计算机视觉与深度学习-循环神经网络与注意力机制-RNN(Recurrent Neural Network)、LSTM-【北邮鲁鹏】
目录
- 举例应用
- 槽填充(Slot Filling)
- 解决思路
- 方案
- 使用前馈神经网络
- 输入
- 1-of-N encoding(One-hot)(独热编码)
- 输出
- 问题
- 循环神经网络(Recurrent Neural Network,RNN)
- 定义
- 如何工作
- 学习目标
- 深度
- Elman Network & Jordan Network
- Elman Network
- Jordan Network
- Bidirectional RNN
- 长短期记忆网络(Long Short-Term Memory,LSTM)
- 数学表示
- 怎么工作
- 使用LSTM替换神经元
- 学习目标
- 怎么训练
- BPTT代表基于时间的反向传播(Backpropagation Through Time)
- 基于RNN的神经网络不容易被训练
- RNN的损失函数的坡面
- 为什么出现这种现象?
- LSTM能够很好的应对
- 应用
- 一对一
- 多对一
- 多对多
- output shorter
- CTC
- CTC:Training
- No Limitation
- 存在的问题
- 编码有效性
- 训练效率
- 门控循环单元(Gated Recurrent Unit,GRU)
举例应用
槽填充(Slot Filling)
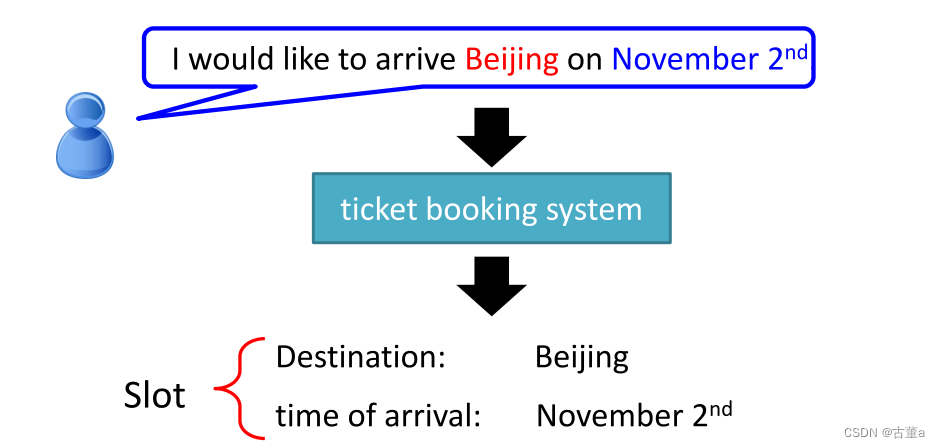
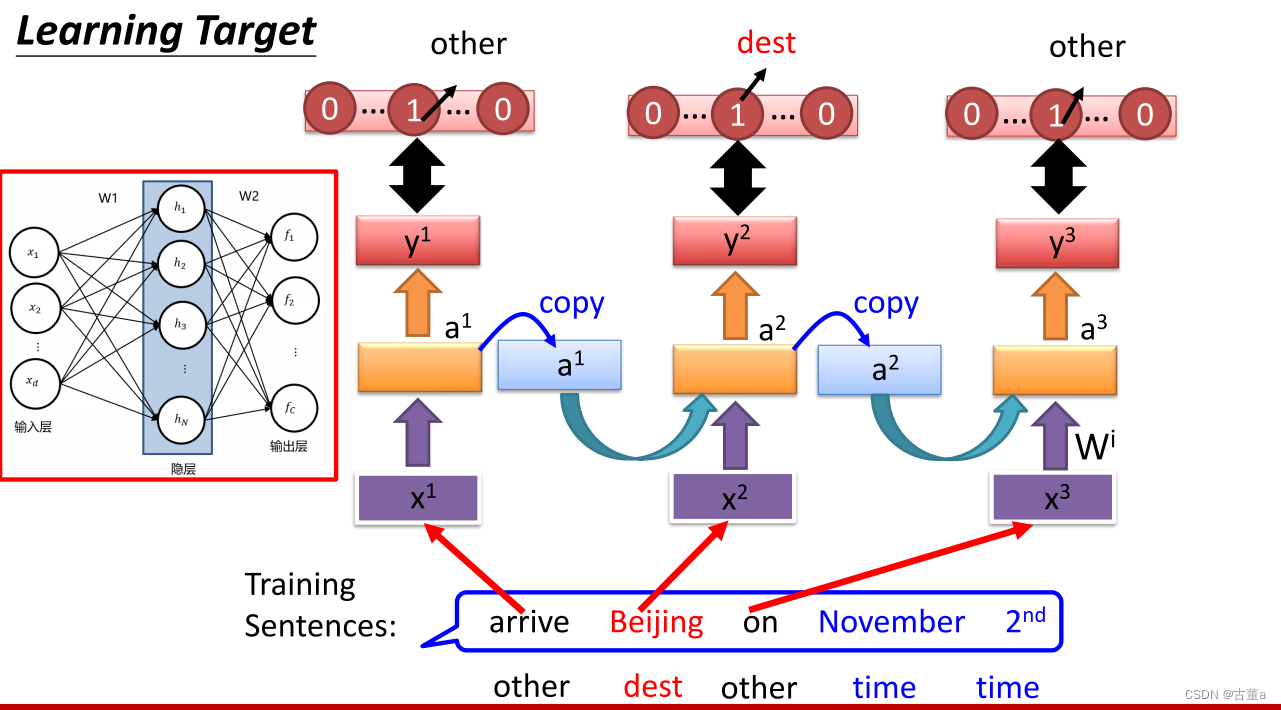
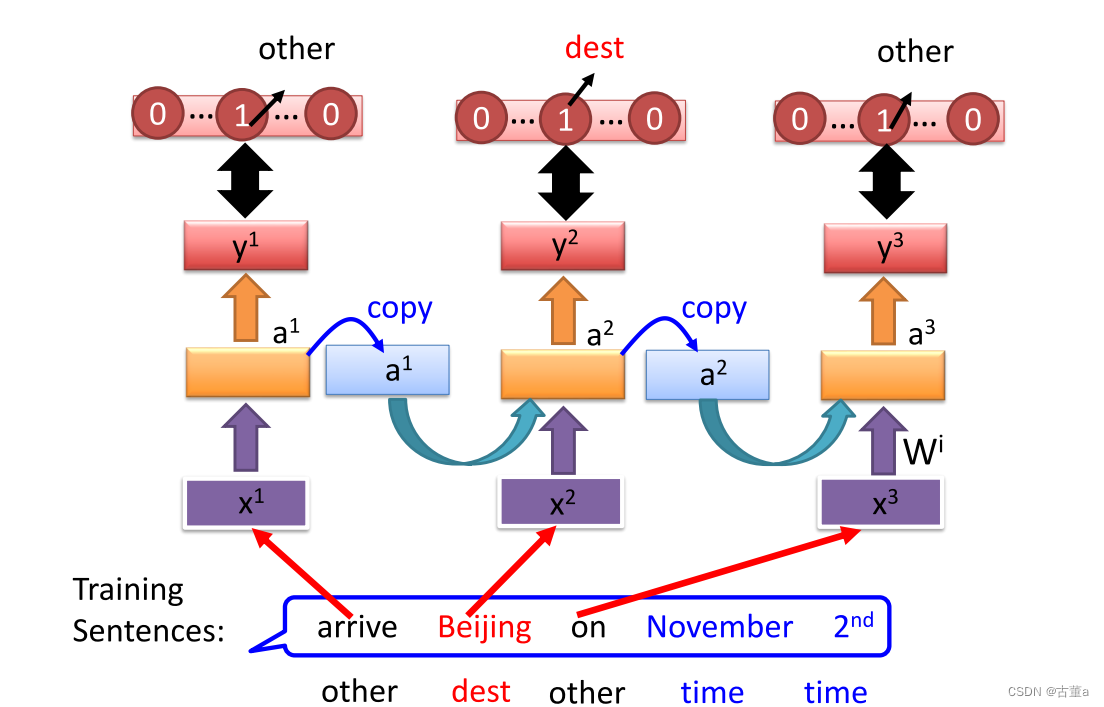
定义这样一个场景,比如说我要做一个订票系统,当用户说了一句话,我将要在十一月二号去到北京

这是一个订票机器人,对于要实现订票这个功能,则需要提取目的地和到达时间
解决思路
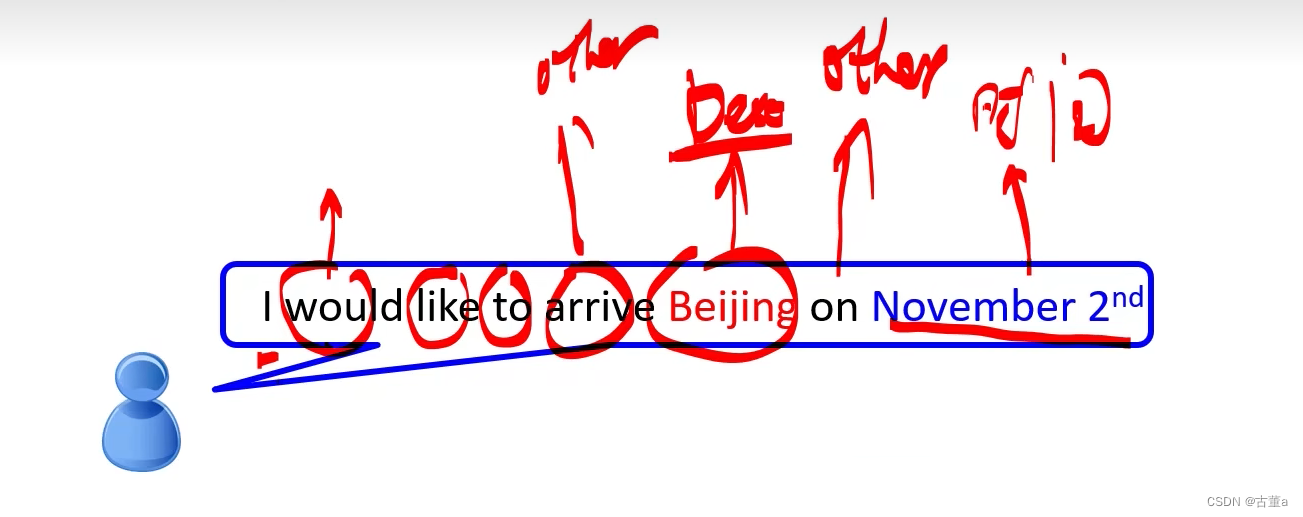
就是要给输入的每一个字,需要判断出它的类别信息。就是对每个单词进行分类的问题
方案
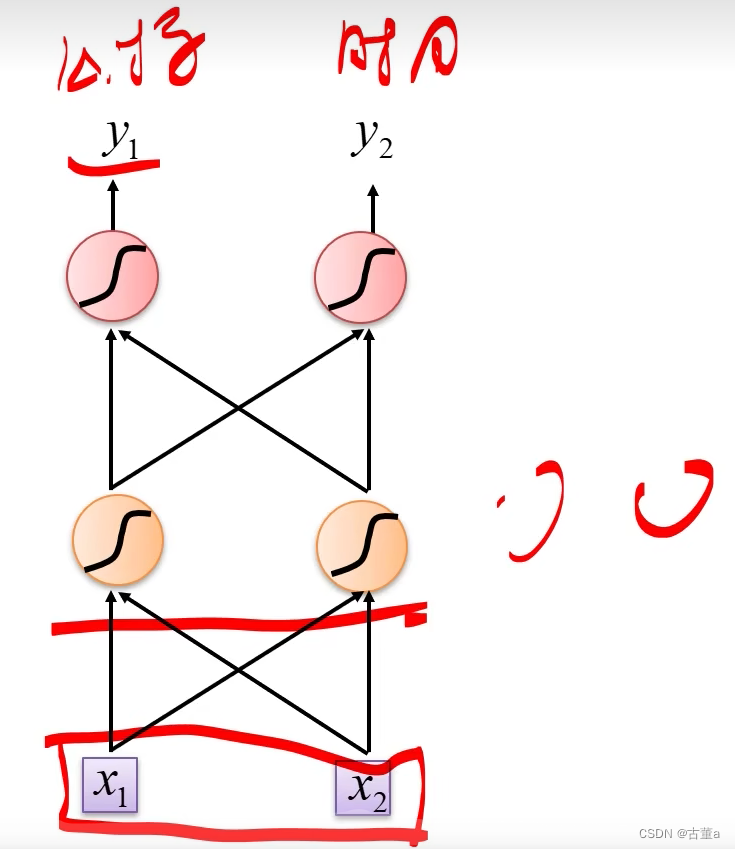
使用前馈神经网络
使用全连接神经网络对单词进行分类
输入
对于文本来说,要想将其输入全连接神经网络,需要将每个单词转变成向量
如何将单词转换成向量
1-of-N encoding(One-hot)(独热编码)
“One-hot” 是一种编码方式,通常用于将离散的分类变量表示为二进制向量。在这种表示方法中,每个类别被表示为一个唯一的向量,其中只有一个元素为1,其他元素都为0。
例如,假设有三个类别:A、B 和 C。使用 one-hot 编码,可以将这三个类别表示为以下向量:
A: [1, 0, 0]
B: [0, 1, 0]
C: [0, 0, 1]

