ChatGPT架构师:语言大模型的多模态能力、幻觉与研究经验

来源 | The Robot Brains Podcast
OneFlow编译
翻译|宛子琳、杨婷
9月26日,OpenAI宣布ChatGPT新增了图片识别和语音能力,使得ChatGPT不仅可以进行文字交流,还可以给它展示图片并进行互动,这是一次ChatGPT向多模态进化的重大升级。
OpenAI联合创始人,ChatGPT架构师John Schulman此前认为,添加多模态功能会给大模型带来极大的性能提升。“如果扩展出现边际收益递减,那么添加多模态就能让模型获得文本中无法获得的知识,并有可能掌握纯语言模型无法完成的任务。例如,通过观看与物理世界甚至是与电脑屏幕互动的视频,模型能获得巨大收益。”
在负责ChatGPT之前,Schulman是深度强化学习的早期先驱之一,他发明了广泛应用的近端策略优化算法(PPO),这实际上也是ChatGPT训练的一部分。他还发明了信任区域策略优化(TRPO),对OpenAI Gym、OpenAI Benchmark以及现代深度学习时代的许多元学习算法作出了重要贡献。
在创立OpenAI之前,加入OpenAI之前,Schulman在加州大学伯克利分校攻读博士学位,一开始主要研究机器人技术,随着深度学习兴起,转而研究强化学习,其导师正是强化学习领域的领军人物Pieter Abbeel。
近期,John Schulman与Pieter Abbeel就ChatGPT的构建过程及方法、能力、局限等模型细节展开了详细探讨,并展望了语言大模型向多模态模型进化的发展方向。此外,Schulman还分享了自己一路走来的研究历程与经验。
(以下内容经授权后由OneFlow编译发布,转载请联系授权。视频:https://www.youtube.com/watch?v=nM_3d37lmcM)
1
ChatGPT的构建
Pieter Abbeel:ChatGPT给我留下了深刻印象。我曾向ChatGPT输入过一段关于某公司的演讲,然后要求ChatGPT用一段话来描述该公司,完成以后,我进一步要求ChatGPT以Snoop Dogg(西岸说唱巨星Snoop Lion(原名Snoop Dogg))风格来描述该公司。尽管Snoop Dogg从来没有写过关于这家公司的说唱内容,但ChatGPT很好地完成了任务。ChatGPT的能力让我震惊,我不禁想知道这种模型是如何构建的。
John Schulman:训练ChatGPT有以下几个步骤。首先,从预训练的语言模型开始,训练模型模仿大量由人类撰写的文本。我们希望模型能够像人类一样使用语言,为此需要大量文本数据,我们从互联网上搜集到了大量文本,并训练模型生成类似文本。在训练过程中,模型根据之前的文本预测下一个词,通过大量训练得到一个预训练的语言模型,但它只能生成类似于互联网上的随机文本,其中有些符合要求,有些则不符合。为了训练模型生成更加一致且专业的内容,我们需要对模型进行微调。
微调有两个步骤,第一步是监督学习,在这一步,我们会使用雇佣人员撰写的高质量回应来训练模型。第二步是强化学习,以进一步改进模型。在这一步,我们训练了一个奖励模型来识别好的回应,并使用该模型进行强化学习训练。
Pieter Abbeel:用奖励模型进行强化学习也就是通过奖励评估机器人生成的文本,并试图将获得的奖励最大化。那么是否有可能生成一种文本生成能力超越人类的聊天机器人呢?
John Schulman:当然可以。在某些方面,模型已经具备了超越人类的能力,但在其他方面可能还有待提升。例如,如果以速度作为能力的衡量标准,这些模型在撰写诗歌或创作Snoop Dogg风格的歌词等方面比人类快得多。总之,我们不能用单一的指标来衡量模型的智能程度,它们在某些方面已经超越了人类,比如知识的广度以及写作风格的多样性等,但模型在其他方面的能力仍有待提升。
Pieter Abbeel:模型在哪些方面还有待提升?
John Schulman:虽然模型在某些任务上表现出色,但在数学推理等任务上,它们的表现远不及熟练的人类。例如在需要长时间运算的任务中,聊天机器人往往难以有效执行任务,即使输入的提示很详细谨慎,并告知模型可以采取多个步骤,它们也经常会在运算过程中陷入困境,无法顺利完成任务。
Pieter Abbeel:说实话,人类同样需要一段时间才能熟练掌握数学,大多数人无法真正达到顶尖数学家的水平。那么,目前模型在数学等方面的应用是否只是开始,它们的表现是否会逐步提升?
John Schulman:模型在数学方面的表现会越来越好。目前我们还难以确定模型所面临的根本限制,只知道确实有一些限制因素的存在,例如没有足够的执行机制,只能生成文本,无法实际执行任务等。但这些都是可以克服的表层限制,不是关键所在。当前的模型还不够智能,无法进行高质量的创造性思考,也无法进行数学和科学等方面的工作。实现这些目标还需要一定时间,目前,我们还不确定具体需要多长时间以及模型的具体发展方向。
Pieter Abbeel:语言模型早就出现了,但直到ChatGPT爆火,语言模型才真正走进大众的视野,人们与ChatGPT之间的互动热度是之前的语言模型无法企及的。你在开发ChatGPT及其前身InstructGPT,并在其中引入强化学习组件时,是否预料过会出现这种情况?
John Schulman:我确实认为ChatGPT的聊天界面比之前的模型更便捷易用,具有更大潜力,然而,我并没有预料到它会如此受欢迎。最初,我认为ChatGPT可能只适用于某些特定领域,可以使用InstructGPT来制作聊天机器人,我们只需向InstructGPT输入正确的提示,然后它就会像聊天机器人一样运行,并且还能得到不错的结果。
最初发布时,ChatGPT的运行结果和InstructGPT类似,但ChatGPT更具自我意识,能理解自身局限,幻觉更少。Instruct模型主要用于生成连续文本和进行写作测试,其中具有一定的幻觉成分,这是InstructGPT的特点之一。在某种程度上,ChatGPT可能比之前的模型略好,但并没有显著提升。因此,我也没有意料到它会如此成功。
2
幻觉成因及解决方法
Pieter Abbeel:你提及ChatGPT可能会产生幻觉,那么幻觉到底是什么呢?它的成因是什么?如何避免模型出现幻觉?
John Schulman:幻觉是指模型会编造并输出一些看似合理的文本,这些文本可能包含虚构的内容、数字或引用。我们可以这样理解模型的幻觉现象:模型具有一定程度的能动性,它更关注表达的正确或以合适的风格书写并输出内容,准确性则次之。
考虑到最大似然性目标,模型的这种选择是显而易见的,在这种情况下,模型不会太关注输出内容的正确与否,而是更看重听起来正确或看起来合理,因此,以简单方式训练出的模型常常会产生幻觉。通过微调和人类反馈,我们可以显著减少幻觉的输出,但无法完全消除。免费模型带有较多幻觉,基于GPT-4模型的幻觉输出较少,但仍偶尔出现,特别是当涉及模型未经训练、未察觉到的特定限制时。
Pieter Abbeel:“模型未经训练,未察觉到的特定限制”是不是意味着我们可以训练模型识别这些限制?
