初级篇—第三章多表查询
文章目录
- 为什么需要多表查询
- 一个案例引发的多表连接
- 初代查询
- 笛卡尔积(或交叉连接)的理解
- 多表查询分类
- 等值连接 vs 非等值连接
- 自连接 vs 非自连接
- 内连接VS外连接
- SQL99语法实现多表查询
- 内连接的实现
- 外连接的实现
- 左外连接
- 右外连接
- 满外连接
- UNION的使用
- 7种SQL JOINS的实现
- SQL99语法新特性
- 自然连接
- USING连接
- 练习
为什么需要多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
- 前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。比如:员工表和部门表,这两个表依靠“部门编号”进行关联
一个案例引发的多表连接
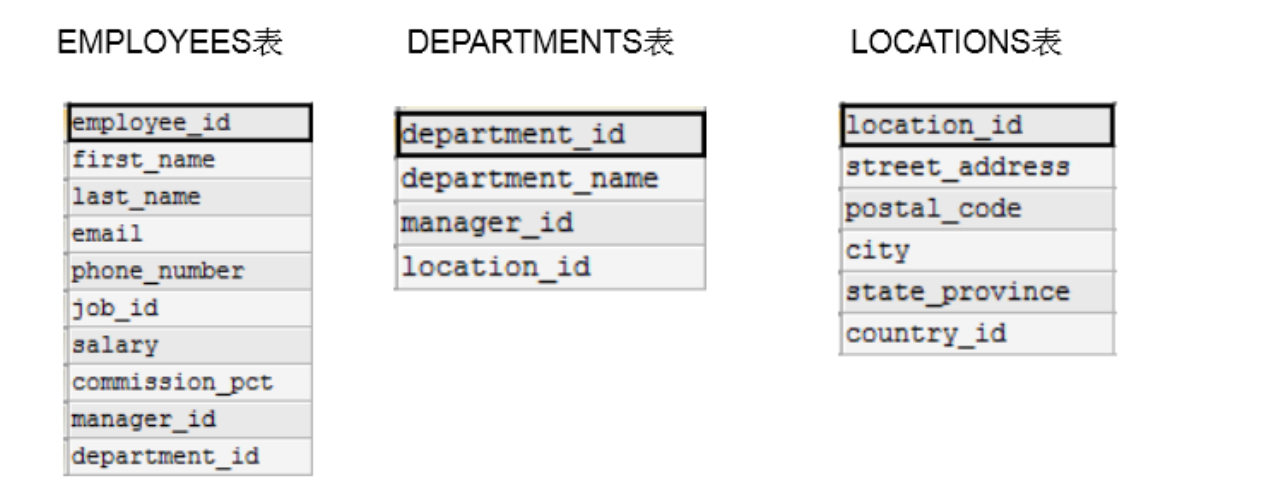
- 员工表,部门表,还有所在地址的表,员工表与部门表通过部门ID进行管理,部门表和地址表通过地址ID关联
这三张表可以放在一个表中吗?理论是可以的,但是实际上不会这样做
- 冗余数据,放在一个表中,那我们的每个员工都需要带着部门的相关数据(比如300个员工,5个部门具体信息和300个部门ID的信息,分表部门信息只需要存储5条,但是不分表,需要存储300条部门的具体信息)
- 且如果这个员工没部门,后面都是null,反之部门没员工,但是该部门信息前面的员工数据都null
- 字段太多,持久化的数据是存储在磁盘中,读取到内存中需要I/O操作,字段太多,表示数据大,每次I/O读取的数据量就会变少,导致I/O次数多
- 再者说,这样分开,我们查其中一张表,就不会涉及到其他表的锁定问题
初代查询
#案例:查询员工的姓名及其部门名称
SELECT last_name, department_name
FROM employees, departments;
- 查询了2889行数据
SELECT COUNT(employee_id) FROM employees;
#输出107行
SELECT COUNT(department_id)FROM departments;
#输出27行
SELECT 107*27 FROM DUAL;
- 我们把上述多表查询中出现的问题称为:笛卡尔积的错误。
笛卡尔积(或交叉连接)的理解
笛卡尔乘积是一个数学运算。假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能组合,也就是第一个对象来自于 X,第二个对象来自于 Y 的所有可能。组合的个数即为两个集合中元素个数的乘积数。
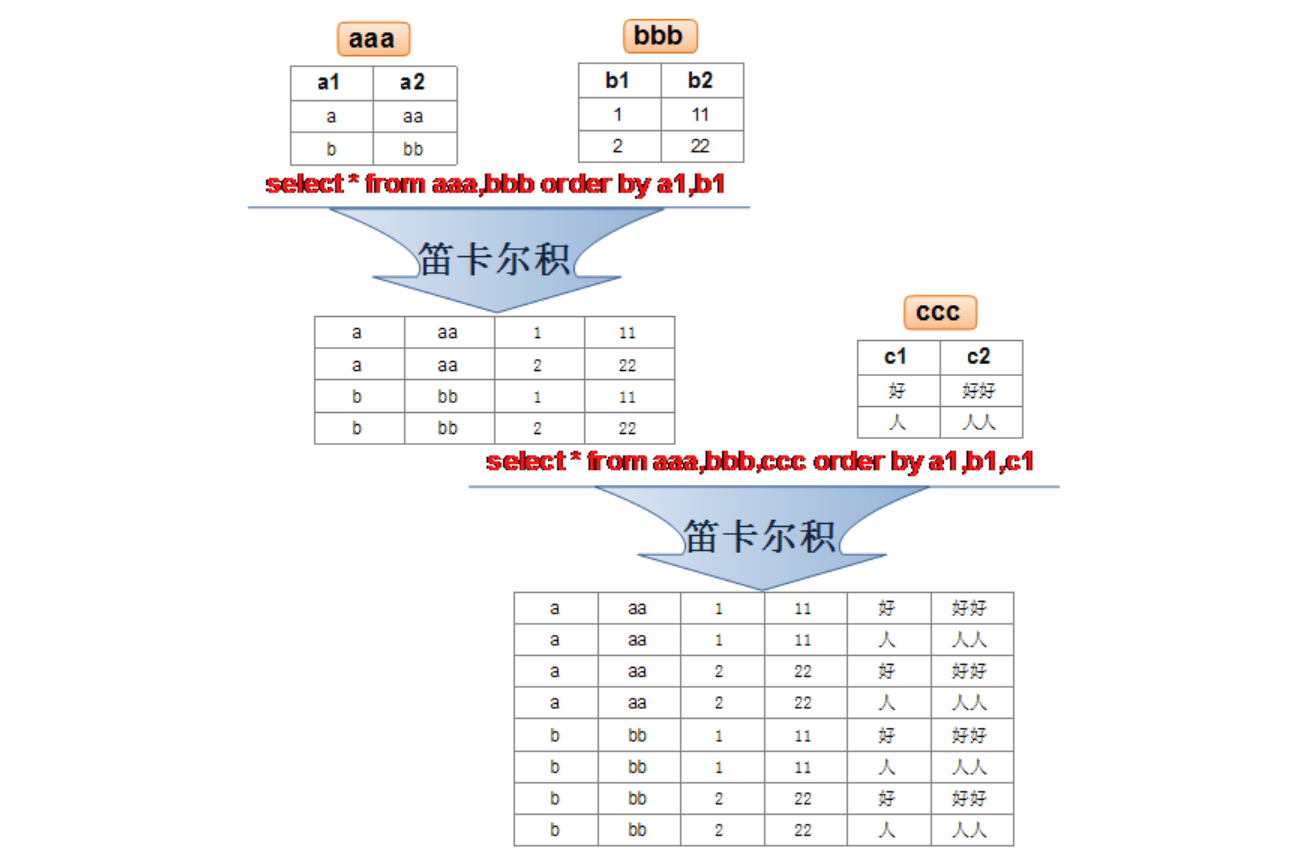
笛卡尔积的错误会在下面条件下产生:
- 省略多个表的连接条件(或关联条件)
- 连接条件(或关联条件)无效
- 所有表中的所有行互相连接
为了避免笛卡尔积, 可以在 WHERE 加入有效的连接条件。
- 加入连接条件后,查询语法:
#案例:查询员工的姓名及其部门名称
SELECT last_name, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id;
- 在表中有相同列时,在列名之前加上表名前缀。
多表查询分类
等值连接 vs 非等值连接
等值连接
#查询员工和员工的部门名
SELECT last_name, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id;
#区分重复的列名
SELECT employees.last_name, departments.department_name,employees.department_id
FROM employees, departments
WHERE employees.department_id = departments.department_id;
