【数据结构】【C++】封装哈希表模拟实现unordered_map和unordered_set容器
【数据结构】&&【C++】封装哈希表模拟实现unordered_map和unordered_set容器
- 一.哈希表的完成
- 二.改造哈希表(泛型适配)
- 三.封装unordered_map和unordered_set的接口
- 四.实现哈希表迭代器(泛型适配)
- 五.封装unordered_map和unordered_set的迭代器
- 六.解决key不能修改问题
- 七.实现map[]运算符重载
一.哈希表的完成
在上一篇哈希表的模拟实现中,已经将哈希表实现完毕,这里不再分析。
#pragma once
using namespace std;
#include <vector>
#include<iostream>//哈希桶//1.第一哈希表的完成//哈希结点
template <class K,class V>
struct HashNode
{pair<K, V> _kv;//存储的数据HashNode<K, V>* _next;//指向下一个结点的指针HashNode(const pair<K,V> kv):_kv(kv),_next(nullptr){}
};template <class K>
struct defaulthashfunc//默认的仿函数可以让数据模
{size_t operator()(const K& key){return (size_t)key;//将key强行类型转化//这样作的意义:可以负数也可以进行模了}
};
template <>
//模板的特化,当数据类型是int的时候就默认使用defaulthashfunc<int>,当数据类型是string类型时,就默认使用defaulthashfunc<string>
struct defaulthashfunc<string>
{size_t operator()(const string& str){//为了减少冲突,我们将字符串的每个字符的值相加size_t hash = 0;for (auto& it : str){hash *= 131;hash += it;}return hash;}
};//要写一个仿函数? 因为不是所有的数据类型都可以模的
// 一般整数是可以模的,string类型是无法模的
// 所以我们要写一个仿函数来达到传的数据可以模
//这样也就是增加了哈希表的一个模板参数l
template<class K,class V,class Hashfunc=defaulthashfunc<K>>
//哈希表
class Hash_table
{typedef HashNode<K, V> Node;//哈希需要将写析构函数,虽然自定义类型vector会自动调用默认析构,但它里面的成员是内置类型,没有默认构造,//所以需要我们自己析构每个结点
public:~Hash_table(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;//要先保存起来delete cur;cur = next;}_table[i] = nullptr;}}Hash_table(){//构造_table.resize(10, nullptr);//首先开出十个空间,每个空间值为空}bool insert(const pair<K, V> _kv){Hashfunc hf;//仿函数可以使数据模//在插入之前,确认一下表里是否已经有了这个值,如果有了就不用插入了if (find(_kv.first)){return false;}//我们自己控制扩容逻辑,虽然vector会自己扩容,但我们要控制。因为扩容完,有的key会冲突有的值又不冲突了。//如果不扩容,那么冲突多了就根单链表一样了//当负载因子大约等于1时就要扩容,平均每个桶里有一个数据if (n == _table.size()){//异地扩容,重新开空间size_t newSize = _table.size() * 2;vector<Node*> newtable;newtable.resize(newSize, nullptr);//不能再复用下面的方法,这样不好,因为就又重开空间,然后又要释放,//我们应该将原来的结点拿过来使用//所以我们遍历旧表,将旧表的结点拿过来,签到新表上for (size_t i = 0; i < _table.size(); i++){//扩容后,空间size变大了,有的数据就可能会存到不同的桶里了//拿下来的结点要重新计算放进哪个位置Node* cur = _table[i];//cur后面可能还有链接的结点while (cur){size_t hashi = hf(cur->_kv.first) % newtable.size();Node* next = cur->_next;//头插到新表cur->_next = newtable[hashi];//头插 这个结点的 接到插入结点的前面对吧//那么next就接到newtavle[i]newtable[hashi] = cur;//往后走接着拿走cur = next;}//当前桶里的结点被拿光后,就置为空_table[i] = nullptr;}//这个新表就是我们想要的表,那么我们利用vector、的交换,让旧表和新表交换_table.swap(newtable);}size_t hashi = hf(_kv.first) % _table.size();Node* newnode = new Node(_kv);newnode->_next = _table[hashi];_table[hashi] = newnode;//将新结点头插到哈希桶里++n;return true;}Node* find(const K& key){Hashfunc hf;size_t hashi = hf(key)% _table.size();Node* cur = _table[hashi];while (cur){if (cur->_kv.first == key)return cur;elsecur = cur->_next;}return nullptr;}void Print(){for (int i = 0; i < _table.size(); i++){printf("[%d]", i);Node* cur = _table[i];while (cur){cout << cur->_kv.first << " ";cur = cur->_next;}cout << endl;}}bool erase(const K& key){Hashfunc hf;//可以复用find吗?先用find找到key然后删除key呢?4//不可以,因为删除一个结点需要找到这个结点的前面和后面的位置,但这里只有key的位置,所以不能直接复用find,但是复用其中的步骤size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){if (cur->_kv.first == key)//找到要删除的结点后{//将前面的结点的指针指向后面的前面//还有一种可能cur就是桶里的第一个,那么就是头删了,prev就是nullptrif (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}else{prev = cur;//每次先记录一下前面的结点位置cur = cur->_next;}}return false;}
private://底层封装的是一个数组//数组里的指针指向的都是哈希结点vector<Node*> _table;//底层还封装一个大小n表示实际表中的数据个数size_t n=0;///用来计算负载因子
};二.改造哈希表(泛型适配)
我们要对哈希表进行改造,因为unordered_map和unordered_set底层用的都是哈希表,虽然不是同一个哈希表,但是是同一个模板实例化出来的哈希表。我们要让哈希表可以适配存储不同的数据类型,因为unordered_set里面存的是K类型,而unordered_map里面存的是pair<K,V>类型。
所以我们一开始并不知道哈希表里存的数据是什么类型,那么就用T表示。当传的模板参数是K类型,哈希表就实例化存的就是K类型,当传的模板参数是pair<K,V>类型,哈希表实例化存的就是pair<K,V>类型,所以我们可以通过传不同的模板参数来决定哈希表里存的是什么数据类型。
所以我们需要改造哈希表,将里面的数据都改成T类型,修改成T类型的原因是我们不知道是什么数据类型,根据传的模板参数决定。
template <class T>
//定义哈希结点
struct HashNode
{T _data;//存储的数据是T类型,根据传过来的模板参数确定HashNode<T>* _next;//指向下一个结点的指针HashNode(const T& data):_data(data), _next(nullptr){}
};
// [问题]:一旦泛型后,我们就不知道数据的具体类型了,那么我们要利用除留余数法计算哈希地址时(我们都是利用key来进行取模的而我们不知道具体的类型是K类型还是pair<K,V>类型),就要写一个仿函数,这个仿函数根据map和set传过来的,然后实例化出哈希表中的仿函数。获取数据中的key,让key进行计算```c
template<class K, class T>
//哈希表
class Hash_table
{typedef HashNode<T> Node;public:~Hash_table(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;//要先保存起来delete cur;cur = next;}_table[i] = nullptr;}}Hash_table(){//构造_table.resize(10, nullptr);//首先开出十个空间,每个空间值为空}bool insert(const T& data){…………………}bool find(const K& key){………………}bool erase(const K& key){……………… }
private:vector<Node*> _table;//底层还封装一个大小n表示实际表中的数据个数size_t n = 0;//用来计算负载因子
};存在问题:
这里不管是插入还是查找还是删除第一步都是需要将数据的哈希地址找到,而哈希地址是利用除留余数法计算得到的,是利用key值进行取模的,但这里一旦适配泛型后,我们就不知道具体的类型是K类型还是pair<K,V>类型,如果是K类型那么就可以直接取模,如果是pair<K,V>类型,那是不可以直接取模的,需要将里面的key值取出来。
解决方法:
我们可以利用一个仿函数,这个仿函数的功能是可以将数据里的Key类型数据取出来。那么我们可以给哈希表增加一个模板参数,给仿函数用。一旦遇到要计算哈希地址或者比较的操作时,我们就可以将数据里的K值取出来进行计算比较。
仿函数实现的原理:当T类型是K类型数据时,直接返回K值即可,当T类型是pair<K,V>数据时,返回里面的first数据即可(就是K值)。
template<class K, class T, class KeyOfT,class Hashfunc = defaulthashfunc<K>>
//哈希表
class Hash_table
{typedef HashNode<T> Node;
public:Hash_table(){//构造_table.resize(10, nullptr);//首先开出十个空间,每个空间值为空}bool insert(const T& data){KeyOfT kt;Hashfunc hf;//仿函数可以使数据模//在插入之前,确认一下表里是否已经有了这个值,如果有了就不用插入了if (find(kt(data))){return false;}if (n == _table.size()){//异地扩容,重新开空间size_t newSize = _table.size() * 2;vector<Node*> newtable;newtable.resize(newSize, nullptr);for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];//cur后面可能还有链接的结点while (cur){size_t hashi = hf(kt(cur->_data)) % newtable.size();Node* next = cur->_next;cur->_next = newtable[hashi];newtable[hashi] = cur;//往后走接着拿走cur = next;}//当前桶里的结点被拿光后,就置为空_table[i] = nullptr;}//这个新表就是我们想要的表,那么我们利用vector、的交换,让旧表和新表交换_table.swap(newtable);}size_t hashi = hf(kt(data)) % _table.size();//这里有两个仿函数kt是用来获取data数据里的key值//hf是用来适配不同的K值,因为string类型无法取模Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;//将新结点头插到哈希桶里++n;return true;}iterator find(const K& key){Hashfunc hf;KeyOfT kt;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (kt(cur->_data) == key)return iterator(cur,this);elsecur = cur->_next;}return iterator(nullptr,this);}bool erase(const K& key){Hashfunc hf;KeyOfT kt;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){//这里仿函数kt是用来获取data数据里的key值if (kt(cur->_data) == key)//找到要删除的结点后{//将前面的结点的指针指向后面的前面//还有一种可能cur就是桶里的第一个,那么就是头删了,prev就是nullptrif (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--n;return true;}else{prev = cur;//每次先记录一下前面的结点位置cur = cur->_next;}}return false;}
private:vector<Node*> _table;//底层还封装一个大小n表示实际表中的数据个数size_t n = 0;//用来计算负载因子
};
三.封装unordered_map和unordered_set的接口
封装set,内部实现仿函数,然后底层封装的是存储K值(结点指针)的哈希表。
#include"Hash.h"
namespace tao
{template<class K>class set{struct setoft//仿函数用来获取数据的key值{const K& operator()(const K& key){return key;}};public:bool insert(const K& key){return _ht.insert(key);}private://底层封装一个哈希表,哈希表里存的是K类型Hash_table<K, K, setoft> _ht;};
};封装map,实现仿函数,底层存储的是pair<K,V>类型的(结点指针)哈希表。
#include"Hash.h"
namespace tao
{template<class K, class V>class map{struct mapoft//仿函数获取数据中的key值{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:bool insert(const pair<K, V>& kv){return _ht.insert(kv);}private://底层封装一个哈希表,哈希表里的数据是pair<K,V>类型Hash_table<K, pair<const K, V>, mapoft> _ht;};
};四.实现哈希表迭代器(泛型适配)
哈希表的迭代器是一个自定义类型,因为原生的结点指针不能满足我们想要的操作,所以我们就直接将结点的指针封装起来,然后自定义一个类型,对这个结点指针增加一些操作来完成我们想要的效果。
首先哈希表的迭代器里肯定要封装一个结点的指针,++后找到下一个结点,在一个哈希桶里,++就代表着找链表下面的结点即可,那么如果该结点就是链表最后一个结点呢?怎么找到下一个不为空的桶呢?又或者你是如何找到第一个不为空的桶的呢?
所以这里我们还需要一个指向哈希表的指针,这样我们才可以找到桶与桶之间的关系,而结点指针是用来找结点与结点之间的关系的。
哈希表的迭代器里封装两个对象,一个是结点指针,一个哈希表指针。
1.迭代器有普通迭代器和const迭代器,普通迭代很好实现,那么const迭代器如何实现呢?
与链表的const迭代器实现原理一样,我们通过三个模板参数(template <class T,class Ref,class Ptr>)来控制函数的返回值,从而控制返回的是普通类型的迭代器还是const类型的迭代器。这里也就是泛型适配,适配多种类型 。
Ref控制解引用函数的返回值,当Ref为T&时,返回的就是普通迭代器,当Ref为const T&时,返回的就是const迭代器。
Ptr控制的->重载函数的返回值,当Ptr为T时,返回的就是普通迭代器,当Ptr为const T时,返回的就是const迭代器。
2.哈希表迭代器的++实现原理:
①假设当前结点在一个桶里,这个桶还没走完,那么直接找下一个结点即可
②如果这个结点是桶里最后一个原生,即桶走完了,那么我们就要找下一个不为空的桶
③如何找到下一个不为空的桶呢?首先将当前结点的哈希地址计算出来,然后将哈希地址++,再利用一个循环,查找后面的桶是否为空,如果不为空,那么这个桶就是最终结果,如果为空就再找后面的桶。
//泛型适配--适配普通迭代器和const迭代器
template<class K, class T,class Ref,class Ptr, class KeyOfT, class Hashfunc>
//哈希表的迭代器里面肯定封装一个结点的指针,但还需要通过表来找到下一个桶,因为我们需要遍历先找到第一个桶,当这个桶遍历完后,怎么找到下一个不为空的桶呢?
//需要通过这个哈希表来找到桶,所以我们还需要一个指向哈希表的指针struct HSIterator
{typedef HashNode<T> Node;/typedef HSIterator<K, T,Ref,Ptr,KeyOfT, Hashfunc> Self;Node* _node;//底层封装着一个结点指针const Hash_table <K,T, KeyOfT,Hashfunc>* _pht;//底层还封装着一个哈希表指针//这里可以加const因为我们不是根据pht来找到哈希表来修改哈希表里的内容HSIterator(Node* node, Hash_table<K, T, KeyOfT,Hashfunc>* hs):_node(node), _pht(hs){}Ref& operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self& operator++(){if (_node->_next)//当前桶没有走完,那么直接找下一个即可{_node = _node->_next;}else//当前桶走到空了,就要找下一个不为空的桶{KeyOfT kof;Hashfunc hf;size_t hashi = hf(kof(_node->_data)) % _pht->_table.size();//这里我们在外面去调用了哈希表的私有成员,所以我们需要让迭代器成为哈希表的友元//找到当前桶的位置++hashi;//找下一个桶不为空while (hashi<_pht->_table.size()){if (_pht->_table[hashi]){_node = _pht->_table[hashi];return *this;}else{++hashi;}}//走到这里就说明桶走走光了,还没找到_node = nullptr;}return *this;}bool operator!=(const Self& s){return _node != s._node;}};【存在问题1】:
这里存在一个相互依赖关系问题,因为在哈希表里我们使用了迭代器,在迭代器里我们又使用了哈希表。我们需要在这里使用前置声明告诉编译器,我们是有哈希表,只不过哈希表在后面。这样就不会报错啦。
//这里存在问题,迭代器里要用哈希,哈希里面要有迭代器,相互依赖关系
//我们这里用前置声明告诉编译器,我们要是有哈希表,这个表是存在的,在后面
template<class K, class T, class KeyOfT, class Hashfunc>
class Hash_table;
template<class K, class T,class Ref,class Ptr, class KeyOfT, class Hashfunc>struct HSIterator
{………………………………………………………………………………………………………………………………
};【存在问题2】:
在迭代器的++里我们在计算当前结点的哈希地址时,取模时,利用哈希指针找到了哈希表里的vector<Node*> _table元素,并访问了它的函数,这里我们在外面调用哈希表的私有成员,这样是不可行,所以我们需要让迭代器成为哈希表的友元类,这样在迭代器里就可以使用哈希表的私有成员了。

