单样本T检验|独立样本T检验|配对样本T检验(绘图)
学生 t 检验的基本思想是通过比较两组数据的均值以及它们的方差来判断是否存在显著差异。下面更详细地解释了学生 t 检验的基本思想:
-
均值比较:学生 t 检验的首要目标是比较两组数据的均值。我们通常有一个零假设(null hypothesis),该假设声称两组数据的均值相等,即没有显著差异。备择假设则声称两组数据的均值不相等,即存在显著差异。
-
方差比较:除了均值,t 检验还考虑了数据的方差。如果两组数据的方差差异很大,那么在比较均值时需要考虑这个差异,以确保显著性测试的准确性。
-
t 统计量:为了比较均值和方差之间的差异,t 检验计算了一个称为 t 统计量的值。这个统计量表示两组数据均值之间的差异相对于它们的方差的一个度量。
-
p 值:t 统计量用于计算一个概率值,称为 p 值。p 值表示在零假设成立的情况下,观察到如此极端结果的概率。较小的 p 值意味着观察到的差异更显著。
-
显著性水平:通常,研究人员会选择一个显著性水平,例如0.05,作为判断是否拒绝零假设的阈值。如果 p 值小于显著性水平,就拒绝零假设,认为存在显著差异。
单样本T检验、独立样本T检验和配对样本T检验是统计学中用于比较样本均值之间差异的常见方法,它们适用于不同的场景:
-
单样本T检验:
- 场景:用于比较一个样本的均值是否与已知的总体均值或理论值有显著差异。
- 示例:你想知道一群学生的平均考试成绩是否显著高于全国平均分(已知的总体均值)。
-
独立样本T检验:
- 场景:用于比较两个独立样本(不相关的样本)的均值是否有显著差异。
- 示例:你想知道男性和女性在某一项测试中的平均得分是否存在显著差异,你会将男性和女性的得分作为两个独立样本进行比较。
-
配对样本T检验:
- 场景:用于比较同一组样本在两个不同条件下的均值差异,这些条件是相关的。
- 示例:你想知道一组患者在治疗前和治疗后的体重是否存在显著差异,你会将每个患者的治疗前和治疗后的体重数据配对进行比较。
这些T检验方法都用于检验均值之间的显著性差异,但在不同的数据情境下使用。选择适当的T检验方法取决于你的研究设计和数据类型。
在Python中,你可以使用不同的库来执行各类T检验。常用的库包括NumPy(用于数据处理)、SciPy(用于科学计算和统计分析)以及StatsModels(用于统计建模)。以下是针对不同T检验的Python实现示例:
单样本T检验:
import numpy as np
from scipy import stats# 创建样本数据
data = np.array([34, 45, 28, 56, 40, 30, 48, 55, 37, 42])# 假设的总体均值
population_mean = 45# 执行单样本T检验
t_statistic, p_value = stats.ttest_1samp(data, population_mean)# 输出结果
print("T统计量:", t_statistic)
print("P值:", p_value)
独立样本T检验:
import numpy as np
from scipy import stats# 创建两组独立样本数据
group1 = np.array([34, 45, 28, 56, 40])
group2 = np.array([30, 48, 55, 37, 42])# 执行独立样本T检验
t_statistic, p_value = stats.ttest_ind(group1, group2)# 输出结果
print("T统计量:", t_statistic)
print("P值:", p_value)
配对样本T检验:
import numpy as np
from scipy import stats# 创建配对样本数据
before = np.array([68, 72, 63, 71, 73])
after = np.array([70, 74, 65, 72, 75])# 执行配对样本T检验
t_statistic, p_value = stats.ttest_rel(before, after)# 输出结果
print("T统计量:", t_statistic)
print("P值:", p_value)
当你执行不同类型的T检验时,有几个关键步骤和考虑因素,我将继续深入说明这些方面:
-
收集和准备数据:
- 在执行T检验之前,首先需要收集和准备你的样本数据。确保数据满足T检验的前提条件,即数据应该是连续的,并且满足正态性和方差齐性的假设。
-
假设检验:
- 在执行T检验时,你需要明确你的零假设(H0)和备择假设(H1)。
- 对于单样本T检验,H0通常是样本均值等于某个特定值。
- 对于独立样本T检验,H0通常是两组样本均值相等,而H1是两组样本均值不相等。
- 对于配对样本T检验,H0通常是配对前后样本均值相等,而H1是均值不相等。
-
计算T统计量和P值:
- 使用适当的Python库函数(如SciPy中的
ttest_1samp、ttest_ind和ttest_rel)来计算T统计量和P值。 - T统计量用于衡量样本均值之间的差异,P值表示在零假设下观察到这种差异的概率。
- 使用适当的Python库函数(如SciPy中的
-
解释结果:
- 检查计算得到的P值。如果P值小于事先选择的显著性水平(通常为0.05),则可以拒绝零假设。
- 如果P值大于显著性水平,那么不能拒绝零假设,表明没有足够的证据来支持备择假设。
-
报告结果:
- 在报告研究结果时,提供T统计量、P值以及你的决策,即是拒绝还是不拒绝零假设。
- 如果拒绝了零假设,解释结果的实际意义。
-
考虑效应大小:
- 除了P值之外,还应该考虑效应大小。效应大小可以帮助你理解观察到的差异的实际重要性。
- 常见的效应大小度量包括Cohen's d等。
-
检验前提条件:
- 在执行T检验之前,还应该检验数据是否满足T检验的前提条件,如正态性和方差齐性。可以使用统计图和检验方法(如Shapiro-Wilk检验和Levene检验)来评估这些前提条件。
