位置编码器
目录
1、位置编码器的作用
2、代码演示
(1)、使用unsqueeze扩展维度
(2)、使用squeeze降维
(3)、显示张量维度
(4)、随机失活张量中的数值
3、定义位置编码器类,我们同样把它看作是一个层,因此会继承nn.Module
1、位置编码器的作用
- 因为在Transformers的编码器结构中,并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失
2、代码演示
(1)、使用unsqueeze扩展维度
position = torch.arange(0,10)
print(position.shape)
position = torch.arange(0,10).unsqueeze(1) #unsqueeze(0) 扩展第一个维度torch.Size([1, 10]),#unsqueeze(1) 扩展第二个维度torch.Size([10, 1])#unsqueeze(2) 是错误的写法
print(position)
print(position.shape)(2)、使用squeeze降维
x = torch.LongTensor([[[1],[4]],[[7],[10]]])
print(x)
print(x.shape)
y = torch.squeeze(x)
print(y.shape)
print(y)tensor([[[ 1],
[ 4]],
[[ 7],
[10]]])
torch.Size([2, 2, 1])
torch.Size([2, 2])
tensor([[ 1, 4],
[ 7, 10]])
在使用squeeze函数进行降维时,只有当被降维的维度的大小为1时才会将其降维。如果被降维的维度大小不为1,则不会对张量的值产生影响。因为上面的数据中第三个维度为1,所以将第三维进行降维,得到一个二维张量
(3)、显示张量维度
x = torch.LongTensor([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(x.size(0))
print(x.size(1))
print(x.size(2))
(4)、随机失活张量中的数值
m = nn.Dropout(p=0.2)
input = torch.rand(4,5)
output = m(input)
print(output)在张量中的 20 个数据中有 20% 的随机失活为0,也即有 4 个
3、定义位置编码器类,我们同样把它看作是一个层,因此会继承nn.Module
import torch
from torch.autograd import Variable
import math
import torch.nn as nn
class PositionalEncoding(nn.Module):def __init__(self,d_model,dropout,max_len=5000):""":param d_model: 词嵌入的维度:param dropout: 随机失活,置0比率:param max_len: 每个句子的最大长度,也就是每个句子中单词的最大个数"""super(PositionalEncoding,self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len,d_model) # 初始化一个位置编码器矩阵,它是一个0矩阵,矩阵的大小是max_len * d_modelposition = torch.arange(0,max_len).unsqueeze(1) # 初始一个绝对位置矩阵div_term = torch.exp(torch.arange(0,d_model,2)*-(math.log(1000.0)/d_model))pe[:,0::2] = torch.sin(position*div_term)pe[:,1::2] = torch.cos(position*div_term)pe = pe.unsqueeze(0) # 将二维矩阵扩展为三维和embedding的输出(一个三维向量)相加self.register_buffer('pe',pe) # 把pe位置编码矩阵注册成模型的buffer,对模型是有帮助的,但是却不是模型结构中的超参数或者参数,不需要随着优化步骤进行更新的增益对象。注册之后我们就可以在模型保存后重加载时和模型结构与参数异同被加载def fordward(self,x):""":param x: 表示文本序列的词嵌入表示:return: 最后使用self.dropout(x)对对象进行“丢弃”操作,并返回结果"""x = x + Variable(self.pe[:, :x.size(1)],requires_grad = False) # 不需要梯度求导,而且使用切片操作,因为我们默认的max_len为5000,但是很难一个句子有5000个词汇,所以要根据传递过来的实际单词的个数对创建的位置编码矩阵进行切片操作return self.dropout(x)
# 构建Embedding类来实现文本嵌入层
class Embeddings(nn.Module):def __init__(self,vocab,d_model):""":param vocab: 词表的大小:param d_model: 词嵌入的维度"""super(Embeddings,self).__init__()self.lut = nn.Embedding(vocab,d_model)self.d_model = d_modeldef forward(self,x):""":param x: 因为Embedding层是首层,所以代表输入给模型的文本通过词汇映射后的张量:return:"""return self.lut(x) * math.sqrt(self.d_model)
# 实例化参数
d_model = 512
dropout = 0.1
max_len = 60 # 句子最大长度
# 输入 x 是 Embedding层输出的张量,形状为 2 * 4 * 512
x = Variable(torch.LongTensor([[100,2,42,508],[491,998,1,221]]))
emb = Embeddings(1000,512)
embr = emb(x)
print('embr.shape:',embr.shape) # 2 * 4 * 512
pe = PositionalEncoding(d_model, dropout,max_len)
pe_result = pe(embr)
print(pe_result)
print(pe_result.shape)相关文章:

位置编码器
目录 1、位置编码器的作用 2、代码演示 (1)、使用unsqueeze扩展维度 (2)、使用squeeze降维 (3)、显示张量维度 (4)、随机失活张量中的数值 3、定义位置编码器类,我…...
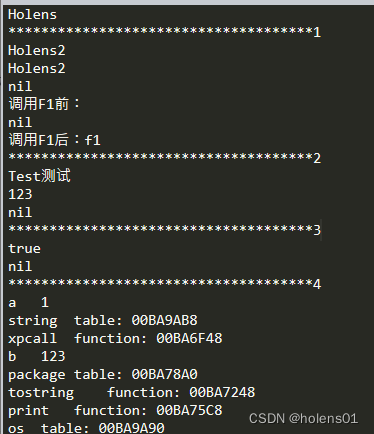
Lua多脚本执行
--全局变量 a 1 b "123"for i 1,2 doc "Holens" endprint(c) print("*************************************1")--本地变量(局部变量) for i 1,2 dolocal d "Holens2"print(d) end print(d)function F1( ..…...
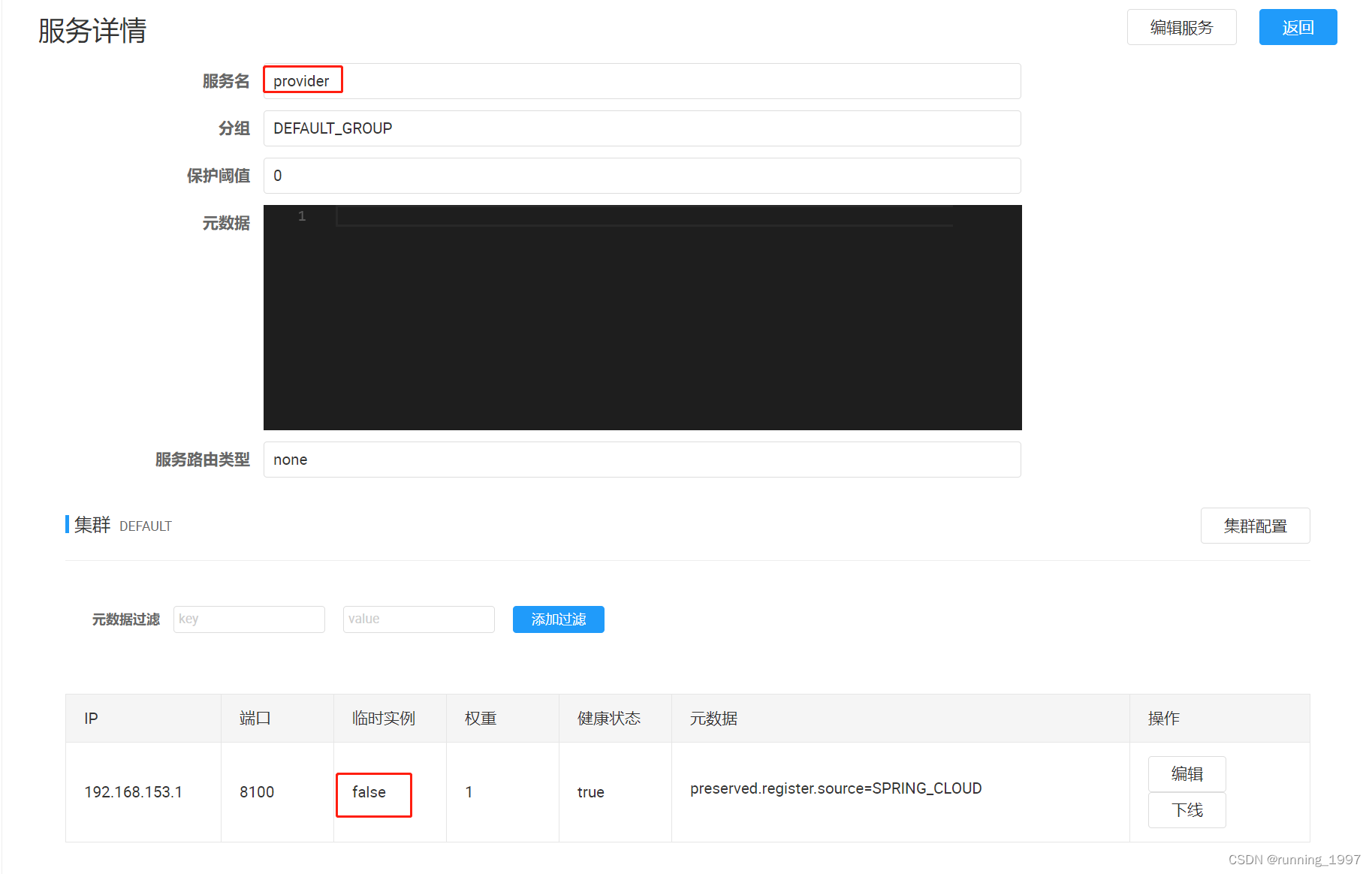
Spirng Cloud Alibaba Nacos注册中心的使用 (环境隔离、服务分级存储模型、权重配置、临时实例与持久实例)
文章目录 一、环境隔离1. Namespace(命名空间):2. Group(分组):3. Services(服务):4. DataId(数据ID):5. 实战演示:5.1 默…...