#表的别名
SELECT e.employee_id, e.last_name, e.department_id, d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id;
- 等值连接就是两张表的连接条件是用等号进行连接
- 多个表中有相同列时,必须在列名之前加上表名前缀。在不同表中具有相同列名的列可以用 表名 加以区分。
- 连接 n个表,至少需要n-1个连接条件。比如,连接三个表,至少需要两个连接条件。
- 需要注意的是,如果我们使用了表的别名,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原有的表名,否则就会报错。
阿里开发规范 :
强制对于数据库中表记录的查询和变更,只要涉及多个表,都需要在列名前加表的别名(或表名)进行限定。说明 :对多表进行查询记录、更新记录、删除记录时,如果对操作列没有限定表的别名(或表名),并且操作列在多个表中存在时,就会抛异常。
正例 :select t1.name from table_first as t1 , table_second as t2 where t1.id=t2.id;
反例 :在某业务中,由于多表关联查询语句没有加表的别名(或表名)的限制,正常运行两年后,最近在某个表中增加一个同名字段,在预发布环境做数据库变更后,线上查询语句出现出1052 异常:Column ‘name’ in field list is ambiguous。
非等值连接
#查询员工名,员工工资和员工的工资水平
select e.`last_name`,e.`salary`,j.`grade_level`
from employees as e,job_grades as j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;`job_grades`;
自连接 vs 非自连接
自连接
SELECT CONCAT(worker.last_name ,' works for ', manager.last_name)
FROM employees worker, employees manager
WHERE worker.manager_id = manager.employee_id ;
- 当table1和table2本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义
- 非自连接,就是两个连接的表不是同一张表
内连接VS外连接
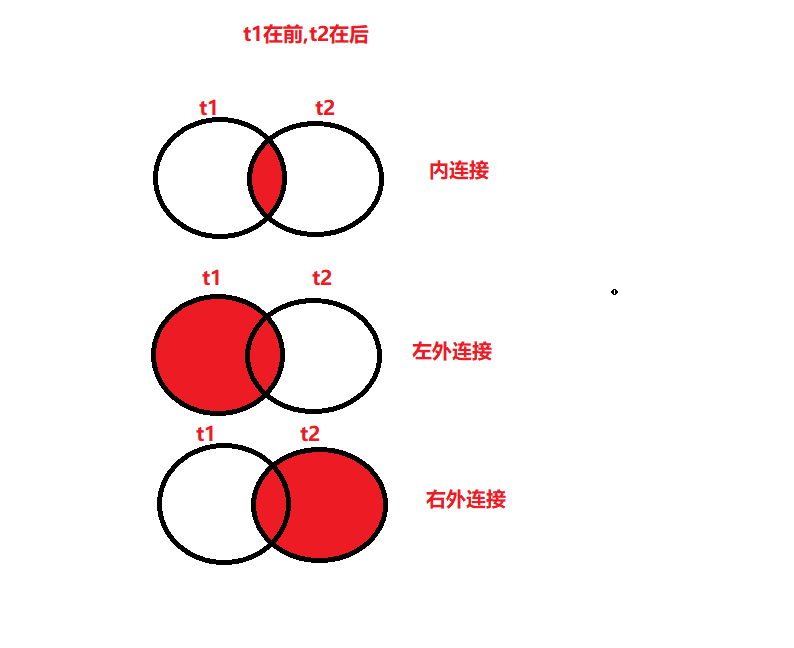
- 内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
- 外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
- 如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
- 如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
- 主表完全显示,从表不匹配的数据就显示null
SQL92:使用(+)创建连接
- 在 SQL92 中采用(+)代表从表所在的位置。即左或右外连接中,(+) 表示哪个是从表。
- Oracle 对 SQL92 支持较好,而 MySQL 则不支持 SQL92 的外连接。
#左外连接
SELECT last_name,department_name
FROM employees ,departments
WHERE employees.department_id = departments.department_id(+);
#右外连接
SELECT last_name,department_name
FROM employees ,departments
