Pytorch学习记录-1-张量
1. 张量 (Tensor):
数学中指的是多维数组;
torch.Tensor
data: 被封装的 Tensor
dtype: 张量的数据类型
shape: 张量的形状
device: 张量所在的设备,GPU/CPU
requires_grad: 指示是否需要计算梯度
grad: data 的梯度
grad_fn: 创建 Tensor 的 Function,是自动求导的关键
is_leaf: 指示是否是叶子结点 (叶子结点指的是用户创建的节点,比如 y=(x+w)*(w+1)中,x和w就是叶子结点【可以用计算图来清楚地表示该过程】)
2. 创建张量:
2.1 直接创建:
2.1.1 从 data 创建 tensor
data: 可以是 list, numpy
dtype: 数据类型,默认与data一致
device: 所在设备
requires_grad: 是否需要梯度
pin_memory: 是否存于锁页内存
# 创建方法
torch.tensor(data,dtype=None,device=None,requires_grad=False,pin_memory=False
)
2.1.2 从 numpy 创建 tensor
用torch.from_numpy()创建的tensor与原始的ndarray共享内存,修改其中一个,另一个也会变。
# 创建方法
torch.from_numpy(ndarray)
# 举例
import torch
import numpy as np# 直接创建
## torch.tensor()
arr = np.ones((3,3))
t = torch.tensor(arr, dtype=torch.float32, device="mps") # 把张量放到 GPU 上 (mac M1)print(t.dtype)
print(t)## torch.from_numpy()
arr = np.array([[1,2,3],[4,5,6]])
t = torch.from_numpy(arr)
print(t.dtype)
print(t)
torch.float32
tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]], device='mps:0')
torch.int64
tensor([[1, 2, 3],[4, 5, 6]])
2.2 根据数值进行创建:
2.2.1 torch.zeros()
创建全0张量
size: 张量的形状
out: 输出的张量 (暂时可以不考虑)
layout:内存中布局形式,有 strided (通常情况下使用), sparse_coo (读取稀疏矩阵会用到)
device: 所在设备
requires_grad: 是否需要梯度
# 创建方法
torch.zeros(*size,out=None,dtype=None,layout=torch.strided,device=False,requires_grad=False
)
2.2.2 torch.zeros_lisk()
根据 input 形状创建全0张量
input: 创建与 input 同形状的张量;
dtype: 数据类型;
layout: 内存中的布局形式;
# 创建方法
torch.zeros_like(input,dtype=None,layout=None,device=None,requires_grad=False
)
2.2.3 torch.ones() 和 torch.ones_like()
创建全1张量
2.2.4 torch.full()和torch.full_like()
创建自定义数值的张量
size: 张量形状
fill_value: 张量的值
2.2.5 torch.arange()
根据数列创建等差1维张量,[start, end)
start: 起始值
end: 结束值
step: 数列公差,默认为1
2.2.6torch.linspace()
创建均分的1维张量,[start, end]
start: 起始值
end: 结束值
step: 数列长度
2.2.7torch.logspace()
创建对数均分的1D张量
start: 起始值
end: 结束值
steps: 数列长度
base: 对数函数的底,默认为10
# 创建方法
torch.logspace(start,end,steps=100,base=10.0,out=None,dtype=None,layout=torch.strided,deivce=None,requires_grad=False
)
2.2.8 torch.eye()
创建单位对角矩阵 (2D张量)
n: 矩阵行数
m: 矩阵列数
# 创建方法
torch.eye(n,m=None,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
# 举例
t = torch.zeros((3,3))
print(t.dtype)
print(t)t = torch.full((3,3),2) # 创建3x3的全2张量
print(t)t = torch.arange(2, 8, 2)
print(t)t = torch.linspace(2, 10, 5)
print(t)
torch.float32
tensor([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]])
tensor([[2, 2, 2],[2, 2, 2],[2, 2, 2]])
tensor([2, 4, 6])
tensor([ 2., 4., 6., 8., 10.])
2.3 根据概率分布创建张量:
2.3.1 torch.normal()
生成正态分布(高斯分布)
四种模式:
| mean | 标量 | std | 标量 |
| mean | 标量 | std | 张量 |
| mean | 张量 | std | 标量 |
| mean | 张量 | std | 张量 |
# 张量
torch.normal(mean,std,out=None
)# 标量
torch.normal(mean,std,size,out=None
)
2.3.2 torch.randn(), torch.randn_like()
生成标准正态分布
torch.randn(*size, ## 张量形状out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
2.3.3 torch.rand(), torch.rand_like()
在[0,1)区间上生成均匀分布
torch.rand(*size, ## 张量形状out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
2.3.4 torch.randint(), torch.randint_like()
在 [low, high) 区间上生成整数均匀分布
torch.randint(low,high,size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
2.3.5 torch.randperm()
生成0到n-1的随机排列
n: 张量长度
torch.randperm(n,out=None,dtype=torch.int64,layout=torch.strided,device=None,requires_grad=False
)2.3.6torch.bernoulli()
以 input 为概率,生成伯努利分布(0-1分布,两点分布)
torch.bernoulli(input,*,generator=None,out=None
)
3. 张量的操作:
张量的操作:拼接、切分、索引和变换:
1. 拼接:
1.1 torch.cat()
将张量按维度 dim 进行拼接 (不回扩张张量维度)
torch.cat(tensors, ## 张量序列dim, ## 要拼接的维度out=None
)
1.2 torch.stack()
在新创建的维度 dim 上进行拼接 (会扩张张量的维度)
torch.stack(tensors, ## 张量序列dim=0, ## 要拼接的维度out=None
)
import torcht = torch.ones((2,3))# torch.cat()
t1 = torch.cat([t,t], dim=0) ## 按照 dim=0 对t进行拼接,得到(4,3)# torch.stack()
t2 = torch.stack([t,t], dim=0) ## 按照 dim=0 对t进行拼接,得到(2,2,3),会在dim=0创建一个新维度print("t1 shape: ", t1.shape)
print("t2 shape: ", t2.shape)
t1 shape: torch.Size([4, 3])
t2 shape: torch.Size([2, 2, 3])
2. 切分
2.1 torch.chunk()
将张量按照维度 dim 进行平均切分,返回张量列表 (如果不能整除,最后一份张量小于其他张量)
torch.chunk(input, ## 要切分的张量chunks, ## 要切分的份数dim=0 ## 要切分的维度
)
2.2 torch.split()
将张量按照维度 dim 进行切分,返回张量列表
torch.split(tensor, ## 要切分的张量split_size_of_sections, ## 为 int 时,表示每一份的长度;为 list 时,按 list 元素切分dim=0 ## 要切分的维度
)
t1 = torch.ones((2,5))# torch.chunk()
list_of_tensors = torch.chunk(t1, dim=1, chunks=2) ## 5不能被2整除,所以最后一个张量形状小雨前面的张量
