连接组学中的机器学习:从表征学习到模型拟合
前言
机器学习(ML)由于其高自动化程度、高灵敏度和特异性优势,在医学影像领域取得了巨大的成功。由于具备这些优势,机器学习已被广泛应用于神经成像数据,目的是提取与感兴趣变量(如疾病状态)相关的特征。这使我们能够形成关于不同条件下大脑结构和功能的详细地图,以数据驱动的方式发现新知识。
与传统的数据驱动方法(如大规模单变量分析)相比,机器学习方法具有两个重要优势。首先,机器学习方法通过检查横跨整个图像领域的元素之间的统计关系,充分利用了高维数据的潜力。尽管存在正常变化,但通过利用所有图像位置的信息,机器学习方法能够准确地识别和测量由疾病或药物干预引起的脑部细微且空间复杂的结构和功能变化。
其次,机器学习方法能够在个体水平上进行预测。相比之下,大规模单变量分析只能在组水平上进行推断,估计最能区分两组的模式或预测感兴趣的变量,从而基本上描述的是组平均数据。然而,这并不能满足通过改进疾病筛查和诊断来实现精准医疗所需的个性化预测需求。
总的来说,这些优势推动了机器学习在多种脑部疾病研究中的应用。这导致了能够量化患病风险或追踪其进展的敏感生物标志物的构建。这些基于机器学习的生物标志物还允许研究临床试验中药物干预的效果,并在可测量的临床效果出现之前提供患者特异性诊断。这方面的早期工作主要涉及结构磁共振成像(MRI)数据上的机器学习应用。这是由于此类数据更易获取,并且具有欧氏结构,因而在计算机视觉领域中较为常见。随着网络科学和图论的发展,以及大脑作为一个高度复杂且相互连接网络的概念化,机器学习在连接组学上的应用越来越受到关注。尽管如此,机器学习在连接组学上的应用并不那么简单。这是由于数据的非欧氏性质,因而需要适当的处理方法。
方法
本节详细阐述了如图1所示的连接组学中ML工作流的步骤3和步骤4。由于连接组学数据的非欧氏性质使其与传统的机器学习算法结合使用并不容易。因此,本文讨论了将图形转化为适合机器学习方法输入的方式。但有时会根据图谱或个体水平的分区来构建连接组,因而可能会得到不同数量节点的单个图(在后一种情况下)。在这里,本文将重点介绍适用于图形约束的方法,该类图形在总体中具有唯一的节点排序。在这类图形中,所有图实例的顶点数量是固定的,并且顶点集的顺序也是固定的(称为固定基数顶点序列)。进一步假设边缘标记函数是标量,并且图形是无向的,这意味着邻接矩阵是对称的。
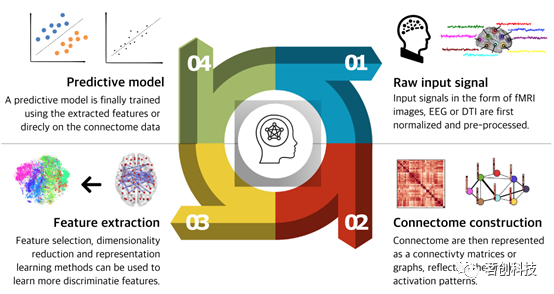
图1.连接组学中的机器学习工作流。
用特征向量概括图形
根据用于解决特定问题的机器学习算法的不同,图形实例可能需要映射到一个d维向量中。当算法只能处理实值特征向量时,就需要进行这种映射。在脑图中,我们通常对保留边缘标签信息感兴趣,一旦获得连接矩阵的向量表征,就可以应用任何需要标量输入特征的传统机器学习算法。通过直接嵌入,提供一个固定的基数顶点序列,邻接矩阵的上三角元素可以很容易地表示为一个特征向量,只要它们表示的连接在所有图实例中保持一致。这种非常简单的嵌入结合了图的全局和局部特征,因为它在为整个图捕获这些信息的同时保留了原始的边缘标签。边缘中包含的判别信息可以在脑连接图中进一步定位和可视化。
