Greenplum 对比 Hadoop
Greenplum属于MPP架构,和Hadoop一样都是为了解决大规模数据的并行计算而出现的技术,两者的相似点在于:
- 分布式存储,数据分布在多个节点服务器上
- 分布式并行计算框架
- 支持横向扩展来提高整体的计算能力和存储容量
- 都支持X86开放集群架构
但两种技术在数据存储和计算方法上,也存在明显的差异:
- 是否有模式概念:Greenplum MPP按照关系数据库行列表方式存储数据(有模式);Hadoop按照文件切片方式分布式存储(无模式)。
- 数据分布机制:MPP主要采用Hash分布,计算节点和存储紧密耦合,数据分布粒度在记录级的更小粒度;Hadoop FS按照文件切块后随机分配,节点和数据无耦合,数据分布粒度在文件块级(缺少64MB)。
- 计算框架:MPP采用SQL并行查询计划,Hadoop采用MapReduce计算框架。
基于上述不同,体现在效率、功能等特性方面也大不相同。
计算效率对比
MapReduce相比而言是一种较为蛮力的计算方式,数据处理过程分为Map->Shuffle->Reduce的过程,相比MPP而言,MapReduce的数据在计算前未经整理和组织,而MPP预先把数据有效的组织,例如:行列表关系、Hash分布、索引、分区、列存、统计信息收集等,这决定了在计算过程中效率大不相同。
- MAP效率。 Hadoop的MAP阶段需要对数据再解析,而MPP数据库则会直接取行列表,效率高。Hadoop按默认64MB拆分文件,而且数据不能保证在所有节点均匀分布,因此,MAP过程的并行化程度低;MPP数据库按照数据记录拆分和Hash分布,粒度更细,数据分布在所有节点中非常均匀,并行化程度更高。Hadoop HDFS 没有灵活的索引、分区、列存等技术,而MPP通常利用这些技术大幅提高数据的检索效率。
- Shuffle效率。 Shuffle对比MPP计算中的重分布,由于 Hadoop数据与节点的无关性,Shuffle基本避免不了;而MPP数据库对于相同Hash分布数据不需要重分布,节点大量网络和CPU消耗。MapReduce没有统计信息,不能做基于cost based的优化;MPP数据库可以利用统计信息很好的进行并行计算优化。例如,MPP对于不同分布的数据可以在计算中基于cost动态决定最优执行路径,如采用重分布还是小表广播。
- Reduce效率。 对比MPP数据库的SQL执行器executor,MapReduce缺乏灵活的Join技术支持;MPP可以基于cost来自动选择Hash Join、Merge Join还是Nested Join,基于可以在Hash Join通过cost选择小表做Hash,在Nested Join中选择index提高Join性能等。MPP对于Aggregation提供Multiple-agg、Group-agg、Sort-agg等多种技术来提供计算性能,MapReduce需要开发人员自己实现。
另外,MapReduce在整个Map->Shuffle->Reduce过程中通过文件来交换数据,效率很低,MapReduce要求每个步骤间的数据都要序列化到磁盘,意味着MapReduce作业的IO成本很高,导致交互分析和迭代算法开销很大,MPP数据库采用Pipline方式在内存数据流中处理数据,效率比文件方式高很多。
总结:MPP数据库在计算并行度、计算算法上比Hadoop更优,效率更高。
功能对比
MPP数据库采用SQL作为交互式语言,SQL简单易学,具有很强的数据操纵能力和过程语言能力,SQL语言是专门为统计和数据分析开发的语言,各种功能和函数琳琅满目,SQL语言不仅适合开发人员,也适用于分析业务人员,大大简化数据的操作和交互过程。
MapReduce编程明显困难,在原生的MapReduce开发框架基础上开发,需要熟悉JAVA开发和并行原理。为了解决易用性的问题,近近来SQL on Haddop技术大量涌现,几乎成为当前Hadoop开发使用的一个技术热点趋势。这些技术包括Hive、HAWQ、Spark SQL、Impala、Presto、Drill、Tajo等。这些技术有些是在MapReduce上做优化,比如Spark采用内存中的MapReduce技术,有的采用C/C++代替Java语言重构Hadoop和MapReduce,有些是直接绕开MapReduce,如Impala、HAWQ借鉴MPP计算思想来做查询优化和内存数据Pipeline计算,以此提高性能。
