Pandas数据结构
文章目录
- 1. Series数据结构
- 1.1 Series数据类型创建
- 1.2 Series的常用属性
- values
- index/keys()
- shape
- T
- loc/iloc
- 1.3 Series的常用方法
- mean()
- max()/min()
- var()/std()
- value_counts()
- describe()
- 1.4 Series运算
- 加/减法
- 乘法
- 2. DataFrame数据结构
- 2.1 DataFrame数据类型创建
- 2.2 布尔索引 ★
- 2.3 DataFrame的常用属性和方法
- 2.4 DataFrame更改操作
- 改行索引
- 解除行索引
- 改行列名
- 修改所有的行列
- 增加、删除列
- 删除行列
- 3. Pandas数据导入导出
1. Series数据结构
Series是Pandas的基础数据结构,代表着一列数据,其底层是由Numpy实现的。
Series的特点:
- 所有的元素类型都是一致的;
- 如果创建Series时,传入整数列表,默认每个元素的类型都是np.int64;
- 如果创建Series时,传入的是小数和整数混合列表,默认每个元素的类型都是np.float64
- 如果创建Series时,传入的是其他类型的混合,默认每个元素的类型都是object;
- 如果创建Series时,传入的是字符串类型列表,默认每个元素的类型也是object。
1.1 Series数据类型创建
利用pd.Series创建一个Series对象,传入的列表作为Series中的数据。
import pandas as pd
s = pd.Series(['Banana', 42])
print(s)'''
代码输出:
0 Banana
1 42
dtype: object
'''
从代码的执行结果中可以发现,当前的Series的数据类型是object。
使用·s.values·属性,可以获去Series中的数据,数据的类型是一个Ndarray。
print(s.values)
print(type(s.values))
'''
代码输出:
['Banana' 42]
<class 'numpy.ndarray'>
'''
如果使用整数和浮点数的混合列表作为参数,Series的默认类型是np.float64类型。
print(pd.Series([1,1.2])
'''
代码输出:
0 1.0
1 1.2
dtype: float64
'''
在创建Series对象时,可以指定行索引index(Series代表一列数据)。
print(pd.Series(['Bill Gates', 'Male'], index=['Name', 'Gender']))
'''
代码输出:
Name Bill Gates
Gender Male
dtype: object
'''
注意:
Series代表Pandas数据结构中的列,在Pandas中没有表示行的数据结构。
1.2 Series的常用属性
使用pd.read_csv从CSV文件中加载数据,同时指定数据中的id列作为行索引。
data = pd.read_csv('data/nobel_prizes.csv',index_col='id')
使用loc获取数据中的第941行,此时的row就是一个Series对象。
row = data.loc[941]
loc对应的是行索引,如果行索引是从0开始的数字(和行编号一致),此时loc和iloc作用相同。
注意:
由于Pandas中没有对应行的数据结构,所以获得第941行之后,数据行被转换成了列,也就是一个Series
使用Print查看数据值:
print(row)
'''
代码输出:
year 2017
category physics
overallMotivation NaN
firstname Rainer
surname Weiss
motivation "for decisive contributions to the LIGO detect...
share 2
Name: 941, dtype: object
'''
values
values属性表示当前Series对象的值,类型是Ndarray:
print(row.values)
print(type(row.values))
'''
代码输出:
[2017 'physics' nan 'Rainer' 'Weiss''"for decisive contributions to the LIGO detector and the observation of gravitational waves"'2]
<class 'numpy.ndarray'>
'''
index/keys()
index属性表示当前Series的行索引:
print(row.index)
'''
代码输出:
Index(['year', 'category', 'overallMotivation', 'firstname', 'surname','motivation', 'share'],dtype='object')
'''
keys()方法可以达到同样的效果:
print(row.keys())
# 代码结果和row.index完全相同
shape
shape属性表示当前Series的行数和列数,是一个元组,由于Series表示一列数据,所以没有列数值:
print(row.shape)
'''
代码输出:
(7,)
'''
T
T属性表示当前Series的转置,由于Pandas没有行数据结构,所以转置之后和没有转置没什么区别:
print(row.T)
'''
代码输出:
year 2017
category physics
overallMotivation NaN
firstname Rainer
surname Weiss
motivation "for decisive contributions to the LIGO detect...
share 2
Name: 941, dtype: object
'''
loc/iloc
loc可以通过行列索引获取对应的行列,iloc通过行列序号获取对应的行列:
print(row.loc['year'])
print(row.iloc[0])
'''
代码输出:
2017
2017
'''
注意:
loc和iloc的完整使用方法是:
loc[行索引,列索引]iloc[行序号,列序号]
1.3 Series的常用方法
首先,使用数据.列名的方式获取一列数据,形成一个Series对象:
share = data.share
print(share)
'''
代码输出:
id
941 2
942 4
943 4
944 3
945 3..
160 1
293 1
569 1
462 2
463 2
Name: share, Length: 923, dtype: int64
'''
mean()
求平均:
print(share.mean())
'''
代码输出:
1.982665222101842
'''
max()/min()
求最大/小值:
print(share.max())
print(share.min())
'''
代码输出:
4
1
'''
var()/std()
方差和标准差:
print(share.var())
print(share.std())
'''
代码输出:
0.8695473357414776
0.9324952202244672
'''
value_counts()
获取每个值在当前Series对象中的个数:
print(share.value_counts())
'''
代码输出:
1 347
2 307
3 207
4 62
Name: share, dtype: int64
'''
以上输出的含义是,单个人获得诺贝尔奖项的有347次,两个人获得诺贝尔奖项的有307次,三个人获得诺贝尔奖项的有207次…
describe()
计算当前Series对象的各种特征值:
print(share.describe())
'''
代码输出:
count 923.000000
mean 1.982665
std 0.932495
min 1.000000
25% 1.000000