在上述表示中,向量的长度等于类别的数量。每个类别在对应的位置上具有值为1,而其他位置上的值为0。这种表示方式使得每个类别之间的距离相互独立,没有大小或顺序的关系。
输出
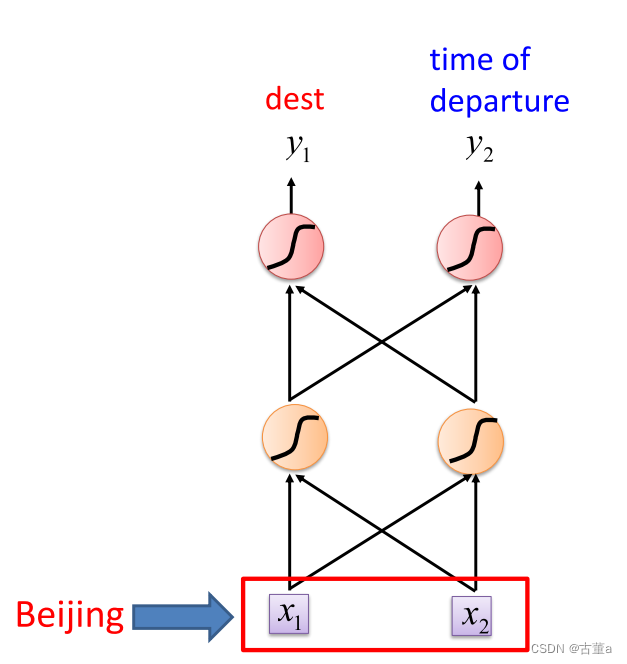
输入字属于槽的概率分布
问题
对于同一个单词“Beijing”来说,在不同的句子中。
arrive Beijing,则Beijing表示目的地
leave Beijing,则Beijing表示出发地
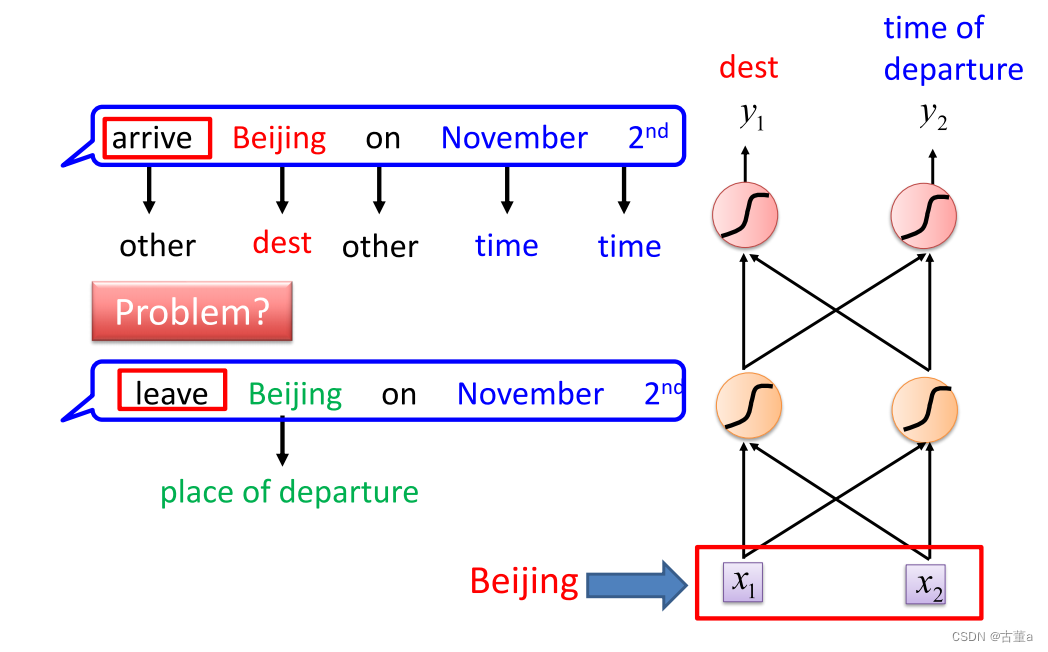
单纯的神经网络处理不了这样的问题。需要我们的网络具有一定的记忆性。就是说在网络在处理完这单词以后,在处理下一个单词的时候,需要考虑上一个单词的处理结果。
引入Memory
循环神经网络(Recurrent Neural Network,RNN)
引入memory了以后 我们的网络就变成循环神经网络RNN(Recurrent Neural Network)
memory是怎么解决这个问题?
我们需要记忆单元 ,比如arrive先进来,处理完了arrive ,我要把arrive的这个隐存信息记录到这个两个单元里,然后我再给第二个单词北京的时候,他要把arrive这个单词的信息和“beijing”这个单词的信息,一起拿进来处理,很显然这个时候就知道这是目的地还是出发地
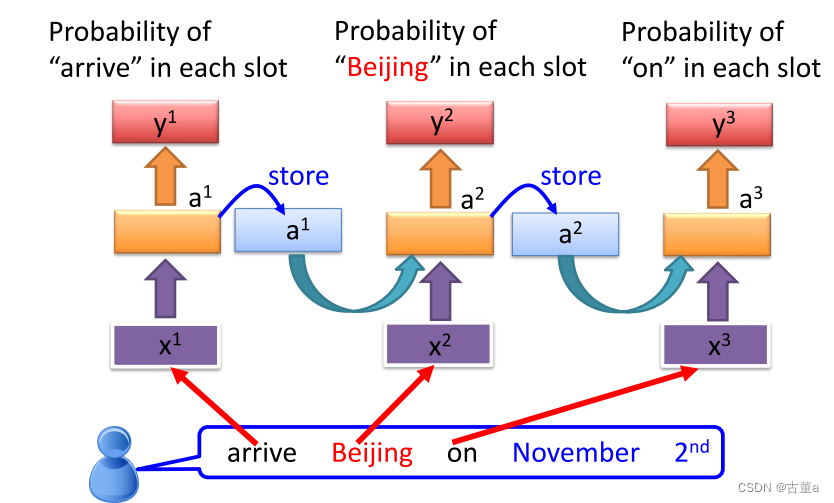
只要我们对神经网络里面引入一个记忆单元,能对我刚才处理过的事情有一定记性的话,在做下一个单词预测的时候,我把我上一个单词的信息和下一个单词一起考虑 。我就能预测正确 ,这到底是发地还是目的地 ,这个就是循环神经网络。
对比arrive和leave
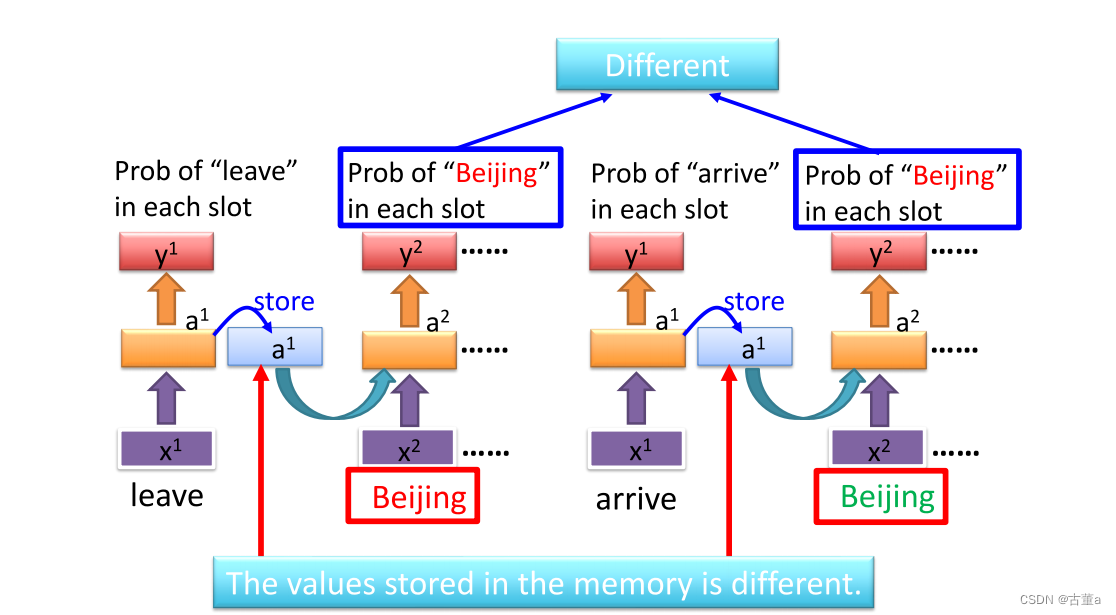
定义
RNN(Recurrent Neural Network,循环神经网络)是一种用于处理序列数据的神经网络模型。相比于传统的前馈神经网络,RNN 具有记忆能力,可以处理具有时序关系的输入。
RNN 的主要特点是引入了循环连接,允许信息在网络内部进行传递。这种循环结构使得 RNN 可以接受变长序列作为输入,并且在每个时间步上都可以利用之前的信息来影响当前的输出。

