LLM - Make Causal Mask 构造因果关系掩码

目录
一.引言
二.make_causal_mask
1.完整代码
2.Torch.full
3.torch.view
4.torch.masked_fill_
5.past_key_values_length
6.Test Main
三.总结
一.引言
Causal Mask 主要用于限定模型的可视范围,防止模型看到未来的数据。在具体应用中,Causal Mask 可将所有未来的 token 设置为零,从注意力机制中屏蔽掉这些令牌,使得模型在进行预测时只能关注过去和当前的 token,并确保模型仅基于每个时间步骤可用的信息进行预测。
在 Transformer 模型中,Multihead Attention 中的 Causal Mask 就是用于解决这个问题,以实现模型对于输入序列的正确处理。下面是 Causal 的可视化示例,在实践中其呈现倒三角形状:
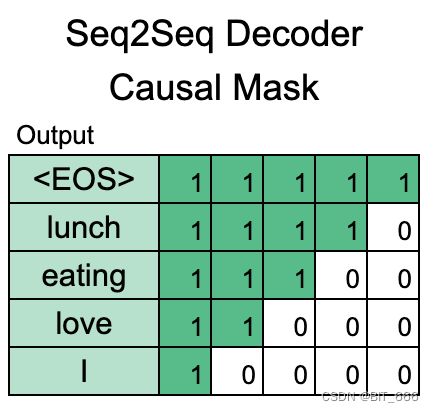
全文为 'I love eating lunch.' ,对于 'love' 而言其只能看到 'I',不能看到未来的 'eating'、'lunch'。
二.make_causal_mask
为了方便后续示例的展示,这里选择较小的参数,batch_size = 2,target_length = 4。
1.完整代码
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
def _make_causal_mask(input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
):"""Make causal mask used for bi-directional self-attention."""bsz, tgt_len = input_ids_shapemask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)mask_cond = torch.arange(mask.size(-1), device=device)mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)mask = mask.to(dtype)if past_key_values_length > 0:mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)代码的 Input 主要就是一个二维的 input_ids_shape,分别为 batch_size 和 target_length,dtype 和 device 在这里比较好理解,还有就是最后的 past_key_values_length,用于补齐,这个也比较简单。Output 则是 (batch_size, 1, target_length, target_length) 的 Causal Mask,其中 Msak 的矩阵 target_length x target_length 就是上面所示的倒三角形状。

2.Torch.full
◆ 函数介绍
该函数用于创建一个具有指定填充值的新张量。该函数的语法如下:
torch.full(size, fill_value, *, dtype=None, device=None, requires_grad=False)参数说明:
size:张量的形状,可以是一个整数或者一个元组,例如:(3, 3) 或 3。fill_value:张量的填充值。dtype:张量的数据类型,默认为None,即根据输入的数据类型推断。device:张量所在的设备,默认为None,即根据输入的设备推断。requires_grad:是否需要计算梯度,默认为False。
该函数返回一个与指定形状相同且所有元素都被设置为指定填充值的新张量。
◆ 函数使用
mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min))
这里 torch.finfo(dtype).min 为对应 torch.dtype 类型的最小值,以 bfloat16 为例:
print(torch.tensor(torch.finfo(dtype).min))
=> tensor(-3.3895e+38)而这一步 mask 的操作就是生成一个 tgt_len x tgt_len 的充满 min 元素的方阵:

3.torch.view
◆ 函数介绍
在 PyTorch 库中,view 函数用于改变一个张量(Tensor)的形状(shape)。它返回一个新的张量,其元素与原始张量相同,但形状(shape)已被改变。view 函数的行为非常类似于 NumPy的 reshape 函数。它会返回一个与原始张量共享数据但具有不同形状的新的张量。如果给定的形状与原始张量的元素总数不匹配,则会引发错误。
import torch x = torch.randn(4, 5) # 创建一个4x5的随机张量
y = x.view(20) # 改变形状为20的一维张量
z = x.view(-1, 10) # 改变形状为10的一维张量,第一维度由其他维度决定◆ 函数使用
mask_cond = torch.arange(mask.size(-1))mask_cond 是一个1维向量:
![]()
(mask_cond + 1).view(mask.size(-1), 1)这一步相当于在 mask_cond 基础上先加常量再 reshape:

