LeetCode Cookbook 哈希表(collections.Counter()和collections.defaultdict())
好久不更了,这次一鼓作气,学完它!
文章目录
- LeetCode Cookbook 哈希表
- 30. 串联所有单词的子串
- 36. 有效的数独(很不错的循环题目)
- 49. 字母异位词分组
- 290. 单词规律
- 447. 回旋镖的数量
- 575. 分糖果
- 594. 最长和谐子序列
- 599. 两个列表的最小索引总和
- 648. 单词替换(字典树 Trie)
- 676. 实现一个魔法字典
- 705. 设计哈希集合
- 745. 前缀和后缀搜索
- 811. 子域名访问计数
- 884. 两句话中的不常见单词
- 961. 在长度 2N 的数组中找出重复 N 次的元素
- 1207. 独一无二的出现次数
- 总结
LeetCode Cookbook 哈希表
本节是与哈希表相关的习题,非常不错的17道题,在这里分享给大家,如果喜欢的话,欢迎点赞收藏家关注哦!
30. 串联所有单词的子串
题目链接:30. 串联所有单词的子串
题目大意:给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
例如,如果 words = [“ab”,“cd”,“ef”], 那么 “abcdef”, “abefcd”,“cdabef”, “cdefab”,“efabcd”, 和 “efcdab” 都是串联子串。 “acdbef” 不是串联子串,因为他不是任何 words 排列的连接。
返回所有串联字串在 s 中的开始索引。你可以以 任意顺序 返回答案。
注意:(1)1 <= s.length <= 10410^4104;(2)1 <= words.length <= 5000;(3)1 <= words[i].length <= 30;(4)words[i] 和 s 由小写英文字母组成
例如:
输入:s = "barfoothefoobarman", words = ["foo","bar"]
输出:[0,9]
解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。
子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。
输出顺序无关紧要。返回 [9,0] 也是可以的。输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
输出:[]
解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。
所以我们返回一个空数组。输入:s = "barfoofoobarthefoobarman", words = ["bar","foo","the"]
输出:[6,9,12]
解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。
子串 "foobarthe" 开始位置是 6。它是 words 中以 ["foo","bar","the"] 顺序排列的连接。
子串 "barthefoo" 开始位置是 9。它是 words 中以 ["bar","the","foo"] 顺序排列的连接。
子串 "thefoobar" 开始位置是 12。它是 words 中以 ["the","foo","bar"] 顺序排列的连接。
- 解题思路: 哈希表比较容易理解一些。
- 时间复杂度:O(n2)O(n^2)O(n2) 方法1滑动窗口为O(n)O(n)O(n)
- 空间复杂度:O(n)O(n)O(n)
class Solution:def findSubstring(self, s: str, words: List[str]) -> List[int]:if not s or not words: return []one_word =len(words[0])all_words = one_word*len(words)n = len(s)nums = len(words)if n<one_word: return []words = Counter(words)ans = []# 方法1 滑动窗口# for i in range(0,one_word):# cur_cnt = 0# left,right = i,i# cur_Counter = Counter()# while right+one_word <= n:# w = s[right:right+one_word]# right += one_word# if w not in words:# left = right# cur_Counter.clear()# cur_cnt = 0# else:# cur_Counter[w] += 1# cur_cnt += 1# while cur_Counter[w] > words[w]:# left_w = s[left:left+one_word]# left += one_word# cur_Counter[left_w] -= 1# cur_cnt -= 1# if cur_cnt == nums:# ans.append(left)# return ans# hash 表for i in range(n-all_words+1):tmp = s[i:i+all_words]c_tmp = []# 把单词分割一下一个一个往里放for j in range(0,all_words,one_word):c_tmp.append(tmp[j:j+one_word])# 使用计数器看一下 是不是子单词都齐全了if Counter(c_tmp) == words:ans.append(i)return ans
36. 有效的数独(很不错的循环题目)
题目链接:36. 有效的数独
题目大意:请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。
1.数字 1-9 在每一行只能出现一次。
2.数字 1-9 在每一列只能出现一次。
3.数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
注意:
(1)一个有效的数独(部分已被填充)不一定是可解的。
(2)只需要根据以上规则,验证已经填入的数字是否有效即可。
(3)空白格用 ‘.’ 表示。
(4)board.length == 9;board[i].length == 9;board[i][j] 是一位数字(1-9)或者 ‘.’。
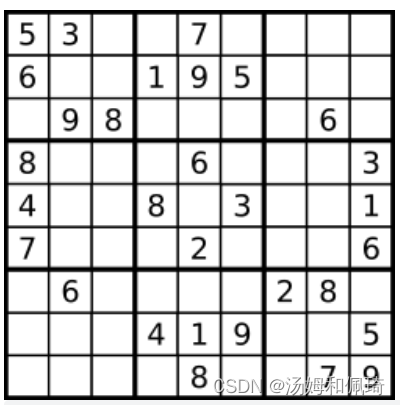
例如:
输入:board =
[["5","3",".",".","7",".",".",".","."]
,["6",".",".","1","9","5",".",".","."]
,[".","9","8",".",".",".",".","6","."]
,["8",".",".",".","6",".",".",".","3"]
,["4",".",".","8",".","3",".",".","1"]
,["7",".",".",".","2",".",".",".","6"]
,[".","6",".",".",".",".","2","8","."]
,[".",".",".","4","1","9",".",".","5"]
,[".",".",".",".","8",".",".","7","9"]]
输出:true
- 解题思路:写好循环,注意九宫格的第三个要求,可以适当记忆一下。在固定的个9*9数据计算中,复杂度不随数据变化而变化。
- 时间复杂度:O(1)O(1)O(1)
- 空间复杂度:O(1)O(1)O(1)
class Solution:def isValidSudoku(self, board: List[List[str]]) -> bool:# 行、列、块row = [[]*9 for _ in range(9)]col = [[]*9 for _ in range(9)]nine = [[]*9 for _ in range(9)]for i in range(9):for j in range(9):tmp = board[i][j]if not tmp.isdigit():continue# 是否同行或同列出现相同的if tmp in row[i] or tmp in col[j]:return False# 判断九宫格if tmp in nine[(j//3)*3+i//3]:return Falserow[i].append(tmp)col[j].append(tmp)nine[(j//3)*3+i//3].append(tmp)return True
49. 字母异位词分组
题目链接:49. 字母异位词分组
题目大意:给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
注意:(1)1 <= strs.length <= 10410^4104;(2)0 <= strs[i].length <= 100;(3)strs[i] 仅包含小写字母。
例如:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]输入: strs = [""]
输出: [[""]]输入: strs = ["a"]
输出: [["a"]]
- 解题思路:注意字符串连接排序后的字符数组需要连接。
- 时间复杂度:O(n(k+∣Σ∣))O(n(k+∣\Sigma∣))O(n(k+∣Σ∣)),其中 nnn 是 strs\textit{strs}strs 中的字符串的数量,kkk 是 strs\textit{strs}strs 中的字符串的的最大长度,Σ\SigmaΣ 是字符集,在本题中字符集为所有小写字母,∣Σ∣=26|\Sigma|=26∣Σ∣=26。需要遍历 nnn 个字符串,对于每个字符串,需要 O(k)O(k)O(k) 的时间计算每个字母出现的次数,O(∣Σ∣)O(|\Sigma|)O(∣Σ∣)的时间生成哈希表的键,以及 O(1)O(1)O(1) 的时间更新哈希表,因此总时间复杂度是 O(n(k+∣Σ∣))O(n(k+|\Sigma|))O(n(k+∣Σ∣))。
- 空间复杂度:O(n(k+∣Σ∣))O(n(k+∣\Sigma∣))O(n(k+∣Σ∣))
class Solution:def groupAnagrams(self, strs: List[str]) -> List[List[str]]:if len(strs)<2:return [strs]d = collections.defaultdict(list)for s in strs:# sorted(s) 返回的内容是字符串数组 需要join一下s1 = "".join(sorted(s))d[s1].append(s)return list(d.values())
290. 单词规律
题目链接:290. 单词规律
题目大意:给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。
注意:(1)1 <= pattern.length <= 300;(2)pattern 只包含小写英文字母;(3)1 <= s.length <= 3000;(4)s 只包含小写英文字母和 ’ ';(5)s 不包含 任何前导或尾随对空格,s 中每个单词都被 单个空格分隔。
例如:
输入: pattern = "abba", s = "dog cat cat dog"
输出: true输入:pattern = "abba", s = "dog cat cat fish"
输出: false输入: pattern = "aaaa", s = "dog cat cat dog"
输出: false
- 解题思路: 哈希表来做,zip()函数非常好用。
- 时间复杂度:O(n+m)O(n+m)O(n+m) n,m分别为pattern和s的长度
- 空间复杂度:O(n+m)O(n+m)O(n+m)
class Solution:def wordPattern(self, pattern: str, s: str) -> bool:def match(word,pattern):mp = {}for m,p in zip(word,pattern):if m not in mp:mp[m] = pelif mp[m] != p:return Falsereturn Trueword = s.split()return match(pattern,word) and match(word,pattern) and len(word) == len(pattern)
447. 回旋镖的数量
题目链接:447. 回旋镖的数量
题目大意:给定平面上 n 对 互不相同 的点 points ,其中 points[i] = [xi,yi][x_i, y_i][xi,yi] 。回旋镖 是由点 (i, j, k) 表示的元组 ,其中 i 和 j 之间的距离和 i 和 k 之间的欧式距离相等(需要考虑元组的顺序)。
返回平面上所有回旋镖的数量。
注意:(1)n == points.length;(2)1 <= n <= 500;(3)points[i].length == 2;(4)−104<=xi,yi<=104-10^4 <= x_i, y_i <= 10^4−104<=xi,yi<=104;(5)所有点都互不相同。
例如:
输入:points = [[0,0],[1,0],[2,0]]
输出:2
解释:两个回旋镖为 [[1,0],[0,0],[2,0]] 和 [[1,0],[2,0],[0,0]]输入:points = [[1,1],[2,2],[3,3]]
输出:2输入:points = [[1,1]]
输出:0
- 解题思路:注意用到了组合公式。
- 时间复杂度:O(n2)O(n^2)O(n2),n为数组长度
- 空间复杂度:O(n)O(n)O(n)
class Solution:def numberOfBoomerangs(self, points: List[List[int]]) -> int:if len(points)<3:return 0ans = 0for a in points:d = collections.defaultdict(int)for b in points:dis = (b[0]-a[0])**2+(b[1]-a[1])**2d[dis] += 1for n in d.values():# 组合公式 从d[b]个中抽2两个排列ans+=n*(n-1)return ans