在 RNN 中,每个时间步都会接收一个输入向量和一个隐藏状态(hidden state)向量。输入向量表示当前时间步的输入数据,隐藏状态向量则用于存储之前时间步的信息。在每个时间步,RNN 会根据当前的输入和上一个时间步的隐藏状态来计算新的隐藏状态。这个过程可以通过循环神经网络的参数来实现。
RNN 的基本结构是一个简单的循环单元(Simple Recurrent Unit,SRU),也被称为 RNN Cell。它可以根据当前时间步的输入和前一个时间步的隐藏状态计算新的隐藏状态。然后,根据需要,可以在 RNN 的输出层上添加其他层,例如全连接层或 softmax 层,用于产生最终的输出。
如何工作
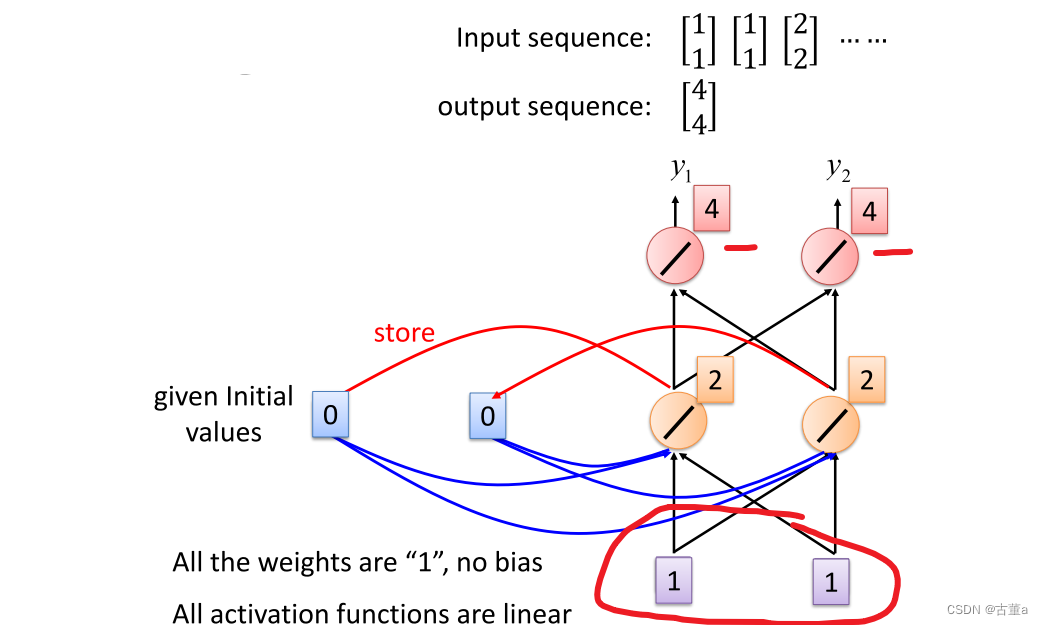
假设我们所有的权重都是1,然后所有的激活单元都是线性单元
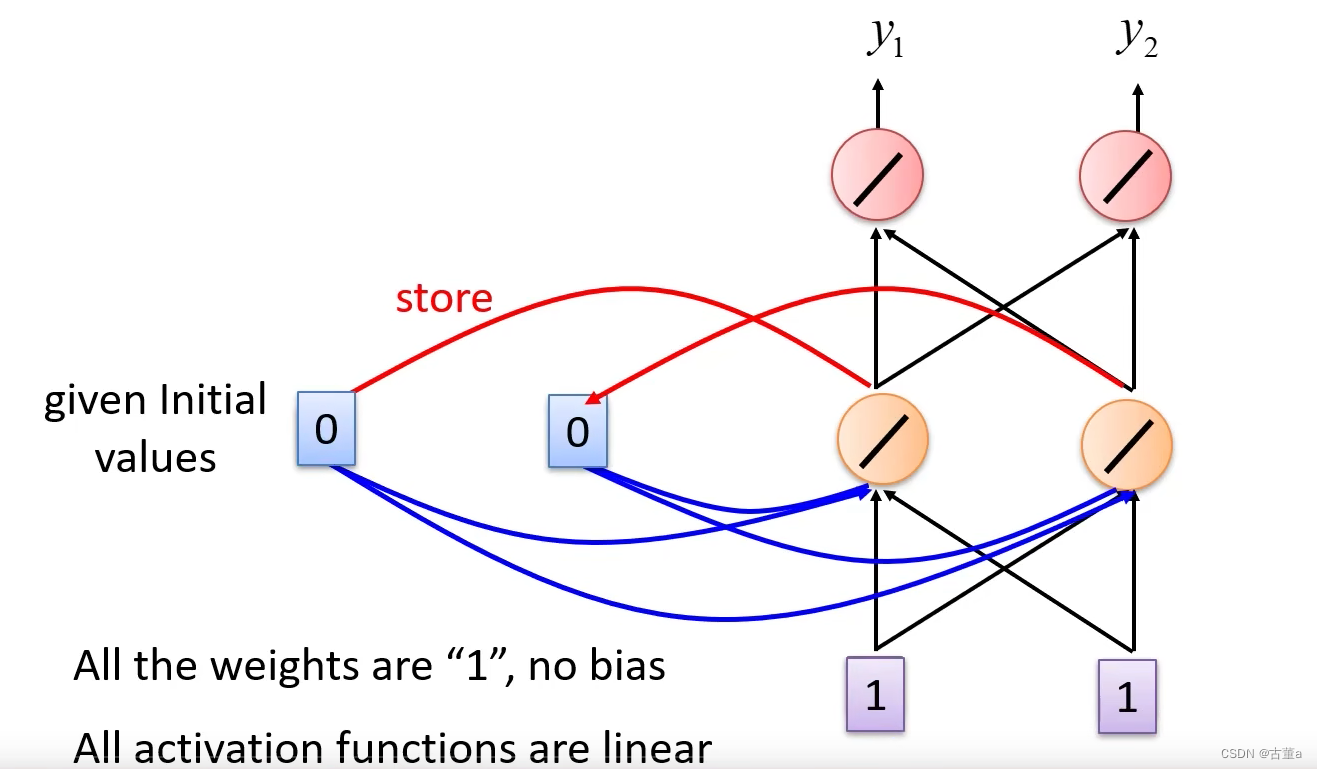
首先 我们先输入第一个序列,假如这里面没有存东西,给定初始值1,此时store里是0,所以 1 + 1 = 2 , 2 + 2 = 4 1+1=2,2+2=4 1+1=2,2+2=4,最后输出结果是[4 4]
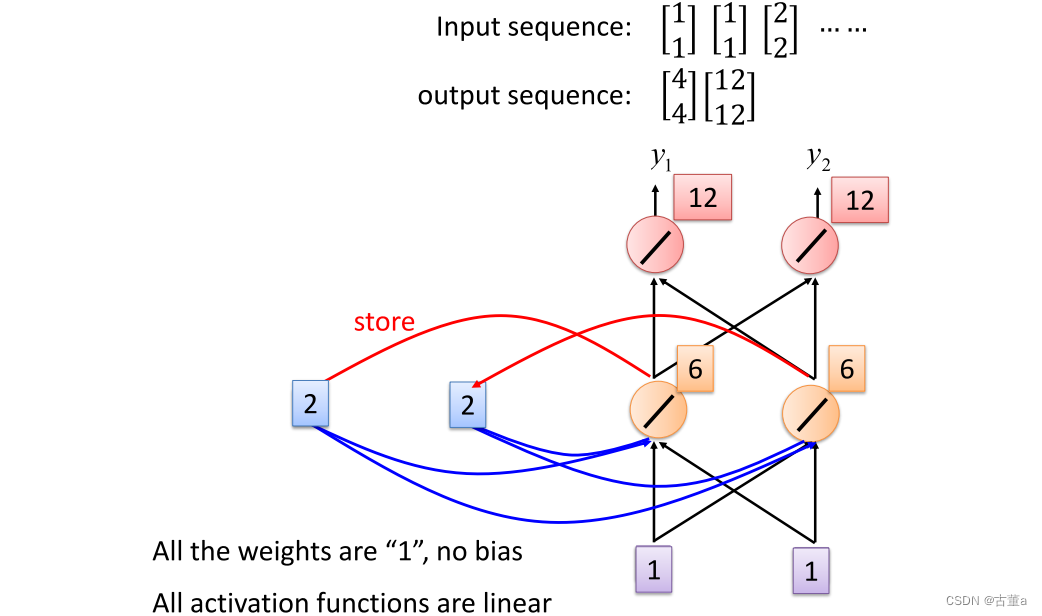
我们先输入第二个序列,给定初始值2,此时store里是2,则 1 + 1 + 2 + 2 = 6 , 6 + 6 = 12 1+1+2+2=6,6+6 = 12 1+1+2+2=6,6+6=12,最后输出结果是[12 12]
学习目标
存在 序列依赖性限制
RNN 存在一种称为短期记忆(short-term memory)的问题,即它们往往只能捕捉到相对短距离的序列依赖性。这意味着如果一个序列非常长,RNN 可能无法有效地捕捉到序列中的长期依赖关系,因为梯度消失问题会使得远距离的信息很难传递到网络的较早层。
当序列很长的时候,处理的第一百个单词的时候,第一个单词对处理这个单词很有帮助,但是由于RNN的特征,第一个单词再第二个单词处理的时候,信息就已经衰减了。所以对处理这第一百个单词的时候用处不大。
深度
深度循环神经网络(Deep RNN):深度循环神经网络是一种结合了时间维度和层次维度的网络结构。除了在时间维度上进行循环计算外,还在层次维度上进行信息传递。在深度 RNN 中,每个时间步上的输入不仅会传递到下一个时间步,还会在同一时间步上传递到下一层的相同时间步。这样,每个时间步上的输入都会经过多个层次的处理和传递,实现了网络的深度。
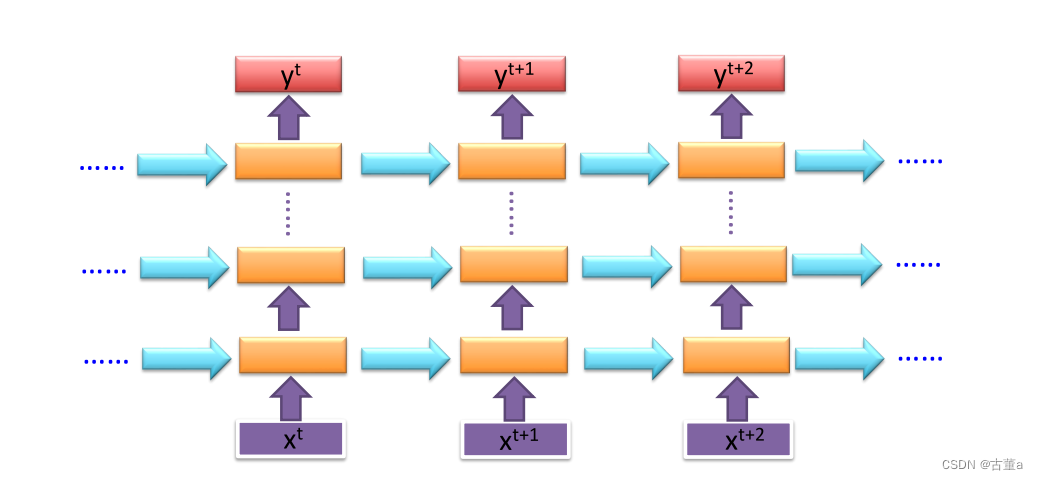
增加了网络的非线性能力
Elman Network & Jordan Network
Elman Network
Elman网络也被称为简单循环网络(Simple Recurrent Network,SRN)。它是一种单向连接的RNN结构,具有一个输入层、一个隐藏层和一个输出层。在Elman网络中,隐藏层和输出层之间存在一个额外的反馈连接,将隐藏层的输出作为下一个时间步的输入。
在每个时间步上,Elman网络接收当前时间步的输入和上一个时间步的隐藏层输出。它通过激活函数(通常是sigmoid函数)将输入和隐藏层的加权和进行非线性变换,然后将结果传递到输出层。隐藏层的输出也会通过反馈连接返回到下一个时间步的隐藏层输入,形成循环。
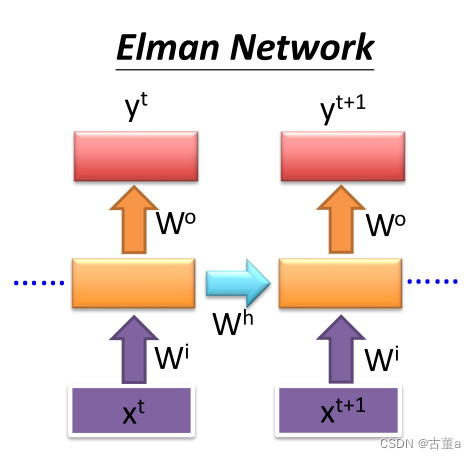
Elman网络适用于处理具有短期依赖关系的任务,例如语音识别、手写体识别等。但对于长期依赖关系的建模,Elman网络可能面临梯度消失或梯度爆炸的问题。
Jordan Network
Jordan网络是另一种RNN结构,与Elman网络类似,它也具有输入层、隐藏层和输出层。然而,与Elman网络不同的是,Jordan网络在隐藏层和输出层之间的反馈连接是从输出层直接反馈到隐藏层,而不是从隐藏层自身反馈。
