2023华为杯数学建模D题-域碳排放量以及经济、人口、能源消费量的现状分析(如何建立指标和指标体系1,碳排放影响因素详细建模过程)
可能建立的指标如下:
经济指标:
地区生产总值(GDP)人均GDP;第一产业(农林部门)产值;第二产业(能源供应和工业部门)产值;第三产业(建筑和交通部门)产值;居民生活消费总额。
人口指标: 总人口 ;人口增长率
能源消耗指标:
总能源消耗量;人均能源消耗量;非化石能源消费比重;各部门(农林、能源供应、工业、建筑、交通、居民生活)的能源消耗量;单位GDP能耗;人均GDP与人均能耗的比值
碳排放指标:总碳排放量;人均碳排放量;各部门(农林、能源供应、工业、建筑、交通、居民生活)的碳排放量;生态碳汇与工程碳汇的比值;间接碳排放量
详细的解题过程可以参考
指标体系:
描述经济发展、人口增长、能源消耗和碳排放之间的关系。
描述各部门在经济发展、能源消耗和碳排放中的角色和贡献。
描述非化石能源消费、单位GDP能耗、人均GDP与人均能耗的比值、生态碳汇与工程碳汇的比值、间接碳排放等指标对碳排放的影响。
碳排放预测:用经济增长率、人口增长率、能源消耗增长率、碳排放增长率等指标的历史数据,通过统计模型结合kaya模型预测未来的碳排放量。
当我们确定了具体的指标后,就可以开始使用熵权法(Entropy Method)来确定每个指标的权重,或者采用遍历系数法来确定每个指标的权重。这个过程通常需要专家的评分和参与(这个评分指的是我们根据,我们对各个指标进行排序(按照其和碳排放的关系(第一次给的代码中有很多结果图,需要你们自己去分析)),给他一个分数,进行)。
公式表述:
指标的权重确定方法:变异系数法
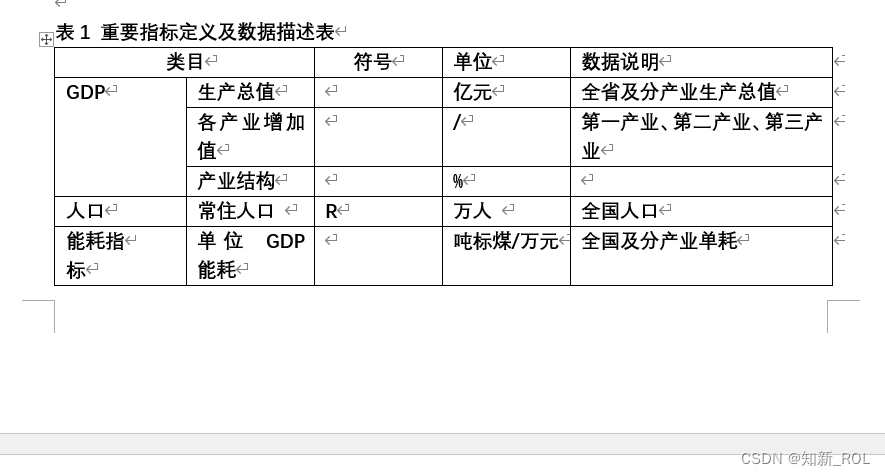
![]() 表示
表示![]() 因素的
因素的![]() 项指标的值,
项指标的值, ![]() 项指标的平均值为:
项指标的平均值为:
![]()
其中,![]() 表示体系数量,
表示体系数量,![]() 表示指标数量,
表示指标数量,![]() 表示
表示![]() 项指标的平均值
项指标的平均值
![]() 项指标的标准差为:
项指标的标准差为:
![]()
![]() 表示
表示![]() 项指标的标准差,然后,我们需要对指标进行无量纲处理,本文通过数据标准化方式对数据进行处理,具体公式如下:
项指标的标准差,然后,我们需要对指标进行无量纲处理,本文通过数据标准化方式对数据进行处理,具体公式如下:
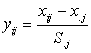
经过标准化处理后的指标![]() 的平均值为:
的平均值为:
![]()
经过标准化处理后的指标![]() 的标准差为
的标准差为
![]()
那么,指标![]() 的变异系数为:
的变异系数为:

其中,![]() 表示指标
表示指标![]() 的变异系数,也成为标准差系数。那么,各项指标的权重为:
的变异系数,也成为标准差系数。那么,各项指标的权重为:

![]() 表示指标
表示指标![]() 的权重系数
的权重系数
本题中已经有了这些年份的碳排放数据,所以不需要一个复杂的指标体系。可以直接比较和分析这些数据,以了解碳排放量随时间的变化情况。
通过计算每年碳排放量的平均值、中位数、最大值、最小值等统计量,以了解碳排放量的分布情况。
通过绘制折线图、柱状图等图形,直观地展示碳排放量随时间的变化情况(第一问给出了很多图,其实就是直接得到他们之间的关系,那么你需要多分析几个参量)
我们通过这种方式
我们选取地区生产总值、人口及能源消费量、产业能耗结构及能耗品种结构等因素,其中地区生产总值以GDP来衡量,人口以人口数量来衡量,能源消费量以碳排放总量来衡量,产业能耗结构是以产业碳排放比重大的产业消耗量为依据即以第一二三产业占比来衡量,本题中以第二产业占比来衡量。能耗品种结构以煤和油品消耗为主。
上述指标中生产总值、人口及能源消费量为第一梯度指标,而产业能耗结构及能耗品种结构等为第二梯度指标,第二梯度指标与第一梯度指标相关,如能源消费量与产业能耗结构及能耗品种结构等有很大关系,下面将建模进行分析。
模型的构建kaya和LMD1
构建碳排放量影响因素分析模型:LMDL模型
对数平均迪氏指数(Logarithmic Mean Divisia Index)法是指数分解法的一种,简称LMDI。LMDI的基本思想是把一个目标变量的变化分解成若干个影响因素变化的组合。
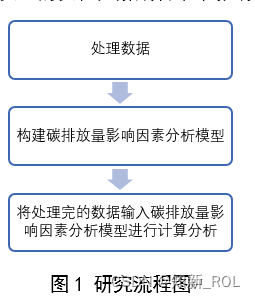
图1 研究流程图

其中,ct为年份t的总碳排放量,I为不同的能源大类集合,包括煤炭、油品、天然气、热力、电力、其他能源;J为各产业部门的集合,包括第一产业、第二产业、第三产业等;ei,j,t
为第t年j类型产业对i类型能源的消费量;αi,t为第t年i类型能源的碳排放因子。
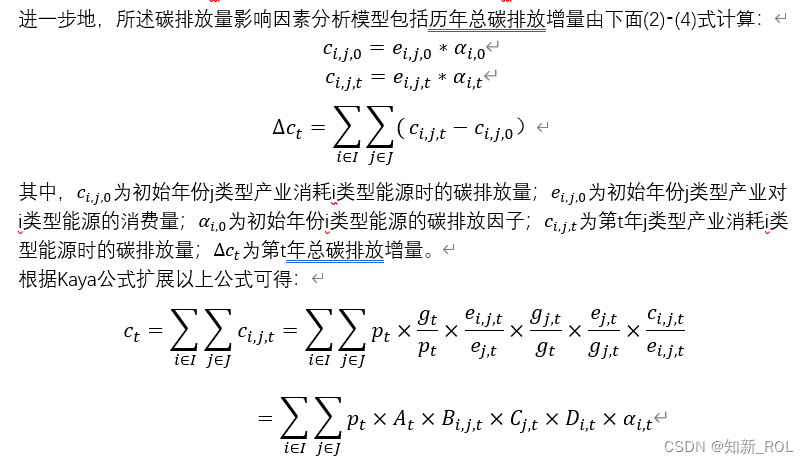

(三)人口、经济增长、能源结构、产业结构、能耗强度和碳排放系数等因素对碳排放增量影响的分析
进一步地,所述碳排放量影响因素分析模型包括由(5)‑(10)式分析人口、经济增长、能源结构、产业结构、能耗强度(单位GDP能耗)以及碳排放系数对碳排放增量的影响:
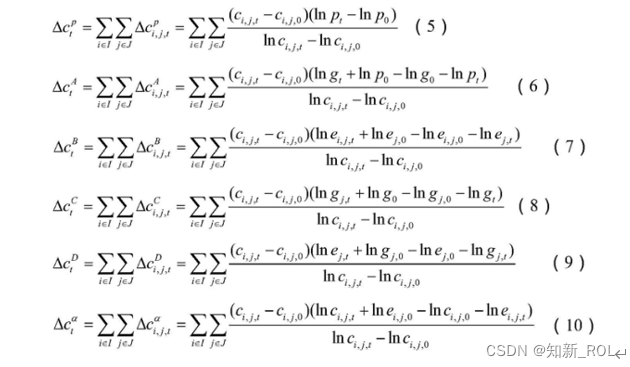