50% 2.000000
75% 3.000000
max 4.000000
Name: share, dtype: float64
'''
1.4 Series运算
创建两个Series对象:
s1 = pd.Series([1,2,3])
s2 = pd.Series([4,5,6])
加/减法
Series执行加法运算时,采用对位相加的方式。
print(s1 + s2)
print(s1 - s2)
'''
代码输出:
0 5
1 7
2 9
dtype: int64
0 -3
1 -3
2 -3
dtype: int64
'''
注意:
对位相加减是基于index值的,也就是说在加减运算执行时,两个index相同的值才算对位。
如果加减运算时,存在index不对位的情况,就会返回NaN值:
print(s1 + pd.Series([0,1]))
'''
代码输出:
0 1.0
1 3.0
2 NaN
dtype: float64
'''
注意!如果我们把其中一个Series对象的index倒序排列,依然不影响最终的结果:
# 倒序排列s2的行索引,再次执行加法,结果不变
print(s1 + s2.sort_index(ascending=False)
乘法
乘法也是对位相乘的:
print(s1 * s2)
'''
代码输出:
0 4
1 10
2 18
dtype: int64
'''
2. DataFrame数据结构
DataFrame是Pandas最重要的数据结构,由一个个的Series组成,可以视为一个二维表:
2.1 DataFrame数据类型创建
pd.DataFrame()方法接收一个字典对象作为参数,每个字典的键值对代表一列数据:
name_list = pd.DataFrame({'Name':['Tom','Bob'],'Job':['Java','Python'],'Age':[28,46]
})
print(name_list)
'''
代码输出:Name Job Age
0 Tom Java 28
1 Bob Python 46
'''
我们也可以在创建DataFrame的时候,直接指定索引:
- 通过index参数指定行索引
- 通过column参数指定列索引
print(pd.DataFrame(data={'Job': ['Java', 'Python'],'Age': [28, 46]},index=['Tom', 'Bob'],columns=['Job', 'Age'])
)
'''
代码输出:Job Age
Tom Java 28
Bob Python 46
'''
2.2 布尔索引 ★
首先,加载数据:
sci = pd.read_csv('data/scientists.csv')
print(sci)
'''
代码输出:Name Born Died Age Occupation
0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist
1 William Gosset 1876-06-13 1937-10-16 61 Statistician
2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse
3 Marie Curie 1867-11-07 1934-07-04 66 Chemist
4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist
5 John Snow 1813-03-15 1858-06-16 45 Physician
6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist
7 Johann Gauss 1777-04-30 1855-02-23 77 Mathematician
'''
取出数据的前5条,head()方法默认取前五条:
sci_5 = sci.head()
布尔索引的使用方法:
bool_index = [True, False, False, False, True]
print(sci_5[bool_index])
'''
代码输出:Name Born Died Age Occupation
0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist
4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist
'''
布尔索引中,对应行的值为True就返回,否则就过滤掉。
布尔索引列表必须和数据长度一致,否则会报错。
在实际使用过程中,不可能手动的构造一个布尔索引,通常情况下会通过计算直接生成一个布尔列表。
比如,针对当前数据,我们可以筛选所有年龄大于平均年龄的科学家数据行:
print(sci[sci.Age > sci.Age.mean()]
)
'''
代码输出:Name Born Died Age Occupation
1 William Gosset 1876-06-13 1937-10-16 61 Statistician
2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse
3 Marie Curie 1867-11-07 1934-07-04 66 Chemist
7 Johann Gauss 1777-04-30 1855-02-23 77 Mathematician
'''
2.3 DataFrame的常用属性和方法
movie = pd.read_csv('data/movie.csv')
movie.shape # 行列数
movie.ndim # 维度
movie.values # 值
movie.size # 元素个数
len(movie) # 行数
movie.count() # 计算行数,过滤空行(空行不算行数)
movie.describe()# 对数值列进行特征计算movie + movie # 数值直接对位相加,字符串直接拼接2.4 DataFrame更改操作
改行索引
将行索引由数字索引更改为movie_title列:
movie.set_index('movie_title',inplace=True)
解除行索引
解除当前的行索引,并使用数字索引:
movie.reset_index()
改行列名
movie.rename(index={'Avatar':'阿凡达','Star Wars: Episode VII - The Force Awakens':'星期大战7'},columns={'director_name':'导演','color':'颜色'},inplace=True
)
修改所有的行列
index = movie.index.to_list()
index[0] = '阿凡达'
movie.index = index
增加、删除列
movie['has_seen'] = 0
movie['社交媒体点赞数量'] = movie.actor_1_facebook_likes+movie.actor_2_facebook_likes+movie.actor_3_facebook_likes+movie.director_facebook_likes# 在指定位置插入指定列
movie.insert(loc=0,column='利润',value=movie.gross - movie.budget
)
删除行列
movie.drop('社交媒体点赞数量',axis=1)
# axis=1表示删除列
movie.drop('阿凡达')
# 删除行
3. Pandas数据导入导出
# movie.to_pickle('data/movie.pickle')
# movie.to_csv('data/movie2.csv')
# movie.to_csv('data/movie2.tsv',sep='\t')
# movie.to_excel('data/movie.xlsx')
# movie.read_csv()
# movie.read_pickle()
# movie.read_csv(sep='\t')
# movie.read_excel()
相关文章:

Pandas数据结构
文章目录 1. Series数据结构1.1 Series数据类型创建1.2 Series的常用属性valuesindex/keys()shapeTloc/iloc 1.3 Series的常用方法mean()max()/min()var()/std()value_counts()describe() 1.4 Series运算加/减法乘法 2. DataFrame数据结构2.1 DataFrame数据类型创建2.2 布尔索引…...

systemverilog function的一点小case
关于function的应用无论是在systemverilog还是verilog中都有很广泛的应用,但是一直有一个模糊的概念困扰着我,今天刚好有时间来搞清楚并记录下来。 关于fucntion的返回值的问题: function integer clog2( input logic[255:0] value);for(cl…...

微服务的初步使用
环境说明 jdk1.8 maven3.6.3 mysql8 idea2022 spring cloud2022.0.8 微服务案例的搭建 新建父工程 打开IDEA,File->New ->Project,填写Name(工程名称)和Location(工程存储位置),选…...
【2023年11月第四版教材】第18章《项目绩效域》(合集篇)
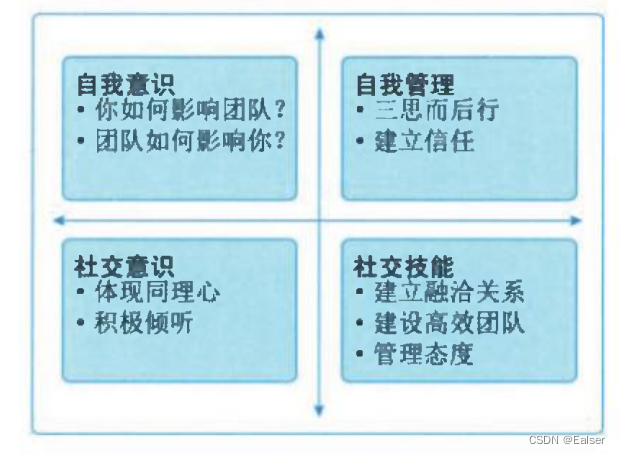
第18章《项目绩效域》(合集篇) 1 章节内容2 干系人绩效域2.1 绩效要点2.2 执行效果检查2.3 与其他绩效域的相互作用 3 团队绩效域3.1 绩效要点3.2 与其他绩效域的相互作用3.3 执行效果检查3.4 开发方法和生命周期绩效域 4 绩效要点4.1 与其他绩效域的相互…...