然而,这种方法部分地忽略了局部或全局的高级结构特征,这些特征在某些应用中尤其重要。另一个局限性是它们考虑了与所有脑区域的所有连接,即使其中一些连接可能对于解决问题来说是“不相关的”(即不具有判别性),而不是只包含最相关连接的子集。因此,它们产生了非常高维的特征表示,这会加剧在小样本研究中的过拟合问题。这将需要某种形式的降维、正则化、大量样本或以上所有方法,以确保该方法可以推广到其他人群。在有助于捕捉这些全局特征的情况下,可以用图属性向量来概括实例。这些属性通常包括平均聚类系数和特征路径长度,而更局部的特征可能包括对应于感兴趣脑区的节点强度。最近,一些更先进的技术,如node2vec,已被用于获得反映结构和功能连接的图嵌入,并表现出很高的预测能力。
降维
降维方法通常用于通过将输入数据映射到捕获数据“本质”的子空间来获得较低维的特征表示。这一步有助于泛化并降低计算复杂度,并且常常在模型拟合之前应用。高维函数往往比低维函数更复杂,而且这些复杂的模式更难辨别。在机器学习模型中,较少的输入维度通常意味着更少的参数(称为自由度)或更简单的结构。具有太多自由度的模型可能会过度拟合训练数据,因此可能在新的未知数据上表现不佳,而这正是我们最终关心的问题。
主成分分析(PCA)是最常用的降维方法之一。PCA通过线性变换到新坐标系来寻求数据变化的主要方向。将原始数据映射到这个坐标系的第一维上,可以捕获数据的最大方差,第二维上是次大方差,以此类推。每个维度(由向量i描述)都需要与前面的(i-1)维度正交。PCA常用于降维,并使用奇异值分解将数据映射到低维空间。然而,它不能很好地适应维数远高于样本数量的问题。
另一种降维方法是RFE(递归特征消除)。这是一种迭代方法,可在训练集上训练岭分类器,并保留在每一步中幸存下来的原始特征向量的维度。在每次迭代中,分类器的系数用于对特征的重要性进行排序(系数越高表示重要性越高),同时从特征向量中剪除辨别性最小的维度。与PCA相比,该方法在连接组学应用中可以产生更好的结果,但由于每次迭代都需要训练一个新的分类器,因此成本往往更高。
与PCA(定义不相关特征向量的正交坐标系)不同,独立成分分析(ICA)旨在寻找非高斯数据的线性表示,使各成分在统计上相互独立,或者尽可能独立。在较高的层次上,主成分分析(PCA)旨在压缩信息并降低信号的维数,而ICA旨在将信息分离为有意义的成分,并用于重建信号。因此,ICA更常用于脑区划分,而PCA用于在将大脑信号输入机器学习模型之前降低维度、减少计算量并缓解过拟合。其他用于连接组数据的降维方法包括多维缩放(MDS)和局部线性嵌入(LLE)。MDS通常将点之间的距离(或相似性)矩阵作为输入,旨在恢复保留这些距离的输入的低维表征。它通常用于根据成对距离矩阵生成数据点的二维可视化(例如在度量学习中)。如果该距离对应于欧氏距离,则经典MDS的结果等价于PCA。而LLE是一种非线性降维技术,可保留用户指定大小的局部邻域内的距离。
图核
图核是一种核函数,通过捕捉图结构中的内在语义来计算两个图之间的内积。内积是一种将两个向量相乘的方法,乘积的结果是标量,并且通常被认为是这些向量之间的相似性度量。这个内积是在与输入图对的原始空间不同的特征空间中计算的。理想情况下,图核应该对个体差异具有稳健性,并可以应用于结构和功能脑网络。R-卷积核比较由相似部分组成的两个结构化对象的分解。分解过程递归地重复,直到产生原子成分。最后,将每个部分的相似性度量值聚合,得到一个标量。因此,图核是一对图的卷积核,一个新的分解关系R会产生一个新的图核。
一种常用的类型是随机游走核,它计算两个图中相同随机游走序列的数量。游走是节点序列,其中某些节点可以重复访问。长度k的游走可以通过邻接矩阵的k次幂来计算。然而,这些操作的计算量非常大,而节点重复可能会导致内核值增长到非常大的值。最短路径核旨在通过计算输入图中所有节点对之间的最短路径长度来缓解这些问题(在路径中,不允许节点重复)。
