C++:stl:stack、queue、priority_queue介绍及模拟实现和容量适配器deque介绍
本文主要介绍c++中stl的栈、队列和优先级队列并对其模拟实现,对deque进行一定介绍并在栈和队列的模拟实现中使用。
目录
一、stack的介绍和使用
1.stack的介绍
2.stack的使用
3.stack的模拟实现
二、queue的介绍和使用
1.queue的介绍
2.queue的使用
3.queue的模拟实现
三、priority_queue的介绍和使用
1.priority_queue的介绍
2.priority_queue的使用
3.priority_queue的模拟实现
四、容器适配器
1.什么是适配器
2.STL标准库中stack和queue的底层结构
3.deque的简单介绍
1.deque的原理介绍
2.deque的优点与缺陷
4.选择deque作为stack和queue的底层默认容器的原因
5.STL标准库中对于stack和queue的模拟实现
1.stack的模拟实现
2.queue的模拟实现
一、stack的介绍和使用
1.stack的介绍
stack的文档介绍
1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
2. stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
3. stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
- empty:判空操作
- back:获取尾部元素操作
- push_back:尾部插入元素操作
- pop_back:尾部删除元素操作
4. 标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器,默认情况下使用deque。

2.stack的使用
| 函数说明 | 接口说明 |
|---|---|
| stack() | 构造空的栈 |
| empty() | 检测stack是否为空 |
| size() | 返回stack中元素的个数 |
| top() | 返回栈顶元素的引用 |
| push() | 将元素val压入stack中 |
| pop() | 将stack中尾部的元素弹出 |
#include<iostream>
#include<vector>
#include<list>
#include<stack>
using namespace std;int main()
{stack<int, vector<int>> st;//指定栈的数据类型 和 容器类型st.push(3);cout << st.size() << endl;//1st.push(2);cout << st.top() << endl;//2st.pop();cout << st.top() << endl;//3st.pop();if (st.empty())cout << "empty" << endl;//emptyreturn 0;
}3.stack的模拟实现
从栈的接口中可以看出,栈实际是一种特殊的vector,因此使用vector完全可以模拟实现stack。
实现stack只需要对vector的接口进行复用即可。
#include<vector>
namespace sss
{template<class T>class stack{public:stack() {}//栈只有vector一个自定义成员变量//初始化时会调用vector的构造函数void push(const T& x) { _con.push_back(x); }void pop() { _con.pop_back(); }T& top() { return _con.back(); }const T& top()const { return _con.back(); }size_t size()const { return _con.size(); }bool empty()const { return _con.empty(); }private:std::vector<T> _con;};
}二、queue的介绍和使用
1.queue的介绍
queue的文档介绍
1. 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。
2. 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
3. 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
- empty:检测队列是否为空
- size:返回队列中有效元素的个数
- front:返回队头元素的引用
- back:返回队尾元素的引用
- push_back:在队列尾部入队列
- pop_front:在队列头部出队列
4. 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque。

