数据结构与算法(四):哈希表
参考引用
- Hello 算法
- Github:hello-algo
1. 哈希表
1.1 哈希表概述
-
哈希表(hash table),又称散列表,其通过建立键 key 与值 value 之间的映射,实现高效的元素查询
- 具体而言,向哈希表输入一个键 key ,则可以在 O(1) 时间内获取对应的值 value
-
如下图所示,给定 n 个学生,每个学生都有 “姓名” 和 “学号” 两项数据。假如希望实现 “输入一个学号,返回对应的姓名” 的查询功能,则可以采用下图所示的哈希表来实现

- 除哈希表外,数组和链表也可以实现查询功能,它们的效率对比如下图所示
- 在哈希表中进行增删查改的时间复杂度都是 O(1),非常高效

1.2 哈希表常用操作
- 哈希表的常见操作包括:初始化、查询操作、添加键值对和删除键值对等
/* 1、初始化哈希表 */
unordered_map<int, string> map;/* 2、添加操作 */
// 在哈希表中添加键值对 (key, value)
map[12836] = "小哈";
map[15937] = "小啰";
map[16750] = "小算";
map[13276] = "小法";
map[10583] = "小鸭";/* 3、查询操作 */
// 向哈希表输入键 key ,得到值 value
string name = map[15937];/* 4、删除操作 */
// 在哈希表中删除键值对 (key, value)
map.erase(10583);
- 哈希表有三种常用遍历方式:遍历键值对、遍历键和遍历值
/* 5、遍历哈希表 */ // 遍历键值对 key->value for (auto kv: map) {cout << kv.first << " -> " << kv.second << endl; } // 单独遍历键 key for (auto kv: map) {cout << kv.first << endl; } // 单独遍历值 value for (auto kv: map) {cout << kv.second << endl; }
1.3 哈希表简单实现
基于数组实现哈希表
- 在哈希表中,将数组中的每个空位称为桶(bucket),每个桶可存储一个键值对。因此,查询操作就是找到 key 对应的桶,并在桶中获取 value。如何基于 key 来定位对应的桶呢?通过哈希函数(hash function)实现
- 哈希函数的作用:将一个较大的输入空间映射到一个较小的输出空间
- 在哈希表中,输入空间是所有 key,输出空间是所有桶(数组索引)。换句话说,输入一个 key,可以通过哈希函数得到该 key 对应的键值对在数组中的存储位置
- 输入一个 key,哈希函数的计算过程分为以下两步
- 通过某种哈希算法 hash() 计算得到哈希值
- 将哈希值对桶数量(数组长度,capacity)取模,从而获取该 key 对应的数组索引 index
index = hash(key) % capacity - 随后,就可以利用 index 在哈希表中访问对应的桶,从而获取 value。设数组长度 capacity = 100、哈希算法 hash(key) = key,易得哈希函数为 key % 100。下图以 key 学号和 value 姓名为例,展示了哈希函数的工作原理

/* 键值对 */
struct Pair {
public:int key;string val;Pair(int key, string val) {// 使用 this 指针来引用当前对象的成员变量,将传入的参数赋值给成员变量 key 和 valthis->key = key;this->val = val;}
};/* 基于数组简易实现的哈希表 */
class ArrayHashMap {
private:vector<Pair *> buckets;public:ArrayHashMap() {// 初始化数组,包含 100 个桶buckets = vector<Pair *>(100);}~ArrayHashMap() {// 释放内存for (const auto &bucket : buckets) {delete bucket;}buckets.clear();}/* 哈希函数 */int hashFunc(int key) {int index = key % 100;return index;}/* 查询操作 */string get(int key) {int index = hashFunc(key);Pair *pair = buckets[index];if (pair == nullptr)return "";return pair->val;}/* 添加操作 */void put(int key, string val) {Pair *pair = new Pair(key, val);int index = hashFunc(key);buckets[index] = pair;}/* 删除操作 */void remove(int key) {int index = hashFunc(key);// 释放内存并置为 nullptrdelete buckets[index];buckets[index] = nullptr;}/* 获取所有键值对 */vector<Pair *> pairSet() {vector<Pair *> pairSet;for (Pair *pair : buckets) {if (pair != nullptr) {pairSet.push_back(pair);}}return pairSet;}/* 获取所有键 */vector<int> keySet() {vector<int> keySet;for (Pair *pair : buckets) {if (pair != nullptr) {keySet.push_back(pair->key);}}return keySet;}/* 获取所有值 */vector<string> valueSet() {vector<string> valueSet;for (Pair *pair : buckets) {if (pair != nullptr) {valueSet.push_back(pair->val);}}return valueSet;}/* 打印哈希表 */void print() {for (Pair *kv : pairSet()) {cout << kv->key << " -> " << kv->val << endl;}}
};
1.4 哈希冲突与扩容
- 本质上看,哈希函数的作用是将所有 key 构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在 “多个输入对应相同输出” 的情况
- 对于上述示例中的哈希函数,当输入的 key 后两位相同时,哈希函数的输出结果也相同。例如,查询学号为 12836 和 20336 的两个学生时,得到
12836 % 100 = 36 20336 % 100 = 36 - 如下图所示,两个学号指向了同一个姓名,这显然是不对的。将这种多个输入对应同一输出的情况称为哈希冲突(hash collision)

- 容易想到,哈希表容量越大,多个 key 被分配到同一个桶中的概率就越低,冲突就越少。因此,可以通过扩容哈希表来减少哈希冲突。如下图所示,扩容前键值对 (136, A) 和 (236, D) 发生冲突,扩容后冲突消失

