Hudi第二章:集成Spark
系列文章目录
Hudi第一章:编译安装
Hudi第二章:集成Spark
文章目录
- 系列文章目录
- 前言
- 一、安装Spark
- 1、安装Spark
- 2.安装hive
- 二、spark-shell
- 1.启动命令
- 2.插入数据
- 3.查询数据
- 1.转换DF
- 2.查询
- 3.更新
- 4.时间旅行
- 5.增量查询
- 6.指定时间点查询
- 7.删除数据
- 1.获取总行数
- 2.取其中2条用来删除
- 3.将待删除的2条数据构建DF
- 4.执行删除
- 5.统计删除数据后的行数,验证删除是否成功
- 三、Spark-SQL
- 1.启动Spark-sql
- 2.建表
- 1.创建非分区表
- 2.创建分区表
- 3.在已有的hudi表上创建新表
- CTAS
- 2.插入数据
- 3.查询
- 4.时间旅行
- 5.更新数据
- 1.update
- 2.MergeInto
- 5.删除数据
- 6.覆盖表
- 7.修改表
- 8.修改分区
- 总结
前言
Hudi可以使用Spark作为搜索引擎。我们写博客记录一下,不知道一次能不能写完。
一、安装Spark
1、安装Spark
只需要简单的上传解压再添加环境变量即可。不做过多演示,具体可以看我之前的博客。
spark第一章:环境安装
spark版本我选用的是3.2。在这里留一个官方的下载地址。
spark-3.2.2-bin-hadoop3.2.tgz
然后我们从编译好的hudi文件夹中,将spark与hudi连接的jar包放入spark中。
cp /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/target/hudi-spark3.2-bundle_2.12-0.12.0.jar /opt/module/spark-3.2.2/jars/
然后需要启动hadoop
2.安装hive
后边hudi会依赖hive的Metastore和HiveServer2
Hive3第一章:环境安装
二、spark-shell
其中大部分命令和Spark很接近,建议学过Spark-shell之后再来学习这一部分。
1.启动命令
#针对Spark 3.2
spark-shell \--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
2.插入数据
dataGen.generateInserts是hudi提供的测试数据生成api,以下是固定写法
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGeneratorval inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))df.write.format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).mode(Overwrite).save(basePath)
说一下这几个参数。
RECORDKEY_FIELD_OPT_KEY:可以理解为MYSQL里的主键。
RECORDKEY_FIELD_OPT_KEY:预聚合字段,当主键相同时,以该字段大小决定,一般用ts字段,也就是时间戳。
PARTITIONPATH_FIELD_OPT_KEY:分区字段
TABLE_NAME:表名称
可以新开一个窗口在本地看一下

