「大数据-2.2」使用命令操作HDFS文件系统
目录
一、HDFS文件系统基本信息
1. HDFS的路径表达形式
2.HDFS和Linux的根目录的区分
二、 使用命令操作HDFS文件系统
0. Hadoop的两套命令体系
1. 创建文件夹
2. 查看指定目录下内容
3. 上传文件到HDFS指定目录下
4. 查看HDFS文件内容
5. 下载HDFS文件
6. 拷贝HDFS文件
7. 追加数据到HDFS文件中
8. HDFS数据移动操作
9. HDFS数据删除操作
拓. 开启HDFS文件系统回收站
10. HDFS的其它命令
三、 HDFS WEB操作HDFS文件系统
1. HDFS WEB浏览HDFS文件系统
2. HDFS WEB操作HDFS文件系统
2.1 默认以匿名用户进入HDFS WEB
2.2 配置core-site.xml文件以特权用户进入HDFS WEB
2.3 使用HDFS WEB对HDFS文件系统进行基本操作
一、HDFS文件系统基本信息
1. HDFS的路径表达形式
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
HDFS同Linux系统一样,均是以/作为根目录的组织形式。
2.HDFS和Linux的根目录的区分
2.1 HDFS和Linux的根目录都是/ 那该如何区分两者的根目录呢?
使用协议头file:// 和 hdfs://namenode:port 来区分。
- Linux :file:///
- HDFS:hdfs://namenode:port/ (namenode:主节点 port:端口号)
示例:
- Linux根目录下的test.txt文件路径 :file:///test.txt
- HDFS根目录下的test.txt文件路径:hdfs://node1:8020/test.txt
2.2 协议头file:/// 或 hdfs://node1:8020/可以省略
一般情况下,命令中需要提供Linux路径的参数,会自动识别为file:// ,需要提供HDFS路径的参数,会自动识别为hdfs://
除非命令的文档中明确需要写或不写会有BUG,否则一般不用写协议头,在下面的命令讲解中我会详细说明。

二、 使用命令操作HDFS文件系统
0. Hadoop的两套命令体系
对于HDFS文件系统的操作,Hadoop有2套命令体系:
- hadoop命令(老版本用法),用法:hadoop fs [generic options]
- hdfs命令(新版本用法),用法:hdfs dfs [generic options]
两者在文件系统操作上,用法完全一致 用哪个都可以
某些特殊操作需要选择hadoop命令或hdfs命令 讲到的时候具体分析
1. 创建文件夹
命令: hadoop fs -mkdir [-p] <path> ... hdfs dfs -mkdir [-p] <path> ... 示例: hadoop fs -mkdir -p /bigdata1/test1 hdfs dfs -mkdir -p /bigdata2/test2说明: 如果不带协议头默认是在hdfs的根目录中创建目录 path 为待创建的目录 -p选项的行为与Linux mkdir -p一致,它会沿着路径创建父目录。

2. 查看指定目录下内容
命令: hadoop fs -ls [-h] [-R] [<path> ...] hdfs dfs -ls [-h] [-R] [<path> ...] 示例: hadoop fs -ls -h -R /bigdata1 hdfs dfs -ls -h -R /bigdata12 说明: path 指定目录路径 -h 显示文件大小,带单位 -R 递归查看指定目录及其子目录
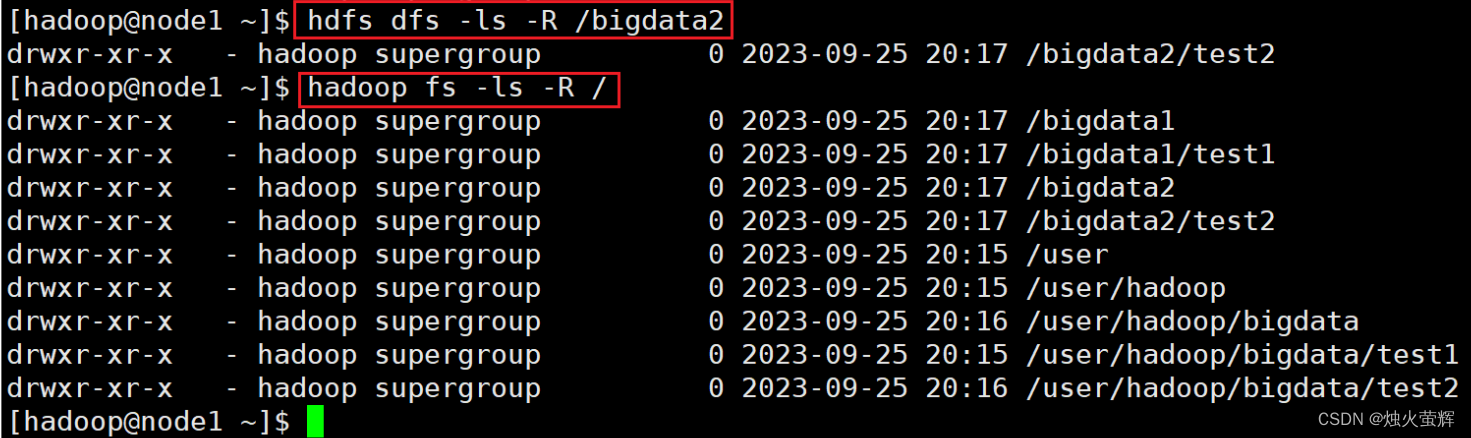
3. 上传文件到HDFS指定目录下
上传命令的作用是从Linux文件系统上传文件到HDFS文件系统下。
命令: hadoop fs -put [-f] [-p] <localsrc> ... <dst> hdfs dfs -put [-f] [-p] <localsrc> ... <dst>示例: hadoop fs -put /data/test.txt / hdfs dfs -put -f /data/test.txt /说明: -f 覆盖目标文件(如果已存在同名文件,只能用-f选项强行覆盖,不然无法上传) -p 保留访问和修改时间、所有权和权限。 localsrc 本地文件系统路径(Linux路径) dst 目标文件系统路径(HDFS路径)

4. 查看HDFS文件内容
命令: hadoop fs -cat <dst> ... hdfs dfs -cat <dst> ...示例: hdfs dfs -cat /test.txt说明: dst HDFS文件系统路径读取大文件可以使用管道符配合more hadoop fs -cat <dst> | more hdfs dfs -cat <dst> | more示例: hadoop fs -cat /test.txt | more hdfs dfs -cat /test.txt | more说明: dst HDFS文件系统路径 | Linux下的管道符 more Linux下的翻页指令 | 和 more配合使用,即可实现翻页查看大文件,不会直接一股脑往后面跳

