机器学习 不均衡数据采样方法:imblearn 库的使用

✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
- imblearn 简介
- imblearn 安装
- 欠采样方法
- ClusterCentroids
- EditedNearestNeighbours
- CondensedNearestNeighbour
- AllKNN
- InstanceHardnessThreshold
- 过采样方法
- SMOTE
- SMOTE-NC
- SMOTEN
- ADASYN
- BorderlineSMOTE
- KMeansSMOTE
- SVMSMOTE
- 组合采样方法
- SMOTETomek
- SMOTEENN
- imblearn 库使用示例
- 导入库
- 查看原始数据分布
- 采样后的数据分布
- 不同采样方法的可视化对比
imblearn 简介
imblearn(全名为 imbalanced-learn )是一个用于处理不平衡数据集的 Python 库。在许多实际情况中,数据集中的类别分布可能是不均衡的,这意味着某些类别的样本数量远远超过其他类别。这可能会导致在训练机器学习模型时出现问题,因为模型可能会偏向于学习多数类别。
imblearn 库提供了一系列处理不平衡数据集的方法,包括:
- 欠采样方法:减少多数类别的样本以使其与少数类别相匹配。
- 过采样方法:通过生成合成样本来增加少数类别的样本数量,使其与多数类别相匹配。
- 组合采样方法:结合了欠采样和过采样的技术,以获得更好的平衡。
imblearn 库包含了许多常用的不平衡数据处理算法,例如SMOTE(Synthetic Minority Over-sampling Technique)、Tomek Links、RandomUnderSampler、RandomOverSampler 等等。
这个库对于处理各种类型的不平衡数据问题非常有用,可以提升在这类数据上训练模型的性能。
imblearn 安装
imblearn 库可以通过 pip 安装:
pip install imblearn
欠采样方法
欠采样方法通过减少多数类别的样本数量来平衡数据集。这些方法通常用于处理大型数据集,因为它们可以减少数据集的大小。
下面我们将介绍 imblearn 库中的一些常用欠采样方法。
ClusterCentroids
ClusterCentroids 是一种欠采样方法,它通过聚类算法来减少多数类别的样本数量。它通过将多数类别的样本聚类为多个簇,然后对每个簇选择其中心作为新的样本来实现。
具体来说,ClusterCentroids 采取以下步骤:
- 将多数类别的样本分成几个簇(clusters)。
- 对于每个簇,选择其中心点作为代表样本。
- 最终的训练集将包含所有少数类别样本以及选定的多数类别样本中心点。
EditedNearestNeighbours
