Apache Hudi初探(五)(与flink的结合)--Flink 中hudi clean操作
背景
本文主要是具体说说Flink中的clean操作的实现
杂说闲谈
在flink中主要是CleanFunction函数:
@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);this.writeClient = FlinkWriteClients.createWriteClient(conf, getRuntimeContext());this.executor = NonThrownExecutor.builder(LOG).waitForTasksFinish(true).build();String instantTime = HoodieActiveTimeline.createNewInstantTime();LOG.info(String.format("exec clean with instant time %s...", instantTime));executor.execute(() -> writeClient.clean(instantTime), "wait for cleaning finish");}@Overridepublic void notifyCheckpointComplete(long l) throws Exception {if (conf.getBoolean(FlinkOptions.CLEAN_ASYNC_ENABLED) && isCleaning) {executor.execute(() -> {try {this.writeClient.waitForCleaningFinish();} finally {// ensure to switch the isCleaning flagthis.isCleaning = false;}}, "wait for cleaning finish");}}@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {if (conf.getBoolean(FlinkOptions.CLEAN_ASYNC_ENABLED) && !isCleaning) {try {this.writeClient.startAsyncCleaning();this.isCleaning = true;} catch (Throwable throwable) {// catch the exception to not affect the normal checkpointingLOG.warn("Error while start async cleaning", throwable);}}}-
open函数
-
writeClient =FlinkWriteClients.createWriteClient(conf, getRuntimeContext())
创建FlinkWriteClient,用于写hudi数据 -
this.executor = NonThrownExecutor.builder(LOG).waitForTasksFinish(true).build();
创建一个只有一个线程的线程池,改线程池的主要作用来异步执行hudi写操作 -
executor.execute(() -> writeClient.clean(instantTime)
异步执行hudi的清理操作,该clean函数的主要代码如下:if (!tableServicesEnabled(config)) {return null;}final Timer.Context timerContext = metrics.getCleanCtx();CleanerUtils.rollbackFailedWrites(config.getFailedWritesCleanPolicy(),HoodieTimeline.CLEAN_ACTION, () -> rollbackFailedWrites(skipLocking));HoodieTable table = createTable(config, hadoopConf);if (config.allowMultipleCleans() || !table.getActiveTimeline().getCleanerTimeline().filterInflightsAndRequested().firstInstant().isPresent()) {LOG.info("Cleaner started");// proceed only if multiple clean schedules are enabled or if there are no pending cleans.if (scheduleInline) {scheduleTableServiceInternal(cleanInstantTime, Option.empty(), TableServiceType.CLEAN);table.getMetaClient().reloadActiveTimeline();}}// Proceeds to execute any requested or inflight clean instances in the timelineHoodieCleanMetadata metadata = table.clean(context, cleanInstantTime, skipLocking);if (timerContext != null && metadata != null) {long durationMs = metrics.getDurationInMs(timerContext.stop());metrics.updateCleanMetrics(durationMs, metadata.getTotalFilesDeleted());LOG.info("Cleaned " + metadata.getTotalFilesDeleted() + " files"+ " Earliest Retained Instant :" + metadata.getEarliestCommitToRetain()+ " cleanerElapsedMs" + durationMs);}return metadata;-
CleanerUtils.rollbackFailedWrites(config.getFailedWritesCleanPolicy(),HoodieTimeline.CLEAN_ACTION,() -> rollbackFailedWrites *
根据配置hoodie.cleaner.policy.failed.writes* 默认是EAGER,也就是在写数据失败的时候,会立即进行这次写失败的数据的清理,在这种情况下,
就不会执行rollbackFailedWrites操作,也就是回滚写失败文件的操作 -
HoodieTable table = createTable *
创建HoodieFlinkMergeOnReadTable*类型的hudi表,用来做clean等操作 -
scheduleTableServiceInternal
如果hoodie.clean.allow.multiple为true(默认为true)或者没有正在运行中clean操作,则会生成Clean计划
这里最终调用的是FlinkWriteClient.scheduleCleaning方法,即CleanPlanActionExecutor.execute方法这里最重要的就是requestClean方法:
CleanPlanner<T, I, K, O> planner = new CleanPlanner<>(context, table, config); Option<HoodieInstant> earliestInstant = planner.getEarliestCommitToRetain(); List<String> partitionsToClean = planner.getPartitionPathsToClean(earliestInstant) int cleanerParallelism = Math.min(partitionsToClean.size(), config.getCleanerParallelism()); Map<String, Pair<Boolean, List<CleanFileInfo>>> cleanOpsWithPartitionMeta = context.map(partitionsToClean, partitionPathToClean -> Pair.of(partitionPathToClean, planner.getDeletePaths(partitionPathToClean)), cleanerParallelism).stream().collect(Collectors.toMap(Pair::getKey, Pair::getValue)) Map<String, List<HoodieCleanFileInfo>> cleanOps = cleanOpsWithPartitionMeta.entrySet().stream().collect(Collectors.toMap(Map.Entry::getKey,e -> CleanerUtils.convertToHoodieCleanFileInfoList(e.getValue().getValue()))) List<String> partitionsToDelete = cleanOpsWithPartitionMeta.entrySet().stream().filter(entry -> entry.getValue().getKey()).map(Map.Entry::getKey).collect(Collectors.toList()) return new HoodieCleanerPlan(earliestInstant.map(x -> new HoodieActionInstant(x.getTimestamp(), x.getAction(), x.getState().name())).orElse(null),planner.getLastCompletedCommitTimestamp(),config.getCleanerPolicy().name(), CollectionUtils.createImmutableMap(),CleanPlanner.LATEST_CLEAN_PLAN_VERSION, cleanOps, partitionsToDelete)- planner.getEarliestCommitToRetain();
根据保留策略,获取到最早需要保留的commit的HoodieInstant,在这里会兼顾考虑到hoodie.cleaner.commits.retained(默认是10)以及hoodie.cleaner.hours.retained默认是24小时以及hoodie.cleaner.policy策略(默认是KEEP_LATEST_COMMITS) - planner.getPartitionPathsToClean(earliestInstant);
根据保留的最新commit的HoodieInstant,得到要删除的分区,这里会根据配置hoodie.cleaner.incremental.mode(默认是true)来进行增量清理,
这个时候就会根据上一次已经clean的信息,只需要删除差量的分区数据就行 - cleanOpsWithPartitionMeta = context
根据上面得到的需要删除的分区信息,获取需要删除的文件信息,具体的实现可以参考CleanPlanner.getFilesToCleanKeepingLatestCommits
这里的操作主要是先通过fileSystemView获取分区下所有的FileGroup,之后再获取每个FileGroup下的所有的FileSlice(这里的FileSlice就有版本的概念,也就是commit的版本),之后再与最新保留的commit的时间戳进行比较得到需要删除的文件信息 - new HoodieCleanerPlan
最后组装成HoodieCleanPlan的计划,并且在外层调用table.getActiveTimeline().saveToCleanRequested(cleanInstant, TimelineMetadataUtils.serializeCleanerPlan(cleanerPlan)); 方法把clean request的状态存储到对应的.hoodie目录下,并建立一个xxxx.clean.requested的元数据文件
- planner.getEarliestCommitToRetain();
-
table.getMetaClient().reloadActiveTimeline()
重新加载timeline,便于过滤出来刚才scheduleTableServiceInternal操作生成的xxxxxxxxxxxxxx.clean.requested的元数据文件 -
table.clean(context, cleanInstantTime, skipLocking)
真正执行clean的部分,主要是调用CleanActionExecutor.execute的方法,最终调用的是*runPendingClean(table, hoodieInstant)*方法:HoodieCleanerPlan cleanerPlan = CleanerUtils.getCleanerPlan(table.getMetaClient(), cleanInstant);return runClean(table, cleanInstant, cleanerPlan);首先是反序列化CleanPlan,然后在进行清理,主要是删除1. 如果没有满足的分区,直接删除该分区,2. 否则删除该分区下的满足条件的文件,最后返回HoodieCleanStat包含删除的文件信息等。
-
-
-
snapshotState方法
- 如果clean.async.enabled是true(默认是true),并且不是正在进行clean动作,则会进行异步清理
this.writeClient.startAsyncCleaning(); 这里最终也是调用的writeClient.clean方法。 - this.isCleaning = true;
设置标志位,用来保证clean操作的有序性
- 如果clean.async.enabled是true(默认是true),并且不是正在进行clean动作,则会进行异步清理
-
notifyCheckpointComplete方法
- 如果clean.async.enabled是true(默认是true),并且正在进行clean动作,则等待clean操作完成,
并且设置清理标识位,用来和snapshotState方法进行呼应以保证clean操作的有序性
- 如果clean.async.enabled是true(默认是true),并且正在进行clean动作,则等待clean操作完成,
相关文章:
(与flink的结合)--Flink 中hudi clean操作)
Apache Hudi初探(五)(与flink的结合)--Flink 中hudi clean操作
背景 本文主要是具体说说Flink中的clean操作的实现 杂说闲谈 在flink中主要是CleanFunction函数: Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);this.writeClient FlinkWriteClients.createWriteClient(conf,…...

