Python函数式编程(一)概念和itertools
Python函数式编程是一种编程范式,它强调使用纯函数来处理数据。函数是程序的基本构建块,并且尽可能避免或最小化可变状态和副作用。在函数式编程中,函数被视为一等公民,可以像值一样传递和存储。
函数式编程概念
编程语言支持通过以下几种方式来解构具体问题:
- 大多数的编程语言都是 过程式 的,所谓程序就是一连串告诉计算机怎样处理程序输入的指令。C、Pascal 甚至 Unix shells 都是过程式语言。
- 在 声明式 语言中,你编写一个用来描述待解决问题的说明,并且这个语言的具体实现会指明怎样高效的进行计算。 SQL 可能是你最熟悉的声明式语言了。 一个 SQL 查询语句描述了你想要检索的数据集,并且 SQL 引擎会决定是扫描整张表还是使用索引,应该先执行哪些子句等等。
- 面向对象 程序会操作一组对象。 对象拥有内部状态,并能够以某种方式支持请求和修改这个内部状态的方法。Smalltalk 和 Java 都是面向对象的语言。 C++ 和 Python 支持面向对象编程,但并不强制使用面向对象特性。
- 函数式 编程则将一个问题分解成一系列函数。 理想情况下,函数只接受输入并输出结果,对一个给定的输入也不会有影响输出的内部状态。 著名的函数式语言有 ML 家族(Standard ML,Ocaml 以及其他变种)和 Haskell。
一些语言的设计者选择强调一种特定的编程方式。 这通常会让以不同的方式来编写程序变得困难。其他多范式语言则支持几种不同的编程方式。Lisp,C++ 和 Python 都是多范式语言;使用这些语言,你可以编写主要为过程式,面向对象或者函数式的程序和函数库。在大型程序中,不同的部分可能会采用不同的方式编写;比如 GUI 可能是面向对象的而处理逻辑则是过程式或者函数式。
在函数式程序里,输入会流经一系列函数。每个函数接受输入并输出结果。函数式风格反对使用带有副作用的函数,这些副作用会修改内部状态,或者引起一些无法体现在函数的返回值中的变化。完全不产生副作用的函数被称作“纯函数”。消除副作用意味着不能使用随程序运行而更新的数据结构;每个函数的输出必须只依赖于输入。
一些语言对纯洁性要求非常严格,以至于没有像 a=3 或 c = a + b 这样的赋值表达式,但是完全消除副作用非常困难。 比如,显示在屏幕上或者写到磁盘文件中都是副作用。举个例子,在 Python 里,调用函数 print() 或者 time.sleep() 并不会返回有用的结果;它们的用途只在于副作用,向屏幕发送一段文字或暂停一秒钟。
函数式风格的 Python 程序并不会极端到消除所有 I/O 或者赋值的程度;相反,他们会提供像函数式一样的接口,但会在内部使用非函数式的特性。比如,函数的实现仍然会使用局部变量,但不会修改全局变量或者有其他副作用。
函数式编程可以被认为是面向对象编程的对立面。对象就像是颗小胶囊,包裹着内部状态和随之而来的能让你修改这个内部状态的一组调用方法,以及由正确的状态变化所构成的程序。函数式编程希望尽可能地消除状态变化,只和流经函数的数据打交道。在 Python 里你可以把两种编程方式结合起来,在你的应用(电子邮件信息,事务处理)中编写接受和返回对象实例的函数。
函数式设计在工作中看起来是个奇怪的约束。为什么你要消除对象和副作用呢?不过函数式风格有其理论和实践上的优点:
- 形式证明。
- 模块化。
- 组合性。
- 易于调试和测试。
形式证明
一个理论上的优点是,构造数学证明来说明函数式程序是正确的相对更容易些。
很长时间,研究者们对寻找证明程序正确的数学方法都很感兴趣。这和通过大量输入来测试,并得出程序的输出基本正确,或者阅读一个程序的源代码然后得出代码看起来没问题不同;相反,这里的目标是一个严格的证明,证明程序对所有可能的输入都能给出正确的结果。
证明程序正确性所用到的技术是写出 不变量,也就是对于输入数据和程序中的变量永远为真的特性。然后对每行代码,你说明这行代码执行前的不变量 X 和 Y 以及执行后稍有不同的不变量 X’ 和 Y’ 为真。如此一直到程序结束,这时候在程序的输出上,不变量应该会与期望的状态一致。
函数式编程之所以要消除赋值,是因为赋值在这个技术中难以处理;赋值可能会破坏赋值前为真的不变量,却并不产生任何可以传递下去的新的不变量。
不幸的是,证明程序的正确性很大程度上是经验性质的,而且和 Python 软件无关。即使是微不足道的程序都需要几页长的证明;一个中等复杂的程序的正确性证明会非常庞大,而且,极少甚至没有你日常所使用的程序(Python 解释器,XML 解析器,浏览器)的正确性能够被证明。即使你写出或者生成一个证明,验证证明也会是一个问题;里面可能出了差错,而你错误地相信你证明了程序的正确性。
模块化
函数式编程的一个更实用的优点是,它强制你把问题分解成小的方面。因此程序会更加模块化。相对于一个进行了复杂变换的大型函数,一个小的函数更明确,更易于编写, 也更易于阅读和检查错误。
易于调试和测试
测试和调试函数式程序相对来说更容易。
调试很简单是因为函数通常都很小而且清晰明确。当程序无法工作的时候,每个函数都是一个可以检查数据是否正确的接入点。你可以通过查看中间输入和输出迅速找到出错的函数。
测试更容易是因为每个函数都是单元测试的潜在目标。在执行测试前,函数并不依赖于需要重现的系统状态;相反,你只需要给出正确的输入,然后检查输出是否和期望的结果一致。
组合性
当你编写函数式风格的程序时,你会写出很多带有不同输入和输出的函数。其中一些不可避免地会局限于特定的应用,但其他的却可以广泛的用在程序中。举例来说,一个接受文件夹目录返回所有文件夹中的 XML 文件的函数; 或是一个接受文件名,然后返回文件内容的函数,都可以应用在很多不同的场合。
久而久之你会形成一个个人工具库。通常你可以重新组织已有的函数来组成新的程序,然后为当前的工作写一些特殊的函数。
迭代器
迭代器是Python函数式编程的基础,前面我们对迭代器进行了反复的学习,回顾迭代器的核心知识:
- 迭代器是一个表示数据流的对象;这个对象每次只返回一个元素。
- 迭代器必须支持 __next__() 方法;这个方法不接受参数,并总是返回数据流中的下一个元素。
- 如果数据流中没有元素,__next__() 会抛出 StopIteration 异常。迭代器未必是有限的;完全有理由构造一个输出无限数据流的迭代器。
- 内置的 iter() 函数接受任意对象并试图返回一个迭代器来输出对象的内容或元素,并会在对象不支持迭代的时候抛出 TypeError 异常。
- Python 有几种内置数据类型支持迭代,最常见的就是列表和字典。
- 如果一个对象能生成迭代器,那么它就会被称作 iterable。
- Python中有很多场景使用迭代器,其中最常见的是在for表达式中,像max()、min()以及前面学到的一些高级函数,都是支持迭代器的。
注意你只能在迭代器中顺序前进;没有获取前一个元素的方法,除非重置迭代器,或者重新复制一份。迭代器对象可以提供这些额外的功能,但迭代器协议只明确了 __next__() 方法。函数可能因此而耗尽迭代器的输出,如果你要对同样的数据流做不同的操作,你必须重新创建一个迭代器。
我们已经知道列表、元组、字符串、字典等类型都支持迭代器,也可以自定义类,实现__iter__()方法和__next__()方法来实现自己的迭代器。
迭代器还支持生成器表达式和列表推导式,这些让操作显得更简单明了。
列表推导式:
[ expression for expr in sequence1if condition1for expr2 in sequence2if condition2for expr3 in sequence3 ...if condition3for exprN in sequenceNif conditionN ]等价于:
for expr1 in sequence1:if not (condition1):continue # Skip this elementfor expr2 in sequence2:if not (condition2):continue # Skip this element...for exprN in sequenceN:if not (conditionN):continue # Skip this element# Output the value of# the expression.生成器表达式只需要把上面的[]替换为()即可。
高阶函数map()、reduce()、filter()等实际就是函数式编程的方式在运转。为了支持更多的函数式编程,itertools模块支持更多的常用的迭代器以及用来组合迭代器的函数。
itertools 模块
本模块实现一系列 iterator ,这些迭代器受到函数式编程语言APL、Haskell和SML等的启发。为了适用于Python,它们都被重新写过。
本模块标准化了一个快速、高效利用内存的核心工具集,这些工具本身或组合都很有用。它们一起形成了“迭代器代数”,这使得在纯Python中有可能创建简洁又高效的专用工具。
例如,SML有一个制表工具: tabulate(f),它可产生一个序列 f(0), f(1), ...。在Python中可以组合 map() 和 count() 实现: map(f, count())。
这些工具也能提供良好的性能,也能与operator模块的功能进行集成。
迭代器
itertools除使用原有的一般迭代器外,还提供了许多扩展的迭代器。
无穷迭代器
无穷迭代器最大的特点是可无限迭代元素,所以在使用时要注意一定要有限制条件来控制迭代器的停止,否则将造成死循环。
序号迭代器count()
itertools.count(start=0, step=1)
创建一个迭代器,它从 start 值开始,返回均匀间隔的值。常用于 map() 中的实参来生成连续的数据点。此外,还用于 zip() 来添加序列号。
参数说明:
- start:起始值
- step:间隔值
大致相当于:
def count(start=0, step=1):# count(10) --> 10 11 12 13 14 ...# count(2.5, 0.5) --> 2.5 3.0 3.5 ...n = startwhile True:yield nn += step当对浮点数计数时,替换为乘法代码有时精度会更好,例如: (start + step * i for i in count()) 。
import itertoolsFruits = ['pear', 'peach', 'apple', 'grape', 'banana', 'cherry', 'strawberry', 'watermelon']fruitList = list(zip(itertools.count(start=1), Fruits))
print(fruitList)‘’'
[(1, 'pear'), (2, 'peach'), (3, 'apple'), (4, 'grape'), (5, 'banana'), (6, 'cherry'), (7, 'strawberry'), (8, 'watermelon')]
‘''循环迭代器cycle()
itertools.cycle(iterable)
创建一个迭代器,返回 iterable 中所有元素并保存一个副本。当取完 iterable 中所有元素,返回副本中的所有元素。无限重复。大致相当于:
def cycle(iterable):# cycle('ABCD') --> A B C D A B C D A B C D ...saved = []for element in iterable:yield elementsaved.append(element)while saved:for element in saved:yield elementimport itertools
import datetimeDays =['星期一', '星期二', '星期三', '星期四', '星期五', '星期六', '星期日']BaseDate = datetime.date(2023, 9, 4)
datelist = [BaseDate + datetime.timedelta(days=d) for d in range(10)]
print(datelist)
daylist = list(zip(datelist, itertools.cycle(Days)))
print(daylist)‘’'
[datetime.date(2023, 9, 4), datetime.date(2023, 9, 5), datetime.date(2023, 9, 6), datetime.date(2023, 9, 7), datetime.date(2023, 9, 8), datetime.date(2023, 9, 9), datetime.date(2023, 9, 10), datetime.date(2023, 9, 11), datetime.date(2023, 9, 12), datetime.date(2023, 9, 13)]