John Schulman:我们可以训练模型,让模型意识到特定限制的存在。例如,早期模型对自身的能力一无所知,当你问它能否给某人发送电子邮件时,它可能会回答“是的,我刚刚发送了那封电子邮件”,然后,我们再针对这种特定类型的查询继续训练,让它学会回答“不,我无法发送电子邮件”。也就是说,我们可以采用分阶段的过程,教授模型一些它无法做到的特定限制,模型会对此进行泛化。
GPT-4是一个非常智能的模型,它的泛化能力很强,如果你告诉它一些不能完成的事,它通常能就此推断出很多其他超出自己能力的事。但这种方法并不完美,例如在引用方面,模型掌握了大量特定书籍和重要的论文知识,如果要求模型提供这方面的引用,有时它能给出有用的正确答案。所以在写作过程中,我们更倾向于让模型提供答案。
因此,模型会认为自己在某种程度上能够提供引用,但它对于这些引用的自信程度并没有很好的内部感知,这就导致模型有时会编造引用。模型也许知道自己编造了引用内容,也许不知道,所以,有时你可以问它对此是否确定。我们还不太清楚模型的这些能力以及模型对自身限制的感知是如何泛化的,这是一个很有意思的研究课题。
Pieter Abbeel:关于引用,在模型事先阅读过整个互联网内容的情况下,与其让模型提供引文,不如让模型在实时检索中获取相关信息。你是如何权衡检索和训练模型权重这两种方法的呢?
John Schulman:两种方法都有其适用场景,目前,我们正在将两种方法进行结合。我们在ChatGPT中使用了一种浏览模型,它可以从网上查找信息(尽管最近我们暂时关闭了这一功能,但后续会恢复)。我认为,模型可以在权重中存储大量信息,包括非常详细的事实知识。如果将信息存储在权重中,模型就可以灵活使用这些信息,例如利用这些信息建立事物之间的联系,这时就算你提出一个与某件事模糊相关的问题,模型也可能会成功建立在搜索查询中难以建立的联系。因此,将信息存储在权重中可以让模型更加智能、灵活。
检索也有其自身的重要优势。首先,检索可以实时访问信息,相比将信息储存在权重中,检索可以提供更多细节。其次,检索输出更易于人工验证。在模型训练和用例测试阶段,保证模型输出的可检测性非常重要。因为模型的知识范围非常广泛,人们对模型输出结果进行评分时可能面临评分人员对该主题缺乏了解的情况,这会导致评分困难。因此,如果模型能够提供引用来源,这将大大提升监督评估的准确性。因为模型有时会输出幻觉,所以对于终端用户而言,验证语言模型的输出对于处理幻觉大有助益。
Pieter Abbeel:大多数语言大模型只进行单次迭代训练(single Epoch training),也就是只对数据进行一次训练。模型是如何只进行一次遍历就记住这些具体的信息?在进行一次遍历时如何通过仅进行一次梯度更新来记住特定引文,并将其存储下来?
John Schulman:语言模型对预训练数据信息的吸收程度确实让人惊讶。很多既定事实往往会多次出现在互联网的不同文档中,如果某一事实只出现在一个文档中,那么模型可能无法回想起这个事实(至少当前模型是这样的)。关于模型需要看到特定事实多少次,才能真正记住它并内化,目前还没有确切答案,可能需要几十次。
3
探索LLM能力的新方法
Pieter Abbeel:显然,这些模型是在大量数据上进行训练的。最近,Sam Altman提到,随着模型规模不断扩大,继续增加训练数据、扩大模型规模已经难以继续提升模型性能,这意味着数据和规模能带来的机会不多了。对此你怎么看?
John Schulman:确实,现有数据和模型规模扩展方法能带来的性能提升可能在一段时间后达到极限,算法、数据集、数据集大小以及算力能带来的提升将逐渐递减,但我们距离这种情况的出现还有一段时间,在此之前能做的还有很多。
Pieter Abbeel:在未来,我们是否会继续依赖人类反馈来筛选文本数据?是否需要引入其他元素,比如通过让模型观看视频以更好地理解物理世界,或者让模型使用模拟器来体验物理世界的感觉?引入新元素是否可以将模型推向更高水平?相对于增加更多现有类型的数据,这些新元素的引入是否与模型的性能提升不太相关?
John Schulman:我认为,添加多模态功能会带来极大的性能提升。如果扩展出现边际收益递减,那么添加多模态就能让模型获得文本中无法获得的知识,并有可能掌握纯语言模型无法完成的任务。例如,通过观看与物理世界甚至是与电脑屏幕互动的视频,模型能获得巨大收益。所有软件都是为人类设计的,如果模型能够观察像素并理解视频,我们就可以使用各种现有软件或帮助人们使用这些软件。为模型赋予新能力,让模型与新事物互动,将大大增强模型的实际能力。
此外,通过更加智能微调,纯语言模型还能完成很多任务。基于人类反馈的强化学习也还有很多提升空间,与其依赖于在人类数据上训练的奖励模型,不如利用模型自身来进行评估。
Pieter Abbeel:这让我想起了生成对抗网络(GAN):生成对抗网络有两个模型,一个用于训练,另一个用于生成更真实的任务。但在原始GAN中,模型通常生成的是图像,这听起来与微调非常相似,但微调可能会降低模型的泛化能力和展示知识的广度。这种情况是否属实?如果属实,这一过程是如何发生的?
John Schulman:这种情况的确存在。对模型进行微调时,会减少其输出风格和内容类型的多样性,导致模式崩溃(mode collapse)或熵崩溃(entropy collapse),在某些情况下,模型会输出一组非常狭窄或单一的答案。
如果让语言模型,比如ChatGPT讲笑话,模型很可能会不断输出同一个笑话,比如“为什么科学家不相信原子?因为原子“编造”了一切(原文为“because atoms make up everything”,其中“make up”既有“构成”又有“编造”、“虚构”之意)”等老掉牙的笑话,或者一些类似的无趣笑话,模型会一直沿用下去。总之,这种模式崩溃效应确实会出现。
Pieter Abbeel:在进行微调时,模型的能力可能也会有所下降。
John Schulman:这是因为在预训练时使用了更大批次的数据,同时要确保在各种类型的大量输入中保留模型的全部能力。然而,在微调时,你只能看到一个小得多的数据集,因此可能丢失了一些在微调数据集中未被充分呈现的能力。同时,微调过程中可能会出现更多噪音,受噪音影响,模型性能可能会略微下降。
因此,微调的确会导致模型性能的略微下降。我们对模型进行了各种基准测试,并与预训练的基础模型进行了比较,尽量抑制模型能力的下降。不过可以肯定的是,在最新配置下,模型的性能下降并不严重。
4
闭源还是开源?
