Doris数据库BE——冷热数据方案
新的冷热数据方案是在整合了存算分离模型的基础上建立的,其核心思路是:DORIS本地存储作为热数据的载体,而外部集群(HDFS、S3等)作为冷数据的载体。数据在导入的过程中,先作为热数据存在,存储于BE节点的本地磁盘上。当数据需要转冷的时候,为该热数据分片创建一个冷数据的副本分片,然后将数据转储到冷数据指定的外部集群上,当冷数据副本生成完毕后,将热数据分片删除。
如下图所示,当数据变为冷数据后,BE本地将保留一个冷数据的元数据信息。当查询命中冷数据时,BE将通过这个元数据信息将冷数据缓存到本地使用。
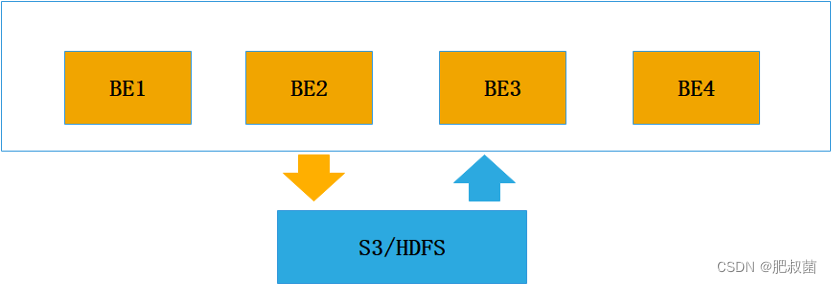
对于冷数据,其使用的频率是很低的,这样可以做到使用有限的BE节点来管理更多的数据,成本将远远低于纯本地存储的方案。
冷热数据转换规则 StoragePolicy 由 FE 的 PolicyMgr 进行管理,用来配置冷热数据的转换规则。该信息会随着心跳同步给每一个 BE(refreshStoragePolicy()),BE 将以此作为数据进行冷热数据转换的依据。
根据用户的使用习惯,以及数据的业务特性,冷热数据转换规则可分为两类:
第一类:明确指定冷却时间点:有些数据拥有时间特性,前一年的数据在后一年就已经失去了时效性,这种数据通过指定具体的时间来界定其转为冷数据的时间。
第二类:根据活跃时间指定数据冷却时间:有些数据有着固定的活跃时间,比如用户行为数据,每月生成的用户行为数据在当月是使用最频繁的,而随着时间的推移,这些数据的重要性逐步降低,最终转为不活跃数据。这种情况下可以对数据指定活跃时间,当数据活跃时间结束后,该数据转为冷数据。
冷热数据的调度流程,是从 TABLE 的冷热数据配置信息开始。在建表时指定所要使用的冷热数据规则名(storage_policy),映射为 StoragePolicy。
CREATE TABLE ( …… ) PROPERTIES ( "storage_policy" = "storage_policy_name1" );
上面的配置,可以为整个表指定冷热数据规则,而大多数情况下,我们的数据是拆分成多个PARTITION的,每个PARTITION所需要的冷热数据规则有可能是不同的,这时就需要针对PARTITION来进行配置:
ALTER TABLE TblPxy01 ADD PARTITION p2 VALUES [("10000"), ("20000")) ("remote_storage_policy" = "testPolicy");
配置中的 storage_policy 信息存放在 PARTITION 的每个TABLET中,当创建及修改TABLET时,storage_policy 信息随着TABLET下发给 BE,由 BE 来判断该 TABLET 何时可以开始进行冷热数据转换。
冷热数据转换守护进程 cooldown_tasks_producer_thread 是 BE 的一条守护进程,其对本 BE 的所有存活的TABLET进行遍历,检查每个TABLET的配置信息。当发现该 TABLET 配置了 storage_policy,说明需要对其进行冷热数据转换。
根据 storage_policy 中的配置,BE 将从缓存信息中的 StoragePolicy 列表中获取对应的规则信息,然后根据这个规则,判断当前tablet是否需要进行冷热数据转换,将数据存放于远程存储集群上(如S3)。