Android 11.0 mt6771新增分区功能实现三
1.前言 在11.0的系统开发中,在对某些特殊模块中关于数据的存储方面等需要新增分区来保存, 所以就需要在系统分区新增分区,接下来就来实现这个功能,看系列三的实现过程 2.mt6771新增分区功能实现三的核心类 build/make/tools/releasetools/common.py device/mediatek/mt6…...
计算机网络——计算机网络的性能指标(上)-速率、带宽、吞吐量、时延
目录 速率 比特 速率 例1 带宽 带宽在模拟信号系统中的意义 带宽在计算机网络中的意义 吞吐量 时延 发送时延 传播时延 处理时延 例2 例3 速率 了解速率之前,先详细了解一下比特: 比特 计算机中数据量的单位,也是信息论中信…...
)
每日一题 518零钱兑换2(完全背包)
题目 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带符号整…...
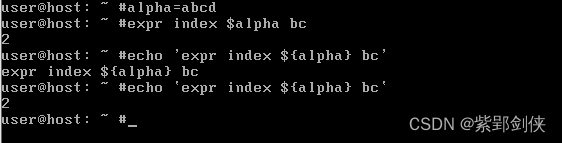
Linux shell编程学习笔记8:使用字符串
一、前言 字符串是大多数编程语言中最常用最有用的数据类型,这在Linux shell编程中也不例外。 本文讨论了Linux Shell编程中的字符串的三种定义方式的差别,以及字符串拼接、取字符串长度、提取字符串、查找子字符串等常用字符串操作,,以及反…...
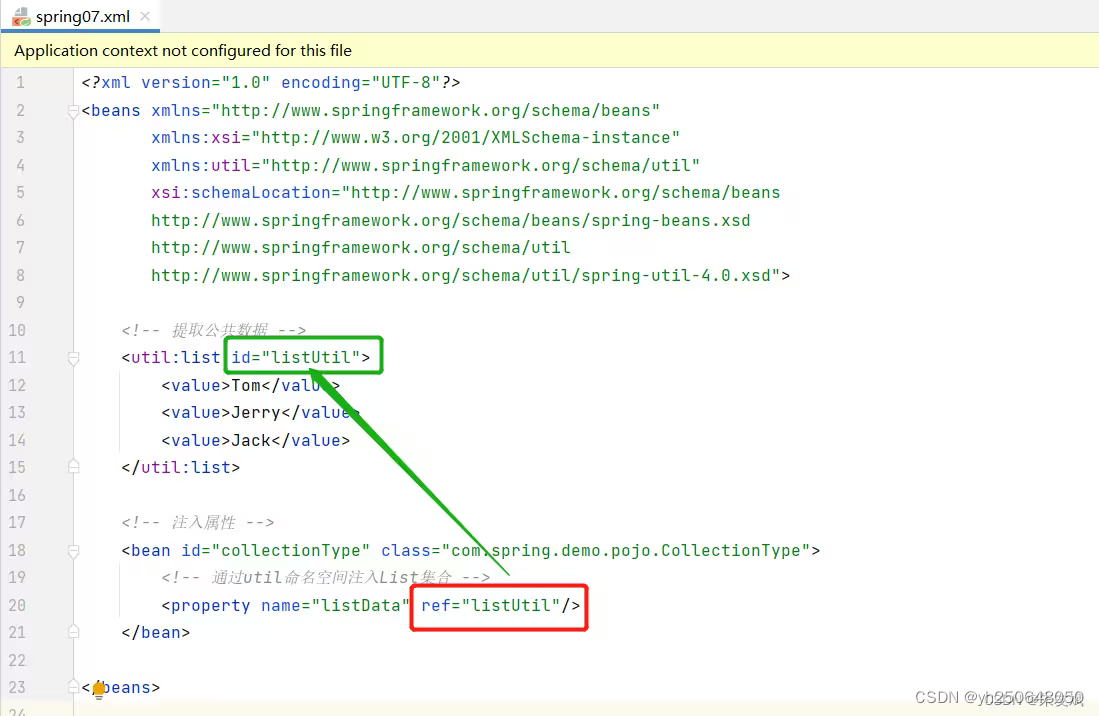
【Spring笔记03】Spring依赖注入各种数据类型
这篇文章,详细介绍一下Spring框架中如何注入各种数据类型,包含:注入基本数据类型、数组、集合、Map映射、Property属性、注入空字符串、注入null值、注入特殊字符等内容,以及如何使用命名空间进行依赖注入。 目录 一、注入各种数据…...