[(datetime.date(2023, 9, 4), '星期一'), (datetime.date(2023, 9, 5), '星期二'), (datetime.date(2023, 9, 6), '星期三'), (datetime.date(2023, 9, 7), '星期四'), (datetime.date(2023, 9, 8), '星期五'), (datetime.date(2023, 9, 9), '星期六'), (datetime.date(2023, 9, 10), '星期日'), (datetime.date(2023, 9, 11), '星期一'), (datetime.date(2023, 9, 12), '星期二'), (datetime.date(2023, 9, 13), '星期三')]
‘''重复迭代器repeat()
itertools.repeat(object[, times])
重复的提供times个object,如果不设置times,则提供无限个。
import itertoolsfor it in itertools.repeat('fruits', times=3):print(it)’’’
fruits
fruits
fruits
‘’‘短序列迭代器
根据最短输入序列长度停止的迭代器
累积迭代器accumulate
itertools.accumulate(iterable[, func, *, initial=None])
创建一个迭代器,返回累积汇总值或其他双目运算函数的累积结果值(通过可选的 func 参数指定)。
例如一个序列为[1,2,3,4,5]
- 迭代器的第1个值等于序列的第1个值,为1
- 迭代器的第2个值为迭代器的第1个值加上序列的第2个值,1+2为3
- 迭代器的第3个值为迭代器的第2个值加上序列的第3个值,3+3为6
- 依次类推
import itertoolsnums = [1,2,3,4,5]
anums = [it for it in itertools.accumulate(nums)]
print(anums)‘’'
[1, 3, 6, 10, 15]
‘''如果提供了 func,它应当为带有两个参数的函数。 输入 iterable 的元素可以是能被 func 接受为参数的任意类型。 (例如,对于默认的加法运算,元素可以是任何可相加的类型包括 Decimal 或 Fraction。)
例如我们改为连乘:
import itertoolsnums = [1,2,3,4,5]
anums = [it for it in itertools.accumulate(nums, func=lambda a,b:a*b)]
print(anums)‘’'
[1, 2, 6, 24, 120]
‘''通常,输出的元素数量与输入的可迭代对象是一致的。 但是,如果提供了关键字参数 initial,则累加会以 initial 值开始,这样输出就比输入的可迭代对象多一个元素。
序列连接迭代器chain
itertools.chain(*iterables)
创建一个迭代器,它首先返回第一个可迭代对象中所有元素,接着返回下一个可迭代对象中所有元素,直到耗尽所有可迭代对象中的元素。可将多个序列处理为单个序列。
import itertoolsfruits = ['mango', 'pear', 'peach']
nums = [1,2,3,4,5]anums = list(itertools.chain(fruits, nums))
print(anums)‘’'
['mango', 'pear', 'peach', 1, 2, 3, 4, 5]
‘''展开迭代器 chain.from_iterable
classmethod chain.from_iterable(iterable)
可以把一个嵌套的list展开成一维的迭代器。
import itertoolsfruits = ['mango', 'pear', 'peach']
nums = [1,2,3,4,5]anums = list(itertools.chain.from_iterable([fruits, nums, 'ABCDE']))
print(anums)alist = [['mango', 'pear', 'peach'], ['grape', 'banana', 'cherry'], (['a', 'b', 'c'], ('n', 'l', 1)), {'k1':'v1', 'k2':'v2'}]
nlist = list(itertools.chain.from_iterable(alist))
print(nlist)blist = list(itertools.chain(alist))
print(blist)‘’'
['mango', 'pear', 'peach', 1, 2, 3, 4, 5, 'A', 'B', 'C', 'D', 'E']
['mango', 'pear', 'peach', 'grape', 'banana', 'cherry', ['a', 'b', 'c'], ('n', 'l', 1), 'k1', 'k2']
[['mango', 'pear', 'peach'], ['grape', 'banana', 'cherry'], (['a', 'b', 'c'], ('n', 'l', 1)), {'k1': 'v1', 'k2': 'v2'}]‘''从上面的例子可以看到,只做一次的展开,不会深入。
简单过滤迭代器compress
itertools.compress(data, selectors)
创建一个迭代器,它返回 data (iterable对象)中经 selectors(iterable对象) 真值测试为 True 的元素。迭代器在两者较短的长度处停止。
print(list(itertools.compress(['mango', 'pear', 'peach', 'grape', 'banana'], [1,0,0,1])))
#['mango', 'grape']跳过开头迭代器dropwhile
itertools.dropwhile(predicate, iterable)
predicate是一个函数对象,接受一个参数,即iterable的元素。
创建一个迭代器,如果前面元素的 predicate 连续为True,迭代器丢弃这些元素,如果出现第一个False的元素,就开始返回后面的元素(不再检查那些元素的predicate是否为真)。注意,迭代器在 predicate 首次为false之前不会产生任何输出(直接跳过),所以可能需要一定长度的启动时间。大致相当于:
def dropwhile(predicate, iterable):# dropwhile(lambda x: x<5, [1,4,6,4,1]) --> 6 4 1iterable = iter(iterable)for x in iterable:if not predicate(x):yield xbreakfor x in iterable:yield x例子:
import itertools
import datetimeDays =['星期一', '星期二', '星期三', '星期四', '星期五', '星期六', '星期日']BaseDate = datetime.date(2023, 9, 1)def checkMonday(d:datetime.date):print(f'{d}, {d.weekday()}')if d.weekday() == 0:return Falseelse:return Truedatelist = [BaseDate + datetime.timedelta(days=d) for d in range(14)]
print(datelist)
daylist = list(zip(Days, itertools.dropwhile(checkMonday,datelist)))
print(daylist)‘’’
[datetime.date(2023, 9, 1), datetime.date(2023, 9, 2), datetime.date(2023, 9, 3), datetime.date(2023, 9, 4), datetime.date(2023, 9, 5), datetime.date(2023, 9, 6), datetime.date(2023, 9, 7), datetime.date(2023, 9, 8), datetime.date(2023, 9, 9), datetime.date(2023, 9, 10), datetime.date(2023, 9, 11), datetime.date(2023, 9, 12), datetime.date(2023, 9, 13), datetime.date(2023, 9, 14)]
2023-09-01, 4
2023-09-02, 5
2023-09-03, 6
2023-09-04, 0
[('星期一', datetime.date(2023, 9, 4)), ('星期二', datetime.date(2023, 9, 5)), ('星期三', datetime.date(2023, 9, 6)), ('星期四', datetime.date(2023, 9, 7)), ('星期五', datetime.date(2023, 9, 8)), ('星期六', datetime.date(2023, 9, 9)), ('星期日', datetime.date(2023, 9, 10))]
’‘’跳过尾部迭代器takewhile
itertools.takewhile(predicate, iterable)
创建一个迭代器,只要前面的元素的 predicate 连续为真就从可迭代对象中返回元素,只要有一个元素的predicate为False,就立即终止(不再检查后面的元素的predicate)
predicate是一个函数对象,接受一个参数,即iterable的元素。
alist = list(itertools.takewhile(lambda x:x<10, [1,3,5,6,7,11,3,2,1]))
print(alist) #[1, 3, 5, 6, 7]
tee迭代器
itertools.tee(iterable, n=2)
从一个可迭代对象中返回 n 个独立的迭代器。
例如将[1,2,3,4,5],变成[[1,2,3,4,5],[1,2,3,4,5]]
its = itertools.tee([1,2,3,4,5,6,7], 3)
for it in its:print(list(it))‘’'
[1, 2, 3, 4, 5, 6, 7]
[1, 2, 3, 4, 5, 6, 7]
[1, 2, 3, 4, 5, 6, 7]
‘''zip补齐迭代器
itertools.zip_longest(*iterables, fillvalue=None)
zip会按最短的迭代对象压缩迭代器,zip_longest()按最长的进行压缩,如果一个迭代器长度不够,使用fillvalue进行填充。
alist = [1,2,3,4,5,6,7,8]
blist = ['mango', 'pear', 'peach', 'grape', 'banana', 'cherry','apricot', 'persimmon','medlar', 'watermelon', 'apple', 'pomegranate', 'currant', 'blackberry', 'avocado']zip1 = zip(alist, blist)
print(list(zip1))
#[(1, 'mango'), (2, 'pear'), (3, 'peach'), (4, 'grape'), (5, 'banana'), (6, 'cherry'), (7, 'apricot'), (8, 'persimmon')]zip2 = itertools.zip_longest(alist, blist, fillvalue=0)
print(list(zip2))
#[(1, 'mango'), (2, 'pear'), (3, 'peach'), (4, 'grape'), (5, 'banana'), (6, 'cherry'), (7, 'apricot'), (8, 'persimmon'), (0, 'medlar'), (0, 'watermelon'), (0, 'apple'), (0, 'pomegranate'), (0, 'currant'), (0, 'blackberry'), (0, 'avocado')]否定过滤迭代器filterfalse
