【学习笔记】深度学习分布式系统
深度学习分布式系统
- 前言
- 1. 数据并行:参数服务器
- 2. 流水线并行:GPipe
- 3. 张量并行:Megatron LM
- 4. 切片并行:ZeRO
- 5. 异步分布式:PATHWAYS
- 总结
- 参考链接
前言
最近跟着李沐老师的视频学习了深度学习分布式系统的发展。这里说是分布式系统,其实还是有点勉强,准确来说是分布式的框架,但是毕竟是系统的文章,基于提出的框架也做了很多系统上的优化,姑且算是分布式系统吧。深度学习近些年随着Transformer模型的流行,呈现出模型越来越大,层数越来越深的趋势,然而在硬件方面,由于成本和技术的限制,难以匹配模型容量的快速发展,比如现有最新的深度学习专业加速器H100,其在容量上也只有80G,连LLaMA 7B都训不起来,因此单机多卡或者多机多卡已经成为模型训练主流的硬件配置。模型如何在多卡上高效运行,不同卡之间如何通信便是本篇学习笔记所关注的重点。
本篇博客主要从数据并行,模型并行,张量并行和参数切片四个方向对深度学习分布式系统进行介绍,分别涉及参数服务器、GPipe、Megatron-LM和Zero四篇文章,此外还会提及来自谷歌的Pathways,该文章的核心是如何将Jax拓展到上千TPU核上。
1. 数据并行:参数服务器
参数服务器这篇工作可谓是李沐老师成名之作,发表在OSDI2014。这篇文章提出了一个用于分布式机器学习问题的参数服务器框架。数据和任务都分布在工作节点上,而服务器节点维护全局的共享参数,表示为密集或稀疏的向量和矩阵。该框架管理节点之间的异步数据通信,支持灵活的一致性模型,具有弹性可扩展和持续容错特性。
对于大规模机器学习系统一直面临三个方面的问题:规模,算法和效率,如何在大规模的模型下,执行高效的分布式算法是业界的痛点。
参数服务器提供了五个关键的特性:高效通信,灵活一致模型,弹性可扩展性,容错性和耐久性和易用性。这些特性使得参数服务器可以作为通用的分布式系统处理工业界最大规模的数据。
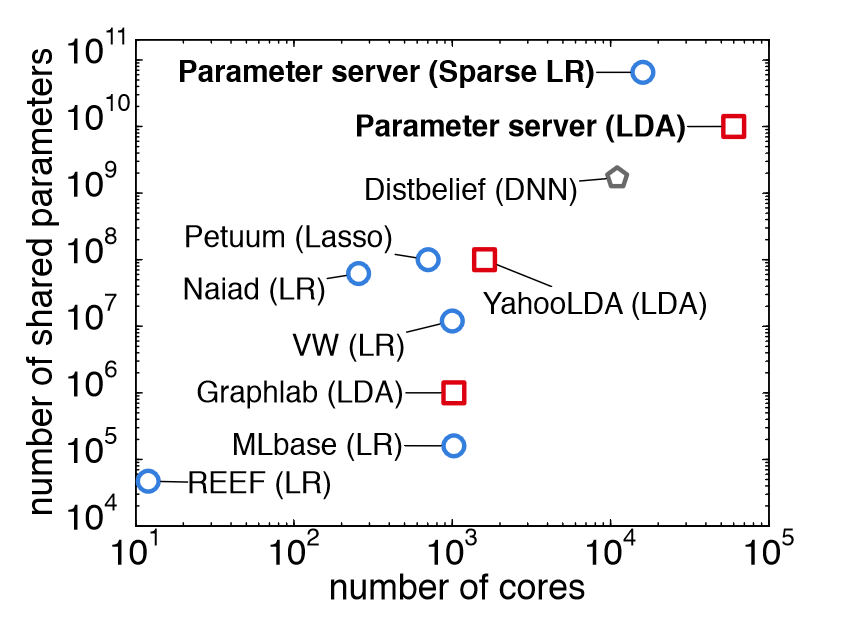
上图是同时期,在不同系统上执行最大监督和无监督学习实验的规模。很明显,本文的系统能够在数量级更大的处理器上覆盖数量级更大的数据。下图是参数服务器的架构图:

参数服务器节点分组为一个服务器组和多个工作组,如上图所示。
对于服务器组:
- 服务器组中的一个服务器节点维护全局共享参数的一个分区。
- 服务器节点之间相互通信以复制或迁移参数以实现可靠性和可扩展性。
- 服务器管理节点维护服务器数据一致性,如节点的生命周期。
对于工作组:
- 每个工作组运行一个应用程序。
- 节点通常在本地存储一部分训练数据用来计算局部统计数据如梯度。
- 节点仅与服务器节点之间通信,更新和共享参数。
- 每个工作组都有一个调度程序节点,分配任务并监控节点。
参数服务器支持独立的参数命令空间,这允许工作组将其共享的参数集与其他组分离。当然不同工作组也可以共享命名空间,可以用多个工作组并行处理深度学习应用。
参数服务器旨在简化分布式机器学习应用程序。
- 共享参数表示为(key, value)向量,利于线性代数运算。
- 共享参数分布在一组服务器节点上。
- 任何节点都可以上传本地参数并从远程节点拉取参数。
- 默认情况下任务是工作节点执行,也可以通过用户定义的函数分配给服务器节点。
- 任务是异步的并且并行运行。
- 参数服务器为算法设计者提供了灵活性,可以通过任务依赖图和判断来选择一致性模型传输参数的子集。
方法部分其实有很多精妙的方法和细节的实现,包括一致性模型,KKT过滤器,值缓存,压缩零等,这些细节可以看这篇博客进行深入的理解。下图是参数服务器和其他分布式机器学习系统的对比:
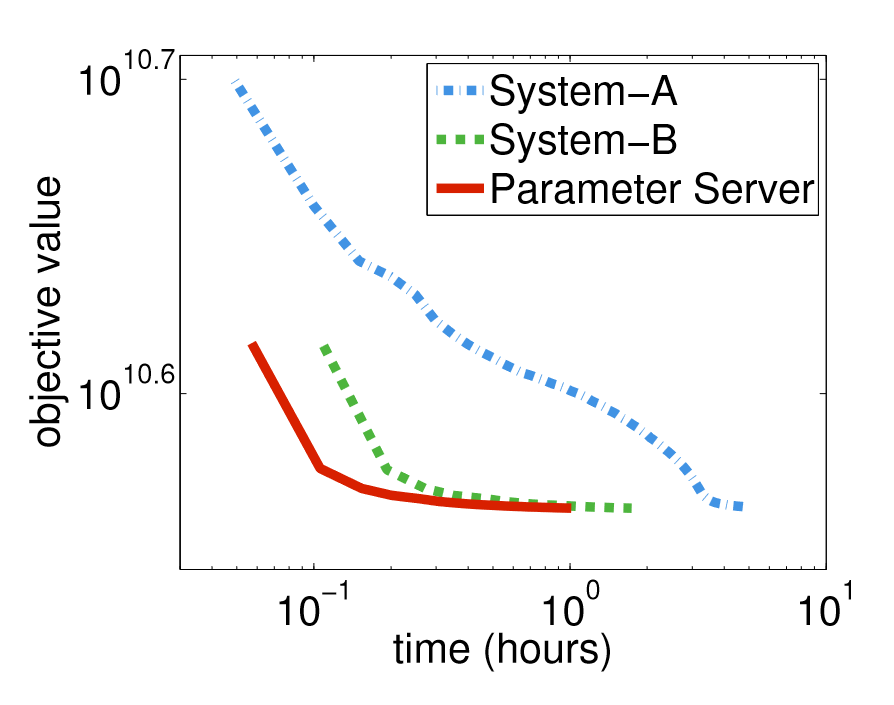
在回归模型收敛速度上,系统B优于A,因为实现了更好的算法。参数服务器优于系统B,因为参数服务器降低了网络流量以及应用了宽松一致性的模型。
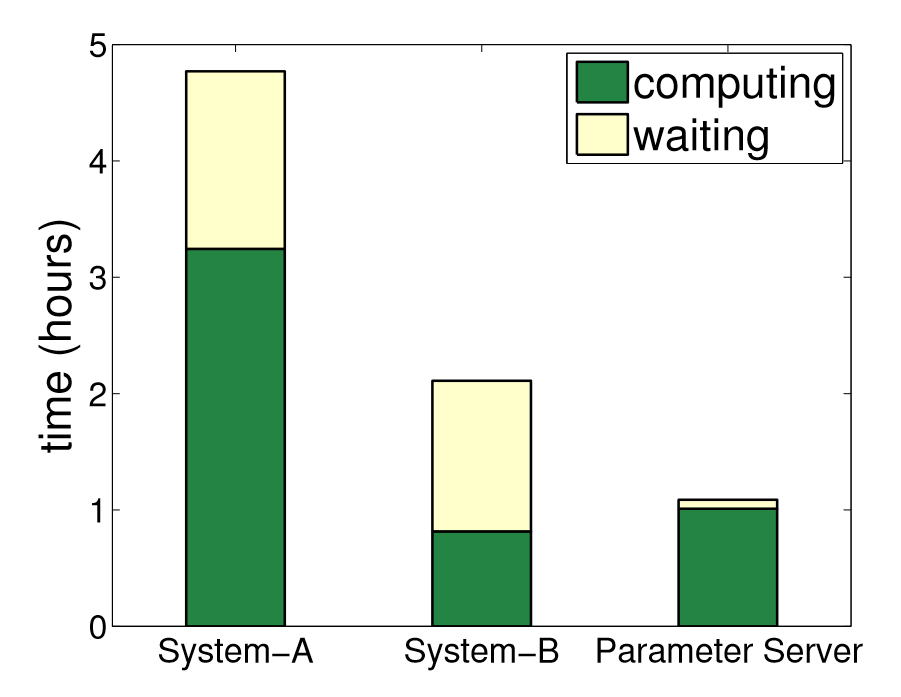
上图是逻辑回归期间,每个节点在计算和等待上的时间,显然参数服务器可以更好提高工作节点的利用率。
在我的这篇博客中,我做了针对于参数服务器的总结和个人的一些思考,主要分析其前瞻性,但是在我看了更多的前沿分布式机器学习系统后,我发现参数服务器的本质的工作是数据并行,只不过沐神将更多精力放在了节点之间通信开销和模型执行效率上,并没有过多提及数据并行的问题。
在大模型飞速发展的今天,传统的数据并行方法已经难以支撑大模型在单个工作节点上的运行,如何在可控开销范围内,将大模型运行起来,是当前相关研究人员亟待解决的问题。
2. 流水线并行:GPipe
为了解决大模型无法在单张显卡上运行的问题,GPipe提出了模型并行的方法,这篇工作来自于google团队,并中稿于NeurIPS2019。一篇系统的文章中稿于机器学习三大顶会之一的NeurIPS实属罕见,也恰恰证明这篇工作在深度学习领域的影响力。
GPipe的核心是模型并行,或者说是流水线并行。现有的模型模型并行方法在结构上有限制或要求,或者只能针对特定的任务。然而模型并行是大势所趋,下面是现有的模型在CV和NLP任务上的表现:
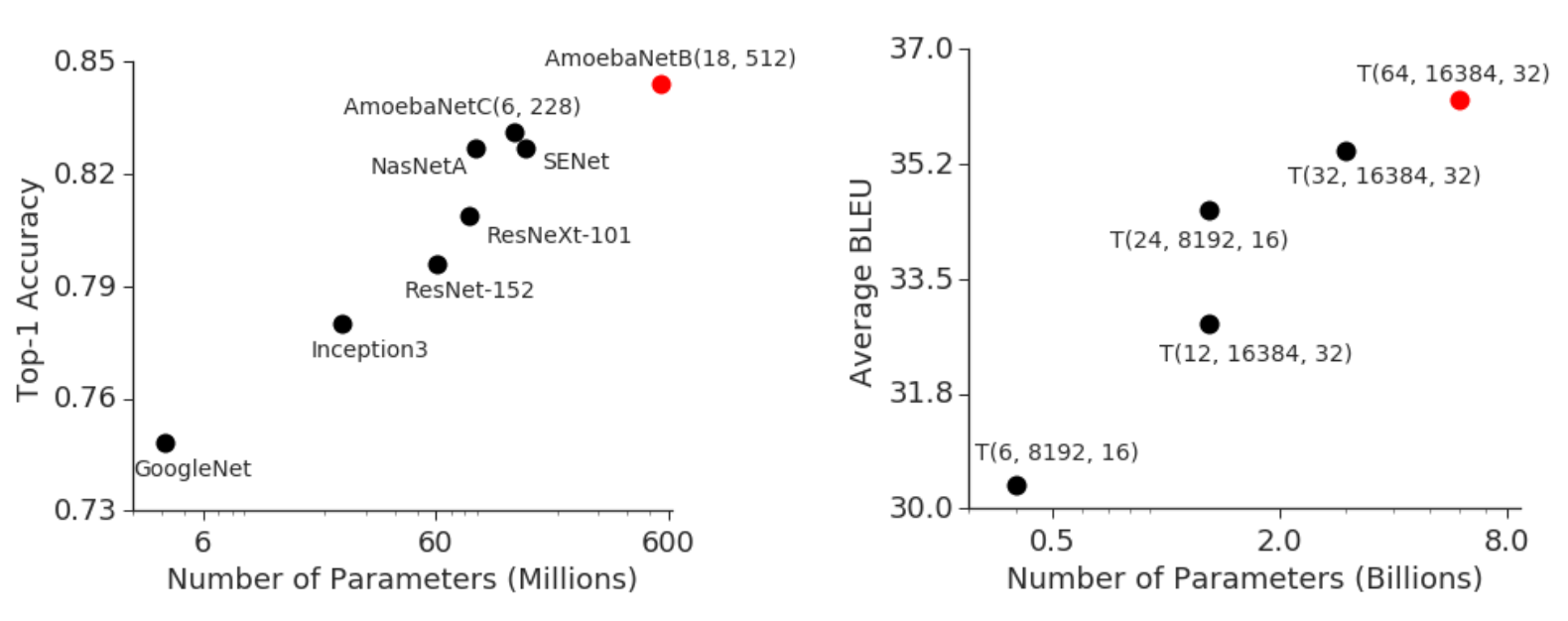
可以看到模型的参数越多,模型的性能就越好,而模型太大现有的硬件难以支持,因此一个通用的模型并行的算法可以解燃眉之急。
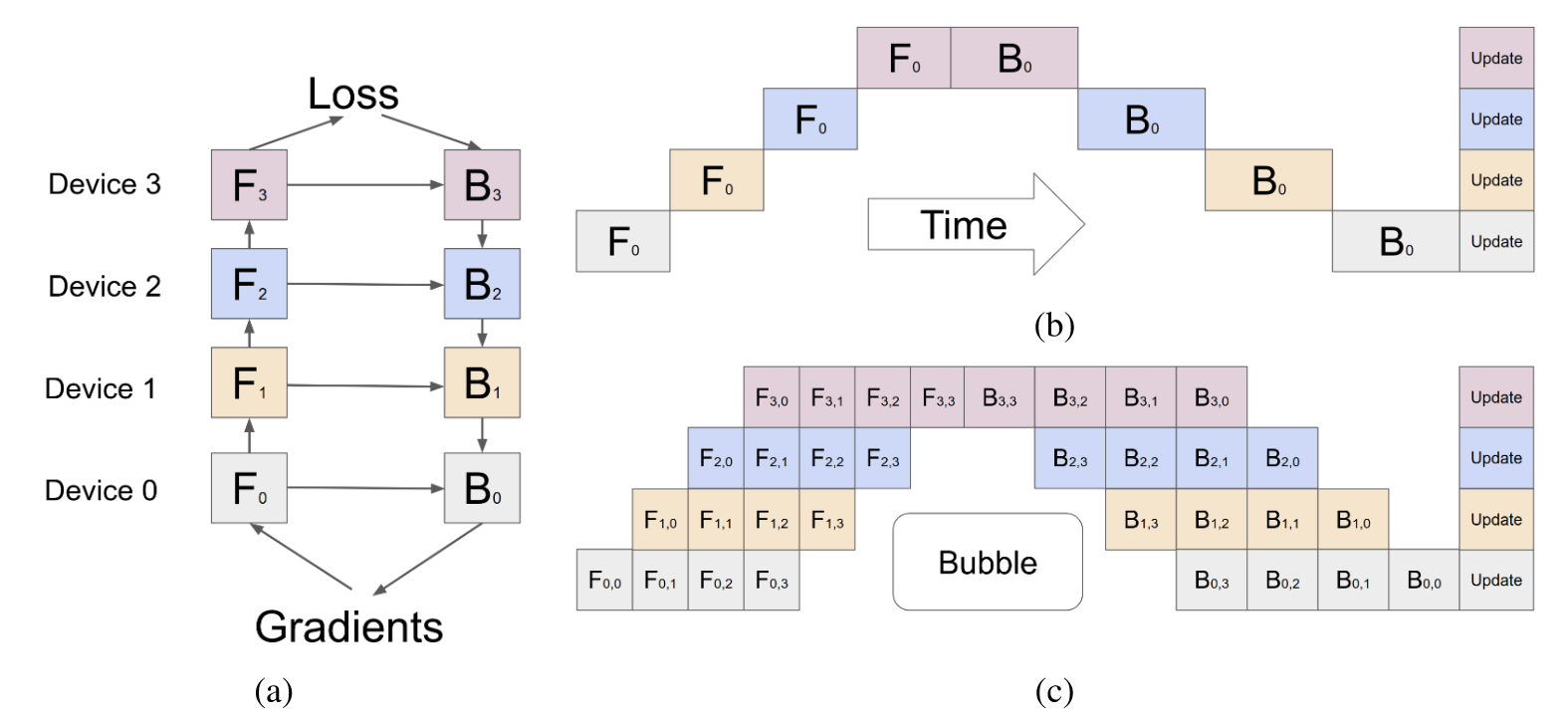
上图是GPipe的解决方案,其核心思想可以分为三点:
- 模型按层进行分组,每个组是连续的层序列。
- 提出microbatch的概念。
- re-materialization方法。
具体来说,(a)中将整个模型分成四个组,分别存储在四个不同的加速器中,这样虽然能够将模型运行起来,但是效率低下,如(b)所示,在训练阶段,每次只有一个加速器在执行计算,其它机器都在等待。为此,作者提出了microbatch,将输入的mini-batch进一步切分,达到类似于操作系统中流水线并行的效果,如(c)所示,除了Bubble的部分没有利用起来,其它时间段所有机器都在执行训练任务,大大提高了训练效率。
尽管如此,在训练过程中,由于梯度反向传播阶段需要保留每个microbatch的激活才能计算,因此占用了大量内存,如下图所示:
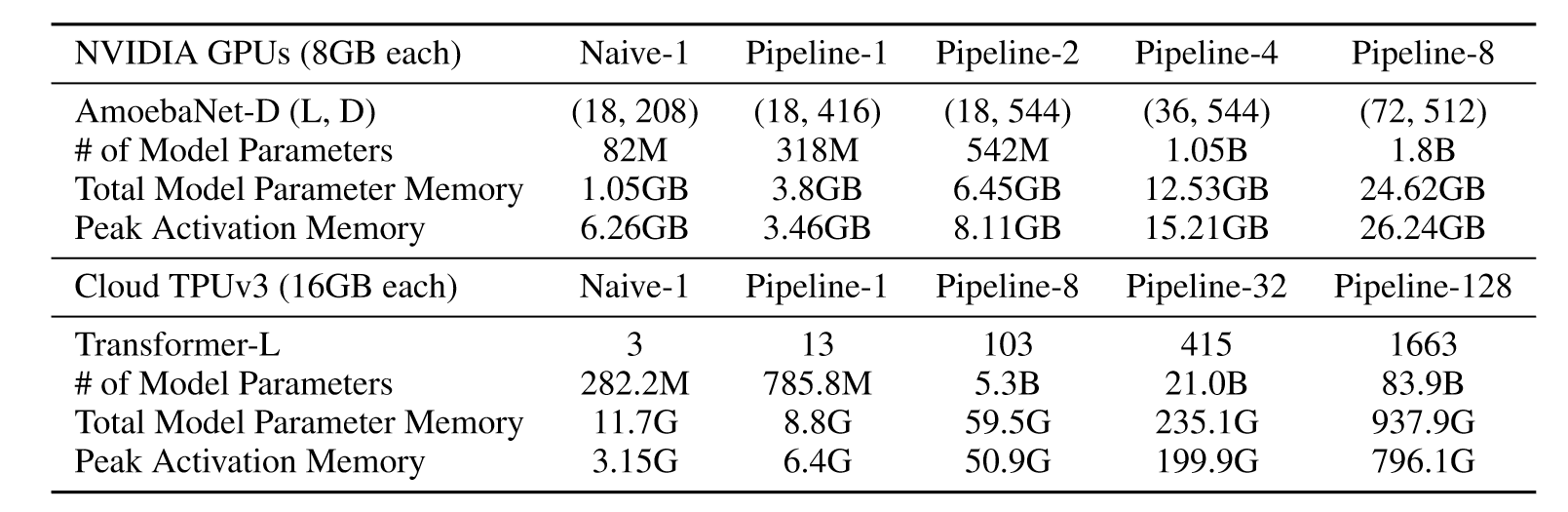