以上是执行T检验时的一般步骤和要考虑的重要事项。根据你的具体研究问题和数据,你可以选择适当类型的T检验并按照上述步骤进行分析。
------------------
在执行T检验之前,确保数据满足T检验的前提条件非常重要。这两个主要的前提条件是正态性和方差齐性。
-
正态性(Normality):
- 正态性假设是指样本数据应该来自一个正态分布(或近似正态分布)。如果数据不满足正态性假设,T检验可能不可靠。
- 你可以使用统计图形(如直方图和Q-Q 图)来可视化数据的分布,以及正态性检验方法(如Shapiro-Wilk检验、Kolmogorov-Smirnov检验)来检验数据的正态性。
-
方差齐性(Homogeneity of Variance):
- 方差齐性假设是指不同样本的方差应该大致相等。如果不同组的方差明显不相等,T检验的结果可能不准确。
- 方差齐性可以使用Levene检验或Bartlett检验来检验。
如果数据不满足这些前提条件,你可以考虑以下选项:
-
数据不满足正态性但满足方差齐性:在这种情况下,你可以考虑使用非参数检验方法,如Wilcoxon符号秩检验(对应于单样本T检验)或Mann-Whitney U检验(对应于独立样本T检验)。
-
数据不满足方差齐性:你可以使用修正的T检验方法,如Welch's T检验,它允许在方差不相等的情况下执行独立样本T检验。这个修正考虑了方差不齐的情况。
-
数据不满足正态性和方差齐性:在这种情况下,非参数检验可能是更合适的选择。
确保在执行T检验之前,检查和报告数据是否满足这些前提条件,以确保你的统计分析结果的可信度。如果数据不满足这些条件,选择适当的替代方法来进行假设检验。
正态性检验(Shapiro-Wilk检验):
import numpy as np
from scipy import stats# 创建样本数据
data = np.array([34, 45, 28, 56, 40, 30, 48, 55, 37, 42])# 执行Shapiro-Wilk正态性检验
statistic, p_value = stats.shapiro(data)# 输出结果
print("Shapiro-Wilk统计量:", statistic)
print("P值:", p_value)# 判断是否满足正态性假设
alpha = 0.05
if p_value > alpha:print("数据看起来满足正态性假设")
else:print("数据不满足正态性假设")
方差齐性检验(Levene检验):
import numpy as np
from scipy import stats# 创建两组独立样本数据
group1 = np.array([34, 45, 28, 56, 40])
group2 = np.array([30, 48, 55, 37, 42])# 执行Levene方差齐性检验
statistic, p_value = stats.levene(group1, group2)# 输出结果
print("Levene统计量:", statistic)
print("P值:", p_value)# 判断是否满足方差齐性假设
alpha = 0.05
if p_value > alpha:print("数据满足方差齐性假设")
else:print("数据不满足方差齐性假设")
对于小样本,Shapiro-Wilk检验通常比Kolmogorov-Smirnov检验更合适,因为Shapiro-Wilk检验对样本量的要求较小,而且在小样本情况下通常更具有统计功效(能够更准确地检测正态性假设的违背)。
Shapiro-Wilk检验的优势在于它可以有效地处理小样本,并且对于正态性的敏感性相对较高。它是许多统计学家和研究者首选的正态性检验方法,尤其是在小样本研究中。但请注意,对于非常小的样本,即使数据是正态分布的,Shapiro-Wilk检验也可能会因样本量不足而产生不显著的结果。
总之,对于小样本,建议使用Shapiro-Wilk检验来检验正态性,但也要谨慎解释结果,尤其是当样本数量非常有限时。在小样本情况下,始终考虑其他检验方法或可视化技巧来评估数据的正态性,例如正态概率图(Q-Q 图)或直方图。综合使用多种方法可以更全面地评估数据的分布特征。
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import seaborn as sns# 生成一个示例数据集,替换成你的实际数据
data = np.random.normal(loc=0, scale=1, size=20)# 正态性检验 - Shapiro-Wilk检验
stat, p = stats.shapiro(data)
print("Shapiro-Wilk检验统计量:", stat)
print("Shapiro-Wilk检验p值:", p)# 可视化 - 正态概率图(Q-Q图)
stats.probplot(data, dist="norm", plot=plt)
plt.title("Q-Q Plot")
plt.show()# 可视化 - 直方图
sns.histplot(data, kde=True)
plt.title("Histogram with Kernel Density Estimate")
plt.show()
多种方式整合
import numpy as np
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as pltdata = np.random.normal(loc=12, scale=2.5, size=120)
df = pd.DataFrame({'Data': data})# 描述性统计分析
mean = df['Data'].mean()
std_dev = df['Data'].std()
skewness = df['Data'].skew()
kurtosis = df['Data'].kurtosis()print("均值:", mean)