3.查询数据
1.转换DF
val tripsSnapshotDF = spark.read.format("hudi").load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
2.查询
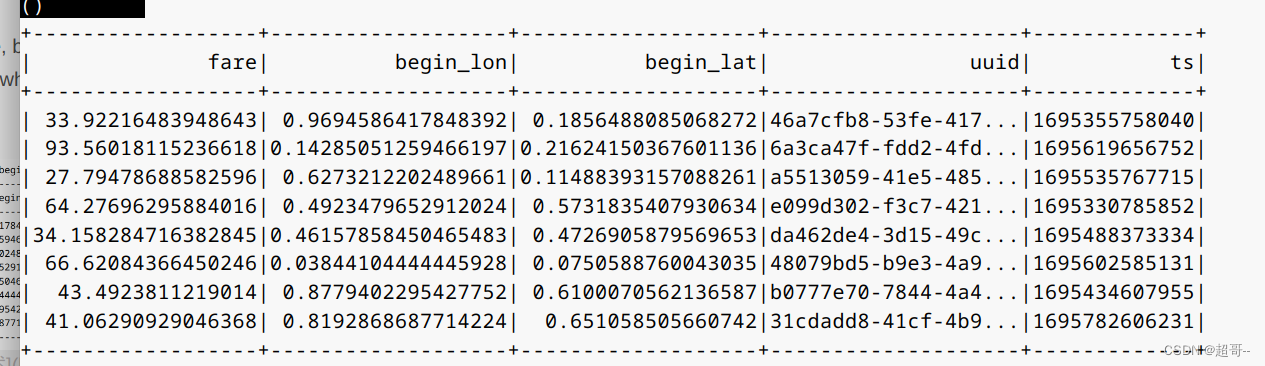
spark.sql(“select fare, begin_lon, begin_lat, uuid, ts from hudi_trips_snapshot where fare > 20.0”).show()
3.更新
和插入数据差不多,但是需要把mode从Overwrite换成Append。将其从覆盖编程追加
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).mode(Append).save(basePath)
更新之后我们再次查询。
val tripsSnapshotDF = spark.read.format("hudi").load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")spark.sql("select fare, begin_lon, begin_lat, uuid, ts from hudi_trips_snapshot where fare > 20.0").show()
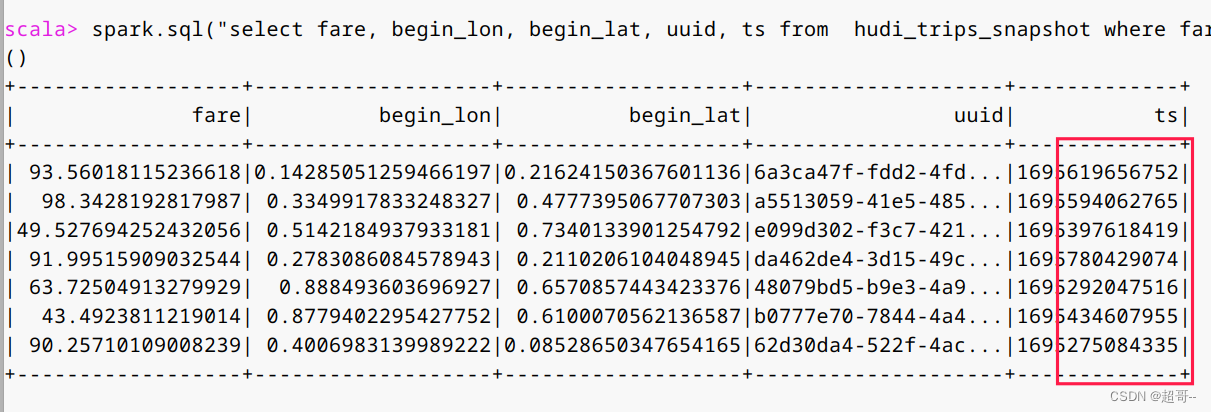
可以看到ts明显增大
4.时间旅行
当数据不断更新时,我们该如何寻找更新前的数据。这个在MYSQL数据库中是没有的,但hudi有,我们只需要找到当初更新数据的时间戳即可。
spark.sql("select _hoodie_commit_time, ts, uuid, fare from hudi_trips_snapshot").show()
因为我们只有两次提交,所以我们只有两种时间戳
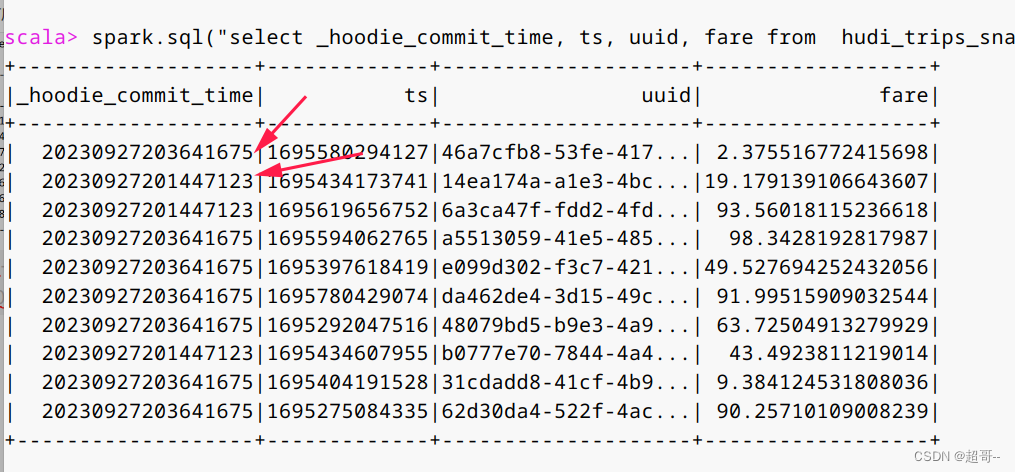
这就是最简单的年月日时分秒。
现在我们回到第一次提交时的数据。
val tripsSnapshotDF1 = spark.read.format("hudi").option("as.of.instant", "20230927201447123").load(basePath)tripsSnapshotDF1.createOrReplaceTempView("hudi_trips_snapshot1")
现在在新的虚拟表中查询。
spark.sql("select fare, begin_lon, begin_lat, uuid, ts from hudi_trips_snapshot1 where fare > 20.0").show()