WHERE employees.department_id(+) = departments.department_id;
- 而且在 SQL92 中,只有左外连接和右外连接,没有满(或全)外连接。
SQL99语法实现多表查询
使用JOIN…ON子句创建连接的语法结构:
SELECT table1.column, table2.column,table3.column
FROM table1
JOIN table2 ON table1 和 table2 的连接条件
JOIN table3 ON table2 和 table3 的连接条件
SQL99 采用的这种嵌套结构非常清爽、层次性更强、可读性更强,即使再多的表进行连接也都清晰可见。如果你采用 SQL92,可读性就会大打折扣。
语法说明:
- 可以使用 ON 子句指定额外的连接条件。
- 这个连接条件是与其它条件分开的。
- ON 子句使语句具有更高的易读性。
- 关键字
JOIN、INNER JOIN、CROSS JOIN的含义是一样的,都表示内连接
内连接的实现
语法
SELECT 字段列表
FROM A表 INNER JOIN B表
ON 关联条件
WHERE 等其他子句;
#查询员工的ID和员工姓名和对应的员工部门地址的ID
SELECT e.employee_id, e.last_name, e.department_id, d.department_id, d.location_id
FROM employees e JOIN departments d #employees e INNER JOIN departments d
ON (e.department_id = d.department_id);
- 用内连接查询出106行数据
外连接的实现
左外连接
语法
#实现查询结果是A
SELECT 字段列表
FROM A表 LEFT JOIN B表
ON 关联条件
WHERE 等其他子句;
SELECT e.last_name, e.department_id, d.department_name
FROM employees e LEFT OUTER JOIN departments d # employees e LEFT JOIN departments d
ON (e.department_id = d.department_id) ;
- 使用左外连接查询出107行数据
右外连接
#实现查询结果是A
SELECT 字段列表
FROM A表 LEFT JOIN B表 ON 关联条件
WHERE 等其他子句;
SELECT e.last_name, e.department_id, d.department_name
FROM employees e RIGHT OUTER JOIN departments d #employees e RIGHT JOIN departments d
ON (e.department_id = d.department_id) ;
- 查询出122行数据
需要注意的是,LEFT JOIN 和 RIGHT JOIN 只存在于 SQL99 及以后的标准中,在 SQL92 中不存在,只能用 (+) 表示。
满外连接
- 满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
- SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
- 需要注意的是,MySQL不支持FULL JOIN,但是可以用 LEFT JOIN UNION RIGHT join代替。
UNION的使用
合并查询结果 利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNIONALL关键字分隔。
语法格式:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2

