机器学习必修课 - 如何处理缺失数据
运行环境:Google Colab
处理缺失数据可简单分为两种方法:1. 删除具有缺失值的列 2. 填充
!git clone https://github.com/JeffereyWu/Housing-prices-data.git
- 下载数据集
import pandas as pd
from sklearn.model_selection import train_test_split
- 导入库
# Read the data
X_full = pd.read_csv('/content/Housing-prices-data/train.csv', index_col='Id')
X_test_full = pd.read_csv('/content/Housing-prices-data/test.csv', index_col='Id')
- 读取数据
index_col='Id'是为了将数据框的索引列设置为’Id’列。
# Remove rows with missing target, separate target from predictors
X_full.dropna(axis=0, subset=['SalePrice'], inplace=True)
y = X_full.SalePrice
X_full.drop(['SalePrice'], axis=1, inplace=True)
- SalePrice 是我们尝试预测的目标变量。
- 删除训练数据中带有缺失目标值(‘SalePrice’)的行。
- 将目标值(‘SalePrice’)存储在变量y中,并从特征中删除。
# To keep things simple, we'll use only numerical predictors
X = X_full.select_dtypes(exclude=['object'])
X_test = X_test_full.select_dtypes(exclude=['object'])
- 将特征数据限制为仅包含数值型特征
select_dtypes函数用于根据数据类型(在这里是’object’,即非数值型)选择特定类型的列。
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,random_state=0)
- 使用
train_test_split函数将训练数据X和目标值y分成训练集和验证集。train_size参数指定了训练集的比例(80%),test_size参数指定了验证集的比例(20%),random_state参数用于控制随机分割的种子,以确保每次运行代码时分割结果都一样。
1. 了解训练数据的形状和每列数据中缺失值的数量
# Shape of training data (num_rows, num_columns)
print(X_train.shape)# Number of missing values in each column of training data
missing_val_count_by_column = (X_train.isnull().sum())
print(missing_val_count_by_column[missing_val_count_by_column > 0])

- 首先使用
.isnull()方法将每个单元格是否为缺失值进行检查,然后使用.sum()方法计算每列中缺失值的总数。 - 最后,它打印出那些包含至少一个缺失值的列的缺失值数量。
- 这段代码可以帮助你了解哪些特征(列)在训练数据中存在缺失值,以便在数据预处理过程中采取适当的措施来处理这些缺失值,例如填充它们或者删除相关的特征。
考虑到数据中缺失值的数量并不是很多,如果我们删除带有缺失值的列,那么就会丢失掉很多有用的信息。因此,更好的做法是对缺失值进行填充(imputation),以尽量保留数据的完整性。填充缺失值通常可以采用一些方法,如用平均值、中位数或者其他相关数据来替代缺失值,这样可以更好地保留数据的特征和信息,提高模型的性能。
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error# Function for comparing different approaches
def score_dataset(X_train, X_valid, y_train, y_valid):model = RandomForestRegressor(n_estimators=100, random_state=0)model.fit(X_train, y_train)preds = model.predict(X_valid)return mean_absolute_error(y_valid, preds)
RandomForestRegressor是一个随机森林回归模型,用于机器学习中的回归问题。mean_absolute_error是一个评估回归模型性能的函数,它用于计算预测值与实际值之间的平均绝对误差。- 函数的目的是通过比较不同数据集处理方法的分数来评估哪种方法在机器学习任务中效果最好。
# Get names of columns with missing values
cols_with_missing = [col for col in X_train.columnsif X_train[col].isnull().any()]# Drop columns in training and validation data
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
- 创建了一个列表
cols_with_missing,用于存储训练数据X_train中具有缺失值的列名。 - 遍历
X_train的每一列,使用.isnull().any()来检查每列是否包含任何缺失值。如果某列中至少有一个缺失值,就将其列名添加到cols_with_missing列表中。 - 使用
.drop()方法从训练数据X_train和验证数据X_valid中删除具有缺失值的列。cols_with_missing列表中包含了所有具有缺失值的列名,通过axis=1参数,可以指定删除列而不是行。
print("MAE (Drop columns with missing values):")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))

