LeetCodeHOT100热题02
写在前面
- 主要是题目太多,所以和前面的分开来记录。
- 有很多思路的图都来源于力扣的题解,如侵权会及时删除。
- 不过代码都是个人实现的,所以有一些值得记录的理解。
- 之前的算法系列参看:
- 剑指offer算法题01
- 剑指offer算法题02
七、动态规划
1. 最长回文子串
- 题目:https://leetcode.cn/problems/longest-palindromic-substring/
-
思路:

-
由于可以用
dp[i+1][j-1]推出到dp[i][j],故只能从左下到右上遍历; -
由于
i<=j,因此dp矩阵为上三角矩阵; -
代码:
class Solution {
public:/*dp[i][j]的含义为:子串[i:j]是回文子串dp[i][j] = true, if s[i]==s[j] && dp[i+1][j-1]==true && i+1<=j-1= true, if s[i]==s[j] && i+1==j= false, elsedp[i][i] = 100 01 02 03 ... 0n11 12 13 ... 1n22 23 ... 2n...nn从dp[i+1][j-1]到dp[i][j]是向右上方走,故dp的顺序是从下往上,从左边到右边*/string longestPalindrome(string s) {int n = s.length() - 1;vector<vector<bool>> dp(n + 1, vector<bool>(n + 1, false));int re_i, re_j; // 记录最长回文子串左右两个指针int re_len = 0; // 记录最长回文子串的长度for(int i=n;i>=0;--i) {for(int j=i;j<=n;++j) {if(i == j) {// 一个字符的子串dp[i][j] = true; }else {if(i == j - 1) {// 两个字符的子串 if(s[i] == s[j]) {dp[i][j] = true;}else {dp[i][j] = false;}}else {// 大于两个字符的子串if(dp[i+1][j-1] && s[i]==s[j]) {dp[i][j] = true;}else {dp[i][j] = false;}}}if(dp[i][j]) {// [i:j]是回文子串,则尝试更新最长回文子串if(j - i + 1 > re_len) {re_i = i;re_j = j;re_len = j - i + 1;}}}}return s.substr(re_i, re_len);}
};
补充:关于bool类型的%d输出值
- 如上代码,dp矩阵为bool类型;
- 输出时,若是如下printf,则均输出一个非0整数,无论是为true还是为false:
printf("%d", dp[i][j]); // 是一个非0整数
printf("%d", int(dp[i][j])); // 是一个非0整数
- 如要输出0/1,则应该如下printf:
printf("%d", dp[i][j] == true); // 若dp[i][j] = true为1
- 只有以下printf为1,也就是说,1对应true,0对应false:
printf("%d", 1 == true); // 是1
printf("%d", 0 == false); // 是1
- true是1,false是0:
printf("%d", true); // 是1
printf("%d", false); // 是0
- 综上,为了稳妥起见,无论是在c还是c++中都还是直接使用int类型代替bool类型比较好;
- 如果真的要使用bool类型,则输出时需要和true和false类型比较,而不要直接输出;
变体1. 回文子串
- 题目:https://leetcode.cn/problems/palindromic-substrings/
- 思路:
- 用动态规划的思路和最长回文子串的思路相同,只不过统计量不同,这里是统计
dp[i][j]==1的个数而不是统计j-i+1的最大值; - 一些动态规划的推导在下面代码的注释部分;
- 另外还有一种Manacher算法,时间复杂度降至O(N),空间复杂度降至O(1),但指针的计算和移动很麻烦,我没有复现成功>﹏<,原理参看博客:Manacher算法,说得很明白了;
- 代码:
class Solution {
public:/*动态规划:dp[i][j]:s[i:j]是否是回文子串dp[i][j] = dp[i+1][j-1] && s[i]==s[j] if i+1<=j-1= s[i]==s[j] otherwisedp[i][i] = 1;*/int countSubstrings(string s) {int n = s.length();vector<vector<int>> dp(n, vector<int>(n, 0));int re_sum = 0;for(int i=n-1;i>=0;--i) {for(int j=i;j<n;++j) {if(i == j) {dp[i][j] = 1;++re_sum;}else {if(i+1 <= j-1) {if(dp[i+1][j-1] && s[i] == s[j]) {dp[i][j] = 1;++re_sum;}}else {if(s[i] == s[j]) {dp[i][j] = 1;++re_sum;}}}}}return re_sum;}
};
2. 最长有效括号
- 题目:https://leetcode.cn/problems/longest-valid-parentheses/
-
思路:
-
(1) 动态规划思路如下:

-
针对以第i个字符结尾的最长子串长度进行动态规划;
-
如果最后两个字符是
(),则在dp[i-2]的基础上直接加上2,也就是()的长度即可; -
如果最后两个字符是
)),也就是需要看是否有和最后一个)对应的(,也就是第i-1 -dp[i-1]个字符是否为(;- 如果是的话,则长度是完整的
))所对应子串长度dp[i-1] + 2,再加上完整的))之前的最长子串长度dp[i-1 -dp[i-1] -1],相当于是拼接了两个子串; - 如果不是的话,则这个子串不合规,
dp[i]=0;
- 如果是的话,则长度是完整的
-
当然还要注意往前查找的时候,计算出的数组下标是否越界(小于0);
-
另外需要额外记录最大值,因为dp数组的含义不是问题所求的解;
-
空间复杂度是O(N),时间复杂度是O(N);
-
(2) 也可以使用左右括号的计数器来处理,是类似于双指针的思路:

-
当左右括号的计数相同时,子串有效;
-
当右括号数量大于左括号数量时,子串失效,所有的计数归零,然后左指针要指向右指针同步;
-
然而这样遍历一次是不能统计出
((()里面的()的,因此还要倒序再遍历一次; -
仍然是左右括号计数相同时,子串有效;
-
当左括号数量大于右括号数量时,子串失效,所有的计数归零,然后右指针要指向左指针同步;
-
这样遍历一次不能统计出
()))中的(),但这种情况已经在上面的从左到右遍历中统计过了; -
注意滞后的指针如果是初始时指向后一位可以方便一点,虽然这一位可能已经超出字符串范围了;
-
虽然两次遍历有统计上的重复,但由于是找最大值,所以无妨;
-
空间复杂度是O(1),时间复杂度是O(2N);
-
推荐还是用动态规划来写,比较优雅一点( ̄︶ ̄)↗;
-
代码:
-
(1) 动态规划:
class Solution {
public:/*dp[i]:以第i个字符结尾的最长子串长度// ()()((1) s[i] = '(', 则dp[i] = 0// ()()(2) s[i] = ')' && s[i-1] = '(', dp[i] = dp[i-2] + 2// )((()()) 7 - 1 - 4 - 1s[i] = ')' && s[i-1] = ')' && dp[i-1 -dp[i-1]] = '(', dp[i] = dp[i-1 -dp[i-1] -1] + dp[i-1] + 2*/int longestValidParentheses(string s) {vector<int> dp(s.length(), 0);int re_max = 0;for(int i=1;i<s.length();++i) {if(s[i] == '(') {dp[i] = 0;}else {if(s[i-1] == '(') {if(i-2 >= 0) {dp[i] = dp[i-2] + 2;}else {dp[i] = 2;} }else {// 定位当前)对应的(的位置并检验是否为(int leftParIndex = i - 1 - dp[i-1];if(leftParIndex>=0 && s[leftParIndex] == '(') {if(leftParIndex-1 >= 0) {// 左括号左边还有字符串,// dp[leftParIndex-1]: 0 -> )(// dp[i-1]: 4 -> ()()dp[i] = dp[leftParIndex-1] + dp[i-1] + 2;}else {// 左括号左边没有字符串dp[i] = dp[i-1] + 2;}}else {dp[i] = 0;}}}// 记录最大值if(re_max < dp[i]) {re_max = dp[i];}}return re_max;}
};
- (2) 类双指针:
class Solution {
public:int longestValidParentheses(string s) {int re_max = 0;// 从左往右遍历int leftParNum = 0, rightParNum = 0;int i = s.length() - 1, j = s.length();while(i >= 0) {if(s[i] == '(') {++leftParNum;}if(s[i] == ')') {++rightParNum;}if(leftParNum == rightParNum) {int subLen = j - i;if(re_max < subLen) {re_max = subLen;}}if(leftParNum > rightParNum) {// 则右边不可能配对了j = i;leftParNum = 0;rightParNum = 0;}--i;}// 从右往左遍历leftParNum = 0, rightParNum = 0;i = 0, j = -1;while(i < s.length()) {if(s[i] == '(') {++leftParNum;}if(s[i] == ')') {++rightParNum;}if(leftParNum == rightParNum) {int subLen = i - j;if(re_max < subLen) {re_max = subLen;}}if(leftParNum < rightParNum) {// 则左边不可能配对了j = i;leftParNum = 0;rightParNum = 0;}++i;}return re_max;}
};
[3]. 最大子数组和
- 题目:https://leetcode.cn/problems/maximum-subarray/

- 思路:
- 比较容易是用动态规划来做;
- 和剑指offer算法题02的七、3. 连续子数组的最大和同题;

- 代码:
class Solution {
public:/*dp[i]: 以第i个元素结尾的最大子数组和dp[i] = max{dp[i-1]+nums[i], nums[i]}另外要用一个变量存储最大值*/int maxSubArray(vector<int>& nums) {vector<int> dp(nums.size(), 0);dp[0] = nums[0];int re_max = dp[0];for(int i=1;i<nums.size();++i) {if(dp[i-1] <= 0) {dp[i] = nums[i];}else {dp[i] = dp[i-1] + nums[i];}if(dp[i] > re_max) {re_max = dp[i];}}return re_max;}
};
4. 不同路径 [向右向下棋盘]
- 题目:https://leetcode.cn/problems/unique-paths/
- 思路:

-
如果使用深度遍历搜索,时间复杂度是O(2MN)O(2^{MN})O(2MN),远超动态规划的O(MN)O(MN)O(MN);
-
和剑指offer算法题02中的七、6. 礼物的最大价值十分类似,但比它简单一点;
-
也可以用组合数学一步直接计算到位,如下:

-
代码:
-
动态规划代码如下:
class Solution {
public:// dp[i][j]: 走到[i][j]有多少种可能// dp[i][j] = dp[i-1][j] + dp[i][j-1]// dp[0][j] = 1; 第一行为1// dp[i][0] = 1; 第一列为1int uniquePaths(int m, int n) {vector<vector<int>> dp(m, vector<int>(n, 1));for(int i=1;i<m;++i) {for(int j=1;j<n;++j) {dp[i][j] = dp[i-1][j] + dp[i][j-1];}}return dp[m-1][n-1];}
};
[5]. 最小路径和 [向右向下棋盘]
- 题目:https://leetcode.cn/problems/minimum-path-sum/

- 思路:

- 和剑指offer算法题02中的七、6. 礼物的最大价值几乎同题;
- 和上题的思路一脉相承;
- 代码:
class Solution {
public:// dp[i][j]: 到达[i][j]时的最小路径和// dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j];int minPathSum(vector<vector<int>>& grid) {int m = grid.size();int n = grid[0].size();vector<vector<int>> dp(m, vector<int>(n, 0));for(int i=0;i<m;++i) {for(int j=0;j<n;++j) {if(i==0 && j==0) {// 原点dp[i][j] = grid[i][j];}if(i==0 && j!=0) {// 第一行dp[i][j] = dp[i][j-1] + grid[i][j];}if(i!=0 && j==0) {// 第一列dp[i][j] = dp[i-1][j] + grid[i][j];}if(i!=0 && j!=0) {dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j];}}}return dp[m-1][n-1];}
};
[6]. 爬楼梯
- 题目:https://leetcode.cn/problems/climbing-stairs/

- 思路:
- 和剑指offer算法题02中的七、2. 青蛙跳台阶问题同题;
- 代码:
class Solution {
public:// dp[i]: 到第i阶楼梯有多少种方式// dp[i] = dp[i-1] + dp[i-2]// dp[0] = 1; dp[1] = 1;int climbStairs(int n) {vector<int> dp(n+1, 0);dp[0] = 1;dp[1] = 1;for(int i=2;i<=n;++i) {dp[i] = dp[i-1] + dp[i-2];}return dp[n];}
};
7. 编辑距离
- 题目:https://leetcode.cn/problems/edit-distance/submissions/
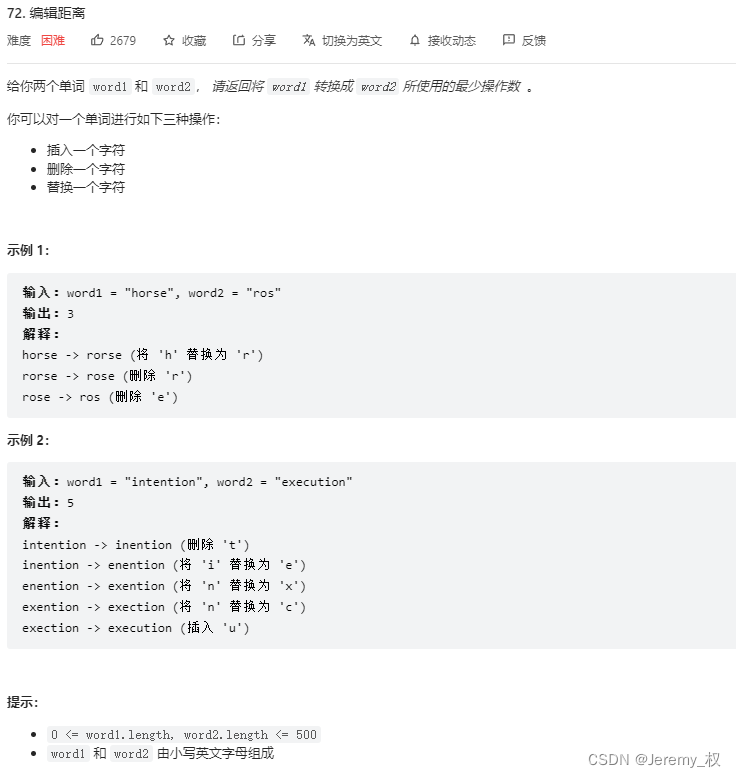
- 思路:

- dp递推公式如下:
dp[i][j]={min{dp[i−1][j]+1,dp[i][j−1]+1,dp[i−1][j−1]},若word1[i]==word2[j]min{dp[i−1][j]+1,dp[i][j−1]+1,dp[i−1][j−1]+1},若word1[i]!=word2[j]dp[i][j]=\left\{ \begin{aligned} min\{dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1]\}, & 若 word1[i] == word2[j] \\ min\{dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1]+1\} , &若word1[i] != word2[j] \end{aligned} \right. dp[i][j]={min{dp[i−1][j]+1,dp[i][j−1]+1,dp[i−1][j−1]},min{dp[i−1][j]+1,dp[i][j−1]+1,dp[i−1][j−1]+1},若word1[i]==word2[j]若word1[i]!=word2[j]
-
dp[i][j]的含义:- 长度是
i的word1和长度是j的word2之间的编辑距离;
- 长度是
-
如果
word1[i] == word2[j]:dp[i-1][j] + 1:在长度是i-1的word1上再增加一个字符;dp[i][j-1] + 1:在长度是j-1的word2上再增加一个字符;- 因为
dp[i-1][j]和dp[i][j-1]与dp[i][j]都只相差了一个字符,所以使两个字符串相同是一定要再增加一个字符的; dp[i-1][j-1]:直接用dp[i-1][j-1]的编辑距离;- 因为两个字符串最后一位字符相等,所以最后一位都增加不需要增加编辑距离;
-
如果
word1[i] != word2[j]:- 基本同上;
- 但
dp[i-1][j-1]+1:两个字符串都再增加一个字符,这样编辑距离也是+1; - 因为两个字符串最后一位字符不相等,所以最后一位都增加后是一定要进行修改的;
-
代码:
class Solution {
public:// dp[i][j]: 长度i的word1和长度j的word2之间的编辑距离// dp[i][j] = min{dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1]} 若word1[i] == word2[j]// = min{dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1]} 若word1[i] != word2[j]// dp[0][0] = 0, dp[0][j] = j, dp[i][0] = iint minDistance(string word1, string word2) {int m = word1.length();int n = word2.length();vector<vector<int>> dp(m+1, vector<int>(n+1, 0));for(int i=0;i<=m;++i) {dp[i][0] = i;}for(int j=0;j<=n;j++) {dp[0][j] = j;}for(int i=1;i<=m;++i) {for(int j=1;j<=n;++j) {if(word1[i-1] == word2[j-1]) {dp[i][j] = min(dp[i-1][j]+1, dp[i][j-1]+1);dp[i][j] = min(dp[i][j], dp[i-1][j-1]);}else {dp[i][j] = min(dp[i-1][j]+1, dp[i][j-1]+1);dp[i][j] = min(dp[i][j], dp[i-1][j-1]+1);}}}return dp[m][n];}
};
8. 不同的二叉搜索树
- 题目:https://leetcode.cn/problems/unique-binary-search-trees/
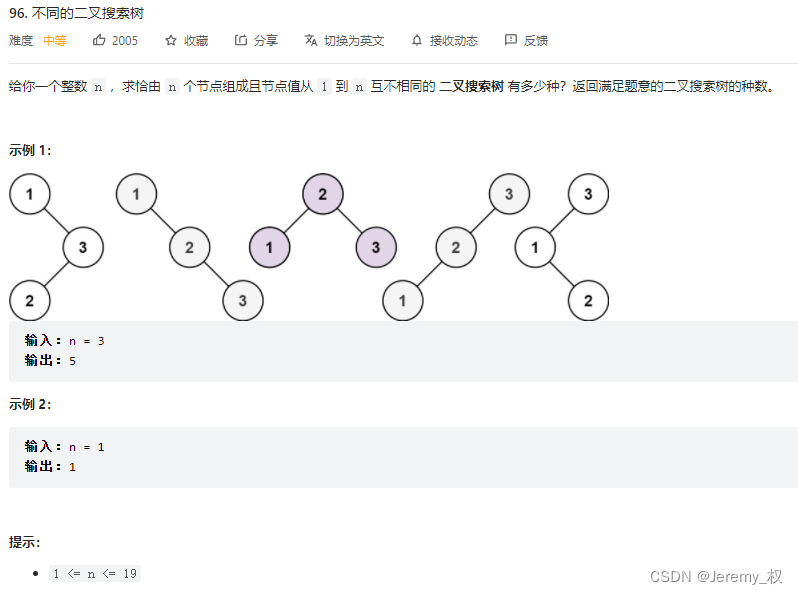
- 思路:

-
相当于是问二叉搜索树(或者说是二叉树)的形状有多少种;
-
和普通的二叉树相比,限定为二叉搜索树是为了避免考虑固定形状后节点值的排列;
-
普通二叉树的数量还要在二叉树的基础上增加节点值的遍历,每种形状共有
n!种值的排列; -
代码:
class Solution {
public:/*动态规划:dp[i]: i个节点能够组成的二叉搜索树dp[i]: sum(k->[0, i-1], dp[k] * dp[i-k-1])dp[k] => 左子树节点dp[i-k-1] => 右子树节点即dp[i] = 左右子树节点的组合数的乘积之和k + i-k-1 = i-1 => 除去根节点的其余节点dp[0] = 1;dp[1] = 1; 限制为二叉搜索树的原因是:1. 一旦选定某个节点为根节点,则它左边的节点和右边的节点的数量和值就都可以确定2. 相当于是问二叉树的形状有多少种3. 普通二叉树的数量还要在二叉树的基础上增加节点的遍历,每种形状共有n!种排列*/int numTrees(int n) {vector<int> dp(n+1, 0);dp[0] = 1;dp[1] = 1;for(int i=2;i<=n;++i) {for(int k=0;k<i;++k) {dp[i] += dp[k] * dp[i-k-1];}}return dp[n];}
};
[9]. 买卖股票的最佳时机
- 题目:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/
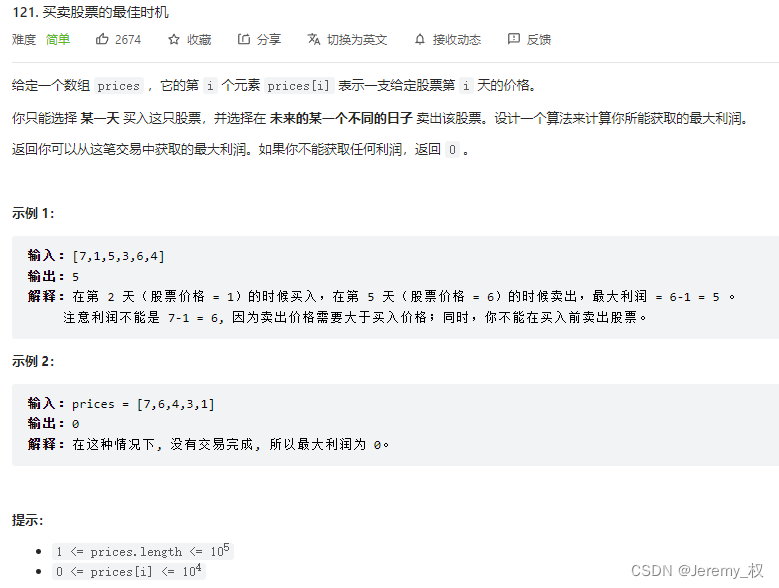
- 思路:
- 记录之前的最小值,然后用当前值减去最小值即可;
- 虽然说是动态规划,但其实有点贪心的感觉;
- 和剑指offer算法题02中的七、10. 股票的最大利润同题;
- 代码:
class Solution {
public:/*dp[i] = max(prices[i]-min, max)*/int maxProfit(vector<int>& prices) {int min_val = prices[0];int max_re = 0;int i;for(i=1;i<prices.size();++i) { if(prices[i] < min_val) {// 更新最低价格min_val = prices[i];}if(prices[i] - min_val > max_re) {// 更新最大收益max_re = prices[i] - min_val;}}return max_re;}
};
10. 单词拆分
- 题目:https://leetcode.cn/problems/word-break/

- 思路:
- 状态转移方程如下:
dp[i]=dp[i−word[j].len]&&dp[i−word[j].len:i]==word[j]dp[i] = dp[i-word[j].len] \ \&\& \ dp[i-word[j].len:i]==word[j] dp[i]=dp[i−word[j].len] && dp[i−word[j].len:i]==word[j] dp[i]意为s的前i个字符是否能用字典拼出;- 代码:
class Solution {
/*动态规划:1. dp[i] = dp[i-word[j].len] && dp[i-word[j].len:i]==word[j]2. dp[i]意为s的前i个字符是否能用字典拼出
*/
public:bool wordBreak(string s, vector<string>& wordDict) {vector<bool> dp(s.length() + 1, false);dp[0] = true;for(int i=1;i<=s.length();++i) {for(int j=0;j<wordDict.size();++j) {int len = wordDict[j].length();if(i-len>=0 && dp[i-len] && wordDict[j]==s.substr(i-len, len)) {dp[i] = true;break;}}}return dp[s.length()];}
};
补充:两种关于C++string类型的值比较方式
- 使用
str1.compare(str2) == 0,如果返回值小于0,则有字典序上的str1 < str2; - 使用
str1 == str2,如果有str1 < str2,则有字典序上的str1 < str2;
11. 乘积最大子数组
- 题目:https://leetcode.cn/problems/maximum-product-subarray/?favorite=2cktkvj

- 思路:

- 如果是像剑指offer算法题02的3. 连续子数组的最大和那样求和的话,则只需记录以前一个
nums[i-1]为结尾的字串的最大和即可推出以nums[i]结尾的最大和; - 但由于乘积有它的特殊性:
nums[i]结尾的最大乘积可能是由两个正数相乘得到的;- 也有可能是由两个负数相乘得到的;
- 这取决于当前的
nums[i]是正数还是负数;
- 因此,需要同时记录
nums[i-1]的最大值和最小值,分别对应上面的两种情况,这样无论当前的nums[i]是正数还是负数,都能求得乘积最大值; - 事实上,只要不和
0相乘,乘积的绝对值肯定是越来越大的; - 另外,也可以不用
dp数组,而用两个(甚至是一个)临时变量存储nums[i-1],这样没有这么直观,但可以进一步优化空间复杂度为O(1),但要注意两者的相互调用关系; - 代码:
class Solution {
public:/*dp[i]:以nums[i]结尾的最大非空连续子数组乘积dp_min[i] = min{dp_min[i-1]*nums[i], dp_max[i-1]*nums[i], nums[i]}dp_max[i] = max{dp_min[i-1]*nums[i], dp_max[i-1]*nums[i], nums[i]}*/int maxProduct(vector<int>& nums) {vector<int> dp_max(nums.size(), 0);vector<int> dp_min(nums.size(), 0);dp_max[0] = nums[0];dp_min[0] = nums[0];int re_max = dp_max[0];for(int i=1;i<nums.size();++i) {dp_max[i] = max(dp_max[i-1]*nums[i], nums[i]);dp_max[i] = max(dp_max[i], dp_min[i-1]*nums[i]);dp_min[i] = min(dp_max[i-1]*nums[i], nums[i]);dp_min[i] = min(dp_min[i], dp_min[i-1]*nums[i]);if(dp_max[i] > re_max) {// 记录最大值re_max = dp_max[i];}}return re_max;}
};
12. 打家劫舍
- 题目:https://leetcode.cn/problems/house-robber/
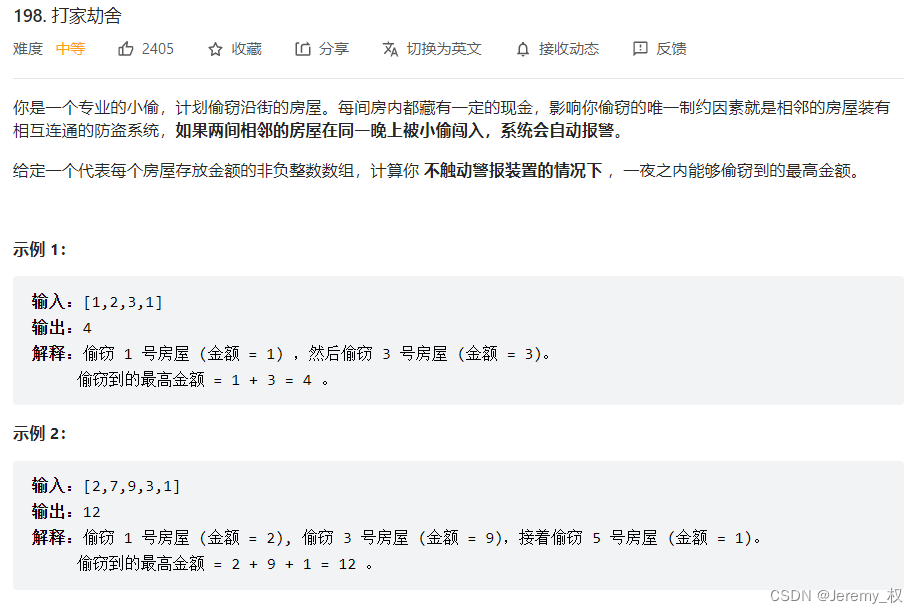
- 思路一:
dp[i]意为走到第i房屋时偷窃第i房屋可得的最高金额;- 则递推方程为:
dp[i]=max(dp[i−2]+nums[i],dp[i−3]+nums[i])dp[i] = max(dp[i-2]+nums[i], dp[i-3]+nums[i]) dp[i]=max(dp[i−2]+nums[i],dp[i−3]+nums[i]) - 注意第
i个房屋是一定要偷的,则i-1房屋不能偷; - 如果
i-2房屋偷了,则,i-4后面的如果可以获得更高的金额的话也可以偷,这是因为i-4和i-2不冲突,已经包括在i-2的子问题内了; - 同理,
i-3房屋如果偷了,则i-5后面的也已经考虑在内了; - 因此
i-2和i-3选一间房屋来偷即可; - 有点点复杂,
dp[i]的意义不是很直观,推理也不一定对,但这个是我自己想出来的递推关系( •̀ .̫ •́ )✧; - 代码一:
class Solution {
public:/*dp[i]:走到i房屋时偷窃i房屋可得的最高金额dp[i] = max(dp[i-2]+nums[i], dp[i-3]+nums[i])*/int rob(vector<int>& nums) {vector<int> dp(nums.size(), 0); int re_max = 0; for(int i=0;i<nums.size();++i) {if(i <= 1) {dp[i] = nums[i];}else {dp[i] = max(dp[i], dp[i-2]+nums[i]);if(i >= 3) {dp[i] = max(dp[i], dp[i-3]+nums[i]);}} re_max = max(re_max, dp[i]);}return re_max;}
};
-
思路二:

-
是另一种思路,
dp[i]表示经过第i房屋时可得的最高金额,第i房屋可以不偷; -
则要么偷第
i房屋,金额是第i-2房屋时的可得最大加上nums[i]; -
要么不偷,金额用第
i-1房屋时的可得最大; -
代码二:
class Solution {
public:/*dp[i]:走到i房屋时可得的最高金额dp[i] = max(dp[i-2]+nums[i], dp[i-1])*/int rob(vector<int>& nums) { if(nums.size() == 1) {return nums[0];}if(nums.size() == 2) {return max(nums[0], nums[1]);}vector<int> dp(nums.size(), 0); dp[0] = nums[0];dp[1] = max(dp[0], nums[1]);for(int i=2;i<nums.size();++i) {dp[i] = max(dp[i-1], dp[i-2]+nums[i]); }return dp[nums.size()-1];}
};
变体1. 打家劫舍 III
- 题目:https://leetcode.cn/problems/house-robber-iii/

- 思路:
- 虽然是变体,但其实处理的思路已经大不相同了,虽然仍然可以看出点动态规划的端倪,但总体的思路变成了树的后序遍历;
- 每个节点都考虑在打劫和不打劫之后,其所在的子树能获得的最大金额;

- 代码
class Solution {
private:struct returnType {int rob; // 打劫该节点时子树可获得的最大值int unrob; // 不打劫该节点时子树可获得的最大值};returnType dfs(TreeNode *root) {if(root == nullptr) {return {0, 0};}returnType left = dfs(root->left);returnType right = dfs(root->right);// 打劫root,则子节点都不能打劫int root_rob = root->val + left.unrob + right.unrob;// 不打劫root,则子节点可以打劫也可以不打劫int root_unrob = max(left.rob, left.unrob) + max(right.rob, right.unrob);return {root_rob, root_unrob};}
public:int rob(TreeNode* root) {returnType re = dfs(root);return max(re.rob, re.unrob);}
};
13. 最大正方形
- 题目:https://leetcode.cn/problems/maximal-square/

-
思路:
-
转移方程如下:

-
一个例子如下:
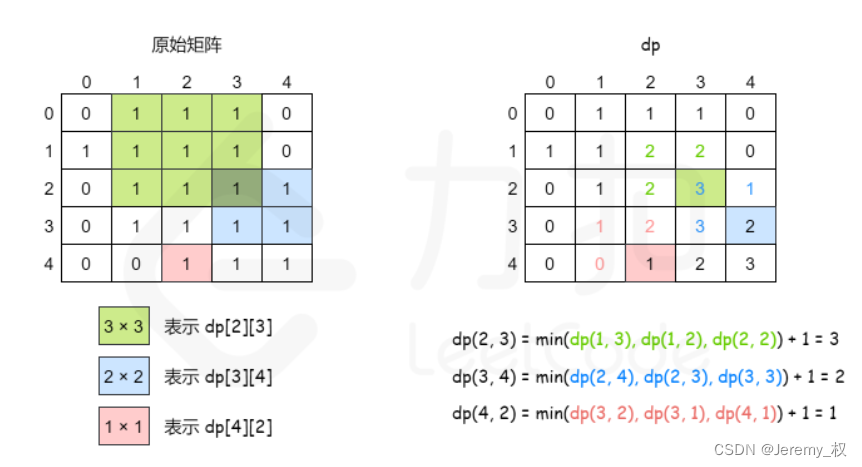
-
对于状态转移方程的说明:

-
另外,第一列和第一行要初始化,遇到
'1'则dp[i][j] = 1,并不需要考虑左侧、上侧和左上角的元素值; -
代码:
class Solution {
public:/*dp[i][j]:以matrix[i][j]结尾的正方形的最大边长dp[i][j] = min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1]) + 1 (if matrix[i][j]==1)0 (otherwise)*/int maximalSquare(vector<vector<char>>& matrix) {vector<vector<int>> dp(matrix.size(), vector<int>(matrix[0].size(), 0));int re_max = 0;// 初始化第一列和第一行for(int i=0;i<matrix.size();++i) {if(matrix[i][0] == '1') {dp[i][0] = 1;}if(dp[i][0] > re_max) {re_max = dp[i][0];}}for(int j=0;j<matrix[0].size();++j) {if(matrix[0][j] == '1') {dp[0][j] = 1;}if(dp[0][j] > re_max) {re_max = dp[0][j];}}// 计算剩下的dpfor(int i=1;i<matrix.size();++i) {for(int j=1;j<matrix[0].size();++j) {if(matrix[i][j] == '1') {dp[i][j] = min(dp[i-1][j-1], min(dp[i-1][j], dp[i][j-1])) + 1;}else {dp[i][j] = 0;}if(dp[i][j] > re_max) {re_max = dp[i][j];}}}// 返回面积 = 边长*边长return re_max*re_max;}
};
14. 完全平方数 [完全背包]
- 题目:https://leetcode.cn/problems/perfect-squares/
- 思路:
- 是完全背包问题,即组成
n的每个完全平方数均可以多次使用; - 注意的点如下:
- 是恰好组成
n,因此初始化的时候仅dp[0][0]或者dp[0]可以有初始值,其余为INT_MAX(因为是最小化问题); - 用一维形式的话,
dp数组空间为n+1,两重循环,内循环采用正序遍历; - 外循环遍历
value,在这里是完全平方数的类型,遍历到sqrt(n)即可; - 内循环遍历
weight到n,weight在这里是完全平方数占据的空间,即value*value;
- 是恰好组成
- 其实是类似零钱问题,零钱问题也是完全背包问题,也是恰好装满
n; - 代码:
class Solution {
public:/*dp[i][j]:用前i个完全平方数,和为j的最小数量dp[i][j] = min(dp[i-1][j], dp[i-1][j-i^2]+1);降为一维,dp[j] = min(dp[j], dp[j-i^2]+1);初始值:dp[0] = 0,其余为INT_MAX*/int numSquares(int n) {int max_value = int(sqrt(n));vector<int> dp(n+1, INT_MAX);dp[0] = 0;for(int i=1;i<=max_value;++i) {int weight = i*i;for(int j=weight;j<=n;++j) {dp[j] = min(dp[j], dp[j-weight]+1);}}return dp[n];}
};
15. 最长递增子序列
- 题目:https://leetcode.cn/problems/longest-increasing-subsequence/