5. 下载HDFS文件
命令: hadoop fs -get [-f] [-p] <src> ... <localdst> hdfs dfs -get [-f] [-p] <src> ... <localdst>示例: hadoop fs -get ./test.txt . hdfs dfs -get ./test.txt .说明: 下载文件到本地文件系统指定目录,localdst必须是目录 -f 覆盖目标文件(如果已存在同名文件,只能用-f选项强行覆盖,不然无法下载) -p 保留访问和修改时间,所有权和权限。下载命令的作用是从HDFS文件系统下载文件到Linux文件系统下。

6. 拷贝HDFS文件
命令: hadoop fs -cp [-f] <src> ... <dst> hdfs dfs -cp [-f] <src> ... <dst>示例: hadoop fs -cp /test.txt /bigdata1/test1/说明: -f 覆盖目标文件(已存在下) src HDFS文件系统路径(HDFS路径) dst 目标HDFS文件系统路径(HDFS路径) 该命令用于HDFS文件系统中文件拷贝,从Linux到HDFS这叫上传

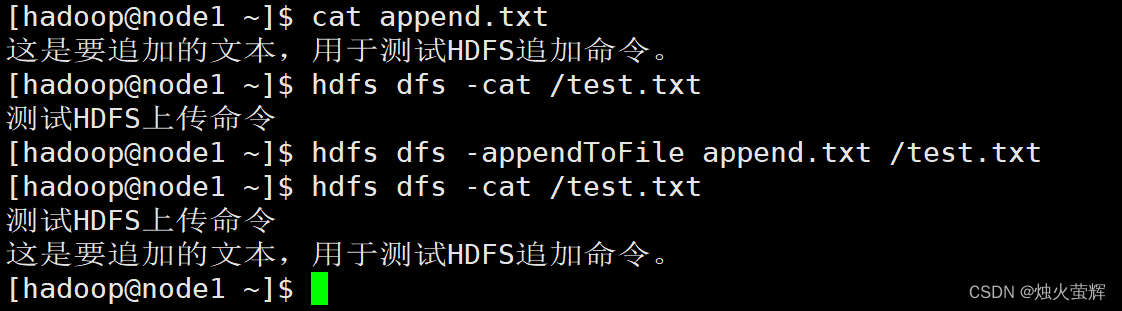
7. 追加数据到HDFS文件中
命令: hadoop fs -appendToFile <localsrc> ... <dst> hdfs dfs -appendToFile <localsrc> ... <dst>示例: hadoop fs -appendToFile说明: 该命令用于将给定本地文件的内容追加到给定HDFS文件末尾。 dst如果文件不存在,将创建该文件。 对于HDFS中的文件,我们只能追加和删除,无法随意修改。 如果<localSrc>为-,则输入为从标准输入中读取。
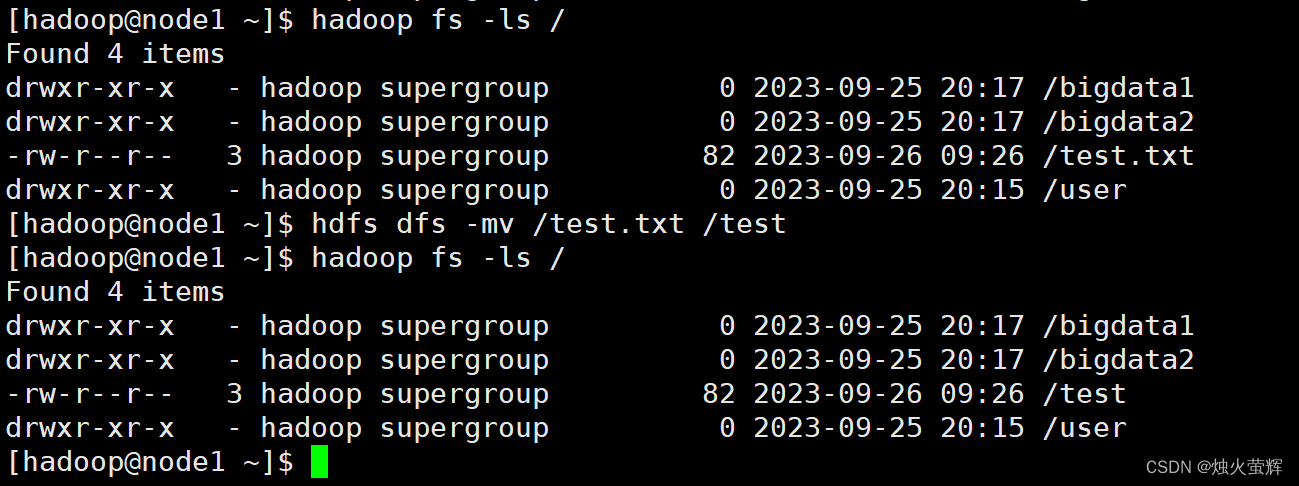
8. HDFS数据移动操作
命令: hadoop fs -mv <src> ... <dst> hdfs dfs -mv <src> ... <dst>示例: hadoop fs -mv /test.txt /test hdfs dfs -mv /test.txt /test说明: 该命令可以移动HDFS文件到指HDFS定文件夹下 也可以使用该命令对文件进行重命名
9. HDFS数据删除操作
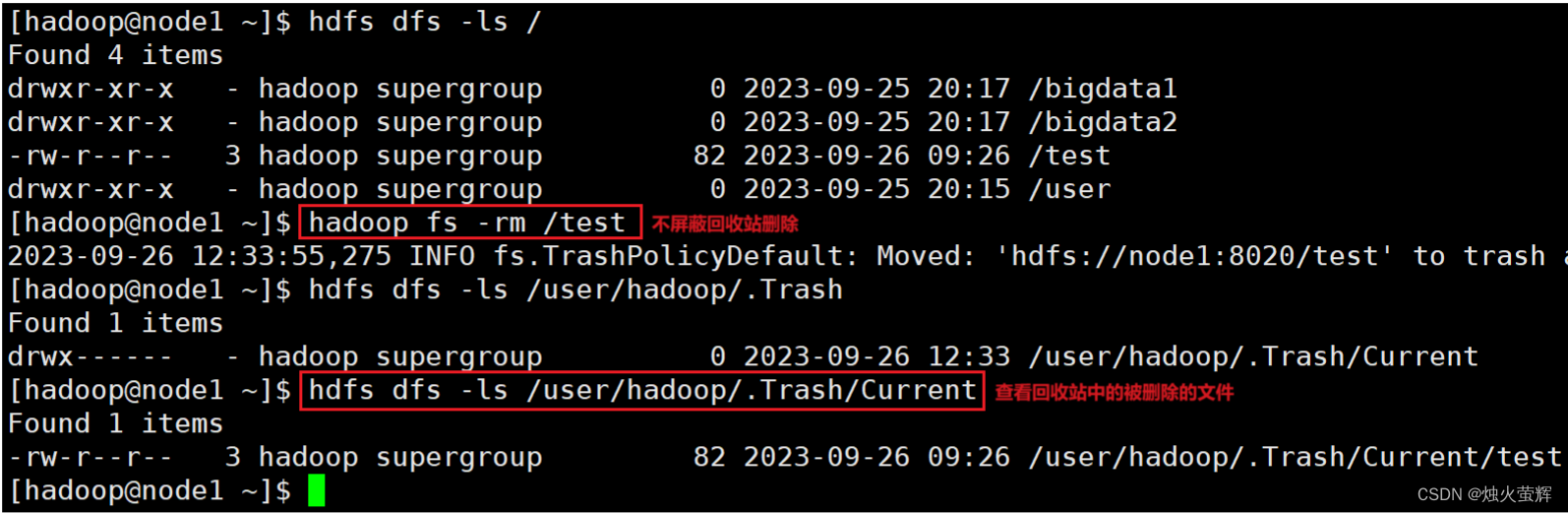
命令: hadoop fs -rm -r [-skipTrash] URI [URI ...] hdfs dfs -rm -r [-skipTrash] URI [URI ...] 示例: hadoop fs -rm -r bigdata说明: 带-r就是删除文件夹 删除指定路径的文件或文件夹 -skipTrash 跳过回收站,直接删除(如果没有设置回收站,不用这个选项也是直接删除)