2. 数据填充
from sklearn.impute import SimpleImputer# Imputation
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))# Imputation removed column names; put them back
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
- 导入了Scikit-learn库中的
SimpleImputer类,该类用于处理缺失值,它可以用于填充数据中的缺失值。 - 分别使用
fit_transform方法来对训练数据X_train和验证数据X_valid进行缺失值填充。 - 在训练过程中,模型需要学习如何处理缺失值以及其他特征,因此使用
fit_transform方法对训练数据进行预处理。 - 使用
transform方法对验证数据进行数据预处理,包括填充缺失值。在验证过程中,模型不应该再次拟合填充器,因为这会导致信息泄露。模型在实际应用中不会在新的数据上重新拟合填充器,而是使用在训练数据上学到的填充策略。 - 将填充后的数据框中的列名恢复为原始数据
X_train和X_valid的列名。这是因为在填充数据时,列名可能被丢失。
print("MAE (Imputation):")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))

这里我们可以看到,填充的方法没有删除的方法成效好。由于数据集中缺失值很少,所以通常来说,使用填充方法来处理缺失值应该比完全删除带有缺失值的列更好。但是在实际情况中,填充的方式也需要谨慎选择,不一定每次都使用均值填充就是最佳选择。具体的填充策略需要根据数据的特点和背后的含义来确定,可能需要尝试不同的填充方式以找到最合适的方法。同时,一些填充方式可能会导致糟糕的结果,因此需要谨慎评估和选择。
3. 对训练数据和验证数据进行最终的数据预处理
# Preprocessed training and validation features
final_imputer = SimpleImputer(strategy='median')
final_X_train = pd.DataFrame(final_imputer.fit_transform(X_train))
final_X_valid = pd.DataFrame(final_imputer.transform(X_valid))final_X_train.columns = X_train.columns
final_X_valid.columns = X_valid.columns
- 设置填充策略为’
median’(中位数)。这意味着缺失值将会使用每列的中位数值来进行填充。
# Define and fit model
model = RandomForestRegressor(n_estimators=100, random_state=0)
model.fit(final_X_train, y_train)# Get validation predictions and MAE
preds_valid = model.predict(final_X_valid)
print("MAE (Your approach):")
print(mean_absolute_error(y_valid, preds_valid))

# Fill in the line below: preprocess test data
final_X_test = pd.DataFrame(final_imputer.transform(X_test))
final_X_test.columns = X_test.columns# Fill in the line below: get test predictions
preds_test = model.predict(final_X_test)
# Save test predictions to file
output = pd.DataFrame({'Id': X_test.index,'SalePrice': preds_test})
output.to_csv('submission.csv', index=False)
相关文章:
机器学习必修课 - 如何处理缺失数据
运行环境:Google Colab 处理缺失数据可简单分为两种方法:1. 删除具有缺失值的列 2. 填充 !git clone https://github.com/JeffereyWu/Housing-prices-data.git下载数据集 import pandas as pd from sklearn.model_selection import train_test_split导…...

阿里云服务器方升架构、自研硬件、AliFlash技术创新
阿里云服务器技术创新:服务器方升架构及自研硬件、自研存储硬件AliFlash和阿里云异构计算加速平台,阿里云百科分享阿里云服务器有哪些技术创新: 目录 服务器技术创新 服务器方升架构及自研硬件 自研存储硬件AliFlash 阿里云异构计算加速…...
知识工程---neo4j 5.12.0+GDS2.4.6安装
(已安装好neo4j community 5.12.0) 一. GDS下载 jar包下载地址:https://neo4j.com/graph-data-science-software/ 下载得到一个zip压缩包,解压后得到jar包。 二. GDS安装及配置 将解压得到的jar包放入neo4j安装目录下的plugi…...