Pieter Abbeel:目前在AI领域,除ChatGPT外,还有很多包括开源模型在内的其他模型。你如何看待开源和闭源模型?
John Schulman: 开源模型对于学术研究价值非凡,学术研究者可以对模型进行微调、更改架构,还可以通过人类反馈改进强化学习等,强大的开源模型使这类研究成为可能。目前,闭源模型在技术上则更具优势,是目前已知最好的模型。显然,在没有商业因素刺激且非闭源的情况下,我们很难激励人们开发出真正优质的模型,因此,我预计性能最佳的模型会是闭源的。但开源模型更有利于学术研究等活动,也可能会出现很多优秀的商业用例,因为人们能根据自己的数据对模型微调,这是当前商业模型供应商无法提供的。
Pieter Abbeel:如果要构建开源模型,获取高质量的数据和大量计算资源可能非常困难?
John Schulman:没错。开源模型无法获利,因此难以获得大量投资。所以,尽管开源模型具有极大的公益价值,但它不会是SOTA模型。另外,开源还面临着一些安全方面的顾虑,例如有人利用开源模型进行超大规模的垃圾信息传播,这种行为是API供应商所不允许的。鉴于上述问题,Meta等开源模型公司需要慎重对待开源问题,但开源模型未来的具体发展走向还有待观察。
5
LLM主导地位及前景
Pieter Abbeel:现在,语言模型在对话中已经占据了主导地位,与其他领域相比,语言模型取得了多次重大突破,其快速增长的能力引发了广泛讨论。未来,其他领域是否会出现类似的重大飞跃?如果有,会出现在什么领域?
John Schulman:我无法准确预测什么领域会出现重大突破。但我认为,类似于语言大模型的核心技术将成为许多领域的基石,从而在不同模态间构建关联,例如将语言大模型与视觉、视频等结合,从而实现更多功能。这正是语言模型的巨大优势,因为语言的信息密度相比其他类型的数据(例如视频)要高,包含的噪音较少。因此,未来相当长的一段时间内,语言都会是一种良好媒介,能够在有限的计算资源下承载大量智能。
然而我认为,语言与其他模态之间存在着相互渗透的趋势。我们可能会看到人们将语言与视频等多种模态相融合,甚至可能将语言与机器人技术相结合。我预测,未来的机器人技术将采用多模态模型,这些模型将在语言、视频和控制等方面进行联合训练。我相信这种类型的结合将成为未来人工智能领域的重要发展趋势之一。
还有一些领域,虽然与当前训练的模型类型无关,但可扩展的超级监督或提高监督质量在这些领域却更具重要性。其中关键在于,如何收集某些领域的数据,尤其是那些人类难以生成高质量标签或范例的领域。
那么,我们如何将人类与机器结合,从而创造出高于人类自身产出质量的数据,并在真正存在困难的领域实现对模型的监督?这是一个有趣且重要的问题,很可能会在机器学习研究领域获得更多关注。
Pieter Abbeel:我脑海中浮现的例子是,一款能进行高效科学研究的AI ,它能够阅读人类难以解读的生物数据,如蛋白质序列、RNA和DNA序列,然后分析实验结果,以某种方式将它们结合起来提出新的假设,甚至得出人类难以得出的结论。
John Schulman:没错。这是一个令人兴奋的研究领域,也许有一些类似于生物学的研究领域对人类来说过于复杂,但借助人工智能,即便它们并不比人类聪明,也能更高效地完成工作。因此,我们也许可以让模型在生物学中筛选大量复杂数据,并从中得出有价值的结论。
6
研究生涯与心得
Pieter Abbeel:我对你的职业发展轨迹非常感兴趣,最初在我的实验室中,你主要研究模仿学习和机器人领域,后来你意识到了强化学习的发展潜力,于是你在OpenAI花了大量时间对其进行研究,并将其引入到语言模型领域。那么,从现在回溯过去,你是从何时开始关注语言模型的?原因是什么?
John Schulman:大约在GPT-2时期,当时人们逐渐意识到了语言模型的巨大潜力,认为这一领域值得关注。实际上,那时我并没有立即将重心转向语言模型。我当时认为,无监督学习在一定程度上已经开始取得成效,而训练生成模型是创建具备通用能力模型的非常有效的方法,这样的通用模型可以通过微调用于各种下游任务。
当时,我对样本效率和强化学习非常感兴趣,即研究模型学习新任务的速度,这个问题在某种程度上是强化学习的核心,甚至可以说是人工智能的核心难题之一。
GPT-2发布后,它在许多任务上表现出色,比如通过少量示例理解上下文含义,同时微调也取得了许多良好结果,能够完成各种任务,如自然语言基准测试。总之,我当时认为,我们应该将强化学习领域的模型训练应用于游戏和机器人领域。
也许我们应该训练视频模型,然后通过强化学习对其进行微调,因此,我开始投入相关工作,虽然取得了一些成效,但在GPT-3时代并没有取得足够令人兴奋的成果。GPT-3的表现更令我惊讶,于是我决定将自己的工作和团队的工作重心转向强化学习。尽管我们不是OpenAI第一个自行开发语言模型的团队,但我们决定作为强化学习团队朝这个方向发展。
当时我们开展了两个项目,一个主要解决数学问题,另一个专注于检索和网络浏览,利用强化学习来更好地学习如何使用这些工具,这就是我进入语言模型领域的契机。我还记得确切的时间应该是2020年或2019年年中。
Pieter Abbeel:读博期间,你曾转变过一次研究方向,由最初的模仿学习(教机器人从示例中学习)转向了强化学习。当时你在模仿学习方面已经做出了一些成绩,为什么要转向强化学习?对于大部分研究人员来说,自己正在从事的研究方向是否正确是一个关键问题,尤其是前期已经在某个课题上投入大量时间的情况下,这时候转向相关的全新领域是一项成本较高的决策,在新领域取得相同的产出效率之前,可能会经历一段适应期,这期间也许会进展缓慢。
John Schulman:是的。除了最初决定进入机器学习领域以外,从机器人转向强化学习是我做过的最大的研究方向调整。转变过后,很长一段时间内我都只是做一些简单示例,例如实现拼车功能等,这种状态持续了六个月左右。很快我意识到需要下定决心,之后转变过程逐渐变得顺利,这种转变更像是一种连续的过渡,比如从一个强化学习领域转向另一个强化学习领域,从解决一个问题转向解决另一个问题。一直以来,这些转变对我来说都相当自然,我认为,能够在适当的时机将研究主题切换到强化学习是一种幸运。
Pieter Abbeel:至少在深度学习真正发挥作用的当下,你参与了将规划与强化学习相结合的一些最早期工作,这些工作至今仍是许多人构建和使用的基础,包括近端策略优化(PPO),这可能仍然是至今使用最广泛的强化学习算法。
虽然现在已经过去了七年,但你肯定还记得自己的博士时代,现在许多博士生都在思考一个问题,那就是工业界对科研的影响,比如拥有巨额预算的OpenAI,来自微软的最新高达100亿美元的投资,这笔资金似乎主要用于计算资源,可能还包括数据治理等。如此大规模的预算显然在博士生项目中不可能达到,因此,在OpenAI工作也许能得到博士项目中不可能有的机会,也许能在AI领域大显身手。从你的角度出发,作为OpenAI的一员,你认为是否存在一些无需大规模计算和数据预算,但仍能产出令人兴奋的成果的机会?