EditedNearestNeighbours (简称 ENN)是一种欠采样方法,它通过删除多数类别中的异常值来减少多数类别的样本数量。它通过以下步骤实现:
- 对于每一个多数类别的样本,找到它的 k 个最近邻居(根据指定的距离度量)。
- 如果多数类别的样本的大多数最近邻居属于与它不同的类别(即多数类别样本的大多数邻居属于少数类别),则将该样本移除。
CondensedNearestNeighbour
CondensedNearestNeighbour 是一种欠采样方法,它通过选择多数类别样本的子集来减少多数类别的样本数量。它通过以下步骤实现:
- 将少数类别的样本全部保留在训练集中。
- 逐一考察多数类别的样本。对于每一个多数类别的样本,找到它的k个最近邻居(根据指定的距离度量)。
- 如果多数类别的样本能够被少数类别样本所代表,即该多数类别样本的最近邻居中存在少数类别样本,则将该多数类别样本移除。
AllKNN
AllKNN 是一种欠采样方法,它在执行时会多次应用 ENN(Edited Nearest Neighbours)算法,并在每次迭代时逐步增加最近邻的数量。
AllKNN 通过多次应用 ENN,并逐步增加最近邻的数量,可以更加彻底地清除位于类别边界附近的噪声样本。
InstanceHardnessThreshold
InstanceHardnessThreshold 是一种欠采样方法,它通过计算每个样本的难度分数来减少多数类别的样本数量。它通过以下步骤实现:
- 计算多数类别中每个样本的难度分数。
- 剔除难度分数低于指定阈值的样本。
- 将剩余样本与少数类别的样本组合成新的训练集。
过采样方法
过采样方法通过生成合成样本来增加少数类别的样本数量,使其与多数类别相匹配。这些方法通常用于处理小型数据集,因为它们可以增加数据集的大小。
下面我们将介绍 imblearn 库中的一些常用过采样方法。
SMOTE
SMOTE(Synthetic Minority Over-sampling Technique)是一种过采样方法,它通过生成合成样本来增加少数类别的样本数量,使其与多数类别相匹配。
SMOTE 的原理基于对少数类样本的插值。具体而言,它首先随机选择一个少数类样本作为起始点,然后从该样本的近邻中随机选择一个样本作为参考点。然后,SMOTE 通过在这两个样本之间的线段上生成新的合成样本来增加数据集的样本数量。
SMOTE-NC
SMOTE-NC(SMOTE for Nominal and Continuous features)是一种用于处理同时包含数值和分类特征的数据集的过采样方法。它是对传统的 SMOTE 算法的扩展,能够处理同时存在数值和分类特征的情况,但不适用于仅包含分类特征的数据集。
SMOTE-NC 的原理与 SMOTE 类似,但在生成合成样本时有所不同。它的生成过程如下:
- 对于选定的起始点和参考点,计算它们之间的差距,得到一个向量。
- 将连续特征(数值特征)的差距乘以一个随机数,得到新样本的位置。这一步与传统的 SMOTE 相同。