类似于数组扩容,哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时。并且由于哈希表容量 capacity 改变,需要通过哈希函数来重新计算所有键值对的存储位置,这进一步提高了扩容过程的计算开销。为此,通常会预留足够大的哈希表容量,防止频繁扩容
- 负载因子是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常被作为哈希表扩容的触发条件
2. 哈希冲突
-
通常情况下哈希函数的输入空间远大于输出空间,因此理论上哈希冲突是不可避免的。比如,输入空间为全体整数,输出空间为数组容量大小,则必然有多个整数映射至同一桶索引
-
哈希冲突会导致查询结果错误,严重影响哈希表的可用性。为解决该问题,可以每当遇到哈希冲突时就进行哈希表扩容,直至冲突消失为止。此方法简单粗暴且有效,但效率太低,因为哈希表扩容需要进行大量的数据搬运与哈希值计算。为了提升效率,可以采用以下策略
- 改良哈希表数据结构,使得哈希表可以在存在哈希冲突时正常工作
- 仅在哈希冲突比较严重时,才执行扩容操作
哈希表的结构改良方法主要包括 “链式地址” 和 “开放寻址”
2.1 链式地址
- 在原始哈希表中,每个桶仅能存储一个键值对。链式地址(separate chaining)将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。下图展示了一个链式地址哈希表的例子

-
基于链式地址实现的哈希表的操作方法发生了以下变化
- 查询元素
- 输入 key,经过哈希函数得到桶索引,即可访问链表头节点,然后遍历链表并对比 key 以查找目标键值对
- 添加元素
- 先通过哈希函数访问链表头节点,然后将节点(即键值对)添加到链表中
- 删除元素
- 根据哈希函数的结果访问链表头部,接着遍历链表以查找目标节点,并将其删除
- 查询元素
-
链式地址存在以下局限性
- 占用空间增大,链表包含节点指针,它相比数组更加耗费内存空间
- 查询效率降低,因为需要线性遍历链表来查找对应元素
/* 链式地址哈希表 */
class HashMapChaining {private:int size; // 键值对数量int capacity; // 哈希表容量double loadThres; // 触发扩容的负载因子阈值int extendRatio; // 扩容倍数vector<vector<Pair *>> buckets; // 桶数组public:/* 构造方法 */HashMapChaining() : size(0), capacity(4), loadThres(2.0 / 3.0), extendRatio(2) {buckets.resize(capacity);}/* 析构方法 */~HashMapChaining() {for (auto &bucket : buckets) {for (Pair *pair : bucket) {// 释放内存delete pair;}}}/* 哈希函数 */int hashFunc(int key) {return key % capacity;}/* 负载因子 */double loadFactor() {return (double)size / (double)capacity;}/* 查询操作 */string get(int key) {int index = hashFunc(key);// 遍历桶,若找到 key 则返回对应 valfor (Pair *pair : buckets[index]) {if (pair->key == key) {return pair->val;}}// 若未找到 key 则返回空字符串return "";}/* 添加操作 */void put(int key, string val) {// 当负载因子超过阈值时,执行扩容if (loadFactor() > loadThres) {extend();}int index = hashFunc(key);// 遍历桶,若遇到指定 key ,则更新对应 val 并返回for (Pair *pair : buckets[index]) {if (pair->key == key) {pair->val = val;return;}}// 若无该 key ,则将键值对添加至尾部buckets[index].push_back(new Pair(key, val));size++;}/* 删除操作 */void remove(int key) {int index = hashFunc(key);auto &bucket = buckets[index];// 遍历桶,从中删除键值对for (int i = 0; i < bucket.size(); i++) {if (bucket[i]->key == key) {Pair *tmp = bucket[i];bucket.erase(bucket.begin() + i); // 从中删除键值对delete tmp; // 释放内存size--;return;}}}/* 扩容哈希表 */void extend() {// 暂存原哈希表vector<vector<Pair *>> bucketsTmp = buckets;// 初始化扩容后的新哈希表capacity *= extendRatio;buckets.clear();buckets.resize(capacity);size = 0;// 将键值对从原哈希表搬运至新哈希表for (auto &bucket : bucketsTmp) {for (Pair *pair : bucket) {put(pair->key, pair->val);// 释放内存delete pair;}}}/* 打印哈希表 */void print() {for (auto &bucket : buckets) {cout << "[";for (Pair *pair : bucket) {cout << pair->key << " -> " << pair->val << ", ";}cout << "]\n";}}
};
当链表很长时,查询效率 O(n) 很差。此时可以将链表转换为 “AVL 树” 或 “红黑树”,从而将查询操作的时间复杂度优化至 O(log n)
2.2 开放寻址
- 开放寻址(open addressing)不引入额外的数据结构,而是通过 “多次探测” 来处理哈希冲突,探测方式主要包括线性探测、平方探测、多次哈希等
2.2.1 线性探测
-
线性探测采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同
- 插入元素
- 通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为 1),直至找到空桶,将元素插入其中
- 查找元素
- 若发现哈希冲突,则使用相同步长向后线性遍历,直到找到对应元素,返回 value 即可
- 如果遇到空桶,说明目标元素不在哈希表中,返回 None
- 插入元素
-
下图展示了开放寻址(线性探测)哈希表的键值对分布。根据此哈希函数,最后两位相同的 key 都会被映射到相同的桶。而通过线性探测,它们被依次存储在该桶以及之下的桶中