除了基于游走和路径的方法,基于子树的核也已用于连接组学研究。子树是从图中提取的子图,其中不存在循环,也就是说,任意一对节点都可以通过一条简单的路径相连。Weisfeiler-Lehman子树核就是这样一种方法,它基于Weisfeiler-Lehman图同构检验,采用了一种有效的方法来构造图核。
机器学习中的线性方法
支持向量机(SVM)是基于一组d维向量,试图找出表示两个类别之间最大间距或距离的(d-1)维超平面。超平面定义为一个比它所在环境空间维数小1的子空间,它将该空间分为两个部分。例如,在二维空间中,一条线就是一个超平面。同样地,如果空间是三维的,那么它的超平面就是二维平面。在SVM中,选择超平面的方式是使得每个类别最近数据点的距离最大化。如果存在这样的超平面,则称为最大间隔超平面。SVMs的主要优势之一是在高维空间和维数大于样本数的情况下的效率较高。此外,SVM的存储效率很高,因为它只使用决策函数中训练点的一个子集,即所谓的支持向量。SVM在连接组学应用中的最重要特征是其灵活性,即可以使用不同的核函数作为决策函数,例如上文所提到的随机游走核或Weisfeiler-Lehman子树核。多核也可以与多核SVM结合使用,多核SVM可以表示为基核的线性组合。
岭分类是连接组学中常用的另一种方法。该方法适用于拟合具有多重共线性的多元回归数据。在这种现象中,一个预测变量(即输入特征)可以通过其他预测变量进行高精度的线性预测。连接组数据通常可以证明这种行为,特别是在其高维形式中,因为通常有比观测值(即受试者)更多的变量(例如边缘)。岭回归或Tikhonov正则化通过在相关矩阵的对角元素上添加一个小值λ来解决这个问题。当λ=0时,岭估计器简化为普通最小二乘法。
深度学习
深度学习在计算机视觉和医学成像应用中取得了许多成功,包括图像分割和分类,以及更复杂的任务,如地标定位和疾病结果预测。深度学习算法已经被证明可以学习输入特征的复杂非线性函数,并捕获欧氏空间中的分层模式(如图像像素和体素网格)。这些技术的“深度”方面是指其“堆叠”滤波器(卷积或全连接)的关键特征,以捕获不同空间尺度上的判别模式。尽管这些算法在欧氏空间中取得了成功,但它们在图形中,特别是脑图上的应用并不简单。首先,与图像体素不同,并非每个节点都具有相同数量的相邻节点。此外,相邻节点的排列不是固定的,即没有左/右等概念。
因此,在最近的宏连接组计算工作中,用于图的深度学习方法引起了很多关注。其中一个例子是BrainNetCN,该框架包括边到边、边到节点和图像体素等。前两个操作类似于局部聚合器,而最后一个操作则类似于全局聚合器。具体而言,边到边的图层计算滤波器映射,其值对应于相邻边的加权和。在训练过程中学习这些滤波器映射(以及跨层)的权重。边到节点的层降低了原始输入的空间维度,并将输入边的隐藏表征聚合为节点表征。最后,节点到图层的作用类似于全局聚合器,并估计隐藏节点表征的加权和,以产生单个标量值。这种设置在需要为每个连接组生成单个预测的情况下非常方便(无论是用于分类问题还是回归问题)。