for idx, t in enumerate(list_of_tensors):print("order {}, shape is {}".format(idx+1, t.shape))# torch.split()
list_of_tensors = torch.split(t1, [2,1,2], dim=1)
for idx, t in enumerate(list_of_tensors):print("order {}, shape is {}".format(idx+1, t.shape))
order 1, shape is torch.Size([2, 3])
order 2, shape is torch.Size([2, 2])
order 1, shape is torch.Size([2, 2])
order 2, shape is torch.Size([2, 1])
order 3, shape is torch.Size([2, 2])
3. 索引
3.1 torch.index_select()
在维度 dim 上,按照 index 索引数据,返回依index索引数据拼接的张量 (先索引,再拼接)
torch.index_select(input, ## 要索引的张量dim, ## 要索引的维度index, ## 要索引数据的序号,数据类型必须是 torch.longout=None
)
3.2 torch.masked_select()
按照 mask 中的 True 进行索引,返回一维张量
torch.masked_select(input,mask, ## 与 input 同形状的布尔类型张量out=None
)
# torch_index_select()
t = torch.randint(0,9,size=(3,3))
idx = torch.tensor([0,2],dtype=torch.long)
t_select = torch.index_select(t, dim=1, index=idx)
print(t)
print(t_select)# torch.masked_select()
mask = t.ge(5) ## 表示张量中 >= 5的元素;ge()表示大于等于;gt()表示大于;le()表示小于等于;lt()表示小于
t_select = torch.masked_select(t, mask=mask)
print(t)
print(mask)
print(t_select)
tensor([[3, 8, 1],[6, 0, 0],[7, 6, 8]])
tensor([[3, 1],[6, 0],[7, 8]])
tensor([[3, 8, 1],[6, 0, 0],[7, 6, 8]])
tensor([[False, True, False],[ True, False, False],[ True, True, True]])
tensor([8, 6, 7, 6, 8])
4. 变换
4.1 torch.reshape()
变换张量形状 (张量在内存中是连续时,新张量与input共享数据内存)
torch.reshape(input,shape ## 新张量的形状
)
4.2 torch.transpose()
交换张量的两个维度
torch.transpose(input,dim0,dim1
)
4.3 torch.t()
2维张量转置
torch.t(input)
4.4 torch.squeeze()
压缩长度为1的维度
torch.squeeze(input,dim=None, ## 若 dim=None,则移除所有长度为1的轴;若指定维度而且维度长度为1,则可以移除该维度out=None
)
4.5 torch.unsqueeze()
根据 dim 扩展维度
torch.unsqueeze(input,dim,out=None
)
## torch.reshapet = torch.randperm(8)
t_reshape = torch.reshape(t, (2,4)) ## 如果是 (-1,2,2),那么-1表示的是:不需要关心-1处的维度是多少,根据后两个维度进行计算得到(比如:这里就是 8/2/2 = 2,即-1处的维度是2)print(t.shape)
print(t_reshape.shape)## torch.transpose()
t = torch.rand((2,3,4))
t_transpose = torch.transpose(t, dim0=1, dim1=2) ## 把第1维和第2维进行交换
print(t.shape)
print(t_transpose.shape)## torch.squeeze()
t = torch.rand((1,2,3,1))
t_squeeze = torch.squeeze(t)
t_squeeze_0 = torch.squeeze(t,dim=0)
t_squeeze_1 = torch.squeeze(t,dim=1)
print(t_squeeze.shape)
print(t_squeeze_0.shape)
print(t_squeeze_1.shape)## torch.unsqueeze()
t = torch.rand((2,3))
t_unsqueeze = torch.unsqueeze(t, dim=2)
print(t_unsqueeze.shape)
torch.Size([8])
torch.Size([2, 4])
torch.Size([2, 3, 4])
torch.Size([2, 4, 3])
torch.Size([2, 3])
torch.Size([2, 3, 1])
torch.Size([1, 2, 3, 1])
torch.Size([2, 3, 1])
3.2 张量的数学运算:
加减乘除
torch.add()
torch.addcdiv()
torch.addcmul()
torch.sub()
torch.div()
torch.mul()
重点: torch.add()和torch.addcmul()
torch.add(): 逐元素计算 input + alpha x other
torch.add(input, ## 第一个张量alpha=1, ## 乘项因子 (alpha x other + input)other, ## 第二个张量out=None
)
torch.addcmul()
out = input + value x tensor1 x tensor2
torch.addcmul(input,value=1.tensor1,tensor2,out=None
)
对数、指数、幂函数
torch.log(input, out=None)
torch.log10(input, out=None)
torch.log2(input, out=None)
torch.exp(input, out=None)
torch.pow()
三角函数
torch.abs(input, out=None)
torch.acos(input, out=None)
torch.cosh(input, out=None)
torch.cos(input, out=None)
torch.asin(input, out=None)
torch.atan(input, out=None)
torch.atan2(input, other=None, out=None)
4. 计算图与动态图
1. 计算图
计算图是用来描述运算的有向无环图,包括两个主要元素:节点和边。节点表示数据(比如 向量、矩阵、张量);边表示运算(比如 加减乘除卷积等)。
叶子结点:指的是由用户创建的节点,其他非叶子结点都是由叶子结点通过直接或间接的运算得到的。(之所以会有叶子结点的概念,是因为梯度反向传播结束后,只有叶子结点的梯度会被保留,非叶子结点的梯度会被从内存中释放掉。可以通过
.is_leaf()方法查看是否为叶子结点)。
如果想要使用非叶子结点的梯度,实现方法是 在计算梯度之后,用
.retain_grad()方法保存非叶子结点的梯度。
grad_fn: 记录创建该张量(非叶子结点)时所用的方法,比如 y=a*b,那么 y.grad_fn = <MulBackward0>
2. 动态图
计算图可以根据搭建方式的不同,分为:动态图 (运算与搭建同时进行,灵活,易调节,比如 pytorch) 和静态图 (先搭建,后运算,高效,不灵活,比如 tensorflow)。
5. 自动求导系统 autograd
1. torch.autograd.backward
自动计算图中各个结点的梯度
torch.autograd.backward(tensors, ## 用于求导的张量(比如 loss)grad_tensors=None, ## 多梯度权重retain_grap=None, ## 保存计算图create_graph=False ## 创建导数的计算图,同于高阶求导
)
2. torch.autograd.grad
求取梯度
torch.autograd.grad(outputs, ## 用于求导的张量 (比如 loss)inputs, ## 需要梯度的张量grad_outputs=None, ## 多梯度权重 retain_graph=None, ## 保存计算图create_graph=False ## 创建导数计算图,用于高阶求导
)
3. Pytorch 自动求导系统中有3个需要注意的点:
梯度不自动清零 (手动清零
.grad.zero_());依赖于叶子结点结点,requires_grad 默认为 True;
叶子结点不可执行 in-place,即叶子结点不能执行原位操作;
4. 机器学习模型的5个训练步骤:
数据, 模型, 损失函数, 优化器, 迭代训练
相关文章:

Pytorch学习记录-1-张量
1. 张量 (Tensor): 数学中指的是多维数组; torch.Tensor data: 被封装的 Tensor dtype: 张量的数据类型 shape: 张量的形状 device: 张量所在的设备,GPU/CPU requires_grad: 指示是否需要计算梯度 grad: data 的梯度 grad_fn: 创建 Tensor 的 Functio…...
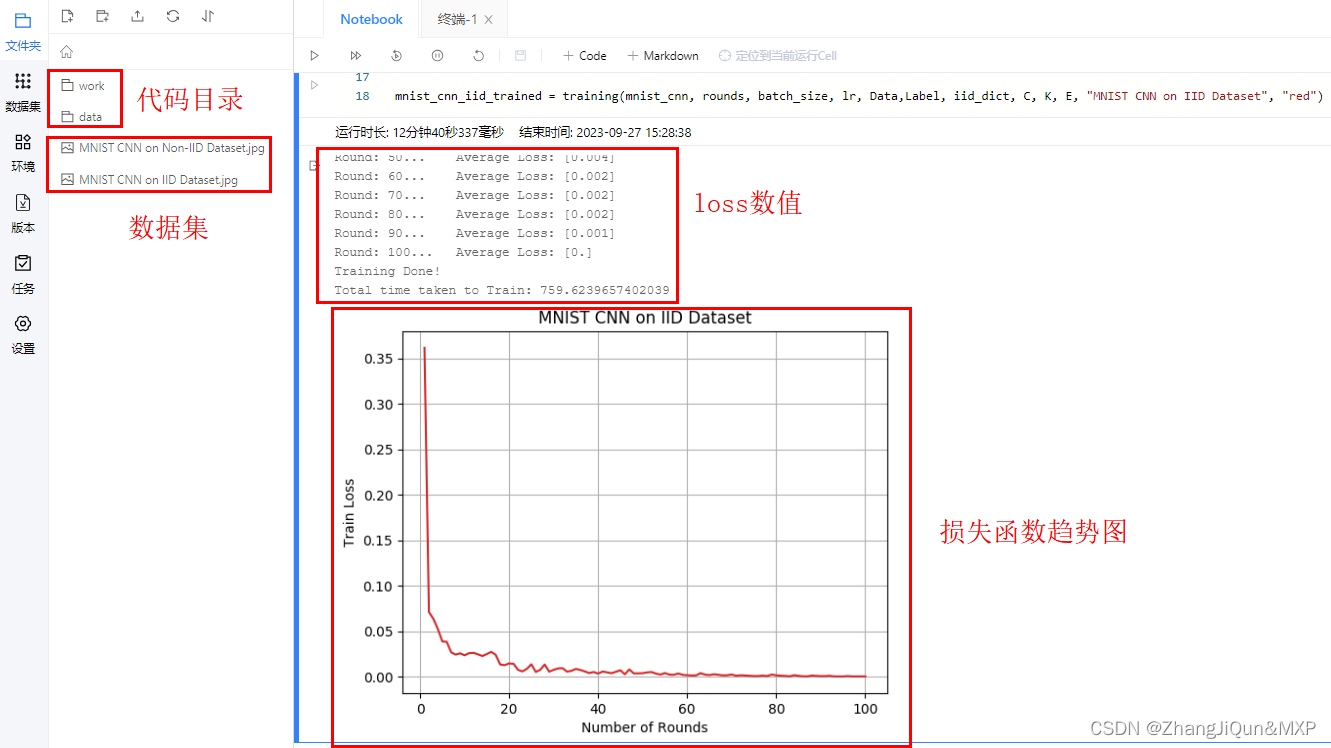
paddle2.3-基于联邦学习实现FedAVg算法-CNN
目录 1. 联邦学习介绍 2. 实验流程 3. 数据加载 4. 模型构建 5. 数据采样函数 6. 模型训练 1. 联邦学习介绍 联邦学习是一种分布式机器学习方法,中心节点为server(服务器),各分支节点为本地的client(设备&#…...