BUUCTF reverse wp 81 - 85
[SCTF2019]babyre 反编译失败, 有花指令 有一个无用字节, 阻止反编译, patch成0x90 所有标红的地方nop掉之后按p重申函数main和loc_C22, F5成功 int __cdecl main(int argc, const char **argv, const char **envp) {char v4; // [rspFh] [rbp-151h]int v5; // [rsp10h] [rb…...
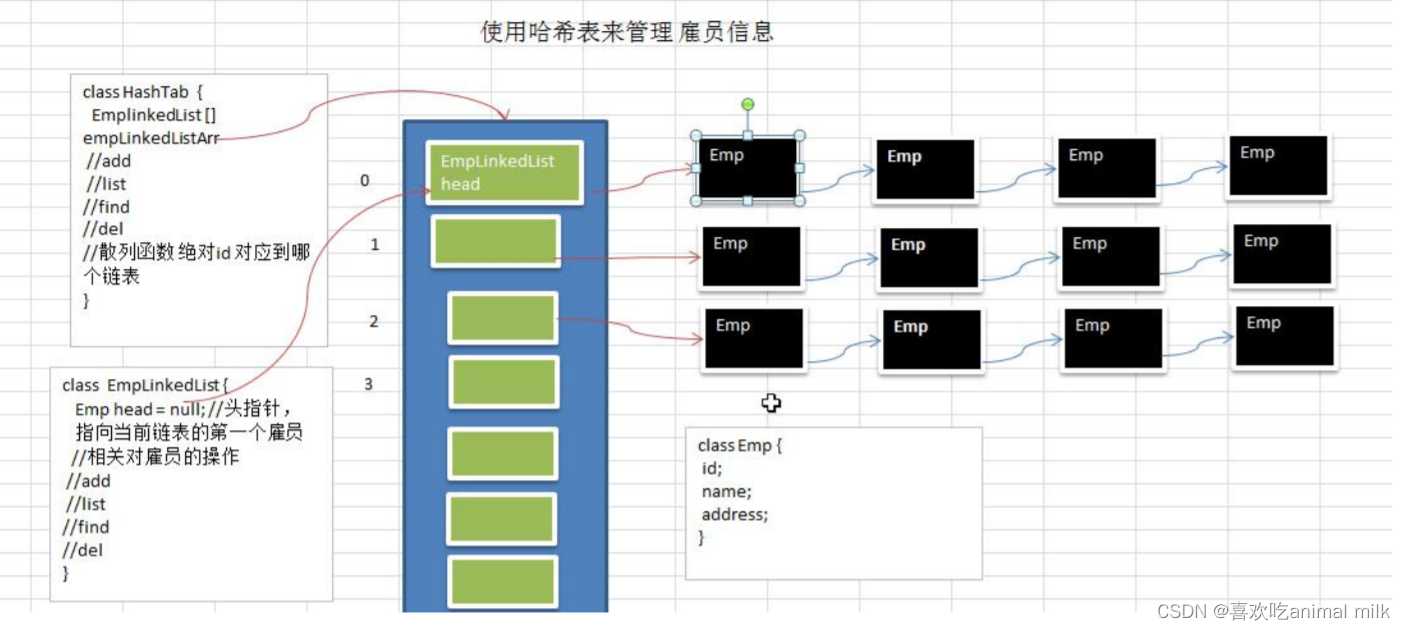
数据结构-哈希表
系列文章目录 1.集合-Collection-CSDN博客 2.集合-List集合-CSDN博客 3.集合-ArrayList源码分析(面试)_喜欢吃animal milk的博客-CSDN博客 4.数据结构-哈希表_喜欢吃animal milk的博客-CSDN博客 文章目录 目录 系列文章目录 文章目录 前言 一 . 什么是哈希表&a…...