BE在存储TABLET数据的时候,TABLET下面还会有 ROWSET 和 SEGMENT 的划分。其中 ROWSET 代表着数据导入批次,同一个ROWSET 一般代表着一个批次的导入任务,比如一次 stream load,一个 begin/commit 事务等,都对应一个 ROWSET,ROWSET 的这种特性,意味着其具有着事务的特点,即是说,同一个rowset可以作为一个独立的数据单元存在,其中的数据要么全部有效,要么全部无效。
正因为如此,以 ROWSET 为基本单元对数据进行冷热转换,可以更容易的解决冷热数据迁移过程中有新数据写入的问题。
如下图所示,对于进入冷热数据转换状态的 TABLET,其 ROWSET 被分成两部分。
一部分在本地,这部分数据往往是新写入的数据,还未触发上传操作。
另一部分在远程存储集群(S3/HDFS),这部分数据相对较早,是在此前已经触发上传到了存储集群上的数据。
两部分合在一起才是完整的一个 TABLET。
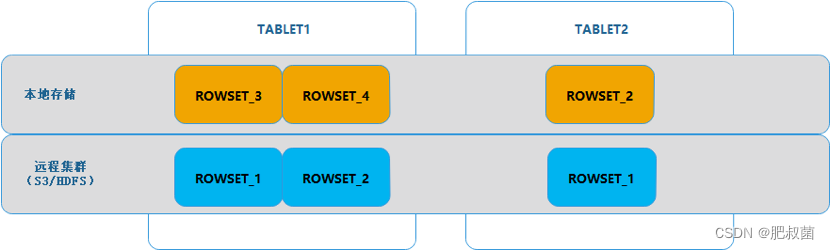
当冷数据需要读取的时候,由于数据已经被拆分成了两部分,需要从本地和远程存储集群(S3/HDFS)上分别读取数据。
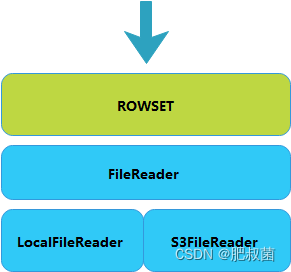
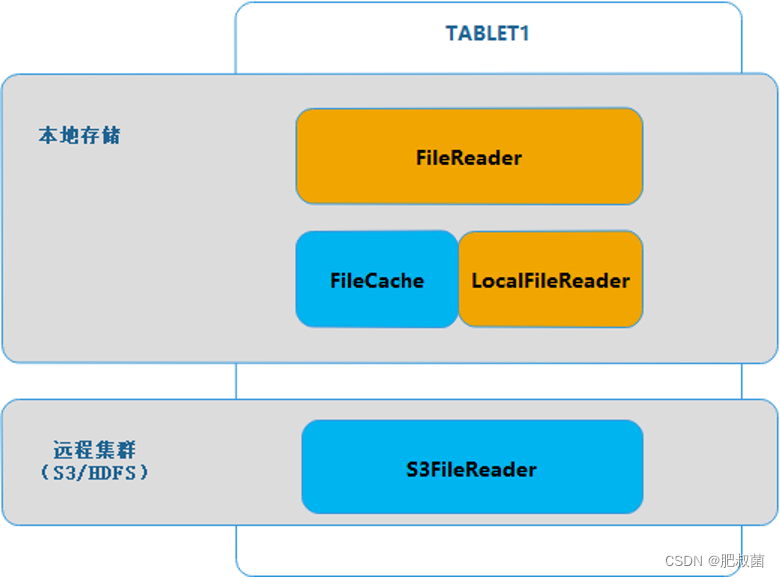
在数据读写中,IO 层将远程文件与本地文件抽象出 FileReader、FileWriter 层,将远程数据的读写与本地数据的读写统一,实现了最基本的冷热数据读写能力。
如下图所示,本地文件和远程文件的读取被封装成了一个跟 FileReader 的虚基类,实现两个派生类 LocalFileReader 和 S3FileReader,分别对应本地文件读取与 S3 文件读取。当有读取请求到达 TABLET 时,TABLET会根据条件找到对应的ROWSET,这些 ROWSET 有些是本地存储,有些是远程存储(S3)。通过映射关系,ROWSET 找到各自的 FileReader,完成数据读取,合并后即是完整的TABLET数据。
在这里,远程数据文件为了保证读取效率,可以有多种优化的方向,比如加一层本地缓存,比如使用本地索引等。这些在后续文章中详细说明。
与冷数据读取相似,冷数据写入也封装了一个 FileWriter 虚基类,如下图所示:
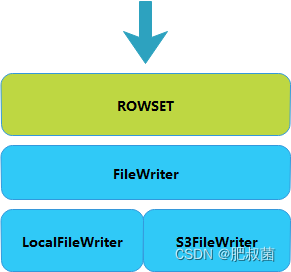
新写入的数据会在TABLET的本地存储部分新增一个ROWSET,这与普通的TABLET相同,也保证了冷数据也可写入的特性。而这部分写入到本地的数据在某个时间点会与远程的冷数据进行合并,并上传到远程存储集群。这一步骤则是由前文提到的守护进程 cooldown_tasks_producer_thread来 完成的。
FileCache 即是冷数据在本地的缓存层,其是远程数据在本地的镜像,当访问的Segment 是冷数据(存储在远程集群)时,会触发生成缓存层,将远程数据拉取到本地,生成缓存文件。这样在下一次访问时,可以直接读取缓存文件,而不需要从远程集群上拉取数据。
当一个查询请求到来时,SQL 被解析并重组成 PlanFragment ,通过元数据指定到 BE 里的Tablet 上,而 Tablet 本身是由多个 Segment 组成。当访问的 Segment 是热数据(本地文件)时,直接读取本地文件即可;当访问的 Segment 是冷数据(远程文件)时,直接读取远程文件代价是较高的,这时就会触发缓存机制,生成缓存文件。
缓存文件是远程文件的映射,缓存文件中每一条数据,在远程文件上都有对应的存在。但是这并不说缓存文件就等于是远程文件,两者之间是存在区别的。这是因为:
远程文件一般是比较大的,将这么大的文件整个拉取到本地的代价很高,反而会影响到查询的效率。
查询请求在下推时,往往只是读取Segment其中一部分数据,比如在 Select * from Table limit
1 这样的请求中,需要使用的往往只是其中几 KB 的数据,这时将几 GB 大小的文件全部拉到本地反而会增加不必要的时间开销。
同一个 Segment 中的缓存数据也存在着使用频率的差异,有可能只是 Segment 其中的一小部分数据被经常使用,当需要清理缓存数据时,我们更希望将使用不频繁的数据清除。
正因为如此,缓存文件采取了文件切割的方式,也即是说,远程的文件会被拆分成几个相对较小的子文件存放在本地作为缓存。当对 Segment 进行读取的时候,该请求会定位到远程文件指定位置的数据( offset +
length ),缓存机制将从远程文件中切分一部分出来,作为子文件写入到本地的缓存目录下。

根据缓存文件的重要性、磁盘的容量情况等,缓存文件的清理分成以下几种策略:
缓存文件在生成之后的一段时间内,用户再次访问该段数据的可能性是最高的,因此这时也是缓存数据最活跃的时期。随着时间的推移,用户访问该数据的可能性变小。当用户有较长的一段时间未访问时,该数据已经不活跃,即可对其进行清理。
BE 中使用 CacheManager 来对这些缓存进行管理,当用户的查询触发并生成了 Cache 文件时,这些 Cache 文件会注册到 CacheManager 中。
最后活跃时间是用于检查的重要指标,每当一个 Cache 被访问到时,其最后活跃时间即会更新,代表着该 Cache 近期有活跃动作。
CacheManager 会定时检查这些缓存文件的最后活跃时间,当某些 Cache 的最后活跃时间较早时,代表着该 Cache 已经不再活跃,CacheManager 将对这些 Cache 进行清除。
缓存文件占用的是本地磁盘空间。当占用的空间足够大的时候,可能会影响本地文件的读写,这就需要对这些缓存文件进行清理。
当缓存文件较多时,很可能很多缓存文件并没有达到活跃时间的阈值,而这时候其占用的磁盘空间已经过大了,这就需要提前将这些文件进行清理。
清理的时候,将缓存文件按最后活跃时间分成几个批次,从较早的文件开始,按时间逐步清理,直到降低到指定的磁盘占用空间上限。
由于BE本身有可能出现重启、IO 异常等情况,缓存文件也可能生成一些垃圾文件。例如:文件写到一半时 IO 异常、文件生成过程中BE重启等。这些文件并不处在 CacheManager 的管理之中,为了保证缓存层的干净,需要定期对这些文件进行清理。
由于在原本的逻辑中 Tablet 层已经有了一个垃圾文件清理的模块,会清理异常的 Tablet 。因此,缓存层的清理不需要再关注那些异常的 Tablet ,只需要关注 TabletManager 中管理的Tablet 即可。
缓存层垃圾清理对 TabletManager 中的 Tablet 目录进行遍历,查询每一个缓存目录,检查其是否在 CacheManager 中已经注册。如果在 CacheManager 中已经存在,这些 Cache 就不是垃圾文件,可以通过前面的两种缓存清理策略进行清理。如果在 CacheManager 中不存在,这些 Cache 则有可能是垃圾缓存,这时需要检查这些缓存文件的生成时间,根据生成时间来决定是否删除。
相关文章:
Doris数据库BE——冷热数据方案
新的冷热数据方案是在整合了存算分离模型的基础上建立的,其核心思路是:DORIS本地存储作为热数据的载体,而外部集群(HDFS、S3等)作为冷数据的载体。数据在导入的过程中,先作为热数据存在,存储于B…...
