第2篇 机器学习基础 —(1)机器学习方式及分类、回归

前言:Hello大家好,我是小哥谈。机器学习是一种人工智能的分支,它使用算法和数学模型来使计算机系统能够从经验数据中学习和改进,而无需显式地编程。机器学习的目标是通过从数据中发现模式和规律,从而使计算机能够自动进行预测和决策。机器学习有许多应用领域,包括模式识别、数据挖掘、计算机视觉、语音识别和自然语言处理等。🌈
目录
🚀1.什么是机器学习?
🚀2.监督学习
💥💥2.1 定义
💥💥2.2 核心步骤及优缺点
💥💥2.3 常见的监督学习算法
🚀3.无监督学习
💥💥3.1 定义
💥💥3.2 核心步骤及优缺点
💥💥3.3 常见的无监督学习算法
🚀4.半监督学习
💥💥4.1 定义
💥💥4.2 核心步骤及优缺点
💥💥4.3 常见的半监督学习算法
🚀5.强化学习
💥💥5.1 定义
💥💥5.2 核心步骤及优缺点
💥💥5.3 常见的强化学习算法
🚀6.机器学习分类和回归
💥💥6.1 定义
💥💥6.2 常见的分类算法
💥💥6.3 常见的回归算法
💥💥6.4 机器学习分类回归术语表

🚀1.什么是机器学习?
机器学习是一种人工智能的分支,它使用算法和数学模型来使计算机系统能够从经验数据中学习和改进,而无需显式地编程。机器学习的目标是通过从数据中发现模式和规律,从而使计算机能够自动进行预测和决策。机器学习有许多应用领域,包括模式识别、数据挖掘、计算机视觉、语音识别和自然语言处理等。在机器学习中,通过使用训练数据来训练模型,然后使用该模型来进行预测或决策。训练数据是已知输入和输出的样本集合,模型通过学习这些样本中的模式和规律来进行预测或决策。
人类在成长、生活过程中积累了很多的历史与经验。人类定期地对这些经验进行“归纳”,获得了生活的“规律”。当人类遇到未知的问题或者需要对未来进行“推测”的时候,人类使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作。
机器学习中的“训练”与“预测”过程可以对应到人类的“归纳”和“推测”过程。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。由于机器学习不是基于编程形成的结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关性结论。✅