- 然而,线性探测容易产生 “聚集现象”。具体来说,数组中连续被占用的位置越长,这些连续位置发生哈希冲突的可能性越大,从而进一步促使该位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化
- 不能在开放寻址哈希表中直接删除元素。这是因为删除元素会在数组内产生一个空桶 None,而当查询元素时,线性探测到该空桶就会返回,因此在该空桶之下的元素都无法再被访问到,程序可能误判这些元素不存在

-
为了解决该问题,可以采用懒删除(lazy deletion)机制
- 它不直接从哈希表中移除元素,而是利用一个常量 TOMBSTONE 来标记这个桶
- 在该机制下,None 和 TOMBSTONE 都代表空桶,都可以放置键值对
- 但不同的是,线性探测到 TOMBSTONE 时应该继续遍历,因为其之下可能还存在键值对
-
然而,懒删除可能会加速哈希表的性能退化。这是因为每次删除操作都会产生一个删除标记,随着 TOMBSTONE 的增加,搜索时间也会增加,因为线性探测可能需要跳过多个 TOMBSTONE 才能找到目标元素
- 为此,考虑在线性探测中记录遇到的首个 TOMBSTONE 的索引,并将搜索到的目标元素与该 TOMBSTONE 交换位置。这样做的好处是当每次查询或添加元素时,元素会被移动至距离理想位置(探测起始点)更近的桶,从而优化查询效率
-
以下代码实现了一个包含懒删除的开放寻址(线性探测)哈希表。为了更加充分地使用哈希表的空间,将哈希表看作是一个 “环形数组”,当越过数组尾部时,回到头部继续遍历
/* 开放寻址哈希表 */ class HashMapOpenAddressing {private:int size; // 键值对数量int capacity = 4; // 哈希表容量const double loadThres = 2.0 / 3.0; // 触发扩容的负载因子阈值const int extendRatio = 2; // 扩容倍数vector<Pair *> buckets; // 桶数组Pair *TOMBSTONE = new Pair(-1, "-1"); // 删除标记public:/* 构造方法 */HashMapOpenAddressing() : size(0), buckets(capacity, nullptr) {}/* 析构方法 */~HashMapOpenAddressing() {for (Pair *pair : buckets) {if (pair != nullptr && pair != TOMBSTONE) {delete pair;}}delete TOMBSTONE;}/* 哈希函数 */int hashFunc(int key) {return key % capacity;}/* 负载因子 */double loadFactor() {return (double)size / capacity;}/* 搜索 key 对应的桶索引 */int findBucket(int key) {int index = hashFunc(key);int firstTombstone = -1;// 线性探测,当遇到空桶时跳出while (buckets[index] != nullptr) {// 若遇到 key ,返回对应桶索引if (buckets[index]->key == key) {// 若之前遇到了删除标记,则将键值对移动至该索引if (firstTombstone != -1) {buckets[firstTombstone] = buckets[index];buckets[index] = TOMBSTONE;return firstTombstone; // 返回移动后的桶索引}return index; // 返回桶索引}// 记录遇到的首个删除标记if (firstTombstone == -1 && buckets[index] == TOMBSTONE) {firstTombstone = index;}// 计算桶索引,越过尾部返回头部index = (index + 1) % capacity;}// 若 key 不存在,则返回添加点的索引return firstTombstone == -1 ? index : firstTombstone;}/* 查询操作 */string get(int key) {// 搜索 key 对应的桶索引int index = findBucket(key);// 若找到键值对,则返回对应 valif (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {return buckets[index]->val;}// 若键值对不存在,则返回空字符串return "";}/* 添加操作 */void put(int key, string val) {// 当负载因子超过阈值时,执行扩容if (loadFactor() > loadThres) {extend();}// 搜索 key 对应的桶索引int index = findBucket(key);// 若找到键值对,则覆盖 val 并返回if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {buckets[index]->val = val;return;}// 若键值对不存在,则添加该键值对buckets[index] = new Pair(key, val);size++;}/* 删除操作 */void remove(int key) {// 搜索 key 对应的桶索引int index = findBucket(key);// 若找到键值对,则用删除标记覆盖它if (buckets[index] != nullptr && buckets[index] != TOMBSTONE) {delete buckets[index];buckets[index] = TOMBSTONE;size--;}}/* 扩容哈希表 */void extend() {// 暂存原哈希表vector<Pair *> bucketsTmp = buckets;// 初始化扩容后的新哈希表capacity *= extendRatio;buckets = vector<Pair *>(capacity, nullptr);size = 0;// 将键值对从原哈希表搬运至新哈希表for (Pair *pair : bucketsTmp) {if (pair != nullptr && pair != TOMBSTONE) {put(pair->key, pair->val);delete pair;}}}/* 打印哈希表 */void print() {for (Pair *pair : buckets) {if (pair == nullptr) {cout << "nullptr" << endl;} else if (pair == TOMBSTONE) {cout << "TOMBSTONE" << endl;} else {cout << pair->key << " -> " << pair->val << endl;}}} };
2.2.2 平方探测
-
平方探测与线性探测类似,都是开放寻址的常见策略之一。当发生冲突时,平方探测不是简单地跳过一个固定的步数,而是跳过 “探测次数的平方” 的步数,即 1, 4, 9, … 步
-
平方探测优点
- 平方探测通过跳过平方的距离,试图缓解线性探测的聚集效应
- 平方探测会跳过更大的距离来寻找空位置,有助于数据分布得更加均匀
-
平方探测缺点
- 仍然存在聚集现象,即某些位置比其他位置更容易被占用
- 由于平方的增长,平方探测可能不会探测整个哈希表,这意味着即使哈希表中有空桶,平方探测也可能无法访问到它
2.2.3 多次哈希
- 多次哈希使用多个哈希函数 f_1(x)、f_2(x)、f_3(x)、… 进行探测
- 插入元素
- 若哈希函数 f_1(x) 出现冲突,则尝试 f_2(x),以此类推,直到找到空桶后插入元素
- 查找元素
- 在相同的哈希函数顺序下进行查找,直到找到目标元素时返回
- 或当遇到空桶或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回 None
- 插入元素
与线性探测相比,多次哈希方法不易产生聚集,但多个哈希函数会增加额外的计算量
3. 哈希算法
无论是开放寻址还是链地址法,它们只能保证哈希表可以在发生冲突时正常工作,但无法减少哈希冲突的发生
- 如果哈希冲突过于频繁,哈希表的性能则会急剧劣化。如下图所示,对于链地址哈希表,理想情况下键值对平均分布在各个桶中,达到最佳查询效率;最差情况下所有键值对都被存储到同一个桶中,时间复杂度退化至 O(n)