随便找一条对比
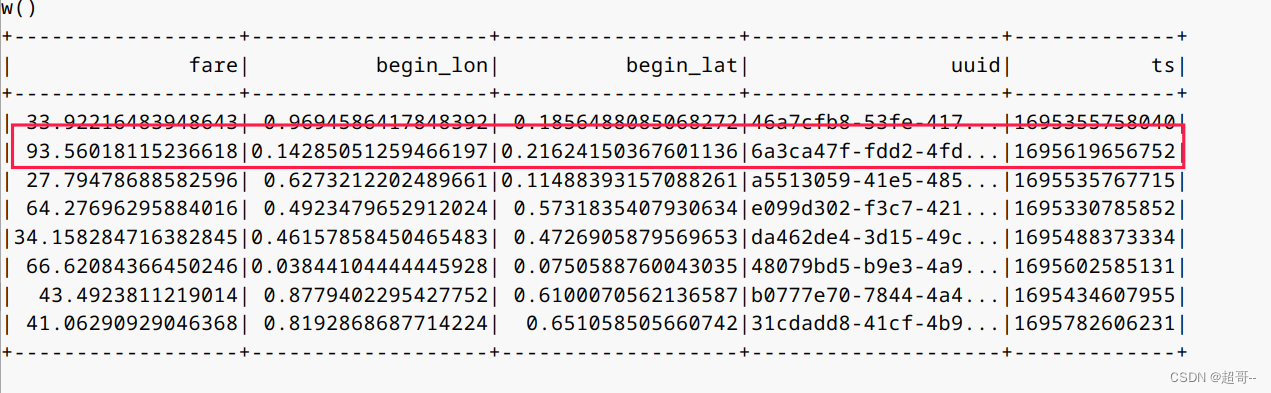
可以看到和之前的第一条是一样的。
时间旅行还可以这样写
spark.read.
format(“hudi”).
option(“as.of.instant”, “2023-09-27 20:14:47:123”).
load(basePath)
效果和上边一样。
5.增量查询
查询某一次提交之后的数据。
现在我在插入三次数据。
重复执行三次
df.write.format("hudi").options(getQuickstartWriteConfigs).option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).mode(Append).save(basePath)
然后重新生成虚拟表
spark.read.format("hudi").load(basePath).createOrReplaceTempView("hudi_trips_snapshot")
因为每次提交,查询时间会被覆盖,所以我们选择从本地获取。
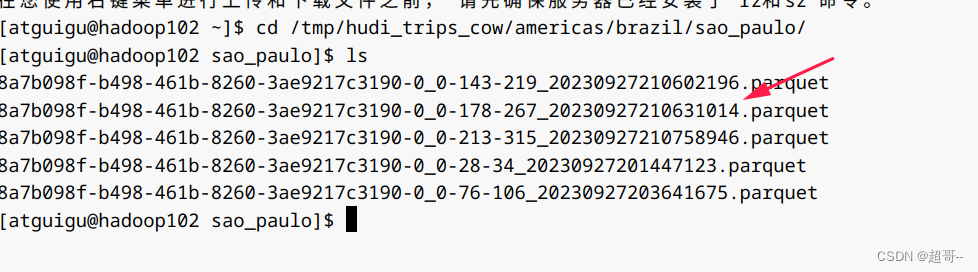
咱们选择第四次之后的数据
val beginTime = "20230927210631014"# 增量查询表
val tripsIncrementalDF = spark.read.format("hudi").option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental").show()
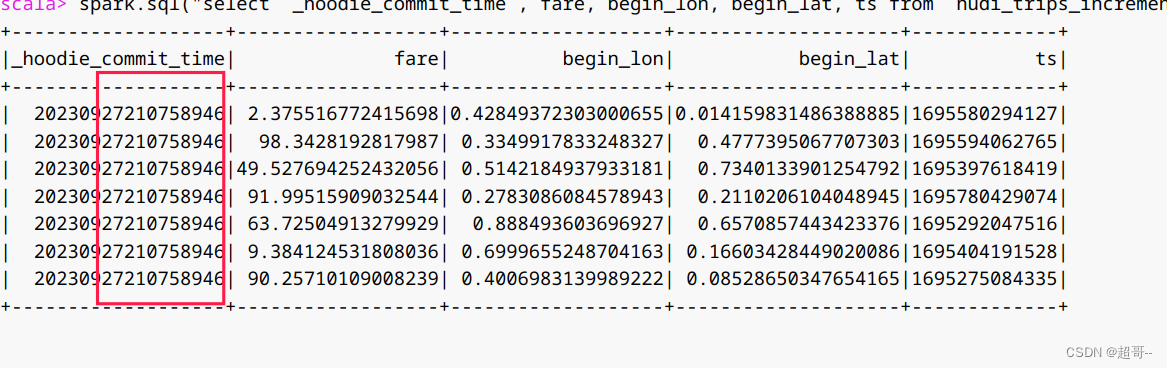
可以看到都是第四次之后的数据。
6.指定时间点查询
增量查询可以查询某一次提交之后的数据,指定时间点查询可以查询,一段时间内的数据。
val beginTime = "000"
val endTime = "20230927210631014"val tripsPointInTimeDF = spark.read.format("hudi").option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).option(END_INSTANTTIME_OPT_KEY, endTime).load(basePath)
tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where").show()
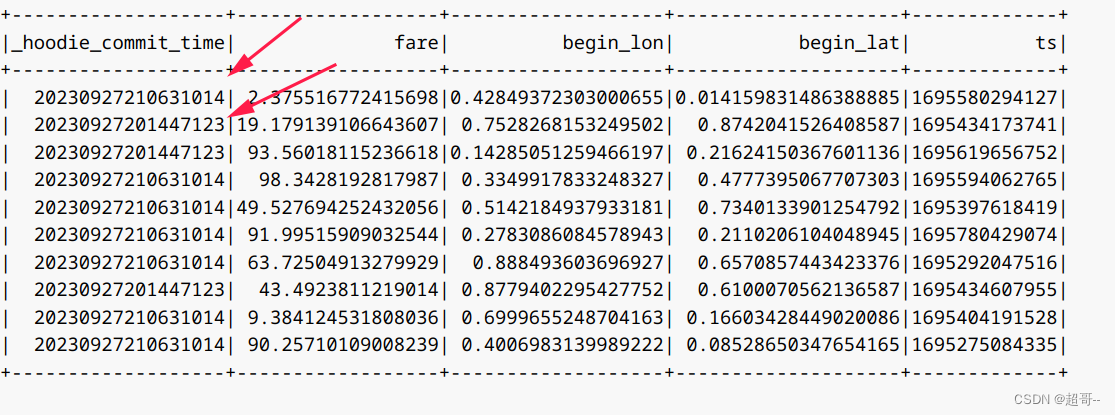
都是endTime之前的。
7.删除数据
1.获取总行数
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()

