Elasticsearch:使用 Elasticsearch 进行语义搜索
在数字时代,搜索引擎在通过浏览互联网上的大量可用信息来检索数据方面发挥着重要作用。 此方法涉及用户在搜索栏中输入特定术语或短语,期望搜索引擎返回与这些确切关键字匹配的结果。
虽然关键字搜索对于简化信息检索非常有价值,但它也有其局限性。 主要缺点之一在于它对词汇匹配的依赖。 关键字搜索将查询中的每个单词视为独立的实体,通常会导致结果可能与用户的意图不完全一致。 此外,不明确的查询可能会产生不同的解释,从而导致混合或不准确的结果。
当处理上下文严重影响含义的语言时,会出现另一个关键限制。 词语的含义在很大程度上取决于具体情况。 单独使用关键字可能无法正确捕获这些查询,这可能会导致误解。
随着我们的数字环境不断发展,我们对更精致、更直观的搜索体验的期望也在不断变化。 这为语义搜索的出现铺平了道路,语义搜索是一种旨在超越传统基于关键字的方法的局限性的方法。 通过关注搜索查询的意图和上下文含义,语义搜索为关键字搜索带来的挑战提供了一种有前景的解决方案。

如上面的图片所示,如果我们通过 keyword 来进行搜索,我们想搜索的是 apple 水果,但是我们最终可能得到是关于 apple(苹果)公司的有关信息。其实它并不是我们想要的。
什么是语义搜索?
语义搜索是在互联网上搜索内容的高级方式。 它不仅仅是匹配单词,而是理解你真正在寻找的内容。 它能找出你的话背后的含义以及它们之间的关系。
这项技术使用人工智能和理解人类语言等技术。 几乎就像它在说人类一样! 它着眼于大局,检查具有相似含义的单词以及与你所问问题相关的其他想法。
基本上,语义搜索可以帮助你从互联网上的大量内容中准确获取所需的内容。 这就像与一个超级聪明的搜索引擎交谈,它不仅可以获取你所说的单词,还可以获取你真正想要查找的内容。 这使得它非常适合做研究、查找信息,甚至获得符合你兴趣的建议。

语义搜索的好处
- 精确度和相关性:语义搜索通过理解用户意图和上下文提供高度相关的结果。
- 自然语言理解:它理解复杂的查询,使自然语言交互更加有效。
- 消除歧义:它解决歧义查询,根据用户行为和上下文提供准确的结果。
- 个性化:语义搜索从用户行为中学习以获取定制结果,从而随着时间的推移提高相关性。
Elastic Search 中的语义搜索
Elastic Search 提供语义搜索,重点关注搜索查询的含义和上下文,而不仅仅是匹配关键字。 它使用自然语言处理(NLP)和向量搜索来实现这一目标。 Elastic 有自己的预训练表示模型,称为 Elastic Learned Sparse EncodeR (ELSER)。
在进入 ELSER 之前,让我们更多地了解 NLP 和向量搜索。
自然语言处理(NLP)
自然语言处理是人工智能的一个分支,致力于使计算机能够以有价值且有用的方式理解、解释和生成人类语言。

NLP 涉及一组允许计算机处理和分析大量自然语言数据的技术和算法。 这包括以下任务:
- 文本理解:NLP 帮助计算机理解一篇文章的内容。 它可以找出文本中的重要内容,例如姓名、关系和感受。
- 文本处理:这涉及将句子分解为单词或短语、将单词简化为其基本形式以及识别句子的不同部分等任务。
- 命名实体识别 (NER):NLP 可以识别文本中的特殊事物,例如人名、地名或组织名称。 这有助于理解正在讨论的内容。
向量搜索
向量搜索是一种涉及将数据点或信息表示为多维空间中的向量的技术。 空间的每个维度代表文档或数据点的不同特征或属性。
在这个向量空间中,相似的文档或数据点彼此距离更近。 这允许有效的基于相似性的搜索。 例如,如果你正在搜索与给定文档相似的文档,则可以计算表示文档的向量之间的相似度以查找最接近的匹配项。
向量搜索广泛用于各种应用,包括:
- 推荐系统:它有助于根据用户的喜好向他们推荐类似的项目。
- 信息检索:它允许在大型语料库中查找相似的文档。
- 异常检测:它有助于识别异常或异常数据点。
NLP 与向量搜索的工作原理
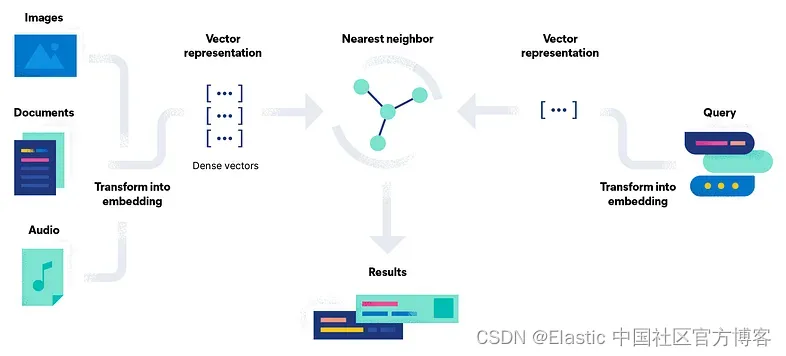
1)Vector embedding:
在此步骤中,NLP 涉及将文本数据转换为数值向量。 使用词嵌入等技术将文本中的每个单词转换为高维向量
2.相似度分数:
引擎将向量化查询与向量化文档进行比较以确定它们的相似性。