2.queue的使用
| 函数声明 | 接口说明 |
|---|---|
| queue() | 构造空的队列 |
| empty() | 检测队列是否为空,是返回true,否则返回false |
| size() | 返回队列中有效元素的个数 |
| front() | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| push() | 在队尾将元素val入队列 |
| pop() | 将队头元素出队列 |
#include<iostream>
#include<list>
#include<queue>
using namespace std;
int main()
{queue<int, list<int>> q;q.push(3);q.push(2);q.push(1);cout << q.size() << endl;//3cout << q.front() << endl;//3cout << q.back() << endl;//1q.pop();q.pop();q.pop();if (q.empty())cout << "empty" << endl;//emptyreturn 0;
}3.queue的模拟实现
因为queue的接口中存在头删和尾插,因此使用vector来封装效率太低,故可以借助list来模拟实现queue。
#include <list>
namespace sss
{template<class T>class queue{public:queue() {}void push(const T& x) { _con.push_back(x); }void pop() { _con.pop_front(); }T& back() { return _con.back(); }const T& back()const{ return _con.back(); }T& front() {return _con.front(); }const T& front()const { return _con.front();}size_t size()const { return _con.size(); }bool empty()const { return _con.empty(); }private:std::list<T> _con;};
}三、priority_queue的介绍和使用
1.priority_queue的介绍
priority_queue文档介绍
1. 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
3. 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
4. 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
- empty():检测容器是否为空
- size():返回容器中有效元素个数
- front():返回容器中第一个元素的引用
- push_back():在容器尾部插入元素
- pop_back():删除容器尾部元素
5.标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector。
6.需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作。
2.priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用priority_queue。注意: 默认情况下priority_queue是大堆。
(堆的概念、结构、实现和应用)
| 函数声明 | 接口说明 |
|---|---|
| priority_queue()/priority_queue(first, last) | 构造一个空的优先级队列 |
| empty() | 检测优先级队列是否为空,是返回true,否则返回 false |
| top() | 返回优先级队列中最大(最小元素),即堆顶元素 |
| push(x) | 在优先级队列中插入元素x |
| pop() | 删除优先级队列中最大(最小)元素,即堆顶元素 |
注意:
1. 默认情况下,priority_queue是大堆。
#include<iostream>
#include <vector>
#include <queue>
#include <functional> // greater算法的头文件
using namespace std;
void priority_queue_test()
{// 默认情况下,创建的是大堆,其底层按照小于号比较vector<int> v{ 3,2,7,6,0,4,1,9,8,5 };priority_queue<int> q1;for (auto& e : v)q1.push(e);cout << q1.top() << endl;//9q1.pop();cout << q1.top() << endl;//8// 如果要创建小堆,将第三个模板参数换成greater比较方式priority_queue<int, vector<int>, greater<int>> q2(v.begin(), v.end());cout << q2.top() << endl;//0q2.pop();cout << q2.top() << endl;//1
}2. 如果在priority_queue中放自定义类型的数据,用户需要在自定义类型中提供> 或者< 的重载。
(以日期类为例)
class Date
{
public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const//<的重载{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const//>的重载{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}
private:int _year;int _month;int _day;
};
void TestPriorityQueue()
{// 大堆,需要用户在自定义类型中提供<的重载priority_queue<Date> q1;q1.push(Date(2023, 10, 2));q1.push(Date(2023, 10, 1));q1.push(Date(2023, 10, 3));cout << q1.top() << endl;//2023-10-3q1.pop();cout << q1.top() << endl; //2023-10-2// 如果要创建小堆,需要用户提供>的重载priority_queue<Date, vector<Date>, greater<Date>> q2;q2.push(Date(2023, 10, 2));q2.push(Date(2023, 10, 1));q2.push(Date(2023, 10, 3));cout << q2.top() << endl;//2023-10-1q2.pop();cout << q2.top() << endl;//2023-10-2
}3.priority_queue的模拟实现
通过对priority_queue的底层结构就是堆,因此此处只需对对进行通用的封装即可。
#include <iostream>
#include <vector>
using namespace std;// priority_queue--->堆
namespace sss
{template<class T>struct less//<的重载{bool operator()(const T& left, const T& right){return left < right;}};template<class T>struct greater//>的重载{bool operator()(const T& left, const T& right){return left > right;}};template<class T, class Container = std::vector<T>, class Compare = less<T>>//默认为<class priority_queue{public:// 创造空的优先级队列priority_queue() : _con() {}template<class Iterator>priority_queue(Iterator first, Iterator last): _con(first, last){// 将c中的元素调整成堆的结构int count = _con.size();int root = ((count - 2) >> 1);for (; root >= 0; root--)AdjustDown(root);}void push(const T& data){_con.push_back(data);AdjustUp(_con.size() - 1);}void pop(){if (empty())return;swap(_con.front(), _con.back());_con.pop_back();AdjustDown(0);}size_t size()const{return _con.size();}bool empty()const{return _con.empty();}// 堆顶元素不允许修改,因为:堆顶元素修改可以会破坏堆的特性const T& top()const{return _con.front();}private:// 向上调整void AdjustUp(int child){int parent = ((child - 1) >> 1);while (child){if (Compare()(_con[parent], _con[child])){swap(_con[child], _con[parent]);child = parent;parent = ((child - 1) >> 1);}else{return;}}}// 向下调整void AdjustDown(int parent){size_t child = parent * 2 + 1;while (child < _con.size()){// 找以parent为根的较大的孩子if (child + 1 < _con.size() && Compare()(_con[child], _con[child + 1]))child += 1;// 检测双亲是否满足情况if (Compare()(_con[parent], _con[child])){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}elsereturn;}}private:Container _con;};
}四、容器适配器
1.什么是适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
2.STL标准库中stack和queue的底层结构
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认使用deque,比如:

3.deque的简单介绍
1.deque的原理介绍
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。

deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
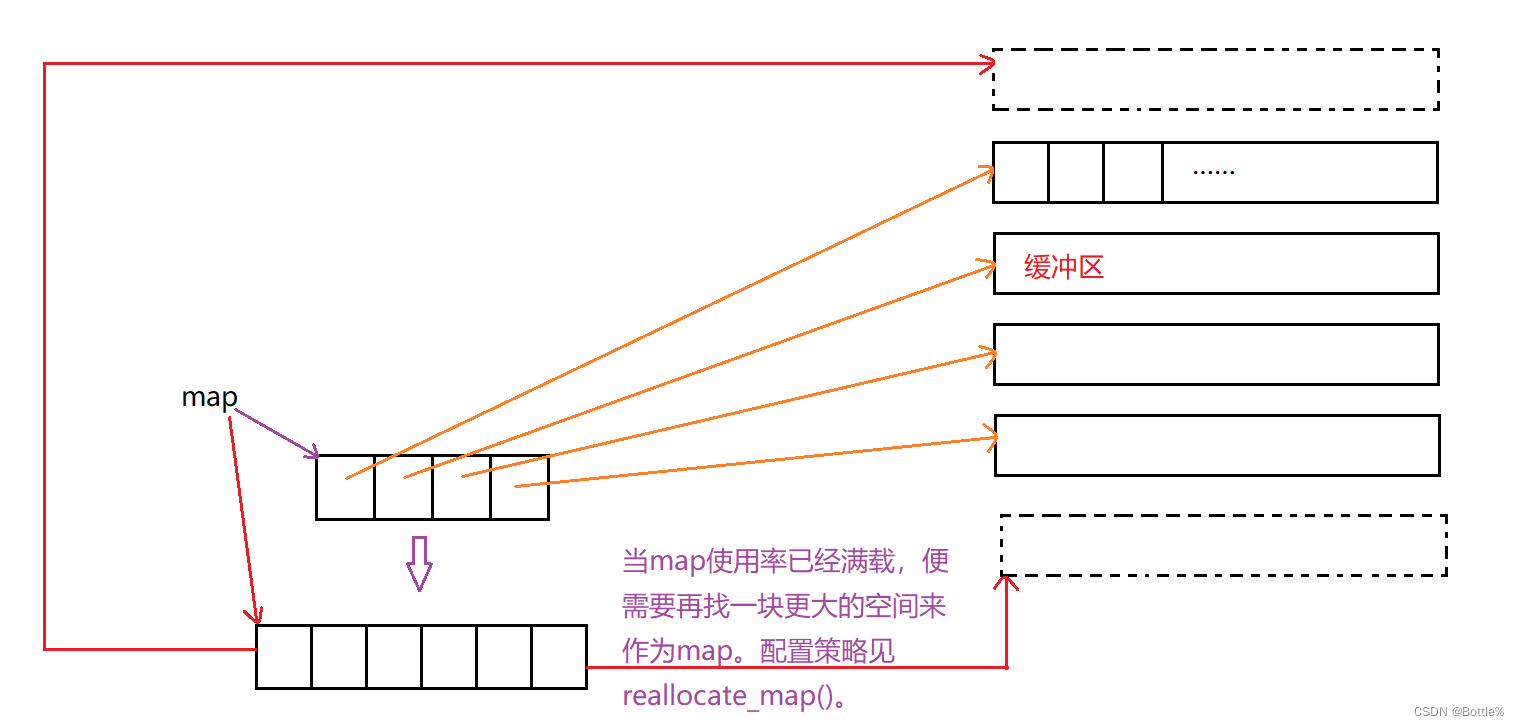
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
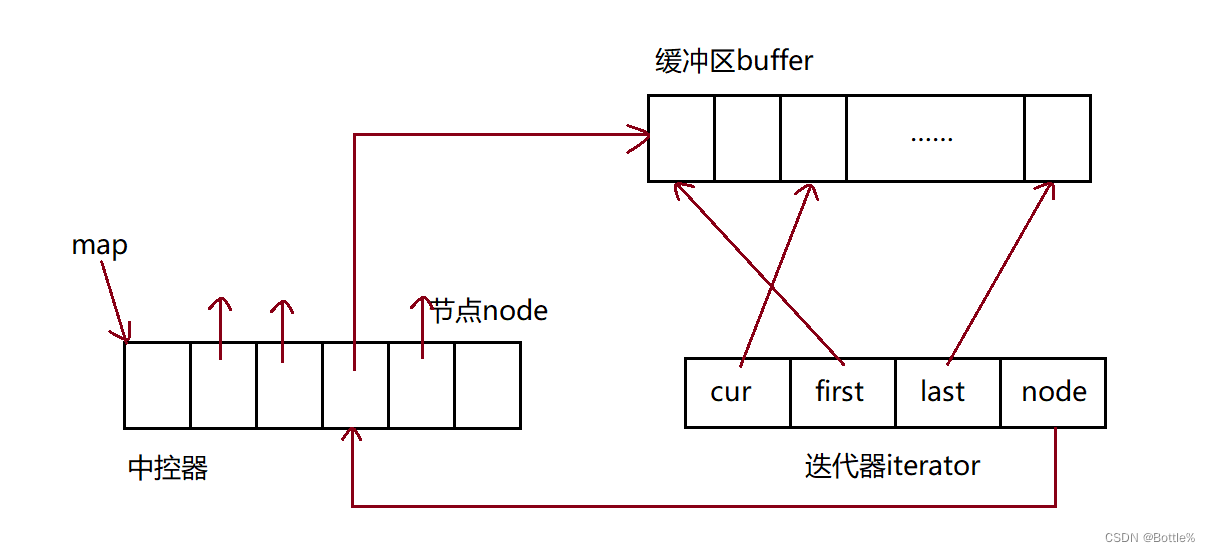
2.deque的优点与缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作 为stack和queue的底层数据结构。
4.选择deque作为stack和queue的底层默认容器的原因
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。
结合了deque的优点,而完美的避开了其缺陷。
5.STL标准库中对于stack和queue的模拟实现
1.stack的模拟实现
#include<deque>
namespace sss
{template<class T, class Con = deque<T>>//template<class T, class Con = vector<T>>//template<class T, class Con = list<T>>class stack{public:stack() {}void push(const T& x) { _con.push_back(x);}void pop() { _con.pop_back();}T& top() { return _con.back();}const T& top()const { return _con.back();}size_t size()const { return _con.size();}bool empty()const { return _con.empty();}private:Con _con;};
}2.queue的模拟实现
#include <list>
namespace sss
{template<class T, class Con = deque<T>>//template<class T, class Con = list<T>>class queue{public:queue() {}void push(const T& x) { _con.push_back(x); }void pop() { _con.pop_front();}T& back() { return _con.back();}const T& back()const { return _con.back(); }T& front() { return _con.front(); }const T& front()const { return _con.front();}size_t size()const { return _con.size(); }bool empty()const{ return _con.empty(); }private:Con _con;};
}相关文章:
C++:stl:stack、queue、priority_queue介绍及模拟实现和容量适配器deque介绍
本文主要介绍c中stl的栈、队列和优先级队列并对其模拟实现,对deque进行一定介绍并在栈和队列的模拟实现中使用。 目录 一、stack的介绍和使用 1.stack的介绍 2.stack的使用 3.stack的模拟实现 二、queue的介绍和使用 1.queue的介绍 2.queue的使用 3.queue的…...

