7、【Qlib】【主要组件】Data Layer:数据框架与使用
7、【主要组件】Data Layer:数据框架与使用
- 简介
- 数据准备
- Qlib 格式数据
- Qlib 格式数据集
- 自动更新日频率数据
- 将 CSV 格式转换为 Qlib 格式
- 股票池(市场)
- 多股票模式
- 数据API
- 数据检索
- 特征
- 过滤器
- 数据加载器
- QlibDataLoader
- StaticDataLoader
- Interface
- 数据处理器
- DataHandlerLP
- Processor
- Example
- 数据集
- 缓存
- 全局内存缓存
- ExpressionCache
- 数据集缓存
简介
Data Layer 提供了用户友好的 API 来管理和检索数据。它提供了高性能的数据基础设施。
它是为量化投资设计的。例如,用户可以轻松地使用 Data Layer 构建公式化的 alpha 值。
- 数据准备
- 数据API
- 数据加载器
- 数据处理器
- 数据集
- 缓存
- 数据和缓存文件结构
以下是一个 Qlib 数据工作流的典型示例
- 用户下载数据并将数据转换成 Qlib 格式(文件名后缀为 .bin)。在这一步中,通常只有一些基本数据被存储在硬盘上(例如 OHLCV)。
- 基于 Qlib 的表达式引擎创建一些基本特征(例如,“Ref($close, 60) / $close”,即过去 60 个交易日的收益)。表达式引擎支持的运算符可以在这里找到。这一步通常在 Qlib 的数据加载器中实现,该加载器是数据处理器的一个组成部分。
- 如果用户需要更复杂的数据处理(例如数据归一化),数据处理器支持用户自定义的处理器来处理数据(有预定义的处理器)。这些处理器与表达式引擎中的运算符不同。它是为了设计一些在表达式引擎的运算符中难以支持的复杂数据处理方法。
- 最后,数据集负责从数据处理器处理过的数据中准备模型特定的数据集。
数据准备
Qlib 格式数据
我们特别设计了一个数据结构来管理财务数据,这些数据将以文件名后缀 .bin 存储(我们将它们称为 .bin 文件,.bin 格式或 qlib 格式)。.bin 文件是为了在财务数据上进行科学计算而设计的。
Qlib 提供了两种不同的现成数据集:
| Dataset | US Market | China Market |
|---|---|---|
| Alpha360 | √ | √ |
| Alpha158 | √ | √ |
| 此外,Qlib 还提供了一个高频数据集。 |
Qlib 格式数据集
Qlib 提供了一个现成的 .bin 格式数据集,用户可以使用 scripts/get_data.py 脚本来下载以下的中国股票数据集。用户也可以使用 numpy 来加载 .bin 文件以验证数据。价格和成交量数据看起来与实际交易价格不同,这是因为它们已经被调整了(调整后的价格)。然后你可能会发现,不同的数据源之间的调整价格可能会有所不同。这是因为不同的数据源在调整价格的方式上可能会有所不同。在调整它们时,Qlib 将每只股票的第一个交易日的价格标准化为 1。用户可以利用 $factor 来获取原始的交易价格(例如,使用 $close / $factor 来获取原始的收盘价格)。
这里有一些关于 Qlib 价格调整的讨论。
- https://github.com/microsoft/qlib/issues/991#issuecomment-1075252402
# download 1d
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn# download 1min
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/qlib_cn_1min --region cn --interval 1min
除了中国股票数据外,Qlib 还包括一个美国股票数据集,可以使用以下命令下载:
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/us_data --region us
在运行上述命令后,用户可以在 ~/.qlib/qlib_data/cn_data 目录和 ~/.qlib/qlib_data/us_data 目录中分别找到以 Qlib 格式存储的中国股票和美国股票数据。
Qlib 也在 scripts/data_collector 文件夹中提供了脚本,以帮助用户爬取互联网上的最新数据并将其转换为 qlib 格式。
当使用这个数据集初始化 Qlib 时,用户可以使用它来构建和评估他们自己的模型。
自动更新日频率数据
建议用户手动更新一次数据(–trading_date 2021-05-25),然后将其设置为自动更新。
- 每个交易日自动更新数据至“qlib”目录(Linux)
- 使用 crontab:crontab -e
- 设置定时任务:
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
script path:scripts/data_collector/yahoo/collector.py
- 手动更新数据
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
- trading_date:开始交易日
- end_date:交易日结束(不包括)
将 CSV 格式转换为 Qlib 格式
Qlib提供了脚本 scripts/dump_bin.py,只要数据格式正确,就能将CSV格式的任何数据转换为.bin文件(Qlib格式)。
除了下载准备好的演示数据外,用户还可以直接从收集器下载演示数据,以参考CSV格式。以下是一些例子:
每日数据:
python scripts/get_data.py download_data --file_name csv_data_cn.zip --target_dir ~/.qlib/csv_data/cn_data
一分钟数据:
python scripts/data_collector/yahoo/collector.py download_data --source_dir ~/.qlib/stock_data/source/cn_1min --region CN --start 2021-05-20 --end 2021-05-23 --delay 0.1 --interval 1min --limit_nums 10
用户也可以提供自己的CSV格式数据。然而,CSV数据必须满足以下标准:
- CSV文件以特定股票命名,或CSV文件包含股票名称的列
- 以股票命名CSV文件:SH600000.csv,AAPL.csv(不区分大小写)。
- CSV文件包含一个股票名称的列。在导出数据时,用户必须指定列名。以下是一个例子:
python scripts/dump_bin.py dump_all ... --symbol_field_name symbol
其中数据的格式如下:
| symbol | close |
|---|---|
| close | 120 |
- CSV文件必须包含一个日期列,在导出数据时,用户必须指定日期列的名称。以下是一个例子:
