HuggingFace Transformers教程(1)--使用AutoClass加载预训练实例
知识的搬运工又来啦
☆*: .。. o(≧▽≦)o .。.:*☆
【传送门==>原文链接:】https://huggingface.co/docs/transformers/autoclass_tutorial
🚗🚓🚕🛺🚙🛻🚌🚐🚎🚑🚒🚚🚛🚜🚘🚔🚖🚍🚗🚓🚕🛺🚙🛻🚌🚐🚎🚑🚒🚚
由于存在许多不同的Transformer架构,因此为您的检查点(checkpoint)创建一个可能很具有挑战性。作为🤗Transformers核心理念的一部分,使库易于使用、简单和灵活,AutoClass自动推断并从给定的检查点加载正确的架构。【from_pretrained()】方法允许您快速加载任何架构的预训练模型,因此您无需花费时间和资源从头开始训练模型。生产此类检查点不可知代码意味着,如果您的代码适用于一个检查点,则它将适用于另一个检查点——只要它是为类似的任务进行训练的,即使架构不同。
请记住,架构是指模型的骨架,检查点是给定架构的权重。例如,BERT是一种架构,而bert-base-uncased是一个检查点。模型是一个通用术语,可以表示架构或检查点。
在本教程中,我们可以学习:
- 加载预训练的分词器。
- 加载预训练的图像处理器。
- 加载预训练的特征提取器。
- 加载预训练的处理器。
- 加载预训练模型。
AutoTokenizer
几乎每个NLP任务都始于分词器。分词器将您的输入转换为模型可以处理的格式。
使用AutoTokenizer.from_pretrained()加载分词器:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")然后按照下面所示进行分词:
sequence = "In a hole in the ground there lived a hobbit."
print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}AutoImageProcessor
对于视觉任务,图像处理器将图像处理成正确的输入格式。
from transformers import AutoImageProcessorimage_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")AutoFeatureExtractor
对于音频任务,特征提取器将音频信号处理成正确的输入格式。
使用AutoFeatureExtractor.from_pretrained()加载特征提取器:
from transformers import AutoFeatureExtractorfeature_extractor = AutoFeatureExtractor.from_pretrained("ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
)AutoProcessor
多模态任务需要一个处理器来结合两种类型的预处理工具。例如,LayoutLMV2模型需要一个图像处理器来处理图像和一个分词器来处理文本;处理器将两者结合起来。
使用AutoProcessor.from_pretrained()加载处理器:
from transformers import AutoProcessorprocessor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")AutoModel
Pytorch
最后,AutoModelFor类允许您加载给定任务的预训练模型(请参见此处以获取可用任务的完整列表)。例如,使用AutoModelForSequenceClassification.from_pretrained()加载序列分类模型:
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")可以轻松地重复使用相同的检查点,以加载不同任务的架构:
from transformers import AutoModelForTokenClassificationmodel = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")对于PyTorch模型,from_pretrained()方法使用torch.load(),它在内部使用pickle,并已知存在安全问题。一般来说,永远不要加载可能来自不可信源或可能被篡改的模型。针对Hugging Face Hub上托管的公共模型,这种安全风险在一定程度上得到了缓解,因为每次提交时都会对其进行恶意软件扫描。请参阅Hub文档以了解最佳实践,例如使用GPG进行签名提交验证。
TensorFlow和Flax检查点不受影响,并且可以在PyTorch架构中使用from_pretrained方法的from_tf和from_flax参数来加载,以绕过此问题。
通常,我们建议使用AutoTokenizer类和AutoModelFor类来加载预训练模型的实例。这将确保您每次都加载正确的架构。在下一个教程中,学习如何使用新加载的分词器、图像处理器、特征提取器和处理器对数据集进行预处理,以进行微调。
TensorFlow
最后,TFAutoModelFor类允许您加载给定任务的预训练模型(请参见此处以获取可用任务的完整列表)。例如,使用TFAutoModelForSequenceClassification.from_pretrained()加载序列分类模型:
from transformers import TFAutoModelForSequenceClassificationmodel = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")可以轻松地重复使用相同的检查点,以加载不同任务的架构:
from transformers import TFAutoModelForTokenClassificationmodel = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")通常,我们建议使用AutoTokenizer类和TFAutoModelFor类来加载预训练模型的实例。这将确保您每次都加载正确的架构。在下一个教程中,学习如何使用新加载的分词器、图像处理器、特征提取器和处理器对数据集进行预处理,以进行微调。
相关文章:
HuggingFace Transformers教程(1)--使用AutoClass加载预训练实例
知识的搬运工又来啦 ☆*: .。. o(≧▽≦)o .。.:*☆ 【传送门>原文链接:】https://huggingface.co/docs/transformers/autoclass_tutorial 🚗🚓🚕🛺🚙🛻🚌Ƕ…...