2023计算机保研——双非上岸酒吧舞
我大概是从22年10月份开始写博客的,当时因为本校专业的培养方案的原因,课程很多,有些知识纸质记录很不方便,于是选择了打破了自己的成见使用博客来记录学习生活。对于我个人而言,保研生活在前一大半过程中都比较艰难&a…...
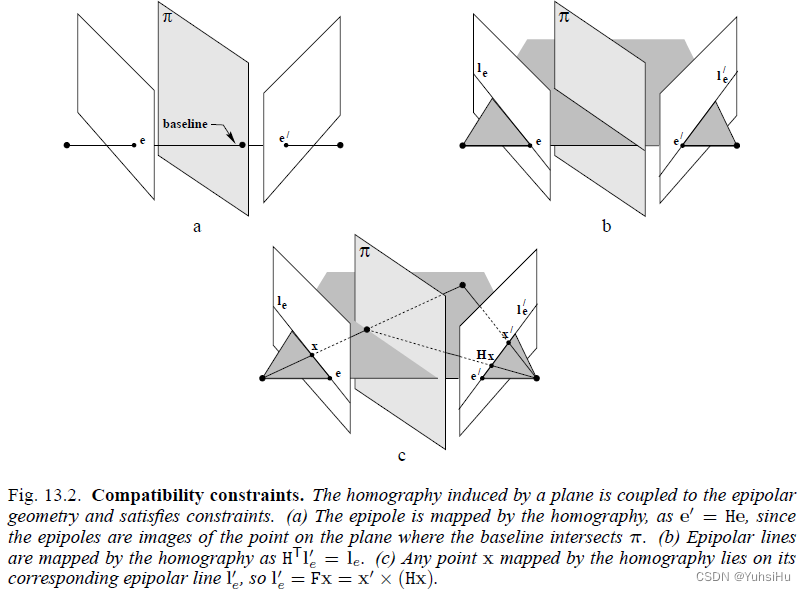
《计算机视觉中的多视图几何》笔记(13)
13 Scene planes and homographies 本章主要讲述两个摄像机和一个世界平面之间的射影几何关系。 我们假设空间有一平面 π \pi π,平面上的一点为 x π x_{\pi} xπ。 x π x_{\pi} xπ分别在两幅图像 P , P ′ P, P P,P′上形成了 x , x ′ x, x x,x′。 那…...
H5移动端购物商城系统源码 小型商城全新简洁风格全新UI 支持易支付接口
一款比较简单的 H5 移动端购物商城系统源码,比较适合单品商城、小型商城使用。带有易支付接口。 源码下载:https://download.csdn.net/download/m0_66047725/88391704 源码下载2:评论留言或私信留言...
