哈希/散列--哈希表[思想到结构][==修订版==]
文章目录
- 1.何为哈希?
- 1.1百度搜索
- 1.2自身理解
- 1.3哈希方法/散列方法
- 1.4哈希冲突/哈希碰撞
- 1.5如何解决?
- 哈希函数的设计
- 2.闭散列和开散列
- 2.1闭散列/开放定址法
- 2.2开散列/链地址法/开链法
- 1.概念
- 2.容量问题
- 3.字符串问题
- 4.开散列性能测试
- 5.开散列与闭散列比较
- 3.代码实现[配备详细注释]
- 3.1闭散列
- 3.2开散列

1.何为哈希?
1.1百度搜索

1.2自身理解
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应关系
在查找一个元素时,必须要经过key的多次比较。
顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(logN).
有没有这样一种方法 不经过任何比较 直接从表中得到要查找的元素。
大佬神作: 构造一种存储结构,通过某种函数使元素的存储位置与key之间建立一一映射的关系,在查找时通过该函数找到该元素.
1.3哈希方法/散列方法
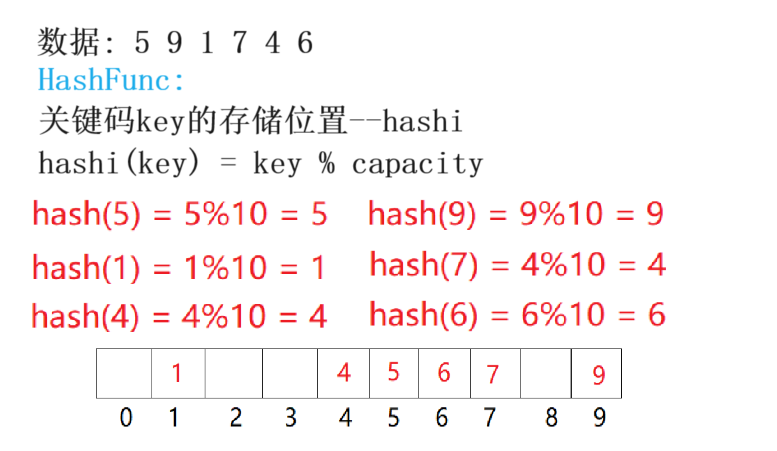
插入元素:
将待插入元素的key,以某个函数[哈希函数/散列函数]计算出该元素的存储位置并按此位置存放,构造出一个结构[哈希表/散列表]
搜索元素:
对元素的key进行同样的计算,求得的函数值即为元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
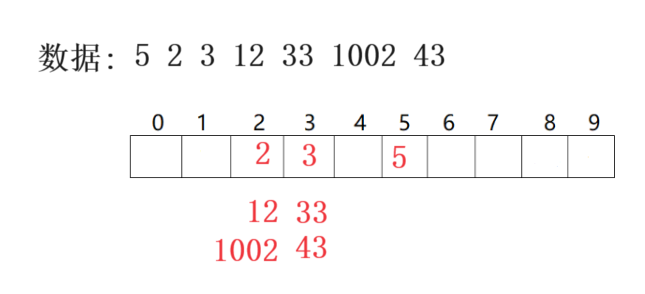
1.4哈希冲突/哈希碰撞
- 不同关键码通过哈希函数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞.
- 把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
1.5如何解决?
哈希函数的设计
设计一个合理的哈希函数
哈希函数设计原则:
- 简单方便
- 哈希函数要使得关键码均分分布
- 定义域为所有key 值域为[0, n)
常见哈希函数
- 直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hashi(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况 否则导致—数据量小 但是需要的空间极大 例如 :数据-1 2 3 9999下标: 1 2 3 9999
使用场景:数值小且分布集中 - 除留余数法–(常用)
设散列表中允许地址数为n,除数p的取值规则: 小于等于n 接近/等于n的质数
哈希函数:Hashi(key) = key % p(p <= n) - 平方取中法–(了解)
假设关键码为6392,它的平方为40857664,抽取中间的3位857或576作为hashi;
使用场景:不知道关键码的分布 位数不是很大 - 折叠法–(了解)
将关键码从左到右分割成位数近似相等的几部分 将这几部分叠加求和
按散列表表长 取后几位作为hashi
使用场景:无所谓关键码的分布 位数较大 - 随机数法–(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即Hashi(key) = random(key)
使用场景:关键字长度不等 - 数学分析法–(了解)
假设关键字为某一地区的手机号,大部分前几位都相同的 取后面的四位作为hashi
还出现冲突–对抽取数字进行反转(如1234改成4321)、右环移位(如1234改成4123)、左环移位、前两数与后两数叠加(如1234改成12+34=46)等.
使用场景:关键字位数比较大 事先知道关键字的分布 关键字的若干位分布较均匀
== 注意:哈希冲突只可缓解 不可避免 ==
2.闭散列和开散列
2.1闭散列/开放定址法
当发生哈希冲突时,如果哈希表未被装满,把key存放到冲突位置的==“下一个” ==空位置
寻找空位置:
- 线性探测
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置