- 键值对的分布情况由哈希函数决定
index = hash(key) % capacity // 哈希函数- 当哈希表容量 capacity 固定时,哈希算法 hash() 决定了输出值,进而决定了键值对在哈希表中的分布情况。这意味着,为了减小哈希冲突的发生概率,应当将注意力集中在哈希算法 hash() 的设计上
3.1 哈希算法的设计
- 加法哈希
- 对输入的每个字符的 ASCII 码进行相加,将得到的总和作为哈希值
- 乘法哈希
- 利用了乘法的不相关性,每轮乘以一个常数,将各个字符的 ASCII 码累积到哈希值中
- 异或哈希
- 将输入数据的每个元素通过异或操作累积到一个哈希值中
- 旋转哈希
- 将每个字符的 ASCII 码累积到一个哈希值中,每次累积之前都会对哈希值进行旋转操作
/* 加法哈希 */ int addHash(string key) {long long hash = 0;const int MODULUS = 1000000007;for (unsigned char c : key) {hash = (hash + (int)c) % MODULUS;}return (int)hash; }/* 乘法哈希 */ int mulHash(string key) {long long hash = 0;const int MODULUS = 1000000007;for (unsigned char c : key) {hash = (31 * hash + (int)c) % MODULUS;}return (int)hash; }/* 异或哈希 */ int xorHash(string key) {int hash = 0;const int MODULUS = 1000000007;for (unsigned char c : key) {hash ^= (int)c;}return hash & MODULUS; }/* 旋转哈希 */ int rotHash(string key) {long long hash = 0;const int MODULUS = 1000000007;for (unsigned char c : key) {hash = ((hash << 4) ^ (hash >> 28) ^ (int)c) % MODULUS;}return (int)hash; } - 每种哈希算法的最后一步都是对大质数 1000000007 取模,以确保哈希值在合适的范围内。值得思考的是,为什么要强调对质数取模,或者说对合数取模的弊端是什么?
- 当使用大质数作为模数时,可以最大化地保证哈希值的均匀分布。因为质数不会与其他数字存在公约数,可以减少因取模操作而产生的周期性模式,从而避免哈希冲突
- 通常选取质数作为模数,并且这个质数最好足够大,以尽可能消除周期性模式,提升哈希算法的稳健性
3.2 常见哈希算法
上述简单哈希算法比较脆弱,比如:由于加法和异或满足交换律,因此加法哈希和异或哈希无法区分内容相同但顺序不同的字符串,这可能会加剧哈希冲突,并引起一些安全问题
- 在实际中,通常会用一些标准哈希算法,例如 MD5、SHA-1、SHA-2、SHA3 等。它们可以将任意长度的输入数据映射到恒定长度的哈希值
- MD5 和 SHA-1 已多次被成功攻击,因此它们被各类安全应用弃用
- SHA-2 系列中的 SHA-256 是最安全的哈希算法之一,仍未出现成功的攻击案例,因此常被用在各类安全应用与协议中
- SHA-3 相较 SHA-2 的实现开销更低、计算效率更高,但目前使用覆盖度不如 SHA-2 系列

3.3 数据结构的哈希值
-
哈希表的 key 可以是整数、小数或字符串等数据类型。编程语言通常会为这些数据类型提供内置的哈希算法,用于计算哈希表中的桶索引
int num = 3; size_t hashNum = hash<int>()(num); // 整数 3 的哈希值为 3bool bol = true; size_t hashBol = hash<bool>()(bol); // 布尔量 1 的哈希值为 1double dec = 3.14159; size_t hashDec = hash<double>()(dec); // 小数 3.14159 的哈希值为 4614256650576692846string str = "Hello 算法"; size_t hashStr = hash<string>()(str); // 字符串 Hello 算法 的哈希值为 15466937326284535026// 在 C++ 中,内置 std:hash() 仅提供基本数据类型的哈希值计算 // 数组、对象的哈希值计算需要自行实现 -
在许多编程语言中,只有不可变对象才可作为哈希表的 key。假如将列表(动态数组)作为 key ,当列表的内容发生变化时,它的哈希值也随之改变,就无法在哈希表中查询到原先的 value
-
虽然自定义对象(比如链表节点)的成员变量是可变的,但它是可哈希的。这是因为对象的哈希值通常是基于内存地址生成的,即使对象的内容发生了变化,但它的内存地址不变,哈希值仍然是不变的
相关文章:
数据结构与算法(四):哈希表
参考引用 Hello 算法 Github:hello-algo 1. 哈希表 1.1 哈希表概述 哈希表(hash table),又称散列表,其通过建立键 key 与值 value 之间的映射,实现高效的元素查询 具体而言,向哈希表输入一个键…...
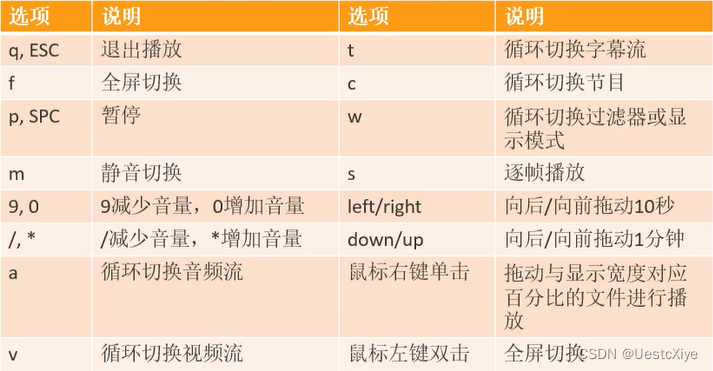
FFmpeg 命令:从入门到精通 | ffplay 播放控制选项
FFmpeg 命令:从入门到精通 | ffplay 播放控制选项 FFmpeg 命令:从入门到精通 | ffplay 播放控制选项选项表格图片 FFmpeg 命令:从入门到精通 | ffplay 播放控制选项 选项表格 项目说明Q,Esc退出播放F,鼠标左键双击全…...