虽然SQL on Hadoop比原始MapReduce在易用上有所提高,但SQL成熟度和关系分析上目前还与MPP数据库有较大差距。
上述产品,除了HAWQ外,对SQL的支持非常有限,特别是分析型复杂SQL,如SQL 2003 OLAP 窗口函数,几乎都不支持。由于Hadoop本身Append-only特性,SQL on Hadoop大多不支持数据局部更新和删除功能,基本上都缺少索引和存储过程等特征。除HAWQ外,大多对于ODBC/JDBC/DBI/OLEDB/.NET接口的支持有限,与主流第三方BI报表工具的兼容性不如MPP数据库。
SQL on Hadoop不擅长交互式的Ad Hoc查询,大多通过预关联的方式规避这个问题。另外,在并发处理方面能力较弱。高并发场景下,需要控制计算请求的并发度,避免资源过载导致的稳定性问题和性能下降问题。
架构灵活性对比
为保证数据的高性能计算,MPP数据库节点和数据之间是紧耦合的,相反,Hadoop的节点和数据是没有耦合关系的。这决定了Hadoop的架构更加灵活,存储节点和计算节点的无关性,现在在2个方面:
- 扩展性。 Hadoop架构支持单独增加数据节点或计算节点,依托Hadoop的SQL on Hadoop系统,例如HAWQ、SPARK均可单独增加计算层的节点或数据层的HDFS存储节点,HDFS数据存储对计算层来说是透明的。MPP数据库扩展时,一般情况下是计算节点和数据节点一起增加的,增加节点后需要对数据做重分布才能保证数据与节点的紧耦合,进而保证系统的性能。Hadoop增加存储层节点后虽然也需要Rebalance数据,但不是那么紧迫。
- 节点退服。 Hadoop节点宕机退服对系统影响较小,并且系统会自动将数据在其它节点扩充到3份;MPP数据库节点宕机时,系统性能损耗大于Hadoop。HAWQ实现了计算节点和HDFS数据节点的解耦,采用MR2.0的YARN来进行资源调度,同时具有Hadoop的灵活伸缩的架构特性和MPP的高效能计算能力。不过HAWQ比Greenplum MPP数据库要低一倍左右,但比其它基于MapReduce的SQL on Hadoop性能要好。
选择MPP还是Hadoop?
如果数据需要频繁的计算和统计并且希望具有更好的SQL交互式支持和更快计算性能及复杂SQL语法支持,建议选择MPP数据库。特别如数据仓库、集市、ODS、交互式分析数据平台等系统,MPP有明显的优势。
如果数据加载后只会被用于读取少数次的任务和用于少数次的访问,而且主要用于Batch,对计算性能不是很敏感,选择Hadoop也不错,Hadoop不需要花费较多的精力来模式化你的数据,节点数据模型设计和数据加载设计方面的投入。包括历史数据系统、ETL临时数据区、数据交换平台等。
相关文章:

Greenplum 对比 Hadoop
Greenplum属于MPP架构,和Hadoop一样都是为了解决大规模数据的并行计算而出现的技术,两者的相似点在于: 分布式存储,数据分布在多个节点服务器上分布式并行计算框架支持横向扩展来提高整体的计算能力和存储容量都支持X86开放集群架…...

OJ练习第182题——字典树(前缀树)
字典树(前缀树) 208. 实现 Trie (前缀树)题目描述示例知识补充官解代码 211. 添加与搜索单词 - 数据结构设计题目描述示例思路Java代码 208. 实现 Trie (前缀树) 力扣链接:208. 实现 Trie (前缀树) 题目描述 示例 知识补充 插入字符串 我…...

前端知识总结
在前端开发中,y x是一种常见的自增运算符的使用方式。它表示将变量x的值自增1,并将自增后的值赋给变量y。 具体来说,x是一种后缀自增运算符,表示将变量x的值自增1。而y x则是将自增前的值赋给变量y。这意味着在执行y x之后&am…...
)
中国JP-10燃料行业市场研究与预测报告(2023版)
内容简介: 高密度燃料是指以石油基、煤基和生物质基烃类为原料,通过聚合、加氢、异构等工艺合成的密度大于0.85 gcm-3的饱和多环碳氢化合物,广泛应用于航空航天领域。由于高密度燃料密度大和体积热值高等特点,飞行器在油箱体积一…...

