C++ - 封装 unordered_set 和 unordered_map - 哈希桶的迭代器实现
前言
unordered_set 和 unordered_map 两个容器的底层是哈希表实现的,此处的封装使用的 上篇博客当中的哈希桶来进行封装,相当于是在 哈希桶之上在套上了 unordered_set 和 unordered_map 。
哈希桶的逻辑实现:
C++ - 开散列的拉链法(哈希桶) 介绍 和 实现-CSDN博客
在本篇博客当中的思路只是大体介绍,这个封装过程哟点复杂,如果有问题的可以参考下述 博客 对 map 和 set 两个容器的封装,这两个容器是底层实现是 红黑树,在这篇博客当中介绍更为详细,是按照源代码当中的封装逻辑进行的模拟实现:
C++ - map 和 set 的模拟实现上篇 - 红黑树当中的仿函数 - 红黑树的迭代器实现-CSDN博客
C++ - set 和 map 的实现(下篇)- set 和 map 的迭代器实现_chihiro1122的博客-CSDN博客
基础封装 unordered_set 和 unordered_map
unordered_set 基础结构:
namespace unordered
{template<class K>class unordered_set{// set 当中从 T 当中取出 key 的仿函数struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:bool insert(const K& key){return _ht.Insert(key);}private:hash_bucket::hash<K, K, SetKeyOfT> _ht;};
}unordered_map 基础结构:
namespace unordered
{template<class K, class V>class unordered_map{// map 当中从 T 当中取出key 的仿函数struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:bool insert(const pair<K, V>& kv){return _ht.Insert(kv);}private:hash_bucket::hash<K, pair<K, V>, MapKeyOfT> _ht;};
}上述两个框架的实现逻辑在这里大体说明一下:
在经过 unordered_set 和 unordered_map 包裹直线,原本的 哈希桶在使用之上已经非常麻烦了,所以一般是直接使用 在 哈希桶之上的 unordered_set 和 unordered_map 。
在 unordered_set 和 unordered_map 当中的 insert()函数是直接复用 哈希桶当中的 Insert()函数。
其中的 SetKeyOfT 和 MapKeyOfT 两个内部类是用来实现 在 两个容器当中的 不同取 key 逻辑的。其实 在 set 当中只有key ,是不可以不写的,但是在 map 当中就需要从 pair 当中的first 拿出,所以,为了在 哈希桶当中key 值的实现,实现一份代码在 set 和 map 当中都可以使用的话,就要 让 set 做出牺牲,和 map 一样实现 从 T 当中 取 key 的仿函数。所以你才会看到 在 set 当中创建的 哈希桶,要传入两个 K 作为哈希桶的模版参数。
而在哈希桶当中,对 需要用 key 值的地方都用 set 和 map 当中实现的 仿函数来调用,对 key 值的取出进行判断,我们用 哈系统当中 Insert()函数来做演示:
bool Insert(const T& data){HashFunc hf;KeyOfT kot;if (find(data)){return false;}// 负载因子 到 1 就扩容(每一个桶当中都有数据)if (_n == _table.size()){size_t newsize = _table.size() * 2;vector<Node*> newTable;newTable.resize(newsize, nullptr);for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next; // 保存链表的下一个结点// 头插到新表当中size_t hashi = hf(kot(cur->_data)) % newTable.size();cur->_next = newTable[hashi];newTable[hashi] = cur;// 向链表后迭代cur = next;}}// 交换 两个表在 对象当中的指向,让编译器 帮我们释放旧表的空间_table.swap(newTable); }红黑树的参数模版:
template<class K, class T,class KeyOfT , class HashFunc = DefaultHashFunc<K>>class hash{
·········
········
········
········其中的 T 这模版参数,在 set 当中传入的是 K,而在 map 当中传入的是一个 pair,这个pair 当中 存储的是一个结点的 key-value 键值对。而 KeyOfT 模版参数就是上述所说的,在 set 和 map 当中实现不同 取 key 逻辑的 仿函数的类的类型。这里就是要和 set 和 map 都可以使用一个 哈希桶的代码,实现泛型编程。
