MySQL——四、SQL语句(下篇)
MySQL
- 一、常见的SQL函数
- 1、数学函数
- 2、日期函数
- 3、分组函数(聚合函数)
- 4、流程控制函数
- 二、where条件查询和order by排序
- 三、分组统计
- 四、多表关联查询
- 1、交叉连接CROSS
- 2、内连接inner
- 3、外连接:outer
- 4、子查询
- 五、分页查询
一、常见的SQL函数
1、length(str):获取参数的字节数
- a)
length(): 单位是字节,utf8编码下,一个汉字三个字节,一个数字或字母一个字节。gbk编码下,一个汉字两个字节,一个数字或字母一个字节。 - b)
char_length():单位为字符,不管汉字还是数字或者是字母都算是一个字符。
注意: varchar(20)中的20表示字节数,如果存放utf-8编码的话只能放6个汉字。varchar(n),这里的n表示字节数。
MySQL 5.0.3 之后: varchar(20)表示字符数,不管什么编码,既汉字也能放20个。0-65532也就是最多占65532字节。
varchar(n)这里的n表示字符数,比如varchar(200),不管是英文还是中文都可以存放200个。
mysql> select length('abcd');
+----------------+
| length('abcd') |
+----------------+
| 4 |
+----------------+
1 row in set (0.00 sec)
mysql> select first_name,char_length(first_name) as '字符个数' from employees;
+-------------+--------------+
| first_name | 字符个数 |
+-------------+--------------+
| Steven | 6 |
| Neena | 5 |
| Lex | 3 |
| Alexander | 9 |
| Bruce | 5 |
mysql> select length('小白abc');
+---------------------+
| length('小白abc') |
+---------------------+
| 9 |
+---------------------+
1 row in set (0.00 sec)
2. concat(str1,str2,...):连接字符串
mysql> select concat(last_name,'--',first_name) as 姓名 from employees;
3. 字符串替换insert,replace
- (1)
insert(str1,x,len,'str2')字串替换函数 str1返回的字串,字串字符的起始位置重1开始,当x为0值或负值(-2)时返回原始字符串;len是字串长度;str2是替换的字串
mysql> select insert(first_name,1,4,'000') from employees;
mysql> select insert('zhangsan',1,5,'li');
+-----------------------------+
| insert('zhangsan',1,5,'li') |
+-----------------------------+
| lisan |
+-----------------------------+
1 row in set (0.00 sec)
- (2)
replace(‘目标字符串’,‘被替换子串’,‘用于替换的新串’)替换
mysql> select replace('目标字符串','字符','哈哈');
+----------------------------------------------+
| replace('目标字符串','字符','哈哈') |
+----------------------------------------------+
| 目标哈哈串 |
+----------------------------------------------+
1 row in set (0.00 sec)
4、upper(str):小写字母变大写;lower(str):大写字母变小写;
mysql> select UPPER('hehe');
+---------------+
| upper('hehe') |
+---------------+
| HEHE |
+---------------+
1 row in set (0.00 sec)
mysql> select lower('XIXI');
+---------------+
| lower('XIXI') |
+---------------+
| xixi |
+---------------+
1 row in set (0.00 sec)
5.字符截取left right substr
- (1)
substr == substring SUBSTR(str,pos,len)第一个数字是开始截取的索引值,第二个数数截取的长度 -
- 案例:截取字符串,从第4个字符(包含)开始到最后
mysql> select substr('目标字符串',4) as out_put;
+---------+
| out_put |
+---------+
| 符串 |
+---------+
1 row in set (0.00 sec)
-
- 案例:截取字符串,从第二个开始接到第三个
mysql> select substr('目标字符串',2,1) as out_put;
+---------+
| out_put |
+---------+
| 标 |
+---------+
1 row in set (0.00 sec)
- (2)
left('str1',4)从左开始截取四个字符 - (3)
right('str1',4)从右开始截取四个字符
6、trim 删除字符串左右两侧的空格,作用是去掉字符串前后的空格,中间空格去不掉
mysql> select trim(' hello world ');
+-------------------------+
| trim(' hello world ') |
+-------------------------+
| hello world |
+-------------------------+
1 row in set (0.00 sec)
去掉前后两端的其他字符:
mysql> select trim('a' from 'abcasadefa'); 将a字符从指定的字符串中剔除(首和末尾)
+-----------------------------+
| trim('a' from 'abcasadefa') |
+-----------------------------+
| bcasadef |
+-----------------------------+
1 row in set (0.00 sec)
7.判断字符第一次出现的位置 instr locate
- (1)
instr(‘源字符串’,‘子字符串’):作用返回子字符串子源字符串里的起始索引.