- 对于分类特征,随机选择起始点或参考点的特征值作为新合成样本的特征值。
- 对于连续特征和分类特征,分别使用插值和随机选择的方式来生成新样本的特征值。
通过这种方式,SMOTE-NC 能够处理同时包含数值和分类特征的数据集,并生成新的合成样本来增加少数类样本的数量。这样可以在平衡数据集的同时保持数值和分类特征的一致性。
SMOTEN
SMOTEN(Synthetic Minority Over-sampling Technique for Nominal)是一种专门针对分类特征的过采样方法,用于解决类别不平衡问题。它是对 SMOTE 算法的扩展,适用于仅包含分类特征的数据集。
SMOTEN 的原理与 SMOTE 类似,但在生成合成样本时有所不同。它的生成过程如下:
- 对于选定的起始点和参考点,计算它们之间的差距,得到一个向量。
- 对于每个分类特征,统计起始点和参考点之间相应特征的唯一值(类别)的频率。
- 根据特征的频率,确定新样本的位置。具体而言,对于每个分类特征,随机选择一个起始点或参考点的类别,并在该类别中随机选择一个值作为新合成样本的特征值。
- 对于连续特征,采用传统的 SMOTE 方式,通过在差距向量上乘以一个随机数,确定新样本的位置,并使用插值来生成新样本的特征值。
ADASYN
ADASYN(Adaptive Synthetic)是一种基于自适应合成的过采样算法。它与 SMOTE 方法相似,但根据类别的局部分布估计生成不同数量的样本。
ADASYN 根据样本之间的差距,计算每个样本的密度因子。密度因子表示该样本周围少数类样本的密度。较低的密度因子表示该样本所属的区域缺乏少数类样本,而较高的密度因子表示该样本周围有更多的少数类样本。
BorderlineSMOTE
BorderlineSMOTE(边界 SMOTE)是一种过采样算法,是对原始 SMOTE 算法的改进和扩展。它能够检测并利用边界样本生成新的合成样本,以解决类别不平衡问题。
BorderlineSMOTE 在 SMOTE 算法的基础上进行了改进,通过识别边界样本来更有针对性地生成新的合成样本。边界样本是指那些位于多数类样本和少数类样本之间的样本,它们往往是难以分类的样本。通过识别并处理这些边界样本,BorderlineSMOTE 能够提高分类器对难以分类样本的识别能力。
KMeansSMOTE
KMeansSMOTE 的关键在于使用 KMeans 聚类将数据样本划分为不同的簇,并通过识别边界样本来有针对性地进行合成样本的生成。这种方法可以提高合成样本的多样性和真实性,因为它仅在边界样本周围进行过采样,而不是在整个少数类样本集上进行。
SVMSMOTE
SVMSMOTE 是一种基于 SMOTE 算法的变体,其特点是利用支持向量机(SVM)算法来检测用于生成新的合成样本的样本。通过将数据集中的少数类样本划分为支持向量和非支持向量,SVMSMOTE 能够更准确地选择样本进行合成。对于每个少数类支持向量,它选择其最近邻中的一个作为参考点,并通过计算其与参考点之间的差距来生成新的合成样本。
