轻量级的日志采集组件 Filebeat 讲解与实战操作
文章目录
- 一、概述
- 二、Kafka 安装
- 三、Filebeat 安装
- 1)下载 Filebeat
- 2)Filebeat 配置参数讲解
- 3)filebeat.prospectors 推送kafka完整配置
- 1、filebeat.prospectors
- 2、processors
- 3、output.kafka
- 4)filebeat.inputs 与 filebeat.prospectors区别
- 5)filebeat.yml 配置
- 6)启动 Filebeat 服务
- 7)检测日志是否已经采集到 kafka
一、概述
Filebeat是一个轻量级的日志数据收集工具,属于Elastic公司的Elastic Stack(ELK Stack)生态系统的一部分。它的主要功能是从各种来源收集日志数据,将数据发送到Elasticsearch、Logstash或其他目标,以便进行搜索、分析和可视化。
以下是Filebeat的主要概述和特点:
-
轻量级:Filebeat是一个轻量级的代理,对系统资源的消耗非常低。它设计用于高性能和低延迟,可以在各种环境中运行,包括服务器、容器和虚拟机。
-
多源收集:Filebeat支持从各种来源收集数据,包括日志文件、系统日志、Docker容器日志、Windows事件日志等。它具有多个输入模块,可以轻松配置用于不同数据源的数据收集。
-
模块化:Filebeat采用模块化的方式组织配置,每个输入类型都可以作为一个模块,易于扩展和配置。这使得添加新的数据源和日志格式变得更加简单。
-
自动发现:Filebeat支持自动发现服务,可以在容器化环境中自动识别新的容器和服务,并开始收集其日志数据。
-
安全性:Filebeat支持安全传输,可以使用TLS/SSL加密协议将数据安全地传输到目标。它还支持基于令牌的身份验证。
-
数据处理:Filebeat可以对数据进行简单的处理,如字段分割、字段重命名和数据过滤,以确保数据适合进一步处理和分析。
-
目标输出:Filebeat可以将数据发送到多个目标,最常见的是将数据发送到Elasticsearch,以便进行全文搜索和分析。此外,还可以将数据发送到Logstash、Kafka等目标。
-
实时性:Filebeat可以以实时方式收集和传输数据,确保日志数据及时可用于分析和可视化。
-
监控和管理:Filebeat具有自身的监控功能,可以监视自身的状态和性能,并与Elasticsearch、Kibana等工具集成,用于管理和监控数据收集。
工作的流程图如下:
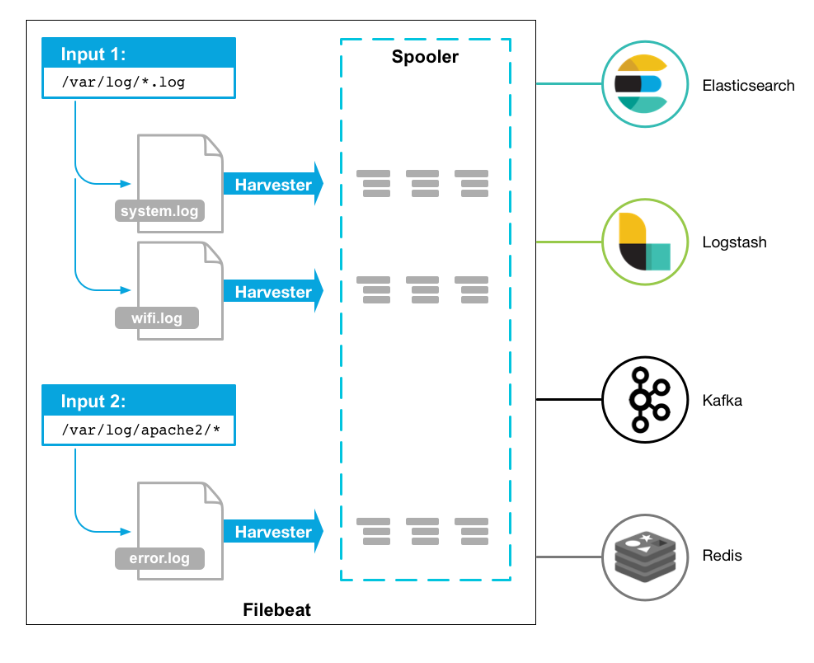
Filebeat的采集原理的主要步骤
-
数据源检测:
- Filebeat首先配置要监视的数据源,这可以是日志文件、系统日志、Docker容器日志、Windows事件日志等。Filebeat可以通过输入模块配置来定义数据源。
-
数据收集:
- 一旦数据源被定义,Filebeat会定期轮询这些数据源,检查是否有新的数据产生。
- 如果有新数据,Filebeat将读取数据并将其发送到后续处理阶段。
-
数据处理:
- Filebeat可以对采集到的数据进行一些简单的处理,例如字段分割、字段重命名、数据解析等。这有助于确保数据格式适合进一步的处理和分析。
-
数据传输:
- 采集到的数据将被传输到一个或多个目标位置,通常是Elasticsearch、Logstash或Kafka等。
- Filebeat可以配置多个输出目标,以便将数据复制到多个地方以增加冗余或分发数据。
-
安全性和可靠性:
- Filebeat支持安全传输,可以使用TLS/SSL协议对数据进行加密。
它还具有数据重试机制,以确保数据能够成功传输到目标位置。
- Filebeat支持安全传输,可以使用TLS/SSL协议对数据进行加密。
-
数据目的地:
- 数据被传输到目标位置后,可以被进一步处理、索引和分析。目标位置通常是Elasticsearch,用于全文搜索和分析,或者是Logstash用于进一步的数据处理和转换,也可以是Kafka等其他消息队列。
-
实时性和监控:
- Filebeat可以以实时方式监视数据源,确保新数据能够快速传输和处理。
- Filebeat还可以与监控工具集成,以监控其自身的性能和状态,并将这些数据发送到监控系统中。
总的来说,Filebeat采集原理是通过轮询监视数据源,将新数据采集并发送到目标位置,同时确保数据的安全传输和可靠性。它提供了一种高效且灵活的方式来处理各种类型的日志和事件数据,以便进行后续的分析和可视化。
二、Kafka 安装
为了快速部署,这里选择通过docker-compose部署,可以参考我这篇文章:【中间件】通过 docker-compose 快速部署 Kafka 保姆级教程
# 先安装 zookeeper
git clone https://gitee.com/hadoop-bigdata/docker-compose-zookeeper.git
cd docker-compose-zookeeper
docker-compose -f docker-compose.yaml up -d# 安装kafka
git clone https://gitee.com/hadoop-bigdata/docker-compose-kafka.git
cd docker-compose-kafka
docker-compose -f docker-compose.yaml up -d