mysql> select instr('目标字符串','字符'); //判断某字符在字符串中的第一次出现的位置
+--------------------------------------+
| instr('目标字符串','字符') |
+--------------------------------------+
| 3 |
+--------------------------------------+
1 row in set (0.00 sec)
返回结果3, 如果找不到返回0
(2)mysql> select locate('a','dfdakfhsdf'); a字符在字符串中第一次出现的位置
+--------------------------+
| locate('a','dfdakfhsdf') |
+--------------------------+
| 4 |
+--------------------------+
1 row in set (0.00 sec)
8.lpad字串填充
lpad(‘目标字符串’,10,‘填充字符’); 将填充字符填充到目标字符的左边,补足10个
mysql> select lpad('哈哈哈',10,'*');
+--------------------------+
| lpad('哈哈哈',10,'*') |
+--------------------------+
| *******哈哈哈 |
+--------------------------+
1 row in set (0.00 sec)
mysql> select rpad('哈哈哈',10,'*');
+--------------------------+
| rpad('哈哈哈',10,'*') |
+--------------------------+
| 哈哈哈******* |
+--------------------------+
1 row in set (0.00 sec)
9.反显示字串 reverse
mysql> select reverse('dfdakfhsdf');
+-----------------------+
| reverse('dfdakfhsdf') |
+-----------------------+
| fdshfkadfd |
+-----------------------+
1 row in set (0.00 sec)
10.比较两个字串顺序,strcmp如果这两个字符串相等返回0,如果第一个参数是根据当前的排序小于第二个参数顺序返回-1,否则返回1。
mysql> select strcmp('a','b')-> ;
+-----------------+
| strcmp('a','b') |
+-----------------+
| -1 |
+-----------------+
1 row in set (0.00 sec)
11.正则匹配regexp
mysql> select first_name from employees where first_name regexp 'Su?an';
+------------+
| first_name |
+------------+
| Susan |
+------------+
1 row in set (0.00 sec)
? 前一个字符字符匹配 0 次或 1 次
^ 字符串的开始
$ 字符串的结尾
. 任何单个字符 .{3}
[. . . ] 在方括号内的字符列表
[^ . . . ] 非列在方括号内的任何字符
p1 | p2 | p3 交替匹配任何模式p1,p2或p3
* 零个或多个前面的元素
+ 前面的元素的一个或多个实例
{n} 前面的元素的n个实例
{m , n} m到n个实例前面的元素
char_length substr
1、数学函数
1.round 四舍五入
mysql> select round(1.45);
+-------------+
| round(1.45) |
+-------------+
| 1 |
+-------------+
1 row in set (0.00 sec)
mysql> select round(1.567,2);
+----------------+
| round(1.567,2) |
+----------------+
| 1.57 |
+----------------+
1 row in set (0.00 sec)
2.ceil 向上取整
mysql> select ceil(-1.3);
+------------+
| ceil(-1.3) |
+------------+
| -1 |
+------------+
1 row in set (0.00 sec)
mysql> select ceil(1.3);
+-----------+
| ceil(1.3) |
+-----------+
| 2 |
+-----------+
1 row in set (0.00 sec)
3.floor 向下取整
mysql> select floor(1.3);
+------------+
| floor(1.3) |
+------------+
| 1 |
+------------+
1 row in set (0.00 sec)
mysql> select floor(-1.8);
+-------------+
| floor(-1.8) |
+-------------+
| -2 |
+-------------+
1 row in set (0.00 sec)
4.truncate 截断小数点开始截取
mysql> select truncate(1.65,1);
+------------------+
| truncate(1.65,1) |
+------------------+
| 1.6 |
+------------------+
1 row in set (0.00 sec)
mysql> select truncate(1.6565,1);
+--------------------+
| truncate(1.6565,1) |
+--------------------+
| 1.6 |
+--------------------+
1 row in set (0.01 sec)
mysql> select truncate(1.6565,2);
+--------------------+
| truncate(1.6565,2) |
+--------------------+
| 1.65 |
+--------------------+
1 row in set (0.00 sec)
5.mod 取余
mysql> select mod(10,3);
+-----------+
| mod(10,3) |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
2、日期函数
1.now 用户返回当前日期时间
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2021-08-02 14:37:15 |
+---------------------+
1 row in set (0.00 sec)
2.curdate 返回当前系统日期,没有时间部分
mysql> select curdate();
+------------+
| curdate() |
+------------+
| 2021-08-02 |
+------------+
1 row in set (0.00 sec)
3.curtime 返回当前系统时间,没有日期部分
mysql> select curtime();
+-----------+
| curtime() |
+-----------+
| 14:38:32 |
+-----------+
1 row in set (0.00 sec)
4.可以单独获取年/月/日
mysql> select year(now());
+-------------+
| year(now()) |
+-------------+
| 2021 |
+-------------+
1 row in set (0.00 sec)
mysql> select year('2021-1-1');
+------------------+
| year('2021-1-1') |
+------------------+
| 2021 |
+------------------+
1 row in set (0.00 sec)
mysql> select month(now());
+--------------+
| month(now()) |
+--------------+
| 8 |
+--------------+
1 row in set (0.00 sec)
mysql> select day(now());
+------------+
| day(now()) |
+------------+
| 2 |
+------------+
1 row in set (0.00 sec)
hour minute second一样
5. 日期格式转换
mysql> select str_to_date('2021-08-02 10:20:30','%Y-%m-%d %H:%i:%s');
+--------------------------------------------------------+
| str_to_date('2021-08-02 10:20:30','%Y-%m-%d %H:%i:%s') |
+--------------------------------------------------------+
| 2021-08-02 10:20:30 |
+--------------------------------------------------------+
1 row in set (0.00 sec)
mysql> select date_format(now(),'%y-%m-%d');
+-------------------------------+
| date_format(now(),'%y-%m-%d') |
+-------------------------------+
| 21-08-02 |
+-------------------------------+
1 row in set (0.00 sec)
案例:查询入职日期是1992-4-3的员工信息:
mysql> select * from employees where hiredate='1992-4-3';
mysql> select * from employees where hiredate=STR_TO_DATE('1992 4 3','%Y %m %d');
3、分组函数(聚合函数)
分组函数和前面讲的函数不同在于,前面的对内容本身的处理,而分组函数的主要功能是统计
常用的分组函数sum , avg , max , min , count
mysql> select sum(salary) as 单月所发总工资 from employees;
+-----------------------+
| 单月所发总工资 |
+-----------------------+
| 691400.00 |
+-----------------------+
1 row in set (0.00 sec)
mysql> select avg(salary) as 单月所发平均工资 from employees;
+--------------------------+
| 单月所发平均工资 |
+--------------------------+
| 6461.682243 |
+--------------------------+
1 row in set (0.00 sec)
mysql> select max(salary) as 单月所发最多工资 from employees;
+--------------------------+
| 单月所发最多工资 |
+--------------------------+
| 24000.00 |
+--------------------------+
1 row in set (0.00 sec)
mysql> select min(salary) as 单月所发最少工资 from employees;
+--------------------------+
| 单月所发最少工资 |
+--------------------------+
| 2100.00 |
+--------------------------+
1 row in set (0.00 sec)
mysql> select count(*) as 总人数 from employees;
+-----------+
| 总人数 |
+-----------+
| 107 |
+-----------+
1 row in set (0.05 sec)
mysql> select count(salary) from employees;
+---------------+
| count(salary) |
+---------------+
| 107 |
+---------------+
1 row in set (0.00 sec)
mysql> select count(distinct salary) from employees;
+------------------------+
| count(distinct salary) |
+------------------------+
| 57 |
+------------------------+
1 row in set (0.00 sec)
4、流程控制函数
1.if函数
mysql> select if('10>1','大','小');
+------------------------+
| if('10>1','大','小') |
+------------------------+
| 大 |
+------------------------+
1 row in set, 1 warning (0.00 sec)
2.case函数
case 要判断的字段或表达式
when case的结果是常量1 then 要显示的值1(或语句1;)
when case的结果是常量2 then 要显示的值2(或语句2;)......