3)人工神经网络算法:
近似最近邻 (ANN) 算法可有效查找高维空间中的近似最近邻。
4)查询处理:
用户的查询经历与文档类似的处理以生成向量表示。
5)距离计算:
引擎计算向量化查询和文档之间的距离(相似度分数)。
6)最近邻搜索:
引擎查找嵌入最接近查询嵌入的文档。
7)排名结果:
结果根据相似度分数进行排名。
ELSER
ELSER 是一个经过专门设计的预训练模型,可以出色地理解上下文和意图,而无需进行复杂的微调。 ELSER 目前仅适用于英语,其开箱即用的适应性使其成为各种自然语言处理任务的宝贵工具。 它对稀疏向量表示的利用提高了处理文本数据的效率。 ELSER 的词汇表中包含约 30,000 个术语,通过用上下文相关的对应项替换术语来优化查询,确保精确而全面的搜索结果。
让我们深入探讨如何利用 ELSER 的潜力来增强 Elasticsearch 中的搜索能力。你可以参考文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR” 来配置自己的 ELSER。
第 1 步:创建具有所需映射的索引
- 在 Elasticsearch 中,“索引 (index)” 是指具有共同特征或属于相似类别的文档的集合。 它类似于关系数据库中的表或其他一些 NoSQL 数据库中的类型。 索引中的每个文档都分配有一个唯一标识符,并且包含 JSON 格式的结构化数据。
- 定义索引的映射,该映射将包含模型根据您的输入生成的 token。 该索引必须有一个 rank_features 字段类型的字段来索引 ELSER 输出。
PUT <index-name>
{"mappings": {"properties": {"ml.tokens": { "type": "rank_features" },"name": { "type": "text" }}}
}第 2 步:使用推理处理器创建摄取管道
- Elasticsearch 中的摄取管道使您能够在索引之前对数据应用各种转换。 这些转换包括字段删除、文本值提取和数据丰富等任务。
- 管道包含一组称为处理器的可定制任务。 这些处理器以顺序方式运行,对传入文档实施特定修改。使用推理处理器创建摄取管道,以使用 ELSER 对正在摄取的数据进行推理。
PUT _ingest/pipeline/<pipeline-name>
{"processors": [{"inference": {"model_id": ".elser_model_1","target_field": "ml","field_map": { "text": "text_field"},"inference_config": {"text_expansion": { "results_field": "tokens"}}}}]
}第 3 步:将数据添加到索引
- 索引映射和摄取管道已设置,现在我们可以开始向索引添加数据。
- 摄取管道作用于传入数据并将相关标记添加到文档中
curl -X POST 'https://<url>/<index-name>/_doc?pipeline=<ingest-pipeline-name' -H 'Content-Type: application/json' -H 'Authorization: ApiKey <Replace_with_created_API_key>' -d '{"name" : "How to Adapt Crucial Conversations to Global Audiences"
}'摄取管道作用于传入数据并将相关 token 添加到文档中:
{"name" : "How to Adapt Crucial Conversations to Global Audiences","ml":{"tokens": {"voice": 0.057680283,"education": 0.18481751,"questions": 0.4389099,"adaptation": 0.6029656,"language": 0.4136539,"quest": 0.082507774,"presentation": 0.035054933,"context": 0.2709603,"talk": 