如果仅仅只是为测试也可以部署一个单机kafka
官方下载地址:http://kafka.apache.org/downloads
### 1、下载kafka
wget https://downloads.apache.org/kafka/3.4.1/kafka_2.12-3.4.1.tgz --no-check-certificate
### 2、解压
tar -xf kafka_2.12-3.4.1.tgz### 3、配置环境变量
# ~/.bashrc添加如下内容:
export PATH=$PATH:/opt/docker-compose-kafka/images/kafka_2.12-3.4.1/bin### 4、配置zookeeper 新版Kafka已内置了ZooKeeper,如果没有其它大数据组件需要使用ZooKeeper的话,直接用内置的会更方便维护。
# vi kafka_2.12-3.4.1/config/zookeeper.properties
#注释掉
#maxClientCnxns=0#设置连接参数,添加如下配置
#为zk的基本时间单元,毫秒
tickTime=2000
#Leader-Follower初始通信时限 tickTime*10
initLimit=10
#Leader-Follower同步通信时限 tickTime*5
syncLimit=5#设置broker Id的服务地址
#hadoop-node1对应于前面在hosts里面配置的主机映射,0是broker.id, 2888是数据同步和消息传递端口,3888是选举端口
server.0=local-168-182-110:2888:3888### 5、配置kafka
# vi kafka_2.12-3.4.1/config/server.properties
#添加以下内容:
broker.id=0
listeners=PLAINTEXT://local-168-182-110:9092
# 上面容器的zookeeper
zookeeper.connect=local-168-182-110:2181
# topic不存在的,kafka就会创建该topic。
#auto.create.topics.enable=true### 6、启动服务
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
./bin/kafka-server-start.sh -daemon config/server.properties### 7、测试验证
#创建topic
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --create --topic topic1 --partitions 8 --replication-factor 1#列出所有topic
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --list#列出所有topic的信息
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe#列出指定topic的信息
kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe --topic topic1#生产者(消息发送程序)
kafka-console-producer.sh --broker-list local-168-182-110:9092 --topic topic1#消费者(消息接收程序)
kafka-console-consumer.sh --bootstrap-server local-168-182-110:9092 --topic topic1
三、Filebeat 安装
1)下载 Filebeat
官网地址:https://www.elastic.co/cn/downloads/past-releases#filebeat
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.2-linux-x86_64.tar.gztar -xf filebeat-7.6.2-linux-x86_64.tar.gz
2)Filebeat 配置参数讲解
Filebeat的配置文件通常是YAML格式,包含各种配置参数,用于定义数据源、输出目标、数据处理和其他选项。以下是一些常见的Filebeat配置参数及其含义:
-
filebeat.inputs:指定要监视的数据源。可以配置多个输入,每个输入定义一个数据源。每个输入包括以下参数:type:数据源的类型,例如日志文件、系统日志、Docker日志等。paths:要监视的文件路径或者使用通配符指定多个文件。enabled:是否启用该输入。
示例:
filebeat.inputs:- type: logpaths:- /var/log/*.log- type: dockerenabled: true
-
filebeat.modules:定义要加载的模块,每个模块用于解析特定类型的日志或事件数据。每个模块包括以下参数:module:模块名称。enabled:是否启用模块。var:自定义模块变量。
示例:
filebeat.modules:- module: apacheaccess:enabled: trueerror:enabled: true
-
output.elasticsearch:指定将数据发送到Elasticsearch的配置参数,包括Elasticsearch主机、索引名称等。- hosts:Elasticsearch主机列表。