4.torch.masked_fill_
◆ 函数介绍
在 PyTorch 库中,masked_fill_() 函数是一个张量(Tensor)方法,用于将张量中的指定区域填充为特定值。此函数需要一个掩码(mask)作为输入,该掩码应与原张量具有相同的形状。掩码中的 True 值表示需要填充的区域,False 值表示需要保留的原始值。
torch.Tensor.masked_fill_(mask, value)
参数说明:
mask(Bool tensor) - 掩码张量,用于指定需要填充的区域。value(float) - 填充的值。
◆ 示例
假设我们有一个 3x3 的张量,我们想要将所有大于 5 的元素替换为 -1。我们可以使用该函数来实现这个目标。
import torch # 创建一个3x3的张量
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 创建一个掩码,其中大于5的元素为True,其余为False
mask = x > 5 # 使用masked_fill_函数将大于5的元素替换为-1
x.masked_fill_(mask, -1) print(x)输出:
tensor([[ 1, 2, 3], [ 4, 5, 6], [-1, -1, -1]])◆ 函数使用
mask_cond < (mask_cond + 1).view(mask.size(-1), 1)传入函数的 mask 如下,呈倒三角形态,其中 True 的部分填充新值,False 部分保持不变:

mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
根据 mask 对 target x target 的方阵进行填充 0 得到我们上面提到的倒三角:

5.past_key_values_length
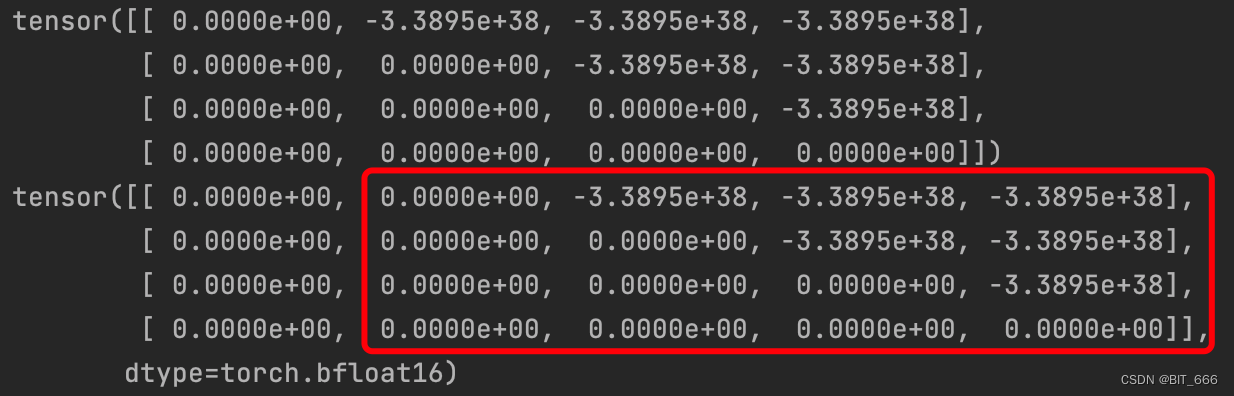
在 PyTorch 中,past_key_values_length 是一个参数,用于指定在使用 Transformer 模型时,过去键值缓存(past key-value cache)的长度。该参数通常与 Transformer 模型中的自注意力机制(self-attention mechanism)一起使用。在过去键值缓存中,模型保存了过去的键和值向量,以便在生成序列时重复使用它们。这些过去的键和值向量可以用于计算自注意力分数,从而提高生成序列的效率。较大的past_key_values_length可以增加模型的表现力,但也会增加计算量和内存消耗。因此,需要根据具体任务和资源限制来选择合适的值。
if past_key_values_length > 0:mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype), mask], dim=-1)这里定义 past_key_values_length = 1,代码逻辑就是在原有的 tgt x tgt 方阵前补 past_key_values_length 个 0:
6.Test Main
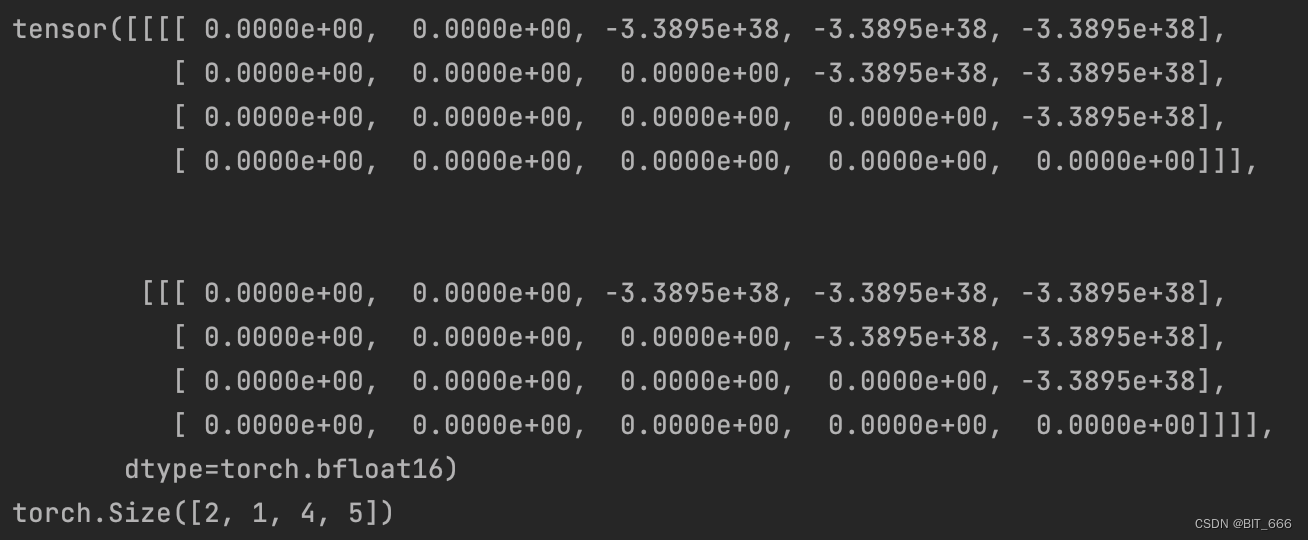
mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)if __name__ == '__main__':batch_size = 2target_length = 4input_shape = (batch_size, target_length)data_type = torch.bfloat16causal_mask = _make_causal_mask(input_shape, data_type, 1)print(causal_mask)print(causal_mask.shape)=> pask_key_length = 1填充后,tgt x tgt 变为 tgt x (1 + tgt)
