagger:⼀个开源的图 像标注平台。
Anno-Mage:⼀个利⽤深度学习模型半⾃动图像标注⼯具,预训练模型是基于MS COCO数据 集,⽤ RetinaNet 训练的。
当然还有⼀些数据标注公司,可能包含更多标注功能,例如对三维⽬标检测的标注(3D Bounding box Labelling),激光雷达点云的标注(LIDAR 3D Point Cloud Labeling)等。
🚀6.目标检测常用术语表
| 英文全写 | 英文简写 | 中文名称 |
| one stage | — | 一阶段检测 |
| two stage | — | 两阶段检测 |
| region proposal | RP | 候选区域(一个有可能包含待检物体的预选框) |
| bounding boxes | bb | 候选框 |
| Non-Maximum Suppression | NMS | 非极大值抑制 |
| selective search | SS | 选择搜索 |
| Regions with CNN features | R-CNN | — |
| You Only Look Once | YOLO | — |
| region of interest | RoI | 感兴趣区域(候选区域) |
| frame per second | fps | 帧/每秒 |
| High Resolution Classifier | — | 高分辨率分类器 |
| Batch Normalization | BN | 批量正则化 |
| Mean Average Precision | mAP | 平均精度均值 |
| Intersection over Union | IoU | 交并比(“预测的边框” 和 “真实的边框” 的交集和并集的比值) |
| Fine-Grained Features | — | 细粒度特征 |
| Feature Pyramid Network | FPN | 特征金字塔网络 |

相关文章:
第1篇 目标检测概述 —(1)目标检测基础知识
前言:Hello大家好,我是小哥谈。目标检测是计算机视觉领域中的一项任务,旨在自动识别和定位图像或视频中的特定目标,目标可以是人、车辆、动物、物体等。目标检测的目标是从输入图像中确定目标的位置,并使用边界框将其标…...

Discuz论坛网站标题栏Powered by Discuz!版权信息如何去除或是修改?
当我们搭建好DZ论坛网站后,为了美化网站,想把标题栏的Powered by Discuz!去除或是修改,应该如何操作呢?今天飞飞和你分享,在操作前务必把网站源码和数据库都备份到本地或是网盘。 Discuz的版权信息存在两处…...
springboot整合aop,实现日志操作
前言: 整合之前,我们要明白aop是什么,为什么要用aop,aop能帮我们做什么。 答:AOP是面向切面编程(Aspect-Oriented Programming)的简称,它是一种编程思想,旨在在面向对象…...

openjdk和oracle jdk的区别
OpenJDK 和 Oracle JDK 都是 Java Development Kit (JDK) 的不同实现,用于开发和运行 Java 应用程序。它们有一些区别,但也有很多相似之处。以下是它们之间的主要区别: 开源性质: OpenJDK 是开源的,由一个社区维护和开…...

深度学习-Python调用ONNX模型
目录 ONNX模型使用流程 获取ONNX模型方法 使用ONNX模型 手动编写ONNX模型 Python调用ONNX模型 常见错误 错误raise ValueError...: 错误:Load model model.onnx failed 错误:CUDAExecutionProvider is not in available provider 错…...

[2023.09.24]: 今天差点又交白卷
今天周日,搞定了家里装修的一件事情,周末的事特别多,总算在10点的时候,解决了昨天那个输入焦点设置失败的问题。 在探索Rust编写基于web_sys的WebAssembly编辑器:挑战输入光标定位的实践中,我们总结了设置光…...

css,环形
思路: 1.先利用conic-gradient属性画一个圆,然后再叠加 效果图 <template><div class"ring"><div class"content"><slot></slot></div></div> </template> <script> import …...