print("标准差:", std_dev)
print("偏度:", skewness)
print("峰度:", kurtosis)# 创建一个2x1的子图布局
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(6, 8))
# 可视化 - 正态概率图(Q-Q图)
stats.probplot(data, plot=ax1, dist='norm', fit=True, rvalue=True)
ax1.set_title("Q-Q Plot")# 可视化 - 直方图
ax2.hist(data, bins=10, rwidth=0.8, density=True) # bins个柱状图,宽度是rwidth(0~1),=1没有缝隙
ax2.set_title("Histogram with Kernel Density Estimate")# 调整子图之间的间距
plt.tight_layout()
# 显示图形
plt.show()# 正态性检验 - Shapiro-Wilk检验
stat, p = stats.shapiro(data)
print("Shapiro-Wilk检验统计量:", stat)
print("Shapiro-Wilk检验p值:", p)# Anderson-Darling检验
result = stats.anderson(df['Data'], dist='norm')
print("Anderson-Darling检验统计量:", result.statistic)
print("Anderson-Darling检验临界值:", result.critical_values)# 执行单样本K-S检验,假设数据服从正态分布
statistic, p_value = stats.kstest(data, 'norm')
print("K-S检验统计量:", statistic)
print("K-S检验p值:", p_value)
---------------------
如果数据无法通过变换满足正态性假设,可以考虑使用非参数统计方法,如Wilcoxon秩和检验或Kruskal-Wallis检验,来进行假设检验。
Wilcoxon秩和检验(也称为Wilcoxon符号秩检验或Wilcoxon-Mann-Whitney检验)是一种非参数统计方法,用于比较两个独立样本的中位数是否存在显著差异。这个检验适用于不满足正态分布假设的数据。以下是使用Python进行Wilcoxon秩和检验的示例代码:
import numpy as np
from scipy.stats import wilcoxon# 生成两个示例数据集,替换成你的实际数据
group1 = np.array([75, 80, 85, 90, 95])
group2 = np.array([60, 70, 75, 80, 85])# 执行Wilcoxon秩和检验
statistic, p_value = wilcoxon(group1, group2)# 输出检验结果
print("Wilcoxon秩和检验统计量:", statistic)
print("Wilcoxon秩和检验p值:", p_value)# 判断显著性
alpha = 0.05 # 设置显著性水平
if p_value < alpha:print("拒绝原假设:两组数据的中位数存在显著差异")
else:print("无法拒绝原假设:两组数据的中位数没有显著差异")
Kruskal-Wallis检验是一种非参数统计方法,用于比较三个或更多独立样本的中位数是否存在显著差异。与Wilcoxon秩和检验类似,Kruskal-Wallis检验也适用于不满足正态分布假设的数据。以下是使用Python进行Kruskal-Wallis检验的示例代码:
import numpy as np
from scipy.stats import kruskal# 生成三个示例数据集,替换成你的实际数据
group1 = np.array([75, 80, 85, 90, 95])
group2 = np.array([60, 70, 75, 80, 85])
group3 = np.array([70, 75, 78, 82, 88])# 执行Kruskal-Wallis检验
statistic, p_value = kruskal(group1, group2, group3)# 输出检验结果
print("Kruskal-Wallis检验统计量:", statistic)
print("Kruskal-Wallis检验p值:", p_value)# 判断显著性
alpha = 0.05 # 设置显著性水平
if p_value < alpha:print("拒绝原假设:至少有一组数据的中位数存在显著差异")
else:print("无法拒绝原假设:各组数据的中位数没有显著差异")
相关文章:
)
单样本T检验|独立样本T检验|配对样本T检验(绘图)
学生 t 检验的基本思想是通过比较两组数据的均值以及它们的方差来判断是否存在显著差异。下面更详细地解释了学生 t 检验的基本思想: 均值比较:学生 t 检验的首要目标是比较两组数据的均值。我们通常有一个零假设(null hypothesis)…...
全面解读 SQL 优化 - 统计信息
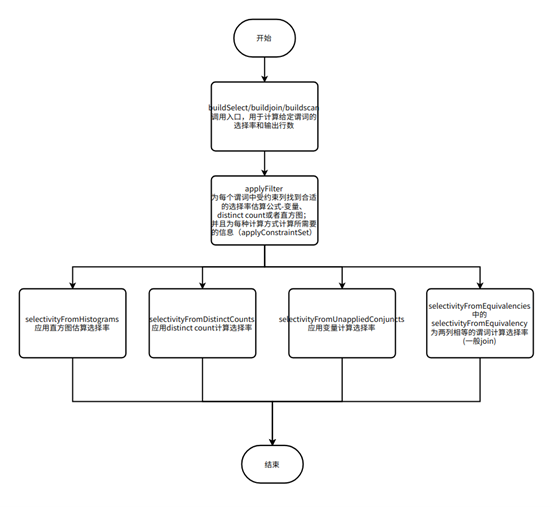
一、简介 数据库中的优化器(optimizer)是一个重要的组件,用于分析 SQL 查询语句,并生成执行计划。在生成执行计划时,优化器需要依赖数据库中的统计信息来估算查询的成本,从而选择最优的执行计划。以下是关…...
Spring整合RabbitMQ——生产者
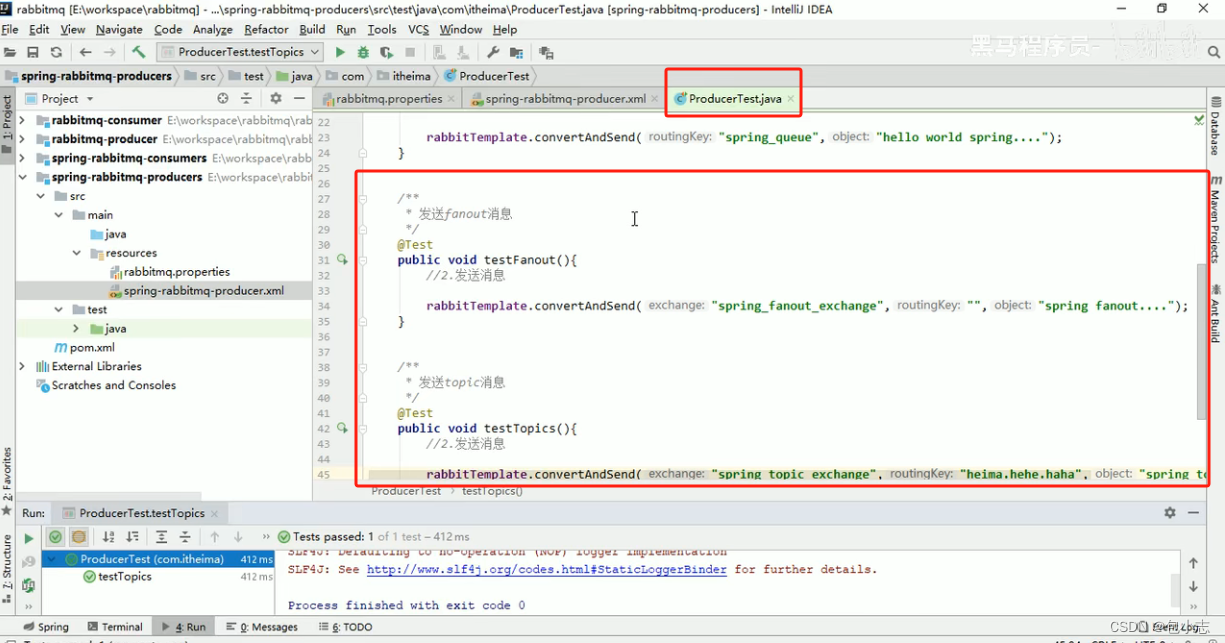
1.生产者整合步骤 添加依赖坐标,在producer和consumer模块的pom文件中各复制一份。 配置producer的配置文件 配置producer的xml配置文件 编写测试类发送消息...