Python无废话-办公自动化Excel格式美化
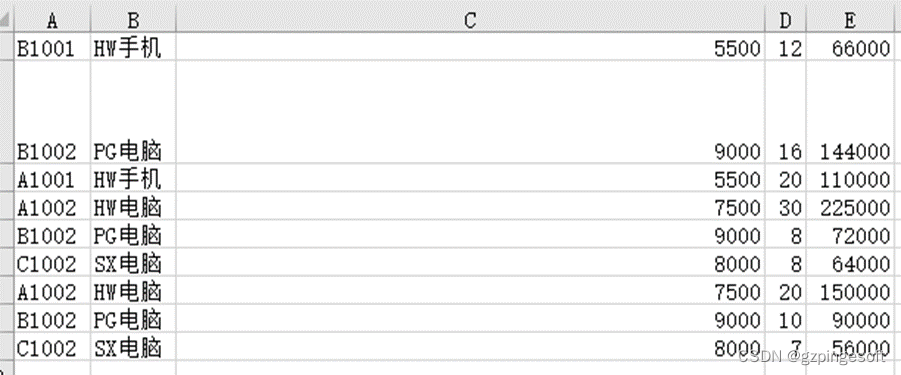
设置字体 在使用openpyxl 处理excel 设置格式,需要导入Font类,设置Font初始化参数,常见参数如下: 关键字参数 数据类型 描述 name 字符串 字体名称,如Calibri或Times New Roman size 整型 大小点数 bold …...

竞赛 机器视觉的试卷批改系统 - opencv python 视觉识别
文章目录 0 简介1 项目背景2 项目目的3 系统设计3.1 目标对象3.2 系统架构3.3 软件设计方案 4 图像预处理4.1 灰度二值化4.2 形态学处理4.3 算式提取4.4 倾斜校正4.5 字符分割 5 字符识别5.1 支持向量机原理5.2 基于SVM的字符识别5.3 SVM算法实现 6 算法测试7 系统实现8 最后 0…...
)
Django 数据库迁移(Django-04)
一 数据库迁移 数据库迁移是一种数据库管理技术,它用于在应用程序的开发过程中,根据模型(Model)的变化自动更新数据库结构,以保持数据库与代码模型的一致性。数据库迁移的主要目的是确保数据库与应用程序的模型定义同…...

Redis相关概念
1. 什么是Redis?它主要用来什么的? Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提…...
Scala第十八章节
Scala第十八章节 scala总目录 文档资料下载 章节目标 掌握Iterable集合相关内容.掌握Seq集合相关内容.掌握Set集合相关内容.掌握Map集合相关内容.掌握统计字符个数案例. 1. Iterable 1.1 概述 Iterable代表一个可以迭代的集合, 它继承了Traversable特质, 同时也是其他集合…...

JAVA学习(4)-全网最详细~
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...
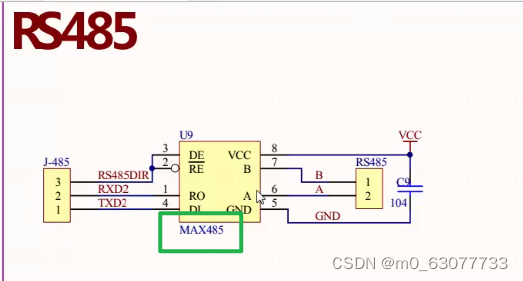
【单片机】12-串口通信和RS485
1.通信有关的常见概念 区分:串口,COM口,UART,USART_usart和串口区别-CSDN博客 串口、COM口、UART口, TTL、RS-232、RS-485区别详解-CSDN博客 1.什么是通信 (1)人和人之间的通信:说话ÿ…...