在每个时间步上,Jordan网络接收当前时间步的输入和上一个时间步的隐藏层输出。它通过激活函数将输入和隐藏层的加权和进行非线性变换,并将结果传递到输出层。输出层的输出会通过反馈连接返回到隐藏层的输入。
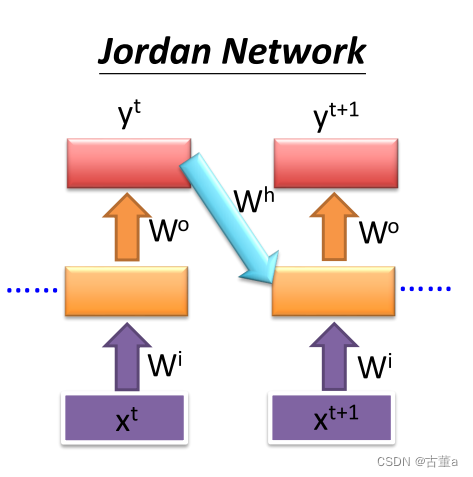
Jordan网络相对于Elman网络更适用于处理具有长期依赖关系的任务,因为它的反馈连接是从输出层直接反馈,可以更好地捕捉到输出对隐藏状态的依赖。然而,Jordan网络也可能面临梯度消失或梯度爆炸的问题。
Bidirectional RNN
双向循环神经网络(Bidirectional Recurrent Neural Network,BiRNN)是传统循环神经网络(RNN)的扩展,能够同时处理正向和逆向的输入序列。它结合了两个RNN,一个按照正向顺序处理序列,另一个按照逆向顺序处理序列。两个方向的输出通常会被连接或以某种方式组合形成最终的输出。
在BiRNN中,输入序列的每个时间步会被处理两次:一次是正向传递,一次是逆向传递。这使得网络能够捕捉到每个时间步的过去和未来上下文信息。通过考虑未来上下文,BiRNN可以提高对输入序列的理解和表示能力。
正向的RNN按照从第一个时间步到最后一个时间步的顺序处理输入序列,而逆向的RNN则按照相反的顺序,从最后一个时间步到第一个时间步进行处理。在每个时间步,隐藏状态会根据当前输入以及相应方向上的前一个时间步的隐藏状态进行更新。
BiRNN的最终输出可以通过连接或组合正向和逆向RNN的输出来获得。这种组合表示可以捕捉到输入序列过去和未来上下文的依赖关系和模式。
BiRNN常用于需要考虑双向上下文重要性的任务,例如语音识别、命名实体识别、情感分析和机器翻译。通过利用双向信息,它们能够有效地捕捉长期依赖关系,并提高序列建模任务的性能。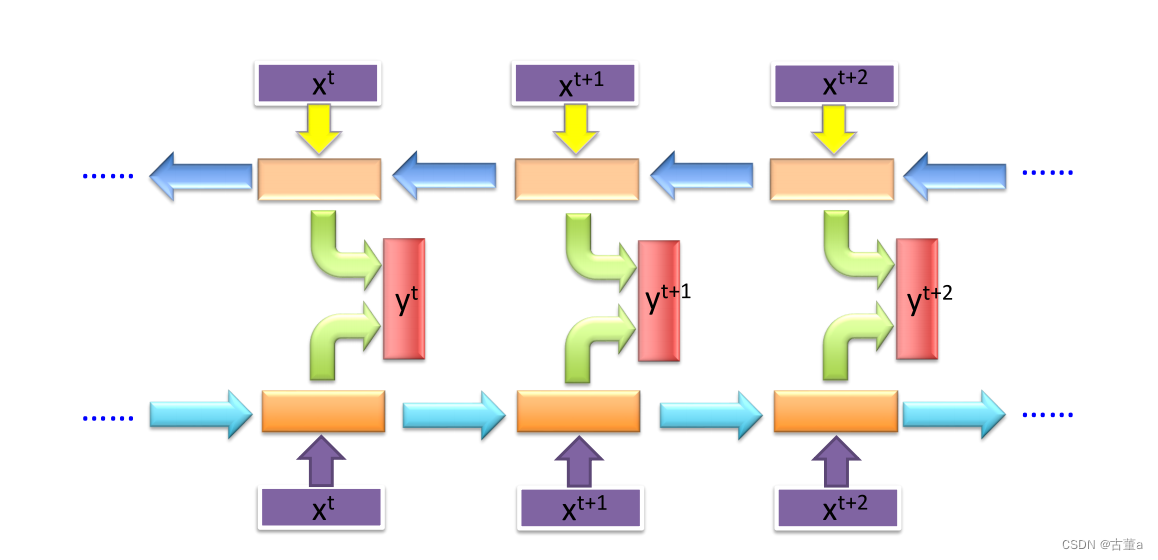
一般有些时候我们是看前面的单词来决定我这个这个当前单词是啥意思,有时候我还要看后面那个单词来决定我当前单词是啥意思。
苹果手机很好用 苹果很好吃 苹果到底什么其实要靠后面的单词来决定
好吃决定苹果是水果
好用决定苹果是手机
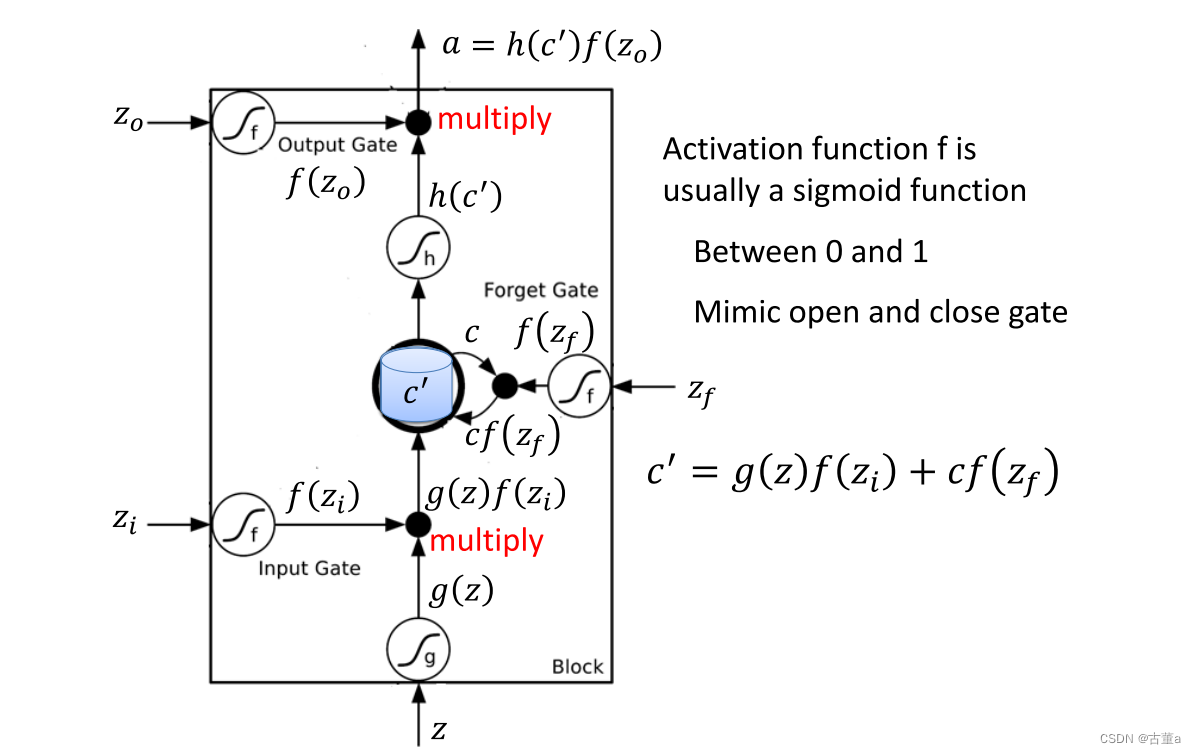
长短期记忆网络(Long Short-Term Memory,LSTM)
长短期记忆网络(Long Short-Term Memory,LSTM)是一种特殊的循环神经网络(RNN)架构,LSTM从被设计之初就被用于解决一般递归神经网络中普遍存在的长期依赖问题,使用LSTM可以有效的传递和表达长时间序列中的信息并且不会导致长时间前的有用信息被忽略(遗忘)。与此同时,LSTM还可以解决RNN中的梯度消失/爆炸问题。
LSTM通过引入门控机制来控制信息的流动,主要包括以下几个组件:
-
细胞状态(Cell State):LSTM通过一个细胞状态来存储并传递信息,它在整个序列过程中一直存在。它可以被看作是LSTM网络的记忆单元。
-
输入门(Input Gate):输入门决定是否将当前输入信息纳入细胞状态的更新。它通过使用sigmoid激活函数来产生一个0到1之间的值,表示对应位置上输入的重要程度。
-
遗忘门(Forget Gate):遗忘门决定是否将前一时刻细胞状态中的信息保留到当前时刻。它通过使用sigmoid激活函数来产生一个0到1之间的值,表示对应位置上细胞状态中信息的保留程度。
-
输出门(Output Gate):输出门决定当前时刻细胞状态的输出。它通过使用sigmoid激活函数来产生一个0到1之间的值,表示对应位置上细胞状态的输出程度。此外,还有一个tanh激活函数用于产生一个在-1到1之间的值,表示对应位置上细胞状态的候选输出。
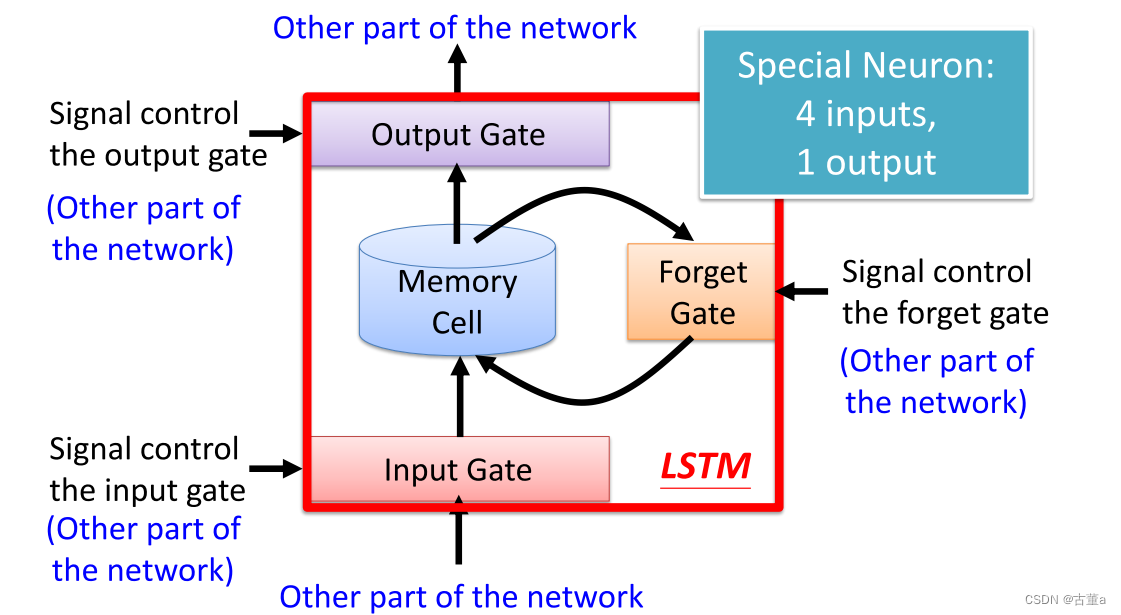
数学表示
怎么工作
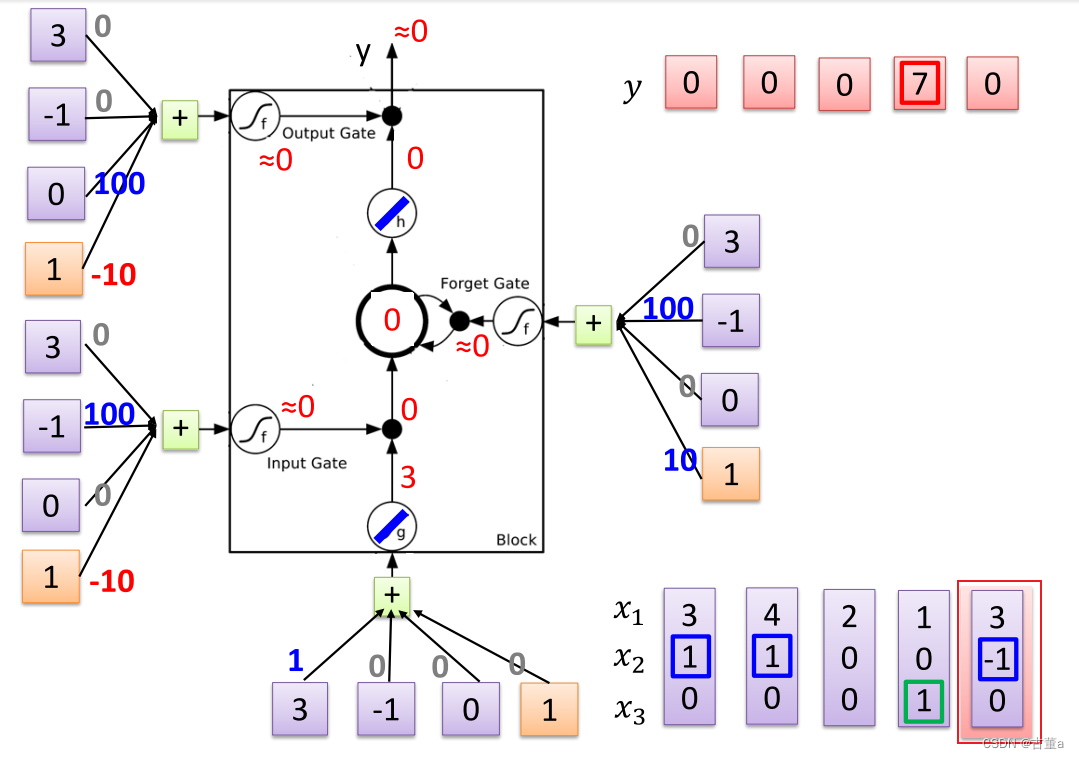