2.取其中2条用来删除
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
3.将待删除的2条数据构建DF
val deletes = dataGen.generateDeletes(ds.collectAsList())
val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2))
4.执行删除
df.write.format("hudi").options(getQuickstartWriteConfigs).option(OPERATION_OPT_KEY,"delete").option(PRECOMBINE_FIELD_OPT_KEY, "ts").option(RECORDKEY_FIELD_OPT_KEY, "uuid").option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").option(TABLE_NAME, tableName).mode(Append).save(basePath)
5.统计删除数据后的行数,验证删除是否成功
val roAfterDeleteViewDF = spark.read.format("hudi").load(basePath)roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")// 返回的总行数应该比原来少2行
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()

三、Spark-SQL
1.启动Spark-sql
#针对Spark 3.2
spark-sql \--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
2.建表
单独创建一个数据库,用作学习。
create database spark_hudi;
use spark_hudi;
1.创建非分区表
hudi中默认分为cow和mor两种表,他们后台的存储方式不太一样,但是前端看起来没区别。
创建一个cow表,默认primaryKey ‘uuid’,不提供preCombineField
create table hudi_cow_nonpcf_tbl (uuid int,name string,price double
) using hudi;
创建一个mor非分区表
create table hudi_mor_tbl (id int,name string,price double,ts bigint
) using hudi
tblproperties (type = 'mor',primaryKey = 'id',preCombineField = 'ts'
);
2.创建分区表
创建一个cow分区外部表,指定primaryKey和preCombineField
create table hudi_cow_pt_tbl (id bigint,name string,ts bigint,dt string,hh string
) using hudi
tblproperties (type = 'cow',primaryKey = 'id',preCombineField = 'ts')
partitioned by (dt, hh)
location '/tmp/hudi/hudi_cow_pt_tbl';
3.在已有的hudi表上创建新表
create table hudi_existing_tbl0 using hudi
location 'file:///tmp/hudi/dataframe_hudi_nonpt_table';create table hudi_existing_tbl1 using hudi
partitioned by (dt, hh)
location 'file:///tmp/hudi/dataframe_hudi_pt_table';
因为实际路径上并没有数据,所以就不创建了。
CTAS
Create Table As Select
为了提高向hudi表加载数据的性能,CTAS使用批量插入作为写操作,所以也可以用来插入数据。
通过CTAS创建cow非分区表,不指定preCombineField
create table hudi_ctas_cow_nonpcf_tbl
using hudi
tblproperties (primaryKey = 'id')
as
select 1 as id, 'a1' as name, 10 as price;

