C++中实现雪花算法来在秒级以及毫秒及时间内生成唯一id

1、雪花算法原理
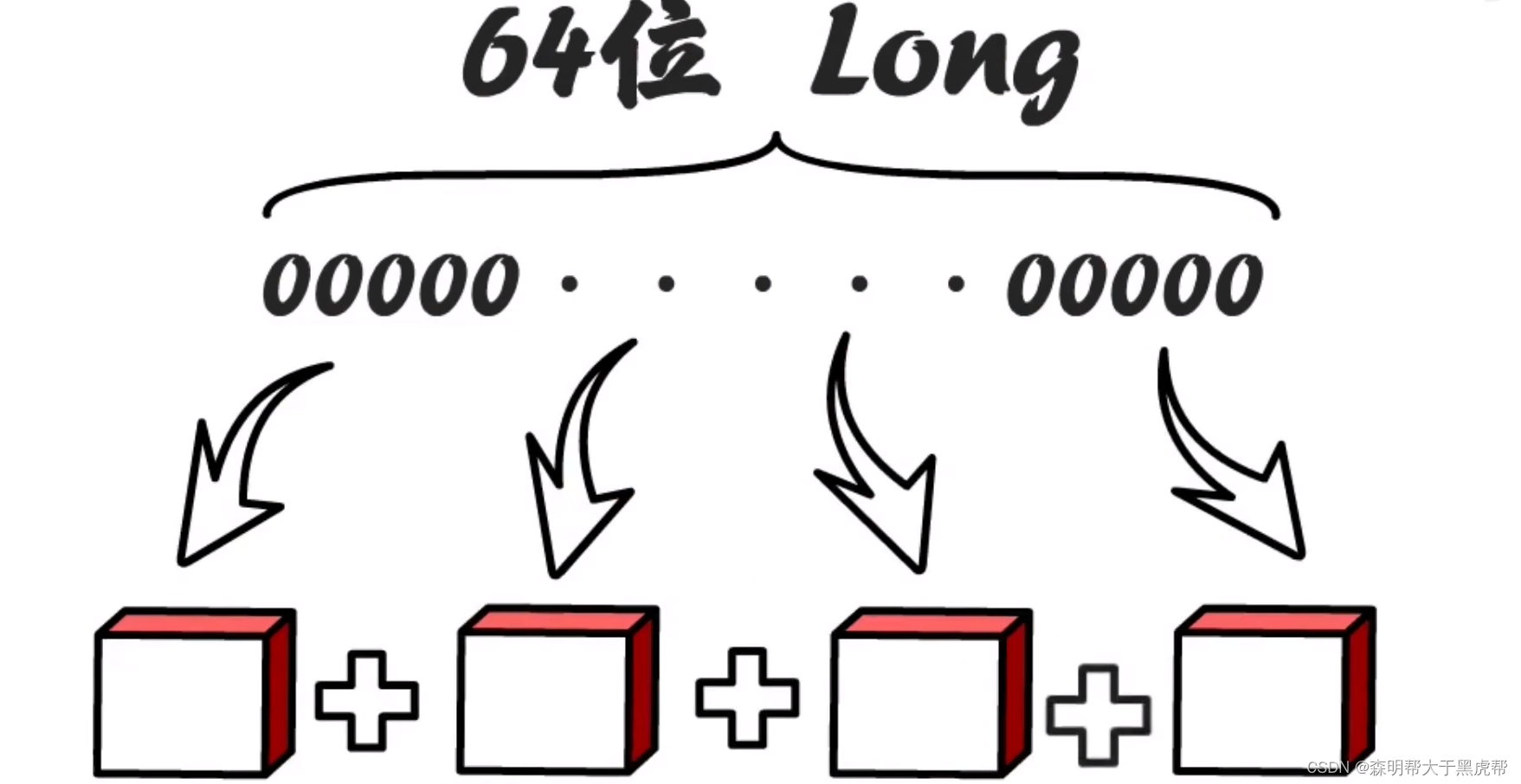
雪花算法(Snowflake Algorithm)是一种用于生成唯一ID的算法,通常用于分布式系统中,以确保生成的ID在整个分布式系统中具有唯一性。它的名称来源于雪花的形状,因为生成的ID通常是64位的整数,其二进制结构看起来像雪花。
雪花算法(Snowflake Algorithm)的实现原理相对简单,主要通过将一个64位的整数分成不同的部分来确保生成的ID在分布式系统中具有唯一性和有序性。以下是雪花算法的主要实现原理:
-
时间戳部分(41位): 雪花算法使用了41位来表示时间戳。这些位用于存储自"雪花纪元"(一个自定义的固定时间点,通常是系统首次启动的时间)以来的毫秒数。由于使用41位来表示时间戳,因此可以表示的时间范围大约为69年。
-
雪花算法的时间戳部分是算法中非常重要的一部分,它用于确保生成的唯一ID在分布式系统中具有一定的有序性。以下是雪花算法时间戳部分的原理:
-
时间戳的起始点(雪花纪元): 雪花算法中的时间戳是以一个自定义的起始时间点为基准的。这个起始时间点通常称为"雪花纪元"(Snowflake Epoch),它是一个固定的时间点,作为时间戳的起始值。通常情况下,雪花纪元是一个可配置的值,可以根据需要设置。例如,可以将雪花纪元设置为系统首次启动的时间点或其他特定时间。
-
毫秒级时间戳: 雪花算法使用毫秒级别的时间戳来表示从雪花纪元开始的时间流逝。这个时间戳是一个整数值,通常占据41位。这意味着,从雪花纪元开始计算,可以表示的时间范围大约为69年,因为 2^41 毫秒大约等于69年。
-
时间戳的递增: 时间戳部分的值在每次生成唯一ID时都会递增。这是确保生成的ID在一定程度上具有有序性的关键因素。在同一毫秒内生成的ID,时间戳部分的值相同;而在不同毫秒生成的ID,时间戳部分的值会递增。
-
时钟同步和时钟回拨处理: 为了保持时间戳的准确性,分布式系统中的机器需要进行时钟同步,以确保它们的系统时钟是一致的。此外,雪花算法还包括时钟回拨处理,以防止系统时钟回拨。如果检测到时钟回拨,算法会等待,直到时钟回拨结束为止。
-
总之,雪花算法的时间戳部分是基于一个自定义的起始时间点(雪花纪元)开始计算的,使用毫秒级别的时间戳表示时间的流逝。通过递增时间戳部分的值,确保在分布式系统中生成的唯一ID具有一定的有序性。时钟同步和时钟回拨处理也是算法中的重要部分,用于维护时间戳的准确性。这种设计使得雪花算法适用于大规模分布式系统中生成唯一ID的需求。
-
-
数据中心ID(5位): 数据中心ID用于区分不同的数据中心。这部分通常在多数据中心的环境中使用,以确保每个数据中心分配的机器具有不同的标识。数据中心ID的范围是0到31(5位二进制)。
-
工作机器ID(5位): 工作机器ID用于区分同一数据中心内的不同机器。这确保了在同一数据中心中的多台机器生成的ID不会冲突。工作机器ID的范围也是0到31(5位二进制)。
-
序列号部分(12位): 序列号部分用于处理同一毫秒内生成多个ID的情况,以防止ID冲突。通过使用12位的序列号,可以在同一毫秒内生成4096个不同的ID。
-
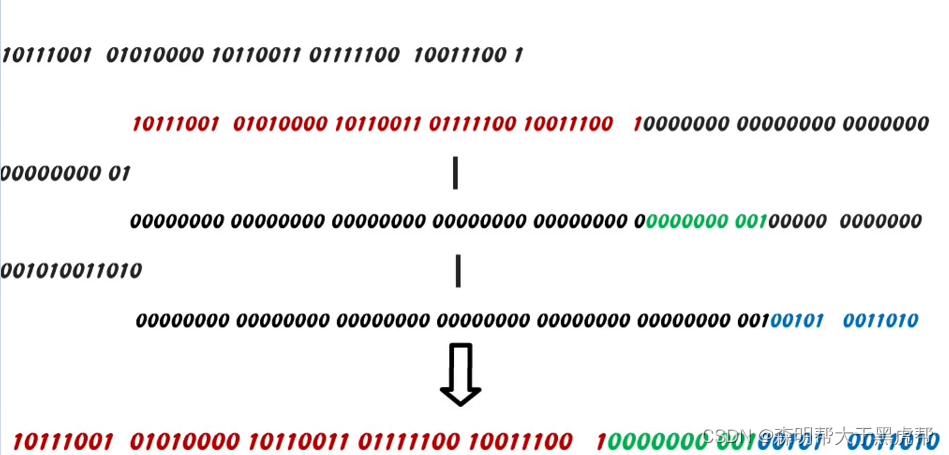
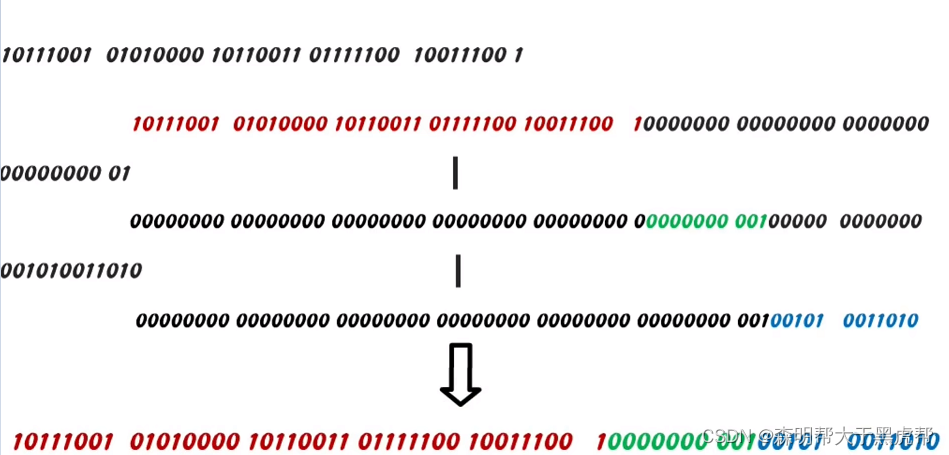