为了进一步减少内存的开销,作者提出re-materialization重计算技术,训练时将中间的激活丢弃,在反向传播时重新计算。这样虽然会带来额外的20%—30%计算开销,但也显著降低了加速器的内存占用。
最后总结一下GPipe这篇工作,GPipe具有高效性、灵活性和可靠性的特点,方法简单,效果显著,但是GPipe的缺点在于很难均匀地切分模型,导致每一块加速器运行时间很难同步,就会造成等待的现象。此外,额外的计算开销降低了模型的效率。因此,既然横向切分还是存在一定的问题,纵向切分可不可以解决这些问题呢?这就是接下来提到的张量并行,也是很多工作认为的真正的模型并行。
3. 张量并行:Megatron LM
来自NVIDIA的Megatron LM是典型的张量并行方法,它的通用性不如GPipe,只针对Transformer模型。现有的模型并行方法主要分为两种:流水线并行和张量并行。
- 流水线并行把模型的不同层放在不同的设备上。
- 张量并行则是层内纵向切分,将权重参数放到不同的设备中。
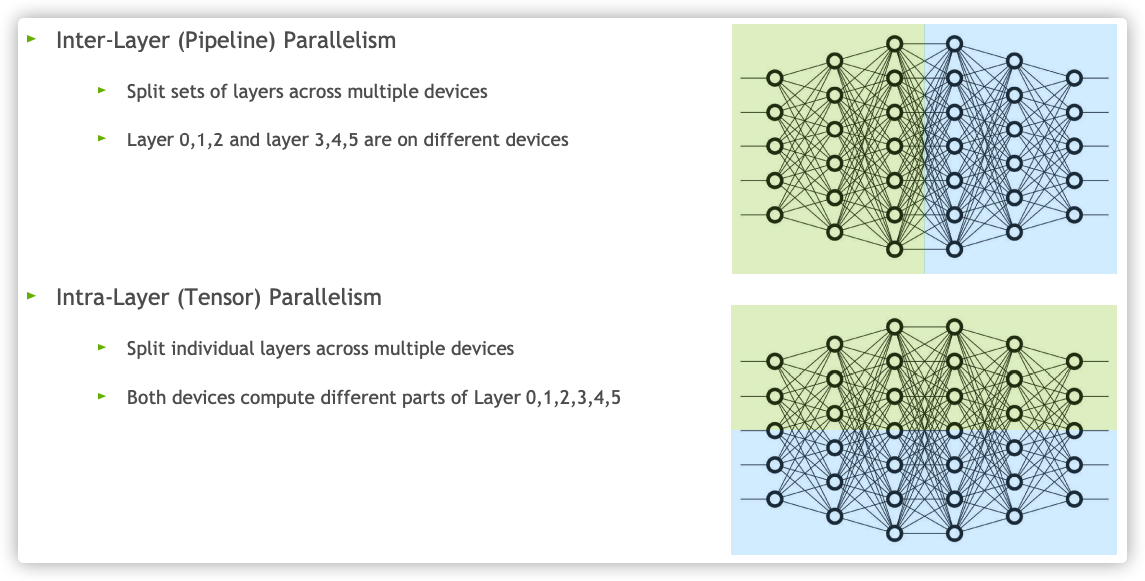
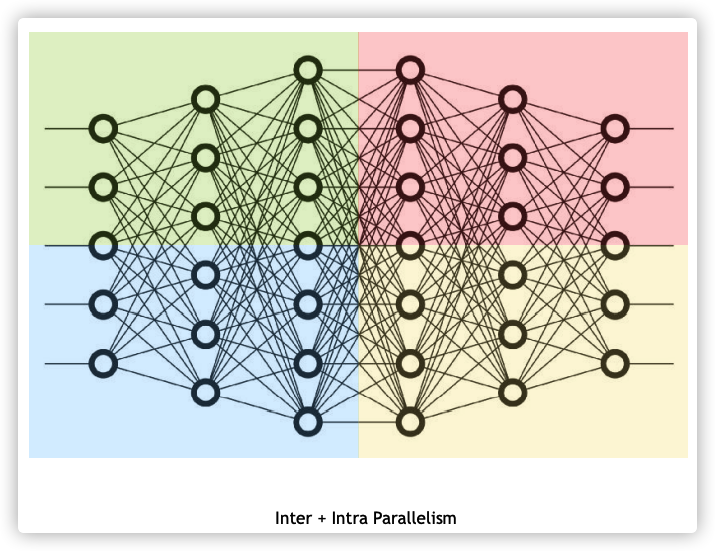
从另个角度来看,两种切分同时存在,是正交和互补的。
Megatron LM对Transformer的张量切片在每一层要进行两次,一次是对自注意力层进行切分,另一次是对FFN层进行切分。具体的切分过程如下图所示:
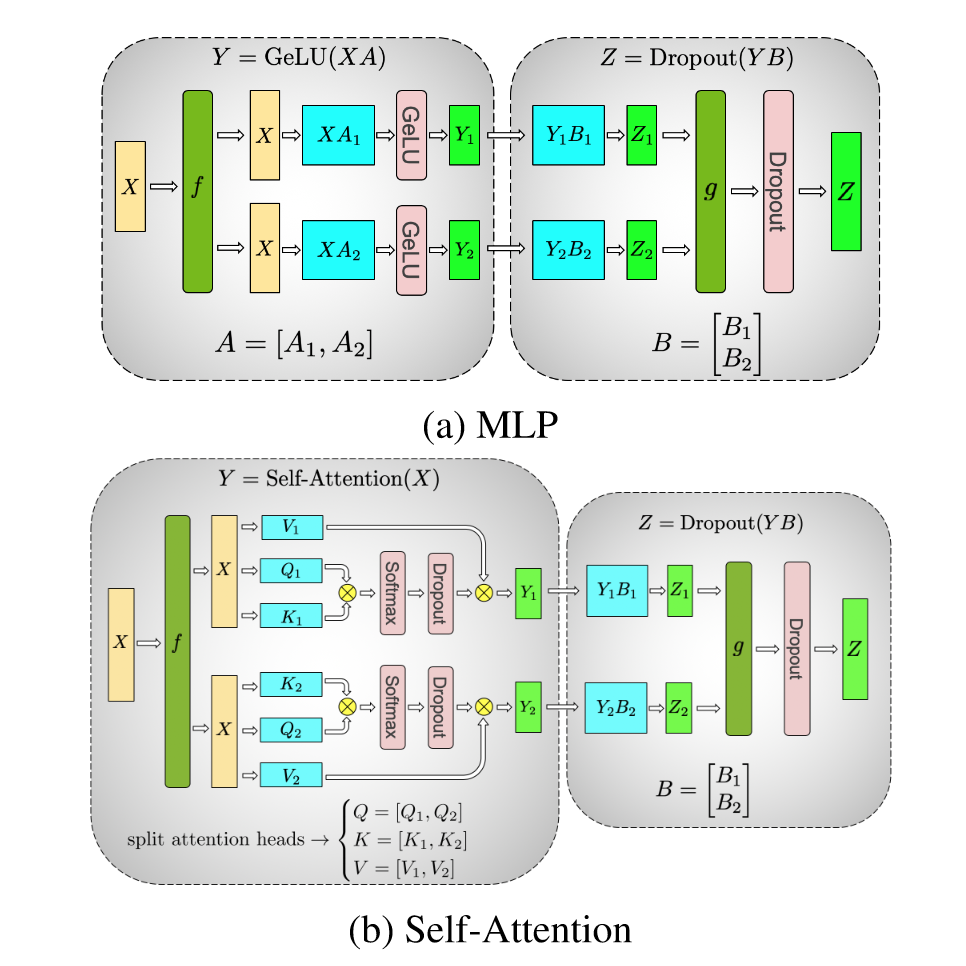
对于切割的部分,每次经过一层就要进行all-reduce,来保证参数的传递,这就导致了两个问题:
- all-reduce通信通过服务器之间的链接,这比服务器内多卡带宽NVLink要慢的多。
- 高度的模型并行产生很多小矩阵乘法,会降低GPU的利用率。
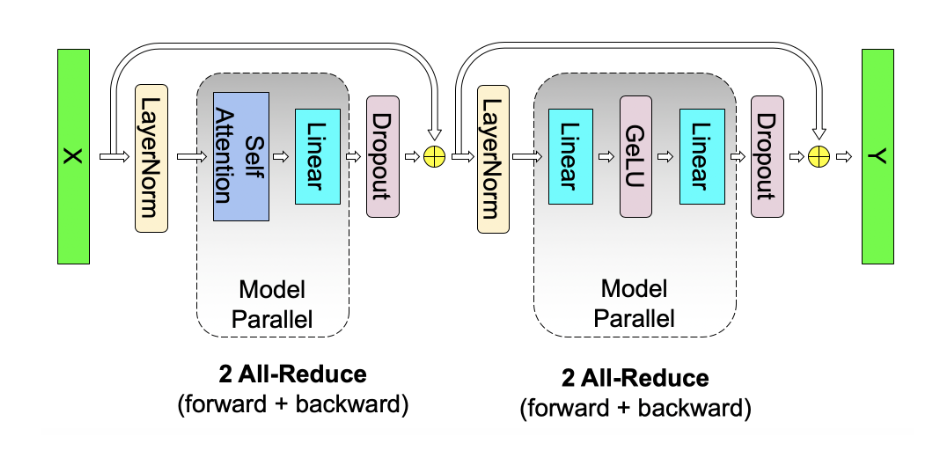
每层Transformer模块就需要进行四次的操作(前向两次,反向两次),也就是说,随着模型的层数加深,Megatron LM所需的通信成本就要线性增大。
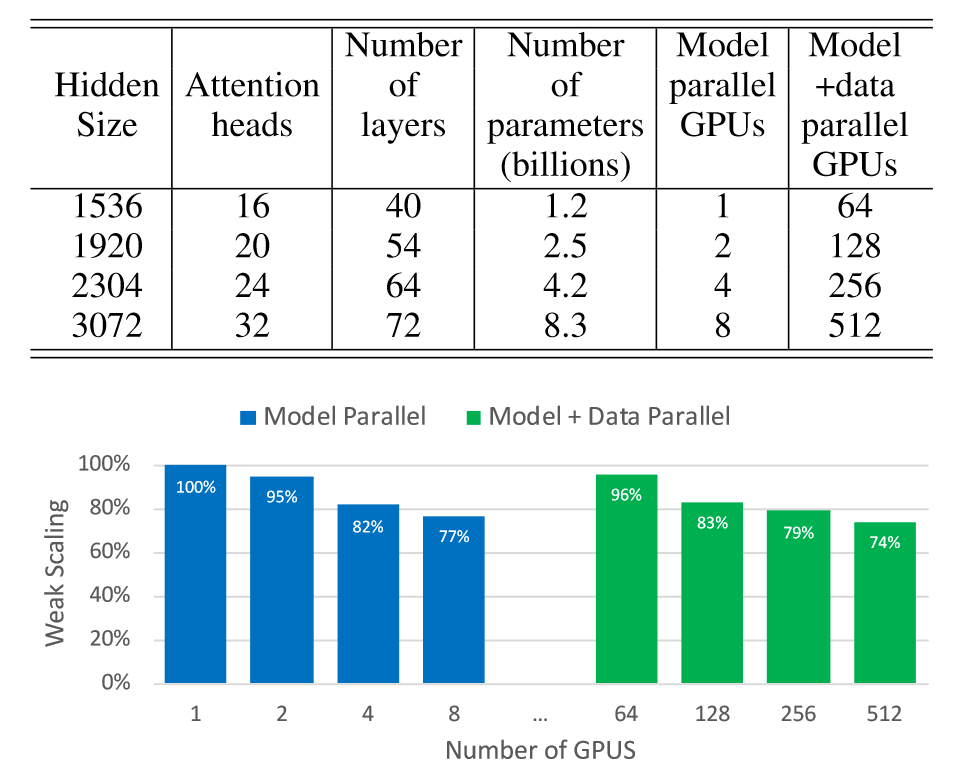
上图展示了Megatron LM的性能,随着单组GPU的增加,模型的性能稳定下降,在多服务器单卡时,模型仍有96%的性能,随着每个服务器中GPU的增加,模型的性能相对于单服务器相同卡的情况性能要略差些。
最后总结一下,Megatron实现了张量的并行,在训练性能上要优于GPipe,可以接近真正意义上的单卡训练,并且切分起来更加方便,无需考虑均匀分配问题。此外,它的局限性也很明显,首先它只对Transformer进行切分,第二它的通信量很大(大概是GPipe的10倍),不能做异步,等于用时间换空间。最后,这里的Megatron LM最多只能做到八卡并行,因为每张卡都存储了相同的输入和输出,占用了大量的显存空间,这在切片并行时可以得到解决。
4. 切片并行:ZeRO
在2022年3月,PyTorch提出了一个新的分布式API名叫FSDP,即完全分片的数据并行,其背后的思想就来自于ZeRO。ZeRO考虑的是如何将数据并行用到超大规模的神经网络训练上,并且在模型过大的时候如何将不需要的模块放到一个地方,在需要的时候再拿过来用。所以,也可以说ZeRO的核心思想是数据并行和模型并行。
当前对于模型装不下GPU的情况,虽然有模型并行和张量并行等方法,但是仍有scaling的瓶颈。比如张量并行对模型垂直切开,对于每个层都需要进行通信,当模型进一步扩大时性能会急速下降。ZeRO的作者分析,现有模型内存消耗主要分为两个部分:
- 对于大型模型,大部分内存被模型参数占用,包括Adam动量和方差、梯度和参数等。
- 激活值,临时缓存和碎片。
这里举个例子来说,对于1.5B的GPT-2模型,训练时采用半精度fp16,在Adam更新模型时需要采用fp32,这一块占用24GB的空间,然而真正算梯度的时候只需要3GB的显存,其余的21GB大部分时间都不会用上。此外在长度为1000、batch为32时,中间结果需要60GB的显存来存储。