0.17953876,"communication": 1.0619682,"international": 0.38651025,"different": 0.25769454,"conversation": 1.03593,"train": 0.021380302,"audience": 0.97641367,"development": 0.33928272,"adapt": 0.90020984,"certification": 0.45675382,"cultural": 0.63132435,"distraction": 0.38943478,"success": 0.09179027,"cultures": 0.82463825,"essay": 0.2730616,"institute": 0.21582486,},"model_id":".elser_model_1"}
}第 4 步:执行语义搜索
- 使用 text expansion 查询来执行语义搜索。 提供查询文本和 ELSER 模型 ID。
- 文本扩展查询使用自然语言处理模型将查询文本转换为 token 权重对列表,然后将其用于针对 rank_features 字段的查询。
GET <index-name>/_search
{"query":{"text_expansion":{"ml.tokens":{"model_id":".elser_model_1","model_text":<query_text>}}}
}第 5 步:将语义搜索与其他查询结合起来
- 我们还可以将 text_expansion 与复合查询中的其他查询结合起来,以获得更精细的结果。
GET my-index/_search
{"query": {"bool": { "should": [{"text_expansion": {"ml.tokens": {"model_text": <query_text>,"model_id": ".elser_model_1",}}},{"query_string": {"query": <query_text>,}}]}}
}我们还可以将 text_expansion 与复合查询中的其他查询结合起来,以获得更精细的结果。
与 Elasticsearch 中的其他查询相比,text_expansion 查询通常会产生更高的分数。 我们可以使用 boost 参数调整相关性分数。
更多阅读:
-
Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR
-
Elasticsearch:使用 ELSER 进行语义搜索
-
Elasticsearch:使用 ELSER 释放语义搜索的力量:Elastic Learned Sparse EncoderR
相关文章:
Elasticsearch:使用 Elasticsearch 进行语义搜索
在数字时代,搜索引擎在通过浏览互联网上的大量可用信息来检索数据方面发挥着重要作用。 此方法涉及用户在搜索栏中输入特定术语或短语,期望搜索引擎返回与这些确切关键字匹配的结果。 虽然关键字搜索对于简化信息检索非常有价值,但它也有其局…...

JVM的主要组成及其作用
jvm主要组成部分有: 类加载器、运行时数据区 (内存结构)、执行引擎、本地接口库、垃圾回收机制 Java程序运行的时候,首先会通过类加载器把Java 代码转换成字节码。然后运行时数据区再将字节码加载到内存中,但字节码文件只是JVM 的一套指令集规范…...
会议AISTATS(Artificial Intelligence and Statistics) Latex模板参考文献引用问题
前言 在看AISTATS2024模板的时候,发现模板里面根本没有教怎么引用,要被气死了。 如下,引用(Cheesman, 1985)的时候,模板是自己手打上去的?而且模板提供的那三个引用,根本也没有Cheesman这个人,…...
2023最新外贸建站:WordPress搭建外贸独立站零基础小白保姆级教程
想从零开始建立一个外贸自建站,那么你来对地方了。 如果你还在找外贸建站或者是WordPress建站教程,不妨看看这篇文章,本教程涵盖了2023最新的外贸建站教程,你将学会使用WordPress自建外贸独立站,步骤包括购买域名主机…...