nuiapp保存canvas绘图
要保存一个 Canvas 绘图,可以使用以下步骤: 获取 Canvas 元素和其绘图上下文: var canvas document.getElementById("myCanvas"); var ctx canvas.getContext("2d");使用 Canvas 绘图 API 绘制图形。 使用 toDataUR…...
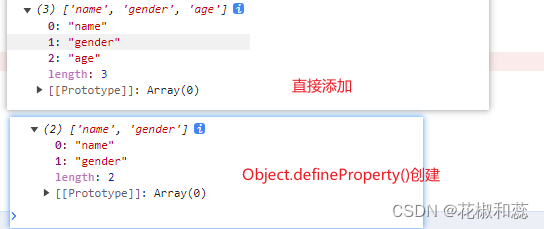
Object.defineProperty()方法详解,了解vue2的数据代理
假期第一篇,对于基础的知识点,我感觉自己还是很薄弱的。 趁着假期,再去复习一遍 Object.defineProperty(),对于这个方法,更多的还是停留在面试的时候,面试官问你vue2和vue3区别的时候,不免要提一提这个方法…...

Linux 磁盘管理
Linux 系统的磁盘管理直接关系到整个系统的性能表现。磁盘管理常用三个命令为: df、du 和 fdisk。 df df(英文全称:disk free)。df 命令用于显示磁盘空间的使用情况,包括文件系统的挂载点、总容量、已用空间、可用空间…...