python scripts/dump_bin.py dump_all ... --date_field_name date
其中数据的格式如下:
| symbol | date | close | open | volume |
|---|---|---|---|---|
| SH600000 | 2020-11-01 | 120 | 121 | 12300000 |
| SH600000 | 2020-11-02 | 123 | 120 | 12300000 |
假设用户在目录~/.qlib/csv_data/my_data中准备了他们的CSV格式数据,他们可以运行以下命令来开始转换。
python scripts/dump_bin.py dump_all --csv_path ~/.qlib/csv_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --include_fields open,close,high,low,volume,factor
要查看在将数据导出到.bin文件时支持的其他参数,用户可以通过运行以下命令来参考信息:
python dump_bin.py dump_all --help
转换后,用户可以在目录 ~/.qlib/qlib_data/my_data 中找到他们的 Qlib 格式数据。
–include_fields 的参数应与 CSV 文件的列名相对应。由 Qlib 提供的数据集的列名应至少包括开盘价(open)、收盘价(close)、最高价(high)、最低价(low)、交易量(volume)和因子(factor)。
- open 经调整的开盘价
- close 经调整的收盘价
- high 经调整的最高价
- low 经调整的最低价
- volume 经调整的交易量
- factor 复权因子。通常来说,复权因子(factor)= 调整后价格(adjusted_price)/ 原始价格(original_price)
在 Qlib 数据处理的约定中,如果股票被暂停,开盘价(open)、收盘价(close)、最高价(high)、最低价(low)、交易量(volume)、金额(money)和复权因子(factor)将被设置为 NaN(非数字)。如果您想使用您自己的 alpha 因子,而它不能通过 OCHLV(开、收、高、低、量)计算,比如 PE、EPS 等,您可以将其与 OHCLV 一起添加到 CSV 文件中,然后将其转储为 Qlib 格式数据。
股票池(市场)
Qlib 将股票池定义为股票列表及其日期范围。可以按照以下方式导入预定义的股票池(例如 csi300)。
python collector.py --index_name CSI300 --qlib_dir <user qlib data dir> --method parse_instruments
多股票模式
Qlib现在为用户提供了两种不同的股票模式:中国股票模式和美国股票模式。以下是这两种模式的一些不同设置:
| Region | Trade Unit | Limit Threshold |
|---|---|---|
| China | 100 | 0.099 |
| US | 1 | None |
交易单位定义了一个交易中可以使用的股票单位数量,而限制阈值定义了设定给股票涨跌百分比的边界。
- 如果用户在中国股票模式下使用 Qlib,需要中国股票数据。用户可以按照以下步骤在中国股票模式下使用 Qlib:
- 下载 Qlib 格式的中国股票数据
- 初始化Qlib为中国股票模式
假设用户将Qlib格式的数据下载到了目录~/.qlib/qlib_data/cn_data中。那么用户只需要像下面这样初始化Qlib:
from qlib.constant import REG_CN
qlib.init(provider_uri='~/.qlib/qlib_data/cn_data', region=REG_CN)
- 如果用户想要使用Qlib的美股模式,需要准备美股的数据。Qlib也提供了下载美股数据的脚本。用户可以按照以下步骤使用Qlib的美股模式:
- 下载 Qlib 格式的美国股票数据
- 初始化Qlib为美股模式
假设用户已经将Qlib格式的数据放在了目录~/.qlib/qlib_data/us_data中。那么用户只需要像下面这样初始化Qlib:
from qlib.config import REG_US
qlib.init(provider_uri='~/.qlib/qlib_data/us_data', region=REG_US)
数据API
数据检索
用户可以使用 qlib.data 中的API来获取数据。
特征
Qlib提供了Feature和ExpressionOps来根据用户的需求获取特征。
-
Feature
从数据提供商加载数据。用户可以获取诸如 h i g h 、 high、 high、low、 o p e n 、 open、 open、close等特征,这些特征应该与–include_fields的参数相对应。 -
ExpressionOps
ExpressionOps 将使用运算符进行特征构建。要了解更多关于运算符的信息,请参考运算符API。此外,Qlib支持用户定义自己的自定义运算符,示例已在tests/test_register_ops.py中提供。
过滤器
Qlib提供了NameDFilter和ExpressionDFilter,以根据用户的需求筛选工具。
-
NameDFilter
根据规定的名称格式筛选仪器。需要提供名称规则的正则表达式。 -
ExpressionDFilter
根据特定表达式筛选仪器。需要提供表示特定特征字段的表达式规则。- 基本特征过滤器:规则表达式 = ‘ c l o s e / close/ close/open>5’
- 横截面特征过滤器:规则表达式 = ‘ r a n k ( rank( rank(close)<10’
- 时间序列特征过滤器:规则表达式 = ‘ R e f ( Ref( Ref(close, 3)>100’
以下是一个简单的示例,演示了如何在基本的Qlib工作流配置文件中使用过滤器:
filter: &filterfilter_type: ExpressionDFilterrule_expression: "Ref($close, -2) / Ref($close, -1) > 1"filter_start_time: 2010-01-01filter_end_time: 2010-01-07keep: Falsedata_handler_config: &data_handler_configstart_time: 2010-01-01end_time: 2021-01-22fit_start_time: 2010-01-01fit_end_time: 2015-12-31instruments: *marketfilter_pipe: [*filter]
数据加载器
Qlib中的数据加载器旨在从原始数据源加载原始数据。这些数据将在数据处理模块中加载和使用。
QlibDataLoader
在Qlib中,QlibDataLoader类是一个接口,允许用户从Qlib数据源加载原始数据。