针对上面问题,作者首先提出对模型的优化算法ZeRO-DP,即将模型切块放在不同地方,用的时候再拿来。其次是如何优化中间状态,称作ZeRO-R。
具体来说,对于ZeRO-DP,有如下的insight:
- 数据并行比模型并行效率高。
- 当前的并行方法都需要维护中间值。
因此ZeRO-DP采用数据并行的方法,并且对于某个中间值,只存储在一个GPU上,当别的GPU需要的时候再通信从该GPU上接收数据,其思想类似于参数服务器。
对于ZeRO-R,它的思想是说在Megatron中,每一层的参数虽然是并行的,但是输入却是相同的,即复制的,这个值可能会很大,因此ZeRO-R将这些输入也分成块,当一个GPU需要的时候,向其他拥有该分块的节点发送请求,这是一种带宽换空间的方法。对于缓存,给定固定的大小,当数据不用时就删除。对于碎片则采用内存整理。
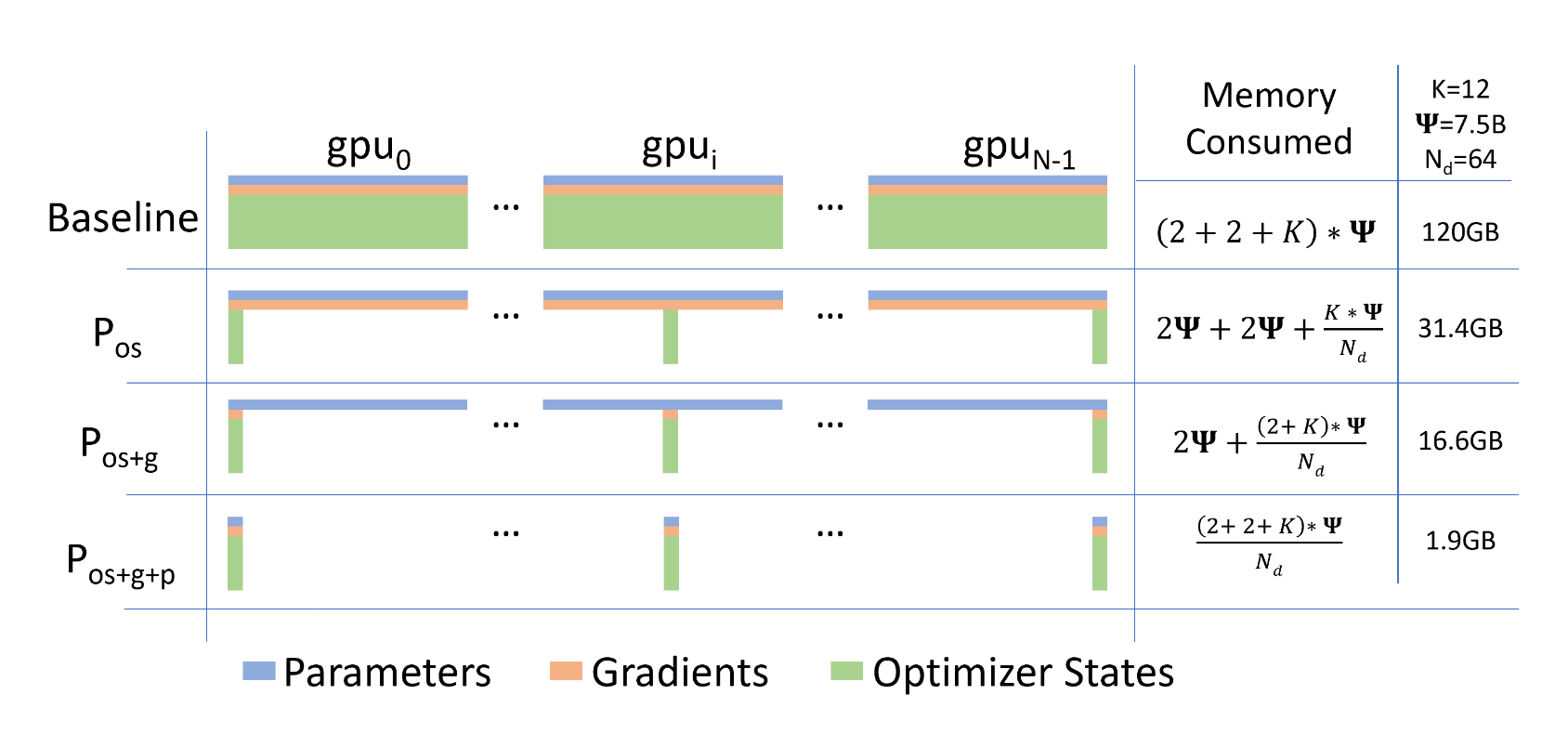 、
、
ZeRO-DP的过程如上表所示,其中 P o s \mathrm{P_{os}} Pos、 P o s + g \mathrm{P_{os+g}} Pos+g和 P o s + g + p \mathrm{P_{os+g+p}} Pos+g+p分别称为zero1,zero2和zero3,zero1对应着优化器参数的切片,zero2对应着zero1和梯度的切片,而zero3对应着zero2和模型参数的切片,可以看到当三种切片都采用的时候,单张卡上的显存占用明显减少。下表是不同规模模型对zero的使用情况:
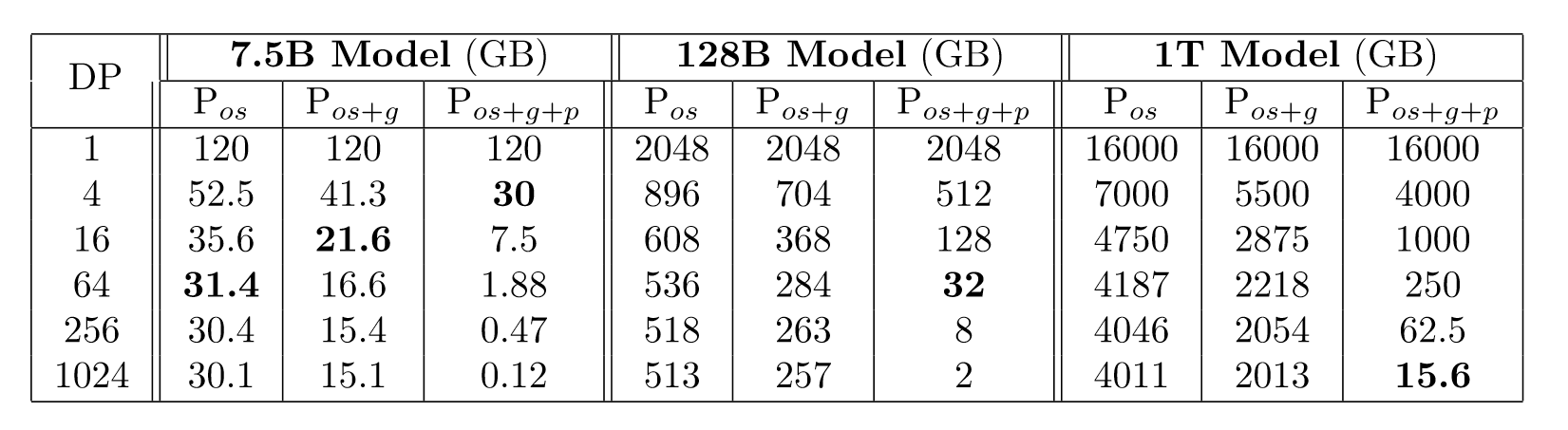
当模型越来越大的时候,比如1T的模型,也能在zero3、1024张GPU下运行。
ZeRO-R对中间变量进行处理降低其占用的内存。 P a P_a Pa对输入(激活)做切分,和张量并行结合使用。 C B \mathrm{C}_B CB对模型的通信参数做了一个固定的缓存,在同时并行GPU数量很多的情况下,每次向单个GPU发送的参数数量可能很小,因此通过设计一个缓存来尽可能发送更多的数据,提高模型的带宽通信效率,同时通过一个计时器防止较大的通信延时。但是过多的缓存会带来碎片问题, M D \mathrm{M}_D MD进行了碎片化管理,它将需要维护的内存开在了预选设定好的位置,其他位置都是可以随时析构的。
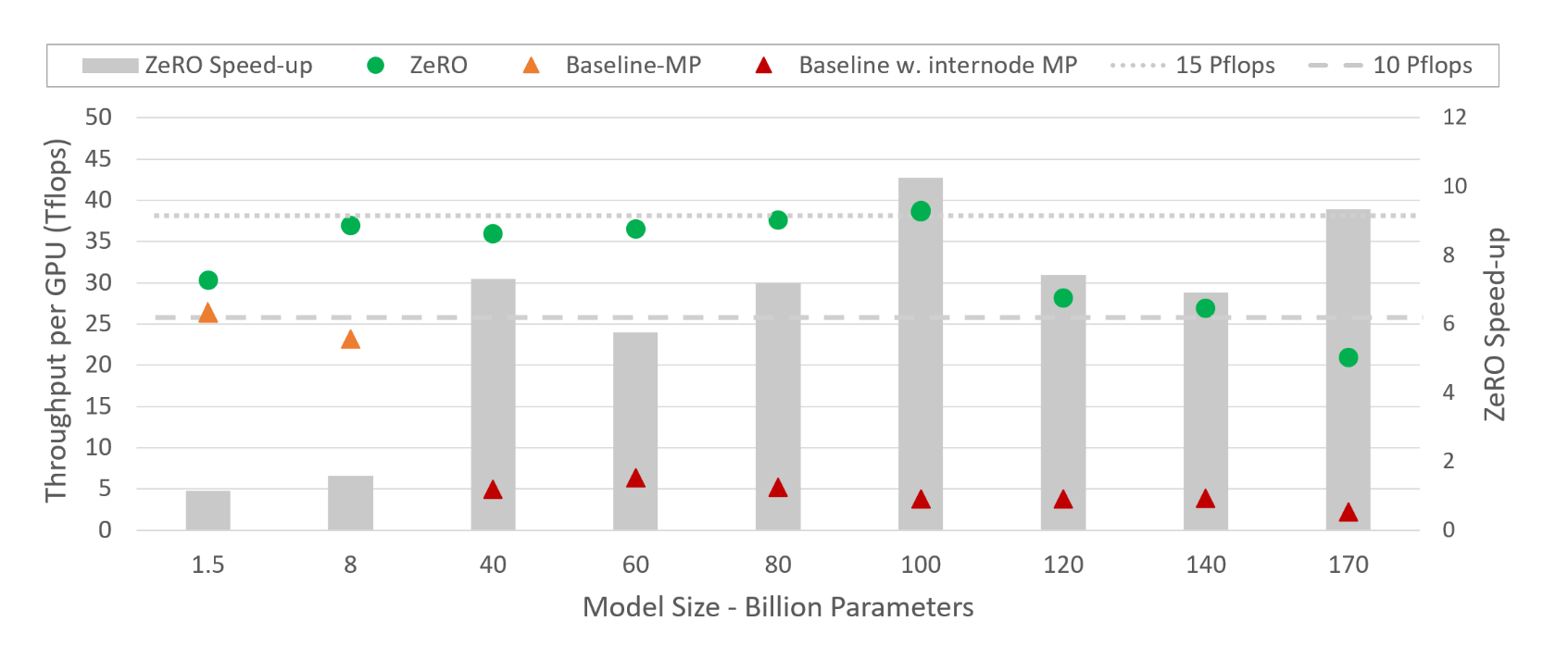
实验见上图所示,ZeRO和基线Megatron LM进行了对比,其中Megatron LM在超过8卡上由于需要不同机器之间的通信因此带来巨大的通信开销,导致性能大幅下降,而ZeRO却能一直保持比较稳定的计算峰值,当然也随着机器的增多逐渐下滑。
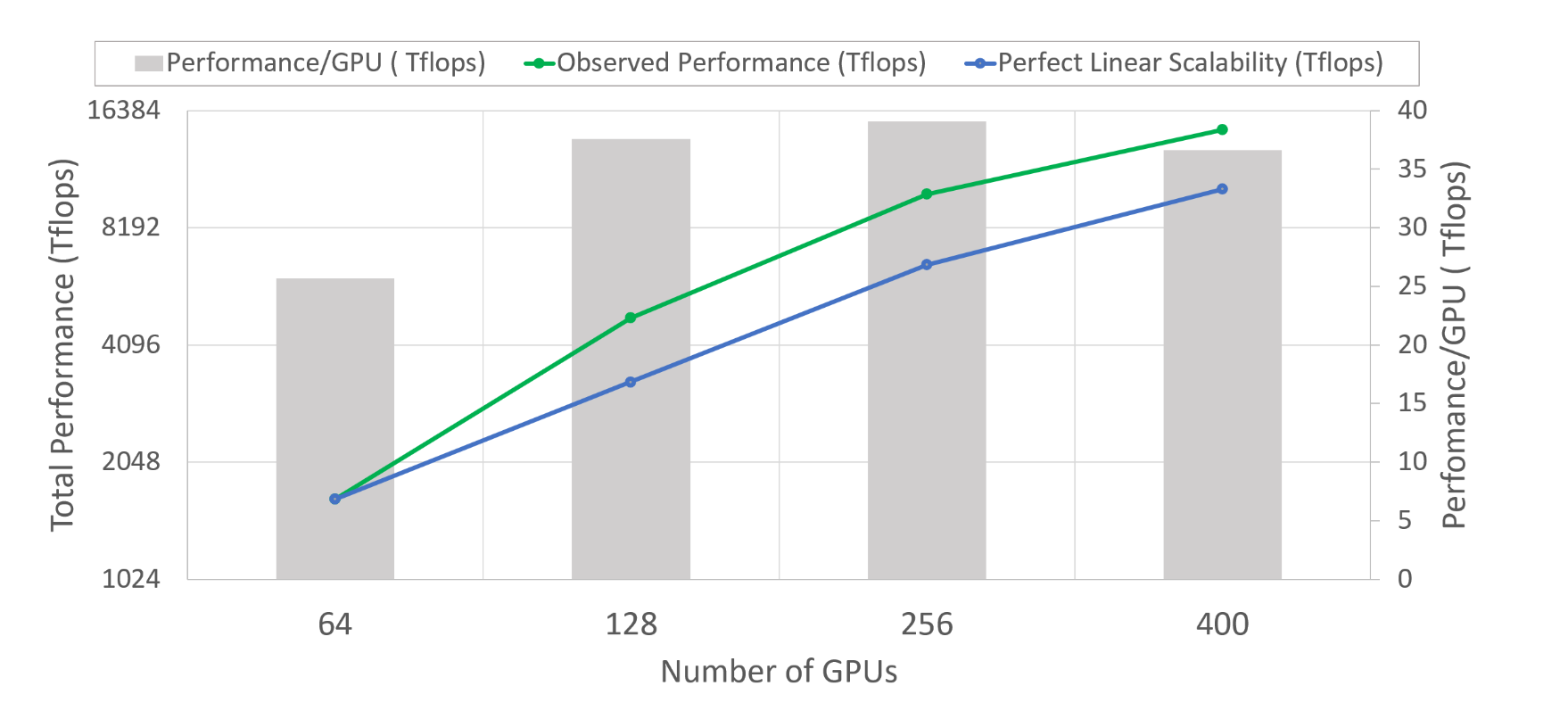
上图更能直接展示ZeRO超线性增长的趋势,其中随着GPU数量翻倍,模型的整体性能翻了不止一倍,这是因为随着单张卡上模型的参数变小,可以输入更大批量的数据,每块卡上矩阵变大,可以更高效利用GPU的多核,此外计算和通信比也变得更好了。
总结一下,ZeRO的算法相对来说还是比较简单实用的,其核心思想是all reduce时不需要在所有节点上重复,只需要在各自节点上all reduce就好。在不用完整数据的时候,维护好自己那一块就好,当需要的时候,再通过通信得到完整的数据。
5. 异步分布式:PATHWAYS
最后简单提及一下来自谷歌的PATHWAYS工作。该工作的核心为两点:
- 异步:通信延迟和调度延迟的处理。
- 分布式:针对更大规模模型在TPU上运行的处理。
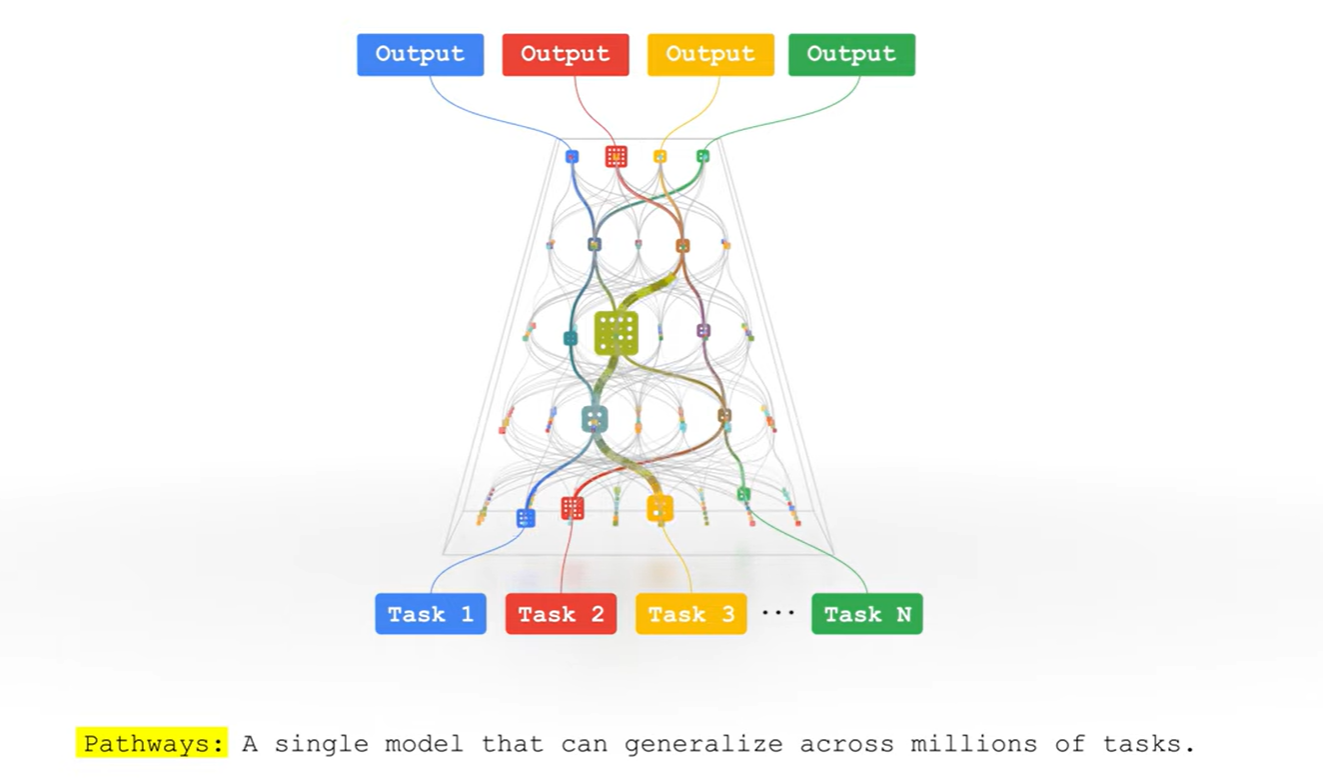
当前的分布式ML系统有着模型较大、计算稀疏、硬件异构等特性,并且难以进行异步计算。作者提出了岛的概念,来解决硬件异构性的问题,提高模型的灵活性,以及提升硬件的利用率。作者的愿景是开发出标准化的基础模型,可以适应多个下游任务,通过多任务多路复用资源提高集群的利用率,如下图所示:
现有的ML分布式系统架构如下图所示:

其中单控制器模型虽然灵活但是效率低,多控制器通信和调度延迟会带来挑战。
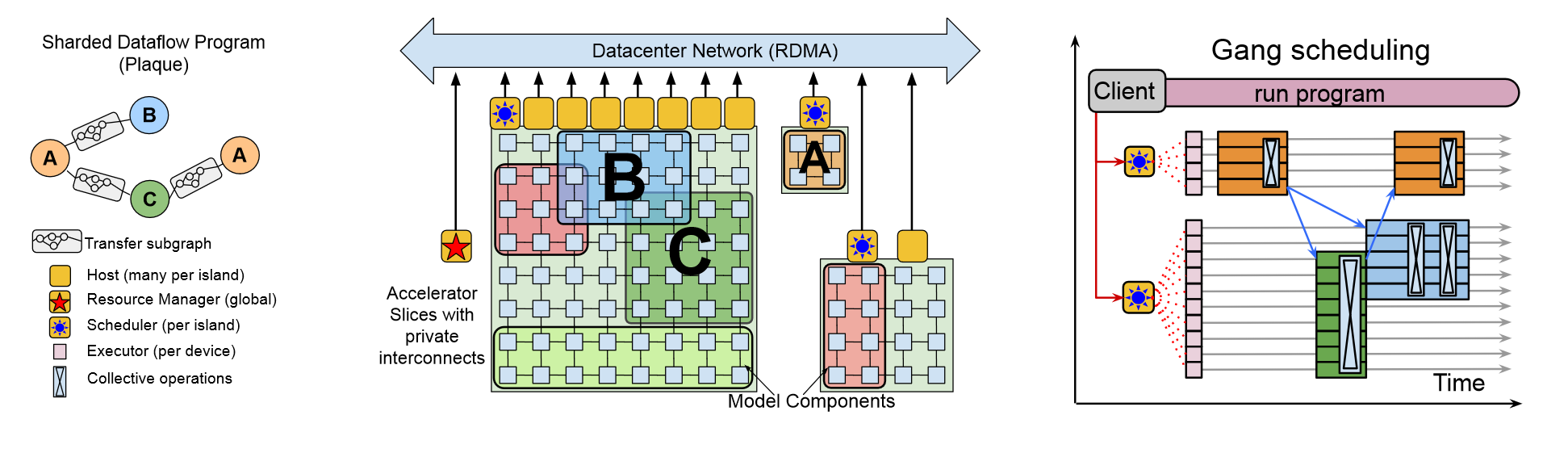
PASSWAYS的设计如上图所示,其中PLAQUE优化支持稀疏通信,让模型能够高效收发数据,一组加速器构成了PASSWAYS的后端,这些加速器被分为紧密相连的孤岛,孤岛之间通过DCN连接。岛内的TPU是高带宽连接的,岛与岛之间需要共享的数据中心网络,速度较慢。PASSWAYS的资源管理器负责集中管理岛屿上的设备,可以根据用户的需求进行加速器的分配。
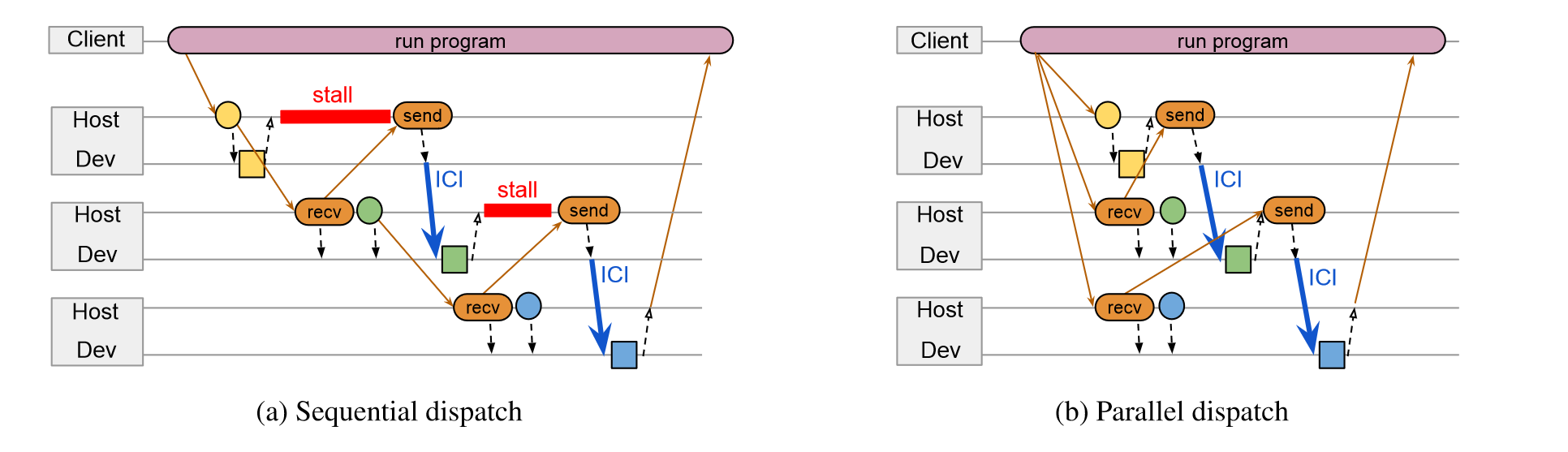
数据的分发上也采用了并行的分发,客户端编译后提前知道了发送的形状和接受的形状,减少了服务器额外的等待时间。
之所以没有细说PATHWAYS是因为它只是针对谷歌的TPU进行优化,而不能泛化到GPU中,并且文中的设想并没有真正实现,因此只需要简单了解就好了。
总结
本文对近十年来面向大模型的分布式机器学习的系统进行了介绍,从一开始的数据并行,到后来的流水线并行,再到张量并行,以及最后的切片并行,分布式机器学习系统的工作把能并行的数据都做了并行,大大减少了单张卡上的内存占用,也让更大的模型在大规模集群上运行起来成为了可能,当然,并行上的工作已经差不多了,后续的工作更多会在通信上进行优化,以及模型异步的实现,其本质的目标都是让即使是很大的模型也像在单张卡上运行的效果,正如PASSWAYS的设想那样,让多个小模型集成为一个超大的模型,从而泛化到更多任务上,或者是大一统的模型,能够处理所有任务,总之,这样的工作都离不开底层分布式系统的设计,除非在硬件上真正实现巨大的突破。
参考链接
https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf
https://blog.csdn.net/HERODING23/article/details/128701938
https://proceedings.neurips.cc/paper/2019/file/093f65e080a295f8076b1c5722a46aa2-Paper.pdf
https://arxiv.org/pdf/1910.02054.pdf
https://arxiv.org/pdf/1909.08053.pdf
https://arxiv.org/pdf/2203.12533.pdf
相关文章:
【学习笔记】深度学习分布式系统
深度学习分布式系统 前言1. 数据并行:参数服务器2. 流水线并行:GPipe3. 张量并行:Megatron LM4. 切片并行:ZeRO5. 异步分布式:PATHWAYS总结参考链接 前言 最近跟着李沐老师的视频学习了深度学习分布式系统的发展。这里…...