=> 通过 None + expand 的组合,tgt x (1 + tgt) 变为 bsz x 1 x tgt x (1 + tgt)
三.总结
新系列博文一方面是阅读 HF 上 LLM 模型实现的源码,了解对应知识的实现过程。另一方面是之前很多同学主要接触 TF 1.x、TF 2.x 以及 Estimator 和 Keras 这一类深度学习工具,趁此机会也能熟悉 Torch 的使用方法。
相关文章:
LLM - Make Causal Mask 构造因果关系掩码
目录 一.引言 二.make_causal_mask 1.完整代码 2.Torch.full 3.torch.view 4.torch.masked_fill_ 5.past_key_values_length 6.Test Main 三.总结 一.引言 Causal Mask 主要用于限定模型的可视范围,防止模型看到未来的数据。在具体应用中,Caus…...
概念和itertools)
Python函数式编程(一)概念和itertools
Python函数式编程是一种编程范式,它强调使用纯函数来处理数据。函数是程序的基本构建块,并且尽可能避免或最小化可变状态和副作用。在函数式编程中,函数被视为一等公民,可以像值一样传递和存储。 函数式编程概念 编程语言支持通…...
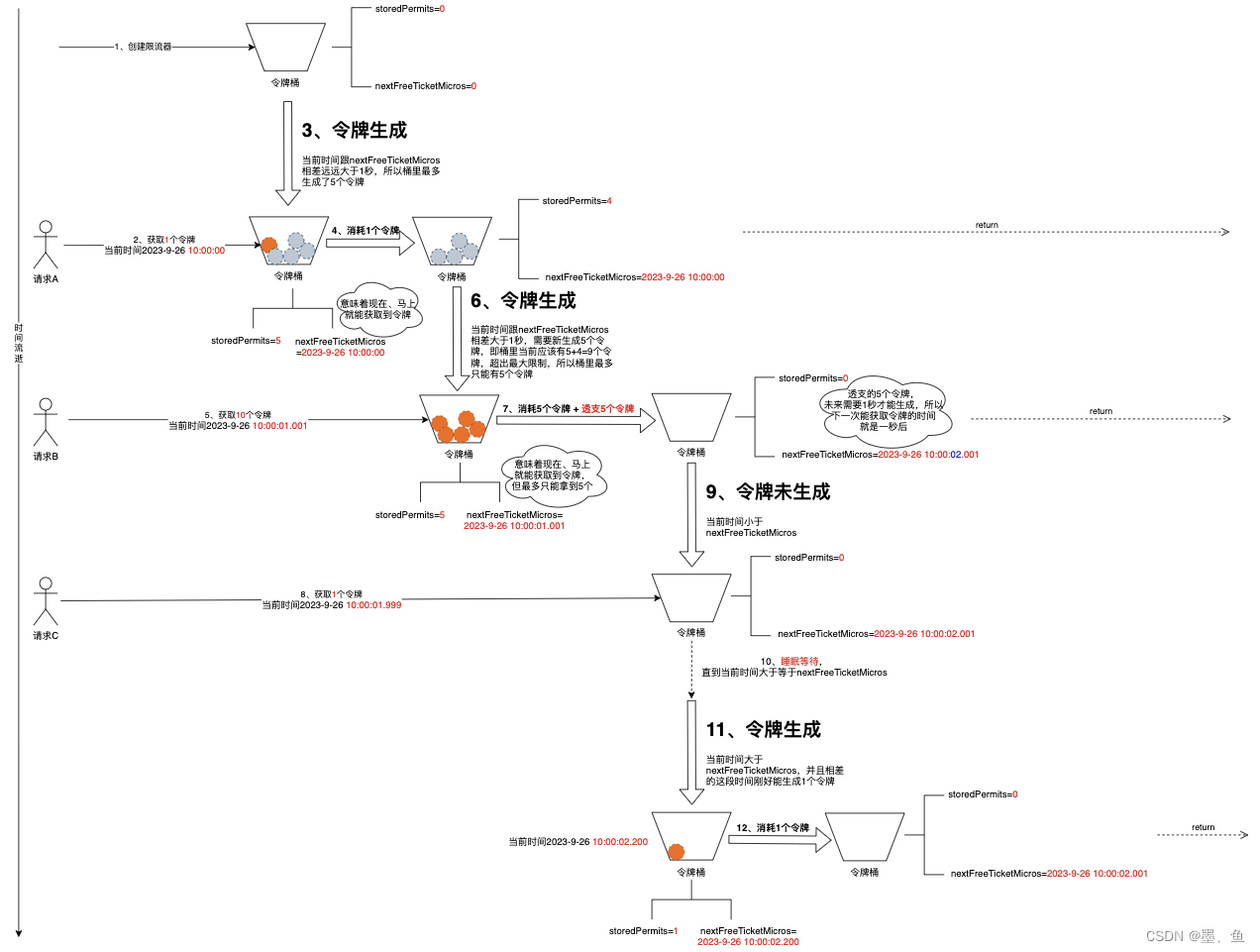
Guava限流器原理浅析
文章目录 基本知识限流器的类图使用示例 原理解析限流整体流程问题驱动1、限流器创建的时候会初始化令牌吗?2、令牌是如何放到桶里的?3、如果要获取的令牌数大于桶里的令牌数会怎么样4、令牌数量的更新会有并发问题吗 总结 实际工作中难免有限流的场景。…...