)
HTTP请求交互基础(基于GPT3.5,持续更新)
HTTP交互基础 目的HTTP定义详解HTTP协议(规范)1. 主要组成部分1.1 请求行(Request Line):包含请求方法、请求URI(Uniform Resource Identifier)和HTTP协议版本。1.2 请求头部(Reques…...
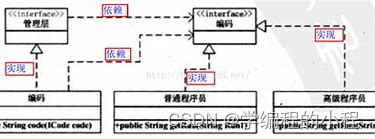
小谈设计模式(6)—依赖倒转原则
小谈设计模式(6)—依赖倒转原则 专栏介绍专栏地址专栏介绍 依赖倒转原则核心思想关键点分析abc 优缺点分析优点降低模块间的耦合度提高代码的可扩展性便于进行单元测试 缺点增加代码的复杂性需要额外的设计和开发工作 Java代码实现示例分析 总结 专栏介绍…...
JetBrains常用插件
Codota AI Autocomplete Java and JavaScript:自动补全插件 Background Image plus:背景图片设置 rainbow brackets:彩虹括号,便于识别 CodeGlance2: 类似于 Sublime 中的代码缩略图(代码小地图ÿ…...
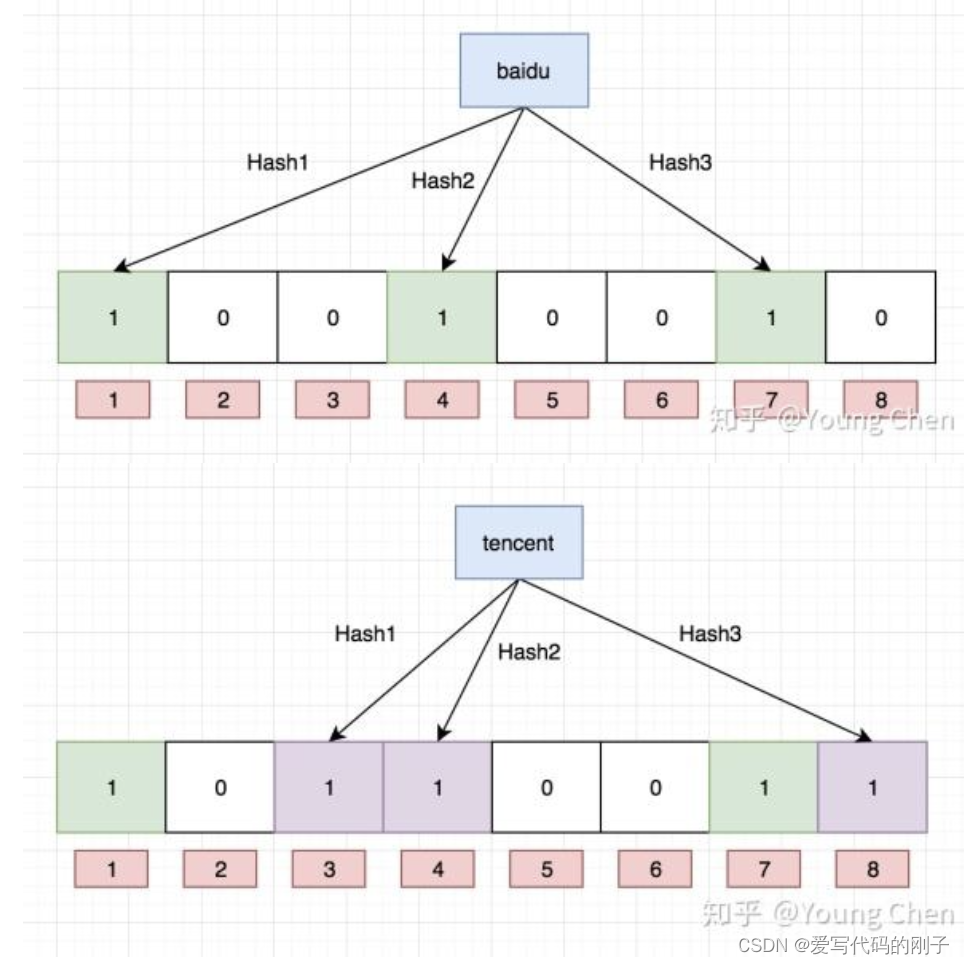
【C++哈希应用】位图、布隆过滤器
【C哈希应用】位图、布隆过滤器 目录 【C哈希应用】位图、布隆过滤器位图概念位图的实现位图改造位图应用总结布隆过滤器布隆过滤器的提出布隆过滤器的概念布隆过滤器的查找布隆过滤器删除布隆过滤器优点布隆过滤器缺陷 作者:爱写代码的刚子 时间:2023.9…...