【Java】面向对象程序设计 课程笔记 面向对象基础
🚀Write In Front🚀 📝个人主页:令夏二十三 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:Java 💬总结:希望你看完之后,能对你有…...
Hive【Hive(五)函数-高级聚合函数、炸裂函数】
高级聚合函数 多进一出(多行输入,一个输出) 普通聚合函数:count、sum ... 1)collect_list():收集并形成 list 集合,结果不去重 select sex,collect_list(job) from e…...
zabbix(二)
文章目录 1. zabbix自定义监控项【配置】2. zabbix自定义监控项【传参】3. zabbix自定义触发器4. zabbix邮件告警4. zabbix企业微信告警 1. zabbix自定义监控项【配置】 目前有主机zabbix-server: 10.0.0.10 zabbix-slave: 10.0.0.11 zabbix监控的内容,想平滑转移到…...

容器安全检测工具KubeHound使用
前言 Kubernetes集群攻击路径AES工具 安装 下载kubehound git clone https://github.com/DataDog/KubeHound.git 安装docker compose插件 Docker compose插件安装_信安成长日记的博客-CSDN博客 启动kubehound后端服务 即要开大内存,不然db起不来,…...
机器学习笔记 - 基于强化学习的贪吃蛇玩游戏
一、关于深度强化学习 如果不了解深度强化学习的一般流程的可以考虑看一下下面的链接。因为这里的示例因为在PyTorch 之上实现深度强化学习算法。 机器学习笔记 - Deep Q-Learning算法概览深度Q学习是一种强化学习算法,它使用深度神经网络来逼近Q函数,用于确定在给定状态下采…...

C++_pen_类
类的成员函数 构造函数析构函数普通成员函数 构造函数与析构函数 #include <stdio.h> class STU{ public:STU(){printf("STU\n");}STU(int id){printf("STU(int id)\n");}~STU(){printf("STU Bye!!!\n");} };int main(int argc, char c…...

MySQL 多表关联查询优化实践和原理解析
目录 一、前言二、表数据准备三、表关联查询原理和两种算法3.1、研究关联查询算法必备知识点3.2、嵌套循环连接 Nested-Loop Join(NLJ) 算法3.3、基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法3.4、被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 Nested…...
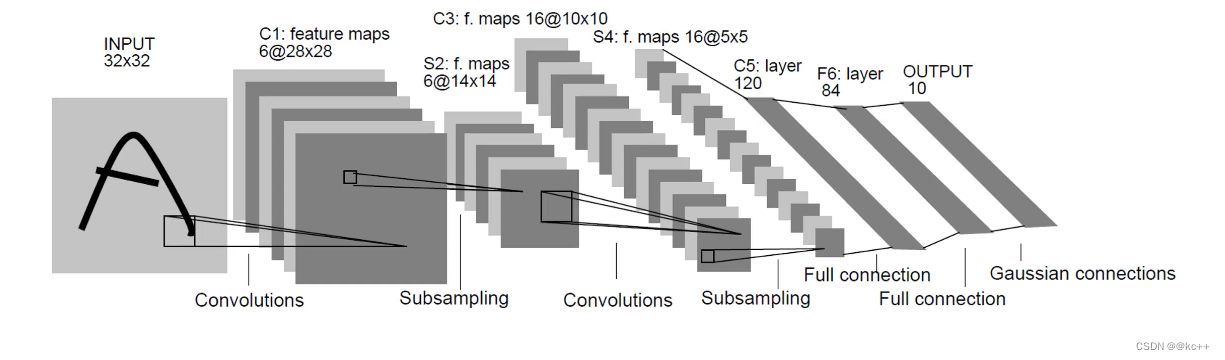
LeNet网络复现
文章目录 1. LeNet历史背景1.1 早期神经网络的挑战1.2 LeNet的诞生背景 2. LeNet详细结构2.1 总览2.2 卷积层与其特点2.3 子采样层(池化层)2.4 全连接层2.5 输出层及激活函数 3. LeNet实战复现3.1 模型搭建model.py3.2 训练模型train.py3.3 测试模型test…...