通过CTAS创建cow分区表,指定preCombineField
create table hudi_ctas_cow_pt_tbl
using hudi
tblproperties (type = 'cow', primaryKey = 'id', preCombineField = 'ts')
partitioned by (dt)
as
select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-01' as dt;
通过CTAS从其他表加载数据
了解即可
# 创建内部表
create table parquet_mngd using parquet location 'file:///tmp/parquet_dataset/*.parquet';# 通过CTAS加载数据
create table hudi_ctas_cow_pt_tbl2 using hudi location 'file:/tmp/hudi/hudi_tbl/' options (type = 'cow',primaryKey = 'id',preCombineField = 'ts')
partitioned by (datestr) as select * from parquet_mngd;
2.插入数据
向非分区表插入数据
insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;
insert into hudi_mor_tbl select 1, 'a1', 20, 1000;
向分区表动态分区插入数据
insert into hudi_cow_pt_tbl partition (dt, hh)
select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
向分区表静态分区插入数据
insert into hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='11') select 2, 'a2', 1000;
3.查询
和基本的SQL语句一样
select name,price from hudi_cow_nonpcf_tbl;

4.时间旅行
建一张新表
create table hudi_cow_pt_tbl1 (id bigint,name string,ts bigint,dt string,hh string
) using hudi
tblproperties (type = 'cow',primaryKey = 'id',preCombineField = 'ts')
partitioned by (dt, hh)
location '/tmp/hudi/hudi_cow_pt_tbl1';
插入一条数据并查询
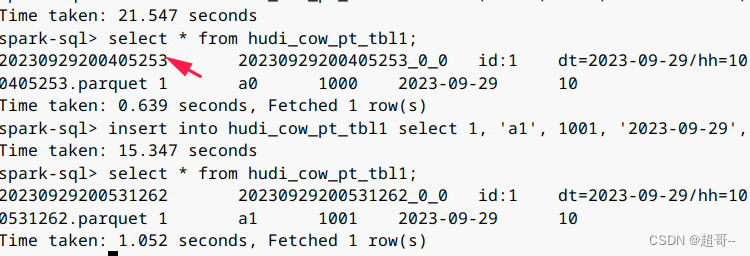
insert into hudi_cow_pt_tbl1 select 1, 'a0', 1000, '2023-09-29', '10';
select * from hudi_cow_pt_tbl1;

现在我们更新这条数据再次查询。
insert into hudi_cow_pt_tbl1 select 1, 'a1', 1001, '2023-09-29', '10';
select * from hudi_cow_pt_tbl1;

可以看到第二次的ts更大,所以name已经更新,现在我们进行时间旅行,找到刚刚的时间戳。
select * from hudi_cow_pt_tbl1 timestamp as of '20230929200405253';

这就可以查询到之前的数据。
5.更新数据
1.update
hudi也是可以使用update更新数据的。
先查看一下
select * from hudi_mor_tbl ;

在更新数据。
update hudi_mor_tbl set price = price * 2, ts = 1111 where id = 1;
select * from hudi_mor_tbl ;

2.MergeInto
这个语法有点类似于join,用于两张表的拼接。
创建一张表,并插入数据。
create table merge_source (id int, name string, price double, ts bigint) using hudi
tblproperties (primaryKey = 'id', preCombineField = 'ts');insert into merge_source values (1, "old_a1", 22.22, 2900), (2, "new_a2", 33.33, 2000), (3, "new_a3", 44.44, 2000);
我们将新表的内容插入hudi_mor_tbl
merge into hudi_mor_tbl as target
using merge_source as source
on target.id = source.id
when matched then update set *
when not matched then insert *;
查看hudi_mor_tbl。
select * from hudi_mor_tbl ;

5.删除数据
delete from hudi_mor_tbl where id = 1;
select * from hudi_mor_tbl ;

6.覆盖表
insert overwrite hudi_mor_tbl select 99, 'a99', 20.0, 900;
select * from hudi_mor_tbl ;