‘)
Qt 编译纯c的C99的项目, error: undefined reference to `f()‘
把Cpp的后缀该为C是什么样的 尝试引用一个奇门排盘的c程序,在git上找到的叫cqm, 然后总是报错 error: undefined reference to f() 很是郁闷 于是新建了个项目试验一下,终于摸清了需要命名空间。 后来这么写就可以了 a.h namespace XX …...
TensorFlow入门(五、指定GPU运算)
一般情况下,下载的TensorFlow版本如果是GPU版本,在运行过程中TensorFlow能自动检测。如果检测到GPU,TensorFlow会默认利用找到的第一个GPU来执行操作。如果机器上有超过一个可用的GPU,除第一个之外的其他GPU默认是不参与计算的。如果想让TensorFlow使用这些GPU执行操作,需要将运…...
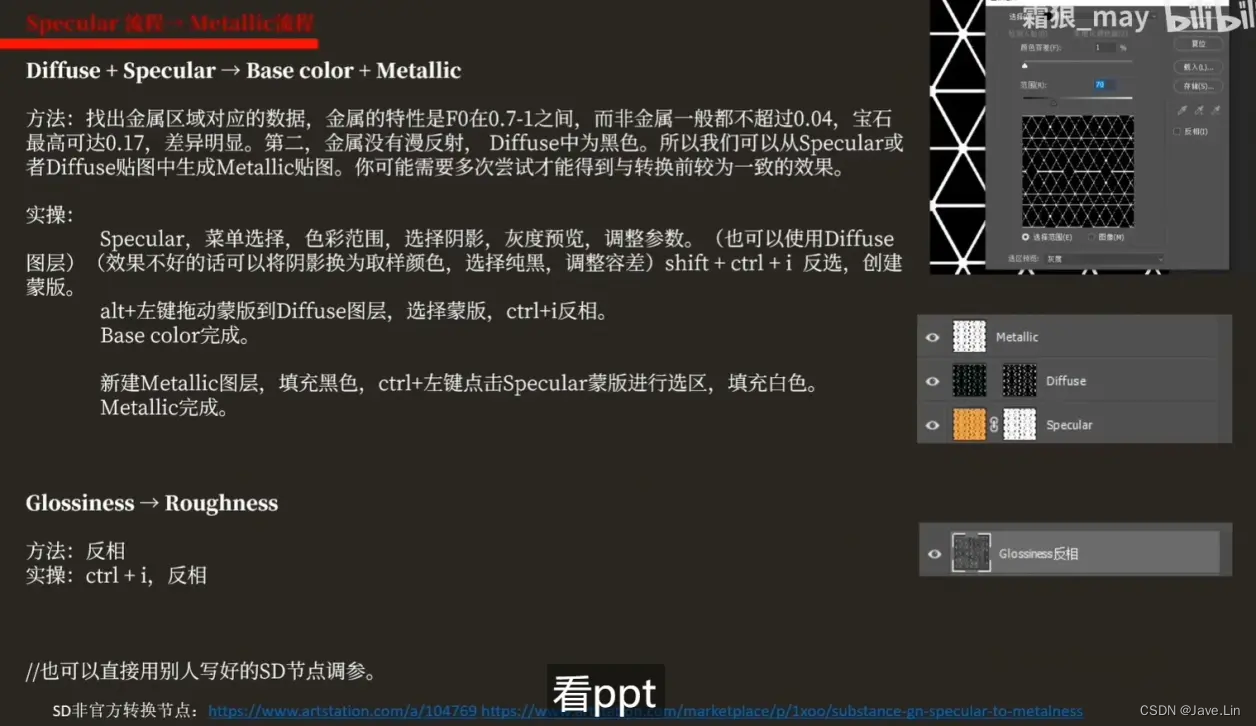
Unity - 实践: Metallic流程贴图 转 Specular流程贴图
文章目录 目的Metallic Flow - SP - 输出输出的 MRA (MGA) 贴图 Metallic->Specular (根据教程一步一步实践)1. Base color Metallic -> Diffuse2. Base color Metallic -> Specular3. Roughness -> Glossiness输出贴图,在 unity 中展示:M…...
