LLM(二)| LIMA:在1k高质量数据上微调LLaMA1-65B,性能超越ChatGPT
本文将介绍在Lit-GPT上使用LoRA微调LLaMA模型,并介绍如何自定义数据集进行微调其他开源LLM
监督指令微调(Supervised Instruction Finetuning)
什么是监督指令微调?为什么关注它?
目前大部分LLM都是decoder-only,通常是续写任务,有时候未必符合用户的需求,SFT是通过构造指令输入和期待的输出数据微调LLM,让LLM根据输入的指令输出期待的内容,这样微调好的LLM会输出更符合用户需求或者特点任务,
SFT数据格式一般如下所示:
-
Instruction text
-
Input text (optional)
-
Output text
Input是可选的,下面是SFT数据格式的示例:

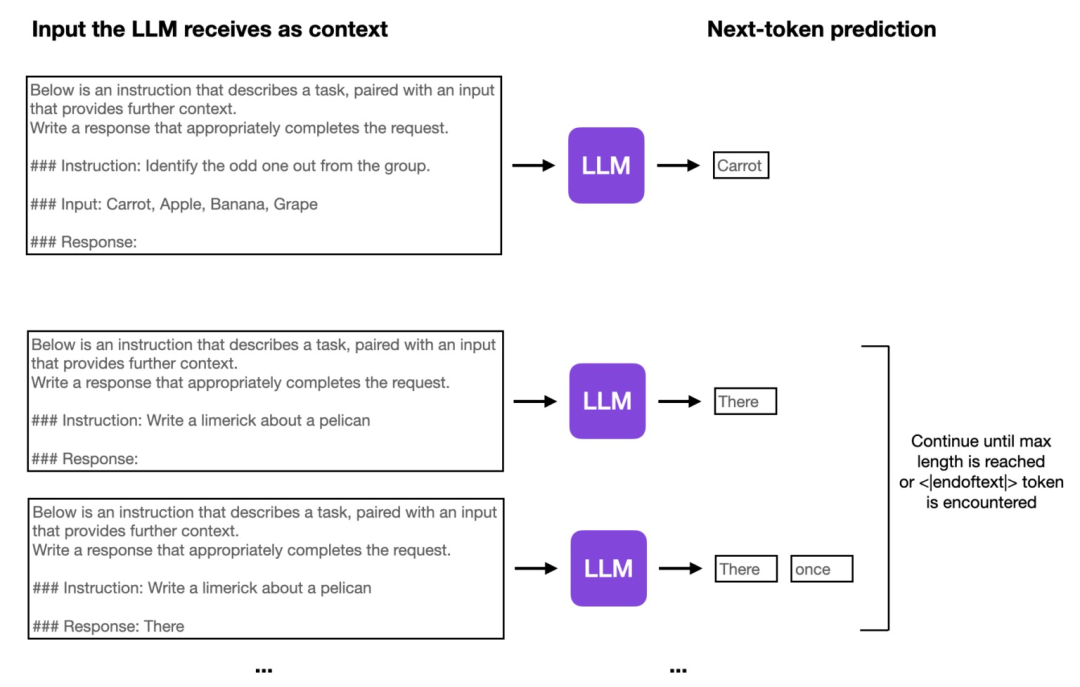
SFT的微调和Pre-training是一样的,也是根据上文预测下一个token,如下图所示:
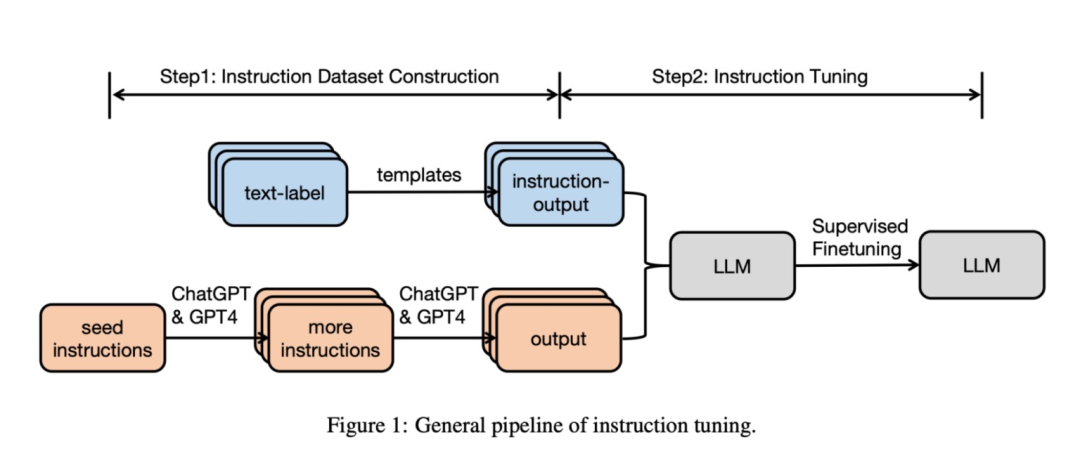
SFT数据集如何生成?
SFT数据集构建通常有两种方法:人工标注和使用LLM(比如GPT-4)来生成的,人工标注对于构建垂直领域比较合适,可以减少有偏数据,但是成本略高;使用LLM生成,可以在短时间内生成大量数据。
SFT数据集构建以及SFT微调Pipeline如下图所示:
LLM生成SFT数据方法总结
Self-Instruct
Self-Instruct(https://arxiv.org/abs/2212.10560):一个通过预训练语言模型自己引导自己来提高的指令遵循能力的框架。
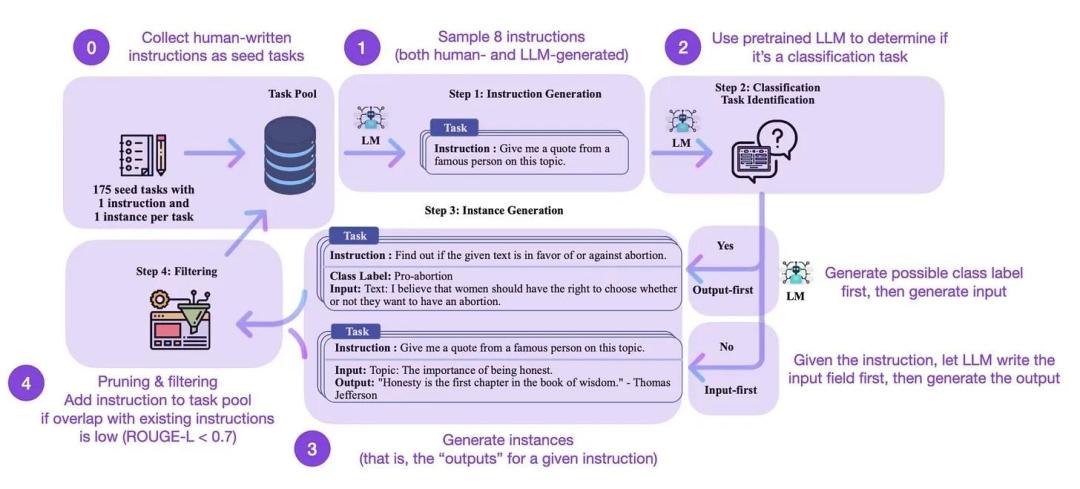
Self-Instruct有如下四个阶段:
-
步骤1:作者从 175个种子任务中随机抽取 8 条自然语言指令作为示例,并提示InstructGPT生成更多的任务指令。
-
步骤2:作者确定步骤1中生成的指令是否是一个分类任务。如果是,他们要求 InstructGPT 根据给定的指令为输出生成所有可能的选项,并随机选择特定的输出类别,提示 InstructGPT 生成相应的“输入”内容。对于不属于分类任务的指令,应该有无数的“输出”选项。作者提出了“输入优先”策略,首先提示 InstructGPT根据给定的“指令”生成“输入”,然后根据“指令”和生成的“输入”生成“输出”。
-
步骤3:基于第 2 步的结果,作者使用 InstructGPT 生成相应指令任务的“输入”和“输出”,采用“输出优先”或“输入优先”的策略。
-
步骤4:作者对生成的指令任务进行了后处理(例如,过滤类似指令,去除输入输出的重复数据),最终得到52K条英文指令
完整的Self-Instruct流程如下图所示:
Alpaca dataset(https://github.com/gururise/AlpacaDataCleaned)的52K数据就是采用该方法生成的。
Backtranslation
回译在传统的机器学习中是一种数据增强方法,比如从中文翻译成英文,再从英文翻译会中文,这样生成的中文与原来的中文在语义上是一致的,但是文本不同;然而SFT数据生成的回译(https://arxiv.org/abs/2308.06259)则是通过输出来生成指令,具体步骤如下图所示:
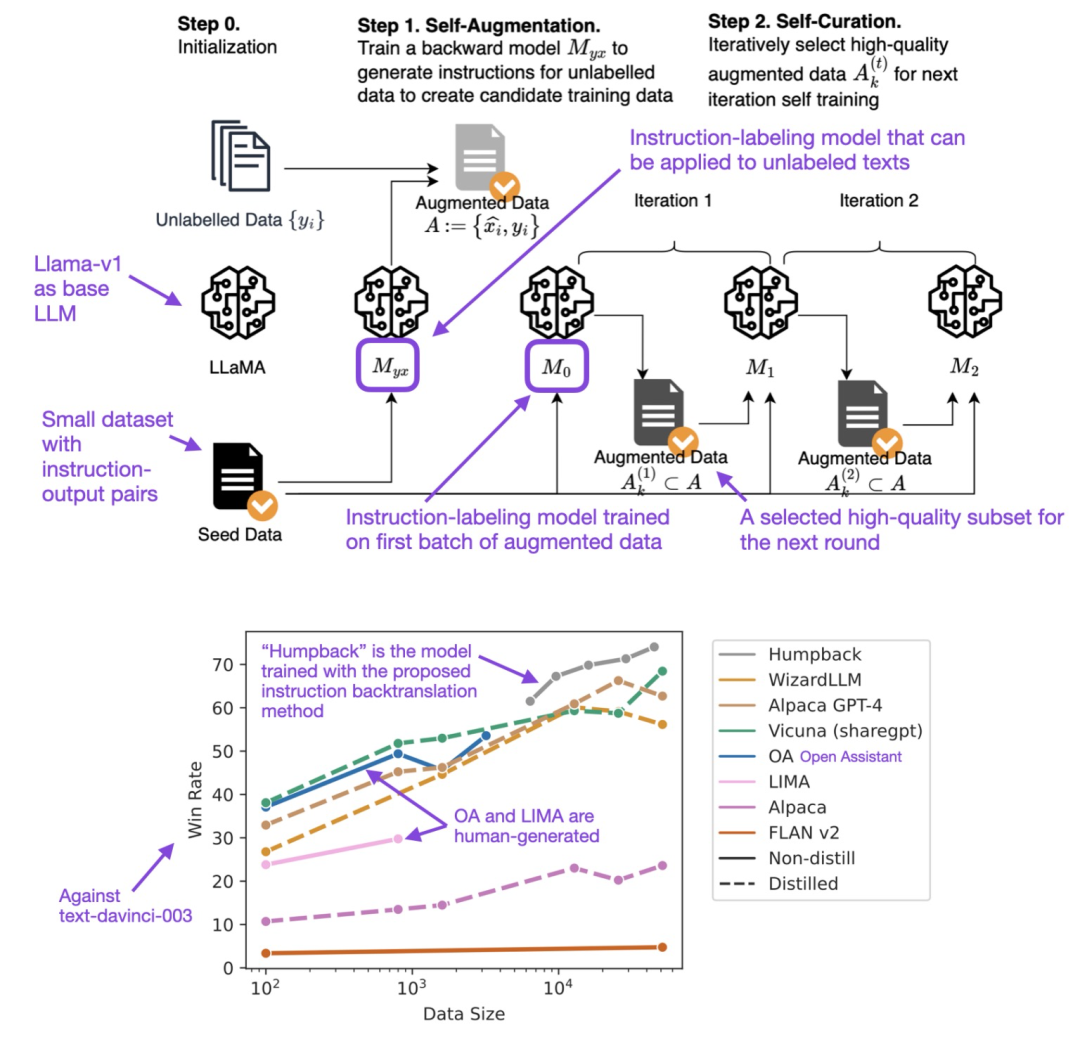
LIMA
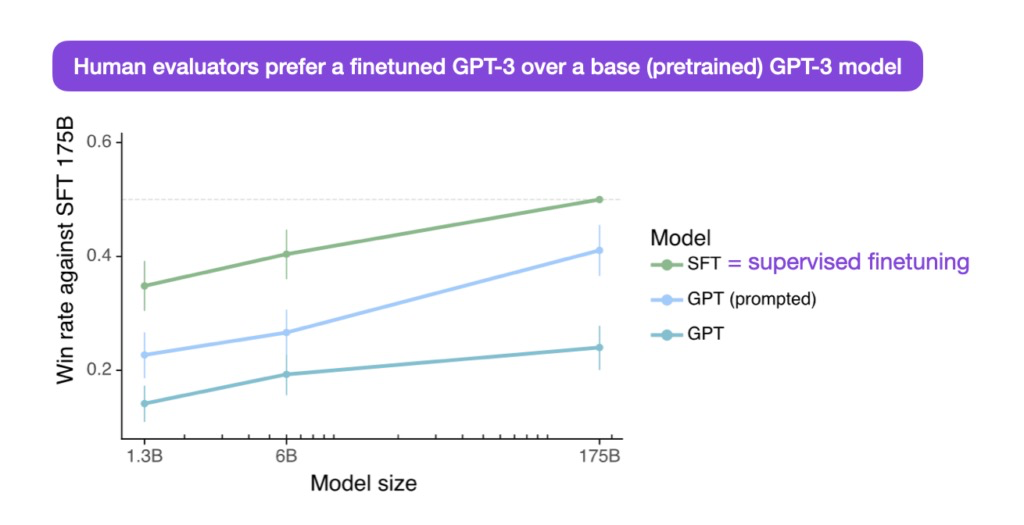
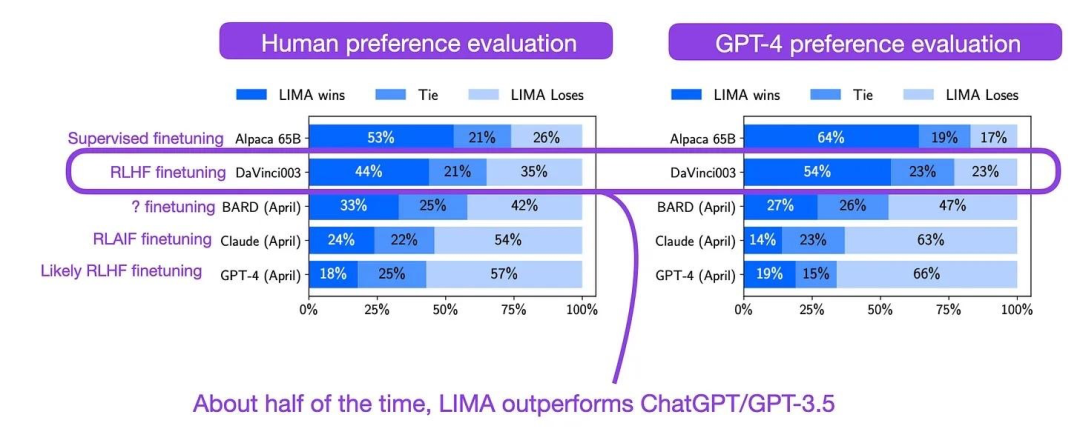