else case的结果都不前面的时候显示;
end 结束
案例:员工表中, 部门号是30,显示的工资是1.1倍
部门号是50,显示的工资是1.2倍
其他显示原工资
mysql> select salary as 原工资,department_id,-> case department_id-> when 30 then salary*1.1-> when 50 then salary*1.2-> else salary-> end as 新工资-> from employees;
+-----------+---------------+-----------+
| 原工资 | department_id | 新工资 |
+-----------+---------------+-----------+
| 24000.00 | 90 | 24000.00 |
| 17000.00 | 90 | 17000.00 |
| 17000.00 | 90 | 17000.00 |
| 9000.00 | 60 | 9000.00 |
| 6000.00 | 60 | 6000.00 |
3.多重if
case
when 条件1 then 要显示的值1(或语句1;)
when 条件2 then 要显示的值2(或语句2;)
......
else 前面的条件都不符合时候显示;
end 结束
mysql> select salary,-> case-> when salary>20000 then 'A级工资'-> when salary>10000 then 'B级工资'-> else 'C级工资'-> end as 工资等级-> from employees;
+----------+--------------+
| salary | 工资等级 |
+----------+--------------+
| 24000.00 | A级工资 |
| 17000.00 | B级工资 |
| 17000.00 | B级工资 |
综合练习:
查询first_name字段字符长度小于字节长度的所有first_name;
mysql> select first_name,char_length(first_name)
as '字符',length(first_name) as '字节'
from emp where
char_length(first_name) < length(first_name);
二、where条件查询和order by排序
select column_name from table_Name;
select column_name from table_Name
where
group by
having
order by
limit
where条件查询
语法 : select 查询列表 from 表名称 where 筛选条件
**按照条件表达式来筛选:**条件运算符: > , < , = , != / <>, >= , <=
按照逻辑表达式筛选逻辑运算符:and , not , or
模糊查询:% _ , like , between…and , in , is null ,is not null,regexp() .任意单个字符 * 匹配前一个字符任意次 ?匹配任意字符0或1次
条件表达式
案例:查询员工工资大于12000的员工有哪些?
mysql> select * from employees where salary > 12000;
案例:查询部门编号不等于90号的员工名和部门编号:
mysql> select concat(last_name,first_name) as 姓名,
department_id
from employees
where department_id<>90;
逻辑表达式
案例:工资在10000到20000之间到员工名,工资和奖金
mysql> select last_name,salary,commission_pct
from employees
where salary>=10000
and salary<=20000;
案例:查询部门编号不是在90到110之间的,或者工资高于15000的员工信息
mysql> select * from employees
where department_id<90 or department_id>110
or salary>15000;
select * from employees
where not(department_id<90
and department_id>110)
or salary>15000;
模糊查询:
like
between and
in
is null | is not null
like:
案例:查询员工名中包含了"a"字符的所有员工的信息
select * from employees where last_name like '%a%';
%:通配符,表示任意多个字符,也可表示0个字符,
_:任意一个字符;
案例:查询第三个字符为n或第五个字符为l的员工信息
mysql> select * from employees where last_name like '__n_l%';
案例:查询员工信息表中员工名第二个字符是"_"的员工信息
mysql> select * from employees where last_name like '_\_%'; _ \_
mysql> select * from employees where last_name like '_&_%' escape '&'; #推荐写法
escape '&':说明&这个符号是转义字符
between and:
案例:查询员工工资中10000到20000之间到员工信息
mysql> select * from employees where salary>=10000 and salary<=20000;
mysql> select * from employees where salary between 10000 and 20000;
注意: 使用between and
- 1.可以简洁sql语句
- 2.并且包含临界值
- 3.临界值不能调换位置,小的在左边,大的值在右边.
in:(列表值)
案例:查询员工的工种编号是 it_prog,ad_vp,ad_pres中任意一个的员工信息
select * From employees
where job_id='it_prog'
or job_id='ad_vp'
or job_id='ad_pres';select * from employees
where job_id in ('it_prog','ad_vp','ad_pres');select * from employees
where job_id Not in ('it_prog','ad_vp','ad_pres');select * from employees l
where job_id in ('it_prog','ad_vp','ad_pres',null);select * from employees
where job_id not in ('it_prog','ad_vp','ad_pres',null);is null | is no null:
案例:查询没有奖金率的员工信息
mysql> select * from employees where commission_pct is null;
查询奖金率的就取反:
mysql> select * from employees where commission_pct is not null;
注意: commission_pct=null这个写法不能判断null值
is not也不能换成<>不等号.