575. 分糖果
题目链接:575. 分糖果
题目大意:Alice 有 n 枚糖,其中第 i 枚糖的类型为 candyType[i] 。Alice 注意到她的体重正在增长,所以前去拜访了一位医生。
医生建议 Alice 要少摄入糖分,只吃掉她所有糖的 n / 2 即可(n 是一个偶数)。Alice 非常喜欢这些糖,她想要在遵循医生建议的情况下,尽可能吃到最多不同种类的糖。
给你一个长度为 n 的整数数组 candyType ,返回: Alice 在仅吃掉 n / 2 枚糖的情况下,可以吃到糖的 最多 种类数。
注意:(1)n == candyType.length;(2)2<=n<=1042 <= n <= 10^42<=n<=104;(3)n 是一个偶数;(4)−105<=candyType[i]<=105-10^5 <= candyType[i] <= 10^5−105<=candyType[i]<=105。
例如:
输入:candyType = [1,1,2,2,3,3]
输出:3
解释:Alice 只能吃 6 / 2 = 3 枚糖,由于只有 3 种糖,她可以每种吃一枚。输入:candyType = [1,1,2,3]
输出:2
解释:Alice 只能吃 4 / 2 = 2 枚糖,不管她选择吃的种类是 [1,2]、[1,3] 还是 [2,3],她只能吃到两种不同类的糖。输入:candyType = [6,6,6,6]
输出:1
解释:Alice 只能吃 4 / 2 = 2 枚糖,尽管她能吃 2 枚,但只能吃到 1 种糖。
- 解题思路:不难,可以用 集合容器(set) 进行去重。
- 时间复杂度:O(n)O(n)O(n) n为candyType的长度
- 空间复杂度:O(n)O(n)O(n)
class Solution:def distributeCandies(self, candyType: List[int]) -> int:n1 = len(candyType)//2n2 = len(set(candyType))return n1 if n2>=n1 else n2
594. 最长和谐子序列
题目链接:594. 最长和谐子序列
题目大意:和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。
现在,给你一个整数数组 nums ,请你在所有可能的子序列中找到最长的和谐子序列的长度。
数组的子序列是一个由数组派生出来的序列,它可以通过删除一些元素或不删除元素、且不改变其余元素的顺序而得到。
注意:(1)1<=nums.length<=2∗1041 <= nums.length <= 2 * 10^41<=nums.length<=2∗104;(2)−109<=nums[i]<=109-10^9 <= nums[i] <= 10^9−109<=nums[i]<=109。
例如:
输入:nums = [1,3,2,2,5,2,3,7]
输出:5
解释:最长的和谐子序列是 [3,2,2,2,3]输入:nums = [1,2,3,4]
输出:2输入:nums = [1,1,1,1]
输出:0
- 解题思路:巧用 Counter() 容器
- 时间复杂度:O(n)O(n)O(n) n为数组长度
- 空间复杂度:O(n)O(n)O(n)
class Solution:def findLHS(self, nums: List[int]) -> int:if len(nums)<2: return 0cnt = collections.Counter(nums)ans = 0for k in cnt:if k+1 in cnt:t = cnt[k]+cnt[k+1]ans = t if t>ans else ansreturn ans
599. 两个列表的最小索引总和
题目链接:599. 两个列表的最小索引总和
题目大意:假设 Andy 和 Doris 想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。
你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设答案总是存在。
注意:(1)1 <= list1.length, list2.length <= 1000;(2)1 <= list1[i].length, list2[i].length <= 30 ;(3)list1[i] 和 list2[i] 由空格 ’ ’ 和英文字母组成;(4)list1 的所有字符串都是 唯一 的,list2 中的所有字符串都是 唯一 的。
例如:
输入: list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"]
输出: ["Shogun"]
解释: 他们唯一共同喜爱的餐厅是“Shogun”。输入:list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["KFC", "Shogun", "Burger King"]
输出: ["Shogun"]
解释: 他们共同喜爱且具有最小索引和的餐厅是“Shogun”,它有最小的索引和1(0+1)。
- 解题思路: 按题意做就行
- 时间复杂度:O(n+m)O(n+m)O(n+m) ,n,m分别为list1和list2的长度
- 空间复杂度:O(n)O(n)O(n)
class Solution:def findRestaurant(self, list1: List[str], list2: List[str]) -> List[str]:d = {s:i for i,s in enumerate(list2)}ans,f = [],2000for i,s in enumerate(list1):if s in d:t = i+d[s]if t < f:f = i+d[s]ans = [s]elif t == f:ans.append(s) return ans
648. 单词替换(字典树 Trie)
题目链接:648. 单词替换
题目大意:在英语中,我们有一个叫做 词根(root) 的概念,可以词根后面添加其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典 dictionary 和一个用空格分隔单词形成的句子 sentence。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
注意:(1)1 <= dictionary.length <= 1000;(2)1 <= dictionary[i].length <= 100;(3)dictionary[i] 仅由小写字母组成;(4)1 <= sentence.length <= 10610^6106;(5)sentence 仅由小写字母和空格组成,sentence 中单词的总量在范围 [1, 1000] 内,sentence 中每个单词的长度在范围 [1, 1000] 内,sentence 中单词之间由一个空格隔开,sentence 没有前导或尾随空格。
例如:
输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"输入:dictionary = ["a","b","c"], sentence = "aadsfasf absbs bbab cadsfafs"
输出:"a a b c"
- 解题思路: 字典树,背诵吧。
- 时间复杂度:O(n+m))O(n+m))O(n+m)) n,m分别为dictionary和sentence的长度
- 空间复杂度:O(n×C)O(n \times C)O(n×C) C=26
class Trie:# 字典序 模板def __init__(self) -> None:self.next = collections.defaultdict(Trie)self.end = Falsedef add(self, word: str) -> None:cur = selffor c in word:cur = cur.next[c]if cur.end:returncur.end = Truedef contain_prefix(self,word: str) -> bool:cur = selfprefix = ''for c in word:if c in cur.next:cur = cur.next[c]prefix += c else:return Falseif cur.end:return prefixreturn Falseclass Solution: def replaceWords(self, dictionary: List[str], sentence: str) -> str:trie = Trie()for word in dictionary:trie.add(word)ans = []for word in sentence.split():if prefix := trie.contain_prefix(word):ans.append(prefix)else:ans.append(word)return ' '.join(ans)
676. 实现一个魔法字典
题目链接:676. 实现一个魔法字典
题目大意:设计一个使用单词列表进行初始化的数据结构,单词列表中的单词 互不相同 。 如果给出一个单词,请判定能否只将这个单词中一个字母换成另一个字母,使得所形成的新单词存在于你构建的字典中。
实现 MagicDictionary 类:
MagicDictionary() 初始化对象
void buildDict(String[] dictionary) 使用字符串数组 dictionary 设定该数据结构,dictionary 中的字符串互不相同
bool search(String searchWord) 给定一个字符串 searchWord ,判定能否只将字符串中 一个 字母换成另一个字母,使得所形成的新字符串能够与字典中的任一字符串匹配。如果可以,返回 true ;否则,返回 false 。
注意:(1)1 <= dictionary.length <= 100;(2)1 <= dictionary[i].length <= 100;(3)dictionary[i] 仅由小写英文字母组成;(4)dictionary 中的所有字符串 互不相同;(5)1 <= searchWord.length <= 100;(6)searchWord 仅由小写英文字母组成,buildDict 仅在 search 之前调用一次;(7)最多调用 100 次 search。
例如:
输入
["MagicDictionary", "buildDict", "search", "search", "search", "search"]
[[], [["hello", "leetcode"]], ["hello"], ["hhllo"], ["hell"], ["leetcoded"]]
输出
[null, null, false, true, false, false]解释
MagicDictionary magicDictionary = new MagicDictionary();
magicDictionary.buildDict(["hello", "leetcode"]);
magicDictionary.search("hello"); // 返回 False
magicDictionary.search("hhllo"); // 将第二个 'h' 替换为 'e' 可以匹配 "hello" ,所以返回 True
magicDictionary.search("hell"); // 返回 False
magicDictionary.search("leetcoded"); // 返回 False
-
解题思路:使用 list
-
时间复杂度:O(qnl)O(qnl)O(qnl),其中 nnn 是数组 dictionary 的长度,lll 是数组 dictionary 中字符串的平均长度,qqq 是函数 search(searchWord)\text{search(searchWord)}search(searchWord) 的调用次数。
-
空间复杂度:O(nl)O(nl)O(nl)
class MagicDictionary:def __init__(self):self.word = list()def buildDict(self, dictionary: List[str]) -> None:self.word = dictionarydef search(self, searchWord: str) -> bool:for word in self.word:if len(word) != len(searchWord):continuediff = 0for a,b in zip(word,searchWord):if a != b:diff += 1if diff > 1:breakif diff == 1:return Truereturn False# Your MagicDictionary object will be instantiated and called as such:
# obj = MagicDictionary()
# obj.buildDict(dictionary)
# param_2 = obj.search(searchWord)
705. 设计哈希集合
题目链接:705. 设计哈希集合
题目大意:不使用任何内建的哈希表库设计一个哈希集合(HashSet)。
实现 MyHashSet 类:
void add(key) 向哈希集合中插入值 key 。
bool contains(key) 返回哈希集合中是否存在这个值 key 。
void remove(key) 将给定值 key 从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
注意:(1)0 <= key <= 10610^6106;(2)最多调用 10410^4104 次 add、remove 和 contains。
例如:
输入:
["MyHashSet", "add", "add", "contains", "contains", "add", "contains", "remove", "contains"]