机器学习的主要类型包括监督学习、无监督学习、半监督学习和强化学习。
- 监督学习通过给定的输入和对应的标签,训练模型以预测未知数据的标签。
- 无监督学习则从未标记的数据中发现模式和结构。
- 半监督学习结合了有标签数据和无标签数据的训练,用于解决标记数据有限但无标签数据丰富的问题。
- 强化学习则通过试错和奖励的机制,在不断与环境交互的过程中学习最优行为策略。
🚀2.监督学习
💥💥2.1 定义
监督式学习是一种机器学习方法,其中算法通过使用带有标签的训练数据集来学习模式和规律。在监督式学习中,我们有一个包含输入特征和对应标签的训练数据集,算法通过学习输入与标签之间的关系,从而能够对新的输入进行预测或分类。
具体来说,监督式学习的目标是通过找到一个函数,将输入映射到输出。这个函数被称为模型,它可以是线性模型、决策树、支持向量机、神经网络等等。在训练阶段,模型使用训练数据集来调整自身的参数,使其能够最好地拟合训练数据中的特征和标签之间的关系。然后,在预测阶段,模型可以根据已学习到的规律对新的输入进行预测或分类。
举个例子,如果我们想构建一个垃圾邮件过滤器,我们可以使用监督式学习。我们会收集一批已经标记好的电子邮件(训练数据集),其中包含了垃圾邮件和非垃圾邮件,并提取出一些特征,比如邮件中的单词、发件人信息等。然后,我们使用这些特征和标签进行训练,让模型学会识别垃圾邮件和非垃圾邮件之间的模式和规律。最后,当我们有一个新的未标记的电子邮件时,模型可以根据已学习到的规律预测它是垃圾邮件还是非垃圾邮件。
总结来说,监督式学习是一种常用的机器学习方法,通过使用带有标签的训练数据集来训练模型,并用于预测或分类新的输入数据。🍃
💥💥2.2 核心步骤及优缺点
监督学习核心步骤:
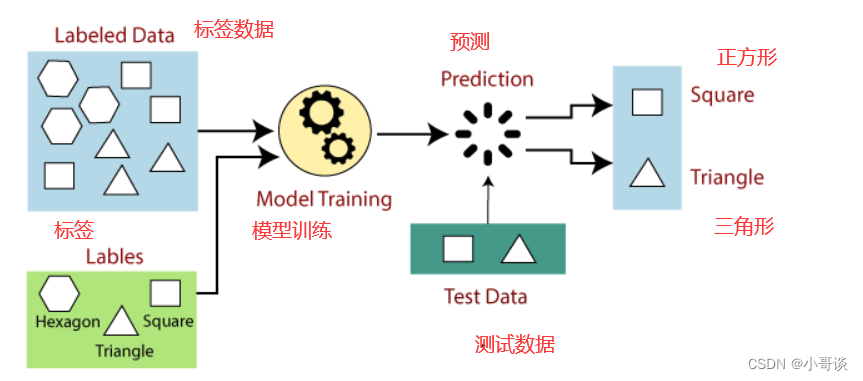
🍀(1)使用标签数据训练机器学习模型
- “标签数据”是指由输入数据对应的正确的输出结果。
- “机器学习模型”将学习输入数据与之对应的输出结果间的函数关系。
🍀(2)调用训练好的机器学习模型,根据新的输入数据预测对应的结果。
监督学习的优点:
- 在监督学习的帮助下,模型可以根据先前的经验预测输出。
- 在监督学习中,我们可以对对象的类别有一个准确的认识。
- 监督学习模型帮助我们解决各种现实问题,例如欺诈检测、垃圾邮件过滤等。
监督学习的缺点:
- 监督学习模型不适合处理复杂的任务。
- 如果测试数据与训练数据集不同,监督学习无法预测正确的输出。
- 训练需要大量的计算时间。
- 在监督学习中,我们需要足够的关于对象类别的知识。
💥💥2.3 常见的监督学习算法
常见的监督学习算法包括:
- K-近邻算法(K-Nearest Neighbors,KNN):根据样本的特征值和类别标签,通过计算样本之间的距离,将新的样本分配到距离最近的K个训练样本中占比最大的类别。
- 朴素贝叶斯分类(Naive Bayesian classification):基于贝叶斯定理和特征之间的条件独立性假设,通过计算给定特征条件下的类别概率,选择概率最大的类别作为预测结果。
- 决策树算法(Decision Tree):通过对属性值进行递归划分构建一棵树状结构,每个内部节点表示一个属性测试,每个叶子节点表示一个类别。
- 支持向量机(Support Vector Machines,SVM):通过寻找一个最优的超平面来将不同类别的样本分离开来,使得两个类别之间的间隔最大化。
- 逻辑回归(Logistic Regression):通过将线性回归模型的输出映射到一个概率值,在给定输入的情况下,预测样本属于某个类别的概率。
- 随机森林(Random Forest):通过集成多个决策树,每个决策树都是在随机子集上训练得到的,最后通过投票或平均的方式来进行预测。
- 梯度提升树(Gradient Boosting Trees):通过将多个弱分类器进行加权组合,每个弱分类器都是在前一个弱分类器的残差上训练得到的,逐步优化目标函数来提升预测性能。
🚀3.无监督学习
💥💥3.1 定义
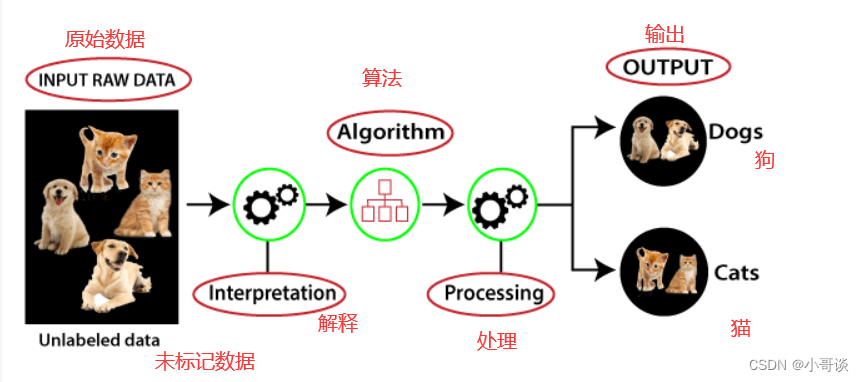
无监督学习是一种机器学习方法,它使用未标记的数据集来训练模型,并且不需要任何监督来操作这些数据。无监督学习的目标是从数据中发现模式、结构或者其他有用的信息,以便对数据进行进一步的理解和分析。与监督学习相比,无监督学习更适用于未标记和未分类的数据。通过无监督学习,我们可以更好地处理复杂的任务,因为它可以帮助我们从未标记的数据中获取更多的信息。然而,与监督学习相比,无监督学习更加困难,因为它没有与之对应的输出。因此,无监督学习算法的结果可能不太准确,需要进一步的验证和分析。
💥💥3.2 核心步骤及优缺点
无监督学习的核心步骤可以概括为以下几个:
-
数据预处理:对原始数据进行清洗、标准化和特征选择等预处理操作,以减少噪声和冗余信息。
-
特征提取:从预处理后的数据中提取有意义的特征,用于描述数据的关键信息。
-
模型选择:选择适合任务的无监督学习模型,如聚类、降维或生成模型等。