StaticDataLoader
在Qlib中,StaticDataLoader类是一个接口,允许用户从文件或提供的数据加载原始数据。
Interface
以下是QlibDataLoader类的一些接口:
classqlib.data.dataset.loader.DataLoader
DataLoader旨在从原始数据源加载原始数据。
load(instruments, start_time=None, end_time=None) → pandas.core.frame.DataFrame
将数据加载为pd.DataFrame。
数据处理器
Qlib中的数据处理器模块旨在处理大多数模型将使用的常见数据处理方法。
用户可以通过qrun在自动工作流中使用数据处理器。
DataHandlerLP
除了可以通过qrun在自动工作流中使用数据处理器外,数据处理器还可以作为一个独立的模块,用户可以通过它轻松地预处理数据(标准化、删除NaN等)并构建数据集。
为了实现这一目标,Qlib提供了一个基础类 qlib.data.dataset.DataHandlerLP。这个类的核心思想是:我们将拥有一些可学习的处理器,它们可以学习数据处理的参数(例如,z分数归一化的参数)。当新数据进入时,这些经过训练的处理器可以处理新数据,从而使得以高效方式处理实时数据成为可能。
Processor
Qlib中的处理器模块被设计为可学习的,并且负责处理数据处理任务,如归一化和删除无/空值的特征/标签。
Qlib 提供了以下处理器:
- DropnaProcessor:删除 N/A 特征的处理器。
- DropnaLabel:删除 N/A 标签的处理器。
- TanhProcess:使用双曲正切函数处理噪声数据的处理器。
- ProcessInf:处理无穷值的处理器,它将用该列的均值替换无穷值。
- Fillna:处理 N/A 值的处理器,它将用0或其他给定数字填充 N/A 值。
- MinMaxNorm:应用最小-最大归一化的处理器。
- ZscoreNorm:应用 z-分数归一化的处理器。
- RobustZScoreNorm:应用稳健 z-分数归一化的处理器。
- CSZScoreNorm:应用横截面 z-分数归一化的处理器。
- CSRankNorm:应用横截面排名归一化的处理器。
- CSZFillna:以横截面方式填充 N/A 值的处理器,通过该列的均值来填充 N/A 值。
用户也可以通过继承处理器的基类来创建自己的处理器。
Example
数据处理器可以通过修改配置文件与 qrun 一起运行,也可以作为单独的模块使用。
Qlib提供了实现好的数据处理器Alpha158。以下示例展示了如何将Alpha158作为单独模块运行。
用户首先需要用 qlib.init 初始化 Qlib。
import qlib
from qlib.contrib.data.handler import Alpha158data_handler_config = {"start_time": "2008-01-01","end_time": "2020-08-01","fit_start_time": "2008-01-01","fit_end_time": "2014-12-31","instruments": "csi300",
}if __name__ == "__main__":qlib.init()h = Alpha158(**data_handler_config)# get all the columns of the dataprint(h.get_cols())# fetch all the labelsprint(h.fetch(col_set="label"))# fetch all the featuresprint(h.fetch(col_set="feature"))
在Alpha158中,Qlib使用标签 Ref( c l o s e , − 2 ) / R e f ( close, -2)/Ref( close,−2)/Ref(close, -1) - 1,表示从T+1到T+2的变化,而不是使用 Ref( c l o s e , − 1 ) / close, -1)/ close,−1)/close - 1。其中的原因是,当获取中国股票的T日收盘价时,股票可以在T+1日购买并在T+2日出售。
数据集
Qlib 的 Dataset 模块旨在为模型训练和推断准备数据。
此模块的动机是我们想最大化不同模型处理适合自身的数据的灵活性。该模块赋予模型以独特方式处理其数据的灵活性。例如,像 GBDT 这样的模型可能会在包含 nan 或 None 值的数据上表现良好,而像 MLP 这样的神经网络在此类数据上则会崩溃。
如果用户的模型需要以不同的方式处理其数据,用户可以实现自己的 Dataset 类。如果模型的数据处理不特殊,可以直接使用 DatasetH。
DatasetH 类是带有数据处理器 (Data Handler) 的数据集。以下是该类最重要的接口:
classqlib.data.dataset.__init__.DatasetH(handler: Union[Dict[KT, VT], qlib.data.dataset.handler.DataHandler], segments: Dict[str, Tuple], fetch_kwargs: Dict[KT, VT] = {}, **kwargs)
缓存
缓存是一个可选模块,通过将一些频繁使用的数据保存为缓存文件来帮助加速数据提供。Qlib 提供了一个 Memcache 类,用于将最常用的数据缓存在内存中,一个可继承的 ExpressionCache 类,以及一个可继承的 DatasetCache 类。
全局内存缓存
Memcache 是一个全局内存缓存机制,由三个 MemCacheUnit 实例组成,用于缓存 Calendar(日历),Instruments(工具),和 Features(特征)。MemCache 在 cache.py 中被全局定义为 H。用户可以使用 H[‘c’],H[‘i’],H[‘f’] 来获取/设置内存缓存。
ExpressionCache
ExpressionCache 是一个缓存机制,用于保存例如 Mean($close, 5) 这样的表达式。用户可以继承这个基类,根据以下步骤定义自己的缓存机制,以保存表达式。
- 重写 self._uri 方法以定义如何生成缓存文件路径
- 重写 self._expression 方法以定义将缓存哪些数据以及如何缓存它。
Qlib 目前已提供了从 ExpressionCache 继承的磁盘缓存 DiskExpressionCache 的实现。表达式数据将被存储在磁盘上。
数据集缓存
DatasetCache 是一个保存数据集的缓存机制。特定的数据集受股票池配置(或一系列工具,虽然不推荐)、一系列表达式或静态特征字段、收集特征的开始时间和结束时间以及频率的规定。用户可以继承这个基类,根据以下步骤定义自己的保存数据集的缓存机制。
- 重写 self._uri 方法以定义如何生成缓存文件路径
- 重写 self._expression 方法以定义将缓存哪些数据以及如何缓存它。
相关文章:

7、【Qlib】【主要组件】Data Layer:数据框架与使用
7、【主要组件】Data Layer:数据框架与使用 简介数据准备Qlib 格式数据Qlib 格式数据集自动更新日频率数据将 CSV 格式转换为 Qlib 格式股票池(市场)多股票模式 数据API数据检索特征过滤器 数据加载器QlibDataLoaderStaticDataLoaderInterfac…...
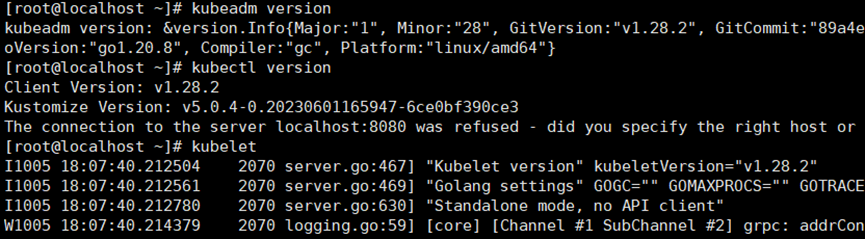
Kubernetes安装部署 1
本文主要描述kubernetes的安装部署,kubernetes的安装部署主要包括三个关键组件,其中,包括kubeadm、kubelet、kubectl,这三个组件的功能描述如下所示: Kubeadm 用于启动与管理kubernetes集群 Kubelet 运行在所有集群的…...