[[], [1], [2], [1], [3], [2], [2], [2], [2]]
输出:
[null, null, null, true, false, null, true, null, false]解释:
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = [1]
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(1); // 返回 True
myHashSet.contains(3); // 返回 False ,(未找到)
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(2); // 返回 True
myHashSet.remove(2); // set = [1]
myHashSet.contains(2); // 返回 False ,(已移除)
- 解题思路:尽量优化一些
- 时间复杂度:O(1)O(1)O(1)
- 空间复杂度:O(数据范围)O(数据范围)O(数据范围)
class MyHashSet:def __init__(self):self.d = []def add(self, key: int) -> None:if key not in self.d:self.d.append(key)else: return def remove(self, key: int) -> None:if len(self.d) == 0 or key not in self.d:return else:id = self.d.index(key)del(self.d[id])def contains(self, key: int) -> bool:if key in self.d:return Trueelse: return False# Your MyHashSet object will be instantiated and called as such:
# obj = MyHashSet()
# obj.add(key)
# obj.remove(key)
# param_3 = obj.contains(key)
745. 前缀和后缀搜索
题目链接:745. 前缀和后缀搜索
题目大意:设计一个包含一些单词的特殊词典,并能够通过前缀和后缀来检索单词。
实现 WordFilter 类:
WordFilter(string[] words) 使用词典中的单词 words 初始化对象。
f(string pref, string suff) 返回词典中具有前缀 prefix 和后缀 suff 的单词的下标。如果存在不止一个满足要求的下标,返回其中 最大的下标 。如果不存在这样的单词,返回 -1 。
注意:(1)1 <= words.length <= 10410^4104;(2)1 <= words[i].length <= 7;(3)1 <= pref.length, suff.length <= 7;(4)words[i]、pref 和 suff 仅由小写英文字母组成;(5)最多对函数 f 执行 10410^4104 次调用。
例如:
输入
["WordFilter", "f"]
[[["apple"]], ["a", "e"]]
输出
[null, 0]
解释
WordFilter wordFilter = new WordFilter(["apple"]);
wordFilter.f("a", "e"); // 返回 0 ,因为下标为 0 的单词:前缀 prefix = "a" 且 后缀 suff = "e" 。
- 解题思路:尽量优化一些
- 时间复杂度:初始消耗O(∑i=0n−1wi3)O(\sum\limits_{i=0}^{n-1}w_i^3)O(i=0∑n−1wi3),其中wiw_iwi为每个单词的字符数。每次检索消耗O(p+s)O(p+s)O(p+s),其中p和s分别为输入的pref和suff的长度。
- 空间复杂度:初始消耗O(∑i=0n−1wi3)O(\sum\limits_{i=0}^{n-1}w_i^3)O(i=0∑n−1wi3),每次检索消耗O(p+s)O(p+s)O(p+s)。
class WordFilter:def __init__(self, words: List[str]):self.d = {}for i,word in enumerate(words):m = len(word)for pre in range(1,m+1):for suf in range(1,m+1):self.d[word[:pre]+'#'+word[-suf:]] = idef f(self, pref: str, suff: str) -> int:return self.d.get(pref+'#'+suff,-1)# Your WordFilter object will be instantiated and called as such:
# obj = WordFilter(words)
# param_1 = obj.f(pref,suff)
811. 子域名访问计数
题目链接:811. 子域名访问计数
题目大意:网站域名 “discuss.leetcode.com” 由多个子域名组成。顶级域名为 “com” ,二级域名为 “leetcode.com” ,最低一级为 “discuss.leetcode.com” 。当访问域名 “discuss.leetcode.com” 时,同时也会隐式访问其父域名 “leetcode.com” 以及 “com” 。
计数配对域名 是遵循 “rep d1.d2.d3” 或 “rep d1.d2” 格式的一个域名表示,其中 rep 表示访问域名的次数,d1.d2.d3 为域名本身。
例如,“9001 discuss.leetcode.com” 就是一个 计数配对域名 ,表示 discuss.leetcode.com 被访问了 9001 次。
给你一个 计数配对域名 组成的数组 cpdomains ,解析得到输入中每个子域名对应的 计数配对域名 ,并以数组形式返回。可以按 任意顺序 返回答案。
注意:(1)1 <= cpdomain.length <= 100;(2)1 <= cpdomain[i].length <= 100;(3)cpdomain[i] 会遵循 "repid1i.d2i.d3i""rep_i \ d1_i.d2_i.d3_i""repi d1i.d2i.d3i" 或 "repid1i.d2i""rep_i \ d1_i.d2_i""repi d1i.d2i" 格式;(4)repirep_irepi 是范围 [1,104][1, 10^4][1,104] 内的一个整数;(5)d1id1_id1i、d2id2_id2i 和 d3id3_id3i 由小写英文字母组成。
例如:
输入:
输入:cpdomains = ["9001 discuss.leetcode.com"]
输出:["9001 leetcode.com","9001 discuss.leetcode.com","9001 com"]
解释:例子中仅包含一个网站域名:"discuss.leetcode.com"。
按照前文描述,子域名 "leetcode.com" 和 "com" 都会被访问,所以它们都被访问了 9001 次。输入:cpdomains = ["900 google.mail.com", "50 yahoo.com", "1 intel.mail.com", "5 wiki.org"]
输出:["901 mail.com","50 yahoo.com","900 google.mail.com","5 wiki.org","5 org","1 intel.mail.com","951 com"]
解释:按照前文描述,会访问 "google.mail.com" 900 次,"yahoo.com" 50 次,"intel.mail.com" 1 次,"wiki.org" 5 次。
而对于父域名,会访问 "mail.com" 900 + 1 = 901 次,"com" 900 + 50 + 1 = 951 次,和 "org" 5 次。
- 解题思路:Counter
- 时间复杂度:O(L)O(L)O(L) L是数组 cpdomains 的长度
- 空间复杂度:O(L)O(L)O(L)
class Solution:def subdomainVisits(self, cpdomains: List[str]) -> List[str]:counter = collections.Counter()for cpdomain in cpdomains:n, ch = cpdomain.split()num = int(n)counter[ch] += numwhile '.' in ch:ch = ch[(ch.index('.')+1):]counter[ch] += numreturn [f'{n} {ch}' for ch,n in counter.items()]
884. 两句话中的不常见单词
题目链接:884. 两句话中的不常见单词
题目大意:句子 是一串由空格分隔的单词。每个 单词 仅由小写字母组成。
如果某个单词在其中一个句子中恰好出现一次,在另一个句子中却 没有出现 ,那么这个单词就是 不常见的 。
给你两个 句子 s1 和 s2 ,返回所有 不常用单词 的列表。返回列表中单词可以按 任意顺序 组织。
注意:(1)1 <= s1.length, s2.length <= 200;(2)s1 和 s2 由小写英文字母和空格组成,s1 和 s2 都不含前导或尾随空格,s1 和 s2 中的所有单词间均由单个空格分隔。
例如:
输入:s1 = "this apple is sweet", s2 = "this apple is sour"
输出:["sweet","sour"]输入:s1 = "apple apple", s2 = "banana"
输出:["banana"]
- 解题思路:使用Counter()
- 时间复杂度:O(n+m)O(n+m)O(n+m),n和m分别为s1和s2的长度
- 空间复杂度:O(n+m)O(n+m)O(n+m)
class Solution:def uncommonFromSentences(self, s1: str, s2: str) -> List[str]:ans = []s = (s1+' '+s2).split()cnt = collections.Counter(s)for s in cnt:if cnt[s] == 1:ans.append(s)return ans
961. 在长度 2N 的数组中找出重复 N 次的元素
题目链接:961. 在长度 2N 的数组中找出重复 N 次的元素
题目大意:给你一个整数数组 nums ,该数组具有以下属性:
1.nums.length == 2 * n.
2.nums 包含 n + 1 个 不同的 元素
3.nums 中恰有一个元素重复 n 次
4.找出并返回重复了 n 次的那个元素。
注意:(1)2 <= n <= 5000;(2)nums.length == 2 * n;(3)0 <= nums[i] <= 10410^4104;(5)nums 由 n + 1 个 不同的 元素组成,且其中一个元素恰好重复 n 次。
例如:
输入:nums = [1,2,3,3]
输出:3输入:nums = [2,1,2,5,3,2]
输出:2输入:nums = [5,1,5,2,5,3,5,4]
输出:5
- 解题思路:参考官方题解
- 时间复杂度:O(n)O(n)O(n)
- 空间复杂度:O(1)O(1)O(1)
class Solution:def repeatedNTimes(self, nums: List[int]) -> int:# nums = sorted(nums)# i = len(nums)//2# return nums[i] if nums[i] == nums[i+1] else nums[i-1]# found = set()# for num in nums:# if num in found:# return num# found.add(num)# return -1n = len(nums)# 最多间隔两个元素for gap in range(1,4):for i in range(n-gap):if nums[i] == nums[i+gap]:return nums[i]return -1
1207. 独一无二的出现次数
题目链接:1207. 独一无二的出现次数
题目大意:给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。
如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。
注意:(1)1 <= arr.length <= 1000;(2)-1000 <= arr[i] <= 1000。
例如:
输入:arr = [1,2,2,1,1,3]
输出:true
解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。输入:arr = [1,2]
输出:false输入:arr = [-3,0,1,-3,1,1,1,-3,10,0]
输出:true
- 解题思路:使用Counter和defaultdict
- 时间复杂度:O(n)O(n)O(n) n为数组arr的长度
- 空间复杂度:O(n)O(n)O(n)
class Solution:def uniqueOccurrences(self, arr: List[int]) -> bool:cnt = collections.Counter(arr)d = collections.defaultdict(list)ans = []for i in cnt:d[cnt[i]].append(i)if len(d[cnt[i]])>1:return Falsereturn False
总结
努力 奋斗!找工作。
相关文章:
LeetCode Cookbook 哈希表(collections.Counter()和collections.defaultdict())
好久不更了,这次一鼓作气,学完它! 文章目录LeetCode Cookbook 哈希表30. 串联所有单词的子串36. 有效的数独(很不错的循环题目)49. 字母异位词分组290. 单词规律447. 回旋镖的数量575. 分糖果594. 最长和谐子序列599. …...