代码随想录day59
647. 回文子串 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成&#…...
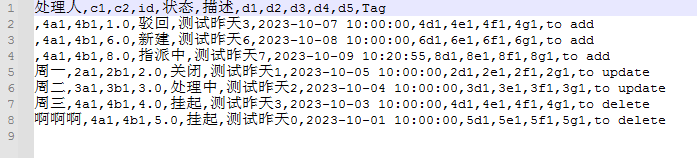
【小工具-生成合并文件】使用python实现2个excel文件根据主键合并生成csv文件
1 小工具说明 1.1 功能说明 一般来说,我们会先有一个老的文件,这个文件内容是定制好相关列的表格,作为每天的报告。 当下一天来的时候,需要根据新的报表文件和昨天的报表文件做一个合并,合并的时候就会出现有些事新增…...
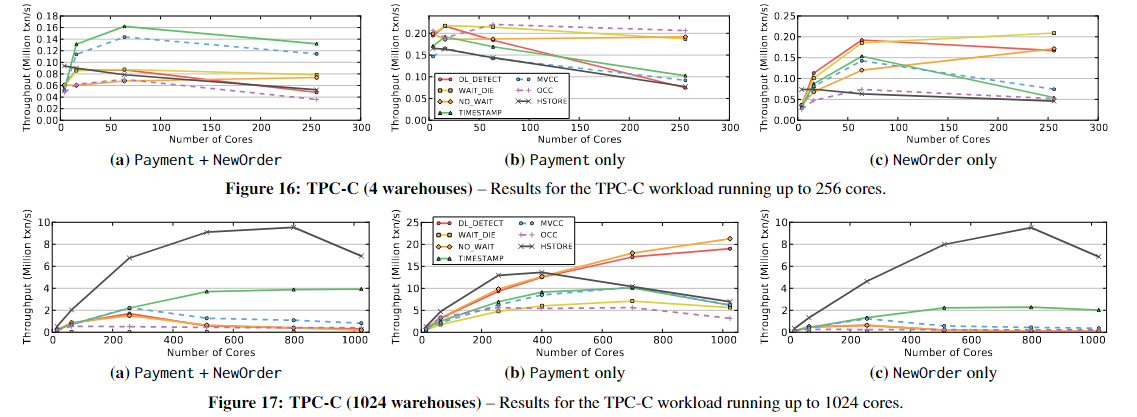
【论文阅读】An Evaluation of Concurrency Control with One Thousand Cores
An Evaluation of Concurrency Control with One Thousand Cores Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores ABSTRACT 随着多核处理器的发展,一个芯片可能有几十乃至上百个core。在数百个线程并行运行的情况下&…...
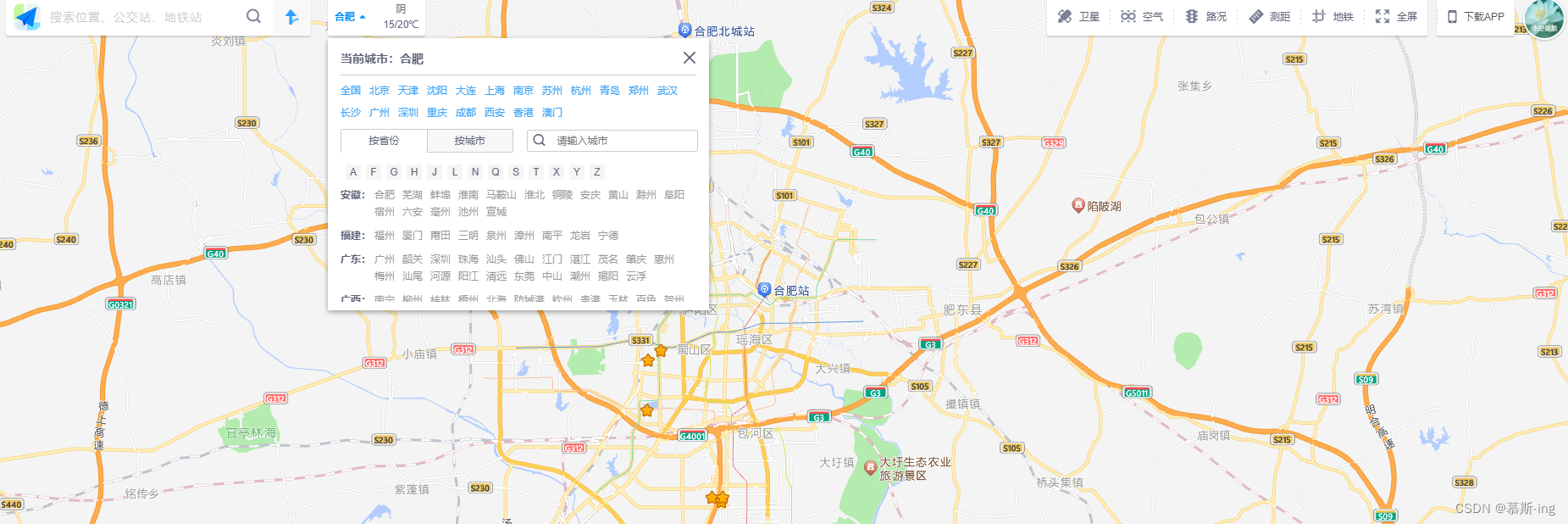
网页版”高德地图“如何设置默认城市?
问题: 每次打开网页版高德地图时默认定位的都是“北京”,想设置起始点为目前本人所在城市,烦恼的是高德地图默认的初始位置是北京。 解决: 目前网页版高德地图暂不支持设置起始点,打开默认都是北京,只能将…...