itertools.filterfalse(predicate, iterable)
创建一个迭代器,如果 predicate 为True,迭代器丢弃这些元素,返回后面为False的元素,如果predicate未None,直接对元素的真假进行判断,大致相当于:
def filterfalse(predicate, iterable):# filterfalse(lambda x: x%2, range(10)) --> 0 2 4 6 8if predicate is None:predicate = boolfor x in iterable:if not predicate(x):yield x例子:
import itertools#奇数的无限序列
odd = itertools.filterfalse(lambda x:x%2 == 0, itertools.count(start=1))
for num in odd:print(num)if num == 11:break‘’’
1
3
5
7
9
11
’‘’分组迭代器groupby
itertools.groupby(iterable, key=None)
创建一个迭代器,返回 iterable 中相邻的重复的键分组在一起。key 是一个计算元素键值函数。如果未指定或为 None,key 缺省为恒等函数(identity function),返回元素不变。一般来说,iterable 需用同一个键值函数预先排序。
groupby() 操作类似于Unix中的 uniq。当每次 key 函数产生的键值改变时,迭代器会分组或生成一个新组(这就是为什么通常需要使用同一个键值函数先对数据进行排序)。这种行为与SQL的GROUP BY操作不同,SQL的操作会忽略输入的顺序将相同键值的元素分在同组中。
返回的组本身也是一个迭代器,它与 groupby() 共享底层的可迭代对象。因为源是共享的,当 groupby() 对象向后迭代时,前一个组将消失。因此如果稍后还需要返回结果,可保存为列表:
groups = []
uniquekeys = []
data = sorted(data, key=keyfunc)
for k, g in groupby(data, keyfunc):groups.append(list(g)) # Store group iterator as a listuniquekeys.append(k)大致相当于:
class groupby:# [k for k, g in groupby('AAAABBBCCDAABBB')] --> A B C D A B# [list(g) for k, g in groupby('AAAABBBCCD')] --> AAAA BBB CC Ddef __init__(self, iterable, key=None):if key is None:key = lambda x: xself.keyfunc = keyself.it = iter(iterable)self.tgtkey = self.currkey = self.currvalue = object()def __iter__(self):return selfdef __next__(self):self.id = object()while self.currkey == self.tgtkey:self.currvalue = next(self.it) # Exit on StopIterationself.currkey = self.keyfunc(self.currvalue)self.tgtkey = self.currkeyreturn (self.currkey, self._grouper(self.tgtkey, self.id))def _grouper(self, tgtkey, id):while self.id is id and self.currkey == tgtkey:yield self.currvaluetry:self.currvalue = next(self.it)except StopIteration:returnself.currkey = self.keyfunc(self.currvalue)例子1:
import itertoolsfruits = ['hippopotamus', 'pear', 'peach', 'grape', 'banana', 'cherry','mulberry', 'persimmon','strawberry', 'watermelon', 'apple', 'pomegranate']newfruits = itertools.groupby(fruits, key=len)
# newfruits = itertools.groupby(fruits, key=lambda x:x[0])
for k,v in newfruits:print(f'---{k}---')for vit in v:print(vit)’’’
---12---
hippopotamus
---4---
pear
---5---
peach
grape
---6---
banana
cherry
---8---
mulberry
---9---
persimmon
---10---
strawberry
watermelon
---5---
apple
---11---
pomegranate
‘’‘从上面的例子看,有两个5的分组。
例子2:
import itertoolsfruits = ['hippopotamus', 'pear', 'peach', 'grape', 'banana', 'cherry','mulberry', 'persimmon','strawberry', 'watermelon', 'apple', 'pomegranate']# newfruits = itertools.groupby(fruits, key=len)
newfruits = itertools.groupby(fruits, key=lambda x:x[0])
for k,v in newfruits:print(f'---{k}---')for vit in v:print(vit)
’’’
---h---
hippopotamus
---p---
pear
peach
---g---
grape
---b---
banana
---c---
cherry
---m---
mulberry
---p---
persimmon
---s---
strawberry
---w---
watermelon
---a---
apple
---p---
pomegranate
‘’‘有3个p的分组。说明group是不进行排序的,需要我们事先进行排序。
import itertoolsfruits = ['hippopotamus', 'pear', 'peach', 'grape', 'banana', 'cherry','mulberry', 'persimmon','strawberry', 'watermelon', 'apple', 'pomegranate']fruitsnew = sorted(fruits, key=lambda x:x[0])
# newfruits = itertools.groupby(fruits, key=len)
newfruits = itertools.groupby(fruitsnew, key=lambda x:x[0])
for k,v in newfruits:print(f'---{k}---')for vit in v:print(vit)‘’'
---a---
apple
---b---
banana
---c---
cherry
---g---
grape
---h---
hippopotamus
---m---
mulberry
---p---
pear
peach
persimmon
pomegranate
---s---
strawberry
---w---
watermelon
‘''切片迭代器islice
itertools.islice(iterable, stop)
itertools.islice(iterable, start, stop[, step])
获取iterable的一段切片,start是开始位置,stop是结束位置,step是步长。
等价于iterable[start:stop:step]
import itertoolsfruits = ['mango', 'pear', 'peach', 'grape', 'banana', 'cherry','apricot', 'persimmon','medlar', 'watermelon', 'apple', 'pomegranate', 'currant', 'blackberry', 'avocado','walnut', 'walnut', 'coconut', 'bilberry', 'plum']for it in itertools.islice(fruits, 3, 10, 2):print(it)‘’'
grape
cherry
persimmon
watermelon
‘''重叠对迭代器pairwise
itertools.pairwise(iterable)
返回从输入 iterable 中获取的连续重叠对。
输出迭代器中 2 元组的数量将比输入的数量少一个。 如果输入可迭代对象中少于两个值则它将为空。
import itertoolsfruits = ['mango', 'pear', 'peach', 'grape', 'banana']for it in itertools.pairwise(fruits):print(it)for it in itertools.pairwise('ABCDE'):print(it)‘’'
('mango', 'pear')
('pear', 'peach')
('peach', 'grape')
('grape', 'banana')
('A', 'B')
('B', 'C')
('C', 'D')
('D', 'E')
‘''多参数map-starmap
itertools.starmap(function, iterable)
map函数只能接受单个参数,startmap可以接受多个参数,要求iterable是一个元素的迭代对象(类似于:[(a1,a2,...),(b1,b2,...),...],每一个元组是function的一组参数。
import itertoolsdatalist = [(2,4), (3,7), (19,14), (20,31)]sumlist = list(itertools.starmap(lambda x,y:x+y, datalist))
print(sumlist) #[6, 10, 33, 51],类似于 2+4,3+7,19+14,20+31multilist = list(itertools.starmap(lambda x,y:x*y, datalist))
print(multilist) #[8, 21, 266, 620]powlist = list(itertools.starmap(lambda x,y:x**y, datalist))
print(powlist) #[16, 2187, 799006685782884121, 21474836480000000000000000000000000000000]
排列组合迭代器
排列迭代器permutations
itertools.permutations(iterable, r=None)
连续返回由 iterable 元素生成长度为 r 的排列。
如果 r 未指定或为 None ,r 默认设置为 iterable 的长度,这种情况下,生成所有全长排列。
import itertoolsfruits = ['mango', 'pear', 'peach']for it in itertools.permutations(fruits):print(it)’’’
('mango', 'pear', 'peach')
('mango', 'peach', 'pear')
('pear', 'mango', 'peach')
('pear', 'peach', 'mango')
('peach', 'mango', 'pear')
('peach', 'pear', 'mango')
‘’‘如果设置了r,是从iterable选出r个元素进行全排列,数据量会比较大