大数据与人工智能的未来已来
大数据与人工智能的定义 大数据: 大数据指的是规模庞大、复杂性高、多样性丰富的数据集合。这些数据通常无法通过传统的数据库管理工具来捕获、存储、管理和处理。大数据的特点包括"3V": 大量(Volume):大数…...

【AI视野·今日Robot 机器人论文速览 第四十一期】Tue, 26 Sep 2023
AI视野今日CS.Robotics 机器人学论文速览 Tue, 26 Sep 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers Extreme Parkour with Legged Robots Authors Xuxin Cheng, Kexin Shi, Ananye Agarwal, Deepak Pathak人类可以通过以高度动态…...
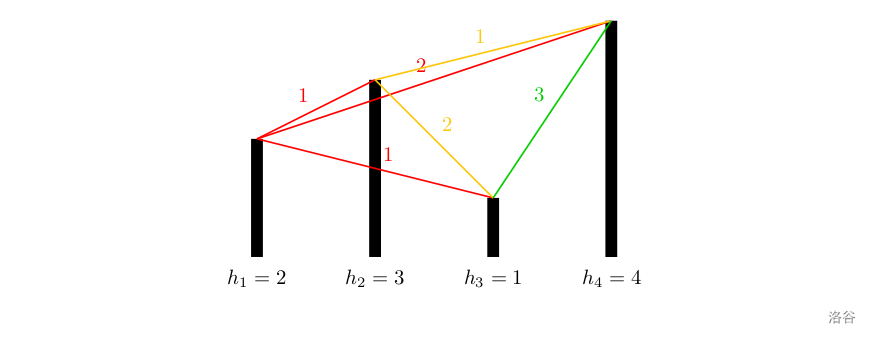
[NOIP2012 提高组] 开车旅行
[NOIP2012 提高组] 开车旅行 题目描述 小 A \text{A} A 和小 B \text{B} B 决定利用假期外出旅行,他们将想去的城市从 $1 $ 到 n n n 编号,且编号较小的城市在编号较大的城市的西边,已知各个城市的海拔高度互不相同,记城市 …...