小谈设计模式(8)—代理模式
小谈设计模式(8)—代理模式 专栏介绍专栏地址专栏介绍 代理模式代理模式角色分析抽象主题(Subject)真实主题(Real Subject)代理(Proxy) 应用场景远程代理虚拟代理安全代理智能引用代…...

queryWrapper的使用教程
大于、等于、小于 eq 等于 例:queryWrapper.eq("属性","lkm") ——> 属性 lkm ne 不等于 例:queryWrapper.ne("属性","lkm") ——> 属性<> lkm gt 大于 例:queryWrapper.gt("属性…...

数组模拟双链表
文章目录 QuestionIdeasCode Question 实现一个双链表,双链表初始为空,支持 5 种操作: 在最左侧插入一个数; 在最右侧插入一个数; 将第 k 个插入的数删除; 在第 k 个插入的数左侧插入一个数; …...
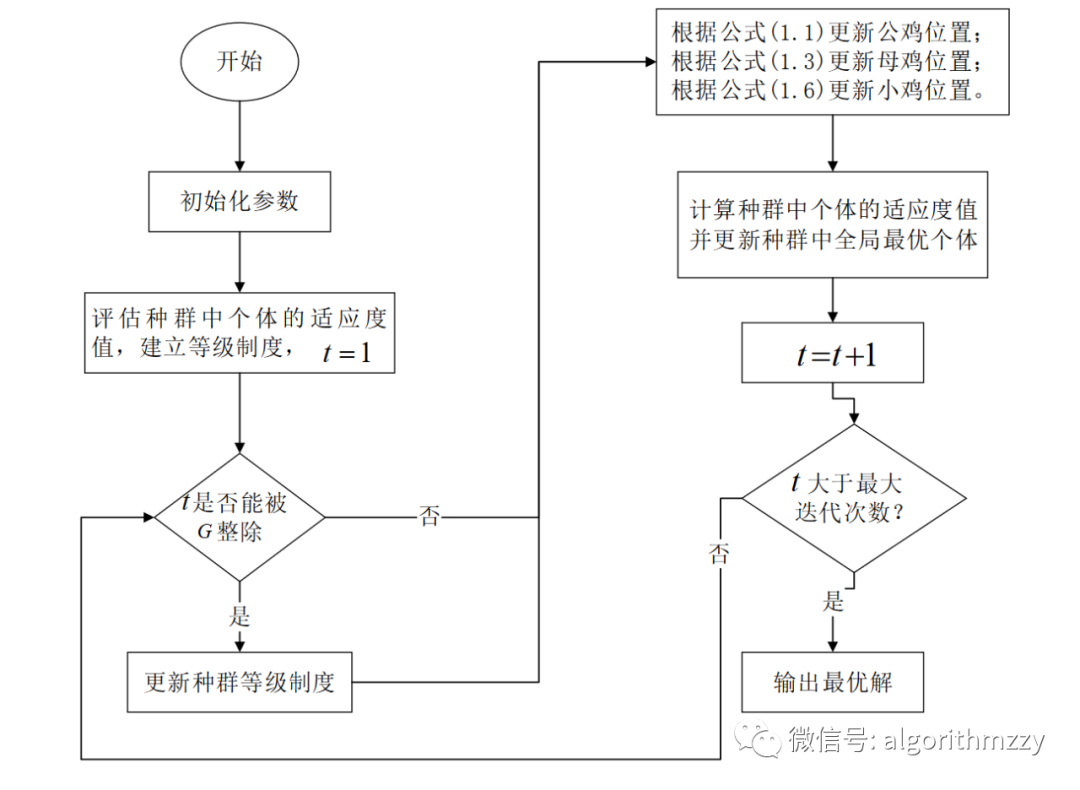
鸡群优化(CSO)算法(含MATLAB代码)
先做一个声明:文章是由我的个人公众号中的推送直接复制粘贴而来,因此对智能优化算法感兴趣的朋友,可关注我的个人公众号:启发式算法讨论。我会不定期在公众号里分享不同的智能优化算法,经典的,或者是近几年…...
3. 安装lombok maven镜像设置
安装lombok & maven镜像设置 一、maven镜像设置 Maven:负责进行项目管理、依赖工具管理的 软件。 快捷解决方案: 1.方法一 直接配置系统默认的文件 各个人因为登录的用户名不同,所以目录名不同。 2.方法二 自定义本地仓库的位置 完成之后重新打…...