<=>判断空值 is null
mysql> select * from employees where commission_pct <=>null;
排序查询
语法: select 查询列表 from 表 where 条件 order by 排序字段列表 asc | desc;
案例:查询所有员工信息,要求工资从大到小排列:
mysql> select * from employees order by salary desc;
- descend:降序
- ascend:升序
反过来从小到大排列:
mysql> select * from employees order by salary asc;
mysql> select * from employees order by salary; asc 可以省略,默认升序
案例:查询部门编号大于等于90的员工信息,按照入职时间的先后排序
mysql> select * from employees where department_id>=90 order by hiredate asc;
案例:实现按表达式排序:按年薪的高低显示员工信息
select last_name,department_id,salary*12*(1+ifnull(commission_pct,0)) as 年薪
from employees
order by salary*12*(1+ifnull(commission_pct,0)) desc;select last_name,department_id,(salary+ifnull(commission_pct,0))*12 年薪 from employees
order by (salary+ifnull(commission_pct,0))*12 desc;select *,salary*12*(1+ifnull(commission_pct,0)) as 年薪
from employees
order by 年薪 desc;
案例:使用函数来排序:按姓名的长度显示员工信息
mysql> select *,length(last_name) as 姓名的长度 from employees order by length(last_name) desc;
mysql> select *,length(last_name) as 姓名的长度 from employees order by 姓名的长度 desc;
案例:实现多字段排序:查询员工信息,首先用工资高低排序,工资一样的在按员工id大到小排序
mysql> select * from employees order by salary desc,employee_id desc;
查询employees表中所有员工的姓名以及薪资并将每人薪资+1000;
查询employees表显示每位员工薪资的位数;
注意: ceil()取整 或floor()
查询employees表中first_name和last_name连接显示并标记为’姓名’; concat
select concat(first_name,'-',last_name) as 姓名 from employees;
查询员工表中的job_id类型有哪些;
select distinct job_id from employees;
查询每位员工电话号的后四位数字;
select right(phone_number,4) from employees;
三、分组统计
分组查询:
group by关键字实现分组,group by放在where条件语句之后,order by放置中group by的后面,后面跟上having关键字,总体的循序先后为:
where条件group by 分组语句having 分组的条件order by排序语句
where条件是针对所有记录的,having条件只是局限的针对每一组的记录的
分组查询语法:
select列(这个列要求必须只能是group by的后面字段),分组函数()
from表名
where筛选条件(针对表的所有记录)
group by分组字段列表
having(只能配合group by使用)与分组有关的筛选条件(针对分组后的每组内记录)
order by排序
案例:查询每个工种的最高工资
mysql> select max(salary),job_id from employees group by job_id;
案例:查询每个地方的部门个数
mysql> select count(*),location_id from departments group by location_id;
案例:查询每个部门每个工种的员工的平均工资
mysql> select count(*) 个数,avg(salary),department_id,job_id
from employees
group by department_id,job_id;
(部门号和工种号都相同的员工分一组)
案例:查询员工邮箱里包含"a"字母的,每个部门的平均工资
mysql> select avg(salary) 部门平均工资 , department_id
from employees where email like '%a%'
group by department_id;
案例:查询的有奖金的每个领导手下员工的最高工资
mysql> select max(salary) 最高工资 , manager_id
from employees
where commission_pct is not null
group by manager_id
案例:查询部门的员工个数>5的,并显示所有部门的员工数
- 1)查询每个部门的员工个数
mysql> select count(*) c,department_id
from employees
group by department_id;
- 2)在第一步的结果中找那个部门的员工个数>5
mysql> select count(*) c,department_id
from employees
group by department_id
having c>5; (聚合函数的结果条件过滤)
案例:查询的没有奖金的每个领导手下员工的最高工资且最高工资工资大于12000,并且按升序排序。
- 1)首先查询每个领导手下没有奖金的
mysql> select max(salary) 最高工资,manager_id
from employees
where commission_pct is null
group by manager_id;
- 2)在1点结果中在选工资大于12000
mysql> select max(salary) 最高工资,manager_id
from employees
where commission_pct is null
group by manager_id
having 最高工资>12000;
mysql> select max(salary) maxsalary,manager_id
from employees
where commission_pct is null
group by manager_id
having maxsalary>12000
order by maxsalary;
四、多表关联查询
1、交叉连接CROSS
将两张表或多张表联合起来查询,这就是连接查询。交叉连接返回的结果是被连接的两个表中所有数据行的笛卡儿积。
笛卡尔积是必须要知道的一个概念。在没有任何限制条件的情况下,两表连接必然会形成笛卡尔积。(如表1 m行a列,表2 n行b列,则无条件连接时则会有m*n,a+b列。)交叉连接查询在实际运用中没有任何意义
注意: 连接条件必须是唯一字段,如果非唯一字段则会产生笛卡尔积。
\>select * from 表1,表2;
2、内连接inner
指连接结果仅包含符合连接条件的行,参与连接的两个表都应该符合连接条件。
\>select * from 表1,表2 where 表1.字段=表2.字段;\>select * from employees e,departments d where e.department_id=d.department_id;
- 1)等值连接:表之间用=连接
案例:查询员工名和对应的部门名
mysql> select last_name,department_name
from employees,departments
where employees.department_id=departments.department_id;
可以使用别名
mysql> select last_name,department_name
from employees e,departments d
where e.department_id=d.department_id;
案例:查询有奖金的员工名以及所属部门名:
mysql> select last_name,department_name
from employees e,departments d
where e.department_id=d.department_id
and e.commission_pct is not null;
案例:查询每个城市的部门个数
mysql> select count(*) as 个数 ,city
from departments d,locations l
where d.location_id=l.location_id
group by city;
案例:查询有奖金的每个部门的部门名和部门的领导编号和该部门的最低工资
mysql> select d.department_name,d.manager_id,min(e.salary)
from departments d,employees e
where d.department_id = e.department_id
and e.commission_pct is not null
group by d.department_name,d.manager_id;
注意: sql中select后面的字段必须出现在group by后面,或者被聚合函数包裹,不然会抛出以下的错误
sql_mode=only_full_group_by
案例:查询每个工种的工种名和员工个数,并且按照员工个数排序降序
mysql> select job_title,count(*)
from employees e,jobs j where e.job_id=j.job_id
group by job_title
order by count(*) desc;
案例:查询员工名,部门名和所在城市名
mysql> select last_name,department_name,city
from employees e,departments d,locations l
where e.department_id=d.department_id
and d.location_id=l.location_id;
SELECT column_list
FROM t1
INNER JOIN t2 ON join_condition1
INNER JOIN t3 ON join_condition2
...