拓. 开启HDFS文件系统回收站
HDFS文件系统是支持回收站的,不过回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
1. 使用vim打开core-site.xml文件: vim /export/server/hadoop/etc/hadoop/core-site.xml2. 按i进入插入模式3. 在<configuration></configuration>中间加入以下内容: <property> <name>fs.trash.interval</name> <value>1440</value> </property><property> <name>fs.trash.checkpoint.interval</name> <value>120</value> </property>4. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!和回车保存文件并退出。说明: 1. <name>fs.trash.interval</name> <value>1440</value> 是在设置回收站保留时间,这里设置的是保留1440分钟,也就是一天。 2. <name>fs.trash.checkpoint.interval</name> <value>120</value> 是在设置回收站检查时间,检查回收站要删除的文件,这里设置的是120分钟。 3.无需重启集群,在哪个机器配置的,保存配置后,在哪个机器执行命令就生效。 4.回收站默认位置在:/user/用户名(hadoop)/.Trash

10. HDFS的其它命令
HDFS还有其他许多命令,博主在这里只介绍几个日常中常用的基本命令,如果对这块感兴趣的话,可以看这个:命令官方指导文档
三、 HDFS WEB操作HDFS文件系统
1. HDFS WEB浏览HDFS文件系统
除了使用命令操作HDFS文件系统外,在HDFS的WEB UI上也可以查看HDFS文件系统的内容。
1. 在浏览器输入http://node1:9870/进入HDFS WEB
2. 选择导航栏Utilities下的Browse the file system


2. HDFS WEB操作HDFS文件系统
2.1 默认以匿名用户进入HDFS WEB
我们进入HDFS WEB是以匿名用户(dr.who)进入,只有只读权限,默认是没有权限操作HDFS文件系统的。
2.2 配置core-site.xml文件以特权用户进入HDFS WEB
想要操作的话需要以特权用户在浏览器中进行操作,需要配置core-site.xml文件并重启集群。
步骤:
1. 使用vim打开core-site.xml文件: vim /export/server/hadoop/etc/hadoop/core-site.xml2. 按i进入插入模式3. 在<configuration></configuration>中间加入以下内容:<property><name>hadoop.http.staticuser.user</name><value>hadoop</value></property>4. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!和回车保存文件并退出。说明: <name>hadoop.http.staticuser.user</name> <value>hadoop</value> 默认以hadoop用户登录HDFS WEB,hadoop在之前已经被授权为了最高级别用户。
2.3 使用HDFS WEB对HDFS文件系统进行基本操作
现在我们能使用HDFS WEB对HDFS文件系统进行基本操作了。
博主写这个,这是想告诉大家我们可以这样做。但是,不推荐这样做!
因为以匿名用户(dr.who)进入HDFS WEBUI,只有只读权限就够了,我们用HDFS WEBUI能简单浏览即可,如果给与高权限,会有很大的安全问题,如容易造成数据泄露或丢失。

------------------------END-------------------------
才疏学浅,谬误难免,欢迎各位批评指正。
相关文章:

「大数据-2.2」使用命令操作HDFS文件系统
目录 一、HDFS文件系统基本信息 1. HDFS的路径表达形式 2.HDFS和Linux的根目录的区分 二、 使用命令操作HDFS文件系统 0. Hadoop的两套命令体系 1. 创建文件夹 2. 查看指定目录下内容 3. 上传文件到HDFS指定目录下 4. 查看HDFS文件内容 5. 下载HDFS文件 6. 拷贝HDFS文件 7.…...

面试买书复习就能进大厂?
大家好,我是苍何。 现在进大仓是越来越难了,想通过简单的刷题面试背书,比几年前难的不少, 但也并非毫无希望,那究竟该如何准备才能有希望进大厂呢? 我总结了 4 点: 1、不差的学历背景 2、丰富…...

使用Http Interface客户端解析text/html类型参数
前言 Spring6和Spring Boot3的正式发布也有一段时间了,最低支持的java版本也是直接跳到了17。而且最近java21也出来了,作为一个javaer,你不会还在坚守java8吧? Http Interface是Spring6新推出的一个声明式http客户端,…...

Linux - linux命令进阶
打包压缩解压 基本概述 打包 将多数文件或目录汇总成一个整体 打包默认没有压缩功能,不节省磁盘空间 压缩 将大文件压缩成小文件 可以节省磁盘空间 打包压缩 将一堆零散的文件打包到一起,然后再压缩,可以节省磁盘空间 打包命令 命令格式 ta…...