【数据结构】树、二叉树的概念和二叉树的顺序结构及实现
目录 前言:一、树的概念及结构1.树的概念2.树的相关概念3.树的存储4.树在实际中的运用 二、二叉树概念及结构1.概念2.特殊的二叉树(1)满二叉树(2)完全二叉树 3.二叉树的性质4.二叉树的存储(1)顺序存储(2)链式存储 三、…...

rust学习-string
介绍 A UTF-8–encoded, growable string(可增长字符串). 拥有string内容的所有权 A String is made up of three components: a pointer to some bytes, a length, and a capacity. The length is the number of bytes currently stored in the buffer pub fn as_bytes(&…...

No167.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...
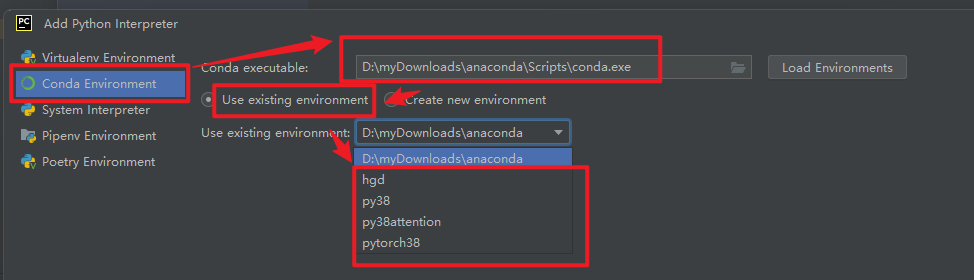
【python】pycharm导入anaconda环境
参考 Pycharm导入anaconda环境的教程图解 - 知乎 (zhihu.com)...
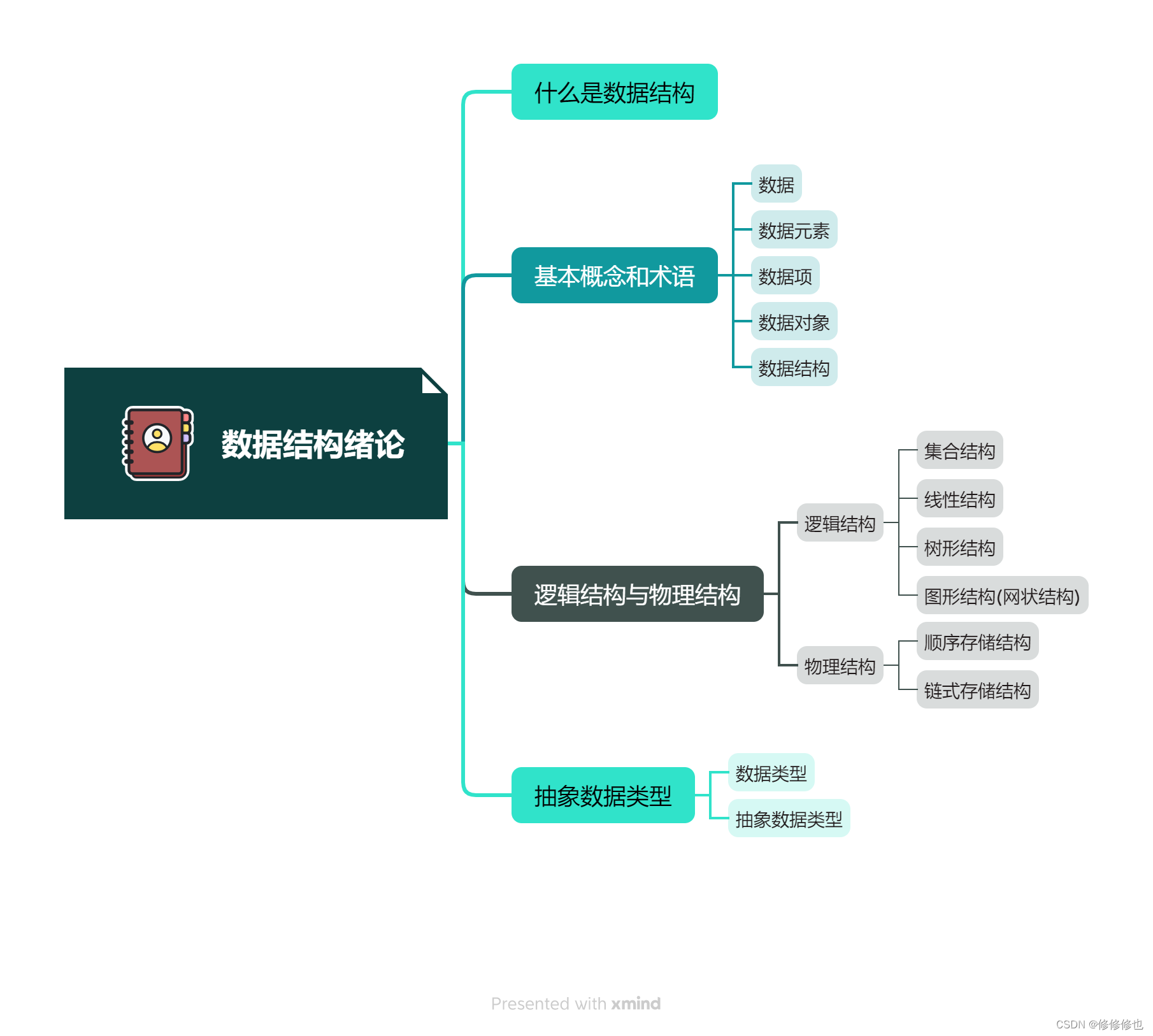
【数据结构】逻辑结构与物理结构
🦄个人主页:修修修也 🎏所属专栏:数据结构 ⚙️操作环境:Visual Studio 2022 目录 🌳逻辑结构 1.集合结构 2.线性结构 3.树形结构 4.图形结构或网状结构 🌳物理结构 1.顺序存储结构 2.链式存储结构 结语 根据视点的不同,我…...