而 HashFunc 这个模版参数是为了 在哈希当中能以多种 类型 作为 key 值来实现的仿函数。(在上一篇博客对哈希表的介绍当中有具体说明:C++ - 开放地址法的哈希介绍 - 哈希表的仿函数例子_chihiro1122的博客-CSDN博客)
哈希桶的迭代器实现
哈希桶的遍历非常的简单,直接按照指针数组的顺序来遍历其中的 哈希桶就行了:
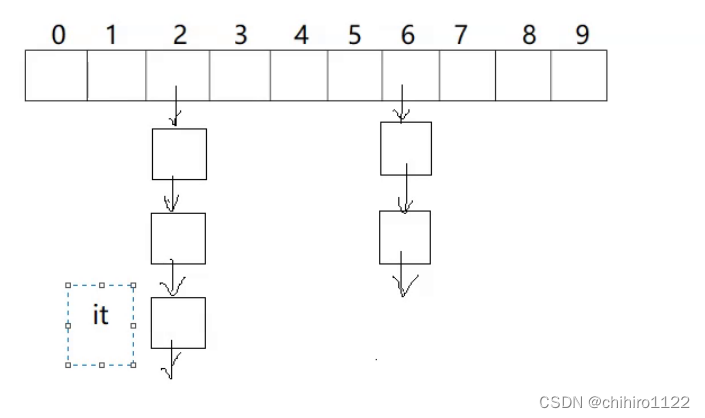
但是,遍历简单,但是对于迭代器当中的 operator++()函数 和 operator--()函数,这两个函数的实现就要推敲一下。
比如 ,当it 迭代器遍历到其中某一个 结点,那么 operator--()如何找到上一个结点;当 it 迭代器遍历到 某一个哈希桶的最后一个结点的时候,operator++()函数如何找到下一个哈希桶的位置。
在 迭代器当中用 key 计算 hash 值,也是需要用 set 和 map 当中的仿函数来调用不同的 key 值取出的方法的。
key 取出来了,还有哈希桶当中的 不同类型的 key 值的计算方式,也需要仿函数去计算。
首先,每一个结点当中的值,都是按照哈希桶的规则插入进去的,我们可以计算出当前这个结点的key值,计算出当前结点是在哪一个桶;这样的话就可以直接从头开始遍历找到当前结点的上一个结点了,也可以找到下一个桶和上一个桶。
operator++()函数
在迭代器类当中存储的有当前结点的指针_node,那么当 _node->_next 不为空的时候,就继续遍历 这个哈希桶;为空说明已经遍历到这个哈希桶的最后一个结点了,就要找下一个哈希桶。
怎么找,在上述已经说明了,就是计算当前结点的 key 值,计算当前哈希桶在指针数组的位置,找到下一个 哈希桶的位置。
当找不到下一个桶,
但是,想找到下一个哈希桶的位置,就要有 指针数组,但是指着数组在 哈希桶类 内当中,迭代器是另一个专门的类,如果在迭代器当中取到 这个 指针数组呢?
我们就在 迭代器类当中多一个 成员来存储一个 哈希桶对象的指针。这样就可以找到指针数组了。
Self& operator++(){if (_node->_next){// 当前桶还没完// 就继续遍历当前桶_node = _node->_next;}else{// 两个仿函数类的实例化KeyOfT kot;HashFunc hf;// 计算当前结点的 hash值size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();// 从下一个位置查找查找下一个不为空的桶++hashi;while (hashi < _pht->_table.size()){// 如果遍历到的桶不为空if (_pht->_table[hashi]){// 把桶的第一个元素赋值给 _node_node = _pht->_table[hashi];return *this;}else{// 如果桶为空 继续寻找下一个桶++hashi;}}// 走到这说明 后面的桶都为空// 或者当前桶就是最后一个桶了_node = nullptr;}return *this;}类模板的有元
但是 哈希桶当中的 _table 这个 vector 容器是 private 的,在 迭代器类当中不能访问,所以此时我们就要把 迭代器 作为 哈希表的有元出现,届时迭代器才能访问到 哈希表当中的 私有成员。
但是此处不是友元函数,是一个类模板的 有元,类模板的有元要在之前把模版参数加上:
template<class K, class T,class KeyOfT , class HashFunc = DefaultHashFunc<K>>class hash{// 有元声明template<class K, class T, class KeyOfT, class HashFunc>friend struct HTIterator;
··················
·················· };哈希桶类当中的 begin()和 end()
找到第一个桶也很简单,和上述 operator++()找下一个桶一样;end ()的话是最后一个结点的下一个位置,也就是说 nullptr,所以说,直接构造一个空的迭代器返回就行了:
iterator begin(){// 找第一个桶for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];// 当前桶的不为空if (cur){// 返回需要构造一个迭代器返回return iterator(cur, this);}}// 没找到就返回一个 空的迭代器return iterator(nullptr, this);}iterator end(){// 构造一个空的迭代器返回return iterator(nullptr, this);}在 set 和 map 当中的 begin()和 end()也都是套用 哈希桶当中的 begin()和end()了:
//unordered_set.htypedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}// unordered_map.htypedef typename hash_bucket::HashTable<K, pair<K, V>, MapKeyOfT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}哈希桶的迭代器类 和 哈希桶类的相互依赖问题