注意:执行UNION ALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
#查询部门编号>90或邮箱包含a的员工信息
#方式1
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;
#方式2
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
#查询中国用户中男性的信息以及美国用户中年男性的用户信息
SELECT id,cname FROM t_chinamale WHERE csex='男'
UNION ALL
SELECT id,tname FROM t_usmale WHERE tGender='male';
7种SQL JOINS的实现

#中图:内连接 A∩B
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
#左上图:左外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#左中图:A - A∩B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
#右中图:B-A∩B
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
#左下图
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右下图
#左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
SQL99语法新特性
自然连接
SQL99 在 SQL92 的基础上提供了一些特殊语法,比如 NATURAL JOIN 用来表示自然连接。我们可以把自然连接理解为 SQL92 中的等值连接。它会帮你自动查询两张连接表中 所有相同的字段 ,然后进行 等值连接 。
在SQL92标准中:
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
AND e.`manager_id` = d.`manager_id`;
在 SQL99 中你可以写成:
SELECT employee_id,last_name,department_name
FROM employees e NATURAL JOIN departments d;
USING连接
当我们进行连接的时候,SQL99还支持使用 USING 指定数据表里的 同名字段 进行等值连接。但是只能配合JOIN一起使用。比如:
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
USING (department_id)
你能看出与自然连接 NATURAL JOIN 不同的是,USING 指定了具体的相同的字段名称,你需要在 USING的括号 () 中填入要指定的同名字段。同时使用JOIN…USING 可以简化 JOIN ON 的等值连接。它与下面的 SQL 查询结果是相同的:
SELECT employee_id,last_name,department_name
FROM employees e ,departments d
WHERE e.department_id = d.department_id;
表连接的约束条件可以有三种方式:WHERE, ON, USING
- WHERE:适用于所有关联查询
- ON :只能和JOIN一起使用,只能写关联条件。虽然关联条件可以并到WHERE中和其他条件一起写,但分开写可读性更好。
- USING:只能和JOIN一起使用,而且要求两个关联字段在关联表中名称一致,而且只能表示关联字段值相等
练习
# 1.显示所有员工的姓名,部门号和部门名称。
SELECT t1.last_name,t1.department_id,t2.department_name
FROM employees t1
LEFT JOIN departments t2 #这里说了是所有员工,所以是左外连接
ON t1.department_id = t2.department_id;# 2.查询90号部门员工的job_id和90号部门的location_id
SELECT t1.job_id,t2.location_id
FROM employees t1
INNER JOIN departments t2
ON t1.department_id = t2.department_id
WHERE t1.department_id = 90;SELECT t1.job_id,t2.location_id
FROM employees e, departments d
WHERE e.`department_id` = d.`department_id`
AND e.`department_id` = 90;# 3.选择所有有奖金的员工的 last_name , department_name , location_id , city
SELECT t1.`last_name`,t2.`department_name`,t3.`location_id`,t3.`city`
FROM employees t1
LEFT JOIN departments t2 ON t1.department_id = t2.department_id
LEFT JOIN locations t3 ON t2.location_id = t3.location_id
WHERE t1.commission_pct IS NOT NULL;# 4.选择city在Toronto工作的员工的 last_name , job_id , department_id , department_name
SELECT t1.last_name, t1.`job_id`,t1.`department_id`,t2.`department_name`
FROM employees t1
INNER JOIN departments t2 ON t1.department_id = t2.department_id
INNER JOIN locations t3 ON t2.location_id = t3.location_id
WHERE t3.city = 'Toronto';# 5.查询员工所在的部门名称、部门地址、姓名、工作、工资,其中员工所在部门的部门名称为’Executive’
SELECT t2.`department_name`, t3.`street_address`,t1.`last_name`,t1.`salary`,t1.`job_id`
FROM employees t1
INNER JOIN departments t2 ON t1.department_id = t2.department_id
INNER JOIN locations t3 ON t2.`location_id` = t3.`location_id`
WHERE t2.`department_name` = 'Executive';# 6.选择指定员工的姓名,员工号,以及他的管理者的姓名和员工号,结果类似于下面的格式
#employees Emp# manager Mgr#
#kochhar 101 king 100
SELECT CONCAT(t1.`last_name`,' ',t1.`employee_id` ,' ',t2.`last_name`,' ',t2.`employee_id`)
FROM employees t1
INNER JOIN employees t2 ON t1.`manager_id` = t2.`employee_id`;# 7.查询哪些部门没有员工
SELECT t1.*
FROM departments t1
LEFT JOIN employees t2 ON t1.`department_id` = t2.`department_id`
WHERE t2.`department_id` IS NULL;# 8. 查询哪个城市没有部门
SELECT t1.*
FROM locations t1
LEFT JOIN departments t2 ON t1.`location_id` = t2.`location_id`
WHERE t2.`location_id` IS NULL;# 9. 查询部门名为 Sales 或 IT 的员工信息
SELECT t1.*
FROM employees t1
INNER JOIN departments t2 ON t1.`department_id` = t2.`department_id`
WHERE t2.`department_name` IN ('Sales','IT');
#1.所有有门派的人员信息( A、B两表共有)
SELECT t1.*
FROM t_emp t1
INNER JOIN t_dept t2 ON t1.`deptId`= t2.`id`;#2.列出所有用户,并显示其机构信息(A的全集)
SELECT t1.*
FROM t_emp t1
LEFT JOIN t_dept t2 ON t1.`deptId`= t2.`id`;#3.列出所有门派(B的全集)
SELECT *
FROM t_dept b;#4.所有不入门派的人员(A的独有)
SELECT t1.*
FROM t_emp t1
LEFT JOIN t_dept t2 ON t1.`deptId`= t2.`id`
WHERE t2.`id` IS NULL;#5.所有没人入的门派(B的独有)
SELECT *
FROM t_dept b
LEFT JOIN t_emp a ON a.deptId = b.id
WHERE a.deptId IS NULL;#6.列出所有人员和机构的对照关系(AB全有)
#MySQL Full Join的实现 因为MySQL不支持FULL JOIN,下面是替代方法
#left join + union(可去除重复数据)+ right join
SELECT *
FROM t_emp A LEFT JOIN t_dept B
ON A.deptId = B.id
UNION
SELECT *
FROM t_emp A RIGHT JOIN t_dept B
ON A.deptId = B.id#7.列出所有没入派的人员和没人入的门派(A的独有+B的独有)
SELECT t1.*
FROM t_emp t1
LEFT JOIN t_dept t2 ON t1.`deptId`= t2.`id`
UNION
WHERE t2.`id` IS NULL;
SELECT *
FROM t_dept b
LEFT JOIN t_emp a ON a.deptId = b.id
WHERE a.deptId IS NULL;
相关文章:
初级篇—第三章多表查询
文章目录 为什么需要多表查询一个案例引发的多表连接初代查询笛卡尔积(或交叉连接)的理解 多表查询分类等值连接 vs 非等值连接自连接 vs 非自连接内连接VS外连接 SQL99语法实现多表查询内连接的实现外连接的实现左外连接右外连接满外连接 UNION的使用7种…...
<Xcode> Xcode IOS无开发者账号打包和分发
关于flutter我们前边聊到的初入门、数据解析、适配、安卓打包、ios端的开发和黑苹果环境部署,但是对于苹果的打包和分发,我只是给大家了一个链接,作为一个顶级好男人,我认为这样是对大家的不负责任,那么这篇就主要是针…...