在连接组学领域广泛使用的另一种深度学习方法是图卷积网络,特别是ChebNet。与在图空间域中进行滤波的BrainNetCNN不同,ChebNet的原理来自Shuman等人(2013)的图谱理论。这表明学习到的滤波器是基于拉普拉斯连接矩阵进行参数化的。拉普拉斯矩阵定义为L=D-A,其中D为度矩阵,A为邻接矩阵。这种方法被用于两种不同的设置:在转导设置中,总体被表示为一个图,其中每个个体对应于该图中的一个节点,该节点与节点特征向量相关联,这本质上是连接组的嵌入。在归纳设置中,ChebNet可以直接应用于个体的连接组图上,唯一的限制是需要在样本之间保持图结构。Ktena等人(2018)解决此问题的方式是计算总体平均连接矩阵,并将大脑节点的连接特征作为特征向量。
评估指标
根据目标应用(即分类与回归)的不同,我们常用和报告的评估指标会有所不同。在分类设置中,我们对分类准确率感兴趣,通常将其报告为所有测试样本(与类别无关)中正确预测的百分比。此外,在分类应用中,通常会报告模型的精度、召回率、敏感度和特异度。精度是指真阳性(例如,识别患者状态)与所有阳性预测数量的比值,即:
![]()
召回率(或敏感度)是指真阳性与真阳性和假阴性之和的比率,即:
![]()
图2显示了不同分类器可能在精度和召回率之间的权衡。特异度是指真阴性预测占所有阴性样本的比率,即:
![]()
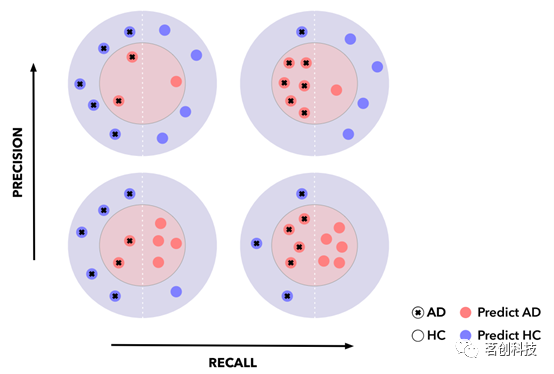
图2.在7个阳性和5个阴性样本的数据集上演示阿尔茨海默病分类(AD=阿尔茨海默病患者,HC=健康对照组)的精度/召回率权衡。
在疾病预测中,我们特别关注在不影响特异性的情况下实现高敏感度,因为检测尽可能高的阳性率非常重要。另一个经常报告的指标是受试者工作特征曲线下面积(ROC-AUC)。ROC曲线反映了敏感度和假阳性率(等于1-特异度)之间的关系。AUC的值越高,分类器的质量越好,因为提高敏感度不会增加假阳性率。然而,当测试数据集存在严重的类别不平衡时,精度-召回率曲线下面积(PRAUC)被证明比ROC-AUC具有更大的信息量。在这种情况下,F1分数等指标也常被使用。
![]()
在回归应用中,最常用的指标包括平均绝对误差(MAE)、均方误差(MSE)和皮尔逊相关系数。MAE和MSE之间的主要区别在于MSE会对误差较大的情况进行更大的惩罚,因此适用于对误差较为敏感的情况。皮尔逊相关系数测量了预测得分和真实得分之间的线性关系,因此对输入数据的分布影响较小,但不能揭示回归模型可能存在的潜在偏差,即预测值过高或过低。
在分类和回归应用中,最好报告上述指标在不同情况下的均值和标准差,因为这可确保指标尽可能无偏,并反映分类器或回归器的真实性能。
限制
将机器学习(ML)应用于连接组学是具有挑战性的。在应用ML算法并评估其结果时,应考虑以下局限性。首先,ML性能高度依赖于算法所接收到的输入数据的质量,无论是传统机器学习还是深度学习技术都是如此。为了确保准确的训练和有意义的预测,需要对数据进行仔细的预处理和全面的数据质量检查。对于由fMRI和dMRI生成的连接组来说尤其如此。特别是扫描期间的头动已被证明对功能和结构连接的多个测量指标有着显著影响。在fMRI和dMRI中,已经研究了几种减轻运动效应的策略。然而,由于缺乏真实标准,很难确定头动对测量的影响程度。这在特定人群(例如儿童或患者)中的影响可能更大。因而会极大地混淆感兴趣的效应并限制了检测到真正信号的能力。
混淆变化是限制机器学习模型泛化能力的一个重要挑战。机器学习模型在检测数据细微模式方面表现出更高的敏感性。然而,这往往会导致模型专注于学习数据中的混淆变化,例如由于图像采集参数(如扫描仪强度或序列)而引起的信号变化。这限制了它们适应不同环境中收集新数据的能力,从而降低了可重复性。这在处理多站点数据时尤其成问题,因为多站点数据是增加样本量的必要手段。