import itertoolsfruits = ['mango', 'pear', 'peach', 'grape', 'banana']for it in itertools.permutations(fruits, 3):print(it)’’’
('mango', 'pear', 'peach')
('mango', 'pear', 'grape')
('mango', 'pear', 'banana')
('mango', 'peach', 'pear')
('mango', 'peach', 'grape')
('mango', 'peach', 'banana')
('mango', 'grape', 'pear')
('mango', 'grape', 'peach')
('mango', 'grape', 'banana')
('mango', 'banana', 'pear')
('mango', 'banana', 'peach')
('mango', 'banana', 'grape')
('pear', 'mango', 'peach')
('pear', 'mango', 'grape')
('pear', 'mango', 'banana')
('pear', 'peach', 'mango')
('pear', 'peach', 'grape')
('pear', 'peach', 'banana')
('pear', 'grape', 'mango')
('pear', 'grape', 'peach')
('pear', 'grape', 'banana')
('pear', 'banana', 'mango')
('pear', 'banana', 'peach')
('pear', 'banana', 'grape')
('peach', 'mango', 'pear')
('peach', 'mango', 'grape')
('peach', 'mango', 'banana')
('peach', 'pear', 'mango')
('peach', 'pear', 'grape')
('peach', 'pear', 'banana')
('peach', 'grape', 'mango')
('peach', 'grape', 'pear')
('peach', 'grape', 'banana')
('peach', 'banana', 'mango')
('peach', 'banana', 'pear')
('peach', 'banana', 'grape')
('grape', 'mango', 'pear')
('grape', 'mango', 'peach')
('grape', 'mango', 'banana')
('grape', 'pear', 'mango')
('grape', 'pear', 'peach')
('grape', 'pear', 'banana')
('grape', 'peach', 'mango')
('grape', 'peach', 'pear')
('grape', 'peach', 'banana')
('grape', 'banana', 'mango')
('grape', 'banana', 'pear')
('grape', 'banana', 'peach')
('banana', 'mango', 'pear')
('banana', 'mango', 'peach')
('banana', 'mango', 'grape')
('banana', 'pear', 'mango')
('banana', 'pear', 'peach')
('banana', 'pear', 'grape')
('banana', 'peach', 'mango')
('banana', 'peach', 'pear')
('banana', 'peach', 'grape')
('banana', 'grape', 'mango')
('banana', 'grape', 'pear')
('banana', 'grape', 'peach')
‘’‘组合迭代器combinations
itertools.combinations(iterable, r)
返回由输入 iterable 中元素组成长度为 r 的子序列,在iterable中任选r个元素的组合序列。
alist = itertools.combinations('ABCDEFG', 3)
print(list(alist))#[('A', 'B', 'C'), ('A', 'B', 'D'), ('A', 'B', 'E'), ('A', 'B', 'F'), ('A', 'B', 'G'), ('A', 'C', 'D'), ('A', 'C', 'E'), ('A', 'C', 'F'), ('A', 'C', 'G'), ('A', 'D', 'E'), ('A', 'D', 'F'), ('A', 'D', 'G'), ('A', 'E', 'F'), ('A', 'E', 'G'), ('A', 'F', 'G'), ('B', 'C', 'D'), ('B', 'C', 'E'), ('B', 'C', 'F'), ('B', 'C', 'G'), ('B', 'D', 'E'), ('B', 'D', 'F'), ('B', 'D', 'G'), ('B', 'E', 'F'), ('B', 'E', 'G'), ('B', 'F', 'G'), ('C', 'D', 'E'), ('C', 'D', 'F'), ('C', 'D', 'G'), ('C', 'E', 'F'), ('C', 'E', 'G'), ('C', 'F', 'G'), ('D', 'E', 'F'), ('D', 'E', 'G'), ('D', 'F', 'G'), ('E', 'F', 'G')]
可重复的组合迭代器combinations_with_replacement
itertools.combinations_with_replacement(iterable, r)
上面的那个组合迭代器选的元素都是不同的,这个可以选自己。
alist = itertools.combinations_with_replacement('ABCDEFG', 3)
print(list(alist))#[('A', 'A', 'A'), ('A', 'A', 'B'), ('A', 'A', 'C'), ('A', 'A', 'D'), ('A', 'A', 'E'), ('A', 'A', 'F'), ('A', 'A', 'G'), ('A', 'B', 'B'), ('A', 'B', 'C'), ('A', 'B', 'D'), ('A', 'B', 'E'), ('A', 'B', 'F'), ('A', 'B', 'G'), ('A', 'C', 'C'), ('A', 'C', 'D'), ('A', 'C', 'E'), ('A', 'C', 'F'), ('A', 'C', 'G'), ('A', 'D', 'D'), ('A', 'D', 'E'), ('A', 'D', 'F'), ('A', 'D', 'G'), ('A', 'E', 'E'), ('A', 'E', 'F'), ('A', 'E', 'G'), ('A', 'F', 'F'), ('A', 'F', 'G'), ('A', 'G', 'G'), ('B', 'B', 'B'), ('B', 'B', 'C'), ('B', 'B', 'D'), ('B', 'B', 'E'), ('B', 'B', 'F'), ('B', 'B', 'G'), ('B', 'C', 'C'), ('B', 'C', 'D'), ('B', 'C', 'E'), ('B', 'C', 'F'), ('B', 'C', 'G'), ('B', 'D', 'D'), ('B', 'D', 'E'), ('B', 'D', 'F'), ('B', 'D', 'G'), ('B', 'E', 'E'), ('B', 'E', 'F'), ('B', 'E', 'G'), ('B', 'F', 'F'), ('B', 'F', 'G'), ('B', 'G', 'G'), ('C', 'C', 'C'), ('C', 'C', 'D'), ('C', 'C', 'E'), ('C', 'C', 'F'), ('C', 'C', 'G'), ('C', 'D', 'D'), ('C', 'D', 'E'), ('C', 'D', 'F'), ('C', 'D', 'G'), ('C', 'E', 'E'), ('C', 'E', 'F'), ('C', 'E', 'G'), ('C', 'F', 'F'), ('C', 'F', 'G'), ('C', 'G', 'G'), ('D', 'D', 'D'), ('D', 'D', 'E'), ('D', 'D', 'F'), ('D', 'D', 'G'), ('D', 'E', 'E'), ('D', 'E', 'F'), ('D', 'E', 'G'), ('D', 'F', 'F'), ('D', 'F', 'G'), ('D', 'G', 'G'), ('E', 'E', 'E'), ('E', 'E', 'F'), ('E', 'E', 'G'), ('E', 'F', 'F'), ('E', 'F', 'G'), ('E', 'G', 'G'), ('F', 'F', 'F'), ('F', 'F', 'G'), ('F', 'G', 'G'), ('G', 'G', 'G')]
笛卡尔集迭代器product
itertools.product(*iterables, repeat=1)
可迭代对象输入的笛卡儿积。
大致相当于生成器表达式中的嵌套循环。例如, product(A, B) 和 ((x,y) for x in A for y in B) 返回结果一样。
嵌套循环像里程表那样循环变动,每次迭代时将最右侧的元素向后迭代。这种模式形成了一种字典序,因此如果输入的可迭代对象是已排序的,笛卡尔积元组依次序发出。
要计算可迭代对象自身的笛卡尔积,将可选参数 repeat 设定为要重复的次数。例如,product(A, repeat=4) 和 product(A, A, A, A) 是一样的。
import itertoolsfruits = ['mango', 'pear', 'peach']
ids =['1', '2']for it in itertools.product(fruits, ids):print(it)‘’'
('mango', '1')
('mango', '2')
('pear', '1')
('pear', '2')
('peach', '1')
('peach', '2')
‘''import itertoolsfruits = ['mango', 'pear', 'peach']
ids =['1', '2']for it in itertools.product(fruits, repeat=2):print(it)print('----')
for it in itertools.product(fruits, fruits):print(it)‘’'
('mango', 'mango')
('mango', 'pear')
('mango', 'peach')
('pear', 'mango')
('pear', 'pear')
('pear', 'peach')
('peach', 'mango')
('peach', 'pear')
('peach', 'peach')
----
('mango', 'mango')
('mango', 'pear')
('mango', 'peach')
('pear', 'mango')
('pear', 'pear')
('pear', 'peach')
('peach', 'mango')
('peach', 'pear')
('peach', 'peach')
‘''相关文章:
概念和itertools)
Python函数式编程(一)概念和itertools
Python函数式编程是一种编程范式,它强调使用纯函数来处理数据。函数是程序的基本构建块,并且尽可能避免或最小化可变状态和副作用。在函数式编程中,函数被视为一等公民,可以像值一样传递和存储。 函数式编程概念 编程语言支持通…...
Guava限流器原理浅析
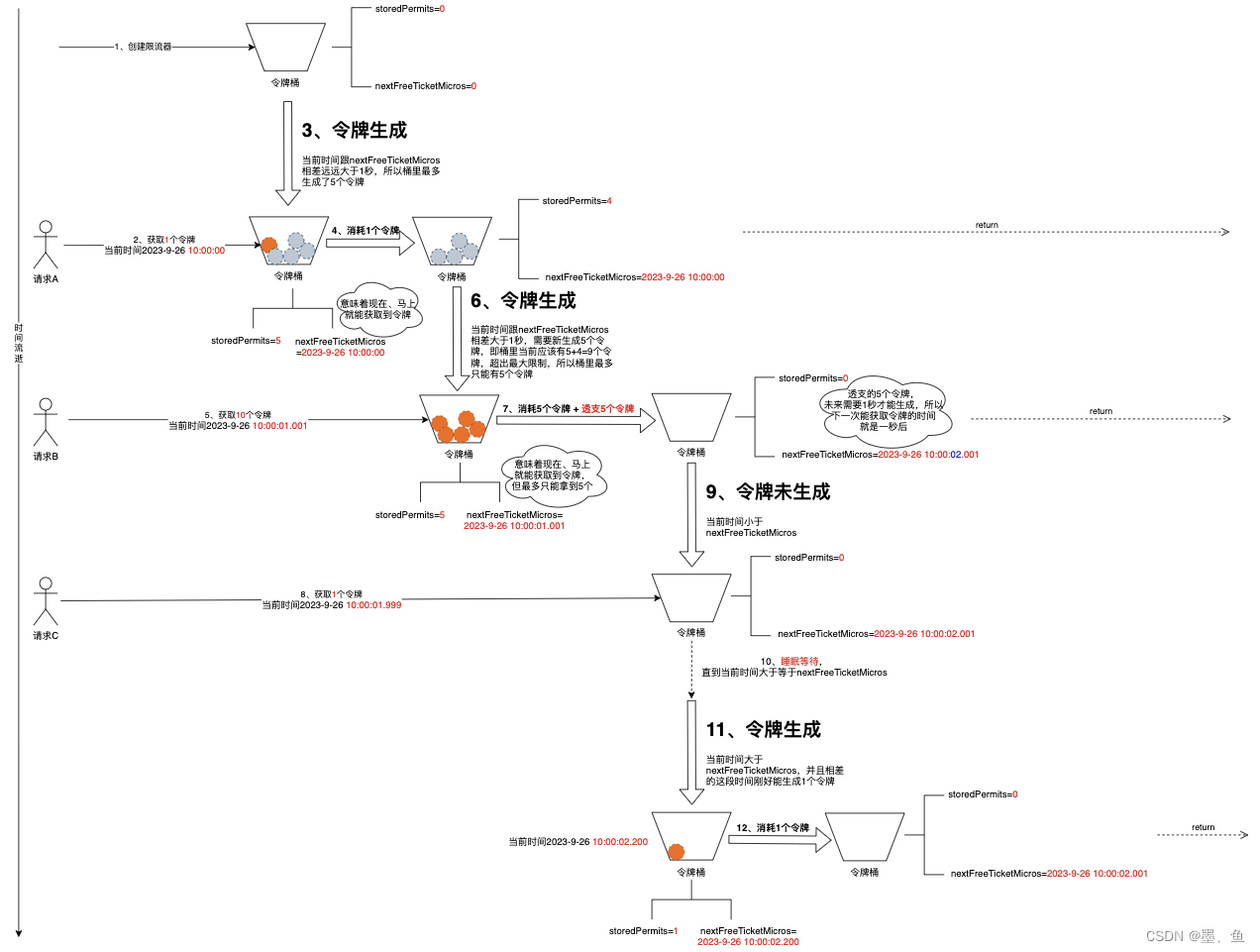
文章目录 基本知识限流器的类图使用示例 原理解析限流整体流程问题驱动1、限流器创建的时候会初始化令牌吗?2、令牌是如何放到桶里的?3、如果要获取的令牌数大于桶里的令牌数会怎么样4、令牌数量的更新会有并发问题吗 总结 实际工作中难免有限流的场景。…...