LIMA来自论文《The LIMA: Less Is More for Alignment》,LIMA是在LLaMA V1 65B模型上使用1k高质量数据进行微调获得的,性能如下:
在Lit-GPT库上微调LLM
Lit-GPT支持的模型如下表所示:
| Model and usage | Reference |
| Meta AI Llama 2 | Touvron et al. 2023 |
| Stability AI FreeWilly2 | Stability AI 2023 |
| Stability AI StableCode | Stability AI 2023 |
| TII UAE Falcon | TII 2023 |
| OpenLM Research OpenLLaMA | Geng & Liu 2023 |
| LMSYS Vicuna | Li et al. 2023 |
| LMSYS LongChat | LongChat Team 2023 |
| Together RedPajama-INCITE | Together 2023 |
| EleutherAI Pythia | Biderman et al. 2023 |
| StabilityAI StableLM | Stability AI 2023 |
| Platypus | Lee, Hunter, and Ruiz 2023 |
| NousResearch Nous-Hermes | Org page |
| Meta AI Code Llama | Rozière et al. 2023 |
下面以LLaMA2-7B为例说明在 上进行微调的步骤,首先需要clone
Lit-GPT仓库,微调步骤如下:
1)下载、准备模型
export HF_TOKEN=your_tokenpython scripts/download.py \--repo_id meta-llama/Llama-2-7b-hf