深度学习在图像识别领域还有哪些应用?
深度学习在图像识别领域的应用非常广泛,除了之前提到的图像分类、目标检测、语义分割和图像生成,还有其他一些应用。 图像超分辨率重建:深度学习技术可以用于提高图像的分辨率,例如通过使用生成对抗网络(GANÿ…...
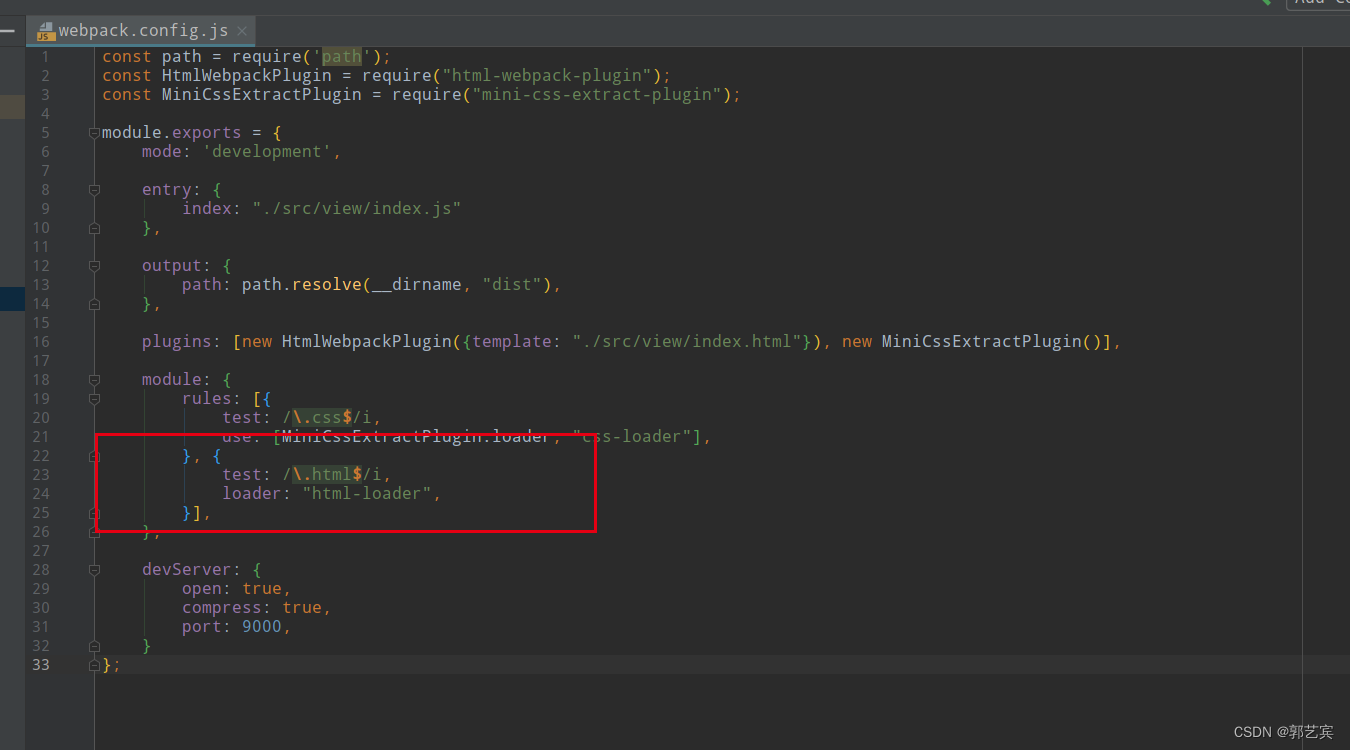
前端项目练习(练习-005-webpack-03)
学习前,首先,创建一个web-005项目,内容和web-004一样。(注意将package.json中的name改为web-005) 前面的代码中,打包工作已经基本完成了,下面开始在本地启动项目。这里需要用到webpack-dev-serv…...

『力扣每日一题10』:字符串中的单词数
因为身体原因,再加上学校的 DeadLine 比较多,太忙太累,拖更了半个月。现在开始重拾日更,期待我们一起遇见更好的自己! 一、题目 统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。 请注意&a…...

初级篇—第三章多表查询
文章目录 为什么需要多表查询一个案例引发的多表连接初代查询笛卡尔积(或交叉连接)的理解 多表查询分类等值连接 vs 非等值连接自连接 vs 非自连接内连接VS外连接 SQL99语法实现多表查询内连接的实现外连接的实现左外连接右外连接满外连接 UNION的使用7种…...
<Xcode> Xcode IOS无开发者账号打包和分发
关于flutter我们前边聊到的初入门、数据解析、适配、安卓打包、ios端的开发和黑苹果环境部署,但是对于苹果的打包和分发,我只是给大家了一个链接,作为一个顶级好男人,我认为这样是对大家的不负责任,那么这篇就主要是针…...

vertx的学习总结2
一、什么是verticle verticle是vertx的基本单元,其作用就是封装用于处理事件的技术功能单元 (如果不能理解,到后面的实战就可以理解了) 二、写一个verticle 1. 引入依赖(这里用的是gradle,不会吧&#…...
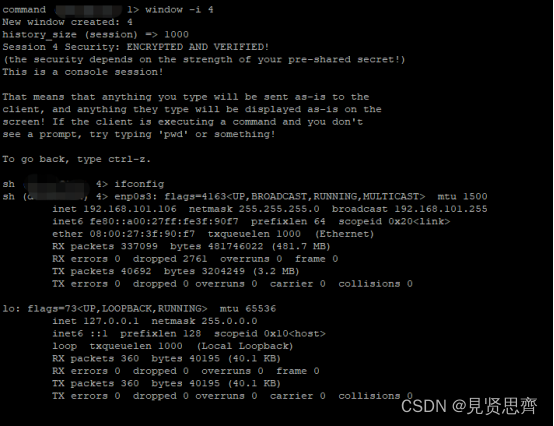
网络安全内网渗透之DNS隧道实验--dnscat2直连模式
目录 一、DNS隧道攻击原理 二、DNS隧道工具 (一)安装dnscat2服务端 (二)启动服务器端 (三)在目标机器上安装客户端 (四)反弹shell 一、DNS隧道攻击原理 在进行DNS查询时&#x…...