扫描仪之间的差异并不是导致数据偏差的唯一原因。训练数据通常包含性别、种族和文化偏差。机器学习方法不仅会继承这种偏差,而且往往会放大这种偏差。防止潜在偏差的一个重要保障是模型的可解释性。机器学习和深度学习模型通常被视为分析高维神经成像数据并将其压缩为特定个体疾病指标的“黑匣子”。虽然该指标具有重要的诊断和预后价值,但它并不能告诉我们每个大脑连接或区域是如何影响这一决策的。然而,对于临床医生和研究人员来说,能够理解模型是如何做出这样的决策是非常重要的。这将使得自动化系统对人类专家的验证透明化,从而能够检查任何潜在的偏倚。重要的是,它能够提取关于不同大脑系统对不同病理的选择性易感性的新知识,从而阐明疾病机制,为更有效的治疗铺平道路。因此,越来越多的研究集中在开发用于解释神经成像中ML模型的方法和协议上。
最后,训练、验证和机器学习方法所面临的一个重大挑战是大型数据集的处理。现有的神经成像数据共享计划(如自闭症脑成像数据库(ABIDE)、开放获取系列成像研究(OASIS)和英国生物银行)对于支持机器学习研究至关重要,但还需要更多的努力来实现机器学习工具的广泛实施和使用。
建议
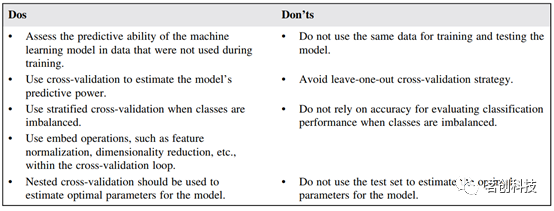
在连接组学中应用机器学习的一个重要环节是测量模型的预测能力。值得注意的是,不能使用相同的数据来训练和测试模型以评估模型的预测能力。这是因为机器学习模型常常会通过学习特定样本的噪声来过拟合训练数据,导致模型预测结果过高,从而不利于得出有效的结论。因此,样本内测量结果不能作为预测准确性的证据。相反,应该使用单独的数据集来测试模型。
然而,由于神经成像数据的可用性有限,可能无法使用单独的测试集。为此,可以采用k折交叉验证的方法。这是一个将数据划分为用户指定数量(k个)子集(折)的过程。每个子集被用作测试集,用来评估使用其他子集训练的模型的性能。通过对所有子集进行迭代,可以通过平均所有试次的误差来估计模型的有效性。在其最简单的形式中,每个数据点都被视为一个子集,这就是所谓的留一法交叉验证。这种方法的优点是提供了充足的训练数据。然而,测试集并不能代表整个数据集,估计结果通常不稳定且有偏差。因此,最好是将数据分割成更大的子集,通常占数据的10%-20%(即10折或5折交叉验证)。重复随机划分可以获得更准确的预测能力测量。
实施交叉验证并不总是那么简单。我们应该确保每个折都代表了数据的所有层。对于数据不平衡的情况,这尤为具有挑战性。在这种情况下,应使用分层交叉验证来确保在各个折中给定分类值的观测比例相似。此外,应适当加权观测数据以减少选择偏差。需要注意的是,当类别不平衡时,标准指标(如分类精度)变得不可靠。在这种情况下,应优先报告精度-召回率曲线和F1测量值。
最后,在实施交叉验证时需要记住的是,应该避免将信息从测试数据泄漏到训练数据。这意味着模型应该在独立于测试集的训练集上进行训练。否则,对预测能力的估计可能会过于乐观。
总的来说,在连接组学中应用机器学习时需要注意以下事项:
参考文献:Sofia Ira Ktena, Aristeidis Sotiras, Enzo Ferrante, Machine learning in connectomics: from representation learning to model fitting, 2023, P267-287.