排序篇(一)----插入排序
1.直接插入排序 插入排序的思想: 把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。 你可以想像成打牌一样,比如说斗地主,一张一张的摸牌,然后把手上的这些牌变成手续的排列.…...
通俗讲解深度学习轻量网络MobileNet-v1/v2/v3
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)。MobileNet网络…...

mmpretrain学习笔记
深度学习模型的训练涉及几个方面 1、模型结构:模型有几层、每层多少通道数等 2、数据:数据集划分、数据文件路径、批大小、数据增强策略等 3、训练优化 :梯度下降算法、学习率参数、训练总轮次、学习率变化策略等 4、运行时:GPU、…...

rhel8 网络操作学习
一、查询dns服务器地址汇总 1.查询dns服务器地址: (1)方法一:执行命令 cat /etc/resolv.conf 执行结果如下: nameserver后面就是dns服务器的ip地址。 (2)方法2:查看/etc/syscon…...
,车厂(CarFactory),经销商(Distributor)三个表)
有车型(CarModel),车厂(CarFactory),经销商(Distributor)三个表
用drf编写 1 有车型(CarModel),车厂(CarFactory),经销商(Distributor)三个表, 一个车厂可以生产多种车型,一个经销商可以出售多种车型,一个车型可以有多个经销商出售车型:车型名,车型…...
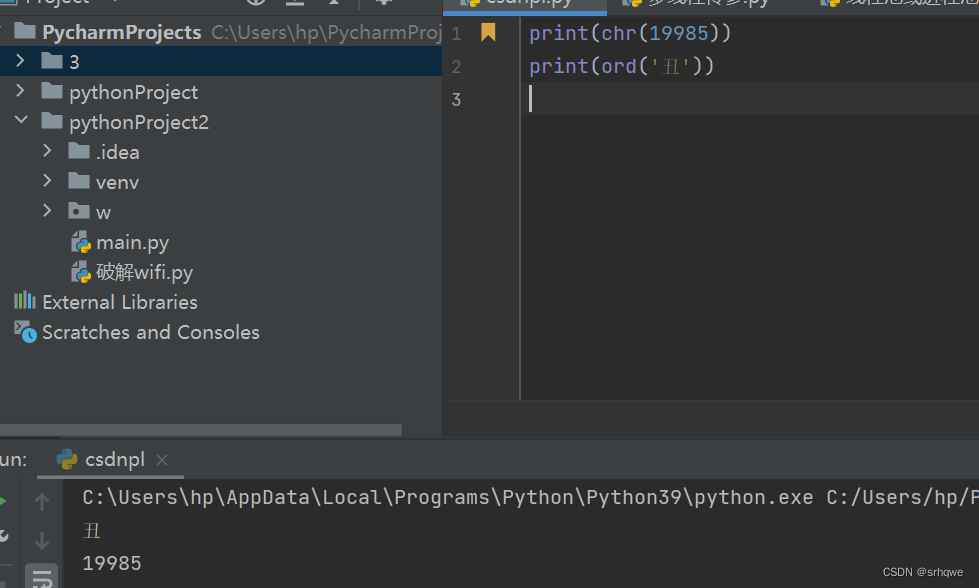
Python函数:chr()和ord()
两个函数是基于Unicode编码表进行进行字符与字码之间的转换。 chr()函数是通过字码转换成字符: 如图,坐标(1,4e10)丑 使用chr需要线将坐标相加得到:4e11 chr默认传入10进制的字码. 如图是各进制的字码。 也可以传入其他进制,不过需要在前面传入的参数最前…...

flink sql 使用
1.准备工作 安装flink 1.16.2 将以下jar包放到/data/cmpt/flink-1.16.2/lib 目录下 antlr-runtime-3.5.2.jar flink-connector-hive_2.12-1.16.2.jar flink-connector-jdbc-1.16.2.jar mysql-connector-java-6.0.6.jar hive-exec-3.1.3.jar libfb303-0.9.3.ja…...

面试官:谈谈 Go 泛型编程
大家好,我是木川 泛型编程是一种编程范式,它允许编写具有参数化类型的代码,从而增加代码的复用性和灵活性。在泛型编程中,你可以编写一段代码,使其适用于不同类型的参数,而不需要为每种类型编写不同的实现。…...

脚手架开发流程详解
开发流程 创建npm项目创建脚手架入口文件,最上方添加 #!/usr/bin/env/ node配置package.json,添加bin属性编写脚手架代码将脚手架发布到npm 使用流程 安装脚手架 npm install -g your-own-cli使用脚手架 your-own-cli脚手架开发难点解析 分包&…...
)
架构真题2021(四十三)
产品配置是指一个产品在其生命周期各个阶段所产生的各种形式(机器刻可读或人工可读)和各种版本()的集合。 需求规格说明、设计说明、测试报告需求规则说明、设计说明、计算机程序设计说明、用户手册、计算机程序文档、计算机程序…...
数据统计和分析怎么做?spss如何做好数据分析?
为什么要做数据分析?数据分析有什么意义?数据分析可以为企业和组织提供多方面的帮助,包括提高工作效率、优化业务流程、升职加薪、提高管理效率以及改进汇报效果等方面。 IBM SPSS Statistics 26是一款功能强大的统计分析软件,适用于Mac操作…...