组合采样方法
组合采样方法结合了欠采样和过采样的技术,以获得更好的平衡。
下面我们将介绍 imblearn 库中的一些常用组合采样方法。
SMOTETomek
SMOTETomek 是一种组合采样方法,它结合了 SMOTE 和 Tomek Links 算法。Tomek Links 是一种欠采样方法,它通过删除多数类别样本和少数类别样本之间的边界样本来减少多数类别的样本数量。
SMOTETomek 通过结合 SMOTE 和 Tomek Links 算法,能够同时处理多数类别和少数类别的样本,以获得更好的平衡。
SMOTEENN
SMOTEENN 是一种组合采样方法,它结合了 SMOTE 和 ENN 算法。
相比于 SMOTETomek,由于 SMOTEENN 结合了 ENN 算法,因此它能够更容易地清除位于类别边界附近的噪声样本。
imblearn 库使用示例
下面我们将通过一个示例来演示 imblearn 库的使用。
导入库
首先,我们需要导入一些需要用到的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsfrom sklearn.datasets import load_breast_cancer # sklearn 乳腺癌数据集
from imblearn.under_sampling import ClusterCentroids, EditedNearestNeighbours
from imblearn.over_sampling import SMOTE, ADASYN
from imblearn.combine import SMOTEENN, SMOTETomek
查看原始数据分布
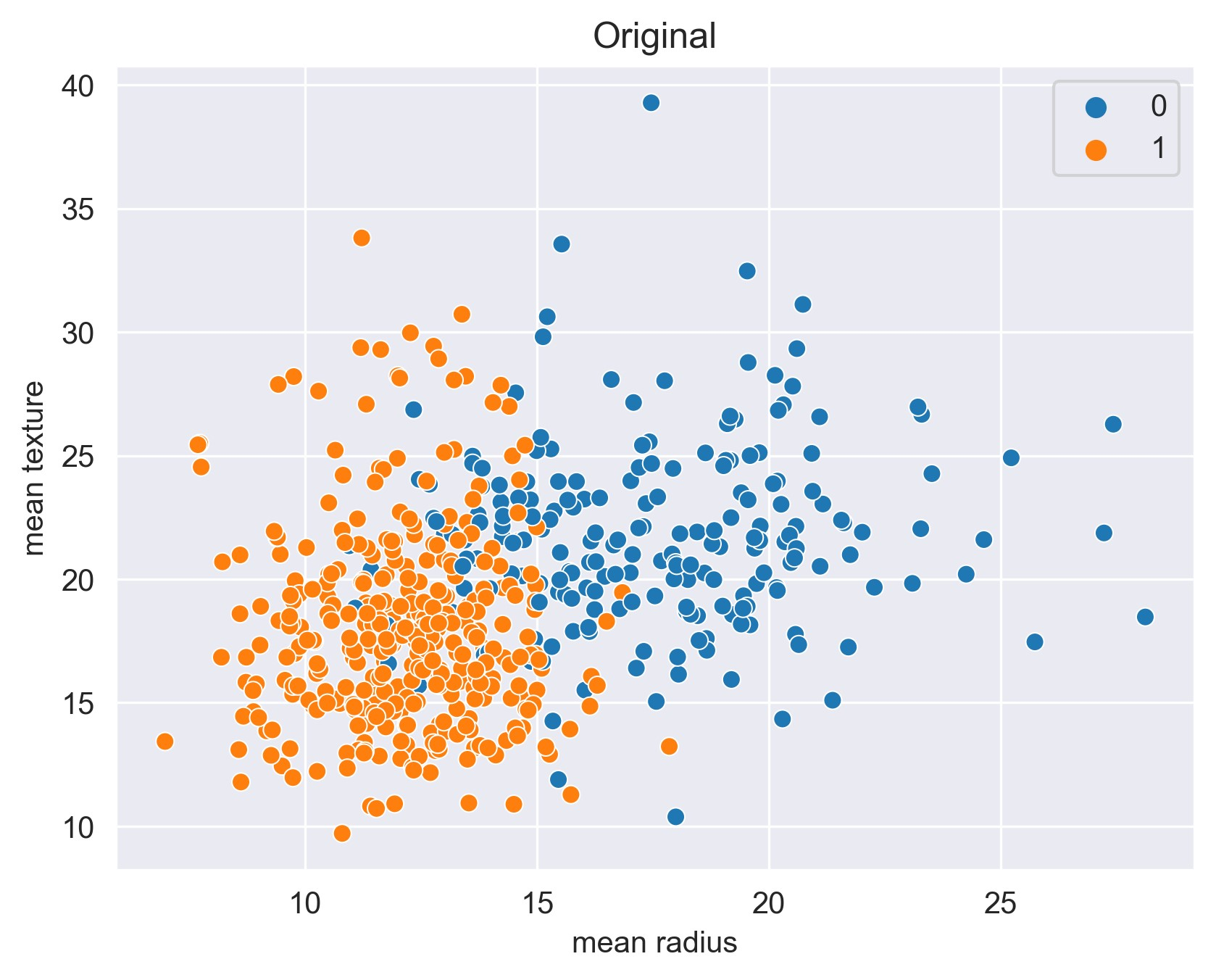
我们使用 sklearn 自带的乳腺癌数据集作为示例数据集。首先,我们导入数据集,并查看数据集的基本信息:
data = load_breast_cancer()X = data.data
y = data.targetprint(f"类别为 0 的样本数: {X[y == 0].shape[0]}, 类别为 1 的样本数: {X[y == 1].shape[0]}")sns.set_style("darkgrid")
sns.scatterplot(data=data, x=X[:, 0], y=X[:, 1], hue=y)
plt.xlabel(f"{data.feature_names[0]}")
plt.ylabel(f"{data.feature_names[1]}")
plt.title("Original")
plt.show()
输出结果如下:
类别为 0 的样本数: 212, 类别为 1 的样本数: 357
采样后的数据分布
接下来,我们使用 imblearn 库中的一些采样方法来处理数据集,以获得更好的平衡。