护眼灯显色指数应达多少?眼科医生推荐灯光显色指数多少合适
台灯的显色指数是其非常重要的指标,它可以表示灯光照射到物体身上,物体颜色的真实程度,一般用平均显色指数Ra来表示,Ra值越高,灯光显色能力越强。常见的台灯显色指数最低要求一般是在Ra80以上即可,比较好的…...

AI 大模型
随着人工智能技术的迅猛发展,AI 大模型逐渐成为推动人工智能领域提升的关键因素,大模型已成为了引领技术浪潮研究和应用方向。大模型即大规模预训练模型,通常是指那些在大规模数据上进行了预训练的具有庞大规模和复杂结构的人工智能模型&…...

一个案例熟悉使用pytorch
文章目录 1. 完整模型的训练套路1.2 导入必要的包1.3 准备数据集1.3.1 使用公开数据集:1.3.2 获取训练集、测试集长度:1.3.3 利用 DataLoader来加载数据集 1.4 搭建神经网络1.4.1 测试搭建的模型1.4.2 创建用于训练的模型 1.5 定义损失函数和优化器1.6 使…...
)
MySQL - limit 分页查询 (查询操作 五)
功能介绍:分页查询(limit)是一种常用的数据库查询技术,它允许我们从数据库表中按照指定的数量和顺序获取数据,它在处理大量数据时特别有用,可以提高查询效率并减少网络传输的数据 语法:SELECT …...
代码随想录笔记--动态规划篇
1--动态规划理论基础 动态规划经典问题:① 背包问题;② 打家劫舍;③ 股票问题; ④ 子序列问题; 动态规划五部曲: ① 确定 dp 数组及其下标的含义; ② 确定递推公式; ③ 确定 dp 数组…...

vue之vuex
Vuex 是 Vue.js 的一个状态管理模式和库,为应用中的所有组件提供了一个集中式的存储管理,并提供了一种强大的方式来管理应用的状态。Vuex 包含以下核心概念: State:定义了应用的状态,类似于组件中的 data。 Getters&a…...
)
ISO 26262 系列学习笔记 ———— ASIL定义(Automotive Safety Integration Level)
文章目录 介绍严重度(Severity)暴露概率(Probability of Exposure)可控性(Controllability) 介绍 如果没有另行说明,则应满足ASIL A、B、C和D各分条款的要求或建议。这些要求和建议参考了安全目…...

代码随想录 第8章 二叉树
1、理论知识 (1)、满二叉树 如果一棵二叉树只有度为0的节点和度为2的节点,并且度为0的节点在同一层上,则这棵二叉树为满二叉树。 (2)、完全二叉树 除了底层节点可能没有填满,其余每层的节点…...
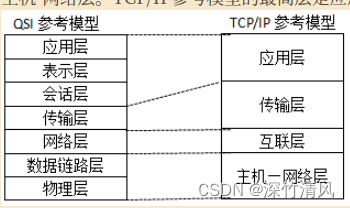
计算机网络工程师多选题系列——计算机网络
2 计算机网络 2.1 网络技术基础 题型1 TCP/IP与ISO模型的问题 TCP/IP由IETF制定,ISO由OSI制定; TCP/IP分为四层,分别是主机-网络层、互联网络层、传输层和应用层;OSI分为七层,分别是物理层、数据链路层、网络层(实…...