- index:索引名称模板。
- username和password:用于身份验证的用户名和密码。
- pipeline:用于数据预处理的Ingest节点管道。
示例:
output.elasticsearch:hosts: ["localhost:9200"]index: "filebeat-%{[agent.version]}-%{+yyyy.MM.dd}"username: "your_username"password: "your_password"
-
output.logstash:指定将数据发送到Logstash的配置参数,包括Logstash主机和端口等。hosts:Logstash主机列表。index:索引名称模板。ssl:是否使用SSL/TLS加密传输数据。
示例:
output.logstash:hosts: ["localhost:5044"]index: "filebeat-%{[agent.version]}-%{+yyyy.MM.dd}"ssl.enabled: true
-
processors:定义对数据的预处理步骤,包括字段分割、重命名、添加字段等。- add_fields:添加字段到事件数据。
- decode_json_fields:解码JSON格式的字段。
- drop_fields:删除指定字段。
- rename:重命名字段。
示例:
processors:- add_fields:target: "my_field"value: "my_value"- drop_fields:fields: ["field1", "field2"]
-
filebeat.registry.path:指定Filebeat用于跟踪已经读取的文件和位置信息的注册文件的路径。 -
filebeat.autodiscover:自动发现数据源,特别是用于容器化环境,配置自动检测新容器的策略。 -
logging.level:指定Filebeat的日志级别,可选项包括info、debug、warning等。
这些是 Filebeat 的一些常见配置参数,具体的配置取决于您的使用场景和需求。您可以根据需要自定义配置文件,以满足您的数据采集和处理需求。详细的配置文档可以在Filebeat官方文档中找到。
3)filebeat.prospectors 推送kafka完整配置
这里主要用到几个核心字段:filebeat.prospectors、processors、output.kafka
1、filebeat.prospectors
filebeat.prospectors:用于定义要监视的数据源和采集规则。每个 prospector 包含一个或多个输入规则,它们指定要监视的文件或数据源以及如何采集和解析数据。
以下是一个示例 filebeat.prospectors 部分的配置:
filebeat.prospectors:
- type: logenabled: truepaths:- /var/log/*.logexclude_files:- "*.gz"multiline.pattern: '^\['multiline.negate: falsemultiline.match: aftertags: ["tag1", "tag2"]tail_files: truefields:app: myappenv: production
在上述示例中,我们定义了一个 filebeat.prospectors 包含一个 type: log 的 prospector,下面是各个字段的解释:
-
type(必需):数据源的类型。在示例中,类型是 log,表示监视普通文本日志文件。Filebeat支持多种类型,如log、stdin、tcp、udp等。 -
enabled:是否启用此prospector。如果设置为 true,则启用,否则禁用。默认为 true。 -
paths(必需):要监视的文件或文件模式,可以使用通配符指定多个文件。在示例中,Filebeat将监视 /var/log/ 目录下的所有以 .log 结尾的文件。 -
exclude_files:要排除的文件或文件模式列表。这里排除了所有以 .gz 结尾的文件。可选字段。 -
multiline.pattern:多行日志的起始模式。如果您的日志事件跨越多行,此选项可用于合并多行日志事件。例如,设置为 ‘pattern’ 将根据以 ‘pattern’ 开头的行来合并事件。 -
multiline.negate:是否取反多行日志模式。如果设置为 true,则表示匹配不包含多行日志模式的行。可选字段,默认为 false。 -
multiline.match:多行匹配模式,可以是 before(与上一行合并)或 after(与下一行合并)。如果设置为 before,则当前行与上一行合并为一个事件;如果设置为 after,则当前行与下一行合并为一个事件。可选字段,默认为after。 -
tags:为采集的事件添加标签,以便后续的数据处理。标签是一个字符串数组,可以包含多个标签。在示例中,事件将被标记为 “tag1” 和 “tag2”。可选字段。 -
tail_files:用于控制Filebeat是否应该跟踪正在写入的文件(tail文件)。当tail_files设置为true时,Filebeat将监视正在被写入的文件,即使它们还没有完成。这对于实时监视日志文件非常有用,因为它允许Filebeat立即处理新的日志行。默认情况下,tail_files是启用的,因此只有在特殊情况下才需要显式设置为 false。 -