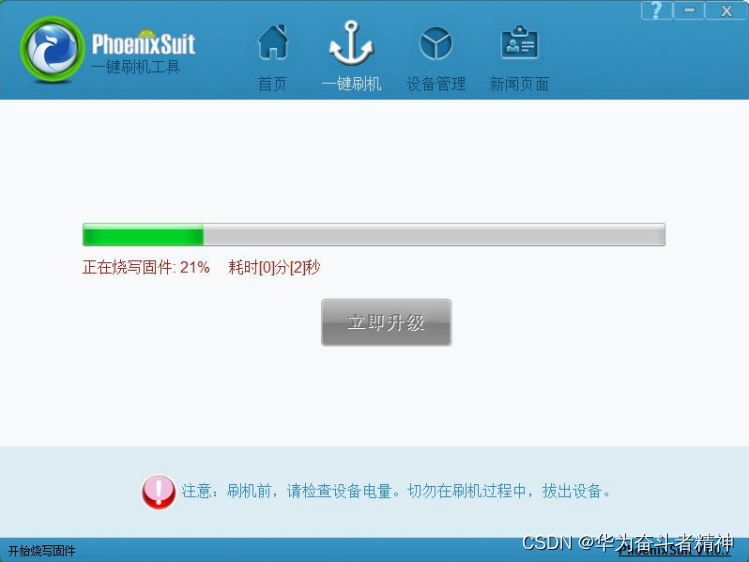
全志ARM926 Melis2.0系统的开发指引⑤
全志ARM926 Melis2.0系统的开发指引⑤ 编写目的8. 固件修改工具(ImageModify)使用8.1.界面说明8.2.操作步骤8.2.1. 配置平台8.2.2. 选择固件8.2.3. 选择要替换的文件8.2.4. 替换文件8.2.5. 保存固件 8.3.注意事项8.4.增加固件修改权限设置8.4.1. 概述8.4.2. 操作说明8.4.2.1.打…...
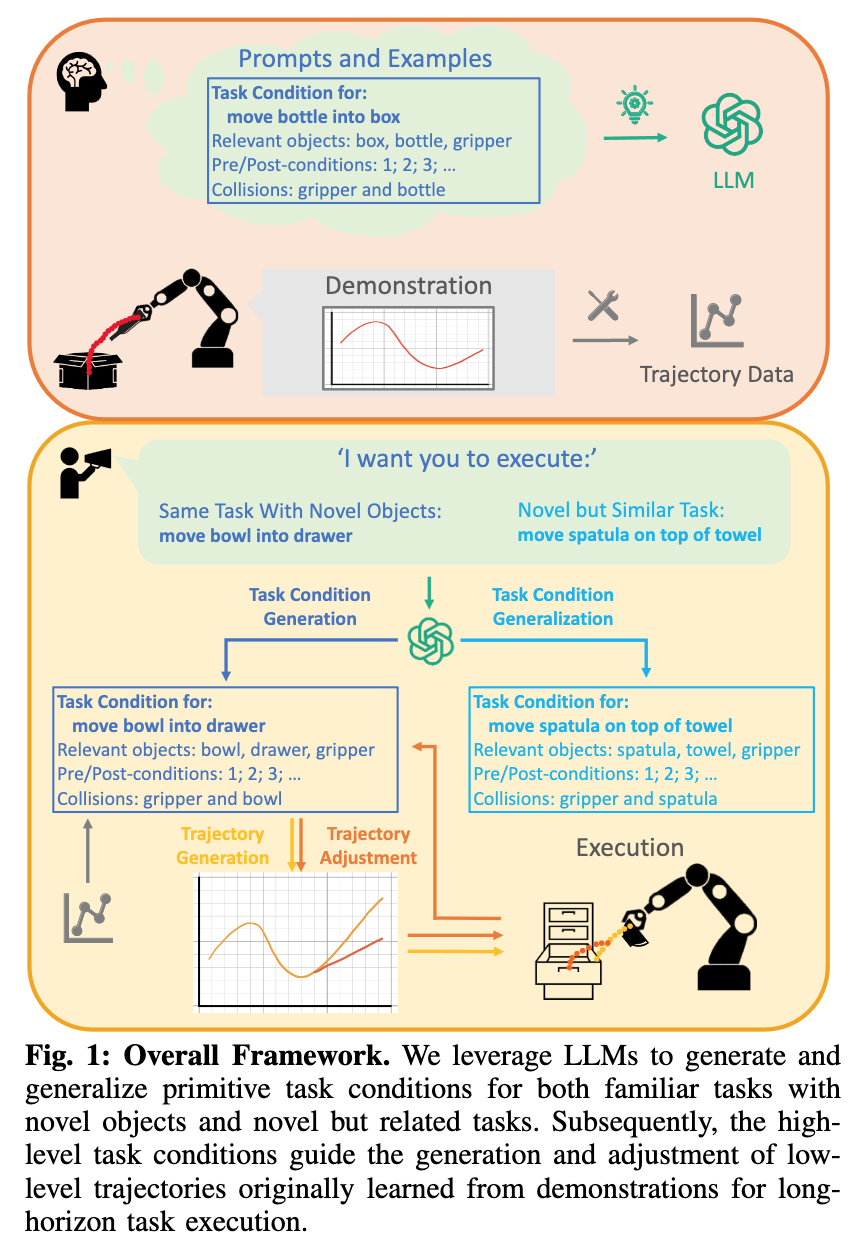
【AI视野·今日Robot 机器人论文速览 第四十七期】Wed, 4 Oct 2023
AI视野今日CS.Robotics 机器人学论文速览 Wed, 4 Oct 2023 Totally 40 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚基于神经网络的多模态触觉感知, classification, position, posture, and force of the grasped object多模态形象的解耦(f…...