HTML5高级部分
目录 一、拖拽API1.1 拖拽元素1.2 监听事件1.3 dataTransfer传递数据 二、媒体API2.1 常用监听事件2.2 常用API 三、画布API3.1 canvas 标签3.2 创建canvas对象3.3 常用API 四、地理API4.1 方法 一、拖拽API 1.1 拖拽元素 页面中设置了draggable"true"的元素可以进…...
浏览器输入 URL 并回车发生了什么
本文节选自我的博客:浏览器输入 URL 并回车发生了什么 💖 作者简介:大家好,我是MilesChen,偏前端的全栈开发者。📝 CSDN主页:爱吃糖的猫🔥📣 我的博客:爱吃糖…...

asp.net core mvc 文件上传,下载,预览
//文件上传用到了IformFile接口 1.1文件上传视图 <form action"/stu/upload" method"post" enctype"multipart/form-data"><input type"file" name"img" /><input type"submit" value"上传&…...

Axios有哪些常用的方法?
Axios是一个常用的JavaScript库,用于进行HTTP请求。它提供了一组简洁而强大的方法来发送各种类型的请求,并处理响应数据。以下是Axios中一些常用的方法及其格式: GET请求: axios.get(url[, config]).then(response > {// 请求…...
PL/SQL+cpolar公网访问内网Oracle数据库
文章目录 前言1. 数据库搭建2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射 3. 公网远程访问4. 配置固定TCP端口地址4.1 保留一个固定的公网TCP端口地址4.2 配置固定公网TCP端口地址4.3 测试使用固定TCP端口地址远程Oracle 前言 Oracle,是甲骨文公司的一款关系…...

stable diffusion和gpt4-free快速运行
这是一个快速搭建环境并运行的教程 stable diffusion快速运行gpt快速运行 包含已经搭建好的环境和指令,代码等运行所需。安装好系统必备anaconda、conda即可运行。 stable diffusion快速运行 github: AUTOMATIC1111/稳定扩散网络UI:稳定扩散网页用户界…...