-
模型训练:使用提取的特征和选择的模型进行训练,学习数据中的潜在模式和结构。
-
模型评估:通过评估指标和实验结果对模型的性能进行评估,以验证模型的有效性和可靠性。
-
结果分析:对训练得到的模型进行结果分析和解释,理解无监督学习算法对数据的理解和表示能力。
无监督学习的优点:
- 与监督学习相比,无监督学习用于更复杂的任务,因为在无监督学习中,我们没有标记的输入数据。
- 无监督学习更可取,因为与标记数据相比,它更容易获得未标记数据。
无监督学习的缺点:
- 无监督学习本质上比监督学习更难,因为它没有相应的输出。
- 无监督学习算法的结果可能不太准确,因为输入数据没有标记,并且算法事先不知道确切的输出。
💥💥3.3 常见的无监督学习算法
常见的无监督学习算法包括聚类算法、降维算法和异常检测算法。
- 聚类算法用于将数据集中的样本划分为不同的组,如K-means和层次聚类算法。
- 降维算法用于减少数据的特征维度,如主成分分析(PCA)和独立成分分析(ICA)。
- 异常检测算法用于识别与其他样本不同的异常值,如基于高斯分布的异常检测算法。
🚀4.半监督学习
💥💥4.1 定义
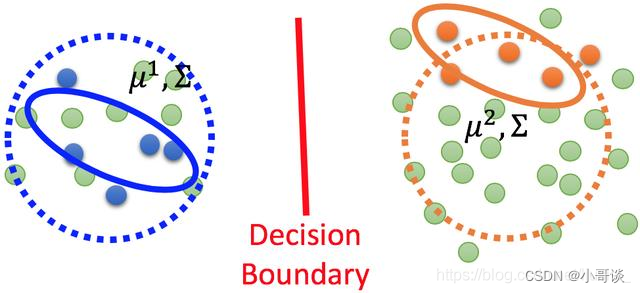
半监督学习是一种机器学习方法,结合了有标签数据和未标签数据进行训练。与传统的监督学习只使用有标签数据不同,半监督学习利用未标签数据来提高模型的性能和泛化能力。在半监督学习中,我们通过使用未标签数据来学习数据分布和决策边界,从而更好地分类或回归未知数据。半监督学习与纯监督学习的区别在于,纯监督学习只使用有标签数据进行训练,并且假设训练过程中观察到的未标签数据不会出现在测试集中。而半监督学习则允许使用未标签数据,并希望通过利用未标签数据来提高模型对未知数据的泛化能力。
💥💥4.2 核心步骤及优缺点
半监督学习的核心步骤如下:
- 收集有标记和无标记的数据:首先需要收集一些有标记的样本数据和大量无标记的样本数据。
- 使用有标记数据进行有监督训练:利用有标记的样本数据训练一个初始模型。
- 根据初始模型预测无标记数据的标签:利用初始模型对无标记数据进行预测,并使用这些预测结果作为无标记数据的伪标签。
- 扩充有标记数据集:将无标记数据与其对应的伪标签合并到有标记数据集中,扩充有标记数据集。
- 重新训练模型:使用扩充后的有标记数据集重新训练模型。
- 迭代步骤3到步骤5:重复以上步骤,直到模型性能收敛或达到预设的迭代次数。
💥💥4.3 常见的半监督学习算法
半监督学习的方法有很多种,其中包括生成式方法、半监督SVM、图半监督学习、基于分歧的方法等。
- 生成式方法是通过建立数据的生成模型来进行学习,然后根据生成模型对未标签数据进行分类或回归。
- 半监督SVM是在支持向量机算法的基础上引入未标签数据,通过优化一个包含未标签数据的目标函数来提高分类的性能。
- 图半监督学习是利用图结构来建模数据之间的关系,通过在图上进行标签传播来推断未标签数据的标签。
- 基于分歧的方法是通过使用多个学习器并将它们集成起来,从而提高模型的性能。
🚀5.强化学习
💥💥5.1 定义
强化学习是一种机器学习的方法,通过智能系统与环境进行交互,在不断尝试和观察中学习最优的行动策略。在强化学习中,智能系统通过与环境进行交互来获取奖励信号,并根据奖励信号调整自己的行为,以获得更高的奖励。强化学习算法通过试错的方式,通过与环境的互动来逐步优化策略,使其能够在给定的任务中达到最佳性能。
与传统的监督学习和无监督学习不同,强化学习没有标注好坏的训练数据,而是通过与环境的交互来逐步学习最优的行动策略。强化学习的核心思想是通过试错来进行学习,即智能系统通过尝试不同的行动并观察结果,然后根据这些观察结果来调整自己的行为。
强化学习算法可以应用于各种领域,如游戏、机器人控制、自动驾驶等。它具有较强的自主学习能力,能够在复杂的环境中通过与环境的交互来自主学习并逐步提高性能。 🐳
💥💥5.2 核心步骤及优缺点
强化学习的核心步骤包括以下几个方面:
-
环境建模与状态定义:首先,我们需要对所面对的问题进行环境建模,将其抽象为一个可处理的强化学习环境。同时,我们需要定义合适的状态来描述环境的特征和当前智能体所处的情境。
-
动作选择与策略定义:在每个时间步骤中,智能体根据当前的状态选择一个行动。为了使智能体能够选择最佳的行动,我们需要定义一个策略函数,它可以基于当前状态来选择一个动作。
-
奖励信号与回报计算:在强化学习中,智能体通过与环境进行交互来获得奖励信号。这些奖励信号用于指导智能体的学习过程。我们需要设计一个回报函数来计算智能体在每个时间步骤中的即时回报,以及累积奖励。
-
值函数与策略评估:为了评估一个策略的好坏,我们通常使用值函数来估计在给定策略下智能体的预期累积回报。值函数可以帮助我们评估当前状态的价值,并指导策略的改进。
-
学习与优化:通过与环境的交互,智能体可以不断地学习和改进自己的策略。通过使用强化学习算法,我们可以优化智能体的策略,使其能够在不同的环境和任务中表现得更好。