【多线程】线程安全的集合类
文章目录 1. 多线程环境使用ArrayList1.1 自己使用同步机制1.2 Collections.synchronizedList(new ArrayList);1.3 使用 CopyOnWriteArrayList 2. 多线程使用队列3. 多线程环境使用哈希表3.1 HashTable3.2 ConcurrentHashMap3.3 Hashtable和HashMap、ConcurrentHashMap 之间的区…...
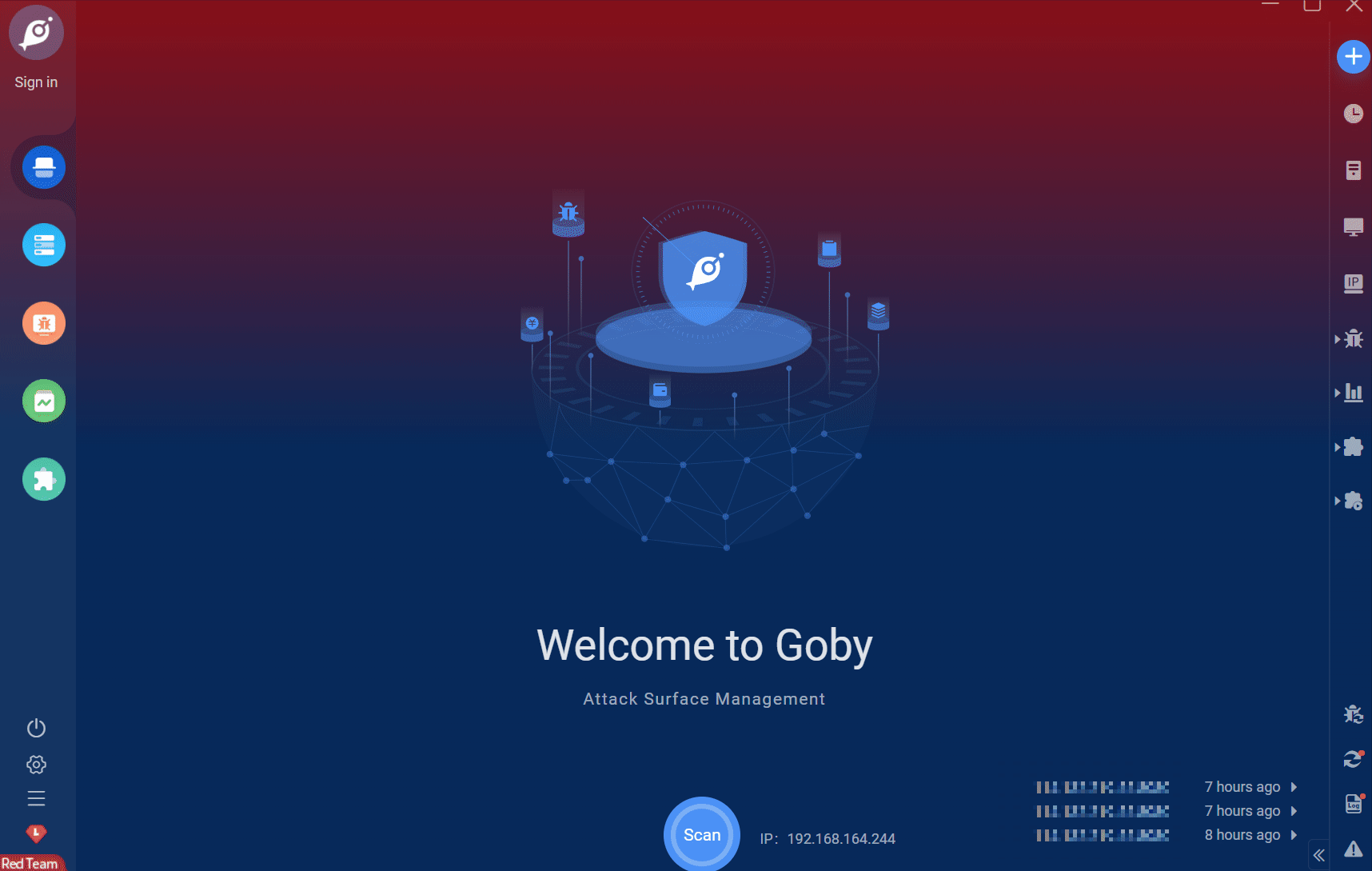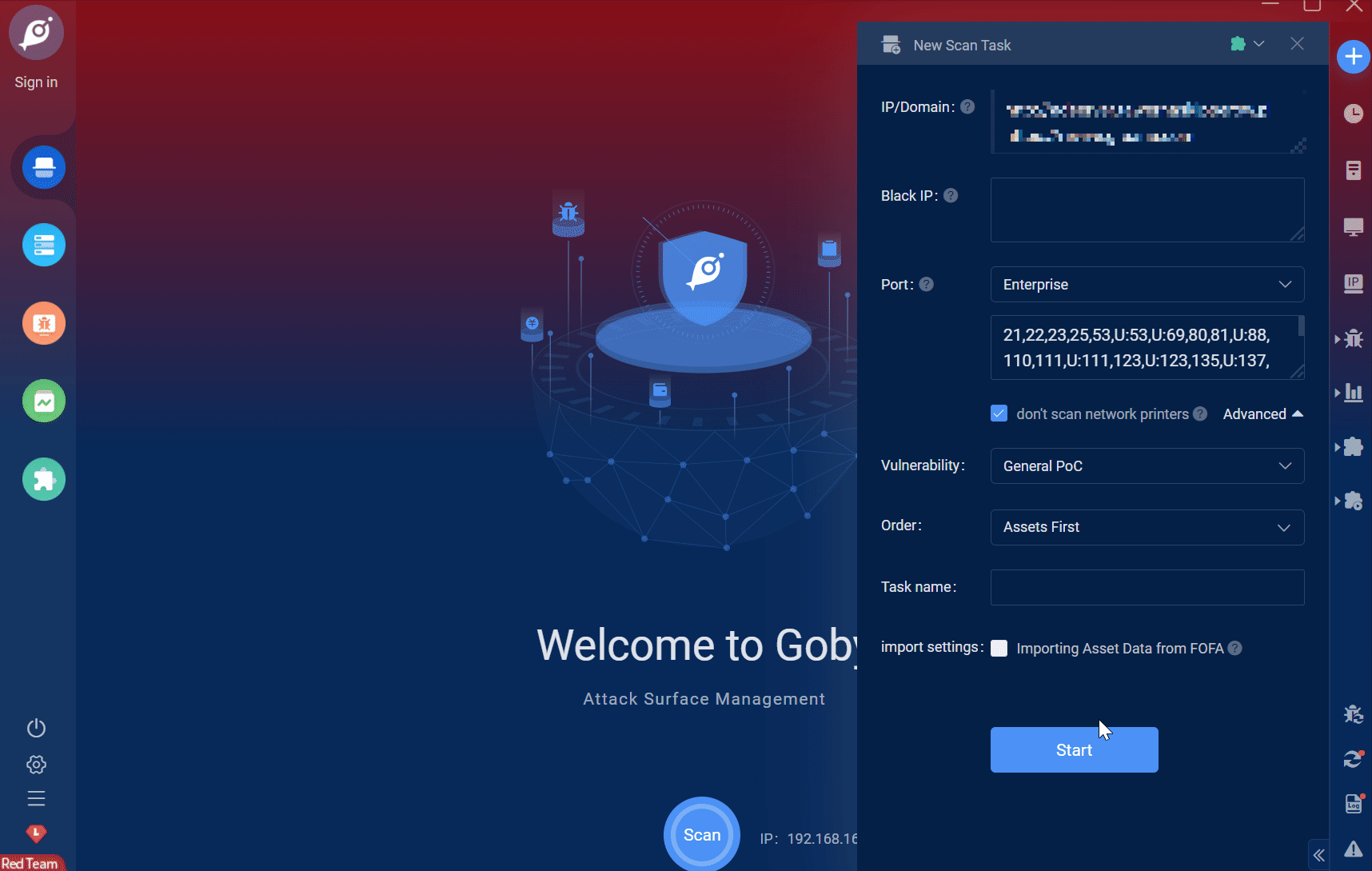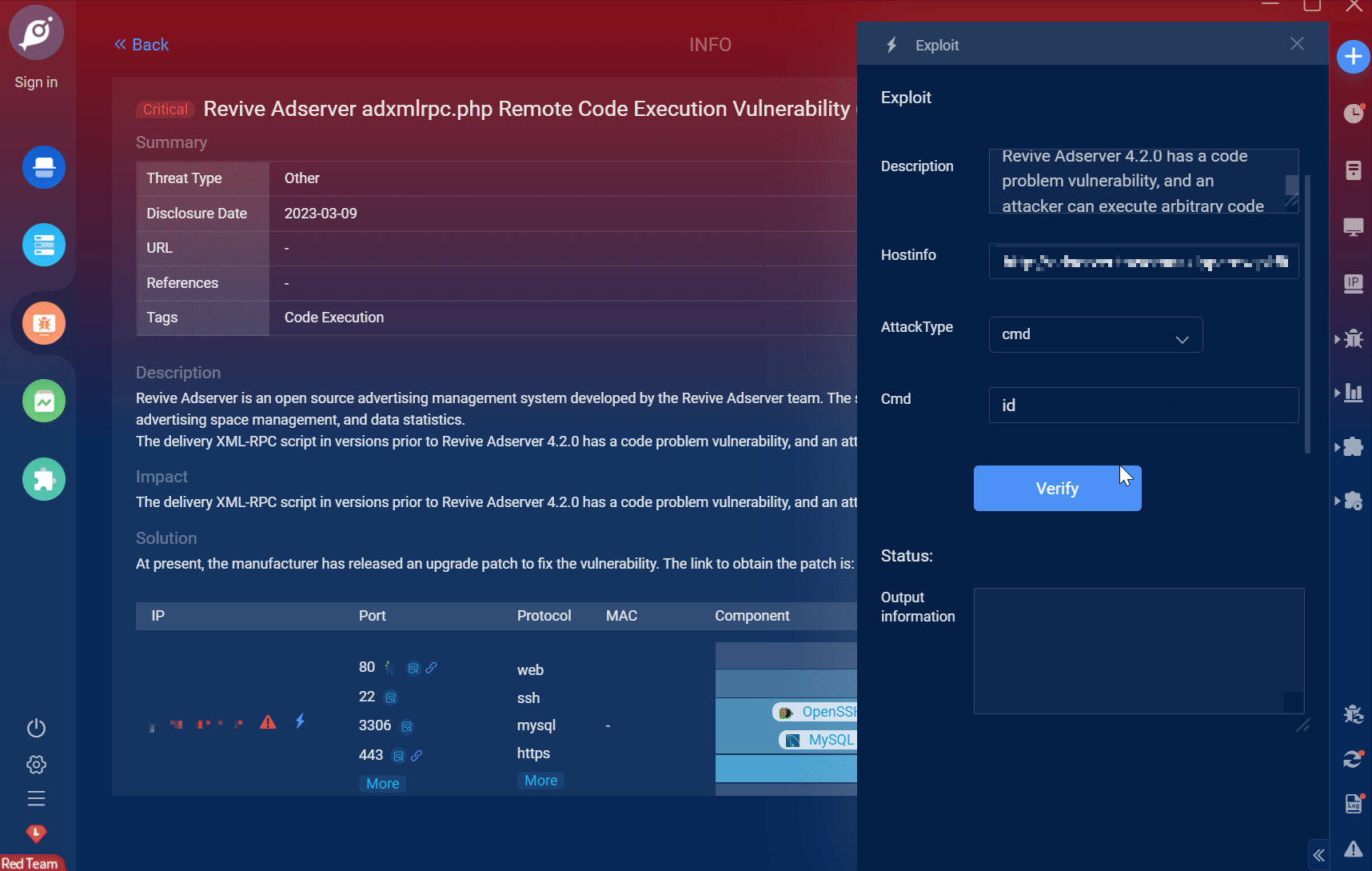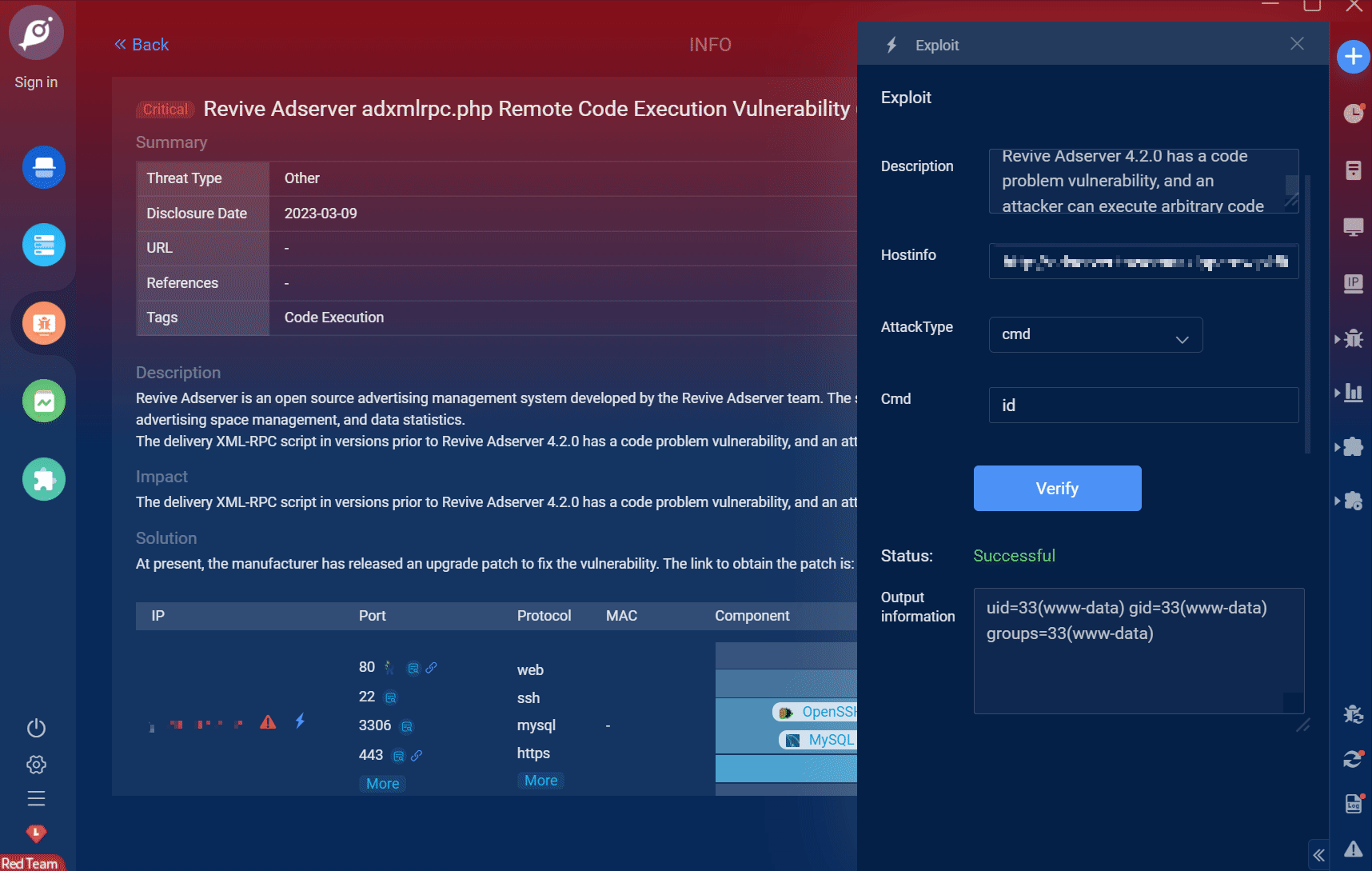
Goby 漏洞发布|Revive Adserver 广告管理系统 adxmlrpc.php 文件远程代码执行漏洞(CVE-2019-5434)