迭代器实现之后,我们就可以在哈希表里,来实现迭代器的begin()和end()了。
begin()就是找哈希表里第一个不为空的桶。
end()就是找最后一个不为空的桶的下一个位置,也就是空。
template<class K, class T, class KeyOfT,class Hashfunc = defaulthashfunc<K>>
//哈希表
class Hash_table
{typedef HashNode<T> Node;template<class K, class T, class Ref,class Ptr,class KeyOfT, class Hashfunc>friend struct HSIterator;//让迭代器成为哈希表的友元
public:typedef HSIterator<K, T,T&,T*, KeyOfT, Hashfunc> iterator;//适配普通迭代器typedef HSIterator<K, T, const T&, const T*, KeyOfT, Hashfunc> const_iterator;//适配const迭代器iterator begin(){//找第一个桶for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){if (cur){return iterator(cur, this);//这里this就是哈希表的指针}}}//最后没有找到return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}const_iterator begin()const{//找第一个桶for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){if (cur){return const_iterator(cur, this);}}}//最后没有找到return const_iterator(nullptr, this);}const_iterator end()const{return const_iterator(nullptr, this);}bool insert(const T& data){…………………………}bool erase(const K& key){…………………………}
private:vector<Node*> _table;//底层还封装一个大小n表示实际表中的数据个数size_t n = 0;//用来计算负载因子
};这样哈希表的迭代器就完成啦。不过这里还有一个问题喔,确实封装哈希表确实比较恶心,比封装红黑树还复杂。
这里的问题在于const修饰begin()和const修饰end()这里是编译不过的。为什么呢?这里提醒没有构造函数可以接收,或者构造函数重载不明确。
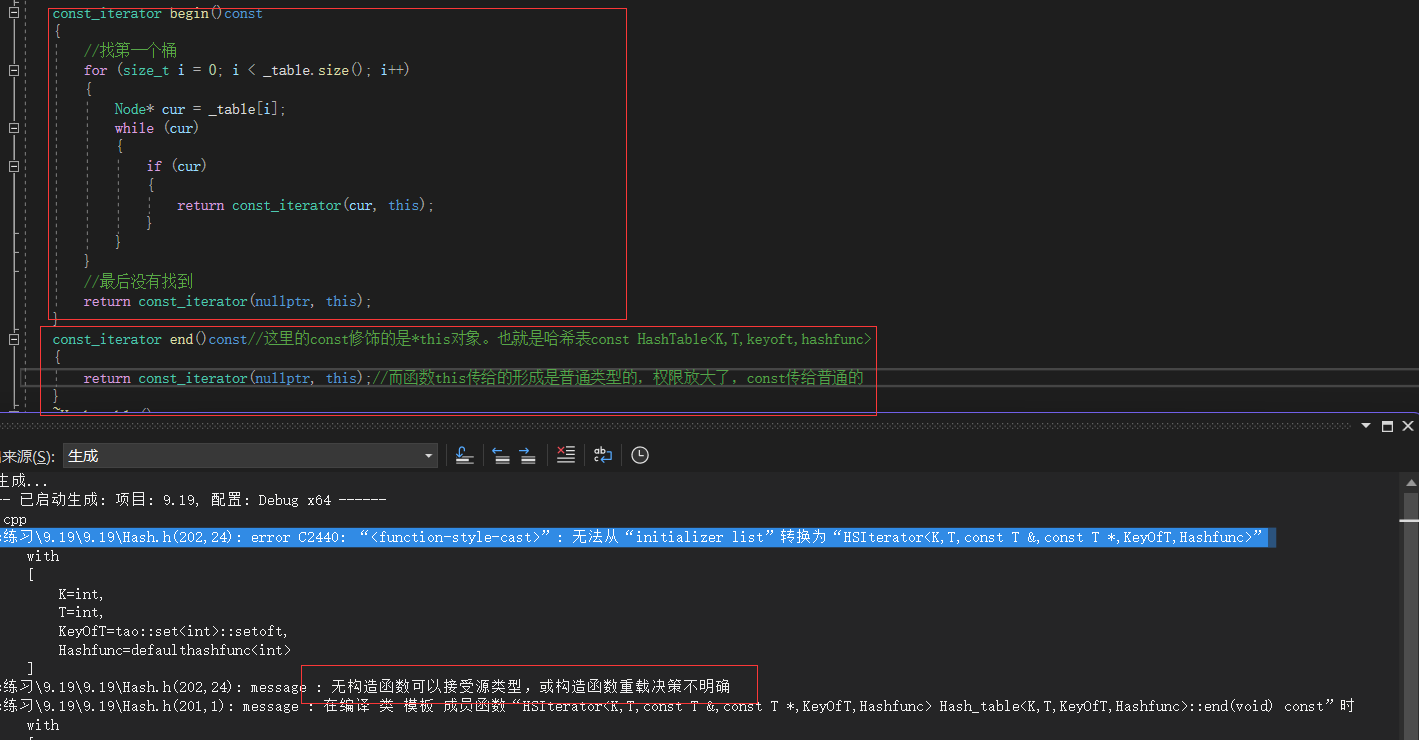
这里的原因是因为const修饰了this指针,导致指向哈希表的指针变成const类型了,而迭代器的构造里,是用普通迭代器构造的。所以当this指针传过去构造时,const是不能传给普通类型的,权限放大了。所以这里我们只需要重载一个参数类型是const类型的哈希表指针即可。
HSIterator(Node* node, Hash_table<K, T, KeyOfT,Hashfunc>* hs)//hs是普通的类型:_node(node), _pht(hs){}//当传过来的哈希表指针是普通指针就走上面--权限的缩小//重载一个,当传过来的是const修饰的哈希表指针就走这里---权限的平移HSIterator(Node* node, const Hash_table<K, T, KeyOfT, Hashfunc>* hs)//hs是普通的类型:_node(node), _pht(hs){}
五.封装unordered_map和unordered_set的迭代器
只有哈希表里的迭代器完成了,才可以封装map和set里的迭代器。
封装set的迭代器,本质就是调用哈希表的迭代器接口。
1.不过要注意的是,在重命名红黑树里的迭代器时,需要在类名前面加上typename,如果不加上typename是不行的,因为这时类模板还没有实例化出对象出来,就算实例化了,也有部分类型没有实例,因为编译器也不知道这个是内置类型还是静态变量,加上是告诉编译器这个是类型,这个类型在类模板里定义,等类模板实例化后再找。
2.定义好普通迭代和const迭代器后,就可以实现begin()和end()了。
namespace tao
{template<class K>class set{struct setoft{const K& operator()(const K& key){return key;}};public:typedef typename Hash_table<K, K, setoft>::iterator iterator;typedef typename Hash_table<K, K, setoft>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}iterator begin()const{return _ht.begin();}iterator end()const{return _ht.end();}bool insert(const K& key){return _ht.insert(key);}private://底层封装一个哈希表,哈希表里存的是K类型Hash_table<K, K, setoft> _ht;};
};封装map的迭代器,本质上就是调用哈希表里的迭代器接口。
#include"Hash.h"
namespace tao
{template<class K, class V>class map{struct mapoft{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename Hash_table<K, pair<K, V>, mapoft>::iterator iterator;typedef typename Hash_table<K, pair< K, V>, mapoft>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}iterator begin()const{return _ht.begin();}iterator end()const{return _ht.end();}bool insert(const pair<K, V>& kv){return _ht.insert(kv);}private://底层封装一个哈希表,哈希表里的数据是pair<K,V>类型Hash_table<K, pair< K, V>, mapoft> _ht;};
};六.解决key不能修改问题
set里面存储的Key值是不能被修改的,map里的存储的K值也是不能被修改,但是Value值是可以被修改!
如果解决这个问题呢?
问题:set里的key值不能被修改。map里的key值不能被修改,value值可以被修改。 set解决原理:
1.set里存储的值就只有Key值,索性我们直接让这个存储的数据无法被修改,只能访问读取,无法修改。即使用const修饰。而我们是通过迭代器来访问到这个数据的,所以我们让普通迭代器变成const迭代器即可。所以在set里,普通迭代器和const迭代器最终都是const迭代器。
2.那么迭代器都是const的了,最终都只会调用const修饰的begin()和end()函数了,普通的begin()和end()就不需要写了。
3.不过这样处理又会出现一个很难搞的问题,这个就是set的insert的返回值问题,我们后面要实现map的[]运算符重载就会讲到。
set的解决方法:public:typedef typename Hash_table<K, K, setoft>::const_iterator iterator;//为了解决set的key不能被修改所以我们让普通迭代器变成const迭代器typedef typename Hash_table<K, K, setoft>::const_iterator const_iterator;//因为普通迭代器也是const所以我们只用写const的begin和end即可。iterator begin()const{return _ht.begin();}iterator end()const{return _ht.end();}//这里的pair<const_iterator,bool>类型的bool insert(const K& key){//return _ht.insert(key);}private://底层封装一个哈希表,哈希表里存的是K类型Hash_table<K, K, setoft> _ht;};
};map的解决原理
1.在存储的时候就让K值无法修改。
2.因为我们知道map里存储的数据是pair<K,V>类型,我们不能想set那个让普通迭代器变成const迭代器,因为map要求Value的值还是可以修改的,所以不让pair<K,V>类型无法修改,而是单纯的让里面的K值无法修改,也就是在里面用const修饰K,那么这样K值就不能被修改,V值可以被修改。
3.pair是可以修改的,但是里面的K是无法被修改的!
map的解决方法:public:typedef typename Hash_table<K, pair<const K, V>, mapoft>::iterator iterator;typedef typename Hash_table<K, pair<const K, V>, mapoft>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}iterator begin()const{return _ht.begin();}iterator end()const{return _ht.end();}bool insert(const pair<K, V>& kv){return _ht.insert(kv);}private://底层封装一个哈希表,哈希表里的数据是pair<K,V>类型Hash_table<K, pair<const K, V>, mapoft> _ht;};
};七.实现map[]运算符重载
map的[ ]运算符重载,底层实现本质是调用了insert函数。然后通过insert函数返回的pair<iterator,bool>类型数据来找到Value值。
所以在实现[ ]运算符重载时,我们需要对哈希表里的insert进行改造,因为原来的insert的返回值是布尔值,我们需要pair类型返回值。
pair<iterator,bool> insert(const T& data){KeyOfT kt;Hashfunc hf;//仿函数可以使数据模//在插入之前,确认一下表里是否已经有了这个值,如果有了就不用插入了iterator it = find(kt(data));if (it!=end()){return make_pair(it,false);}if (n == _table.size()){//异地扩容,重新开空间size_t newSize = _table.size() * 2;vector<Node*> newtable;newtable.resize(newSize, nullptr);//不能再复用下面的方法,这样不好,因为就又重开空间,然后又要释放,//我们应该将原来的结点拿过来使用//所以我们遍历旧表,将旧表的结点拿过来,签到新表上for (size_t i = 0; i < _table.size(); i++){//扩容后,空间size变大了,有的数据就可能会存到不同的桶里了//拿下来的结点要重新计算放进哪个位置Node* cur = _table[i];//cur后面可能还有链接的结点while (cur){size_t hashi = hf(kt(cur->_data)) % newtable.size();Node* next = cur->_next;//头插到新表cur->_next = newtable[hashi];//头插 这个结点的 接到插入结点的前面对吧//那么next就接到newtavle[i]newtable[hashi] = cur;//往后走接着拿走cur = next;}//当前桶里的结点被拿光后,就置为空_table[i] = nullptr;}//这个新表就是我们想要的表,那么我们利用vector、的交换,让旧表和新表交换_table.swap(newtable);}size_t hashi = hf(kt(data)) % _table.size();Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;//将新结点头插到哈希桶里++n;return make_pair(iterator(newnode,this),true);}iterator find(const K& key){Hashfunc hf;KeyOfT kt;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (kt(cur->_data) == key)return iterator(cur,this);elsecur = cur->_next;}return iterator(nullptr,this);}
哈希表的insert改造后,那么set和map里的insert都需要修改,因为底层用的就是调用用哈希表的insert。
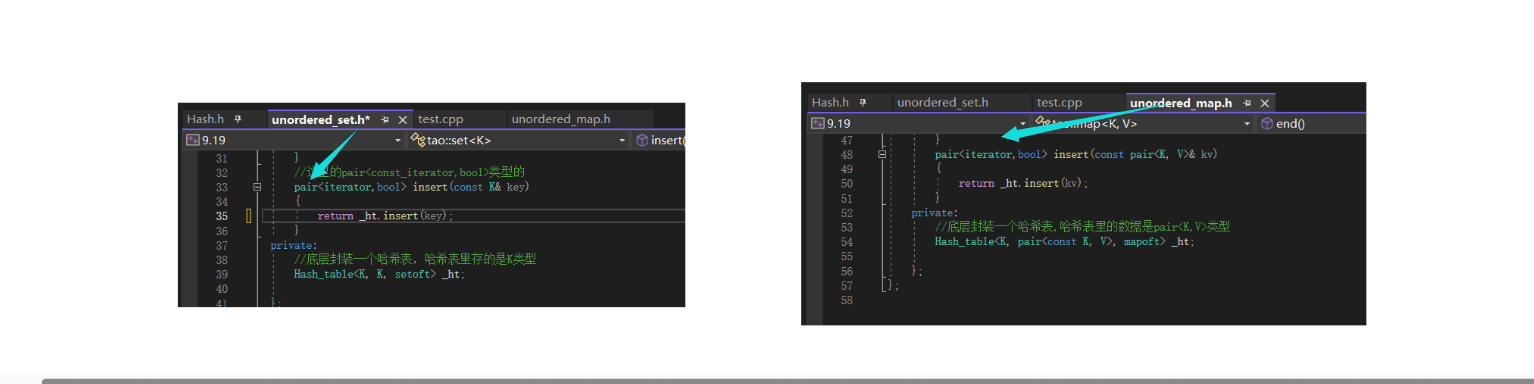
这样修改是对的吗?有没有什么问题呢?
但是这时会出现一个问题,set里面的insert报错。这是为什么呢?
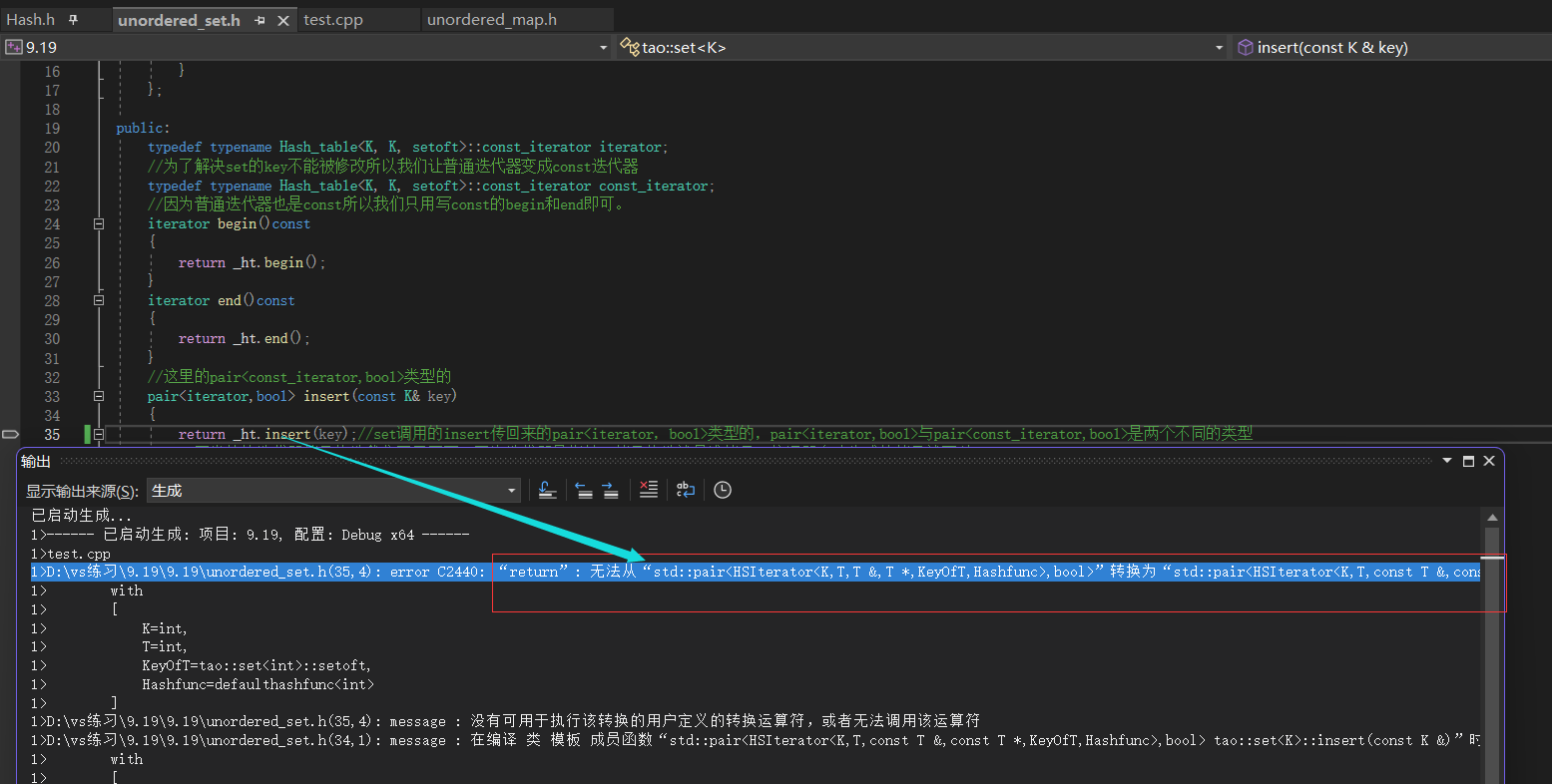
问题在于,我们之前让普通迭代变成const迭代器,而这里的pair<iterator,bool>中的iterator其实本质上是const_iterator。
是pair<const_itearto,bool>类型的。而哈希表里的insert返回的是普通迭代器,也就是pair<iterator,bool>类型的。这是两个不同的类型,无法直接将pair<iterator,bool>类型转换成pair<const_itearto,bool>类型的。所以会报错。