位移和运算: 在生成唯一ID时,将各个部分的值左移位并执行逻辑或(OR)运算,将它们组合成一个64位的整数。
-
唯一性和有序性: 通过使用不同的数据中心ID、工作机器ID和序列号来区分不同的机器和请求,并通过时间戳部分确保ID的有序性。时间戳部分在生成ID时递增,确保较新生成的ID总是大于较旧的ID。
-
时钟回拨处理: 雪花算法还包括时钟回拨处理,以防止时钟回拨(即系统时间向后调整)。如果检测到时钟回拨,算法会等待,直到时钟回拨结束为止。
-
在雪花算法的实际应用中,时钟同步和时钟回拨通常需要由系统管理员或开发人员来实现和处理。雪花算法本身并没有提供内置的时钟同步和时钟回拨处理机制,而是依赖于系统环境来确保时钟的准确性。
-
以下是关于时钟同步和时钟回拨处理的一些考虑和实现方式:
-
时钟同步: 在分布式系统中,确保各个机器的系统时钟保持同步非常重要。一种常见的做法是使用网络时间协议(NTP)或类似的时间同步服务,使所有机器的时钟与网络时间服务器保持一致。这可以通过配置操作系统来实现。
-
时钟回拨处理: 时钟回拨是指系统时钟突然向后调整,可能导致已经生成的ID比新生成的ID时间戳更早。为了处理时钟回拨,可以采用以下策略之一:
-
等待策略: 如果检测到时钟回拨,可以等待一段时间,直到时钟回拨结束,然后再继续生成ID。这样可以确保生成的ID仍然是递增的。
-
拒绝策略: 另一种策略是拒绝生成ID,直到时钟回拨结束。这样可以避免生成不正确的ID。
-
时钟漂移修复策略: 在一些情况下,可以通过检测时钟回拨并调整已生成的ID来修复时钟漂移。这需要更复杂的逻辑和持久化存储。
-
-
具体的实现方式取决于应用的需求和系统环境。时钟同步和时钟回拨处理是确保雪花算法正常运行的重要考虑因素,需要根据实际情况来配置和实施。一般来说,建议使用可靠的时钟同步服务来减小时钟回拨的可能性,并根据应用的要求选择合适的时钟回拨处理策略。
-
-
时间回拨是指系统时钟在某个时刻向后调整,导致系统时间突然变小,相当于时间"倒流"了一段时间。这种情况可能发生在计算机系统中,通常是由于以下原因之一引起的:
-
时钟同步服务: 许多操作系统和计算机网络使用时钟同步服务(如NTP,Network Time Protocol)来保持系统时钟与外部时间源同步。如果时钟同步服务检测到系统时钟与外部时间源之间的时间差距太大,它可能会尝试通过调整系统时钟来将其与外部时间源同步。这种情况下,系统时钟会向后调整,以使其与外部时间源保持一致。
-
手动时钟调整: 系统管理员或用户可能会手动调整系统时钟,导致时间回拨。这通常发生在需要纠正时钟错误或同步系统时钟的情况下。
-
时间回拨可能会对系统和应用程序造成问题,特别是对于依赖时间顺序的应用程序,例如日志记录、数据同步和分布式系统中的唯一ID生成(如雪花算法)。在时间回拨发生时,应用程序可能会出现以下问题:
-
事件顺序混乱:如果应用程序依赖于时间顺序来处理事件,时间回拨可能导致事件的顺序混乱。
-
数据一致性问题:在分布式系统中,时间回拨可能导致数据不一致或冲突。
-
唯一ID冲突:某些ID生成算法,如雪花算法,可能会在时间回拨时生成相同的ID,导致ID冲突。
-
-
为了处理时间回拨,应用程序通常需要实施一些策略,例如等待、拒绝或纠正事件,以确保系统的稳定性和一致性。时钟同步服务的配置和监控也是减少时间回拨影响的重要措施。