对每一个时刻输入的 x 2 x_2 x2感兴趣。根据 x 2 x_2 x2输入的值对 x 1 x_1 x1进行操作。
当 x 2 = 1 x_2=1 x2=1,将 x 1 x_1 x1的值写入内存
当 x 2 = 0 x_2=0 x2=0,对 x 1 x_1 x1的值不感兴趣
当 x 2 = − 1 x_2=-1 x2=−1,将 x 1 x_1 x1的值从内存抹去
同时关注 x 3 x_3 x3的值
当 x 3 = 1 x_3=1 x3=1时,将 x 1 x_1 x1的值进行输出
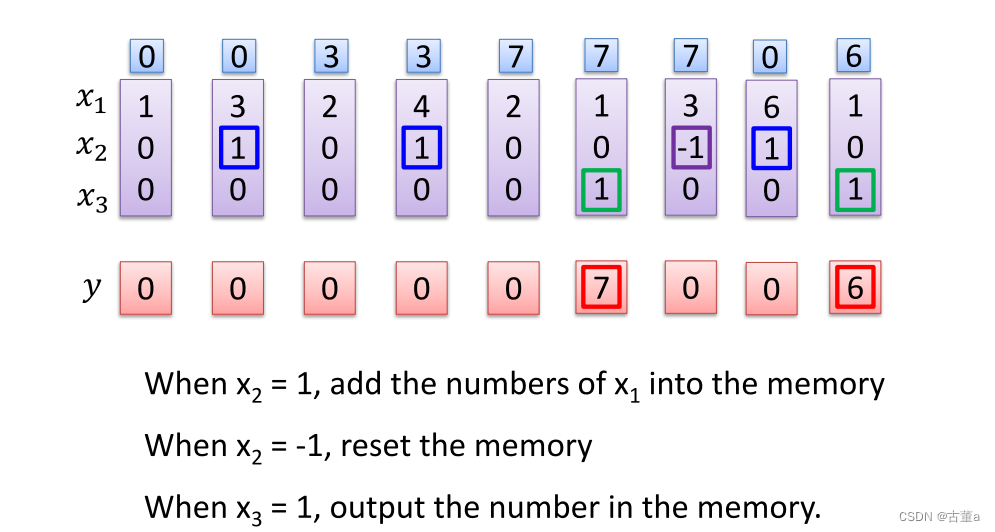
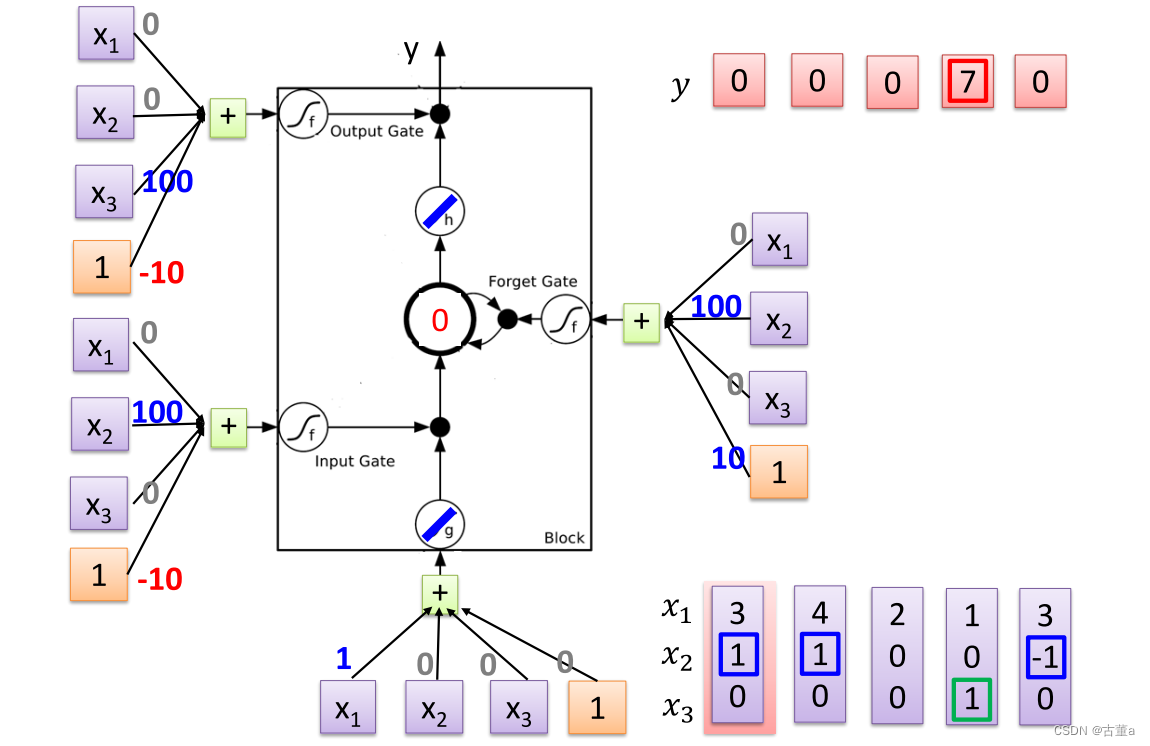
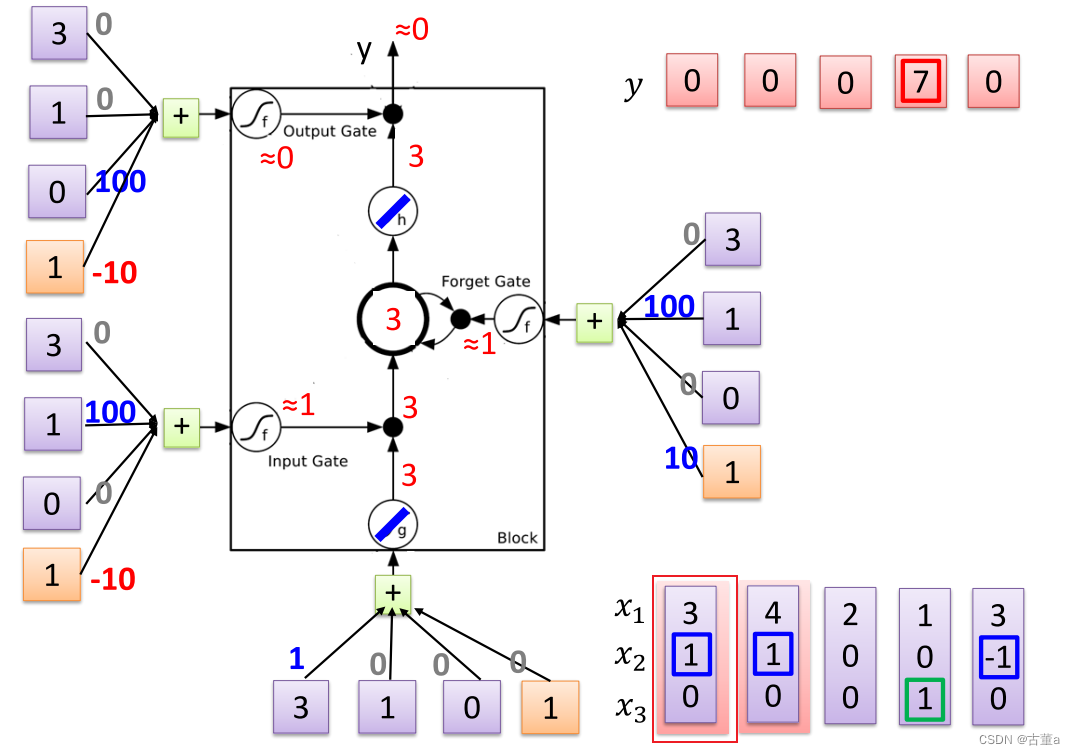
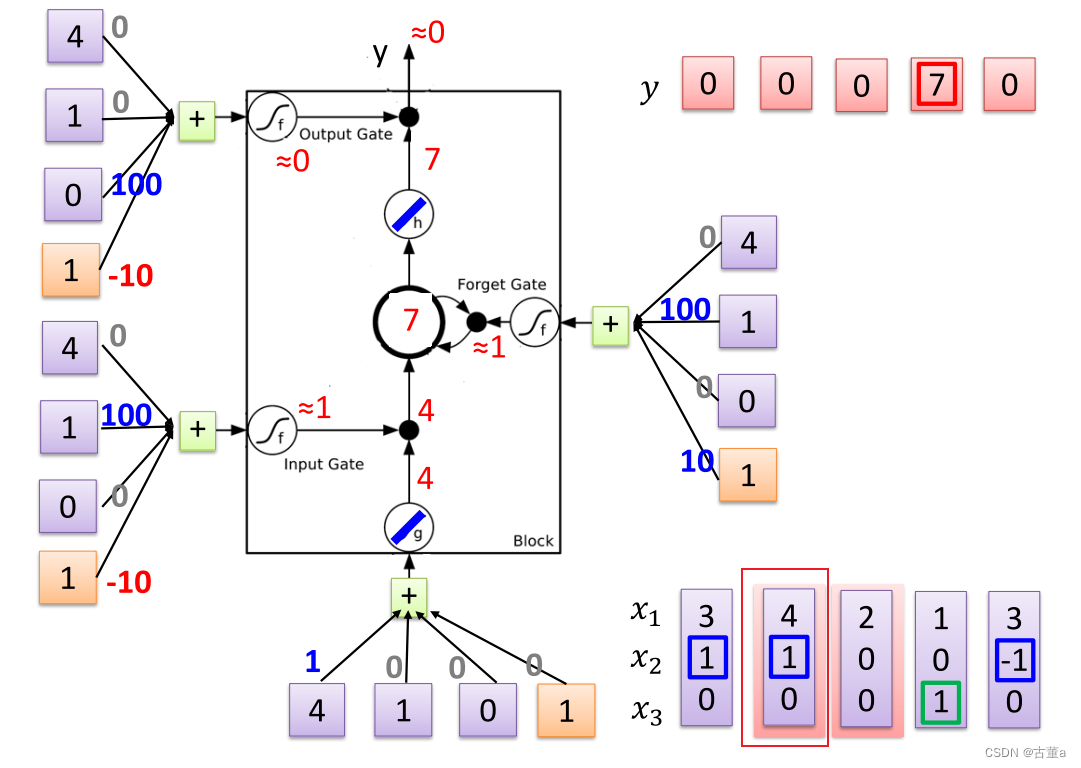
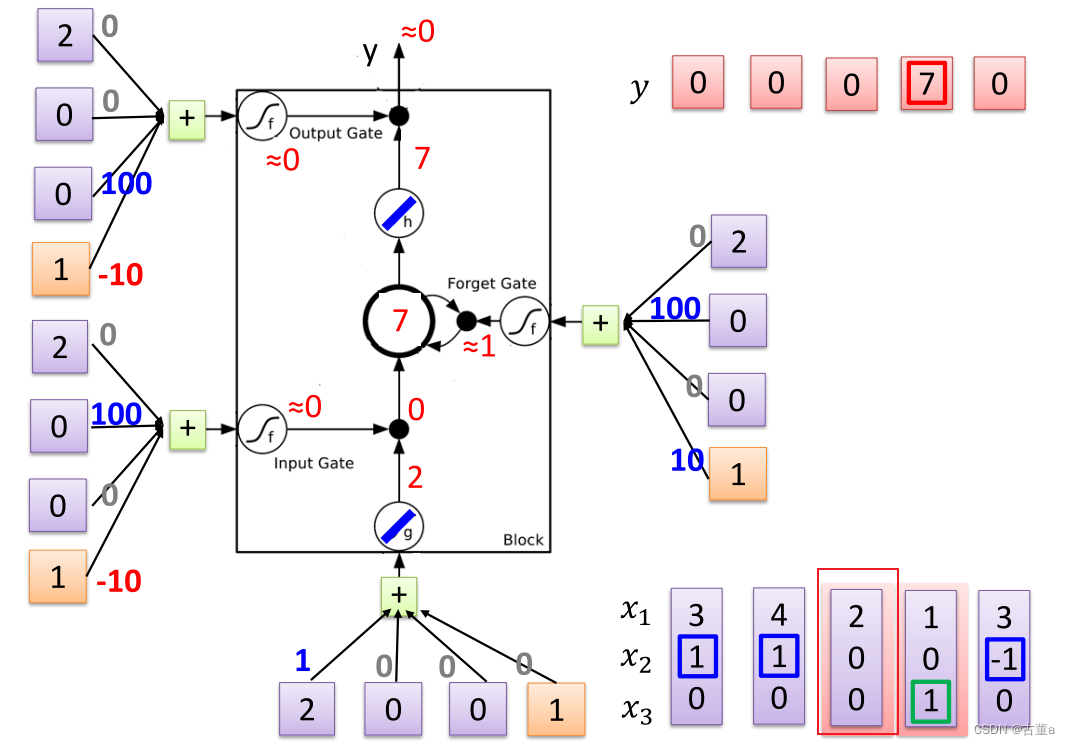
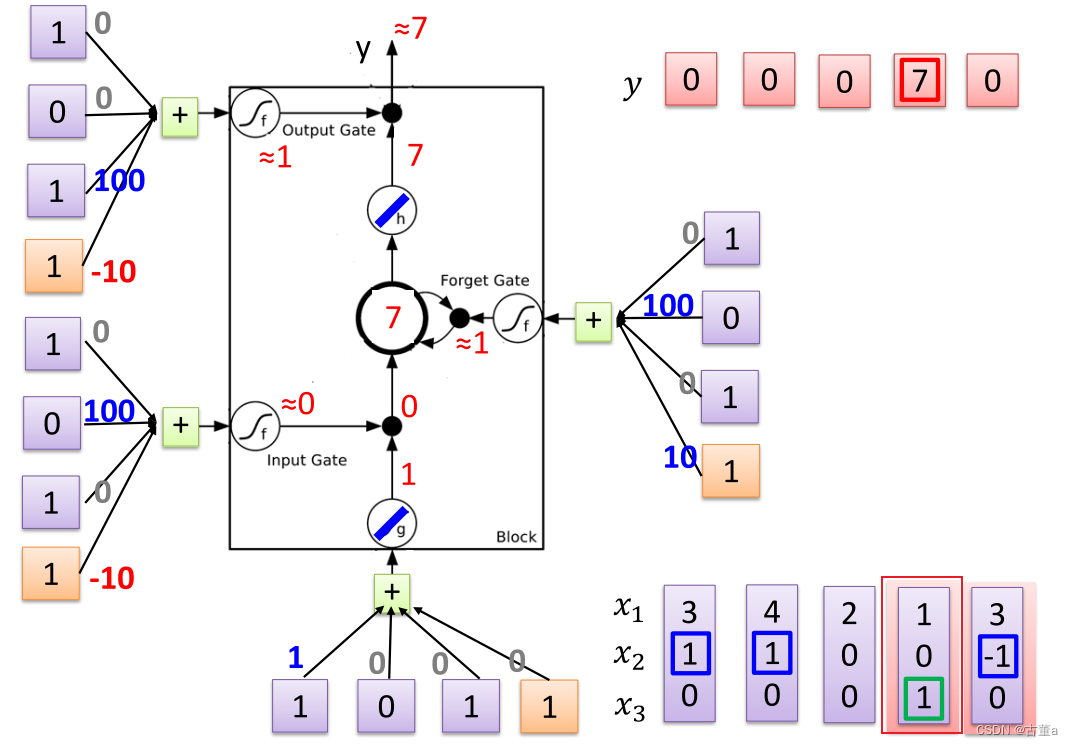
当 x 2 = − 1 x_2=-1 x2=−1,将 x 1 x_1 x1的值从内存抹去
使用LSTM替换神经元
原本的神经元
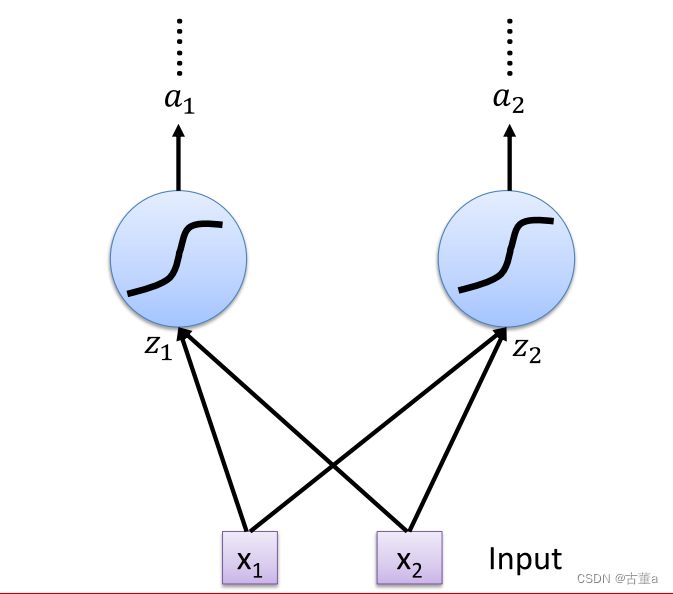
使用LSTM替换后
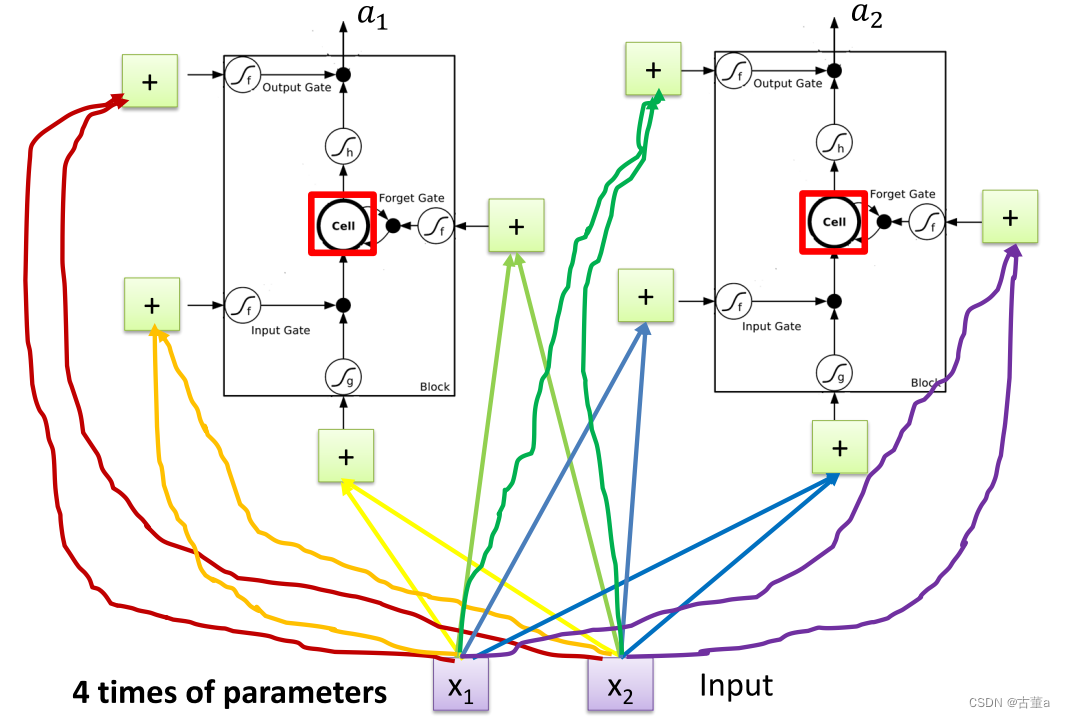
原本一个神经元有一套参数,现在每个神经元都扩大成了原来的四倍,所以我们整个神经网络参数量是原来的四倍 而不是原来的一倍,又直接扩大了四倍,这也是它的缺陷,让普通的神经网络的探索量一下大了四倍。
但是对于循环,对于这种有时序信息的任务,我们用这个方法,性能是非常好的。
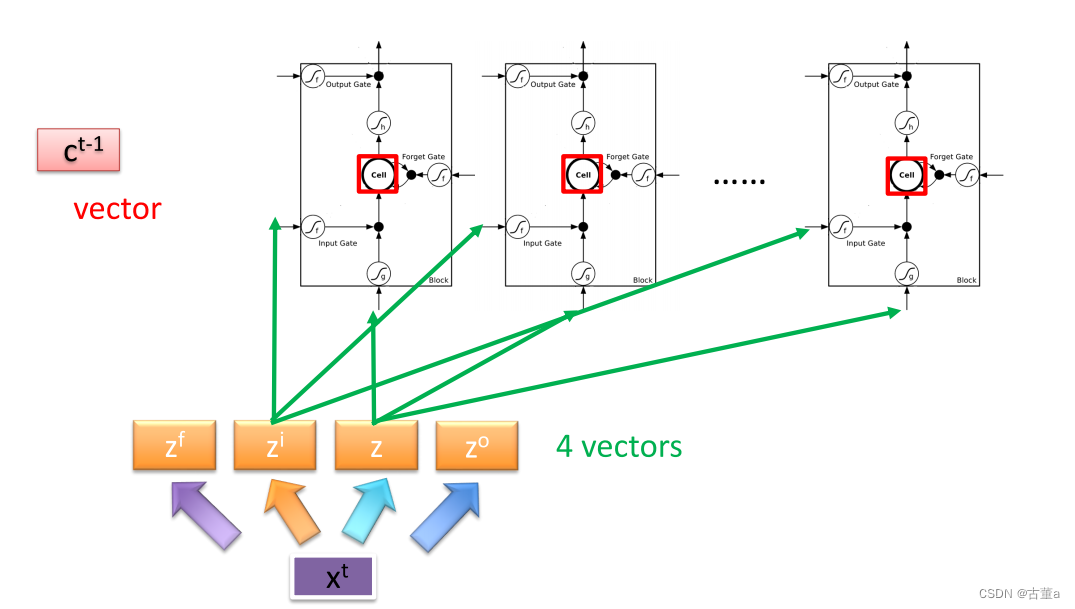
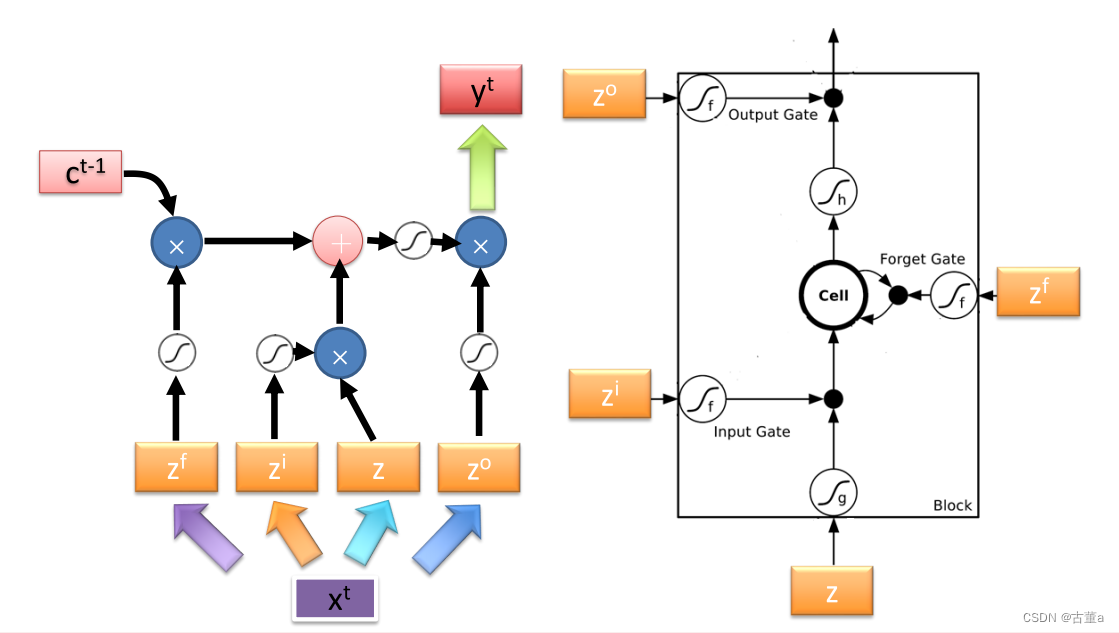
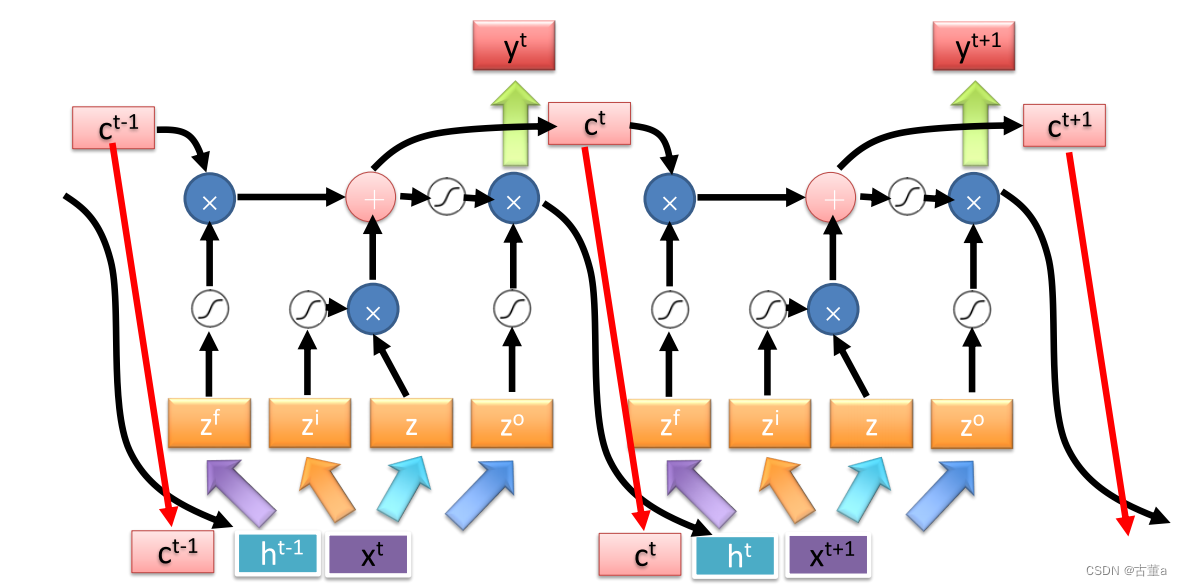
一个标准的多层的LSTM神经网络
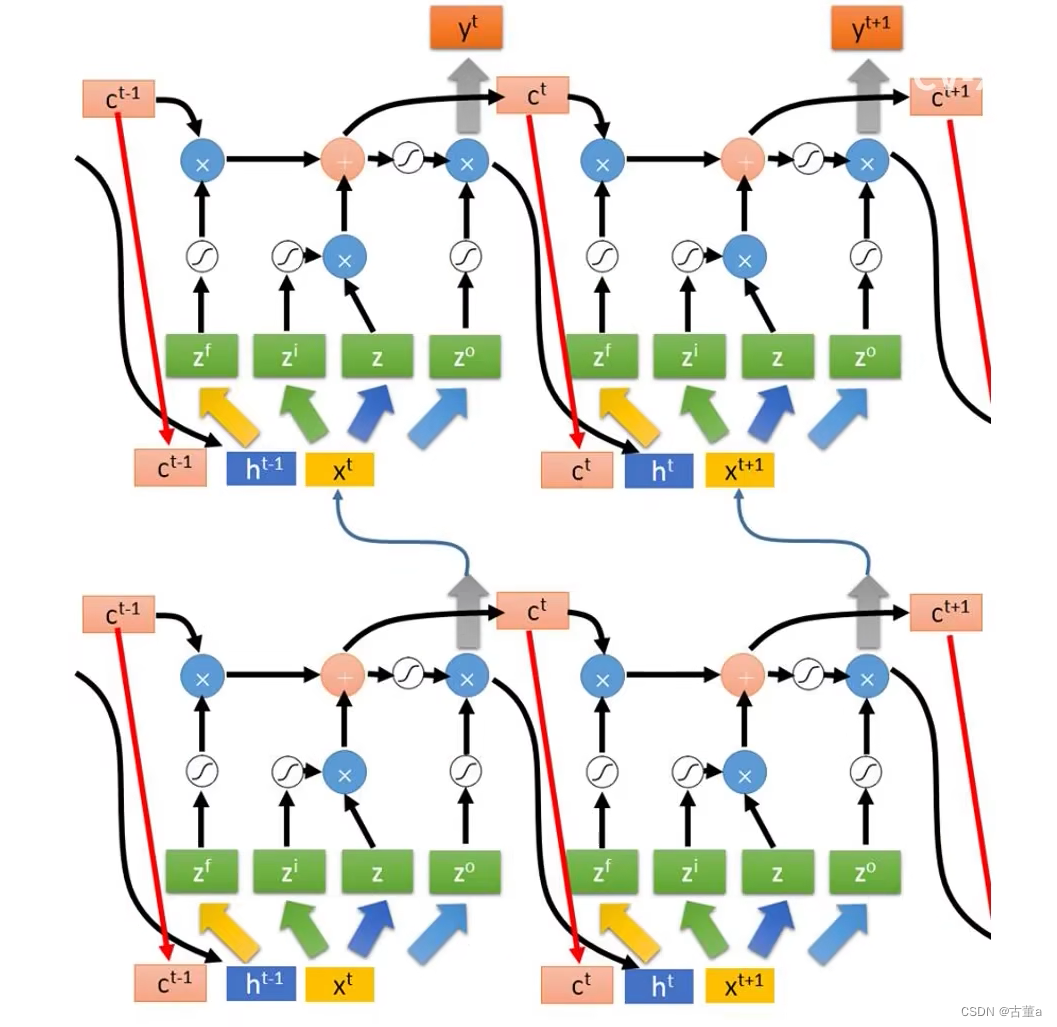
学习目标
对输入的单词进行分类
怎么训练
和普通网络一样,使用反向传播。不过这个反向传播是基于时间的。
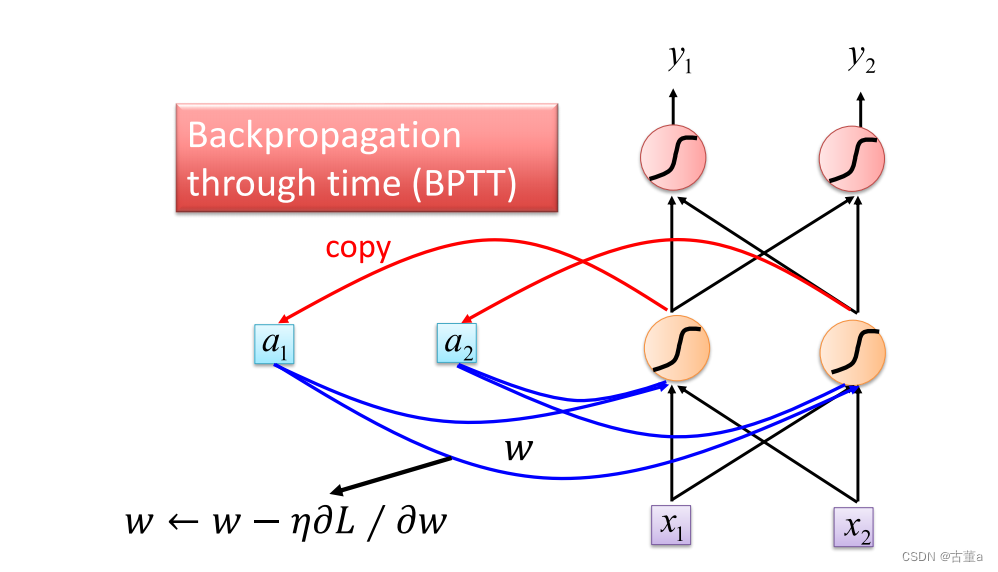
BPTT代表基于时间的反向传播(Backpropagation Through Time)
它是一种用于训练循环神经网络(RNN)的反向传播算法,用于计算和更新网络参数的梯度。
与传统的前向传播和反向传播不同,BPTT需要在时间维度上展开循环神经网络,以便计算梯度。展开过程将RNN展开为一个前馈神经网络,其中每个时间步都被视为网络的一个层。
BPTT的基本步骤如下:
-
前向传播:从网络的初始状态开始,按照时间顺序将输入序列的每个时间步输入到网络中,并计算每个时间步的输出。
-
损失计算:使用网络的输出和预期输出之间的差异来计算损失函数。
-
反向传播:从最后一个时间步开始,根据损失函数计算输出层的梯度,并通过反向传播将梯度传递到前面的时间步。
-
参数更新:根据计算得到的梯度,使用优化算法(如随机梯度下降)来更新网络的参数。
由于BPTT展开了RNN的时间步,反向传播会在每个时间步上进行一次梯度计算,因此在训练过程中,梯度信息会在时间上累积。这也是为什么BPTT在处理长序列时容易遇到梯度消失或梯度爆炸的问题。
基于RNN的神经网络不容易被训练
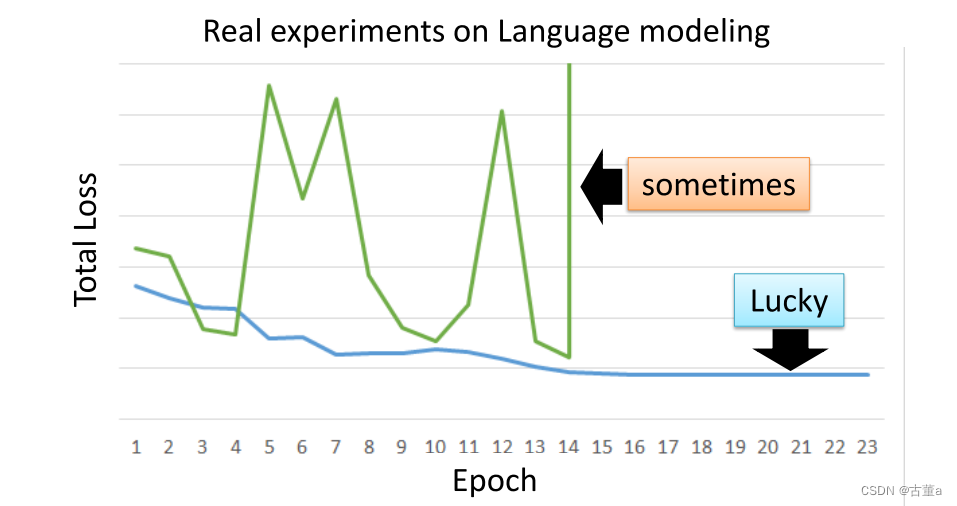
RNN的损失函数的坡面
所以在进行调整的时候,很容出现跳上跳下
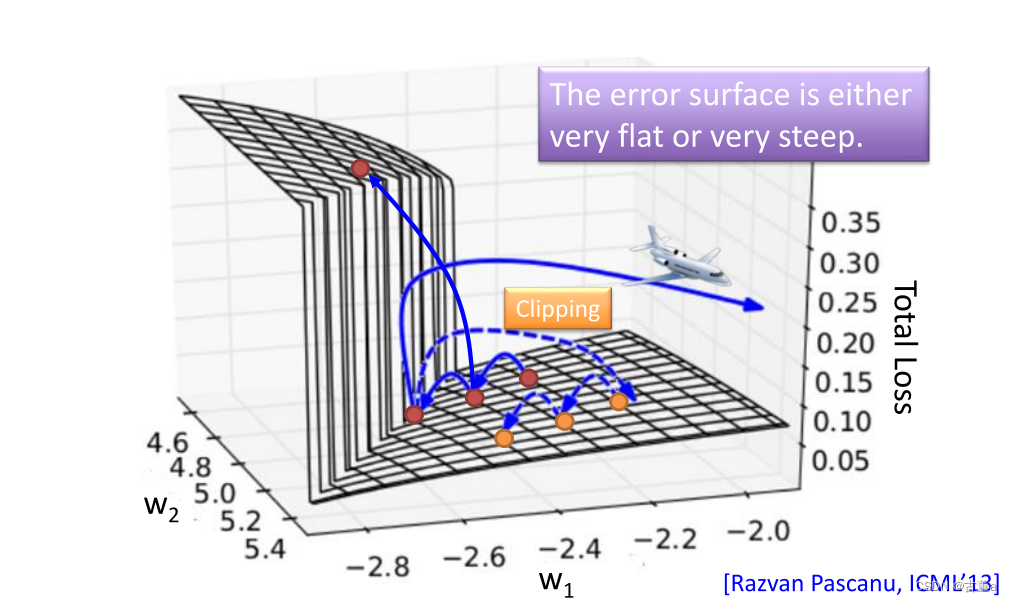
为什么出现这种现象?
从1-1000有1000个时间时刻的输入
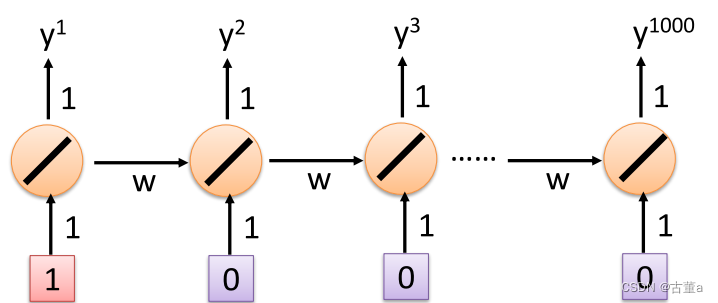
当学习率为1.01,连乘1000后