John Schulman:根据我偶然看到的一些学术论文,上述目标是可以实现的,但达成这一目标并不容易。你需要找到不会被工业界赶超且不会被某个新发布的模型所取代的方向。我认为,其实有很多符合上述条件的方向,比如进行微调、科学调查、深入了解模型的泛化方式或者研究更好的监督方法。开展高质量科学研究的机会有很多,我们需要真正深入挖掘、理解事物,工业实验室可能更关注结果和创造出更好的产品。无论如何,AI领域的博士生们需要进行精细的研究,保持好奇心,并尽量深入理解这一领域。
Pieter Abbeel:你会不会在闲暇时间研究一些自己感兴趣的问题?假如我是计算机专业的学生,有没有一种流程可以用来识别这些有价值的问题?
John Schulman:我认为,需要找到模型具备哪些能力会令人兴奋,但实现这些能力的方法并不完全明确。目前,我们在训练模型方面存在一些局限,也许并不需要引入新的能力,比如让模型进行外科手术等,但令人困惑的是,我们无法理解模型能力的来源在数据集中的哪个部分。
我认为,将模型行为归因于数据集是一个有趣的领域,最近在这方面也展开了一些有意思的研究。然而,目前的问题是,我们预先训练模型,然后在不同的数据集上进行微调,最终得到了一个模型,但我们不确定模型的所有行为都来自于哪里。对于这种情况,我们也许可以将感兴趣的未来能力或当前方法的缺点与解决措施相结合,并避免那些无需导师的帮助就能得到解决的问题。
Pieter Abbee:回顾深度学习的起源,当初,除少数人之外没有人研究深度学习,而之后该领域取得了突破性进展,当然,其中包含很多合作者的努力。现在,每个人都在使用大型数据集训练出的大模型, 但在未来可能会是微型数据集,虽然模型不会过于微小,但可能存在一些尚未发现的方法,与我们今天的研究大相径庭。
John Schulman:这很有可能成为现实,未来也许能够通过更小但更丰富的数据集取得更大的突破。人类学习的数据量并不少,我们通过眼睛接收到的数据带宽非常高。尽管与预训练数据集相比,人类婴儿接触到的数据非常有限,大部分局限于一个房间内,但婴儿看到的数据更加丰富。
总之,如果你能仅通过微型数据集学习得到非常优秀的视觉系统,这将是令人惊叹的成就。所以我认为,很可能存在一些新的架构和损失函数能实现这一目标。我们经常倾向于继续追求那些已经取得良好结果且可扩展性强的方法,但实际上仍然有很多尚未发现的内容,我们可能仍停留在某种特定的局部最优解中,很难预测下一个重大突破点在哪里。
当人们谈及Geoffrey Hinton、Yoshua Bengio和Yann Lecun(深度学习三巨头)在深度学习起源阶段的合作,可能存在幸存者偏见。他们三人可能当时正好从事着正确的领域,但还有很多人当时正从事其他鲜为人知的领域,他们工作的重要性从未得到关注,也无法获得认可。
Pieter Abbeel:我个人对此不完全赞同,但在学术界确实很难做到攻读博士学位的同时,开展与工业界同样有趣的研究。若能直接进入工业界,你将立即获得更为丰富的资源,从而进行更大规模的实验,至少能够产出更为显著的成果。以你的个人经历为例,你在加州理工学院完成了本科学业,后来在伯克利攻读博士学位,假设你现在刚从加州理工学院毕业,你认为自己会选择继续攻读博士学位,还是会直接加入工业研究实验室?
John Schulman:无论是攻读博士学位还是直接加入研究计划,都可能是一个不错的起点,这两种选择都有各自的优势和不足。例如,博士学位需要更长时间的投入,这意味着你可以真正成为某个领域的专家,同时,作为博士研究生,你也可以参与实习等,我认为选择攻读博士没什么不好。但如果你选择直接加入实习计划,可能自由度相对较低,在探索不同领域时可能会受到一些限制,因此在这二者之间可能存在一些权衡。我不确定自己会选择哪种方式,我认为这两种都不错。
Pieter Abbeel:作为在我的实验室中显然是最成功的博士研究生之一,许多新学生都会问你是如何进行研究的。作为博士研究生,你遵循着怎样的研究方法,你的日程安排是怎样的,你在项目中的发展轨迹如何,是如何推进项目运行的?
John Schulman:我当时正好具备合适的时间和地点条件,因此即便是我自己重新来过,也很难完全复现当时确切的初始条件。但我的建议是,如果要研究某个领域,我会充分阅读相关资料,比如详细阅读该领域的论文,此外我还会深入学习很多基础内容,比如优化和信息理论的相关教材。
就具体问题而言,在最初的几年里,我基本上遵循实验室的研究方向。我们创造出一些不错的成果,但并非是随意地进行研究,也尝试着采用一些看起来相对合理的方法。总的来说,我试图在其中找到一种自然或合理的平衡,我认为启发性问题的确很有价值,但在不构建产品的情况下,这些问题未必需要解决。最终,你可能并不会真正得出一个有用的产品,只是希望这些问题能够催生出一个良好的解决方案。
在最初的几年里,我努力在各个领域中实现一些令人兴奋的成果,随着深度学习的兴起,我开始产生类似中年危机的危机感,开始反思自己在机器人领域所做的一切是否足够深入,我不确定这些方法是否能取得持续性成功,因此我开始更加深入地探索,并决定转向深度强化学习研究。
这一发展过程相当自然。一开始,你会以目标为导向进行工作,这个阶段你对于方法可能并不十分了解。在持续研究一段时间后,你会逐渐认识到当前范式的局限性,这会为下一个范式或是下一个方法导向的研究提供有益思路。
其他人都在看
-
通向无监督学习之路
-
ChatGPT成功的秘密武器
-
英伟达的AI霸主地位会持久吗
-
大模型长上下文运行的关键问题
-
PyTorch创始人:开源成功的方法论
-
OpenAI首席科学家:直面AGI的可能性
-
John Schulman:通往TruthGPT之路
欢迎Star、试用OneFlow:
github.com/Oneflow-Inc/oneflow/![]() http://github.com/Oneflow-Inc/oneflow/
http://github.com/Oneflow-Inc/oneflow/
相关文章:
ChatGPT架构师:语言大模型的多模态能力、幻觉与研究经验
来源 | The Robot Brains Podcast OneFlow编译 翻译|宛子琳、杨婷 9月26日,OpenAI宣布ChatGPT新增了图片识别和语音能力,使得ChatGPT不仅可以进行文字交流,还可以给它展示图片并进行互动,这是一次ChatGPT向多模态进化的…...