Qt获取当前所用的Qt版本、编译器、位数等信息
//详细的Qt版本编译器位数 QString compilerString "<unknown>"; { #if defined(Q_CC_CLANG)QString isAppleString; #if defined(__apple_build_version__)isAppleString QLatin1String(" (Apple)"); #endifcompilerString QLatin1String("…...
《C和指针》笔记31:多维数组的数组名、指向多维数组的指针、作为函数参数的多维数组
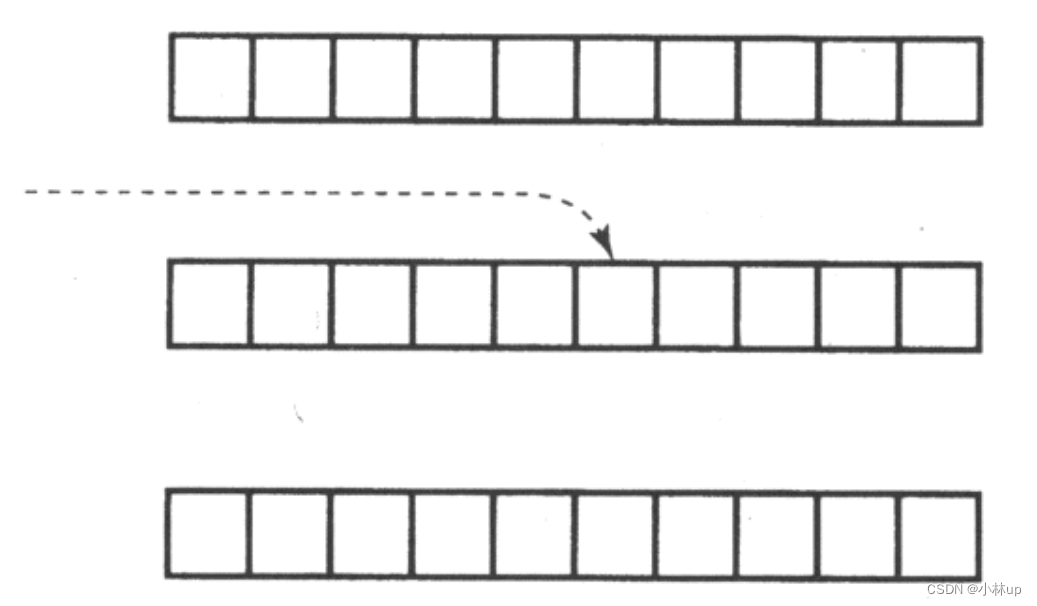
文章目录 1. 指向多维数组的数组名2. 指向多维数组的指针3. 作为函数参数的多维数组 1. 指向多维数组的数组名 我们知道一维数组名的值是一个指针常量,它的类型是“指向元素类型的指针”,它指向数组的第1个元素。那么多维数组的数组名代表什么呢&#x…...
【伪彩色图像处理】将灰度图像转换为彩色图像研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Go Gin Gorm Casbin权限管理实现 - 2. 使用Gorm存储Casbin权限配置以及`增删改查`
文章目录 0. 背景1. 准备工作2. 权限配置以及增删改查2.1 策略和组使用规范2.2 用户以及组关系的增删改查2.2.1 获取所有用户以及关联的角色2.2.2 角色组中添加用户2.2.3 角色组中删除用户 2.3 角色组权限的增删改查2.3.1 获取所有角色组权限2.3.2 创建角色组权限2.3.3 修改角色…...

DNDC模型的温室气体排放分析
DNDC(Denitrification-Decomposition,反硝化-分解模型)是目前国际上最为成功的模拟生物地球化学循环的模型之一,自开发以来,经过不断完善和改进,从模拟简单的农田生态系统发展成为可以模拟几乎所有陆地生态…...

vue、全局前置守卫
需求:在使用商城app的时候,游客(没有登录的用户)可以看到商品信息,当游客点击添加购物车的时候,我们需要把游客“拦”到登录页面,登陆后,才可以添加商品。 游客只可以看得到部分页面…...

