一个案例熟悉使用pytorch
文章目录
- 1. 完整模型的训练套路
- 1.2 导入必要的包
- 1.3 准备数据集
- 1.3.1 使用公开数据集:
- 1.3.2 获取训练集、测试集长度:
- 1.3.3 利用 DataLoader来加载数据集
- 1.4 搭建神经网络
- 1.4.1 测试搭建的模型
- 1.4.2 创建用于训练的模型
- 1.5 定义损失函数和优化器
- 1.6 使用tensorboard(非必要)
- 1.7 定义早停策略等参数
- 1.8 训练模型
- 1.8.1 通过训练得到best_model
- 1.9 验证模型
- 1.9.1标签数据:
- 1.9.2 开始验证模型
- 导入必要的包:
- 读取图片(网上随便找的):
- 转换图像维度:
- 加载best_model
- 开始用模型预测
- 1.10 扩展知识
- 1.10.1 使用GPU加速的方法
- 1.10.2 使用早停策略
- 1.10.3 两种保存模型的方法
- 导包:
- 两种保存模型方式:
- 两种读取模型方式:
- 完整代码获取方式:
1. 完整模型的训练套路
任务:给图片做分类,飞机、鸟、狗、猫。。等共十种标签
ps:针对不同任务,只是在数据处理和模型搭建上有所不同而已,模型的训练流程套路都是一样的。
1.2 导入必要的包
import torchvision
from torch import nn
import torch
1.3 准备数据集
1.3.1 使用公开数据集:
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
1.3.2 获取训练集、测试集长度:
# length长度
train_data_size = len(train_data)
test_data_size = len(test_data)print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
1.3.3 利用 DataLoader来加载数据集
# 利用 DataLoader来加载数据集
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
1.4 搭建神经网络
# 搭建神经网络
class MyModel(nn.Module):def __init__(self):super(MyModel,self).__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self,x):x = self.model(x)return x
1.4.1 测试搭建的模型
# 测试搭建的模型
model1 = MyModel()
input = torch.ones((64,3,32,32))
output = model1(input)
print(output.shape) #torch.Size([64, 10])
1.4.2 创建用于训练的模型
# 定义是否使用gpu加速的设备
# 支持gpu加速的pytorch版本,device = cuda:0,否则为cpu
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device) # cuda:0# 创建模型
model = MyModel()
# model.to(device) # 模型和损失函数不需要另外复制
model = model.to(device)
1.5 定义损失函数和优化器
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,现在常用mse
loss_fn.to(device)learning_rate = 1e-2
# learning_rate = 0.01
# 优化器
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate) #SGD,现在常用Adam
1.6 使用tensorboard(非必要)
# 使用tensorboard
from torch.utils.tensorboard.writer import SummaryWriter
# 添加tensorbord
writer = SummaryWriter("../logs_train")import time
import numpy as np
1.7 定义早停策略等参数
# 定义 Early Stopping 参数
early_stopping_patience = 3 # 如果 3 个 epoch 后性能没有改善,就停止训练
early_stopping_counter = 0
best_loss = float('inf') # 初始化为无穷大 # 初始化最好模型的性能为无穷大
best_valid_loss = float('inf')# 初始化好的准确率
best_accuracy = 0.00
1.8 训练模型
# 设置训练网络的一些参数# 记录测试的次数
total_test_step = 0# 训练的次数
epoch = 100start_time = time.time()
for i in range(epoch):print("----------------第{}轮训练开始----------------".format(i+1))# 训练步骤开始model.train() #训练模式,对DropOut等有用train_loss = []# 记录训练的次数iter_count = 0for data in train_dataloader:imgs,targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = model(imgs) # 调用模型计算输出值loss = loss_fn(outputs,targets) # 计算损失值train_loss.append(loss.item())# 优化器优化模型optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 优化参数iter_count = iter_count + 1 # 迭代次数if (iter_count %100 == 0):end_time = time.time()