vertx的学习总结2
一、什么是verticle verticle是vertx的基本单元,其作用就是封装用于处理事件的技术功能单元 (如果不能理解,到后面的实战就可以理解了) 二、写一个verticle 1. 引入依赖(这里用的是gradle,不会吧&#…...
网络安全内网渗透之DNS隧道实验--dnscat2直连模式
目录 一、DNS隧道攻击原理 二、DNS隧道工具 (一)安装dnscat2服务端 (二)启动服务器端 (三)在目标机器上安装客户端 (四)反弹shell 一、DNS隧道攻击原理 在进行DNS查询时&#x…...

探索ClickHouse——连接Kafka和Clickhouse
安装Kafka 新增用户 sudo adduser kafka sudo adduser kafka sudo su -l kafka安装JDK sudo apt-get install openjdk-8-jre下载解压kafka 可以从https://downloads.apache.org/kafka/下找到希望安装的版本。需要注意的是,不要下载路径包含src的包,否…...

基于监督学习的多模态MRI脑肿瘤分割,使用来自超体素的纹理特征(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
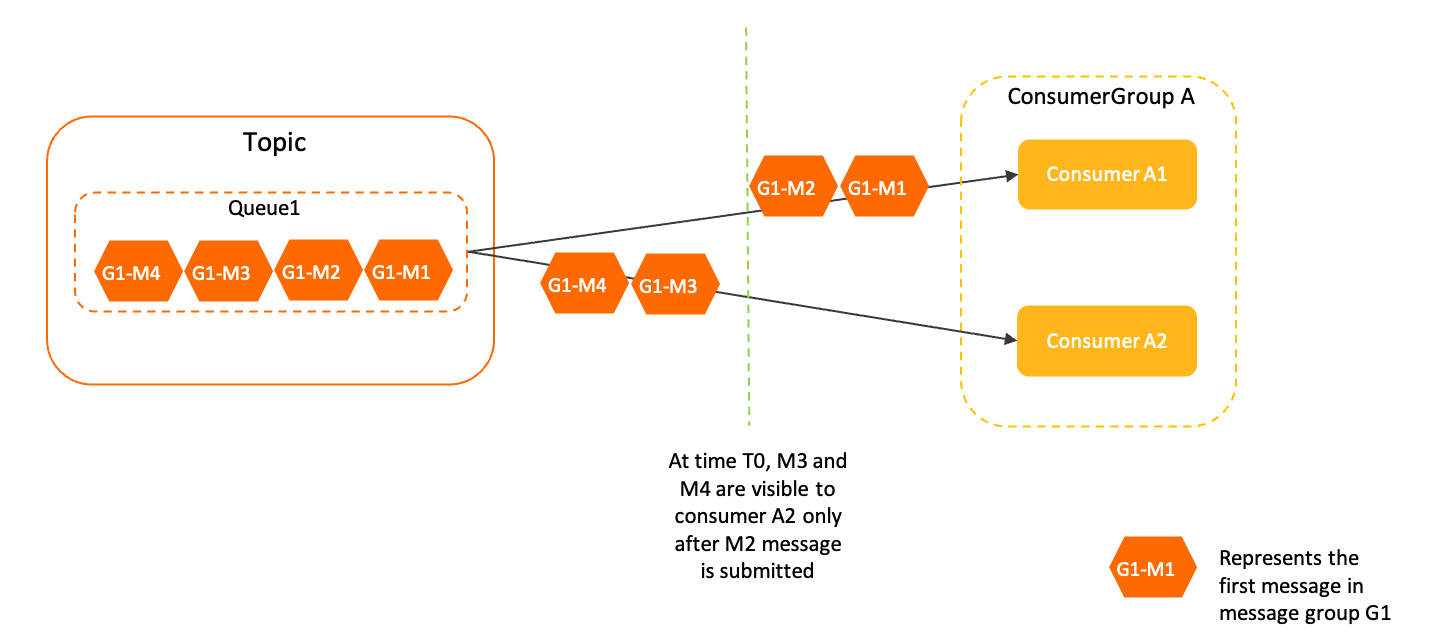
【RocketMQ】(八)Rebalance负载均衡
消费者负载均衡,是指为消费组下的每个消费者分配订阅主题下的消费队列,分配了消费队列消费者就可以知道去消费哪个消费队列上面的消息,这里针对集群模式,因为广播模式,所有的消息队列可以被消费组下的每个消费者消费不…...

线性筛和埃氏筛
线性筛: #define _CRT_SECURE_NO_WARNINGS #include<iostream> #include<cstdio> #include<cstdlib> #include<string> #include<cstring> #include<cmath> #include<ctime> #include<algorithm> #include<ut…...