stream对list数据进行多字段去重
方法一: //根据sj和name去重 List<NursingHandover> testList list.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(o -> o.getj() ";" o.getName() ";&…...
一种基于体素的射线检测
效果 基于体素的射线检测 一个漏检的射线检测 从起点一直递增指定步长即可得到一个稀疏的检测 bool Raycast(Vector3 from, Vector3 forword, float maxDistance){int loop 6666;Vector3 pos from;Debug.DrawLine(from, from forword * maxDistance, Color.red);while (loo…...

利用Docker安装Protostar
文章目录 一、Protostar介绍二、Ubuntu下安装docker三、安装Protostar 一、Protostar介绍 Protostar是一个免费的Linux镜像演练环境,包含五个系列共23道漏洞分析和利用实战题目。 Protostar的安装有两种方式 第一种是下载镜像并安装虚拟机https://github.com/Exp…...

go基础语法10问
1.使用值为 nil 的 slice、map会发生啥 允许对值为 nil 的 slice 添加元素,但对值为 nil 的 map 添加元素,则会造成运行时 panic。 // map 错误示例 func main() {var m map[string]intm["one"] 1 // error: panic: assignment to entry i…...

SpringCloud + SpringGateway 解决Get请求传参为特殊字符导致400无法通过网关转发的问题
title: “SpringCloud SpringGateway 解决Get请求传参为特殊字符导致400无法通过网关转发的问题” createTime: 2021-11-24T10:27:5708:00 updateTime: 2021-11-24T10:27:5708:00 draft: false author: “Atomicyo” tags: [“tomcat”] categories: [“java”] description: …...

vim基本操作
功能: 命令行模式下的文本编辑器。根据文件扩展名自动判别编程语言。支持代码缩进、代码高亮等功能。使用方式:vim filename 如果已有该文件,则打开它。 如果没有该文件,则打开个一个新的文件,并命名为filename 模式…...
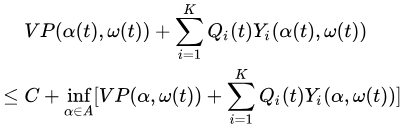
Drift plus penalty 漂移加惩罚Part1——介绍和工作原理
文章目录 正文Methodology 方法论Origins and applications 起源和应用How it works 它是怎样工作的The stochastic optimization problem 随机优化问题Virtual queues 虚拟队列The drift-plus-penalty expression 漂移加惩罚表达式Drift-plus-penalty algorithmApproximate sc…...