- 思路:

- 动态规划的思路是比较容易想到的,但时间复杂度为O(N^2);
- 此外还有一个比较复杂的思路,时间复杂度可以降为O(NlogN),但暂时不想研究了(
累了,叉腰); - 感觉动态规划的思路是比较正统的,而且是第一道自己写出来的动态规划中等题;
- 代码:
class Solution {
public:/*dp[i]:以nums[i]结尾的最长严格递增子序列长度dp[i] = j:0->i-1 max(dp[j]+1) && nums[j]<nums[i]=> dp[i]初始值为1*/int lengthOfLIS(vector<int>& nums) {vector<int> dp(nums.size(), 1);int re_max = 1;for(int i=1;i<nums.size();++i) {for(int j=0;j<i;++j) {if(nums[j] < nums[i]) {dp[i] = max(dp[i], dp[j]+1);// 记录全局最大值re_max = max(re_max, dp[i]);}}}return re_max;}
};
16. 最佳买卖股票时机含冷冻期
- 题目:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-with-cooldown/

-思路:


- 需要注意的点如下:
- dp矩阵记录的是每天结束时的状态;
- 也就是说,昨天卖出的股票此时已经过了冷冻期了;
- 仅有当天卖出的股票才在冷静期内;
- 如果不这样设计的话状态之间的区分会模糊不清;
- 代码:
class Solution {
public:/*动态规划,每一天结束时有三种状态:dp[i][0]:持有股票dp[i][1]:未持有股票且在冷冻期dp[i][2]:未持有股票且不在冷冻期*/int maxProfit(vector<int>& prices) {int n = prices.size();vector<vector<int>> dp(n, vector<int>(3, 0));dp[0][0] = -prices[0]; // 买入当天股票dp[0][1] = 0;dp[0][2] = 0;for(int i=1;i<n;++i) {// 1. 继续持有或者当天买入dp[i][0] = max(dp[i-1][0], dp[i-1][2] - prices[i]);// 2. 今天卖出dp[i][1] = dp[i-1][0] + prices[i];// 3. 昨天卖出或者昨天就已经不在冷冻期dp[i][2] = max(dp[i-1][1], dp[i-1][2]);}// 最后一天的2和3的最大值一定大于1int re_max = max(dp[n-1][1], dp[n-1][2]);return re_max;}
};
17. 零钱兑换 [完全背包]
- 题目:https://leetcode.cn/problems/coin-change/

- 思路:
- 就是完全背包问题的思路,可以降为一维动态规划;
- 注意是恰好装满问题,初始化时仅
dp[0] = 0,其余为最大值; - 最后比较的时候,因为题目说明所有的硬币均为整数,因此最小是
1,最大的解也是amount个硬币,所以用amount和dp[amount]比较即可知道当前值是否从INT_MAX而来(也就是不能恰好装满),当然也可以直接用INT_MAX来比较; - 代码:
class Solution {
public:/*dp[i][j]:用前i个硬币凑j面值的最少硬币数dp[0][0] = 0; dp[0][j] = INT_MAX;降为一维:dp[0] = 0; dp[j] = min(dp[j], dp[j-weight[i]]+1);*/int coinChange(vector<int>& coins, int amount) {vector<int> dp(amount+1, INT_MAX);dp[0] = 0;for(int i=0;i<coins.size();++i) {for(int j=coins[i];j<=amount;++j) {if(dp[j-coins[i]] != INT_MAX) {// 不是从INT_MAX而来,以防溢出dp[j] = min(dp[j], dp[j-coins[i]] + 1);} }}if(dp[amount] == INT_MAX) {return -1;}else {return dp[amount];}}
};
18. 比特位计数
- 题目:https://leetcode.cn/problems/counting-bits/

- 思路:
- 其实就是找规律;
- 第
i个数的1的个数其实就是i-step个数的i的个数再加1; step是不超过i的最大二次幂;- 也就是说
dp[i]一定可以由前面的某个dp+1而来,因此可以用动态规划; - 有点点已有之事后必再有的意思(啊好文艺);
- 代码:
class Solution {
public:/*000:0001:1 = [000] + 1 dp[1] = dp[0] + 1 = dp[i-1] + 1010:1 = [000] + 1 dp[2] = dp[0] + 1 = dp[i-2] + 1 011:2 = [001] + 1 dp[3] = dp[1] + 1 = dp[i-2] + 1100:1 = [000] + 1 dp[4] = dp[0] + 1 = dp[i-4] + 1101:2 = [001] + 1 dp[5] = dp[1] + 1 = dp[i-4] + 1110:2 = [010] + 1111:3 = [011] + 1*/vector<int> countBits(int n) {vector<int> dp(n+1, 0);int step = 1;for(int i=1;i<=n;++i) {if(i >= 2*step) {step *= 2;}dp[i] = dp[i-step] + 1;}return dp;}
};
19. 分割等和子集 [0/1背包]
- 题目:https://leetcode.cn/problems/partition-equal-subset-sum/
- 思路:
- 原题等价于:从数组中取若干个数,能否恰好装满容量是数组和一半的背包;
- 先求数组和,然后再用0/1背包的解法即可;
- 另外注意的点如下:
- 是恰好装满问题;
- 仅一个元素或者数组和是奇数均不符合要求;
- 代码:
class Solution {
public:/*动态规划:0/1背包问题=> 原问题可以转换为求是否能恰好装满数组和一半的背包dp[i][j]:前i个元素能否恰好装满j由于不需要value,即不用求最少/最多的元素数量所以dp数组的类型可以是bool类型转移方程: dp[i][j] = dp[i-1][j] || dp[i-1][j-nums[i]]转为一维: dp[j] = dp[j] || dp[j-nums[i]]*/bool canPartition(vector<int>& nums) {if(nums.size() <= 1) {// 仅一个元素不符合要求return false;}// 求数组和int num_sum = 0;for(int i=0;i<nums.size();++i) {num_sum += nums[i];}if(num_sum % 2 == 1) {// 奇数和也不符合要求return false;}// dpint target = num_sum / 2; // 背包容量vector<bool> dp(target+1, false);dp[0] = true; for(int i=0;i<nums.size();++i) {for(int j=target;j>=0;--j) {if(j-nums[i] >= 0) {dp[j] = dp[j] || dp[j-nums[i]];} }}return dp[target];}
};
20. 目标和 [0/1背包]
- 题目:https://leetcode.cn/problems/target-sum/
- 思路:
- 实际上是可以转换为0/1背包问题,然后用动态规划来做;

- 为什么不用positive作为背包的容量?
- 因为positive的推导式是
(target + sum) / 2,有可能为负数,因此不能做背包的容量,而negative可以证明它一定非负; - 然而,如果
target是非法的话,也就是说把所有数组里面的数加起来也没有办法凑出一个target,则negative就有可能是负数,因此需要提前判断排除这种情况; - 什么情况下才能转为一个0/1背包问题?
- 其实这道题和19. 分割等和子集很类似,也是将问题一分为二,然后只考虑一边的情况是否满足,如果满足则另一边的情况也可以得到满足;
- 两者都是凑一个可以从条件中推导出来的确定的数,这个数要满足非负的要求,而且都是和数组和有关的;
- 只能说还是很巧妙的;
- 代码:
class Solution {
public:/*假设所有数之和是sum,添+的数之和是positive,添-的数之和是negative,则有sum = positive + negative=> target = positive - negative = sum - 2*negative = 2*positive - sum由于target和sum已知,因此positive和negative均可以算出来=> negative = (sum - target) / 2=> positive = (target + sum) / 2=> 也就是原问题等价于能不能用nums中的元素恰好凑出positive或者negative=> 但由于target <= sum且target可以为负数,因此negative一定非负,但positive有可能是负数=> 所以只能用negative作为背包的容量因此转换成一个0/1背包问题dp[i][j]:用前i个数恰好能凑出j的组合数转移方程:dp[i][j] = dp[i-1][j] + dp[i-1][j-nums[i]]初始化:dp[0][0] = 1*/int findTargetSumWays(vector<int>& nums, int target) {int num_sum = 0;for(int i=0;i<nums.size();++i) {num_sum += nums[i];}if(num_sum < target) {// sum一定会大于等于target,否则非法return 0;}if((num_sum - target) % 2 == 1) {// positive不是整数,则target非法return 0;}int negative = (num_sum - target) / 2;vector<int> dp(negative+1, 0);dp[0] = 1;for(int i=0;i<nums.size();++i) {for(int j=negative;j>=nums[i];--j) {dp[j] = dp[j] + dp[j - nums[i]];}}return dp[negative];}
};
21. 戳气球
- 题目:https://leetcode.cn/problems/burst-balloons/
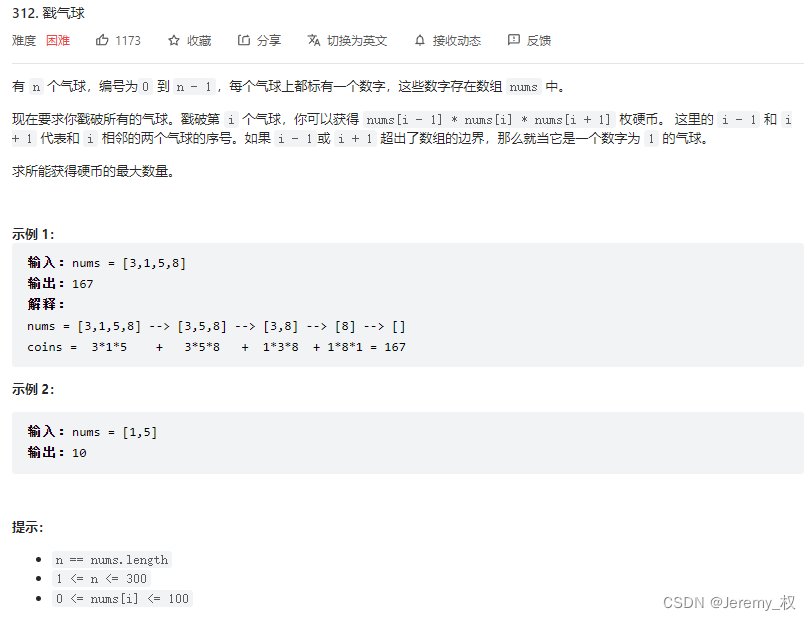
- 思路:
- 很难想到的动态规划::>_<::,而且我看官方的思路都看不太懂,主要是边界和动态规划的设计很巧妙,后面是看一个大佬的题解才豁然开朗而且笑出了声
好一个暴躁小哥,如下:


-
一些难以理解的点:
-
(1) 为什么不用计算
i==j(剩一个气球)和i+1==j(剩两个气球)的情况下的dp值? -
因为按照自定义来看,
dp[i][j]是不含i和j的,也就是说至少要三个气球才能计算; -
另外,从整个算法来看,剩一个气球和剩两个气球虽然是在子问题中出现了,但它是不符合现实的,因为剩一个气球和剩两个气球总能返回到一个更大的子问题中凑够三个气球再来戳破,而不是在剩一个气球和剩两个气球的时候就把它们戳破;
-
当然,如果所有的气球加起来也没有三个,才需要讨论戳破一个气球和戳破两个气球的情况;
-
(2) 为什么要增加一前一后两个伪气球?
-
一方面,是为了规避所有气球加起来也不够三个的情况的讨论,加上两个伪气球就肯定够三个了;
-
另一方面,如果气球的数量超过两个,我们是无法知道最后剩下是哪两个气球给我们戳破,这个时候还要循环遍历所有的可能来讨论,为了避免这个麻烦,我们可以加上两个伪气球把这个讨论整合到子问题中来讨论,因为子问题也是做了
k的组合遍历讨论的; -
(3) dp数组的填入次序是如何决定?
-
一个方便的方法是看最后返回的dp下标矩阵的什么位置,这里是返回
dp[0][n+1],在矩阵的右上角,因此是从下往上遍历,从左往右遍历; -
代码:
class Solution {
public:/*动态规划:dp[i][j]:戳破(i:j)之间的所有气球可以获得的硬币最大数量,注意是开区间1. 转移方程:dp[i][j] = {k:i+1->j-1}max(dp[i][k] + nums[i]*nums[k]*nums[j] + dp[k][j]) if i+1<=j-1= nums[i]*nums[j] + max(nums[i], nums[j]) if i+1==j= nums[i] if i==j2. 剩两个气球和剩一个气球的情况无需考虑因为如果nums.size()>=3,则在戳气球的实际过程中不可能会有两个和一个气球的情况虽然子问题里面会有,但并不处理(戳破),而是直接返回到更大的问题(>=3)中再来戳3. 由于最后剩下的两个气球可以是数组中的任意两个气球所以一定要增加一前一后两个伪气球增加了两个气球之后,也不用讨论剩下的气球数目,因为一定是>=3的*/ int maxCoins(vector<int>& nums) {int n = nums.size();// 增加一前一后两个伪气球,值为1vector<int> new_nums(n+2, 1);for(int i=0;i<n;++i) {new_nums[i+1] = nums[i];}vector<vector<int>> dp(n+2, vector<int>(n+2, 0));for(int i=n+2-1;i>=0;--i) {for(int j=i;j<n+2;++j) {if(i == j) {// 剩一个气球,不讨论//dp[i][j] = new_nums[i];}if(i+1 == j) {// 剩两个气球,不讨论//dp[i][j] = new_nums[i] * new_nums[j] + max(new_nums[i], new_nums[j]);}if(i+1 <= j-1) {// 有三个气球for(int k=i+1;k<=j-1;++k) {dp[i][j] = max(dp[i][j], dp[i][k] + new_nums[i]*new_nums[k]*new_nums[j] + dp[k][j]);}}}}return dp[0][n+1];}
};
八、二分法
1. 寻找两个正序数组的中位数
- 题目:https://leetcode.cn/problems/median-of-two-sorted-arrays/

- 思路:
- 很巧妙的二分法(好难啊〒▽〒);
- 大概是需要利用有序这个条件,寻找第k个数:
- 用
i和j两个指针标定当前两个数组已经排除掉的数; - 分别比较第
i+k/2和j+k/2的两个数,并舍弃掉较小的一方的k/2个数; - 这是因为这些数一定是在中位数的左边,
k/2就是为了将k个数分到两个数组中; - 然后从
k中删去k/2,继续比较;
- 用
- 需要注意比较时出现的三种情况:
- 两个数组第
i+k/2和j+k/2的两个数均没有越界,则按照上面处理即可; - 两个数组有一个越界,则不能舍弃
k/2个数,而是尝试舍弃min(a.size()-i,b.size()-j)个数; - 有一个数组指针已走至尽头,则直接在另一个数组舍弃掉
k个数(而不用再二分取k/2)即可;
- 两个数组第
- 最后移动的指针移动到的数就是第k个数(有可能是
i指针也有可能是j指针,因此需要用一个变量记录每次移动); - 为什么是找第k个数而不是直接找中位数?
- 因为中位数有可能是第k个数(奇数),也有可能是第k个数和第k+1个数的平均值(偶数);
- 一次二分遍历是不能同时找到第k个数和第k+1个数这两个相邻的数的,只能找第k个数;
- 因为在二分的条件下,不具备判断数相邻的条件;
- 因此只能封装一个找第k个数的函数,作为求中位数的辅助;
- 一些图文解释如下:


- 代码:
class Solution {
private: /*findKthSortedArrays:返回两个数组中第rest个数的数值*/int findKthSortedArrays(vector<int>& nums1, vector<int>& nums2, int rest) {int i = -1, j = -1;double re;int move;while(rest > 0) {if(rest == 1) {move = 1;}else {move = rest / 2; // 取一半步长则较小的一方必定都是在中位数左边的}if(i+move < nums1.size() && j+move <nums2.size()) {// 按照rest的一半前进if(nums1[i+move] > nums2[j+move]) {// nums2可以前进 j += move;re = nums2[j];}else {// nums1可以前进i += move;re = nums1[i];}rest -= move;}else {move = min(nums1.size()-i-1, nums2.size()-j-1);if(move == 0) {// 直接取另一个数组的第rest个数if(i == nums1.size() - 1) {// nums2可以前进 j += rest;re = nums2[j];}else {// nums1可以前进i += rest;re = nums1[i];}rest = 0;}else {// 按照最短的move前进if(nums1[i+move] > nums2[j+move]) {// nums2可以前进 j += move;re = nums2[j];}else {// nums1可以前进i += move;re = nums1[i];} rest -= move; } }}return re;}
public:double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {int len = nums1.size() + nums2.size();int rest = len / 2;if(len % 2 == 0) {// 中位数有两个,取平均return 1.0 * (findKthSortedArrays(nums1, nums2, rest) + findKthSortedArrays(nums1, nums2, rest+1)) / 2;}else {// 中位数有一个,直接返回return 1.0 * findKthSortedArrays(nums1, nums2, rest+1);}}
};
2. 搜索旋转排序数组
- 题目:https://leetcode.cn/problems/search-in-rotated-sorted-array/

- 思路:
- 其实利用的是有序的一侧进行
target位置的判断,所以可以和有序数组一样用二分法处理; - 核心点如下:
- 有可能一侧有序一侧无序,也有可能两侧均有序;
- 有序的一侧一定是升序;
- 判断是否在有序的一侧需要同时判断有序序列的头和尾,这个和普通有序数组的二分法不同,因为单纯地比较有序序列的最小值和
target不能判断target一定在有序序列中,因为在无序的一侧可能会有更大值;
- 另外,关于边界的判断其实还蛮复杂的,最好是先把所有的可能情况都列一个例子出来,再考虑要如何确定边界,保证不漏情况;

-
实现代码时,因为是用了二分法,所以要用
low = mid + 1,虽然这道题写low = mid也不会死循环,但为了保险起见还是+1的写法比较好; -
代码:
class Solution {
public:/*主要是利用了有序的一侧来进行判断,所以可以和有序数组一样用二分法处理1. 有可能一侧有序一侧无序,也有可能两侧均有序2. 有序的一侧一定是升序mid的可能情况如下:(1) 4,5,6,7(mid),0,1,2(2) 4,5,6(mid),7,0,1,2(3) 4,5,6,7,0(mid),1,2(4) 7(mid),0*/int search(vector<int>& nums, int target) {int low = 0, high = nums.size() - 1;int re;while(low < high) {int mid = low + (high - low) / 2;if(nums[mid] >= nums[low]) {// 有序在左侧[low, mid]if(nums[mid] >= target && nums[low]<=target) {// [low, target, mid]high = mid;}else {low = mid + 1;}}else {// 有序在右侧[mid, high]if(nums[mid] < target && nums[high] >= target) {// (mid, target, high]low = mid + 1;}else {high = mid;}}}if(nums[low] == target) {return low;}else {return -1;}}
};
[3]. 在排序数组中查找元素的第一个和最后一个位置
- 题目:https://leetcode.cn/problems/find-first-and-last-position-of-element-in-sorted-array/

- 思路:
- 两次二分法查找:
- 找第一个等于
target的下标; - 找第一个大于
target的下标;
- 找第一个等于
- 注意边界条件:
- 可能不存在等于
target的下标; - 可能不存在大于
target的下标;
- 可能不存在等于
- 和剑指offer算法题02中的3. 在排序数组中查找数字 I几乎同题,核心思路是一样的;
- 另外,在使用二分法时注意移动
low和high时均使用的是mid的值,不要错用了low或者high的值; - 代码:
class Solution {
private:// 搜紧确下界,第一个为target的值int searchLowerBound(vector<int>& nums, int target) {int low = 0, high = nums.size() - 1;while(low < high) {int mid = low + (high - low) / 2;if(nums[mid] < target) {low = mid + 1;}else {high = mid;}}if(nums[low] == target) {return low;}else {// 不存在第一个为target的值return -1;}}// 搜上界,第一个大于target的值int searchUpperBound(vector<int>& nums, int target) {int low = 0, high = nums.size() - 1;while(low < high) {int mid = low + (high - low) / 2;if(nums[mid] <= target) {low = mid + 1;}else {high = mid;}}if(nums[low] > target) {return low;}else {// 不存在第一个大于target的值return -1;}}
public:vector<int> searchRange(vector<int>& nums, int target) {if(nums.empty()) {return {-1, -1};}int low = searchLowerBound(nums, target);int high = searchUpperBound(nums, target);if(low == -1) {return {-1, -1};}else {if(high == -1) {return {low, int(nums.size())-1};}else {return {low, high - 1};}}}
};
4. 寻找重复数
- 题目:https://leetcode.cn/problems/find-the-duplicate-number/
-
思路:
-
其实是挺难理解的一道题;
-
比较核心的点如下:
- 下标的域是
[0, n],值域是[1, n],基本上是同域的; - 仅有一个数重复,而且可以重复多次;
- 下标的域是
-
思路一:二分查找
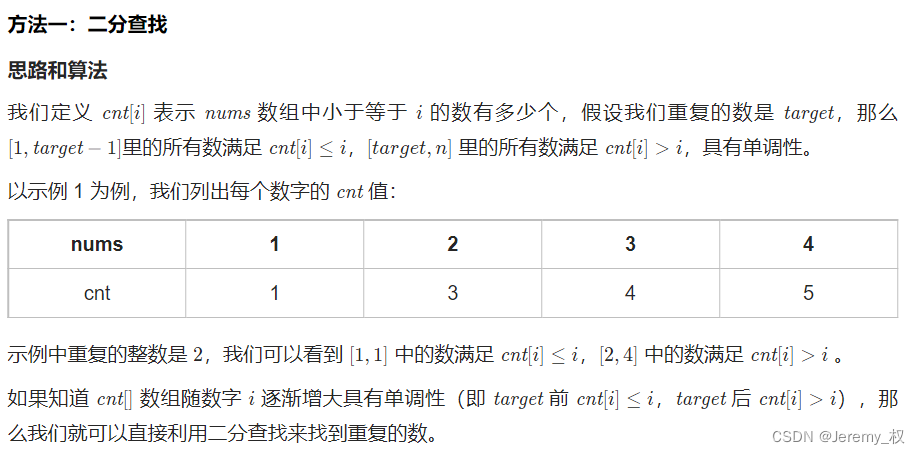
-
时间复杂度是O(NlogN),空间复杂度是O(1);
-
比较关键的点是:
- 统计
cnt是小于等于nums[i]的数量,一定要包括等于; - 目标是找满足
cnt > nums[i]的最小nums[i]; - 二分查找需要原数组有序,这里虽然数组值无序,但数组值和数组索引基本同域且有序,所以可以用数组索引代替数组值进行二分查找;
- 统计
-
一些推导见代码部分;
-
代码一:
class Solution {
public:/*[1, n]中只有一个重复的数,共有n+1个数1 3 4 2 2nums[i]: 1 2 3 4cnt: 1 3 4 5假设当前数是nums[i],则统计小于等于nums[i]的数1. 若less_cnt <= nums[i],则nums[i]不是重复的数,而且小于重复的数==:意味着小于nums[i]的数没有缺失<: 意味着小于nums[i]的数有缺失,但一定没有重复,因为只能有一个数重复2. 若less_cnt > nums[i],则最小的nums[i]是重复的数,其余的是大于重复的数因为前提是:1. 仅有一个数重复;2. 共有n个数;3. 数均在[1, n]中;于是问题转化为找第一个满足less_cnt > nums[i]的nums[i]本来是需要先排序在做二分查找的,但这里限制了不能修改数组,又有额外条件:1. 数组下标是[0, n],而且数组下标是有序的所以可以用数组下标的[1, n]代替nums[i]作为二分查找的左右端*/int findDuplicate(vector<int>& nums) {int low = 1, high = nums.size()-1;while(low < high) {int mid = low + (high-low)/2;int less_cnt = 0;for(int i=0;i<nums.size();++i) {if(nums[i] <= mid) {++less_cnt;}}if(less_cnt <= mid) {low = mid + 1;}else {high = mid;}}return low;}
};
- 思路二:双指针
- 其实双指针的时间复杂度能到O(N),是最优解;
- 但这里还是把这道题放到二分法中,因为这个二分法是很巧妙且典型的,而且双指针的思路很难想到,难点是在如何把这道题转换为有向图求首个入环节点的问题;
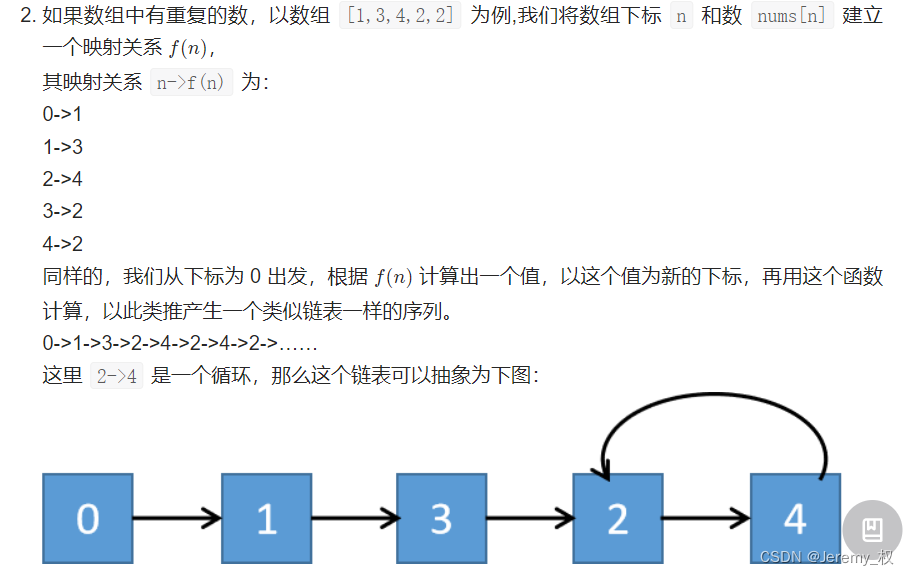
- 比较关键的点是:
0可以看作是伪头节点;- 推导是先假设所有值均不重复,然后从入度和出度来确定图形状;
- 而后再逐个增加重复值,考虑此时图形状的可能;
- 转换之后,和十、双指针的7. 变体1. 环形链表 II同题;
- 一些推导见代码部分;
- 代码二:
class Solution {
public:/*有n+1个数,取值[1, n],下标[0, n]推导如下:1. 假设这n+1个数都不重复,取值在[1, n+1],并把每一个数看做一个节点;2. 则除了0和n+1外,所有的节点的入度为1(下标[0, n]),出度也为1(取值[1, n+1]且不重复);3. 0的出度为1,入度为0,n+1的入度为1,出度为0;4. 按照以上的推导可知,此时所有节点必定是以0为头节点,以n+1为尾节点的有向无环图;5. 将n+1节点的入度换到[1, n]的任一节点中,则必定会出现环,且该节点就是所求的重复整数;如果有多个重复值,则:6. 在上述基础上令某个节点的入度为0,重复值节点增加一个入度,相当于断开某个节点重连;7. 在环外断开则环内不变,环外路径变短,在环内断开则环外不变,环内路径变短;8. 此时必定仍有且只有一个环,只是某些节点可能无法从0开始遍历到;9. 但环是一定可以从0开始遍历到的;因此,可以转换为求有向有环图的首个入环节点问题,用快慢指针来求解,0是伪头节点;快慢指针求入环点的推导如下:1. fs = ss + n*circle = 2*ss;=> ss = n*circle;2. ss = a(环外) + b(环内);=> ss再走a就可以凑够整环回到入环处,从头走a也可以到入环处;*/int findDuplicate(vector<int>& nums) {int fast = 0, slow = 0;while(fast==0 || fast!=slow) {slow = nums[slow];fast = nums[fast];fast = nums[fast];}int slow2 = 0;while(slow != slow2) {slow = nums[slow];slow2 = nums[slow2];}return slow;}
};
九、位运算
1. 只出现一次的数字
- 题目:https://leetcode.cn/problems/single-number/
- 思路:
- 利用的是异或运算的性质,即
x xor x = 0,x xor 0 = x; - 因此从头到尾异或一遍即可,相同的数字可以被异或消掉;
- 此外还有相似类型的进阶题目,参见剑指offer算法题02中的九、2. 数组中数字出现的次数 I和九、3. 数组中数字出现的次数 II;
- 代码:
class Solution {
public:int singleNumber(vector<int>& nums) {int result = 0;for(int i=0;i<nums.size();++i) {result ^= nums[i];}return result;}
};
2. 汉明距离
- 题目:https://leetcode.cn/problems/hamming-distance/
- 思路:
- 就是异或运算;
- 另外注意统计异或结果中1的个数时,可以用
x = x & (x-1)加快效率; - 代码:
class Solution {
public:int hammingDistance(int x, int y) {int n = x ^ y;int re = 0;// 统计异或结果中1的个数while(n != 0) {++re;n = n & (n - 1);}return re;}
};
十、双指针
[1]. 无重复字符的最长子串
- 题目:https://leetcode.cn/problems/longest-substring-without-repeating-characters/
- 思路:
- 使用双指针来定位子串;
- 使用hash map来记录元素是否有重复,而且能记录最后一次出现的下标,方便指针
i快速移动; - 和剑指offer算法题02中的七、7. 最长不含重复字符的子字符串同题,但那个归类为动态规划,可以求任意从头开始的子串的最长不含重复字符的子字符串,同时需要和子串相同长度的dp数组进行保存。这种做法使用的是一个变量保存最大值,空间复杂度是O(1)。而且双指针的思路比较容易想到。
- 代码:
class Solution {
public:/*双指针:i指向子串前一位,j指向字串后一位因此子串长度 = j - i - 1使用unordered_map的时候注意:若出现了map[key]的形式,则无论是读取还是写入,都将会为不存在的key创建之后的map.find将返回true所以测试输出时应当小心使用printf("%d\n", map[key]);*/int lengthOfLongestSubstring(string s) {unordered_map<char, int> map;int i = -1, j = 0;int re = 0;while(j < s.length()) {if(map.find(s[j])!=map.end() && (map[s[j]]>=i && map[s[j]]<j)) {// 更新长度re = max(re, j - i - 1);// 移动指针ii = map[s[j]]; }map[s[j]] = j;// 移动指针j++j;}// 最后一个无重复子串也要判断re = max(re, j - i - 1);return re;}
};
2. 盛最多水的容器
- 题目:https://leetcode.cn/problems/container-with-most-water/
- 思路:
- 比较核心的点在于每次只需移动短板即可,因为移动长板必定会使得面积变小;

- 代码:
class Solution {
public:int maxArea(vector<int>& height) {int i = 0, j = height.size() - 1;int re_max = 0;while(i < j) { // 用短板的高度 * 宽度 int area = min(height[i], height[j]) * (j - i);// 记录面积最大值if(area > re_max) {re_max = area;} // 将短板往中间移动if(height[i] > height[j]) {--j;}else {++i;}}return re_max;}
};
变体1. 接雨水
- 题目:https://leetcode.cn/problems/trapping-rain-water/
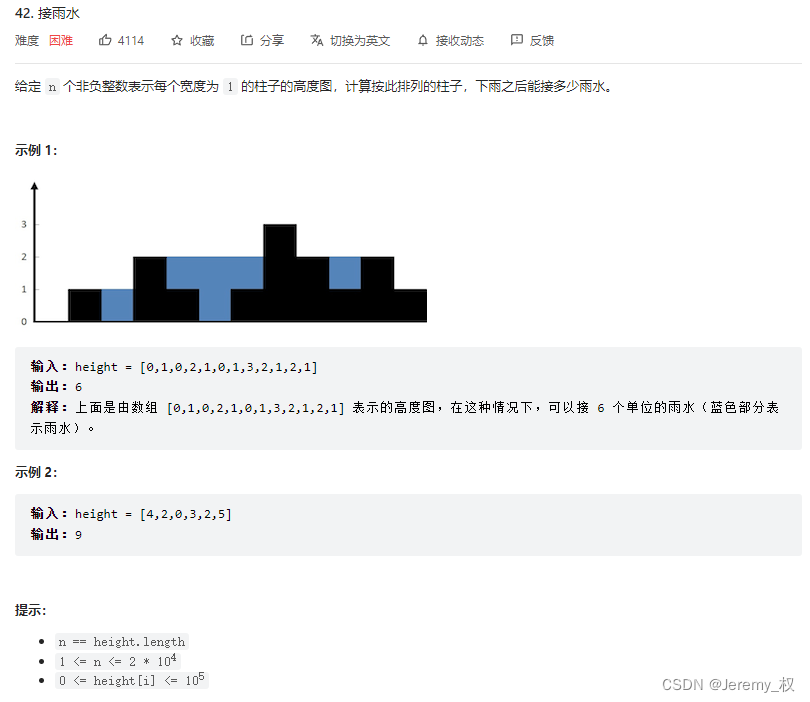
- 其实也不太确定这题是不是可以视作2. 盛最多水的容器的变体,但确实可以将两题对比着看;
- 思路一:正向反向遍历
- 这道题的求解关键是:只考虑
i处能接的雨水,不考虑它两边的容器形状; - 因而,
i处能接的雨水 = 它两边最大容器高度的更低一方 -height[i]; - 为了得到
i两边容器高度的最大值,可以正向遍历得左边容器最大值,反向遍历得右边容器最大值; - 时间复杂度是O(3N)(可以优化到O(2N)),空间复杂度是O(2N);