# print("cost_time:",end_time-start_time)print("训练次数:{0},Loss:{1:.7f}".format(iter_count,loss.item()))writer.add_scalar("train_loss:",loss.item(),iter_count)train_loss = np.average(train_loss)print("第{0}轮训练结束".format(i+1))print("Epoch:{0} | Train_Loss:{1:.7f}\n".format(i+1,train_loss))# 测试步骤开始model.eval()# 测试模式print("第{0}轮测试开始:".format(i+1))test_loss = []test_accuracy = 0with torch.no_grad(): # 不计算梯度for data in test_dataloader:imgs,targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = model(imgs)loss = loss_fn(outputs,targets)test_loss.append(loss.item())accuracy = (outputs.argmax(1) == targets).sum()test_accuracy = test_accuracy+accuracytest_loss = np.average(test_loss)print("Epoch:{0} | Test_Loss:{1:.7f}".format(i+1,test_loss))test_accuracy = test_accuracy/test_data_sizeprint("Test_Accuracy:{0:.7f}".format(test_accuracy))writer.add_scalar("test_loss:",test_loss,total_test_step )writer.add_scalar("test_accuracy:",test_accuracy,total_test_step )total_test_step = total_test_step + 1# 每一轮保存模型# torch.save(model,"model_{}.pth".format(i+1))# torch.save(model.state_dict(),"model_{}.pth".format(i)) # 官方推荐的保存模型方法# # 如果当前模型在验证集上的性能更好,保存该模型 (以Loss为标准)# if test_loss < best_valid_loss: # best_valid_loss = test_loss # torch.save(model.state_dict(), './model/best_model.pth')# print("当前第{}轮模型为best_model,已保存!".format(i+1))# 以正确率为标准if best_accuracy < test_accuracy: best_accuracy = test_accuracy torch.save(model.state_dict(), './model/'+'ac_{0:.4f}_best_model.pth'.format(best_accuracy))print("当前第{}轮模型为best_model,已保存!".format(i+1))early_stopping_counter = 0 #只要模型有更新,早停patience就初始化为0else: #早停策略early_stopping_counter += 1 if early_stopping_counter >= early_stopping_patience: print("Early stopping at epoch {}".format(i+1)) breakprint("\n")writer.close()
训练过程展示(只给出两轮的信息):
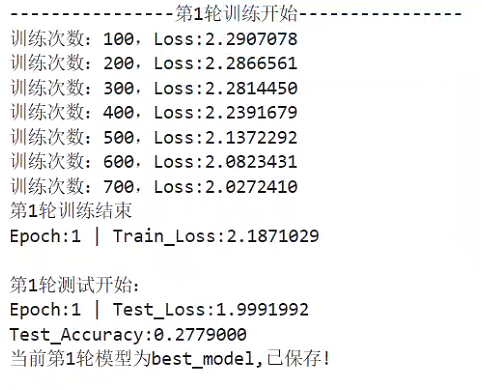
…

1.8.1 通过训练得到best_model
我自得到的best_model :ac_0.6553_best_model.pth
准确率:0.65,还行,练手的项目,就不一一调参多次训练了
1.9 验证模型
1.9.1标签数据:

1.9.2 开始验证模型
导入必要的包:
from PIL import Image
import torchvision
import torch
读取图片(网上随便找的):
图1-dog1:
图2-dog2:

image_path = "./data/dog2.png"
image = Image.open(image_path)
image = image.convert('RGB')
转换图像维度:
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape) #torch.Size([3, 32, 32])
加载best_model
神经网络类:
from torch import nn
class MyModel(nn.Module):def __init__(self):super(MyModel,self).__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4,64),nn.Linear(64,10))def forward(self,x):x = self.model(x)return x因为我保存模型用了state_dict(),(这样的模型小,省空间),所以加载模型需要以下这样加载,下文会给出保存模型的两种方法:
best_model = MyModel()
best_model.load_state_dict(torch.load("./best_model/ac_0.6553_best_model.pth"))
print(best_model)
输出:
MyModel((model): Sequential((0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Flatten(start_dim=1, end_dim=-1)(7): Linear(in_features=1024, out_features=64, bias=True)(8): Linear(in_features=64, out_features=10, bias=True))
)
开始用模型预测
再转换一下图片维度:
image = torch.reshape(image,(1,3,32,32))
best_model.eval()
with torch.no_grad():output = best_model(image)
print(output)
print(output.argmax(1)) # 取出预测最大概率的值
输出结果:由结果可知,预测的十个标签中,从0开始,第5个结果的值最大,查看标签数据知,序号5为dog,预测成功了
ps:我得到的这个模型,把图片dog1,预测成了猫
tensor([[ -3.7735, -9.3045, 6.1250, 2.3422, 4.8322, 11.0666, -2.2375,7.5186, -11.7261, -8.5249]])