data = load_breast_cancer()X = data.data
y = data.targetsampler1 = ClusterCentroids(random_state=0)
sampler2 = EditedNearestNeighbours()
sampler3 = SMOTE(random_state=0)
sampler4 = ADASYN(random_state=0)
sampler5 = SMOTEENN(random_state=0)
sampler6 = SMOTETomek(random_state=0)X1, y1 = sampler1.fit_resample(X, y)
X2, y2 = sampler2.fit_resample(X, y)
X3, y3 = sampler3.fit_resample(X, y)
X4, y4 = sampler4.fit_resample(X, y)
X5, y5 = sampler5.fit_resample(X, y)
X6, y6 = sampler6.fit_resample(X, y)print(f"ClusterCentroids: 类别为 0 的样本数: {X1[y1 == 0].shape[0]}, 类别为 1 的样本数: {X1[y1 == 1].shape[0]}"
)
print(f"EditedNearestNeighbours: 类别为 0 的样本数: {X2[y2 == 0].shape[0]}, 类别为 1 的样本数: {X2[y2 == 1].shape[0]}"
)
print(f"SMOTE: 类别为 0 的样本数: {X3[y3 == 0].shape[0]}, 类别为 1 的样本数: {X3[y3 == 1].shape[0]}"
)
print(f"ADASYN: 类别为 0 的样本数: {X4[y4 == 0].shape[0]}, 类别为 1 的样本数: {X4[y4 == 1].shape[0]}"
)
print(f"SMOTEENN: 类别为 0 的样本数: {X5[y5 == 0].shape[0]}, 类别为 1 的样本数: {X5[y5 == 1].shape[0]}"
)
print(f"SMOTETomek: 类别为 0 的样本数: {X6[y6 == 0].shape[0]}, 类别为 1 的样本数: {X6[y6 == 1].shape[0]}"
)
输出结果如下:
ClusterCentroids: 类别为 0 的样本数: 212, 类别为 1 的样本数: 212
EditedNearestNeighbours: 类别为 0 的样本数: 212, 类别为 1 的样本数: 320
SMOTE: 类别为 0 的样本数: 357, 类别为 1 的样本数: 357
ADASYN: 类别为 0 的样本数: 358, 类别为 1 的样本数: 357
SMOTEENN: 类别为 0 的样本数: 304, 类别为 1 的样本数: 313