7.修改表
修改语法
– Alter table name
ALTER TABLE oldTableName RENAME TO newTableName
– Alter table add columns
ALTER TABLE tableIdentifier ADD COLUMNS(colAndType (,colAndType)*)
– Alter table column type
ALTER TABLE tableIdentifier CHANGE COLUMN colName colName colType
– Alter table properties
ALTER TABLE tableIdentifier SET TBLPROPERTIES (key = ‘value’)
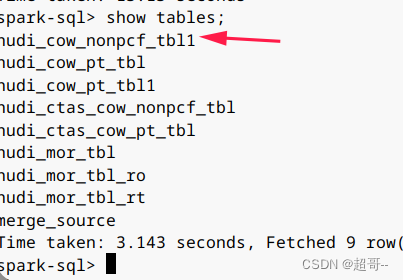
这么我们修改表名做个实例。
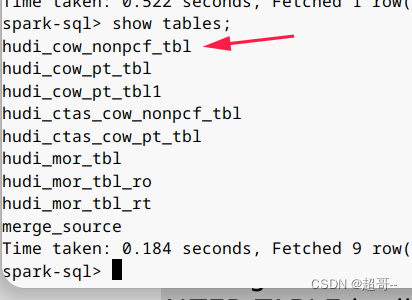
ALTER TABLE hudi_cow_nonpcf_tbl RENAME TO hudi_cow_nonpcf_tbl1;
8.修改分区
show partitions hudi_cow_pt_tbl1;
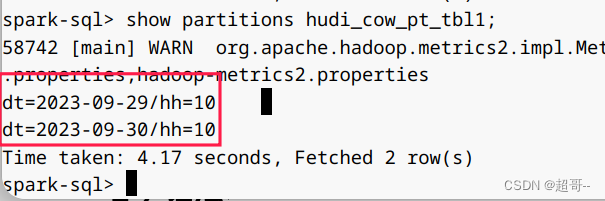
alter table hudi_cow_pt_tbl1 drop partition (dt='2023-09-29', hh='10');
show partitions hudi_cow_pt_tbl1;

总结
这一次就写到这里,东西比较多,关于Spark的东西还要在写一次。
相关文章:
Hudi第二章:集成Spark
系列文章目录 Hudi第一章:编译安装 Hudi第二章:集成Spark 文章目录 系列文章目录前言一、安装Spark1、安装Spark2.安装hive 二、spark-shell1.启动命令2.插入数据3.查询数据1.转换DF2.查询 3.更新4.时间旅行5.增量查询6.指定时间点查询7.删除数据1.获取…...

springboot和vue:八、vue快速入门
vue快速入门 新建一个html文件 导入 vue.js 的 script 脚本文件 <script src"https://unpkg.com/vuenext"></script>在页面中声明一个将要被 vue 所控制的 DOM 区域,既MVVM中的View <div id"app">{{ message }} </div…...

docker-compose内网本地安装
1:通过包管理器安装 Docker Compose,请按照以下步骤进行操作: 首先,确保你的系统上已经安装了 Docker。如果尚未安装 Docker,请根据你的操作系统使用适当的包管理器进行安装打开终端,并运行以下命令下载 D…...

ThreeJs的场景实现鼠标拖动旋转控制
前面一个章节中已经实现在场景中放置一个正方体,并添加灯光使得正方体可见。但是由于是静态的还不能证明是3D的,我们需要添加一些控制器,使得通过鼠标控制正方体可以动起来,实现真正的3D效果,由此引入OrbitControls组件…...

jdk 管理工具比对 jEnv jabba SDKMAN
jEnv、jabba、SDKMAN 这三个 JDK 管理工具进行的比对: jEnv: 地址:https://github.com/jenv/jenv 作者:Gildas Cuisinier 最后更新时间:2021年5月26日 开发语言:Shell Jabba: 地址࿱…...

华为云云耀云服务器L实例评测|部署在线图表和流程图绘制工具drawio
华为云云耀云服务器L实例评测|部署在线图表和流程图绘制工具drawio 一、云耀云服务器L实例介绍1.1 云服务器介绍1.2 优势及其应用场景1.3 支持镜像 二、云耀云服务器L实例配置2.1 重置密码2.2 服务器连接2.3 安全组配置 三、部署 drawio3.1 drawio 介绍3.2 Docker 环…...
elementui引入弹出框报错:this.$alert is not defined 解决方案
1.按需引入文件element.js 注意:引入Message,MessageBox两个组件就行,alert包括在MessageBox里面了。 之前我引入了Alert组件,发现不行 2.在vue的prototype里注册伪名字 3.组件里直接调用就行了 4.实现效果 我发现elementui调用…...

docker的组件和资源管理
Docker是一种开源的容器化平台,它提供了一种轻量级、可移植和可扩展的方式来打包、部署和运行应用程序。Docker的构成包括以下几个关键组件: Docker Engine:Docker Engine是Docker的核心组件,它负责管理容器的生命周期和资源隔离…...

SEO的优化教程(百度SEO的介绍和优化)
百度SEO关键字介绍: 百度SEO关键字是指用户在搜索引擎上输入的词语,是搜索引擎了解网站内容和相关性的重要因素。百度SEO关键字可以分为短尾词、中尾词和长尾词,其中长尾词更具有针对性和精准性,更易于获得高质量的流量。蘑菇号-…...