GPX可视化工具 GPX航迹预览工具
背景 当我们收到别人分享的航迹文档,即gpx文档时,如何快速的进行浏览呢?我们可以使用GIS软件来打开gpx文档并显示gpx中所记录的航迹,例如常用的GIS软件有googleEarth, Basecamp, GPXsee, GPX E…...
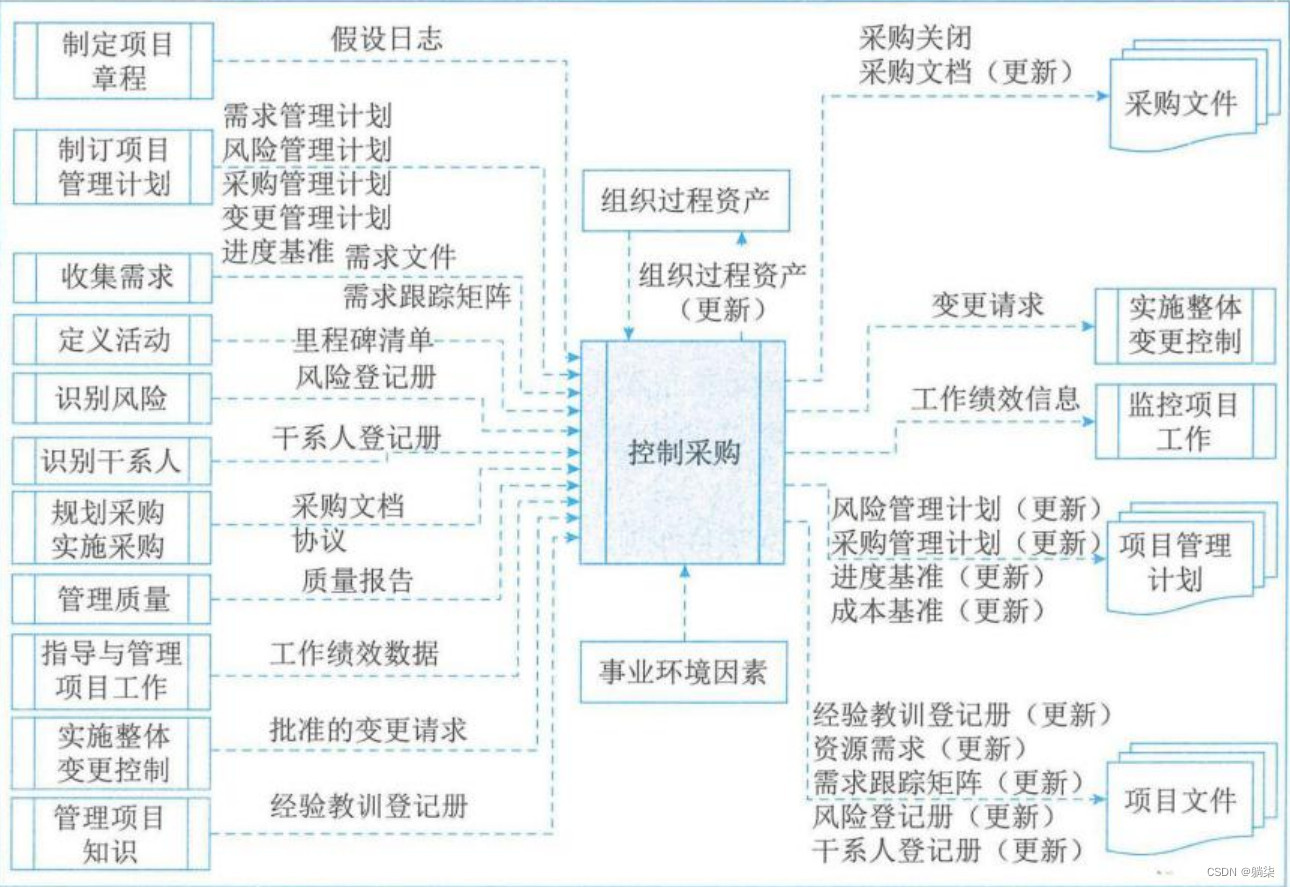
学信息系统项目管理师第4版系列18_采购管理
1. 协议 1.1. 合同 1.1.1. 国际合作的项目经理应牢记,无论合同规定如何详尽,文化和当地法律对合同及其可执行性均有影响 1.2. 服务水平协议(SLA) 1.3. 谅解备忘录 1.4. 协议备忘录(MOA) 1.5. 订购单 …...