人口数据、产业结构数据、各产业GDP数据、各产业对各类型能源的消耗数据以及各类型能源的碳排放系数输入预先构建的碳排放量影响因素分析模型进行数据分析,并将分析结果绘制成条形图。
参考图1:
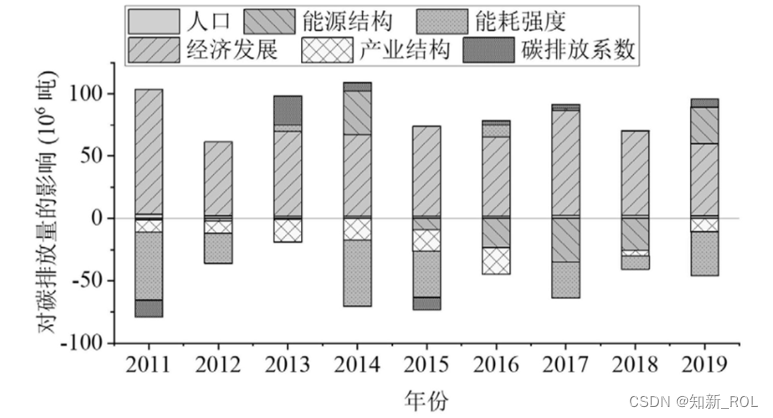
人口、经济增长、能源结构、产业结构、能耗强度和碳排放系数等六个因素对碳排放量的总贡献量分别为20 .86、637 .79、‑108 . 36、‑299 .21和21 .05百万吨。首先,人口对碳排放增长起着促进作用,占碳排放总增长量的6 .72%,由此可见,由于人口增长导致的碳排放增量仍在合理范围内。其次,经济增长是碳排放增长的主要驱动因素,占碳排放总增长量的205 .60%。每年中的该因素导致的碳排放增长量皆为正值,这说明经济增长仍然是以大量消耗高碳排放的能源为代价的。
相关文章:
2023华为杯数学建模D题-域碳排放量以及经济、人口、能源消费量的现状分析(如何建立指标和指标体系1,碳排放影响因素详细建模过程)
可能建立的指标如下: 经济指标: 地区生产总值(GDP)人均GDP;第一产业(农林部门)产值;第二产业(能源供应和工业部门)产值;第三产业(建筑和交通部门…...
Excel·VBA分列、字符串拆分
看到一篇博客《VBA,用VBA进行分列(拆分列)的2种方法》,使用VBA对字符串进行拆分 目录 Excel分列功能将字符串拆分为二维数组,Split函数举例 将字符串拆分为一维数组,正则表达式举例 Excel分列功能 Sub 测…...
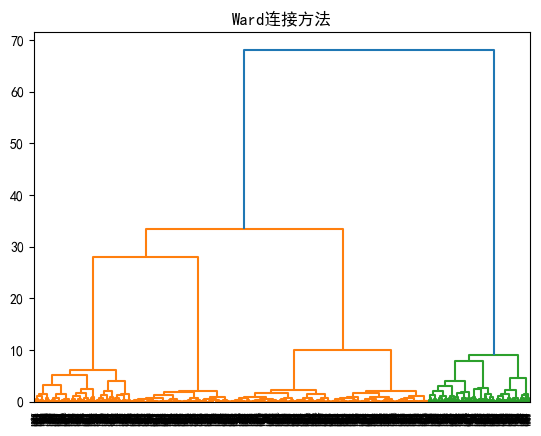
机器学习算法基础--层次聚类法
文章目录 1.层次聚类法原理简介2.层次聚类法基础算法演示2.1.Single-linkage的计算方法演示2.2.Complete-linkage的计算方法演示2.3.Group-average的计算方法演示 3.层次聚类法拓展算法介绍3.1.质心法原理介绍3.2.基于中点的质心法3.3.Ward方法 4.层次聚类法应用实战4.1.层次聚…...
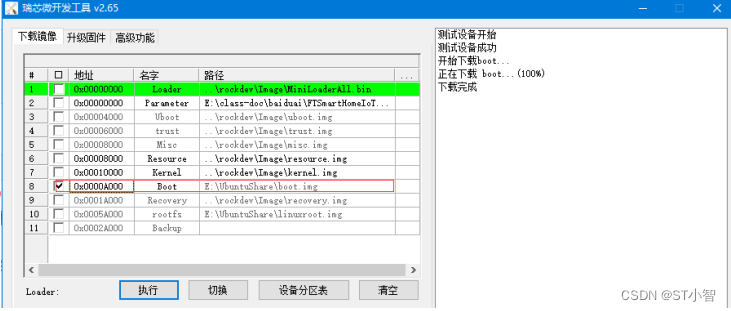
linux系统中wifi移植方法
第一:移植wifi现象 在linux系统的RK3399中空板上,确认rk3399中控板linux系统已经可以正常运行。本操作是在rk3399中控板上的WIFI模块,linux内核加载wifi驱动后,再配置上正确的wifi密码,就可以实现rk3399中控板通过wifi…...