一步步教你使用GDB调试程序:从入门到精通的全面指南
文章目录 Step1:安装GDB1.1、包管理器安装1.2、下载源码编译安装 Step2:编译程序时添加调试信息Step3:GDB启动、退出、查看代码Step4:GDB断点操作Step5:GDB调试操作5.1 单步调试5.2 多进程调试 调试是软件开发中非常重…...
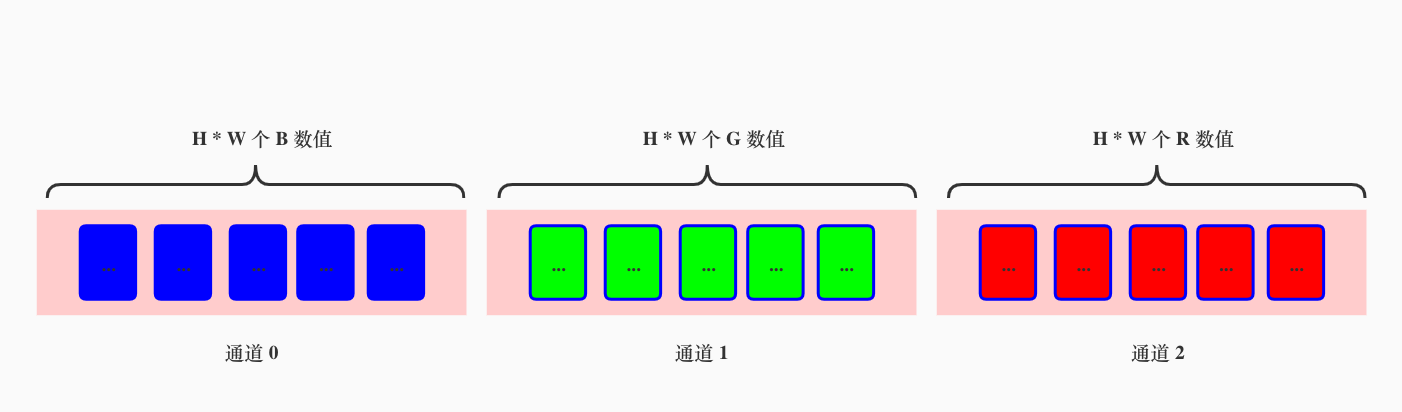
OpenCV读取图像时按照BGR的顺序HWC排列,PyTorch按照RGB的顺序CHW排列
OpenCV读取RGB图像 在OpenCV中,读取的图片默认是HWC格式,即按照高度、宽度和通道数的顺序排列图像尺寸的格式。我们看最后一个维度是C,因此最小颗粒度是C。 例如,一张形状为2562563的RGB图像,在OpenCV中读取后的格式…...

基于安卓android微信小程序的校园维修平台
项目介绍 随着社会的发展,社会的方方面面都在利用信息化时代的优势。互联网的优势和普及使得各种系统的开发成为必需。 本文以实际运用为开发背景,运用软件工程原理和开发方法,它主要是采用java语言技术和mysql数据库来完成对系统的设计。整…...

mysql面试题16:说说分库与分表的设计?常用的分库分表中间件有哪些?分库分表可能遇到的问题有哪些?
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:说说分库与分表的设计? 在MySQL中,分库与分表是常用的数据库水平扩展技术,可以提高数据库的吞吐量和扩展性。下面将具体讲解MySQL中分库与分表…...