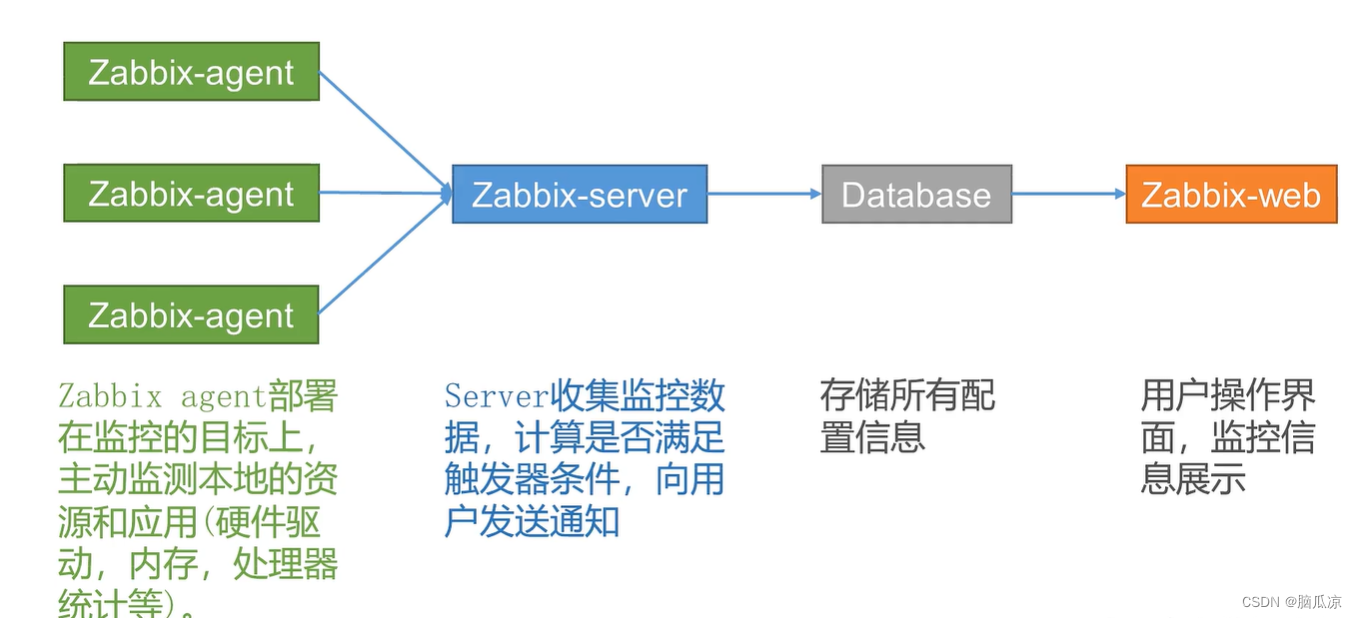
Zabbix5.0_介绍_组成架构_以及和prometheus的对比_大数据环境下的监控_网络_软件_设备监控_Zabbix工作笔记001
z 这里Zabbix可以实现采集 存储 展示 报警 但是 zabbix自带的,展示 和报警 没那么好看,我们可以用 grafana进行展示,然后我们用一个叫睿象云的来做告警展示, 会更丰富一点. 可以看到 看一下zabbix的介绍. 对zabbix的介绍,这个zabbix比较适合对服务器进行监控 这个是zabbix的…...
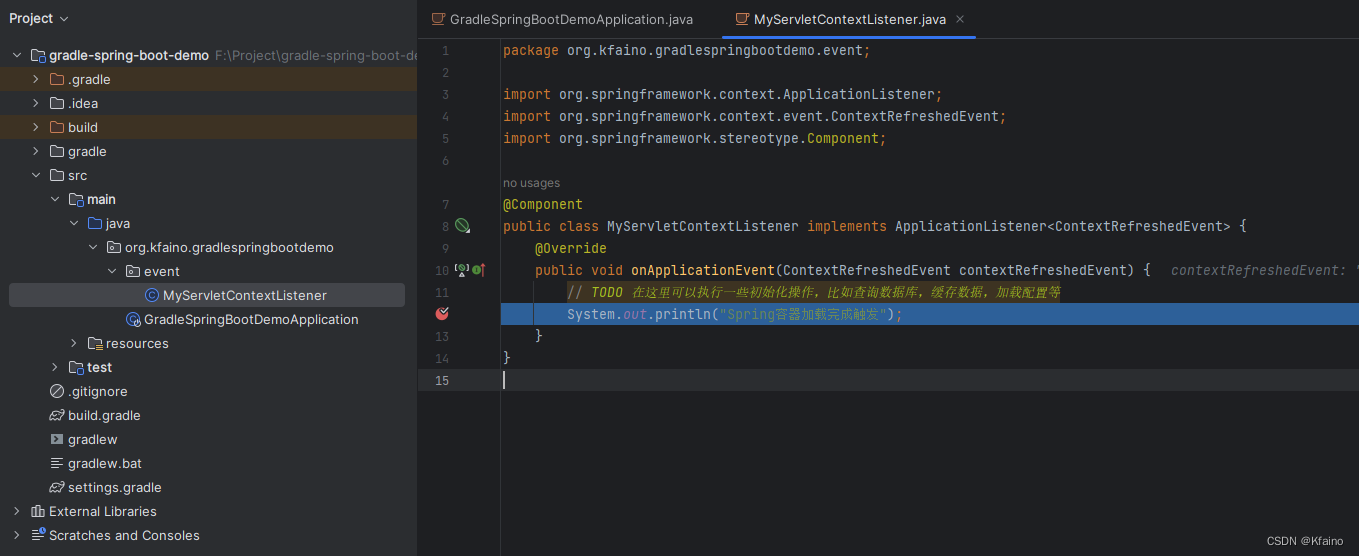
Spring | 事件监听器应用与最佳实践
引言 在复杂的软件开发环境中,组件之间的通信和信息交流显得尤为重要。Spring框架,作为Java世界中最受欢迎的开发框架之一,提供了一种强大的事件监听器模型,使得组件间的通信变得更加灵活和解耦。本文主要探讨Spring事件监听器的…...