Oracle 慢查询排查步骤
目录 1. Oracle 慢查询排查步骤1.1. 前言1.2. 排查步骤1.2.1. 查询慢查询日志1.2.2. Oracle 查询 SQL 语句执行的耗时1.2.3. 定位系统里面哪些 SQL 脚本存在 TABLE ACCESS FULL (扫全表) 行为1.2.4. 查看索引情况1.2.5. 查看锁的竞争情况1.2.6. 其他锁语句 1.3. 慢查询优化1.3.…...

互联网Java工程师面试题·MyBatis 篇·第二弹
目录 16、Xml 映射文件中,除了常见的 select|insert|updae|delete标签之外,还有哪些标签? 17、Mybatis 的 Xml 映射文件中,不同的 Xml 映射文件,id 是否可以重复? 18、为什么说 Mybatis 是半自动 ORM 映射…...
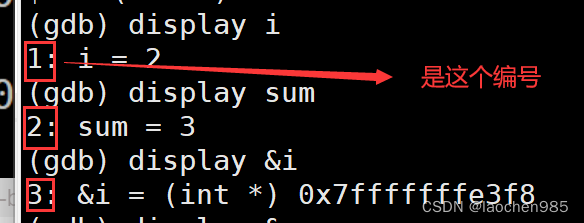
Linux 下如何调试代码
debug 和 release 在Linux下的默认模式是什么? 是release模式 那你怎么证明他就是release版本? 我们知道如果一个程序可以被调试,那么它一定是debug版本,如果它是release版本,它是没法被调试的,所以说我们可以来调试一…...
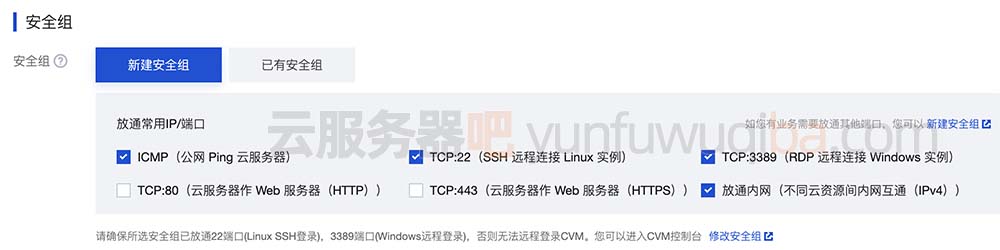
腾讯云服务器简介和使用流程
腾讯云服务器在云服务器CVM或轻量应用服务器页面自定义购买价格比较贵,但是自定义购买云服务器CPU内存带宽配置选择范围广,活动上购买只能选择固定的活动机,选择范围窄,但是云服务器价格便宜比较省钱。腾讯云服务器网来详细说下腾…...

python 二分查找
1.二分查找首先被查找的序列是一个有序的。 2.明确序列的左右边界 3.找出序列中间的元素,判断如果是要查找的元素,返回元素 4.如果中间元素,大于或者小于查找的元素,那么改变左右边间,直到中间的数等于查找的元素。…...