·
解决方法:
1.迭代器的拷贝函数是浅拷贝,我们不需要写,编译器自动生成的拷贝就可以用,编译器自动生成的拷贝函数只能实现普通迭代器拷贝给普通迭代器,const迭代器拷贝给const迭代器。(原理就是拷贝函数的对象类型就是调用这个函数的类型,当普通迭代器调用拷贝时,那么拷贝对象就是普通类型,当const迭代器调用拷贝时,那么拷贝对象就是const类型)
2.而我们需要的是让普通迭代器能够拷贝给const迭代器。所以我们需要自己增加拷贝函数。
3.库里的设计很妙,库里重新定义了一个iterator,作为拷贝对象,而这个iterator固定了就是普通的迭代器,不会随着调用对象而改变类型。所以当普通迭代器调用时,就会将普通iterator拷贝给它。当const迭代器调用时,就会将普通迭代器iterator拷贝给它。
4.所以我们需要对哈希表的迭代器添加拷贝构造。用普通迭代器iteartor作为拷贝对象。
struct HSIterator
{typedef HashNode<T> Node;typedef HSIterator<K, T, T&, T*, KeyOfT, Hashfunc> iterator;typedef HSIterator<K, T,Ref,Ptr,KeyOfT, Hashfunc> Self;Node* _node;const Hash_table <K,T, KeyOfT,Hashfunc>* _pht;//没有取这个类里面的内嵌类型,就不需要加typenameHSIterator(Node* node, Hash_table<K, T, KeyOfT,Hashfunc>* hs)//hs是普通的类型:_node(node), _pht(hs){}//当传过来的哈希表指针是普通指针就走上面--权限的缩小//重载一个,当传过来的是const修饰的哈希表指针就走这里---权限的平移HSIterator(Node* node, const Hash_table<K, T, KeyOfT, Hashfunc>* hs)//hs是普通的类型:_node(node), _pht(hs){}//普通的拷贝构造就是 const迭代器拷贝给const迭代器,普通迭代器拷贝给普通迭代器//而我们写的拷贝构造可以同时支持两个,当调用对象是普通迭代器时,用普通迭代器拷贝,也就是相当于赋值//当调用对象是const迭代器时,也是用普通迭代器拷贝。这样就支持了普通迭代器转化成const迭代器了HSIterator(const iterator& it):_node(it._node),_pht(it._pht){}……………………………………………………};这样处理后,我们再利用pair<iterator,bool>类型的构造函数,将普通迭代器转换成const迭代器。
1.先将insert返回类型利用ret接收
2.利用pair<iteartor,bool>构造将ret里的普通迭代器转换为const迭代器。
pair<iterator,bool> insert(const K& key){//return _ht.insert(key);//set调用的insert传回来的pair<iterator,bool>类型的,pair<iterator,bool>与pair<const_iterator,bool>是两个不同的类型//正常的的迭代器拷贝构造我们不需要写,因为迭代器是指针,拷贝构造就是浅拷贝,编译器自动生成的拷贝就可以//但是这里我们需要自己写拷贝构造; 因为需要将pair<iteartor,bool>类型,转化成pair<const_iterator,bool>类型,如何转化的呢?pair<typename Hash_table<K, K, setoft>::iterator, bool> it = _ht.insert(key);return pair<iterator, bool>(it.first, it.second);}
最后insert的改造到这里就结束了,insert改造完后,就可以实现[ ]运算符重载了。
V& operator[](const K&key){pair<iterator, bool> ret = _ht.insert(make_pair(key,V()));//插入的数据是pair类型,要用make_pair构造return ret.first->second;}
相关文章:
【数据结构】【C++】封装哈希表模拟实现unordered_map和unordered_set容器
【数据结构】&&【C】封装哈希表模拟实现unordered_map和unordered_set容器 一.哈希表的完成二.改造哈希表(泛型适配)三.封装unordered_map和unordered_set的接口四.实现哈希表迭代器(泛型适配)五.封装unordered_map和unordered_set的迭代器六.解决key不能修改问题七.实…...