26663-2011 大型液压安全联轴器 课堂随笔
声明 本文是学习GB-T 26663-2011 大型液压安全联轴器. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了大型液压安全联轴器的分类、技术要求、试验方法及检验规则等。 本标准适用于联接两同轴线的传动轴系,可起到限制…...
ChatGPT架构师:语言大模型的多模态能力、幻觉与研究经验
来源 | The Robot Brains Podcast OneFlow编译 翻译|宛子琳、杨婷 9月26日,OpenAI宣布ChatGPT新增了图片识别和语音能力,使得ChatGPT不仅可以进行文字交流,还可以给它展示图片并进行互动,这是一次ChatGPT向多模态进化的…...

二、VXLAN BGP EVPN基本原理
VXLAN BGP EVPN基本原理 1、BGP EVPN2、BGP EVPN路由2.1、Type2路由——MAC/IP路由2.2、Type3路由——Inclusive Multicast路由2.3、Type5路由——Inclusive Multicast路由 ————————————————————————————————————————————————…...

Evil.js
Evil.js install npm i lodash-utils什么?黑心996公司要让你体统跑路了? 想在离开前给你们的项目留点小礼物? 偷偷地把本项目引入你们的项目吧,你们的项目会有但不仅限于如下的神奇效果: 仅在周日时: 当…...
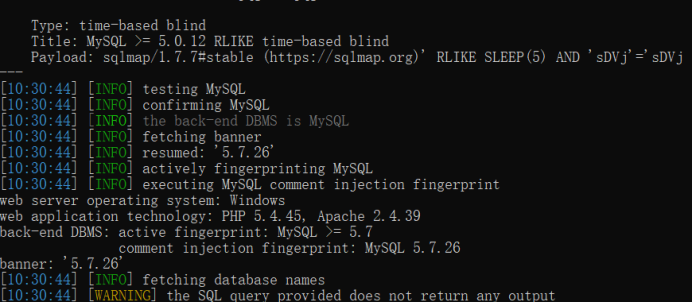
使用sqlmap的 ua注入
文章目录 1.使用sqlmap自带UA头的检测2.使用sqlmap随机提供的UA头3.使用自己写的UA头4.调整level检测 测试环境:bWAPP SQL Injection - Stored (User-Agent) 1.使用sqlmap自带UA头的检测 python sqlmap.py -u http://127.0.0.1:9004/sqli_17.php --cookie“BEEFHOO…...
华为云云耀云服务器L实例评测 | 实例评测使用之体验评测:华为云云耀云服务器管理、控制、访问评测
华为云云耀云服务器L实例评测 | 实例评测使用之体验评测:华为云云耀云服务器管理、控制、访问评测 介绍华为云云耀云服务器 华为云云耀云服务器 (目前已经全新升级为 华为云云耀云服务器L实例) 华为云云耀云服务器是什么华为云云耀…...