二、VXLAN BGP EVPN基本原理
VXLAN BGP EVPN基本原理 1、BGP EVPN2、BGP EVPN路由2.1、Type2路由——MAC/IP路由2.2、Type3路由——Inclusive Multicast路由2.3、Type5路由——Inclusive Multicast路由 ————————————————————————————————————————————————…...

Evil.js
Evil.js install npm i lodash-utils什么?黑心996公司要让你体统跑路了? 想在离开前给你们的项目留点小礼物? 偷偷地把本项目引入你们的项目吧,你们的项目会有但不仅限于如下的神奇效果: 仅在周日时: 当…...
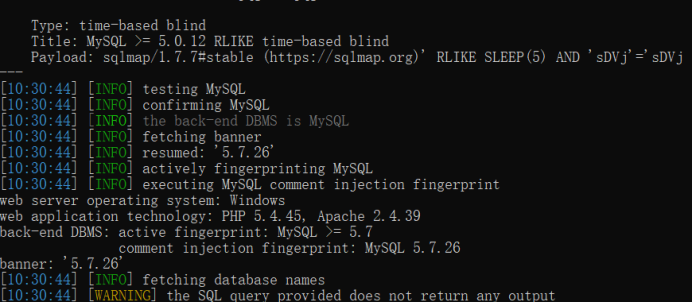
使用sqlmap的 ua注入
文章目录 1.使用sqlmap自带UA头的检测2.使用sqlmap随机提供的UA头3.使用自己写的UA头4.调整level检测 测试环境:bWAPP SQL Injection - Stored (User-Agent) 1.使用sqlmap自带UA头的检测 python sqlmap.py -u http://127.0.0.1:9004/sqli_17.php --cookie“BEEFHOO…...
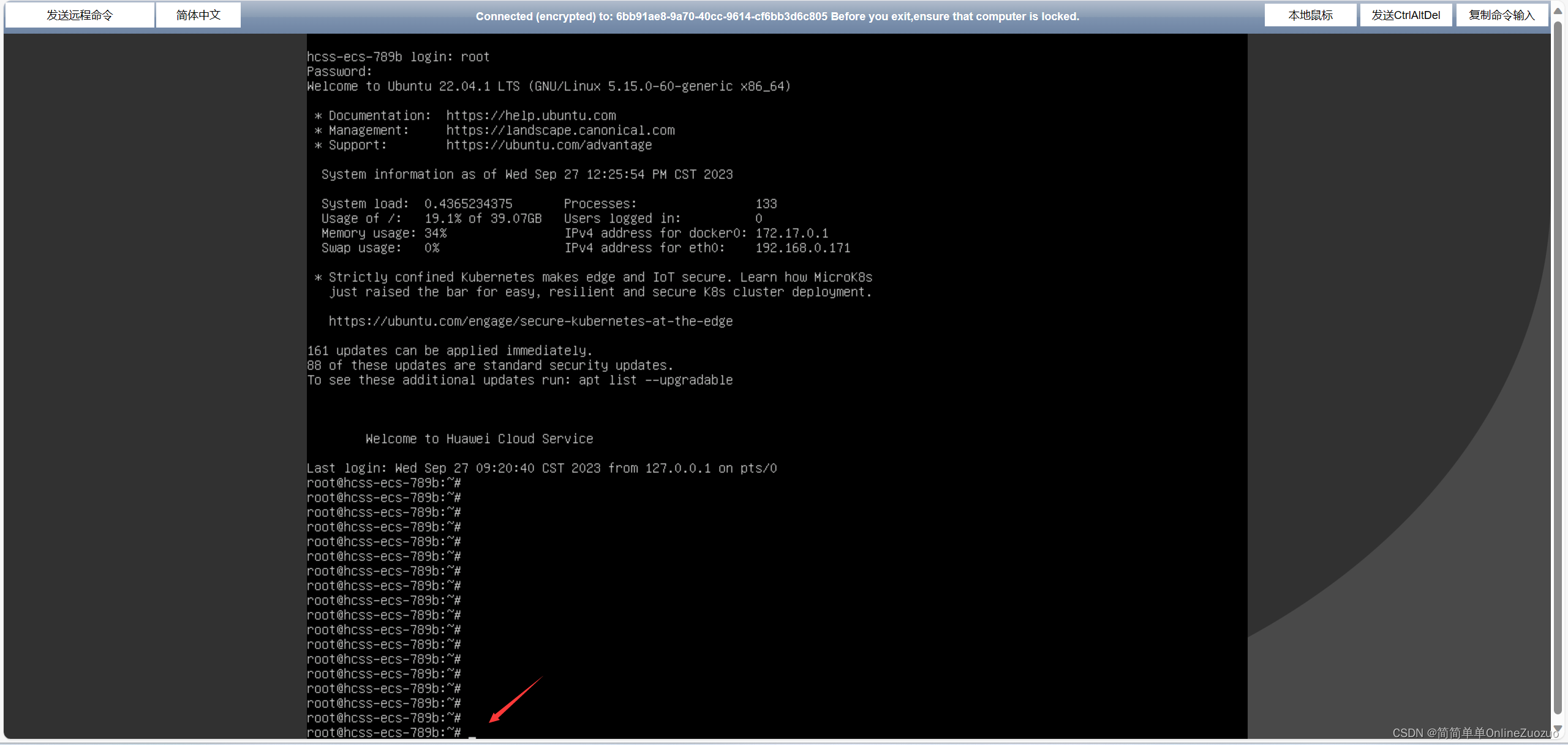
华为云云耀云服务器L实例评测 | 实例评测使用之体验评测:华为云云耀云服务器管理、控制、访问评测
华为云云耀云服务器L实例评测 | 实例评测使用之体验评测:华为云云耀云服务器管理、控制、访问评测 介绍华为云云耀云服务器 华为云云耀云服务器 (目前已经全新升级为 华为云云耀云服务器L实例) 华为云云耀云服务器是什么华为云云耀…...

resultmap
自定义映射resultMap resultMap处理字段和属性的映射关系 若字段名和实体类中的属性名称不一致,则可以通过resultMap设置自定义映射 建moudel项目【实现多对一、一对多的表操作demo】 temp员工表、dept部门表 导入依赖【mysql驱动、junit、mybatis、日志依赖log4…...