总的来说,雪花算法的实现原理是将时间戳、数据中心ID、工作机器ID和序列号等信息合并在一起,确保生成的ID在分布式系统中具有唯一性和有序性。通过适当的配置和时钟同步,它可以在分布式环境中生成高性能的唯一ID。
2、雪花算法实现使用当前时间
以下是一个基于 C++ 的雪花算法使用秒级当前时间示例,用于生成唯一ID:
- 时间戳左移22位,左边添加22个零,10位机器位左移12位,左边添加12个零,最后的序号位无需左移。
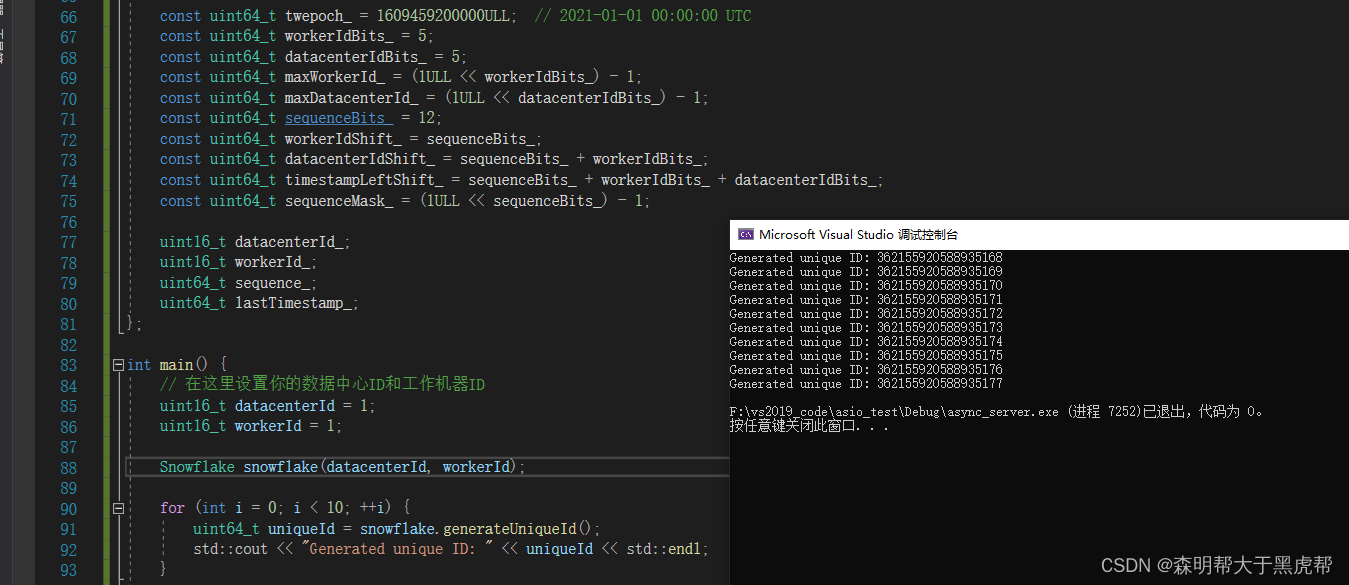
#include <iostream>
#include <cstdint>
#include <ctime>class Snowflake {
public:Snowflake(uint16_t datacenterId, uint16_t workerId): datacenterId_(datacenterId), workerId_(workerId), sequence_(0), lastTimestamp_(0) {if (datacenterId_ > maxDatacenterId_ || workerId_ > maxWorkerId_) {throw std::invalid_argument("Invalid datacenter or worker ID");}}uint64_t generateUniqueId() {uint64_t timestamp = currentTimestamp();if (timestamp < lastTimestamp_) {throw std::runtime_error("Clock moved backwards");}//时间戳原理:获取当前时间戳如果等于上次时间戳(同一毫秒内),咋序列号加一。否则序列号设置为0,从0开始if (timestamp == lastTimestamp_) {sequence_ = (sequence_ + 1) & sequenceMask_;if (sequence_ == 0) {timestamp = waitNextMillis(lastTimestamp_);}} else {sequence_ = 0;}lastTimestamp_ = timestamp;return ((timestamp - twepoch_) << timestampLeftShift_) |((datacenterId_ & maxDatacenterId_) << datacenterIdShift_) |((workerId_ & maxWorkerId_) << workerIdShift_) |(sequence_ & sequenceMask_);}private:uint64_t currentTimestamp() const {return std::time(nullptr) * 1000;}uint64_t waitNextMillis(uint64_t lastTimestamp) {uint64_t timestamp = currentTimestamp();while (timestamp <= lastTimestamp) {timestamp = currentTimestamp();}return timestamp;}//const uint64_t twepoch_ = 1609459200000ULL; // 2021-01-01 00:00:00 UTCconst uint64_t unixEpoch_ = 0ULL; // Unix时间戳起点:1970-01-01 00:00:00 UTCconst uint64_t workerIdBits_ = 5;const uint64_t datacenterIdBits_ = 5;const uint64_t maxWorkerId_ = (1ULL << workerIdBits_) - 1;const uint64_t maxDatacenterId_ = (1ULL << datacenterIdBits_) - 1;const uint64_t sequenceBits_ = 12;const uint64_t workerIdShift_ = sequenceBits_;const uint64_t datacenterIdShift_ = sequenceBits_ + workerIdBits_;const uint64_t timestampLeftShift_ = sequenceBits_ + workerIdBits_ + datacenterIdBits_;const uint64_t sequenceMask_ = (1ULL << sequenceBits_) - 1;uint16_t datacenterId_;uint16_t workerId_;uint64_t sequence_;uint64_t lastTimestamp_;
};int main() {// 在这里设置你的数据中心ID和工作机器IDuint16_t datacenterId = 1;uint16_t workerId = 1;Snowflake snowflake(datacenterId, workerId);for (int i = 0; i < 10; ++i) {uint64_t uniqueId = snowflake.generateUniqueId();std::cout << "Generated unique ID: " << uniqueId << std::endl;}return 0;
}在这个示例中,我们创建了一个 Snowflake 类来实现雪花算法。它能够生成唯一的ID,其中包括时间戳、数据中心ID、工作机器ID和序列号。在 main 函数中,我们设置了数据中心ID和工作机器ID,并使用 generateUniqueId 方法生成10个唯一ID,然后将它们打印到控制台。
请注意,这个示例的时间戳部分使用了当前时间,但在实际应用中,你可能需要更精确的时间戳机制,以确保在同一毫秒内生成的ID也具有唯一性。此外,确保在分布式环境中正确设置数据中心ID和工作机器ID,以避免ID冲突。这个示例是一个简单的演示,用于理解雪花算法的工作原理。
雪花算法核心实现:
return ((timestamp - twepoch_) << timestampLeftShift_) |((datacenterId_ & maxDatacenterId_) << datacenterIdShift_) |((workerId_ & maxWorkerId_) << workerIdShift_) |(sequence_ & sequenceMask_)
-
这行代码是雪花算法中用于生成唯一ID的核心部分,它将各个组成部分组合在一起,形成一个64位的整数,作为最终生成的唯一ID。让我解释这行代码的各个部分的含义:
-
((timestamp - twepoch_) << timestampLeftShift_):这部分计算时间戳的值。首先,它从当前时间戳中减去雪花纪元(twepoch_),以获取自雪花纪元以来的毫秒数。然后,将这个毫秒数左移 timestampLeftShift_ 位,将时间戳占据ID的相应位数。这个部分的目的是确保生成的ID中包含时间戳信息,以保持ID的有序性。
-
((datacenterId_ & maxDatacenterId_) << datacenterIdShift_):这部分计算数据中心ID的值。首先,它使用位与运算符 & 将数据中心ID与最大数据中心ID进行按位与操作,以确保数据中心ID的值不超过其所占据的位数。然后,将结果左移 datacenterIdShift_ 位,将数据中心ID占据ID的相应位数。这个部分的目的是确保生成的ID中包含数据中心ID信息,以确保不同数据中心的机器生成的ID是唯一的。
-
((workerId_ & maxWorkerId_) << workerIdShift_):这部分计算工作机器ID的值,原理与数据中心ID类似。首先,使用位与运算符 & 将工作机器ID与最大工作机器ID进行按位与操作,以确保工作机器ID的值不超过其所占据的位数。然后,将结果左移 workerIdShift_ 位,将工作机器ID占据ID的相应位数。这个部分的目的是确保生成的ID中包含工作机器ID信息,以确保同一数据中心内不同机器生成的ID是唯一的。
-
(sequence_ & sequenceMask_):这部分计算序列号的值。它使用位与运算符 & 将当前序列号与序列号掩码 sequenceMask_ 进行按位与操作,以确保序列号的值不超过其所占据的位数。序列号占据ID的相应位数,以确保在同一毫秒内生成多个ID时,它们的序列号不会冲突。
-
-
最终,这些部分的值通过按位或运算符 | 进行组合,形成了一个64位的整数,作为生成的唯一ID。这个ID包含了时间戳、数据中心ID、工作机器ID和序列号等信息,确保了生成的ID在分布式系统中是唯一且有序的。这种组合方式使得每个部分的信息都能够被提取和分析,同时也保持了整体ID的唯一性和有序性。