SMOTETomek: 类别为 0 的样本数: 349, 类别为 1 的样本数: 349
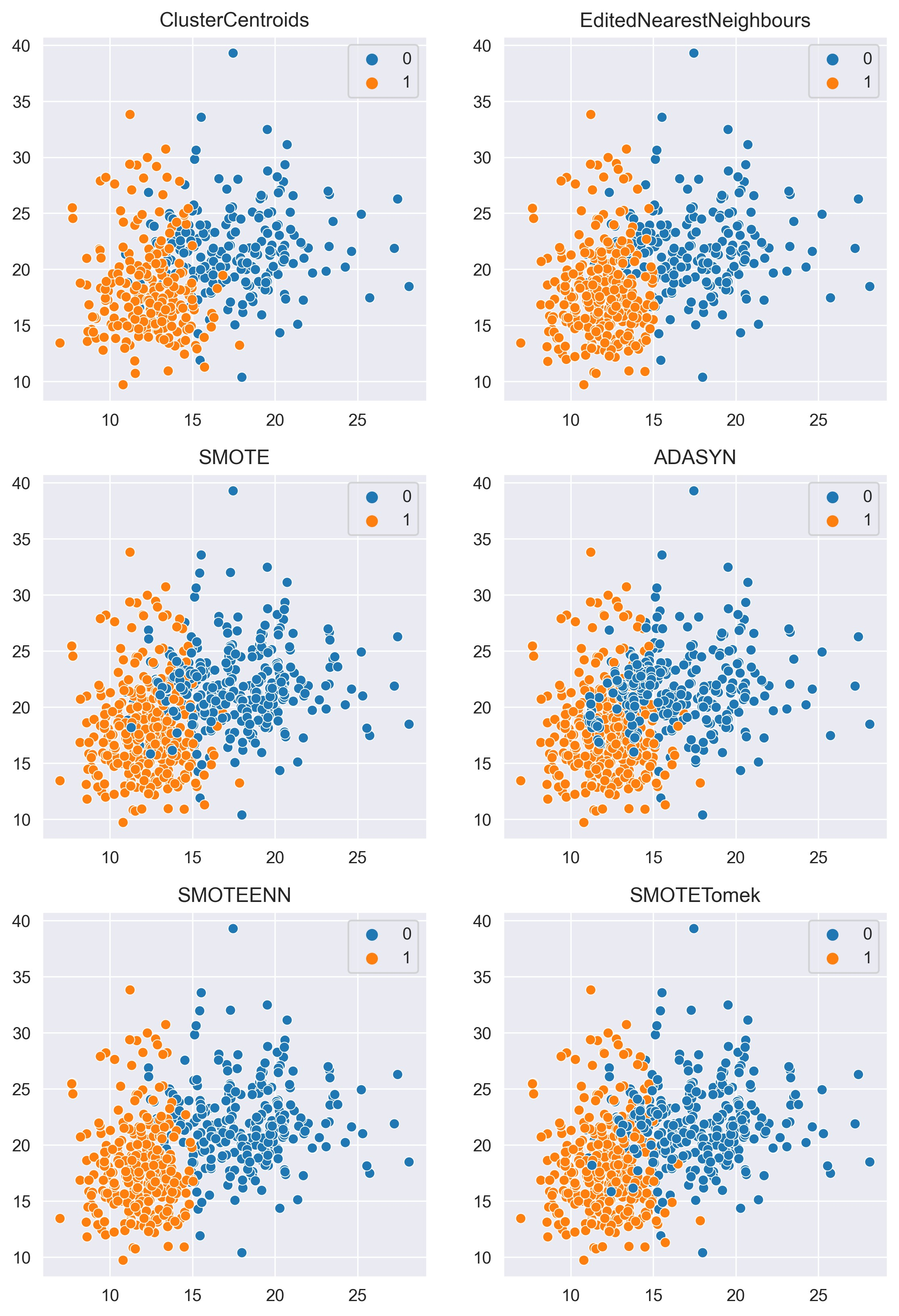
不同采样方法的可视化对比
下面我们将使用 matplotlib 和 seaborn 库来可视化不同采样方法的效果。
sns.set_style("darkgrid")
plt.figure(figsize=(9, 18))plt.subplot(4, 2, 1)
sns.scatterplot(data=data, x=X1[:, 0], y=X1[:, 1], hue=y1)
plt.title("ClusterCentroids")plt.subplot(4, 2, 2)
sns.scatterplot(data=data, x=X2[:, 0], y=X2[:, 1], hue=y2)
plt.title("EditedNearestNeighbours")plt.subplot(4, 2, 3)
sns.scatterplot(data=data, x=X3[:, 0], y=X3[:, 1], hue=y3)
plt.title("SMOTE")plt.subplot(4, 2, 4)
sns.scatterplot(data=data, x=X4[:, 0], y=X4[:, 1], hue=y4)
plt.title("ADASYN")plt.subplot(4, 2, 5)
sns.scatterplot(data=data, x=X5[:, 0], y=X5[:, 1], hue=y5)
plt.title("SMOTEENN")plt.subplot(4, 2, 6)
sns.scatterplot(data=data, x=X6[:, 0], y=X6[:, 1], hue=y6)
plt.title("SMOTETomek")plt.show()
对比结果如下:
相关文章:
机器学习 不均衡数据采样方法:imblearn 库的使用
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

MySQL系统与内建函数
在游戏开发、特别是像《三国志》这样的大型策略游戏中,数据分析是不可或缺的。从玩家行为到游戏内的战役结果,都需要通过高效的数据分析来优化游戏体验。MySQL的系统和内建函数为这样的分析提供了强大的工具。 本文将详细介绍MySQL中常用的系统与内建函数,并通过《三国志》…...
STM32CubeMX学习笔记-USB接口使用(CDC虚拟串口)
STM32CubeMX学习笔记-USB接口使用(CDC虚拟串口) 一、USB简介二、新建工程1. 打开 STM32CubeMX 软件,点击“新建工程”2. 选择 MCU 和封装3. 配置时钟4. 配置调试模式 三、USB3.1 参数配置3.3 配置时钟3.4 USB Device 四、生成代码五、查看端口…...