fields:为事件添加自定义字段。这是一个键值对,允许您添加额外的信息到事件中。在示例中,事件将包含 “app” 字段和 “env” 字段,分别设置为 “myapp” 和 “production”。可选字段。
这些字段允许您配置Filebeat以满足特定的数据源和采集需求。您可以根据需要定义多个 prospector 来监视不同类型的数据源,每个 prospector 可以包含不同的参数。通过灵活配置 filebeat.prospectors,Filebeat可以适应各种日志和数据采集场景。
2、processors
processors 是Filebeat配置中的一个部分,用于定义在事件传输到输出目标之前对事件数据进行预处理的操作。您可以使用 processors 来修改事件数据、添加字段、删除字段,以及执行其他自定义操作。以下是一些常见的 processors 配置示例和说明:
- 添加字段(Add Fields):
可以使用 add_fields 处理器将自定义字段添加到事件中,以丰富事件的信息。例如,将应用程序名称和环境添加到事件中:
processors:- add_fields:fields:app: myappenv: production
- 删除字段(Drop Fields):
使用 drop_fields 处理器可以删除事件中的指定字段。以下示例删除名为 “sensitive_data” 的字段:
processors:- drop_fields:fields: ["sensitive_data"]
- 解码 JSON 字段(Decode JSON Fields):
如果事件中包含JSON格式的字段,您可以使用 decode_json_fields 处理器将其解码为结构化数据。以下示例将名为 “json_data” 的字段解码为结构化数据:
processors:- decode_json_fields:fields: ["json_data"]target: ""
- 字段重命名(Rename Fields):
可以使用 rename 处理器重命名事件中的字段。例如,将 “old_field” 重命名为 “new_field”:
processors:- rename:fields:- from: old_fieldto: new_field
- 条件处理(Conditional Processing):
使用 if 条件可以根据事件的特定字段或属性来选择是否应用某个处理器。以下示例根据事件中的 “log_level” 字段,仅在 “error” 日志级别时添加 “error” 标签:
processors:- add_tags:tags: ["error"]when:equals:log_level: "error"
- 多个处理器(Multiple Processors):
您可以配置多个处理器,它们将按照顺序依次应用于事件数据。例如,您可以先添加字段,然后删除字段,最后重命名字段。
processors 部分允许您对事件数据进行复杂的处理和转换,以适应特定的需求。您可以根据需要组合不同的处理器来执行多个操作,以确保事件数据在传输到输出目标之前满足您的要求。
3、output.kafka
output.kafka 是Filebeat配置文件中的一个部分,用于配置将事件数据发送到Kafka消息队列的相关设置。以下是 output.kafka 部分的常见参数及其解释:
output.kafka:hosts: ["kafka-broker1:9092", "kafka-broker2:9092"]topic: "my-log-topic"partition.round_robin:reachable_only: falserequired_acks: 1compression: gzipmax_message_bytes: 1000000
以下是各个参数的详细解释:
-
hosts(必需):Kafka broker 的地址和端口列表。在示例中,我们指定了两个Kafka broker:kafka-broker1:9092 和 kafka-broker2:9092。Filebeat将使用这些地址来连接到Kafka集群。 -
topic(必需):要发送事件到的Kafka主题(topic)的名称。在示例中,主题名称为 “my-log-topic”。Filebeat将会将事件发送到这个主题。 -
partition.round_robin:事件分区策略的配置。这里的配置是将事件平均分布到所有分区,不仅仅是可达的分区。reachable_only设置为 false,表示即使分区不可达也会发送数据。如果设置为true,则只会发送到可达的分区。 -
required_acks:Kafka的确认机制。指定要等待的确认数,1 表示只需要得到一个分区的确认就认为消息已经成功发送。更高的值表示更多的确认。通常,1 是常见的设置,因为它具有较低的延迟。 -
compression:数据的压缩方式。在示例中,数据被gzip压缩。这有助于减小传输数据的大小,降低网络带宽的使用。 -
max_message_bytes:Kafka消息的最大字节数。如果事件的大小超过此限制,Filebeat会将事件拆分为多个消息。
以上是常见的 output.kafka 参数,您可以根据您的Kafka集群配置和需求来调整这些参数。确保配置正确的Kafka主题和分区策略以满足您的数据传输需求。同时,要确保Filebeat服务器可以连接到指定的Kafka broker地址。