Machine Learning(study notes)
There is no studying without going crazy Studying alwats drives us crazy 文章目录 DefineMachine LearningSupervised Learning(监督学习)Regression problemClassidication Unspervised LearningClustering StudyModel representation(…...

centos7通过docker搭建nginx+php环境
以下环境都是基于centos7.9完成。 1.安装docker yum install docker-ce 说明:这一步,由于centos软件仓库没有收纳docker,需要自己去官网爬文档安装。 安装完成之后,就是启动docker服务以及添加到开机启动。 systemctl enable do…...

Node.js 学习笔记
小插件Template String Converter 当输入${}时,自动为其加上 反引号 一、node入门 node.js是什么 node的作用 开发服务器应用 开发工具类应用 开发桌面端应用 1.命令行工具 命令的结构 常用命令 切换到D盘——D: 查看D盘目录——dir 切换工作目录——c…...

RabbitMQ之发布确认高级
RabbitMQ之发布确认高级 一、发布确认 SpringBoot 版本1.1 确认机制方案1.2 代码架构图1.3 配置文件1.4 添加配置类1.5 消息生产者1.6 回调接口1.7 消息消费者1.8 结果分析 二、回退消息2.1 Mandatory 参数2.2 消息生产者代码2.3 回调接口2.4 结果分析 三、备份交换机3.1 代码架…...
lv5 嵌入式开发-10 信号机制(下)
目录 1 信号集、信号的阻塞 2 信号集操作函数 2.1 自定义信号集 2.2 清空信号集 2.3 全部置1 2.4 将一个信号添加到集合中 2.5 将一个信号从集合中移除 2.6 判断一个信号是否在集合中 2.7 设定对信号集内的信号的处理方式(阻塞或不阻塞) 2.8 使进程挂起(…...

【postgresql】 ERROR: multiple assignments to same column “XXX“
Cause: org.postgresql.util.PSQLException: ERROR: multiple assignments to same column "XXX"; bad SQL grammar []; nested exception is org.postgresql.util.PSQLException: ERROR: multiple assignments to same column "XXX"; 原因:or…...
一文读懂Llama 2(从原理到实战)
简介 Llama 2,是Meta AI正式发布的最新一代开源大模型。 Llama 2训练所用的token翻了一倍至2万亿,同时对于使用大模型最重要的上下文长度限制,Llama 2也翻了一倍。Llama 2包含了70亿、130亿和700亿参数的模型。Meta宣布将与微软Azure进行合…...
完整指南:如何使用 Node.js 复制文件
文件拷贝指的是将一个文件的数据复制到另一个文件中,使目标文件与源文件内容一致。Node.js 提供了文件系统模块 fs,通过该模块可以访问文件系统,实现文件操作,包括拷贝文件。 Node.js 中文件拷贝方法 在 Node.js 中,有…...

ElementUI - 主页面--动态树右侧内容管理
一.左侧动态树 1.定义组件 ①样式&数据处理 <template><el-menu class"el-menu-vertical-demo" background-color"#334157"text-color"#fff" active-text-color"#ffd04b" :collapse"collapsed" router :def…...

全国排名前三的直播公司无锋科技入驻天府蜂巢成都直播产业基地
最近,全国排名前三的直播公司——无锋科技,正式宣布入驻位于成都的天府蜂巢直播产业基地,这一消息引起了业内人士的高度关注。成都直播产业基地一直是中国直播产业的重要地标之一,其强大的技术和资源优势为众多直播公司提供了广阔…...