OpenWRT、Yocto 、Buildroot和Ubuntu有什么区别
OpenWRT: 用途:OpenWRT 是一个专注于路由器和嵌入式网络设备的Linux发行版。它提供了一个优化的Linux环境,旨在将网络设备变成功能丰富、高度可定制的路由器。 包管理器:OpenWRT 使用 opkg 包管理器,它是一个轻量级的…...
数据挖掘(3)特征化
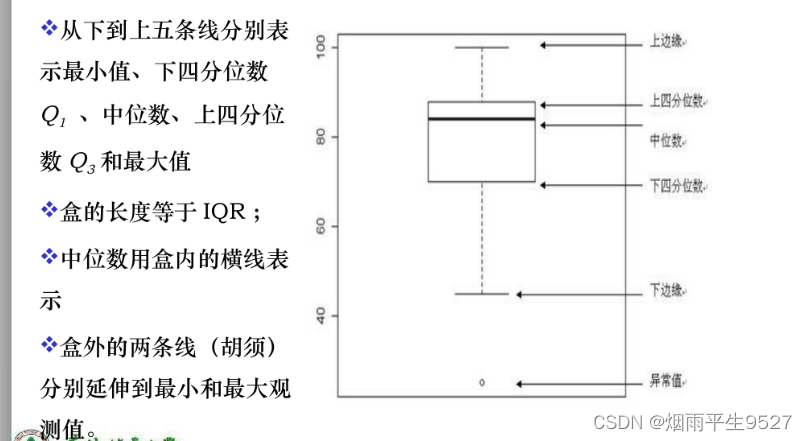
从数据分析角度,DM分为两类,描述式数据挖掘,预测式数据挖掘。描述式数据挖掘是以简介概要的方式描述数据,并提供数据的一般性质。预测式数据挖掘分析数据建立模型并试图预测新数据集的行为。 DM的分类: 描述式DM&#…...
【RabbitMQ 实战】08 集群原理剖析
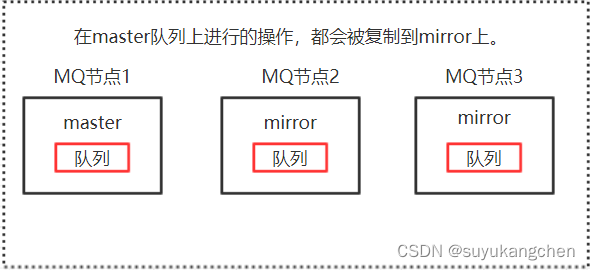
上一节,我们用docker-compose搭建了一个RabbitMQ集群,这一节我们来分析一下集群的原理 一、基础概念 1.1 元数据 前面我们有介绍到 RabbitMQ 内部有各种基础构件,包括队列、交换器、绑定、虚拟主机等,他们组成了 AMQP 协议消息…...

2023年 2月3月 工作经历
2月 #pragma make_public(type) 托管C导出传统C类,另一个托管C项目使用不了。传统C类make_public后,就可以使用了。对模板类无效,比如:std::string。 C#线程绑定CPU 我的方案: 假定我们想把 CPU0 设置成专有CPU。 定…...

selenium京东商城爬取
该项目主要参考与:http://c.biancheng.net/python_spider/selenium-case.html 你看完上述项目内容之后,会发现京东登录是一个比较坑的点,selenium控制浏览器没有登录京东,导致我们自动爬取网页被重定向到京东登录注册页面。 因此,我们要单独…...

用pandas处理数据时,使变量能够在不同的Notebook会话页面进行传递,魔法命令%store
【需求来源】 在使用pandas时,有的时候我想将.ipynb文件分开写 其中一个写清洗数据代码另外一个写数据可视化代码 【解决方案】 但是会涉及到变量转移问题,这个时候我通常使用的方法是: 1、在清洗完数据后导出到本地 2、在文件后面增加当…...

选择适合户外篷房企业的企业云盘解决方案
“户外篷房企业用什么企业云盘好?Zoho WorkDrive企业网盘可以帮助户外篷房企业实现文档统一管理、提高工作效率、加强团队协作,并且支持各种文件类型的预览和编辑。” S公司是一家注重管理规范的大型户外篷房企业,已经有10余年的经验。作为设…...
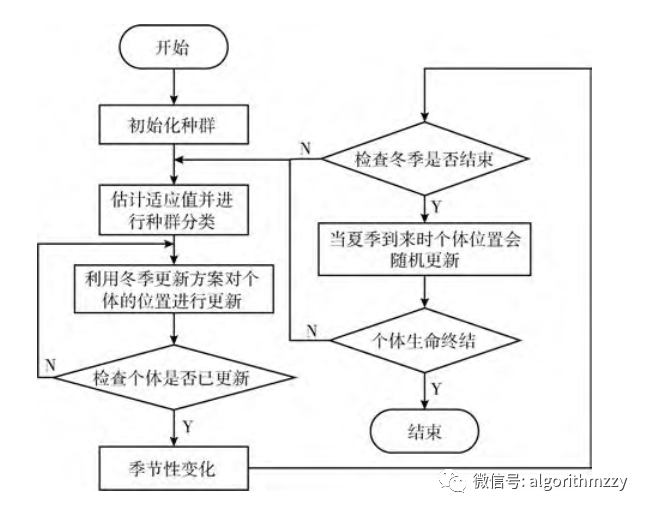
松鼠搜索算法(SSA)(含MATLAB代码)
先做一个声明:文章是由我的个人公众号中的推送直接复制粘贴而来,因此对智能优化算法感兴趣的朋友,可关注我的个人公众号:启发式算法讨论。我会不定期在公众号里分享不同的智能优化算法,经典的,或者是近几年…...