tensor([5])
1.10 扩展知识
1.10.1 使用GPU加速的方法
GPU训练:
- 网络模型
- 数据(输入、标注)
- 损失函数
- .cuda
# 使用GPU训练
import torch device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 将模型移动到 GPU
model = model.to(device) # 将损失函数移动到 GPU
loss_fn = loss_fn.to(device)# 将输入数据移动到 GPU
inputs = inputs.to(device) # 将标签移动到 GPU
labels = labels.to(device)# 命令行的方式查看显卡配置(在jupyter上)
!nvidia-smi
1.10.2 使用早停策略
# 使用早停策略
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.utils.data import DataLoader, TensorDataset # 定义一个简单的模型
class SimpleModel(nn.Module): def __init__(self, input_dim, output_dim): super(SimpleModel, self).__init__() self.linear = nn.Linear(input_dim, output_dim) def forward(self, x): return self.linear(x) # 创建数据
input_dim = 10
output_dim = 1
x_train = torch.randn(100, input_dim)
y_train = torch.randn(100, output_dim)
dataset = TensorDataset(x_train, y_train)
dataloader = DataLoader(dataset, batch_size=10) # 初始化模型、损失函数和优化器
model = SimpleModel(input_dim, output_dim)
criterion = nn.MSELoss()
optimizer = Adam(model.parameters(), lr=0.01) # 定义 Early Stopping 参数
early_stopping_patience = 5 # 如果 5 个 epoch 后性能没有改善,就停止训练
early_stopping_counter = 0
best_loss = float('inf') # 初始化为无穷大 # 训练循环
for epoch in range(100): # 例如我们训练 100 个 epoch for inputs, targets in dataloader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, targets) loss.backward() optimizer.step() # 计算当前 epoch 的损失 current_loss = 0 with torch.no_grad(): for inputs, targets in dataloader: outputs = model(inputs) current_loss += criterion(outputs, targets).item() / len(dataloader) current_loss /= len(dataloader) # 检查是否应提前停止训练 if current_loss < best_loss: best_loss = current_loss early_stopping_counter = 0 else: early_stopping_counter += 1 if early_stopping_counter >= early_stopping_patience: print("Early stopping at epoch {}".format(epoch)) break
1.10.3 两种保存模型的方法
导包:
import torch
import torchvision两种保存模型方式:
vgg16 = torchvision.models.vgg16(weights=None)# 保存方式1,模型结构+参数结构
torch.save(vgg16,"vgg16_method1.pth")# 保存方式2,模型参数(官方推荐)模型较小
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
两种读取模型方式:
# 方式1
model1 = torch.load("vgg16_method1.pth")
# model1
# 方式2
model2 = torch.load("vgg16_method2.pth")
# model2 # 参数结构
# 将方式2 恢复成模型结构
vgg16 = torchvision.models.vgg16(weights=None)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))print(vgg16)
输出结果:
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)
完整代码获取方式:
点赞、收藏、加关注
加我vx:ls888726
相关文章:
一个案例熟悉使用pytorch
文章目录 1. 完整模型的训练套路1.2 导入必要的包1.3 准备数据集1.3.1 使用公开数据集:1.3.2 获取训练集、测试集长度:1.3.3 利用 DataLoader来加载数据集 1.4 搭建神经网络1.4.1 测试搭建的模型1.4.2 创建用于训练的模型 1.5 定义损失函数和优化器1.6 使…...
)
MySQL - limit 分页查询 (查询操作 五)
功能介绍:分页查询(limit)是一种常用的数据库查询技术,它允许我们从数据库表中按照指定的数量和顺序获取数据,它在处理大量数据时特别有用,可以提高查询效率并减少网络传输的数据 语法:SELECT …...
代码随想录笔记--动态规划篇
1--动态规划理论基础 动态规划经典问题:① 背包问题;② 打家劫舍;③ 股票问题; ④ 子序列问题; 动态规划五部曲: ① 确定 dp 数组及其下标的含义; ② 确定递推公式; ③ 确定 dp 数组…...

vue之vuex
Vuex 是 Vue.js 的一个状态管理模式和库,为应用中的所有组件提供了一个集中式的存储管理,并提供了一种强大的方式来管理应用的状态。Vuex 包含以下核心概念: State:定义了应用的状态,类似于组件中的 data。 Getters&a…...