WHERE where_conditions;
- 2)自连接:相当于等值连接,只不过是自己连接自己,不像等值连接是两个不同的表之间的;
案例:查询员工名和他的上司的名字
mysql> select e.last_name,m.last_name
from employees e,employees m
where e.manager_id=m.employee_id;
- 3)非等值连接:等值连接中的等号改成非等号情况
创建一张job_grades工资级别表:
create table job_grades(grade_level varchar(3),lowest_sal int,highest_sal int) ;
insert into job_grades values('A' , 1000,2999);
insert into job_grades values('B' , 3000,5999);
insert into job_grades values('C' , 6000,9999);
insert into job_grades values('D' , 10000,14999);
insert into job_grades values('E' , 15000,24999);
insert into job_grades values('F' , 25000,40000);
案例:查询员工的工资和工资级别
mysql> SELECT
salary,grade_level
FROM
employees e,job_grades j
WHERE
salary BETWEEN j.lowest_sal AND j.highest_sal;
select 查询列表
from 表1 别名
【链接类型】 join 表2 别名
on 链接条件
where 数据筛选条件;
1.查询员工名和其对应所属的部门名
select last_name,department_name
from employees e
inner join departments d
on e.department_id = d.department_id;
2.查询名字中包含e字母的员工名和其对象的部门名
select last_name,department_name
from employees e
inner join departments d
on e.department_id = d.department_id
where last_name like '%e%';
3.查询所在部门个数大于3的城市名和部门个数
select count(d.department_id) count,l.city
from departments d
inner join locations l
on d.location_id = l.location_id
group by l.city
having count>3;
4.查询员工个数大于3的部门名和员工个数,降序排序
SELECT d.department_name,COUNT(e.employee_id) c
FROM employees e
INNER JOIN departments d
ON e.department_id=d.department_id
GROUP BY d.department_name
HAVING c>3
ORDER BY c DESC;
5.查询员工名以及对应的工种名和部门名,按部门名降序排序
select e.last_name,j.job_title,d.department_name
from employees e
inner join departments d
on e.department_id = d.department_id
inner join jobs j
on e.job_id=j.job_id
order by d.department_name desc;
案例:查询员工的工资和工资级别
SELECT
salary,grade_level
FROM
employees e
INNER JOIN
job_grades g
ON
e.salary BETWEEN g.lowest_sal AND g.highest_sal;
案例: 查询员工的名和其对应的直属领导
SELECT
e.last_name employee_name,
m.last_name manager_name
FROM
employees e
INNER JOIN
employees m
ON
e.manager_id=m.employee_id;
3、外连接:outer
外连不但返回符合连接和查询条件的数据行,还返回不符合条件的一些行。外连接分三类:左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)和全外连接(FULL OUTER JOIN)。
三者的共同点是都返回符合连接条件和查询条件(即:内连接)的数据行。不同点如下:
- 左外连接还返回左表中不符合连接条件单符合查询条件的数据行。
- 右外连接还返回右表中不符合连接条件单符合查询条件的数据行。
- 全外连接还返回左表中不符合连接条件单符合查询条件的数据行,并且还返回右表中不符合连接条件单符合查询条件的数据行。全外连接实际是上左外连接和右外连接的数学合集(去掉重复),即“全外=左外 UNION 右外”。
说明: 左表就是在“(LEFT OUTER JOIN)”关键字左边的表。右表当然就是右边的了。在三种类型的外连接中,OUTER 关键字是可省略的。
两张表:ta:id,age字段,tb:id,name,ta_id
create table ta(id int,age int);
create table tb(id int,name varchar(4),ta_id int);
insert into ta(id,age) values(1,12);
insert into ta(id,age) values(2,22);
insert into ta(id,age) values(3,32);
insert into ta(id,age) values(4,42);
insert into ta(id,age) values(5,52);
insert into ta(id,age) values(6,62);
insert into tb(id,name,ta_id) values(1,'任波涛',2);
insert into tb(id,name,ta_id) values(2,'田兴伟',1);
insert into tb(id,name,ta_id) values(3,'唐崇俊',3);
insert into tb(id,name,ta_id) values(4,'夏铭睿',8);
insert into tb(id,name,ta_id) values(5,'包琪',1);
insert into tb(id,name,ta_id) values(6,'夏雨',10);
insert into tb(id,name,ta_id) values(7,'夏铭雨',10);
insert into tb(id,name,ta_id) values(8,'白芳芳',6);
**外连接:**有这样的场景,在ta和tb两表中查询没有对应年龄数据的学生姓名和年龄
SELECT
tb.name,ta.age
FROM
tb
INNER JOIN
ta
ON
tb.ta_id=ta.id
WHERE
ta.id IS NULL;
掌握外连接知识点:
- 1.外连接的查询结果为主表中有的所有记录
外表有对应数据,结果记录上显示对应数据
外表中没有对应的数据,结果记录上填充null -
- 和内连接的区别:
-
- 内连接: 当从表没有记录的时候,主、从表的记录都丢掉!