之前实现的迭代器,都是 本类 当中有一个 迭代器 的 typedef,那么 在本类当中就可以直接按照typedef 当中的模版参数,在需要构造迭代器的地方,按照这个模版参数来构造。也就是说,要想用迭代器,那么 本类就要在前面,这样迭代器才能按照 本类来进行 定义。
但是,我们本次实现的哈希表的 迭代器当中,有哈希表的指针;在哈希表当中还有 迭代器,这是一个相互使用的场景。
当哈希表当中要用迭代器,所以迭代器在 哈希表当中 最前处声明,没问题。但是在 迭代器当中还有哈希表,那么此时,在迭代器当中的哈希表的类型,编译器不认识。

所以,此时就要把 哈希桶类,在 迭代器上声明一下,因为编译器在遇到类型的时候,只会向上寻找定义,那么我们在迭代器上声明一下,高速编译器哈希表在下面定义了。
我们把这种方式称为 前置声明。
// 前置声明template<class K, class T, class KeyOfT, class HashFunc>class HashTable;template<class K, class T, class KeyOfT, class HashFunc>struct HTIterator{·············
·············
·············}template<class K, class T,class KeyOfT , class HashFunc = DefaultHashFunc<K>>class hash{
·············
·············
············· }前置声明当中不用给模版的缺省参数。
const迭代器
上述实现之后,虽然迭代器能够跑了,但是还有一些问题,在上述取出的迭代器,可以修改 哈希桶的当中的key值。我们可以用 const 迭代器来解决这个问题,在 以 红黑树为底层实现的 map 和 set 也使用了这样方法,具体可以参考在前言当中给出的两篇博客。
const 迭代器 和 普通迭代器共用的是一个 迭代器的模版。而之所以 const 的迭代器在外部不能修改,实际上也就是在 operator*() 和 operator->()这两个函数在返回值上做了处理,返回一个 const 的 引用 或者 指针,这个引用的对象 或者 指针指向的对象就不能修改了。
template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>struct HTIterator{typedef hash_bucket::HashNode<T> Node;// 方便下述书写 迭代器的模版参数typedef HTIterator<K, T, Ptr, Ref, KeyOfT, HashFunc> Self;Node* _node;hashtable<K, T, KeyOfT, HashFunc>* _pht;HTIterator(Node* node, hashtable<K, T, KeyOfT, HashFunc>* pht):_node(node), _pht(pht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}
····································
····································
····································}所以,我们只需要把 T* T& 作为 普通迭代器operator*() 和 operator->()的返回值;把 const T* ,const T& 作为 普通迭代器operator*() 和 operator->()的返回值;
因为 我们在 哈希表当中对 iterator 类 的模版参数进行了 typedef ,所以,我们只需要再在哈希表当中 typedef 出一个 const_iterator ,而 iterator 和 const_iterator 的不同就在于 传入给迭代器模版类的 模版参数不同。
template<class K, class T,class KeyOfT , class HashFunc = DefaultHashFunc<K>>class hashtable{typedef HashNode<T> Node;// 有元声明template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>friend struct HTIterator;public:typedef HTIterator<K, T, T*, T&, KeyOfT, HashFunc> iterator;typedef HTIterator<K, T, const T*, const T&, KeyOfT, HashFunc> const_iterator;·····················
·····················