)
ISO 26262 系列学习笔记 ———— ASIL定义(Automotive Safety Integration Level)
文章目录 介绍严重度(Severity)暴露概率(Probability of Exposure)可控性(Controllability) 介绍 如果没有另行说明,则应满足ASIL A、B、C和D各分条款的要求或建议。这些要求和建议参考了安全目…...

代码随想录 第8章 二叉树
1、理论知识 (1)、满二叉树 如果一棵二叉树只有度为0的节点和度为2的节点,并且度为0的节点在同一层上,则这棵二叉树为满二叉树。 (2)、完全二叉树 除了底层节点可能没有填满,其余每层的节点…...
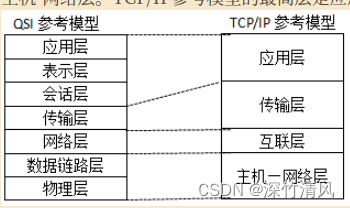
计算机网络工程师多选题系列——计算机网络
2 计算机网络 2.1 网络技术基础 题型1 TCP/IP与ISO模型的问题 TCP/IP由IETF制定,ISO由OSI制定; TCP/IP分为四层,分别是主机-网络层、互联网络层、传输层和应用层;OSI分为七层,分别是物理层、数据链路层、网络层(实…...
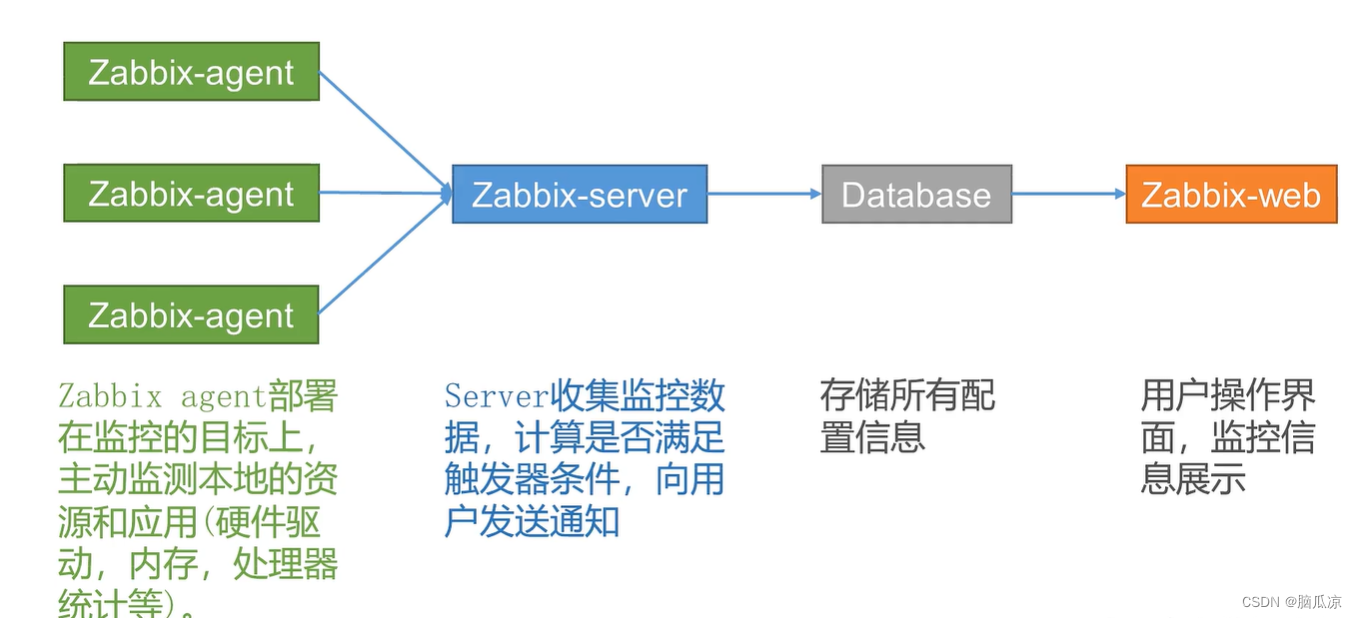
Zabbix5.0_介绍_组成架构_以及和prometheus的对比_大数据环境下的监控_网络_软件_设备监控_Zabbix工作笔记001
z 这里Zabbix可以实现采集 存储 展示 报警 但是 zabbix自带的,展示 和报警 没那么好看,我们可以用 grafana进行展示,然后我们用一个叫睿象云的来做告警展示, 会更丰富一点. 可以看到 看一下zabbix的介绍. 对zabbix的介绍,这个zabbix比较适合对服务器进行监控 这个是zabbix的…...