以下是一个完整的Filebeat配置文件示例,其中包括了 filebeat.prospectors、processors 和 output.kafka 的配置部分,以用于从日志文件采集数据并将其发送到Kafka消息队列:
4)filebeat.inputs 与 filebeat.prospectors区别
Filebeat 从 7.x 版本开始引入了新的配置方式 filebeat.inputs,以提供更灵活的输入配置选项,同时保留了向后兼容性。以下是 filebeat.inputs 和 filebeat.prospectors 之间的主要区别:
-
filebeat.inputs:- filebeat.inputs 是较新版本的配置方式,用于定义输入配置。
- 允许您以更灵活的方式配置不同类型的输入。您可以在配置文件中定义多个独立的输入块,每个块用于配置不同类型的输入。
- 每个输入块可以包含多个字段,用于定制不同输入类型的配置,如 type、enabled、paths、multiline 等。
- 使配置更具可读性,因为每个输入类型都有自己的配置块。
示例:
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/app/*.log- type: syslogenabled: trueport: 514protocol.udp: true
-
filebeat.prospectors:filebeat.prospectors是旧版配置方式,用于定义输入配置。- 所有的输入类型(如日志文件、系统日志、stdin 等)都需要放在同一个部分中。
- 需要在同一个配置块中定义不同输入类型的路径等细节。
- 旧版配置方式,不如
filebeat.inputs配置方式那么灵活和可读性好。
以下是一些常见的 type 值以及它们的含义:
log(常用):用于监视和收集文本日志文件,例如应用程序日志。
- type: logpaths:- /var/log/*.log
stdin:用于从标准输入(stdin)收集数据。
- type: stdin
syslog:用于收集系统日志数据,通常是通过UDP或TCP协议从远程或本地syslog服务器接收。
- type: syslogport: 514protocol.udp: true
filestream:用于收集 Windows 上的文件日志数据。
- type: filestreamenabled: true
httpjson:用于通过 HTTP 请求从 JSON API 收集数据。
- type: httpjsonenabled: trueurls:- http://example.com/api/data
tcp 和 udp:用于通过 TCP 或 UDP 协议收集网络数据。
- type: tcpenabled: truehost: "localhost"port: 12345
- type: udpenabled: truehost: "localhost"port: 12345
总的来说,filebeat.inputs 提供了更灵活的方式来配置不同类型的输入,更容易组织和管理配置。如果您使用的是较新版本的 Filebeat,推荐使用 filebeat.inputs 配置方式。但对于向后兼容性,旧版的 filebeat.prospectors 仍然可以使用。
5)filebeat.yml 配置
filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/*.logmultiline.pattern: '^\['multiline.negate: falsemultiline.match: aftertail_files: truefields:app: myappenv: productiontopicname: my-log-topic
- type: logenabled: truepaths:- /var/log/messagesmultiline.pattern: '^\['multiline.negate: falsemultiline.match: aftertail_files: truefields:app: myappenv: productiontopicname: my-log-topic
processors:- add_fields:fields:app: myappenv: production- drop_fields:fields: ["sensitive_data"]output.kafka:hosts: ["local-168-182-110:9092"]#topic: "my-log-topic"# 这里也可以应用上面filebeat.prospectors.fields的值topic: '%{[fields][topicname]}'partition.round_robin:reachable_only: falserequired_acks: 1compression: gzipmax_message_bytes: 1000000
6)启动 Filebeat 服务
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &# -e 将启动信息输出到屏幕上
# filebeat本身运行的日志默认位置${install_path}/logs/filebeat
要修改filebeat的日子路径,可以添加一下内容在filebeat.yml配置文件:
#logging.level :debug 日志级别
path.logs: /var/log/
使用 systemctl 启动 filebeat
# vi /usr/lib/systemd/system/filebeat.service[Unit]
Description=filebeat server daemon
Documentation=/opt/filebeat-7.6.2-linux-x86_64/filebeat -help
Wants=network-online.target
After=network-online.target[Service]
User=root
Group=root
Environment="BEAT_CONFIG_OPTS=-c /opt/filebeat-7.6.2-linux-x86_64/filebeat.yml"
ExecStart=/opt/filebeat-7.6.2-linux-x86_64/filebeat $BEAT_CONFIG_OPTS
Restart=always[Install]
WantedBy=multi-user.target
【温馨提示】记得更换自己的
filebeat目录。
systemctl 启动 filebeat 服务
#刷新一下配置文件
systemctl daemon-reload# 启动
systemctl start filebeat# 查看状态
systemctl status filebeat# 查看进程
ps -ef|grep filebeat# 查看日志
vi logs/filebeat
7)检测日志是否已经采集到 kafka
# 设置环境变量
export KAFKA_HOME=/opt/docker-compose-kafka/images/kafka_2.12-3.4.1# 查看topic列表
${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server local-168-182-110:9092 --list# 查看topic列表详情
${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe# 指定topic
${KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server local-168-182-110:9092 --describe --topic my-log-topic# 查看kafka数据
${KAFKA_HOME}/bin/kafka-console-consumer.sh --topic my-log-topic --bootstrap-server local-168-182-110:9092#上述命令会连接到指定的Kafka集群并打印my_topic主题上的所有消息。如果要查看特定数量的最新消息,则应将“--from-beginning”添加到命令中。
# 在较高版本的 Kafka 中(例如 Kafka 2.4.x 和更高版本),消费者默认需要明确指定要消费的分区。
#以下是查看特定最新消息数量的示例:
${KAFKA_HOME}/bin/kafka-console-consumer.sh --topic my-log-topic --bootstrap-server local-168-182-110:9092 --from-beginning --max-messages 10 --partition 0# 查看kafka数据量,在较高版本的 Kafka 中(例如 Kafka 2.4.x 和更高版本),消费者默认需要明确指定要消费的分区。
${KAFKA_HOME}/bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list local-168-182-110:9092 --topic my-log-topic --time -1# 消费数据查看数据,这里指定一个分区
${KAFKA_HOME}/bin/kafka-console-consumer.sh --bootstrap-server local-168-182-110:9092 --topic my-log-topic --partition 0 --offset 100# 也可以通过消费组消费,可以不指定分区
${KAFKA_HOME}/bin/kafka-console-consumer.sh --topic my-log-topic --bootstrap-server local-168-182-110:9092 --from-beginning --group my-group
这将返回主题 <topic_name> 的分区和偏移量信息,您可以根据这些信息计算出数据量。
轻量级的日志采集组件 Filebeat 讲解与实战操作就先到这里了,有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~
相关文章:
轻量级的日志采集组件 Filebeat 讲解与实战操作
文章目录 一、概述二、Kafka 安装三、Filebeat 安装1)下载 Filebeat2)Filebeat 配置参数讲解3)filebeat.prospectors 推送kafka完整配置1、filebeat.prospectors2、processors3、output.kafka 4)filebeat.inputs 与 filebeat.pros…...