-
- 外连接: 当从表没有记录的时候,会保留主表的记录,对应从表null
- 2.左外连接:left join左边的是主表,右外连接right join 右边的是主表
- 3.左外连接和右外连接上互通的所以掌握一个就好!
**解决:**在ta和tb两表中查询没有对应年龄数据的学生姓名和年龄
SELECT
tb.name,ta.age
FROM
tb
LEFT JOIN
ta
ON
tb.ta_id=ta.id
WHERE
ta.id IS NULL;
案例:查询没有员工的部门
SELECT d.department_id,d.department_name,e.employee_id
FROM departments d
LEFT JOIN employees e
ON d.department_id=e.department_id
WHERE e.employee_id IS NULL;
全外连接: Oracle、MySQL不支持全连接。可以使用UNION ALL语句来组合左连接和右连接
4、子查询
子查询介绍: 出现在其他语句中的select语句,被包裹的select语句就是子查询或内查询
包裹子查询的外部的查询语句:称主查询语句
比如:
select last_name from employees
where department_id in(select department_id from departmentswhere location_id=1700
);
子查询分类
1、通过位置来分:
select 后面:仅仅支持标量子查询
from 后面:支持表子查询
where 或having 后面:支持标量子查询(重要)\列子查询(重要)\行子查询(用的较少)
exists 后面(相关查询):支持表子查询
2、按结果集的行列数不同分类:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列但有多行)
行子查询(结果集只有一行但有多列)
表子查询(结果集多行多列)
3、子查询特点:
子查询放在小括号内
子查询一般放在条件的右侧
标量子查询,一般搭配着单行操作符来使用(> < >= <= <> =)
列子查询,一般搭配着多行操作符使用:in any/some all
子查询的执行顺序优先于主查询(select后的子查询存在例外)
- 1.where后面的标量子查询
案例:查询工资比Abel这个人的高的员工信息
select * from employees
where salary>(
select salary
from employees
where last_name='Abel'
);
- 2.查询job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
select last_name,job_id,salary
from employees
where job_id=(select job_id from employees
where employee_id=141 ) and salary>(select salary
from employees where employee_id=143);
(这个案例说明一个主查询里可以放很多个子查询)
- 3.子查询里用到分组函数:查询公司工资最少的员工的last_name,job_id和salary
select last_name,job_id,salary
from employees
where salary=(select min(salary) from employees);
- 4.用到having的子查询:查询最低工资大于50号部门最低工资的部门id和其最低工资
select department_id , min(salary) from employees
group by department_id
having min(salary)>(select min(salary) from employees where department_id=50);
-
- where后面的列子查询(多行子查询)
首先来看一下多行操作符:in/not in:等于列表中的任意一个a in(10,20,30); 可以替换 a=10 or a=20 or a=30; any/some:和子查询返回的某一个值比较a > any(10,20,30); 可以替换 a > min(10,20,30);all:和子查询返回的所有值比较a > all(10,20,30); 可以替换 a > max(10,20,30);a >10 and a>20 and a>30
案例:返回location_id是1400或1700的部门中的所有员工的名字
select last_name from employees
where department_id in (select department_id from departments
where location_id in (1400,1700));
案例:查询其他工种中比job_id为’IT_PROG’的员工某一工资低的员工的员工号,姓名,job_id和salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary < ANY(SELECT distinct salary FROM employees WHERE job_id='IT_PROG') and job_id<>'IT_PROG';
案例:查询其他工种中比job_id为’IT_PROG’的员工所有工资低的员工的员工号,姓名,job_id和salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary < all(SELECT distinct salary FROM employees WHERE job_id='IT_PROG')
and job_id<>'IT_PROG';
-
- where后面的行子查询(一行多列)
案例:查询员工编号最小并且工资最高的员工信息
select * from employees
where
employee_id = (select min(employee_id) from employees)
and
salary = (select max(salary) from employees);
下面是行子查询的写法(用的很少,了解就可以):
select * from employees
where (employee_id,salary)=(
select min(employee_id) , max(salary) from employees
);
-
- select 后面(很少用的,可以用前面讲的方法实现):
案例:查询每个部门的部门信息和对应的员工个数(不用连接查询)
select d.*,(
select d.department_name count(*) from employees e
where d.department_id=e.department_id
) from departments d;select *,(select count(*) from employees e,departments dwhere d.department_id=e.department_id group by d.department_name ) temp
from departments temp;
-
- from后面的子查询:
案例:查询每个部门的平均工资等级
select avg(salary),department_id from employees group by department_id;SELECT
avg_res.avgs,avg_res.department_id,g.grade_level
FROM
(
SELECT AVG(salary) avgs,department_id
FROM employees GROUP BY department_id
) avg_res
,job_grades g
WHERE
avg_res.avgs BETWEEN g.lowest_sal AND g.highest_sal;
-
- exists后面(相关子查询)
exists的作用是: 判断子查询有没有结果的存在
案例: select exists(select employee_id from employees); 返回的结果:1;
语法:
select exists(完整的子查询); 子查询有结果返回1,没有结果返回0;
案例:查询有员工的部门名
select department_name from departments d
where exists(select * from employees e where d.department_id=e.department_id );
注意: 能用exists的绝对能用前面讲过的in来实现,所以exists很少使用
select department_name from departments d
where d.department_id in (
select department_id from employees
);
五、分页查询
分页查询:
数据记录条数过多的时候,需要分页来显示
语法:
select 查询字段 from 表名
where ....等等前面学过的所有写法
group by
having
order by
limit offset(开始记录索引,是从0开始的),size(要取出的条数);
案例: 查询前5条员工数据
mysql> select * from employees limit 0,5;
mysql> select * from employees limit 5;
注意: 如果从第一条开始,这个0可以省略:select * form employees limit 5;
案例:查询第11条到第25条
mysql> select * from employees limit 10,15;
案例:查询有奖金且工资最高的前10名的员工信息
select * from employees where commission_pct is not null order by salary desc limit 10;
分页查询的特点:
limit语句是位置上是要放在比order by语句的还后面,其次中sql执行过程中,limit也是最后去执行的语句.