循环神经网络,为什么会挂,就是因为它的连乘太多,当一直不停的连乘下去,这个权值会非常非常的大。权值的次方数会非常非常的大,我本来目前在的位置,要去优化它。
要么往左走一点,这个权值无穷大
往右走一点,权值又很小
所以我们要做一个裁剪,裁剪完了后把学习率调大点
只要大过我就裁剪 那这样训练起来不会让他能够跑起来
LSTM能够很好的应对
通过引入门控机制来更好地应对梯度爆炸和梯度消失的问题。
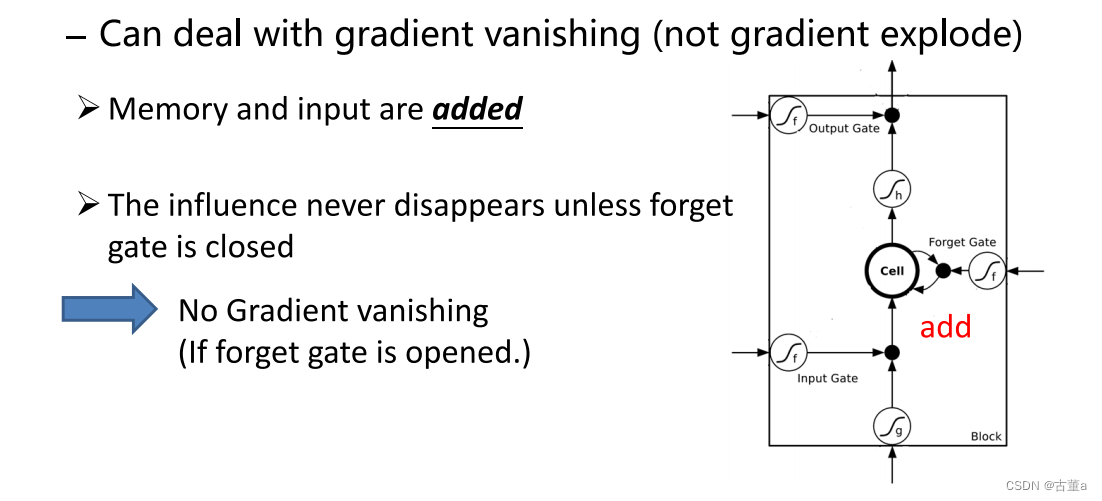
LSTM相对于传统的RNN具有以下特点,使其能够有效地处理梯度问题:
-
长期记忆单元(Cell State):LSTM引入了一个长期记忆单元,它允许网络在一段时间内保留和传递信息,从而减少梯度在时间上的乘积效应。这样,即使梯度消失的情况下,网络也能够在长期记忆单元中存储重要的信息,避免信息的丢失。
-
门控机制:LSTM引入了三个门控单元:输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)。这些门控单元通过使用sigmoid激活函数来控制信息的流动和保留。通过学习门控单元的参数,LSTM可以决定何时更新和遗忘信息,从而更好地控制梯度的传播。
-
前向路径和反向路径:LSTM的结构使得梯度能够沿着前向和反向路径传递。这样,即使在反向传播过程中梯度消失,前向路径上的梯度仍然可以传递信息,避免信息的丢失和梯度的完全消失。
应用
一对一
输入和输出都是长度相同的序列
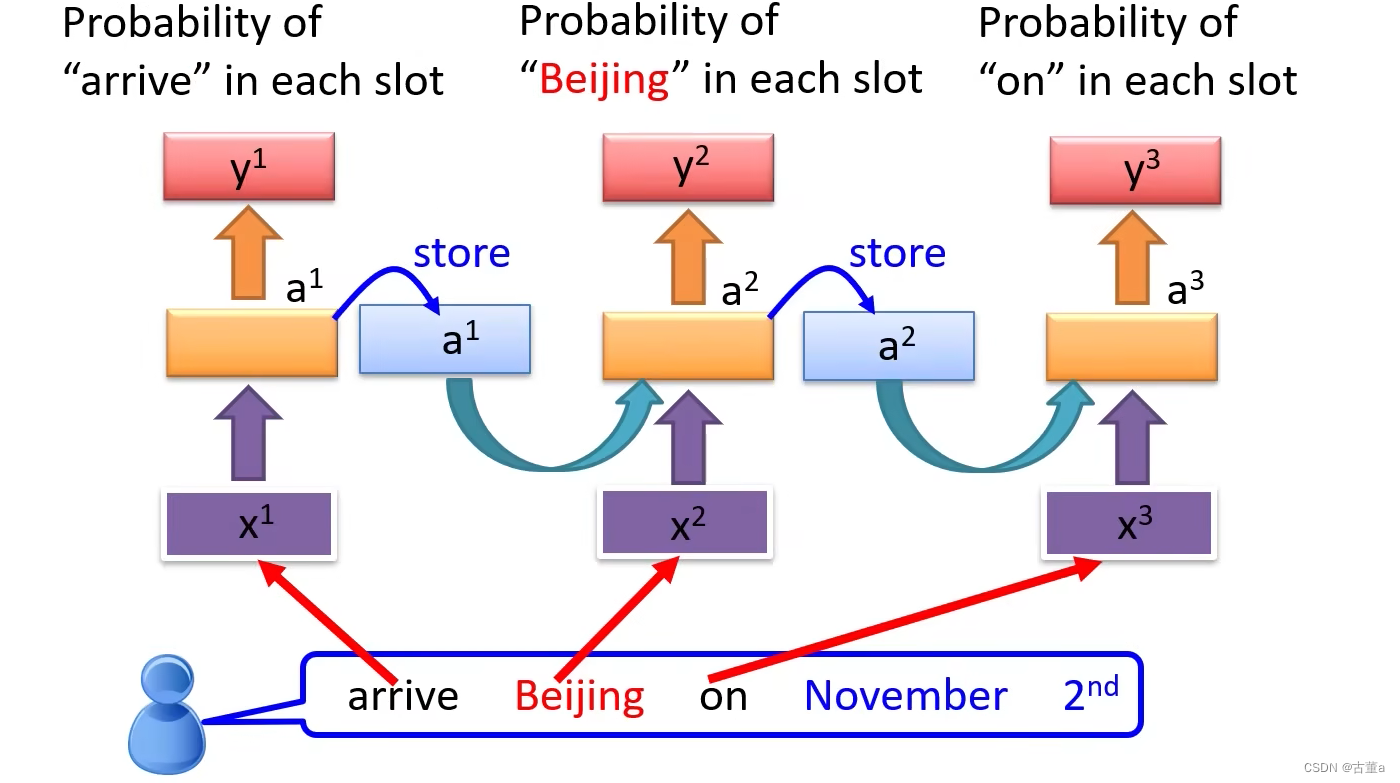
一个输入,一个输出,因为每个输出都要判断它是不是有用的信息,是哪个槽里的信息 。
多对一
输入是一个矢量序列,但输出只有一个矢量
句子的情感分析。比如你给了我一堆句子 我现在要分析这个句子到底是正面还是负面的。
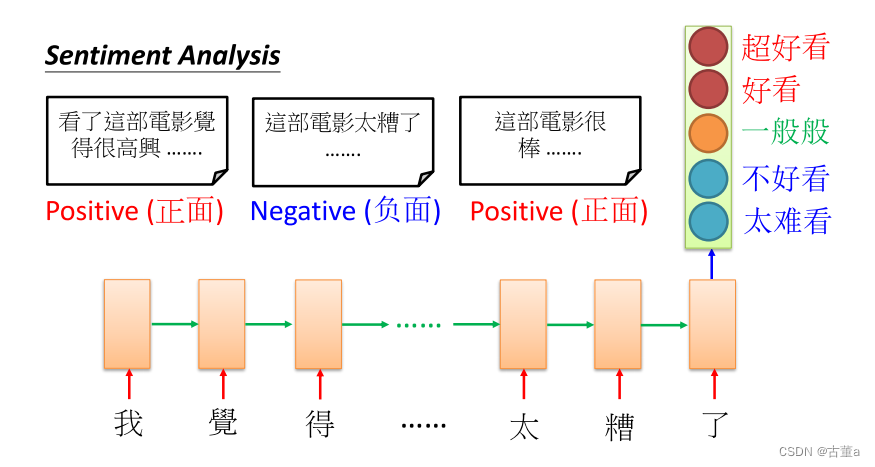
我只关注循环神经网络最后一个单词的信息,因为最后一个单词是把前面单词的信息都看过了,都混合起来的信息去做一个决策,把它分成分五类,去判断这个句子,是认为这篇这个电影好看还是不好看。
多对多
output shorter
输入和输出都是序列,但输出更短
语言识别
等同类别就是输入输出一样,我每个单词都输出,每个时刻我都输出。
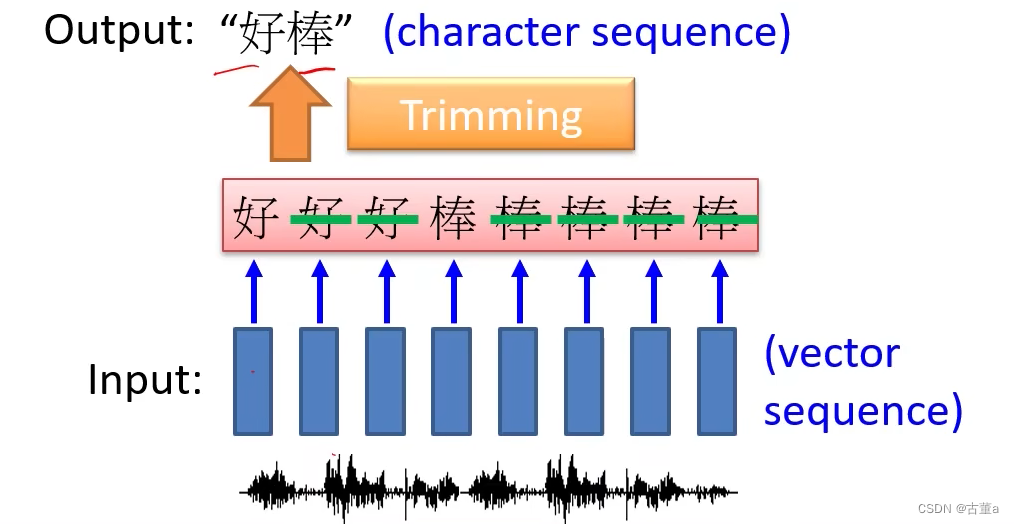
输出成这样,“好好好棒棒棒棒棒”,然后我们做一下剔除。剔除掉就可以得到好棒这个词。
但是这个东西有一种情况你是处理不了,比如“好棒棒”,“亮晶晶”,确确实后面有两个字。
CTC
CTC(Connectionist Temporal Classification)是一种用于序列数据标注和序列转录的方法。CTC的主要目标是学习将输入序列映射到目标序列的对应关系,而不需要对齐它们的具体位置。这使得CTC方法在没有对齐标签的情况下进行序列转录变得可能。
我们引入一个这种无意义的字符,它也当一个单词,我也给他一个编码,这个编码的意思就是结束了。
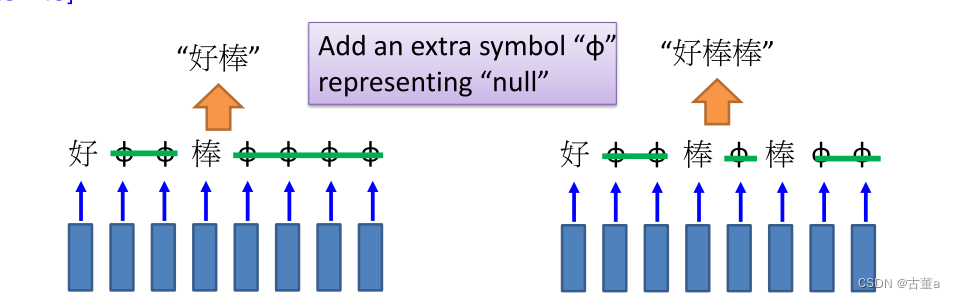
CTC:Training
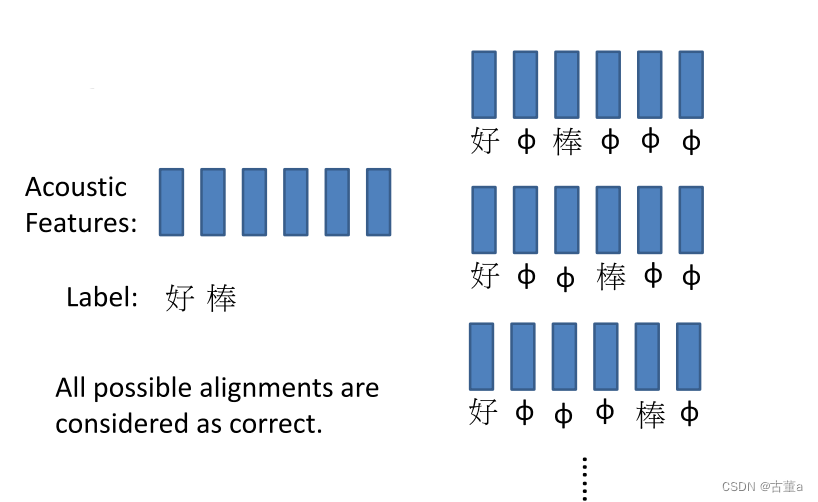
我用一种初举的方法,“好棒”可能是这样的,也可能是这样的。把所有的可能都穷举一下,这些都,拿进去训练,预算是哪一类我都是算对,这样就解决了训练问题,也不用人为的去对齐这个里面跟这个里面的。
No Limitation
输入和输出都是具有不同长度的序列。是序列到序列学习。
机器翻译
用最后一个信息去预测下一个词,当然,最后一个信息希望是编码了所有信息的内容
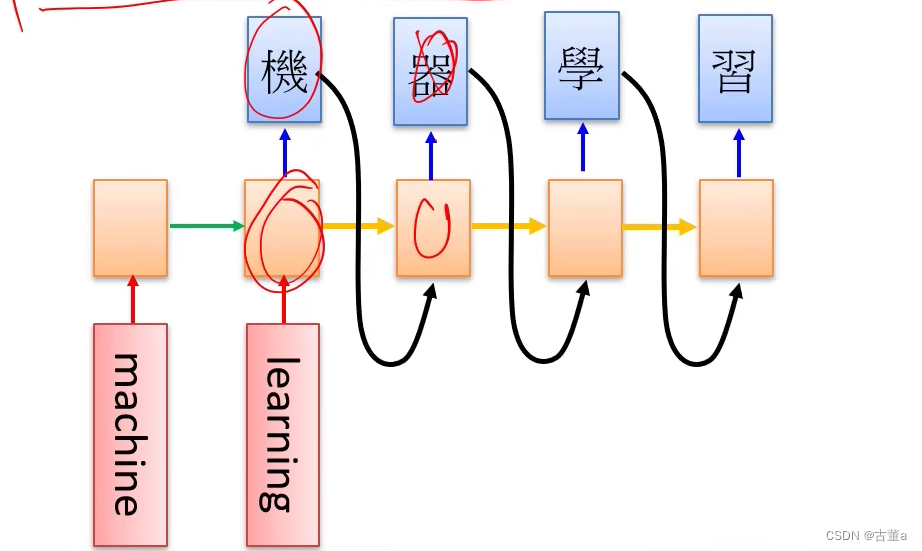
理论上最后一个信息是编码了前面的内容,就是这样的一个结果
这里面还有个问题就是,那你这样学习的时候 什么时候结束呢?
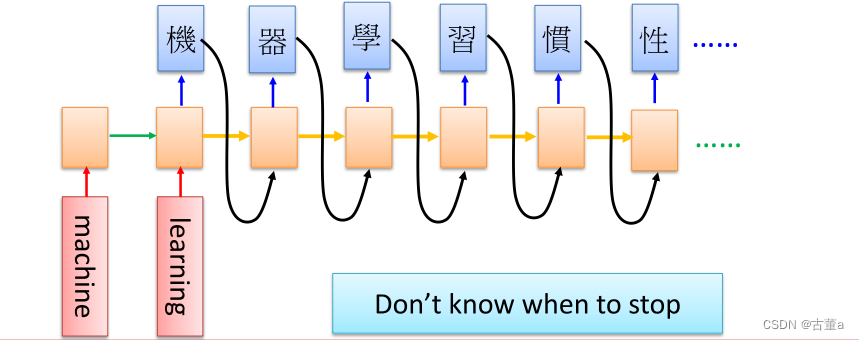
所以这不是我们需要的,我们预测的时候还希望有一个结束,刚才在我们的学了一个占位符是占位,现在需要需要有个结束符。
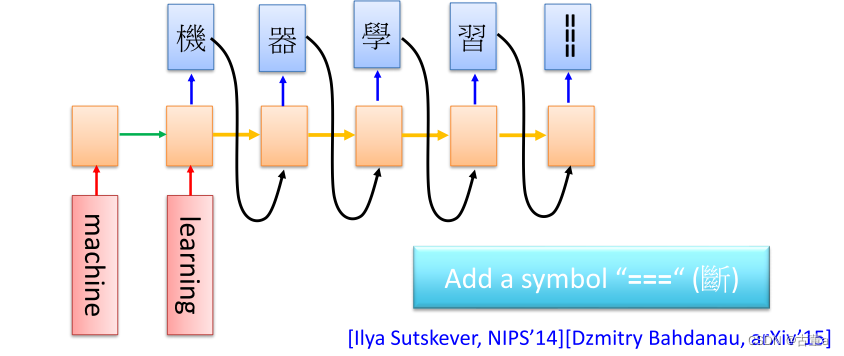
所以在我们真实用的时候,我们会加一个断的结束,当我预测到结束符的时候,我就把前面的字处理出来后面就不再不断了。
这个神经神经网络的训练要先训练“machine”,再训练“learning”,得到这个以后再一个字一个字的翻译这个。这是一个时序的翻译过程,对这个过程是非常慢的。
后面的transformer,主要针对这个问题,就是针对时序问题太慢的问题。transformer可以一次并行做。
语言翻译语言&语音翻译语音
存在的问题
编码有效性
LSTM 的编码有效性指的是它如何捕捉和表示输入序列中的关键信息。尽管 LSTM 的设计旨在解决传统 RNN 中的梯度消失和梯度爆炸问题,但在处理非常长的序列时,LSTM 仍然可能难以有效地捕捉长期依赖关系。这可能导致模型对于先前的输入信息过于依赖,而无法有效地利用更远处的上下文。
比如在翻译“机器学习”的时候,会将所有的字都进行编码,但是在翻译的时候,比如翻译“machine”的时候,只有机器两个的字的编码对翻译是有用的。我们此时用不到学习这两个字的编码。
训练效率
LSTM 的训练效率问题主要涉及其在大规模数据集上的训练时间和计算成本。由于 LSTM 是一种顺序模型,它需要按照序列的顺序逐步计算和更新隐藏状态。这导致 LSTM 的训练速度相对较慢,并且在处理长序列时尤为明显。此外,LSTM 的参数量通常较大,这也增加了训练过程的计算成本。
训练过程中,一个单词一个单词顺序生成的。后面单词的生成依赖于之前单词的生成。
门控循环单元(Gated Recurrent Unit,GRU)
是另一种常用的循环神经网络(RNN)变体,类似于长短期记忆(LSTM),也具有门控机制来解决梯度爆炸和梯度消失的问题。
GRU相对于LSTM具有更简化的结构,同时保持了类似的门控机制。
它包含了以下要素:
-
更新门(Update Gate):决定应该更新多少来自前一时刻的隐藏状态信息。更新门的值范围在0到1之间,0表示完全忽略过去的信息,1表示完全保留过去的信息。
-
重置门(Reset Gate):决定应该忽略多少来自前一时刻的隐藏状态信息。重置门的值范围在0到1之间,0表示完全忽略过去的信息,1表示完全保留过去的信息。
-
候选隐藏状态(Candidate Hidden State):通过结合重置门和当前输入,计算出一个候选隐藏状态。该候选隐藏状态考虑了当前输入和过去隐藏状态的相关性。
-
隐藏状态(Hidden State):根据更新门、候选隐藏状态和前一时刻的隐藏状态,计算出当前的隐藏状态。这个隐藏状态将被传递到下一时刻,并且也可以作为输出。
GRU的门控机制允许它决定如何整合和传递信息,从而有效地解决梯度爆炸和梯度消失的问题。相比于LSTM,GRU的结构更简单,参数更少,计算效率更高,但在某些任务上可能稍微缺乏一些建模能力。
GRU通过引入更新门和重置门,以及候选隐藏状态和隐藏状态的计算,能够控制信息的流动和梯度的传播,从而解决梯度爆炸和梯度消失的问题。它是一种非常流行和有效的RNN变体,在处理序列数据和时间依赖性任务方面得到广泛应用。
相关文章:
计算机视觉与深度学习-循环神经网络与注意力机制-RNN(Recurrent Neural Network)、LSTM-【北邮鲁鹏】
目录 举例应用槽填充(Slot Filling)解决思路方案使用前馈神经网络输入1-of-N encoding(One-hot)(独热编码) 输出 问题 循环神经网络(Recurrent Neural Network,RNN)定义如何工作学习目标深度Elm…...
brew 安装MySQL 5.7
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成…...