- 代码一:
class Solution {
public:/*正向反向遍历:1. 对于每个height[i]而言,它能够接到的雨水(仅考虑在i上,不考虑它两边的实际形状)取决于它两边最大高度的更低一方 - height[i]2. 因此正向遍历得left_max[i],反向遍历得right_max[i]即可*/int trap(vector<int>& height) {vector<int> left_max(height.size(), 0);vector<int> right_max(height.size(), 0);// 正向遍历for(int i=0;i<height.size();++i) {left_max[i] = height[i];if(i-1>=0 && left_max[i]<left_max[i-1]) {left_max[i] = left_max[i-1];}}// 逆向遍历for(int i=height.size()-1;i>=0;--i) {right_max[i] = height[i];if(i+1<height.size() && right_max[i]<right_max[i+1]) {right_max[i] = right_max[i+1];}}// 计算接雨水之和int re_sum = 0;for(int i=0;i<height.size();++i) {re_sum += min(left_max[i], right_max[i]) - height[i];}return re_sum;}
};
-
思路二:双指针
-
但其实这道题的最优解是用双指针,虽然不太直观,但是本质思路也是对思路一的改进;
-
通过双指针,避免了对
left_max[i]和right_max[i]的两次遍历求解; -
因为计算接雨水的量时,本质上并不是需要把
left_max[i]和right_max[i]都求出来,而仅需要它们之间的较小值即可,这样就提供了可优化的空间(但仍然是十分巧妙的双指针,比较难想到); -
一些推导的过程见下面代码的注释部分;
-
时间复杂度降至O(N),空间复杂度降至O(1);
-
代码二:
class Solution {
public:/*双指针:1. 对于每个height[i]而言,它能够接到的雨水(仅考虑在i上,不考虑它两边的实际形状)取决于min(left_max[i], right_max[i]) - height[i]实际上,可以用双指针巧妙地替代计算left_max[i]和right_max[i]的两次遍历2. 定义左指针i,右指针j,i及之前的最大值left_max,j及之后的最大值right_max3. 对于i而言:left_max[i] = left_max;right_max[i] >= right_max;故若left_max < right_max,则必有left_max[i]<right_max[i]4. 同理,对于j而言:left_max[j] >= left_max;right_max[j] = right_max;故若left_max > right_max,则必有left_max[j]>right_max[j]5. 如此可以计算出所有位置两边最大高度更低的一方,交替移动指针即可*/int trap(vector<int>& height) {int i = 0, j = height.size() - 1;int left_max = height[i], right_max = height[j];int re_sum = 0;while(i != j) {if(left_max < right_max) {// i处的雨水可算,移动左指针re_sum += (left_max - height[i]);++i;left_max = max(left_max, height[i]);}else {// j处的雨水可算,移动右指针re_sum += (right_max - height[j]);--j;right_max = max(right_max, height[j]);}}return re_sum;}
};
3. 三数之和
- 题目:https://leetcode.cn/problems/3sum/

-
思路:
-
排序后使用双指针可以将复杂度从O(N3)O(N^3)O(N3)降至O(N2)O(N^2)O(N2);
-
可以视作是两数之和的升级版,参看剑指offer算法题02中的十、4. 和为s的两个数字,但增加了重复数的判断;
-
重复数的判断是难点,但可以通过排序和跳过连续相同的数进行排除,无需使用哈希表(哈希也很难同时判断三个数的重复性吧);

-
代码:
class Solution {
public:vector<vector<int>> threeSum(vector<int>& nums) {// 排序sort(nums.begin(), nums.end());int k = 0;vector<vector<int>> re;while(k < nums.size()) {if(nums[k] > 0) {// 剪枝,提前终止break;}// 固定k之后使用双指针int i = k + 1, j = nums.size() - 1;while(i < j) {int sum = nums[k] + nums[i] + nums[j];if(sum == 0) {vector<int> temp(3, 0);temp[0] = nums[k];temp[1] = nums[i];temp[2] = nums[j];re.push_back(temp);++i;// 跳过重复值while(i<j && nums[i]==nums[i-1]) {++i;}}if(sum < 0) {// 和不够大++i;// 跳过重复值while(i<j && nums[i]==nums[i-1]) {++i;}}if(sum > 0) {// 和太大--j;// 跳过重复值while(i<j && nums[j]==nums[j+1]) {--j;}}}++k;// 跳过重复值while(k<nums.size() && nums[k]==nums[k-1]) {++k;}}return re;}
};
4. 删除链表的倒数第 N 个结点
- 题目:https://leetcode.cn/problems/remove-nth-node-from-end-of-list/

- 思路:
- 用一前一后两个相隔n个节点的指针即可,这样后面的指针到
nullptr时,前面的指针正好是倒数第n个节点; - 但因为要删除节点,所以前面的指针实际上应该指向倒数第n个节点的再前一个节点;
- 另外要特别考虑倒数第n个节点是第一个节点(头节点),也就是说不能指向倒数第n个节点的再前一个节点的情况,当然这种特殊的头节点处理可以通过增加一个伪头节点避免;
- 代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {ListNode *i = head, *j = head;int count = 0; // i和j相距的节点数while(j != nullptr) {j = j->next;++count;if(count > n + 1) {i = i->next;}}if(count == n) {// i是要删除的节点head = i->next;delete i;}else {// i->next是要删除的节点if(i->next != nullptr) {// 因为count>0,所以i->next必不为空,故不用elseListNode *tmp = i->next;i->next = tmp->next;delete tmp;}}return head;}
};
- 下面是使用伪头节点的处理方式:
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {// 增加伪头节点ListNode *fakeHead = new ListNode();fakeHead->next = head;ListNode *i = fakeHead, *j = fakeHead;int count = 0; // i和j相距的节点数while(j != nullptr) {j = j->next;++count;if(count > n + 1) {i = i->next;}}// i->next是要删除的节点if(i->next != nullptr) {// 因为count>0,所以i->next必不为空,故不用elseListNode *tmp = i->next;i->next = tmp->next;delete tmp;} return fakeHead->next;}
};
5. 颜色分类
- 题目:https://leetcode.cn/problems/sort-colors/

- 思路:
- 直接排序的时间复杂度是O(NlogN)O(NlogN)O(NlogN);
- 但如果使用双指针来做的话,时间复杂度是O(N)O(N)O(N),这是因为一共就只有三种元素;
- 如果超过三种元素就不能用双指针来做了;

-
需要注意以下方面:
- 要确保
next0指针不指向元素0和next2指针不指向元素2,可以用while来实现; - 在
cur和两个指针交换元素后,如果交换后cur指向的元素不是1,则该元素仍需再继续处理; - 继续处理的方式可以用回退指针来实现;
- 其实处理的目的就是想让
cur指向的元素为1,另外两种元素则分别交换到头和尾;
- 要确保
-
代码:
class Solution {
public:/*三指针1. next0指向连续0的下一个位置,从左到右遍历2. next2指向连续2的前一个位置,从右到左遍历3. cur指向处理的当前位置,从左到右遍历一些规律如下:1. next0指向的数一定是1或者22. next2指向的数一定是0或者13. 如果nums[cur] == 1,则不需要交换4. 如果nums[cur] == 0或者2,则交换到next0或者next25. 注意交换后的数如果是1,则不需要进一步处理,否则需要回退cur指针重复处理*/void sortColors(vector<int>& nums) {int next0 = 0, next2 = nums.size() - 1;int cur = 0;while(cur < nums.size()) {if(nums[cur] == 0) {while(next0 < cur && nums[next0] == 0) {++next0;}if(next0 < cur) {// next0在cur前面swap(nums[cur], nums[next0]);if(nums[cur] == 2) {// cur回退--cur;}}}else {while(next2 > cur && nums[next2] == 2) {--next2;}if(next2 > cur) {// next2在cur后面swap(nums[cur], nums[next2]);if(nums[cur] == 0) {// cur回退--cur;}}}++cur;}}
};
6. 最小覆盖子串 [滑动窗口]
- 题目:https://leetcode.cn/problems/minimum-window-substring/

-
思路:
-
用的是双指针的滑动窗口,即左右指针均只能从左向右移动;
-
边界条件和特殊情况的处理比较麻烦{{{(>_<)}}};

-
要点如下:
-
需要用两个哈希表,一个记录小串的字符和出现次数,一个记录大串滑动窗口内的字符和出现次数;
-
在大串中移动滑动窗口时:
- 先移动右指针,直到滑动窗口能够覆盖小串的所有字符和次数;
- 再移动左指针,直到滑动窗口恰好不能覆盖小串的所有字符和次数;
-
注意左指针移动时可以和右指针重合;
-
代码:
class Solution {
public:/*1. 移动right,直到全部全部字符均能覆盖2. 移动left,直到某个字符不能覆盖3. 记录此时的right - left*/string minWindow(string s, string t) {unordered_map<char, int> t_map, s_map;int min_length = s.length() + 1;string re;// 初始化两个map// t_map用于记录, 后续不再修改;s_map用于计数,后续修改for(int i=0;i<t.length();++i) {if(t_map.find(t[i]) == t_map.end()) {t_map[t[i]] = 1;s_map[t[i]] = 0; // s_map仅初始化}else {t_map[t[i]] += 1;}}int left = 0, right = 0;int count = 0;// 在s上移动滑动窗口while(right < s.length()) {if(t_map.find(s[right]) != t_map.end()) {// t中含有右指针字符s_map[s[right]] += 1;if(s_map[s[right]] == t_map[s[right]]) {// 符合条件的字符计数 + 1++count;} }if(count == t_map.size()) {// 全部找齐了while(left <= right) {if(t_map.find(s[left]) != t_map.end()) {// t中含有左指针字符s_map[s[left]] -= 1;// 检验是否已不能覆盖if(s_map[s[left]] < t_map[s[left]]) {--count;// 记录最小子串if(min_length > right-left+1) {min_length = right-left+1;re = s.substr(left, min_length); }// break前记得再移动一次左指针++left;break;}} // 移动左指针++left;}}// 移动右指针++right;}return re;}
};
7. 环形链表
- 题目:https://leetcode.cn/problems/linked-list-cycle/
- 思路:
- 当然可以用hash set来做,每经过一个点检查这个点是否已经出现过即可;
- 但这题可以用一个相当巧妙的快慢双指针来判断;
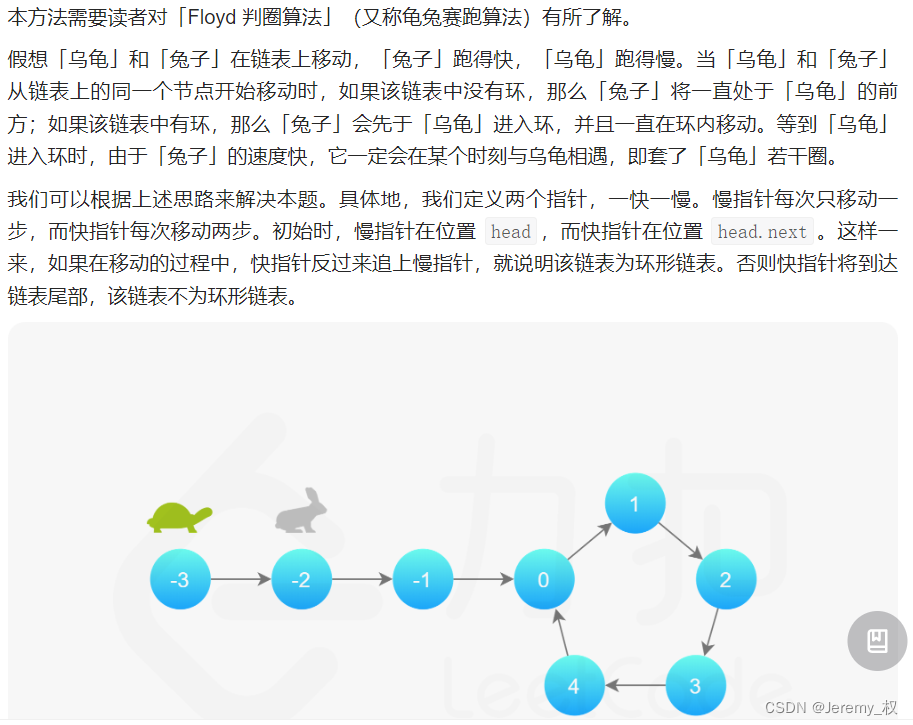
- 要点如下:
- 首先需要判断不含节点和只含一个节点的情况,它们都不可能出现环;
- 快慢指针初始的位置都在
head节点上,快指针每次都比慢指针多走一步; - 注意循环结束的条件是快慢指针有一个为空即可;
- 双指针的方法会比用hash set的速度快很多,因为不用把元素放入set和在set中判断是否有重复元素;
- 代码:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution {
public:bool hasCycle(ListNode *head) { if(head==nullptr || head->next == nullptr) {// 没有节点或仅有一个节点,则不可能成环return false;}ListNode *fast = head;ListNode *slow = head;while(fast!=nullptr && slow!=nullptr) {slow = slow->next;fast = fast->next;if(fast != nullptr) {// fast指针每次多走一步fast = fast->next;}if(slow == fast) {return true;}}return false;}
};
变体1. 环形链表 II
- 题目:https://leetcode.cn/problems/linked-list-cycle-ii/
- 思路:
- 增加的难度在于需要返回第一个入环的节点,而不只是判断是否有环;
- 当然可以用hash set来做,这样和单纯的判断是否有环实现完全相同,但空间复杂度是O(N);
- 如果是双指针的话就稍微复杂一点,需要两次相遇:
- 第一次如果能相遇,则说明存在环;
- 但还需要一次相遇找到第一个入环的节点;
- 简单来说就是再放一个
slow指针从head出发,直到和当前的slow指针相遇; - 推导过程如下:

- 关于为什么
slow指针在入环的第一圈内就能与fast相遇的一些通俗解释:

- 注意,上面的
n是指从环的角度来看,当前slow在fast前面n步; - 代码:
class Solution {
public:/*a:从head到第一个环节点经过的节点b:一个环的节点第一次相遇的时候,fast比slow多走n圈,有:slow: sfast: f = 2*s = s + nb 得s = nb如果要到第一个环节点,需要走:a + nb因此slow再走a个节点就到第一个环节点,这也正好是从head到第一个环节点距离所以还需要一个new_slow从head开始与slow第二次相遇*/ListNode *detectCycle(ListNode *head) {if(head == nullptr || head->next==nullptr) {// 空节点或者只有一个节点都不可能成环return nullptr;}ListNode *fast = head;ListNode *slow = head;while(fast!=nullptr && slow!=nullptr) {slow = slow->next;fast = fast->next;if(fast != nullptr) {fast = fast->next; // fast多走一步}if(slow == fast) {// 存在环,找第一个入环的节点fast = head; // fast充当new_slowwhile(fast != slow) {// 做第二次相遇fast = fast->next;slow = slow->next;}return slow;}}return nullptr;}
};
[8]. 相交链表
- 题目:https://leetcode.cn/problems/intersection-of-two-linked-lists/

- 思路:
- 和剑指offer算法题02中的3. 两个链表的第一个公共节点同题;
- 两个指针分别从两个
head出发,为空则跳到另一个head; - 关键是两个指针最后一定是相同的,无论是否存在公共节点;
- 代码:
class Solution {
public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {ListNode *pa = headA, *pb = headB;while(pa != pb) {if(pa != nullptr) {pa = pa->next;}else {pa = headB;}if(pb != nullptr) {pb = pb->next;}else {pb = headA;}}return pa;}
};
9. 移动零
- 题目:https://leetcode.cn/problems/move-zeroes/