Spring的注解开发-Bean基本注解开发
Bean基本注解开发 Spring除了xml配置文件进行配置之外,还可以使用注解方式进行配置,注解方式慢慢成为xml配置的替代方案。我们有了xml开发的经验,学习注解开发就会方便很多,注解开发更加快捷方便。Spring提供的注解有三个版本 2.…...
【Ubuntu18.04】Autoware.ai安装
Autoware.ai安装 引言1 ROS安装2 Ubuntu18.04安装Qt5.14.23 安装GCC、G4 Autoware.ai-1.14.0安装与编译4.1 源码的编译4.1.1 python2.7环境4.1,2 针对Ubuntu 18.04 / Melodic的依赖包安装4.1.3 先安装一些缺的ros依赖4.1.4 安装eigen3.3.74.1.5 安装opencv 3.4.164.1.6 编译4.1…...

SpringMVC 学习(一)Servlet
本系列文章为【狂神说 Java 】视频的课堂笔记,若有需要可配套视频学习。 1. Hello Servlet (1) 创建父工程 删除src文件夹 引入一些基本的依赖 <!--依赖--> <dependencies><dependency><groupId>junit</groupId><artifactId>…...

26943-2011 升降式高杆照明装置 课堂随笔
声明 本文是学习GB-T 26943-2011 升降式高杆照明装置. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了升降式高杆照明装置的技术要求、试验方法、检验规则以及标志、包装、运输及贮 存等。 本标准适用于公路、广场、机场、港口、…...