正点原子lwIP学习笔记——NETCONN接口简介
1. NETCONN接口简介 NETCONN API 使用了操作系统的 IPC 机制, 对网络连接进行了抽象,使用同一的接口完成UDP和TCP连接。 NETCONN API接口是在RAW接口基础上延申出来的一套API接口 首先会调用netconn_new创建一个pcb控制块,其实际是一个宏定…...
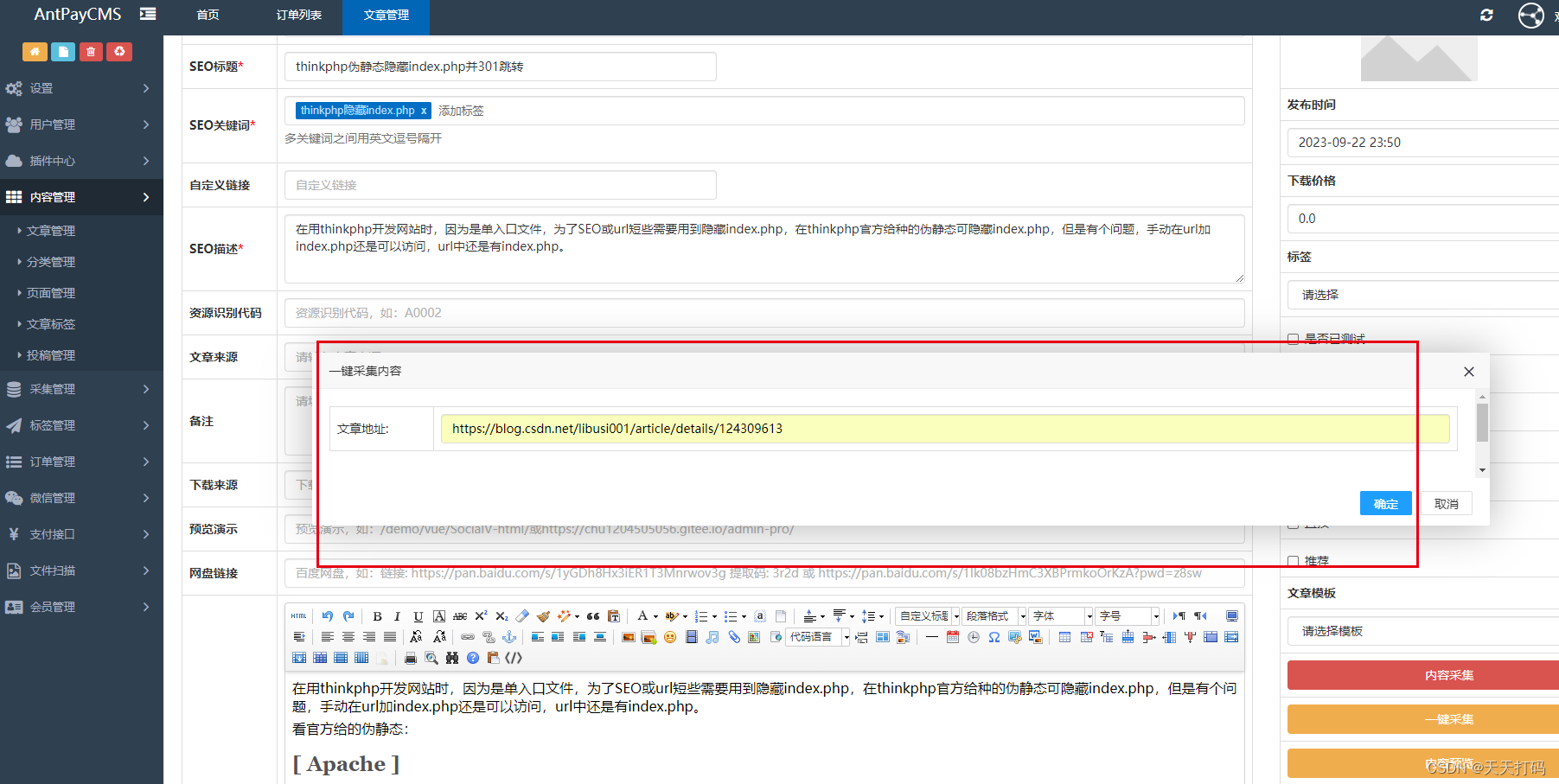
PHP自动识别采集何意网址文章正文内容
在做PHP采集内容时,用过querylist采集组件,但是这个插件采集页面内容时,都必须要写个采集选择器。这样比较麻烦,每个文章页面都必须指定一条采集规则 。就开始着手找一个插件可以能自动识别任意文章url正文内容并采集的࿰…...