第四十二章 持久对象和SQL - 用于创建持久类和表的选项
文章目录 第四十二章 持久对象和SQL - 用于创建持久类和表的选项用于创建持久类和表的选项访问数据 第四十二章 持久对象和SQL - 用于创建持久类和表的选项 用于创建持久类和表的选项 要创建持久类及其对应的 SQL 表,可以执行以下任一操作: 使用 IDE …...

集合-ArrayList源码分析(面试)
系列文章目录 1.集合-Collection-CSDN博客 2.集合-List集合-CSDN博客 3.集合-ArrayList源码分析(面试)_喜欢吃animal milk的博客-CSDN博客 目录 系列文章目录 前言 一 . 什么是ArrayList? 二 . ArrayList集合底层原理 总结 前言 大家好,今天给大家讲一下Arra…...
跨类型文本文件,反序列化与类型转换的思考
文章目录 应用场景序列化 - 对象替换原内容,方便使用编写程序取得结果数组 序列化 - JSON 应用场景 在编写热更新的时候,我发现了一个古早的 ini 文件,记录了许多有用的数据 由于使用的语言年份较新,没有办法较好地对 ini 文件的…...
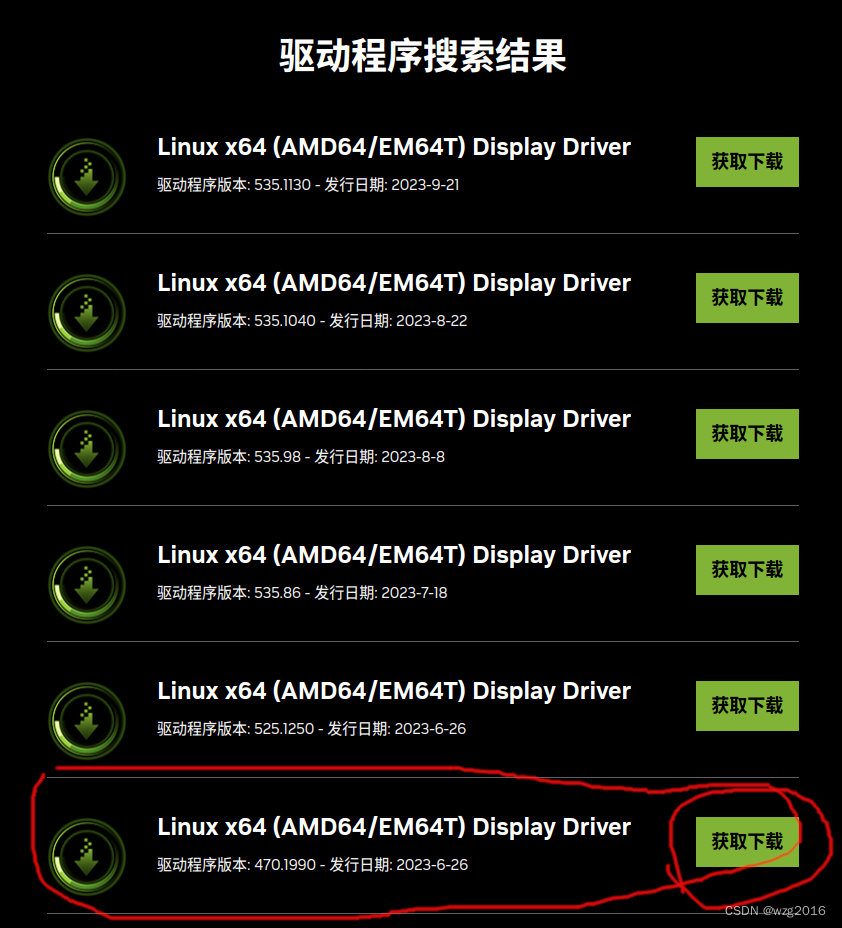
ubuntu20安装nvidia驱动
1. 查看显卡型号 lspci | grep -i nvidia 我的输出: 01:00.0 VGA compatible controller: NVIDIA Corporation GP104 [GeForce GTX 1080] (rev a1) 01:00.1 Audio device: NVIDIA Corporation GP104 High Definition Audio Controller (rev a1) 07:00.0 VGA comp…...