3、雪花算法实现使用毫秒时间
当多个请求在同一毫秒内生成唯一ID时,雪花算法通过使用序列号部分来确保ID的唯一性。以下是一个示例,演示了如何处理同一毫秒内生成多个唯一ID的情况:
- 时间戳左移22位,左边添加22个零,10位机器位左移12位,左边添加12个零,最后的序号位无需左移。
#include <iostream>
#include <cstdint>
#include <ctime>
#include <mutex>class Snowflake {
public:Snowflake(uint16_t datacenterId, uint16_t workerId): datacenterId_(datacenterId), workerId_(workerId), sequence_(0), lastTimestamp_(0) {if (datacenterId_ > maxDatacenterId_ || workerId_ > maxWorkerId_) {throw std::invalid_argument("Invalid datacenter or worker ID");}}uint64_t generateUniqueId() {std::unique_lock<std::mutex> lock(mutex_);uint64_t timestamp = currentTimestamp();if (timestamp < lastTimestamp_) {throw std::runtime_error("Clock moved backwards");}//时间戳原理:获取当前时间戳如果等于上次时间戳(同一毫秒内),咋序列号加一。否则序列号设置为0,从0开始if (timestamp == lastTimestamp_) {sequence_ = (sequence_ + 1) & sequenceMask_;if (sequence_ == 0) {timestamp = waitNextMillis(lastTimestamp_);}} else {sequence_ = 0;}lastTimestamp_ = timestamp;return ((timestamp - twepoch_) << timestampLeftShift_) |((datacenterId_ & maxDatacenterId_) << datacenterIdShift_) |((workerId_ & maxWorkerId_) << workerIdShift_) |(sequence_ & sequenceMask_);}private:uint64_t currentTimestamp() const {return std::time(nullptr) * 1000;}uint64_t waitNextMillis(uint64_t lastTimestamp) {uint64_t timestamp = currentTimestamp();while (timestamp <= lastTimestamp) {timestamp = currentTimestamp();}return timestamp;}//const uint64_t twepoch_ = 1609459200000ULL; // 2021-01-01 00:00:00 UTCconst uint64_t unixEpoch_ = 0ULL; // Unix时间戳起点:1970-01-01 00:00:00 UTCconst uint64_t workerIdBits_ = 5;const uint64_t datacenterIdBits_ = 5;const uint64_t maxWorkerId_ = (1ULL << workerIdBits_) - 1;const uint64_t maxDatacenterId_ = (1ULL << datacenterIdBits_) - 1;const uint64_t sequenceBits_ = 12;const uint64_t workerIdShift_ = sequenceBits_;const uint64_t datacenterIdShift_ = sequenceBits_ + workerIdBits_;const uint64_t timestampLeftShift_ = sequenceBits_ + workerIdBits_ + datacenterIdBits_;const uint64_t sequenceMask_ = (1ULL << sequenceBits_) - 1;uint16_t datacenterId_;uint16_t workerId_;uint64_t sequence_;uint64_t lastTimestamp_;std::mutex mutex_;
};int main() {// 在这里设置你的数据中心ID和工作机器IDuint16_t datacenterId = 1;uint16_t workerId = 1;Snowflake snowflake(datacenterId, workerId);for (int i = 0; i < 10; ++i) {uint64_t uniqueId = snowflake.generateUniqueId();std::cout << "Generated unique ID: " << uniqueId << std::endl;}return 0;
}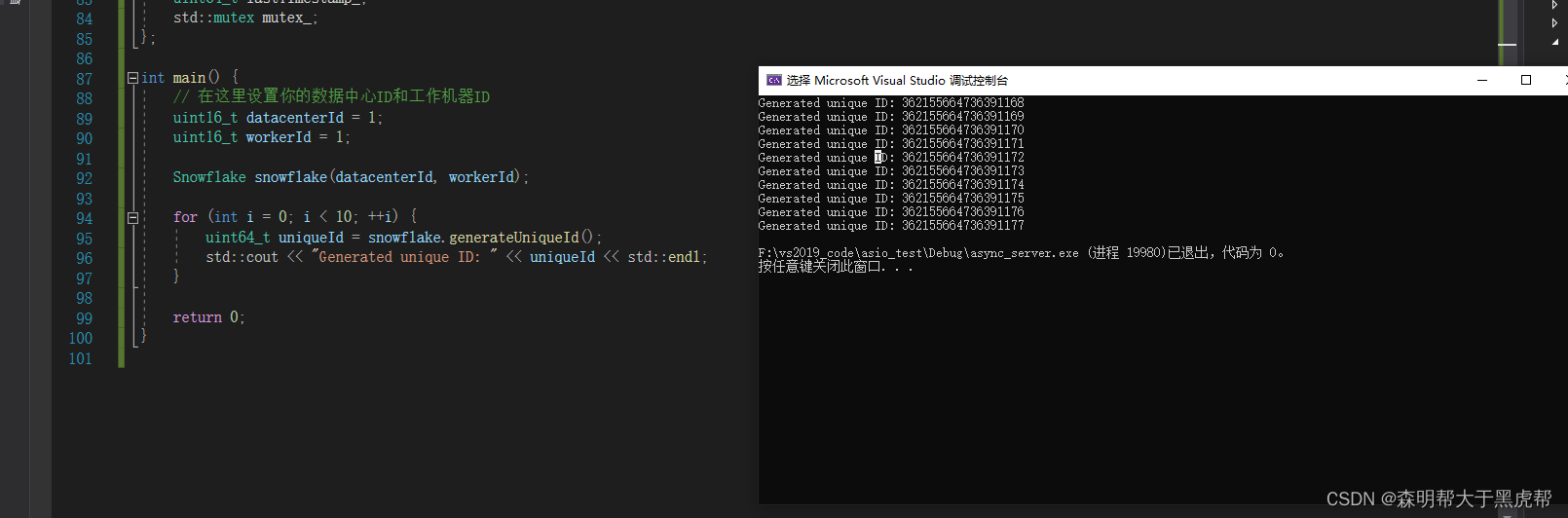
在这个示例中,我们添加了一个互斥锁 (std::mutex) 来确保在同一毫秒内生成多个唯一ID时,只有一个线程能够访问 generateUniqueId 方法。这样可以避免并发生成ID时的冲突。
雪花算法核心实现:
return ((timestamp - twepoch_) << timestampLeftShift_) |((datacenterId_ & maxDatacenterId_) << datacenterIdShift_) |((workerId_ & maxWorkerId_) << workerIdShift_) |(sequence_ & sequenceMask_)
-
这行代码是雪花算法中用于生成唯一ID的核心部分,它将各个组成部分组合在一起,形成一个64位的整数,作为最终生成的唯一ID。让我解释这行代码的各个部分的含义:
-
((timestamp - twepoch_) << timestampLeftShift_):这部分计算时间戳的值。首先,它从当前时间戳中减去雪花纪元(twepoch_),以获取自雪花纪元以来的毫秒数。然后,将这个毫秒数左移 timestampLeftShift_ 位,将时间戳占据ID的相应位数。这个部分的目的是确保生成的ID中包含时间戳信息,以保持ID的有序性。
-
((datacenterId_ & maxDatacenterId_) << datacenterIdShift_):这部分计算数据中心ID的值。首先,它使用位与运算符 & 将数据中心ID与最大数据中心ID进行按位与操作,以确保数据中心ID的值不超过其所占据的位数。然后,将结果左移 datacenterIdShift_ 位,将数据中心ID占据ID的相应位数。这个部分的目的是确保生成的ID中包含数据中心ID信息,以确保不同数据中心的机器生成的ID是唯一的。
-
((workerId_ & maxWorkerId_) << workerIdShift_):这部分计算工作机器ID的值,原理与数据中心ID类似。首先,使用位与运算符 & 将工作机器ID与最大工作机器ID进行按位与操作,以确保工作机器ID的值不超过其所占据的位数。然后,将结果左移 workerIdShift_ 位,将工作机器ID占据ID的相应位数。这个部分的目的是确保生成的ID中包含工作机器ID信息,以确保同一数据中心内不同机器生成的ID是唯一的。
-
(sequence_ & sequenceMask_):这部分计算序列号的值。它使用位与运算符 & 将当前序列号与序列号掩码 sequenceMask_ 进行按位与操作,以确保序列号的值不超过其所占据的位数。序列号占据ID的相应位数,以确保在同一毫秒内生成多个ID时,它们的序列号不会冲突。
-
-
最终,这些部分的值通过按位或运算符 | 进行组合,形成了一个64位的整数,作为生成的唯一ID。这个ID包含了时间戳、数据中心ID、工作机器ID和序列号等信息,确保了生成的ID在分布式系统中是唯一且有序的。这种组合方式使得每个部分的信息都能够被提取和分析,同时也保持了整体ID的唯一性和有序性。
4、雪花算法实现原理
SnowFlake 中文意思为雪花,故称为雪花算法。最早是 Twitter 公司在其内部用于分布式环境下生成唯一 ID。在2014年开源 scala 语言版本。世界上没有两片相同的雪花噢。 因此命名雪花算法来标识不同的uuid。

雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
- 最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
- 接下来 41 位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用 69 年。
- 再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
- 最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。
对于每一个雪花算法服务,需要先指定 10 位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的 10 位比特位的整数值都行。
5、雪花算法优缺点
-
雪花算法有以下几个优点:
- 高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
- 基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
- 不依赖第三方库或者中间件。
- 算法简单,在内存中进行,效率高。
-
雪花算法有如下缺点:
- 依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
相关文章:
C++中实现雪花算法来在秒级以及毫秒及时间内生成唯一id
1、雪花算法原理 雪花算法(Snowflake Algorithm)是一种用于生成唯一ID的算法,通常用于分布式系统中,以确保生成的ID在整个分布式系统中具有唯一性。它的名称来源于雪花的形状,因为生成的ID通常是64位的整数࿰…...
)
OPTEE Gprof(GNU profile)
安全之安全(security)博客目录导读 OPTEE调试技术汇总 目录 一、序言 二、Gprof使用 三、Gprof实现 1、Call graph information 2、PC distribution over time 一、序言 本文描述了如何使用gprof对TA进行概要分析。 配置选项CFG_TA_GPROF_SUPPORTy使OP-TEE能够从在用户模…...

MySQL 事务的操作指南(事务篇 二)
基本操作 事务的提交方式:自动提交(autocommit1)和手动提交(autocommit0) 查询和修改事务提交方式: -- 查看事务提交方式(标识表示这是个系统变量) select autocommit ;-- 修改事务提交方式为自动提交 …...