强化学习的优点:
- 可以通过与环境的交互来学习最优策略,不需要预先标注的标签数据。
- 它可以应用于各种复杂的实际问题,如游戏、机器人控制等。
- 强化学习还能够灵活适应环境的变化,并能够处理连续状态和动作空间的问题。
强化学习的缺点:
- 首先,由于强化学习是通过与环境的交互来学习,因此需要大量的训练时间和经验数据。
- 同时,由于其学习的过程是基于试错,可能导致学习过程中的不稳定性和低效性。
- 此外,强化学习算法的设计和调试也相对困难,需要对环境和问题的理解程度较高。
💥💥5.3 常见的强化学习算法
常见的强化学习算法包括以下几种:SARSA、Q-learning、DQN、Policy Gradient、A3C、DDPG和SAC等。这些算法可以根据具体的问题和任务选择合适的算法进行应用和调整。
🚀6.机器学习分类和回归
💥💥6.1 定义
机器学习中的分类和回归,本质都是对输入做出预测,并且都是监督学习,简单来说就是,分析输入的内容,判断其类别或者预测其值。💯
分类和回归的区别:
A.预测种类不同
🍀(1)分类预测的是物体所属的种类,而回顾预测的是物体的具体数值。例如,最近北京天气变化大,为了能够对明天适宜的衣服以及是否携带雨伞做判断,我们需要根据过去已有的天气情况进行预测。天气可以分为:晴、阴、雨 三类,我们现在已知的是今天及以前的天气情况,预测明天及以后几天的天气情况,如明天阴,后天晴,就是分类。根据今天及前几天的温度,通过之前的气温来预测以后的气温,这就是回归。