区块链实验室(27) - 区块链+物联网应用案例
分享最新的区块链物联网应用案例:HPCLS-BC...
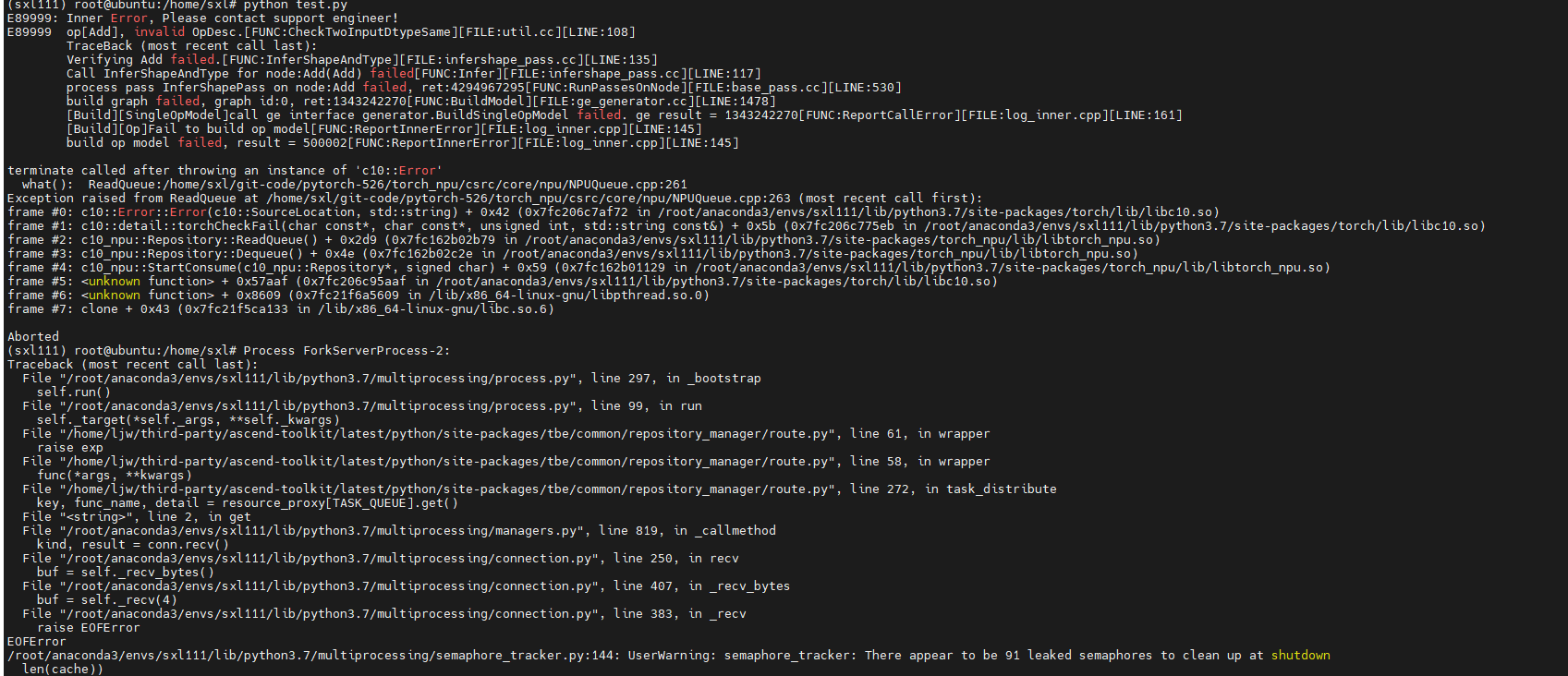
NPU上PyTorch模型训练问题案例
在昇腾AI处理器上训练PyTorch框架模型时,可能由于环境变量设置问题、训练脚本代码问题,导致打印出的堆栈报错与实际错误并不一致、脚本运行异常等问题,那么本期就分享几个关于PyTorch模型训练问题的典型案例,并给出原因分析及解决…...