第四十二章 持久对象和SQL - 用于创建持久类和表的选项
文章目录 第四十二章 持久对象和SQL - 用于创建持久类和表的选项用于创建持久类和表的选项访问数据 第四十二章 持久对象和SQL - 用于创建持久类和表的选项 用于创建持久类和表的选项 要创建持久类及其对应的 SQL 表,可以执行以下任一操作: 使用 IDE …...

集合-ArrayList源码分析(面试)
系列文章目录 1.集合-Collection-CSDN博客 2.集合-List集合-CSDN博客 3.集合-ArrayList源码分析(面试)_喜欢吃animal milk的博客-CSDN博客 目录 系列文章目录 前言 一 . 什么是ArrayList? 二 . ArrayList集合底层原理 总结 前言 大家好,今天给大家讲一下Arra…...
跨类型文本文件,反序列化与类型转换的思考
文章目录 应用场景序列化 - 对象替换原内容,方便使用编写程序取得结果数组 序列化 - JSON 应用场景 在编写热更新的时候,我发现了一个古早的 ini 文件,记录了许多有用的数据 由于使用的语言年份较新,没有办法较好地对 ini 文件的…...
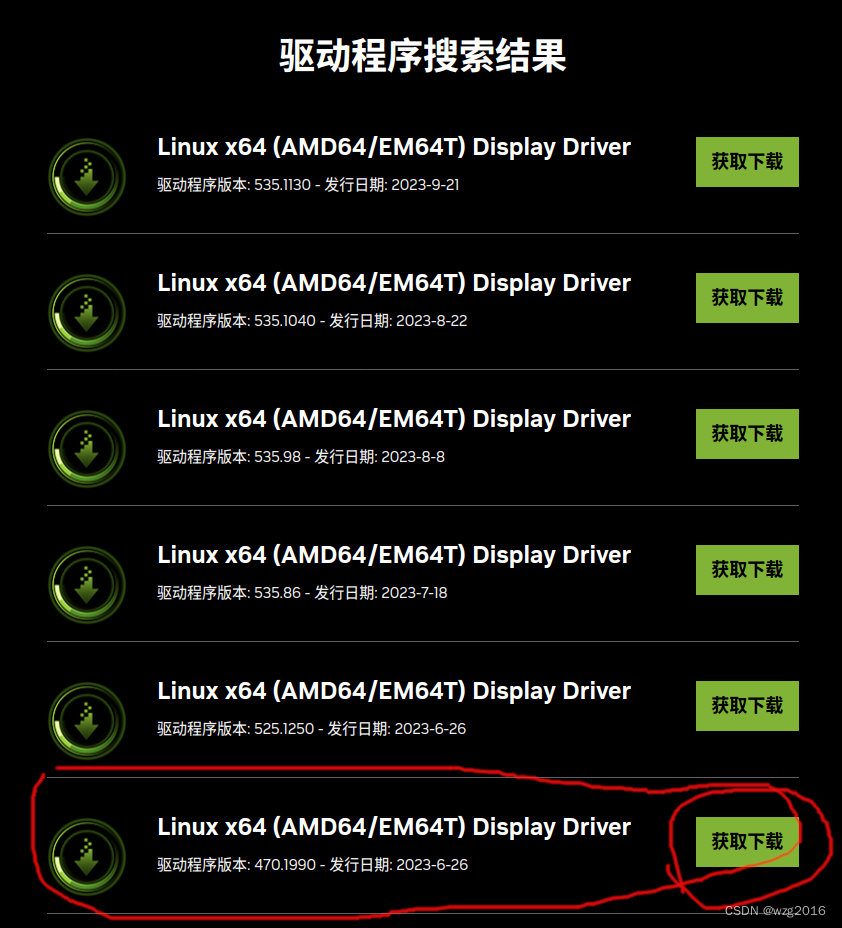
ubuntu20安装nvidia驱动
1. 查看显卡型号 lspci | grep -i nvidia 我的输出: 01:00.0 VGA compatible controller: NVIDIA Corporation GP104 [GeForce GTX 1080] (rev a1) 01:00.1 Audio device: NVIDIA Corporation GP104 High Definition Audio Controller (rev a1) 07:00.0 VGA comp…...