(四)动态阈值分割
文章目录 一、基本概念二、实例解析 一、基本概念 基于局部阈值分割的dyn_threshold()算子,适用于一些无法用单一灰度进行分割的情况,如背景比较复杂,有的部分比前景目标亮,或者有的部分比前景目标暗;又比如前景目标包…...

jvm介绍
1. JVM是什么 JVM是Java Virtual Machine的缩写,即咱们经常提到的Java虚拟机。虚拟机是一种抽象化的计算机,有着自己完善的硬件架构,如处理器、堆栈等,具体有什么咱们不做了解。目前我们只需要知道想要运行Java文件,必…...
数据结构与算法课后题-第三章(顺序队和链队)
#include <iostream> //引入头文件 using namespace std;typedef int Elemtype;#define Maxsize 5 #define ERROR 0 #define OK 1typedef struct {Elemtype data[Maxsize];int front, rear;int tag; }SqQueue;void InitQueue(SqQueue& Q) //初始化队列 {Q.rear …...
SSM - Springboot - MyBatis-Plus 全栈体系(十六)
第三章 MyBatis 三、MyBatis 多表映射 2. 对一映射 2.1 需求说明 根据 ID 查询订单,以及订单关联的用户的信息! 2.2 OrderMapper 接口 public interface OrderMapper {Order selectOrderWithCustomer(Integer orderId); }2.3 OrderMapper.xml 配置…...

k8s--storageClass自动创建PV
文章目录 一、storageClass自动创建PV1.1 安装NFS1.2 创建nfs storageClass1.3 测试自动创建pv 一、storageClass自动创建PV 这里使用NFS实现 1.1 安装NFS 安装nfs-server: sh nfs_install.sh /mnt/data03 10.60.41.0/24nfs_install.sh #!/bin/bash### How to i…...

7.3 调用函数
前言: 思维导图: 7.3.1 函数调用的形式 我的笔记: 函数调用的形式 在C语言中,调用函数是一种常见的操作,主要有以下几种调用方式: 1. 函数调用语句 此时,函数调用独立存在,作为…...

如果使用pprof来进行性能的观测和优化
1. 分析性能瓶颈 在开始优化之前,首先需要确定你的程序的性能瓶颈在哪里。使用性能分析工具(例如 Go 的内置 pprof 包)来检测程序中消耗时间和内存的地方。这可以帮助你确定需要优化的具体部分。 2. 选择适当的数据结构和算法 选择正确的数…...
在移动固态硬盘上安装Ubuntu系统和ROS2
目录 原视频准备烧录 原视频 b站鱼香ros 准备 1.在某宝上买一个usb移动固态硬盘或固态U盘,至少64G 2.下载鱼香ros烧录工具 下载第二个就行了,不然某网盘的速度下载全部要一天 下载后,选择FishROS2OS制作工具压缩包,进行解压…...

【iptables 实战】02 iptables常用命令
一、iptables中基本的命令参数 -P 设置默认策略-F 清空规则链-L 查看规则链-A 在规则链的末尾加入新规则-I num 在规则链的头部加入新规则-D num 删除某一条规则-s 匹配来源地址IP/MASK,加叹号“!”表示除这个IP外-d 匹配目标地址-i 网卡名称 匹配从这块…...

webview_flutter
查看webview内核 https://liulanmi.com/labs/core.html h5中获取设备 https://cloud.tencent.com/developer/ask/sof/105938013 https://developer.mozilla.org/zh-CN/docs/Web/API/Navigator/mediaDevices web资源部署后navigator获取不到mediaDevices实例的解决方案&…...