Oracle 查询 SQL 语句
目录 1. Oracle 查询 SQL 语句1.1. 性能查询常用 SQL1.1.1. 查询最慢的 SQL1.1.2. 列出使用频率最高的 5 个查询1.1.3. 消耗磁盘读取最多的 sql top51.1.4. 找出需要大量缓冲读取(逻辑读)操作的查询1.1.5. 查询每天执行慢的 SQL1.1.6. 从 V$SQLAREA 中查询最占用资源的查询1.1.…...

gin 基本使用
gin 初体验 import ("net/http""github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/ping", func(c *gin.Context) {c.JSON(http.StatusOK, gin.H{"message": "pong",})})r.Run() }gin 路由接受一个 type …...
8月最新修正版风车IM即时聊天通讯源码+搭建教程
8月最新修正版风车IM即时聊天通讯源码搭建教程。风车 IM没啥好说的很多人在找,IM的天花板了,知道的在找的都知道它的价值,开版好像就要29999,后端加密已解,可自己再加密,可反编译出后端项目源码,已增加启动后端需要google auth双重验证,pc端 web端 wap端 android端 ios端 都有 …...

NSDT孪生场景编辑器系统介绍
一、产品背景 数字孪生的建设流程涉及建模、美术、程序、仿真等多种人才的协同作业,人力要求高,实施成本高,建设周期长。如何让小型团队甚至一个人就可以完成数字孪生的开发,是数字孪生工具链要解决的重要问题。考虑到数字孪生复杂…...
3D WEB轻量化引擎HOOPS助力3D测量应用蓬勃发展:效率、精度显著提升
在3D开发工具领域,Tech Soft 3D打造的HOOPS SDK已经崭露头角,成为了全球领先的3D领域开发工具提供商。HOOPS SDK包括四种不同的3D软件开发工具,已成为行业的翘楚。 其中,HOOPS Exchange以其CAD数据转换的能力脱颖而出,…...

【Orange Pi】Orange Pi5 Plus 安装记录
官网:Orange Pi - Orangepi 主控芯片:Rockchip RK3588(8nm LP制程)NPU:内嵌的 NPU 支持INT4/INT8/INT16/FP16混合运算,算力高达 6Top支持的操作系统: Orangepi OS(Droid)Orangepi O…...