🍀(2)分类输出的是离散值,回归输出的是连续值。离散就是规定好有有限个类别,而这些类别是离散的;连续就是理论上可以取某一范围内的任意数值。
🍀(3)分类输出的值是定性的,回归输出的值是定量的。定性是指确定某种东西的确切的组成有什么或者某种物质是什么,不需要测定该物质的各种确切的数值量。定量是指确定一种成分(某种物质)的确切的数值量,这种测定一般不需要关注测定的物质是什么。例如:这是一杯水,这是定性;这杯水有10毫升,这是定量。
B.目的不同
分类的目的是寻找决策边界,用于对数据集中的数据进行分类;回归的目的是找到最优拟合线,这条线可以最优的接近数据集中的各个点。
C.结果不同
分类的结果没有逼近,只有对错,什么类别就是什么类别,最终结果只有一个。回归是对真实值的一种逼近预测,值不确定,当预测值与真实值相近时,即误差较小时,我们认为这是一个好的回归。(例如一个产品的实际价格为5000元,通过回归分析预测值为4999元,我们认为这是一个比较好的回归分析。
💥💥6.2 常见的分类算法
常用的分类算法有决策树分类法,基于规则的分类算法,神经网络,支持向量机和朴素贝叶斯分类法。
下面主要介绍各个算法的一些特点:
🍀(1)决策树
- 决策树归纳是一种构建分类模型的非参数方法。换句话说,它不要求任何先验假设,不假定类和其他的属性服从一定的概率分布。
- 找到最佳的决策树是NP问题。许多决策苏算法采取启发式的方法指导对假设空间的搜索。
- 即使训练集很大,构建决策树的代价也较小。
- 决策树相对容易解释。
- 决策树算法对于噪声的干扰具有相当好的鲁棒性。
- 冗余属性不会对决策树的准确率造成不利的影响。
- 由于大多数的决策树算法都采用自顶向下的递归划分方法,因此沿着树向下,记录会越来越小。在叶节点,记录可能更少,对于叶节点代表的类,不能做出具有统计意义的判决,产生所谓的数据碎片。
- 子树可能在决策树中重复多次,使得决策树过于复杂,并且更难解释。
🍀(2)基于规则的分类算法
- 规则集的表达能力几乎等价于决策树,因为决策树可以用互斥和穷觉的规则集表示。基于规则的分类器和决策树分类器都对属性空间进行直线划分,并将类指派到每个划分。
- 基于规则的分类器通常用来产生更易于解释的描述性模型,而模型的性能却可与决策树分类器相媲美。
- 被很多基于规则的分类器(如RIPPER)所采用的基于类的规则排序方法非常适用于处理类分布不均衡的数据集。
🍀(3)最近邻分类器
- 最近邻分类器是一种基于实例的学习技术,它使用具体的训练实例进行预测,而不必维护源自数据的抽象。
- 最近邻分类器是一种消极学习方法,它不需要建立模型,然而测试样例的开销很大,因为需要逐个计算测试样例和训练样例之间的相似度。相反,积极学习方法通过花费大量计算资源来建立模型,模型一旦建立,分类测试样例就会非常快。
- 最近邻分类器对噪声非常敏感。因为,最近邻分类器基于局部信息进行预测,而决策树和基于规则的分类器则是在拟合在整个输入空间上的全局模型。
- 最近邻分类器的可以生成任意形状的决策边界,这样的决策边界与决策树和基于规则的分类器通常局限的直线决策边界相比,能够提供更加灵活的模型表示。
- 除非采用适当的邻近性度量和数据预处理,否则最近邻分类可能做出错误的预测。
🍀(4)朴素贝叶斯分类器
- 面对孤立的噪声点,朴素贝叶斯分类器是健壮的。因为在从数据中估计条件概率时,这些点被平均。通过在建模和分类时忽略样例,朴素贝叶斯分类器也可以处理属性值遗漏问题。
- 面对无关属性,该分类器是健壮的。
- 相关属性可能会降低朴素贝叶斯分类器的性能。
🍀(5)贝叶斯信念网络(BBN)
- BBN提供了一种用图形模型来捕获特定领域的先验知识的方法。
- 构造网络可能既费时又费力,然而,一旦网络结构确定下来,添加新变量就十分容易。
- 贝叶斯网络很适合处理不完整的数据。对有属性遗漏的实例可以通过对该属性的所有可能取值的概率求和或求积分来加以处理。
- 因为数据和先验知识以概率的方式结合起来了,所以该方法对模型的过分拟合问题是非常鲁棒的。
🍀(6)人工网络
- 至少含有一个隐藏层的多层神经网络是一种普适近似,即可以用来近似任何目标函数。
- ANN可以处理冗余特征,因为权值在训练过程中自动学习。
- 神经网络对训练数据中的噪声非常敏感。
- ANN权值学习使用的梯度下降方法经常会收敛到局部极小值。避免局部极小值的方法是在权值更新公式中加上一个动量项。
- 训练ANN是一个很耗时的过程,特别是当隐藏结点数量很大时。然而,测试样例分类时非常快
🍀(7)支持向量机的特征(SVM)
- SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他的分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
- SVM通过最大化决策边界边缘来控制模型能力。
- 通过对数据中每个分类属性引入一个哑变量,SVM可以应用于分类数据。
💥💥6.3 常见的回归算法
根据不同的特点和应用场景,回归算法可以分为多个类型,下面介绍一些常见的回归算法的分类。
🍀(1)线性回归
- 线性回归是最基本的回归算法之一,其目标是拟合一个线性函数来预测连续的数值型输出。
- 常见的线性回归包括简单线性回归和多元线性回归。
🍀(2)决策树回归
- 决策树回归是一个基于决策树的回归算法。
- 其目标是构建一颗决策树来预测连续的数值型输出。
🍀(3)支持向量回归
- 支持向量回归是一种基于支持向量机的回归算法。
- 其目标是找到一个最大化预测精度的边界,以预测连续的数值型输出。
🍀(4)随机森林回归
- 随机森林回归是一种基于随机森林的回归算法。
- 其目标是使用多个随机树来预测连续的数值型输出。
🍀(5)神经网络回归
- 神经网络回归是一种基于神经网络的回归算法。
- 其目标是通过多个神经元来预测连续的数值型输出。
以上是常见的回归算法分类,除此之外,还有一些其他的回归算法,如岭回归、lasso回归、弹性网络回归等等,每种算法都有其适用的场景和特点。在实际应用中,需要根据具体的问题和数据特征来选择最合适的回归算法。📚
💥💥6.4 机器学习分类回归术语表
样本(sample)或输入(input):进入模型的数据点。
预测(prediction)或输出(output):从模型出来的结果
目标(target):真实值。对外部数据源,理想情况下,模型应该能够预测出目标。
预测误差(perdiction error)或损失值(loss value):模型预测与目标之间的距离。
类别(class):分类问题中供选择的一组标签。例如,对猫狗图像进行分类时,“狗”和“猫”就是两个类别。
标签(label):分类问题中类别标注的具体例子。比如,如果1,2,3,4号图像被标注为包含类别”狗”,那么“”狗”就是1,2,3,4号图像的标签。
真值(ground-truth)或标注(annotation):数据集的所有目标,通常由人工收集。
二分类(binary calssification):一种分类任务,每个输入样本都应该被划分到两个互斥的类别中。
多分类(multiclass classification): 一种分类任务,每个输入样本都应该划分到两个以上的类别中,比如手写数字分类。
多标签分类(multilabel calssiication):一种分类任务,每个输入样本都可以分配多个标签。举个例子,如果一幅图像里可能既有猫又有狗,那么应该同时标注“猫”标签和“狗”标签。每幅图像的标签个数通常是可变的。
标量回归(scalar regression):目标是连续标量值的任务。预测房价就是一个很好的例子,不同的目标价格形成一个连续的空间。
向量回归(vector reression):目标是一组连续值(比如一个连续向量)的任务。如果对多个值(比如图像边界框的坐标)进行回归,那就是向量回归。
小批量(mini-batch)或批量(batch):模型同时处理的一小部分样本(样本数通常为8-128)。样本数通常取2的幂,这样便于GPU上的内存分配。训练时,小批量用来为模型权重计算一次梯度下降更新。
优化(optimization):指调节模型以在训练数据上得到最佳性能(即机器学习中的学习)。
泛化(generalization):指训练好的模型在前所未见的数据上的性能好坏。机器学习的目的就是得到更好的泛化。