出现 conda虚拟环境默认放在C盘 解决方法
目录 1. 问题所示2. 原理分析3. 解决方法3.1 方法一3.2 方法二1. 问题所示 通过conda配置虚拟环境的时候,由于安装在D盘下,但是配置的环境默认都给我放C盘 通过如下命令:conda env list,最后查看该环境的确在C盘下 2. 原理分析 究其根本原因,这是因为默认路径没有足够的…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

C# 表达式和运算符(求值顺序)
求值顺序 表达式可以由许多嵌套的子表达式构成。子表达式的求值顺序可以使表达式的最终值发生 变化。 例如,已知表达式3*52,依照子表达式的求值顺序,有两种可能的结果,如图9-3所示。 如果乘法先执行,结果是17。如果5…...
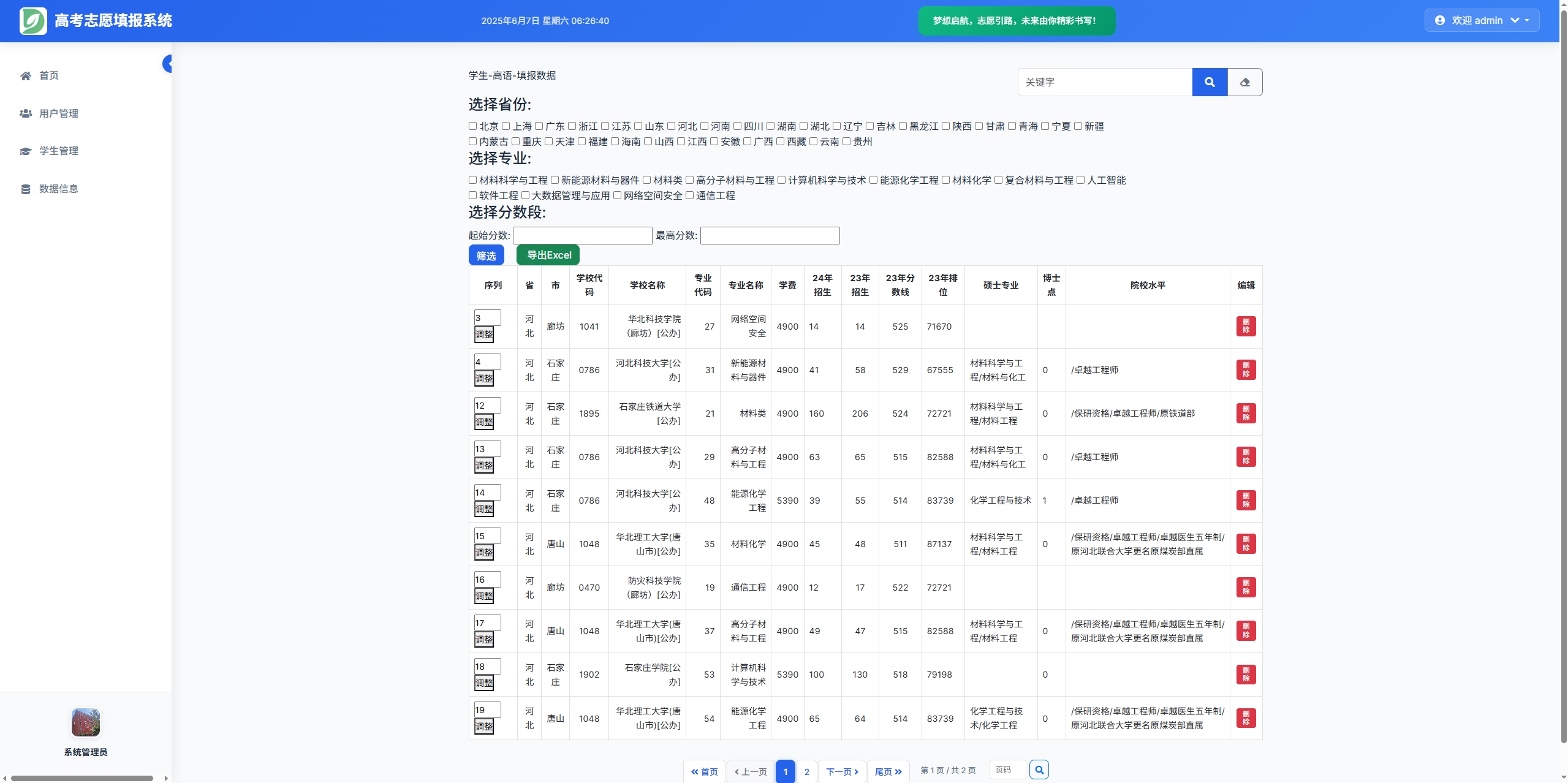