插入:
- 通过哈希函数获取待插入元素在哈希表中的位置
- 该位置没有元素直接插入新元素
- 该位置中有元素 使用线性探测找到下一个空位置 插入新元素
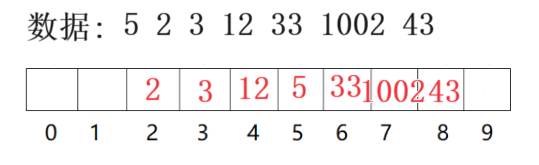
删除:
- 线性探测采用标记的伪删除法来删除一个元素
- 若直接删除 会影响其他元素的搜索
例如上图: 删除对象是33 直接删除 hash6 这个位置应该怎么办? 需要搞一个东西让哈希表的使用者知道这里原来有元素 现在被删除了 置成null? 如果置成空 当想要查找 1002/43即33后面的元素时 遇到hash6 使用者被告知这里是空 停止查找 此时使用者得到的信息是 哈希表中并不存在此元素 这与现实违背 那怎么办? 答案是置成"删除"状态 使得使用者知道何为空何为删除 这就是伪标记删除法
负载因子
哈希表的负载因子定义为: α = 表中的元素个数[ _n ] / 哈希表长[ _tables.size() ]
负载因子a: 哈希表装满程度的标志因子
表长是定值,α与_n成正比
α越大 填入表中的元素越多 哈希冲突可能性越大
α越小 填入表中的元素越少 哈希冲突可能性越小
哈希表的平均查找长度是负载因子α的函数 处理冲突方法不同函数不同
负载因子越大,冲突的概率越高,查找效率越低,空间利用率越高
负载因子越小,冲突的概率越低,查找效率越高,空间利用率越低
容量问题: 1.size是实际能够访问数据的范围 2.capacity是存储数据的空间大小


优点:
实现简单
缺点;
x占据y的位置 y就得放到y+1的位置
冲突累计 产生数据堆积
本意是要减缓哈希冲突
虽然使得有相同hashi的不同数据有位置存放
但是数据堆积时 会使得寻找某关键码的位置需要许多次比较
导致搜索效率降低。
- 二次探测
线性探测寻找空位置的方法[逐个后移]导致线性探测的缺陷[产生冲突的数据堆积]
修改探测的方法:
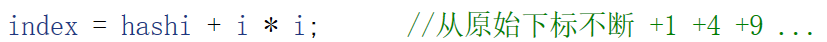
2.2开散列/链地址法/开链法
1.概念
对关键码用哈希函数计算哈希地址,具有相同地址的不同关键码归于同一子集合,每一个子集合称为一个桶各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
2.容量问题
桶的个数有限[即哈希表的表长有限]
随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容
某种情况下 每个哈希桶中刚好挂一个节点, 再继续插入元素时,每一次都会发生哈希冲突,我们假定在元素个数刚好等于桶的个数时,进行扩容 即
需要了解到是 我们最然控制α为1时进行扩容 并不代表此时哈希桶都挂了一个结点 更为普遍的情况是 一些桶为空 一些桶有许多结点 只不过结点总个数为哈希表长度大小

3.字符串问题
在一些函数中 我们遇到了一个问题:
//哈希函数计算的下标
size_t hashi = key % _tables.size();
当key是字符串类型时 无法进行取模操作
改进



不传显示函数 默认调用缺省函数

调用显示传参函数


在解决字符串取模问题时 我们首先想到了搞一个仿函数 由key传参 获得整型 但是这仍然无法解决数据是字符串类型 于是我们想到了 缺省值这一语法 Fun类模板默认接收ConvertFunc 当用户想要使用string类型时 显示传StringToInt 在实现StringToInt时 我们右遇到了另一个问题 当数据对象不同但是ASCII值加和相同 此时又造成了不同数据会哈希冲突的局面 怎么办呢? 这个问题实际上是一个很经典的问题 对于这个问题 业界很多大佬都对其发表了自己的见解 我们采取一种即可 有想对其进行更多了解的 点击链接查阅即可 这里不再赘述
字符串Hash函数对比
4.开散列性能测试