漏洞名称:Revive Adserver 广告管理系统 adxmlrpc.php 文件远程代码执行漏洞(CVE-2019-5434) English Name: Revive Adserver adxmlrpc.php Remote Code Execution Vulnerability (CVE-2019-5434) CVSS core: 9.0 影响资产数&a…...
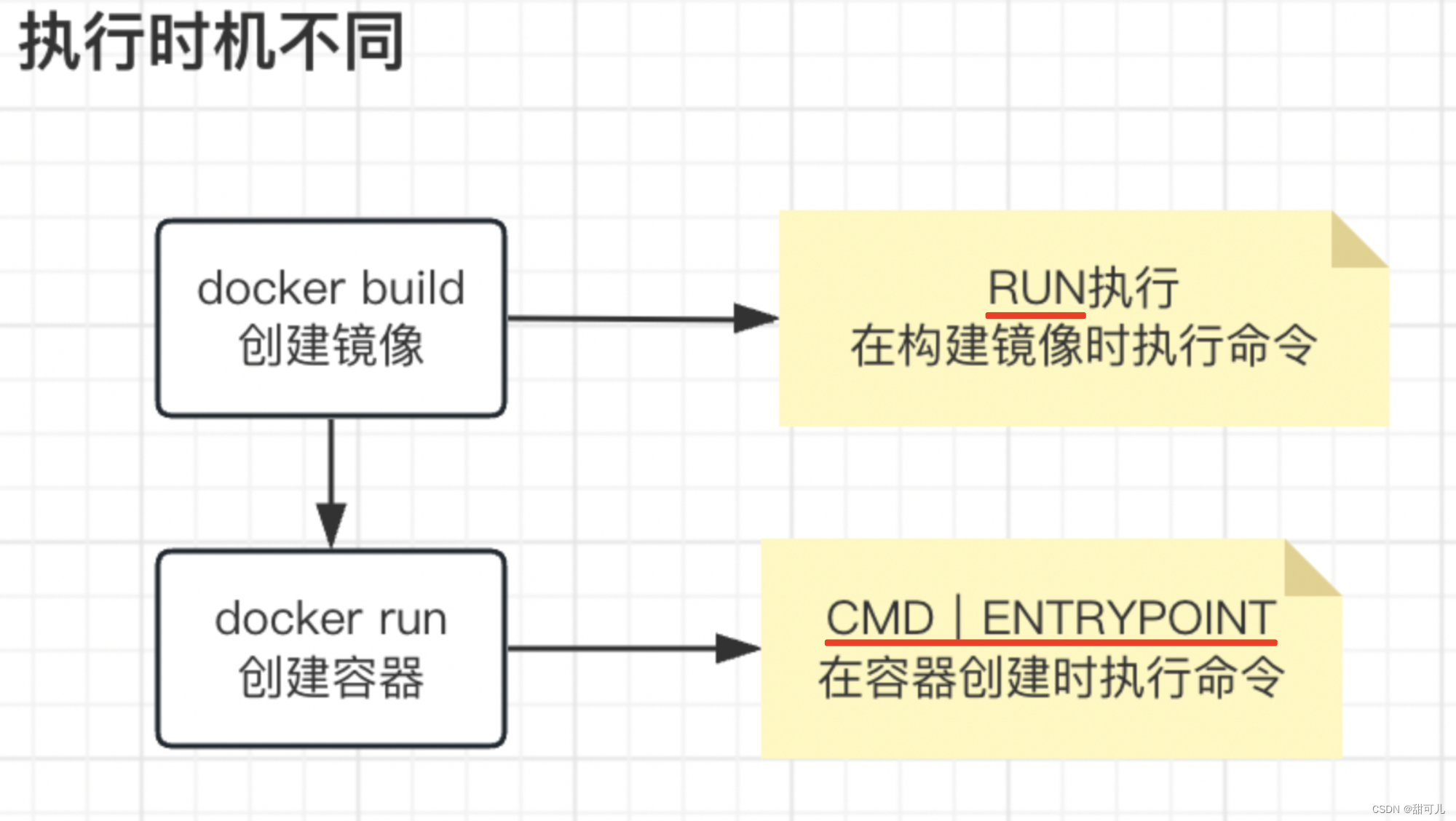
Docker(三)、Dockerfile探究
Dockerfile探究 一、镜像层概念1、通过执行命令显化docker的机制 二、Dockerfile基础命令1、FROM 基于基准镜像【即构建镜像的时候,依托原有镜像做拓展】2、LABEL & MAINTAINER -说明信息3、WORKDIR 设置工作目录4、ADD & COPY 复制文件5、ENV 设置环境常量…...