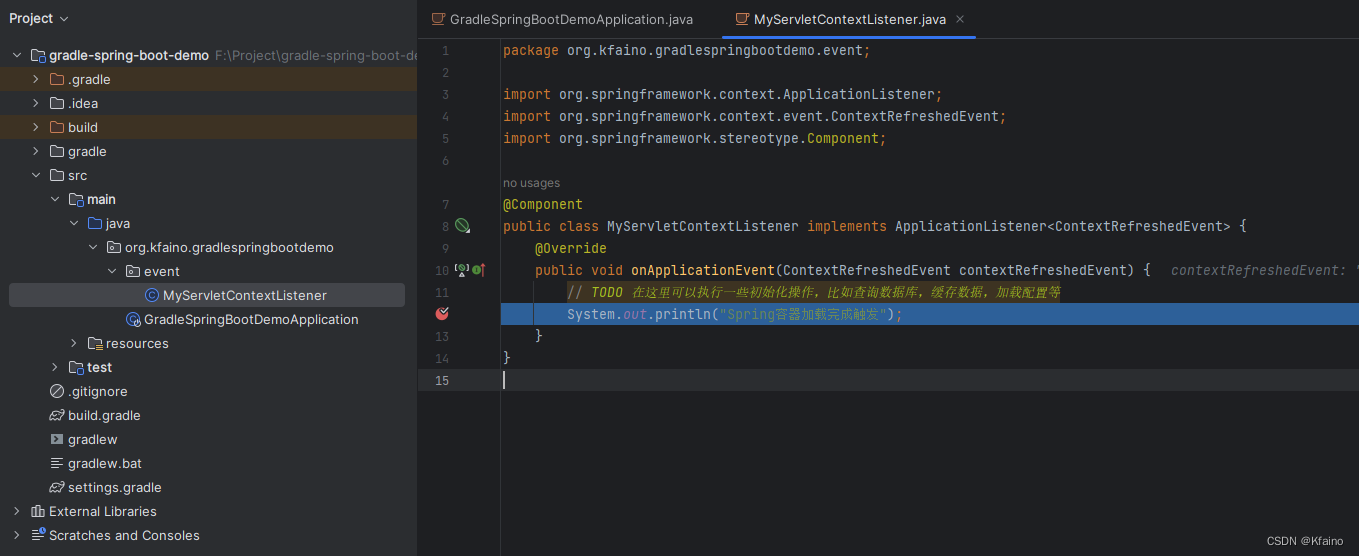
Spring | 事件监听器应用与最佳实践
引言 在复杂的软件开发环境中,组件之间的通信和信息交流显得尤为重要。Spring框架,作为Java世界中最受欢迎的开发框架之一,提供了一种强大的事件监听器模型,使得组件间的通信变得更加灵活和解耦。本文主要探讨Spring事件监听器的…...

正点原子lwIP学习笔记——NETCONN接口简介
1. NETCONN接口简介 NETCONN API 使用了操作系统的 IPC 机制, 对网络连接进行了抽象,使用同一的接口完成UDP和TCP连接。 NETCONN API接口是在RAW接口基础上延申出来的一套API接口 首先会调用netconn_new创建一个pcb控制块,其实际是一个宏定…...