探索ClickHouse——连接Kafka和Clickhouse
安装Kafka 新增用户 sudo adduser kafka sudo adduser kafka sudo su -l kafka安装JDK sudo apt-get install openjdk-8-jre下载解压kafka 可以从https://downloads.apache.org/kafka/下找到希望安装的版本。需要注意的是,不要下载路径包含src的包,否…...

基于监督学习的多模态MRI脑肿瘤分割,使用来自超体素的纹理特征(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
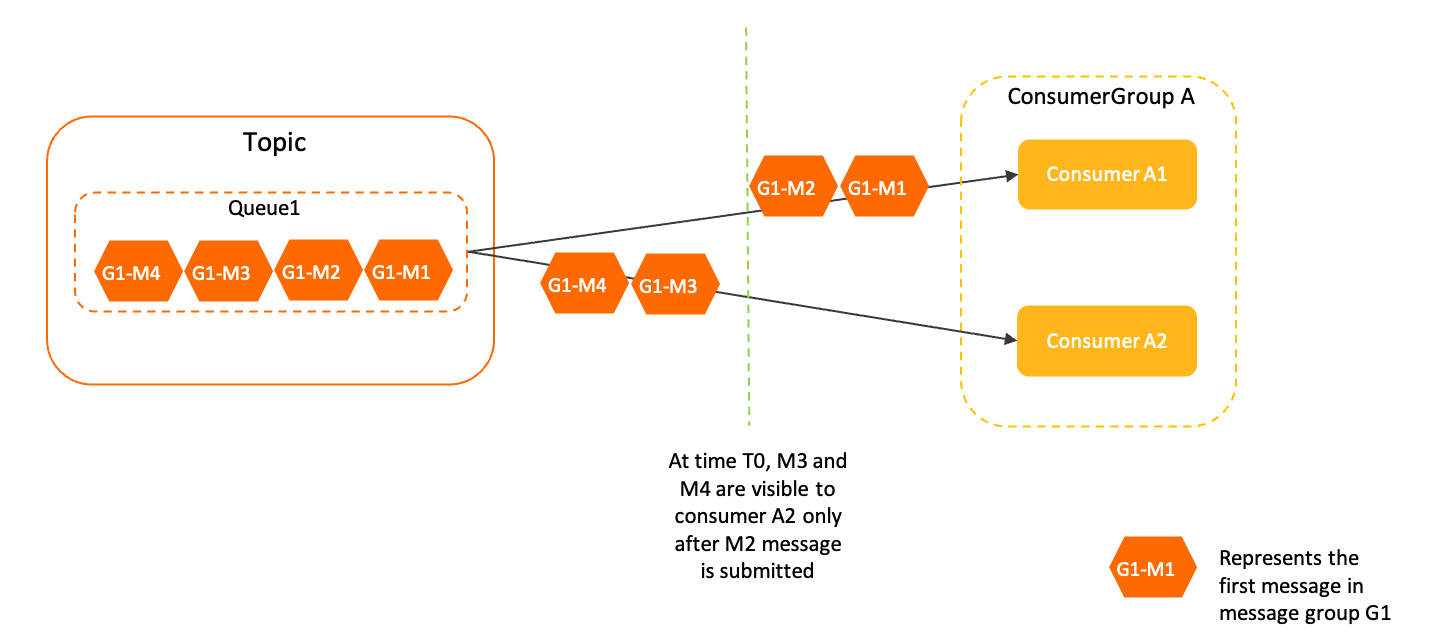
【RocketMQ】(八)Rebalance负载均衡
消费者负载均衡,是指为消费组下的每个消费者分配订阅主题下的消费队列,分配了消费队列消费者就可以知道去消费哪个消费队列上面的消息,这里针对集群模式,因为广播模式,所有的消息队列可以被消费组下的每个消费者消费不…...

线性筛和埃氏筛
线性筛: #define _CRT_SECURE_NO_WARNINGS #include<iostream> #include<cstdio> #include<cstdlib> #include<string> #include<cstring> #include<cmath> #include<ctime> #include<algorithm> #include<ut…...