在VS Code中优雅地编辑csv文件
文章目录 Rainbow csv转表格CSV to Tablecsv2tableCSV to Markdown Table Edit csv 下面这些插件对csv/tsv/psv都有着不错的支持,这几种格式的主要区别是分隔符不同。 功能入口/使用方法Rainbow csv按列赋色右键菜单CSV to Table转为ASCII表格指令CSV to Markdown …...

LCR 128.库存管理 I
题目来源: leetcode题目,网址:LCR 128. 库存管理 I - 力扣(LeetCode) 解题思路: 数组可以分割成两段的升序连续子数组,找到两个子数组的开始元素并返回较小者即可。 解题代码: …...

eigen::Affine3d 转换
平移eigen::vector3d和四元数Eigen::Quaterniond 转 eigen::Affine3d Eigen::Vector3d t Eigen::Vector3d::Zero(); Eigen::Quaterniond q Eigen::Quaterniond ::Identity();Eigen::Affine3d affine3d t * q.toRotationMatrix(); Eigen::Matrix4d 转 eigen::Affine3d Eige…...
【Python从入门到进阶】38、selenium关于Chrome handless的基本使用
接上篇《37、selenium关于phantomjs的基本使用》 上一篇我们介绍了有关phantomjs的相关知识,但由于selenium已经放弃PhantomJS,本篇我们来学习Chrome的无头版浏览器Chrome Handless的使用。 一、Chrome Headless简介 Chrome Headless是一个无界面的浏览…...
)
给Python项目创建一个虚拟环境(enev)
给Python项目创建一个虚拟环境(enev) 为您的Python项目创建一个虚拟环境是一种良好的实践,可以隔离项目的依赖项,以确保它们不会干扰全局Python环境或其他项目。您可以使用venv模块来创建虚拟环境。以下是在Linux上创建虚拟环境的…...