python scripts/convert_hf_checkpoint.py \--checkpoint_dir meta-llama/Llama-2-7b-hf
2)准备微调数据
python scripts/prepare_lima.py \--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf
3)使用LoRA进行微调
python finetune/lora.py \--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf \--data_dir data/lima
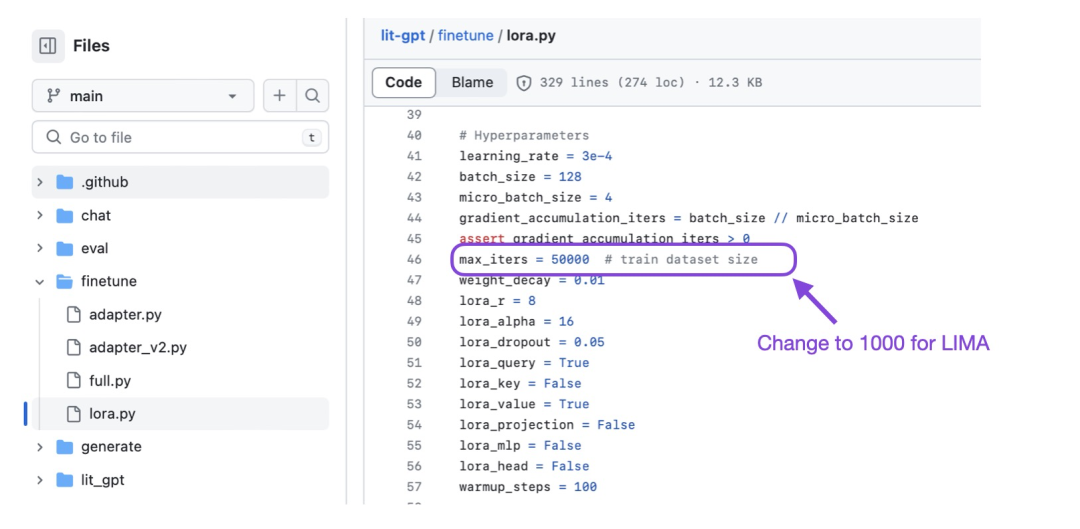
Tips
官方建议数据的tokens控制在2048之内,可以减少GPU显存消耗,对应的代码也需要增加参数--max_seq_length 2048
python scripts/prepare_lima.py \--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf \--max_seq_length 2048
或者也可以修改 finetune/lora.py文件中的参数change override_max_seq_length = None调整为 override_max_seq_length = 2048
对于LIMA模型的1k数据进行微调,需要调整max_iters=1000
Lit-GPT上支持的数据集
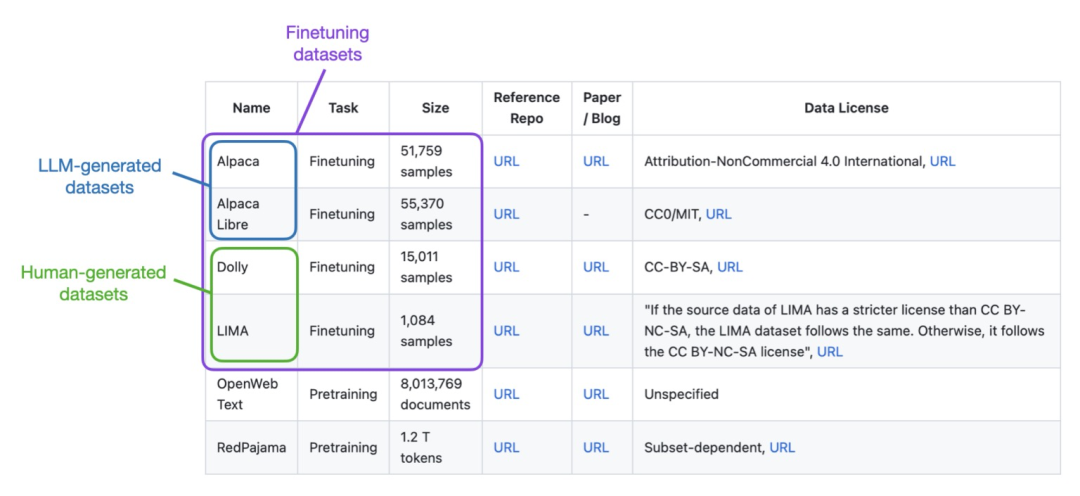
Lit-GPT定义客户化数据集
加载自定义数据集大致需要两步,首先需要准备三列CSV数据,示例如下:

第一步,执行如下脚本:
python scripts/prepare_csv.py \--csv_dir MyDataset.csv \--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf
第二步,与上述LIMA类似,是执行scripts/prepare_dataset.py脚本
参考文献:
[1] https://lightning.ai/pages/community/tutorial/optimizing-llms-from-a-dataset-perspective/
相关文章:
LLM(二)| LIMA:在1k高质量数据上微调LLaMA1-65B,性能超越ChatGPT
本文将介绍在Lit-GPT上使用LoRA微调LLaMA模型,并介绍如何自定义数据集进行微调其他开源LLM 监督指令微调(Supervised Instruction Finetuning) 什么是监督指令微调?为什么关注它? 目前大部分LLM都是decoder-only&…...
)
Android AMS——创建Application(七)
与在 App 内部启动一个 Activity 的不同之处在于,点击桌面 Launcher 首次启动一个应用程序的时候,会先去创建一个该应用程序对应的进程,然后执行 ActivityThread 的 main() 方法去创建该应用对应的 Application,然后再去启动首页 Activity。前面已经分析了进程的创建和启动…...

html 边缘融合加载
html 代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>边缘融合加载</title><style>* {margin: 0;padding: 0;box-sizing: border-box;}body {height: 100vh;padding-bottom: 80px;b…...