NLP 项目:维基百科文章爬虫和分类 - 语料库阅读器
塞巴斯蒂安 一、说明 自然语言处理是机器学习和人工智能的一个迷人领域。这篇博客文章启动了一个具体的 NLP 项目,涉及使用维基百科文章进行聚类、分类和知识提取。灵感和一般方法源自《Applied Text Analysis with Python》一书。 在接下来的文章中,我将…...
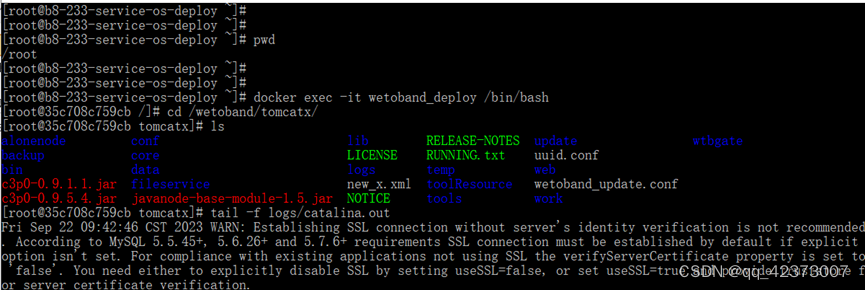
查看吾托帮88.47的docker里的tomcat日志
步骤如下 (1)ssh (2)ssh root192.168.88.47 等待输入密码:fytest (3)pwd #注释:输出/root (4)docker exec -it wetoband_deploy /bin/bash #注释࿱…...

衷心 祝愿
达之云衷心祝愿您,中秋国庆双节快乐,阖家幸福!感谢您们一直以来对达之云的关注与支持。 双节来临之际,达之云发布全新产品——达之云CDP客户数据平台(Dazdata CDP),致力于为中小企业提供互联网营…...

表单中某一项点击添加和删除
<!-- 特殊表单 --><div v-for"(item, index) in form.fwzb" :key"indexfwzb" style"height: 102px"><el-form-item label"经度:" class"form-style":prop"fwzb. index .lon":rules&q…...
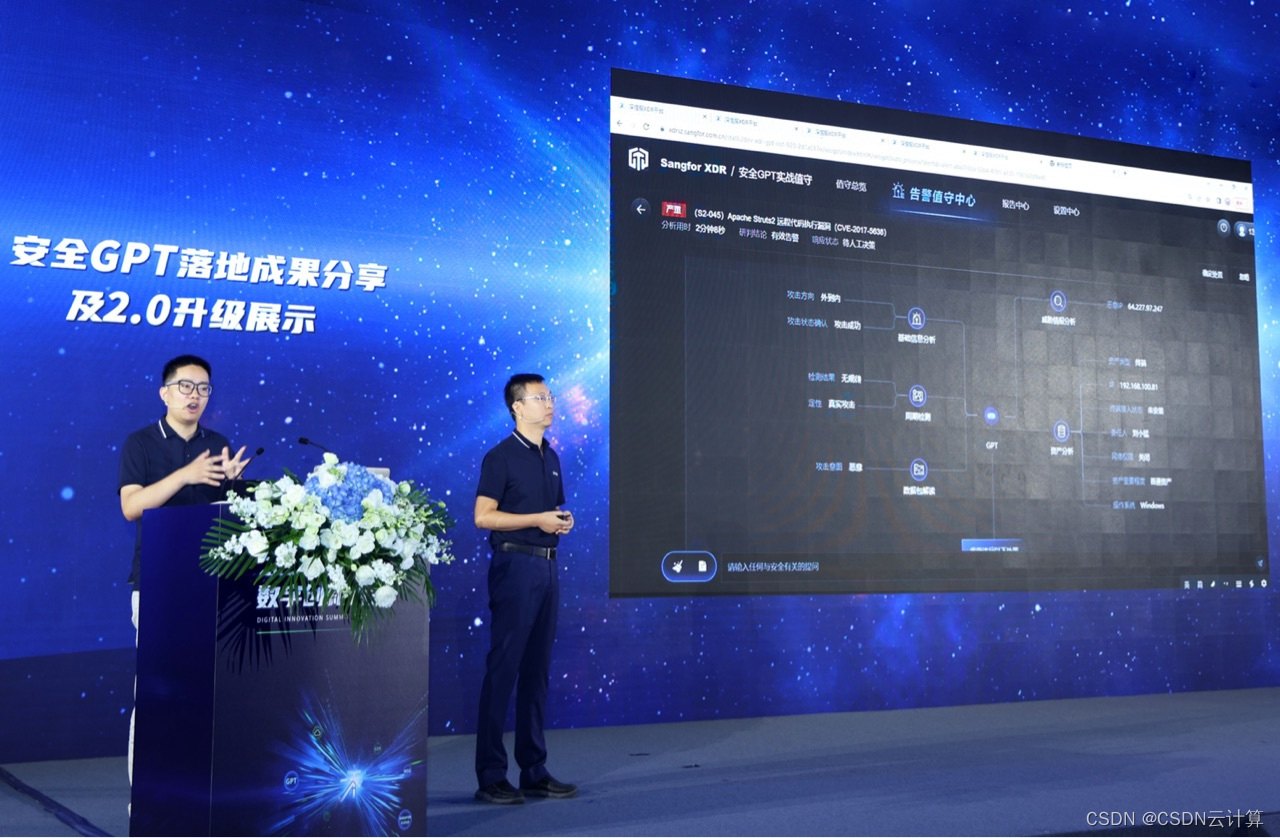
深信服安全GPT 2.0升级,开启安全运营“智能驾驶”旅程
9月22日,深信服对外展示安全GPT落地成果与2.0升级能力。来自各行业权威嘉宾代表:美的集团首席信息安全官(CISO)兼软件工程院院长、欧洲科学院院士(MAE)、IEEE Fellow、IET Fellow、ACM杰出科学家、AAIA Fel…...