【GESP考级C++】1级样题 闰年统计
GSEP 1级样题 闰年统计 题目描述 小明刚刚学习了如何判断平年和闰年,他想知道两个年份之间(包含起始年份和终止年份)有几个闰年。你能帮帮他吗? 输入格式 输入一行,包含两个整数,分别表示起始年份和终止…...
CentOS密码重置
背景: 我有一个CentOS虚拟机,但是密码忘记了,偶尔记起可以重置密码,于是今天尝试记录一下,又因为我最近记性比较差,所以必须要记录一下。 过程: 1、在引导菜单界面(grubÿ…...

Magpie插件管理终极指南:如何让窗口缩放效果始终保持最佳状态
Magpie插件管理终极指南:如何让窗口缩放效果始终保持最佳状态 【免费下载链接】Magpie An all-purpose window upscaler for Windows 10/11. 项目地址: https://gitcode.com/gh_mirrors/mag/Magpie 在Windows窗口缩放领域,Magpie凭借其强大的插件…...

Qwen3-TTS-12Hz-1.7B-CustomVoice效果展示:日语动漫风+韩语偶像音色
Qwen3-TTS-12Hz-1.7B-CustomVoice效果展示:日语动漫风韩语偶像音色 想不想让你的AI助手用元气满满的日语动漫腔跟你打招呼?或者用温柔甜美的韩语偶像音色为你朗读一段歌词?今天,我们就来深度体验一下Qwen3-TTS-12Hz-1.7B-CustomV…...

YOLO X Layout模型测试:基于Pytest的自动化测试框架
YOLO X Layout模型测试:基于Pytest的自动化测试框架 当你辛辛苦苦训练或部署了一个YOLO X Layout模型,准备用它来解析合同、发票或者学术论文时,最怕遇到什么?不是模型本身不够强大,而是某次代码更新后,它…...

手把手教你部署VibeVoice:基于Python的实时TTS系统,300ms超低延迟体验
手把手教你部署VibeVoice:基于Python的实时TTS系统,300ms超低延迟体验 你有没有遇到过这样的场景:开发一个智能助手,用户问完问题,屏幕上的文字回复瞬间就出来了,但语音却要等上好几秒才开始播放ÿ…...

【信号处理实战】从原理到代码:手把手实现三次样条插值
1. 三次样条插值:从数学定义到生活场景 想象你正在用一根柔软的弹性尺子连接一组图钉,这些图钉固定在木板上代表你的数据点。这根尺子需要光滑地穿过每一个图钉,同时保持自然的弯曲形态——这就是三次样条插值要解决的问题。作为信号处理中最…...
)
操作系统面试必考:银行家算法10问10答(含真题解析)
操作系统面试必考:银行家算法10问10答(含真题解析) 银行家算法作为操作系统中经典的死锁避免算法,几乎成为所有技术面试的必考题。无论是校招还是社招,面试官总喜欢用它来考察候选人对资源分配与系统安全的理解深度。本…...

ContextMenuManager:高效管理Windows右键菜单的全方案
ContextMenuManager:高效管理Windows右键菜单的全方案 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是我们日常操作电脑时最常用的…...

AI小剧场:OpenClaw+nanobot镜像多角色对话生成
AI小剧场:OpenClawnanobot镜像多角色对话生成 1. 为什么需要AI辅助剧本创作 作为一个业余编剧爱好者,我经常遇到创作瓶颈——当需要构建多角色对话场景时,很难同时兼顾不同角色的立场连贯性和语言风格差异。传统写作工具只能提供单向输出&a…...

OpCore-Simplify终极指南:如何快速构建完美的OpenCore EFI配置
OpCore-Simplify终极指南:如何快速构建完美的OpenCore EFI配置 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的Hackintosh配置…...
lite-avatar形象库保姆级教学:从CSDN控制台创建GPU实例到数字人上线全过程
lite-avatar形象库保姆级教学:从CSDN控制台创建GPU实例到数字人上线全过程 桦漫AIGC集成开发 | 微信: henryhan1117 1. 开篇:为什么选择lite-avatar形象库? 如果你正在寻找高质量的数字人形象,但又不想从零开始训练模型ÿ…...