相关文章:
连接组学中的机器学习:从表征学习到模型拟合
前言 机器学习(ML)由于其高自动化程度、高灵敏度和特异性优势,在医学影像领域取得了巨大的成功。由于具备这些优势,机器学习已被广泛应用于神经成像数据,目的是提取与感兴趣变量(如疾病状态)相关的特征。这使我们能够形成关于不同条件下大脑…...

数据结构-----二叉树的创建和遍历
目录 前言 二叉树的链式存储结构 二叉树的遍历 1.前序遍历 2.中序遍历 3.后序遍历 二叉树的创建 创建一个新节点的函数接口 1.创建二叉树返回根节点 2.已有根节点,创建二叉树 3.已有数据,创建二叉树 前言 在此之前我们学习了二叉树的定义和储…...

【算法题】1333. 餐厅过滤器
题目: 给你一个餐馆信息数组 restaurants,其中 restaurants[i] [idi, ratingi, veganFriendlyi, pricei, distancei]。你必须使用以下三个过滤器来过滤这些餐馆信息。 其中素食者友好过滤器 veganFriendly 的值可以为 true 或者 false,如果…...

linux脚本笔记
目录 1.增加环境变量 2.自定义命令快捷键 3.关闭selinux和防火墙 4.增加别名快捷键 5.Linux链接 1.增加环境变量 新建add_env.sh #!/bin/bashapp_dir"/root/docker"# 检查配置文件中是否已存在相同的环境变量 if grep -q -E "^export APP_HOME.*" ~…...
)
目标检测YOLO实战应用案例100讲-面向路边停车场景的目标检测(中)
目录 3.1.1 特征图相似度计算 3.1.2 特征图相似度实验 3.1.3 基于GhostBlock的网络结构改进...
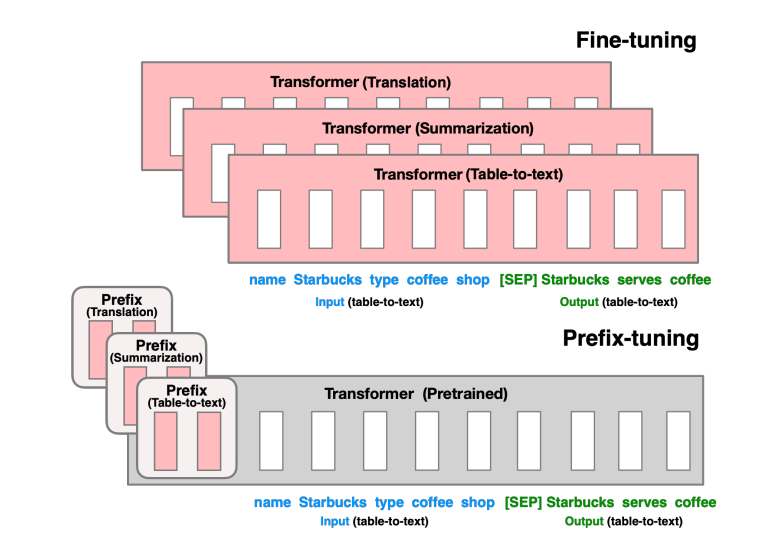
[论文笔记]Prefix Tuning
引言 今天带来微调LLM的第二篇论文笔记Prefix-Tuning。 作者提出了用于自然语言生成任务的prefix-tuning(前缀微调)的方法,固定语言模型的参数而优化一些连续的任务相关的向量,称为prefix。受到了语言模型提示词的启发,允许后续的token序列注意到这些prefix,当成虚拟toke…...
electron快速入门
新建electronstu01文件夹 以管理员身份运行powershell,切换到该文件下 npm init -y安装依赖包 npm install --save-dev electron失败 npm install -g cnpm --registryhttps://registry.npm.taobao.org cnpm install --save-dev electron修改 package.json &qu…...
C语言的stdio.h的介绍
C语言的stdio.h的介绍 C语言的stdio.h的介绍 C语言的stdio.h的介绍C语言stdio.h的介绍 C语言stdio.h的介绍 这个含义是导入标准输入输出库 包含头文件.h,std标准库,io是input output输入输出库 <>代表系统库,自定义的话用""…...