【C++】STL之list深度剖析及模拟实现
目录 前言 一、list 的使用 1、构造函数 2、迭代器 3、增删查改 4、其他函数使用 二、list 的模拟实现 1、节点的创建 2、push_back 和 push_front 3、普通迭代器 4、const 迭代器 5、增删查改(insert、erase、pop_back、pop_front) 6、构造函数和析构函数 6.1、默认构造…...
解释器风格架构C# 代码
/*解释器风格架构是一种基于组件的设计架构,它将应用程序分解为一系列组件,每个组件负责处理特定的任务。这种架构有助于提高代码的可维护性和可扩展性。以下是如何使用C#实现解释器风格架构的步骤:定义组件:首先,定义…...

第七天:gec6818开发板QT和Ubuntu中QT安装连接sqlite3数据库驱动环境保姆教程
sqlite3数据库简介 帮助文档 SQL Programming 大多数关系型数的操作步骤:1)连接数据库 多数关系型数据库都是C/S模型 (Client/Server)sqlite3是一个本地的单文件关系型数据库,同样也有“连接”的过程 2)操作数据库 作为程序员&am…...
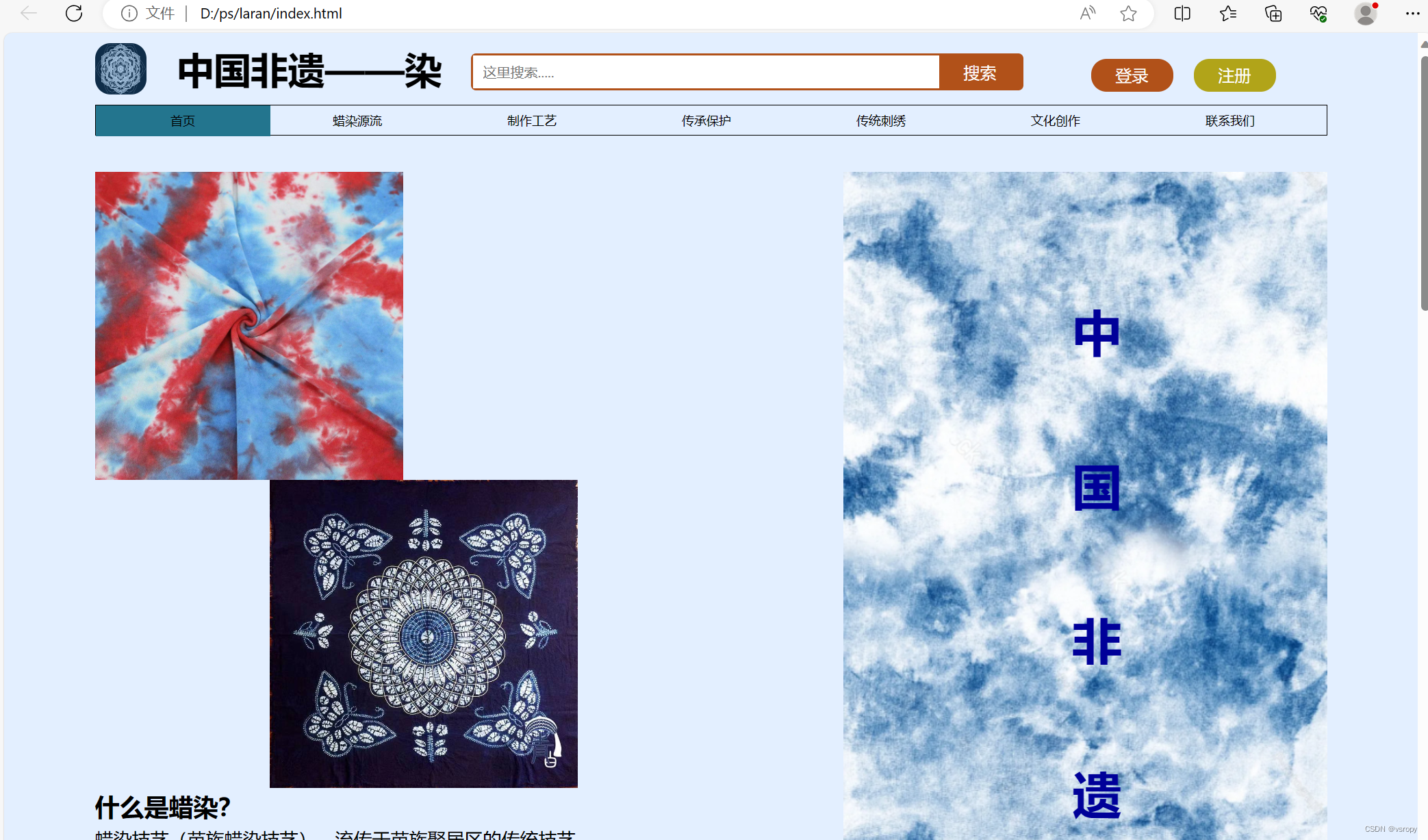
自制网页。
文章目录 注:代码中图片等素材均来自网络,侵删 20230920_213831 index.html <!DOCTYPE html> <html lang="en"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-…...

MySQL单表查询和多表查询
一、单表查询 素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作等 CREATE TABLE worker (部门号 int(11) NOT NULL,职工号 int(11) NOT NULL,工作时间 date NOT NULL,工资 float(8,2) NOT NULL,政治面貌 varchar(10)…...

蓝桥等考Python组别四级006
第一部分:选择题 1、Python L4 (15分) 在Python中,符号“\n”代表( )。 换行空格退格注释正确答案:A 2、Python L4 (15分) 已知大写字母A的ASCII码值为…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...
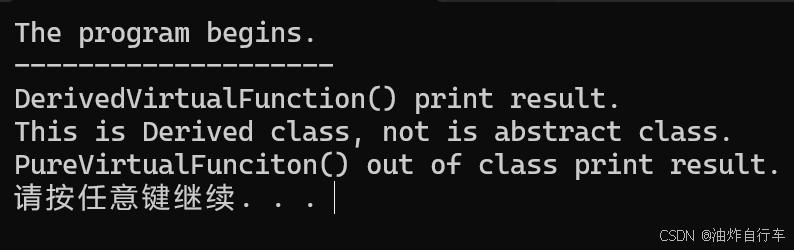
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...