php食堂点餐系统hsg5815ABA2程序-计算机毕业设计源码+数据库+lw文档+系统+部署
php食堂点餐系统hsg5815ABA2程序-(毕业设计毕设项目源代码课程设计程序设计指导xz2023) php食堂点餐系统hsg5815ABA2程序-计算机毕业设计源码数据库lw文档系统部署...
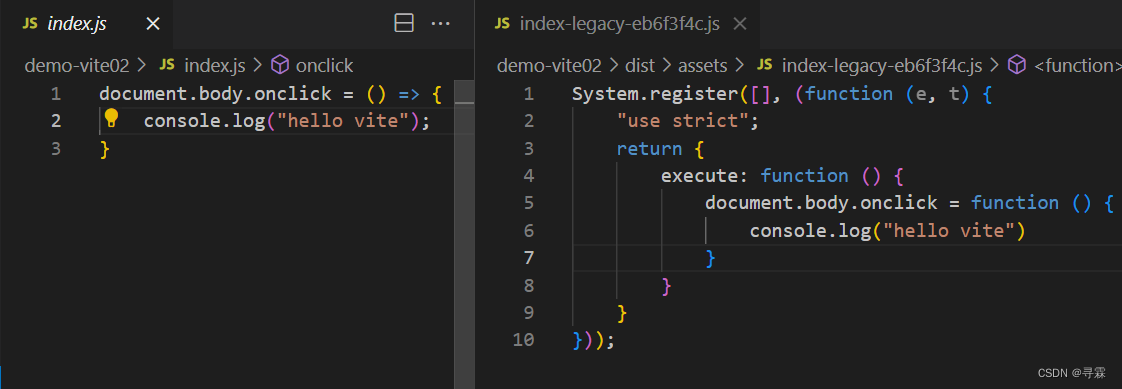
Vite打包时使用plugin解决浏览器兼容问题
一、安装Vite插件 在终端输入如下命令: npm add -D vitejs/plugin-legacy 二、配置config文件 在项目目录下创建vite.config.js文件夹,配置如下代码: import { defineConfig } from "vite"; import legacy from "vitejs/pl…...

java Excel 自用开发模板
下载导出 import com.hpay.admin.api.vo.Message; import com.hpay.admin.dubbo.IConfigDubboService; import com.hpay.admin.dubbo.IFileExportLogDubboService; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang.StringUtils; import org.apache.poi.hss…...

34.CSS魔线图标的悬停效果
效果 源码 index.html <!DOCTYPE html> <html> <head> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Icon Fill Hover Effects</title> <link rel="stylesheet" h…...

Django — 会话
目录 一、Cookie1、介绍2、作用3、工作原理4、结构5、用途6、设置7、获取 二、Session1、介绍2、作用3、工作原理3、类型4、用途5、设置6、获取7、清空信息 三、Cookie 和 Session 的区别1、存储位置2、安全性3、数据大小4、跨页面共享5、生命周期6、实现机制7、适用场景 四、P…...
SpringBoot集成easypoi实现execl导出
<!--easypoi依赖,excel导入导出--><dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-spring-boot-starter</artifactId><version>4.4.0</version></dependency>通过Exce注解设置标头名字和单…...

第9章 【MySQL】InnoDB的表空间
表空间 是一个抽象的概念,对于系统表空间来说,对应着文件系统中一个或多个实际文件;对于每个独立表空间来说,对应着文件系统中一个名为 表名.ibd 的实际文件。大家可以把表空间想象成被切分为许许多多个 页 的池子,当我…...

工作、生活常用免费api接口大全
手机号码归属地:提供三大运营商的手机号码归属地查询。全国快递物流查询:1.提供包括申通、顺丰、圆通、韵达、中通、汇通等600快递公司在内的快递物流单号查询。2.与官网实时同步更新。3.自动识别快递公司。IP归属地-IPv4区县级:根据IP地址查…...

寻找单身狗
在一个数组中仅出现一次,其他数均出现两次,这个出现一次的数就被称为“单身狗“。 一.一个单身狗 我们知道异或运算操作符 ^ ,它的特点是对应二进制位相同为 0,相异为 1。 由此我们容易知道两个相同的数,进行异或运算得到的结果…...
【pytest】 allure 生成报告
1. 下载地址 官方文档; Allure Framework 参考文档: 最全的PytestAllure使用教程,建议收藏 - 知乎 https://github.com/allure-framework 1.2安装Python依赖 windows:pip install allure-pytest 2. 脚本 用例 import pytest class …...

动态链接库搜索顺序
动态链接库搜索顺序 同一动态链接库 (DLL) 的多个版本通常存在于操作系统 (OS) 内的不同文件系统位置。 可以通过指定完整路径来控制从中加载任何给定 DLL 的特定位置。 但是,如果不使用该方法,则系统会在加载时搜索 DLL,如本主题中所述。 DL…...

【CAN、LIN通信的区分】
CAN和LIN是两种不同的通信协议,用于不同的应用场景。CAN(Controller Area Network)是一种高速、可靠、多节点的串行通信协议,主要用于汽车电子领域的高速数据传输和控制;而LIN(Local Interconnect Network&…...
Redis环境配置
【Redis解压即可】链接:https://pan.baidu.com/s/1y4xVLF8-8PI8qrczbxde9w?pwd0122 提取码:0122 【Redis桌面工具】 链接:https://pan.baidu.com/s/1IlsUy9sMfh95dQPeeM_1Qg?pwd0122 提取码:0122 Redis安装步骤 1.先打开Redis…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...