腾讯云 Cloud Studio 实战训练营结营活动获奖公示
点击链接了解详情 “腾讯云 Cloud Studio 实战训练营” 是由腾讯云联合 CSDN 推出的系列开发者技术实践活动,通过技术分享直播、动手实验项目、优秀代码评选、有奖征文活动等,让广大开发者沉浸式体验腾讯云开发者工具 Cloud Studio 的同时,实…...

使用晶体管做布尔逻辑和逻辑门
目录 二进制,三进制,五进制 true,false表示0,1 早期计算机采用进制 布尔逻辑 三个基本操作:NOT,AND,OR 基础“真值表” NOT 如何实现? AND如何实现? OR如何实现? 图标表示…...
Linux系统编程系列之线程的信号处理
一、为什么要有线程的信号处理 由于多线程程序中线程的执行状态是并发的,因此当一个进程收到一个信号时,那么究竟由进程中的哪条线程响应这个信号就是不确定的,只能取决于哪条线程刚好在信号达到的瞬间被调度,这种不确定性在程序逻…...

【C语言】青蛙跳台阶 —— 详解
一、问题描述 跳台阶_牛客题霸_牛客网 (nowcoder.com) LCR 127. 跳跃训练 - 力扣(LeetCode) 二、解题思路 1、当 n 1 时,一共只有一级台阶,那么显然青蛙这时就只有一种跳法 2、当 n 2 时,一共有两级台阶ÿ…...

Java - 基本数据类型和封装类型
基本类型有默认值,而包装类型初始为null。然后再根据这两个特性进行分业务使用,在阿里巴巴的规范里所有的POJO类必须使用包装类型,而在本地变量推荐使用基本类型。 Java语言提供了八种基本类型。六种数字类型(四个整数型ÿ…...
 图论 part 02)
day-63 代码随想录算法训练营(19) 图论 part 02
1020.飞地的数量 分析:求不跟边界接壤的陆地的数量 思路一:深度优先遍历 先从四个侧边找陆地,然后进行深度优先遍历,把所有接壤的陆地(1)全部转换成海洋(0) 深度优先遍历…...

SpringBoot的全局异常拦截
在 Spring Boot 中,可以通过使用 ControllerAdvice 注解和 ExceptionHandler 注解来实现全局异常拦截。 RestControllerAdvice RestControllerAdvice 是 Spring Framework 提供的注解,用于定义全局异常处理类,并且结合 ExceptionHandler 注…...

『力扣每日一题11』:转换成小写字母
一、题目 给你一个字符串 s ,将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。 示例 1: 输入:s "Hello" 输出:"hello"示例 2: 输入:s "here" 输…...
复习Day07:链表part03:21. 合并两个有序链表、2. 两数相加
之前的blog链接:https://blog.csdn.net/weixin_43303286/article/details/131700482?spm1001.2014.3001.5501 我用的方法是在leetcode再过一遍例题,明显会的就复制粘贴,之前没写出来就重写,然后从拓展题目中找题目来写。辅以Lab…...

Ubuntu中启动HDFS后没有NameNode解决办法
关闭进程: stop-dfs.sh 格式化: hadoop namenode -format 出现报错信息: 23/10/03 22:27:04 WARN fs.FileUtil: Failed to delete file or dir [/usr/data/hadoop/tmp/dfs/name/current/fsimage_0000000000000000000.md5]: it still exi…...
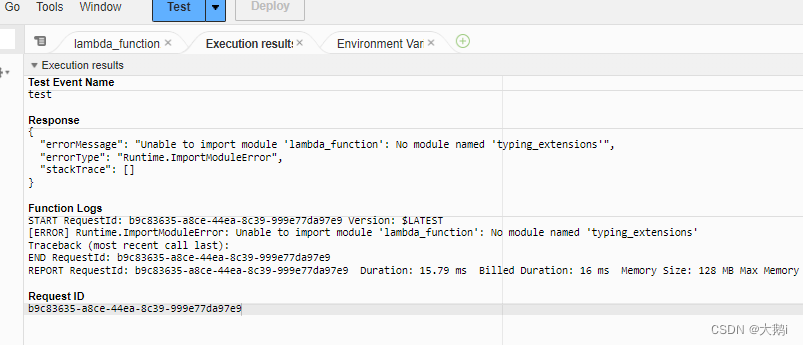
AWS-Lambda之导入自定义包-pip包
参考文档: https://repost.aws/zh-Hans/knowledge-center/lambda-import-module-error-python https://blog.csdn.net/fxtxz2/article/details/112035627 简单来说,以 " alibabacloud_dyvmsapi20170525 " 包为例 ## 创建临时目录 mkdir /tmp cd ./tmp …...