26967-2011 一般用喷油单螺杆空气压缩机
声明 本文是学习GB-T 26967-2011 一般用喷油单螺杆空气压缩机. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了一般用喷油单螺杆空气压缩机(以下简称"单螺杆空压机")的术语和定义、型号、基本 参数、要求、试验方法、…...
Opengl之模板测试
当片段着色器处理完一个片段之后,模板测试(Stencil Test)会开始执行,和深度测试一样,它也可能会丢弃片段。接下来,被保留的片段会进入深度测试,它可能会丢弃更多的片段。模板测试是根据又一个缓冲来进行的,…...
iPhone苹果手机复制粘贴内容提示弹窗如何取消关闭提醒?
经常使用草柴APP查询淘宝、天猫、京东商品优惠券拿购物返利的iPhone苹果手机用户,复制商品链接后打开草柴APP粘贴商品链接查券时总是弹窗提示粘贴内容,为此很多苹果iPhone手机用户联系客服询问如何关闭iPhone苹果手机复制粘贴内容弹窗提醒功能的方法如下…...

释放潜力:人工智能对个性化学习的影响
人工智能有潜力通过使个性化学习成为一种实用且可扩展的方法来彻底改变教育。它使教育工作者能够满足每个学生的独特需求,促进参与并提高整体学习成果。然而,必须解决道德问题,并确保技术仍然是教育工作者手中的工具,为学生创造更…...