-
思路:
-
当然可以使用类似冒泡排序的思路,时间复杂度是O(NlogN);
-
但更巧妙的是使用双指针,时间复杂度可以降为O(N);
- 首先将两个指针均移动到第一个
0的位置,此时左侧均为非0数; - 然后将右指针往右移动,遇到非
0数就和左指针交换; - 当右指针到结尾时,如果左指针还没有到结尾,就让它到结尾,并将移动过程中的数都置为
0; - 整个过程中最多遍历每个数两次;
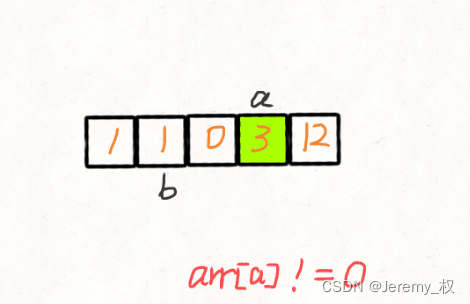
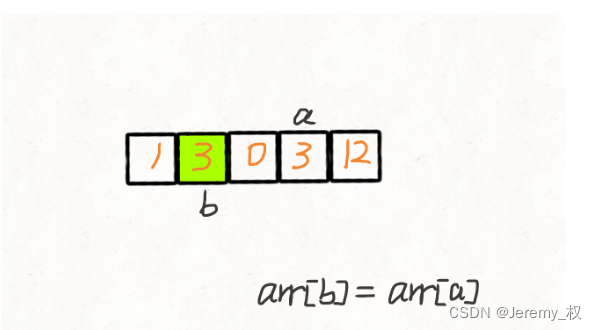
- 首先将两个指针均移动到第一个
-
代码:
class Solution {
public:void moveZeroes(vector<int>& nums) {int p1 = 0, p2 = 0;while(p1 < nums.size() && nums[p1] != 0) {// p1移动到第一个0处,左侧全为非0++p1;}p2 = p1;while(p2 < nums.size()) { // p2继续向右走,遇到非0则和p1交换值 if(nums[p2] != 0) {nums[p1] = nums[p2];++p1;}++p2;}while(p1 < nums.size()) {// 将剩余的值填0nums[p1] = 0;++p1;}}
};
10. 找到字符串中所有字母异位词 [滑动窗口]
- 题目:https://leetcode.cn/problems/find-all-anagrams-in-a-string/
- 思路:
- 用双指针来处理,形成滑动窗口,如果滑动窗口内的字符能够恰好覆盖匹配的字符,则记录下标即可;
- 如何判断滑动窗口内的字符恰好覆盖匹配的字符?
- 这里需要用两个哈希表,一个用于统计目标匹配的字符数量
cnt_map,一个统计当前滑动窗口能匹配的字符数量map; - 如何移动双指针?
- 这里需要分类讨论,边界的讨论比较繁琐,假设左指针
i和右指针j:- (1) 如果
s[j]是p中的字符,且map[s[j]]还没有放满,则将该字符放入map中,并++j; - 此时如果
map完全匹配cnt_map,则还要++i,让map空出位置来进行匹配; - (2) 如果
s[j]是p中的字符,但map[s[j]]已经满了,则移动左指针,同时将s[i]从map中取出,直到map可以放下s[j]为止; - (3) 如果
s[j]不是p中的字符,则移动左指针和右指针到j+1处(因为s[j]及之前的子串必定不满足条件),并在移动左指针的过程中把到j之前的s[i]从map中取出;
- (1) 如果
- 代码:
class Solution {
public:vector<int> findAnagrams(string s, string p) {unordered_map<char, int> cnt_map, map; // cnt_map用来统计p中字符出现的次数 for(char c:p) {++cnt_map[c];}vector<int> re;int rest_num = p.length(); int i = 0, j = 0;while(j < s.length()) { if(cnt_map[s[j]]>0 && map[s[j]]<cnt_map[s[j]]) {// 情况1:从map中填入p字符 ++map[s[j]];--rest_num;// 完整重排pif(rest_num == 0) {re.push_back(i);// 放字符放回map中--map[s[i]];++rest_num;// 移动左指针++i;}// 移动右指针++j;}else {if(cnt_map[s[j]] == 0) {// 情况3:p中不存在这个字符while(i < j) {// 放字符放回map中--map[s[i]];++rest_num;// 移动左指针++i;}++i;++j;}else {// 情况2:p中有这个字符但map放不下while(s[i] != s[j]) {--map[s[i]];++rest_num;++i;}++i;++j;}}}return re;}
};
11. 最短无序连续子数组
- 题目:https://leetcode.cn/problems/shortest-unsorted-continuous-subarray/

- 思路:
- 其实是有点贪心法+两遍双指针的感觉;
- 包含乱序的示意图如下:

- 则乱序区间中的数有以下特点,加粗的字表明了贪心规则:
- 从左往右扫描,乱序的右边界一定小于当前找到的最大值;
- 因为正常的数从左往右是升序,符合升序的数一定大于等于当前的最大值;
- 记录最后一个乱序的数就是乱序区间的右边界;
- 从右往左扫描,乱序的左边界一定大于当前找到的最小值;
- 因为正常的数从右往左是降序,符合降序的数一定小于等于当前的最小值;
- 记录最后一个乱序的数就是乱序区间的左边界;
- 因此进行两轮扫描即可找到乱序区间的左右边界;
- 之所以说是双指针,是因为每轮找边界的时候都需要一个指针进行遍历,一个指针记录在后面记录最后一个乱序的数;
- 当然,因为两轮扫描的长度是一样的,也可以把两轮扫描合并成一轮扫描;
- 注意,如果存在乱序区间,则乱序区间的长度至少是2;
- 代码:
class Solution {
public:int findUnsortedSubarray(vector<int>& nums) {int left = 0, right = -1;int max_num = INT_MIN, min_num = INT_MAX;for(int i=0;i<nums.size();++i) {if(max_num <= nums[i]) {// nums[i]越来越大,表明是正常升序max_num = nums[i];}else {// nums[i]是乱序,更新乱序的右边界right = i;}}for(int i=nums.size()-1;i>=0;--i) {if(min_num >= nums[i]) {// nums[i]越来越小,表明是正常降序min_num = nums[i];}else {// nums[i]是乱序,更新乱序的左边界left = i;}} // 如果right == left,则表明无乱序,因为不会存在长度为1的乱序// 如果right != left,则表明存在乱序,且乱序的长度必定大于等于2return right - left + 1;}
};
十一、堆
1. 数组中的第K个最大元素 [类快排查找]
- 题目:https://leetcode.cn/problems/kth-largest-element-in-an-array/
-
思路:
-
当然可以和求全部前
k个元素一样,用堆来做,实现参考:剑指offer算法题02中的十一、1. 最小的k个数,几乎是一样的,但用小顶堆,需要自定义排序函数,时间复杂度是O(Nlogk); -
用一般的排序则时间复杂度至少是O(NlogN);
-
另外,无论是求第
k个元素还是求前k个元素也可以用类快排方式来求解,加上随机策略之后平均时间复杂度是O(N),不加的话最差是O(N^2),比用堆的方法更慢; -
这里将实现类快排查找方式,实现过程如下:
- 随机选择一个
[low, high]之间的元素作为pivot,并把它交换到nums[low]处,而不是直接选择nums[low]作为pivot,这可以避免最差的时间复杂度是O(N^2); - 然后按照快排的思路,将
pivot移动到中间位置,左边的值均大于pivot,右边的值均小于pivot; - 如果当前
pivot的下标是k-1,则直接返回其值即是第k个元素,因为下标是从0开始的; - 如果
pivot的下标i小于k-1,则只搜索[i+1,high],否则,只搜索[low, i-1],也就是相比于快排只搜索一边;
- 随机选择一个
-
一些需要注意的点:
- 由于
pivot是从nums[low]开始的,所以指针的移动应该先移动j,从high向左移; - 实现的时候应该有两层
while循环,直至i和j指针相遇; - 每个
while和if判断都应该有i<j这个条件; - 结尾需要记得将
pivot重新赋值; - 如果要自己实现
swap函数,则直接用引用+临时变量即可;
- 由于
-
代码:
class Solution {
private:int re;void my_swap(int &a, int &b) {// 用引用+临时变量即可int temp = a;a = b;b = temp;}void quickFind(vector<int>& nums, int low, int high, int& k) {if(low > high) {// 和quickSort不一样,等号的时候也要走一遍,不然i==k-1可能无法取得return;}int i = low, j = high;// 引入随机选择pivot,能够避免最坏为O(n^2),整体是O(n)int rand_index = low + rand()%(high-low+1);my_swap(nums[low], nums[rand_index]);// 往下是快排的写法int pivot = nums[low]; while(i < j) {// 把pivot放到中间,前大后小while(i<j && pivot>=nums[j]){--j;}if(i < j) {nums[i] = nums[j]; // nums[j] = pivot++i;}while(i<j && pivot<=nums[i]) {++i;}if(i < j) {nums[j] = nums[i]; // nums[i] = pivot--j;}} // 重新赋值nums[i] = pivot;if(i == k-1) {re = nums[i];return;}else {// k-1在[low, i-1]中if(i > k-1) { quickFind(nums, low, i-1, k); }// k-1在[i+1, high]中if(i < k-1) { quickFind(nums, i+1, high, k); } }}
public:int findKthLargest(vector<int>& nums, int k) {quickFind(nums, 0, nums.size()-1, k);return re;}
};
2. 前 K 个高频元素 [类快排查找]
- 题目:https://leetcode.cn/problems/top-k-frequent-elements/?favorite=2cktkvj

- 思路:
- 和剑指offer算法题02中的十一、1. 最小的k个数几乎同题;
- 就是找出现频率最高的前
k个数; - 特殊之处,或者说增加的难度主要有两点:
- (1) 需要先统计出现的频率,而不是直接用数组的值;
- 对策是用
unordered_map来遍历一遍统计即可; - (2) 需要使用小顶堆,但标准的
priority_queue是大顶堆,需要进一步改造; - 对策是自定义排序函数,或者不用堆而用类快排的方式;
- 思路一:类快排查找
- 和快排类似的实现,但是只搜索一边即可;
- 注意的点如下:
- 需要另外定义一个
quickFind()函数,注意返回类型和快排一样也必须是void类型,参数包括数组arr,下标low和high,寻找的位置k,用递归实现; - 初始传入的下标必须是紧确界,都可以在数组中取到;
- 递归终止条件和快排不一样,范围要小一点,不能包含
low == high; - 用
while移动指针的时候注意等于的时候也需要移动; - 一定要用随机选择
pivot策略,否则时间复杂度的期望不能到O(N); - 发现结果的条件是
i == k-1,如果用k而且k == arr.size()时是找不到的,因为此时的k不在数组的下标范围内;
- 需要另外定义一个
- 代码:
class Solution {
private:vector<int> re;void quickFind(vector<pair<int, int>>& arr, int low, int high, int k) {// 等号也必须取到if(low > high) {return;} // 取随机数,[low, high]间有high-low+1个元素,1要加上int rand_index = low + rand()%(high - low + 1);swap(arr[low], arr[rand_index]);pair<int, int> pivot = arr[low];int i = low, j = high;while(i < j) {// 注意等于号while(i<j && arr[j].second<=pivot.second) {--j;}if(i<j) {arr[i] = arr[j];++i;}// 注意等于号while(i<j && arr[i].second>=pivot.second) {++i;}if(i<j) {arr[j] = arr[i];--j;}}arr[i] = pivot;// 一定要i==k-1,而不能i==k,否则如果k==arr.size()则是找不出的if(i == k-1) {//printf("k=%d\n", i);for(int index=0;index<=i;++index) {re.push_back(arr[index].first);}return;}else {if(i < k) {quickFind(arr, i+1, high, k);}else {quickFind(arr, low, i-1, k);}return;}}
public:vector<int> topKFrequent(vector<int>& nums, int k) {unordered_map<int, int> count_map;// 统计出现的次数for(int i=0;i<nums.size();++i) {if(count_map.find(nums[i]) == count_map.end()) {count_map[nums[i]] = 0;}++count_map[nums[i]];}// 转存到数组vector<pair<int, int>> count_arr;for(auto i=count_map.begin();i!=count_map.end();++i) {count_arr.push_back({i->first, i->second});}// 类快排查找// 注意上下界均是紧确界quickFind(count_arr, 0, count_arr.size()-1, k);return re;}
};
- 思路二:小顶堆
- 当然也可以用小顶堆来做,时间复杂度略高,但实际运行的时间不一定高多少;
- 找最大的
k个元素用小顶堆; - 找最小的
k个元素用大顶堆; - 自定义比较函数的方式有两种;
- (1) 用仿函数来实现:
- 这种方式是STL标准的实现方式,推荐使用;
- 参考cpp官方文档和博客:优先队列(priority_queue)–自定义排序;
- 代码:
class Solution {
private:// 仿函数struct cmp {bool operator() (const pair<int, int>& a, const pair<int, int>& b) {return a.second > b.second;}};
public:vector<int> topKFrequent(vector<int>& nums, int k) {unordered_map<int, int> count_map;// 统计出现的次数for(int i=0;i<nums.size();++i) {if(count_map.find(nums[i]) == count_map.end()) {count_map[nums[i]] = 0;}++count_map[nums[i]];}// 转存到小顶堆priority_queue<pair<int, int>, vector<pair<int, int>>, cmp> heap;for(auto i=count_map.begin();i!=count_map.end();++i) {if(heap.size() < k) {heap.push({i->first, i->second});}else {pair<int, int> tmp = heap.top();if(i->second > tmp.second) {heap.pop();heap.push({i->first, i->second});}}}// 记录到数组vector<int> re;while(!heap.empty()) {re.push_back(heap.top().first);heap.pop();}return re;}
};
- (2) 用普通的函数指针来实现:
- 这种写法是leetcode官方题解给出的,似乎是C++11新标准的写法;
- 使用了
decltype()函数,用于返回传入参数的类型; - 注意
cmp是一个静态函数; - 代码:
class Solution {
private:static bool cmp(const pair<int, int>& a, const pair<int, int>& b) {return a.second > b.second;}
public:vector<int> topKFrequent(vector<int>& nums, int k) {unordered_map<int, int> count_map;// 统计出现的次数for(int i=0;i<nums.size();++i) {if(count_map.find(nums[i]) == count_map.end()) {count_map[nums[i]] = 0;}++count_map[nums[i]];}// 转存到小顶堆priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(&cmp)> heap(cmp);for(auto i=count_map.begin();i!=count_map.end();++i) {if(heap.size() < k) {heap.push({i->first, i->second});}else {pair<int, int> tmp = heap.top();if(i->second > tmp.second) { heap.pop();heap.push({i->first, i->second});}}}// 记录到数组vector<int> re;while(!heap.empty()) {re.push_back(heap.top().first);heap.pop();}return re;}
};
- 另外,
sort函数的cmp可以用函数指针,也可以用仿函数,但用仿函数的时候用的是T()的形式而不是T,实际上传入的参数仍然是函数指针而不是类对象,参考博客:C++ 仿函数和自定义排序函数的总结;
补充:关于priority_queue的自定义cmp
- 推荐使用仿函数的形式;
- 仿函数的定义如下:
// 仿函数
struct cmp {bool operator() (const T& a, const T& b) {return a严格小于b的条件;}
};
priority_queue的定义如下:
priority_queue<T, vector<T>, cmp> heap;
- 有三个参数类型的说明;
- 因为
priority_queue是vector的配接器,所以要显式给出vector的类型; - 不是
cmp(),而是直接传入整个仿函数类类型cmp; - 如果是标准类型,如
int,也可以直接用STL中的标准greater仿函数,用法如下:
priority_queue<int, vector<int>, greater<int>> heap;
十二、贪心法
1. 跳跃游戏
- 题目:https://leetcode.cn/problems/jump-game/
-
思路:
-
本来还打算用动态规划来做的,但动态规划时间复杂度是O(N2)O(N^2)O(N2),因为对每个
i判断dp[i]是否可达,都要遍历它前面的位置看是否有机会到i; -
其实直接用贪心法就可以了,时间复杂度是O(N)O(N)O(N);
-
核心点:
- 从前往后遍历;
- 记录当前可达的最远下标;
- 遍历一旦超过最远下标即终止;
- 最后如果最远下标大于等于数组的长度,即说明可达整个数组,返回
true;
-
另外要注意遍历时不要超过数组的长度;

-
代码:
class Solution {
public:bool canJump(vector<int>& nums) {int max_reach = 0;int cur = 0;while(cur <= max_reach && cur < nums.size()) {// 仅当cur处于最大可达距离内才遍历max_reach = max(cur + nums[cur], max_reach);++cur;}if(max_reach >= nums.size()-1) {return true;}else {return false;}}
};
2. 合并区间
- 题目:https://leetcode.cn/problems/merge-intervals/

-
思路:
-
先排序,再顺次遍历合并;
-
合并[L1,R1][L_1,R_1][L1,R1]和[L2,R2][L_2,R_2][L2,R2]时:
- 如果R1>=L2R_1>=L_2R1>=L2,则两个区间可合并;
- 如果R1>R2R_1>R_2R1>R2,则合并后的区间是[L1,R1][L_1,R_1][L1,R1],否则为[L1,R2][L_1,R_2][L1,R2];
- 如果不能合并就尝试进行下一个区间的合并;
-
可以证明如果先排序再这样处理是肯定不会漏掉某个能够合并的区间的,证明如下;