有人说当在哈希表中大量数据都插入到了一个桶中 此时最坏的T(N)=O(N)
但实际上 由于存在负载因子α 每进行一次扩容这样的情况就会消失 所以
哈希表的T(N) = O(1) 由下面的性能测试代码可以证明
5.开散列与闭散列比较
闭散列需要开大量空间以确保搜索效率 在这些空间中 有许多空闲空间
开散列虽然增设链表结点和指针 但是与闭散列相比 更节省空间
3.代码实现[配备详细注释]
3.1闭散列
//闭散列/开放地址法
namespace OpenAddressing
{//状态枚举enum State{EMPTY,EXIST,DELETE};//哈希数据元素template<class K, class V>struct HashData{pair<K, V> _pair;State _state = EMPTY;};//哈希表template<class K, class V>class HashTable{public://插入函数bool Insert(const pair<K, V>& pair){//值已存在 插入错误if (Find(pair.first))return false;//负载因子/荷载系数 -- Load_Factor = _n / _tables.size();//(double)_n / (double)_tables.size() >= 0.7//_n * 10 / _tables.size() >= 7//使得扩容发生的条件: size为0 负载因子达到阈值if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7){/ 低级代码 //*//先更新size 由size作为参数扩容 解决只改容量 不更新访问范围的问题size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;//调用vector的有参构造[有参构造里调用reserve] 创建一个新表vector<HashData<K,V>> newtables(newsize);//遍历旧表 由哈希函数更新数据位置for (auto& e : _tables){if (e._state == EXIST){//哈希函数计算出的下标size_t hashi = pair.first % newtables.size();//重新线性探测size_t index = hashi;//index代替hashi进行操作 保留原始hashi的值不变for (size_t i = 1; newtables[index]._state == EXIST; ++i){index = hashi + i; //从原始下标不断 +1 +2 +3 ...index %= newtables.size();//防止越界 只在表内定位index}//将数据放入合适位置newtables[index]._pair = e._pair;newtables[index]._state = EXIST;}}//新表的数据才是我们想要的数据 交换后 newtables中存放的变为旧数据//newtables是个局部变量 让其"自生自灭"_tables.swap(newtables);*/// 高级代码 //size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;HashTable<K, V> other;other._tables.resize(newsize);for (auto& e : _tables){if (e._state == EXIST)other.Insert(e._pair);}_tables.swap(other._tables);///以上高级代码实际是对下面的线性探测进行了复用}//哈希函数计算出的下标size_t hashi = pair.first % _tables.size();// 线性探测size_t index = hashi;//index代替hashi进行操作 保留原始hashi的值不变for (size_t i = 1; _tables[index]._state == EXIST; ++i){index = hashi + i; //从原始下标不断 +1 +2 +3 ...index %= _tables.size();//防止越界 只在表内定位index}//将数据放入合适位置_tables[index]._pair = pair;_tables[index]._state = EXIST;_n++; //数据个数++return true;}//查找函数HashData<K, V>* Find(const K& key){//哈希表为空 返回nullptrif (_tables.size() == 0)return nullptr;//哈希函数计算出的下标size_t hashi = key % _tables.size();// 线性探测size_t index = hashi;for (size_t i = 1; _tables[index]._state != EMPTY; ++i){//obj是key的前提是obj存在if (_tables[index]._state == EXIST&& _tables[index]._pair.first == key){return &_tables[index];}index = hashi + i;index %= _tables.size();//当表中元素状态非exist即delete时 //for循环判断条件一直为真 死循环//解决: 当找了一圈还未找到//表中无此key 返回falseif (index == hashi)break;}return nullptr;}//删除函数bool Erase(const K& key){HashData<K, V>* pos = Find(key);if (pos){pos->_state = DELETE;--_n; //虽然已标记删除 仍然要使数据个数减减 防止有用数据未达到阈值就执行扩容return