【RK3588】YOLO V5在瑞芯微板子上部署问题记录汇总
YOLO V5训练模型部署到瑞芯微的板子上面,官方是有给出案例和转过详情的。并且也提供了Python版本的推理代码,以及C语言的代码。 但是,对于转换过程中的细节,哪些需要改?怎么改?如何改,和为什么…...

别人做的百度百科词条信息不全,如何更正自己的百度百科词条
很多人自己的百度百科词条是别人上传上去的,自己压根不知道,而且里面的信息内容要么不全,要么是有错漏的,但自己想要更正自己的百度百科词条又不知道如何更正,下面洛希爱做百科网和大家介绍一些百科经验知识。 首先百…...
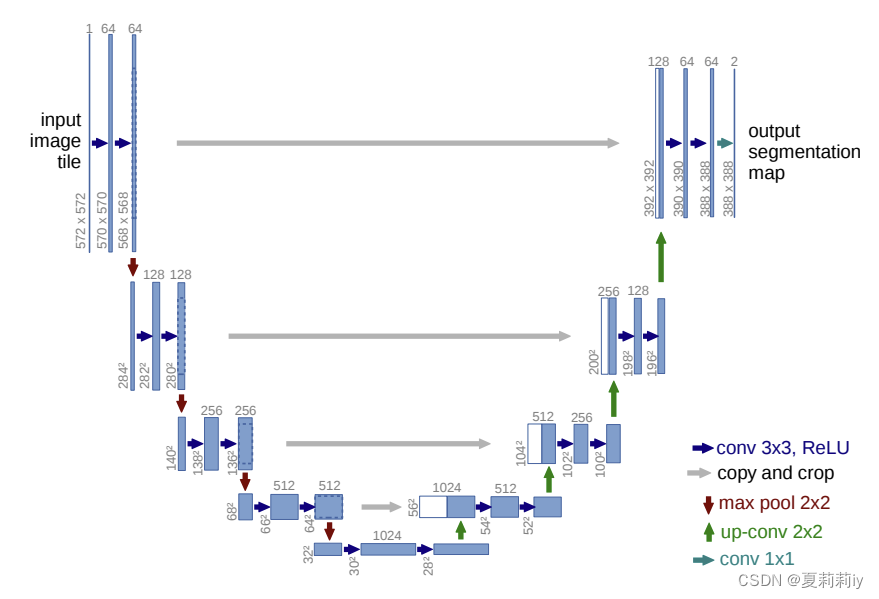
[论文精读]U-Net: Convolutional Networks for BiomedicalImage Segmentation
论文原文:U-Net: Convolutional Networks for Biomedical Image Segmentation (arxiv.org) 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔…...
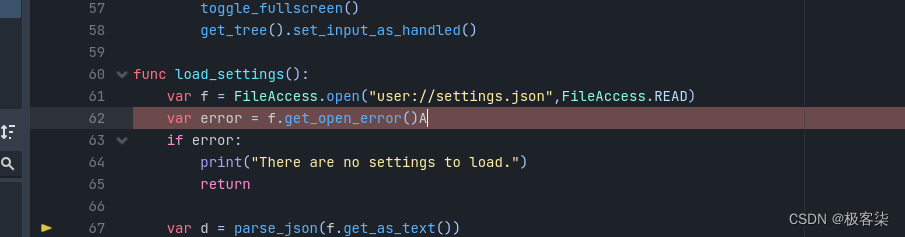
Godot Identifier “File“ not declared in the current scope.
解决方案: f FileAccess.open(savedir, FileAccess.READ)...