-
代码:
class Solution {
public:// 必须是static,因为是成员函数,不用static的话不能在sort中使用// 但如果不是成员函数的话就不需要用static// 传入的参数用引用的话时间和空间都能极大地节省static bool cmp(vector<int>& a, vector<int>& b) {if(a[0] < b[0]) {return true;}if(a[0] > b[0]) {return false;}else {if(a[1] < b[1]) {return true;}else {return false;}}}vector<vector<int>> merge(vector<vector<int>>& intervals) {sort(intervals.begin(), intervals.end(), cmp);vector<vector<int>> re;int i = 0;while(i < intervals.size()) {vector<int> tmp = intervals[i];++i;while(i < intervals.size() && tmp[1] >= intervals[i][0]) {// 注意比较前一个区间的右区间和下一个区间的右区间的大小tmp[1] = max(tmp[1], intervals[i][1]);++i;}re.push_back(tmp);}return re;}
};
补充:关于sort函数的自定义cmp
bool类型返回值;- 传入两个参数
a和b应当用const和引用&修饰,以减少空间和时间开销(很重要!); - 为
true代表a排在b前面; - 如果是成员函数,应当使用
static+private修饰,否则则不需要; vector和string类型都可以用sort进行排序;- 一个例子如上所示;
- 特别注意的是:为
true的时候必须是严格小于,=的情况下不能返回true值,否则存在相等值时递归的过程可能会陷入死循环或者空递归;
3. 根据身高重建队列
- 题目:https://leetcode.cn/problems/queue-reconstruction-by-height/

- 思路:
- 共有两个限制
[h_i, k_i]; - 贪心法实现如下:
- 先按照
h_i来从高到低排序; - 然后依次遍历每个人,把它插入到从前往后数的第
k_i个位置上;
- 先按照
- 为什么贪心法可以奏效?
- 首先对遍历到的第
i个人来说,必定有k_i <= i,也就是说插入的操作是往前面已经排好的队伍里面插入; - (1) 对于第
i个人来说,这样的插入一定是满足条件的,因为前面的人都比它高,所以它放在哪个位置就k_i是多少; - (2) 对于前面已经排好的人来说,因为第
i个人比它们矮,所以无论第i个人插入到哪个位置都不会改变它们原来的k_i值,所以也满足条件; - 于是每处理一个人,满足条件的人数就加一,遍历完后就是结果;
- 首先对遍历到的第
- 代码:
- 插入的操作最好是用
list容器来进行; - 注意容器的迭代器使用,取值用
(*i),需要加括号,而取指针i->等价于先取(*i)再(*i)->; for循环的终止条件用的是!=container.end();list.insert()的第一个参数是迭代器,必须通过list.begin()自增(迭代器自增已重载)得到;- 而且
list底层是双向环状链表,本身也不支持随机读取的逻辑; - 当然,如果是
vector的迭代器,因为它的空间本来就是连续的,而且迭代器本质上是普通指针,所以用vector.begin() + int的形式也可以;
class Solution {
private:static bool cmp(const vector<int>& a, const vector<int>& b) {if(a[0] > b[0]) {return true;}else {if(a[0] == b[0] && a[1] < b[1]) {return true;} }return false;}
public:vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {// 排序peoplesort(people.begin(), people.end(), cmp);list<vector<int>> re_list;for(auto i=people.begin();i!=people.end();++i) {// 顺序遍历,并依次把每个元素插入到第k_i个位置int tmp = (*i)[1];auto tmp_it = re_list.begin();while(--tmp >= 0) {++tmp_it;}re_list.insert(tmp_it, *i); // insert函数是在position之前插入// print_info// for(auto j=re_list.begin();j!=re_list.end();++j) {// printf("[%d, %d], ",(*j)[0], (*j)[1]);// }// printf("\n");}vector<vector<int>> re;for(auto i=re_list.begin();i!=re_list.end();++i) {re.push_back(*i);}return re;}
};
4. 任务调度器
- 题目:https://leetcode.cn/problems/task-scheduler/

- 思路:
- 当然可以按照题目的思路来模拟一下整个调度的过程,每次选不在等待时间内而且剩余执行次数最多的任务来执行即可;
- 但实际上可以构造一个二维矩阵(桶),通过讨论这个矩阵获得最短执行时间,如下:



- 一些自己的推导过程见下面代码的注释部分;
- 代码:
class Solution {
public:/*贪心法:1. 先找出执行次数最多的任务,记录次数为k,如果有并列最多的,记录并列数为x2. 构建一个k行n+1列的矩阵,且最后一行仅有x个任务,这样:(1) 只要每一行内的任务类型不重复,则不会发生有任务处于待命状态而冲突(2) 相同类型的任务填入不同行也不会发生冲突(3) 如果矩阵填不满,则所需要的最短时间不会变,仍然是填满矩阵的时间(4) 如果矩阵填满而且超出,则每一行可以增加列来填入也就是能够安排一种方案让所有任务都不需要等待执行3. 则完成任务的时间为:(1) (k-1) * (n+1) + x, if 填不满或刚好填满(2) tasks.size(), if 超出*/int leastInterval(vector<char>& tasks, int n) {// 桶计数vector<int> bucket_count(26, 0);int k = 0; // 执行次数最多的任务的执行次数int x = 0; // 有并列最多的任务的并列数for(int i=0;i<tasks.size();++i) {++bucket_count[tasks[i]-'A'];if(bucket_count[tasks[i]-'A'] > k) {k = bucket_count[tasks[i]-'A'];x = 1;}else {if(bucket_count[tasks[i]-'A'] == k) {++x;}}}// 注意size()返回的是unsigned_int类型,需要做类型转换return max(int(tasks.size()), (k - 1) * (n + 1) + x);}
};
补充:C++的显式强制类型转换
- 当然可以直接用
(转换后类型)(转换前变量)的方式做强制类型转换,例如int(),double(),(unsigned int)()等; - 但这种方式有三个不足:
- 在调试的时候没有办法快速帮助定位这些强制类型转换,毕竟它的写法和变量的类型定义一模一样,很难通过查找代码的方式快速找到哪些地方用了强制类型转换,之所以需要查找是因为有不少的Bug会出现在强制类型转换的数据丢失上;
- 在形式上很难区分当前的类型转换的意图;
- 不能检查强制类型转换的安全性;
- 因此,C++提供了另外的四种强制类型转换符,如下:
- (1)
static_cast<转换后类型>(转换前变量):- 用于基本数据类型之间的转换;
- 用于调用类重载的强制类型转换运算符;
- 不能进行指针类型和普通类型之间的转换;
- 不能去除常量属性;
- 总的来说,它负责一些安全性高的转换,使用的优先级最高,但它并不提供检查来确保转换的安全性;
- (2)
dynamic_cast<转换后类型>(转换前变量):- 主要用于多态基类指针或者引用转换为派生类指针或者引用(下行转换),且提供安全性检查:如果基类指针确实是指向了要转换的派生类对象,则转换成功,否则,返回空指针;
- 在派生类指针或者引用转换成基类指针或者引用(上行转换),dynamic_cast的效果和static_cast一致,因为转换的安全性比较高;
- 也就是说,允许基类指针指向派生类对象,因为所有功能派生类都有,但不允许派生类指针指向基类对象,因为某些功能基类并没有;
- (3)
const_cast<转换后类型>(转换前变量):- 仅用于带常量属性的指针或者引用向非常量属性指针或者引用的转换,常量属性包括
const、volatile和__unaligned; - 尽量不要使用,因为会破环
const;
- 仅用于带常量属性的指针或者引用向非常量属性指针或者引用的转换,常量属性包括
- (4)
reinterpret_cast<转换后类型>(转换前变量):- 用于不同类型指针之间的转换;
- 用于不同类型引用之间的转换;
- 主要用于指针和能容纳指针的整数类型之间的转换;
- 底层执行的是逐比特的复制操作;
- 拥有最强的转换灵活性,其他类型不能转的它都能转,但是不提供转换的安全性,使用的优先级最低;
- (1)
十三、图
1. 课程表 [有向无环图]
- 题目:https://leetcode.cn/problems/course-schedule/
-
思路:
-
本质是判断图是不是一个有向无环图;
-
等价于能不能从图中获得一个拓扑排序;
-
关于拓扑排序的一些介绍:

-
拓扑排序方法如下:

-
维护入度为
0是通过队列来实现的,所以相当于是广度优先遍历; -
但本质上就是不断找当前入度为
0的节点然后解除它们的入度,也可以用循环来找,空间复杂度低,但时间复杂度会高; -
代码:
-
队列实现版本:
class Solution {
public:/*1. 本质上是判断当前有向图中是否存在环2. 可以转换成是否能够从有向图中获得一个拓扑排序如果可以获得,则无环,反之则有环;3. 拓扑排序是:1) 每次取入度为0的节点2) 直至全部取完,则无环;3) 或无入度为0的节点但未取完,则有环;*/bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {vector<int> indegree(numCourses, 0);// 统计入度for(int i=0;i<prerequisites.size();++i) {++indegree[prerequisites[i][0]];}int remain_node = numCourses;queue<int> q;// 获得入度为0的队列for(int i=0;i<numCourses;++i) {if(indegree[i] == 0) {q.push(i);}}// 获得拓扑排序while(!q.empty() && remain_node>0) {int delete_node = q.front();--remain_node;for(int j=0;j<prerequisites.size();++j) {if(prerequisites[j][1] == delete_node) {--indegree[prerequisites[j][0]];if(indegree[prerequisites[j][0]] == 0) {q.push(prerequisites[j][0]);}}}q.pop();}return remain_node==0;}
};
- 另外有循环实现的版本;
- 特别注意循环查的时候已经处理过的入度为
0的节点一定要避免再次处理;
class Solution {
public:/*1. 本质上是判断当前有向图中是否存在环2. 可以转换成是否能够从有向图中获得一个拓扑排序如果可以获得,则无环,反之则有环;3. 拓扑排序是:1) 每次取入度为0的节点2) 直至全部取完,则无环;3) 或无入度为0的节点但未取完,则有环;*/bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {vector<int> indegree(numCourses, 0);// 统计入度for(int i=0;i<prerequisites.size();++i) {++indegree[prerequisites[i][0]];}int remain_node = numCourses;// 获得拓扑排序bool is_end = false;while(!is_end && remain_node>0) {is_end = true;for(int i=0;i<numCourses;++i) {if(indegree[i] == 0) {is_end = false;--remain_node;// 注意入度为0的节点要确保只处理一次--indegree[i];for(int j=0;j<prerequisites.size();++j) {if(prerequisites[j][1] == i) {--indegree[prerequisites[j][0]];}}break;}}}return remain_node==0;}
};
补充:无向图和有向图判断是否存在环的方法

- 有向图推荐用拓扑排序;
- 无向图推荐用数学方法:
- 如果是无环的话,边数最大只能为节点数-1;
- 如果边数超过节点数-1就表明必定存在环;
- 判断比有向图简单;
其他类型:
1. 多数元素
- 题目:https://leetcode.cn/problems/majority-element/

- 思路:
- 和剑指offer算法题02中的1. 数组中出现次数超过一半的数字同题;
- 代码:
class Solution {
public:/*摩尔投票法*/int majorityElement(vector<int>& nums) {int major;int votes = 0;for(int i=0;i<nums.size();++i) {if(votes == 0) {major = nums[i];++votes;}else {if(major == nums[i]) {++votes;}else {--votes;}}}return major;}
};
[2]. 除自身以外数组的乘积
- 题目:https://leetcode.cn/problems/product-of-array-except-self/
- 思路:
- 就是分两次遍历,得到一个前缀乘积列表和一个后缀乘积列表;
- 然后再进行一次遍历,通过前缀和后缀乘积相乘可以得到结果;
- 当然也可以两次甚至一次遍历完成,但下标的处理会复杂一些;
- 和剑指offer算法题02中的其他类型、4. 构建乘积数组同题;
- 代码:
class Solution {
public:vector<int> productExceptSelf(vector<int>& nums) {int n = nums.size();vector<int> pre_multipy(nums.size(), 0); // 到i的前向乘积(含i)vector<int> post_multipy(nums.size(), 0); // 到j的后向乘积(含j)// 计算前向乘积pre_multipy[0] = nums[0];for(int i=1;i<n;++i) {pre_multipy[i] = pre_multipy[i-1] * nums[i];}// 计算后向乘积post_multipy[n-1] = nums[n-1];for(int i=n-2;i>=0;--i) {post_multipy[i] = post_multipy[i+1] * nums[i];}// 计算结果vector<int> re(n, 0);re[0] = post_multipy[1];re[n-1] = pre_multipy[n-2];for(int i=1;i<n-1;++i) {re[i] = pre_multipy[i-1] * post_multipy[i+1];}return re;}
};
相关文章:
LeetCodeHOT100热题02
写在前面 主要是题目太多,所以和前面的分开来记录。有很多思路的图都来源于力扣的题解,如侵权会及时删除。不过代码都是个人实现的,所以有一些值得记录的理解。之前的算法系列参看: 剑指offer算法题01剑指offer算法题02 七、动…...
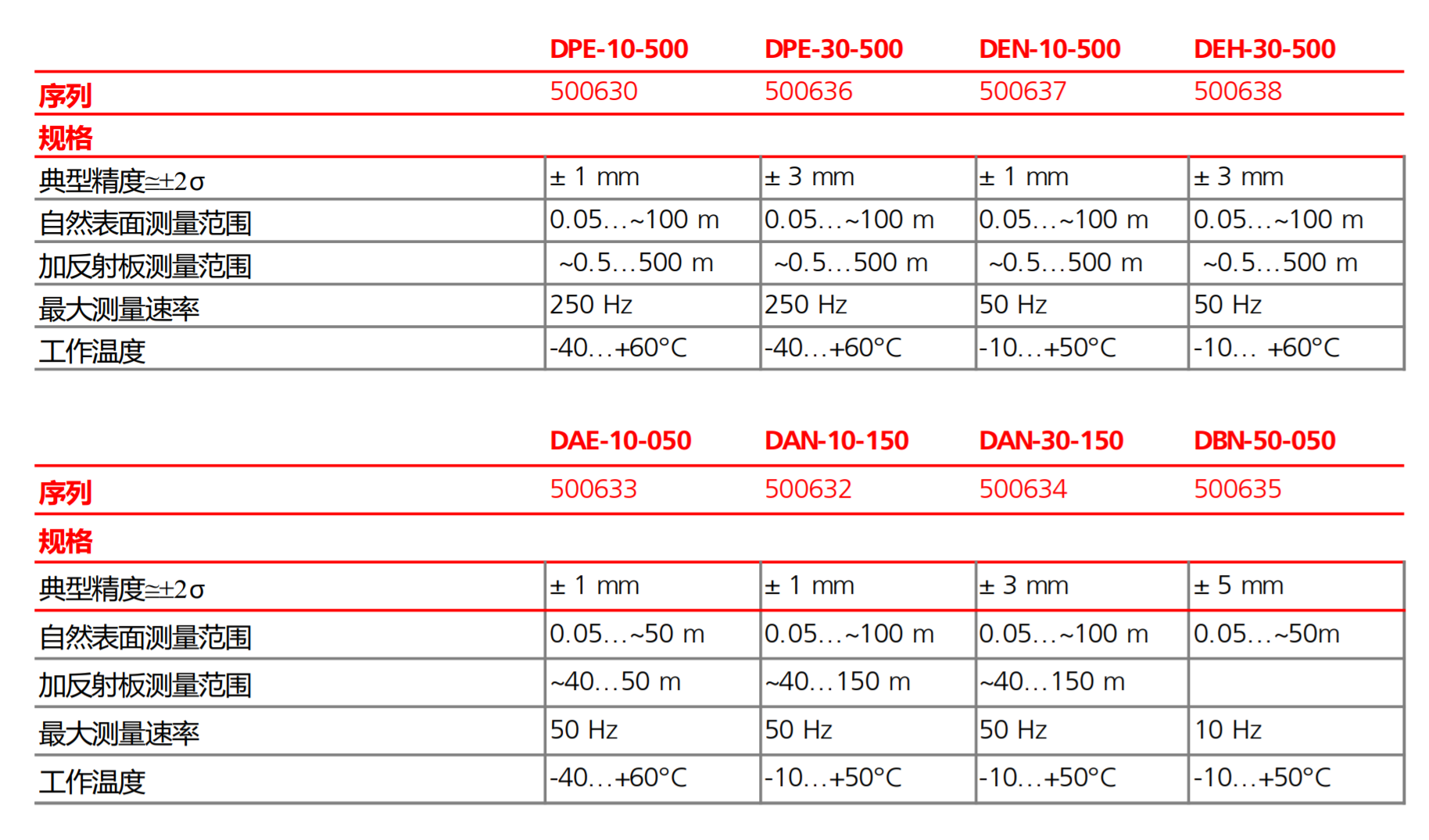
虹科Dimetix激光测距仪在锯切系统中的应用
HK-Dimetix激光测距仪——锯切系统应用 许多生产设施,例如金属服务中心,使用切割锯将每个客户的订单切割成一定长度。定长切割过程通常涉及卷尺和慢跑锯的传送带。但更简单的替代方法是使用虹科Dimetix非接触式激光距离传感器。 为了切断大长度的棒材&…...