true;}elsereturn false;}private:vector<HashData<K, V>> _tables;size_t _n = 0;//存储的数据个数};// 测试函数 ///void TestHashTable(){int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;//插入for (auto& e : a)ht.Insert(make_pair(e, e));//插入第8个数据 达到阈值 测试扩容ht.Insert(make_pair(15, 15));//查找 + 删除int tmp = 12;if (ht.Find(tmp))cout << tmp << "在" << endl;elsecout << tmp << "不在" << endl;ht.Erase(tmp);if (ht.Find(tmp))cout << tmp << "在" << endl;elsecout << tmp << "不在" << endl;}
}
3.2开散列
//开散列/链地址法
namespace ChainAddressing
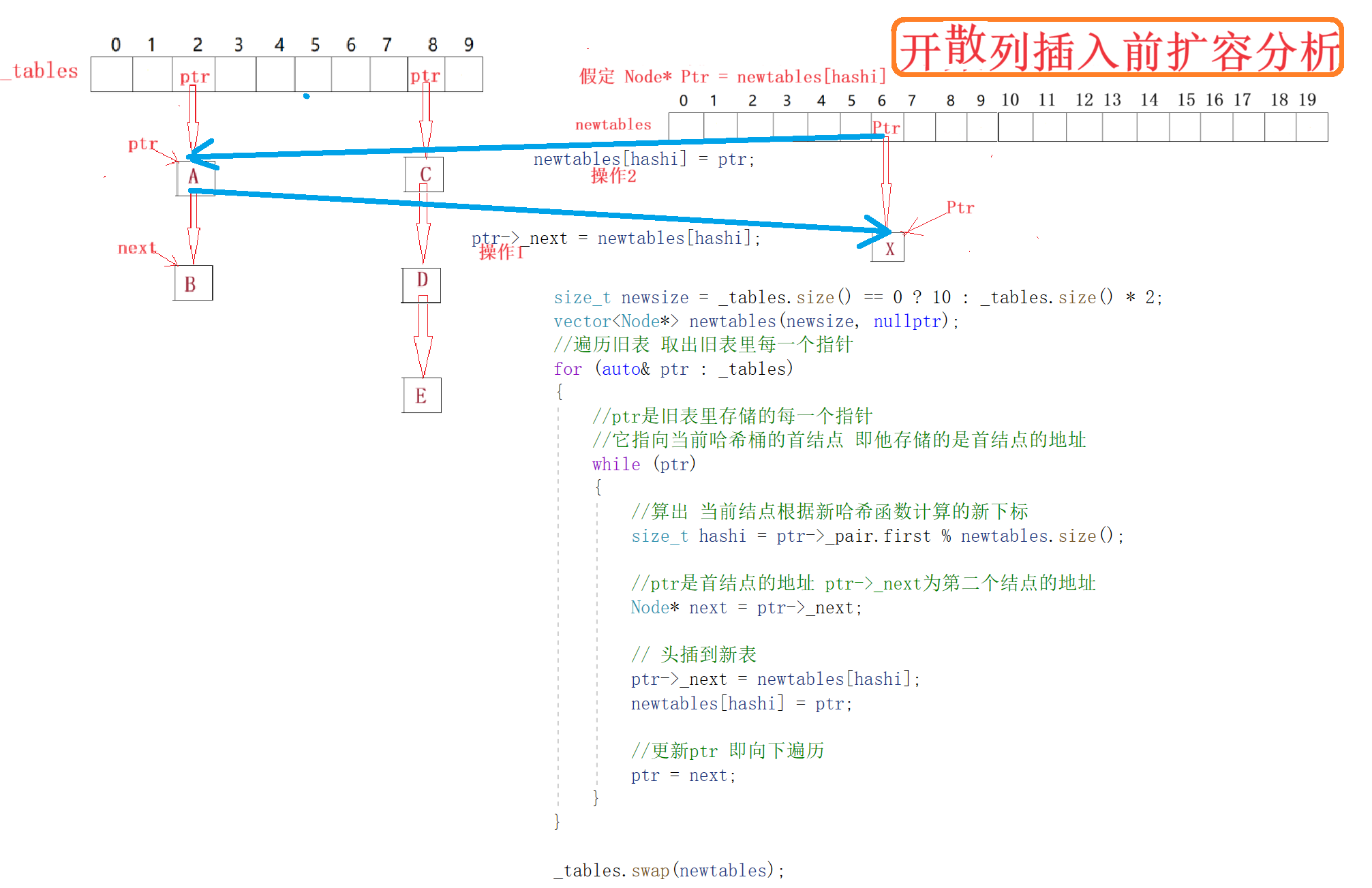
{/*STL库中unordered_map/unordered_set的定义template<class Key,class T,class Hash = hash<Key>,class Pred = equal_to<Key>, class Alloc = allocator< pair<const Key,T> > > class unordered_map;class unordered_set;*///结点类template<class K, class V>struct HashNode{HashNode<K, V>* _next;pair<K, V> _pair;HashNode(const pair<K, V>& pair):_next(nullptr), _pair(pair){}};//转换函数==类模板特化应用场景==[int->int char->int + 特化:string->int]template<class K>struct hash{size_t operator()(const K& key){return key;}};template<>struct hash<string>{size_t operator()(const string& s){size_t value = 0;for (auto ch : s){value = value * 131 + ch;}return value;}};//字符串转换函数/*struct StringToInt{size_t operator()(const string& s){//问题代码://return s[0];//1.如果传空串 违背使用者意愿//2.不同单词相同首字母均会哈希冲突 不太合适 //代码改进size_t value = 0;for (auto& ch : s){value = value * 131 + ch;}return value;}};*///哈希表类template< class K, class V,class Hash = hash<K> >class HashTable{typedef HashNode<K, V> Node;public://析构函数~HashTable(){for (auto& ptr : _tables){while (ptr){//记录下一个结点Node* next = ptr->_next;//释放当前结点delete ptr;//更新ptrptr = next;}ptr = nullptr;}}//查找函数Node* Find(const K& key){//为空不查找 返回nullptrif (_tables.size() == 0)return nullptr;Hash hash;//哈希函数计算的下标size_t hashi = hash(key) % _tables.size();//首先得到表里的指针 即相当于每一个桶的头指针//[实际上 每一个桶就是一个链表 表中的ptr是每一个链表的哨兵指针]Node* ptr = _tables[hashi];while (ptr){if (ptr->_pair.first == key)return ptr;ptr = ptr->_next;}return nullptr;}//删除函数bool Erase(const K& key){Hash hash;//哈希函数计算的下标size_t hashi = hash(key) % _tables.size();//首先得到表里的指针 即相当于每一个桶的头指针//[实际上 每一个桶就是一个链表 表中的ptr是每一个链表的哨兵指针]Node* ptr = _tables[hashi];Node* prv = nullptr;while (ptr){//当前值为目标值 执行删除操作if (ptr->_pair.first == key){if (prv == nullptr)_tables[hashi] = ptr->_next;elseprv->_next = ptr->_next;delete ptr;return true;}//当前值不为目标值 继续向下遍历else{prv = ptr;ptr = ptr->_next;}}return false;}//C++SGI版本STL库:获得下一个素数//在SGI下 设定哈希表的容量为素数//[可能效率更高 有兴趣的可以自行查阅]/*size_t GetNextPrime(size_t index){static const int num = 28;static const unsigned long prime[num] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};size_t i = 0;for (i = 0; i < num; ++i){if (prime[i] > index)return prime[i];}return prime[i];}*///插入函数bool Insert(const pair<K, V>& pair){//表中已有 返回falseif (Find(pair.first))return false;Hash hash;//负载因子/荷载系数 -- Load_Factor = _n / _tables.size();//负载因子 == 1时扩容if (_n == _tables.size()){/// 高级代码1.0 //*size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;HashTable<K, V> newht;newht.resize(newsize);for (auto& ptr : _tables){while (ptr) {newht.Insert(ptr->_pair);ptr = ptr->_next;}}_tables.swap(newht._tables);*///初代扩容size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;//引进stl库素数思想//size_t newsize = GetNextPrime(_tables.size());vector<Node*> newtables(newsize, nullptr);//遍历旧表 取出旧表里每一个指针for (auto& ptr : _tables){//ptr是旧表里存储的每一个指针//它指向当前哈希桶的首结点 即他存储的是首结点的地址while (ptr){//算出 当前结点根据新哈希函数计算的新下标size_t hashi = hash(ptr->_pair.first) % newtables.size();//ptr是首结点的地址 ptr->_next为第二个结点的地址Node* next = ptr->_next;// 头插到新表ptr->_next = newtables[hashi];newtables[hashi] = ptr;//更新ptr 即向下遍历ptr = next;}}_tables.swap(newtables);}//哈希函数计算出的下标size_t hashi = hash(pair.first) % _tables.size();//链表头插Node* newnode = new Node(pair);newnode->_next = _tables[hashi];_tables[hashi] = newnode; ++_n;return true;}//最大桶数据个数size_t MaxBucketSize(){size_t max = 0;for (size_t i = 0; i < _tables.size(); ++i){auto ptr = _tables[i];size_t size = 0;while (ptr){++size;ptr = ptr->_next;}//每个桶数据个数//printf("[%d] -> %d\n", i, size);if (size > max)max = size;}return max;}private:vector<Node*> _tables; // 指针数组size_t _n = 0; // 存储有效数据个数};
测试函数 ////插入测试void TestHashTable1(){int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ ht.Insert(make_pair(e, e));}ht.Insert(make_pair(15, 15));ht.Insert(make_pair(25, 25));ht.Insert(make_pair(35, 35));ht.Insert(make_pair(45, 45));}//插入和删除void TestHashTable2(){int a[] = { 3, 33, 2, 13, 5, 12, 1002 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}ht.Erase(12);ht.Erase(3);ht.Erase(33);}//字符串问题void TestHashTable3(){//不实现类模板特化 显示传StringToInt//HashTable<string, string, StringToInt> ht;//使用类模板特化 不需要显示传 更符合大佬设计的底层哈希HashTable<string, string> ht;ht.Insert(make_pair("Kevin", "凯文"));ht.Insert(make_pair("Eddie", "彭于晏"));ht.Insert(make_pair("Tom", "汤姆"));ht.Insert(make_pair("Jerry", "杰瑞"));ht.Insert(make_pair("", "null_string"));}//性能测试void TestHashTable4(){size_t N = 900000;HashTable<int, int> ht;srand(time(0));for (size_t i = 0; i < N; ++i){size_t x = rand() + i;ht.Insert(make_pair(x, x));}cout << "最大桶数据个数" << ht.MaxBucketSize() << endl;}
}
相关文章:
哈希/散列--哈希表[思想到结构][==修订版==]
文章目录 1.何为哈希?1.1百度搜索1.2自身理解1.3哈希方法/散列方法1.4哈希冲突/哈希碰撞1.5如何解决?哈希函数的设计 2.闭散列和开散列2.1闭散列/开放定址法2.2开散列/链地址法/开链法1.概念2.容量问题3.字符串问题4.开散列性能测试5.开散列与闭散列比较 3.代码实现[配备详细…...