)
第三章:最新版零基础学习 PYTHON 教程(第四节 - Python 运算符—Python 逻辑运算符及示例)
运算符用于对值和变量执行操作。这些是执行算术和逻辑计算的特殊符号。运算符运算的值称为操作数。 表中的内容逻辑运算符 逻辑与运算符 逻辑或运算符 逻辑非运算符 逻辑运算符的求值顺序 逻辑运算符 在 Python 中,逻辑运算符用于条件语句(True 或 False)。它们执行逻辑 AN…...
功能测试 (Functional Testing, FT))
如何做好测试?(三)功能测试 (Functional Testing, FT)
1. 功能测试的详细介绍: 功能测试 (Functional Testing, FT),是一种软件测试方法,旨在验证系统的功能是否按照需求规格说明书或用户期望的方式正常工作。它关注系统的整体行为,以确保各个功能模块和组件之间的交互和集成正确。 …...

Ubuntu-Server-22.04安装桌面+VNC
前提:Ubuntu Server安装好后,ubantu其他版本是否适用这里未知,欢迎大佬们前来评论 一、默认没有图形界面,有时觉得用图形界面操作更简单直接,于是用如下命令安装: 1.更新本地环境 sudo apt-get update s…...
职业规划,什么是职业兴趣 - 我喜欢做什么?
能够在工作岗位上面做出成绩的人,都是结合自身兴趣,对职业进行合理规划的那一类。尤其是步入中年以后,能够创造出巨大价值的人,无一例外都是喜欢自己职业的人。没有将兴趣融入工作的人,只能够忍受默默无闻地活着&#…...

基于Java的高校学生党员发展流程管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

【NLP的python库(03/4) 】: 全面概述
一、说明 Python 对自然语言处理库有丰富的支持。从文本处理、标记化文本并确定其引理开始,到句法分析、解析文本并分配句法角色,再到语义处理,例如识别命名实体、情感分析和文档分类,一切都由至少一个库提供。那么,你…...

面试理论篇三
关于异常机制篇 异常描述 目录 关于异常机制篇异常描述 注:自用 1,Java中的异常分为哪几类?各自的特点是什么? Java中的异常 可以分为 可查异常(Checked Exception)、运行时异常(Runtime Exception) 和 错误(Error)三类。可查异…...

ShardingSphere|shardingJDBC - 在使用数据分片功能情况下无法配置读写分离
问题场景: 最近在学习ShardingSphere,跟着教程一步步做shardingJDBC,但是想在开启数据分片的时候还能使用读写分离,一直失败,开始是一直能读写分离,但是分偏见规则感觉不生效,一直好像是走不进去…...

char s1[len + 1]; 报错说需要常量?
在C中,字符数组的大小必须是常量表达式,不能使用变量 len 作为数组大小。为了解决这个问题,你可以使用 new 运算符动态分配字符数组的内存,但在使用完后需要手动释放。 还有啥是只能这样的,还是说所有的动态都需要new&…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...