spring boot项目中i18n和META-INF.spring下的文件的作用
目录标题一、resource下的文件二、i18n下messages_zh_CN.properties三、spring.factories文件四、org.springframework.boot.autoconfigure.AutoConfiguration.imports一、resource下的文件 org.springframework.boot.autoconfigure.AutoConfiguration.imports ; - …...

3年自动化测试经验,面试连20K都拿不到,现在都这么卷了吗····
我的情况 大概介绍一下个人情况,女,本科,三年多测试工作经验,懂python,会写脚本,会selenium,会性能,会自动化,然而到今天都没有收到一份offer!从2022年11月1…...
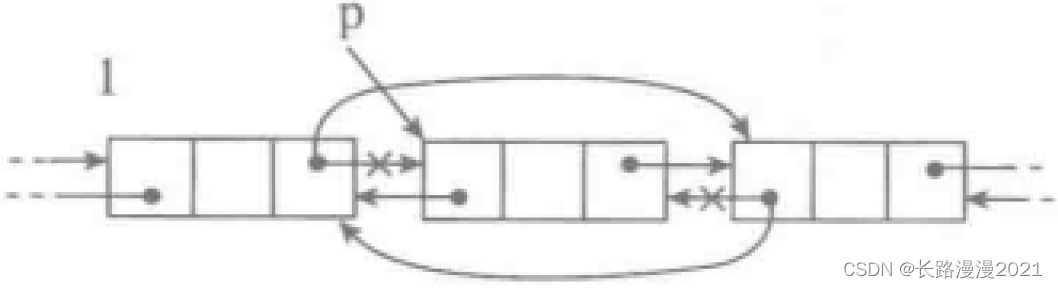
Python数据结构与算法篇(四)-- 链表的实现
实现线性表的另一种常用方式就是基于链接结构,用链接关系显式表示元素之间的顺序关联。基于链接技术实现的线性表称为链接表或者链表。 采用链接方式实现线性表的基本想法如下: 把表中的元素分别存储在一批独立的存储块(称为表的结点)里。保…...