【中国知名企业高管团队】系列22:滴滴
大家好! 今天华研荟的走进中国知名企业高管团队系列带大家认识滴滴。 滴滴公司是出行领域的先行者,也是一个典型样本。通过滴滴公司的名字变迁我们可以感受到滴滴公司的业务发展,这也是整个出行行业公司的发展路径: 第一阶段&a…...

Unity之Hololens如何实现3D物体交互
一.前言 什么是Hololens? Hololens是由微软开发的一款混合现实头戴式设备,它将虚拟内容与现实世界相结合,为用户提供了沉浸式的AR体验。Hololens通过内置的传感器和摄像头,能够感知用户的环境,并在用户的视野中显示虚拟对象。这使得用户可以与虚拟内容进行互动,将数字信…...
IDEA Debug技巧大全,看完就能提升工作效率
作者简介 目录 1.行断点 2.方法断点 3.异常断点 4.字段断点 5.条件表达式 1.行断点 行断点就是平时我们在代码行旁边单击鼠标打上的断点,这个没有什么好说的。关键点在于很多人不知道的,行断点其实是可以右击选择是对改行的全部调用都生效…...

蓝桥等考Python组别六级003
第一部分:选择题 1、PythonL6(15分) 运行下面的程序,输出的值最大可能是()。 importrandom print(random.randint(2,4)*5) 10152030正确答案:C 2、PythonL6(15分) 甲、乙、丙三个人赛跑,已知甲不是第一名,乙不是第二名,名次没有并列的。...
机器学习小白理解之一元线性回归
关于机器学习,百度上一搜一大摞,总之各有各的优劣,有的非常专业,有的看的似懂非懂。我作为一名机器学习的门外汉,为了看懂这些公式和名词真的花了不少时间,还因此去着重学了高数。 不过如果不去看公式&…...