标准化数据模型
标准化数据模型 标准化被定义为减少或消除数据集中冗余的过程。 它已成为关系数据库中数据建模的事实上的方法,很大程度上是由于这些系统最初设计时所围绕的底层资源限制:缓慢的磁盘和昂贵的 RAM。更少的数据冗余/重复意味着更有效地从磁盘读取数据并占…...

linux平台源码编译ffmpeg
目录 编译平台 编译步骤 编译平台 中标麒麟 编译步骤 1 从Download FFmpeg 下载源码,我选中了4.2.9版 2 解压 3 在解压后的目录下输入 ./configure --enable-shared --prefix/usr/local/ffmpeg 4 make 5 sudo make install 6 ffmpeg的头文件、可执行程…...

Vue中如何进行拖拽与排序功能实现
在Vue中实现拖拽与排序功能 在Web应用程序中,实现拖拽和排序功能是非常常见的需求,特别是在管理界面、任务列表和图形用户界面等方面。Vue.js作为一个流行的JavaScript框架,提供了许多工具和库来简化拖拽和排序功能的实现。本文将介绍如何使…...
新款UI动态壁纸头像潮图小程序源码
新款UI动态壁纸头像潮图小程序源码,不需要域名服务器,直接添加合法域名,上传发布就能使用。 可以对接开通流量主,个人也能运营,不需要服务器源码完整。整合头像,动态壁纸,文案功能齐全。 源码…...

SiameseUIE保姆级教程:3步部署nlp_structbert_siamese-uie_chinese-base
SiameseUIE保姆级教程:3步部署nlp_structbert_siamese-uie_chinese-base 信息抽取不再需要标注数据,一个模型搞定NER、关系抽取、事件抽取、情感分析四大任务 1. 什么是SiameseUIE?为什么值得一试 如果你正在处理中文文本信息抽取任务&#…...

深耕.NET开发三载,我靠技术实力买下人生第一套房
作为一名深耕.NET领域的开发者,从刚毕业敲下第一行C#代码的青涩,到如今拿到属于自己的房产证,这一路,是技术能力的层层进阶,是职业道路的稳步前行,更是用代码筑造起现实生活的温暖港湾。在很多人眼里&#…...

795. 广告标识工厂哪家上门维修最及时?
在当今商业社会,广告标识对于企业的品牌展示和宣传起着至关重要的作用。然而,广告标识在使用过程中难免会出现各种问题,这就需要及时的上门维修服务。那么,广告标识工厂哪家上门维修最及时呢?今天就为大家推荐河北兴盛…...

基于本机配置的 YOLO26 Conda ss安装教程:Windows 11 + RTX 3050 Ti 实战版
基于本机配置的 YOLO26 Conda 环境安装教程:Windows 11 RTX 3050 Ti 实战版 这篇文章不是泛泛而谈的“通用装环境教程”,而是按你这台电脑当前的实际配置整理出来的一份可直接照做的安装方案。 如果你以前没有配过深度学习环境,只想先把 co…...

效率提升秘籍:用快马平台快速生成魔鬼面具试戴应用代码骨架
效率提升秘籍:用快马平台快速生成魔鬼面具试戴应用代码骨架 最近在做一个有趣的个人项目——魔鬼面具在线试戴应用。作为一个前端开发者,我深知从零开始搭建这种交互式应用需要花费不少时间在基础框架上。幸运的是,我发现了InsCode(快马)平台…...

Vortex模组管理器:从架构到实战的全方位技术指南
Vortex模组管理器:从架构到实战的全方位技术指南 【免费下载链接】Vortex Vortex: Nexus-Mods开发的游戏模组管理器,用于简化模组的安装和管理过程。 项目地址: https://gitcode.com/gh_mirrors/vor/Vortex 一、Vortex核心架构解析 模组管理的&q…...

企业级后台快速开发解决方案:Element-UI Admin全指南
企业级后台快速开发解决方案:Element-UI Admin全指南 【免费下载链接】element-ui-admin 基于 element-ui 的单页面后台管理项目模版 项目地址: https://gitcode.com/gh_mirrors/el/element-ui-admin Element-UI Admin是一款基于Element-UI组件库的单页面后台…...

Dify工作流HTTP请求配置全攻略:从基础到进阶的系统优化指南
Dify工作流HTTP请求配置全攻略:从基础到进阶的系统优化指南 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-…...
)
CTF选手必看:RSA算法从数学原理到实战解题技巧(附常见题型解析)
CTF选手必看:RSA算法从数学原理到实战解题技巧(附常见题型解析) 1. RSA算法核心数学原理 RSA算法的安全性建立在大整数分解难题和欧拉定理之上。理解以下数学概念是解题基础: 欧拉函数φ(n):对于npq(p、q为…...

如何通过Nginx反向代理部署WeTTY:生产环境完整配置指南
如何通过Nginx反向代理部署WeTTY:生产环境完整配置指南 【免费下载链接】wetty Terminal in browser over http/https. (Ajaxterm/Anyterm alternative, but much better) 项目地址: https://gitcode.com/gh_mirrors/we/wetty WeTTY(Web TTY&…...