····················· iterator begin(){// 找第一个桶for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];// 当前桶的不为空if (cur){// 返回需要构造一个迭代器返回return iterator(cur, this);}}// 没找到就返回一个 空的迭代器return iterator(nullptr, this);}iterator end(){// 构造一个空的迭代器返回return iterator(nullptr, this);}// const 的 begin()和 end()const_iterator begin() const{// 找第一个桶for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];// 当前桶的不为空if (cur){// 返回需要构造一个迭代器返回return const_iterator(cur, this);}}// 没找到就返回一个 空的迭代器return const_iterator(nullptr, this);}const_iterator end() const{// 构造一个空的迭代器返回return const_iterator(nullptr, this);}};哈希桶迭代器的 const *this 问题
在哈希桶当中的 const 版本的 begin()和 end()当中,返回的是一个 迭代器 ,此时我们调用了一个 迭代器的构造函数,这个构造函数当中还传入了 当前哈希桶对象 的 this 指针。但是这个指针在 const 版本的begin()和 end()函数当中是被 const 修饰的,但是 在构造函数当中接受 this 指针的 形参不是 const 的,此时就会发生权限的放大,就会报错。

当然,最简单的方式就是 在构造函数的当中用一个 const 的形参去接受,然后 构造函数对应初始化的成员也应该是 const 的,这样才能正确接受 const 的 this 指针。
虽然在我们之前对 哈希桶当中的实现来看,在迭代器当中我们并没有在迭代器当中使用哈希桶的指针来修改过 哈希桶当中的 _table 这个 vector 等等成员什么的,只是从 _table 当中读数据,所以是对于 const 的指针是没有问题的。
也就是说在 当前实现的 迭代器当中是不会通过 哈希表 指针修改到哈希表的,在迭代器当中是使用 _node 当前迭代器指向的 结点指针来修改 到 哈希表的,所以在当前是没有问题的。
而且,构造函数只用写一个 const this指针的版本就足够了,因为普通迭代器传过来的 普通 this 指针 转给 const 的形参是完全没有问题的,是权限的缩小,然后初始化给 const 的指针也是没有问题
修改之后的代码:
template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>struct HTIterator{
·········const hashtable<K, T, KeyOfT, HashFunc>* _pht;HTIterator(Node* node, const hashtable<K, T, KeyOfT, HashFunc>* pht):_node(node), _pht(pht){}
·········} 库当中实现不是按照上述方式实现的,他是 把 iteator 和 const_iterator 两个迭代器都实现了一遍:
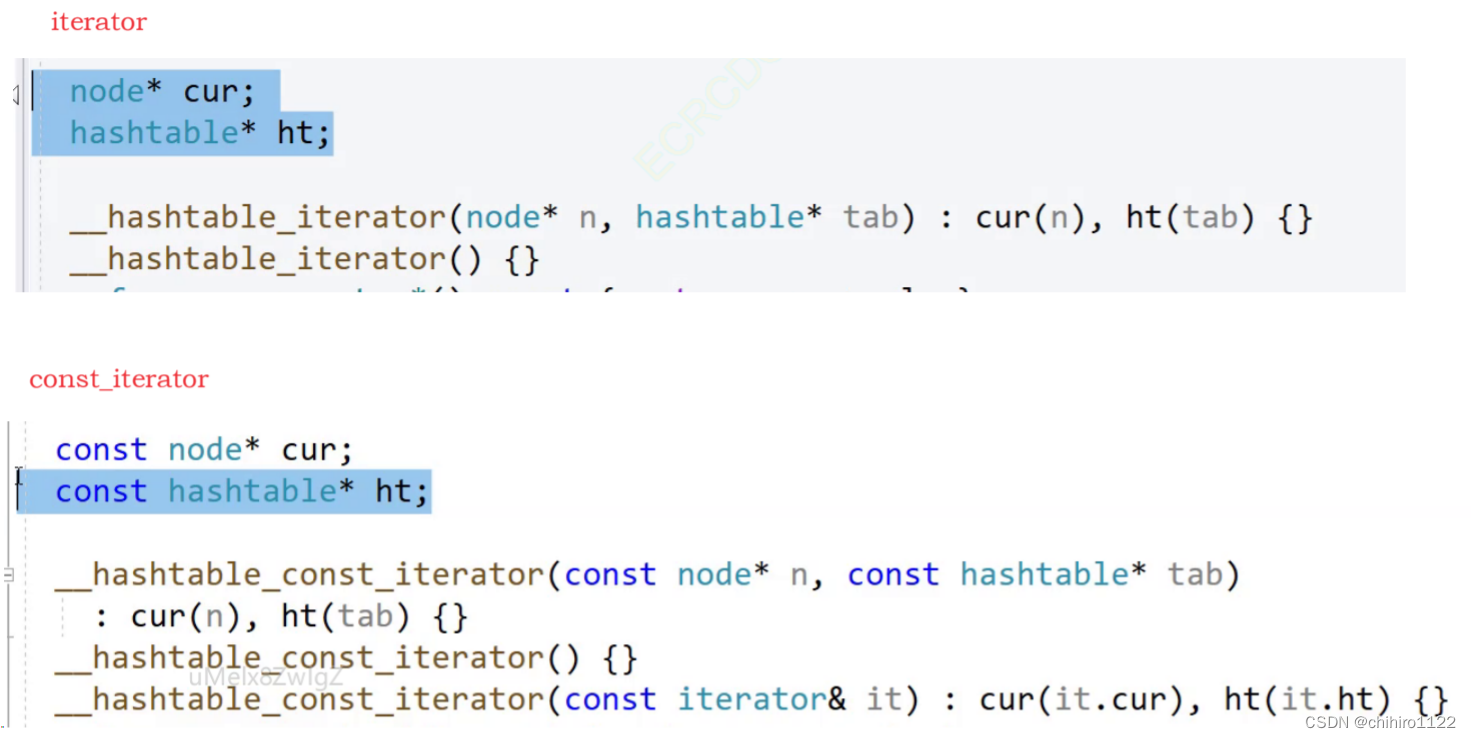
而且,在const_iterator 当中,不仅仅是 哈希桶指针是 const 的,结点的指针也是 const 的。
哈希桶迭代器完整代码
// 前置声明template<class K, class T, class KeyOfT, class HashFunc>class hashtable;// 在哈希表 的 iterator template<K, T, T* , T& , KeyOfT , HashFunc>// 在哈希表 的 const_iterator template<K, T, const T* , const T& , KeyOfT , HashFunc>template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>struct HTIterator{typedef hash_bucket::HashNode<T> Node;// 方便下述书写 迭代器的模版参数typedef HTIterator<K, T, Ptr, Ref, KeyOfT, HashFunc> Self;Node* _node;hashtable<K, T, KeyOfT, HashFunc>* _pht;HTIterator(Node* node, hashtable<K, T, KeyOfT, HashFunc>* pht):_node(node), _pht(pht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self& operator++(){if (_node->_next){// 当前桶还没完// 就继续遍历当前桶_node = _node->_next;}else{// 两个仿函数类的实例化KeyOfT kot;HashFunc hf;// 计算当前结点的 hash值size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();// 从下一个位置查找查找下一个不为空的桶++hashi;while (hashi < _pht->_table.size()){// 如果遍历到的桶不为空if (_pht->_table[hashi]){// 把桶的第一个元素赋值给 _node_node = _pht->_table[hashi];return *this;}else{// 如果桶为空 继续寻找下一个桶++hashi;}}// 走到这说明 后面的桶都为空// 或者当前桶就是最后一个桶了_node = nullptr;}return *this;}bool operator!