什么是Local Storage和Session Storage?它们之间有什么区别?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 什么是 Local Storage 和 Session Storage?Local Storage(本地存储)Session Storage(会话存储) ⭐ 区别⭐ 示例⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的…...
)
单样本T检验|独立样本T检验|配对样本T检验(绘图)
学生 t 检验的基本思想是通过比较两组数据的均值以及它们的方差来判断是否存在显著差异。下面更详细地解释了学生 t 检验的基本思想: 均值比较:学生 t 检验的首要目标是比较两组数据的均值。我们通常有一个零假设(null hypothesis)…...
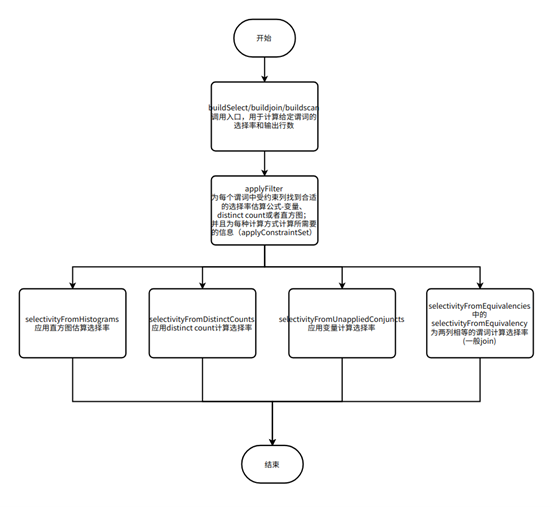
全面解读 SQL 优化 - 统计信息
一、简介 数据库中的优化器(optimizer)是一个重要的组件,用于分析 SQL 查询语句,并生成执行计划。在生成执行计划时,优化器需要依赖数据库中的统计信息来估算查询的成本,从而选择最优的执行计划。以下是关…...
Spring整合RabbitMQ——生产者
1.生产者整合步骤 添加依赖坐标,在producer和consumer模块的pom文件中各复制一份。 配置producer的配置文件 配置producer的xml配置文件 编写测试类发送消息...