通过async方式在浏览器中调用web worker
通过async方式在浏览器中调用web worker 近年来,网络应用程序变得越来越复杂,增加了越来越多的功能。因此,性能和响应性已成为 Web 开发人员关注的重点。解决这个问题的一个办法是使用web worker。 web worker简介 web worker是一个 javas…...

FPGA project : TFT_LCD
实验目标: 驱动TFT_LCD显示十色彩条。 重点掌握的知识: 1,液晶显示器,简称LCD(Liquid Crystal Display),相对于上一代CRT显示器(阴极射线管显示器),LCD显示器具有功耗低、体积小、承载的信息量大及不伤眼…...
2023年-华为机试题库B卷(Python)【满分】
华为机试题库B卷 已于5月10号 更新为2023 B卷 (2023-10-04 更新本文) 华为机试有三道题目,前两道属于简单或中等题,分值为100分,第三道为中等或困难题,分值为200分。总分为 400 分,150分钟考试…...
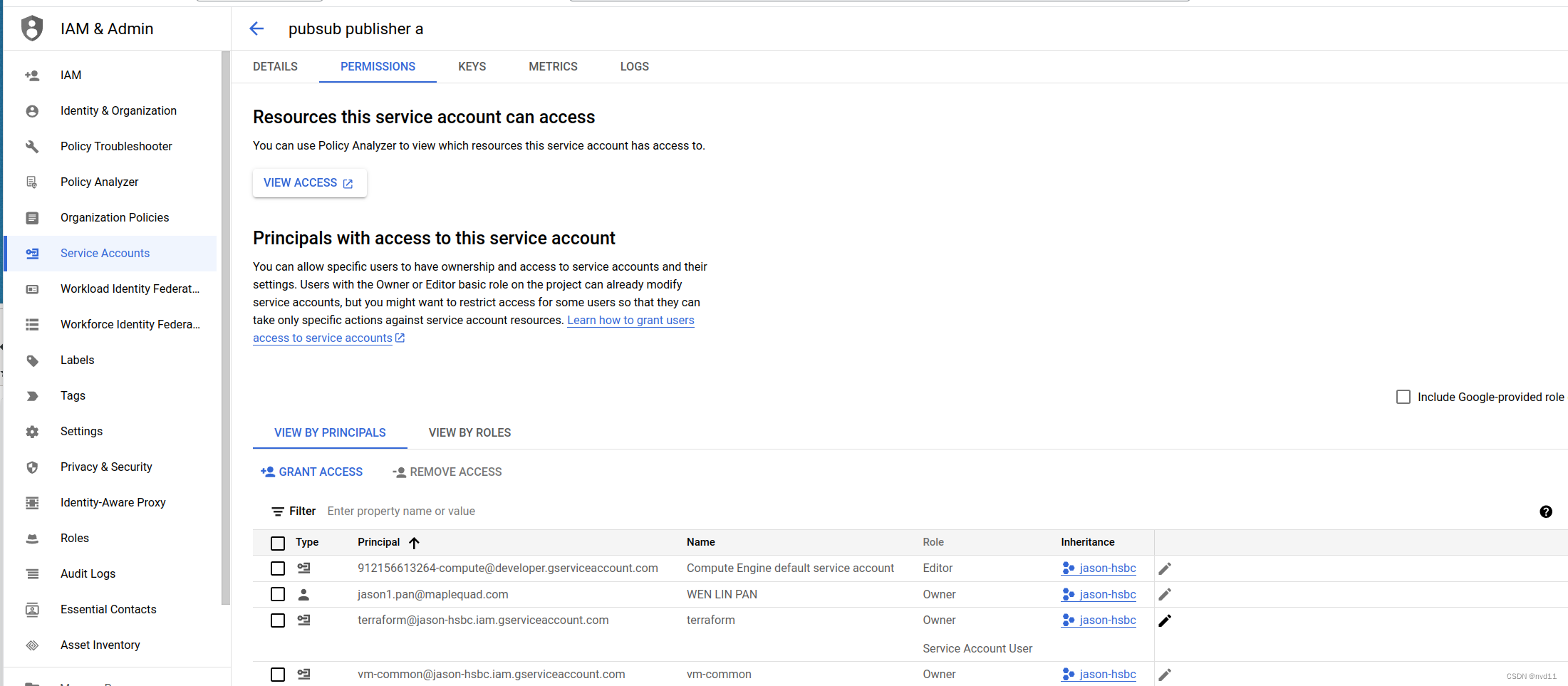
创建GCP service账号并管理权限
列出当前GCP项目的所有service account 我们可以用gcloud 命令 gcloud iam service-accounts list gcloud iam service-accounts list DISPLAY NAME EMAIL DISABLED terraform …...