成都建筑模板批发市场在哪?
成都作为中国西南地区的重要城市,建筑业蓬勃发展,建筑模板作为建筑施工的重要材料之一,在成都也有着广泛的需求。如果您正在寻找成都的建筑模板批发市场,广西贵港市能强优品木业有限公司是一家值得关注的供应商。广西贵港市能强优…...

亨元模式 结构型模式之六
1.定义 享元模式是一种结构型设计模式, 它允许你在消耗少量内存的情况下支持大量对象。 2.滑滑梯问题 在说明亨元模式之前,我们先看看关于滑滑梯的程序设计。小区的楼下只有三个滑滑梯,但是想玩的小朋友却非常多。怎么设计计滑滑梯资源的管理…...

面试题: Spring中Bean的实例化和Bean的初始化有什么区别?
Spring中Bean的实例化和Bean的初始化有什么区别? 背景答案扩展知识什么是实例化什么是初始化 个人评价我的回答 背景 想换工作, 看了图灵周瑜老师的视频想记录一下, 算是学习结果的一个输出. 答案 Spring 在创建一个Bean对象时, 会先创建出一个Java对象, 会通过反射来执行…...

阻塞队列,生产者消费者模型
目标: 1. 认识与使用阻塞队列 2. 认识与实现消费者模型 目录 阻塞队列的特点 生产者消费者模型 生产者消费者模型的优点 阻塞队列实现该模型 阻塞队列的特点 1. 线程安全 2. 带有阻塞特性 (1)如果队列为空,继续出队列&a…...

【RCRL充放电时间相关计算】
一. 基础知识 L、C元件称为“惯性元件”,即电感中的电流、电容器两端的电压,都有一定的“电惯性”,不能突然变化。充放电时间,不光与L、C的容量有关,还与充/放电电路中的电阻R有关。RC电路的时间常数:τRC…...

C++ primer plus--输入、输出和文件
17 输入、输出和文件 17.1 C 输入和输出概述 C 把输入和输出看做字节流。输入时,程序从输入流中抽取字节;输出时,程序将字节插到输出流中。 缓冲区是内存中的临时存储区域,是程序与文件或其他 I/O 设备之间的桥梁。 17.2 使用…...

案例题--Web应用考点
案例题--Web应用考点 负载均衡技术微服务XML和JSON无状态和有状态真题 在选择题中没有考察过web的相关知识,主要就是在案例分析题中考察 负载均衡技术 应用层负载均衡技术 传输层负载均衡技术 就近的找到距离最近的服务器,并进行分发 使用户就近获取…...

MySQL的SQL 优化:提升数据库性能
1. 插入操作优化 1.1 使用多值插入 通常情况下,插入大量数据时,使用多值插入语句比逐行插入更高效。例如,将多个数据行打包成一个 INSERT 语句: INSERT INTO users (name, email) VALUES (Alice, aliceexample.com), (Bob, bob…...
【匠心打造】从0打造uniapp 可视化拖拽设计 c_o 第十篇
一、click one for uniapp置顶: 全部免费开源 (你商业用途也没关系,不过可以告诉我公司名或者项目名,放在官网上好看点。哈哈-_-) 二、写在之前 距离上一篇更新已经大约4个月了,公司的事情,自己的一些琐事一直没时间…...

BIT-5-操作符详解(C语言初阶学习)
1. 各种操作符的介绍。 2. 表达式求值 1. 操作符分类: 算术操作符 移位操作符 位操作符 赋值操作符 单目操作符 关系操作符 逻辑操作符 条件操作符 逗号表达式 下标引用、函数调用和结构成员 2. 算术操作符 - * / % 除了 % 操作符…...
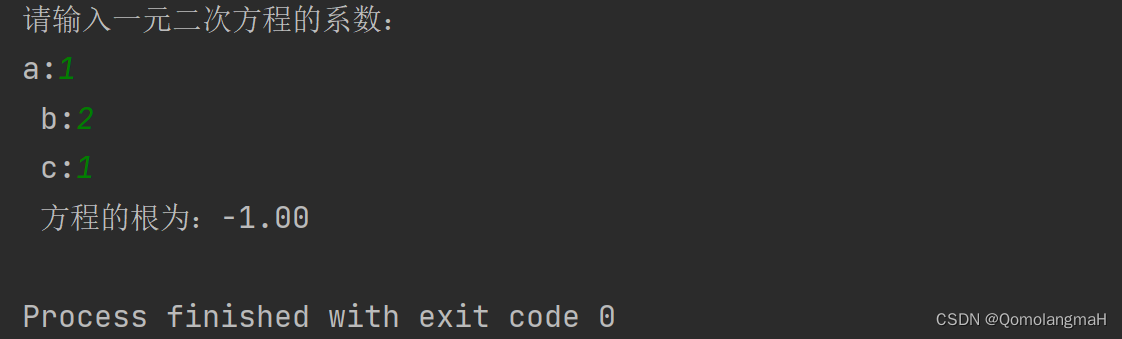
【重拾C语言】三、分支程序设计(双分支和单分支程序设计、逻辑判断、多分支程序设计、枚举类型表示;典型例题:判断闰年和求一元二次方程根)
目录 前言 三、分支程序设计 3.1 判断成绩是否及格——双分支程序设计 3.2 成绩加上获奖信息—单分支程序设计 3.3 逻辑判断——布尔类型 3.4 获奖分等级——多分支程序设计 3.5 表示汽车种类——枚举类型 3.6 例题 3.6.1 例题——判断某个年份是否闰年 3.6.2 例题—…...