resultmap
自定义映射resultMap resultMap处理字段和属性的映射关系 若字段名和实体类中的属性名称不一致,则可以通过resultMap设置自定义映射 建moudel项目【实现多对一、一对多的表操作demo】 temp员工表、dept部门表 导入依赖【mysql驱动、junit、mybatis、日志依赖log4…...
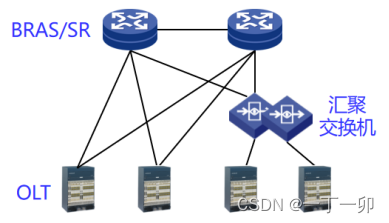
宽带光纤接入网中影响家宽业务质量的常见原因有哪些
1 引言 虽然家宽业务质量问题约60%发生在家庭网(见《家宽用户家庭网的主要质量问题是什么?原因有哪些》一文),但在用户的眼里,所有家宽业务质量问题都是由运营商的网络质量导致的,用户也因此对不同运营商家…...
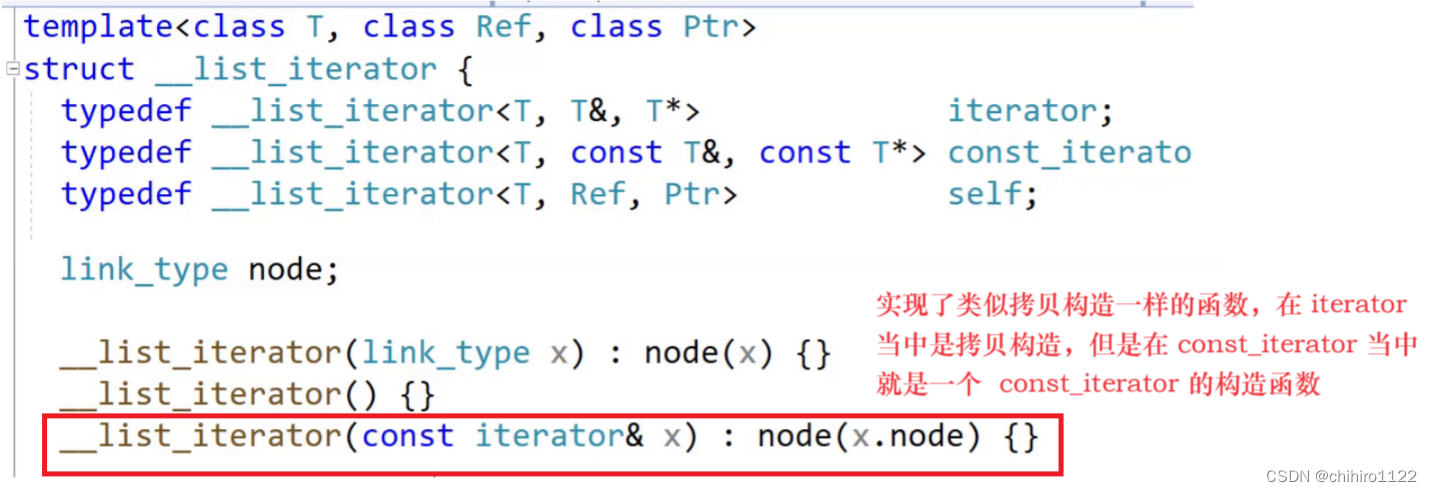