机器人中的数值优化|【五】BFGS算法非凸/非光滑处理
机器人中的数值优化|【五】BFGS算法的非凸/非光滑处理 往期内容回顾 机器人中的数值优化|【一】数值优化基础 机器人中的数值优化|【二】最速下降法,可行牛顿法的python实现,以Rosenbrock function为例 机器人中的数值优化|【三】无约束优化࿰…...
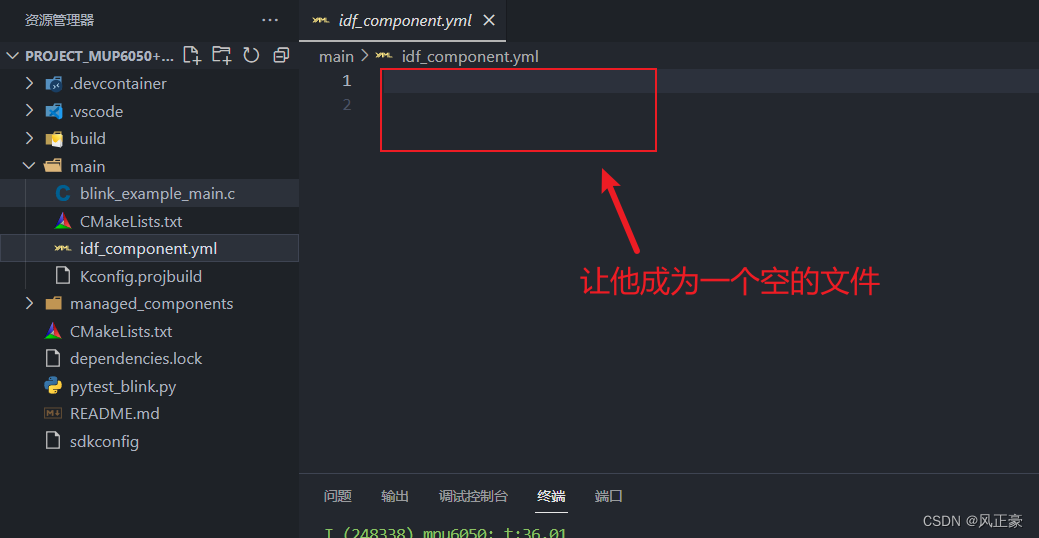
ESP32S3的MPU-6050组件移植教程
前言 (1)实习公司要搞ESP32BOX的驱动移植,所有资料自己找还是比较折磨人的现在我分享几个官方的组件移植资料: <1>Find the most exciting ESP-IDF components(ESP32的官方组件都可以在里面查,按照他…...
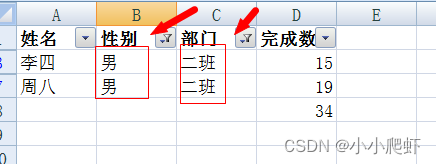
excel筛选后求和
需要对excel先筛选,后对“完成数量”进行求和。初始表格如下: 一、选中表内任意单元格,按ctrlshiftL,开启筛选 二、根据“部门”筛选,比如选择“一班” 筛选完毕后,选中上图单元格,然后按alt后&…...

pyspark 检测任务输出目录是否空,避免读取报错
前言 在跑调度任务时候,有时候子任务需要依赖前置任务的输出,但类似读取 Parquet 或者 Orc 文件时,如果不判断目录是否为空,在输出为空时会报错,所以需要 check 一下,此外Hadoop通常在写入数据时会在目录中…...

「网页开发|前端开发|Vue」10 vuex模块化:将数据划分成不同modules分别管理
本文主要介绍如何使用vuex的modules将状态数据根据不同模块进行划分并分别管理以及如何使用mapGetters快速将状态管理中的数据导入成local变量。 文章目录 本系列前文传送门一、场景说明二、使用modules划分不同模块三、使用Getters获取状态管理数据Getter传参mapGetters 辅助…...

苹果CMS插件-苹果CMS全套插件免费
网站内容的生成和管理对于网站所有者和内容创作者来说是一个挑战。有一些强大的工具可以帮助您轻松地解决这些问题。苹果CMS插件自动采集插件、采集发布插件以及采集伪原创发布插件,是这些工具之一。它们不仅可以极大地节省您的时间和精力,还可以提高您网…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...