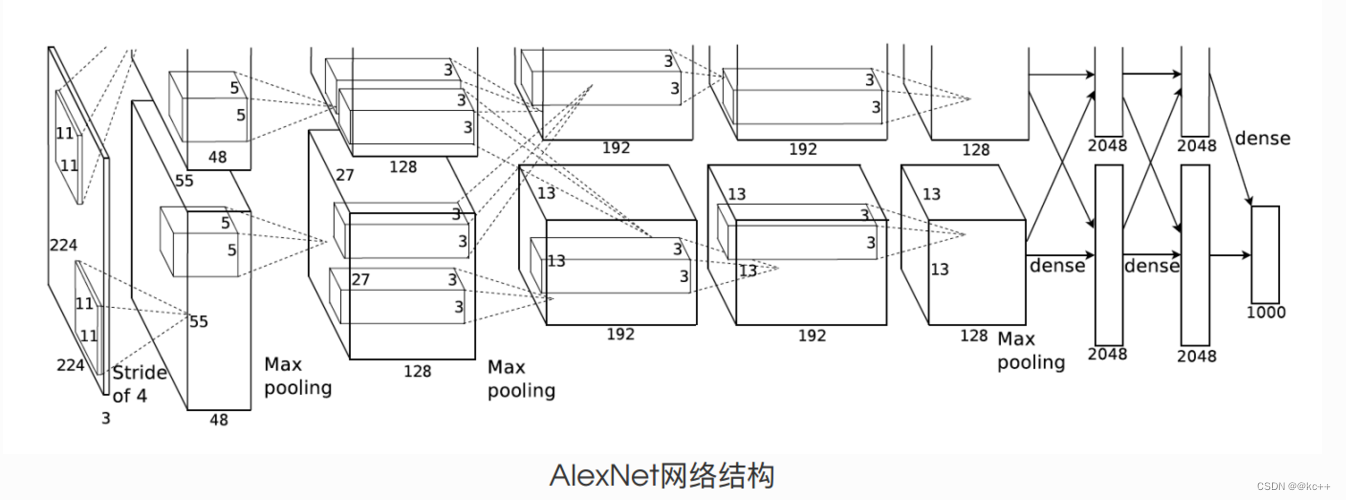
AlexNet网络复现
1. 引言 在现代计算机视觉领域,深度学习已经成为了一个核心技术,其影响力远超过了传统的图像处理方法。但深度学习,特别是卷积神经网络(CNN)在计算机视觉的主导地位并不是从一开始就有的。在2012年之前,计…...

pytorch模型量化和移植安卓详细教程
十一下雨,在家撸模型,希望对pytorch模型进行轻量化,间断摸索了几天,效果不错,做个总结分享出来。 量化是一种常见的技术,人们使用它来使模型在推断时运行更快,具有更低的内存占用和更低的功耗,而无需更改模型架构。在这篇博客文章中,我们将简要介绍量化是什么以及如何…...
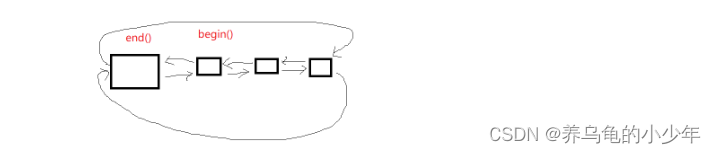
C++(List)
本节目标: 1.list介绍及使用 2.list深度剖析及模拟实现 3.list和vector对比 1.list介绍及使用 1.1list介绍 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向链表结构,…...

分布式架构篇
1、微服务 微服务架构风格,就像是把一个单独的应用程序开发为一套小服务,每个服务运行在自己的进程中,并使用轻量级机制通信,通常是 HTTP API。这些服务围绕业务能力来构建,并通过完全自动化部署机制来独立部署。这些…...
)
ros编译报错-- Could NOT find ros_ethercat_eml (missing: ros_ethercat_eml_DIR)
– Could NOT find ros_ethercat_eml (missing: ros_ethercat_eml_DIR) – Could not find the required component ‘ros_ethercat_eml’. The following CMake error indicates that you either need to install the package with the same name or change your environment …...
VD6283TX环境光传感器驱动开发(3)----测试闪烁频率代码
VD6283TX环境光传感器驱动开发----3.测试闪烁频率代码 概述视频教学样品申请源码下载参考代码开发板设置测试结果 概述 ST提供了6283A1_AnalogFlicker代码在X-NUCLEO-6283A1获取闪烁频率,同时移植到VD6283TX-SATEL。 闪烁频率提取主要用于检测光源的闪烁频率&#…...