想要精通算法和SQL的成长之路 - 验证二叉树
想要精通算法和SQL的成长之路 - 验证二叉树 前言一. 验证二叉树1.1 并查集1.2 入度以及边数检查 前言 想要精通算法和SQL的成长之路 - 系列导航 并查集的运用 一. 验证二叉树 原题链接 思路如下: 对于一颗二叉树,我们需要做哪些校验? 首先…...
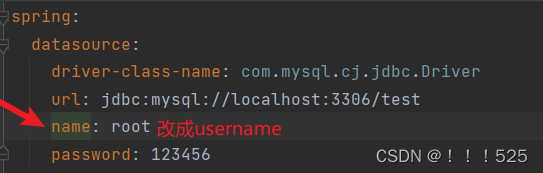
ERROR 6400 --- [ main] com.zaxxer.hikari.pool.HikariPool : root - Exception
在引用的日志中,报告了Hikari连接池初始化期间的异常。具体异常信息是"Exception during pool initialization"。这个异常可能是由于与MySQL数据库的通信链接失败导致的。在引用中也提到了与SSL连接相关的错误。 根据引用中提供的代码,可以看到…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

自定义线程池1.2
自定义线程池 1.2 1. 简介 上次我们实现了 1.1 版本,将线程池中的线程数量交给使用者决定,并且将线程的创建延迟到任务提交的时候,在本文中我们将对这个版本进行如下的优化: 在新建线程时交给线程一个任务。让线程在某种情况下…...
基于微信小程序的作业管理系统源码数据库文档
作业管理系统 摘 要 随着社会的发展,社会的方方面面都在利用信息化时代的优势。互联网的优势和普及使得各种系统的开发成为必需。 本文以实际运用为开发背景,运用软件工程原理和开发方法,它主要是采用java语言技术和微信小程序来完成对系统的…...
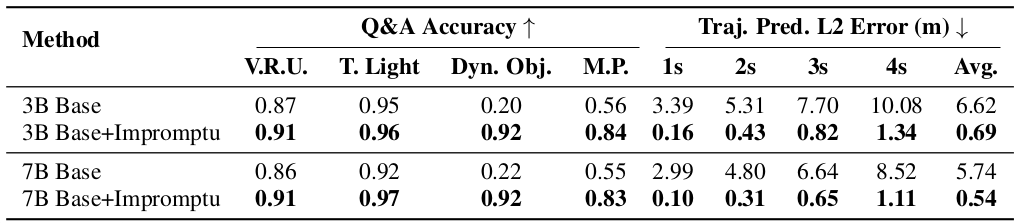
【VLAs篇】02:Impromptu VLA—用于驱动视觉-语言-动作模型的开放权重和开放数据
项目描述论文标题Impromptu VLA:用于驱动视觉-语言-动作模型的开放权重和开放数据 (Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models)研究问题自动驾驶的视觉-语言-动作 (VLA) 模型在非结构化角落案例场景中表现不佳…...