目标检测:FROD: Robust Object Detection for Free
论文作者:Muhammad,Awais,Weiming,Zhuang,Lingjuan,Lyu,Sung-Ho,Bae 作者单位:Sony AI; Kyung-Hee University 论文链接:http://arxiv.org/abs/2308.01888v1 内容简介: 1)方向:目标检测 2)…...
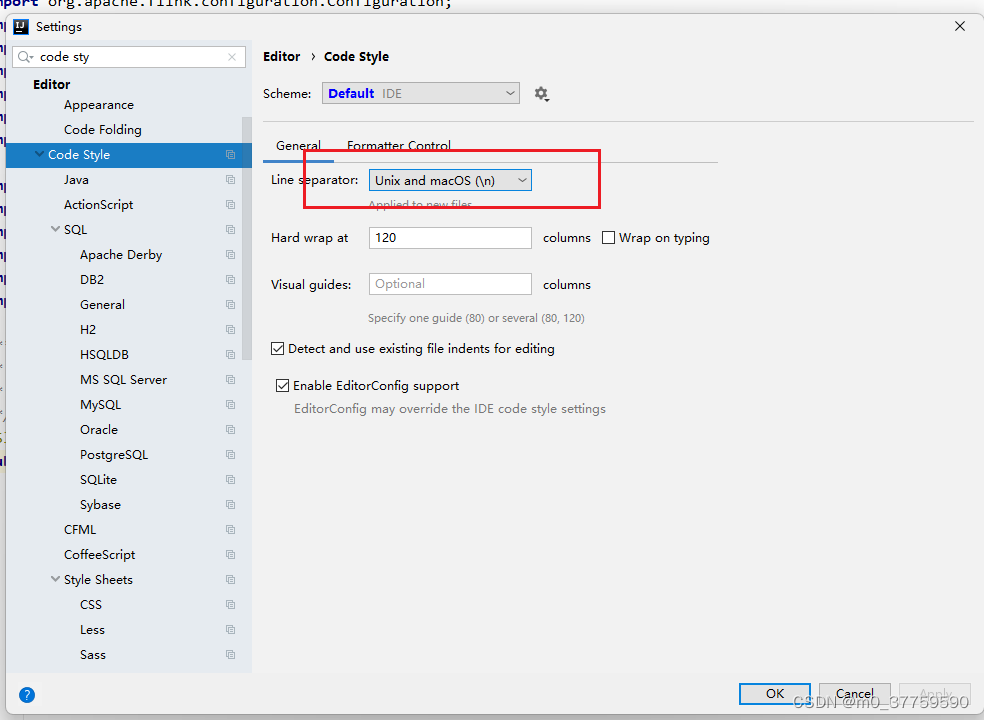
linux 和 windows的換行符不兼容問題
linux 和 windows的換行符: 1.vim 模式下,執行命令: :set ffunix idea中設置code style...
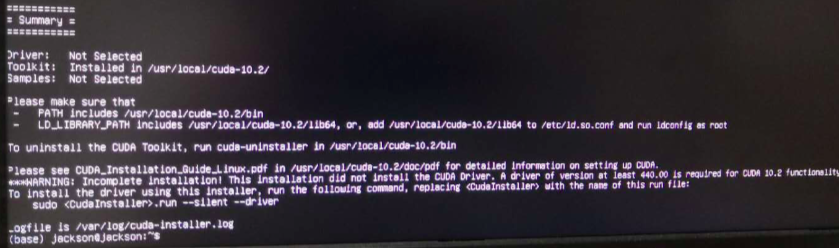
ubuntu 20 安装 CUDA
1. 查看需要安装的cuda版本 nvidia-smi cuda的版本信息如下图所示 2. 去官网下载对应版本的CUDA 官网:CUDA Toolkit Archive | NVIDIA Developer 弹出以下界面,依次点击以下按钮 得到以下内容: 复制下载链接,下载cuda11到本…...

C++友元函数和友元类
友元介绍 类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。 友元可以是一个函数…...
特斯拉——使用人工智能制造智能汽车
特斯拉(Tesla)是电动汽车开发和推广的先驱。特斯拉对自动驾驶汽车的未来寄予厚望--实际上,每一辆特斯拉汽车都有可能通过软件升级成为自动驾驶汽车。该公司还生产和销售高级电池和太阳能电池板。 汽车的自动驾驶是按从1~5的等级划分的。自适应巡航控制和自动停车系…...

如何删除gitlab上多余的文件夹
无意间在提交代码时,包含了多余的 .idea 或者 __pychche__ 缓存文件夹等等,如何一次性删除呢? 实际上没有更好的办法,如果还没有合并,close 掉 MR就行了,重新提交。 如果已经合并了,就会留下记…...

computed和methods有什么区别
面试题:computed和methods有什么区别 标准而浅显的回答 在使用时,computed当做属性使用,而methods则当做方法调用computed可以具有getter和setter,因此可以赋值,而methods不行computed无法接收多个参数,而m…...
、聚集索引、二级索引(索引篇 二))
MySQL索引分类和操作(增删查)、聚集索引、二级索引(索引篇 二)
具体类型索引分类 分类主要作用特点主键索引(primary)针对于表中主键创建的索引默认自动创建, 只能有一个唯一索引(unique)避免同一个表中某数据列中的值重可以有多个常规索引最基本类型,可以加快查询速度可以有多个全文索引(fulltext)查找的是文本中的关键词&…...
(三)Python变量类型和运算符
所有的编程语言都支持变量,Python 也不例外。变量是编程的起点,程序需要将数据存储到变量中。 变量在 Python 内部是有类型的,比如 int、float 等,但是我们在编程时无需关注变量类型,所有的变量都无需提前声明&#x…...

vue三种import导入方式详解?
在Vue.js中,你可以使用三种不同的方式来导入模块或组件: 默认导入 (Default Import): 这种方式用于导入一个模块的默认导出(通常是一个组件或一个对象)。例如: import MyComponent from ./MyComponent.vue;…...

深入理解数据库视图
在数据库管理中,视图(View)是一种强大但常常被忽视的功能。它不仅可以简化复杂的查询操作,还可以提供更高层次的数据抽象和保护。 本文将详细解析视图的各个方面,并以《三国志》游戏的数据为例,给出实际应用场景。 文章目录 什么是视图?基本结构创建视图查看视图的定义…...
方法的作用~)
Java中@before和setup()方法的作用~
在Java中,setup()和Before同时使用的作用是在测试方法之前执行一些准备工作, setup()是JUnit中的一个方法,它通常被用来初始化测试对象和设置测试环境,它会在每个测试方法执行之前被调用,并且可以在多个测试方法中共享…...
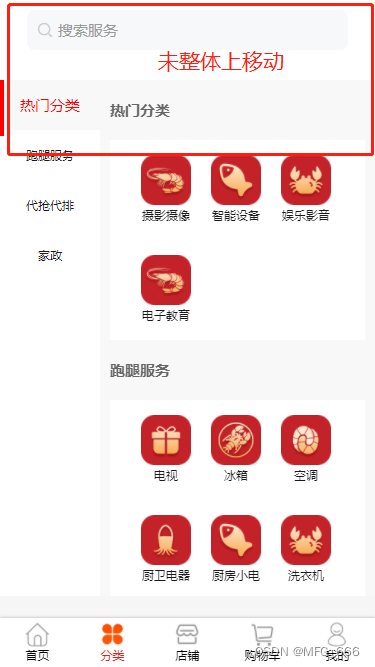
前端uniapp防止页面整体滑动页面顶部以上,设置固定想要固定区域宽高
解决:设置固定想要固定区域宽高 目录 未改前图未改样式改后图改后样式 未改前图 未改样式 .main {display: flex;flex-direction: row;// justify-content: space-between;width: 100vw;// 防止全部移动到上面位置!!!!…...
流水线搭建)
乙巳马年·皇城大门春联生成终端W持续集成与交付(CI/CD)流水线搭建
乙巳马年皇城大门春联生成终端W持续集成与交付(CI/CD)流水线搭建 你是不是也遇到过这样的场景?每次给“乙巳马年皇城大门春联生成终端W”这个微服务应用更新代码,都得手动登录服务器,执行一堆命令:拉代码、…...

Cadence实战:从原理图到PCB的高效转换技巧
1. 从原理图到PCB的高效转换流程 在硬件设计领域,Cadence作为行业标杆工具链,其原理图到PCB的转换效率直接影响项目进度。以常见的IMU传感器MPU6050为例,完整的转换流程包含封装命名、网表生成、PCB初始化三大关键阶段。 首先在原理图编辑器中…...

3个PPTist隐藏功能技巧:让你的在线演示效率翻倍
3个PPTist隐藏功能技巧:让你的在线演示效率翻倍 【免费下载链接】PPTist 基于 Vue3.x TypeScript 的在线演示文稿(幻灯片)应用,还原了大部分 Office PowerPoint 常用功能,实现在线PPT的编辑、演示。支持导出PPT文件。…...
:让AI像团队一样同时思考)
《智能体设计模式》第三章精读 | 并行化模式(Parallelization Pattern):让AI像团队一样同时思考
“AI不是一个超人,而是一支团队。 真正的智能,不在于速度,而在于协作。” ——Antonio Gulli,《智能体设计模式》 🧭 一、回顾:从“结构思考”到“判断分派” 在前两章中,我们为AI系统建立了“…...

查看当前 top activity,通过apk查包名,异常黄金日志
查看当前activityadb shell dumpsys window | grep mCurrentFocus 查看包名aapt dump badging debugmmi.apk | grep package \r黄金关键日志adb logcat|grep "AndroidRuntime" \r...

espeak-ng语音合成终极指南:快速掌握127种语言免费TTS技术
espeak-ng语音合成终极指南:快速掌握127种语言免费TTS技术 【免费下载链接】espeak-ng espeak-ng: 是一个文本到语音的合成器,支持多种语言和口音,适用于Linux、Windows、Android等操作系统。 项目地址: https://gitcode.com/GitHub_Trendi…...

Win11Debloat:Windows系统深度优化与隐私保护终极指南
Win11Debloat:Windows系统深度优化与隐私保护终极指南 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改以简化和改…...

2025年AI视频生成工具大比拼:5款免费神器与谷歌VEO 2的终极对决
1. 2025年AI视频生成工具现状与竞争格局 2025年的AI视频生成领域已经进入白热化阶段,各种工具层出不穷,功能也越来越强大。作为一个长期关注这个领域的技术爱好者,我亲眼见证了从最初的简单动画生成到如今近乎电影级质量的视频创作。现在的AI…...

【自动化测试】MeterSphere接口测试实战:从环境配置到用例设计
1. MeterSphere接口测试入门指南 第一次接触MeterSphere时,我和很多测试新人一样感到无从下手。这个开源测试平台功能强大但界面友好,特别适合中小团队快速搭建自动化测试体系。接口测试作为现代软件测试的核心环节,通过MeterSphere可以轻松实…...

海思平台MLSC标定实战:从网格原理到暗角消除的完整指南
1. MLSC标定基础与核心原理 第一次接触海思平台的MLSC标定时,我和大多数工程师一样被那些专业术语搞得一头雾水。简单来说,MLSC(Mesh Lens Shading Correction)就是通过网格化的方式校正镜头产生的暗角和色彩不均匀问题。想象一下…...