Shiro应用到Web Application
一、权限基础 a) 认证(你是谁?) 判断你(被认证者)是谁的过程。通常被认证者提供用户名和密码。 常见的认证包含如下几种: 匿名认证:允许访问资源,不做任何类型的安全检查。表单认证:访问资源之前,需要提…...

【POST请求-腾讯翻译君-爬虫案例】
原因:尝试多个在线翻译平台,由于返回数据存在加密原因(暂时不会解密),最总找到 ”腾讯翻译君“ 完成爬虫案例POST请求测试 案例测试网址 腾讯翻译 :https://fanyi.qq.com/ import requests import jsoncla…...

多卡片效果悬停效果
效果展示 页面结构 从页面的结构上看,在默认状态下毛玻璃卡片是有层次感的效果叠加在一起,并且鼠标悬停在卡片区域后,卡片整齐排列。 CSS3 知识点 transform 属性的 rotate 值运用content 属性的 attr 值运用 实现页面整体布局 <div …...
首饰饰品经营商城小程序的作用是什么
首饰如耳钉、戒指、手镯等除了高价值产品外,还有很多低价产品,市场需求客户众多,在实际经营中,商家们也会面临一些痛点。 私域话题越来越多加之线上线下同行竞争、流量匮乏等,更对商家选择自建商城经营平台。 通过【…...

华为OD机试真题【服务器能耗统计】
1、题目描述 【服务器能耗统计】 服务器有三种运行状态:空载、单任务、多任务,每个时间片的能耗的分别为1、3、4; 每个任务由起始时间片和结束时间片定义运行时间; 如果一个时间片只有一个任务需要执行,则服务器处于单任务状志; 如果一个时间片有多个任务需要执行,则服务器处于…...
)
ubuntu按下del却出现空格(命令行下键盘错乱)
问题: 有一天远程我的ubuntu 20.04,发现为何按 del 会产生空格后移的效果,up键也会重叠显示,首先感觉是这个远程软件有问题,于是又换了xshell,发现还是不行,只能打开积灰已久的笔记本࿰…...
Go开始:Go基本元素介绍
目录 标识符与关键字Go中的标识符Go关键字关键字示例 具名的函数常规函数代码示例 方法代码示例 高阶函数代码示例 匿名函数与Lambda表达式代码示例 闭包代码示例 具名的值变量基本数据类型复合数据类型指针类型 常量基本常量类型枚举常量常量表达式 定义类型和类型别名类型定义…...
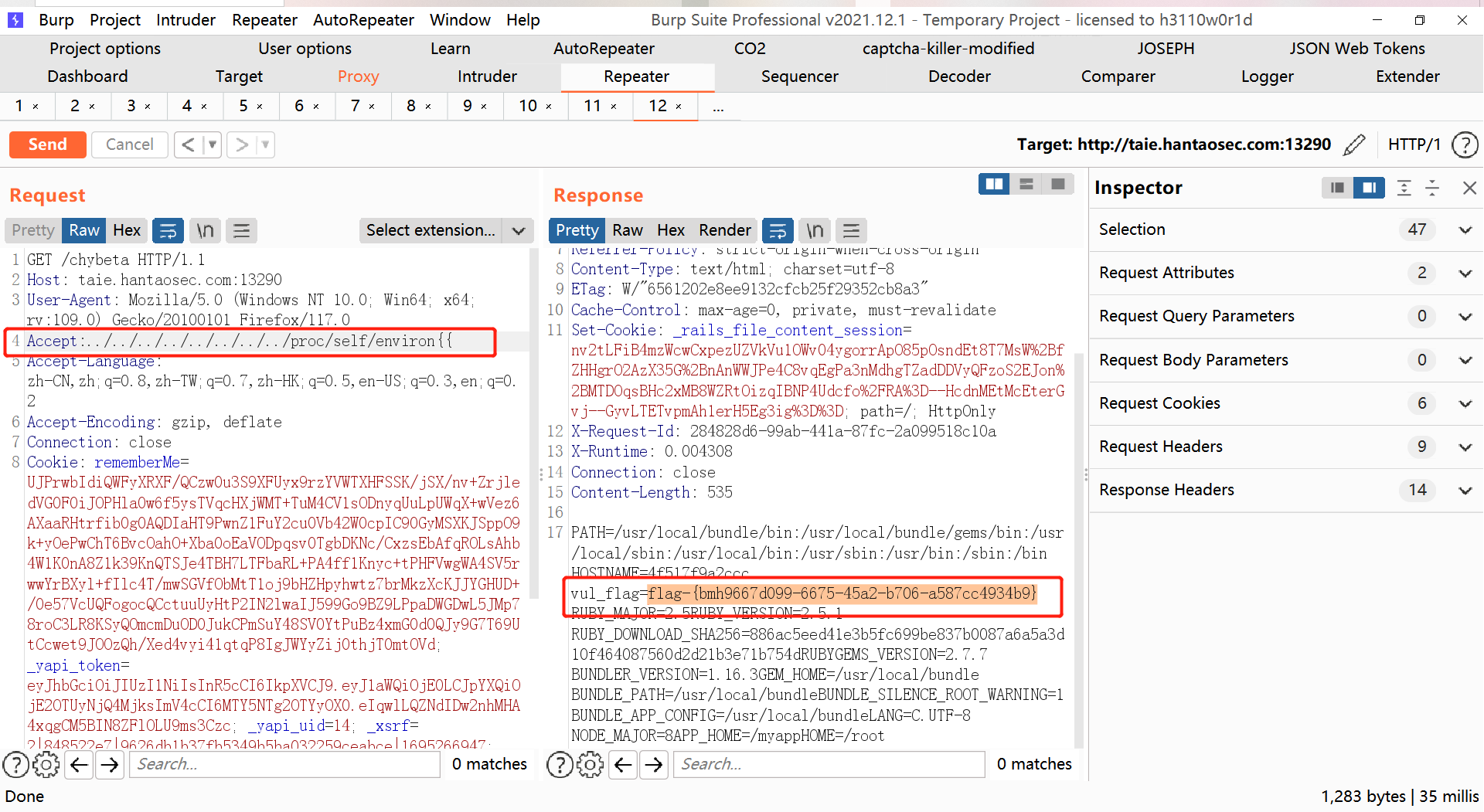
十二、【漏洞复现】Rails任意文件读取(CVE-2019-5418)
十二、【漏洞复现】Rails任意文件读取(CVE-2019-5418) 12.1、漏洞原理 Ruby on Rails是一个使用 Ruby 语言写的开源 Web 应用框架,它是严格按照 MVC 结构开发的。它努力使自身保持简单,来使实际的应用开发时的代码更少,使用最少…...