洛谷题解 | AT_abc321_c Primes on Interval
目录 题目翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 样例 #3样例输入 #3样例输出 #3 题目简化题目思路AC代码 题目翻译 【题目描述】 你决定用素数定理来做一个调查. 众所周知, 素数又被称为质数,其含义就是除了数…...
Quartus医院病房呼叫系统病床呼叫Verilog,源代码下载
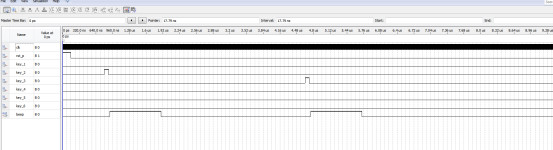
名称:医院病房呼叫系统病床呼叫 软件:Quartus 语言:Verilog 要求: 1、用1~6个开关模拟6个病房的呼叫输入信号,1号优先级最高;1~6优先级依次降低; 2、 用一个数码管显示呼叫信号的号码;没信号呼叫时显示0;有多个信号呼叫时,显…...
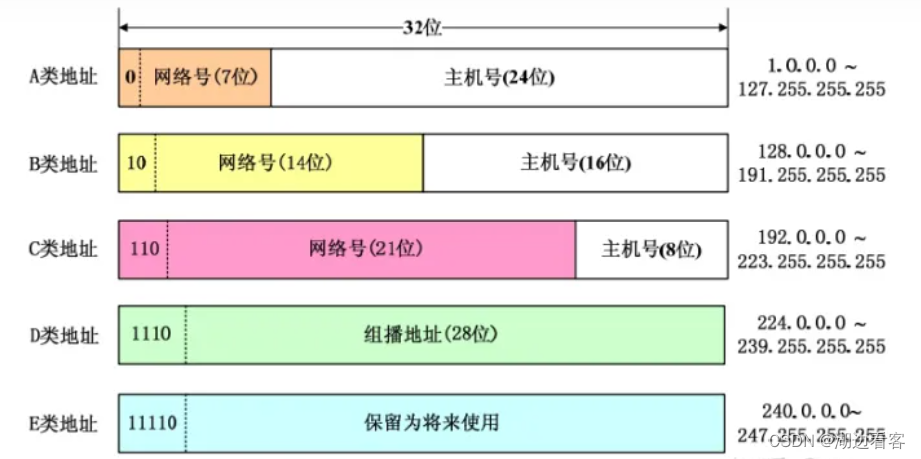
ip的标准分类---分类的Ip
分类的 IP 即将 IP 地址划分为若干个固定类,每一类地址都由两个固定长度的字段组成。 其中第一个字段是网络号(net-id),它标志主机或路由器所连接的网络。一个网络号在整个因特网内必须是唯一的。 第二个字段是主机号…...
)
理解并掌握C#的Channel:从使用案例到源码解读(一)
引言 在C#的并发编程中,Channel是一种非常强大的数据结构,用于在生产者和消费者之间进行通信。本文将首先通过一个实际的使用案例,介绍如何在C#中使用Channel,然后深入到Channel的源码中,解析其内部的实现机制。 使用案…...

如何让git命令仅针对当前目录
背景 我们有时候建的git仓库是这样的,a目录下有b、c、d三个模块(文件夹)。有时候只想查看b下面的变化,而使用 git status、git diff 的时候会把c和d的变化都列出来,要怎么只查b目录的变化? 操作 要查b目…...