详谈Spring
作者:爱塔居 专栏:JavaEE 目录 一、Spring是什么? 1.1 Spring框架的一些核心特点: 二、IoC(控制反转)是什么? 2.1 实现手段 2.2 依赖注入(DI)的实现原理 2.3 优点 三、AO…...
PyTorch入门之【AlexNet】
参考文献:https://www.bilibili.com/video/BV1DP411C7Bw/?spm_id_from333.999.0.0&vd_source98d31d5c9db8c0021988f2c2c25a9620 AlexNet 是一个经典的卷积神经网络模型,用于图像分类任务。 目录 大纲dataloadermodeltraintest 大纲 各个文件的作用&…...
(六)正点原子STM32MP135移植——内核移植
目录 一、概述 二、编译官方代码 三、移植 四、编译 一、概述 前面已经移植好了TF-A、optee、u-boot,在u-boot能正常跑起来的情况下,现在来移植内核。 二、编译官方代码 进入kernel目录 2.1 解压源码、打补丁 /* 解压源码 */ tar xf linux-6.1.28.…...

自媒体工作内容管理助手
内容助手 访问地址:editor.yunwow.cn 背景介绍 最近在学习流量运营, 流量运营的第一站是内容创作, 我试过不少原创内容,都是跟生活相关的例如:录一段联琴的视频、录一段秋天的风景、写一段生活感悟、发一段小宠物的生…...

Echarts 教程一
Echarts 教程一 可视化大屏幕适配方案可视化大屏幕布局方案Echart 图表通用配置部分解决方案1. titile2. tooltip3. xAxis / yAxis 常用配置4. legend5. grid6. series7.color Echarts API 使用全局echarts对象echarts实例对象 可视化大屏幕适配方案 rem flexible.js 关于flex…...

【Kubernetes】Kubernetes 对象是什么?
什么是 Kubernetes 对象?常见的 Kubernetes 对象参考🔎感谢 💖 什么是 Kubernetes 对象? Kubernetes 对象是持久化的实体,用于描述整个集群的状态和配置。它们是在 etcd 等持久化存储中存储的,因此它们的状…...

【C++设计模式之模板模式】分析及示例
C之模板模式 描述实现原理示例步骤1步骤1 分析步骤2步骤2 分析调用输出结果 结论 描述 模板模式(Template Pattern)是设计模式中的一种行为型模式。 该模式定义一个操作中的算法骨架,而将具体的算法实现延迟到子类中。 模板模式使得子类可以…...
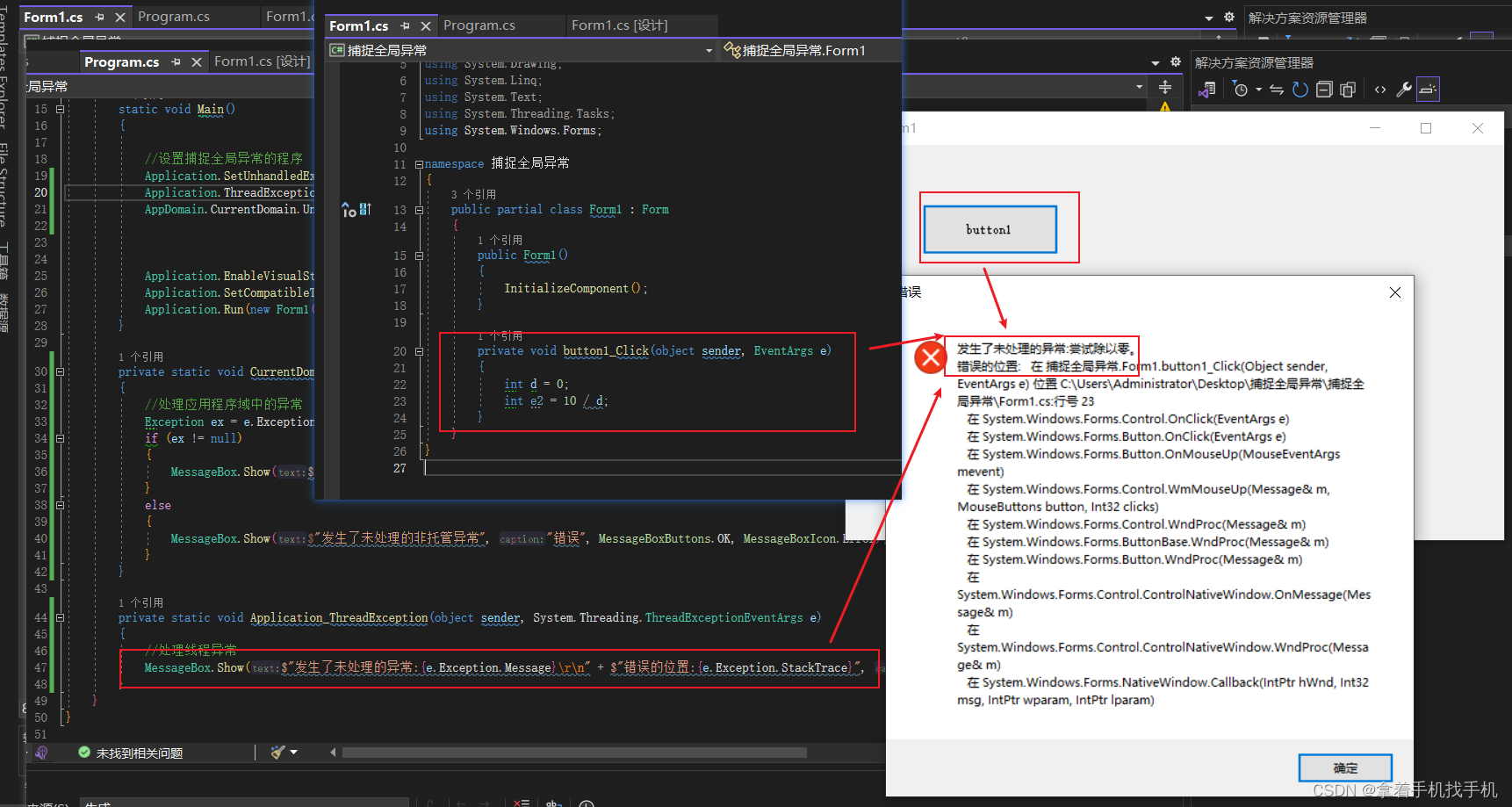
C#捕捉全局异常
1.运行图片 2.源码 using System; using System.Collections.Generic; using System.Linq; using System.Threading.Tasks; using System.Windows.Forms;namespace 捕捉全局异常 {internal static class Program{/// <summary>/// 应用程序的主入口点。/// </summary…...