C# 委托和事件
C# 委托和事件 委托匿名方法事件 委托 当要把方法传送给其他方法时,需要使用委托。首先定义要使用的委托,对于委托,定义它就是告诉编译器这种类型的委托代表了哪种类型的方法,然后创建该委托的一个或多个实例。编译器在后台将创建…...
)
数据结构与算法之字典: Leetcode 349. 两个数组的交集 (Typescript版)
两个数组的交集 https://leetcode.cn/problems/intersection-of-two-arrays/description/ 题目和解题参考 https://blog.csdn.net/Tyro_java/article/details/133279737 使用字典来解题的算法实现 字典:顾名思义,像新华字典一样可查找,基…...
动态规划 part 16)
day-56 代码随想录算法训练营(19)动态规划 part 16
538.两个字符串的删除操作 思路一: 1.dp存储:以word1[i-1]结尾,word2[j-1]结尾,最少进行dp[i][j]次操作2.动态转移方程: if(word1[i-1]word2[i-1]) dp[i][j]dp[i-1][j-1]; else dp[i][j]min(dp[i-1][…...

蓝桥等考Python组别四级005
第一部分:选择题 1、Python L4 (15分) 字符“0”的ASCII码值为48,则字符“5”的ASCII码值为( )。 3953120240正确答案:B 2、Python L4 (15分) 下面哪个是Python中正确的变量名?( ) ABC#sup01Trueif正确答案:B...

【Linux】diff 命令
【Linux】diff 命令——并排格式输出 功能 diff 以逐行的方式,比较文本文件的异同处。 如果指定要比较目录,则 diff 会比较目录中相同文件名的文件,但不会比较其中子目录 diff [参数] [文件A] [文件B]diff [参数] [目录A] [目录B]【参数】…...

【51单片机】9-定时器和计数器
1.定时器的介绍 1.什么是定时器 (1)SoC的一种内部的外设【在单片机里面,但是在CPU外面】 (2)定时器就是CPU的”闹钟“ 2.什么是计数器 (1)定时器就是用计数的原始实现的 (2…...

2023年海南省职业院校技能大赛(高职组)信息安全管理与评估赛项规程
2023年海南省职业院校技能大赛(高职组) 信息安全管理与评估赛项规程 一、赛项名称 赛项名称:信息安全管理与评估 英文名称:Information Security Management and Evaluation 赛项组别:高等职业教育 赛项归属产业&…...

大模型深挖数据要素价值:算法、算力之后,存储载体价值凸显
文 | 智能相对论 作者 | 叶远风 18.8万亿美元,这是市场预计2030年AI推动智能经济可产生的价值总和,其中大模型带来的AI能力质变无疑成为重要的推动力量。 大模型浪潮下,业界对AI发展的三驾马车——算力、算法、数据任何一个维度的关注都到…...

AI文章,AI文章生成工具
在互联网时代,随着信息爆炸式增长,文章的需求愈发旺盛。从博客、新闻、社交媒体到企业宣传,文字作为传达信息、吸引受众的工具变得愈发重要。但问题是,对于很多人来说,创作一篇高质量的文章并不容易。时间、创意、写作…...
mac有必要用清理软件吗?有哪些免费的清理工具
当我们谈到Mac电脑时,很多人都会觉得它比Windows系统更加稳定和高效,也更不容易积累垃圾文件。但实际上,任何长时间使用的操作系统都会逐渐积累不必要的文件和缓存。那么,对于Mac用户来说,有必要使用专门的清理软件吗&…...
React 全栈体系(十八)
第九章 React Router 6 二、代码实战 6. 路由的 params 参数 6.1 routes /* src/routes/index.js */ import About from "../pages/About"; import Home from "../pages/Home"; import Message from "../pages/Message"; import News from &q…...