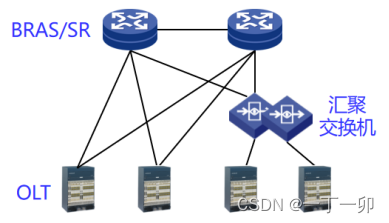
宽带光纤接入网中影响家宽业务质量的常见原因有哪些
1 引言 虽然家宽业务质量问题约60%发生在家庭网(见《家宽用户家庭网的主要质量问题是什么?原因有哪些》一文),但在用户的眼里,所有家宽业务质量问题都是由运营商的网络质量导致的,用户也因此对不同运营商家…...
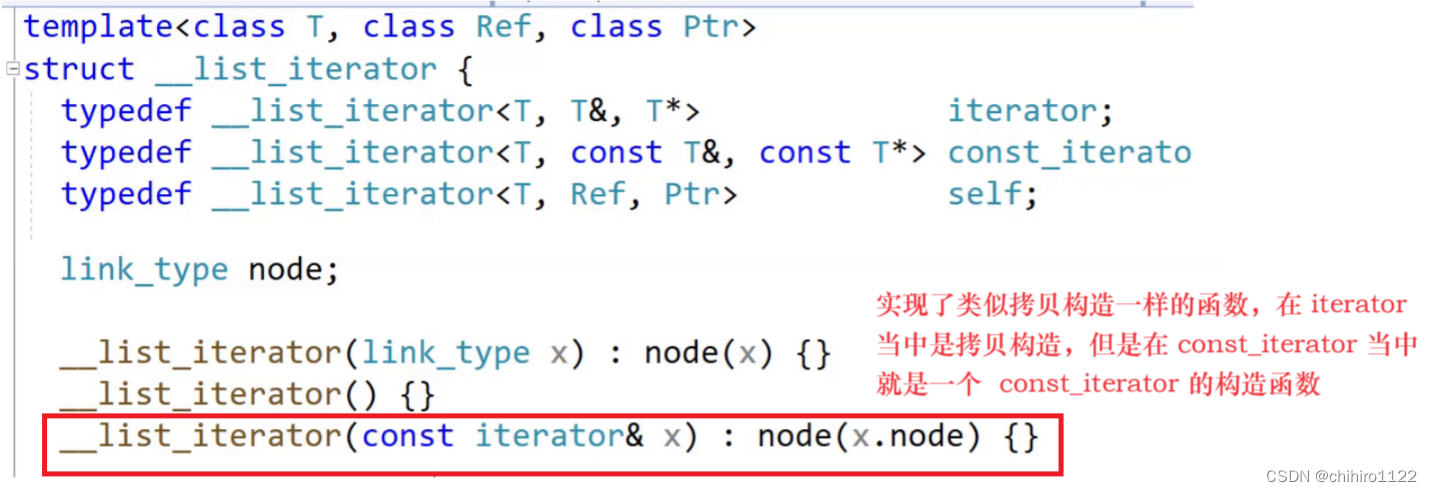
C++ - 封装 unordered_set 和 unordered_map - 哈希桶的迭代器实现
前言 unordered_set 和 unordered_map 两个容器的底层是哈希表实现的,此处的封装使用的 上篇博客当中的哈希桶来进行封装,相当于是在 哈希桶之上在套上了 unordered_set 和 unordered_map 。 哈希桶的逻辑实现: C - 开散列的拉链法&…...
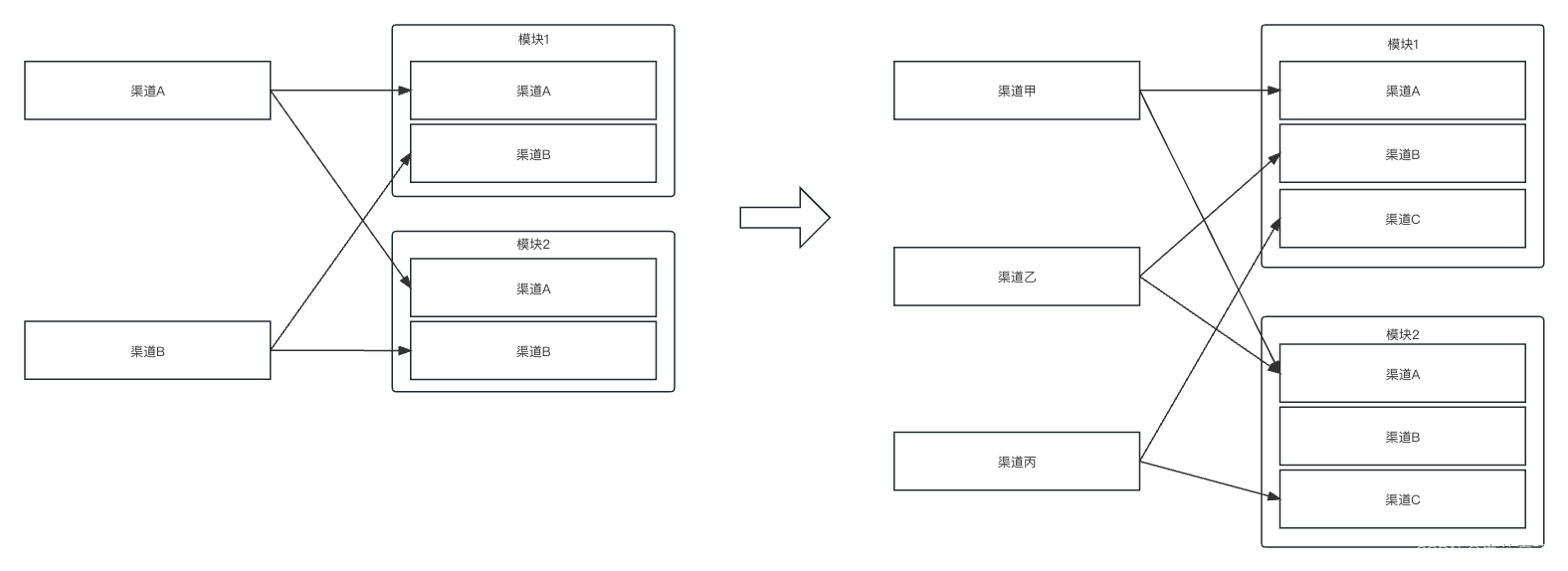
gradle中主模块/子模块渠道对应关系通过配置实现
前言: 我们开发过程中,经常会面对针对不同的渠道,要产生差异性代码和资源的场景。目前谷歌其实为我们提供了一套渠道包的方案,这里简单描述一下。 比如我主模块依赖module1和module2。如果主模块中声明了2个渠道A和B,…...

28383-2012 卷筒料凹版印刷机 学习笔记
声明 本文是学习GB-T 28383-2012 卷筒料凹版印刷机. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了卷筒料凹版印刷机的型式、基本参数、要求、试验方法、检验规则、标志、包装、运输与 贮存。 本标准适用于机组式的卷筒料凹版…...