FreeRTOS入门(02):任务基础使用与说明
文章目录目的创建任务任务调度任务控制延时函数任务句柄获取与修改任务优先级删除任务挂起与恢复任务强制任务离开阻塞状态空闲任务总结目的 任务(Task)是FreeRTOS中供用户使用的最核心的功能,本文将介绍任务创建与使用相关的基础内容。 本…...

ESP通过乐为物联控制灯,微信发送数值,ESP上传传感器数据
暂时放个程序 //ME->>{“method”: “update”,“gatewayNo”: “01”,“userkey”: “2b64c489d5f94237bcf2e23151bb7d01”}&^! //Ser->>{“f”:“message”,“p1”:“ok”}&^! //ME->>{“method”: “upload”,“data”:[{“Name”:“A1C”,“Val…...
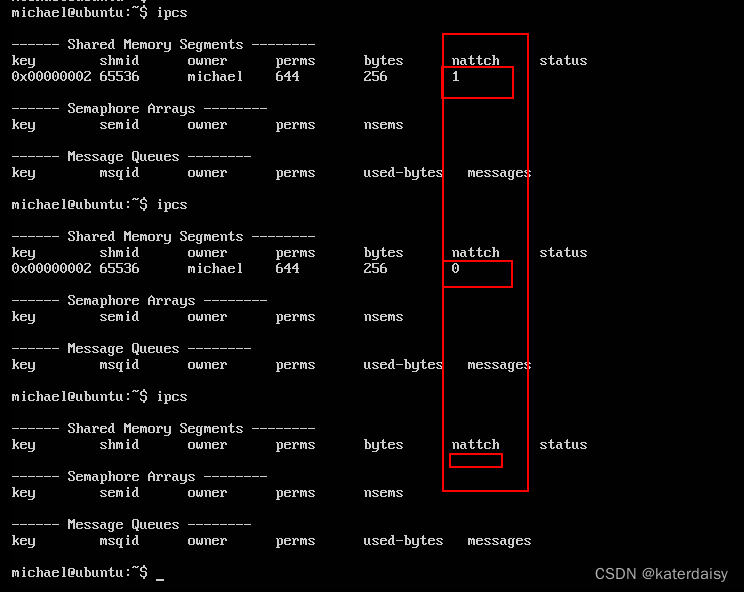
Linux:共享内存api使用
代码: #include <stdlib.h> #include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <string.h> #include <arpa/inet.h> #include <sys/un.h> #include <sys/ipc.h…...

android9.0 java静态库操作JNI实例 动态注册
一、java层 源码 目录:/Demo/java/com/android/simpleini/SimpleJNI.java package com.example.simplejni;import android.app.Activity; import android.os.Bundle; import android.widget.TextView;public class SimpleJNI {private IpoManagerService(Context …...

自定义复杂图片水印
我的社交能力还不如5岁儿童和狗。 文章目录前言一、主要工具类总结前言 之前写过一些简单的图片压缩和图片加水印:JAVA实现图片质量压缩和加水印 本次主要是针对图片加水印进行一个升级,图片水印自定义,自适应大小。 来,先看几…...

文章读后感——《人间清醒,内容为王》
观后感 人间清醒,内容为王 - 技术er究竟该如何写博客?1024上海嘉年华之敖丙演讲观后感。 致敬愿意带领后生的前辈——哈哥 哈哥,《人间清醒,内容为王》这篇,我的鱼获, 是里面传递出来写技术博客的思维与想法…...

51单片机入门 - 驱动多位数码管
我使用的是普中51单片机开发板A2套件(2022),驱动数码管可能需要参考电路原理图。开发环境的搭建教程在本专栏的 51单片机开发环境搭建 - VS Code 从编写到烧录 有过介绍。 关于我的软硬件环境信息: Windows 10STC89C52RCSDCC &am…...

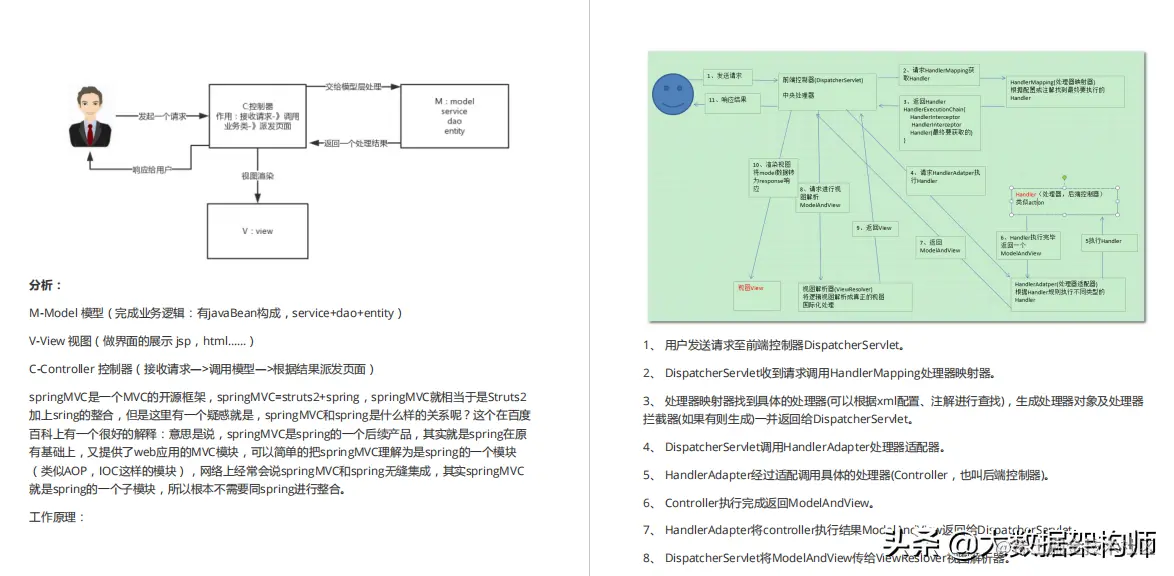
Java进击框架:Spring(一)
Java进击框架:Spring(一)前言创建Spring项目Spring IoC容器和Beans介绍Bean的概述Spring IoC配置元数据实例化Bean依赖注入循环依赖详细配置生命周期回调Bean定义继承基于注解的容器配置Component和进一步的原型注解自动检测类和注册Bean定义…...
)
Java笔记(18)
目录 什么是mvc? 什么是SpringMVC Spring MVC的特点: 原理: 什么是Thymeleaf? thymeleaf依赖包:...

【免费教程】地下水环境监测技术规范HJ/T164-2020解读使用教程
地下水环境监测技术规范依据《中华人民共和国环境保护法》第十一条“国务院环境保护行政主管部门建立监测制度、制订监测规范”和《中华人民共和国水污染防治法》的要求,积极开展地下水环境监测,掌握地下水环境质量,保护地下水水质࿰…...

Html 代码学习
场景:在页面中插入音频 代码 常见属性: src 音频的路径 controls 显示播放的控件 autoplay 自动播放 loop 循环播放 场景:在页面中插入视频 代码 常见属性: src 路径 controls 显示播放的控件 autoplay 自动播放 要配合muted 例如 autoplay muted loop 循环播放 链接 /…...
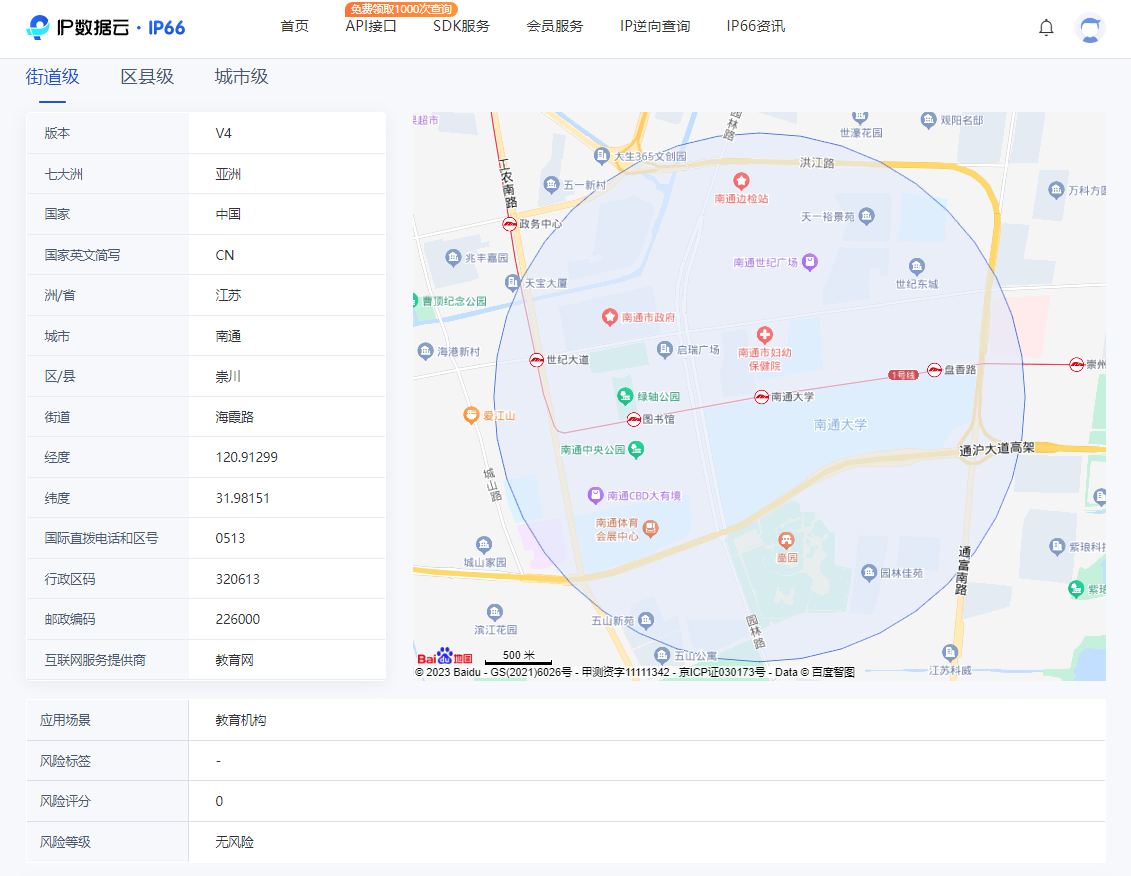
如何通过IP找到地址?
在我们印象中,我们都知道可以通过 IP 地址找到某个人。但当我们细想一下,我们会发现其实 IP 地址与地理位置并不是直接相关的。那我们到底是如何通过 IP 地址找到地址的呢?答案是:通过自治系统(Autonomous System&…...
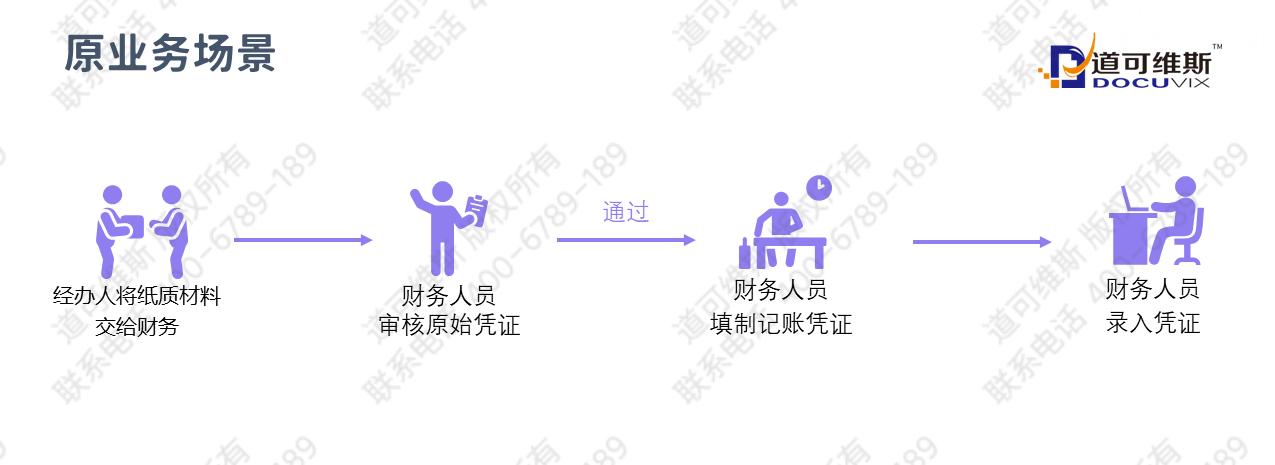
业务单据堆积如山?如何提升会计做账效率?
某集团以“创建现代能源体系、提高人民生活品质”为使命,形成了贯通下游分销、中游贸易储运、上游生产的清洁能源产业链和涵盖健康、文化、旅游、置业的生命健康产品链。目前,某集团在全国21个省,为超过2681万个家庭用户、21万家企业提供能源…...

华为OD机试题,用 Java 解【VLAN 资源池】问题
最近更新的博客 华为OD机试 - 猴子爬山 | 机试题算法思路 【2023】华为OD机试 - 分糖果(Java) | 机试题算法思路 【2023】华为OD机试 - 非严格递增连续数字序列 | 机试题算法思路 【2023】华为OD机试 - 消消乐游戏(Java) | 机试题算法思路 【2023】华为OD机试 - 组成最大数…...
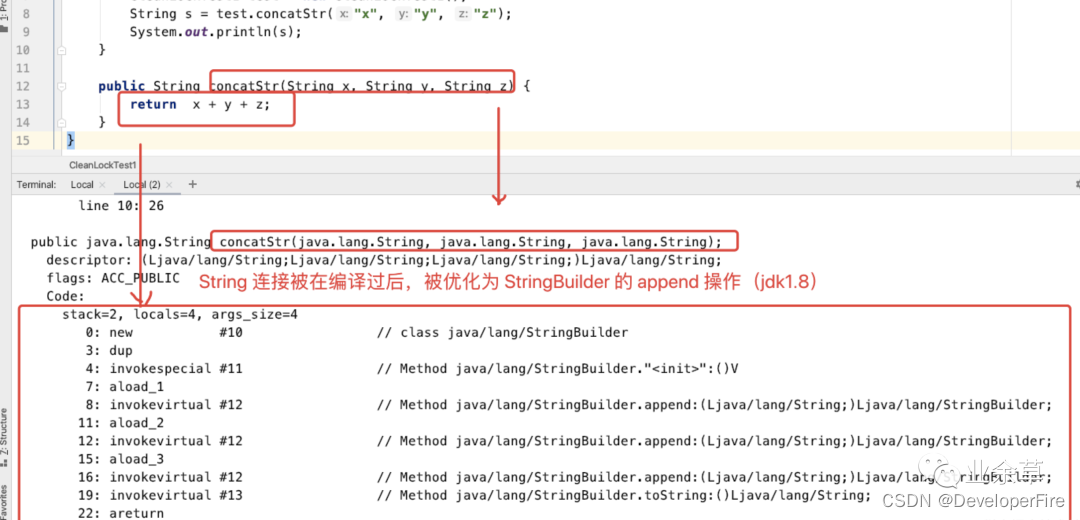
面试加分项:JVM 锁优化和逃逸分析详解
1 锁优化JVM 在加锁的过程中,会采用自旋、自适应、锁消除、锁粗化等优化手段来提升代码执行效率。1.1 自旋锁和自适应自旋现在大多的处理器都是多核处理器 ,如果在多核心处理器,有让两个或者以上的线程并行执行,我们可以让一个等待…...

C++继承、构造函数和析构函数
构造函数 与 析构函数 构造函数代表一个对象的生成,主要作用是初始化类的成员变量,可以被重载 如果没有显式构造函数,则实例化对象时,系统会自动生成一个无参的构造函数 构造函数的名称与类名相同 析构函数代表的是一个对象的销…...
)
Python如何实现异步并发之async(1)
前言 本文是该专栏的第14篇,后面会持续分享python的各种干货知识,值得关注。 在python中使用async方式,实现异步并发,而本文笔者提到的代码案例仅支持python3.7及以上版本,这主要在于不同的版本之间都更新了异步的使用方法,这点暂时不详述了。 而所谓的异步,通常就是程…...
震撼!阿里首次开源 Java 10万字题库,Github仅一天星标就超60K
程序员面试 现在是程序员找工作、跳槽最重要的月份。随着行业的发展程序员面试也越来越难,面试中都是7分的能力,再加上3分的技巧; 对于应聘者,重中之重的就是简历,面试前一定要将最拿手和最能吸引面试官的技能在简历…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...