相关文章:
)
MySQL——四、SQL语句(下篇)
MySQL 一、常见的SQL函数1、数学函数2、日期函数3、分组函数(聚合函数)4、流程控制函数 二、where条件查询和order by排序三、分组统计四、多表关联查询1、交叉连接CROSS2、内连接inner3、外连接:outer4、子查询 五、分页查询 一、常见的SQL函数 1、length(str):获…...

蓝桥杯每日一题2023.10.2
时间显示 - 蓝桥云课 (lanqiao.cn) 题目描述 题目分析 输入为毫秒,故我们可以先将毫秒转化为秒,由于只需要输出时分,我们只需要将天数去除即可,可以在这里多训练一次天数判断 #include<bits/stdc.h> using namespace std…...
红外遥控器 数据格式,按下及松开判断
红外遥控是一种无线、非接触控制技术,具有抗干扰能力强,信息传输可靠,功耗低,成本低,易实现等显著优点,被诸多电子设备特别是家用电器广泛采用,并越来越多的应用到计算机系统中。 同类产品的红…...
)
win32进程间通信方式(13种)
win32进程间通信 文件映射共享内存匿名管道命名管道远程过程调用(RPC)对象连接与嵌入(OLE)动态数据交换(DDE)剪贴板WM_COPYDATA消息邮件槽其它 文件映射 特点:本地间通信,不能用于网…...

基于Vue+ELement搭建动态树与数据表格实现分页模糊查询
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《ELement》。🎯🎯 …...

多线程案例 - 单例模式
单例模式 ~~ 单例模式是常见的设计模式之一 什么是设计模式 你知道象棋,五子棋,围棋吗?如果,你想下好围棋,你就不得不了解一个东西,”棋谱”,设计模式好比围棋中的 “棋谱”. 在棋谱里面,大佬们,把一些常见的对局场景,都给推演出来了,照着棋谱来下棋,基本上棋力就不会差到哪…...
云原生Kubernetes:对外服务之 Ingress
目录 一、理论 1.Ingress 2.部署 nginx-ingress-controller(第一种方式) 3.部署 nginx-ingress-controller(第二种方式) 二、实验 1.部署 nginx-ingress-controller(第一种方式) 2.部署 nginx-ingress-controller(第二种方式) 三、问题 1.启动 nginx-ingress-controll…...

Java21 新特性
文章目录 1. 概述2. JDK21 安装与配置3. 新特性3.1 switch模式匹配3.2 字符串模板3.3 顺序集合3.4 记录模式(Record Patterns)3.5 未命名类和实例的main方法(预览版)3.6 虚拟线程 1. 概述 2023年9月19日 ,Oracle 发布了…...

Rest Template 使用
大家好我是苏麟 今天带来Rest Template . spring框架中可以用restTemplate来发送http连接请求, 优点就是方便. Rest Template 使用 Rest Template 使用步骤 /*** RestTemple:* 1.创建RestTemple类并交给IOC容器管理* 2. 发送http请求的类*/ 1.注册RestTemplate对象 SpringB…...
IDEA git操作技巧大全,持续更新中
作者简介 目录 1.创建新项目 2.推拉代码 3.状态标识 5.cherry pick 6.revert 7.squash 8.版本回退 9.合并冲突 1.创建新项目 首先我们在GitHub上创建一个新的项目,然后将这个空项目拉到本地,在本地搭建起一个maven项目的骨架再推上去࿰…...