Tomcat以及UDP
一、Tomcat 服务端 自定义 S Tomcat服务器 S :Java后台开发 客户端 自定义 C 浏览器 B 认识一些常用的目录: bin:存放开始和结束的程序 conf:配置文件 lib:组成包 logs:输出日志 webapps&#x…...

NLP 04(GRU)
一、GRU GRU (Gated Recurrent Unit)也称门控循环单元结构,它也是传统RNN的变体,同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象,同时它的结构和计算要比LSTM更简单,它的核心结构可以分为两个部分去解析: 更新门、重置门 GRU的内…...
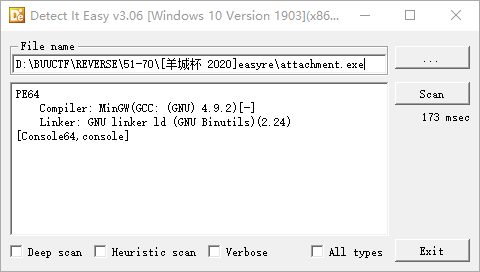
BUUCTF reverse wp 51 - 55
findKey shift f12 找到一个flag{}字符串, 定位到关键函数, F5无效, 大概率是有花指令, 读一下汇编 这里连续push两个byte_428C54很奇怪, nop掉下面那个, 再往上找到函数入口, p设置函数入口, 再F5 LRESULT __stdcall sub_401640(HWND hWndParent, UINT Msg, WPARAM wPara…...

WebGL笔记:使用鼠标绘制多个线条应用及绘制动感线性星座
使用鼠标绘制多个线条 多个线条,肯定不是一笔画过的,而是多次画的线条既然是多线,那就需要有个容器来管理它们 1 )建立容器对象 建立一个 lineBox 对象,作为承载多边形的容器 // lineBox.js export default class …...
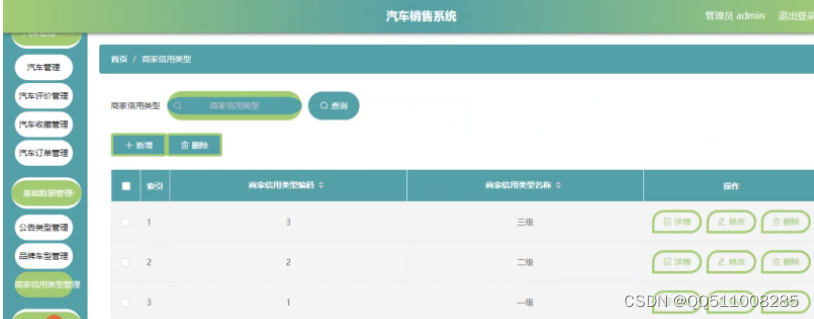
nodejs+vue 汽车销售系统elementui
第三章 系统分析 10 3.1需求分析 10 3.2可行性分析 10 3.2.1技术可行性:技术背景 10 3.2.2经济可行性 11 3.2.3操作可行性: 11 3.3性能分析 11 3.4系统操作流程 12 3.4.1管理员登录流程 12 3.4.2信息添加流程 12 3.4.3信息删除流程 13 第四章 系统设计与…...

leetcode76 Minimum Window Substring
给定两个字符串s和t, 找到s的一个子串,使得t的每个字符都出现在子串中,求最短的子串 由于要每个字符出现,所以顺序其实没有关系 因此我们可以定义一个map,统计t中字符出现次数 然后在s中慢慢挪动滑动窗口,…...

简单工厂模式~
我们以生产手机作为应用场景展开讲解! 手机是一个抽象的概念,它包含很多的品牌,例如华为,苹果,小米等等,因此我们可将其抽象为一个接口,如下所示: public interface tel {void pro…...