gma 2 成书计划
随着 gma 2 整体构建完成。下一步计划针对库内所有功能完成一个用户指南(非网站)。 封皮 主要章节 章节完成度相关链接第 1 章 GMA 概述已完成第 2 章 地理空间数据操作已完成第 3 章 坐标参考系统已完成第 4 章 地理空间制图已完成第 5 章 数学运算模…...
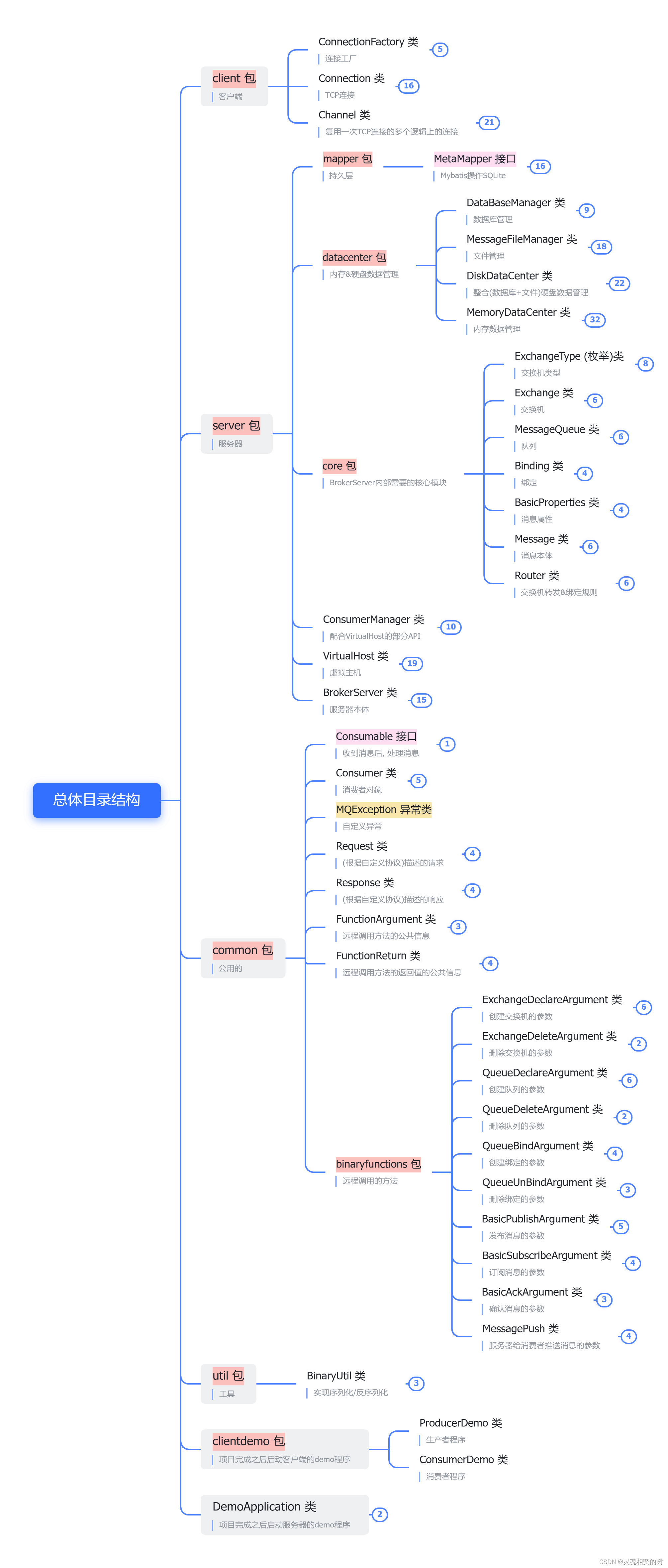
从零手搓一个【消息队列】项目设计、需求分析、模块划分、目录结构
文章目录 一、需求分析1, 项目简介2, BrokerServer 核心概念3, BrokerServer 提供的核心 API4, 交换机类型5, 持久化存储6, 网络通信7, TCP 连接的复用8, 需求分析小结 二、模块划分三、目录结构 提示:是正在努力进步的小菜鸟一只,如有大佬发现文章欠佳之…...