【0223】源码剖析smgr底层设计机制(3)
1. smgr设计机制 PG内核中smgr完整磁盘存储介质的管理是通过下面三部分实现的。 1.1 函数指针结构体 f_smgr 函数指针结构体 f_smgr。 通过该函数指针类型,可完成类似于UNIX系统中的VFD功能,上层只需要调用open()、read()、write()等系统函数,用户不必去关系底层的文件系统…...

Visual Studio 2019 C# winform CefSharp 中播放视频及全屏播放
VS C# winform CefSharp 浏览器控件,默认不支持视频播放,好在有大佬魔改了dll,支持流媒体视频播放。虽然找了很久,好歹还是找到了一个版本100.0.230的dll(资源放在文末) 首先创建一个项目 第二、引入CefSha…...

天选之子Linux是如何发展起来的?为何对全球IT行业的影响如此之大?
天选之子Linux是如何发展起来的?为何对全球IT行业的影响如此之大? 前言一、UNIX发展史二、Linux发展历史三、开源四、官网五、 企业应用现状六、发行版本 前言 上面这副图是博主历时半小时完成的,给出了Linxu的一些发展背景。球球给位看官老…...
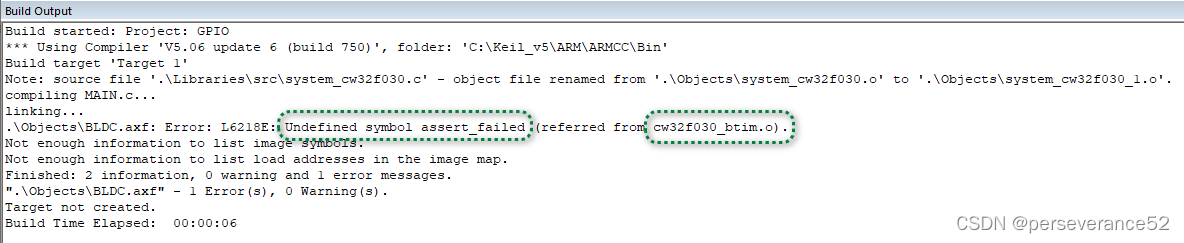
MDK报错:Undefined symbol assert_failed报错解决策略