使用香橙派 在Linux环境中安装并学习Python
前言 在实际项目中,经常会遇到需要使用人工智能的场景,如人脸识别,车牌识别等...其一般的流程就是由单片机采集数据发送给提供人工智能算法模型的公司(百度云,阿里云...),然后人工智能将结果回…...

如何开发物联网 APP?
如何开发物联网 APP? 这个问题本身是不严谨的,APP只是手机端的一个控制或者用于显示的人机交互页面,物联网是通过传感器,物联网卡等模块把物体接入网络以方便远程监控或者控制等。 你问的应该是怎么开发出来一个远程控制物体的APP吧&#x…...

配置pytorchGPU虚拟环境-python3.7
cuda版本的pytorch包下载地址戳这里 winR->输入cmd->输nvcc -V回车 cuda 11.0 输入以下命令来查找 CUDA 的安装路径: Windows: where nvcc 输入以下命令来查找 cuDNN 的版本号: Windows: where cudnn* cuDNN 8.0 本机安装的是cuda 11.0&…...
Logic Pro X10.7.9(mac乐曲制作软件)
Logic Pro X是由苹果公司开发的一款专业音频制作软件,主要用于音乐制作、录音、混音和母带处理等方面。以下是Logic Pro X的特点: 强大的音频编辑功能:Logic Pro X提供了丰富的音频编辑工具,包括波形编辑器、音频自动化、时间拉伸…...
第一部分:HTML5
目录 一:网页 1.1:什么是网页? 1.2:什么是HTML? 1.3:网页的形成 二:常用浏览器 三:Web标准 3.1:为什么需要Web标准? 3.2:Web标准的构成 四&a…...
Linux 基础入门
目录 一、计算机 1、组成 2、功能 二、操作系统 1、定义 2、主要工作 3、操作系统内核功能 4、常见的操作系统 三、Linux的组成 四、搭建Linux学习环境 五、安装远程连接Linux的软件 1、安装xshell 2、安装mobaxterm 六、Linux操作系统学习大纲 一、计算机 1、组…...

【数据结构】插入排序:直接插入排序、折半插入排序、希尔排序的学习知识总结
目录 1、排序的基本概念 2、直接插入排序 2.1 算法思想 2.2 代码实现 3、折半插入排序 3.1 算法思想 3.2 代码实现 4、希尔排序 4.1 算法思想 4..2 代码实现 1、排序的基本概念 排序是将一组数据按照预定的顺序排列的过程,排序的基本概念包括以下内容…...
Magic Battery for Mac:让你的设备电量管理变得轻松简单
Mac电脑用户们,你们是否曾经为了给设备充电而感到烦恼?是否希望能够方便地查看连接设备的电量情况?现在,有了Magic Battery for macOS,这些问题都将成为过去! Magic Battery是一个实用的应用程序ÿ…...
nodejs+vue大学食堂订餐系统elementui
可以查看会员信息,录入新的会员信息,对会员的信息进行管理。 网站管理模块对整个网站中的信息进行管理,可以查看会员留在留言栏中的信息,设置网站中的参数等。用户管理模块主要实现用户添加、用户修改、用户删除等功能。 近年来&…...

nat综合实验
路漫漫其修远兮,吾将上下而求索。 实验目的如图 实验思路:配置内网,再配置外网,再做nat clien1配置 clien2配置 pc3配置 lsw1配置 sysname lsw1 # vlan batch 10 20 30 # interface MEth0/0/1 # interface Eth-Trunk1port link-type trunkp…...

【iOS逆向与安全】好用的一套 TCP 类
初始化 //页面 %hook xxxxxxxViewController//- (void)viewWillAppear:(BOOL)animated{ //NSLog("View Will Appear,再次进入刷新"); - (void)viewDidLoad{//启动tcp[[Xddtcp sharedTcpManager] connectServer] ;} 发送数据 //发送数据 [[Xddtcp shared…...

Ubuntu Kafka开机自启动服务
1、创建service文件 在/lib/systemd/system目录下创建kafka.service文件 [Unit] DescriptionApache Kafka Server Documentationhttp://kafka.apache.org/documentation.html Requireszookeeper.service[Service] Typesimple Environment"JAVA_HOME/usr/local/programs/j…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...