【Spring Cloud】深入探索 Nacos 注册中心的原理,服务的注册与发现,服务分层模型,负载均衡策略,微服务的权重设置,环境隔离
文章目录 前言一、初识 Nacos 注册中心1.1 什么是 Nacos1.2 Nacos 的安装,配置,启动 二、服务的注册与发现三、Nacos 服务分层模型3.1 Nacos 的服务分级存储模型3.2 服务跨集群调用问题3.3 服务集群属性设置3.4 修改负载均衡策略为集群策略 四、根据服务…...

No156.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...

如何在PIL图像和PyTorch Tensor之间进行相互转换,使用pytorch进行PIL和tensor之间的数据转换
目录 引言PIL简介PyTorch和Torchvision简介PIL转换为TensorTensor转换为PIL实例代码和解释结论参考文献 📝 引言 在计算机视觉领域,使用图像处理库对图像进行预处理是非常常见的。其中,Python Imaging Library(PIL)以…...
STM32F4X UCOSIII任务消息队列
STM32F4X UCOSIII任务消息队列 任务消息队列和内核消息队列对比内核消息队列内核消息队列 UCOSIII任务消息队列API任务消息队列发送函数任务消息队列接收函数 UCOSIII任务消息队列例程 之前的章节中讲解过消息队列这个机制,UCOSIII除了有内核消息队列之外࿰…...
8个居家兼职,帮助自己在家搞副业
越来越多的人开始追求居家工作的机会,无论是为了获得更多收入以改善生活质量,还是为了更好地平衡工作和家庭的关系,居家兼职已成为一种趋势。而在家中从事副业不仅能够为我们带来额外的收入,更重要的是,它可以让我们在…...