相关文章:
第2篇 机器学习基础 —(1)机器学习方式及分类、回归
前言:Hello大家好,我是小哥谈。机器学习是一种人工智能的分支,它使用算法和数学模型来使计算机系统能够从经验数据中学习和改进,而无需显式地编程。机器学习的目标是通过从数据中发现模式和规律,从而使计算机能够自动进…...

uniapp echarts 适配H5与微信小程序
文章目录 前言一、修改 ec-canvas组件1.1 在ec-canvas组件methods中定义一个initChart方法1.2 用initChart全局替换this.ec.onInit1.3 监听数据变化1.4 ec-canvas完整代码参考 二、H5 echarts组件三、供外部调用的组件外部调用组件 uni-chart代码使用uni-chart 前言 接上文&…...

第46节——redux中使用不可变数据+封装immer中间件——了解
一、为什么redux中要使用不可变数据 Redux 要求使用不可变数据,是因为它遵循了函数式编程的原则。在函数式编程中,数据不可变是一项重要的原则,这有助于避免状态更改产生的不可预知的副作用。 在 Redux 中,每当 action 被分发&a…...

《数字图像处理-OpenCV/Python》连载(10)图像属性与数据类型
《数字图像处理-OpenCV/Python》连载(10)图像属性与数据类型 本书京东优惠购书链接:https://item.jd.com/14098452.html 本书CSDN独家连载专栏:https://blog.csdn.net/youcans/category_12418787.html 第2章 图像的数据格式 在P…...