数据库设计流程---以案例熟悉
案例名字:宠物商店系统 课程来源:点击跳转 信息->概念模型->数据模型->数据库结构模型 将现实世界中的信息转换为信息世界的概念模型(E-R模型) 业务逻辑 构建 E-R 图 确定三个实体:用户、商品、订单...

Miniconda创建paddlepaddle环境
1、conda env list 2、conda create --name paddle_env python3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ 3、activate paddle_env 4、python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple 5、pip install "p…...
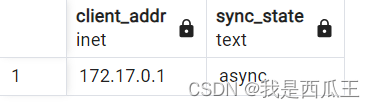
postgresql实现单主单从
实现步骤 1.主库创建一个有复制权限的用户 CREATE ROLE 用户名login # 有登录权限的角色即是用户replication #复制权限 encrypted password 密码;2.主库配置开放从库外部访问权限 修改 pg_hba.conf 文件 (相当于开放防火墙) # 类型 数据库 …...
提取PDF数据:Documents for PDF ( GcPdf )
在当今数据驱动的世界中,从 PDF 文档中无缝提取结构化表格数据已成为开发人员的一项关键任务。借助GrapeCity Documents for PDF ( GcPdf ),您可以使用 C# 以编程方式轻松解锁这些 PDF 中隐藏的信息宝藏。 考虑一下 PDF(最常用的文档格式之一…...

adb连接切换到模拟器端口
查看连接状态 adb devices出现以下情况 C:\Users\22560>adb devices List of devices attached 127.0.0.1:5555 offline emulator-5554 device可以发现我们想要连接的雷电模拟器的5555端口目前没有连接,只有emulator-5554被连接了,此时我们需要关…...
为何每个开发者都在谈论Go?
目录 一、引言Go的历史回顾关键时间节点 使用场景Go的语言地位技术社群与企业支持资源投入和生态系统 二、简洁的语法结构基本组成元素变量声明与初始化代码示例 类型推断函数与返回值代码示例输出 接口与结构体:组合而非继承错误处理:明确而不是异常小结…...
【Leetcode】 501. 二叉搜索树中的众数
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。 如果树中有不止一个众数,可以按 任意顺序 返回。 假定 BST 满足如下定义…...

怎样给Ubuntu系统安装vmware-tools
首先我要告诉你:Ubuntu无法安装vmware-tools,之所以这么些是因为我一开始也是这样认为的,vmware-tools是给Windows系统准备的我认为,毕竟Windows占有率远远高于Linux,这也可以理解。 那么怎么样实现Ubuntu虚拟机跟Wind…...

DDS信号发生器波形发生器VHDL
名称:DDS信号发生器波形发生器 软件:Quartus 语言:VHDL 要求: 在EDA平台中使用VHDL语言为工具,设计一个常见信号发生电路,要求: 1. 能够产生锯齿波,方波,三角波&…...

Python3操作SQLite3创建表主键自增长|CRUD基本操作
Win11查看安装的Python路径及安装的库 Python PEP8 代码规范常见问题及解决方案 Python3操作MySQL8.XX创建表|CRUD基本操作 Python3操作SQLite3创建表主键自增长|CRUD基本操作 anaconda3最新版安装|使用详情|Error: Please select a valid Python interpreter Python函数绘…...

B. Comparison String
题目: 样例: 输入 4 4 <<>> 4 >><< 5 >>>>> 7 <><><><输出 3 3 6 2 思路: 由题意,条件是 又因为要使用尽可能少的数字,这是一道贪心题,所以…...

python端口扫描
扫描所有端口 import socket, threading, os, timedef port_thread(ip, start, step, timeout):for port in range(start, start step):s socket.socket()s.settimeout(timeout)try:s.connect((ip, port))print(f"port[{port}] 可用")except Exception as e:# pri…...