ElasticSearch - 在 微服务项目 中基于 RabbitMQ 实现 ES 和 MySQL 数据异步同步(考点)
目录 一、数据同步 1.1、什么是数据同步 1.2、解决数据同步面临的问题 1.3、解决办法 1.3.1、同步调用 1.3.2、异步通知(推荐) 1.3.3、监听 binlog 1.3、基于 RabbitMQ 实现数据同步 1.3.1、需求 1.3.2、在“酒店搜索服务”中 声明 exchange、…...
Springboot+vue的企业人事管理系统(有报告),Javaee项目,springboot vue前后端分离项目。
演示视频: Springbootvue的企业人事管理系统(有报告),Javaee项目,springboot vue前后端分离项目。 项目介绍: 本文设计了一个基于Springbootvue的前后端分离的企业人事管理系统,采用M(model&am…...

初识Java 11-1 函数式编程
目录 旧方式与新方式 lambda表达式 方法引用 Runnable 未绑定方法引用 构造器方法引用 函数式接口 带有更多参数的函数式接口 解决缺乏基本类型函数式接口的问题 本笔记参考自: 《On Java 中文版》 函数式编程语言的一个特点就是其处理代码片段的简易性&am…...
【Ambari】银河麒麟V10 ARM64架构_安装Ambari2.7.6HDP3.3.1问题总结
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的帮助🌸文…...

李宏毅机器学习第一课(结尾附作业模型详细分析)
机器学习就是让机器找一个函数f,这个函数f是通过计算机找出来的 如果参数少的话,我们可以使用暴搜,但是如果参数特别多的话,我们就要使用Gradient Descent Regression (输出的是一个scalar数值) Classification (在…...