Spring的注解开发-Bean基本注解开发
Bean基本注解开发 Spring除了xml配置文件进行配置之外,还可以使用注解方式进行配置,注解方式慢慢成为xml配置的替代方案。我们有了xml开发的经验,学习注解开发就会方便很多,注解开发更加快捷方便。Spring提供的注解有三个版本 2.…...
【Ubuntu18.04】Autoware.ai安装
Autoware.ai安装 引言1 ROS安装2 Ubuntu18.04安装Qt5.14.23 安装GCC、G4 Autoware.ai-1.14.0安装与编译4.1 源码的编译4.1.1 python2.7环境4.1,2 针对Ubuntu 18.04 / Melodic的依赖包安装4.1.3 先安装一些缺的ros依赖4.1.4 安装eigen3.3.74.1.5 安装opencv 3.4.164.1.6 编译4.1…...

SpringMVC 学习(一)Servlet
本系列文章为【狂神说 Java 】视频的课堂笔记,若有需要可配套视频学习。 1. Hello Servlet (1) 创建父工程 删除src文件夹 引入一些基本的依赖 <!--依赖--> <dependencies><dependency><groupId>junit</groupId><artifactId>…...

26943-2011 升降式高杆照明装置 课堂随笔
声明 本文是学习GB-T 26943-2011 升降式高杆照明装置. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了升降式高杆照明装置的技术要求、试验方法、检验规则以及标志、包装、运输及贮 存等。 本标准适用于公路、广场、机场、港口、…...