【java基础】循环语句、中断控制语句
文章目录循环while循环for循环for each循环中断控制语句breakcontinue带标签的break(相当于goto)循环 在java中有3种循环,分别是while循环,for循环,for each循环 while循环 while循环的形式是 while(condition) statement int i 5;while …...
万字长文带你实战 Elasticsearch 搜索
ES 高级实战 前言 上篇我们讲到了 Elasticsearch 全文检索的原理《别只会搜日志了,求你懂点原理吧》,通过在本地搭建一套 ES 服务,以多个案例来分析了 ES 的原理以及基础使用。这次我们来讲下 Spring Boot 中如何整合 ES,以及如何在 Spring Cloud 微服务项目中使用 ES 来…...
Web网页测试全流程解析论Web自动化测试
1、功能测试 web网页测试中的功能测试,主要测试网页中的所有链接、数据库连接、用于在网页中提交或获取用户信息的表单、Cookie 测试等。 (1)查看所有链接: 测试从所有页面到被测特定域的传出链接。 测试所有内部链接。 测试链…...

初识Python——“Python”
各位CSDN的uu们你们好呀,今天进入到了我们的新专栏噢,Python是小雅兰的专业课,那么现在,就让我们进入Python的世界吧 计算机基础概念 什么是计算机? 什么是编程? 编程语言有哪些? Python背景知…...