对日项目工作总结
从18年8月到23年中秋节,目前已经入职主营对日车载项目的公司满5年了,一般来说,在一家公司工作工作超过3年,如果是在比较大型以及流程规范的公司,那么该公司的工作流程,工作思维会深深地烙印在该员工的脑海中…...

设计模式探索:从理论到实践的编码示例 (软件设计师笔记)
😀前言 设计模式,作为软件工程领域的核心概念之一,向我们展示了开发过程中面对的典型问题的经典解决方案。这些模式不仅帮助开发者创建更加结构化、模块化和可维护的代码,而且也促进了代码的复用性。通过这篇文章,我们…...
【内网穿透】在Ubuntu搭建Web小游戏网站,并将其发布到公网访问
目录 前言 1. 本地环境服务搭建 2. 局域网测试访问 3. 内网穿透 3.1 ubuntu本地安装cpolar 3.2 创建隧道 3.3 测试公网访问 4. 配置固定二级子域名 4.1 保留一个二级子域名 4.2 配置二级子域名 4.3 测试访问公网固定二级子域名 前言 网:我们通常说的是互…...

在cesuim上展示二维模型
前提问题:在cesuim上展示二维模型 解决过程: 1.获取或定义所需变量 2.通过window.cesium.viewer.imageryLayers.addImageryProvider和new Cesium.UrlTemplateImageryProvider进行建模 3.传入url路径后拼接{z}/{x}/{y}.png 4.聚焦到此模型window.ces…...
c/c++中如何输入pi
标准的 C/C 语言中没有π这个符号及常量,一般在开发过程中是通过开发人员自己定义这个常量的,最常见的方式是使用宏定义: 方法1:#define pi 3.1415926 方法2:使用反三角函数const double pi acos(-1.0);...

python爬虫:JavaScript 混淆、逆向技术
Python爬虫在面对JavaScript混淆和逆向技术时可能会遇到一些挑战,因为JavaScript混淆技术和逆向技术可以有效地阻止爬虫对网站内容的正常抓取。以下是一些应对这些挑战的方法: 分析网页源代码:首先,尝试分析网页的源代码…...

Vue error:0308010C:digital envelope routines::unsupported
vue项目,npm run dev的时候出现:Error: error:0308010C:digital envelope routines::unsupported vue项目,npm run dev的时候出现:Error: error:0308010C:digital envelope routines::unsupported 这个是node的版本问题。我的nod…...

gitee 远程仓库操作基础(一)
git remote add <远程仓库名> <仓库远程地址> :给远程仓库取个别名,简化一大堆字符串操作 git remote add origin xxx.git :取个Origin名字 git remote -v :查看本地存在的远程仓库 git pull <远程仓库名><远程分支名>:<本地分支名> 相同可取消…...
)
DRM全解析 —— ADD_FB2(0)
本文参考以下博文: DRM驱动(四)之ADD_FB 特此致谢! 在笔者之前的libdrm全解析系列文章中,讲到了drmIoctl(fd, DRM_IOCTL_MODE_ADDFB, &f)以及其封装函数drmModeAddFB。对应的文章链接为: libdrm全解…...

01Redis的安装和开机自启的配置
安装Redis 单机安装Redis 大多数企业都是基于Linux服务器来部署项目,而且Redis官方也没有提供Windows版本的安装包(此处选择的Linux版本的CentOS 7) Windows版直接下载对应版本的.zip压缩包解压即可使用 第一步: Redis是基于C语言编写的,因此首先需要…...
进入IT行业:选择前端开发还是后端开发?
一、前言 开发做前端好还是后端好?这是一个常见的问题,特别是对于初学者来说。在编程世界中,前端开发和后端开发分别代表着用户界面和数据逻辑,就像城市的两个不同街区一样。但是,究竟哪个街区更适合我们作为开发者呢…...