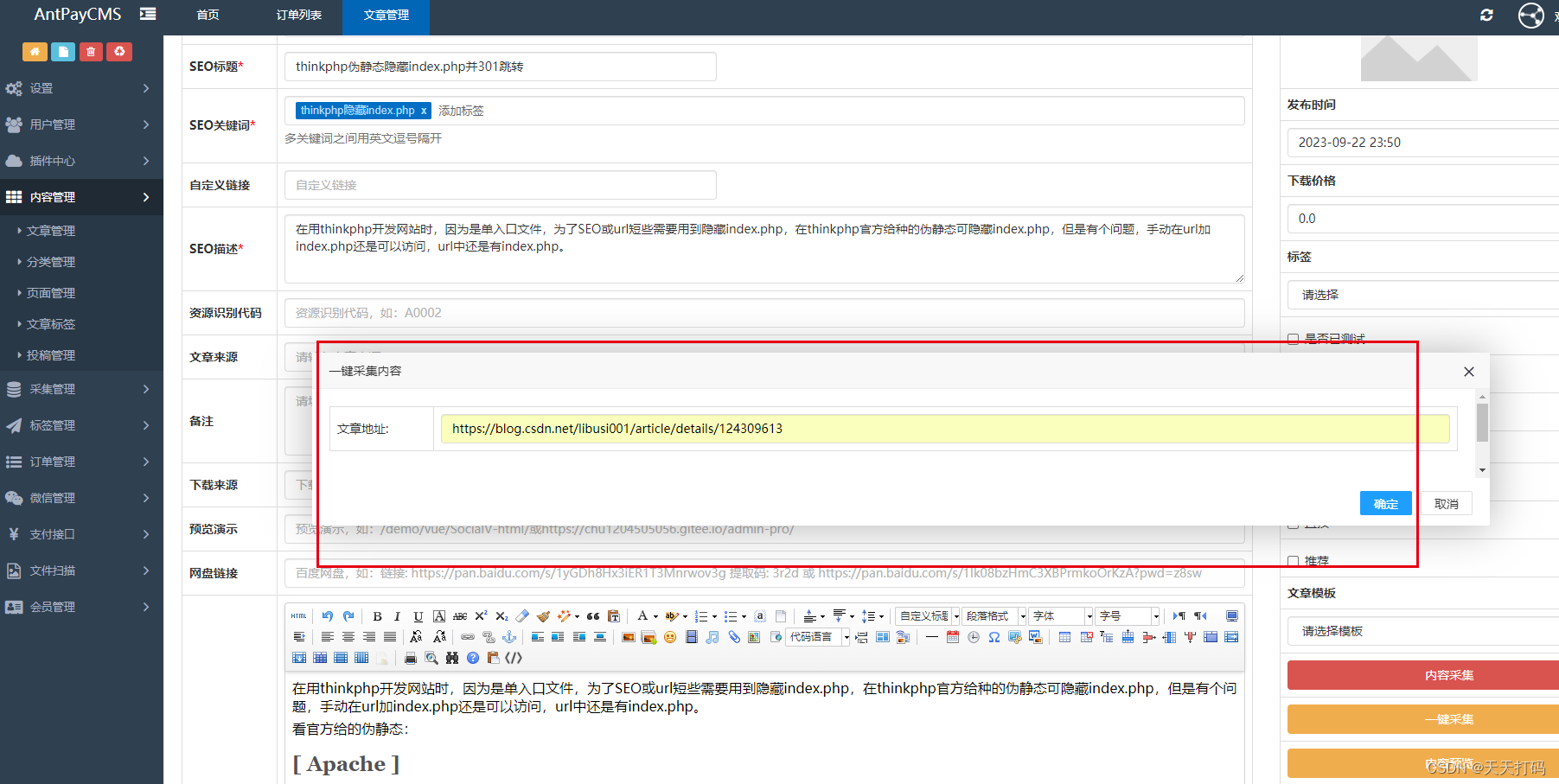
PHP自动识别采集何意网址文章正文内容
在做PHP采集内容时,用过querylist采集组件,但是这个插件采集页面内容时,都必须要写个采集选择器。这样比较麻烦,每个文章页面都必须指定一条采集规则 。就开始着手找一个插件可以能自动识别任意文章url正文内容并采集的࿰…...

区块链实验室(27) - 区块链+物联网应用案例
分享最新的区块链物联网应用案例:HPCLS-BC...