折半+dp之限制转状态+状压:CF1767E
https://vjudge.net/problem/CodeForces-1767E/origin 首先40,必然折半。然后怎么做? 分析性质。每次可以走1步or2步,等价什么?等价任意相邻2个必选一个!然后就可以建图 这个图是个限制图,我们折半后可以…...

如何写出优质代码
(本文转载自其他博主但是个人忘记了出处) 优质代码是什么? 优质代码是指那些易于理解、易于维护、可读性强、结构清晰、没有冗余、运行效率高、可复用性强、稳定性好、可扩展性强的代码。 这类代码不仅能够准确执行预期功能,同时也便于其他开发者理解…...
ChatGLM2-6B的通透解析:从FlashAttention、Multi-Query Attention到GLM2的微调、源码解读
前言 本文最初和第一代ChatGLM-6B的内容汇总在一块,但为了阐述清楚FlashAttention、Multi-Query Attention等相关的原理,以及GLM2的微调、源码解读等内容,导致之前那篇文章越写越长,故特把ChatGLM2相关的内容独立抽取出来成本文 …...
3D人脸生成的论文
一、TECA 1、论文信息 2、开源情况:comming soon TECA: Text-Guided Generation and Editing of Compositional 3D AvatarsGiven a text description, our method produces a compositional 3D avatar consisting of a mesh-based face and body and NeRF-based ha…...