Java集成Onlyoffice以及安装和使用示例,轻松实现word、ppt、excel在线编辑功能协同操作,Docker安装Onlyoffice
安装Onlyoffice 拉取onlyoffice镜像 docker pull onlyoffice/documentserver 查看镜像是否下载完成 docker images 启动onlyoffice 以下是将本机的9001端口映射到docker的80端口上,访问时通过服务器ip:9001访问,并且用 -v 将本机机/data/a…...

如何用Sunshine打造个人游戏串流中心:跨设备畅玩的终极指南
如何用Sunshine打造个人游戏串流中心:跨设备畅玩的终极指南 【免费下载链接】Sunshine Sunshine: Sunshine是一个自托管的游戏流媒体服务器,支持通过Moonlight在各种设备上进行低延迟的游戏串流。 项目地址: https://gitcode.com/GitHub_Trending/su/S…...

医美私信获客新范式:快商通AI私信机器人如何实现高效客户转化
医美私信获客新范式:快商通AI私信机器人如何实现高效客户转化 关键要点: 医美行业夜间咨询流失率高达 78% ,响应不及时是主要原因 快商通AI私信机器人实现 724小时 智能接待,开口率从 22% 提升至 100% 实际应用数据显示࿰…...

别再手动校正了!用Landsat 9 L2SP地表反射率数据,在QGIS里5分钟搞定NDVI和水体提取
遥感分析效率革命:用Landsat 9 L2SP数据在QGIS中实现5分钟精准制图 当遥感数据处理流程从传统数小时缩短至五分钟,这意味着什么?去年在亚马逊雨林监测项目中,我们团队曾因大气校正步骤延误错过了最佳干预时机。如今Landsat 9 L2SP…...

医疗陪护管理系统:信息化管理在医院的应用
博主介绍: 所有项目都配有从入门到精通的安装教程,可二开,提供核心代码讲解,项目指导。 项目配有对应开发文档、解析等 项目都录了发布和功能操作演示视频; 项目的界面和功能都可以定制,包安装运行…...

MecanumBase:轻量级全向轮运动学逆解C库
1. MecanumBase 库概述MecanumBase 是一个专为全向移动机器人设计的轻量级底层控制库,核心目标是将复杂的轮式运动学解耦为工程师可直观理解的输入指令:平移方向角(θ)与旋转角速度(ω)。该库不依赖任何特定…...

基于CATIA有限元的焊装夹具Base板应力分析与优化设计
1. 为什么焊装夹具Base板需要应力分析? 在汽车制造领域,焊装夹具是确保车身焊接精度的关键设备。其中Base板作为夹具的支撑基础,承受着来自机器人抓手和工件的全部载荷。很多新手工程师常犯的错误是直接套用经验公式设计,结果要么…...

OpenClaw可视化监控:为nanobot任务添加Web仪表盘
OpenClaw可视化监控:为nanobot任务添加Web仪表盘 1. 为什么需要可视化监控? 去年夏天,我部署了一个基于OpenClaw的nanobot自动化任务,用于定时抓取行业动态并生成日报。最初几周运行良好,直到某天早上发现连续三天的…...

嵌入式软件架构设计:硬件抽象层实践
嵌入式软件架构设计:建立硬件抽象层的工程实践 1. 嵌入式软件架构概述 1.1 架构设计的必要性 在嵌入式系统开发中,软件架构设计直接影响产品的可维护性、可扩展性和可移植性。良好的架构设计能够: 减少不必要的返工 建立宏观层面的开发规…...

斗鱼季报图解:营收9亿同比降19% 经调整净利1260万
雷递网 雷建平 3月26日斗鱼(Nasdaq: DOYU)日前发布截至2025年12月31日的全年及第四季度财报。财报显示,斗鱼2025年营收为38.19亿元(约5.46亿美元),较上年同期的42.71亿元下降10.58%。斗鱼2025年毛利为4.9亿元,经调整净…...

半导体仿真进阶:如何用Silvaco DOPING语句精确控制掺杂分布
半导体仿真进阶:如何用Silvaco DOPING语句精确控制掺杂分布 在半导体器件设计与工艺开发中,精确控制掺杂分布是决定器件性能的关键因素之一。Silvaco TCAD工具链中的DOPING语句,为工程师提供了从简单均匀掺杂到复杂梯度分布的灵活控制能力。…...