C++读取文件夹下多个文件,包括图片等等
话不多说,直接上代码: int main() {//读入图片路径下的所有文件,D:\APP\VS\vs_projects_repos\Isp\imagesstring imgdirpath"D:\\APP\\VS\\vs_projects_repos\\Isp\\proimages\\";// 只读取文件夹下的png的文件名,也可以改成“*.b…...
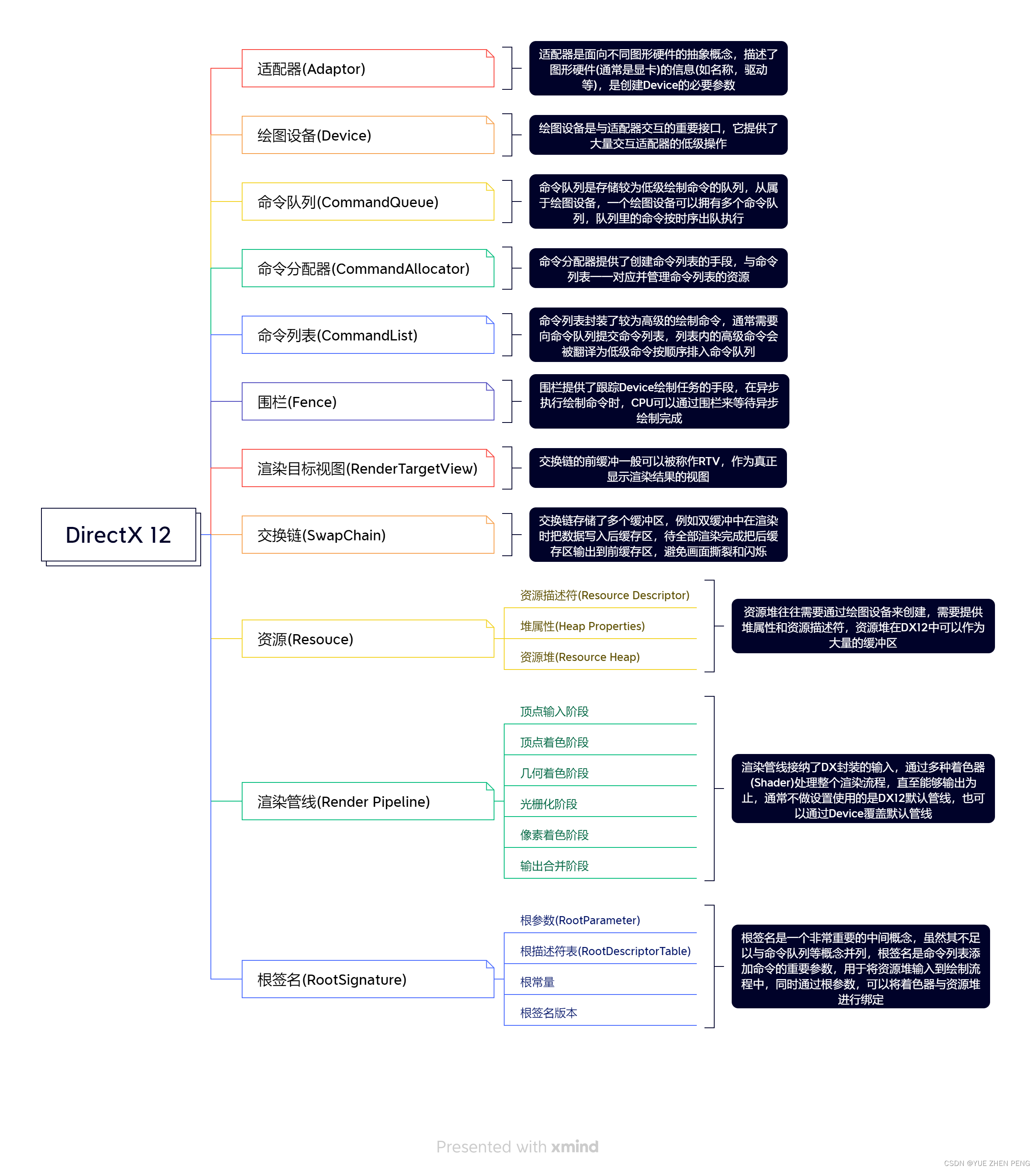
DirectX 12 学习笔记 -结构
上篇文章我们创建了一个窗口,看样子还不难,我们继续玩DX12 引用一些文件 头文件 #include <d3d12.h> #include <dxgi1_4.h> #include <wrl.h>还有一些库 #pragma comment(lib, "d3d12.lib") #pragma comment(lib, "…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...
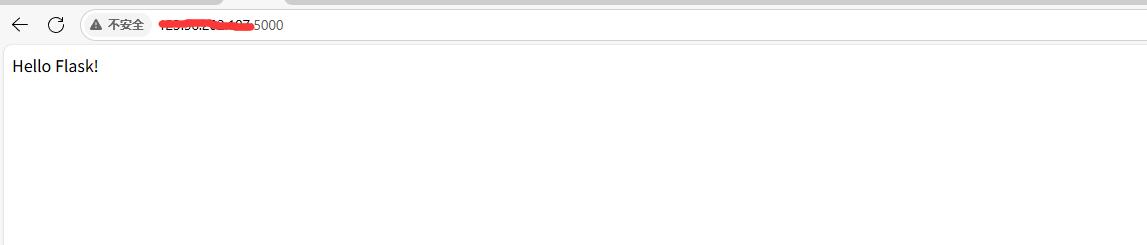
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...