分享三个国内可用的免费GPT-AI网站
AIchatOS国内的不需要梯子 AItianhu同上 国内百度的文心一言一样非常优秀...
使用SDKMAN在Linux系统上安装JDK
本文使用的Linux发行版为Rocky Linux 9.2,可以当做CentOS的平替产品。 SDKMAN是一个sdk包管理工具,通过自带的命令可以快速切换软件环境, 官网地址:https://sdkman.io/。 1、安装sdkman: # curl -s "https://ge…...
MySQL(8) 优化、MySQL8、常用命令
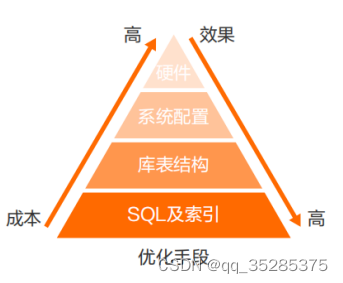
一、MySQL优化 从上图可以看出SQL及索引的优化效果是最好的,而且成本最低,所以工作中我们要在这块花更多时间。 服务端参数配置; max_connections3000 连接的创建和销毁都需要系统资源,比如内存、文件句柄,业务说的支持…...

前端JavaScript入门到精通,javascript核心进阶ES6语法、API、js高级等基础知识和实战 —— Web APIs(三)
思维导图 全选案例 大按钮控制小按钮 小按钮控制大按钮 css伪类选择器checked <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><…...

嵌入式汇编大合集
嵌入式汇编 内联汇编的基本格式: asm volatile( /* volatile : 可选,禁止编译器对汇编代码进行优化 */"汇编指令" /* 汇编指令间使用\n分隔 */:"=限制符"(输出参数):"限制符"(输入参数):保留列表 )共四个部分:汇编语句,输出部分,输入部分…...

C#WPF框架MvvMLight应用实例
本文实例演示C#WPF框架MvvMLight应用实例。 目录 一、MVVM概述 二、MVVMLight概述 三、使用MVMLight框架 一、MVVM概述 MVVM概述MVVM是Model-View-ViewModel的简写,主要目的是为了解耦视图(View)和模型(Model)。...
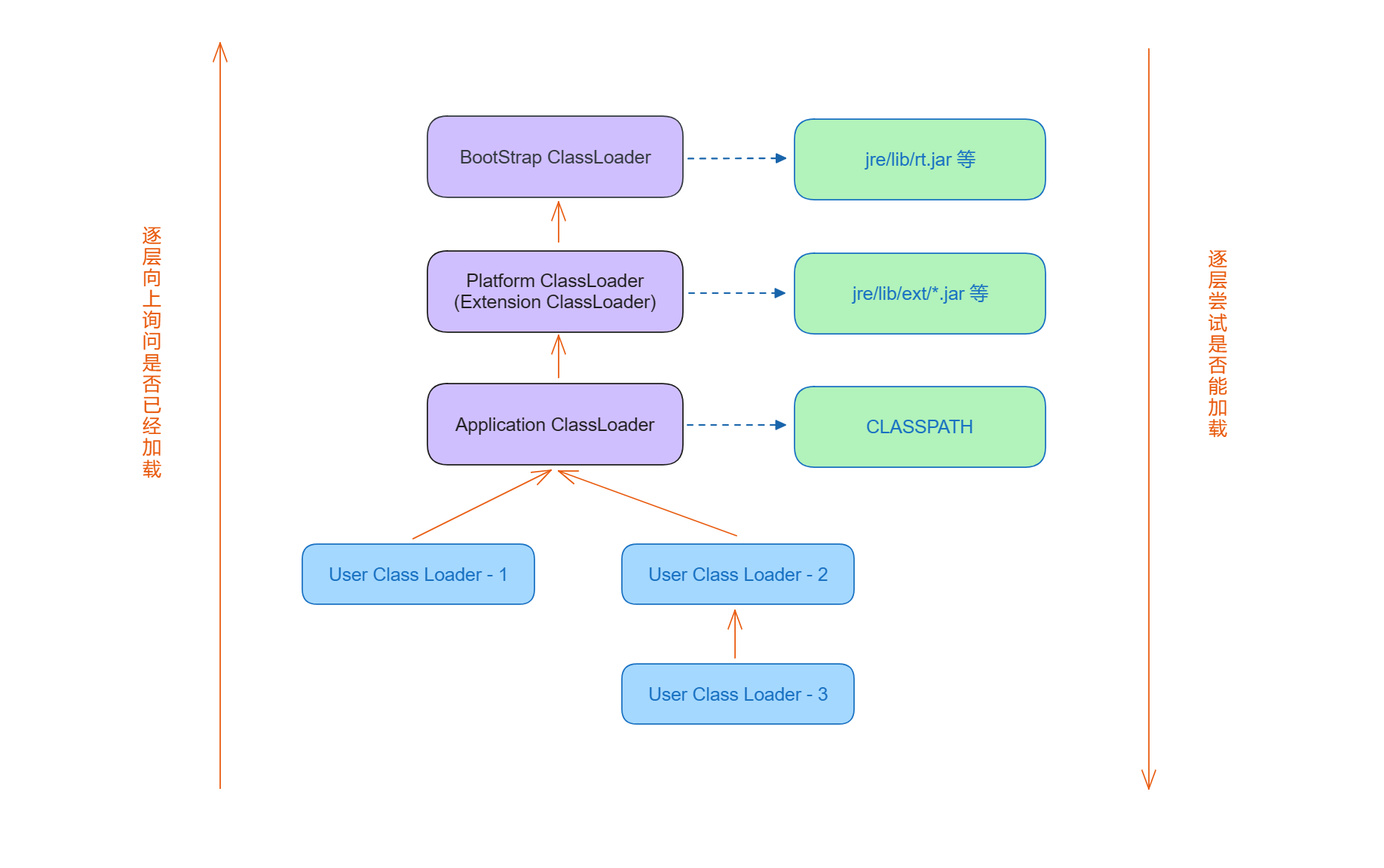
【JVM】双亲委派模型
双亲委派模型 1. 什么是双亲委派模型2. 双亲委派模型的优点 1. 什么是双亲委派模型 提到 类加载 机制,不得不提的一个概念就是“双亲委派模型”。 双亲委派模型指的就是 JVM 中的类加载器如何根据类的全限定名找到 .class 文件的过程 类加载器: JVM 里面专门提供…...
多叉树+图实现简单业务流程
文章目录 场景整体架构流程业务界面技术细节小结 场景 这次遇到一个需求,大致就是任务组织成方案,方案组织成预案,预案可裁剪调整.预案关联事件等级配置,告警触发预案产生事件.然后任务执行是有先后的,也就是有流程概念. 整体架构流程 方案管理、预案管理构成任务流程的基础条…...
)
毕业设计 深度学习的人体跌倒检测与识别(源码+论文)
文章目录 0 前言1 项目运行效果2 相关技术原理2.1卷积神经网络2.2 YOLO简介2.3 YOLOv5s 模型算法流程和原理2.4 数据集处理数据标注简介数据保存 2.5 模型训练 4 最后 0 前言 🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创…...
v1.0,集成 Matt Pocock 全套技能,实现零幻觉开发)
构建企业级 AI 编程助手(AI-OS)v1.0,集成 Matt Pocock 全套技能,实现零幻觉开发
告别单文件 Prompt:构建企业级 AI 编程助手(AI-OS)v1.0,集成 Matt Pocock 全套技能,实现零幻觉开发 引言:为什么你的 AI 编程总是“翻车”? 在使用 OpenCode、Cursor、Cline 等 AI 编程工具时&a…...
如何免费解决BT下载速度慢问题?终极trackerslist配置指南
如何免费解决BT下载速度慢问题?终极trackerslist配置指南 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 你是否曾为BT下载的龟速而烦恼?种子明明显…...

长期使用Token Plan套餐在Taotoken平台带来的月度成本控制感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在Taotoken平台带来的月度成本控制感受 作为一名需要频繁调用大模型API进行项目开发的工程师,成…...
)
ElevenLabs甘肃话语音合成技术解析(西北方言TTS工程化白皮书)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs甘肃话语音合成技术概览 ElevenLabs 是全球领先的语音合成平台,原生支持英语、西班牙语、法语等数十种主流语言,但**不直接内置甘肃话(属中原官话秦陇片&a…...
)
为什么你的“丝绸”总像锡纸?Midjourney材质语义断层诊断:87%用户忽略的材质动词前置语法(drape, crumple, refract)
更多请点击: https://intelliparadigm.com 第一章:材质语义断层的本质:从物理光学到提示词编码的跨模态失配 材质在真实世界中由微观结构、折射率、表面粗糙度、各向异性散射等物理属性共同定义,其视觉表现依赖于光与物质的连续相…...

一款多功能显示控制器芯片,FHD 120/144Hz,支持最高1920x1080@120Hz.
主要特性特性类别具体规格输入接口1VGA (模拟RGB)、1HDMI 1.4 (带HDCP1.4/2.2)、1DP1.2 组合接口 (兼容HDMI 1.4,带HDCP1.4/2.2)输出接口2 Port LVDS,支持8bit/10bit最大分辨率1920x1200100Hz 或 1920x1080120Hz (带ODC)色彩深度输入:6/8/10b…...

在自动化脚本中使用Taotoken实现多模型备援与降级策略
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化脚本中使用Taotoken实现多模型备援与降级策略 构建高可用的AI应用时,服务的稳定性直接影响终端用户体验。当单…...

配置Hermes Agent使用自定义Taotoken作为模型供应商的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置Hermes Agent使用自定义Taotoken作为模型供应商的步骤 1. 准备工作:获取必要的凭证 在开始配置之前,你…...
)
Midjourney构图进阶实战指南(98%用户从未调过的--sref与--style参数协同逻辑大揭秘)
更多请点击: https://intelliparadigm.com 第一章:Midjourney构图进阶实战指南(98%用户从未调过的--sref与--style参数协同逻辑大揭秘) 在Midjourney V6中, --sref(Style Reference)与 --style…...