TCP/UDP
TCP:可靠的有序传输 TCP是一种面向连接的协议,旨在提供可靠、有序的数据传输。它通过以下方式实现这一目标: 1. 连接建立和维护 在使用TCP传输数据之前,必须先建立连接。这个过程包括三次握手,即客户端和服务器之间…...

c++内存对齐
原文在这里。https://blog.csdn.net/WangErice/article/details/103598081 但是内容有错误。我在自己的这里修改并变成红色了。 内存在使用过程并不是单一的依次排列,而是按照某种既定的规则来进行对齐,以方便快速访问.内存的对齐原则有以下三条&#…...
leetcode 33. 搜索旋转排序数组
2023.9.26 本题暴力法可以直接A,但是题目要求用log n的解法。 可以想到二分法,但是一般二分法适用于有序数组的,这里的数组只是部分有序,还能用二分法吗? 答案是可以的。因为数组是经过有序数组旋转得来的,…...

VCS flow学习
VCS VCS 是IC从业者常用软件,该篇文章是一个学习记录,会记录在使用过程中各种概念及options。 VCS Flow VCS Flow 可以分为Two-step Flow和Three-step Flow两类。 两步法 两步法只支持Verilog HDL和SystemVerilog的design,两步法主要包括…...
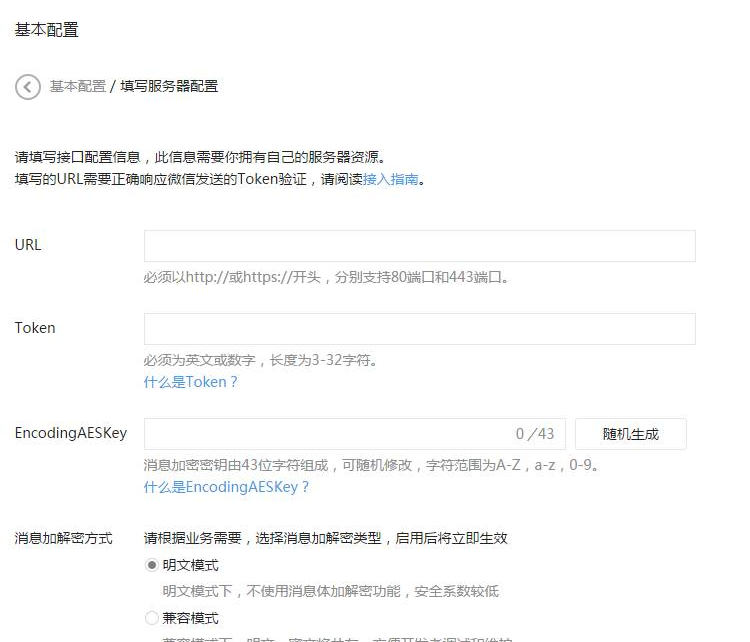
微信扫码关注公众号登录功能php实战分享
1、安装easywechat 基于easywechat框架开发,首先下载安装easywechat composer require overtrue/wechat 2、公众号配置 先去公众号后台基本配置/ 填写服务器配置配置接口,需要是线上能正确收到微信推送消息的地址,关注如果有关注、扫码、收到消息等事件都会推送到该地址…...

Git 精简快速使用
安装 Git 忽略,自行搜索 新建项目,或者在仓库拉取项目,进入到项目目录 Github 给出的引导,新项目和旧项目 echo "# testgit" >> README.md git init git add README.md git commit -m "first commit"…...

线性约束最小方差准则(LCMV)波束形成算法仿真
常规波束形成仅能使得主波束对准目标方向,从而在噪声环境下检测到目标,但无法对复杂多变的干扰做出响应,所以不能称之为真正意义上的自适应滤波。自适应阵列处理指的是采用自适应算法对空间阵列接收的混合信号进行处理,又可称为自…...
什么是内容运营?
关于内容运营,在不同种类的公司,侧重点也不一样。 电商平台的内容运营岗更偏内容营销;产品功能比较简单的公司,内容运营和新媒体运营的岗位职责差不多;而内容平台的内容运营更多的是做内容的管理和资源整合。...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...