sheng的学习笔记-【中文】【吴恩达课后测验】Course 2 - 改善深层神经网络 - 第三周测验
课程2_第3周_测验题 目录:目录 第一题 1.如果在大量的超参数中搜索最佳的参数值,那么应该尝试在网格中搜索而不是使用随机值,以便更系统的搜索,而不是依靠运气,请问这句话是正确的吗? A. 【 】对 B.…...
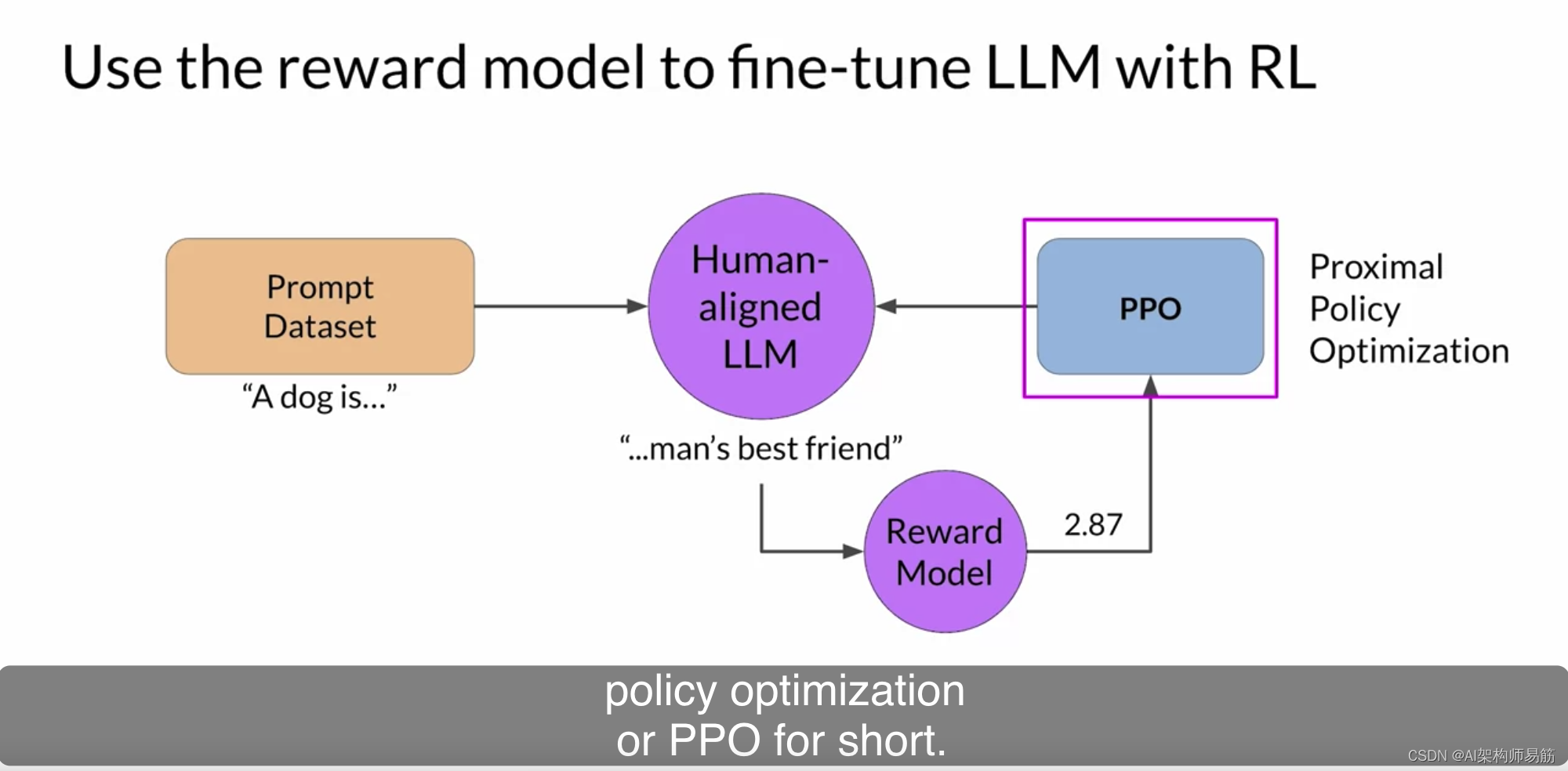
LLMs 用强化学习进行微调 RLHF: Fine-tuning with reinforcement learning
让我们把一切都整合在一起,看看您将如何在强化学习过程中使用奖励模型来更新LLM的权重,并生成与人对齐的模型。请记住,您希望从已经在您感兴趣的任务上表现良好的模型开始。您将努力使指导发现您的LLM对齐。首先,您将从提示数据集…...
iMazing 2.17.10官方中文版含2023最新激活许可证码
iMazing 2.17.10官方中文版是一款iOS设备管理软件,该软件支持对基于iOS系统的设备进行数据传输与备份,用户可以将包括:照片、音乐、铃声、视频、电子书及通讯录等在内的众多信息在Windows/Mac电脑中传输/备份/管理。 iMazing 2.17.10官方中文…...

如何在windows系统环境下使用tail命令查看日志
答案是: 使用tail for Windows工具 tail for Windows 是便携式软件不需要安装,它可用于显示文件的最后一行并跟踪/监视文件的更改。 下载地址: https://tail-for-windows.en.softonic.com/ 点击直接下载 解压使用 解压后需将tail.exe放入 c:…...

设计模式——访问者模式
访问者模式是什么? 表示一个作用于某对象结构中的各元素的操作,它使你可以再不改变各元素的类的前提下定义作用于这些元素的新操作 访问者模式解决什么问题? 男女在不同情境下表现的不同 abstract class Person {protected String action…...
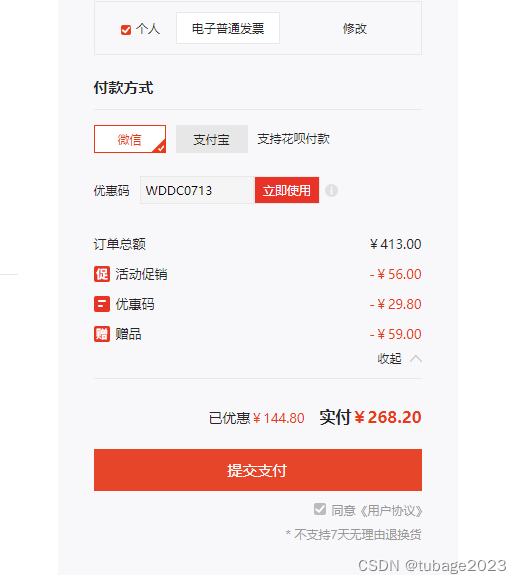
一文读懂UTF-8的编码规则
之前写过一篇文章“一文彻底搞懂计算机中文编码”里面只是介绍了GB2312编码知识,关于utf8没有涉及到,经过查询资料发现utf8是对unicode的一种可变长度字符编码,所以再记录一下。 现在国家对于信息技术中文编码字符集制定的标准是《GB 18030-…...
二叉树题目:路径总和 II
文章目录 题目标题和出处难度题目描述要求示例数据范围 前言解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:路径总和 II 出处:113. 路径总和 II 难度 4 级 题目描述 要求 给你二叉树的根结点 root \tex…...