gma 2 成书计划
随着 gma 2 整体构建完成。下一步计划针对库内所有功能完成一个用户指南(非网站)。 封皮 主要章节 章节完成度相关链接第 1 章 GMA 概述已完成第 2 章 地理空间数据操作已完成第 3 章 坐标参考系统已完成第 4 章 地理空间制图已完成第 5 章 数学运算模…...
从零手搓一个【消息队列】项目设计、需求分析、模块划分、目录结构
文章目录 一、需求分析1, 项目简介2, BrokerServer 核心概念3, BrokerServer 提供的核心 API4, 交换机类型5, 持久化存储6, 网络通信7, TCP 连接的复用8, 需求分析小结 二、模块划分三、目录结构 提示:是正在努力进步的小菜鸟一只,如有大佬发现文章欠佳之…...

【Spring Cloud】深入探索 Nacos 注册中心的原理,服务的注册与发现,服务分层模型,负载均衡策略,微服务的权重设置,环境隔离
文章目录 前言一、初识 Nacos 注册中心1.1 什么是 Nacos1.2 Nacos 的安装,配置,启动 二、服务的注册与发现三、Nacos 服务分层模型3.1 Nacos 的服务分级存储模型3.2 服务跨集群调用问题3.3 服务集群属性设置3.4 修改负载均衡策略为集群策略 四、根据服务…...

No156.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...

如何在PIL图像和PyTorch Tensor之间进行相互转换,使用pytorch进行PIL和tensor之间的数据转换
目录 引言PIL简介PyTorch和Torchvision简介PIL转换为TensorTensor转换为PIL实例代码和解释结论参考文献 📝 引言 在计算机视觉领域,使用图像处理库对图像进行预处理是非常常见的。其中,Python Imaging Library(PIL)以…...
STM32F4X UCOSIII任务消息队列
STM32F4X UCOSIII任务消息队列 任务消息队列和内核消息队列对比内核消息队列内核消息队列 UCOSIII任务消息队列API任务消息队列发送函数任务消息队列接收函数 UCOSIII任务消息队列例程 之前的章节中讲解过消息队列这个机制,UCOSIII除了有内核消息队列之外࿰…...
8个居家兼职,帮助自己在家搞副业
越来越多的人开始追求居家工作的机会,无论是为了获得更多收入以改善生活质量,还是为了更好地平衡工作和家庭的关系,居家兼职已成为一种趋势。而在家中从事副业不仅能够为我们带来额外的收入,更重要的是,它可以让我们在…...

管理与系统思维
技术管理者不仅仅需要做事情,还需要以系统思维的方式推动组织变革,从而帮助团队和个人做到更好。原文: Management and Systems Thinking 图片来源: Dall-E "除非管理者考虑到组织的系统性,否则大多数提高绩效的努力都将注定失败。"…...

电死人的是电流还是电压?
先说答案,是电流。 这个有两个派别,一个是电流派,一个是电压派。 举个例子,拿我们的头发或者指甲之类的高电阻物质去接触高压,你会发现基本没有什么作用;还有就是冬天我们脱毛衣的时候,噼里啪啦…...

mac 编译问题记录
1、mac 编译提示 Unsupported option ‘--no-pie‘ Linux 上用 --no-pie mac 上用 -no-pie 2、mac 找不到 malloc.h 使用 #include <sys/malloc.h> Mac上使用malloc函数报错_mac malloc.h-CSDN博客...

centos 7.9同时安装JDK1.8和openjdk11两个版本
1.使用的原因 在服务器上,有些情况因为有一些系统比较老,所以需要使用JDK8版本,但随着时间的发展,新的软件出来,一般都会使用比较新的JDK版本。所以就出现了我们标题的需求,一个系统内同时安装两个不同的版…...

【JavaEE】HTML
JavaWeb HTML 超文本标记语言 超文本:文本、声音、图片、视频、表格、连接标记:有许许多多的标签组成 vscode开发工具搭建 因为我使用的IDEA是社区版,代码高亮补全缩进都有些问题,使用vscode是最好的选择~ 安装 Visual Stu…...
【数据结构--八大排序】之堆排序
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...