【Java 进阶篇】JDBC ResultSet 类详解
在Java应用程序中,与数据库交互通常涉及执行SQL查询以检索数据。一旦执行查询,您将获得一个ResultSet对象,该对象包含查询结果的数据。本文将深入介绍ResultSet类,它是Java JDBC编程中的一个核心类,用于处理查询结果。…...
)
Centos7常用服务脚本(.service)
Centos7常用服务脚本(.service) 注意:[Service]中配置路径必须使用绝对路径。 启停: systemctl { start | stop | restart | reload } xxx.service 自启动: systemctl { enable | disable } xxx.service nginx.se…...
)
MySQL 视图View的SQL语法和更新(视图篇 二)
视图语法基本操作 创建 -- [ ]表示可选 create [or replace] view 视图名称[(列名列表)] as select语句 [ with [cascaded | local ] check option ]; 添加(虽然视图是虚拟表,但是向视图操作的数据实际上会影响到实际关联的表数据) -- 视图添…...
38 翻转二叉树
翻转二叉树 理解题意,翻转即每个结点的左右子树翻转/对调题解1 递归——自下而上题解2 迭代——自上而下 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 提示: 树中节点数目范围在 [0, 100] 内-100 < Node.…...
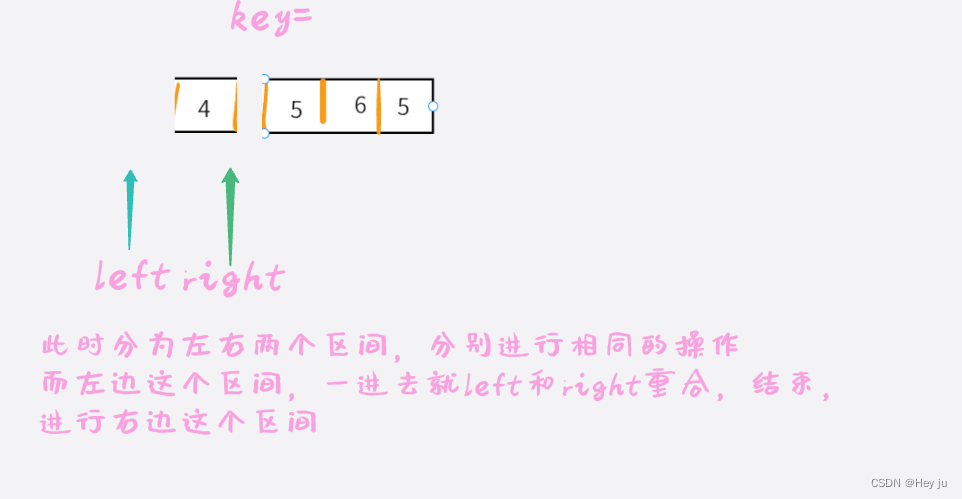
数据结构-快速排序-C语言实现
引言:快速排序作为一种非常经典且高效的排序算法,无论是工作还是面试中广泛用到,作为一种分治思想,需要熟悉递归思想。下面来讲讲快速排序的实现和改进。 老规矩,先用图解来理解一下:(这里使用快…...