高考志愿填报管理系统---开发介绍
高考志愿填报管理系统是一款专为教育机构、学校和教师设计的学生信息管理和志愿填报辅助平台。系统基于Django框架开发,采用现代化的Web技术,为教育工作者提供高效、安全、便捷的学生管理解决方案。 ## 📋 系统概述 ### 🎯 系统定…...
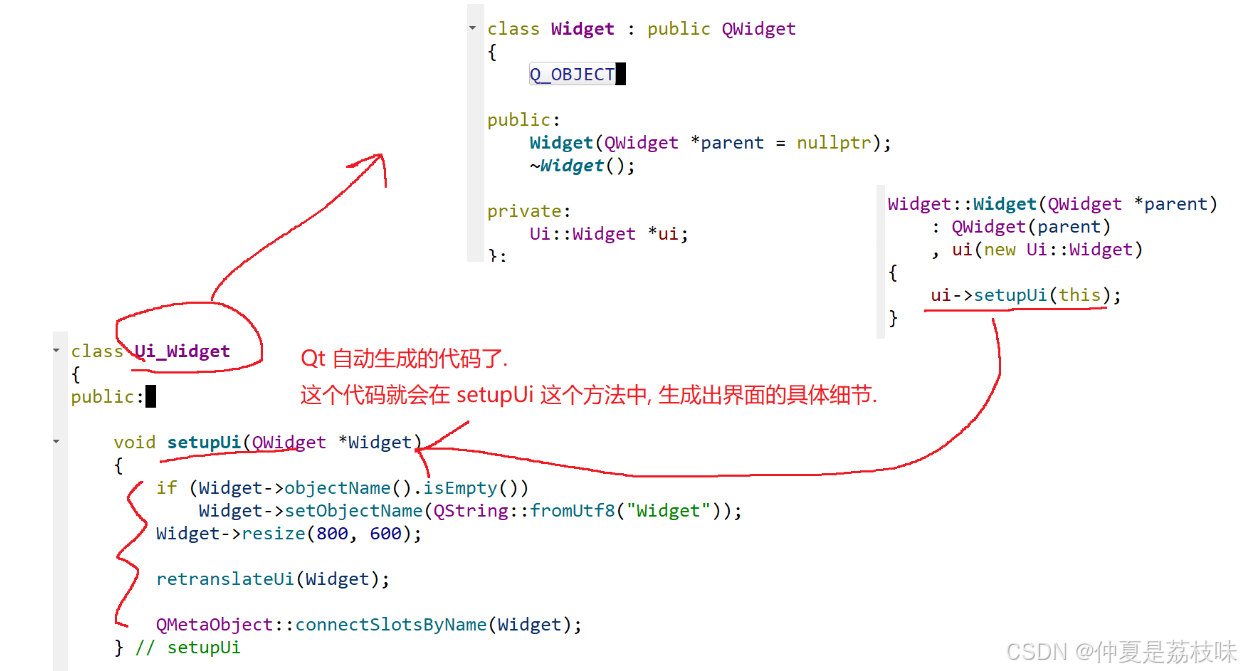
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...

Python第七周作业
Python第七周作业 文章目录 Python第七周作业 1.使用open以只读模式打开文件data.txt,并逐行打印内容 2.使用pathlib模块获取当前脚本的绝对路径,并创建logs目录(若不存在) 3.递归遍历目录data,输出所有.csv文件的路径…...