MDK报错:Undefined symbol assert_failed报错解决策略 🎯🪕在全网搜索相关MDK编译报错:Error: L6218E: Undefined symbol assert_param (referred from xxx.o). ✨有些问题看似很简单,可能产生的问题是由于不经意的细节原因导致。…...
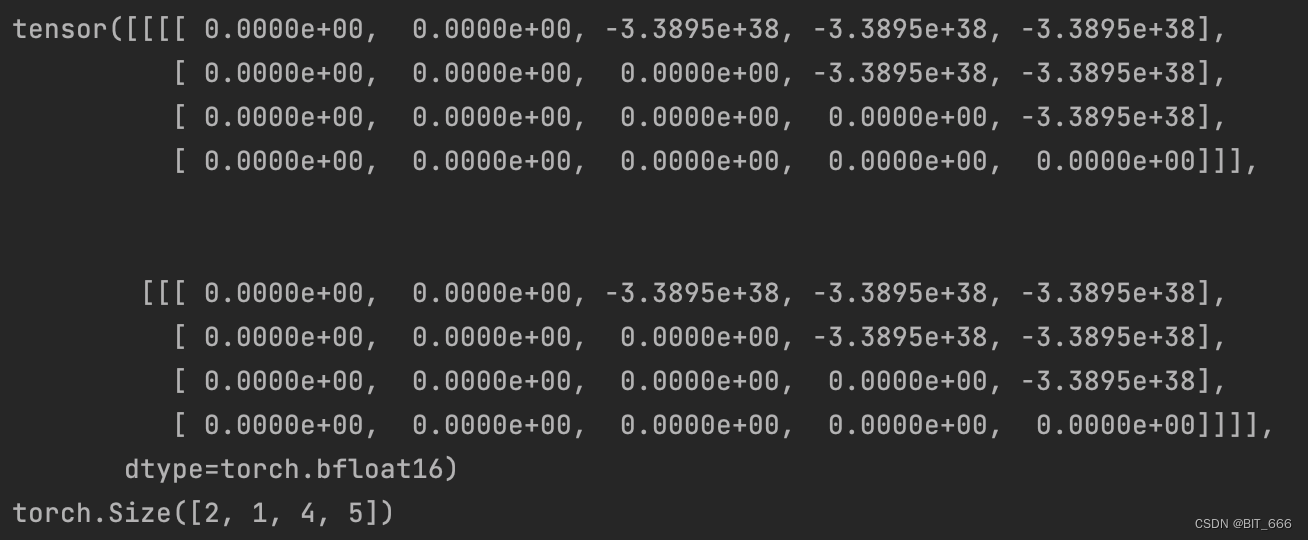
LLM - Make Causal Mask 构造因果关系掩码
目录 一.引言 二.make_causal_mask 1.完整代码 2.Torch.full 3.torch.view 4.torch.masked_fill_ 5.past_key_values_length 6.Test Main 三.总结 一.引言 Causal Mask 主要用于限定模型的可视范围,防止模型看到未来的数据。在具体应用中,Caus…...
概念和itertools)
Python函数式编程(一)概念和itertools
Python函数式编程是一种编程范式,它强调使用纯函数来处理数据。函数是程序的基本构建块,并且尽可能避免或最小化可变状态和副作用。在函数式编程中,函数被视为一等公民,可以像值一样传递和存储。 函数式编程概念 编程语言支持通…...
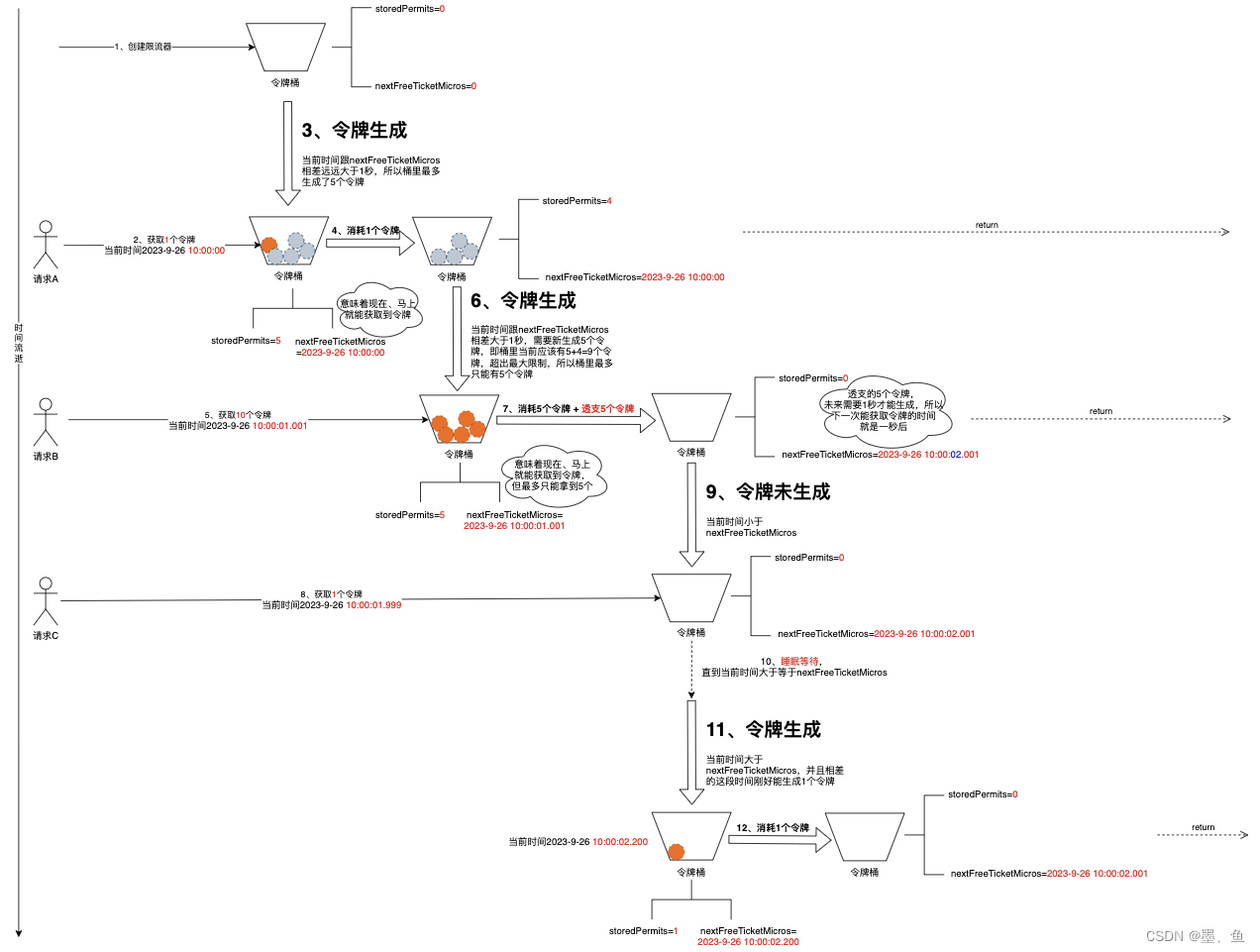
Guava限流器原理浅析
文章目录 基本知识限流器的类图使用示例 原理解析限流整体流程问题驱动1、限流器创建的时候会初始化令牌吗?2、令牌是如何放到桶里的?3、如果要获取的令牌数大于桶里的令牌数会怎么样4、令牌数量的更新会有并发问题吗 总结 实际工作中难免有限流的场景。…...