管理与系统思维
技术管理者不仅仅需要做事情,还需要以系统思维的方式推动组织变革,从而帮助团队和个人做到更好。原文: Management and Systems Thinking 图片来源: Dall-E "除非管理者考虑到组织的系统性,否则大多数提高绩效的努力都将注定失败。"…...

电死人的是电流还是电压?
先说答案,是电流。 这个有两个派别,一个是电流派,一个是电压派。 举个例子,拿我们的头发或者指甲之类的高电阻物质去接触高压,你会发现基本没有什么作用;还有就是冬天我们脱毛衣的时候,噼里啪啦…...

mac 编译问题记录
1、mac 编译提示 Unsupported option ‘--no-pie‘ Linux 上用 --no-pie mac 上用 -no-pie 2、mac 找不到 malloc.h 使用 #include <sys/malloc.h> Mac上使用malloc函数报错_mac malloc.h-CSDN博客...

centos 7.9同时安装JDK1.8和openjdk11两个版本
1.使用的原因 在服务器上,有些情况因为有一些系统比较老,所以需要使用JDK8版本,但随着时间的发展,新的软件出来,一般都会使用比较新的JDK版本。所以就出现了我们标题的需求,一个系统内同时安装两个不同的版…...

【JavaEE】HTML
JavaWeb HTML 超文本标记语言 超文本:文本、声音、图片、视频、表格、连接标记:有许许多多的标签组成 vscode开发工具搭建 因为我使用的IDEA是社区版,代码高亮补全缩进都有些问题,使用vscode是最好的选择~ 安装 Visual Stu…...
【数据结构--八大排序】之堆排序
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...

c# 中的类
反射 Activator.CreateInstance class Program {static void Main(string[] args){//反射Type t typeof(Student);object o Activator.CreateInstance(t, 1, "FJ");Student stu o as Student;Console.WriteLine(stu.Name);//动态编程dynamic stu2 Activator.Cre…...

Flutter 三方库 altogic_dart 的鸿蒙化适配指南 - 玩转全栈式 BaaS、在鸿蒙端实现 Serverless 极速开发实战
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net Flutter 三方库 altogic_dart 的鸿蒙化适配指南 - 玩转全栈式 BaaS、在鸿蒙端实现 Serverless 极速开发实战 前言 在 Flutter for OpenHarmony 的创新应用开发中,研发效能往往…...

Arduino UNO R3 + 继电器控制风扇:从硬件连接到代码调试的完整指南
Arduino UNO R3 继电器控制风扇:从硬件连接到代码调试的完整指南 在智能家居和自动化控制领域,Arduino因其简单易用、成本低廉而成为众多创客和电子爱好者的首选。本文将带您完成一个实用又有趣的项目——使用Arduino UNO R3通过继电器控制风扇的开关。…...

Alpamayo-R1-10B镜像免配置:预装AlpaSim+Physical AI数据集开箱即用
Alpamayo-R1-10B镜像免配置:预装AlpaSimPhysical AI数据集开箱即用 1. 项目简介 1.1 什么是Alpamayo-R1-10B? Alpamayo-R1-10B是一款专为自动驾驶研发设计的开源视觉-语言-动作(VLA)模型,由100亿参数构成。这个镜像预装了完整的开发环境&a…...

wan2.1-vae惊艳细节展示:发丝纹理/布料褶皱/文字笔画等微观表现力
wan2.1-vae惊艳细节展示:发丝纹理/布料褶皱/文字笔画等微观表现力 你有没有想过,为什么有些AI生成的图片,乍一看很惊艳,但放大一看,总觉得少了点什么?可能是人物的发丝糊成一团,衣服的布料像塑…...

国标文献格式难题终结方案:gbt7714-bibtex-style全解析
国标文献格式难题终结方案:gbt7714-bibtex-style全解析 【免费下载链接】gbt7714-bibtex-style GB/T 7714-2015 BibTeX Style 项目地址: https://gitcode.com/gh_mirrors/gb/gbt7714-bibtex-style 据调研,83%的中文研究者曾因参考文献格式不符期刊…...

Arduino舵机控制进阶:从基础运动到外部设备联动
1. 从“能动”到“会动”:舵机控制的进阶之路 玩Arduino的朋友,估计没人能绕开舵机这个小东西。它就像一个听话的关节,你让它转多少度,它就乖乖转过去,是机器人、机械臂、智能小车的核心执行部件。很多新手朋友照着教程…...

nlp_structbert_sentence-similarity_chinese-large代码实例:扩展支持CSV批量句子对相似度计算
nlp_structbert_sentence-similarity_chinese-large代码实例:扩展支持CSV批量句子对相似度计算 你是不是也遇到过这样的问题?手里有一大堆句子对,需要批量计算它们的相似度,但一个个手动输入太麻烦,用脚本处理又得写一…...

多模态预演:all-MiniLM-L6-v2文本Embedding如何为多模态系统打基础
多模态预演:all-MiniLM-L6-v2文本Embedding如何为多模态系统打基础 1. 认识all-MiniLM-L6-v2:轻量级语义表示专家 all-MiniLM-L6-v2是一个专门为高效语义表示设计的轻量级句子嵌入模型。它基于BERT架构,但通过精巧的设计实现了性能与效率的…...

RMBG-1.4多场景落地:直播电商实时抠像+虚拟背景合成技术方案
RMBG-1.4多场景落地:直播电商实时抠像虚拟背景合成技术方案 1. 直播电商的“背景”难题 想象一下这个场景:一位主播正在家里直播带货,身后是略显杂乱的客厅。他想把背景换成品牌专卖店或者一个充满科技感的虚拟空间,让直播画面更…...

工具与方法 - 高效二进制文件编辑软件推荐与实战技巧
1. 为什么你需要一个趁手的二进制编辑器? 如果你是一个程序员、安全研究员、逆向工程师,或者只是一个对电脑底层运作充满好奇的极客,那么你迟早会碰到一个场景:你需要打开一个文件,但用记事本或者常规的文本编辑器一看…...