Spring Boot + MyBatis 集成支付宝支付流程
Spring Boot MyBatis 集成支付宝支付流程 核心流程 商户系统生成订单调用支付宝创建预支付订单用户跳转支付宝完成支付支付宝异步通知支付结果商户处理支付结果更新订单状态支付宝同步跳转回商户页面 代码实现示例(电脑网站支付) 1. 添加依赖 <!…...
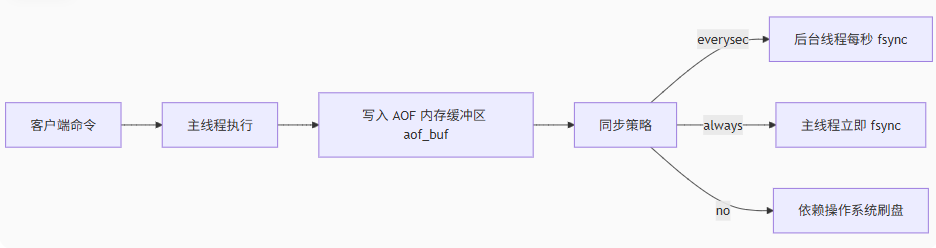
Redis上篇--知识点总结
Redis上篇–解析 本文大部分知识整理自网上,在正文结束后都会附上参考地址。如果想要深入或者详细学习可以通过文末链接跳转学习。 1. 基本介绍 Redis 是一个开源的、高性能的 内存键值数据库,Redis 的键值对中的 key 就是字符串对象,而 val…...