【Java 进阶篇】JDBC ResultSet 类详解
在Java应用程序中,与数据库交互通常涉及执行SQL查询以检索数据。一旦执行查询,您将获得一个ResultSet对象,该对象包含查询结果的数据。本文将深入介绍ResultSet类,它是Java JDBC编程中的一个核心类,用于处理查询结果。…...
)
Centos7常用服务脚本(.service)
Centos7常用服务脚本(.service) 注意:[Service]中配置路径必须使用绝对路径。 启停: systemctl { start | stop | restart | reload } xxx.service 自启动: systemctl { enable | disable } xxx.service nginx.se…...
)
MySQL 视图View的SQL语法和更新(视图篇 二)
视图语法基本操作 创建 -- [ ]表示可选 create [or replace] view 视图名称[(列名列表)] as select语句 [ with [cascaded | local ] check option ]; 添加(虽然视图是虚拟表,但是向视图操作的数据实际上会影响到实际关联的表数据) -- 视图添…...
38 翻转二叉树
翻转二叉树 理解题意,翻转即每个结点的左右子树翻转/对调题解1 递归——自下而上题解2 迭代——自上而下 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 提示: 树中节点数目范围在 [0, 100] 内-100 < Node.…...

Mac鼠标优化终极指南:告别原生限制,解锁专业级操控体验
Mac鼠标优化终极指南:告别原生限制,解锁专业级操控体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - A simple way to make your mouse better. 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 你是否曾为Mac上的鼠标滚轮卡…...

为什么开发者都在使用Nord tmux?探索其设计哲学
为什么开发者都在使用Nord tmux?探索其设计哲学 【免费下载链接】tmux 项目地址: https://gitcode.com/gh_mirrors/tmux10/tmux Nord tmux是一款基于北极蓝调色彩的优雅tmux主题,专为流畅清晰的工作流程设计。作为GitHub加速计划的一部分&#x…...

微信聊天记录永久归档方案:GitHub_Trending/we/WeChatMsg使用教程
微信聊天记录永久归档方案:GitHub_Trending/we/WeChatMsg使用教程 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trendi…...

Clawdbot+Qwen3:32B实战:一键部署私有AI对话网关
ClawdbotQwen3:32B实战:一键部署私有AI对话网关 1. 这个镜像能帮你解决什么问题 想象一下这样的场景:你已经在本地成功运行了Qwen3:32B大模型,通过Ollama的命令行接口可以流畅地进行对话测试。但当你想要分享给团队成员使用,或者…...

StructBERT情感分析应用场景:短视频弹幕实时情感聚类与热词提取
StructBERT情感分析应用场景:短视频弹幕实时情感聚类与热词提取 1. 引言:弹幕数据的情感价值 你有没有在刷短视频时,被满屏的弹幕吸引过?那些快速滚动的文字,不仅是观众的真实反应,更是宝贵的情感数据金矿…...

CVX工具箱安装避坑指南:从下载到运行测试代码的全流程
CVX工具箱安装避坑指南:从下载到运行测试代码的全流程 在工程优化和学术研究领域,凸优化问题无处不在。CVX作为MATLAB平台上最受欢迎的凸优化建模工具包,以其直观的语法和强大的求解能力赢得了广泛认可。然而,对于初次接触CVX的用…...

文献管理如何突破效率瓶颈:WPS-Zotero插件的平民化应用指南
文献管理如何突破效率瓶颈:WPS-Zotero插件的平民化应用指南 【免费下载链接】WPS-Zotero An add-on for WPS Writer to integrate with Zotero. 项目地址: https://gitcode.com/gh_mirrors/wp/WPS-Zotero 学术写作中,文献管理往往成为非技术背景研…...

学术党必备!用Pdfarranger高效处理双栏论文PDF的5个实用技巧
学术党必备!用Pdfarranger高效处理双栏论文PDF的5个实用技巧 作为一名常年与学术论文打交道的科研人员,最头疼的莫过于阅读双栏排版的PDF文献——狭窄的页边距让批注无处安放,频繁左右滚动屏幕又容易打断思路。直到发现Pdfarranger这款开源工…...

用ggplot2玩转多维度数据:CO2/iris数据集散点图进阶案例解析
用ggplot2玩转多维度数据:CO2/iris数据集散点图进阶案例解析 生态学和生物统计学研究中,数据可视化是探索复杂关系的核心工具。当面对包含多个分类变量、连续变量的数据集时,如何清晰呈现变量间的交互关系成为研究者面临的普遍挑战。R语言的g…...

前端页面白屏排查思路总结
前端页面白屏排查思路总结 在开发或维护前端项目时,白屏问题是最常见的故障之一。用户打开页面时一片空白,不仅影响体验,还可能造成业务损失。如何快速定位和解决白屏问题?本文将从几个关键方面总结排查思路,帮助开发…...