=(const Self& s){return _node != s._node;}};// 哈希桶当中 begin 和 end 代码部分演示template<class K, class T,class KeyOfT , class HashFunc = DefaultHashFunc<K>>class hashtable{typedef HashNode<T> Node;// 有元声明template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc>friend struct HTIterator;public:typedef HTIterator<K, T, T*, T&, KeyOfT, HashFunc> iterator;typedef HTIterator<K, T, const T*, const T&, KeyOfT, HashFunc> const_iterator;hashtable(){_table.resize(10, nullptr);}iterator begin(){// 找第一个桶for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];// 当前桶的不为空if (cur){// 返回需要构造一个迭代器返回return iterator(cur, this);}}// 没找到就返回一个 空的迭代器return iterator(nullptr, this);}iterator end(){// 构造一个空的迭代器返回return iterator(nullptr, this);}// const 的 begin()和 end()const_iterator begin() const{// 找第一个桶for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];// 当前桶的不为空if (cur){// 返回需要构造一个迭代器返回return const_iterator(cur, this);}}// 没找到就返回一个 空的迭代器return const_iterator(nullptr, this);}const_iterator end() const{// 构造一个空的迭代器返回return const_iterator(nullptr, this);}
·······················
·······················
·······················};unordered_set 和 unordered_map 当中复用 哈希桶的迭代器
unordered_set
set 当中只有 key ,用户是不能对 这个 key 进行修改的,所以,在 unordered_set 当中 ,不管是 iterator 还是 const_iteartor 都是 const_iteartor。想实现这样的功能,直接把 const_iteartor typedef 出 iterator 和 const_iteartor 就可以实现。
unordered_set 当中就只有 const 版本的 begin()和 end()函数,实现:
public:typedef typename hash_bucket::hashtable<K, K, SetKeyOfT>::const_iterator iterator;typedef typename hash_bucket::hashtable<K, K, SetKeyOfT>::const_iterator const_iterator;// 返回值是 iterator 还是 const_iterator 都一样,都是 const_iteratoriterator begin() const{return _ht.begin();}iterator end() const{return _ht.end();}如果只提供const 版本的迭代器的话,不管是 const 对象还是 普通对象都可以调用它,普通对象调用就是 权限的缩小,const 调用就是 权限的平移。
#pragma once
#include"hash.h"namespace unordered
{template<class K>class unordered_set{// set 当中从 T 当中取出 key 的仿函数struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename hash_bucket::hashtable<K, K, SetKeyOfT>::const_iterator iterator;typedef typename hash_bucket::hashtable<K, K, SetKeyOfT>::const_iterator const_iterator;iterator begin() const{return _ht.begin();}iterator end() const{return _ht.end();}pair<iterator, bool> insert(const K& key){pair<typename hash_bucket::hashtable<K, K, SetKeyOfT>::iterator, bool> pit = _ht.Insert(key);return pair<iterator, bool>(pit.first, pit.second);}private:hash_bucket::hashtable<K, K, SetKeyOfT> _ht;};