玩客云Armbian_23.08.0-trunk_Onecloud_bookworm_edge_6.4.14.burn配置
固定IP # interface file auto-generated by buildrootauto lo iface lo inet loopback// 上面是默认的内容,下面是新增的内容,上下之间需要一个空行隔开 // 接口顶格写,属性的前面有一个tab的缩进 # The primary network interfaceauto eth0 iface eth0 inet staticaddress 1…...

Nginx查找耗时的接口
Nginx查找耗时的接口 # grep 是筛选的域名 awk中的$5是判断的状态码 sort中的15是指的upstream_response_time 当然也可以统计request_time的时间cat access.log | grep zhhll.icu | awk $5 200{print $0} | sort -k 15 -n -r | head -10 https://zhhll.icu/2021/linux/实…...

C++ Primer 一 变量和基本类型
本章讲解C内置的数据类型(如:字符、整型、浮点数等)和自定义数据类型的机制。下一章讲解C标准库里面定义的更加复杂的数据类型,比如可变长字符串和向量等。 1.基本内置类型 C内置的基本类型包括:算术类型和空类型。算…...

实体行业数字化转型怎么做?线上线下相结合的新零售体系怎么做?
如今,实体行业想要取得收入增长,只做线下业务或者只做线上业务,在当前的市场环境中是难以长久生存的,因此一定要线上线下相结合,将流量运作与线下转化进行充分结合,才能更好地发挥实体优势,带来…...
JAVA面经整理(5)
创建线程池不是说现用先创建,而是要是可以复用线程池中的线程,就很好地避免了大量用户态和内核态的交互,不需要频繁的创建和销毁线程 一)什么是池化技术?什么是线程池? 1)池化技术是提前准备好一些资源,在…...

【牛客网-面试必刷TOP101】二分查找题目
目录 二维数组中的查找_牛客题霸_牛客网 (nowcoder.com) 寻找峰值_牛客题霸_牛客网 (nowcoder.com) 数组中的逆序对_牛客题霸_牛客网 (nowcoder.com) 旋转数组的最小数字_牛客题霸_牛客网 (nowcoder.com) 二维数组中的查找_牛客题霸_牛客网 (nowcoder.com) 题意:…...
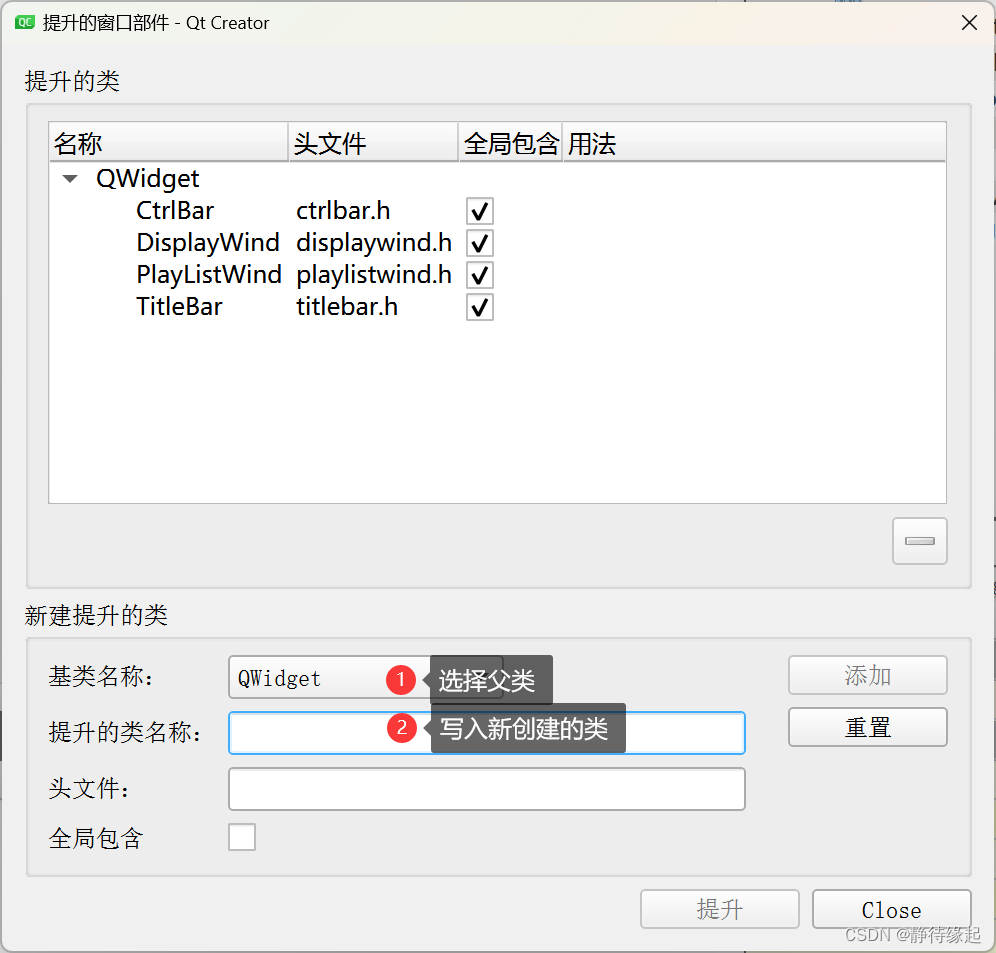
【QT】自定义组件ui类添加到主ui界面方法
1.添加自定义组件到项目中 add new选择如下 写好类方法,确定即可 2.将新创建的ui类加入到主ui界面 选中新创建ui类的父类空块,右键选择提升为 选择并添加新创建的类...