Java ORM Bee,多表关联更新
Bee V2.1.8 增加支持多表的update, insert, delete; 使用FK注解进行关联. 如果子实体没有用上FK声明的字段(即FK的字段没有值),则不执行,防止更新到多余记录 外键有一个没有设置时,跳过。 更多实例,请查看样例工程:https://gitee.com/automvc/bee-exam 或:h…...

Java 读取excel文件
导入: 先导入依赖: <!-- 文件上传 --> <dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpmime</artifactId><version>4.5.7</version> </dependency> <!-- JSON -…...
:数据分析 | 数据挖掘 | 十大算法之一)
PageRank(上):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...

吃鸡达人专享!提高战斗力,分享干货,查询装备皮肤,保护账号安全!
大家好!作为专业吃鸡行家,我将为您带来一些热门话题和实用内容,帮助您提升游戏战斗力,分享顶级游戏作战干货,并提供便捷的作图工具和查询服务。让我们一起享受吃鸡的乐趣! 首先,我要推荐一款绝地…...
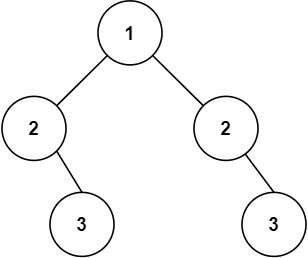
力扣第101题 c++ 递归 迭代 双方法 +注释 ~
题目 101. 对称二叉树 简单 给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true示例 2: 输入:root [1,2,2,null,3,null,3] 输出:false提示&a…...
Go:实现SMTP邮件发送订阅功能(包含163邮箱、163企业邮箱、谷歌gmail邮箱)
需求很简单,就是用户输入自己的邮箱后,使用官方邮箱给用户发送替邮件模版 目录 前置邮件模版邮箱开启SMTP服务163邮箱163企业邮箱谷歌gmail邮箱腾讯企业邮箱-失败其他邮箱-未操作 邮件发送核心代码config.yaml配置读取邮件相关配置发送邮件 附录 前置 邮…...
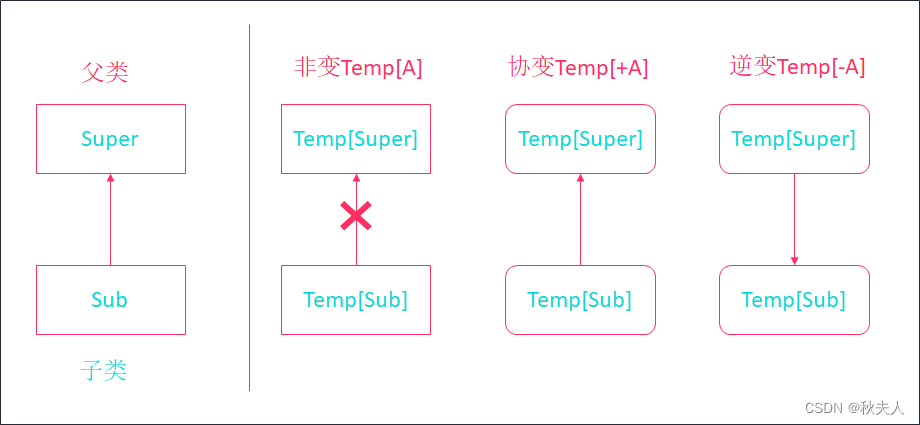
Scala第十六章节
Scala第十六章节 scala总目录 文档资料下载 章节目标 掌握泛型方法, 类, 特质的用法了解泛型上下界相关内容了解协变, 逆变, 非变的用法掌握列表去重排序案例 1. 泛型 泛型的意思是泛指某种具体的数据类型, 在Scala中, 泛型用[数据类型]表示. 在实际开发中, 泛型一般是结合…...