}
unordered_map
unordered_map 当中,按照 map 和 set 当中一样的性质进行套用和封装,在 unordered_map 当中的哈希桶构造的时候,对 pair 当中的 key 就使用 const 的方式,这样就可以修改到 value 而不修改到 key 了。
当然,insert()也不能再像直线一样返回一个 bool 值了,得返回一个 迭代器和 bool 值,pair<iterator, bool>。
而且 find()函数也要返回一个 迭代器 ,修改如下:
pair<iterator, bool> Insert(const T& data){HashFunc hf;KeyOfT kot;iterator it = find(kot(data));if (it != end()){return make_pair(iterator, false);}// 负载因子 到 1 就扩容(每一个桶当中都有数据)if (_n == _table.size()){size_t newsize = _table.size() * 2;vector<Node*> newTable;newTable.resize(newsize, nullptr);for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next; // 保存链表的下一个结点// 头插到新表当中size_t hashi = hf(kot(cur->_data)) % newTable.size();cur->_next = newTable[hashi];newTable[hashi] = cur;// 向链表后迭代cur = next;}}// 交换 两个表在 对象当中的指向,让编译器 帮我们释放旧表的空间_table.swap(newTable); }// 计算hash值size_t hashi = hf(data) % _table.size();Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return make_pair(iterator(newnode, this), true);}
iterator find(const K& key){HashFunc hf;KeyOfT kot;size_t hash = hf(kot(key)) % _table.size();Node* cur = _table[hash];while (cur){// 如果找到就返回 迭代器,不在返回结点的指针if (kot(cur->_data) == key)return iterator(cur, this);cur = cur->_next;}return nullptr;}在上述修改之后,在 unordered_set 和 unordered_map 当中的 insert()函数也要进行修改,它的返回值也应该是一个 pair<iterator, bool>。但是在上述修改之后就会引发另一个问题,如下所示:
在 set 当中的insert()函数的 pair<iterator, bool> 的iterator 是 const_iterator ; 哈希桶当中的pair<iterator, bool> 的 iterator 就是 iterator。就类似于 vector<int> 和 vector<double> 的关系,是两个模版实例化出的类型,已经不是权限的放大和缩小了,根本就不是一个类型了。vector<int> 和 vector<const int> 两个也是不同的类型。
而 map 中不会,因为map 当中的 iteartor 就是 iterator,const_iterator 就是 const_iterator。
但是前提是 实现了 传入 iterator 就构造 const_iteartor 的const 的构造函数,我们在 map 和 set 当中也就行了说明,他是 一份函数代码,在 iterator 和 const_iteartor 当中可以 实例化出两种函数,在 iteartor 就是 传入 iterator 的拷贝构造函数,在 const_iteartor 就是 传入 iterator 就构造 一个const_iteartor 的构造函数,具体可以参考 map 和 set 的博客。
修改就是 增加一个 拷贝构造函数/const构造函数。
像上述的修改方式在 list 当中也支持,如果用一个 iterator 取 构造 const_iterator 在 list 当中是支持的:

我们可以看到it2 迭代器是 const 迭代器,但是 it 是 普通 list 对象,那么调用的迭代器的就是 普通迭代器,像上述的方式是支持的。库当中是这样实现的:
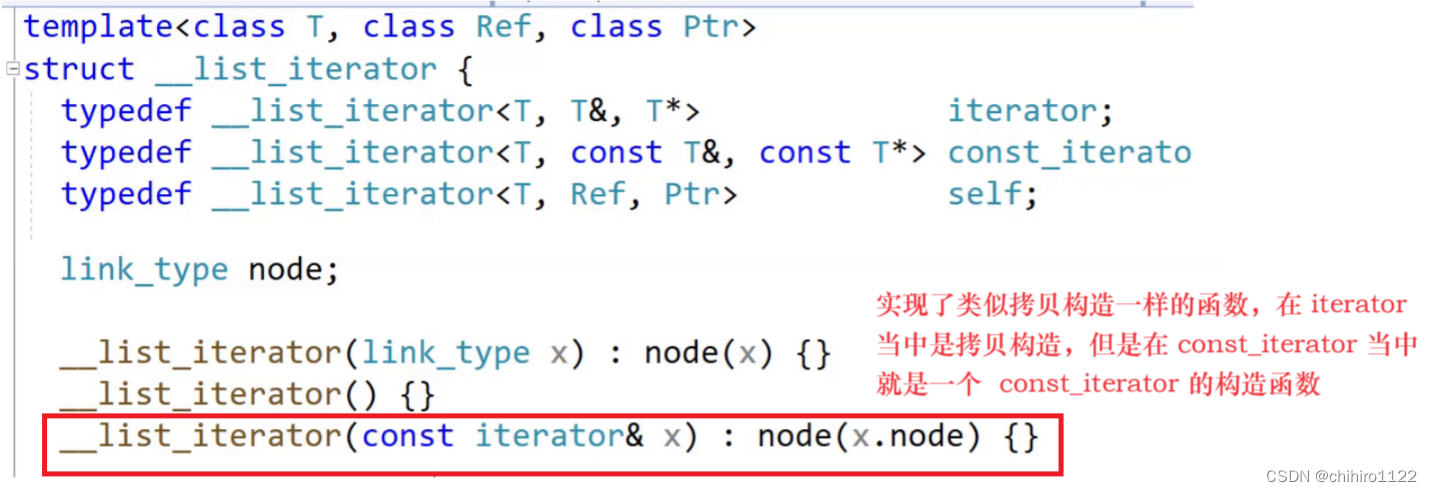