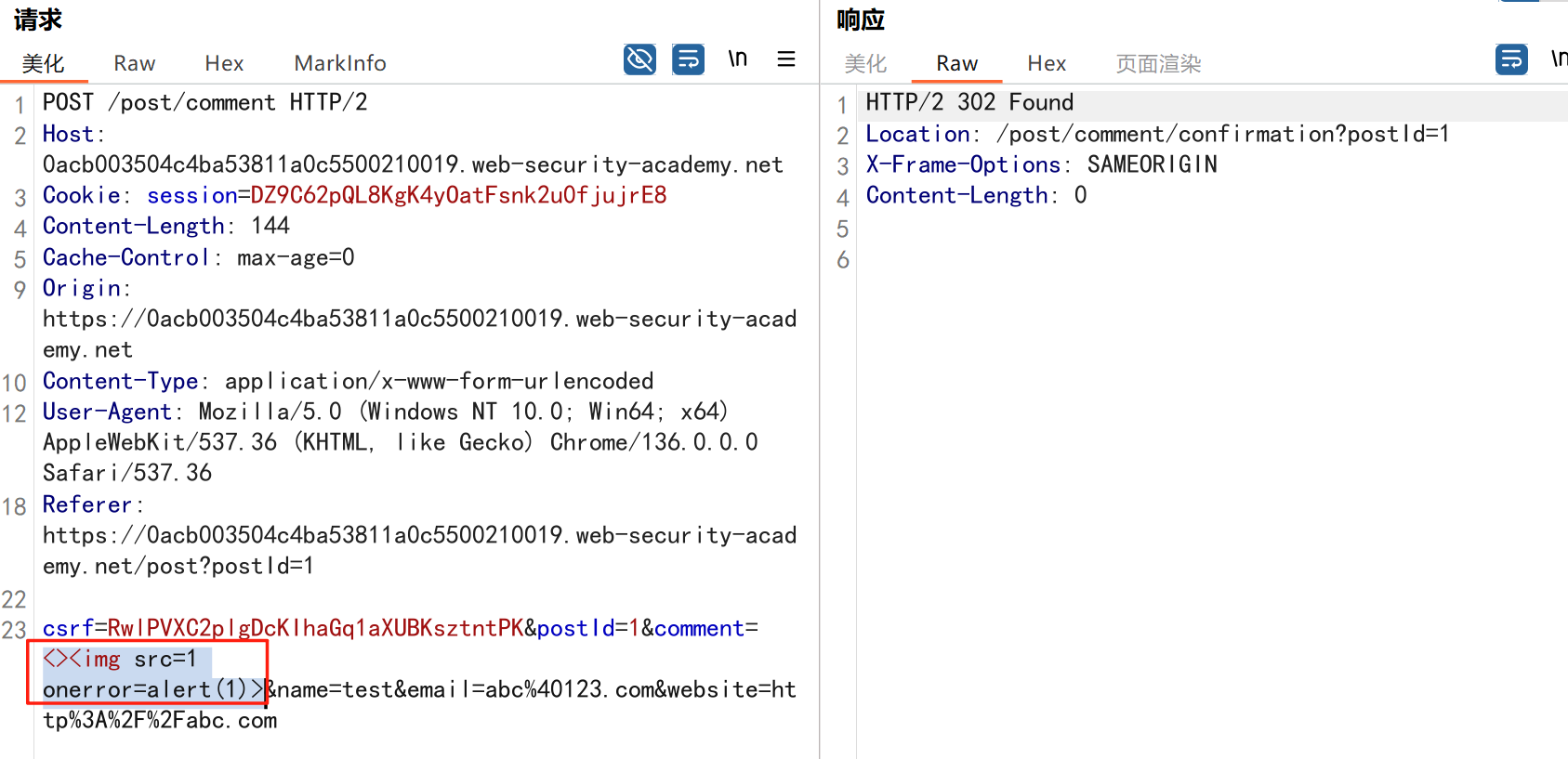
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...