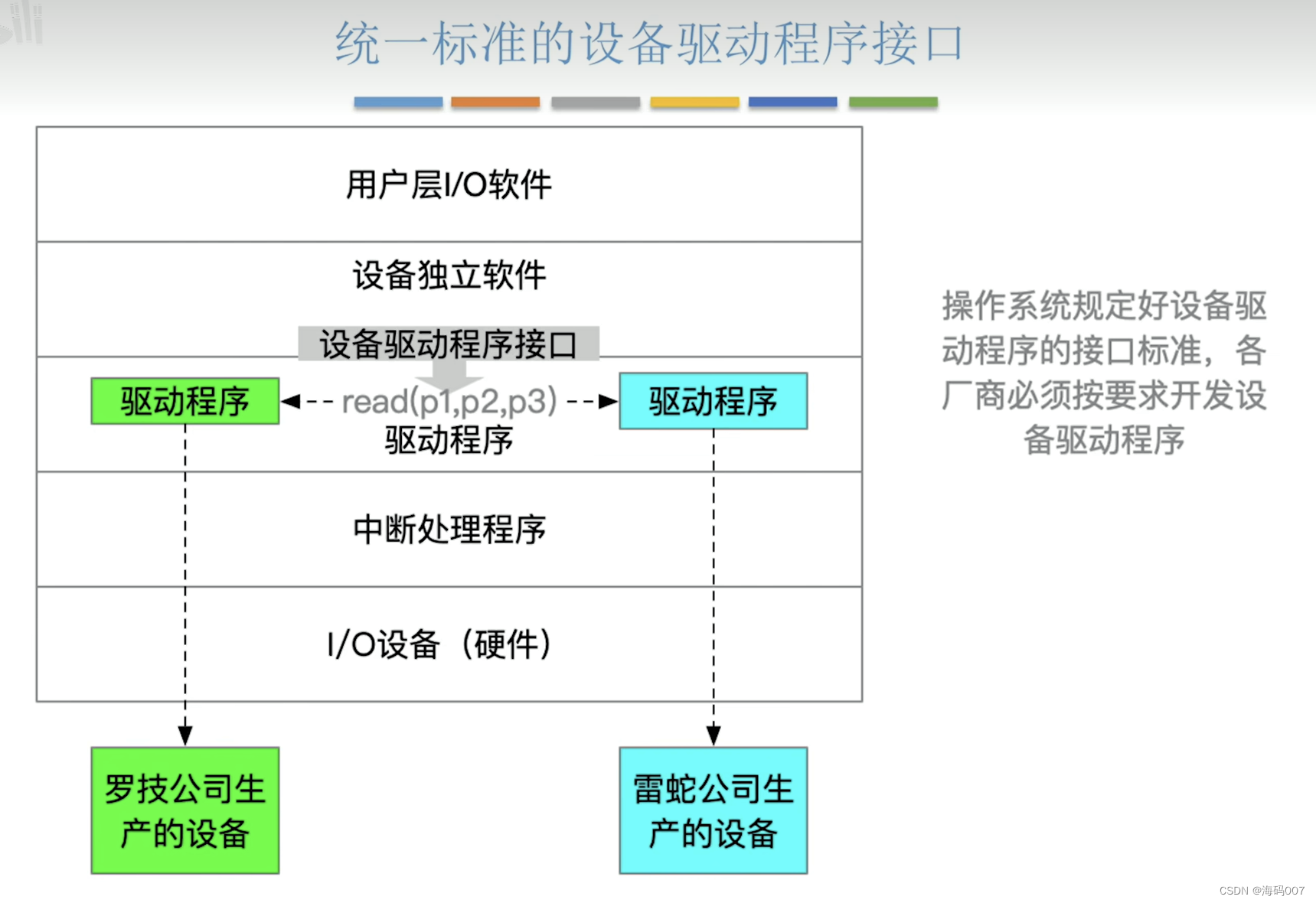
计算机操作系统 (王道考研)笔记(四)I/O系统
目录 1 I/O1.1 I/O 概念和分类1.1.1 I/O 定义1.1.2 I/O 分类 1.2 I/O控制器1.3 I/O 软件层次结构1.4 I/O 应用程序接口和驱动程序应用接口 1 I/O 1.1 I/O 概念和分类 1.1.1 I/O 定义 BIOS(英文:Basic Input/Output System),即基…...
【Java基础】抽象类和接口的使用
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【JavaSE_primary】 本专栏旨在分享学习JavaSE的一点学习心得,欢迎大家在评论区讨论💌 目录 一、抽象类抽象类概念…...

Golang的性能优化
欢迎,学习者们,来到Golang性能优化的令人兴奋的世界!作为开发者,我们都努力创建高效、闪电般快速的应用程序,以提供出色的用户体验。在本文中,我们将探讨优化Golang应用程序性能的基本技巧。所以࿰…...

实现两栏布局的五种方式
本文节选自我的博客:实现两栏布局的五种方式 💖 作者简介:大家好,我是MilesChen,偏前端的全栈开发者。📝 CSDN主页:爱吃糖的猫🔥📣 我的博客:爱吃糖的猫&…...

博物馆门票预约APP的设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...
【AI视野·今日Robot 机器人论文速览 第四十四期】Fri, 29 Sep 2023
AI视野今日CS.Robotics 机器人学论文速览 Fri, 29 Sep 2023 Totally 38 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚NCF,基于Neural Contact Fields神经接触场的方法实现有效的外部接触估计和插入操作。 (from FAIR ) 操作插入处理结果&am…...
一维数组和二维数组的使用(char类型)
目录 导读1. 字符数组1.1 字符数组的创建1.2 字符数组的初始化1.3 不同初始化在内存中的不同1.3.1 strlen测试1.3.2 sizeof测试1.3.3 差异原因 1.4 字符数组的使用 2. 数组越界3. 数组作为函数参数博主有话说 导读 我们在前面讲到了 int 类型的数组的创建和使用: 一…...
1.基本概念 进入Java的世界
1.1 Java的工作方式 1.2 Java的程序结构 类存于源文件里面,方法存于类中,语句(statement)存于方法中 源文件(扩展名为.java)带有类的定义。类用来表示程序的一个组件,小程序或许只会有一个类…...

程序在线报刊第一期
文章目录 程序在线报刊第一期排序算法:优化数据处理效率的核心技术回顾区块链技术:去中心化引领数字经济新时代展望AI未来:智能化时代的无限可能 程序在线报刊第一期 排序算法:优化数据处理效率的核心技术 近年来,随…...

k8s 拉取镜像报错 no basic auth credentials
文章目录 [toc]基于现有凭据创建 Secret通过命令行创建 Secretpod 使用指定 secret 认证私有镜像仓库 省流提醒: 本次解决的问题是 docker login 可以正常登录,docker pull 也可以正常拉取镜像,只是 k8s 在启动 pod 的时候,没有指…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...
Python环境安装与虚拟环境配置详解
本文档旨在为Python开发者提供一站式的环境安装与虚拟环境配置指南,适用于Windows、macOS和Linux系统。无论你是初学者还是有经验的开发者,都能在此找到适合自己的环境搭建方法和常见问题的解决方案。 快速开始 一分钟快速安装与虚拟环境配置 # macOS/…...