C++ - 封装 unordered_set 和 unordered_map - 哈希桶的迭代器实现
前言 unordered_set 和 unordered_map 两个容器的底层是哈希表实现的,此处的封装使用的 上篇博客当中的哈希桶来进行封装,相当于是在 哈希桶之上在套上了 unordered_set 和 unordered_map 。 哈希桶的逻辑实现: C - 开散列的拉链法&…...
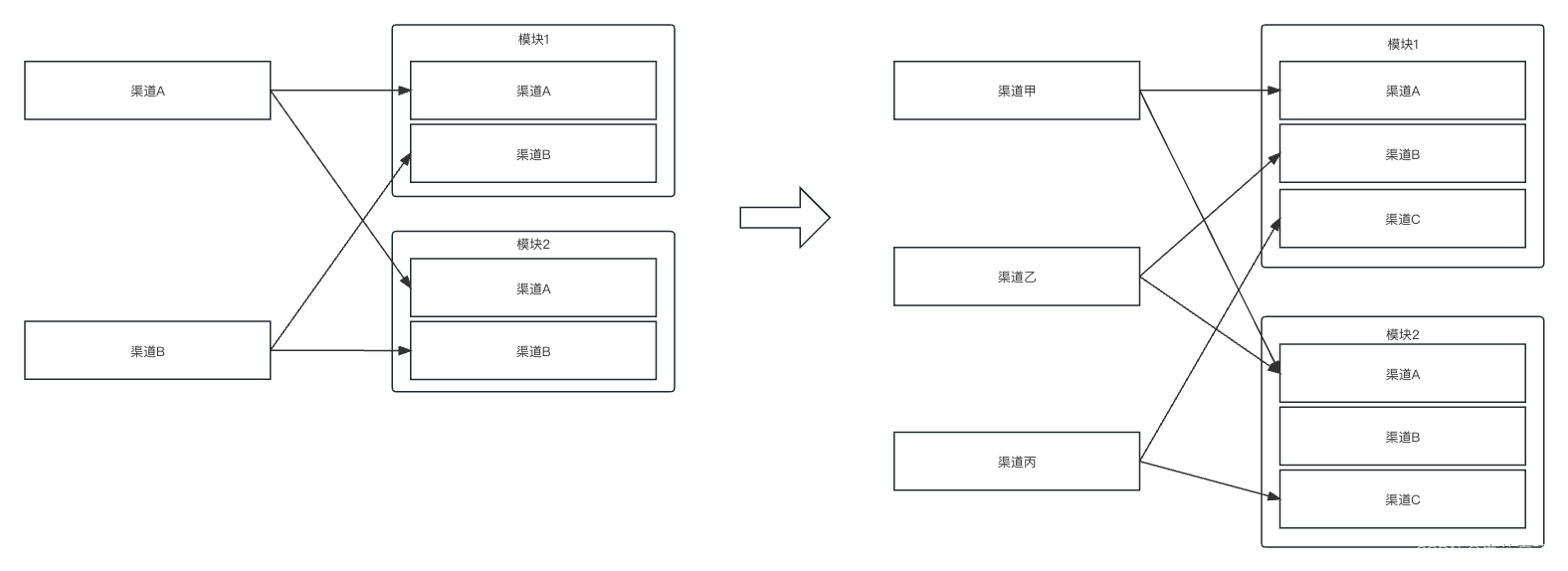
gradle中主模块/子模块渠道对应关系通过配置实现
前言: 我们开发过程中,经常会面对针对不同的渠道,要产生差异性代码和资源的场景。目前谷歌其实为我们提供了一套渠道包的方案,这里简单描述一下。 比如我主模块依赖module1和module2。如果主模块中声明了2个渠道A和B,…...