LocalDateTime使用
开发中常常需要用到时间,随着jdk的发展,对于时间的操作已经摒弃了之前的Date等方法,而是采用了LocalDateTime方法,因为LocalDateTime是线程安全的。 下面我们来介绍一下LocalDateTime的使用。 时间转换 将字符串转换为时间格式…...
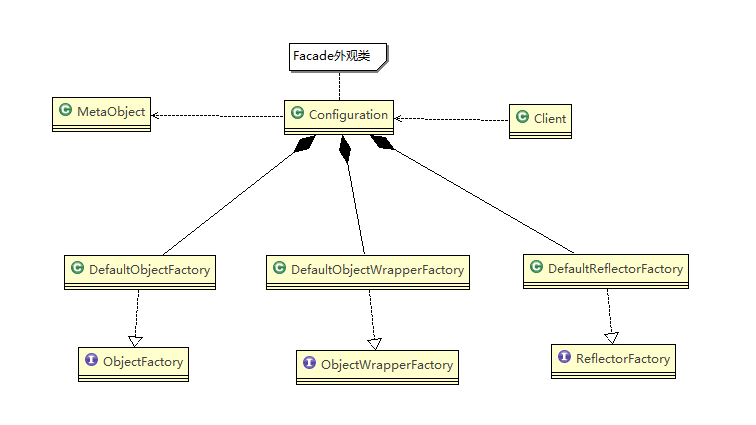
设计模式学习笔记 - 外观模式
设计模式学习笔记 - 外观模式一、影院管理问题二、传统方式解决影院管理问题三、外观模式介绍1、基本介绍2、原理类图四、外观模式解决影院管理问题五、外观模式在MyBatis框架应用的源码分析六、外观模式的注意事项和细节一、影院管理问题 组建一个家庭影院:DVD 播放…...