基于Java的会员管理系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

数据结构 图 并查集 遍历方法 最短路径算法 最小生成树算法 简易代码实现
文章目录 前言并查集图遍历方法广度优先遍历深度优先遍历 最小生成树算法Kruskal算法Prim算法 最短路径算法Dijkstra算法BellmanFord算法FloydWarshall算法 全部代码链接 前言 图是真的难,即使这些我都学过一遍,再看还是要顺一下过程;说明方…...
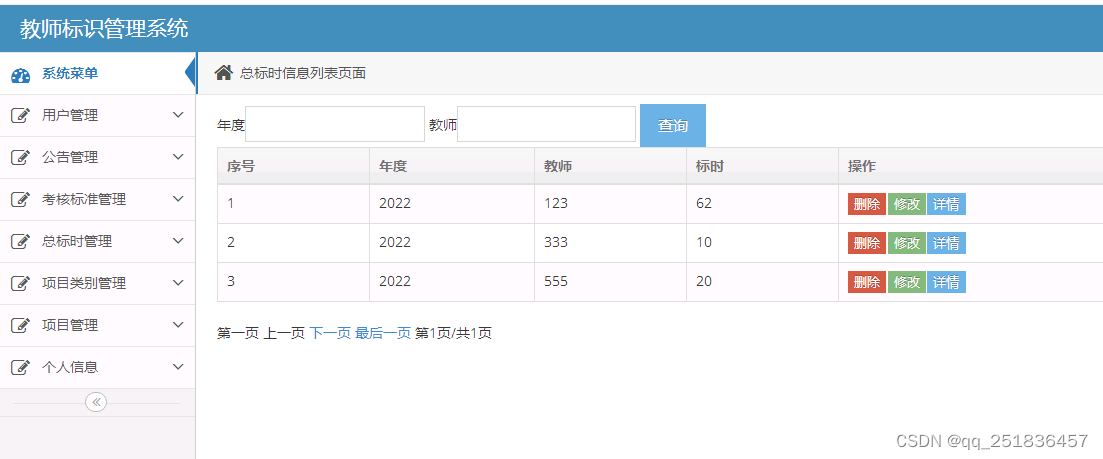
idea Springboot 教师标识管理系统开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot 教师标识管理系统是一套完善的信息系统,结合springboot框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发),系统 具有完整的源代码和数据库&…...
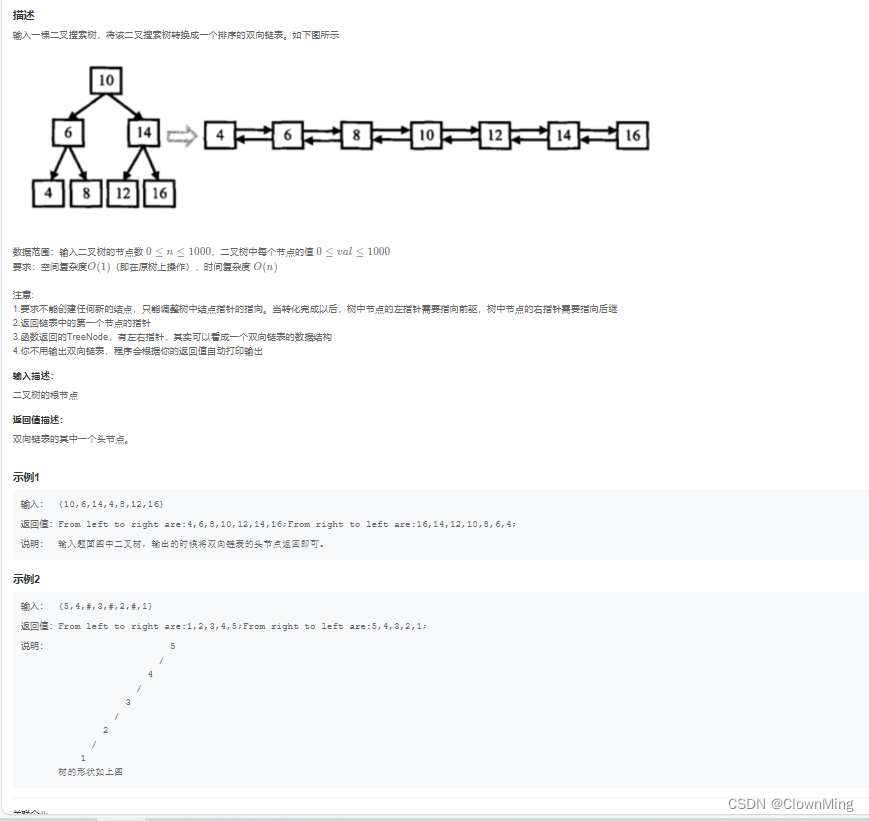
2023-9-30 JZ36 二叉搜索树与双向链表
题目链接:二叉搜索树与双向链表 import java.util.*; /** public class TreeNode {int val 0;TreeNode left null;TreeNode right null;public TreeNode(int val) {this.val val;}} */ public class Solution {TreeNode pre null;public TreeNode Convert(Tree…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...

Elastic 获得 AWS 教育 ISV 合作伙伴资质,进一步增强教育解决方案产品组合
作者:来自 Elastic Udayasimha Theepireddy (Uday), Brian Bergholm, Marianna Jonsdottir 通过搜索 AI 和云创新推动教育领域的数字化转型。 我们非常高兴地宣布,Elastic 已获得 AWS 教育 ISV 合作伙伴资质。这一重要认证表明,Elastic 作为 …...