C语言 实现 链 显示 效果 查找 修改 删除
显示所有信息 2023年10月1日的描述:今天放假 2023年10月2日的描述:今天有体育 2023年10月3日的描述:今天有数学 2023年10月4日的描述:今天有语文 2023年10月5日的描述:今天有政治 2023年10月6日的描述:今天交学费 2023年10月7日的描述:今天周末 2023年10月8日的描述:今天给家里…...

CSS基础语法第一天
目录 一、CSS 简介 1.1 CSS简介 1.2 CSS语法 1.3 CSS 语法规范 1.4 CSS 代码风格 1.4.1 样式格式书写 1.4.2 样式大小写 1.4.3 空格规范 二、CSS 基础选择器 2.1选择器分类 2.2标签选择器 2.3 类选择器 2.4 id选择器 2.5 通配符选择器 三、盒子尺寸和背景色 …...

告别数据灾难:Linux下flash_erase命令的‘锁’与‘备份’实操指南
告别数据灾难:Linux下flash_erase命令的‘锁’与‘备份’实操指南 在嵌入式开发和物联网设备管理中,Flash存储器的操作如同走钢丝——稍有不慎就会导致数据灾难。我曾亲眼见证过一个实验室因为一条未加锁的擦除命令,导致价值数十万的测试数据…...
)
保姆级教程:用sys.argv[0]一劳永逸解决PyInstaller打包exe的路径问题(附完整代码对比)
彻底解决Python打包exe路径问题的工程实践指南 当我们将Python脚本打包成独立可执行文件时,最常遇到的"拦路虎"之一就是路径问题。许多开发者在IDE中调试时一切正常,但一旦用PyInstaller打包成exe后,程序就开始报No such file or …...

Solon框架解析:高性能Java轻量级框架的架构设计与实战
1. 从零到一:为什么我们需要另一个Java框架?如果你是一个有几年经验的Java开发者,看到“Solon”这个名字,你的第一反应可能是:“又来了一个框架?Spring Boot还不够用吗?” 我完全理解这种想法。…...

如何快速在Windows上安装APK文件:APK-Installer完整使用指南
如何快速在Windows上安装APK文件:APK-Installer完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接安装安卓应用却不想安装…...

一键下载30+文档平台:kill-doc免费开源脚本终极指南
一键下载30文档平台:kill-doc免费开源脚本终极指南 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决…...

5分钟掌握LinkSwift:彻底解决你的网盘下载难题
5分钟掌握LinkSwift:彻底解决你的网盘下载难题 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / …...

别再傻傻分不清了!一文搞懂4G/5G打电话背后的三种技术:CSFB、VoLTE和VoNR到底啥区别?
移动通信语音技术演进:从CSFB到VoNR的深度解析 第一次用5G手机打电话时,很多人会注意到状态栏的"HD"标志突然出现,而有些时候又会看到网络从5G自动切换到了4G。这些现象背后,是移动通信领域三种截然不同的语音技术方案在…...

多模态大模型在长对话场景中的评估与优化
1. 项目背景与核心挑战当前多模态大模型(VLM)在单轮问答任务上已展现出惊人能力,但当面对需要跨模态持续推理的多轮对话场景时,模型表现往往出现显著退化。我们在实际业务场景中发现,现有评估基准存在三个关键缺陷&…...

AI赋能算法设计:让快马平台帮你构思Ubuntu OpenClaw自适应抓取代码
AI赋能算法设计:让快马平台帮你构思Ubuntu OpenClaw自适应抓取代码 最近在开发Ubuntu OpenClaw项目时,遇到了一个棘手的问题:如何让机械爪自适应地抓取不同材质和重量的物体,既不会因为力度过大损坏物品,又不会因为力…...

PhpWebStudy版本管理实战:告别环境配置困扰的全栈开发解决方案
PhpWebStudy版本管理实战:告别环境配置困扰的全栈开发解决方案 【免费下载链接】PhpWebStudy Lightweight Native Local Dev Toolbox for Windows, macOS & Linux. Run Hermes Agent/OpenClaw/n8n/Apache/Nginx/Caddy/Tomcat/PHP/Node.js/Bun/Deno/Python/Java/…...