java.text.ParseException: Unparseable date: “2023-09-06T09:08:18“
问题描述: java.text.ParseException: Unparseable date: “2023-09-06T09:08:18” 这是在String类型转Date类型出现的错误,主要是String类型时间中间有一个T在转换的过程出现问题. 解决方法: SimpleDateFormat simpleDateFormat new SimpleDateFormat…...

Gorilla技术创新奖:表彰推动API调用领域发展的杰出贡献者
Gorilla技术创新奖:表彰推动API调用领域发展的杰出贡献者 【免费下载链接】gorilla Gorilla: An API store for LLMs 项目地址: https://gitcode.com/gh_mirrors/go/gorilla Gorilla作为领先的API调用平台,始终致力于推动大语言模型(L…...

pydata-book窗口函数应用:滚动统计与扩展窗口计算完全指南
pydata-book窗口函数应用:滚动统计与扩展窗口计算完全指南 【免费下载链接】pydata-book wesm/pydata-book: 这是Wes McKinney编写的《Python for Data Analysis》一书的源代码仓库,书中涵盖了使用pandas、NumPy和其他相关库进行数据处理和分析的实践案例…...

麒麟服务器操作系统中安装NVIDIA5080显卡驱动
编辑配置文件禁用开源驱动: 在终端中输入如下命令 vi /usr/lib/modprobe.d/dist-blacklist.conf调用编辑器,在最后两行加入以下命令,保存修改。 blacklist nouveau options nouveau modeset=0 3.3.将路径/boot/initrd.img-xxxx文件备份 mv /boot/initramfs-$(uname -r).…...
Flutter 三方库 w_transport 的鸿蒙化适配指南 - 构建高可靠网络传输层、实现鸿蒙端复杂协议交互实战
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net Flutter 三方库 w_transport 的鸿蒙化适配指南 - 构建高可靠网络传输层、实现鸿蒙端复杂协议交互实战 前言 在开发 Flutter for OpenHarmony 大型商业应用时,简单的 HTTP 请求…...

De Boor算法实战:从理论到B样条曲线点计算的完整实现
1. 从“搭积木”到“画曲线”:为什么你需要De Boor算法? 如果你玩过3D建模、做过动画路径设计,或者搞过机器人轨迹规划,那你肯定遇到过“画一条光滑曲线”这个看似简单、实则让人头疼的问题。直接用直线段连接控制点?太…...

数电核心:从74HC194到序列信号,揭秘移位寄存器的三大实战应用
1. 从“记忆”到“流动”:重新认识移位寄存器 很多刚接触数字电路的朋友,一听到“寄存器”这个词,头就大了,总觉得它和锁存器、触发器搅在一起,分不清楚。其实,你可以把它们想象成仓库管理员。锁存器就像一…...
)
JavaScript重定义this指向(apply、call、bind)
一、apply() 在JavaScript中,apply()是函数的原型方法(Function.prototype.apply),用于调用一个函数,并显式指定该函数内部的this值,同时以数组(或类数组对象)的形式传入参数。基本语…...

MFC CDialog触摸屏长按不响应右键消息解决方案
方案1 重写虚函数GetGestureStatus,返回0即可。方案2 响应WM_TABLET_QUERYSYSTEMGESTURESTATUS消息,返回0即可。方案3 用vs2010之前的版本编译,vs2010开始默认CWnd类出于性能原因返回TABLET_DISABLE_PRESSANDHOLD。注意:如果子窗口…...

Leather Dress Collection部署案例:高校服装设计课程AI辅助教学落地实践
Leather Dress Collection部署案例:高校服装设计课程AI辅助教学落地实践 1. 引言 想象一下,服装设计专业的学生在构思毕业设计作品时,脑海中浮现出一个大胆的想法:一套融合了未来主义与复古元素的皮革连衣裙。传统的设计流程需要…...

CLIP-GmP-ViT-L-14与AI Agent联动:构建自主图文分析与报告生成智能体
CLIP-GmP-ViT-L-14与AI Agent联动:构建自主图文分析与报告生成智能体 你有没有遇到过这样的场景?市场部同事发来一张新品海报和一段宣传文案,问你:“你觉得这图和文案搭不搭?” 或者,你需要快速分析一批电…...