在以前的迭代器实现当中,我们没有写这样的,类似拷贝构造函数一样的 函数,因为以前的迭代器的拷贝就是一个浅拷贝,只需要拷贝迭代器当中的指针就行了,而编译器自动生成的 浅拷贝的拷贝构造函数就已经够用了,不需要我们在写了。而上述写了之后,相当于是把 iterator 的不需要写的浅拷贝的拷贝构造函数写了,把 const_iterator 的构造函数写了,但是在 iterator 当中本来是不用写的,编译器自己写的就够用了,但是需要写一个 传入 iterator 构造 const_iterator 的构造函数,写了这个函数也就相当于是把 iterator 的浅拷贝函数给写了。
而且这个函数的参数类型没有用 self ,而是用的 iterator,如果用 self 那么这个函数不管在哪都是一个拷贝构造函数;但是用的是 iterator,T* 和 T& 是写死的,此处就是绝妙之处。
还需要注意的是, 不同的对象但是类模版类型相同,是可以访问到对方的private 对象的,如果是不同累模版类型就不能了:
比如 A<int, double&> 和 A<int, double&> 的两个对象是可以访问的,但是如果是 A<int, double&> 和 A<int, const double> 两个对象就不行了。在库当中可以实现是因为 人家不是类模板,是 struct的。因为类有类域。
#pragma once
#include"hash.h"namespace unordered
{template<class K, class V>class unordered_map{// map 当中从 T 当中取出key 的仿函数struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename hash_bucket::hashtable<K, pair<const K, V>, MapKeyOfT>::iterator iterator;typedef typename hash_bucket::hashtable<K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator begin() const{return _ht.begin();}const_iterator end() const {return _ht.end();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}private:hash_bucket::hashtable<K, pair<const K, V>, MapKeyOfT> _ht;};
}
相关文章:
C++ - 封装 unordered_set 和 unordered_map - 哈希桶的迭代器实现
前言 unordered_set 和 unordered_map 两个容器的底层是哈希表实现的,此处的封装使用的 上篇博客当中的哈希桶来进行封装,相当于是在 哈希桶之上在套上了 unordered_set 和 unordered_map 。 哈希桶的逻辑实现: C - 开散列的拉链法&…...
gradle中主模块/子模块渠道对应关系通过配置实现
前言: 我们开发过程中,经常会面对针对不同的渠道,要产生差异性代码和资源的场景。目前谷歌其实为我们提供了一套渠道包的方案,这里简单描述一下。 比如我主模块依赖module1和module2。如果主模块中声明了2个渠道A和B,…...

28383-2012 卷筒料凹版印刷机 学习笔记
声明 本文是学习GB-T 28383-2012 卷筒料凹版印刷机. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了卷筒料凹版印刷机的型式、基本参数、要求、试验方法、检验规则、标志、包装、运输与 贮存。 本标准适用于机组式的卷筒料凹版…...
stable diffusion学习笔记【2023-10-2】
L1:界面 CFG Scale:提示词相关性 denoising:重绘幅度 L2:文生图 女性常用的负面词 nsfw,NSFW,(NSFW:2),legs apart, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, (…...
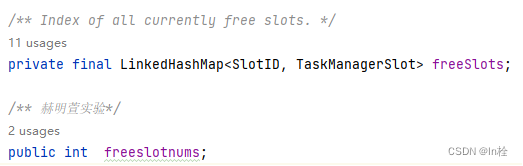
flink选择slot
flink选择slot 在这个类里修改 package org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl; findMatchingSlot(resourceProfile):找到满足要求的slot(负责从哪个taskmanager中获取slot)对应上图第8,9&…...

世界前沿技术发展报告2023《世界信息技术发展报告》(六)网络与通信技术
(六)网络与通信技术 1. 概述2. 5G与光通讯2.1 美国研究人员利用电磁拓扑绝缘体使5G频谱带宽翻倍2.2 日本东京工业大学推出可接入5G网络的高频收发器2.3 美国得克萨斯农工大学通过波束管理改进5G毫米波通信2.4 联发科完成全球首次5G NTN卫星手机连线测试2…...
spark SQL 任务参数调优1
1.背景 要了解spark参数调优,首先需要清楚一部分背景资料Spark SQL的执行原理,方便理解各种参数对任务的具体影响。 一条SQL语句生成执行引擎可识别的程序,解析(Parser)、优化(Optimizer)、执行…...

算法练习2——移除元素
LeetCode 27 移除元素 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑…...