Qwen2.5-7B快速搭建:结合vLLM实现高效推理的Gradio应用
Qwen2.5-7B快速搭建:结合vLLM实现高效推理的Gradio应用 1. 引言 在当今AI技术快速发展的背景下,大型语言模型的应用越来越广泛。Qwen2.5-7B作为阿里开源的最新语言模型,在知识量、编程能力和数学能力等方面都有显著提升。本文将介绍如何快速…...

Palantir的缺点
Palantir(水晶球)的“威力未在对等博弈中验证”及“在复杂人机环境中失效”的问题,本质是其技术逻辑与“对抗性、非理性、动态性”博弈场景的根本冲突——它擅长在“己方数据占优、对手无反制能力”的非对称场景中整合信息,但在“…...
)
UniApp打包避坑指南:从证书生成到上架全流程(Android/iOS双平台)
UniApp跨平台打包实战:Android/iOS全流程避坑手册 第一次将UniApp项目打包成原生应用时,我踩遍了所有能想到的坑——从证书过期导致的打包失败,到渠道包统计失灵,再到App Store审核被拒。这份手册正是基于三年跨平台开发经验&…...

FR机械臂ROS开发环境配置避坑指南:从Ubuntu20.04到MoveIt完整流程
FR机械臂ROS开发环境配置避坑指南:从Ubuntu20.04到MoveIt完整流程 当第一次接触FR机械臂的ROS开发时,许多工程师都会在环境配置阶段踩坑。不同于普通的ROS开发,FR机械臂对系统环境、网络配置和依赖管理有着更严格的要求。本文将带你完整走通从…...

ChatGPT与国内大模型的技术差距解析:从架构到应用场景
ChatGPT与国内大模型的技术差距解析:从架构到应用场景 在评估大语言模型时,基准测试是衡量其综合能力的重要标尺。以MMLU(大规模多任务语言理解)和C-Eval(中文语言理解评估基准)为例,GPT-4在MM…...

BepInEx插件框架零门槛掌握:3个核心场景带你轻松上手Unity游戏模组
BepInEx插件框架零门槛掌握:3个核心场景带你轻松上手Unity游戏模组 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 副标题:零基础玩家必备指南——解决Unit…...

技术分享-ai助力开发-【trae开发工具教程】_day01
trae开发工具 是什么?AI代码编辑工具 可以理解需求、调用工具各类开发 可以做什么? 智能代码生成项目构建对话式编程 - 核心功能多任务并行 前端开发、接口调试、bug修复等 智能写作 solo code 协助子智能体开发任务 多种语言 Javapythongorust… …...
)
从电影黑客到真实渗透:用Kali Linux和MSFconsole复现一次对MySQL的‘安全评估’(环境搭建避坑指南)
从电影黑客到真实渗透:用Kali Linux和MSFconsole复现一次对MySQL的‘安全评估’(环境搭建避坑指南) 你是否曾被电影中黑客轻松入侵系统的场景所吸引?那些快速滚动的代码行和炫目的界面背后,其实隐藏着一套严谨的技术逻…...

OpenRocket:从零开始掌握专业级火箭设计与飞行仿真
OpenRocket:从零开始掌握专业级火箭设计与飞行仿真 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket OpenRocket是一款功能强大的开源火箭设计与…...
)
终极指南:Webgrind与主流IDE集成的简单方法(VSCode、TextMate等)
终极指南:Webgrind与主流IDE集成的简单方法(VSCode、TextMate等) 【免费下载链接】webgrind Xdebug Profiling Web Frontend in PHP 项目地址: https://gitcode.com/gh_mirrors/we/webgrind Webgrind作为一款强大的Xdebug Profiling W…...