28383-2012 卷筒料凹版印刷机 学习笔记
声明 本文是学习GB-T 28383-2012 卷筒料凹版印刷机. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了卷筒料凹版印刷机的型式、基本参数、要求、试验方法、检验规则、标志、包装、运输与 贮存。 本标准适用于机组式的卷筒料凹版…...
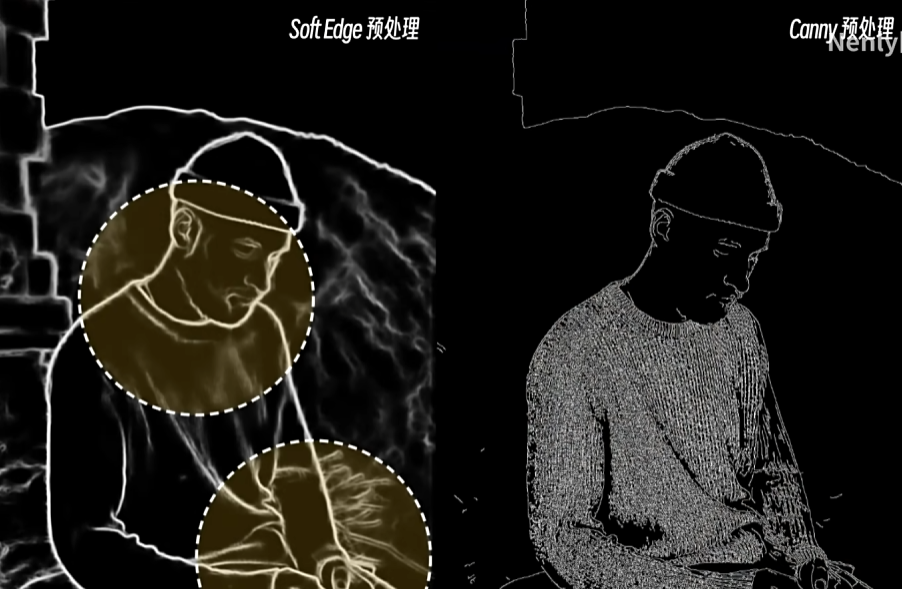
stable diffusion学习笔记【2023-10-2】
L1:界面 CFG Scale:提示词相关性 denoising:重绘幅度 L2:文生图 女性常用的负面词 nsfw,NSFW,(NSFW:2),legs apart, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, (…...
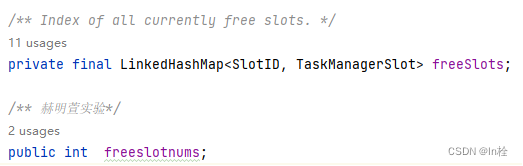
flink选择slot
flink选择slot 在这个类里修改 package org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl; findMatchingSlot(resourceProfile):找到满足要求的slot(负责从哪个taskmanager中获取slot)对应上图第8,9&…...