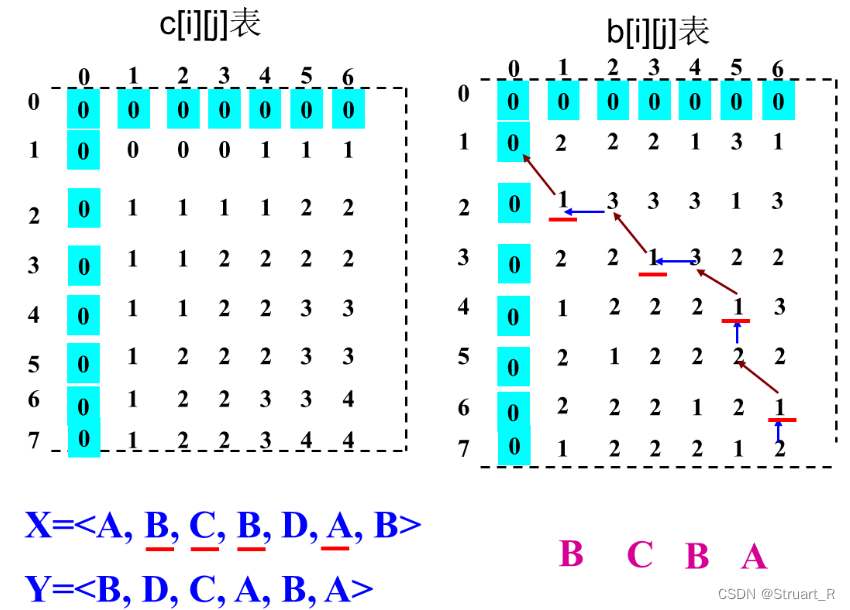
动态规划算法(2)--最大子段和与最长公共子序列
目录 一、最大子段和 1、什么是最大子段和 2、暴力枚举 3、分治法 4、动态规划 二、最长公共子序列 1、什么是最长公共子序列 2、暴力枚举法 3、动态规划法 4、完整代码 一、最大子段和 1、什么是最大子段和 子段和就是数组中任意连续的一段序列的和,而…...
CentOS上网卡不显示的问题
文章目录 1.问题描述 1.问题描述 ifconfig下看不到ens33网卡了。systemctl status network #查看网卡状态报下面的问题网上说的解决方式有以下三种: 第一种: 和 NetworkManager 服务有冲突,这个好解决,直接关闭 NetworkManger 服…...

localStorage实现历史记录搜索功能
📝个人主页:爱吃炫迈 💌系列专栏:JavaScript 🧑💻座右铭:道阻且长,行则将至💗 文章目录 为什么使用localStorage如何使用localStorage实现历史记录搜索功能(…...

计算机网络(一):概述
参考引用 计算机网络微课堂-湖科大教书匠计算机网络(第7版)-谢希仁 1. 计算机网络在信息时代的作用 计算机网络已由一种通信基础设施发展成为一种重要的信息服务基础设施计算机网络已经像水、电、煤气这些基础设施一样,成为我们生活中不可或…...

visual code 下的node.js的hello world
我装好了visual code ,想运行一个node.js 玩玩。也就是运行一个hello world。 一:安装node.js : 我google 安装node.js 就引导我到下载页面:https://nodejs.org/en/download 有 Windows Installer (.msi) 还有Windows Binary (…...
)
MySQL——四、SQL语句(下篇)
MySQL 一、常见的SQL函数1、数学函数2、日期函数3、分组函数(聚合函数)4、流程控制函数 二、where条件查询和order by排序三、分组统计四、多表关联查询1、交叉连接CROSS2、内连接inner3、外连接:outer4、子查询 五、分页查询 一、常见的SQL函数 1、length(str):获…...

蓝桥杯每日一题2023.10.2
时间显示 - 蓝桥云课 (lanqiao.cn) 题目描述 题目分析 输入为毫秒,故我们可以先将毫秒转化为秒,由于只需要输出时分,我们只需要将天数去除即可,可以在这里多训练一次天数判断 #include<bits/stdc.h> using namespace std…...
红外遥控器 数据格式,按下及松开判断
红外遥控是一种无线、非接触控制技术,具有抗干扰能力强,信息传输可靠,功耗低,成本低,易实现等显著优点,被诸多电子设备特别是家用电器广泛采用,并越来越多的应用到计算机系统中。 同类产品的红…...
)
win32进程间通信方式(13种)
win32进程间通信 文件映射共享内存匿名管道命名管道远程过程调用(RPC)对象连接与嵌入(OLE)动态数据交换(DDE)剪贴板WM_COPYDATA消息邮件槽其它 文件映射 特点:本地间通信,不能用于网…...

基于Vue+ELement搭建动态树与数据表格实现分页模糊查询
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《ELement》。🎯🎯 …...

多线程案例 - 单例模式
单例模式 ~~ 单例模式是常见的设计模式之一 什么是设计模式 你知道象棋,五子棋,围棋吗?如果,你想下好围棋,你就不得不了解一个东西,”棋谱”,设计模式好比围棋中的 “棋谱”. 在棋谱里面,大佬们,把一些常见的对局场景,都给推演出来了,照着棋谱来下棋,基本上棋力就不会差到哪…...
云原生Kubernetes:对外服务之 Ingress
目录 一、理论 1.Ingress 2.部署 nginx-ingress-controller(第一种方式) 3.部署 nginx-ingress-controller(第二种方式) 二、实验 1.部署 nginx-ingress-controller(第一种方式) 2.部署 nginx-ingress-controller(第二种方式) 三、问题 1.启动 nginx-ingress-controll…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...