如何写出一份优秀的简历和求职信?
写一份优秀的简历和求职信是成功求职的重要一步。 01、简历 突出重点信息:把最重要的信息放在简历的前面,例如您的工作经验和教育背景等。 使用简明扼要的语言:在简历中使用简短的句子和简明扼要的语言,让招聘者能够快速了解您的…...

OpenGL超级宝典学习笔记:原子计数器
前言 本篇在讲什么 本篇为蓝宝书学习笔记 原子计数器 本篇适合什么 适合初学Open的小白 本篇需要什么 对C语法有简单认知 对OpenGL有简单认知 最好是有OpenGL超级宝典蓝宝书 依赖Visual Studio编辑器 本篇的特色 具有全流程的图文教学 重实践,轻理论&#…...

深圳/东莞/惠州师资比较强的CPDA数据分析认证
深圳/东莞/惠州师资比较强的CPDA数据分析认证培训机构 CPDA数据分析师认证是中国大数据领域有一定权威度的中高端人才认证,它不仅是中国较早大数据专业技术人才认证、更是中国大数据时代先行者,具有广泛的社会认知度和权威性。 无论是地方政府引进人才、…...
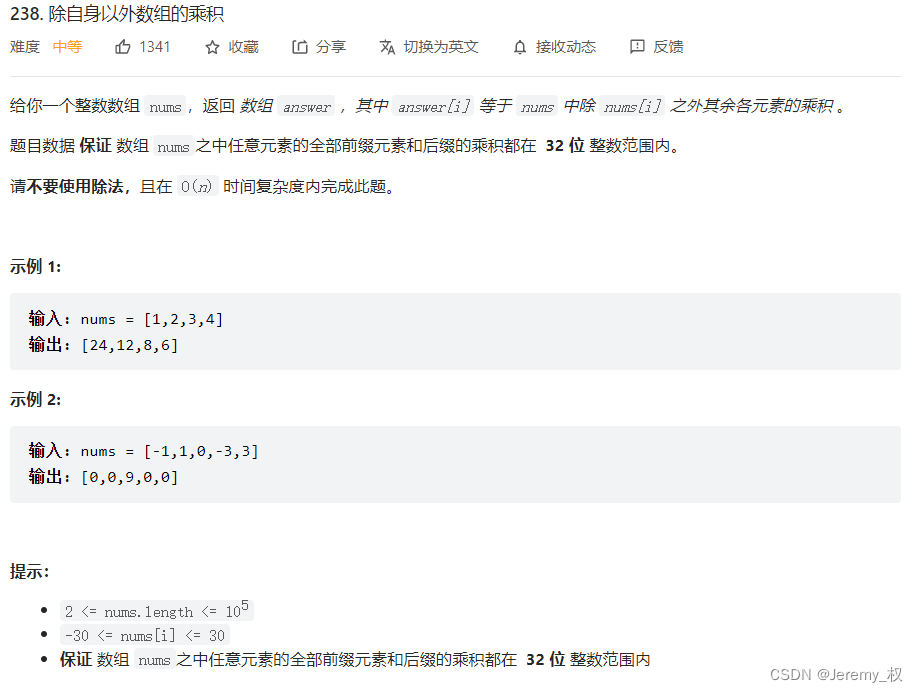
LeetCodeHOT100热题02
写在前面 主要是题目太多,所以和前面的分开来记录。有很多思路的图都来源于力扣的题解,如侵权会及时删除。不过代码都是个人实现的,所以有一些值得记录的理解。之前的算法系列参看: 剑指offer算法题01剑指offer算法题02 七、动…...
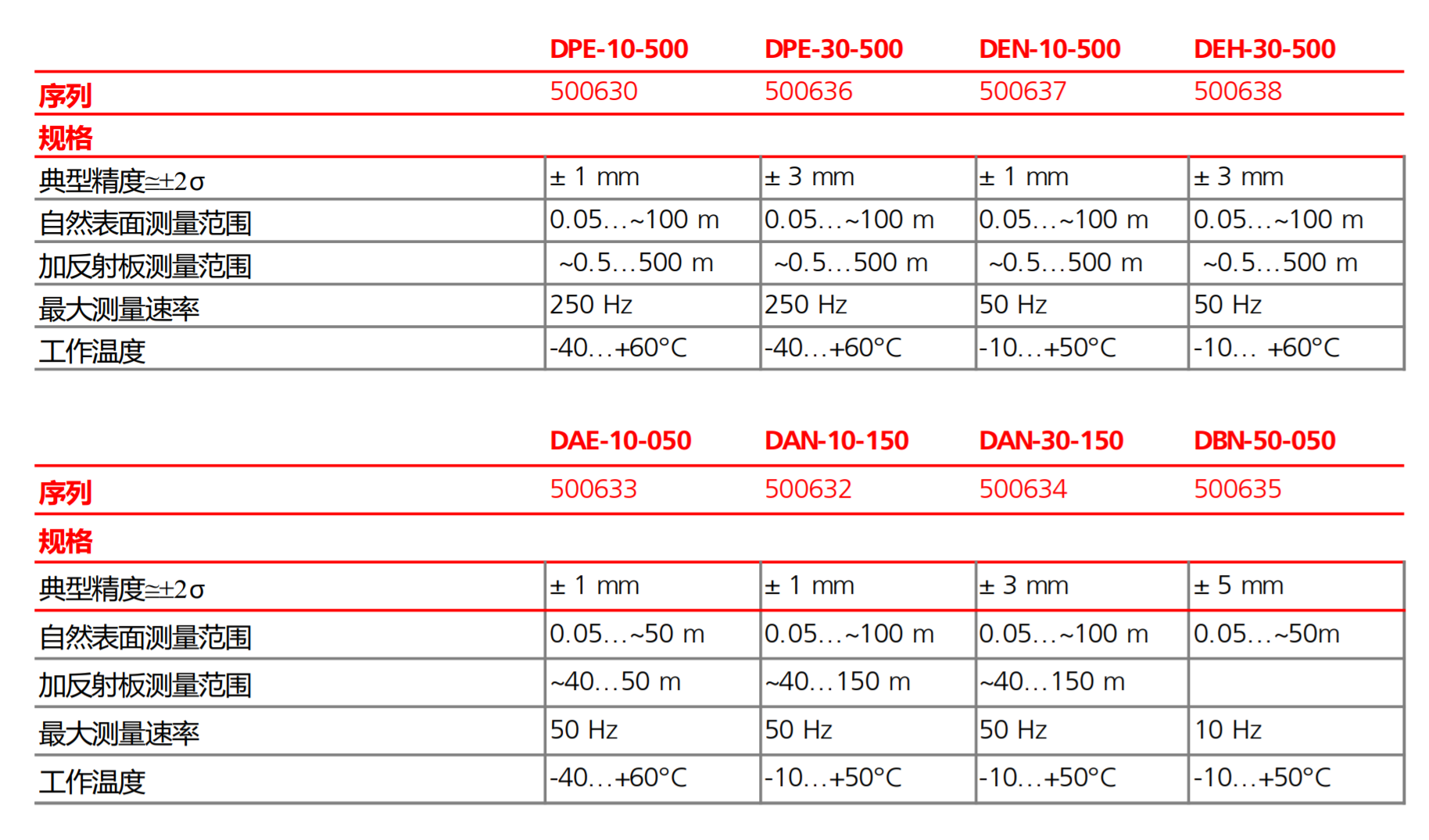
虹科Dimetix激光测距仪在锯切系统中的应用
HK-Dimetix激光测距仪——锯切系统应用 许多生产设施,例如金属服务中心,使用切割锯将每个客户的订单切割成一定长度。定长切割过程通常涉及卷尺和慢跑锯的传送带。但更简单的替代方法是使用虹科Dimetix非接触式激光距离传感器。 为了切断大长度的棒材&…...