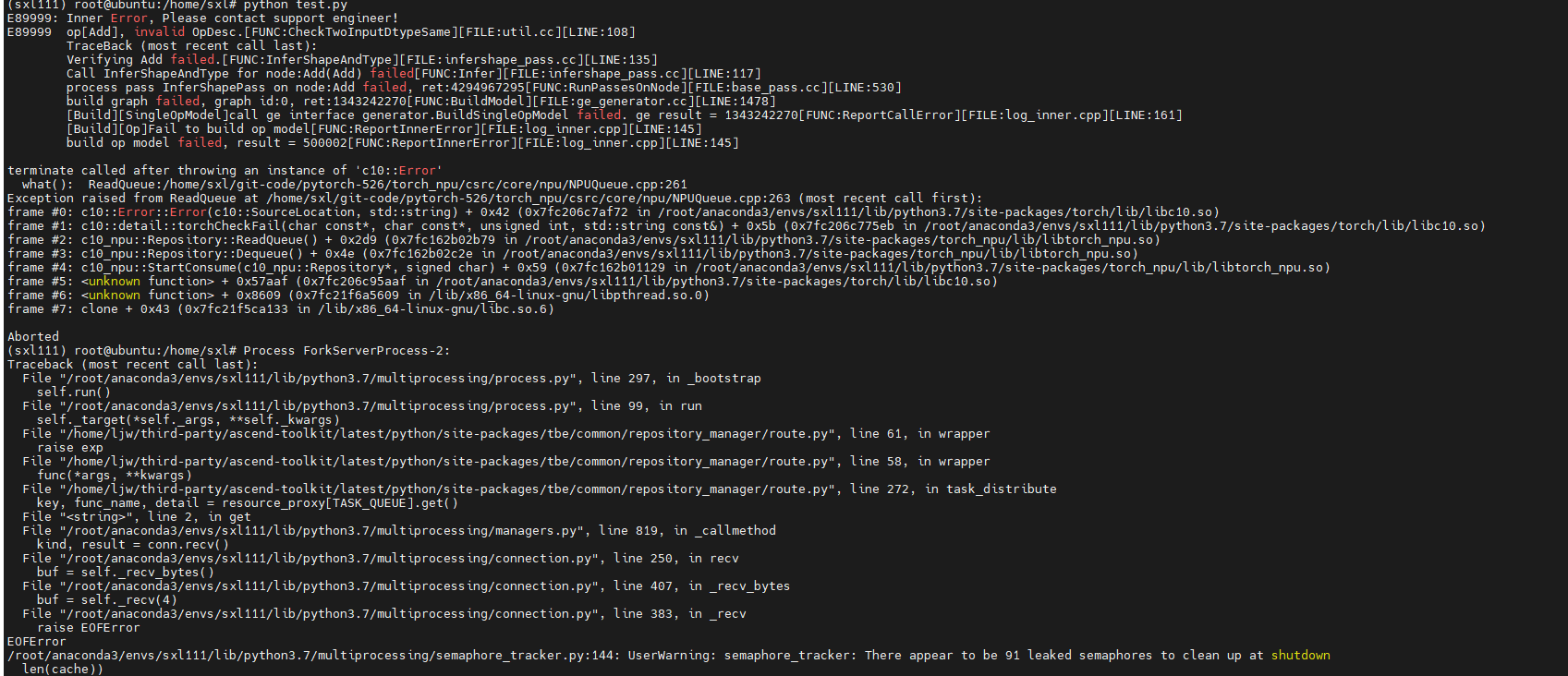
NPU上PyTorch模型训练问题案例
在昇腾AI处理器上训练PyTorch框架模型时,可能由于环境变量设置问题、训练脚本代码问题,导致打印出的堆栈报错与实际错误并不一致、脚本运行异常等问题,那么本期就分享几个关于PyTorch模型训练问题的典型案例,并给出原因分析及解决…...

出现 conda虚拟环境默认放在C盘 解决方法
目录 1. 问题所示2. 原理分析3. 解决方法3.1 方法一3.2 方法二1. 问题所示 通过conda配置虚拟环境的时候,由于安装在D盘下,但是配置的环境默认都给我放C盘 通过如下命令:conda env list,最后查看该环境的确在C盘下 2. 原理分析 究其根本原因,这是因为默认路径没有足够的…...

Ubuntu Postgresql开机自启动服务
1. 建立service文件 sudo vim /etc/systemd/system/postgresql.service2. postgresql service文件 [Unit] DescriptionPostgreSQL 14 database server Documentationman:postgres(1) Documentationhttp://www.postgresql.org/docs/14/static/ Afternetwork.target[Service] T…...

COTS即Commercial Off-The-Shelf 翻译为“商用现成品或技术”或者“商用货架产品”
COTS 使用“不再做修理或改进”的模式出售的商务产品 COTS即Commercial Off-The-Shelf 翻译为“商用现成品或技术”或者“商用货架产品”,指可以采购到的具有开放式标准定义的接口的软件或硬件产品,可以节省成本和时间。 中文名 商用现成品或技术 外文…...