MAC 如何解决GitHub下载速度慢的问题
说在前面 解决github下载速度慢的方法很多,本文主要介绍通过Git镜像的方式解决下载慢的问题。 主要步骤有:1、找到gitconfig文件, 2、通过git命令查看当前生效的config 配置 3、使用git config命令编辑并添加国内镜像源 1、gitconfig 文件在…...
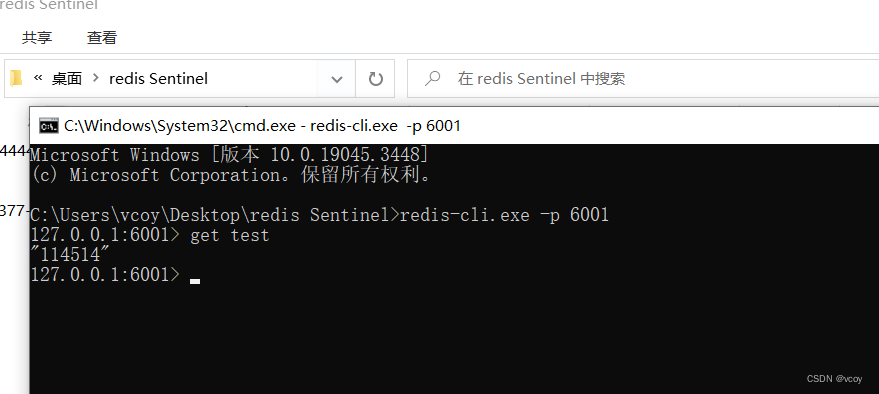
Redis与分布式-哨兵模式
接上文 Redis与分布式-主从复制 1.哨兵模式 启动一个哨兵,只需要修改配置文件即可, sentinel monitor lbwnb 1247.0.0.1 6001 1先将所有服务关闭,然后修改配置文件,redis Master,redis Slave,redis Slave…...

创建型设计模式 原型模式 建造者模式 创建者模式对比
创建型设计模式 单例 工厂模式 看这一篇就够了_软工菜鸡的博客-CSDN博客 4.3 原型模式 4.3.1 概述 用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型对象相同的新对象。 4.3.2 结构 原型模式包含如下角色: 抽象原型类:规定了…...
HTML详细基础(二)文件路径
目录 一.相对路径 二.绝对路径 三.超链接标签 四.锚点链接 首先,扩展一些HTML执行的原理: htmL(hypertext markup Language) 是一种规范(或者说是一种标准),它通过标记符(tag)来标记要显示…...
大数据-玩转数据-Flink 海量数据实时去重
一、海量数据实时去重说明 借助redis的Set,需要频繁连接Redis,如果数据量过大, 对redis的内存也是一种压力;使用Flink的MapState,如果数据量过大, 状态后端最好选择 RocksDBStateBackend; 使用布隆过滤器,…...

1.在vsCode上创建Hello,World
(1).编译器的安装配置 使用vsCode进行编写c语言,首先需要安装gcc编译器,可以自己去寻找资料或者gcc官网进行下载. 下载好后,将文件夹放入到自己指定的目录后,配置系统环境变量,将path指向编译器的bin目录 进入bin目录打开cmd,输入gcc -v,然后就会成功输出信息. (2).vsCode配…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...