世界前沿技术发展报告2023《世界信息技术发展报告》(六)网络与通信技术
(六)网络与通信技术 1. 概述2. 5G与光通讯2.1 美国研究人员利用电磁拓扑绝缘体使5G频谱带宽翻倍2.2 日本东京工业大学推出可接入5G网络的高频收发器2.3 美国得克萨斯农工大学通过波束管理改进5G毫米波通信2.4 联发科完成全球首次5G NTN卫星手机连线测试2…...
spark SQL 任务参数调优1
1.背景 要了解spark参数调优,首先需要清楚一部分背景资料Spark SQL的执行原理,方便理解各种参数对任务的具体影响。 一条SQL语句生成执行引擎可识别的程序,解析(Parser)、优化(Optimizer)、执行…...

算法练习2——移除元素
LeetCode 27 移除元素 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑…...
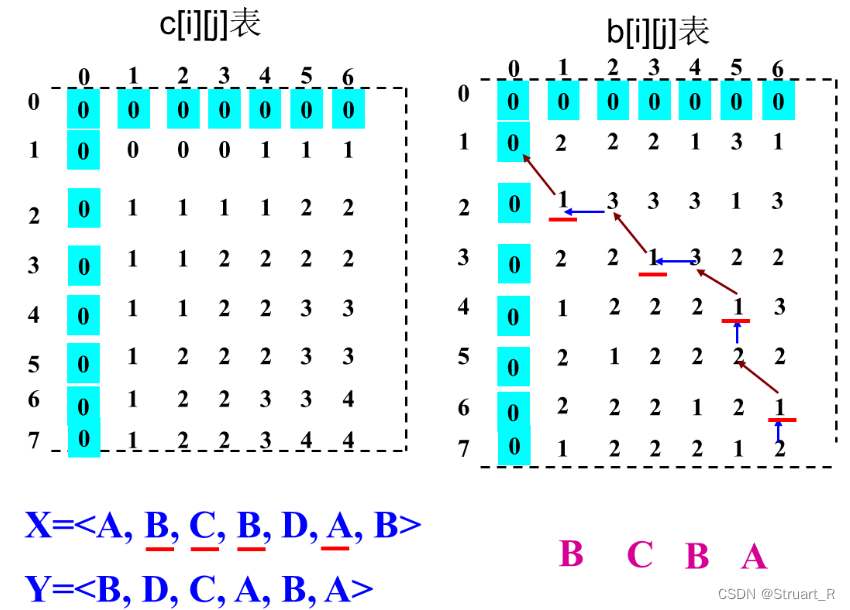
动态规划算法(2)--最大子段和与最长公共子序列
目录 一、最大子段和 1、什么是最大子段和 2、暴力枚举 3、分治法 4、动态规划 二、最长公共子序列 1、什么是最长公共子序列 2、暴力枚举法 3、动态规划法 4、完整代码 一、最大子段和 1、什么是最大子段和 子段和就是数组中任意连续的一段序列的和,而…...

为Hermes Agent配置自定义大模型供应商Taotoken
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Hermes Agent配置自定义大模型供应商Taotoken Hermes Agent 是一个流行的智能体开发框架,它允许开发者灵活地接入不同…...

Amphenol ICC DRPC215001340线束组件在工业设备中的应用与替代分析
在工业自动化和高速设备不断发展的背景下,线束组件的重要性越来越高。很多设备故障,表面看是系统问题,实际上往往与内部连接稳定性有关。而高品质线束组件,正是保障设备长期稳定运行的重要基础。 近期,Amphenol ICC&am…...

华硕笔记本性能控制终极指南:用GHelper告别臃肿,拥抱高效
华硕笔记本性能控制终极指南:用GHelper告别臃肿,拥抱高效 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivoboo…...

为Claude Code配置Taotoken密钥与模型解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken密钥与模型解决访问限制 Claude Code 作为一款高效的编程助手,其原生服务有时会因地域或配额…...

AI学习-朴素贝叶斯垃圾邮件识别:从理论到实现
朴素贝叶斯垃圾邮件识别:从理论到实现 摘要 本文从理论推导角度,完整解释朴素贝叶斯模型做垃圾邮件识别的可行性,包括:为什么文字需要向量化、贝叶斯公式如何推导出分类规则、"朴素"假设为什么不严格但仍然好用、训练…...

通过 TaoToken 统一网关体验不同主流模型的生成效果差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 TaoToken 统一网关体验不同主流模型的生成效果差异 1. 引言:统一接口下的模型体验 在构建基于大语言模型的应用时…...

CV产线MLOps平台:图像原生处理与硬件感知交付
1. 项目概述:这不是又一个“模型训练平台”,而是一套能真正跑通CV产线的MLOps工作流“Streamline Your Computer Vision Stack with an End-to-End MLOps Platform”——这个标题里藏着三个被太多团队长期忽视的关键事实:第一,“C…...

生产环境救急指南:当Navicat连不上时,用MongoDB Shell命令行搞定一切
生产环境救急指南:当Navicat连不上时,用MongoDB Shell命令行搞定一切 凌晨三点,服务器告警突然响起——某个关键服务因数据库查询超时而崩溃。你迅速打开Navicat准备排查,却发现生产环境的安全策略早已屏蔽了所有图形化工具的直接…...

2026年转型风口:理发店转战植物染发,能占据市场前10%吗?
2026年,理发店转型的风口已经悄然来临。据数据显示,植物染发和养护市场增速保持在15%以上,而白发脱发人群的比例不断增大,这无疑给众多理发店提供了巨大的转型机会。本文将通过具体的数据、案例和观点,探讨理发店转型植…...

戴森球计划蓝图库:5000+工厂设计方案助你快速建造星际帝国
戴森球计划蓝图库:5000工厂设计方案助你快速建造星际帝国 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 在《戴森球计划》这款复杂的工厂建造游戏中࿰…...