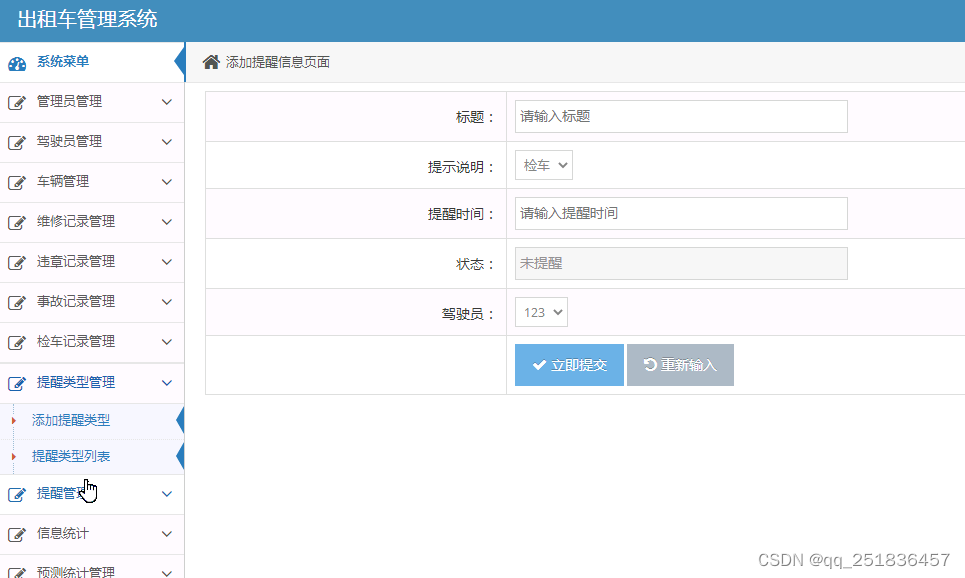
idea开发Springboot出租车管理系统VS开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot 出租车管理系统是一套完善的完整信息系统,结合springboot框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发), 系统具有完整的源代码和数据…...

Linux nohup
nohup 命令用于在 Linux 中将命令或程序在后台运行,并且在终端关闭后仍然保持运行。 nohup命令 描述 nohup 命令用于将命令或程序以不受终端挂断影响的方式在后台运行。 语法 nohup command [arguments] &参数 command:要在后台运行的命令或程…...
Linux 常见问题
1. 使用 sudo 命令时,提示 is not in the sudoers file. 是由于对应用户没有添加到 sudoers 文件中,可以在该文件中指定用户权限。运行以下命令即可打开该文件: visudo 添加上对应用户的权限 Ctrl x 退出保存即可。 2. Debian 新建的普通用…...

仕达利恩飞讯软件TPM设备管理项目正式启动,向数字化再迈一步
9月25日,仕达利恩(惠州)科技有限公司(以下简称“仕达利恩”)设备智能数采项目启动会成功召开,仕达利恩首席崔浩渊、杨翠琼次长携项目主要负责人共同出席本次启动会。为解决仕达利恩现阶段生产过程中的设备管理、设备配件仓管理以及…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...

PH热榜 | 2025-06-08
1. Thiings 标语:一套超过1900个免费AI生成的3D图标集合 介绍:Thiings是一个不断扩展的免费AI生成3D图标库,目前已有超过1900个图标。你可以按照主题浏览,生成自己的图标,或者下载整个图标集。所有图标都可以在个人或…...
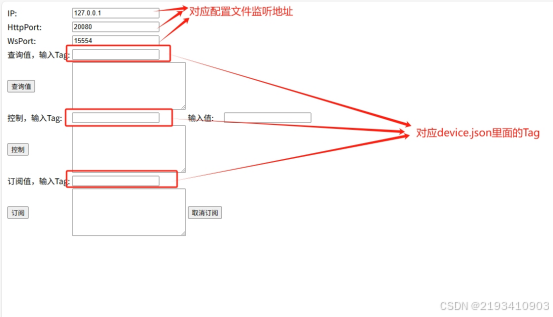
如何把工业通信协议转换成http websocket
1.现状 工业通信协议多数工作在边缘设备上,比如:PLC、IOT盒子等。上层业务系统需要根据不同的工业协议做对应开发,当设备上用的是modbus从站时,采集设备数据需要开发modbus主站;当设备上用的是西门子PN协议时…...