解决问题:可以用什么方式实现自动化部署
自动化部署可以使用多种工具来实现: 脚本编写:可以使用 Bash、Python 等编写脚本来实现自动化部署。例如,可以使用 Bash 脚本来自动安装、配置和启动应用程序。 配置管理工具:像 Ansible、Puppet、Chef、Salt 等配置管理工具可以…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...
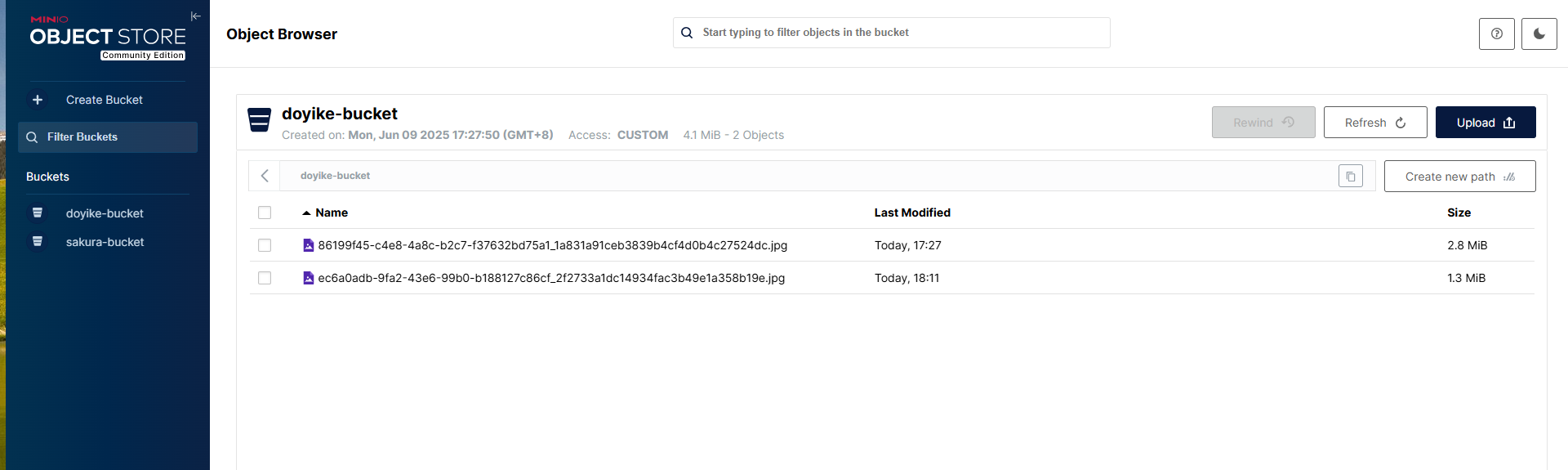
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...
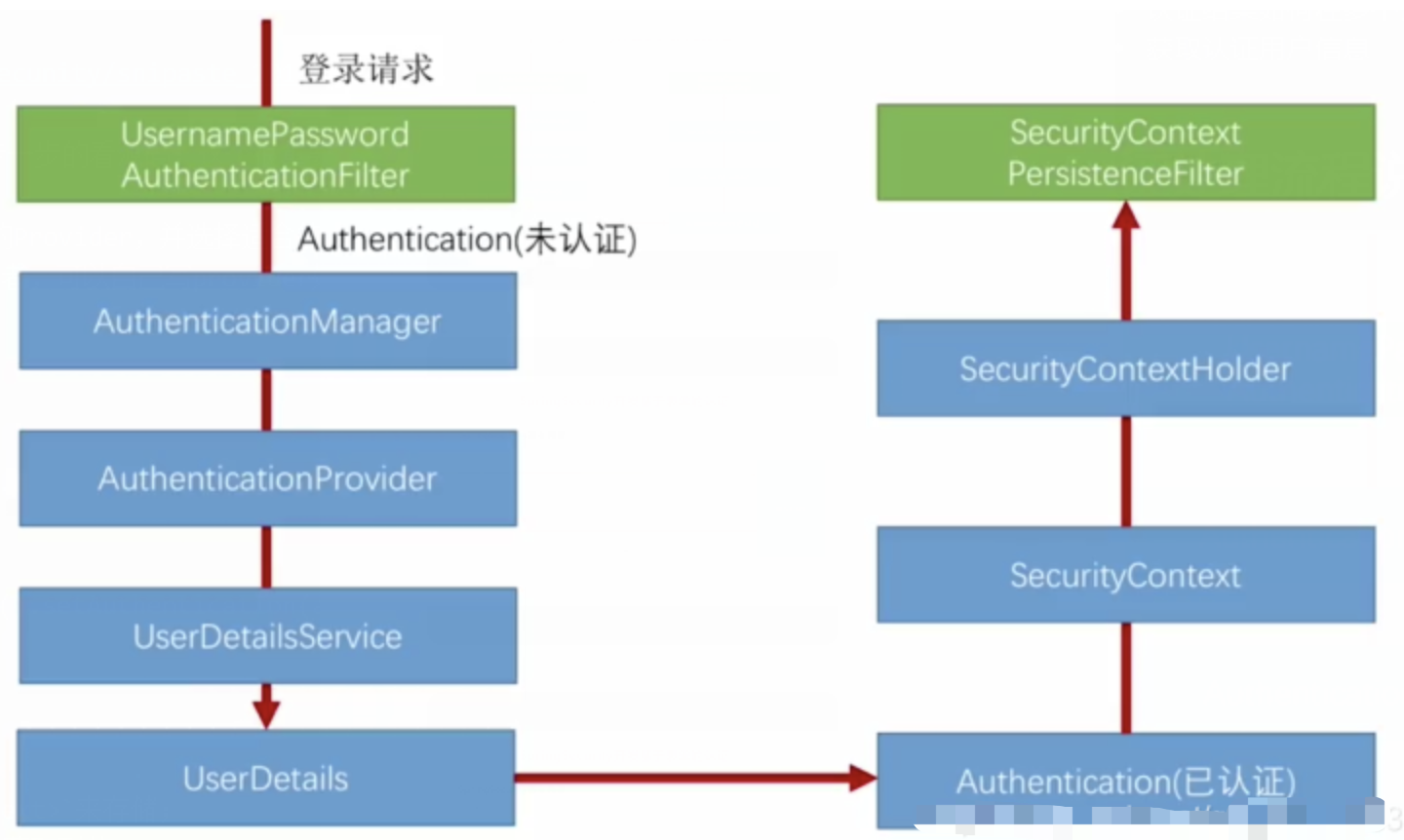
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...

Netty自定义协议解析
目录 自定义协议设计 实现消息解码器 实现消息编码器 自定义消息对象 配置ChannelPipeline Netty提供了强大的编解码器抽象基类,这些基类能够帮助开发者快速实现自定义协议的解析。 自定义协议设计 在实现自定义协议解析之前,需要明确协议的具体格式。例如,一个简单的…...