Alienware灯光控制终极指南:轻量级工具完整解决方案
Alienware灯光控制终极指南:轻量级工具完整解决方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 还在为臃肿的Alienware Command Center…...

告别网盘限速烦恼!八大网盘直链下载助手完整使用指南
告别网盘限速烦恼!八大网盘直链下载助手完整使用指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

MogFace人脸检测模型-WebUI实操手册:Linux服务器部署、日志排查、性能调优
MogFace人脸检测模型-WebUI实操手册:Linux服务器部署、日志排查、性能调优 1. 服务简介与核心价值 MogFace人脸检测模型是基于ResNet101架构的高精度检测解决方案,在CVPR 2022会议上发表并获得了广泛认可。这个WebUI服务让用户能够通过直观的界面快速部…...

CANdevStudio完全指南:终极免费开源CAN总线仿真开发平台
CANdevStudio完全指南:终极免费开源CAN总线仿真开发平台 【免费下载链接】CANdevStudio Development tool for CAN bus simulation 项目地址: https://gitcode.com/gh_mirrors/ca/CANdevStudio 在汽车电子和工业控制领域,CAN总线仿真工具是开发调…...

Cursor Pro功能激活终极方案:突破AI编程助手限制的完整指南
Cursor Pro功能激活终极方案:突破AI编程助手限制的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

Cursor破解工具终极指南:三步实现AI编程助手无限免费使用
Cursor破解工具终极指南:三步实现AI编程助手无限免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your …...

Linux内核OOM Killer机制深度解析:从配置到实战
1. 为什么你的进程突然消失了?认识OOM Killer 你有没有遇到过这种情况:服务器上跑得好好的程序突然消失了,查看日志只留下一句"Killed"?这很可能就是Linux内核的OOM Killer(Out-Of-Memory Killer)…...

10个免费Illustrator脚本:彻底改变你的设计工作流
10个免费Illustrator脚本:彻底改变你的设计工作流 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否厌倦了在Adobe Illustrator中重复执行枯燥的操作?是…...

为什么 RAW 域和 YUV 域都需要降噪模块
目录 一、RAW 域降噪(RawNR / BayerNR) 二、YUV 域降噪(YNR/CNR、2D/3DNR) 三、总结 一、RAW 域降噪(RawNR / BayerNR) 位置:BLC、DPC、LSC 之后,Demosaic 之前核心定位ÿ…...

Z-Image LoRA 训练全流程解析:从数据准备到模型部署的 ai-toolkit 实战指南
1. Z-Image LoRA训练入门指南 最近在AI绘画圈子里,Z-Image LoRA训练越来越火。作为一个从去年就开始折腾LoRA训练的老玩家,我发现很多新手朋友对这个技术既好奇又害怕。其实只要掌握正确的方法,训练一个可用的LoRA模型并没有想象中那么难。今…...