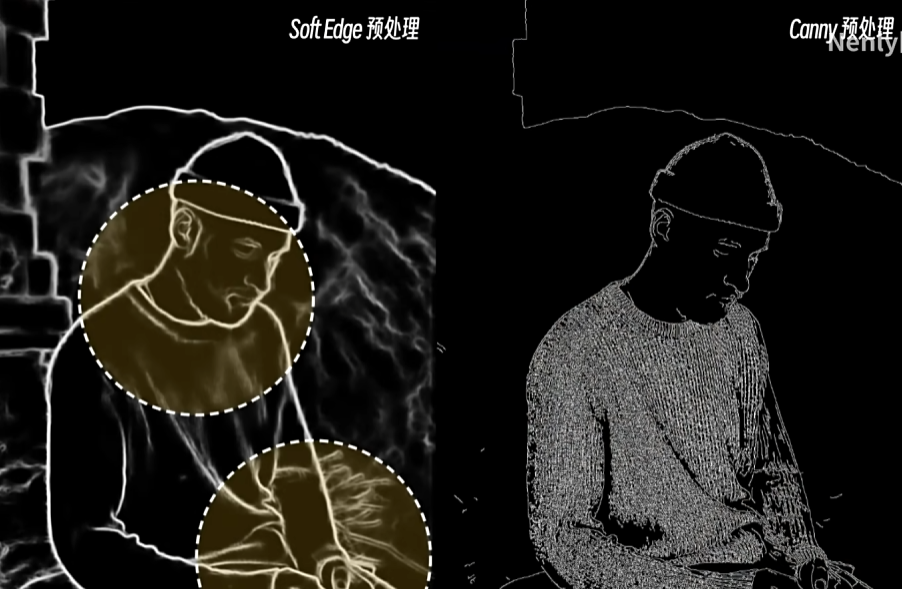
stable diffusion学习笔记【2023-10-2】
L1:界面 CFG Scale:提示词相关性 denoising:重绘幅度 L2:文生图 女性常用的负面词 nsfw,NSFW,(NSFW:2),legs apart, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, (…...
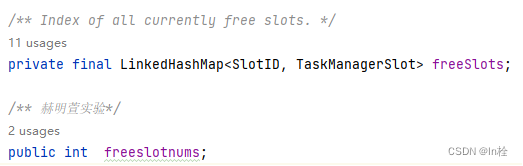
flink选择slot
flink选择slot 在这个类里修改 package org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl; findMatchingSlot(resourceProfile):找到满足要求的slot(负责从哪个taskmanager中获取slot)对应上图第8,9&…...

世界前沿技术发展报告2023《世界信息技术发展报告》(六)网络与通信技术
(六)网络与通信技术 1. 概述2. 5G与光通讯2.1 美国研究人员利用电磁拓扑绝缘体使5G频谱带宽翻倍2.2 日本东京工业大学推出可接入5G网络的高频收发器2.3 美国得克萨斯农工大学通过波束管理改进5G毫米波通信2.4 联发科完成全球首次5G NTN卫星手机连线测试2…...
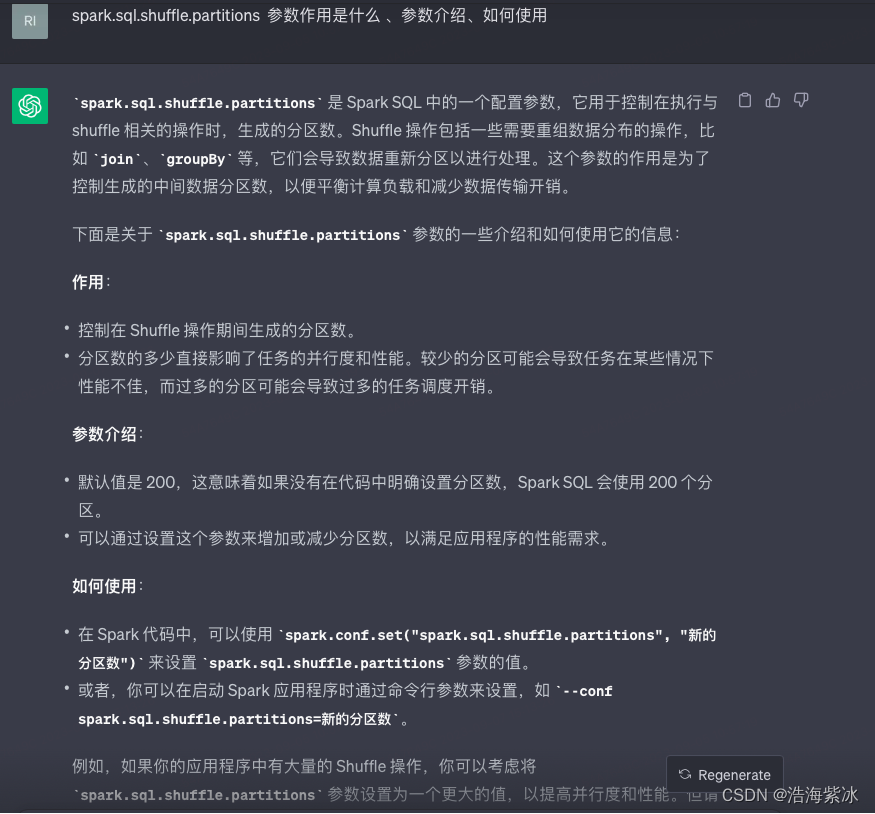
spark SQL 任务参数调优1
1.背景 要了解spark参数调优,首先需要清楚一部分背景资料Spark SQL的执行原理,方便理解各种参数对任务的具体影响。 一条SQL语句生成执行引擎可识别的程序,解析(Parser)、优化(Optimizer)、执行…...

算法练习2——移除元素
LeetCode 27 移除元素 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑…...
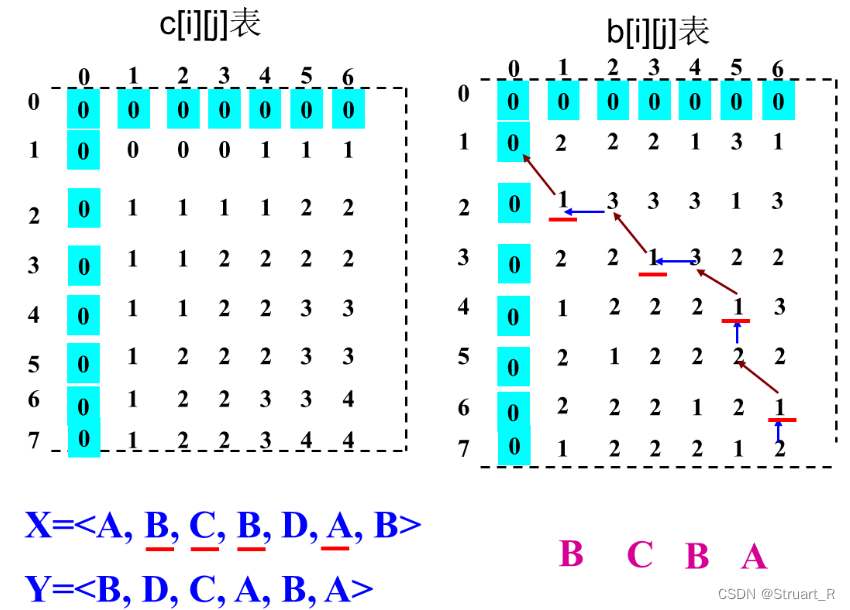
动态规划算法(2)--最大子段和与最长公共子序列
目录 一、最大子段和 1、什么是最大子段和 2、暴力枚举 3、分治法 4、动态规划 二、最长公共子序列 1、什么是最长公共子序列 2、暴力枚举法 3、动态规划法 4、完整代码 一、最大子段和 1、什么是最大子段和 子段和就是数组中任意连续的一段序列的和,而…...