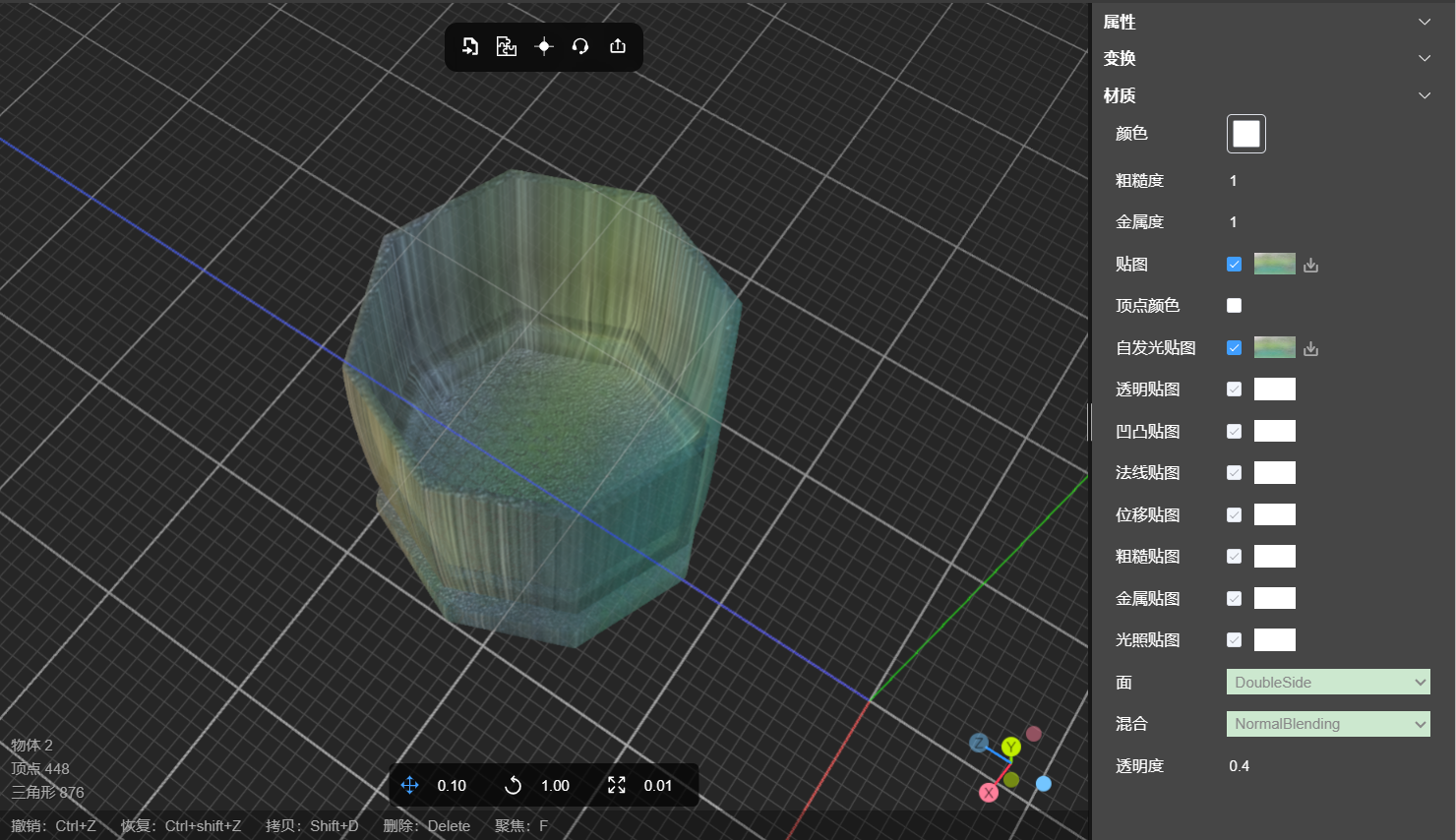
透明度和透明贴图制作玻璃水杯
1、什么是透明度 模型透明度是指一个物体或模型在呈现时的透明程度。它决定了物体在渲染时,是否显示其后面的物体或背景。 在图形渲染中,透明度通常以0到1之间的值表示。值为0表示完全透明,即物体不可见,背景或其他物体完全穿透…...

【前后缀技巧】2022牛客多校3 A
登录—专业IT笔试面试备考平台_牛客网 题意: 思路: 这种是典中典中典,对于gcd,背包问题都是一样的处理方式 预处理出前缀lca和后缀lca,枚举哪个消失即可,可以统计方案数 Code: #include &l…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...