第四十二章 持久对象和SQL - 用于创建持久类和表的选项
文章目录 第四十二章 持久对象和SQL - 用于创建持久类和表的选项用于创建持久类和表的选项访问数据 第四十二章 持久对象和SQL - 用于创建持久类和表的选项 用于创建持久类和表的选项 要创建持久类及其对应的 SQL 表,可以执行以下任一操作: 使用 IDE …...

TOMs插件生态系统:10个必装的官方认证扩展推荐
TOMs插件生态系统:10个必装的官方认证扩展推荐 【免费下载链接】TOMs TOMs is a fully open-source, high-performance, systematic, plugin-oriented, and scenario-agnostic general-purpose development framework. 项目地址: https://gitcode.com/gh_mirrors…...

python-docx常见问题解答:新手必知的15个错误和解决方案
python-docx常见问题解答:新手必知的15个错误和解决方案 【免费下载链接】python-docx Create and modify Word documents with Python 项目地址: https://gitcode.com/gh_mirrors/py/python-docx python-docx是一个强大的Python库,用于创建和修改…...

终极指南:如何快速参与BERT-pytorch开源项目的开发与维护
终极指南:如何快速参与BERT-pytorch开源项目的开发与维护 【免费下载链接】BERT-pytorch Google AI 2018 BERT pytorch implementation 项目地址: https://gitcode.com/gh_mirrors/be/BERT-pytorch BERT-pytorch是Google AI 2018年提出的BERT模型的Pytorch实…...

AI绘画模型下载的终极优化指南:10个高效解决方案
AI绘画模型下载的终极优化指南:10个高效解决方案 【免费下载链接】comfyui_controlnet_aux 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 在AI绘画的世界里,模型下载往往是创作之旅的第一道关卡。ComfyUI ControlNet Au…...

跨微服务的“数据孤岛”解法:利用声明式 API 构建去中心化的数据联邦
在领域驱动设计(DDD)和微服务架构的演进中,**“每个微服务拥有独立数据库(Database-per-service)”**被奉为圭臬。这一原则从物理层面实现了业务边界的隔离,使得订单服务(Order Service…...

Gemma-3-12b-it低成本GPU方案:消费级显卡跑12B多模态模型教程
Gemma-3-12b-it低成本GPU方案:消费级显卡跑12B多模态模型教程 想体验多模态大模型,但被动辄几十GB的显存要求和昂贵的专业显卡劝退?别担心,今天就来分享一个亲测可行的方案:用消费级显卡,比如RTX 3090或RT…...
: QLineEdit)
QT编程(10): QLineEdit
一、QLineEdit核心定义与继承关系 QLineEdit是Qt Widgets模块中最基础、最常用的单行文本输入与显示控件,专门用于处理短文本内容的交互,仅支持单行纯文本输入,不支持换行和富文本格式,是Qt界面开发中短文本交互的核心组件&#x…...
✅)
计算机毕业设计源码:Python 携程旅游数据分析大屏系统 Django框架 selenium 爬虫 大数据 大模型 数据分析 agent 机器学习 旅行 出游 出行(建议收藏)✅
1、项目介绍 技术栈 Python作为主要开发语言,MySQL作为数据存储数据库,Django作为后端Web框架,selenium用于携程网旅游数据的爬取采集,HTML用于前端页面展示。 功能模块旅游景点信息采集模块注册登录模块系统数据概况模块…...

Flutter 三方库 shader 的鸿蒙化适配指南 - 玩转 Fragment Shader、在鸿蒙端实现影院级视觉特效实战
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net Flutter 三方库 shader 的鸿蒙化适配指南 - 玩转 Fragment Shader、在鸿蒙端实现影院级视觉特效实战 前言 在追求视觉极致的 Flutter for OpenHarmony 应用开发中,传统的 Widg…...

如何在Bullet Physics中实现软体模拟?开发者必看教程
如何在Bullet Physics中实现软体模拟?开发者必看教程 【免费下载链接】bullet3 Bullet是一个开源的物理引擎,主要用于计算机游戏和仿真应用程序中的刚体和软体物理模拟。它以C编写,提供了高效的碰撞检测和物理响应计算功能。 项目地址: htt…...