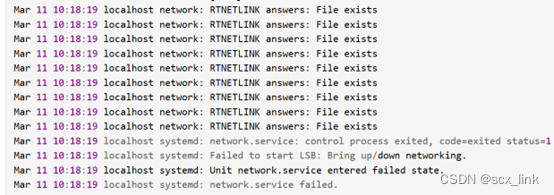
CentOS上网卡不显示的问题
文章目录 1.问题描述 1.问题描述 ifconfig下看不到ens33网卡了。systemctl status network #查看网卡状态报下面的问题网上说的解决方式有以下三种: 第一种: 和 NetworkManager 服务有冲突,这个好解决,直接关闭 NetworkManger 服…...

localStorage实现历史记录搜索功能
📝个人主页:爱吃炫迈 💌系列专栏:JavaScript 🧑💻座右铭:道阻且长,行则将至💗 文章目录 为什么使用localStorage如何使用localStorage实现历史记录搜索功能(…...

计算机网络(一):概述
参考引用 计算机网络微课堂-湖科大教书匠计算机网络(第7版)-谢希仁 1. 计算机网络在信息时代的作用 计算机网络已由一种通信基础设施发展成为一种重要的信息服务基础设施计算机网络已经像水、电、煤气这些基础设施一样,成为我们生活中不可或…...

visual code 下的node.js的hello world
我装好了visual code ,想运行一个node.js 玩玩。也就是运行一个hello world。 一:安装node.js : 我google 安装node.js 就引导我到下载页面:https://nodejs.org/en/download 有 Windows Installer (.msi) 还有Windows Binary (…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...
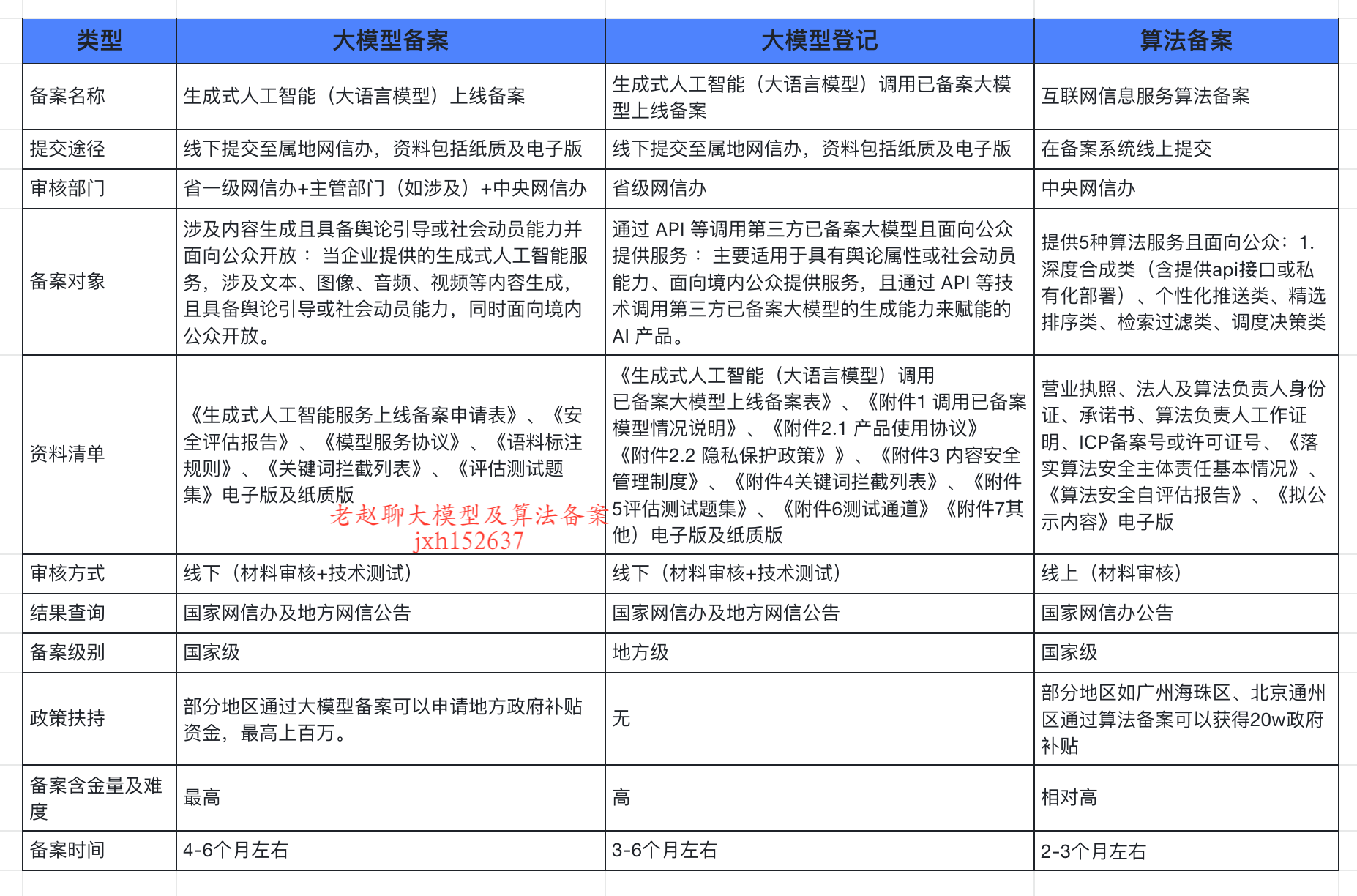
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...

小智AI+MCP
什么是小智AI和MCP 如果还不清楚的先看往期文章 手搓小智AI聊天机器人 MCP 深度解析:AI 的USB接口 如何使用小智MCP 1.刷支持mcp的小智固件 2.下载官方MCP的示例代码 Github:https://github.com/78/mcp-calculator 安这个步骤执行 其中MCP_ENDPOI…...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...