FreeRTOS入门(02):任务基础使用与说明
文章目录目的创建任务任务调度任务控制延时函数任务句柄获取与修改任务优先级删除任务挂起与恢复任务强制任务离开阻塞状态空闲任务总结目的 任务(Task)是FreeRTOS中供用户使用的最核心的功能,本文将介绍任务创建与使用相关的基础内容。 本…...

ESP通过乐为物联控制灯,微信发送数值,ESP上传传感器数据
暂时放个程序 //ME->>{“method”: “update”,“gatewayNo”: “01”,“userkey”: “2b64c489d5f94237bcf2e23151bb7d01”}&^! //Ser->>{“f”:“message”,“p1”:“ok”}&^! //ME->>{“method”: “upload”,“data”:[{“Name”:“A1C”,“Val…...
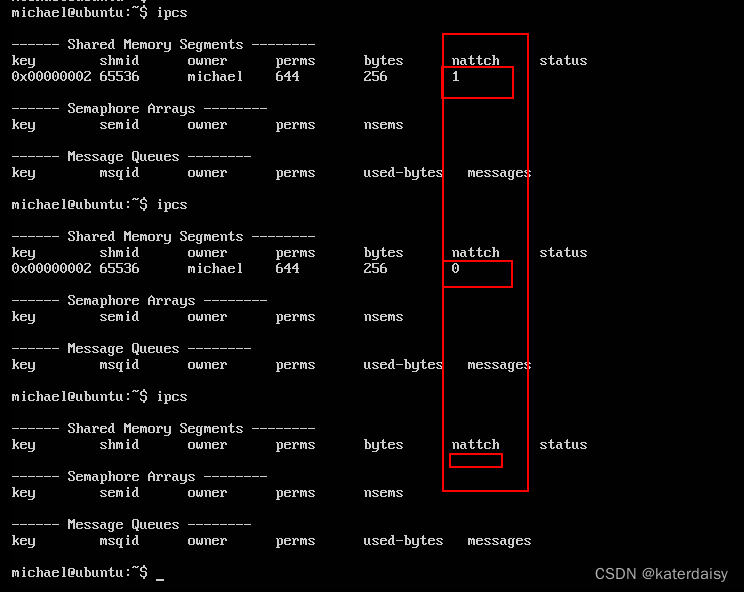
Linux:共享内存api使用
代码: #include <stdlib.h> #include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <string.h> #include <arpa/inet.h> #include <sys/un.h> #include <sys/ipc.h…...

android9.0 java静态库操作JNI实例 动态注册
一、java层 源码 目录:/Demo/java/com/android/simpleini/SimpleJNI.java package com.example.simplejni;import android.app.Activity; import android.os.Bundle; import android.widget.TextView;public class SimpleJNI {private IpoManagerService(Context …...

自定义复杂图片水印
我的社交能力还不如5岁儿童和狗。 文章目录前言一、主要工具类总结前言 之前写过一些简单的图片压缩和图片加水印:JAVA实现图片质量压缩和加水印 本次主要是针对图片加水印进行一个升级,图片水印自定义,自适应大小。 来,先看几…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...

FOPLP vs CoWoS
以下是 FOPLP(Fan-out panel-level packaging 扇出型面板级封装)与 CoWoS(Chip on Wafer on Substrate)两种先进封装技术的详细对比分析,涵盖技术原理、性能、成本、应用场景及市场趋势等维度: 一、技术原…...

Ray框架:分布式AI训练与调参实践
Ray框架:分布式AI训练与调参实践 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 Ray框架:分布式AI训练与调参实践摘要引言框架架构解析1. 核心组件设计2. 关键技术实现2.1 动态资源调度2.2 …...

构建Docker镜像的Dockerfile文件详解
文章目录 前言Dockerfile 案例docker build1. 基本构建2. 指定 Dockerfile 路径3. 设置构建时变量4. 不使用缓存5. 删除中间容器6. 拉取最新基础镜像7. 静默输出完整示例 docker runDockerFile 入门syntax指定构造器FROM基础镜像RUN命令注释COPY复制ENV设置环境变量EXPOSE暴露端…...