Qt model/view 理解01
在 Qt 中对数据处理主要有两种方式:1)直接对包含数据的的数据项 item 进行操作,这种方法简单、易操作,现实方式单一的缺点,特别是对于大数据或在不同位置重复出现的数据必须依次对其进行操作,如果现实方式改…...

c与c++中的字符串
在c中,string本质上是一个类; string与char *有些区别: char*是一个指针;string是一个类,类内封装了char*,管理这一个字符串,是一个char*的容器 在使用string类型时,要加上其头文…...
Android 获取IP地址的Ping值 NetworkPingUtils
项目里需要对动态配置的Ip列表都去ping下延迟,取出其中最小的三个进行随机取值然后去连接,倒腾了一下午终于搞出来了! 需求实现思路: 1.找到方法去ping IP地址; 2.同时去Ping,不能让用户等待;…...
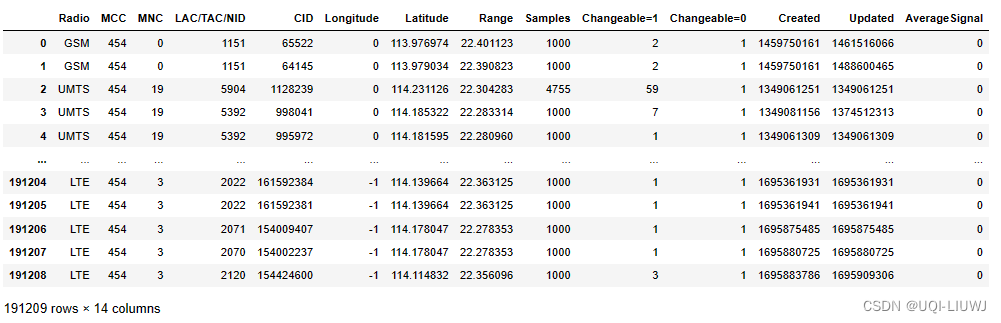
数据集笔记:OpenCelliD(手机基站开放数据库)
下载数据的方式可见:【数据获取】全球最大手机基站开源数据库 1 读取数据 import pandas as pdpd.read_csv(C:/Users/16000/Downloads/454.csv/454.csv,headerNone,names[radio,mcc,net,area,cell,unit,lon,lat,range,samples,changeable1,created1,updated,AveSi…...

Windows电脑多开器的使用心得分享
Windows电脑多开器是一种非常实用的软件工具,它可以让我们在同一个电脑上同时运行多个不同的应用程序,从而提高我们的工作和学习效率。以下是我在使用Windows电脑多开器时的一些心得分享: 确保你的电脑配置足够强大 多开软件需要消耗大量的…...
Android Studio实现简易计算器(带横竖屏,深色浅色模式,更该按钮颜色,selector,style的使用)
目录 前言 运行结果: 运行截屏(p50e) apk文件 源码文件 项目结构 总览 MainActivity.java drawable 更改图标的方法: blackbutton.xml bluebuttons.xml greybutton.xml orangebuttons.xml whitebutton.xml layout 布…...
虚拟机通过nat模式端口映射实现内网穿透
虚拟机通过nat模式端口映射实现内网穿透 1.网络状态 windows虚拟主机的IP为局域网的私有IP192.168.1.7linux的虚拟主机IP为nat的172.36.4.1062.linux修改nat模式的端口映射 3.windows宿主机防火墙添加规则,(或者直接关闭公共网络防火墙,不安全…...

计算机网络(六):应用层
参考引用 计算机网络微课堂-湖科大教书匠计算机网络(第7版)-谢希仁 1. 应用层概述 应用层是计算机网络体系结构的最顶层,是设计和建立计算机网络的最终目的,也是计算机网络中发展最快的部分 早期基于文本的应用 (电子邮件、远程登…...
Sublime Text 4 for Mac激活下载
Sublime Text for Mac是一款适用于Mac平台的文本编辑器。它具有快速的性能和丰富的功能,可以帮助用户快速进行代码编写和文本编辑。 软件下载:Sublime Text 4 for Mac激活下载 该软件具有直观的界面和强大的功能,包括多行选择、代码折叠、自动…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

C# 表达式和运算符(求值顺序)
求值顺序 表达式可以由许多嵌套的子表达式构成。子表达式的求值顺序可以使表达式的最终值发生 变化。 例如,已知表达式3*52,依照子表达式的求值顺序,有两种可能的结果,如图9-3所示。 如果乘法先执行,结果是17。如果5…...