FLUX.1-devGPU算力优化:显存碎片整理Expandable Segments原理与实测效果
FLUX.1-dev GPU算力优化:显存碎片整理Expandable Segments原理与实测效果 1. 项目背景与核心价值 FLUX.1-dev作为当前开源界最强的文本生成图像模型之一,拥有120亿参数的庞大架构,能够生成影院级光影质感的图像。但在实际部署中,…...

Vue3结合exceljs实现动态Excel报表生成与数据校验
1. 为什么选择Vue3exceljs处理Excel报表 在前端开发中,处理Excel文件一直是个让人头疼的问题。我最近在做一个数据填报系统时,就遇到了需要动态生成Excel报表并实现数据校验的需求。经过多次尝试,最终选择了Vue3exceljs这个组合方案ÿ…...

BGE Reranker-v2-m3在RAG中的应用:提升生成式AI准确性
BGE Reranker-v2-m3在RAG中的应用:提升生成式AI准确性 1. 引言 想象一下,你正在使用一个智能问答系统,输入问题后,系统返回的答案却与你的问题毫不相关。这种糟糕的体验在早期的RAG(检索增强生成)系统中并…...
深入YOLOv12网络结构:基于Transformer的Backbone设计与实现解析
深入YOLOv12网络结构:基于Transformer的Backbone设计与实现解析 最近在目标检测领域,YOLO系列的新成员YOLOv12又带来了不少新东西。如果你已经熟悉了YOLOv5、v8这些基于CNN的架构,可能会好奇,当YOLO遇上Transformer会擦出什么火花…...
)
别再复制粘贴了!手把手教你用Vite+Vue3定制专属CKEditor5编辑器(含字体、高亮、对齐插件)
ViteVue3深度定制CKEditor5全攻略:从插件配置到性能优化 在Vue3生态中,富文本编辑器的集成一直是开发者面临的挑战之一。CKEditor5作为行业领先的解决方案,其模块化设计允许深度定制,但官方文档对Vite构建工具的支持说明相对简略。…...

DeOldify开源生态巡礼:GitHub上相关的优秀工具与插件合集
DeOldify开源生态巡礼:GitHub上相关的优秀工具与插件合集 如果你用过DeOldify给老照片上色,可能会觉得它的效果确实惊艳,但有时候也想,要是能更方便地批量处理、或者有个网页界面直接上传图片就好了。其实,DeOldify的…...

Qwen2.5-VL与Anaconda集成:Python环境配置指南
Qwen2.5-VL与Anaconda集成:Python环境配置指南 1. 引言 你是不是遇到过这样的情况:好不容易下载了Qwen2.5-VL这个强大的多模态模型,准备大展身手,结果一堆依赖冲突让你头疼不已?或者在不同项目间切换时,环…...

Adafruit Debounce:嵌入式无阻塞按键消抖库详解
1. 项目概述Adafruit Debounce 是一个专为嵌入式微控制器平台(尤其是 Arduino 生态)设计的轻量级、无阻塞(non-blocking)GPIO 按键消抖库。其核心目标并非提供复杂的状态机或高级事件抽象,而是以极简、可预测、零依赖的…...

Cosmos-Reason1-7B多场景:支持图像/视频双模态输入的物理AI生产部署
Cosmos-Reason1-7B多场景:支持图像/视频双模态输入的物理AI生产部署 想象一下,你给AI看一张厨房的照片,它不仅能告诉你“桌上有杯水”,还能推理出“杯子放在桌沿,如果被碰到可能会摔碎”。或者给它看一段机器人抓取物…...
)
数值模拟中的耗散与色散:如何选择算法提升计算精度(附MATLAB/Python代码示例)
数值模拟中的耗散与色散:如何选择算法提升计算精度(附MATLAB/Python代码示例) 在计算流体力学(CFD)和有限元分析(FEA)领域,数值模拟的精度直接影响工程决策的可靠性。当我们用计算机求解Navier-Stokes方程或波动方程时,…...