洛谷题解 | AT_abc321_c Primes on Interval
目录 题目翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 样例 #3样例输入 #3样例输出 #3 题目简化题目思路AC代码 题目翻译 【题目描述】 你决定用素数定理来做一个调查. 众所周知, 素数又被称为质数,其含义就是除了数…...
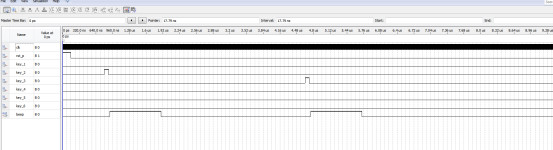
Quartus医院病房呼叫系统病床呼叫Verilog,源代码下载
名称:医院病房呼叫系统病床呼叫 软件:Quartus 语言:Verilog 要求: 1、用1~6个开关模拟6个病房的呼叫输入信号,1号优先级最高;1~6优先级依次降低; 2、 用一个数码管显示呼叫信号的号码;没信号呼叫时显示0;有多个信号呼叫时,显…...
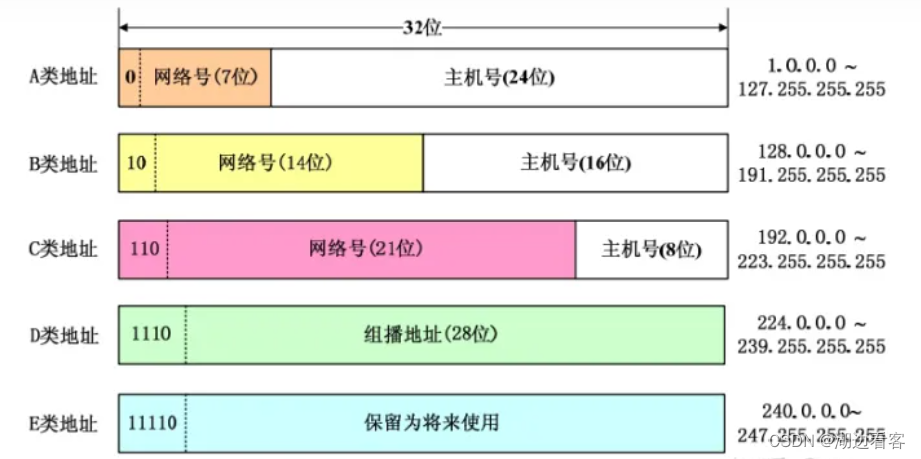
ip的标准分类---分类的Ip
分类的 IP 即将 IP 地址划分为若干个固定类,每一类地址都由两个固定长度的字段组成。 其中第一个字段是网络号(net-id),它标志主机或路由器所连接的网络。一个网络号在整个因特网内必须是唯一的。 第二个字段是主机号…...
)
理解并掌握C#的Channel:从使用案例到源码解读(一)
引言 在C#的并发编程中,Channel是一种非常强大的数据结构,用于在生产者和消费者之间进行通信。本文将首先通过一个实际的使用案例,介绍如何在C#中使用Channel,然后深入到Channel的源码中,解析其内部的实现机制。 使用案…...

如何让git命令仅针对当前目录
背景 我们有时候建的git仓库是这样的,a目录下有b、c、d三个模块(文件夹)。有时候只想查看b下面的变化,而使用 git status、git diff 的时候会把c和d的变化都列出来,要怎么只查b目录的变化? 操作 要查b目…...

【0223】源码剖析smgr底层设计机制(3)
1. smgr设计机制 PG内核中smgr完整磁盘存储介质的管理是通过下面三部分实现的。 1.1 函数指针结构体 f_smgr 函数指针结构体 f_smgr。 通过该函数指针类型,可完成类似于UNIX系统中的VFD功能,上层只需要调用open()、read()、write()等系统函数,用户不必去关系底层的文件系统…...

Visual Studio 2019 C# winform CefSharp 中播放视频及全屏播放
VS C# winform CefSharp 浏览器控件,默认不支持视频播放,好在有大佬魔改了dll,支持流媒体视频播放。虽然找了很久,好歹还是找到了一个版本100.0.230的dll(资源放在文末) 首先创建一个项目 第二、引入CefSha…...

PyFlow输入系统定制化:创建专属快捷键映射的完整指南
PyFlow输入系统定制化:创建专属快捷键映射的完整指南 【免费下载链接】PyFlow Visual scripting framework for python 项目地址: https://gitcode.com/gh_mirrors/py/PyFlow PyFlow作为一款强大的Python可视化脚本框架,允许用户通过直观的节点编…...

系统整体设计方案
业务架构设计项目架构图业务流程设计文档向量整个流程从用户上传文档开始,用户通过前端页面选择文档并设置相关的组织标签和可见信后系统开始接收文档。这个阶段的关键是建立文档的基本记录信息,包括文件的Md5哈希值文件原始名文件大小上传用户等信息。系…...

OpenClaw多账户管理:Kimi-VL-A3B-Thinking不同项目的环境隔离方案
OpenClaw多账户管理:Kimi-VL-A3B-Thinking不同项目的环境隔离方案 1. 为什么需要多账户环境隔离 上周我同时处理三个项目时遇到了一个尴尬场景:个人博客自动发布脚本误读了工作项目的敏感数据,导致草稿内容错乱。这次事故让我意识到——当O…...

Qwen3.5-9B-AWQ-4bit操作系统概念学习与实验指导
Qwen3.5-9B-AWQ-4bit操作系统概念学习与实验指导 1. 当AI成为你的操作系统课助教 想象一下,凌晨两点你正在赶操作系统课程的作业,突然卡在进程调度算法上。这时候如果有个随时在线的助教,能清晰解释概念、提供实验思路,甚至给出…...

45V耐压CSM7345SG ESOP8,可调12V输出+使能端+散热片,低压差线性稳压器
CSM7345 ESOP8可调12V输出带使能端 全方案深度分析我会从芯片核心特性、12V输出原理、使能端设计、电路参数计算、保护机制、PCB设计要点等维度,做完整的工程级拆解,帮你彻底吃透这个方案。一、芯片核心特性(适配12V输出的关键参数࿰…...

Graphormer效果展示:PCQM4M榜单SOTA级分子属性预测结果集
Graphormer效果展示:PCQM4M榜单SOTA级分子属性预测结果集 1. 模型概述 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM4M等分子基准测试中表…...
| Codex 配置(插件安装))
Claude Code教程(四)| Codex 配置(插件安装)
Claude Code教程(四)| Codex 配置(插件安装)一、核心定位(一句话看懂)二、前置准备(必做)2.1 核心环境要求(极简)2.2 关键说明(重要)三…...

类OpenClaw智能体优选指南,企业级+个人级全覆盖
2026年初,OpenClaw开源智能体框架凭借“自主规划、工具调用、端到端执行”的核心能力,打破传统AI“只对话不行动”的壁垒,在GitHub迅速斩获25万星标,引发全球科技圈热潮,国内厂商纷纷入局推出类OpenClaw产品࿰…...

MIL图像库实战:从采集卡配置到Qt应用开发
1. 工业视觉项目开发全流程解析 第一次接触MIL图像库时,我被它强大的硬件抽象能力震撼到了。这个由Matrox开发的图像处理库,就像一位经验丰富的翻译官,把不同品牌采集卡的硬件差异统统屏蔽掉。想象一下,你手里有Basler、AVT、Dals…...

DLSS Swapper实战指南:高效管理DLSS版本3步达成游戏性能跃升
DLSS Swapper实战指南:高效管理DLSS版本3步达成游戏性能跃升 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 当你在4K分辨率下启动《赛博朋克2077》,满心期待沉浸在夜之城的霓虹中时,…...